Geomagnetism-Aided Indoor Wi-Fi Radio-Map Construction via Smartphone Crowdsourcing

1
Academy of Opto-Electronics, Chinese Academy of Sciences, Beijing 100094, China
2
University of Chinese Academy of Sciences, Beijing 100049, China
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(5), 1462; https://doi.org/10.3390/s18051462
Submission received: 13 February 2018
/
Revised: 17 April 2018
/
Accepted: 25 April 2018
/
Published: 8 May 2018
(This article belongs to the Collection Positioning and Navigation)
Abstract
:Wi-Fi radio-map construction is an important phase in indoor fingerprint localization systems. Traditional methods for Wi-Fi radio-map construction have the problems of being time-consuming and labor-intensive. In this paper, an indoor Wi-Fi radio-map construction method is proposed which utilizes crowdsourcing data contributed by smartphone users. We draw indoor pathway map and construct Wi-Fi radio-map without requiring manual site survey, exact floor layout and extra infrastructure support. The key novelty is that it recognizes road segments from crowdsourcing traces by a cluster based on magnetism sequence similarity and constructs an indoor pathway map with Wi-Fi signal strengths annotated on. Through experiments in real world indoor areas, the method is proved to have good performance on magnetism similarity calculation, road segment clustering and pathway map construction. The Wi-Fi radio maps constructed by crowdsourcing data are validated to provide competitive indoor localization accuracy.
1. Introduction
Location-based service (LBS) is some of the most important content that provides convenient and precise services for users, such as navigation for pedestrians or cars, mobile payment, taxi finding, bicycle sharing, intelligent guiding, loss prevention and so on. The global navigation satellite system (GNSS) can provide positioning services in most outdoor environments, however in the indoor environment, such as a big shopping mall, underground parking and museums, other positioning techniques should be considered due to the signal occlusion problem of GNSS. Currently, the indoor positioning techniques commonly used in consumer applications mainly include Wi-Fi signal strength fingerprint methods [1,2], range measurement methods using wireless signal [3,4], geomagnetic field matching methods [5,6], dead reckoning (DR) methods based on smartphone-mounted micro electro mechanical system (MEMS) [7,8] and localization using context recognition and landmarks [9,10]. All the mentioned localization methods have their own advantages and disadvantages, but the Wi-Fi fingerprint method usually plays the main role in indoor localization, for the reason that Wi-Fi has been deployed in almost all public places and its received signal strength (RSS) has good ability in location differentiation within a floor or between distinct floors.
Fingerprint-based Wi-Fi indoor localization system always consist of two phases: offline radio map construction and online localization by fingerprint matching. In the offline phase, RSS from Wi-Fi access points (APs) are labeled using the location coordinates of each reference point (RP), and all the RP data are stored together as a fingerprint database. In the online phase, user’s real time RSS measurements are matched to the fingerprint database using an algorithm, and the position with most similar RSS measurements is given as final position solution. To realize the offline phase, it is ideal that the RSS of all the detected APs be carefully calibrated to a location grid which completely covers the indoor map, and then the Wi-Fi radio map can be constructed exactly. However, this method is time-consuming and labor-intensive, as it needs repeated measurements on each RP to obtain statistical value of RSS and professional work to realize exact calibration of the indoor coordinates. Another challenge is that the constructed radio map would lose stability and even become invalid in some situations like fluctuating air humidity and indoor architecture changes [11]. In order to solve the above problems, some new kind Wi-Fi fingerprint construction techniques have been proposed, including data collection with the help of volunteers [12], simultaneous localization and mapping (SLAM) using Wi-Fi signal strength [13], RSS prediction based on exist fingerprints [14], and fingerprint construction using passive crowdsourcing data [15].
Redpin [16] and OIL [12] are previously proposed fingerprint-based indoor localization systems that omit the time-consuming training phase, in which the volunteer users report their current locations with room-level accuracy and corresponding Wi-Fi signal-strength. The more users that are uploading fingerprints at different locations, the more areas the database can cover. Aiming for a more flexible and scalable point in the design space of user-generated Wi-Fi localization system, Molé [17] arranges places in a hierarchy instead of an accurate map for floor plan and labels users fingerprints by semantic locations. These solutions depend on the active participation of users that results in inconveniences for the user experience and unknown measurement noises [18].
Ferris et al. [13] and Huang et al. [19] proposed signal-strength-based SLAM techniques. Reference [13] uses a Gaussian Process Latent Variable Model (GPLVM) to determine the latent-space locations of unlabeled signal strength data. Reference [19] presents a GraphSLAM-like algorithm for signal strength SLAM, which is viable for a broader range of environments due to its lack of special constraints and reduction of runtime complexity. WiFi-SLAM serves a promising solution for the problem of collection and maintenance of WiFi sensor models for large-scale localization, but it needs user trajectories with some closed loops and requires more calculation.
HIWL [20] uses K-means to produce discrete signal observation sequences, and train Hidden Markov Model (HMM) parameters by limited topology information of indoor environments. Through HMM training, the system learns the mapping relationship in geographical and signal distribution, and then matches the unlabeled fingerprints to the corresponding physical locations based on the mapping model. UMLI [21] proposes using nonparametric clustering methods to classify the unlabeled signal observations through two classification layers. By utilizing the clustering method, unlabeled signal data are classified into locations or rooms having similar RSS, achieving less site survey and labeling work. Chang et al. [14] developed a Minimum Inverse Distance (MID) algorithm to build a virtual database with uniformly distributed virtual RPs. The Local Gaussian Process (LGP) is then applied to estimate the virtual RPs’ RSSI values based on the crowdsourcing surveyed data. These methods need a set of surveyed fingerprints for model training and RSS prediction, so the quantity and quality of labeled data will seriously impact their accuracy.
With the popularization of smartphones and the increasing number of location-based service (LBS) users, research on passive methods of Wi-Fi radio map construction based on crowdsourcing has become a research hot spot currently. Its greatest advantage is that the crowdsourcing data can be obtained passively through user’s common behaviors when they use smartphone applications (APP). Meanwhile, the Wi-Fi radio map can be formed automatically and is easy to update thanks to the continuous uploading of user data.
WILL [22] is proposed as a wireless indoor logical localization approach that achieves room level location accuracy without site surveys. By exploiting user motions from mobile phones, independent radio signatures are previously connected following certain semantic rules to make a logical floor plan, and finally mapping it with a physical floor plan. Wang et al. [23] proposed an indoor subarea localization scheme which first constructs subarea fingerprints from crowdsourced RSS measurements using RL-clustering and then matches them to indoor layouts. They also proposed an online localization algorithm to deal with the device diversity issue. Both the WILL and Wang proposed methods divide user data into some clusters by RSS similarity and match them to subareas in a floor plan map. They can only provide room level localization rather than continuous positioning when a user walks in the indoor environment. Other systems use DR to compute user trajectories and furthermore label fingerprints in the indoor map pathway, which can provide a continuous localization in the indoor corridors (roads). Zee [24] use the inertial sensors present in the mobile phone to track them by a motion estimator (e.g., step counter, heading offset and stride length estimator) in an indoor environment, and implements an augmented particle filter both using floor map showing the pathways (e.g., hallways) and barriers (e.g., walls) and Wi-Fi scans to acquire crowdsourcing users’ position. RACC [25] identifies the indoor anchors (doors) as reference positions of the whole radio-map, in which doors’ RSS fingerprints can be identified according to motion detection when users walk through doors annotated with their corresponding physical locations by an adjacent recursive matching method. RCILS [26] detects people’s activities and trajectories in the indoor environment and matches them to a semantic graph of the indoor map using HMM. Then RSS collected along the trajectories can be labeled with location information. The air pressure detected by the barometer is used for elevator/stairs detection. RCILS also propose a trajectory fingerprint-based method in the online localization phase, which performs better when longer trajectory window is used in the sequence matching. Zee, RACC and RCILS can provide an accurate location solution in about 1~2 m, but they need an exact floor layout. PiLoc [15] divides a user’s single trajectory into disjoint path segments (turns and long straight lines) by detecting steps and turns, and utilized movement displacement (distance and direction) as well as the associated Wi-Fi signal to match path segments. Then PiLoc merges the clustered path segments annotated with displacement and signal strength information to derive a floor plan of walking paths annotated with radio signal strengths. It does not require manual calibration, prior knowledge and infrastructure support. A comparison of fingerprint localization methods without site survey via passive crowdsourcing data is shown in Table 1.
