Multimodal Biometric Recognition Based on Convolutional Neural Network by the Fusion of Finger-Vein and Finger Shape Using Near-Infrared (NIR) Camera Sensor

Abstract
:1. Introduction
2. Related Works
- -
- Convex polygons were generated using the algorithm that finds the coordinates of the outermost pixels of finger ROIs to calibrate the empty spaces of the images. Then, robust finger ROIs for misalignment were extracted after conducting in-plane rotation compensation based on the angle of tilting measured based on the boundaries of the upper, lower, left, and right pixels.
- -
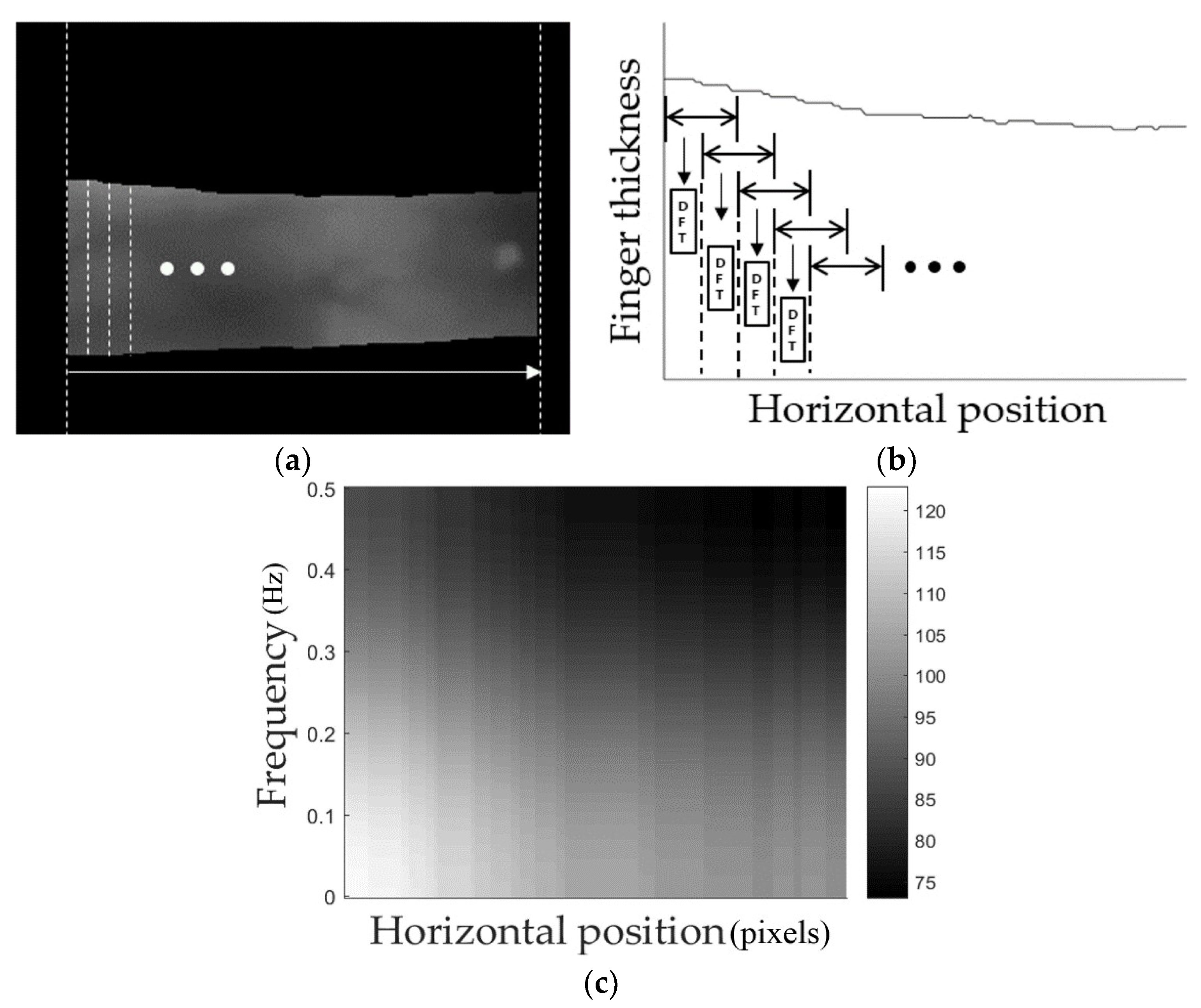
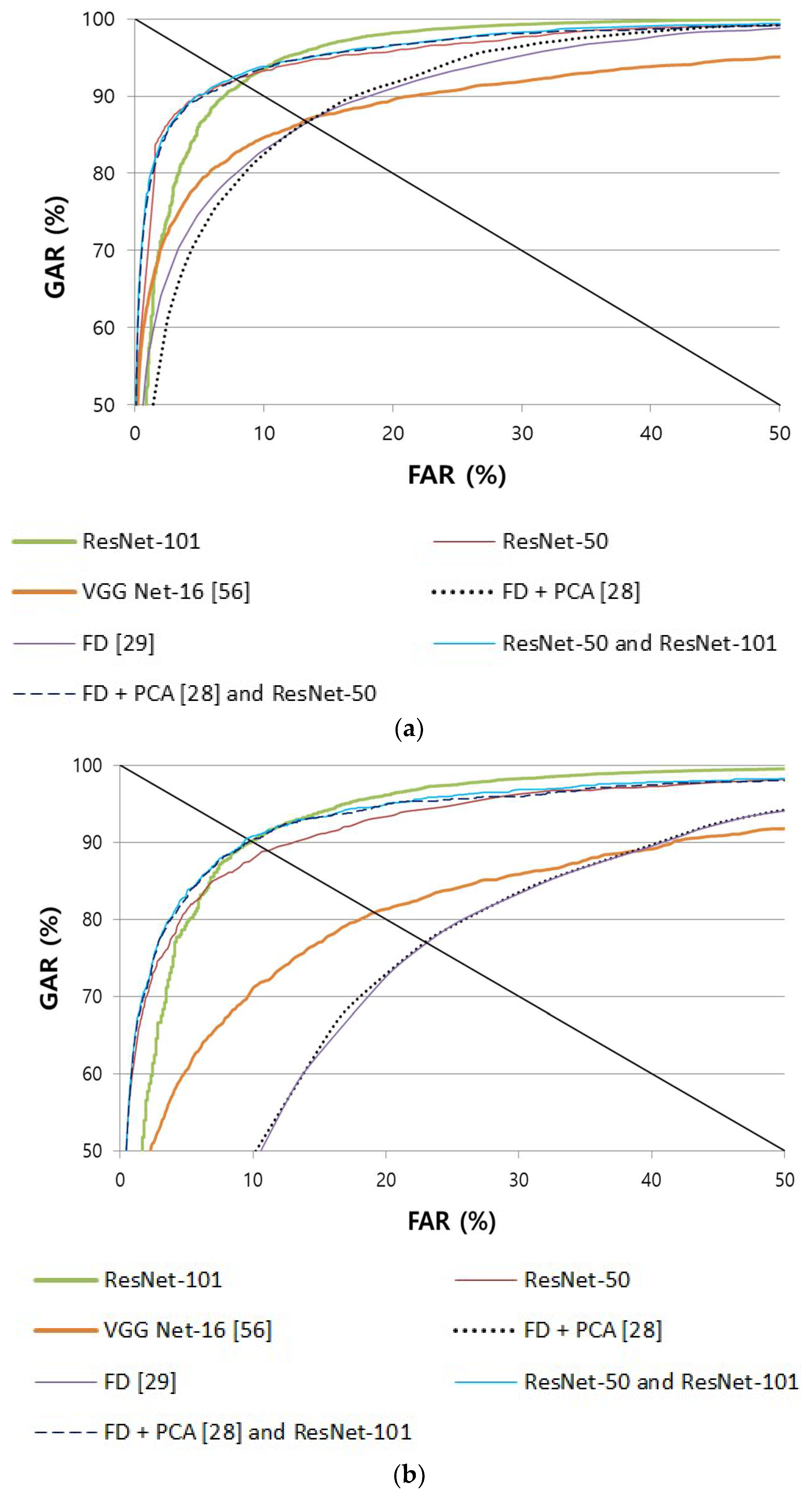
- Two-dimensional spectrogram images that express finger-thickness frequency-component changes depending on the horizontal position of fingers were obtained and used as CNN inputs for finger shape recognition.
