Energy-Efficient Nonuniform Content Edge Pre-Caching to Improve Quality of Service in Fog Radio Access Networks


1
School of Information Engineering, Minzu University of China, Beijing 100081, China
2
School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China
3
School of Information and Communication Engineering, Beijing University of Posts and Telecommunication, Beijing 100876, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(6), 1422; https://doi.org/10.3390/s19061422
Submission received: 9 February 2019
/
Revised: 3 March 2019
/
Accepted: 15 March 2019
/
Published: 22 March 2019
(This article belongs to the Special Issue Advanced Technologies on Green Radio Networks)
Abstract
:The fog radio access network (F-RAN) equipped with enhanced remote radio heads (eRRHs), which can pre-store some requested files in the edge cache and support mobile edge computing (MEC). To guarantee the quality-of-service (QoS) and energy efficiency of F-RAN, a proper content caching strategy is necessary to avoid coarse content storing locally in the cache or frequent fetching from a centralized baseband signal processing unit (BBU) pool via backhauls. In this paper we investigate the relationships among eRRH/terminal activities and content requesting in F-RANs, and propose an edge content caching strategy for eRRHs by mining out mobile network behavior information. Especially, to attain the inference for appropriate content caching, we establish a pre-mapping containing content preference information and geographical influence by an efficient non-uniformed accelerated matrix completion algorithm. The energy consumption analysis is given in order to discuss the energy saving properties of the proposed edge content caching strategy. Simulation results demonstrate our theoretical analysis on the inference validity of the pre-mapping construction method in static and dynamic cases, and show the energy efficiency achieved by the proposed edge content pre-caching strategy.
1. Introduction
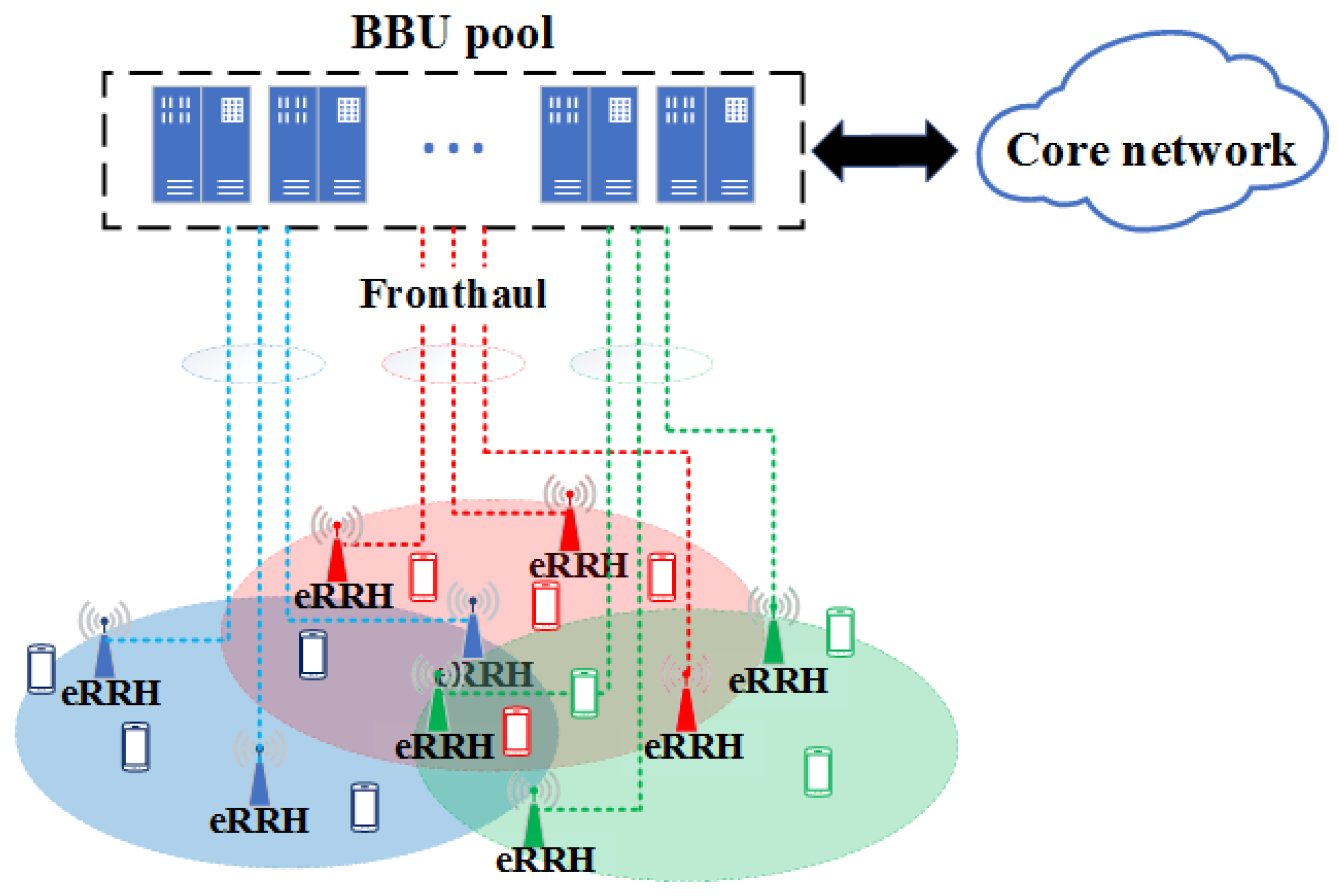
Recently, the fog radio access network (F-RAN) has been proposed as an emerging network architecture of a cloud radio access network (C-RAN) for fifth generation wireless systems (5G), which aims to address the limitations of previous cellular standards and be a prospective key enabler for future Internet-of-Things (IoT) [1]. In a typical C-RAN, a centralized baseband signal processing unit (BBU) pool is equipped for baseband processing of a remote radio heads (RRHs) set, connected to the BBUs by fronthaul links, to save on operational expenditures and reduce energy consumption [2,3,4,5]. Although some efficient signal compression methods have been proposed for C-RANs [6], it is insufficient to satisfy the dramatically increasing requirements from mobile users for real-time services with high quality-of-service (QoS) guarantees. To address this challenge, the enhanced architecture of F-RAN allowing the RRHs with the capability of storage and signal processing functionalities, was proposed [7,8,9]. With the enhanced RRHs (eRRHs), edge caching can be performed to pre-fetch some requested files to the eRRHs local caches (as illustrated in Figure 1). Subsequently, the burden on backhaul is relieved and higher spectral efficiency or lower delivery latency can be obtained for users’ requesting cached files from incorporating caching units. In general, the goal of F-RAN architecture is to optimize the system performance in terms of delivery rate by leveraging both BBU and edge caching, which is different from that in C-RAN.
As a cache-aided system, F-RAN operates in the pre-fetching and delivery phases [10,11,12]. The pre-fetching normally stores the content by constant popularity ranking in the large time scale corresponding to multiple transmission intervals. Instead, the delivery phase operates separately on each transmission interval based on the cached file messages. Several recent studies involved the scheme and the performance of F-RAN in this context. In [7,10] the fronthaul-aware design via the pre-fetching policy was studied to minimize the average delivery latency with the cache memory constraints, and in [13] the optimal caching and delivery strategies that minimize the delivery latency are characterized for system designing. In [12,14], trade-off between the total power consumed and the total backhaul capacity needed in the downlink of the cache-aided RAN was studied. It has shown that the energy consumption is decreased due to the increase of spatial diversity by cooperative communication, meanwhile the backhaul burden is increased due to the delivery of uncached files to more eRRHs. The aforementioned research indicates that the content edge-storage strategy design plays a critical role in improving the performances of F-RAN.
Designing content edge caching strategies to more closely meet the needs can greatly alleviate the burden on backhauls, and reduce the delay and energy consumption for a large number of users. Notice that caching popular files can make the design of the delivery phase more meaningful and sensible to meet the needs of most users; almost all the content edge-storage strategies via pre-fetching were directly proposed due to this most-popular-caching premise. To the best of our knowledge, the content edge-storage strategies in the literature are considered to be based on an assumption that all files are available at the BBU and the popularity of the file is modeled by Zipf distribution [15]. More specifically, for Zipf distribution, let the files be labeled in the order of popularity from the most to the least popular ones, such that the most popular file has index and the least popular file has index . Then the probability of a requested file is satisfying . Therefore, consider that user equipments (UEs) in an F-RAN are served by multiple eRRHs that are connected to a BBU pool through digital fronthaul links, UE selects file with the probability , and the requested files are independent across the index k. The increasing of the exponent s makes the probability of selecting a small group of files larger. When the parameter s is adjusted appropriately, only a few popular files are frequently requested by UEs.
Although the above content selecting criterion can simplify the discussion, the real situation of the content obtaining in F-RANs is much more complex due to the users’ social and activity limitation, which has noticeable impact on the performances of F-RAN. For instance, there are usually some certain activity regions for different users, which endows the content request of the individual with regional features. Also, the preferences of the users in different districts, such as the area around the school, the airport or the mall, are often relatively different, which can make the content distribution non-uniformed for different groups. Moreover, for some multimedia users, the obtained information is inevitably lagging behind once the cached contents are not desired by them. It means that judging which content to be cached from past requesting actions is reasonable and necessary in order to guarantee the QoS. It is shown that such contradictions are particularly prominent under the condition of limited edge cache in eRRH, and a straightforward way to utilize Zipf distribution for content caching is inappropriate to realistic needs. However, notice that the massive data on the activity of request is recorded and the powerful computational capacity is provided by the computing resources of the cloud, it is possible to design more efficient content-obtaining strategies relying on these foundations.
With this consideration, in this paper, we propose a caching content selection strategy by digging out users’ network behavior information and improving the distribution on content allocation. We analyze the relationship between scope of eRRH/UEs’ activities and content requests in an F-RAN, and then establish pre-mapping inferred by an efficient matrix completion algorithm for an appropriate content edge pre-caching. Especially, the proposed matrix completion algorithm gets better at the accuracy in the case of non-uniform data sampling and computational efficiency. Furthermore, we analyze the energy consumption of the content edge pre-caching strategy based on the proposed pre-mapping. Numerical results are provided to prove the effectiveness of the given inference method for the pre-mapping construction in static and dynamic cases, and illustrate the energy saving characteristics of the content edge pre-caching.