In addition, localization based on geomagnetic field has attracted attention in the indoor localization area for the fact it does not need infrastructure support and its stability compared to Wi-Fi signals. GROPING [27] utilizes magnetic fingerprinting collected by crowdsensing users and construct a floor map from an arbitrary set of walking trajectories. Map explorer records magnetic fields using smartphones and tags road junctions manually to help GROPING partition trajectories into segments. The similarity of magnetic intensity sequences is used to infer the overlapping segments among trajectories and stick them together. Reference [28] presents a SLAM algorithm based on measurements of the ambient magnetic field strength (MagSLAM) for pedestrians with foot-mounted sensors. Reference [29] considers magnetic field SLAM exploration using a mobile robot with a magnetometer and wheel encoders.
Different from the above methods, we propose in this paper a geomagnetism-aided indoor radio-map construction method via passive smartphone crowdsourcing. The proposed method don’t need exact floor layouts, but rather utilizes crowdsourcing traces to form the pathway map of a floor plan with merged Wi-Fi radio signal strengths annotated on it. It recognizes road segments from crowdsourcing traces by a cluster based on magnetism sequence similarity, which can be calculated exactly by a proposed feature matching algorithm even though the walking speeds may be different for each user.
2. Problem and Algorithm Overview
2.1. Opportunity and Challenge
Currently, sensors mounted in smartphones are abundant, and their performance is better. The sensors mainly utilized in indoor localization are accelerometers, gyroscopes, magnetometers, electronic compasses, barometers and Wi-Fi, which provide acceleration, angular velocity, magnetic field, orientation, barometric pressure and Wi-Fi RSS. Most of the sensors measurements can be uploaded by users via smartphone APPs that provide payment, navigation, map or shop information services in indoor environments, called crowdsourcing data. Based on these data, the Wi-Fi radio map of the indoor environment can be constructed. The main components for indoor radio map construction via crowdsourcing data are users’ trajectory tracking and Wi-Fi fingerprint labeling to accurate locations. In the following content, we discuss the opportunities and challenges on the resources and techniques available in our problem. It mainly covers pedestrian dead reckoning (PDR) and fingerprint localization.
2.1.1. Pedestrian Dead Reckoning
PDR is a technique which estimates relative locations and follow the tracks of a pedestrian via step detection, stride length estimation and heading determination. It is widely used in indoor localization systems with or without crowdsourcing, for its autonomy in pedestrian localization. In a smartphone-based PDR system, the accelerometer, gyroscope and magnetometer embedded with the smartphone are generally utilized to realize the PDR algorithm. 3-axis acceleration can be used to detect walking steps and estimate stride length. Besides, 3-axis angular velocity and magnetic field data are usually fused to determine the heading of pedestrians. There are some key challenges in this technique, which are addressed as follows [8,30]:
- The unconstrained human motions and smartphone postures make it complex to capture user’s motion modes, detect steps and estimate accurate walking orientation.
- Long/short term drift of accelerometer and gyroscope, which perform worse due to the low-cost IMU sensors embedded in smartphones, as well as magnetic disturbances result in inaccurate stride length estimation and heading determination.
- As a result of the above-mentioned two issues, the PDR localization output calculated by Equation (1) would not converge since its lacks an efficacious reference source:
Consequently, it is hard to use PDR directly for users’ trajectory tracking by crowdsourcing data. However, it still can benefit for distance estimation approximately in a limited area.
2.1.2. Fingerprint
The Wi-Fi fingerprint on a location point is a vector of the RSS from all the scanned Wi-Fi APs at a same time. For different locations in indoor areas, the detected Wi-Fi RSS vectors are correspondingly different, due to the diversity of signal attenuation caused by different ranges, wall blocks and multipath from each APs to the smartphone. Meanwhile, the Wi-Fi RSS vectors are similar for adjacent locations. The location correlation of Wi-Fi fingerprint makes it available in indoor positioning. Similarly, the Bluetooth fingerprint and magnetic field fingerprint can also be used in the indoor localization based on the same principle as Wi-Fi fingerprints, and they are all available in crowdsourcing, so we will talk about them together and compare their advantages and disadvantages. For the reasons that the Bluetooth fingerprint has almost same features as the Wi-Fi fingerprint as they are all based on the wireless electromagnetic signal of similar frequency (2.4 GHz), and Bluetooth launchers are always few in most public indoor environments for their lack of internet access functions compared with Wi-Fi, so in this section we will focus on discussion of Wi-Fi fingerprints and magnetic fields, and furthermore show the opportunities and challenges of using them for indoor localization.
(1) Fingerprint Stability
Stability comparisons between Wi-Fi and magnetic fingerprints have been given in some works. Here we adopt the stability index proposed in [27] to judge the stability between Wi-Fi RSS and magnetic field intensity. Stability index is the mean-to-standard deviation ratio of intensity, like Signal-to-Noise Radio (SNR). The Wi-Fi RSS of a settled AP and the magnitude of magnetic field are detected at a same location point and compared using the stability index. We detect six location points in an office room and corridor (staying for 5 min on each point), and calculate the stability index of the Wi-Fi and magnetic field signals. Figure 1 shows the result. It is seen that the magnetic field is obviously more stable than the Wi-Fi RSS.
In addition, it is known that the 2.4 GHz Wi-Fi signal is easily absorbed by the human body, which leads to obvious changes of RSS with or without ambient crowds. Figure 2 shows the comparison of Wi-Fi RSS and magnetic field when a pedestrian walks along a corridor in two opposite directions. The magnetic field shows good consistence with the corridor in different directions, but on the contrary, the Wi-Fi RSS is changing.
(2) Location Differentiation Ability
The measured magnetic field is the 3-axis magnetic intensity, and the intensity on each axis is dependent on the pose of the smartphone, so the resultant intensity is usually used to indicate the magnetic fingerprint. Therefore, for a single location point the magnetic fingerprint is a scalar, but the Wi-Fi fingerprint is a RSS vector whose dimensions will increase with the number of ambient APs. As shown in Figure 3a, the magnetic intensity is the same in some location points of one corridor (the resultant magnetic field intensities are all 50 μT at location points 1, 2, 3 and 4), but the Wi-Fi RSS vectors (seven APs are detected in the corridor) ate these location points are different, as shown in Figure 3b.
On the other hand, the magnetic fingerprint performs better in differentiation among corridors (or roads in indoor parking) than Wi-Fi, even when measured in the opposite direction (shown in Figure 2). Figure 4 shows the comparison of magnetism sequences measured in the same corridor and different corridors. It is obvious that magnetism sequences show highly similar shapes in the same corridor and low similarity in different corridors, so it is useful for crowdsourcing data to be divided into different corridors or clustered into same one. This is the principle for our proposed method. Since the similar shape of magnetic sequences in same corridor is based on the location correlation of the magnetic field; when the magnetic field time sequences are obtained by crowdsourcing users with different walking speeds (most of the time, users’ walking speeds are different, and hard to estimate accurately using crowdsourcing data), magnetism sequences would show an uncertain zooming state compared with the true space scale between two sample points.
In summary, the Wi-Fi fingerprint has a better performance in single location differentiation while the magnetic field shows better stability and ability in corridor division when used in sequence. Thus, a geomagnetism-aided method is designed to construct the indoor Wi-Fi radio-map via smartphone crowdsourcing in this paper.
