2.1. Principle of the Complete Kernel Fisher Discriminant Analysis (CKFDA)
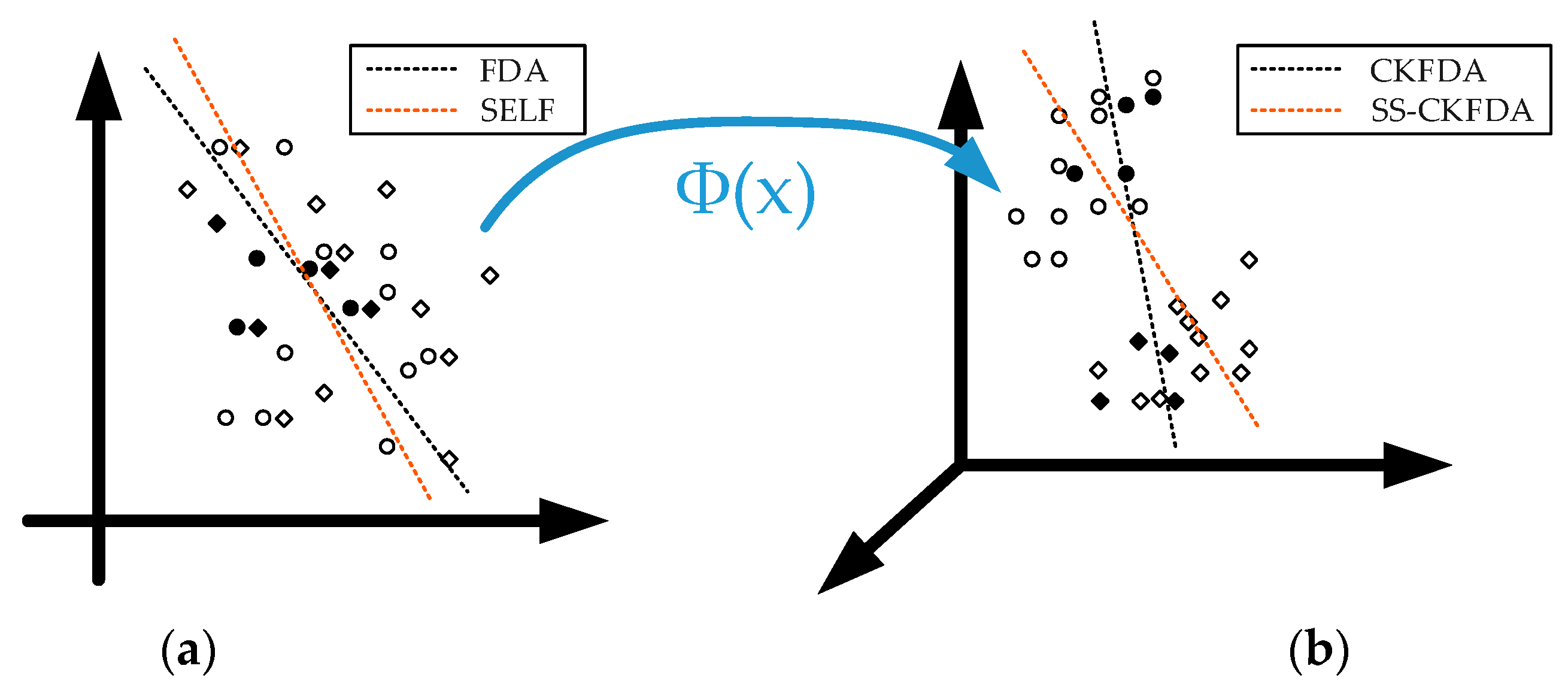
The CKFDA algorithm was proposed based on a novel framework, KPCA plus LDA, which makes full use of irregular discriminant information that exists in the null space of the within-class scatter matrix [
14]. The irregular discriminant subspace, which is neglected in the previous KFDA algorithm, is as powerful as the regular discriminant subspace for feature recognition. Combined with discriminant vectors in regular and irregular subspaces, CKFDA can outperform other FDA-based algorithms. Although CKFDA was proposed as an effective tool for solving the “small sample size” problem, it has also been proven to be suitable for “large sample size” problems. The principle of CKFDA is as follows:
First, KPCA [
15] is performed to transform the original input space
into a m-dimensional space
. Hence, we first set forth the KPCA algorithm in detail.
It is assumed that a set of
training samples
in space
can be mapped into a feature space
by a given nonlinear mapping
. Then, the covariance matrix on the feature space can be given by:
where
. In addition, for every eigenvector of
,
can be linearly expanded by
.
In order to obtain the expansion coefficients,
and the Gram matrix
were denoted, and the elements can be gained using the kernel trick:
Kernel function can be any function that fulfills Mercer’s condition [
16]. The most common kernel functions are Gaussian kernel, polynomial kernel and sigmoid kernel.
Before the following operation, the Gram matrix
should be centralized [
16].
The orthonormal eigenvectors
of
are calculated, which correspond to the m largest eigenvalues
. Then, eigenvector
of
can also be obtained by:
Lastly, the KPCA-transformed feature vector
can be obtained by:
Next, LDA is performed in the KPCA-transformed space and the regular and irregular discriminant features are extracted. Suppose that there are
pattern classes, the between-class scatter matrix
and the within-class scatter matrix
in the KPCA-transformed space can be defined through the following pairwise forms [
17]:
where:
and:
and
are the corresponding coefficient matrix of
and
.
It was assumed that are the orthonormal eigenvectors of , and the first ones correspond to positive eigenvalues, . Then, the irregular space of is the subspace , and its orthogonal complementary space is the regular space.