This paper is structured as follows. In Section 2 we introduce the system model considered and state the caching file selection strategy. The data structure corresponding to the UEs’ requests for the entire researched F-RAN is established mathematically as well. in Section 3, the optimization problem of the content edge caching pre-mapping construction is presented and the non-uniform non-convex matrix completion algorithm is proposed for solving the problem. The corresponding energy consumption analysis for the caching content selection strategy is provided in Section 4. Simulation results of the algorithm and the energy consumption performances are shown in Section 5, followed by the conclusion in Section 6.
2. System Model and Problem Statement
We consider the downlink transmission of an F-RAN as illustrated in Figure 1. N eRRHs are deployed in the network and cooperatively serve all users. Each eRRH, equipped with L antennas and a cache of the same size, can connect to the BBU pool via individual backhaul links with finite capacity. The cluster-scale joint management, such as scheduling and resource allocation, can be implemented. On the other hand, UEs are uniformly and independently distributed within the network. In each scheduling interval, K users will be scheduled, and send their content requests according to some preferences. Assume that each user can request at most one content at its scheduled time and the content cache in BBU pool stores the set of all content objects required by the users, which is denoted as a set , with all of the same size and belonging to I types. Then in their own activity regions, UEs requesting the contents that belong to the same subset (with the same color icon shown in Figure 1) can form a multicast UE cluster . The m-th cluster , limited by the preferences and activity regions, is served cooperatively by a cluster of eRRHs, which is denoted as . It should be noted that, although the eRRH clusters serving UE clusters can overlap with each other, the overlap of the eRRH clusters is relatively small and irregular since the service area of an eRRH is limited and the eRRH equipments are deployed in the sufficiently large area. With this consideration, we ignore this characteristic here to simplify the analysis and assume that the users in the overlap are served by only one eRRH cluster with high probability, i.e., and , .
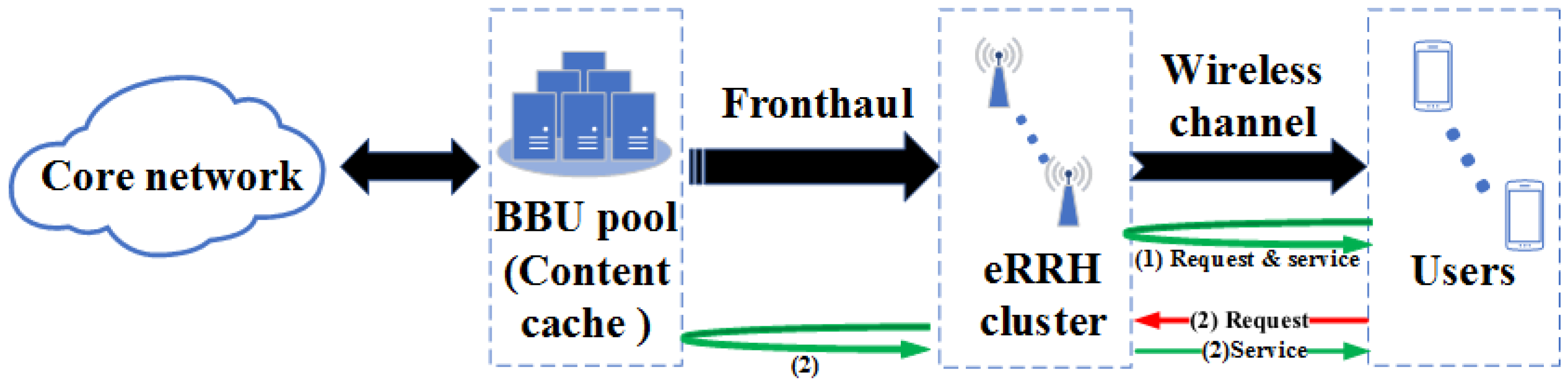
Content caching and transmission: Without loss of generality, we set and focus on a typical eRRH/UE cluster, i.e., and (represent by the icons with the same color in Figure 1). While the content cache of BBU pool is deployed to fully exploit the potential of content caching in the F-RAN, the content cache of each eRRH in the same cluster only contains the contents that are most likely to be requested by the users in the same area. The content requests from served users are aggregated at the edge eRRH cluster in the F-RAN, and can be treated as follows: First, the eRRH cluster checks its cluster content caches and the requests can be served immediately if the desired content is available at the caches (illustrated as the procedure (1) in Figure 2). Otherwise, the requests will be forwarded to the BBU pool content cache, and then the corresponding content can be provided through the fronthaul link from the BBU pool. Then the requests can be handled similarly to the case in which the content resides in the content caches in the cluster (illustrated as the procedure (2) in Figure 2).
To increasing the operability, the preferences of the UEs’ requests and the corresponding contents will be classified into different types. For each type, the contents will be sorted according to the timeliness and the popularity, and pre-cached in the eRRHs according to the UEs’ preferences inferred by the requests. Because the caching via the preferences of the individual can reduce the probability of the procedure (2) execution, which can lead to improved QoS guarantees with low power consumption in practical F-RANs, it is reasonable to propose an eRRH content per-caching strategy depending on the UEs’ behaviors.
Content preference data model: Note that the restricted mobility and the randomness of request for UEs in line with the assumptions at the beginning of this section, we establish the content preference data model associated with the UEs’ requests based on the following setting: (i) the users usually stay in some limited areas depending on the occupation and habit, etc. This results in that only a limited part of the eRRHs (compared with the overall scale in the researched F-RAN) can serve the certain UEs; (ii) Due to the restricted mobility of each UE, the eRRH in the service cluster to receive the UE’s request can be deemed to be selected randomly. This means that some eRRHs in the serving cluster may not obtain the request of the UE in the ; (iii) It is also obvious that the number of content types interested in is far less than the scale of the users. Hence, with these prerequisites, we first let j and k denote the indices of eRRHs and UEs respectively, the basic dataset reflecting the content types that the UEs’ requests and can be structured as the preference matrix with the entry as follows:
where is a positive integer and . The value of can be set as an arbitrary integer for simplicity provided that there is no popular rank. However, if the popular rank exists, the value of will be set according to the way used for Zipf distribution setting and refer to the request history of the corresponding user.
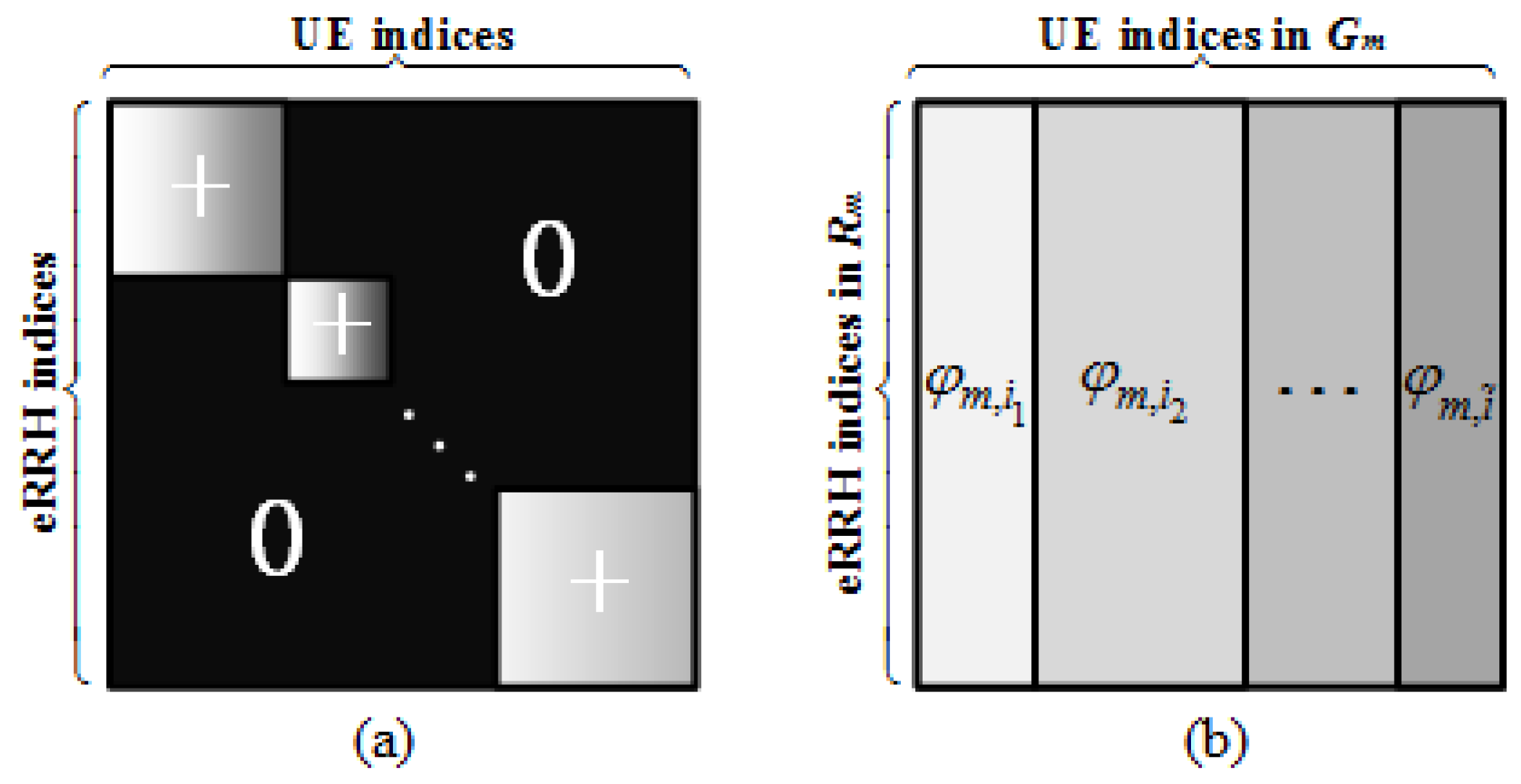
We now show that the preference matrix A with the complete request dataset is low rank. For UE k, the entries corresponding to the m-th eRRH cluster are assigned as the same since all eRRHs in the cluster should serve UE k. Thus, with a suitable realignment of users and eRRHs, can be represented as a block-diagonal matrix where the entries within the diagonal blocks are positive and the others within the off-diagonal blocks are all 0’s. Furthermore, for each “positive” block, all entries of the diagonal sub-blocks are (shown in Figure 3). The following theorem provides the upper bound for the rank of the complete preference matrix.