2.2. Problem Setting
In this paper, we only concentrate on the 2D indoor localization problem. The crowdsourcing data collected by smartphone users are utilized to construct a Wi-Fi radio map automatically. Crowdsourcing data mentioned here generally include acceleration, angular velocity, magnetic field, orientation and Wi-Fi RSS provided respectively by the accelerometer, gyroscope, magnetometer, electronic compass and Wi-Fi connector mounted on a user’s smartphone. These data are generated and uploaded by crowdsourcing users when they are walking around the indoor environment, and meanwhile, recorded by the time identification stamp. Assuming that these data are continuous in time for each user, and we call them the moving traces of users, which are denoted as . Each moving trace is recorded as:
is the user’s moving orientation valued in which is the reading from the electronic compass. However, due to magnetic field anomalies in indoor environments and the unconstrained smartphone poses of crowdsourcing users, it is essential to estimate the user’s heading using acceleration, angular velocity and magnetic field by some better algorithm rather than using readings directly from the electronic compass. The heading estimation method raised in [30] is a kind of solution for the orientation problem. is the 3-axis acceleration, denoted as . is the 3-axis angular velocity, denoted as . is the 3-axis magnetic field intensity, denoted as . is the Wi-Fi fingerprint, include of AP Mac and RSS, denoted as , here is the total number of Wi-Fi APs scanned by the smartphone and is the time identification.
Since indoor localization generally happens in corridors (or roads in indoor parking) which lead to rooms (or function sections) and entries of a floor (like stairs and elevators); in our method, the indoor map is handled as a pathway graph and indicated by topology. As shown in Figure 5, in a pathway graph of the indoor plan, the edges represent all the pathways that users can walk from one place to another; and the vertexes represent the turning corners and the endings of pathways. The indoor graph is denoted as in this paper, which is described as:
is a set of coordinates of all the vertexes in the graph, denoted as . In this paper, we use 2D coordinates to describe , so, the vector can also be denoted as . Here is the total number of vertexes. is a matrix to represent the length of each edge between two vertexes, denoted as , here is Euclidean distance between p-th and q-th vertex.
In order to construct an indoor pathway graph by crowdsourcing user’s moving traces in our algorithm, the user’s trace will be broken down into some distinct road segments like the edges in a map. A road segment trace is a continuous trace with the turning connection or pathway ending only on its start or end points. The road segment is denoted as:
is the mean value of in the road segment trace, and it is a scalar identifying the displacement orientation of the road segment, valued in . And other elements in are defined as same as . The connection between two road segments is denoted as , which is recorded as:
It represents the connection between road segment and . is the connection type including four kinds as shown in Figure 6, which is defined as:
is the rotation angle between two road segments and in connection , defined as the angle rotated from vector to vector . The value of is in , negative for clockwise rotation and positive for anticlockwise rotation. Figure 7 shows an example of connection between road segments. It’s obvious that there are four road segments (, , and ) and three connections (, and ) in this moving trace. The connections will be denoted respectively as , and .
Finally, it is expected that through the proposed method the topology of the indoor map (pathway graph) is acquired by crowdsourcing user traces, and Wi-Fi fingerprints are labeled on the map. The constructed Wi-Fi fingerprint database is represented as:
where is the total number of RPs. is the number of available Wi-Fi APs in the area.
2.3. Algorithm Overview
Through the discussion on the opportunities and challenges of smartphone-based indoor localization, a method of geomagnetism-aided indoor radio-map construction via smartphone crowdsourcing is proposed in this paper. In this method, the acceleration, angular velocity, orientation, Wi-Fi RSS and magnetic field from crowdsourcing data are utilized to realize the algorithm. The architecture of our method is shown in Figure 8, which includes five parts: trace segmentation, geomagnetism-based similarity calculation, road segment clustering, topology construction and final radio map construction.
First of all, the turning detection using angular velocity is implemented for the users traces, and the long traces will be segmented into some short ones which are generated in distinct corridors (or roads), called road segment traces.
Since there are usually more than one user trace generated in a corridor (road) in crowdsourcing data, we design a clustering method here to make these road segment traces from different users match together and cluster them into some distinct corridors. In order to realize clustering, a kind of matching method for road segment traces is designed by calculating the similarity of magnetism sequences of these, based on the stable shape of the magnetic field in one corridor (road). As discussed in Section 2.1, to deal with the uncertain zooming of magnetism sequences for different user traces, the magnetism features are extracted firstly, and then based on them one sequence is zoomed to a same distance scale as another one and consequently, the similarity of two road segment traces is calculated exactly.
Supported by the magnetism similarity, road segment traces are clustered to some collections with highly magnetic similarity. The clustering algorithm is designed based on the Density-Based Spatial Clustering of Application with Noise (DBSCAN) algorithm, using a kind of magnetism similarity neighborhood. In addition, a preprocessing step is implemented before clustering to make the magnetism sequences be generated based on the same orientation.
Furthermore, the length of road segments and connections between them are estimated, and then the topology map is constructed. To deal with the topology mistakes caused by inaccurate connection angles and road lengths, the topology modification is carried out to get a final pathway graph. Finally, the crowdsourcing Wi-Fi RSSs are carefully labeled by location coordinates, and merged together on the generated Wi-Fi RPs along the constructed pathway graph. Thus, the final Wi-Fi radio map (fingerprint database) is constructed on the floor.
3. Algorithm Details
3.1. Trace Segmentation
In this paper, only the 2D indoor localization problem is considered. Considering the features of the pathway graph, we segment a user’s trace through turn detection. The variation of orientations can obviously show the turning behavior of the user, but considering the heading errors caused by magnetic field anomalies in indoor environments and unconstrained smartphone poses, the reading changes of the gyroscope are used to detect user’s turning instead. Figure 9 shows a user’s walking trace and the vertical component of the angular velocity. When the pedestrian walks straight, the values of angular velocity oscillate up and down around zero. On the contrary, when the pedestrian turns left or right, the absolute value of angular velocities will rise to a peak and then decline to normal, corresponding with the turn start and finish. The change would be obvious for quickly turning and gentle for a slow turn. Moreover, it shows that the angular velocities will go negative for clockwise turning and positive for anticlockwise turning.
As discussed above, in this paper, we use angular velocity readings from the gyroscope to detect turns, calculate turning angles and finally segment user’s traces. Before turn detection, the vertical component of the angular velocity is calculated by gravitational acceleration and coordinate transformation. For dealing with the measurement noise, the angular velocity will be smoothed using a moving average filter before turn detection. Three rules are made as follows to realize turning detection and turning angle estimation:
- The peaks of angular velocities are detected when the following conditions are satisfied. Here is a positive constant. The position of each peak is recorded using the sample count n:
- The start of turn is settled as the first point ascending from zero to the peak, and the end of turn is settled as the last declining point from the peak to zero.
- The user trace is segmented by detected peaks to some road segments, denoted as . is the number of peaks detected. The orientation of each road segment is the mean value of data in this road; and the rotation angle of the turning is the integration from to , shown in the following equations:
Figure 10 shows the turn detection result when setting . There are three turns detected in this trace . Then, we segment the user trace into four road segment traces , , and , and three connections, which are denoted respectively by , and . To deal with smartphone pose changes (false detection) and gentle turns (undetected) of the user, the turn detection result would be checked again by the user headings. If the offset of between two separate road segment traces are close to the detected turning angle, it is proved that there is a real turn. If the orientation change happens inside one road segment trace, the truing detection algorithm will be re-implement using an angular velocity with a lower . Of course, the erroneous road segments can also be eliminated by failing magnetic field matching in the following process.
3.2. Geomagnetism-Based Similarity Calculation
As discussed in Section 2.1, the geomagnetism sequence in the road segment obtained in the above process will be utilized to calculate the similarity between two road segment traces in our proposed method. To deal with the different scales of sequences, [6] used a Dynamic Time Warping (DTW) algorithm for sequence similarity computation, but DTW algorithms need a large amount of calculation, so in this section, we propose a novel method for similarity calculation using geomagnetism features. The details of geomagnetism-based similarity calculation will be described below, consisting of magnetism feature extraction, sequence zooming based on matched feature points, and final similarity calculation.
3.2.1. Feature Extraction
The geomagnetism measurements from a smartphone are 3-axis magnetism intensities (one reading for each axis). Considering the uncertain pose of smartphones, which causes measuring coordinate system changes, before we extract magnetism features from a data sequence, the vector module of the magnetic field is calculated firstly as the resultant magnetism intensity. The resultant magnetism intensity is acquired by the following equation, and only related to the position of the smartphone:
We define peaks and troughs from the sequence of resultant magnetism intensities Mag which satisfy the settled constraints as the magnetism features of the user trace. To remove the noise in magnetism sequence and extract its main shape, we smooth the magnetism vector using a moving average filter before feature extraction. The magnetism features are identified by the following criteria:
- All the peaks and troughs are detected from sequence Mag by the following equation, and MP and MT are respectively peak candidates and trough candidates:
- The candidates (both peaks and troughs together), whose magnetism intensity difference with one of the two interfacing candidates is below the defined threshold , are removed from candidates.