- -
- Matching distances calculated based on the features of finger-vein and finger shape that were obtained using ResNet models were score fused using various fusion methods, such as the weight sum, weighted product, and perceptron.
- -
- The trained CNN models and algorithms developed in this study were open through [30] so that other researchers can use them in fair performance evaluations.
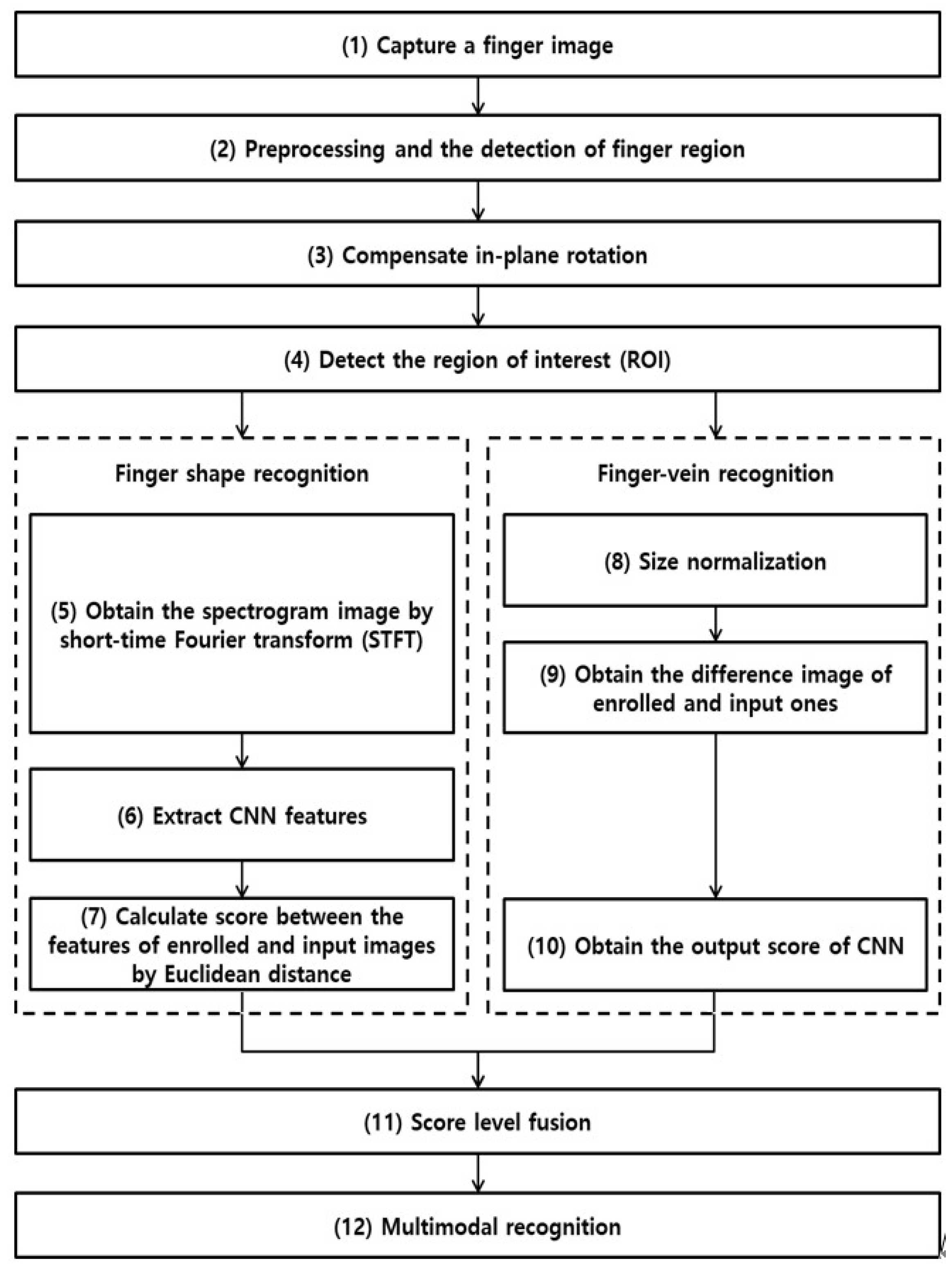
3. Proposed Method
3.1. Overview of Proposed Method
3.2. Preprocessing and Detection of Finger Region
3.3. In-Plane Rotation Compensation
3.4. 2-Dimensional Spectrogram Image for Finger Shape Recognition
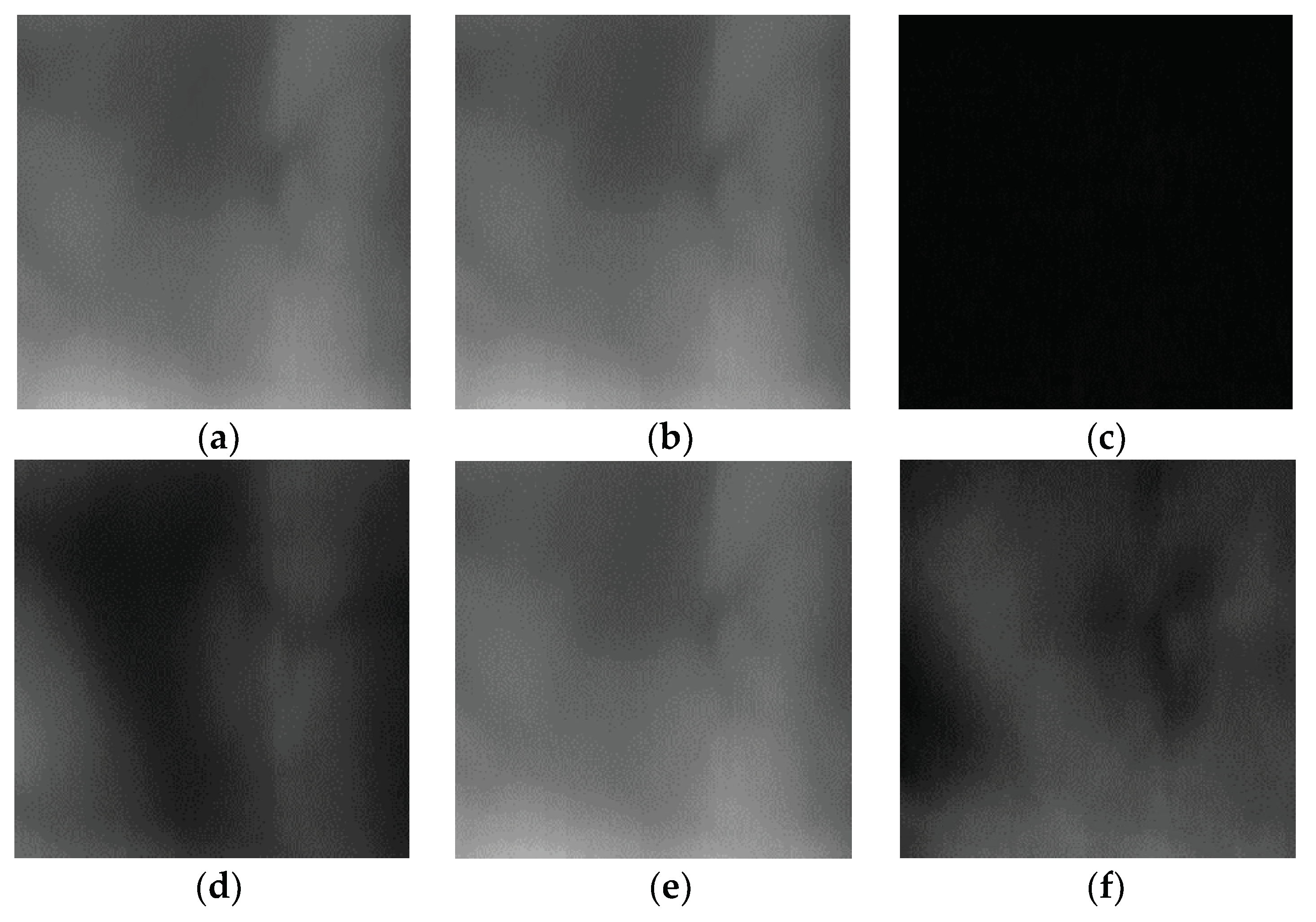
3.5. Difference Image Finger-Vein Recognition
3.6. CNN-Based Finger-Vein and Finger Shape Recognition
3.7. Finger Recognition Based on Score-Level Fusion
4. Experimental Results
4.1. Experimental Data
4.2. Data Augmentation
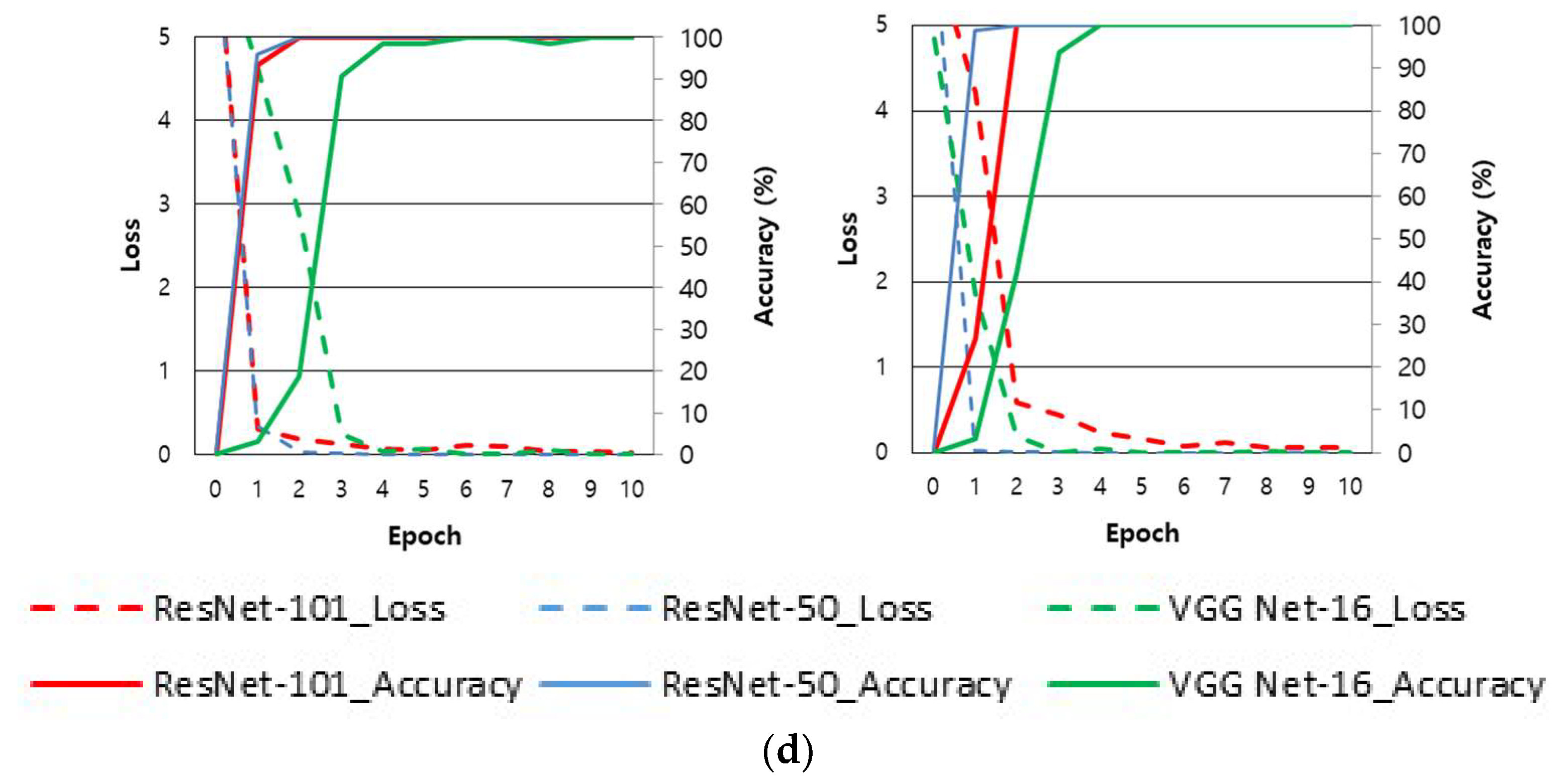
4.3. Training of CNN
4.4. Testing of Proposed CNN-Based Recognition
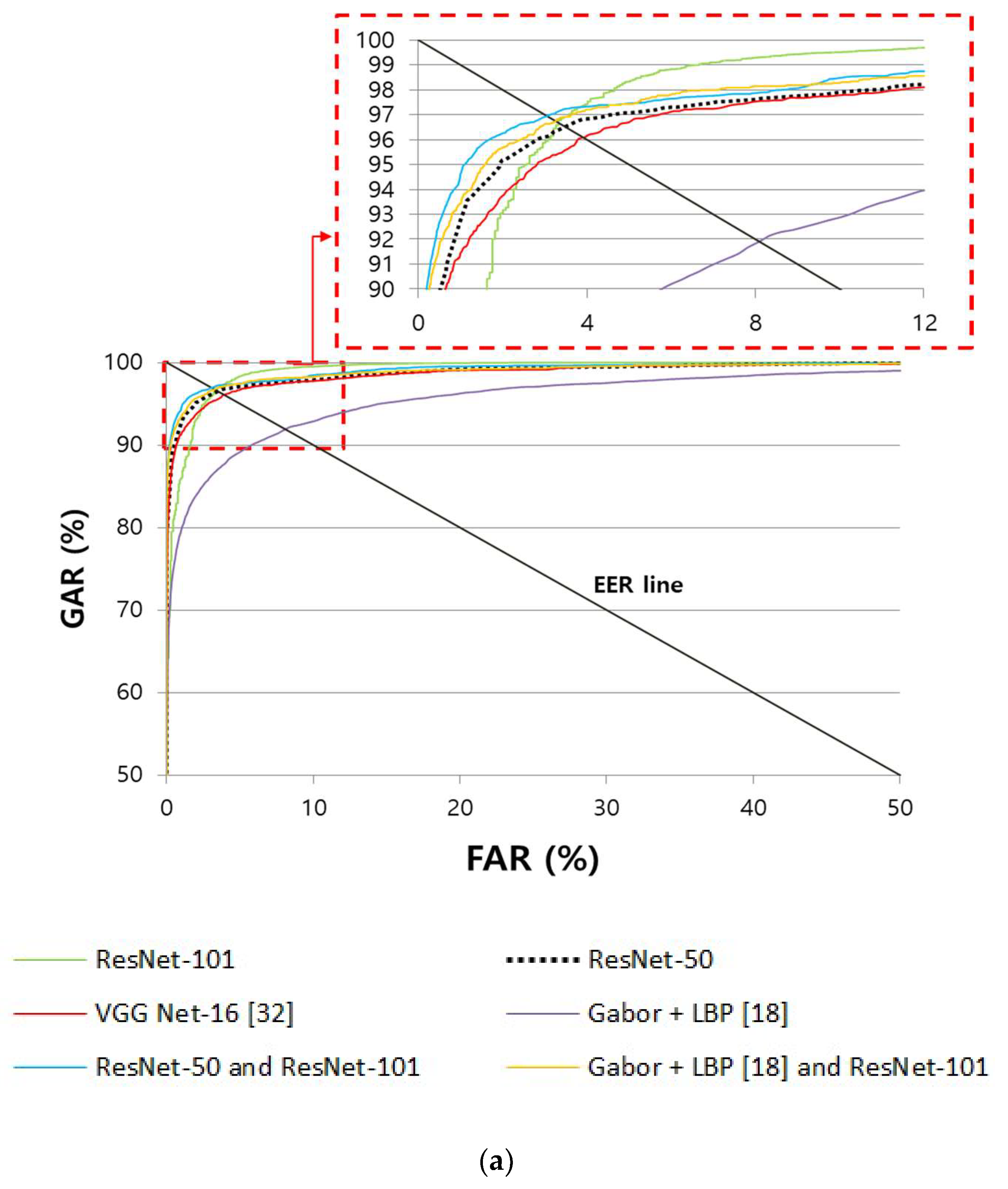
4.4.1. Comparison of the Accuracy of Finger-Vein Recognition
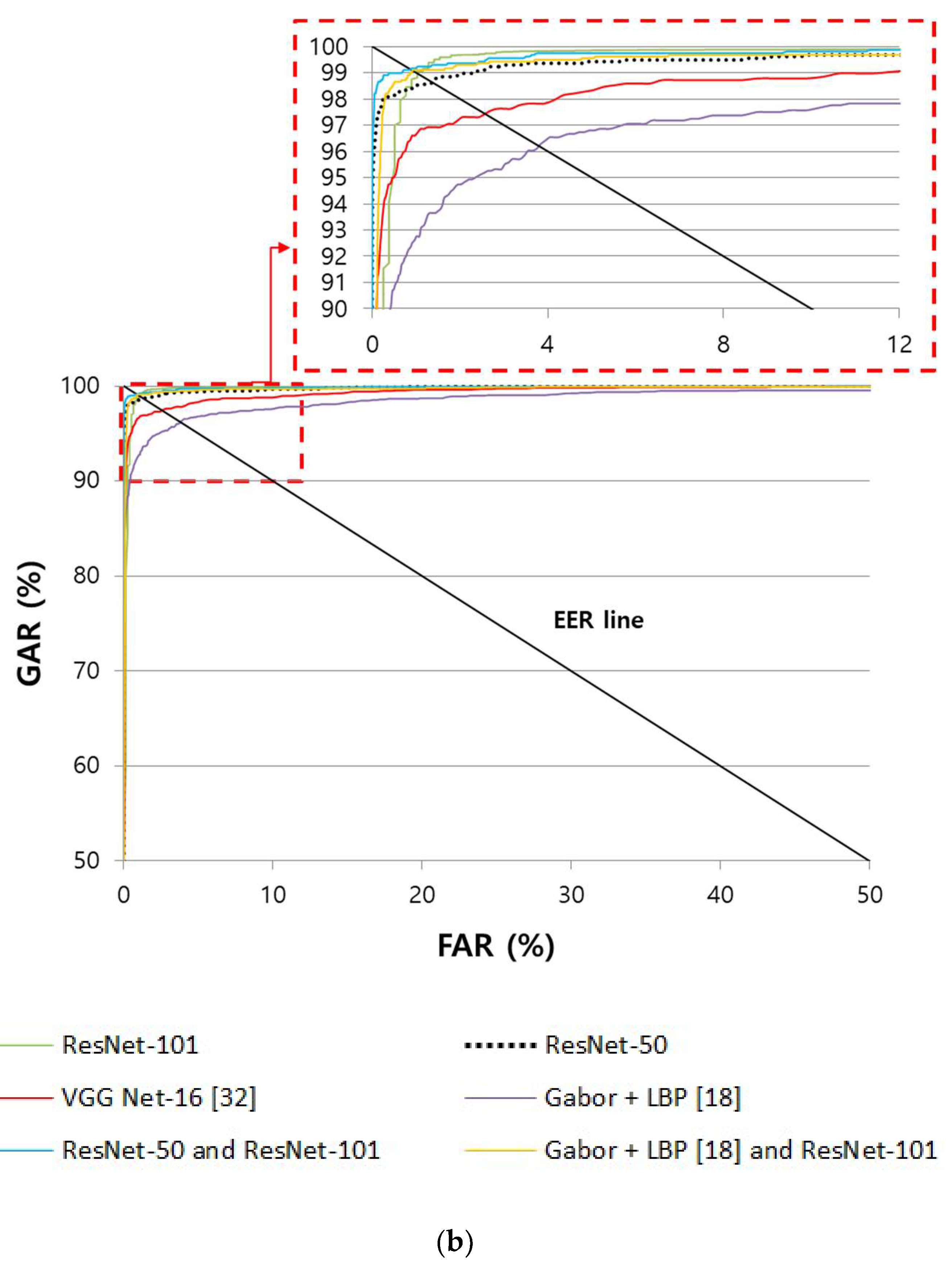
4.4.2. Comparison of the Accuracy of Finger Shape Recognition
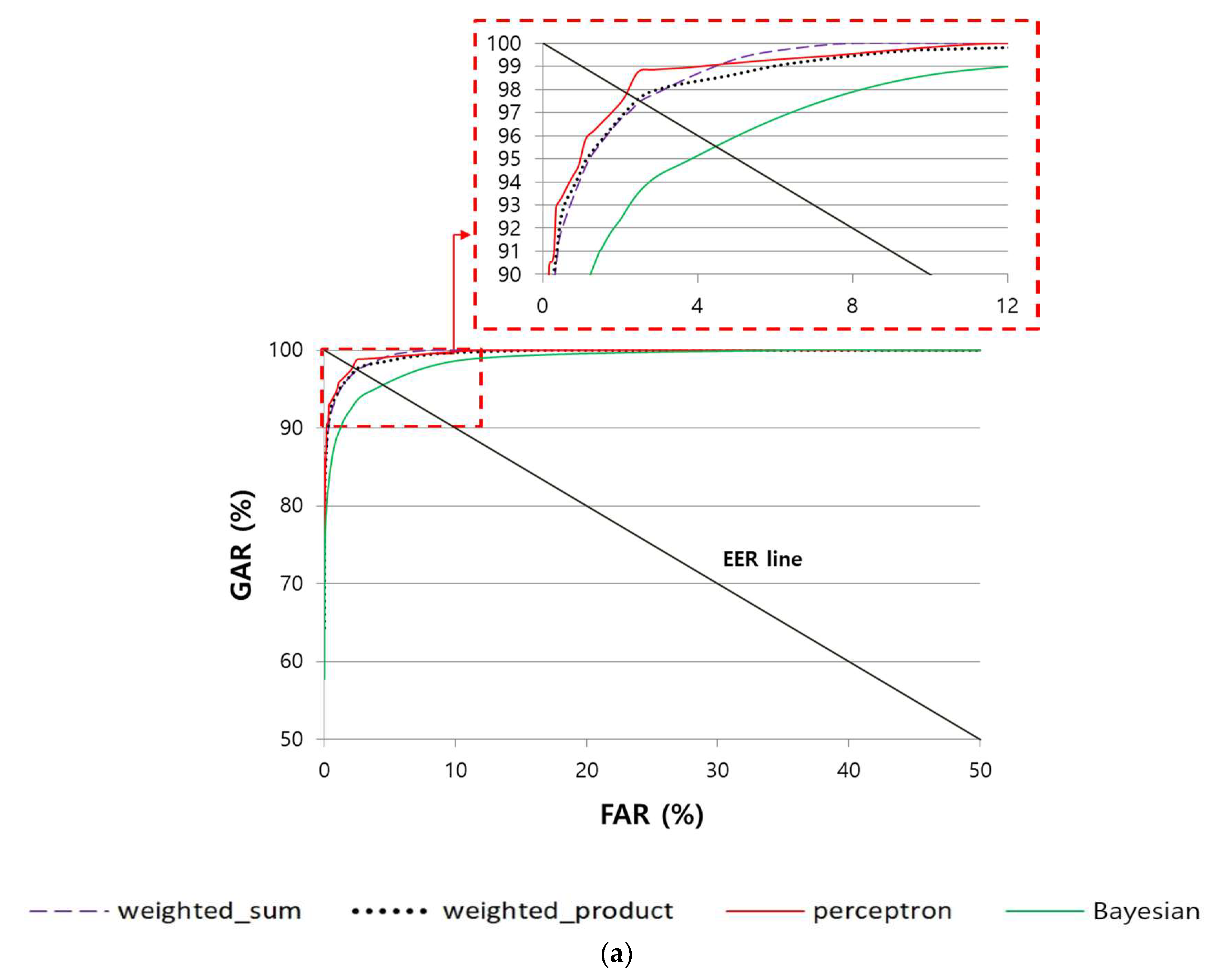
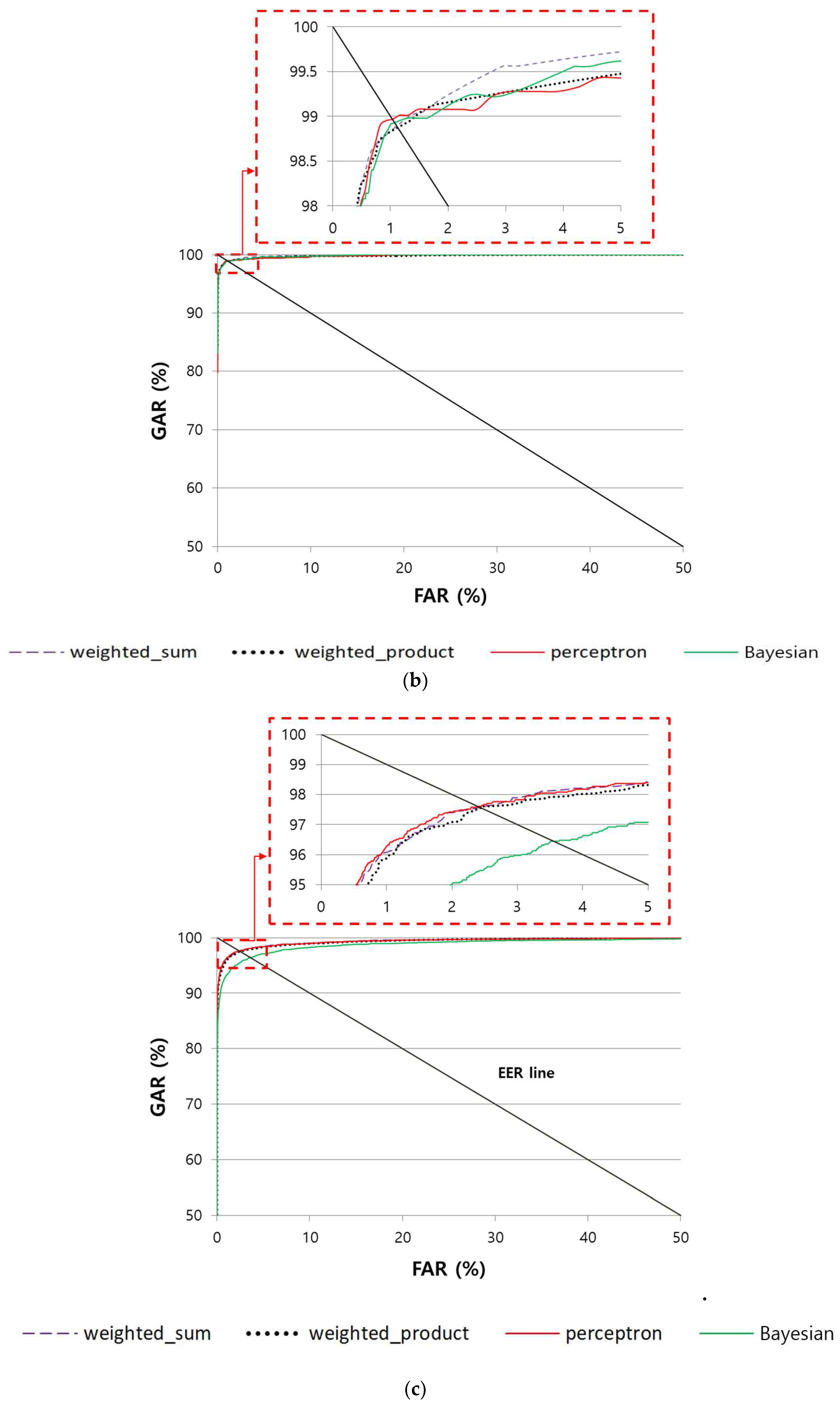
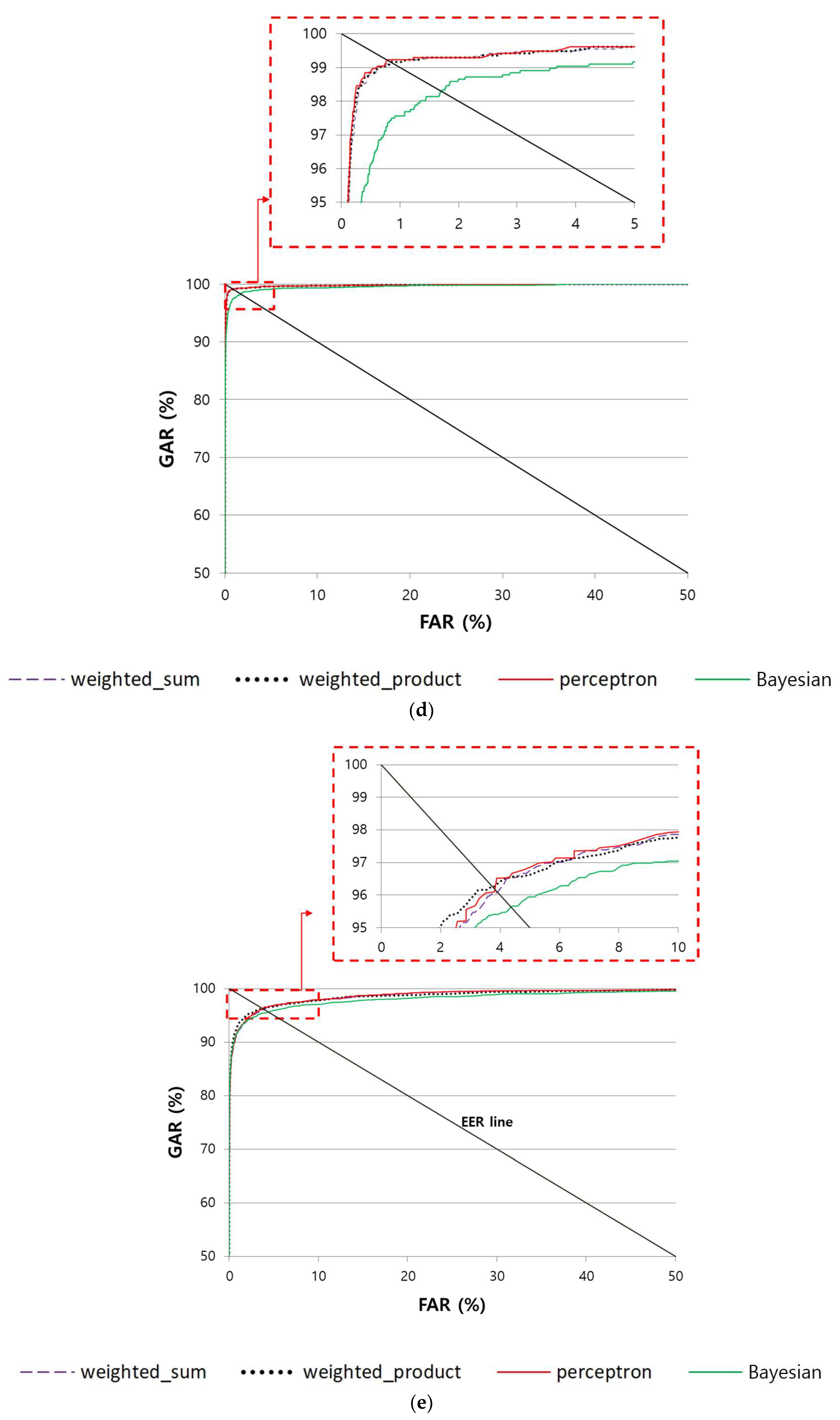