Theorem 1.
(Low rank structure of request preference data model): The complete preference matrix has rank at most, where and I correspond to the number of multicast eRRH/UE clusters and that of content types respectively.
Proof.
Suppose that all clusters of eRRHs are in service, then the eRRHs set can be divided into clusters, i.e., , . Further, for each eRRH/UE cluster, the UEs of can be classified into several common preference sub-groups, denoted by and the number of the sub-group in the entire network is no more than . After suitable reordering indices of nodes (UEs) in , the corresponding row vector of are all identical to the following form
where is the cardinality of the requested content type subset in and . Then let us take all UE subgroups into account, we operate column vectors of the sub-group by the column elementary transformation, which is equivalent to subtracting the first column vector of the i-th sub-group from the other ones, etc. Do the similar operations for row vectors of and rearrange the rows and columns of , we obtain
where and . denotes arbitrary for convenience. It is easy to deduce that , therefore . □
Despite of a clear structure retained by complete preference matrix A, the restricted mobility and the randomness of request for UEs (i.e., the Prerequisite (i) and (ii)) lead to a serious observation missing on the complete request preference data (the preference matrix A). The more likely situation is that a very limited number of requests are recorded and can be indicated by where is the index set of the recorded entries, denotes the orthogonal projection operator onto the span of matrices vanishing outside of , so that the (j,k)-th component of is equal to the (j,k)-th component of when and zero otherwise. Especially, for each row (column) of , we find that the number of non-zero entries in the row indicates the activity of the corresponding UE. Therewith, we denote the number of non-zero entries in the kth column as , and then define the activity of the kth UE as , where represents the number of observed non-zero entries in . The activity vector of all UEs can be further defined as . Similarly, the activity of eRRH means the measurement that the eRRH caches the proper contents and serves UEs. The activity vector of all eRRHs can also be defined as where ( is the number of non-zero entries in the jth row). It is observed that activity brings out the non-uniform observations/samples.
With these known conditions, we define the content edge-caching pre-mapping construction as preference data matrix inferring. More specifically, the core mission is inferring the unknown potential relationships between the UE and eRRH in the F-RAN, and further partitioning the cluster according to the criterion associated with preference and randomness of requests in active area. On this basis, our eRRH content per-caching strategy is designed as follows: Guided by the entries of the inferred preference matrix (i.e., the pre-mapping), BBU pool selects the most popular content of each type according to the inferred results, and then pre-sends contents to several alternative eRRHs for the corresponding UE cluster service. Besides, if the eRRH cache exists in free space, the most popular contents except the pre-sent ones will be transmitted to the eRRH until no space left in the edge-cache. Due to the prediction, this strategy based on pre-mapping seems to satisfy the users’ needs with high probability and meaningful in the scenario such as the super-resolution videos pre-caching for high throughput transmission QoS and low energy consumption.
3. Nonuniform Pre-Mapping Construction via Nonconvex Optimization
In this section, on the basis of Theorem 1 and properties aforementioned, we establish a non-uniform pre-mapping to infer the unknown potential preference data in the F-RAN and further achieve eRRH/UE cluster partition according to the structure of the preference matrix. Since the complete preference matrix A obeys the low-rank structure, it is reasonable to utilize the low-rank matrix completion [16,17,18] to achieve pre-mapping construction. However, main methods based upon low-rank matrix completion algorithms are assumed that the data are sampled under uniform distribution. This does not hold for our scenario and system model, owing to the close relationship between the preference data distribution and the distinct activity levels of participants. To overcome the obstacle of non-uniform observation, we propose the non-convex matrix completion with iteratively re-weighted modified trace norm regularization for clustering:
Given a distribution ( and ) that reflects the UEs’ activity of requesting, for the objective matrix , the modified trace norm of is defined as Here, denotes the trace norm, denotes the -th singular value of the matrix and redesignated as for simplicity. is the diagonal matrix with the activity vector of all participants: , where represents the row marginal, i.e., . Similarly corresponds to the columns of and possesses similar relations (i.e., ) (see Section 2). With this definition, matrix completion with modified trace norm regularization involves the following optimization
Note that compared to norm, the quasi-norm, , makes a closer approximation to the counting norm , which is the number of nonzero entries of x, the variants of non-convex for have been used to develop algorithms for recovering low-rank matrices in [19,20]. With this consideration, we let and the substitution of the optimization (4) can be given as follows:
where . We then propose an accelerated non-convex non-uniformed matrix completion algorithm (ANNMC) via variant quasi-norm optimization to adapt to the preference inference and eRRH/UE cluster partition for pre-caching in this section. The iteratively re-weighted framework and the accelerated framework are utilized for the algorithm design.
3.1. Nonconvex Nonuniformed Matrix Completion Agorithm
Inspired by the iterately re-weighted framework via norm in compressed sensing, an iterative procedure for solving the minimization problem (5) is as follows:
- Set the iteration count and , .
- Solve the weighted modified trace norm minimization problem
- Update the weights: for each ,where in order to provide stability and to ensure that a zero-valued does not strictly prohibit a nozero estimate at the next step.
- Terminate on convergence or when . Otherwise, increment t and go to step 2.
In this method, using an iterative framework to construct the tends to allow for successively better estimation of the nonzero coefficients. Even though the early iterations may find inaccurate signal estimates, the largest signal coefficients are most likely to be identified as nonzero. Once these locations are identified, their influence is downweighted in order to allow more sensitivity for identifying the remaining small but nonzero signal coefficients.
3.2. Accelerated Agorithm for Convex Subproblem
Subsequently, we develop an accelerated variant for non-convex non-uniformed low-rank matrix completion algorithm. By referring optimization in [21], the subproblem (6) in iteration t can come down to
Its Lagrangian function is defined as
and its dual function is
We then intend to utilize the dual function (10) to solve the subproblem (8). To this end, We first deduce the properties of the dual function and then illustrate how to achieve the optimal solution of the subproblem (8) from its dual optimum directly. Now the following results should be given, which are essential to obtain the properties of . We omit the proofs of the properties here and present them in Appendix A.
Theorem 2.
For , and , , the solution of the optimal problem obeys
where , and .
Theorem 2 plays the crucial role in formulating the optimal of the subproblem (8). Additionally, is equal to when vector , which is the crucial value for the traditional trace norm minimization solving. Based on the properties of Moreau-Yosida regularization and Theorem 2, we obtain the following result.
Theorem 3.
For any , we have:
which indicates that is globally Lipschitz continuous with modulus 1.
With Theorems 2 and 3, we obtain the following property of the dual function .
Theorem 4.
With the above properties, let . Since is the dual function of (8), is concave and subsequently is convex. Thus, for any , . From Equations (A8) and (A10) in Appendix A, it is also easy to show that satisfies and belongs to , which is the class of convex functions with Lipschitz gradient (i.e., for some and any , satisfies and ). Therefore, optimization (8) can be solved by minimizing the objective function , i.e.,
After acquiring this equivalent optimization , in the following we propose to solve this smooth convex optimization problem by using the Nesterov’s method, a very powerful optimization technique for class [22]. For belonging to , The Nesterov’s method for this problem utilizes two sequences: and , ,
where is a tuning parameter, and is the step size. By utilizing the Nemirovski’s line search scheme [23], which developed from the Nesterov’s method, for and , the update scheme is that and is independent on . Starting from an initial point , and can be computed recursively, and arrive at the optimal solution . We get Algorithm 1 to achieve the optimal solution of the subproblem (8) in the t-th iteration from its dual optimum directly. By using the Nesterov’s and Nemirovski’s scheme framework, the Algorithm 1 for the subproblem can achieve the convergence rate of .
| Algorithm 1 Accelerated Algorithm for Subproblem (6) |
| Input:; Output:, ;
|
We then summarize the proposed ANNMC algorithm and represent the execution steps. For the t-th iteration, we solve the subproblem (8) by Algorithm 1 to get a coarse result firstly. Since the entries of the objective preference matrix belong to the set , we add the quantification steps to ensure the result matrix in the feasible domain. To fit the observations better, the quantification thresholds are amended by the rate of value in the observations. Thus let the rate where is the number of in the observation and the quantification rule is shown in Algorithm 2. It aims to reduce the number of iterations as much as possible that the quantification is integrated in the t-th iteration but not after solving problem (5). In addition, the convergence of the ANNMC algorithm can be guaranteed due to the convergence of the iteratively re-weighted minimization for quasi-norm [19]. Specifically, because the ANNMC algorithm is based on the iteratively re-weighted framework and the is generated by solving subproblem (8), there exists , an accumulation point of , which is the first-order stationary point of problem (5). The method of the convergence proof is analogous to the method in [19,24], we omit it for conciseness.
There exists an additional remark that in practice the pre-mapping constructed by the proposed algorithms can only predict the preference-caching relations between UEs and eRRHs accurately with high probability due to the posteriori estimation. However, based on sufficient sampled data in a certain period, the preference/caching manner can be mining via the pre-mapping. The edge pre-caching strategy mentioned in Section 2 can facilitate the service with high QoS for users based on recommendation.
