A Personalized Behavior Learning System for Human-Like Longitudinal Speed Control of Autonomous Vehicles


1
School of Mechanical Engineering, Beijing Institute of Technology, Beijing 100081, China
2
School of Mechanical and Aerospace Engineering and School of Electrical and Electronic Engineering, Nanyang Technological University, Singapore 639798, Singapore
3
Department of Mechanical and Mechatronics Engineering, University of Waterloo, 200 University Avenue West Waterloo, Waterloo, ON N2L3G1, Canada
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(17), 3672; https://doi.org/10.3390/s19173672
Submission received: 6 July 2019
/
Revised: 2 August 2019
/
Accepted: 20 August 2019
/
Published: 23 August 2019
(This article belongs to the Section Intelligent Sensors)
Abstract
:As the main component of an autonomous driving system, the motion planner plays an essential role for safe and efficient driving. However, traditional motion planners cannot make full use of the on-board sensing information and lack the ability to efficiently adapt to different driving scenes and behaviors of different drivers. To overcome this limitation, a personalized behavior learning system (PBLS) is proposed in this paper to improve the performance of the traditional motion planner. This system is based on the neural reinforcement learning (NRL) technique, which can learn from human drivers online based on the on-board sensing information and realize human-like longitudinal speed control (LSC) through the learning from demonstration (LFD) paradigm. Under the LFD framework, the desired speed of human drivers can be learned by PBLS and converted to the low-level control commands by a proportion integration differentiation (PID) controller. Experiments using driving simulator and real driving data show that PBLS can adapt to different drivers by reproducing their driving behaviors for LSC in different scenes. Moreover, through a comparative experiment with the traditional adaptive cruise control (ACC) system, the proposed PBLS demonstrates a superior performance in maintaining driving comfort and smoothness.
1. Introduction
During the last several decades, considerable efforts have been made to design and develop highly autonomous vehicles that can drive with little or even no interventions from human drivers. However, the overall architecture for designing autonomous vehicles has not been improved too much. Most of the existing autonomous vehicles share the same three-layer system architecture, i.e., “sensing and perception” layer, “motion planner” layer, and “vehicle controller” layer [1,2].
Of the three layers, motion planner is responsible for generating a feasible reference trajectory for the low-level controllers to follow [3]. In the simple traffic environment with little or even no surrounding vehicles, this kind of motion planner has shown its effectiveness and has been successfully applied for autonomous driving [4]. However, when more complex environments with dense traffic are considered, the increased requirements of driving smoothness, comfort, and personalized adaptation complicate the motion planner and make it difficult to find a feasible reference trajectory within the time limit [1]. It has been found that experienced human drivers seem to work well in such complex environments without using a sophisticated algorithm to compute the optimal trajectory [5,6]. Moreover, human-like driving can improve the acceptance of autonomous vehicles by considering human personalities [7]. Therefore, how to learn and extract the behavior of human drivers and use the learned behavior to improve the motion planner has attracted increasing attention in the autonomous driving community [1,6,7,8]. To this end, during the last decades, some studies have been done to model human driving behavior and develop human-like control systems for vehicles.
In the work carried out by [9], a fuzzy system is developed to model the behavior of an experienced human driver for parking a vehicle. A number of rules for the parking task can be extracted from the human experience and used to control the vehicle autonomously. Hybrid systems composed of both continuous models and discrete models are considered in [10] to model the driving behavior of drivers. A widely used hybrid model named autoregressive exogenous model (ARX) is selected because of its simplicity and high accuracy. In their model, human driving behavior is classified into different modes, and each mode corresponds to a continuous ARX model. By combining this kind of hybrid model with an MPC (model predictive control) controller, the driving behavior can be converted to the control commands for the vehicle [11].
Although the aforementioned rule- and model-based methods can reproduce human driving behavior in some cases, prior knowledge about the rule base and the model structure is usually required. For complex and dynamic scenarios, this kind of knowledge cannot be obtained easily in advance. In addition, human behaviors are strongly nonlinear, and it is very difficult to model human behaviors precisely using a physical model. Under such circumstances, learning-based methods that can learn directly from driving scenes and human demonstrators without prior knowledge are proposed. This kind of method is usually named learning from demonstration (LFD), which has been widely used in the humanoid robot domain to generate human-like movements [12]. For the vehicle control problem, the LFD method can help to reproduce the motion trajectories of the vehicle observed from human demonstrators [13].
Artificial neural networks (ANN) (both shallow and deep neural networks) [2,6,14,15,16,17,18] and Gaussian mixture models (GMM) [1,19,20,21] are commonly used methods for learning from driving scenes and drivers. Usually, driving data collected from drivers are used to train the ANN and the GMM offline, and, after training, the learned models can be connected with vehicle controllers to realize human-like control. Although these models have been applied to deal with complex traffic environments, the lack of online learning ability makes it difficult for these models to do the personalized adaptation during the learning process. Because of the online learning capability, reinforcement learning (RL) has been considered as a promising technology to improve the autonomous driving systems in recent years [22]. For instance, the Monte Carlo RL method is used by a collaborative driving system presented in [23] to improve the longitudinal control of vehicles. To solve both the longitudinal and the lateral control problems, a cooperative adaptive cruise control (CACC) system using the policy-gradient RL is built in [24]. For helping with the autonomous overtaking control, Q-learning (a kind of RL algorithm) is adopted by [25,26] to build the learning-based control systems. An actor-critic RL method is developed in [27] to improve the tracking precision and the driving smoothness for an autonomous vehicle. Although these RL-based systems can improve navigation and motion control for vehicles, the problem of learning personalized driving behavior and realizing the human-like control is not tackled by these studies.
This paper aims to develop a personalized behavior learning system (PBLS) based on RL with particular focus on the longitudinal speed control (LSC) problem for autonomous driving. The main contributions of this paper are as follows:
- A reinforcement-learning-based system is proposed in this paper to learn the driver behavior and realize the human-like control. Based on RL, the system dynamics are not required and can be learned directly from the interaction between drivers and the driving environment.
- By incorporating the controller into the learning system, the learned driving behavior can be converted to control commands for autonomous vehicles online, which realizes the personalized adaption for newly-involved drivers.
The remainder of this paper is organized as follows. Section 2 describes the system architecture of PBLS and gives the definition of different modules in the architecture. Then, Section 3 presents a solution algorithm for training PBLS. After that, two tests based on the driving simulator and the real driving data are shown in Section 4 and Section 5 to evaluate the performance of PBLS. Finally, Section 6 concludes the paper and gives future directions of the research.
2. Proposed Personalized Behavior Learning System
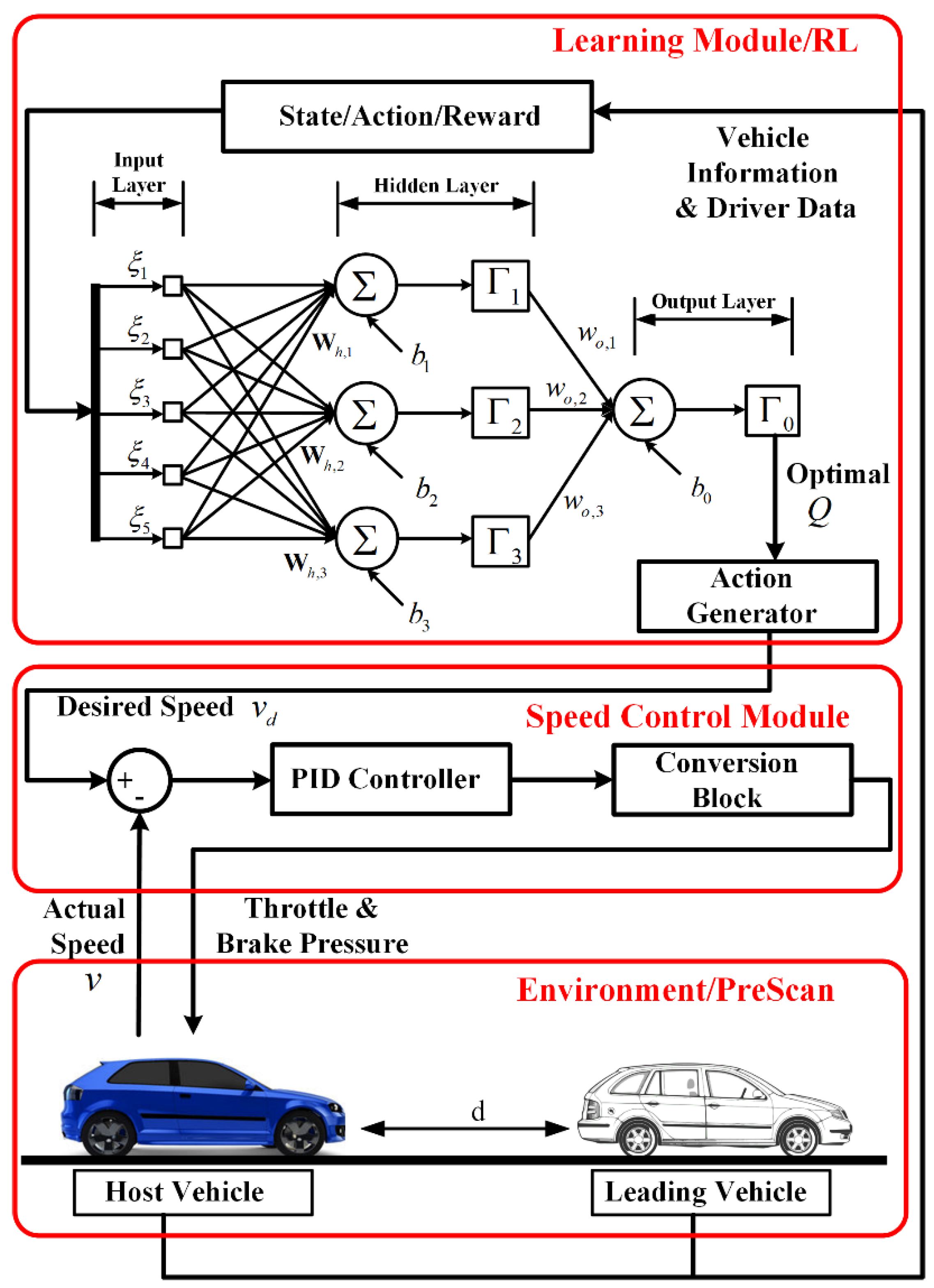
The system architecture for PBLS is shown in Figure 1, where the learning module is combined with a proportion integration differentiation (PID) controller to interact with the traffic environment during the learning process. In this study, the focus is on a typical LSC problem for car following. Considering the difficulties and the risks of testing the online learning system in real-world scenarios, the testing traffic scenarios are built in PreScan, a simulation tool for simulating vehicle dynamics and traffic environments [28]. The testing scenario for LSC consists of one host vehicle and one leading vehicle. The objective of the host vehicle is to follow the leading vehicle and try to keep a stable distance to the leading vehicle. Here, the host vehicle can either be controlled by a human driver or the proposed system. The driving data collected from the on-board sensors can be directly transferred to the learning module to activate the learning process.