- Peaks and troughs that satisfy the above constraint are the final magnetism features which are marked by P and T, respectively. At the same time, peaks and troughs would be ensured to appear alternately.
Figure 11 shows an example of a magnetism feature extraction result. Points A, C and E marked in the figure are detected peaks, and B and D are detected troughs. When we set as 1 μT, the difference between B and A exceeds , but the difference between B and C doesn’t exceed , so trough point B is not a feature point we need. On the contrary, peak D is a feature point, as the difference between D and A as well as D and E both exceed the . Consequently, as shown in Figure 11, the trough B and the peak C would be removed since they don’t satisfy the constraint, but the trough D and the peaks A and E are the extracted magnetism features, so though the abovementioned method, all the peaks and troughs are extracted as the magnetism features that can describe the fluctuation of the resultant magnetism intensity in the user’s trace.
3.2.2. Sequence Zooming
In this part, we propose a method to zoom the distance scale of one magnetism sequence to another through magnetism features in order to match them together. It includes four key steps:
- Step 1: First of all, we estimate the movement distance from the start point of the user trace to each magnetic field sampling time using an empirical stride length. Then two pairs of magnetism features from the two sequences are selected randomly as the initial assumed matching feature points, if the ratio of two estimated distances between features in each sequence is within a reasonable range of pedestrian stride length.
- Step 2: Secondly, using the distance ratio calculated by the initial matching feature pairs, the remaining part of the second sequence is zoomed to the same stride length as the first one.
- Step 3: Thirdly, to deal with the common case of uneven walking speed in one trace, the rest of the feature points from two sequences are matched together based on the initial matched features.
- Step 4: Finally, the number of matched feature points is counted, and if the proportion of matched features is greater than the settled threshold, one time of Sequence Zooming is finished.
The details of the above steps will be respectively depicted in the following paragraphs.
(1) Initial Feature Matching
We use detected steps and stride length to estimate the trace length. The acceleration is utilized for step detection. The algorithm for step detection is the same as the Feature Extraction algorithm presented in 3.2.1. The detected peaks of resultant acceleration which satisfy the settled constraint are user steps, and the amount of steps is marked as . Other algorithms can also be used to realize step detection, like the one described in [31]. Stride length is set as an empirical value like 0.6 m, so the length of the user trace is estimated by:
The trace length do not need to be exact, as it is only used to provide a rough distance between each magnetism feature, and the similarity of the queues of magnetism features is the main criterion to estimate whether two traces are generated on the same road segment. The procedures of features alignment and similarity calculation will be proposed in the following context.
When we get the length of the trace, the distances from start point of the trace to each magnetism sampling time, denoted as , can be estimated by:
Here is the i-th count of magnetic field readings, is the total number of the field data on a road segment trace. We use a linear model here to estimate distance each time, for it is hard to get the exact walking speed of users, and the linear moving model will simplify the procedures to acquire a rough distance sequence. In case of the uneven walking speed in one trace, the magnetism features alignment will be implemented in Step 3.
Considering two road segment data of different users, denoted by and . The magnetism sequences of them are and , denoted as and . The data length of each sequences are respectively and . Though the above mentioned method, the distance sequences corresponding to and are obtained, denoted as and .
Then the magnetism features are extracted from and , recorded by , , and :
and are respectively the total numbers of peaks and troughs in . Similarly, and are respectively the total numbers of peaks and troughs in .
At the beginning of Sequence Zooming, we pick up two couples of magnetism features respectively from and randomly. They are recorded by , (a feature point pair from ) and , (a feature point pair from ). The following constraint should be satisfied in selection of feature point pairs:
The above equation means that the feature point pairs from and should have the same pattern and same order in their queues. For example, when we choose as feature point couple in , we should use in to match with them. The subscripts a, b, c and d should meet the conditions and .
If and are generated at a same location point A, and at the same time, and are at a same location point B, the trace distances between and , as well as and would be equal, assuming that the walking paths on the road segment are unique for users, so we can obtain the following equality:
in which, and are respectively the number of detected steps from location A to B on road segment traces R1 and R2. and are the real stride length of users on R1 and R2. is the actual trace length between location A and B. Stride length is the empirical value that we use to estimate the distances from the start point to each magnetic field sampling point, so it can also be obtained that:
Then the stride length ratio is reckoned as:
The normal range of pedestrian stride lengths is about 0.4 m to 0.8 m, so the stride length ratio should be on the range of [0.5, 2]. When the calculated is in this range, the feature points (,) and (,) can be assumed as the initial matched feature points of R1 and R2. On the contrary, if is out of this range, this procedure will be implemented again for another pair of feature points, until the initial matched points are found.
(2) Rough Zooming
Based on the initial matched feature points (,), the data on will be zoomed using , and will be translated to . The new distance sequence is calculated by the following equation:
here . Then we get a new distance sequence for R2. may have some negative data, for its start point would not be the same as for R1.
After rough zooming in the above procedure, the magnetism feature points on R2 are basically matched together with those on R1 if the initial matching points (,) are correct. Because of the rough zooming is an even zooming only based on the scalar , if users’ walking speeds are uneven, which is a very common situation, the feature points will not match well only by rough zooming. The following step is designed to deal with this issue.
(3) Features Alignment
In this step, the feature points in R2 are aligned based on the current initial matched feature points ((,) and (,)) and matched with other feature points in R1 using the principle of proximity. Therefore, when the initial matched feature points are really sampled on the same location point, the Features Alignment would make other feature points on R2 and R1 match exactly, so that the magnetism similarity of R1 and R2 can be calculated accurately. When the initial assumed matching feature points are not matched correctly, this procedure will also be carried out and the final matching result will be judged by the result of Similarity Calculation in the following step.
We denote the assemblage of aligned feature points as . Based on the initial matched feature points, the initial of the assemblage is shown in the following:
For the peak , the candidate matching area in R1 is settled at first, which is indicated by . The edge of matching area is the feature points of R1 in , whose matched feature points in R2 are the closest ones respectively to left and right side of . This can be expressed as:
When only has one side neighbor with aligned feature points, then the matching area will be settled as or . is the data length of .
Then all the peaks of R1 in the range of are traversed to find the matching point of . The matching point would satisfy two requirements, including:
- The difference between and is minimum compared with other candidate peaks. For the have been accorded with , the difference between them indicates the probable location distance between and , and the closest pair may have the biggest probability to be sampled on a same location.
- In case of some feature points are undetected, and R1 and R2 have different trace lengths, we set a distance threshold to restrict the difference of distance between matching points. The in this paper is settled as an empirical value.
The matching qualification is expressed by the following equation:
The matched peak couples would be added into as a new element , and further used for matching area choosing of the new prepared for alignment.
For the troughs , the same method is implemented to find the matching troughs in R1. At the same time, the matched trough couples will also be added into as a new element, recorded by .
For the matched feature couples should be apparent in same order both in R1 and R2, and peaks and troughs should appear alternately, the element in (all the matched peaks and troughs) will be resolved by the data order of feature points in (or feature points in ). Finally, we obtained all the matched feature couples in :
is the total number of matched feature couples between R1 and R2.
Then, based on the matched feature pairs in , the would be updated using the following equation:
It means that all the matched feature points in R2 will be aligned to the same distance of in R1 and the distance of other sample points will be zoomed using the local ratio, estimated by the closest two feature point couples. In the start or end part of the R2, only translation is implemented to the , since the zooming ratio cannot be estimated only by one pair of matched feature point. Finally, we get the updated distance sequence for R2.
(4) Matched Features Amount Judgment
In this step we count the amount of matched feature couples in , and calculate the matching proportion using the following equation:
and are respectively total numbers of peaks and troughs in . and are respectively the total numbers of peaks and troughs in . is the total number of matched feature pairs between and . When is greater than the settled threshold , one time of Sequence Zooming is finished.