At the end of this section, we provide a concise example from an application to illustrate our algorithm at work. Assume that there exist C files prepared to be sent to eRRHs for pre-caching. Then, we execute the following steps to accomplish the task: (i) By recording the fragmentary request information of the UEs in the designated region, we first use the ANNMC algorithm to get the pre-mapping which concludes the UEs’ preference inferences and the corresponding eRRHs accessing information associated with the geographical influence. (ii) Since there are many intersection among the preference sets of different UEs in the same group, we merge these preference sets and regard the derived union as the criterion of the edge pre-caching. (iii) Classify the C files as I types according to the UEs’ preferences, and rank the file types and the files of each type respectively via the popularity in society and history of the UEs’ requests. (iv) Determine which eRRH cluster serves the corresponding UE group by using the pre-mapping. Then divide files into messages of the same size and deliver to the eRRHs based on the criterion of the edge pre-caching, until the cache capacity is exhausted. (V) If the pre-cached messages match the requests of the served UEs, the messages will be sent to the UEs and get the subsequent messages of the same files from BBU pool. Otherwise the fragmentary request information record of the UEs will be updated and then the pre-mapping is modified based on the ANNMC algorithm, and so on.
| Algorithm 2 ANNMC Algorithm |
| Input:; Output:, ;
|
4. Energy Consumption Analysis
In light of mass data generated by billions of devices, we always prefer less energy consumption in data transmission, storing and processing. For this reason, edge caching aims to reduce repeated data transmission from original servers, which means that unnecessary energy consumption on packet delivery between the edge tier and the server tier can be saved. Moreover, caching itself also consumes extra energy while keeping RAM or disk memory running. To determine and sum up the overall cost of the entire simulation on the F-RAN network architecture, in summary, we may consider three parts of the energy consumption, the energy for device maintaining, content caching and transmission. Based on the content service strategy mentioned in Section 2 (also shown in Figure 2), we present the calculation of total energy consumption for each eRRH as follows:
Note that once the devices are deployed and work, the part to maintain all devices in the F-RAN can not be expressed in the total energy consumption since it is a fixed cost and can only be reduced by shutting down some devices [25]. Therefore, consider a fixed number of devices (eRRHs and users) in the F-RAN obeying the content per-caching strategy in Section 2 and all eRRHs are received and caches contents with the same size and number as the initial state. Then the total energy consumption analysis for each eRRH can be equivalent to the discussion on its total energy consumption change, which is the total energy cost for the content caching and the transmission for content update:
Especially, the caching energy cost
where is the power consumption of keeping a content object in an eRRH and is the is the size of the eRRH cache (the number of the content object). Meanwhile, since the content transmission energy cost of each eRRH contains the content sending and receiving energy cost by BBU pool and eRRH respectively, the transmission energy cost for the single content update . Then similar to the energy consumption linear model in [26,27],
where represents fixed costs and represents the rate of the required contents for the cluster users in the cache (i.e., represents the content update rate).
With this energy consumption analysis model, we discuss under the condition upon the implement of the pre-mapping constructed by the proposed preference inference algorithm, i.e., ANNMC. For , one part of the , because the inference algorithm with appropriate non-uniform sampling rate may accurately estimate the preference data of the cluster with high probability, the number of the caching contents would be less than that of the blind caching. In other words, the accurate preference estimation may prompt the eRRH cluster cache only several certain kinds of contents but not as many kinds as possible to ensure the QoS of F-RAN. On the other hand, for , will be determined by the inference error of the preference data. Thus, the directly associates with the accuracy of the proposed inference algorithm. Let denote the minimum number of cached content objects and denote the specific maximum number of contents allowed for caching, then the range of the total energy consumption change for each eRRH with the inference guidance is
Especially, with the low-rank assumption of the preference data and the proper low non-uniform sampling rate, the proposed ANNMC for inference can ensure the total energy consumption to approximate the lower bound with high probability, due to the foreseeable algorithm accuracy.
5. Performance Evaluations
The performance evaluations are illustrated in this section by using MATLAB. We first perform experiments on the synthetic networks, including static and dynamic cases, and show that our system model and the proposed pre-mapping construction method is feasible on the task of content preference distribution inference for the pre-caching in the F-RAN. Additionally, experimental simulations about the energy consumption performance of the pre-caching strategy are provided as well. To ensure that our results are reliable, we conduct all experiments 200 times, and average the results from all of the trials.
5.1. Performance of the Preference Inference
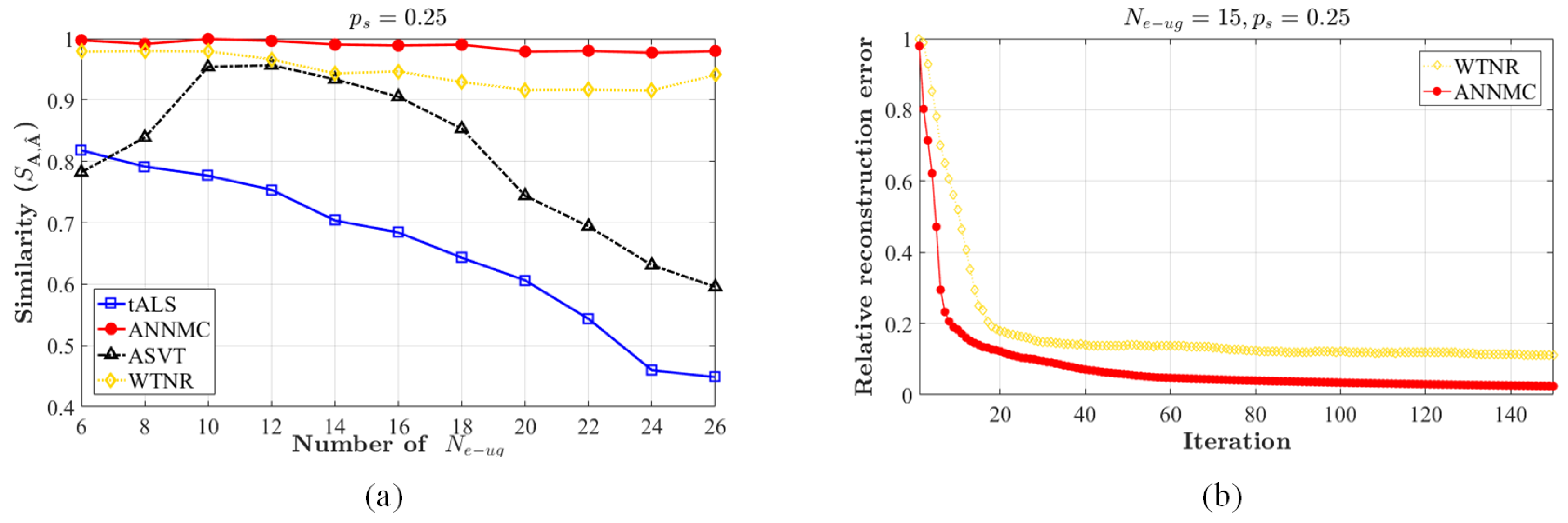
To verify the validity, we first consider a pre-mapping (complete preference matrix ) constructed by the synthetic F-RAN link data. The observation matrix is formed by sampling some entries from . To be specific, for the F-RAN, we set several eRRH clusters. The clusters of UEs are formed on the basic pattern of the and located randomly. Each UE cluster is served by one of eRRH cluster. Accordingly, possesses complete diagonal-block structure which is mentioned and analysed in Section 2. The size of each UE cluster is larger than 20 and the sum of the sizes is and the size of each eRRH cluster is larger than 5 and the sum of the sizes is . Meanwhile, in the F-RAN the content types is sorted via popularity and its number . For convenience, the preferred type subset of each UE cluster is sampled from the type set by Zipf distribution obeying the sorting. We further assume that only a part of requests are recorded by non-uniform sampling and the file types are valued by different integers (the max number of the content types contained by each eRRH cluster is set to be 5 as an example). The probability distribution of sampling ensures that each row (column) of the original matrix is sampled with different , and the practical sampling-rate of the original matrix is defined as , where is equal to the number of non-zero entries in the matrix. Then we use our proposed ANNMC algorithm to estimate the complete matrix and compare the performance of our approach to traditional Alternating Least Square (tALS) [28], the weighted trace norm regularization (WTNR) [29] and Accelerated Singular Value Thresholding (ASVT) [30] for the content caching pre-mapping construction problem. The details of the ANNMC parameters are shown in Table 1, and the experimental settings of the compared methods are the same with the corresponding literatures.
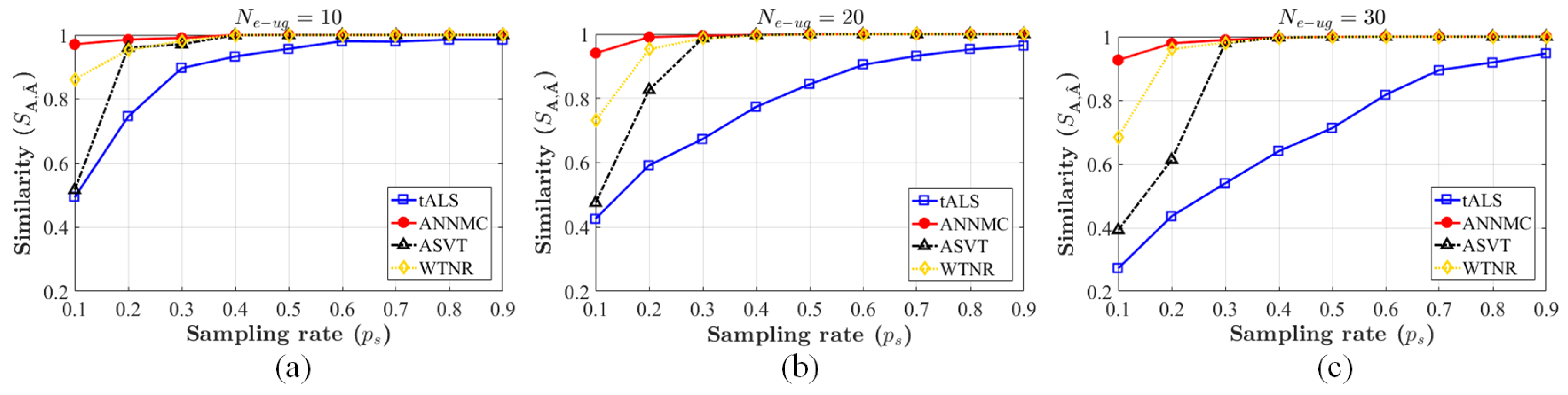
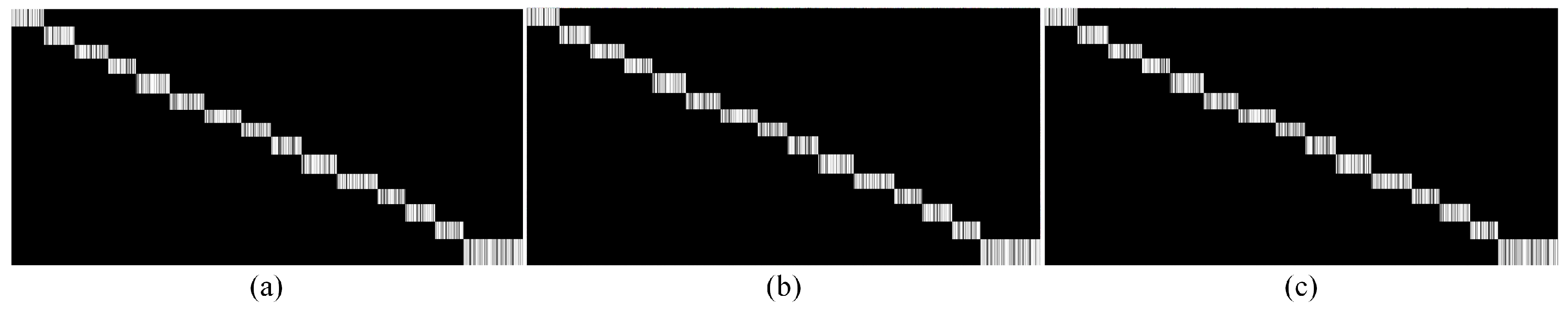
We evaluate the performances by the similarity between the inferred matrix and the original matrix to indicate the accuracy of estimation, the definition of which is . The range of the practical sampling-rate is from 0.1 to 0.9 and plot the inference accuracy in Figure 4. Apparently, the proposed non-uniform algorithm outperforms others due to higher accuracy. Moreover, we choose matrices () with ranks (i.e., the number of the clusters) and non-uniform sampling rate for matrix completion. For each algorithm, we complete the structure with different and compute recovery relative accuracy by similarity. The result is shown in Figure 5a. It is observed that ANNMC possesses the better robustness of non-uniform matrix completion in the certain range of eRRH/UE cluster number. We further compare ANNMC and WTNR due to their better estimation performance than the others in the simulation. As the results shown in Figure 5b, ANNMC outperforms WTNR with non-uniform sampling on low sampling-rate based estimation, even though its convergence rate is only slightly faster than WTNR. An visualized example of the pre-mapping constructed by ANNMC algorithm is also shown in Figure 6 ( and with sampling rates and ), which consists with our results.