The learning module is based on RL and can learn the desired longitudinal speed from human drivers when they are controlling the host vehicle. Using a PID controller, the desired speed can be converted to the low-level control commands for throttle and brake pressure. In this way, the human car-following behavior can be reproduced.
2.1. Formulation of the Learning Module
The objective of the learning module is to learn the desired speed of the human driver, i.e., to track the speed trajectory of a human driver. Thus, the learning problem can be defined as a trajectory tracking problem for the given system and a desired trajectory . Let , , thus the trajectory tracking problem can be solved by a linear quadratic regulator (LQR) for minimizing the following cost function:
such that,
where is the time index, is the state vector of the trajectory tracking problem, is the control action, and are matrices related to the system dynamics, and and are positive-definite matrices for weighting the cost function. The system dynamics is required for solving this problem based on the traditional LQR. For the real applications, the system dynamics are usually difficult to know in advance. In this case, an RL method can be used to learn the optimal solution to the trajectory tracking problem defined above.
Following [29], the cost at each time step can be defined by:
It should be noted that is different from its counterpart in the traditional RL problem where is the reward at each time step and is used to formulate a maximization problem. Here, is related to the tracking error for the human behavior and thus should be minimized. For each state-action pair , the Q function can be defined following the Bellman equation and is given as follows:
where , , , and are matrices related to the system dynamics and the weights of the cost function. By setting the derivative of with respect to to 0, i.e., , the optimal action can be derived and expressed by:
For the car-following scenario considered here, the system dynamics are highly related to the distance between the host vehicle and the leading vehicle (denoted by ) as well as the speed of the host vehicle (denoted by ). Thus, for the system , the following variables can be defined:
Therefore, the state and the control action of the tracking problem can be defined as:
where and are the speeds of the host vehicle controlled by the learning system and the human driver at time step , respectively, and are the distances controlled by the learning system and the human driver at time step , respectively, and and are the accelerations of the host vehicle controlled by the learning system and the human driver at time step , respectively.
Given the definition of state and action, the weights for the cost function can be determined as:
where .
2.2. Function Approximation Using ANN
It can be seen from (4) that, to get the explicit Q value for each state-action pair, the system dynamics are required, i.e., the exact values of , , , and should be given. In the learning problem considered in this study, the system dynamics are not known in advance, thus an alternative way is used to learn the Q values from data samples and estimate , , , and for the purpose of calculating the optimal action.
Assume that the Q function can be approximated by a linear function shown below:
where
Under the definition of Equation (9), Equation (4) can be rewritten as a linear function by setting:
By substituting Equation (12) into Equation (4), the following equation can be obtained:
According to Equation (13), one can easily get:
In this way, , , , and can be constructed when is obtained.
From the definition of state and action, it can be seen that both of these two variables are continuous, thus traditional RL methods such as the standard Q-learning that can only deal with the discrete state and action space cannot be used here. Under such circumstances, the neural Q-learning (NQL) algorithm is adopted by this study to deal with the continuous problem. Under the framework of NQL, the continuous Q function can be approximated by an artificial neural network, and thus all the possible state and action values can be coped with.
As shown in Figure 1, a three-layer feed forward ANN similar to [29] is designed for the learning module. To guarantee the performance of the ANN, all the input variables should be normalized [30]. For the feed forward ANN considered in this study, the state and action defined in Equation (7) are normalized as follows.
where , , , and are the maximum values of these two variables, and and are the minimum values of these two variables. Here, , , , and can be obtained from the data. In this way, both and can be normalized into a range between −1 and 1.
Similarly, the action can be normalized as:
In this way, all the elements of are normalized into [−1, 1]. Let be the input vector for the input layer, then the feed forward ANN can be defined by its activation functions for each node. The output of ANN is the optimal Q function, which can be expressed by:
where ( for five input variables) is the weight vector for the th node in the hidden layer, is the weight for the link from the th hidden node to the output node, is the bias for the th hidden node, and is the bias of the output node. When the optimal Q value is obtained, the elements of the parameter vector can be calculated by:
Then, the optimal action can be derived from Equation (5) through reconstructing and from according to Equation (14).
2.3. Speed Control Module
Given the action, the desired speed can be easily derived from Equation (16) and calculated by:
where and are the desired speeds for the th and the th time step, respectively.
The speed control module can then convert the desired speed to control commands for the throttle and the break pressure control of the host vehicle using a PID controller [31].
where is the tracking error between the desired speed and the actual speed, is the proportional gain, is the integral time, is the derivative time, and is the output of the controller, which can be converted to the throttle and the breaking control commands by a conversion block. Both the PID controller and the conversion block are embedded in PreScan and implemented as a module named “Path follower”. In this study, the default parameter values (provided by PreScan) for the PID controller are applied for all of the experiments. These default parameters provided by PreScan are set as: , , and .
3. Training Algorithm for PBLS
Technically, the goal of the learning system is to find the optimal Q value and its corresponding parameter vector . Temporal difference (TD) learning [32] is a method to solve this problem by making the TD error defined by Equation (21) approach zero:
Here, the feed forward ANN is used to accomplish this goal. For time steps, the errors should be cumulated to formulate the loss function for ANN. For ease of calculation, a quadratic loss function is defined as follows:
The first term of Equation (22) is related to the sum of squares of errors, which should be minimized by ANN. The second part of Equation (22) is named weight decay term, which is used here to avoid over-fitting by reducing the magnitude of the weights [33].
From the definition of , it can be seen that the bias of the hidden node does not affect the loss function and thus can be removed from Equation (17). Let be a linear function and be a number of hyperbolic tangent functions, then Equation (17) can be rewritten as:
The hyperbolic tangent function is selected, as it is a typical activation function for ANN and has been proven to be effective in many practical cases [30].
Thus, according to Equations (18) and (21), the elements of can be obtained from:
The second part of Equation (24) is very small when the weights and the biases are small and can be ignored, as suggested by [29]. Therefore, is only related to the weight matrix of the ANN and can be calculated when and are updated. As the objective of ANN is to minimize the loss function shown in Equation (22), the gradient decent method can be used here to update the weights. The weights for the output layer can be updated by:
where is the updating index, and the network is updated every time steps. Similarly, the weights for the hidden layer and the biases can be calculated by:
and
The key issue right now is how to get the gradients of weights and biases at each updating step, i.e., the terms , , and . To this end, the back propagation (BP) algorithm can be used to train the ANN via a mini-batch training method. Frequently updating the weights of the neural network, e.g., step-by-step update with = 1, may lead to poor generalization and unstable learning curves, especially for learning unstable human behaviors. To overcome this limitation, the network weights are usually updated every steps ( > 1) by using a small batch of data. This kind of training method is named mini-batch training and has been widely used for training neural networks [34]. In this paper, the mini-bath training is used to train the feedforward ANN, and, as suggested by [34], a small with the value 10 (between two and 32) is selected. This kind of setting can help to avoid the bias of newly collected driving data and guarantee a relatively smooth learning curve in our experiment. Based on BP, the whole algorithm for the learning system is developed and shown in Algorithm 1.
| Algorithm 1: Pseudo-code for PBLS |
Initialization
|
4. Experiments with Constant Speed
The proposed learning system (PBLS) is tested in a simulation platform built by PreScan and Matlab/Simulink in this section. As mentioned in Section 2, the vehicle information and the driver data are required by the learning system. In PreScan, both the host and the leading vehicles are equipped with a virtual lidar system, a Global Positioning System (GPS), and vehicle-to-vehicle (V2V) communication systems. The vehicle information in terms of location, speed, and distance between the host vehicle and the leading vehicle can be obtained through these on-board systems.