4.4.3. Comparison of the Accuracy of Multimodal Recognition of Finger-Vein and Finger Shape According to Various Score-Level Fusion Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Xie, S.J.; Yoon, S.; Shin, J.; Park, D.S. Effective fingerprint quality estimation for diverse capture sensors. Sensors 2010, 10, 7896–7912. [Google Scholar] [CrossRef] [PubMed]
- Medina-Pérez, M.A.; García-Borroto, M.; Gutierrez-Rodríguez, A.E.; Altamirano-Robles, L. Improving fingerprint verification using minutiae triplets. Sensors 2012, 12, 3418–3437. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Tian, Y.; Li, L. A new approach for inner-knuckle-print recognition. J. Vis. Lang. Comput. 2014, 25, 33–42. [Google Scholar] [CrossRef]
- Kumar, A.; Ravikanth, C. Personal authentication using finger knuckle surface. IEEE Trans. Inf. Forensic Secur. 2009, 4, 98–110. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Zhang, D.; Zhu, H. Ensemble of local and global information for finger–knuckle-print recognition. Pattern Recognit. 2011, 44, 1990–1998. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Li, H. Encoding local image patterns using Riesz transforms: With applications to palmprint and finger-knuckle-print recognition. Image Vis. Comput. 2012, 30, 1043–1051. [Google Scholar] [CrossRef]
- Aoyama, S.; Ito, K.; Aoki, T. Finger-knuckle-print recognition using BLPOC-based local block matching. In Proceedings of the 1st Asian Conference on Pattern Recognition, Beijing, China, 28–30 November 2011; pp. 525–529. [Google Scholar]
- Zhang, L.; Zhang, L.; Zhang, D.; Guo, Z. Phase congruency induced local features for finger-knuckle-print recognition. Pattern Recognit. 2012, 45, 2522–2531. [Google Scholar] [CrossRef] [Green Version]