3.2.3. Similarity Calculation
Through the method of Sequence Zooming provided in the above section, the distance scales of and are basically uniform. If the feature points are matched correctly, the similarity between and can be calculated accurately. In this paper, the correlation coefficient of two magnetism sequences is identified as the similarity of two road segment traces R1 and R2.
Before correlation coefficient calculation, the data length of and would be made to be equal using original magnetism data and zoomed distance data, based on linear interpolation. The equation to calculate the new magnetism sequence , which has the same data length with , is shown in the following:
Symbol “Null” in the equation means that it is a null element in sequence , and there isn’t a valid mathematical result in this element.
Then we find the index of valid element in , and calculate the correlation coefficient between and . The indexes of the start and end point of valid element are respectively denoted as and . is the correlation coefficient between and . They are obtained by:
For each time of Sequence Zooming, the correlation coefficient would be calculated, until all the probable initial matched features in R1 and R2 are tested. Afterwards, the maximum of all the calculated between R1 and R2 is selected as the road segment similarity between R1 and R2, denoted as . Correspondingly, the final zooming ratio of R2 based on R1 (denoted as ) is calculated and given by:
The matching position between R1 and R2 is settled as . and is obtained by Equation (29). and are ascertained by:
3.2.4. Similarity Calculation Result
In this section, we show magnetism matching and similarity calculation results for some typical situations, including two traces generated on the same road segment and on different road segments. These results are shown in Figure 12, Figure 13 and Figure 14.
Figure 12 shows the magnetism matching and similarity calculation result for two traces generated on a same road segment. Figure 12a shows the smoothed magnetism sequences from road segment trace 1 and road segment trace 2, in which the distances from start point to each magnetic field sampling point are estimated by detected step and empirical stride length (). We can see that the magnetism sequences of the two traces have highly similar shape and different distance scales. Figure 12b shows the features matching result and similarity (correlation coefficient) of these two magnetism sequences. The distance threshold used in features alignment is settled as , and the minimum threshold of the proportion between matched feature couples in and the total number of features is settled as . It shows that through features matching and sequence zooming, the matched features are translated to a same distance point, and two magnetism sequences are overlapped to the highest extent. The calculated correlation coefficient (valued in ) is 0.98, which shows a high similarity between this two traces, and the result agrees with the real situation.
Figure 13 and Figure 14 show another two situations using the same parameters as those in Figure 12. In Figure 13, trace 2 is partly generated on the road segment that trace 1 was generated on. Through feature matching and sequence zooming, trace 2 is matched closely to the right part of trace 1, and the correlation coefficient (=0.91) shows a high similarity between them. Furthermore, it also shows that the intensity offset between the magnetism sequences of these two traces didn’t impact the similarity calculation result, since the correlation is mainly dependent on the shape of the two sequences. In Figure 14, traces on different road segments are processed using our algorithm, some peaks and troughs are matched together, but the similarity is at a low level of 0.46.
As the results above show, the proposed geomagnetism-based similarity calculation algorithm is proved to have a good performance for judging the similarity between two road segment traces.
3.3. Road Segment Clustering
3.3.1. Preprocessing Before Clustering
For one road segment, there are two possible walking directions for users, identified as the positive and the opposite direction. Due to this fact, a preprocessing step is implemented for the users’ road segment traces obtained by trace segmentation (shown in Section 3.1) before clustering to make the magnetism sequence be generated on a generally similar direction. Consequently the correlation coefficient between two magnetism sequences can be calculated correctly.
We use in the user’s road segment trace R for walking direction judgment of two road segment traces (in the same direction or opposite direction). is the mean value of all the data in R (the details can be found in Section 3.1).
For two user’s road segment traces R1 and R2, the road orientations are denoted as and . The difference between and is denoted as . Considering the uniqueness of , we use value between and to indicate it, and the value of can be calculated by:
Considering the orientation offset between and the real orientation, we set as the uncertainty of road orientation , as shown in Figure 15, so the true orientation of the road segment can be indicated by:
Here is the true orientation and is the measured value. Thus, the difference between measured orientations ( and ) can also be indicated by:
If R1 and R2 are generated on the same walking direction (), the orientation difference would fall in . If R1 and R2 are generated on the opposite walking direction (), the orientation difference would be in .
As discussed above, we calculate the orientation difference between R1 and R2, and implement data processing shown as following:
- When , it is estimated that R1 and R2 are generated in the same direction, and the similarity calculation will be implemented directly between and using the algorithm shown in Section 3.2. Here and are the resultant magnetism sequences from R1 and R2, respectively.
- When , it is estimated that R1 and R2 are generated in the opposite direction, so before similarity calculation, sequence would be reversed firstly, denoted as , and then the similarity with calculated.
- If , as shown in the above two bullets, the similarity would be calculated twice using both and , and the higher one is settled as the final similarity between R1 and R2.
In actual cases, the probability that R1 is perpendicular to R2 exists when , but in this step, only whether R1 and R2 are in the same direction or the opposite direction is it generally detected to decide whether or would be used for similarity calculation. Whether R1 and R2 are generated on a same road segment or not will be judged mainly by the magnetism similarity in the following procedures.
3.3.2. Road Trace Clustering
In this step, the preprocessed road segment traces are clustered into some separate road segment clusters based on the DBSCAN algorithm. A road segment cluster is defined as a collection of users’ road segment traces whose magnetism sequences are similar to other ones in the same cluster and are dissimilar to those in other clusters. DBSCAN is a kind of density-based spatial clustering method which is commonly used in many fields [32]. In the DBSCAN algorithm, a centre-based density is defined using a distance metric, and the number of points within the settled distance metric is the density of the central point. If the density of the central point reaches a settled threshold, then it will be defined as a core point.
(1) C-neighborhood DBSCAN Clustering
For the database of user road segment traces, denoted as ; the elements in it are road segment traces to be clustered, denoted as ; the road segment cluster is a collection of road segment traces which are generated in a same road segment, denoted as . To implement the DBSCAN algorithm to get road segment cluster from database , the notion of Eps-neighborhood and values of and are defined firstly.
As discussed in the above sections, we use magnetism similarity between two road segment traces to indicate the distance between two points. Since the correlation coefficient was utilized for similarity calculation between two road segments, we define a kind of correlation coefficient neighborhood (CC-neighborhood) for clustering.
CC-neighborhood of a road segment trace is defined as the road segment traces whose magnetism similarity (correlation coefficient of magnetism sequence) is within the settled range () is termed as CC-neighborhood of road segment represented as . It is defined as following equation:
means the magnetism sequence correlation coefficient between and using the method in Section 3.2. The is settled as in this paper. Then the core road segment is defined as the one whose CC-neighborhoods are not littler than , and is directly density-reachable from respect to and when , defined as:
In the DBSCAN algorithm, if is directly density-reachable from , and is directly density-reachable from , then accordingly is density-reachable from , and consequently , and will be collected into the same cluster. Considering the case that and are both generated in road segment and is from road segment ; assuming that the magnetism from are interfered with by noise which lead to a high similarity (respect to ) between and ; then, when we carry out CC-neighborhood DBSCAN clustering, all the traces from road segment and would be judged to belong to the same cluster. However, if we assume that magnetism interference happens occasionally, and would intersect in a few of elements. On the contrary, when and intersect in a large amount of elements, it is probable that and are generated on the same road segment.
As discussed above, we define notion of C-neighborhood based on CC-neighborhood via adding the requirement of coincidence between and .
C-neighborhood of a road segment trace is defined as: the road segment traces , which is a CC-neighborhood of and whose CC-neighborhood (denoted as ) coincide with respect to a settled proportion, is termed as C-neighborhood of road segment represented as . It is defined as following equation:
is coincidence proportion between and . is the accepted minimum of . We set in this paper.
Consequently, for the database of user road segment traces , the road segment clusters are obtained using C-neighborhood DBSCAN Clustering by the following steps:
- All the core traces are found using C-neighborhood with respect to , and , represented by:
- Road segment traces directly density-reachable and density-reachable from one core trace (denoted as ) are found from database , and a cluster is settled by:
- Other clusters are found by repeating the second step, and the collection of road segment clusters are obtained finally, represented by:where is the total number of clusters. Traces that couldn’t be collected to any clusters will be treated as noise and don’t participate in the following process.