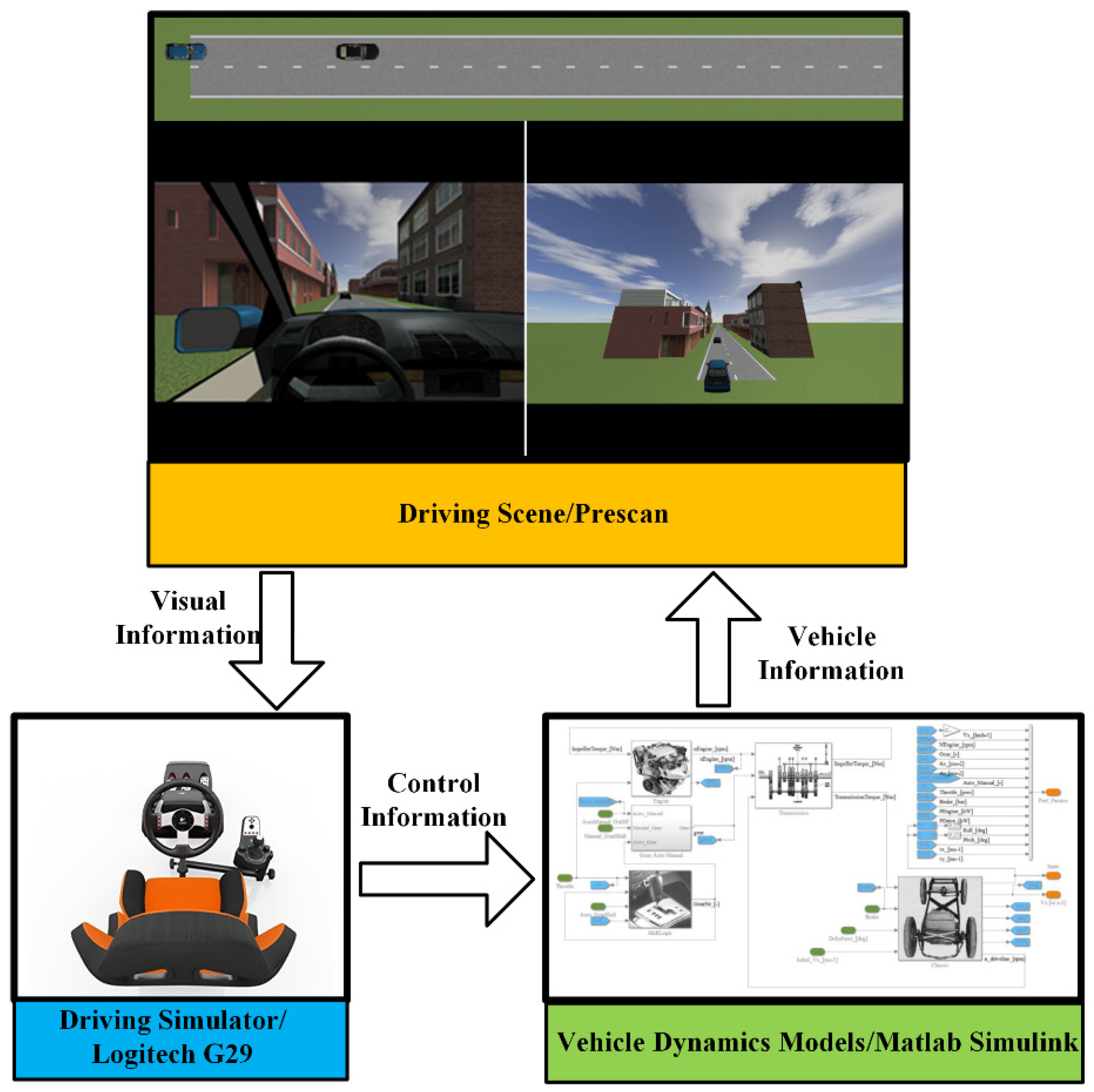
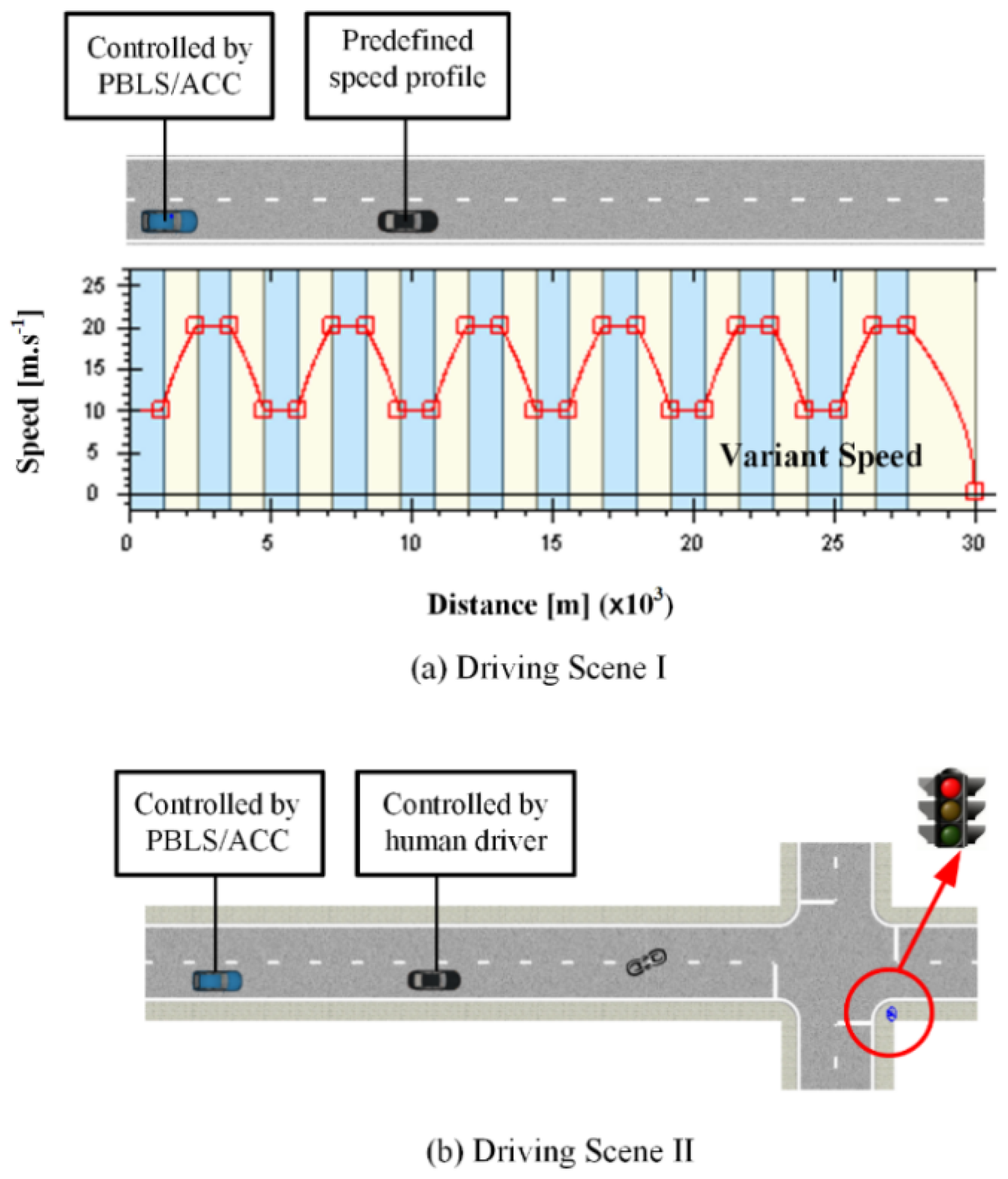
As shown in Figure 2, driver data can be collected by the Logitech G29 driving simulator through the human-in-the-loop experiments. For real applications, the driving data can be obtained through the on-board sensing system. The vehicles involved in the experiments are modeled by the typical 2-D vehicle dynamics models (single-track model), which are embedded in Matlab/Simulink. The traffic environment and the driving scene are simulated in PreScan, which is connected to the driving simulator and provides drivers with the visual information. Two groups of experiments with different speed profiles—constant speed (CS) and variant speed (VS)—for the leading vehicle are carried out to evaluate the performance of the proposed system.
In all the tests, the weight values are set as to guarantee that each part of the cost has the same importance. Other parameters for PBLS are shown in Table 1, which are chosen according to experience and can guarantee a stable performance of PBLS.
4.1. Experimental Settings
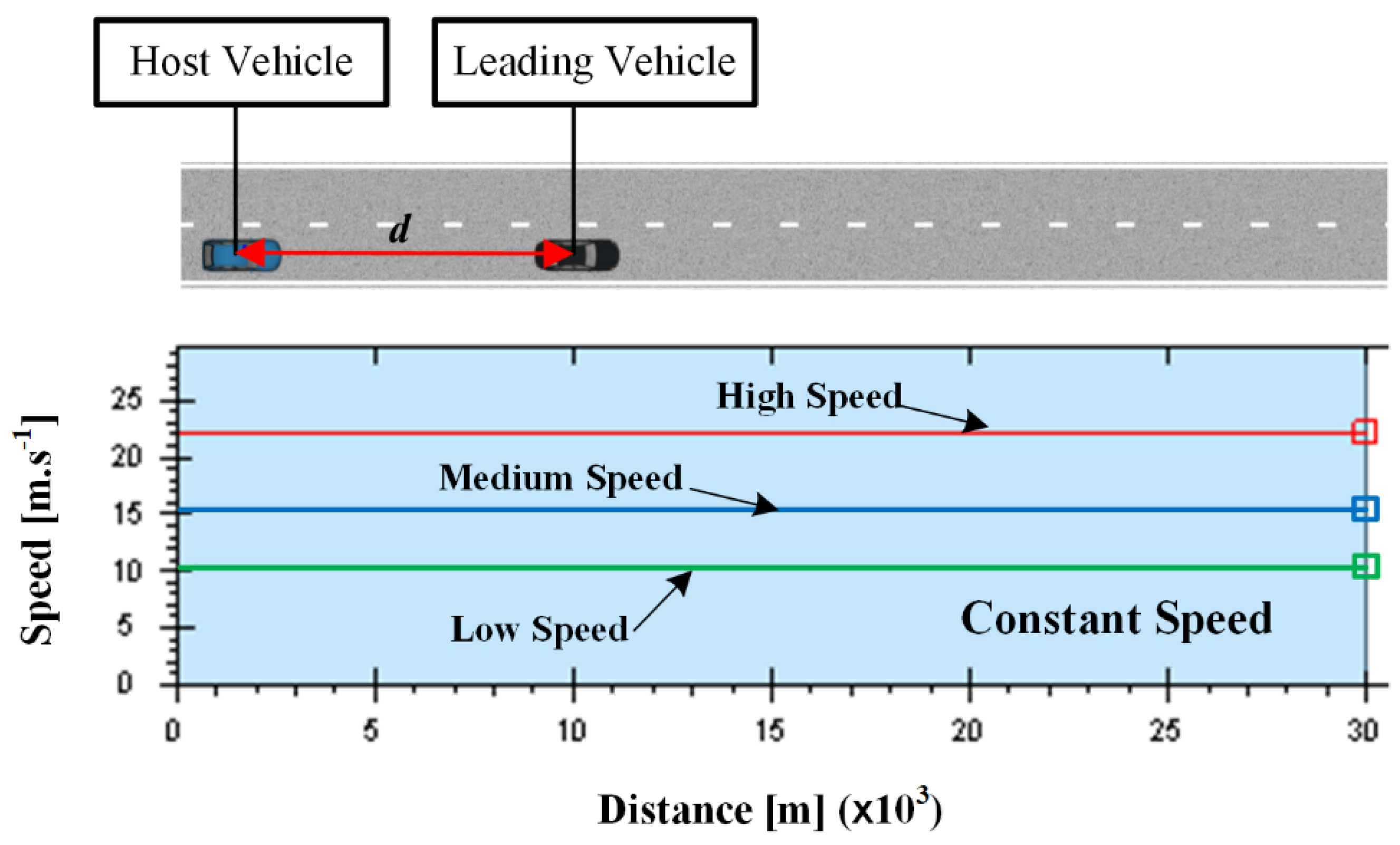
The driving scene used by the constant speed scenarios is shown in Figure 3. A straight two-lane urban road with a length of 30 km is considered. In the test, the driver is asked to drive the host vehicle first, and then the driving data collected from the driver are transferred to PBLS, which is used to control the host vehicle in the same scene and learn the driving behavior from the collected driving data online. When the learning algorithm is converged, PBLS can reproduce the learned behavior by setting the learning rate as zero.
In the first test, the leading vehicle keeps a constant speed, and three speed profiles, namely, low speed (L, 10 m·s−1), medium speed (M, 15 m·s−1), and high speed (H, 22 m·s−1), are designed to form three different test scenarios. To test the adaptive learning ability of the proposed system, two drivers (A and B) are involved and asked to follow the leading vehicle in all three scenarios. Then, the learning system is triggered to learn the driving behavior from these two drivers. It should be noted here that the focus of this study is to develop a personalized learning system that has the ability to adapt to different driving behaviors. This kind of adaptation can be tested by involving two different drivers in this section. Analytical work involving more drivers can be considered in our future study to analyze the algorithm performance under various kinds of driving behaviors.