- Aoyama, S.; Ito, K.; Aoki, T. A finger-knuckle-print recognition algorithm using phase-based local block matching. Inf. Sci. 2014, 268, 53–64. [Google Scholar] [CrossRef]
- Kusanagi, D.; Aoyama, S.; Ito, K.; Aoki, T. A practical person authentication system using second minor finger knuckles for door security. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 1–13. [Google Scholar] [CrossRef]
- Qin, H.; He, X.; Yao, X.; Li, H. Finger-vein verification based on the curvature in radon space. Expert Syst. Appl. 2017, 82, 151–161. [Google Scholar] [CrossRef]
- Song, W.; Kim, T.; Kim, H.C.; Choi, J.H.; Kong, H.-J.; Lee, S.-R. A finger-vein verification system using mean curvature. Pattern Recognit. Lett. 2011, 32, 1541–1547. [Google Scholar] [CrossRef]
- Miura, N.; Nagasaka, A.; Miyatake, T. Extraction of finger-vein patterns using maximum curvature points in image profiles. In Proceedings of the IAPR Conference on Machine Vision Applications, Tsukuba Science City, Japan, 16–18 May 2005; pp. 347–350. [Google Scholar]
- Yang, J.; Shi, Y.; Jia, G. Finger-vein image matching based on adaptive curve transformation. Pattern Recognit. 2017, 66, 34–43. [Google Scholar] [CrossRef]
- Miura, N.; Nagasaka, A.; Miyatake, T. Feature extraction of finger-vein patterns based on repeated line tracking and its application to personal identification. Mach. Vis. Appl. 2004, 15, 194–203. [Google Scholar] [CrossRef]