In the regular space,
, and the optimal regular mapping vectors can be gained by maximizing the Fisher criterion
, where
,
and
represents the optimal vectors of Fisher criterion. The optimization problem is proven to be equal to the generalized eigenvalue problem:
. After working out
, which correspond to the
largest positive eigenvalues of
, the optimal regular discriminant feature vector can be obtain, as follows:
In a similar way, in the irregular space,
, and the criterion is converted into
, where
. The optimal vector
of
are the orthonormal eigenvectors of
, which corresponds to
largest eigenvalues. Then, the optimal irregular discriminant feature vector can be obtained, as follows:
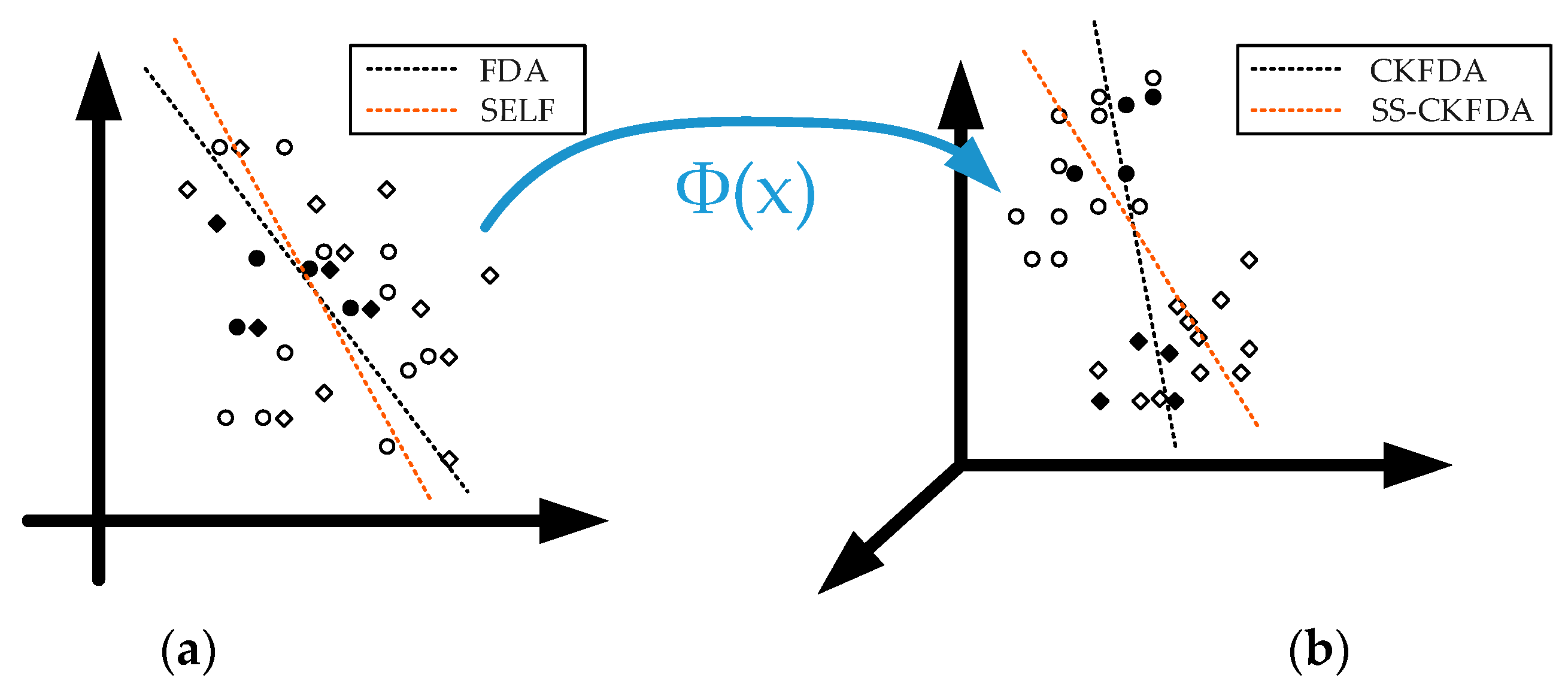
Finally, the two kinds of discriminant features are fused for classification. The normalized-distance between sample
and training samples
is defined by:
where
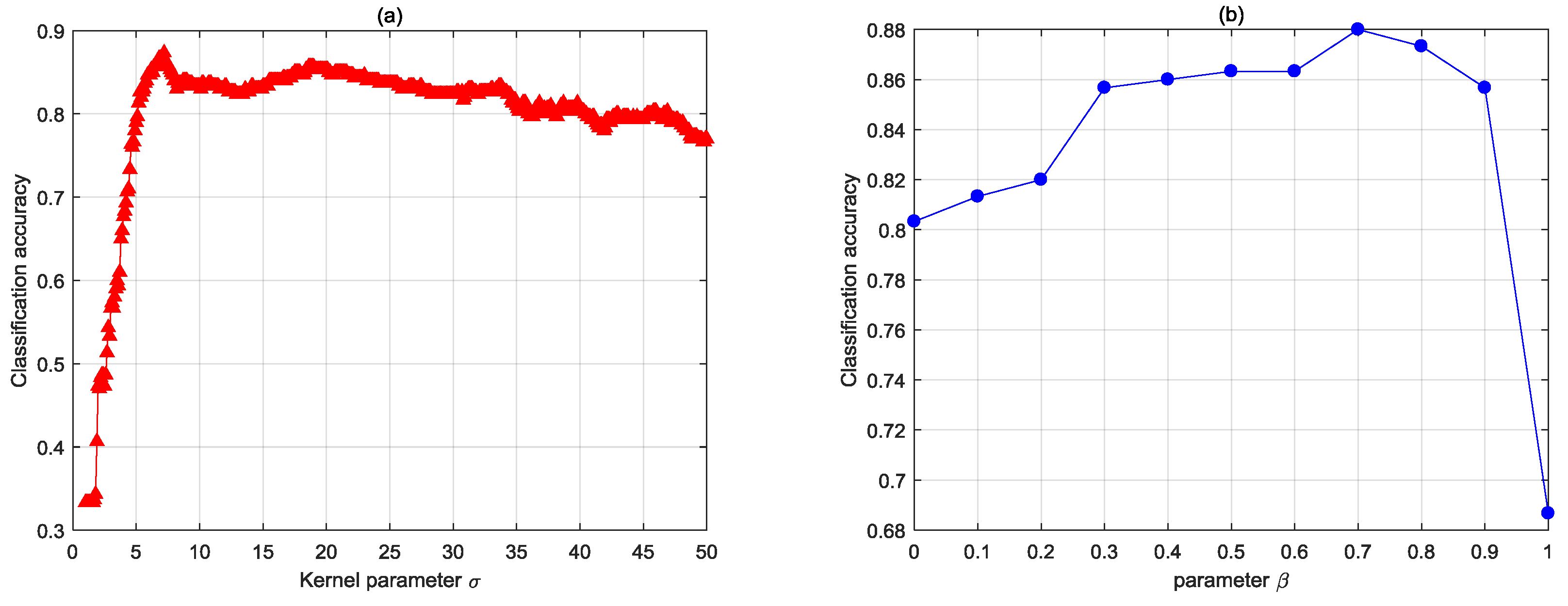
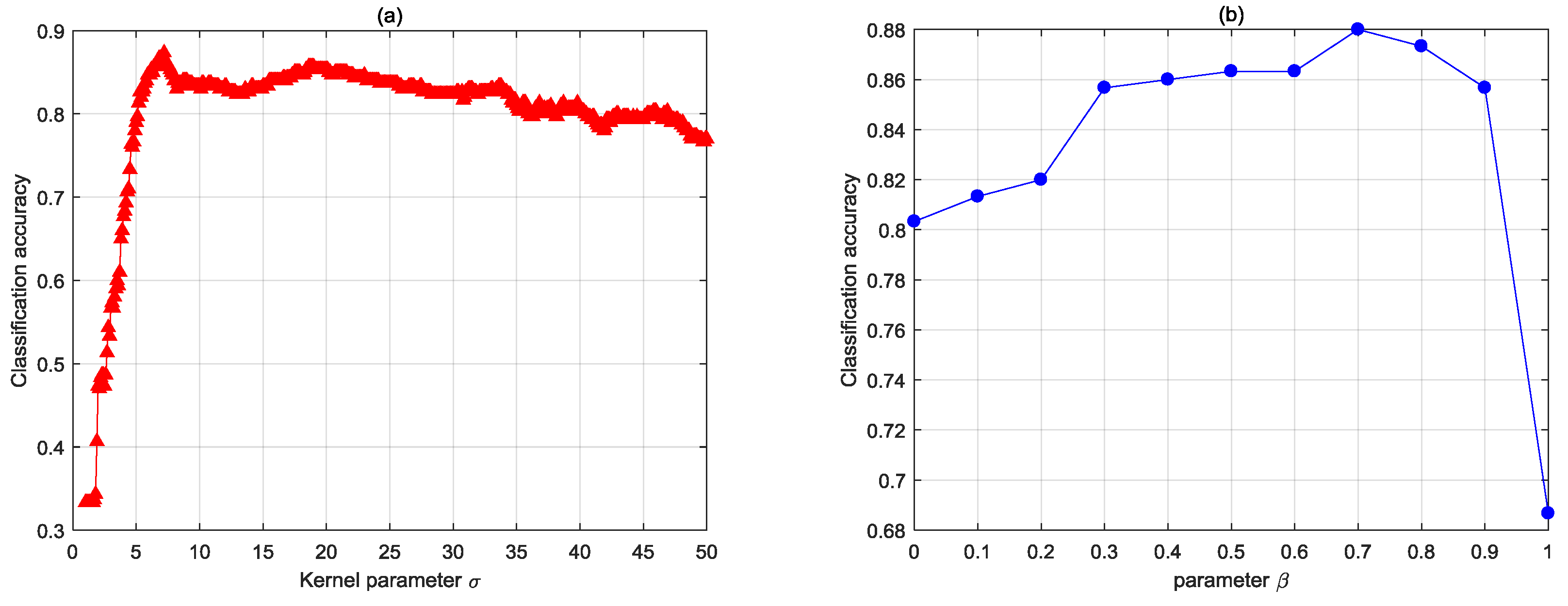
is the fusion coefficient, which determines the weight of the regular discriminant information in the decision level. In this study,
was set to 1.
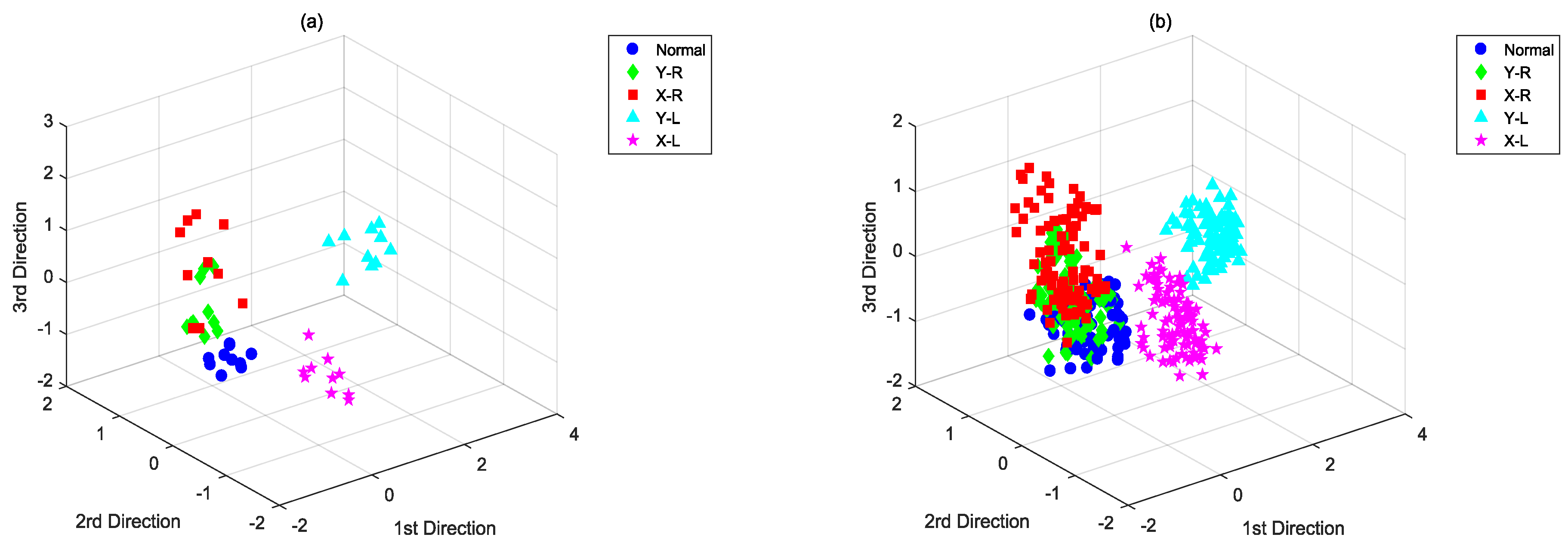
To this point, the feature extraction process of CKFDA has been completed. The original features are reduced to two kinds of discriminant features , and the normalized-distance can be used for the next classification with one distance classifier.