5.2. Performance of the Dynamic Preference Inference
In general, the pre-mapping varies during a time period long enough. Accordingly, the observations of this dynamic preference matrix over time essentially introduce time dimension to the problem of mining the potential eRRH/content-UE relationships. Therefore, a more realistic scenario is inferring the by utilizing the historical records of the eRRH content caching and UEs’ requests in global and temporal evolvement perspectives. In particular, assume that we are given an incomplete non-uniformed observation tensor (or 3-dimensional array), which consists of the preference matrix pattern corresponding to the snapshots of the underlying dynamic relationships at time . Then the preference inference task is to estimate the possible pattern of the dynamic preference matrix at time based on the given the 3-dimensional observation tensor. It is notice that, despite maintaining the dynamic property, the underlying eRRH/content-UE relationships in reality always display some “redundancy” attributed to the gradual periodic variation and the relatively stability [31]. With this property, the tensor consisting of the preference matrix patterns at T can be considered to be low-rank.
To construct synthetic networks for simulation, we first consider a complete dynamic eRRH/content-UE relationship network whose preference tensor is , . The slide of at time T is an preference matrix pattern in the form of (1). In addition, for the gradual periodic variation, only a few kinds of (eRRH-UE group partition styles) exist in and the patterns similar to each others are usually close in time. The observation tensor is formed by sampling some entries from non-uniformly. Concretely, we let the F-RAN with the same settings in Section 5.1. Besides, for , let the eRRH-UE cluster number be varied from 10 to 30 with step size 5, and for each cluster, 4 eRRH-UE group styles are generated randomly with Gaussian distribution as the basic styles. Then each basic style generates the other derived styles by perturbation and the total number of group style set is 40. We further assume that and each group style appears randomly but more than once. The non-uniform sampling-rate of the original tensor from 0.1 to 0.9 (it is realized by non-uniform sampling each slide with the given sampling-rate). Then with the given observed , the task of the preference inference at time is achieved by solving the following problem:
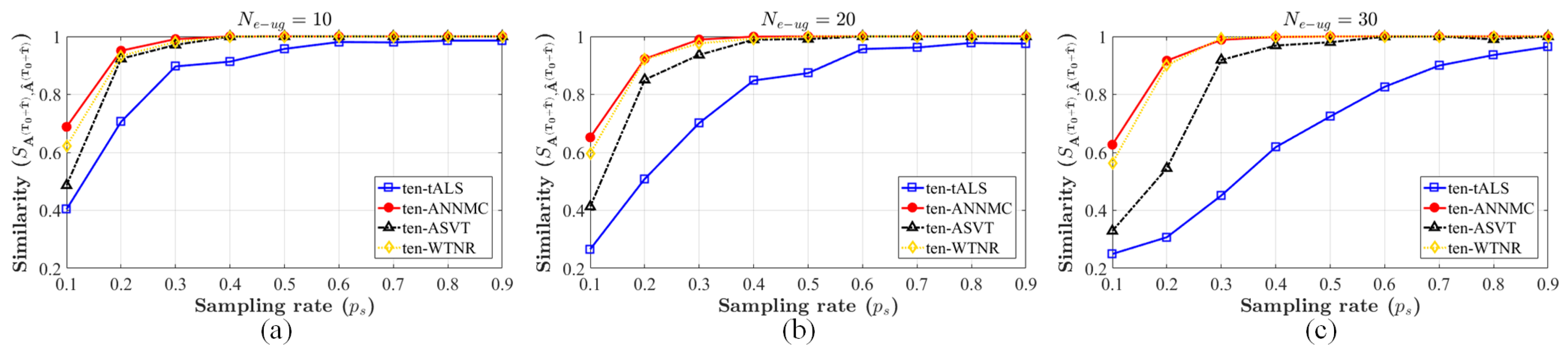
where is the kth mode on , and extracting the slide of at the time as the inferred pattern .
Similar with the approach in Section 3, we use ten-ANNMC, the variation of the algorithm (2) for tensor completion problem (19) to estimate , and compare the performance of our approach to the variations of the same algorithms in Section 5.1 for tensor completion (ten-tALS, ten-ASVT and ten-WTNR). , the similarity between the inferred matrix and the original setting , is utilized to indicate the accuracy of estimation as well. We implement the algorithms to infer one of the group patterns generated before with the eRRH-UE cluster number = 10, 20, 30 respectively and plot the inference accuracy in Figure 7. The inferred results is shown that our inference approach can almost be accurately estimated the objective group style and apparently outperforms the others. Meanwhile, the results for tensor completion case is worse than the matrix completion in Section 5.1 when the sampling-rate is low ( and ). This phenomenon is due to the fact that the inference based on tensor completion blends the the observation records of the different patterns with the . However, this strategy is benefit for the content pre-caching since the inferred matrix pattern can partly integrate the features of the observation () and be more likely to meet the requests.
5.3. Performance of the Energy Consumption
In this section, simulation results are provided to evaluate the energy consumption of the proposed cluster content caching strategy in the F-RAN. The terms for energy consumption simulation are consistent with the description in Section 4. Referring to the linear energy consumption model and the real energy measurements in [26], the power consumption of the single content caching for the eRRH and backhaul transmissions are set as W·sec and W·sec, respectively. Assume that the content type number I and , the number of the best popular contents corresponding to the different types, are given and large enough. Also, all of the eRRHs in one cluster cache the same contents to ensure the service quality. We then construct the complete preference matrix according to the method mentioned in Section 5.1 at the beginning as reference. The contents cached in each eRRH cluster for UEs’ requests are determined by using pre-caching strategy in Section 2 (which can be presented by the value set of the corresponding block in ). Since the caching contents in this scenario are exactly matched the UEs’ requests without retransmission, the corresponding average total energy cost for each eRRH can be considered to be the minimum, i.e, W·sec.
With the aforementioned assumptions, two pre-caching strategies are applied and compared for energy consumption analysis. The first one is the proposed edge caching/transmission strategy based on the content caching pre-mapping and description in Section 2. Due to the fact that is the is the size of the eRRH cache (see Equation (16)) and , to improve the QoS for users, we will use the residual memory space to non-repetitively cache the contents by Zipf distribution, which obeys the popularity sorting for all contents. Subsequently, all cache in eRRH will be used and the average caching anergy cost is W·sec. Furthermore, note that the probability of retransmission is closely associated with the accuracy of the inferred by ANNMC, we set is equal to the similarity between the and the , i.e., . Therefore, with (16) and (17), the average total energy cost for each eRRH based on the proposed strategy is presented as W·sec ( in (17) is omitted since it is extremely smaller than the other terms). To compare performances, the traditional uniform per-caching strategy is given for simulation. For the traditional one, the active eRRHs in the F-RAN utilize all caches to retain the same content set selected by Zipf distribution obeying the popularity sorting for all contents. Hence, while the is equal to that of the proposed strategy, the retransmission energy cost is W·sec where . Then W·sec. Both of the strategies are compared with the minimum consumption , which represents the lower bound.