- Huang, B.; Dai, Y.; Li, R.; Tang, D.; Li, W. Finger-vein authentication based on wide line detector and pattern normalization. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1269–1272. [Google Scholar]
- Liu, T.; Xie, J.B.; Yan, W.; Li, P.Q.; Lu, H.Z. An algorithm for finger-vein segmentation based on modified repeated line tracking. Imaging Sci. J. 2013, 61, 491–502. [Google Scholar] [CrossRef]
- Pham, T.D.; Park, Y.H.; Nguyen, D.T.; Kwon, S.Y.; Park, K.R. Nonintrusive finger-vein recognition system using NIR image sensor and accuracy analyses according to various factors. Sensors 2015, 15, 16866. [Google Scholar] [CrossRef] [PubMed]
- Syarif, M.A.; Ong, T.S.; Teoh, A.B.J.; Tee, C. Enhanced maximum curvature descriptors for finger vein verification. Multimed. Tools Appl. 2017, 76, 6859–6887. [Google Scholar] [CrossRef]
- Yang, J.; Shi, Y. Finger–vein ROI localization and vein ridge enhancement. Pattern Recognit. Lett. 2012, 33, 1569–1579. [Google Scholar] [CrossRef]
- Bin, F.; Jianwen, C.; Xinyan, X. A novel adaptive vein image contrast enhancement method based on fuzzy and retinex theory. In Proceedings of the IEEE International Conference on Information and Automation, Harbin, China, 20–23 June 2010; pp. 2447–2450. [Google Scholar]
- Su, C.-L. Finger shape expansion and recognition by wavelet transform. Appl. Math. Comput. 2007, 190, 1583–1592. [Google Scholar] [CrossRef]