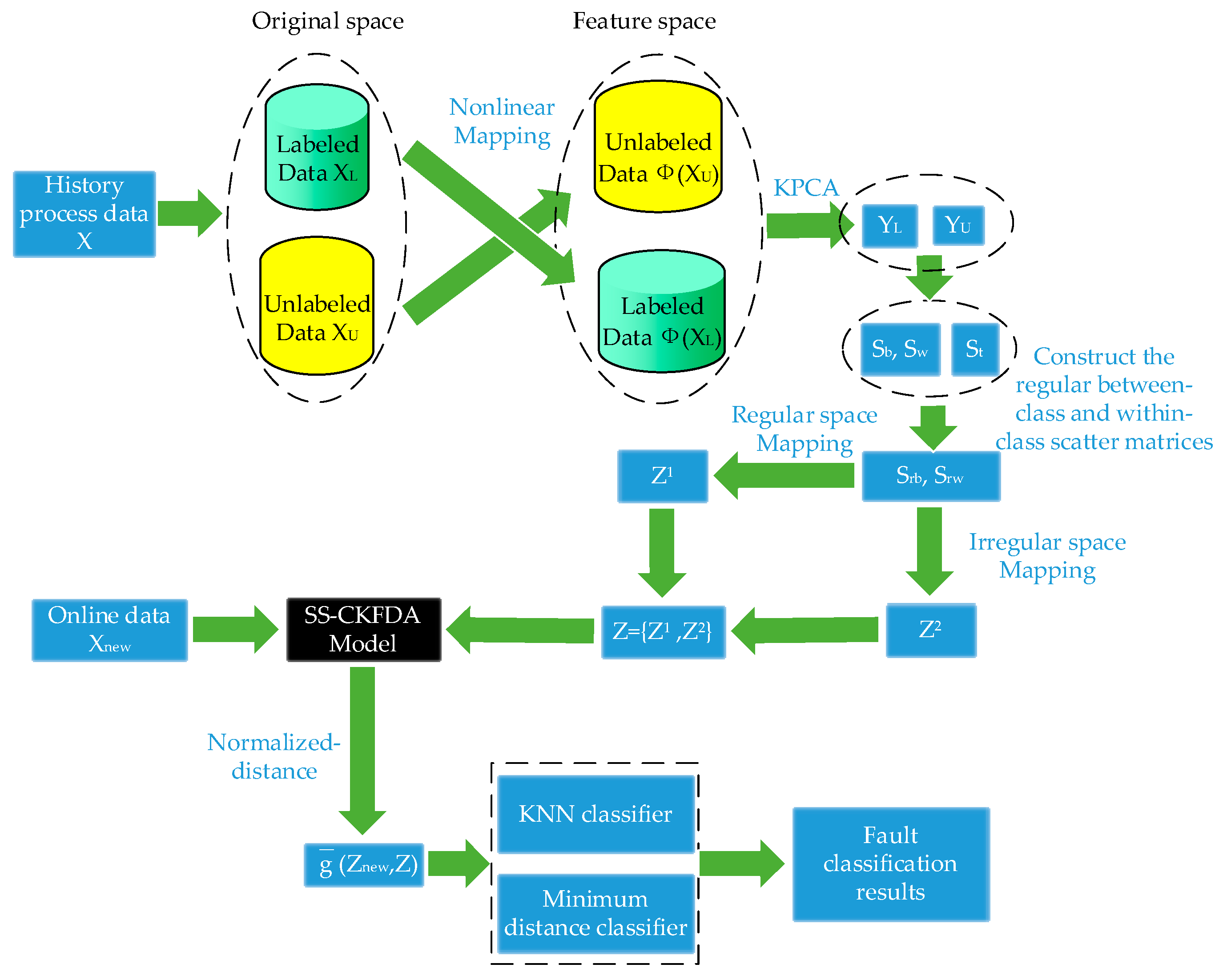
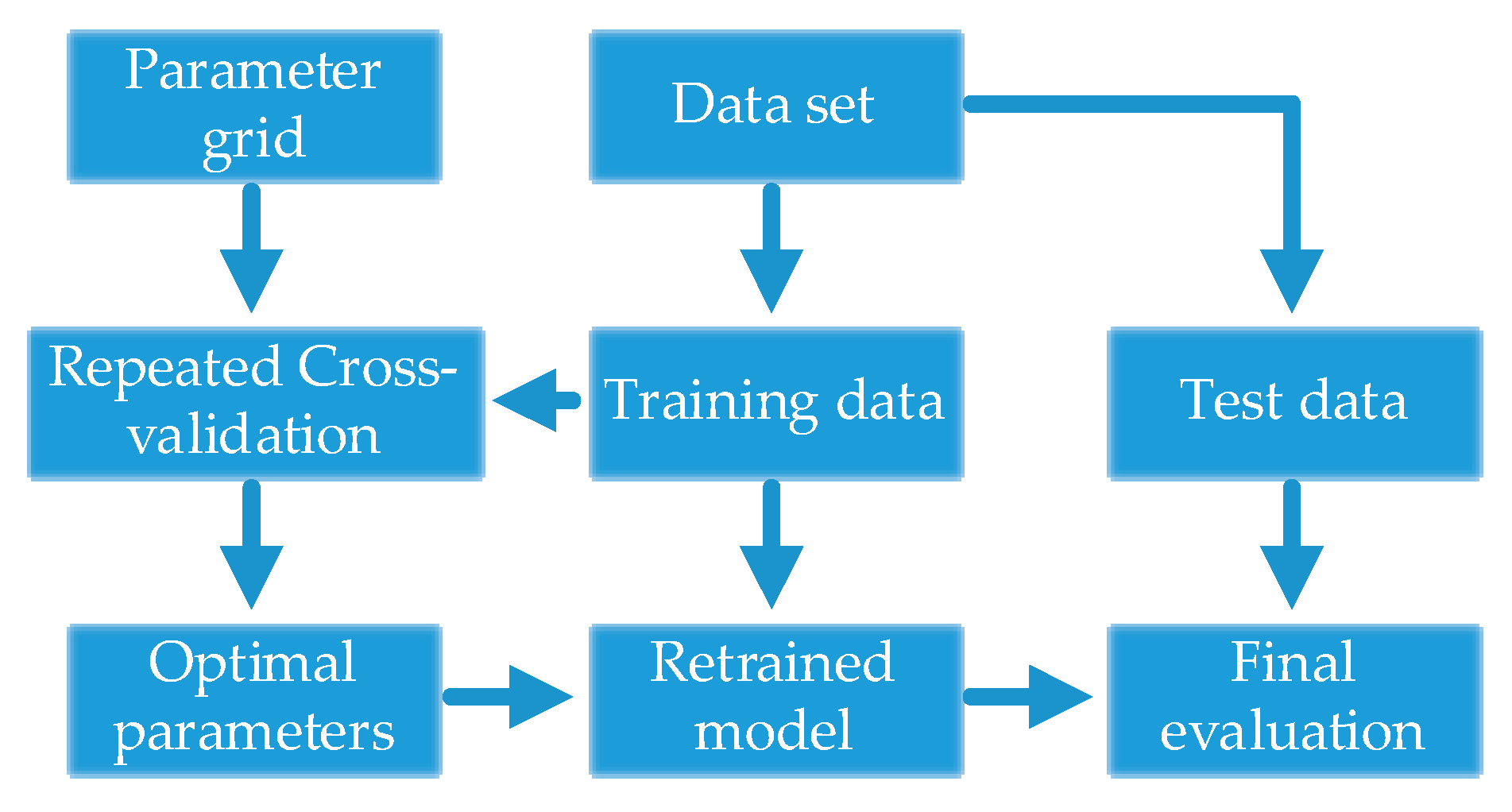
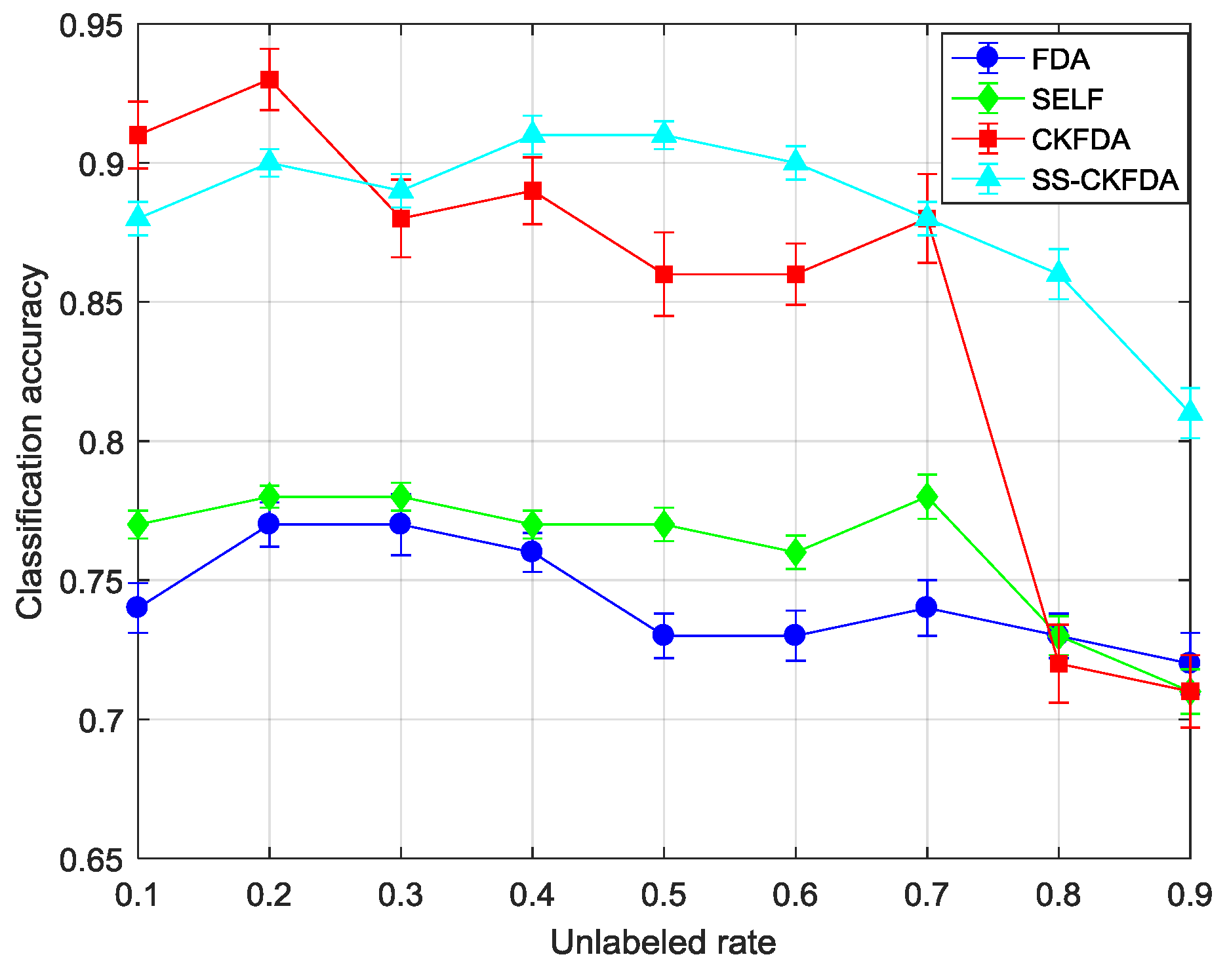
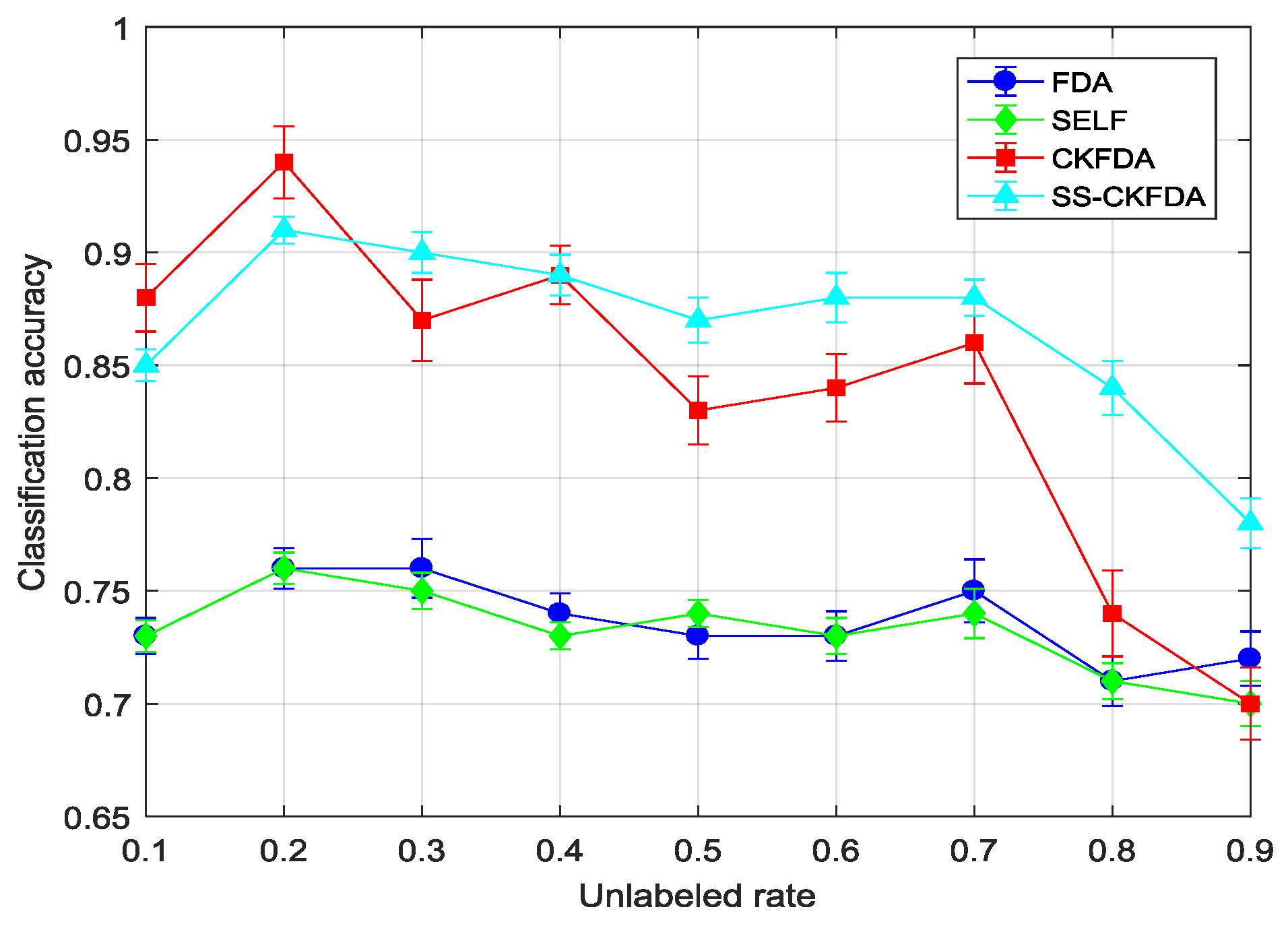
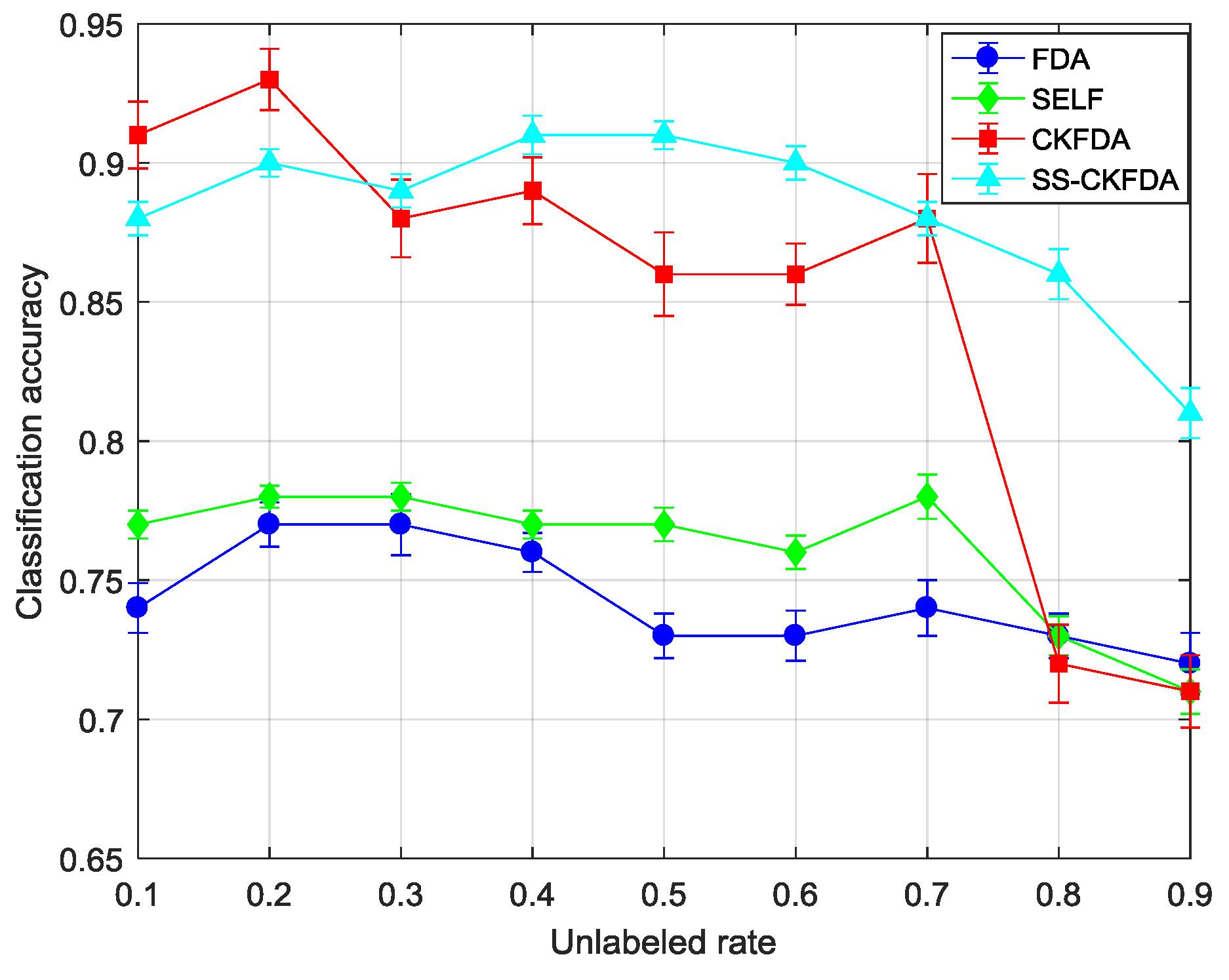
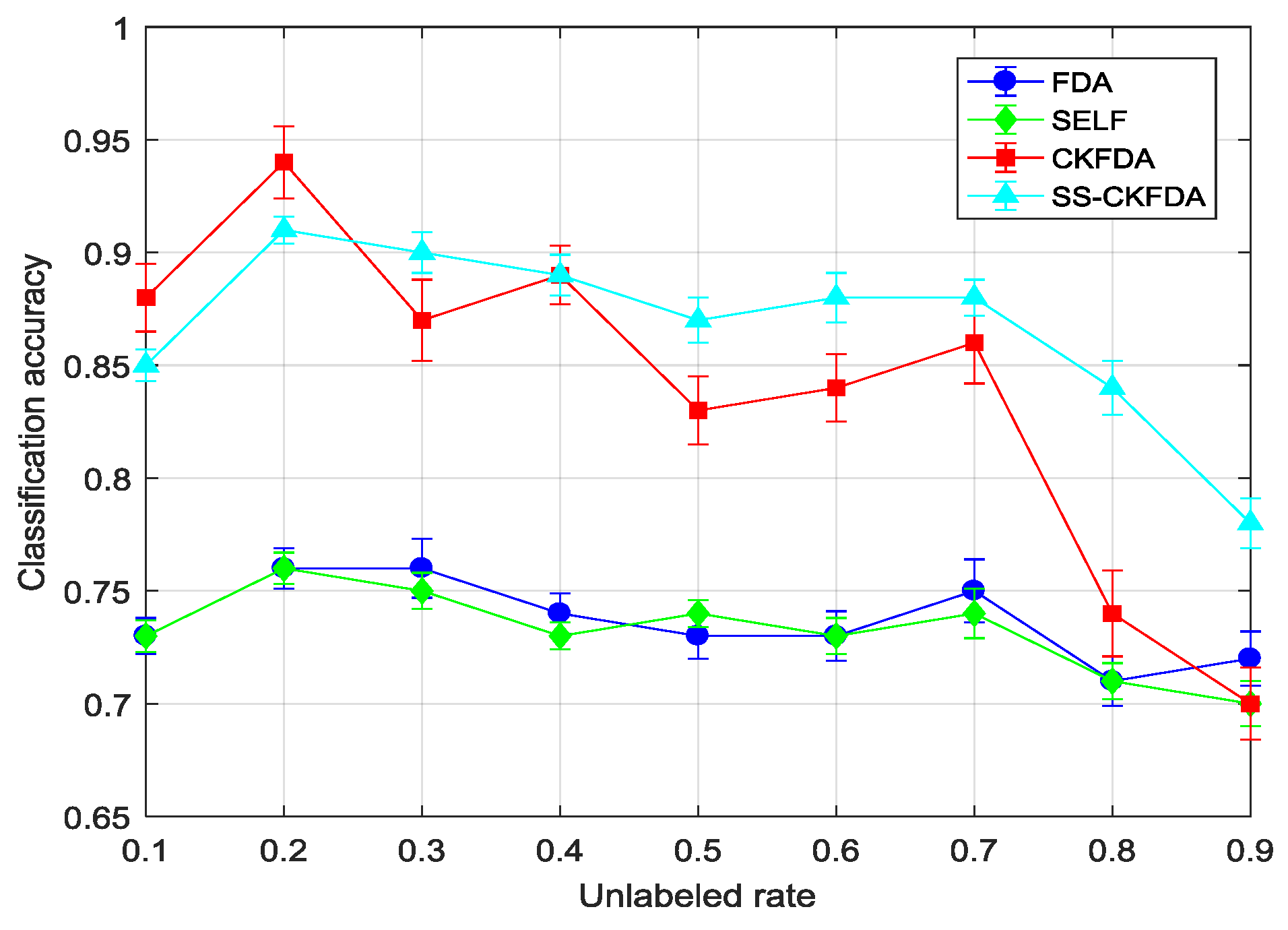
2.3. SS-CKFDA for Fault Diagnosis
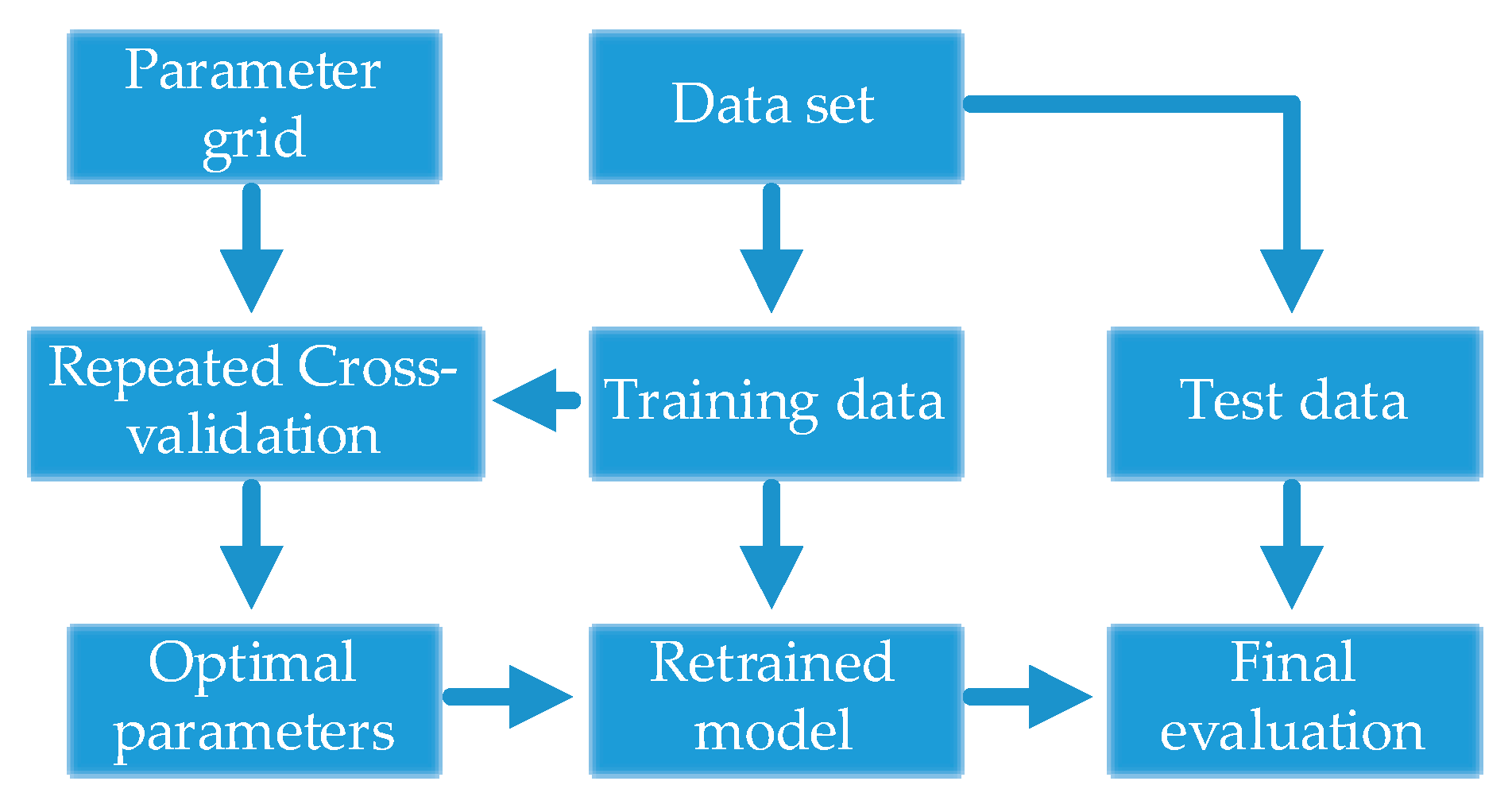