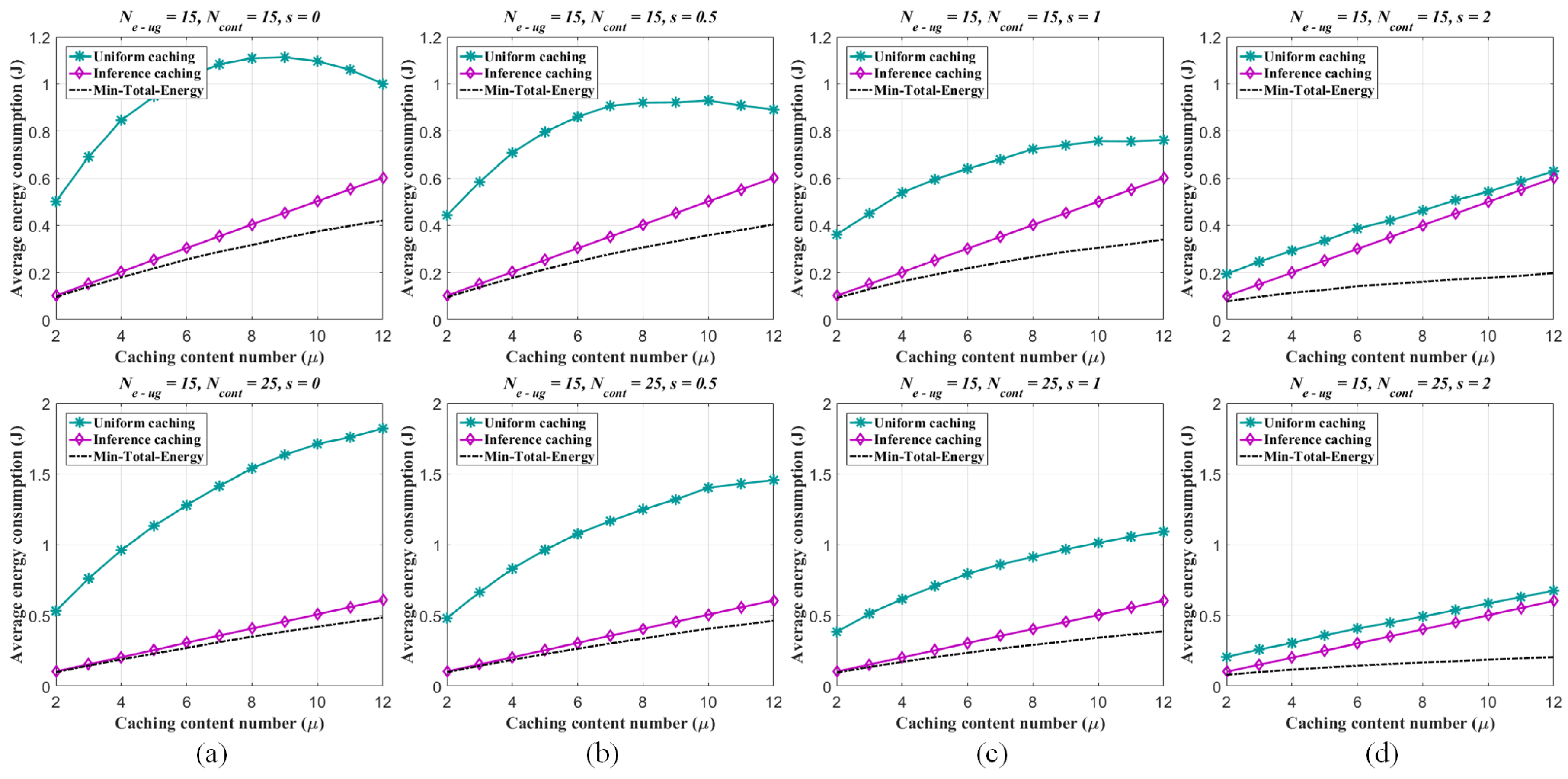
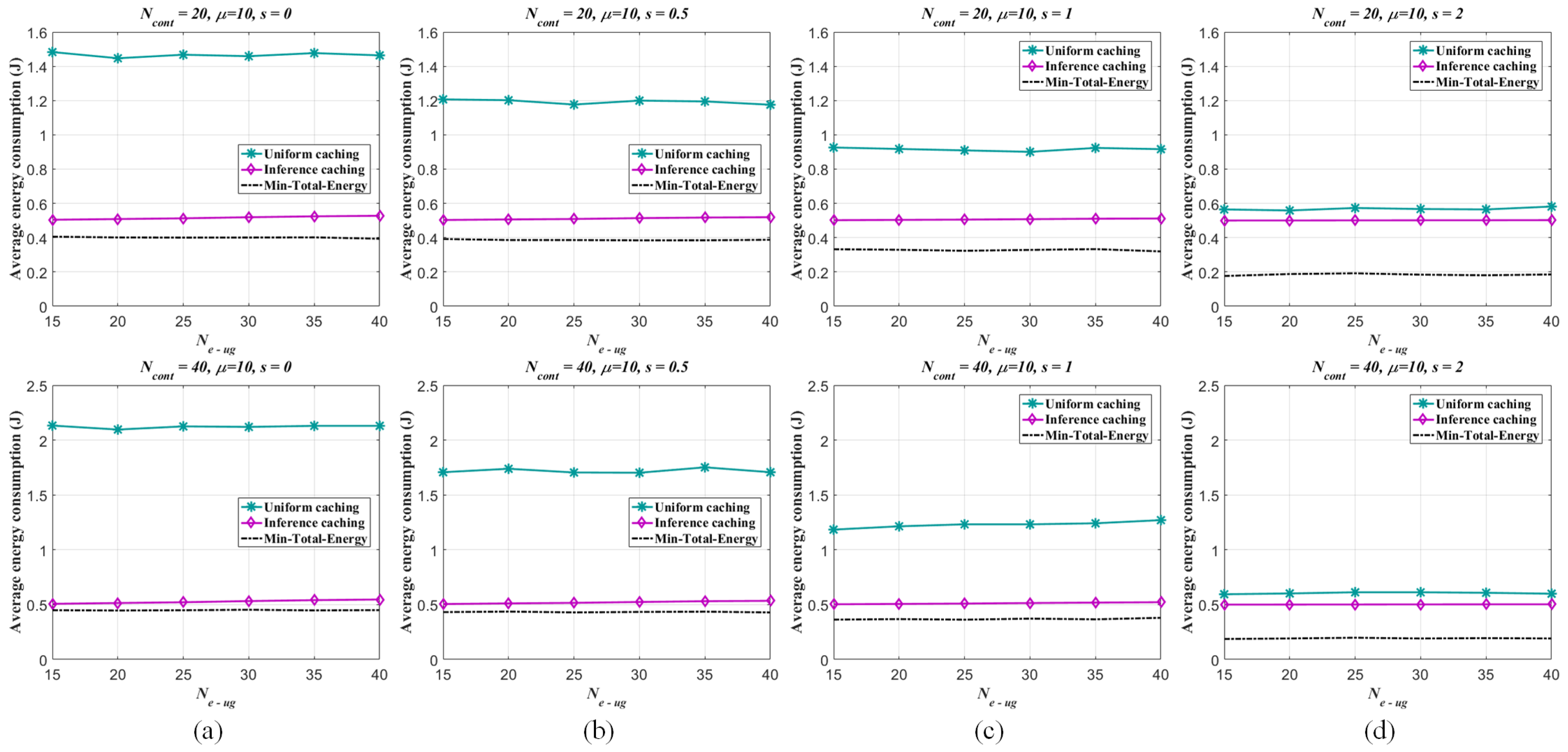
The energy consumption performances of the per-caching strategies are evaluated as follows. For one thing, given the numbers of the UEs and eRRHs respectively (, ) and fixed the UE/eRRH cluster number (), the number of the all alternative contents and the Zipf exponent s are changed respectively (; ). The non-uniform sampling rate for pre-mapping construction by ANNMC is set to be and the corresponding inference similarity . The average energy consumptions generated by the different number of caching contents in each eRRH are illustrated in Figure 8. By given and , the trends of the energy consumption via the changes of the caching content number and the alternative content number are shown in Figure 9 as well. As shown in the figures, the proposed caching strategy via the pre-mapping inference emerges better performance of the energy efficiency than the traditional one.
Meanwhile, the energy efficiency performance of the traditional strategy is approximating to the caching strategy via inference as s increasing, since the user interests converge to fewer popular content objects stored in the BBU pool. For the other, we fix and the number of caching contents in each eRRH () and show the energy consumption associated with the number of the UE/eRRH clusters in Figure 10. While the better performance of the proposed strategy and the similar properties related to the Zipf exponent s are illustrated in this figure, the average energy consumption of the proposed strategy slightly increases as the UE/eRRH cluster number is enlarged (i.e., the size of the cluster is decreased), since the rank of the matrix (i.e., ) effects the inferring accuracy by using ANNMC ( when changes from 15 to 40 with 5 interval). Also, due to the user interests converging to fewer popular content objects when s is increasing as well, the average energy consumption increasing trend is weaken. Furthermore, by given , and varied form 40 to 200, the trends of the energy consumption via the changes of the caching content number and the UE/eRRH cluster number are shown in Figure 11. It illustrates that the energy efficiency performance is weaken along with the increasing of the caching content number and the UE/eRRH cluster number. Especially, fixing the caching content number, the worst energy efficiency performance of our proposed strategy is almost reached when the UE/eRRH cluster number meets the maximum (i.e., ).
6. Conclusions
In this paper, based on digging out the non-uniform observed users’ network behavior information, we propose an edge content pre-caching strategy in F-RANs to improve the QoS for the users and energy efficiency. Especially, we analyze the relationships among the users’ activity, the content requesting and the state of the eRRH caching, and established pre-mapping for users’ content preference inferring by an accelerated non-convex matrix completion algorithm with the non-uniform observations. The dynamic scenario is also discussed and the developed variation based on tensor completion possesses good performance for the inferring task. In addition, the energy consumption analysis is given to reveal the properties of the pre-mapping based caching strategy. The simulation results show that the inferring algorithm for pre-mapping construction (preference inferring) is effective. Meanwhile, the inferring-based caching strategy possesses the advantages in energy saving compared to traditional uniform caching via Zipf distribution.
Author Contributions
Y.C. (Yi Cen) contributes mostly to this paper on introduction, system model and solutions. Y.C. (Yi Cen) and K.W. main contribution is to the algorithm design. Y.C. (Yi Cen), Y.C. (Yigang Cen) and J.L. main contribution is to the simulation and analysis part.
Funding
This research was funded by the National Natural Science Foundation of China (61602538, 61872034, 61572067), Project D010109, the Double-First Class Fund and the Scientific Research Fund for Young Teachers of Minzu University of China.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof of Theorem 2.
Let and , which implies the nonzero entries of the diagonal matrices are in non-increasing order. Since the penalty term only depends on the singular values of , problem can be equivalently written as
For the inner minimization, due to von Neumann’s trace inequality, we have
Especially the equality holds when admits the singular value decomposition , where and are defined as the left and right singular matrices of . Meanwhile , where and are defined as the left and right singular matrices of . Then the optimization reduces to
Note that , i.e.,
the objective function is completely separable and is minimized only when
where denotes the gradient for .