- Asaari, M.S.M.; Rosdi, B.A. A single finger geometry recognition based on widths and fingertip angels. In Proceedings of the IAPR International Conference on Machine Vision Applications, Kyoto, Japan, 20–23 May 2013; pp. 256–259. [Google Scholar]
- Yang, J.; Zhang, X. Feature-level fusion of fingerprint and finger-vein for personal identification. Pattern Recognit. Lett. 2012, 33, 623–628. [Google Scholar] [CrossRef]
- Peng, J.; El-Latif, A.A.A.; Li, Q.; Niu, X. Multimodal biometric authentication based on score level fusion of finger biometrics. Optik 2014, 125, 6891–6897. [Google Scholar] [CrossRef]
- Khellat-Kihel, S.; Abrishambaf, R.; Monteiro, J.L.; Benyettou, M. Multimodal fusion of the finger vein, fingerprint and the finger-knuckle-print using kernel fisher analysis. Appl. Soft. Comput. 2016, 42, 439–447. [Google Scholar] [CrossRef]
- Veluchamy, S.; Karlmarx, L.R. System for multimodal biometric recognition based on finger knuckle and finger vein using feature-level fusion and k-support vector machine classifier. IET Biom. 2017, 6, 232–242. [Google Scholar] [CrossRef]
- Kang, B.J.; Park, K.R.; Yoo, J.-H.; Kim, J.N. Multimodal biometric method that combines veins, prints, and shape of a finger. Opt. Eng. 2011, 50, 017201-1–017201-13. [Google Scholar]
- Kang, B.J.; Park, K.R. Multimodal biometric method based on vein and geometry of a single finger. IET Comput. Vis. 2010, 4, 209–217. [Google Scholar] [CrossRef]
- Dongguk Multimodal Recognition CNN of Finger-Vein and Finger Shape (DMR-CNN) with Algorithm. Available online: http://dm.dgu.edu/link.html (accessed on 13 May 2018).