RMSE (Root Mean Square Error) can be used to measure the learning error of the learning system, which is calculated by:
where is the data point related to the learning system at step , and is the observed data from human drivers at step .
4.2. Experimental Results
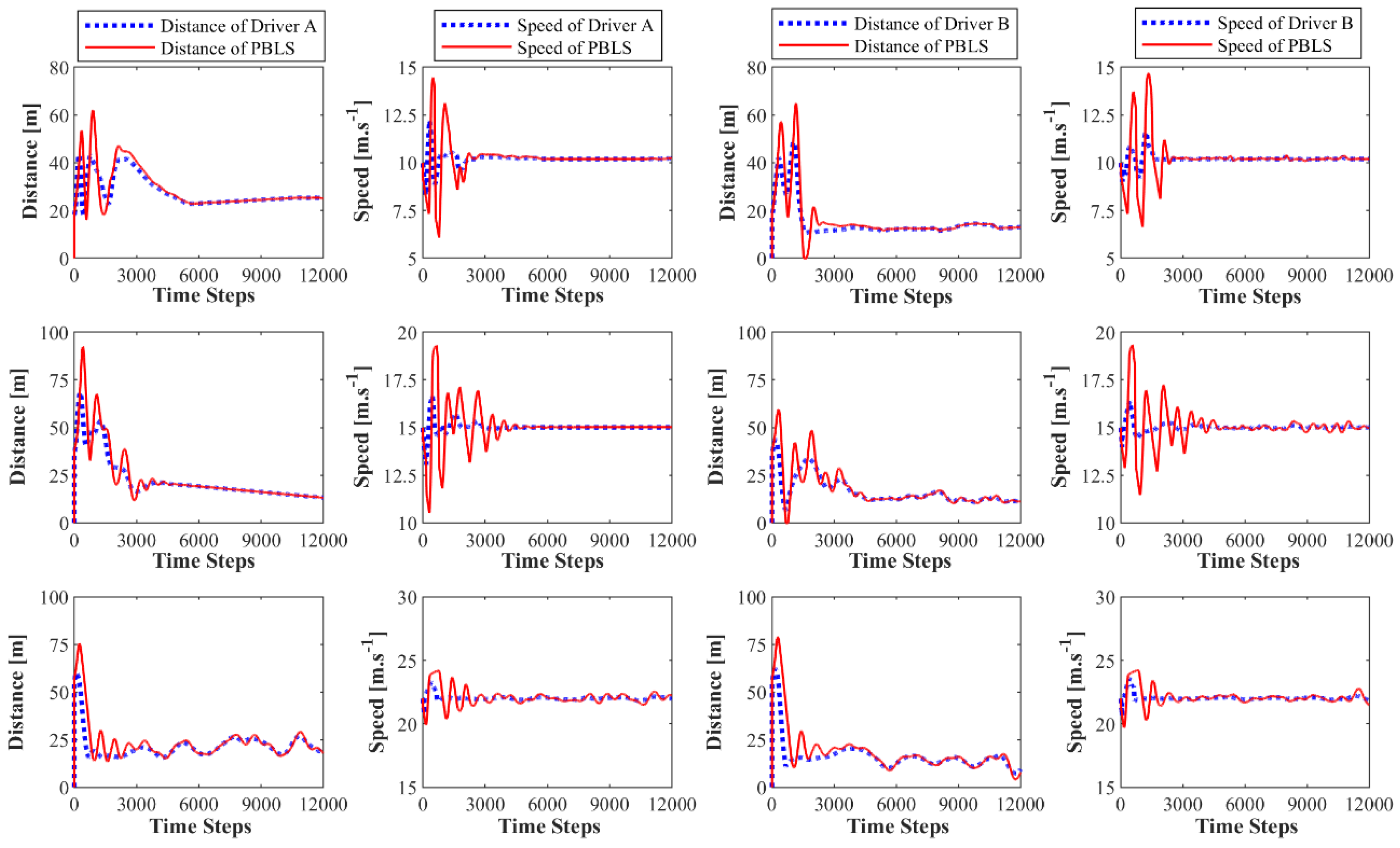
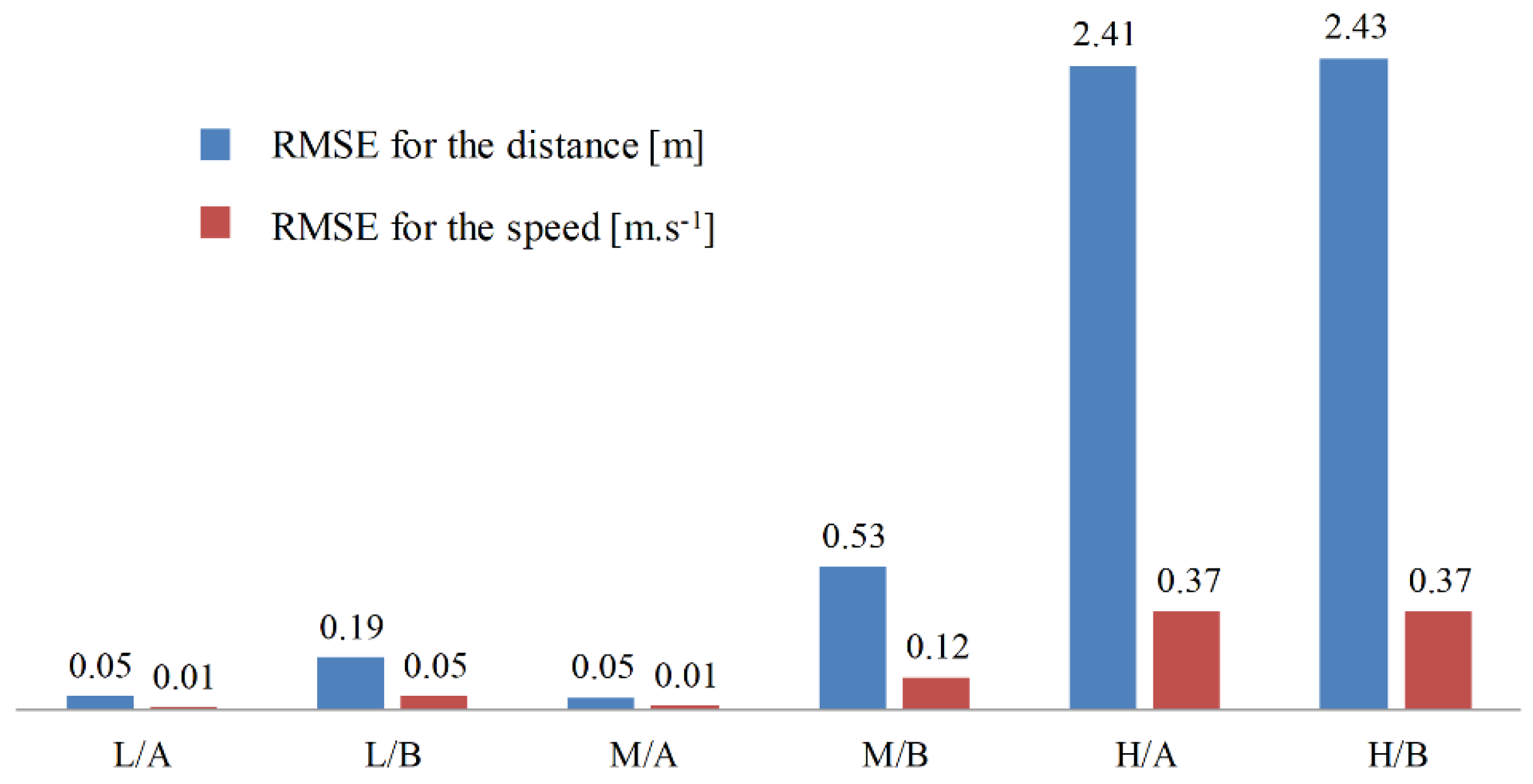
Figure 4 presents the learning curves of PBLS for different speed scenarios. In all three scenarios, the learning system can learn the stable distance and the speed curves within 5000 time steps (250 s). As shown in Figure 5, in the low speed scenario, the learning RMSE for both the speed and the distance of two drivers can be kept at a very low level close to zero. However, with the growth of speed for the leading vehicle, the performance of PBLS gets worse with RMSE for the speed increasing from 0.01 m·s−1 to 0.37 m·s−1 and RMSE for the distance increasing from 0.05 m to 2.43 m. This result is reasonable, as in the low-speed scenario, both drivers can perform well in keeping a stable distance to the leading vehicle. In this situation, the curves for speed and distance are very smooth without large fluctuation after around 5000 time steps, and thus PBLS performs better in this scenario.
In all three scenarios, PBLS shows a better performance on reproducing the behavior of Driver A than Driver B with lower RMSE for Driver A. This is mainly because Driver A has more experience in driving and can keep a relatively stable curve for both speed and distance.
5. Experiments with Variant Speed
In the previous section, the learning ability of the proposed system was tested in scenarios with constant speed. In this section, three driving scenes with variant speeds for the leading vehicle are considered. In the first two driving scenes, the whole test is similar to the constant speed case, except that a traditional adaptive cruise control (ACC) system is considered here to make a comparison with PBLS, which is the focus of this section. In the third driving scene, driving data collected from real vehicles on the real road are used to test the learning system. The driver (Driver A) with more driving experience is involved in this section. In the following test, PBLS only learns from Driver A.
The ACC system is a widely used longitudinal speed control system, which is designed to assist drivers to keep a pre-set time headway between the host vehicle and the leading vehicle [35]. The time headway is defined as the ratio of the distance () to the speed of the host vehicle (). The desired time headway for ACC is set as 1.8 s in the test, which can keep between 20 m and 40 m when the leading vehicle has a speed between 10 m·s−1 and 20 m·s−1. In this way, the kept by ACC and PBLS can be ranged to the same level, which helps to make a fair comparison.