A detail flowchart of the SS-CKFDA modeling method for online fault diagnosis is presented in
Figure 2. For the new data sample
, the first step is to extract its discriminant feature
using the SS-CKPCA model. The next step is to conduct a discriminant analysis based on the discriminant feature
to determine which fault type the new sample
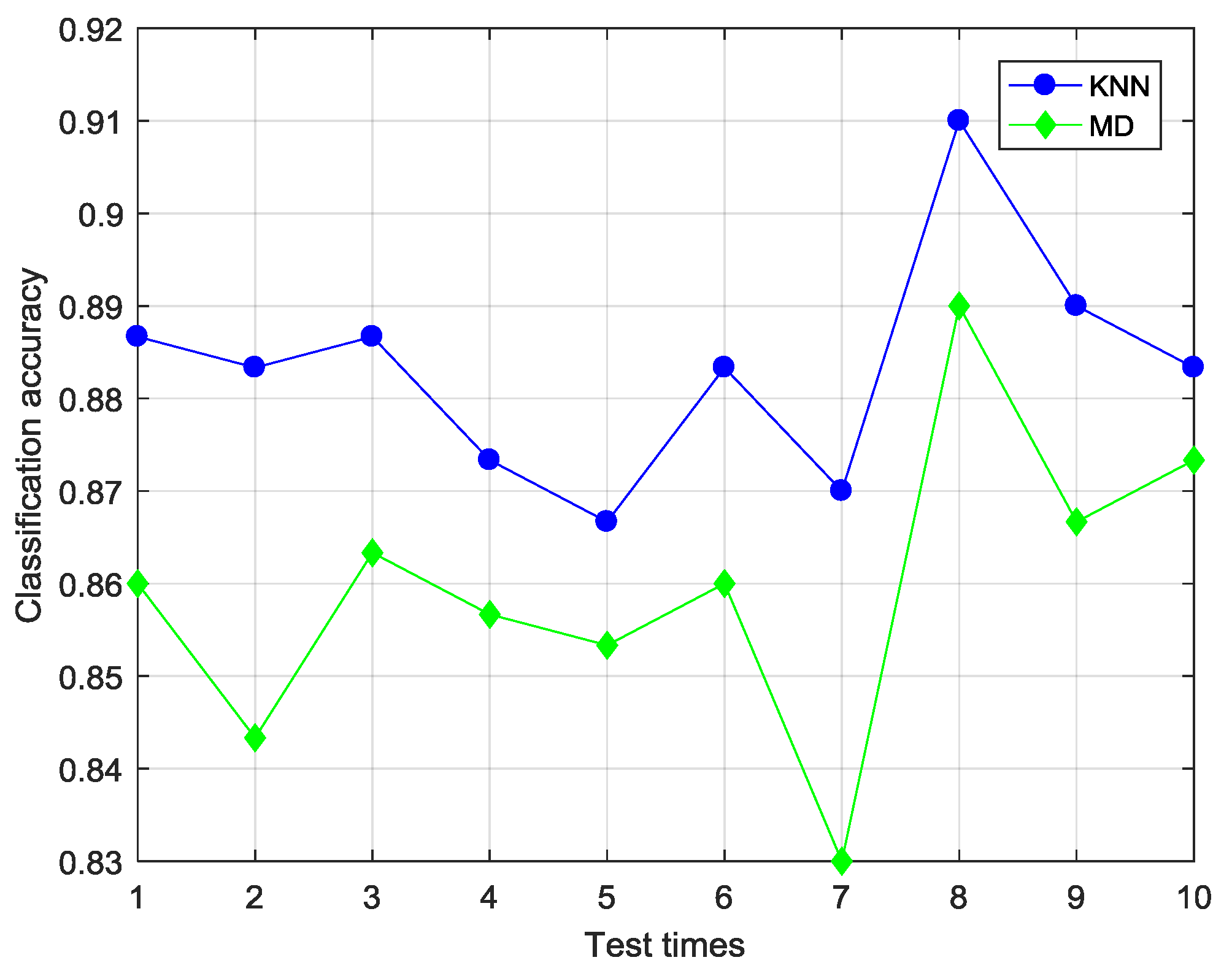