- Zhang, L.; Zhang, L.; Zhang, D. Finger-knuckle-print verification based on band-limited phase-only correlation. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Münster, Germany, 2–4 September 2009; pp. 141–148. [Google Scholar]
- Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional neural network-based finger-vein recognition using NIR image sensors. Sensors 2017, 17, 1. [Google Scholar] [CrossRef] [PubMed]
- Qin, H.; El-Yacoubi, M.A. Deep representation-based feature extraction and recovering for finger-vein verification. IEEE Trans. Inf. Forensic Secur. 2017, 12, 1816–1829. [Google Scholar] [CrossRef]
- Barber, C.B.; Dobkin, D.P.; Huhdanpaa, H. The Quickhull algorithm for convex hulls. ACM Trans. Math. Softw. 1996, 22, 469–483. [Google Scholar] [CrossRef]
- Kumar, A.; Zhou, Y. Human identification using finger images. IEEE Trans. Image Process. 2012, 21, 2228–2244. [Google Scholar] [CrossRef] [PubMed]
- Maas, A.L.; Qi, P.; Xie, Z.; Hannun, A.Y.; Lengerich, C.T.; Jurafsky, D.; Ng, A.Y. Building DNN acoustic models for large vocabulary speech recognition. Comput. Speech Lang. 2017, 41, 195–213. [Google Scholar] [CrossRef] [Green Version]
- Huzaifah, M. Comparison of time-frequency representations for environmental sound classification using convolutional neural networks. arXiv 2017, arXiv:1706.07156v1. [Google Scholar]
- Mitra, V.; Franco, H. Time-frequency convolutional networks for robust speech recognition. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Scottsdale, AZ, USA, 13–17 December 2015; pp. 317–323. [Google Scholar]
- Kekre, H.B.; Kulkarni, V.; Gaikar, P.; Gupta, N. Speaker identification using spectrograms of varying frame sizes. Int. J. Comput. Appl. 2012, 50, 27–33. [Google Scholar]
- Tivive, F.H.C.; Bouzerdoum, A.; Amin, M.G. A human gait classification method based on radar doppler spectrograms. EURASIP J. Adv. Signal Process. 2010, 2010, 10. [Google Scholar] [CrossRef]
- Schlüter, J.; Böck, S. Improved musical onset detection with convolutional neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Florence, Italy, 4–9 May 2014; pp. 6979–6983. [Google Scholar]
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Laurent, C.; Bengio, Y.; Courville, A. Towards end-to-end speech recognition with deep convolutional neural networks. arXiv 2017, arXiv:1701.02720v1. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- CS231n Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/#overview (accessed on 27 May 2018).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Heaton, J. Artificial Intelligence for Humans; Deep Learning and Neural Networks; Heaton Research, Inc.: St. Louis, MO, USA, 2015; Volume 3. [Google Scholar]
- Akhtar, Z.; Fumera, G.; Marcialis, G.L.; Roli, F. Evaluation of multimodal biometric score fusion rules under spoof attacks. In Proceedings of the 5th IAPR International Conference on Biometrics, New Delhi, India, 29 March–1 April 2012; pp. 402–407. [Google Scholar]
- SDUMLA-HMT Finger Vein Database. Available online: http://mla.sdu.edu.cn/info/1006/1195.htm (accessed on 7 May 2018).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Geforce GTX Titan X. Available online: https://www.geforce.com/hardware/desktop-gpus/geforce-gtx-titan-x/specifications (accessed on 27 May 2018).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. arXiv 2014, arXiv:1408.5093v1. [Google Scholar]
- Visual Studio 2013. Available online: https://www.microsoft.com/en-us/search/result.aspx?q=visual+studio+2013 (accessed on 5 June 2018).
- Bottou, L. Large-scale machine learning with stochastic gradients descent. In Proceedings of the 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Advantage | Disadvantage | |
|---|---|---|---|---|
| Single modal based | Fingerprint | SVM-based quality estimation [1] and minutiae triplets [2] | Cost and size of system are most effective | - Vulnerable to fake attack - Affected by the skin condition of finger |
| Finger knuckle print | Subspace [4], Local and global feature [5], Riesz transform [6] and Band-Limited Phase-Only Correlation (BLPOC) [5,9,10,31] | Less affected by the skin condition of finger than fingerprint recognition | More vulnerable to finger movement and skin deformations than fingerprint recognition | |
| Finger-vein | Radon transform [11], mean curvature [12], maximum curvature [13], Gabor filter [18,20], Hessian filter [19], fuzzy system [21], and convolutional neural network (CNN) [32,33] | - More resistant to fake attacks than fingerprint and finger knuckle-print recognition - Not affected by the skin condition of finger | Affected by shadows caused by NIR light, finger misalignment, and skin light scattering blur | |
| Finger shape | Wavelet transform [22], and Fourier descriptor and principal component analysis [23] | Not affected by the skin condition of finger | - Affected by thickness of finger according to age or health condition - The device size is bigger than fingerprint, finger knuckle-print, and finger-vein recognition devices - Extraction is hindered by stuck fingers | |
| Multi-modal based | Multiple sensors based | Fusion of fingerprint and finger-vein [24], Fusion of finger-vein, finger shape, fingerprint, and finger knuckle print [25], fusion of finger-vein, fingerprint, and finger knuckle print [26], and fusion of finger-vein and finger knuckle print [27] | Better recognition performance than single-model methods by using 2 or more biometric traits | - High cost and large system size due to the use of 2 or more image-acquisition devices - Slow image-acquisition speed due to inability to acquire multimodal images simultaneously |
| Single-sensor based | Handcrafted features and SVM [28,29] | Simultaneous finger-vein, fingerprint, and finger shape recognition using 1 device [28] Simultaneous finger-vein and finger shape recognition using 1 device [29] | Limited recognition performance improvement due to the use of handcraft features | |