Two indicators suggested by [36] are used here to evaluate and compare the performance of PBLS and ACC on driving comfort and smoothness. These two indicators are given by:
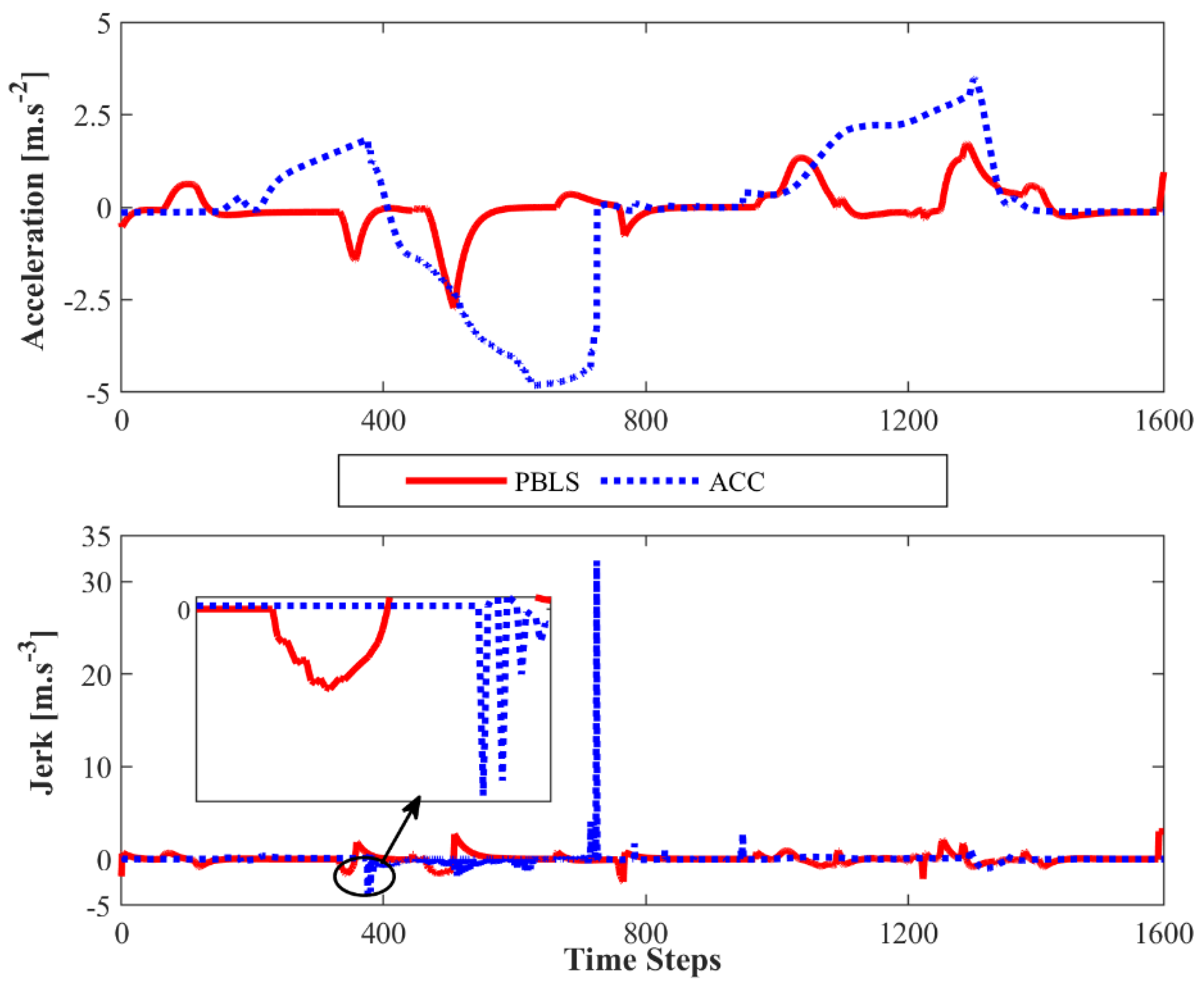
where the driving comfort is measured by , which is obtained by dividing the average acceleration by the average speed , and the driving smoothness is measured by , which is the jerk of the vehicle.
The driving comfort is considered low when is at a high level, while a high driving smoothness corresponds to a low and stable .
5.1. Driving Scene I
As shown in Figure 6a, in the first driving scene, the road layout is the same as in Section 4, while the speed of the leading vehicle changes between 10 m·s−1 and 20 m·s−1 during the whole test. For data collection, the driver in the host vehicle is asked to follow the leading vehicle with variant speed in the first run. After that, the proposed PBLS is triggered for behavior learning. In this case, the algorithm runs for 80,000 time steps (around 1 h for convergence) for learning and then runs for 40,000 time steps by setting the learning rate as zero to reproduce the learned behavior.
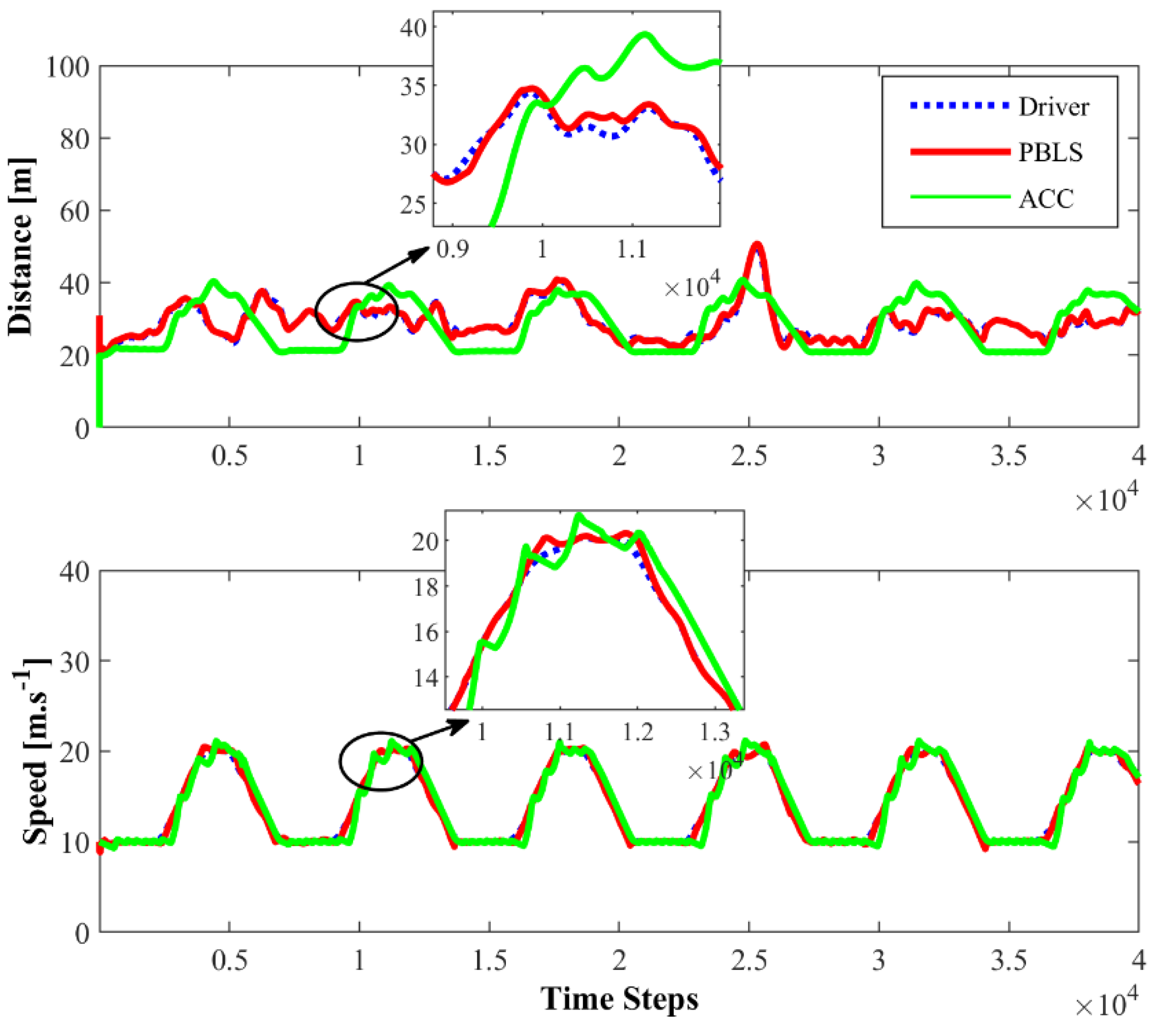
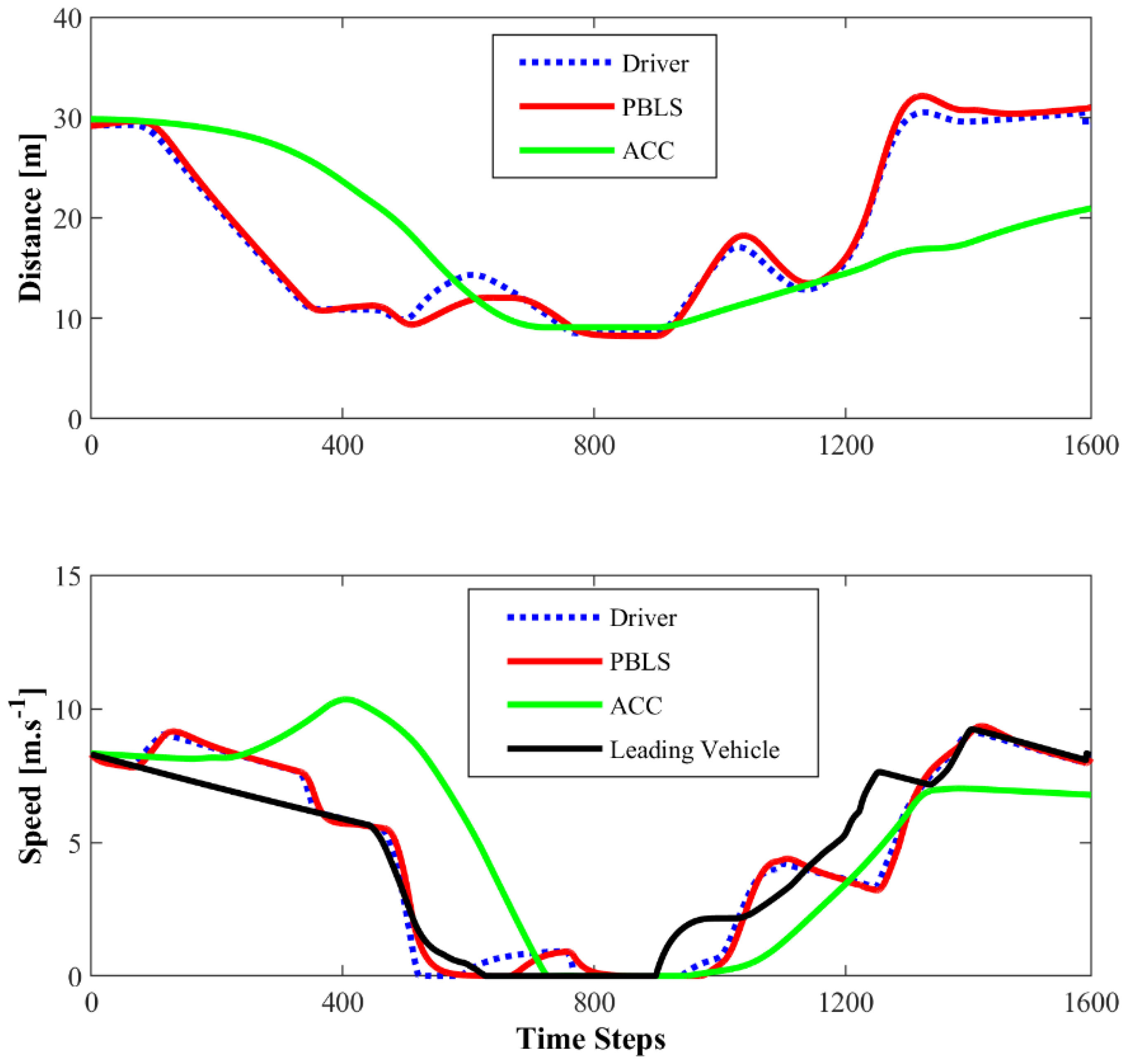
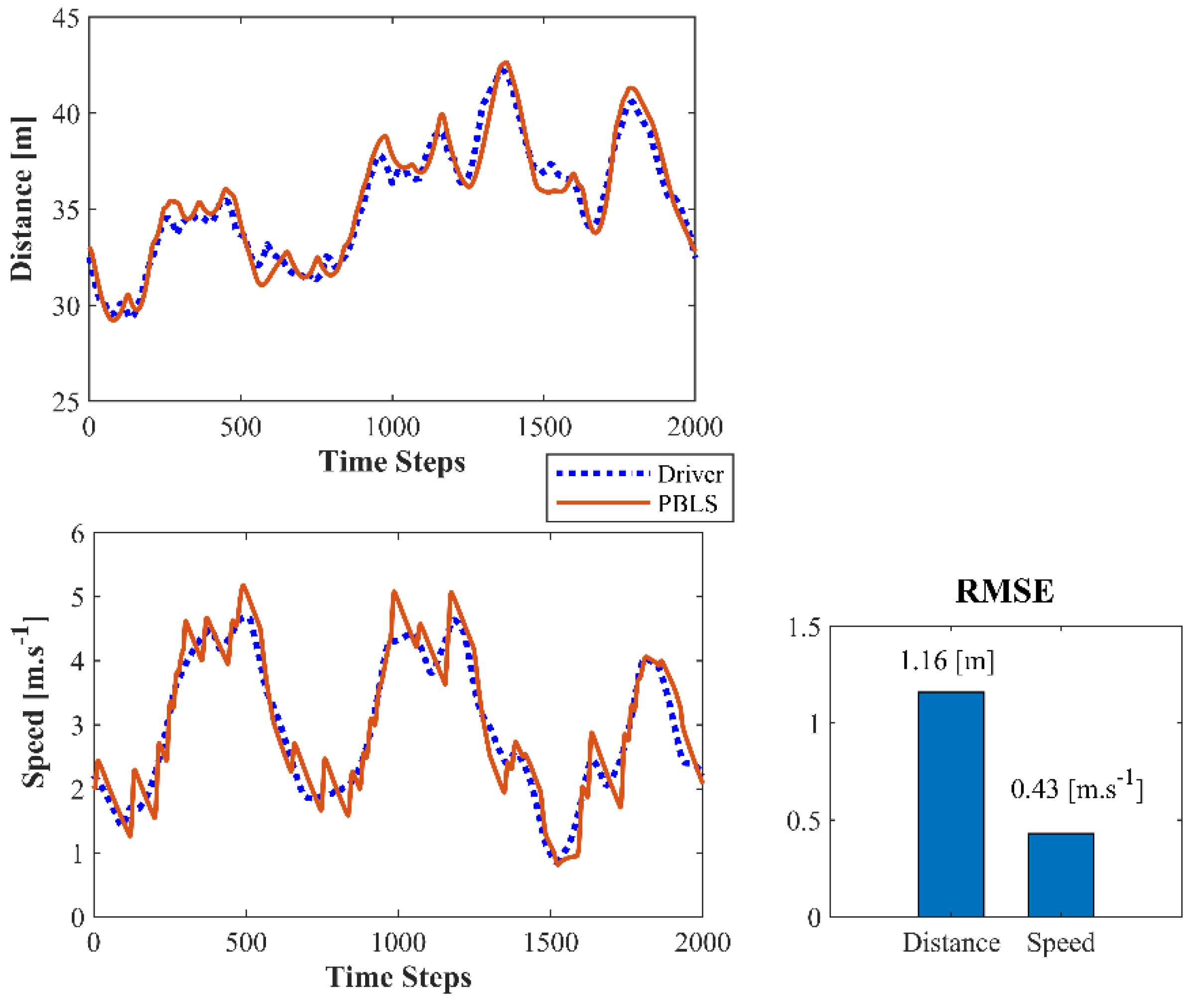
Figure 7 presents the distance and the speed comparison among the driver with PBLS and ACC in the first driving scene. PBLS performs well in learning from the driver with the distance and the speed curves close to the driver, which means the learning error (RMSE) of PBLS is at a very low level.