Finally, the number of road segments in a floor (the number of clusters) and clusters of user traces from each road segments are obtained from the crowdsourcing database, represented by:
is the -th road segment trace in the -th cluster, and is the total number of traces in the -th cluster.
(2) Clustering Result
We collect one hundred test traces from five different corridors (road segments) using different type smartphones to test the performance of the proposed clustering algorithm. Table 2 shows the cluster result after applying C-neighborhood DBSCAN. The correct clustering trace is the one which is collected in the cluster in which most traces are generated in the same corridors with it. The incorrect clustering trace is the one which is collected in a cluster in which most traces are not generated in the same corridors with it.
As shown in Table 2, the correct clustering ratio is 100%, but the number of obtained clusters is more than that of corridors. Through data analysis, we found that the data in the overdetected four clusters are all acquired from one same smartphone. This result proves the good classification performance of proposed C-neighborhood DBSCAN algorism, and the overdetected clusters will be merged in the following procedure by connection estimation between different road segment clusters.
3.4. Topology Construction
In this section, traces in each cluster are merged, while connections between clusters are estimated using turns detected from the original user traces in Section 3.1, and finally, the topology map of all the road segments obtained from user traces is constructed. Moreover, topology modification is implemented to deal with errors resulting from the angle and road length estimation.
3.4.1. Road Length Estimating
For road segment cluster , is the total number of traces in cluster . The trace with most magnetism features is chosen as the basic trace (denoted as ), and other traces in it are matched with using the method proposed in Section 3.2. Then we can get the zooming radio and distance sequence after features alignment. Finally, all the elements (except ) are zoomed to the same distance scale and translated to same start point () with .
In Section 3.1, the original user trace is segmented into some straight sub-traces corresponding with different road segments, and turns connecting each sub-trace are detected and denoted as:
In the above procedures, and will be clustered to different road segment clusters, denoted as and . Assuming that, for one original trace, the user’s walking state would be basically stable, then the distance scales would be same of them, represented as:
Then it can be reckoned that:
where represents the distance scale of a road segment trace. Then based on Equation (46), the distance scale of other from different road segment clusters can be set identically to in cluster (called the base road segment) by connected sub-traces. Furthermore, the distance sequence in each (except base road segment) would be updated to the new distance scale, denoted as for in . The process is represented as Figure 16.
After that, the length of each road segment is estimated based on the same distance scale, using the following equation:
where is the total number of traces in cluster . is the length of the road segment cluster .
3.4.2. Connection Estimating Between Clusters
Utilizing turning connections between and clustering in different clusters, the connections between different road segment clusters are found by:
is the connection between and . and are respectively the distance identification of this connection in and . is the connection angle defined as the same with connection between two different road segments trace, and valued by the mean of all the detected turning angles between and . This is shown in Figure 17.
3.4.3. Topology Modification and Map Construction
After estimation of road segment length and connection angle of all the clusters, the topology of the road segments can be constructed. Setting the start point of base road segment (minimum of distance sequence from base road segment cluster) as in a 2D plan, and then all the road segments can be displayed in the plan by geometry calculation. Since there should be measurement and calculation errors for lengths and angles, topology modification will be implemented to revise topology errors. The topology error is typically shown in Figure 18.
The sum of all the inner angles in a loop road is a fixed value, represented by:
Here is the number of road segments forming the loop. In most cases, the road loop is shaped as a quadrilateral, and the sum of the inner angles is . Therefore we modify the topology map using loop angle correction. As shown in Figure 19, starting with point C, the position of points D, A, B, C’ are calculated using geometry by the road segment lengths and connection angles (respectively denoted as and , , is the total number of road segments in this loop). In fact, for a loop, point C’ should be overlapped with C, so the angles , will be revised to , , until they can satisfy:
indicates the geometry calculation for lengths and angles. , are the modified angles that satisfied the requirement shown in Equation (50). To keep the main shape of the loop, the angle modification will be carried out in range of for each angle. Finally, the topology of the map will be modified using new angles, represented by:
is a vector of coordinates of all the vertexes in the graph, and is a matrix to represent the length of each edge. is the total number of vertexes.
In addition, the map can be adjusted further, if we get the real length and orientation of one road segment in the constructed map.
What needs to be explained here is that we have adopted a simpler method for the topological modification of the map. It can reduce the complexity of the algorithm and is suitable for the layout of most indoor corridors. However, this method is only applicable to straight road segments (corridors). For curved corridors and non-channel open areas, the desired results may not be obtained. Of course, for more complex indoor scenes, we can use more indoor map information and implement detection for curved corridors to achieve better result.
3.5. Radio Map Construction
After final topology is constructed by the user traces, the 2D position coordinates of the magnetism sample points will be estimated using vertexes coordinates and distance sequence for each road segment in cluster , denoted as . Because of Wi-Fi fingerprint in the user’s road segment trace has a different sample frequency form magnetism intensity , the 2D position coordinates will be interpolated linearly on each fingerprint sample time, denoted as . So far, the Wi-Fi fingerprint collected by crowdsourcing users have been labeled by position coordinates. Since there is more than one user trace in road segment cluster , in this step, we will merge RSSs collected from different crowdsourcing traces in the same road segment to generate Wi-Fi RPs which form the radio map.
3.5.1. RP Generation
Considering one of the edges in the constructed map , the vertexes connected by this edge are and . The Wi-Fi RPs will be generated along this edge to make a grid with even distance . The coordinates of RPs are calculated by:
means getting a round number downward. Then all the vertexes and calculated grid points for each road segment cluster constitute the RP location points in our map.
3.5.2. RSS Merging on RP
For each RP generated above, we use Gaussian interpolation weights to merge Wi-Fi RSS from different user traces to the RPs locations. On RP location , the RSS for one of the detected Wi-Fi APs is calculated by:
are the coordinates of the labeled fingerprint in one road segment cluster, and is the corresponding RSS value for the m-th Wi-Fi AP.
Then for the road segment cluster , the fingerprint database is acquired and represented by:
is the fingerprint database for road segment cluster . are the RP coordinates for fingerprint . is the number of RPs. is the Wi-Fi RSS received from . is the total number of APs which can be scanned in . Finally, the fingerprint database for the whole topology is constructed by:
where is the whole fingerprint database for . is the number of road segment clusters.
4. Results and Discussion
In this section we show the radio map construction result and validate its localization performance. The experiment took place in an underground parking garage of the Beijing New Technology Park of Chinese Academy of Sciences, which is covered with Wi-Fi signals (2.4 GHz). Figure 19 shows the floor plan of the underground parking and some test traces (imitating crowdsourcing user traces) used in our experiment. The crowdsourcing data are only collected in the parking area except for the entry and exit paths of the car. The size of the parking area is about 60 m × 100 m. In Figure 19b, we show the floor plan of the parking area and high light the pathway (road) in this area using blue. In order to imitate the crowdsourcing data, they are collected by four different persons, whose height and weight are shown in Table 3. Pedestrians walk along the road optionally in the experimental area and meanwhile record orientation, acceleration, angular velocity, magnetic field and Wi-Fi RSS of smartphone. The sensors data are collected using AndroSensor APP, and Wi-Fi RSSs are collected using self-developed RSSCollection APP.
Using test crowdsourcing data, the road segments are picked out and the topology map of the pathway in the experimental area is constructed through the proposed method mentioned in Section 3. Furthermore the Wi-Fi fingerprint map is constructed along each pathway. In the following content, we give the topology map construction result and Wi-Fi fingerprint localization result using the constructed Wi-Fi radio map. In addition, discussion and test result are given about the road width influence during the geomagnetism based similarity calculation of road segment.
4.1. Topology Map Construction Result
Figure 20 shows the pathway map constructed by the crowdsourcing traces. Figure 20a is the rough result of the topology map after road length estimation and connection estimation between road segment clusters. The blue lines represent road segments and red points represent connections between them. Some obvious topology mistakes are shown in this result because of measurement and calculation errors for lengths and angles. Figure 20b is the pathway map after topology modification. We can get that inner angle revising makes each road segments displayed on right connection points which is alike to the real pathway in the experimental area. Figure 20c is the result after orientation and length correction of the left road segment using and real road length.