| Deep features by CNN (proposed method) | - Simultaneous finger-vein and finger shape re cognition with 1 device - High recognition performance through the use of deep features | Requires intensive CNN training | ||
| Layer Name | Number of Filters | Size of Feature Map | Size of Filters | Number of Strides | Number of Padding | Number of Iterations | |
|---|---|---|---|---|---|---|---|
| Image input layer | 224 × 224 × 3 | ||||||
| Conv1 | 64 | 112 × 112 × 64 | 7 × 7 × 3 | 2 | 3 * | 1 | |
| Max pool | 1 | 56 × 56 × 64 | 3 × 3 | 2 | 0 | 1 | |
| Conv2 | Conv2_1 | 64 | 56 × 56 × 64 | 1 × 1 × 64 | 1 | 0 | 3 |
| Conv2_2 | 64 | 56 × 56 × 64 | 3 × 3 × 64 | 1 | 1 * | ||
| Conv2_3 | 256 | 56 × 56 × 256 | 1 × 1 × 64 | 1 | 0 | ||
| Conv2_4 (Shortcut) | 256 | 56 × 56 × 256 | 1 × 1 × 64 | 1 | 0 | ||
| Conv3 | Conv3_1 | 128 | 28 × 28 × 128 | 1 × 1 × 256 | 2/1 ** | 0 | 4 |
| Conv3_2 | 128 | 28 × 28 × 128 | 3 × 3 × 128 | 1 | 1 * | ||
| Conv3_3 | 512 | 28 × 28 × 512 | 1 × 1 × 128 | 1 | 0 | ||
| Conv3_4 (Shortcut) | 512 | 28 × 28 × 512 | 1 × 1 × 256 | 2 | 0 | ||
| Conv4 | Conv4_1 | 256 | 14 × 14 × 256 | 1 × 1 × 512 | 2/1 ** | 0 | 23 |
| Conv4_2 | 256 | 14 × 14 × 256 | 3 × 3 × 256 | 1 | 1* | ||
| Conv4_3 | 1024 | 14 × 14 × 1024 | 1 × 1 × 256 | 1 | 0 | ||
| Conv4_4 (Shortcut) | 1024 | 14 × 14 × 1024 | 1 × 1 × 512 | 2 | 0 | ||
| Conv5 | Conv5_1 | 512 | 7 × 7 × 512 | 1 × 1 × 1024 | 2/1 ** | 0 | 3 |
| Conv5_2 | 512 | 7 × 7 × 512 | 3 × 3 × 512 | 1 | 1* | ||
| Conv5_3 | 2048 | 7 × 7 × 2048 | 1 × 1 × 512 | 1 | 0 | ||
| Conv5_4 (Shortcut) | 2048 | 7 × 7 × 2048 | 1 × 1 × 1024 | 2 | 0 | ||
| AVG pool | 1 | 1 × 1 × 2048 | 7 × 7 | 1 | 0 | 1 | |
| FC layer | #class | 1 | |||||
| Softmax | #class | 1 | |||||
| SDU-DB | PolyU-DB | |||
|---|---|---|---|---|
| Original images | # of images | 3816 | 1872 | |
| # of people | 106 | 156 | ||
| # of hands | 2 | 1 | ||
| # of fingers | 3 (index, middle, and ring fingers) | 2 (index and middle fingers) | ||
| # of classes (# of images per class) | 636 (6) | 312 (6) | ||
| Data augmentation for training | Finger shape image | # of images | 230,868 (318 classes × 6 images × 121 times) | 113,256 (156 classes × 6 images × 121 times) |
| Finger-vein image | # of images | 48,972 | 24,024 | |
| # of images for genuine matching | 24,486 (6 images × (13 times − 1) × 318 classes) | 12,012 (6 images × (13 times − 1) × 156 classes) | ||
| # of images for imposter matching (Random selection) | 24,486 | 12,012 | ||
| Dataset | # of Output Class | CNN Model | Max. # of Iteration (Epoch) | Mini-Batch Size | Learning Rate | Momentum/Gamma | |
|---|---|---|---|---|---|---|---|
| SDU-DB | Finger-vein | 2 | VGG Net-16 | 7651 (10) | 64 | 0.001 | 0.9/0.1 |
| ResNet-50 | 24,486 (10) | 20 | |||||
| ResNet-101 | 32,648 (10) | 15 | |||||
| Finger shape | 318 | VGG Net-16 | 36,073 (10) | 64 | |||
| ResNet-50 | 115,434 (10) | 20 | |||||
| ResNet-101 | 153,912 (10) | 15 | |||||
| PolyU-DB | Finger-vein | 2 | VGG Net-16 | 3753 (10) | 64 | ||
| ResNet-50 | 12,012 (10) | 20 | |||||
| ResNet-101 | 16,016 (10) | 15 | |||||
| Finger shape | 156 | VGG Net-16 | 17696 (10) | 64 | |||
| ResNet-50 | 56,628 (10) | 20 | |||||
| ResNet-101 | 75,504 (10) | 15 | |||||
| Method | EER | ||
|---|---|---|---|
| SDU-DB | PolyU-DB | ||
| Non-training based method | Maximum Curvature [13] | 4.54* | 3.51 |
| Repeated line tracking [15] | 5.46* | 2.17 | |
| Wide line detector [16] | 22.7* | 1.80 | |
| Gabor + LBP [18] | 8.096 | 3.61 | |
| Training-based method | VGG Net-16 [32] | 3.906 | 2.491 |
| ResNet-50 | 3.4931 | 1.3435 | |
| ResNet-101 | 3.3653 | 1.0779 | |
| Score-level fusion of ResNet-50 and ResNet-101 by weighted product rule | 3.0653 | 0.8888 | |
| Non-training and training-based method | Score-level fusion of Gabor + LBP [18] and ResNet-101 by weighted product rule | 3.2426 | 0.9138 |
| Method | EER | ||
|---|---|---|---|
| SDU-DB | PolyU-DB | ||
| Non-training-based method | Fourier descriptor (FD) [29] | 13.8753 | 22.855 |
| FD + PCA [28] | 13.574 | 22.8718 | |
| Training-based method | VGG Net-16 [56] | 13.2758 | 19.2294 |
| ResNet-50 | 7.98 | 10.914 | |
| ResNet-101 | 8.305 | 9.9553 | |
| Score-level fusion of ResNet-50 and ResNet-101 by weighted product rule | 7.5665 | 9.5631 | |
| Non-training and training-based method | Score-level fusion of FD + PCA [28] and ResNet * by weighted product rule | 7.8147 | 9.8094 |
| Method | EER | ||
|---|---|---|---|
| SDU-DB | PolyU-DB | ||
| 1 channel gray spectrogram image (Proposed method) | 1st fold | 5.35 | 10.096 |
| 2nd fold | 11.26 | 9.8146 | |
| Average | 8.305 | 9.9553 | |
| 3 channels color spectrogram image | 1st fold | 6.431 | 13.748 |
| 2nd fold | 14.711 | 18 | |
| Average | 10.571 | 15.874 | |
| Method | EER | ||||||
|---|---|---|---|---|---|---|---|
| SDU-DB | PolyU-DB | ||||||
| Model | VGG Net-16 | ResNet-50 | ResNet-101 | VGG Net-16 | ResNet-50 | ResNet-101 | |
| Score-level fusion | Weighted sum | 3.892 | 2.4718 | 2.4258 | 2.491 | 1.1145 | 0.8255 |
| Weighted product | 3.7217 | 2.4015 | 2.4088 | 2.3763 | 1.143 | 0.8265 | |
| Perceptron | 3.8516 | 2.3445 | 2.398 | 2.4433 | 1.0235 | 0.7859 | |
| Bayesian | 4.3621 | 4.3857 | 3.509 | 3.7196 | 1.0965 | 1.706 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, W.; Song, J.M.; Park, K.R. Multimodal Biometric Recognition Based on Convolutional Neural Network by the Fusion of Finger-Vein and Finger Shape Using Near-Infrared (NIR) Camera Sensor. Sensors 2018, 18, 2296. https://doi.org/10.3390/s18072296
Kim W, Song JM, Park KR. Multimodal Biometric Recognition Based on Convolutional Neural Network by the Fusion of Finger-Vein and Finger Shape Using Near-Infrared (NIR) Camera Sensor. Sensors. 2018; 18(7):2296. https://doi.org/10.3390/s18072296
Chicago/Turabian StyleKim, Wan, Jong Min Song, and Kang Ryoung Park. 2018. "Multimodal Biometric Recognition Based on Convolutional Neural Network by the Fusion of Finger-Vein and Finger Shape Using Near-Infrared (NIR) Camera Sensor" Sensors 18, no. 7: 2296. https://doi.org/10.3390/s18072296