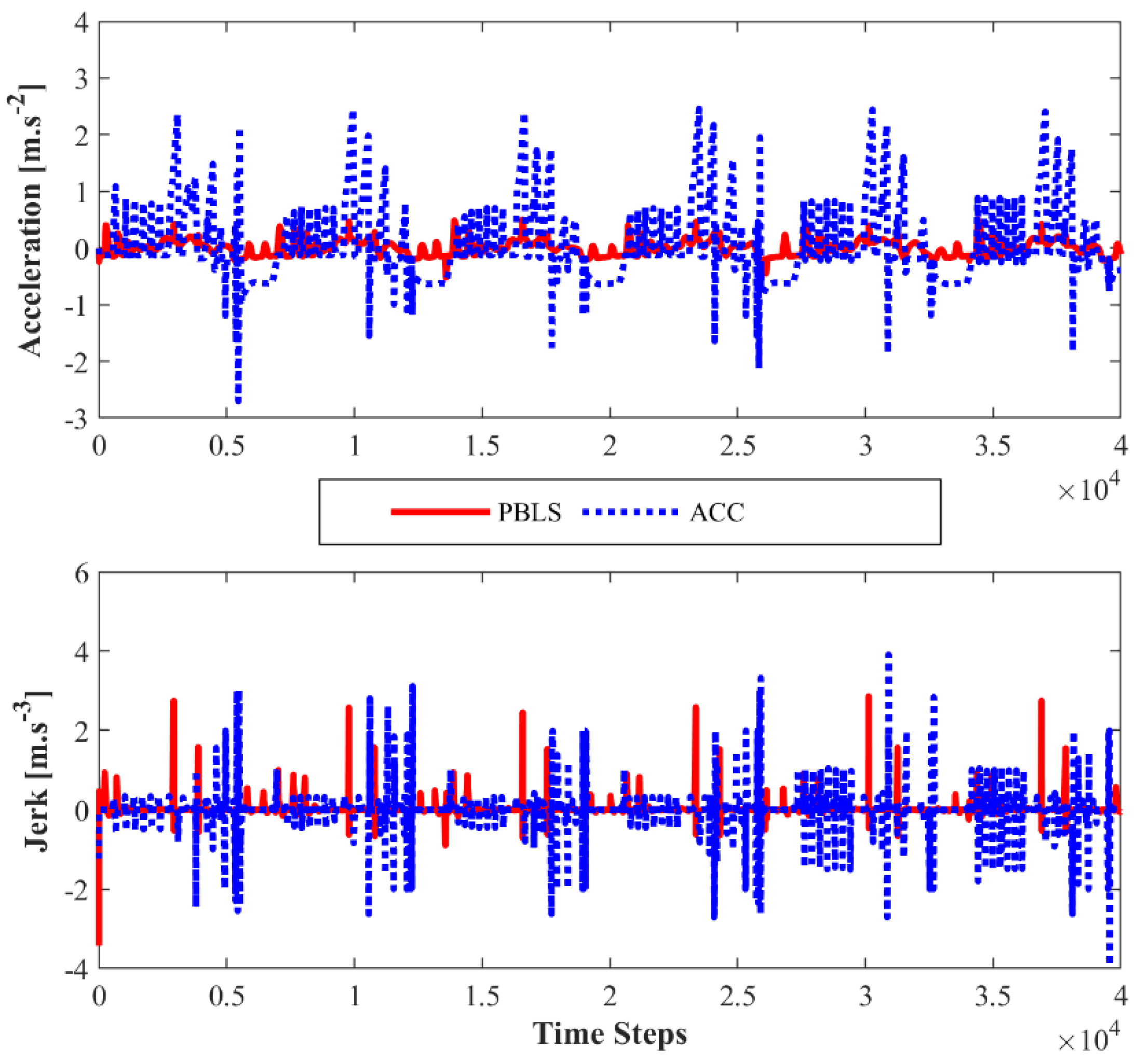
Compared to PBLS, the speed of ACC fluctuates more greatly, especially when the speed is close to 20 m·s−1. As shown in Figure 8, the acceleration and the jerk () of ACC vary significantly during the whole test, while PBLS can keep a relatively stable curve for both the acceleration and the jerk. Thus, PBLS can provide better driving smoothness than ACC.
5.2. Driving Scene II
In the second driving scene presented in Figure 6b, the leading vehicle is controlled by a human driver without predefined speed profiles. Therefore, in the data collection phase, both the host vehicle and the leading vehicle are driven by human drivers. A typical intersection with a traffic light is involved to form Driving Scene II.
In this scene, the leading vehicle is asked to go through the intersection according to the traffic light, and the host vehicle follows the leading vehicle all the time. The traffic light changes following the order: yellow, red, and green. The time for the yellow light is set as 5 s (100 steps), and the red light lasts for 40 s (800 steps). There is no time limit for the green light, which guarantees that both vehicles can pass through the intersection.
The initial speed for the leading vehicle and the host vehicle is 8 m·s−1, and the initial distance between these two vehicles is 30 m. It can be seen from Figure 9 that, because of the yellow and the red light, the leading vehicle slows down in the first 600 steps (30 s) when it is approaching the stop line. Then, it restarts and speeds up after 300-step waiting at the stop line.