In the experiment, we collected a total of 35 sets of data, and 85 sets of road segment traces are segmented from them. After calculating the magnetic field similarity and implementing the clustering algorithm, we obtained seven road clusters, which are labeled as C1~C7 in Figure 20a. It can be seen that there are topology errors in Figure 20a and the path cannot form a loop like a real road. Therefore, we then used the loop angle correction algorithm proposed in this paper to correct the topology. Because there are mainly quadrilateral roads in this testing area, we only modified the angle using quadrilateral loop in order to improve the computational efficiency. There are eight loops that used in this process, and they are [C1,C2,C3,C4], [C1,C2,C5,C4], [C1,C2,C6,C4], [C2,C3,C4,C5], [C2,C3,C4,C6], [C2,C3,C7,C5], [C2,C5,C4,C6] and [C3,C4,C5,C7].
We measure the accurate 2D coordinates of each connection points in the experiment area, and calculate the distance error of the connection points in the constructed map. Table 4 shows the distance error of each connection points (the vertex ID is shown in Figure 20c). The average distance error of the map vertex is 1.52 m. The minimum error is about 0.05 m and maximum one is 4.69 m. And the standard uncertainty is 1.4 m.
Based on the calculation result of the corner position error, we find that the position error of Vertex10 is the largest, reaching 4.68 m. In addition, the Vertex5 and Vertex9 errors also exceed 2 m. Others are below 2 m. Compared with the real indoor map, it can be seen that the error of the Vertex10 is mainly from the length estimation error of C2. Because there is no floor plan information, the road segment length is difficult to correct. Therefore, when the topology correction is performed, we only correct the connection angle so that the error of the length estimation is not eliminated. At the same time, in the loop correction, in order to obtain the final connection path, road segment length optimization is performed at the same time as the angle correction. However, in the simulation software algorithm, we extract the loop according to the list number of the detected road segment cluster. Therefore, C1 and C2 are always located at the beginning of the loop. And in loop optimization, their length is not adjusted. Then after the calibration using true length and direction of C1, the length error of C2 becomes more obvious. In addition, the test area is an underground parking, with a wide road width (more than 6 m) and a large area at each corners, which may also cause deviations in length estimations. Our algorithm does not rely on accurate indoor floor plan, but if more accurate map information can be introduced, this error can be further eliminated.
4.2. Radio Map Construction and Positioning Result
The Wi-Fi radio map are finally acquired using the constructed pathway map that is shown in Figure 21. Each point in the figure indicates RP points in the fingerprint. The distance in RP grid is settled as 2 m. The parameter for RSS merging is 2 m.
In order to validate localization performance of the constructed Wi-Fi radio map, we pick 25 position points as test locations in the experiment area and at each test location we measure Wi-Fi RSS twice and calculate the fingerprint positioning result using the KNN algorithm (K = 3). The localization error is statistically 1.8 m (50%) and 5 m (70%), which is competitive compared with other systems based on crowdsourcing data.
Table 5 shows the comparison of our algorithm with other similar methods. These algorithms all use passive crowdsourcing user data and can provide continuous corridor localization. Zee’s reported positioning accuracy is superior to ours, but it uses a floor plan. The positioning result of RACC is similar to ours, and a floor plan is also used in this method. Our algorithm does not depend on an accurate floor plan, which makes it perform better in an unknown indoor area. PiLoc does not require a floor plan, and the authors report higher positioning accuracy than our algorithm, however, the authors’ experimental scenario is an office floor, in which the isolation of the Wi-Fi signal is better compared with the underground parking garage we used for our test. This helps the PiLoc system to form a Wi-Fi intensity distribution map with obvious features and obtain better positioning results. In addition, the PiLoc also used an optimized positioning algorithm instead of the basic KNN algorithm.
Figure 22 shows another set of test results. The test site is a floor of an office building. There is one major corridor in this area and some smaller corridors leading to the stairs, elevators and toilets. The office rooms are on two sides of the corridor. Figure 22a shows a floor plan of the experimental area, and the red lines show a part of the typical user traces in our test. Through our clustering algorithm, the major corridor in the map is identified. Because traces in small hallways or office rooms are often shorter in distance and have few magnetic features, they are not clustered into corridors in our algorithm, but they are still accurately drawn out in the constructed pathway map through their connections with the major corridor. Figure 22b shows the final pathway map after orientation correction of the major corridor. Figure 22c shows the labeled Wi-Fi sample points using coordinates of constructed map. The average positioning error in this test area is 1.7 m.
4.3. Road Width Influence
When we use magnetism sequences to calculate road segment similarity, the road (or corridor) is abstracted as a line. However the road has a certain width in space, and when users walk along the road (corridor), these exact positions on the transverse of the road may be different from each other. To check out the influence of different transverse positions of users’ traces on the road segment similarity calculation, we collected sensor data five times on one road segment using different transverse positions and likely traces on the other road segments beside it two times, and calculated the magnetism similarity between them. Figure 23a shows the test traces (red lines, numbered from 1 to 7), and the magnetism sequence collected by the seven test traces are compared together in Figure 23b. The road width is 6 m, and the transverse interval between each trace from 1 to 5 is 1 m. It is seen in Figure 23b that the magnetism sequences have similar shape on the same road but different shapes on other roads.
Table 6 shows the similarity calculation results between each test trace. Trace 1, 2, 3, 4 and 5 show higher similarities with each other, especially with adjacent ones. On the contrary, trace 6 and 7 show lower similarity with all the other ones. We apply the C-neighborhood DBSCAN clustering proposed in this paper using the parameters as , and . The algorithm obtains one cluster of {1,2,3,4,5}, and two noise traces of 6 and 7, which matches the real situation. Consequently, when we have collected abundant user data on one road segment, the road width would not impact the road segment clustering. Even if the traces on one road segment are divided into more than one cluster, these traces still have the chance to be merged together in the graph construction phase by same connections.
4.4. Unconstrained Smartphone Influence
In the real scenario, it would happen that a pedestrian uses his/her smartphone in different postures while walking, like messaging, calling or just holding it in the hands. The unconstrained smartphone attitude mainly affects on two factors of the proposed algorithm: one is the user’s heading and the other is the magnitude of the magnetic field, so when we using crowdsourcing user data for radio map construction in our method, these two factors would be considered:
4.4.1. User heading
In order to obtain more accurate user headings, especially in the situation of unconstrained smartphone poses, it is better to use some complex algorithms to calculate the user heading, rather than use readings directly from the electronic compass. Some researchers have published relevant research results on this issue, like [30,33,34], but it is maybe still hard to estimate the exact user heading for crowdsourcing data, so during the algorithm design, we made great efforts to minimize the reliance on heading, mainly including:
- (1)
- The proposed method uses angular velocity changes for turning detection and road segmentation, which makes it free from magnetic interference.
- (2)
- We use the mean value of detected user headings to indicate the road segment orientation, which can partly eliminate heading errors due to local magnetic field anomalies and other short duration errors.
- (3)
- When constructing the spatial magnetic sequence of a trace, the magnetic sampling distances are estimated only by the step count and stride length. During this period, the heading interference will not affect it, and therefore the headings will not affect the magnetic sequence similarity calculation result. In addition, the magnetic field disturbance in the indoor building would enrich the magnetic features of corridors, which is conducive to good matching and separation for indoor corridors.
- (4)
- When constructing a pathway map, starting from the base road segment, we use the estimated lengths of the road segments and the connection angles between road segments to calculate the plane coordinates of each vertex in the map. The whole map can be further corrected if the actual orientation and length of the base road segment are known.
4.4.2. Magnitude of the magnetic field
In our method, the location differentiation ability of the geomagnetic field is utilized for corridor differentiation. This means that the magnitude of the magnetic field is correspondingly different at different locations in an indoor area, but similar for adjacent locations. We use the magnitude of the magnetic field (the resultant magnetism intensity) in our method to evaluate the similarity of the user’s trajectory. The magnitude of the magnetic field is only related to the position of the smartphone rather than any rotation of the smartphone axis. When the user uses or carries the smartphone in different postures, the smartphones are in close proximity around the user body. Therefore, we speculate that under different smartphone postures, the magnitudes of magnetic field that users get are similar, and we can still use it for magnetic sequence similarity calculation.