Utilizing and , we have
i.e.,
Therefore is a global optimal solution to the optimization problem. The uniqueness of the solution follows by the equality condition for the von Neumann’s trace inequality when has distinct nonzero singular values, and the uniqueness of the strictly convex optimization (A2). This concludes the proof. □
Proof of Theorem 4.
Since ,
For , using the well-known properties of Moreau-Yosida Regularization [32], we get the results that is a globally continuously differentiable convex function.
Moreover, and is continuously differentiable with Lipschitz continuous gradient 1, i.e., for any ,
Then the gradient of can be obtained as follows:
It follows that for any ,
Following from Theorem 3 and Cauchy-Schwarz inequality, we have
When the dual optimal is obtained, by using the result of Equation (A6), we can get
This concludes the proof. □
References
- Zikria, Y.; Kim, S.; Afzal, M.; Wang, H.; Rehmani, M. 5G Mobile services and scenarios: Challenges and solutions. Sustainability 2018, 10, 3626. [Google Scholar] [CrossRef]
- Checko, A.; Christiansen, H.L.; Yan, Y.; Scolari, L.; Kardaras, G.; Berger, M.S.; Dittmann, L. Cloud RAN for mobile networks—A technology overview. IEEE Commun. Surv. Tutor. 2015, 17, 405–426. [Google Scholar] [CrossRef]
- Peng, M.; Wang, C.; Lau, V.; Poor, H.V. Fronthaul-constrained cloud radio access networks: Insights and challenges. IEEE Wirel. Commun. 2015, 22, 152–160. [Google Scholar] [CrossRef]
- Wang, K.; Li, X.; Ji, H.; Du, X. Modeling and optimizing the LTE discontinuous reception mechanism under self-similar traffic. IEEE Trans. Veh. Technol. 2016, 65, 5595–5610. [Google Scholar] [CrossRef]
- Wang, K.; Yu, X.; Lin, W.; Deng, Z.; Liu, X. Computing aware scheduling in mobile edge computing system. Wirel. Netw. 2019. [Google Scholar] [CrossRef]
- Park, S.H.; Simeone, O.; Sahin, O.; Shitz, S.S. Fronthaul compression for cloud radio access networks: Signal processing advances inspired by network information theory. IEEE Signal Process. Mag. 2014, 31, 69–79. [Google Scholar] [CrossRef]
- Peng, M.; Yan, S.; Zhang, K.; Wang, C. Fog-computing-based radio access networks: Issues and challenges. IEEE Netw. 2015, 30, 46–53. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, R.; Ding, Z.; Cui, S. Wireless communications in the era of big data. Commun. Mag. IEEE 2015, 53, 190–199. [Google Scholar] [CrossRef] [Green Version]
- Park, S.H.; Simeone, O.; Shitz, S.S. Joint optimization of cloud and edge processing for fog radio access networks. IEEE Trans. Wirel. Commun. 2016, 15, 7621–7632. [Google Scholar] [CrossRef]
- Peng, X.; Shen, J.C.; Zhang, J.; Letaief, K.B. Backhaul-aware caching placement for wireless networks. In Proceedings of the 2015 IEEE Global Communications Conference, San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Tandon, R.; Simeone, O. Cloud-aided wireless networks with edge caching: Fundamental latency trade-offs in fog radio access networks. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 2029–2033. [Google Scholar]
- Tao, M.; Chen, E.; Zhou, H.; Yu, W. Content-centric sparse multicast beamforming for cache-enabled cloud RAN. IEEE Trans. Wirel. Commun. 2016, 15, 6118–6131. [Google Scholar] [CrossRef]
- Sengupta, A.; Tandon, R.; Simeone, O. Fog-aided wireless networks for content delivery: Fundamental latency tradeoffs. IEEE Trans. Inf. Theory 2017, 63, 6650–6678. [Google Scholar] [CrossRef]
- Zhao, Z.; Peng, M.; Ding, Z.; Wang, W.; Poor, H.V. Cluster content caching: An energy-efficient approach to improve quality-of-service in cloud radio access networks. IEEE J. Sel. Areas Commun. 2016, 34, 1207–1221. [Google Scholar] [CrossRef]
- Shanmugam, K.; Golrezaei, N.; Dimakis, A.G.; Molisch, A.F.; Caire, G. FemtoCaching: Wireless content delivery through distributed caching helpers. IEEE Trans. Inf. Theory 2013, 59, 8402–8413. [Google Scholar] [CrossRef]
- Candes, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717. [Google Scholar] [CrossRef]
- Keshavan, R.H.; Montanari, A.; Oh, S. Matrix completion from noisy entries. J. Mach. Learn. Res. 2009, 11, 2057–2078. [Google Scholar]
- Boumal, N.; Absil, P.A. Low-rank matrix completion via preconditioned optimization on the Grassmann manifold. Linear Algebra Appl. 2015, 475, 200–239. [Google Scholar] [CrossRef]
- Lai, M.J.; Xu, Y.; Yin, W. Improved iteratively re-weighted least squares for unconstrained smoothed ∖ell_q minimization. SIAM J. Numer. Anal. 2013, 51, 927–957. [Google Scholar] [CrossRef]
- Marjanovic, G.; Solo, V. On l_q optimization and matrix completion. IEEE Trans. Signal Process. 2012, 60, 5714–5724. [Google Scholar] [CrossRef]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science and Business Media: Berlin, Germany, 2013; Volume 87. [Google Scholar]
- Nemirovski, A. Efficient Methods in Convex Programming; Technion: Haifa, Israel, 2005. [Google Scholar]
- Cen, Y.; Cen, Y.; Wang, K.; Li, J.; Chen, S.; Zhang, L.; Tao, D. Low-rank tensor estimation via generalized norm/quasi-norm difference regularization. In Proceedings of the 2018 4th International Conference on Big Data Computing and Communications (BIGCOM), Chicago, IL, USA, 7–9 August 2018; pp. 144–149. [Google Scholar]
- Gabry, F.; Bioglio, V.; Land, I. On energy-efficient edge caching in heterogeneous networks. IEEE J. Sel. Areas Commun. 2016, 34, 3288–3298. [Google Scholar] [CrossRef]
- Feeney, L.M.; Nilsson, M. Investigating the energy consumption of a wireless network interface in an ad hoc networking environment. In Proceedings of the Twentieth Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM 2001), Anchorage, AK, USA, 22–26 April 2001; Volume 3, pp. 1548–1557. [Google Scholar]
- Xu, J.; Ota, K.; Dong, M. Saving energy on the edge: In-memory caching for multi-tier heterogeneous networks. IEEE Commun. Mag. 2018, 56, 102–107. [Google Scholar] [CrossRef]
- Hsieh, C.J.; Chiang, K.Y.; Dhillon, I.S. Low rank modeling of signed networks. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 507–515. [Google Scholar]
- Salakhutdinov, R.; Srebro, N. Collaborative filtering in a non-uniform world: Learning with the weighted trace norm. In Proceedings of the 23rd International Conference on Neural Information Processing Systems-Volume 2, Vancouver, BC, Canada, 6–9 December 2010; pp. 2056–2064. [Google Scholar]
- Hu, Y.; Zhang, D.; Liu, J.; Ye, J.; He, X. Accelerated singular value thresholding for matrix completion. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 298–306. [Google Scholar]
- Dunlavy, D.M.; Kolda, T.G.; Acar, E. Temporal link prediction using matrix and tensor factorizations. ACM Trans. Knowl. Discov. Data (TKDD) 2011, 5, 10. [Google Scholar] [CrossRef]
- Hiriart-Urruty, J.B.; Lemaréchal, C. Convex Analysis and Minimization Algorithms I: Fundamentals; Springer Science and Business Media: Berlin, Germany, 2013; Volume 305. [Google Scholar]
Figure 1.
An architecture of F-RAN scheduling framework. The UEs with the same preference are denoted by the same color and the dotted loops of different colors denote the areas where the corresponding preferences are dominant.
Figure 1.
An architecture of F-RAN scheduling framework. The UEs with the same preference are denoted by the same color and the dotted loops of different colors denote the areas where the corresponding preferences are dominant.

Figure 2.
Queueing model of content object transmission with one eRRH-cluster content caching in F-RANs.
Figure 2.
Queueing model of content object transmission with one eRRH-cluster content caching in F-RANs.

Figure 3.
The structure of matrix A corresponding to the complete request data for the entire F-RAN. (a) presents the structure of the entire matrix; (b) is used to illustrate each positive sub-block with different shades of gray, the rows and the columns of the sub-block correspond to the users and the eRRHs in the same cluster.
Figure 3.
The structure of matrix A corresponding to the complete request data for the entire F-RAN. (a) presents the structure of the entire matrix; (b) is used to illustrate each positive sub-block with different shades of gray, the rows and the columns of the sub-block correspond to the users and the eRRHs in the same cluster.

Figure 4.
Comparison of similarity by different preference inferring algorithms (tALS, ASVT, WTNR and ANNMC) on the synthetic dataset. The number of blocks corresponding to (a), 20 corresponding to (b) and 30 corresponding to (c). The range of the non-uniform sampling-rate is varied from 0.1 to 0.9 and the content types .
Figure 4.
Comparison of similarity by different preference inferring algorithms (tALS, ASVT, WTNR and ANNMC) on the synthetic dataset. The number of blocks corresponding to (a), 20 corresponding to (b) and 30 corresponding to (c). The range of the non-uniform sampling-rate is varied from 0.1 to 0.9 and the content types .

Figure 5.
(a) shows the estimation similarity of the structure estimation for the preference matrix with the number of the content types , the number of groups and the non-uniform sampling-rate ; (b) is Convergence rate of ANNMC and WTNR on the synthetic data with the number of the content types , and the non-uniform sampling-rate .
Figure 5.
(a) shows the estimation similarity of the structure estimation for the preference matrix with the number of the content types , the number of groups and the non-uniform sampling-rate ; (b) is Convergence rate of ANNMC and WTNR on the synthetic data with the number of the content types , and the non-uniform sampling-rate .

Figure 6.
An visualized example of the pre-mapping construction for the preference matrix (, ). (a) is the original preference matrix; (b) is the estimation result with non-uniform samples (the similarity is 0.9942); (c) is the estimation result with non-uniform samples (the similarity is 0.9991).