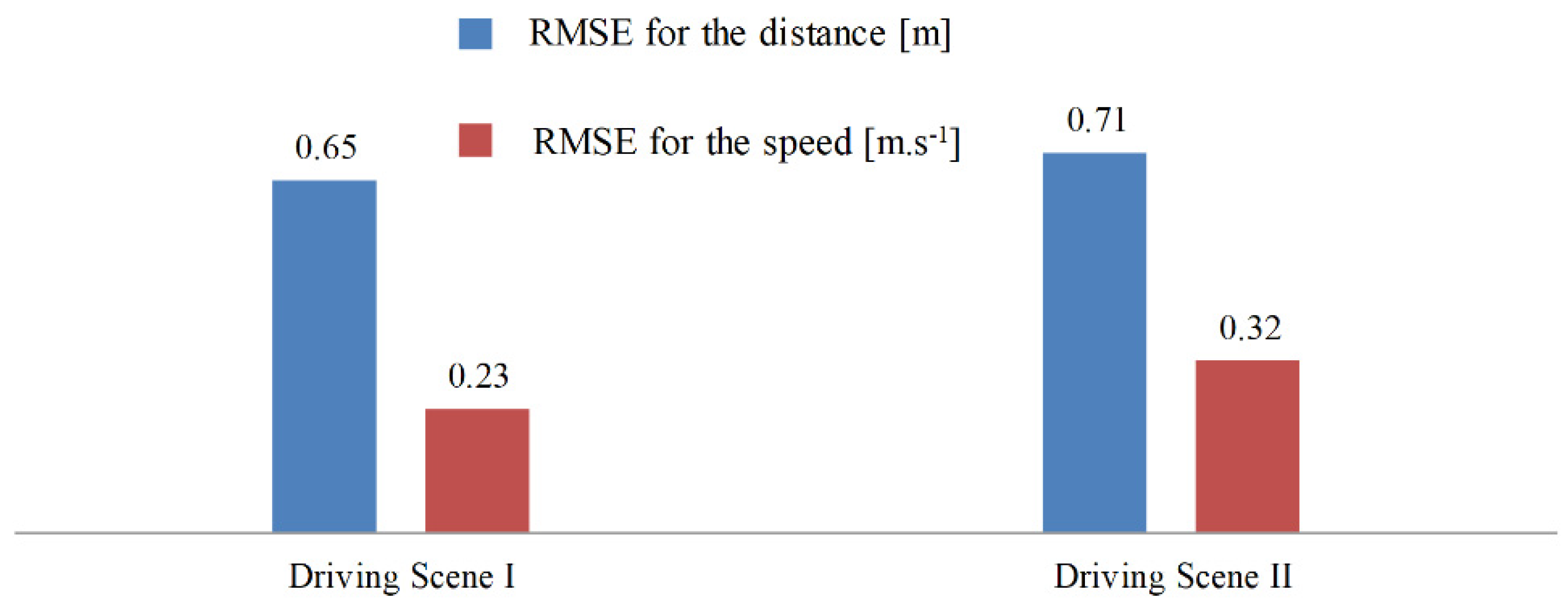
In this test, the algorithm runs for 12,000 time steps (600 s) to get convergence, which means the whole test needs to repeat 10 times. Similar to the test in Driving Scene I, after learning, the learning rate of the algorithm is set as zero to reproduce the learned behavior. As shown in Figure 10, compared with ACC, PBLS has better driving smoothness with smoother acceleration and jerk trajectories. From Figure 11, it can be seen that PBLS can reproduce the behavior of the driver who controls the host vehicle with a very low RMSE, while the difference between the curves of ACC and the driver is very large (see Figure 9). Thus, compared with ACC, PBLS is more consistent with the driver’s behavior and habits. Except for the driving smoothness, PBLS also performs better than ACC in the driving comfort. As shown in Figure 12, the of PBLS is much smaller than the of ACC.
5.3. Driving Scene III
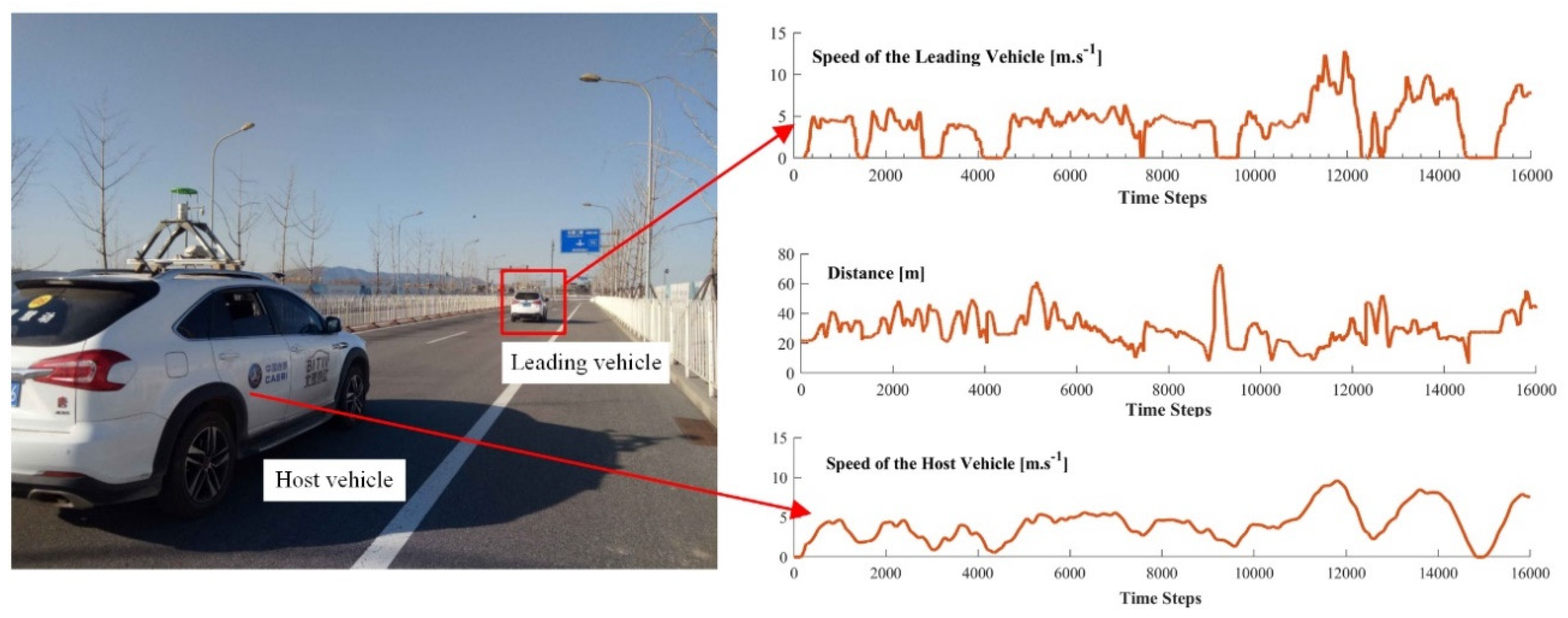
In the third driving scene, as shown in Figure 13, two real vehicles are involved for collecting the real driving data. The Beijing Institute of Technology (BIT) intelligent vehicle [37] is used as the host vehicle in this work. This vehicle is equipped with on-board sensing systems to capture the speed and the distance information. The detailed description of the host vehicle can be found in [37]. Both host and leading vehicles are driven by human drivers. The driver in the leading vehicle is asked to drive along a straight road with a changeable speed.
After the data collection process, real driving data are used to test the learning system. Testing the on-line learning and control system directly on a real-world road is highly risky, as slight learning deviations may lead to severe safety issues for both testing and surrounding vehicles. Thus, in this study, the real driving data are used to reproduce the observed real driving scene in PreScan, where the simulated leading vehicle follows the speed profile observed from the real world. The real behavior data collected from the host vehicle are used to train the PBLS in PreScan. The collected data shown in Figure 13 are divided into eight groups, and each group contains the data collected from 2000 time steps. Seven groups of data are used to train the algorithm, and the remaining group is used for testing. The test result is shown in Figure 14.
Compared with Driving Scenes I and II, PBLS in Driving Scene III performs slightly worse with higher RMSE for both distance and speed. This is mainly because the real driving data are noisier than the simulation data, especially when the leading vehicle has a changeable speed.
6. Conclusions
A personalized behavior learning system (PBLS) was proposed in this paper to learn the human driving behavior from demonstrations. PBLS is based on a reinforcement learning method named neural Q-learning (NQL), which can approximate the Q function in a continuous state and action space, such that the human-like longitudinal speed control (LSC) problem can be solved properly. To train PBLS online, a batch-updating algorithm based on back-propagation (BP) was developed.
A series of driving simulator experiments with different speed profiles for the leading vehicle were carried out to evaluate the performance of PBLS. In all the experiments, PBLS kept a low learning error, especially for the driver who had a stable operation. In the test with variant speed, by learning from an experienced driver, PBLS achieved higher driving comfort and smoothness than the traditional adaptive cruise control (ACC) system.
As mentioned in Section 4, this study focused on developing a personalized behavior learning system that can adapt to different drivers. In future work, a systematic analysis involving more drivers will be conducted to investigate the effects of different drivers and driving styles on the performance of the learning system.