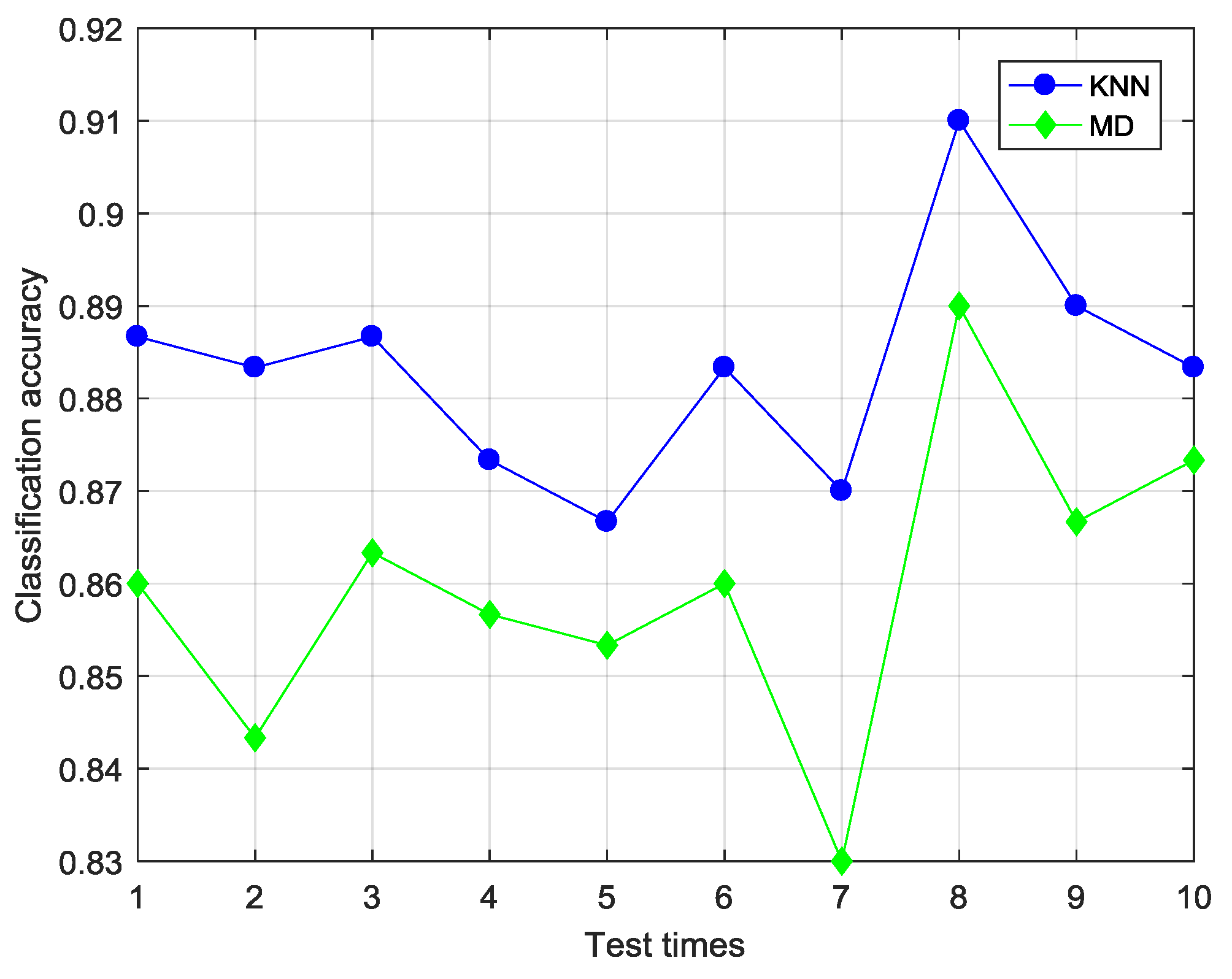
belongs to. In the present study, two distance classifiers, KNN classifier and MD classifier, were designed for fault classification.
The KNN classifier, which is a common non-parameter classification method, has extensive research and application background in pattern recognition, machine learning and data mining due to features of being intuitionistic, simple, effective and easy to realize [
20]. Its working principle is to first determine the k nearest neighbor of the data sample to be classified in the training set. Then, the data sample is classified by the majority vote of its neighbors. Distance metric is a key part of the KNN classifier, and plays an important role in the performance of the algorithm. In SS-CKFDA, normalized-distance
defined by Equation (16) is the distance metric. The MD classifier is another simple and easy-to-used distance classifier. First, the mean vector
of class
in the training sample is calculated. Then, for the new online data
, if
, then
belongs to class k.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}