Figure 6.
An visualized example of the pre-mapping construction for the preference matrix (, ). (a) is the original preference matrix; (b) is the estimation result with non-uniform samples (the similarity is 0.9942); (c) is the estimation result with non-uniform samples (the similarity is 0.9991).

Figure 7.
Comparison of similarity by different preference inferring algorithms for tensor completion (ten-tALS, ten-ASVT, ten-WTNR and ten-ANNMC) on the synthetic dataset. The number of blocks corresponding to (a), 20 corresponding to (b) and 30 corresponding to (c). The range of the non-uniform sampling-rate is varied from 0.1 to 0.9 and the content types .
Figure 7.
Comparison of similarity by different preference inferring algorithms for tensor completion (ten-tALS, ten-ASVT, ten-WTNR and ten-ANNMC) on the synthetic dataset. The number of blocks corresponding to (a), 20 corresponding to (b) and 30 corresponding to (c). The range of the non-uniform sampling-rate is varied from 0.1 to 0.9 and the content types .

Figure 8.
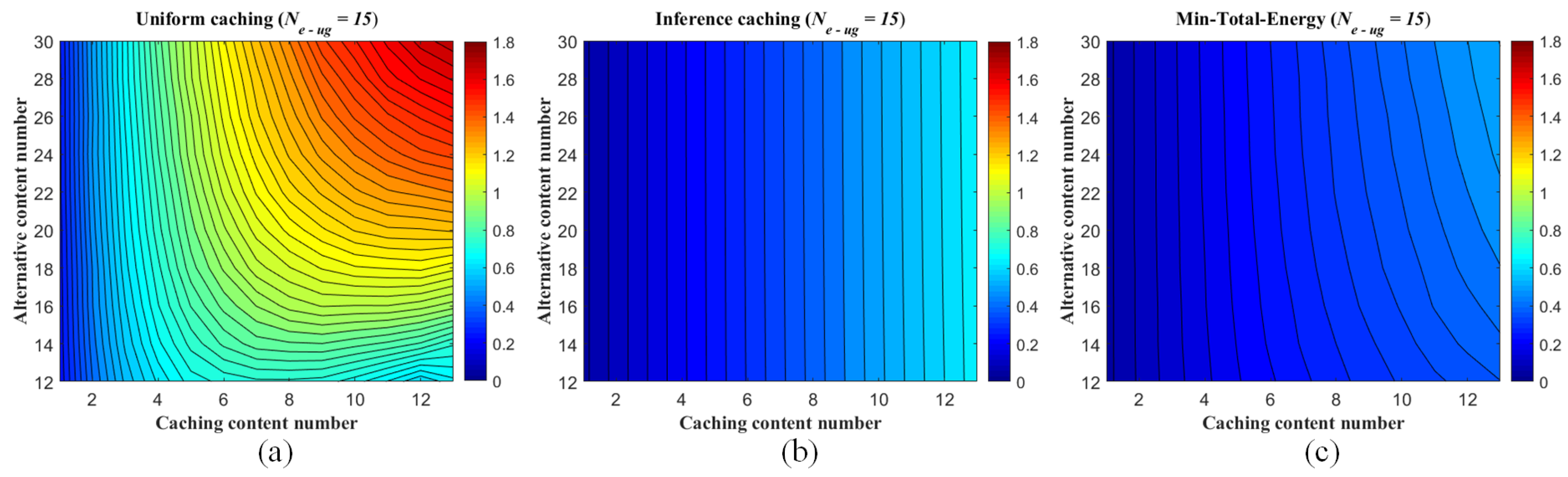
Average energy consumption of each eRRH in the F-RAN on the synthetic dataset (measured as J due to W·sec). Two different edge caching strategies are considered: (i) uniform caching strategy via content Zipf distribution, (ii) inferring caching strategy via pre-mapping (inferred by ANNMC with non-uniform sampling rate ) and Zipf distribution. The average energy consumptions of both strategies are compared with the minimum consumption . The range of the caching content number of each eRRH is varied from 2 to 12. The Zipf exponent , and (a–d) correspond to different s with , and 25.
Figure 8.
Average energy consumption of each eRRH in the F-RAN on the synthetic dataset (measured as J due to W·sec). Two different edge caching strategies are considered: (i) uniform caching strategy via content Zipf distribution, (ii) inferring caching strategy via pre-mapping (inferred by ANNMC with non-uniform sampling rate ) and Zipf distribution. The average energy consumptions of both strategies are compared with the minimum consumption . The range of the caching content number of each eRRH is varied from 2 to 12. The Zipf exponent , and (a–d) correspond to different s with , and 25.

Figure 9.
Average energy consumption range of each eRRH in the F-RAN on the synthetic dataset (measured as J) with the setting that and Zipf exponent . (a) is the uniform caching strategy via content Zipf distribution; (b) is the proposed inferring caching strategy via pre-mapping (inferring by ANNMC with non-uniform sampling rate ) and Zipf distribution; (c) is the minimum consumption .
Figure 9.
Average energy consumption range of each eRRH in the F-RAN on the synthetic dataset (measured as J) with the setting that and Zipf exponent . (a) is the uniform caching strategy via content Zipf distribution; (b) is the proposed inferring caching strategy via pre-mapping (inferring by ANNMC with non-uniform sampling rate ) and Zipf distribution; (c) is the minimum consumption .

Figure 10.
Average energy consumption of each eRRH in the F-RAN on the synthetic dataset ( W·sec). Two different edge caching strategies are considered: (i) uniform caching strategy via content Zipf distribution, (ii) inferring caching strategy via pre-mapping (inferred by ANNMC with non-uniform sampling rate ) and Zipf distribution. The average energy consumptions of both strategies are compared with the minimum consumption . The range of the eRRH/UE cluster number is varied from 15 to 40. The Zipf exponent , and (a–d) correspond to different s with , and 40.
Figure 10.
Average energy consumption of each eRRH in the F-RAN on the synthetic dataset ( W·sec). Two different edge caching strategies are considered: (i) uniform caching strategy via content Zipf distribution, (ii) inferring caching strategy via pre-mapping (inferred by ANNMC with non-uniform sampling rate ) and Zipf distribution. The average energy consumptions of both strategies are compared with the minimum consumption . The range of the eRRH/UE cluster number is varied from 15 to 40. The Zipf exponent , and (a–d) correspond to different s with , and 40.

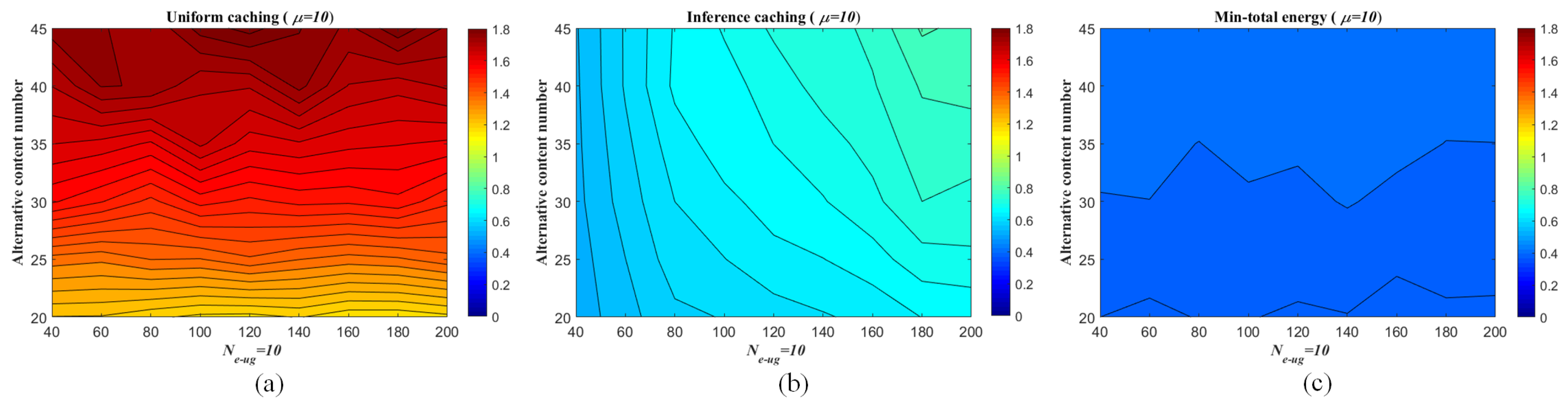
Figure 11.
Average energy consumption range of each eRRH in the F-RAN on the synthetic dataset (measured as J) with the setting that and Zipf exponent . (a) is the uniform caching strategy via content Zipf distribution; (b) is the proposed inferring caching strategy via pre-mapping (inferring by ANNMC with non-uniform sampling rate ) and Zipf distribution; (c) is the minimum consumption .
Figure 11.
Average energy consumption range of each eRRH in the F-RAN on the synthetic dataset (measured as J) with the setting that and Zipf exponent . (a) is the uniform caching strategy via content Zipf distribution; (b) is the proposed inferring caching strategy via pre-mapping (inferring by ANNMC with non-uniform sampling rate ) and Zipf distribution; (c) is the minimum consumption .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The parameter settings of the ANNMC.
| Parameter | |||||||
|---|---|---|---|---|---|---|---|
| Setting | 0.5 | 0.1 | 0.5 | 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cen, Y.; Cen, Y.; Wang, K.; Li, J. Energy-Efficient Nonuniform Content Edge Pre-Caching to Improve Quality of Service in Fog Radio Access Networks. Sensors 2019, 19, 1422. https://doi.org/10.3390/s19061422
AMA Style
Cen Y, Cen Y, Wang K, Li J. Energy-Efficient Nonuniform Content Edge Pre-Caching to Improve Quality of Service in Fog Radio Access Networks. Sensors. 2019; 19(6):1422. https://doi.org/10.3390/s19061422
Chicago/Turabian StyleCen, Yi, Yigang Cen, Ke Wang, and Jingcong Li. 2019. "Energy-Efficient Nonuniform Content Edge Pre-Caching to Improve Quality of Service in Fog Radio Access Networks" Sensors 19, no. 6: 1422. https://doi.org/10.3390/s19061422
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.