Author Contributions
Conceptualization, C.L. (Chao Lu), D.C., and C.L. (Chen Lv); methodology, J.G. and C.L. (Chao Lu); data collection and validation, X.C.; writing—original draft preparation, C.L. (Chao Lu) and Y.C.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 6170304, Beijing Institute of Technology Research Fund Program for Young Scholars and Key Laboratory of Biomimetic Robots and Systems, Beijing Institute of Technology, grant number 2017CX02005.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lefevre, S.; Carvalho, A.; Borrelli, F. A Learning-Based Framework for Velocity Control in Autonomous Driving. IEEE Trans. Autom. Sci. Eng. 2016, 13, 32–42. [Google Scholar] [CrossRef]
- Kocić, J.; Jovičić, N.; Drndarević, V.J.S. An End-to-End Deep Neural Network for Autonomous Driving Designed for Embedded Automotive Platforms. Sensors 2019, 19, 2064. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Chen, H.; Waslander, S.; Yang, T.; Zhang, S.; Xiong, G.; Liu, K.J.S. Toward a more complete, flexible, and safer speed planning for autonomous driving via convex optimization. Sensors 2018, 18, 2185. [Google Scholar] [CrossRef] [PubMed]
- González, D.; Pérez, J.; Milanés, V.; Nashashibi, F. A review of motion planning techniques for automated vehicles. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1135–1145. [Google Scholar] [CrossRef]
- Naranjo, J.E.; Gonzalez, C.; Garcia, R.; De Pedro, T. Lane-change fuzzy control in autonomous vehicles for the overtaking maneuver. IEEE Trans. Intell. Transp. Syst. 2008, 9, 438–450. [Google Scholar] [CrossRef]
- Li, A.; Jiang, H.; Zhou, J.; Zhou, X. Learning Human-Like Trajectory Planning on Urban Two-Lane Curved Roads From Experienced Drivers. IEEE Access 2019, 7, 65828–65838. [Google Scholar] [CrossRef]
- Li, L.; Ota, K.; Dong, M. Humanlike Driving: Empirical Decision-Making System for Autonomous Vehicles. IEEE Trans. Veh. Technol. 2018, 67, 6814–6823. [Google Scholar] [CrossRef] [Green Version]
- Lu, C.; Hu, F.; Cao, D.; Gong, J.; Xing, Y.; Li, Z. Transfer Learning for Driver Model Adaptation in Lane-Changing Scenarios Using Manifold Alignment. IEEE Trans. Intell. Transp. Syst. 2019, 1–13. [Google Scholar] [CrossRef]
- Li, T.-H.S.; Chang, S.-J.; Chen, Y.-X. Implementation of human-like driving skills by autonomous fuzzy behavior control on an FPGA-based car-like mobile robot. Ind. Electron. IEEE Trans. 2003, 50, 867–880. [Google Scholar] [CrossRef]
- Okuda, H.; Ikami, N.; Suzuki, T.; Tazaki, Y.; Takeda, K. Modeling and Analysis of Driving Behavior Based on a Probability-Weighted ARX Model. IEEE Trans. Intell. Transp. Syst. 2013, 14, 98–112. [Google Scholar] [CrossRef]
- Lin, T.; Tseng, E.; Borrelli, F. Modeling driver behavior during complex maneuvers. In Proceedings of the American Control Conference (ACC), Washington, DC, USA, 17–19 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 6448–6453. [Google Scholar]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Yin, X.; Chen, Q. Trajectory Generation With Spatio-Temporal Templates Learned from Demonstrations. IEEE Trans. Ind. Electron. 2017, 64, 3442–3451. [Google Scholar] [CrossRef]
- Zheng, J.; Suzuki, K.; Fujita, M. Car-following behavior with instantaneous driver–vehicle reaction delay: A neural-network-based methodology. Transp. Res. Part C Emerg. Technol. 2013, 36, 339–351. [Google Scholar] [CrossRef]
- Khodayari, A.; Ghaffari, A.; Kazemi, R.; Braunstingl, R. A modified car-following model based on a neural network model of the human driver effects. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2012, 42, 1440–1449. [Google Scholar] [CrossRef]
- Morton, J.; Wheeler, T.A.; Kochenderfer, M.J. Analysis of recurrent neural networks for probabilistic modeling of driver behavior. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1289–1298. [Google Scholar] [CrossRef]
- Yang, S.; Wang, W.; Liu, C.; Deng, W. Scene Understanding in Deep Learning-Based End-to-End Controllers for Autonomous Vehicles. IEEE Trans. Syst. ManCybern. Syst. 2019, 49, 53–63. [Google Scholar] [CrossRef]
- García Cuenca, L.; Sanchez-Soriano, J.; Puertas, E.; Fernandez Andrés, J.; Aliane, N.J.S. Machine learning techniques for undertaking roundabouts in autonomous driving. Sensors 2019, 19, 2386. [Google Scholar] [CrossRef]
- Wiest, J.; Höffken, M.; Kreßel, U.; Dietmayer, K. Probabilistic trajectory prediction with gaussian mixture models. In Proceedings of the Intelligent Vehicles Symposium (IV), Madrid, Spain, 3–7 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 141–146. [Google Scholar]
- Lefèvre, S.; Carvalho, A.; Gao, Y.; Tseng, H.E.; Borrelli, F. Driver models for personalized driving assistance. Veh. Syst. Dyn. 2015, 53, 1705–1720. [Google Scholar] [CrossRef]
- Lv, C.; Xing, Y.; Lu, C.; Liu, Y.; Guo, H.; Gao, H.; Cao, D. Hybrid-Learning-Based Classification and Quantitative Inference of Driver Braking Intensity of an Electrified Vehicle. IEEE Trans. Veh. Technol. 2018, 67, 5718–5729. [Google Scholar] [CrossRef]
- Lu, C.; Wang, H.; Lv, C.; Gong, J.; Xi, J.; Cao, D. Learning Driver-Specific Behavior for Overtaking: A Combined Learning Framework. IEEE Trans. Veh. Technol. 2018, 67, 6788–6802. [Google Scholar] [CrossRef]
- Ng, L.; Clark, C.M.; Huissoon, J.P. Reinforcement learning of dynamic collaborative driving part I: Longitudinal adaptive control. Int. J. Veh. Inf. Commun. Syst. 2008, 1, 208–228. [Google Scholar] [CrossRef]
- Desjardins, C.; Chaib-draa, B. Cooperative adaptive cruise control: A reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1248–1260. [Google Scholar] [CrossRef]
- Ngai, D.C.K.; Yung, N.H.C. A multiple-goal reinforcement learning method for complex vehicle overtaking maneuvers. IEEE Trans. Intell. Transp. Syst. 2011, 12, 509–522. [Google Scholar] [CrossRef]
- Li, X.; Xu, X.; Zuo, L. Reinforcement learning based overtaking decision-making for highway autonomous driving. In Proceedings of the 2015 Sixth International Conference on Intelligent Control and Information Processing (ICICIP), Wuhan, China, 26–28 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 336–342. [Google Scholar]
- Huang, Z.; Xu, X.; He, H.; Tan, J.; Sun, Z. Parameterized Batch Reinforcement Learning for Longitudinal Control of Autonomous Land Vehicles. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 730–741. [Google Scholar] [CrossRef]
- Kim, I.-H.; Bong, J.-H.; Park, J.; Park, S. Prediction of driver’s intention of lane change by augmenting sensor information using machine learning techniques. Sensors 2017, 17, 1350. [Google Scholar] [CrossRef]
- Ten Hagen, S.; Kröse, B. Neural Q-learning. Neural Comput. Appl. 2003, 12, 81–88. [Google Scholar] [CrossRef]
- Priddy, K.L.; Keller, P.E. Artificial Neural Networks: An Introduction; SPIE Press: Bellingham, WA, USA, 2005; Volume 68. [Google Scholar]
- Li, Y.; Ang, K.H.; Chong, G.C. Patents, software, and hardware for PID control: An overview and analysis of the current art. IEEE Control Syst. 2006, 26, 42–54. [Google Scholar]
- Boyan, J.A. Technical update: Least-squares temporal difference learning. Mach Learn 2002, 49, 233–246. [Google Scholar] [CrossRef]
- Gnecco, G.; Sanguineti, M. The weight-decay technique in learning from data: An optimization point of view. Comput. Manag. Sci. 2009, 6, 53–79. [Google Scholar] [CrossRef]
- Masters, D.; Luschi, C. Revisiting small batch training for deep neural networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Marsden, G.; McDonald, M.; Brackstone, M. Towards an understanding of adaptive cruise control. Transp. Res. Part C Emerg. Technol. 2001, 9, 33–51. [Google Scholar] [CrossRef]
- Xu, Y.; Song, J.; Nechyba, M.C.; Yam, Y. Performance evaluation and optimization of human control strategy. Robot. Auton. Syst. 2002, 39, 19–36. [Google Scholar] [CrossRef]
- Wang, B.; Li, Z.; Gong, J.; Liu, Y.; Chen, H.; Lu, C. Learning and Generalizing Motion Primitives from Driving Data for Path-Tracking Applications. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1191–1196. [Google Scholar]
Figure 1.
Architecture of the proposed personalized behavior learning system (PBLS). PID: proportion integration differentiation.
Figure 1.
Architecture of the proposed personalized behavior learning system (PBLS). PID: proportion integration differentiation.

Figure 2.
Driving simulator used for the experiment.

Figure 3.
Driving scene for constant speed scenario.

Figure 4.
Learning curves for the distance and the speed of two drivers: the figures in the first row are for the low speed scenario; the figures in the second row are for the medium speed scenario; the figures in the third row are for the high-speed scenario.
Figure 4.
Learning curves for the distance and the speed of two drivers: the figures in the first row are for the low speed scenario; the figures in the second row are for the medium speed scenario; the figures in the third row are for the high-speed scenario.

Figure 5.
Root Mean Square Error (RMSE) for the constant speed scenarios.

Figure 6.
Driving scenes for variant speed scenarios.

Figure 7.
Distance and speed for Driving Scene I.

Figure 8.
Acceleration and jerk (J2) for Driving Scene I.

Figure 9.
Distance and speed for Driving Scene II.

Figure 10.
Acceleration and jerk (J2) for Driving Scene II.

Figure 11.
RMSE in different scenes.

Figure 12.
Comfort measurement (J1) for different systems in different scenes.

Figure 13.
An illustration of the real driving data and vehicles.

Figure 14.
Test result for Driving Scene III.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameters for PBLS.
| Scenarios | ||||||||
|---|---|---|---|---|---|---|---|---|
| CS/10 [m·s−1] | 0.1 | 0.0005 | 15 | −15 | 80 | 0 | 4 | −4 |
| CS/15 [m·s−1] | 0.1 | 0.0005 | 20 | −20 | 80 | 0 | 4 | −4 |
| CS/22 [m·s−1] | 0.1 | 0.0005 | 25 | −25 | 80 | 0 | 6 | −6 |
| VS/Scene I | 0.01 | 0.05 | 25 | −25 | 80 | 0 | 4 | −4 |
| VS/Scene II | 0.01 | 0.5 | 25 | −25 | 80 | 0 | 8 | −8 |
CS: constant speed; VS: variant speed.
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lu, C.; Gong, J.; Lv, C.; Chen, X.; Cao, D.; Chen, Y. A Personalized Behavior Learning System for Human-Like Longitudinal Speed Control of Autonomous Vehicles. Sensors 2019, 19, 3672. https://doi.org/10.3390/s19173672
AMA Style
Lu C, Gong J, Lv C, Chen X, Cao D, Chen Y. A Personalized Behavior Learning System for Human-Like Longitudinal Speed Control of Autonomous Vehicles. Sensors. 2019; 19(17):3672. https://doi.org/10.3390/s19173672
Chicago/Turabian StyleLu, Chao, Jianwei Gong, Chen Lv, Xin Chen, Dongpu Cao, and Yimin Chen. 2019. "A Personalized Behavior Learning System for Human-Like Longitudinal Speed Control of Autonomous Vehicles" Sensors 19, no. 17: 3672. https://doi.org/10.3390/s19173672
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.