Below, we collected the data of smartphone sensors in the same corridor using three typical smartphone poses, including messaging, calling and swing in-hand. We compared the magnitude of the magnetic field, and calculated the magnetic sequence similarity between each two of the three sets of data using our algorithm. Figure 24 shows magnetism sequences comparison for the three test traces. The calculated similarities between them are listed in Table 7.
Through the comparison result, we find that magnetic sequences of the three test traces show similar shape, especially when they are smoothed using a moving average filter. Most of the similarities show high values (>0.9) between them. Among them, the similarity between trace 2 (calling) and trace 3 (swing in-hand) is a bit lower (0.8632). The result proves that under different smartphone postures, we can still use the proposed algorithm for magnetic sequence similarity calculation. If a user trace can’t be clustered into any of the road segment clusters with other traces, owing to user pose complexity, it will be handled as noise and not be used for map construction.
5. Conclusions
In this paper, we focus on the problem of automatic Wi-Fi radio map construction using crowdsourcing data in indoor fingerprint localization systems. Based on the comparison of current systems and our analysis of the opportunities and challenges of smartphone-based indoor localization methods, we propose a geomagnetism-aided indoor radio-map construction method via passive smartphone crowdsourcing. The proposed method utilizes magnetism sequence similarity and a novel C-neighborhood DBSCAN clustering algorithm to form the pathway graph of a floor plan from crowdsourcing traces without needing an exact floor layout, and generates RPs by merging crowdsourcing Wi-Fi signal strengths to construct the radio map. The main contribution of our method include: (1) it recognizes corridors from user traces using magnetic field similarity which is relatively stable in the scenario of unconstrained smartphone use for crowdsourcing data, and also solves the problem of calculating the exact similarity between magnetism sequences when they are sampled using different walking speeds; (2) it forms the pathway graph of indoor environments using clustered road segments, and merges crowdsourcing Wi-Fi signal strengths on reference points generated along the pathway to construct the radio-map. In the designed experiments, the proposed method is proved to show good ability to construct the indoor pathway graph and Wi-Fi radio map using passive crowdsourcing data. The constructed Wi-Fi radio map can provide competitive indoor localization accuracy.
Our method is only applicable in indoor environments with obvious corridors (or roads), and a hypothesis of straight corridors (road segments) is needed in the topology modification phases. For curved corridors and non-channel open areas the desired results may not be obtained. In more complex indoor scenes, more indoor map information can be used to recognize bent corridors or open areas and they should be constructed using other suitable ways in the pathway map. That will be a focus in our future work.
Author Contributions
H.Y., D.W. and W.L. conceived the framework and designed the algorithm and experiments; W.L. wrote the paper; Q.L. performed the experiments; X.L. analyzed the data. All authors read and approved the final manuscript.
Acknowledgments
This study was supported by Project Y70B13A1BY supported by The Innovation Program of Academy of Opto-Electronics (AOE), Chinese Academy of Science (CAS). The authors also thank to the technical support provided by Xinzheng Lan.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Roos, T.; Myllymki, P.; Tirri, H.; Misikangas, P. A probabilistic approach to WLAN user location estimation. Int. J. Wirel. Inf. Netw. 2002, 9, 155–164. [Google Scholar] [CrossRef]
- Li, W.; Wei, D.Y.; Yuan, H.; Ouyang, G.Z. A novel method of WiFi fingerprint positioning using spatial multi-points matching. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcalá de Henares, Spain, 4–5 October 2016. [Google Scholar]
- Kushki, A.; Plataniotis, K.N.; Venetsanopoulos, A.N. Kernel-Based Positioning in Wireless Local Area Networks. IEEE Trans. Mob. Comput. 2007, 6, 689–705. [Google Scholar] [CrossRef]
- Guvenc, I.; Chong, C.C. A survey on TOA based wireless localization and NLOS mitigation techniques. IEEE Commun. Surv. Tutor. 2009, 11, 107–124. [Google Scholar] [CrossRef]
- Carlos, E.G.; Juan, P.G.V.; Ramon, F.B. Magnetic Field Feature Extraction and Selection for Indoor Location Estimation. Sensors 2014, 14, 11001–11015. [Google Scholar]
- Wang, Q.; Luo, H.Y.; Zhao, F.; Shao, W.H. An Indoor Self-localization Algorithm Using the Calibration of the Online Magnetic Fingerprints and Indoor Landmarks. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcalá de Henares, Spain, 4–5 October 2016. [Google Scholar]
- Azkario, R.P.; Widyawan; Risanuri, H. Smartphone-based Pedestrian Dead Reckoning as an Indoor Positioning System. In Proceedings of the International Conference on System Engineering and Technology, Bandung, Indonesia, 11–12 September 2012. [Google Scholar]
- Renaudin, V.; Combettes, C. Magnetic, Acceleration Fields and Gyroscope Quaternion (MAGYQ)-Based Attitude Estimation with Smartphone Sensors for Indoor Pedestrian Navigation. Sensors 2014, 14, 22864–22890. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Wei, D.Y.; Lai, Q.F.; Li, W.; Yuan, H. A Context-Recognition-Aided PDR Localization Method Based on the Hidden Markov Model. Sensors 2016, 16, 2030. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Xiong, H.J.; Zheng, X.W.; Zhou, Y. Activity Recognition and Semantic Description for Indoor Mobile Localization. Sensors 2017, 17, 649. [Google Scholar] [CrossRef] [PubMed]
- Parikshit, S.; Dipanjan, C.; Nilanjan, B.; Dipyaman, B.; Sheetal, K.A.; Sumit, M. KARMA: Improving WiFi-based Indoor Localization with Dynamic Causality Calibration. In Proceedings of the Eleventh Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Singapore, 30 June–3 July 2014. [Google Scholar]
- Park, J.G.; Charrow, B.; Curtis, D.; Battat, J.; Minkov, E.; Hicks, J.; Teller, S.; Ledlie, J. Growing an organic indoor location system. In Proceedings of the 8th Annual International Conference on Mobile Systems, Applications and Services (MobiSys), San Francisco, CA, USA, 15–18 June 2010. [Google Scholar]
- Ferris, B.; Fox, D.; Lawrence, N.D. WiFi-SLAM Using Gaussian Process Latent Variable Models. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI-07), Hyderabad, India, 6–12 January 2007. [Google Scholar]
- Chang, Q.; Li, Q.; Shi, Z.; Chen, W.; Wang, W.P. Scalable Indoor Localization via Mobile Crowdsourcing and Gaussian Process. Sensors 2016, 16, 381. [Google Scholar] [CrossRef] [PubMed]
- Luo, C.; Hong, H.; Chan, M.C. PiLoc: A self-calibrating participatory indoor localization system. In Proceedings of the 13th International Symposium on Information Processing in Sensor Networks (IPSN), Berlin, Germany, 15–17 April 2014. [Google Scholar]
- Bolliger, P. Redpin—Adaptive, zero-configuration indoor localization through user collaboration. In Proceedings of the 1st ACM International Workshop on Mobile Entity Localization and Tracking in Gps-Less Environments (MELT 2008), San Francisco, CA, USA, 19 September 2008. [Google Scholar]
- Ledlie, J.; Park, J.; Curtis, D.; Cavalcante, A.; Camara, L.; Vieira, R. Molé: A scalable, user-generated WiFi positioning engine. J. Locat. Based Serv. 2012, 6, 21–23. [Google Scholar] [CrossRef]
- He, S.; Gary Chan, S.H. Wi-Fi fingerprint-based indoor positioning: recent advances and comparisons. IEEE Commun. Surv. Tutor. 2016, 18, 466–490. [Google Scholar] [CrossRef]
- Huang, J.; Millman, D.; Quigley, M.; Stavens, D.; Thrun, S.; Aggarwal, A. Efficient, Generalized Indoor WiFi GraphSLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Li, L.; Yang, W.; Wang, G. HIWL: An unsupervised learning algorithm for indoor wireless localization. In Proceedings of the IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Melbourne, VIC, Australia, 12 December 2013. [Google Scholar]
- Nguyen, N.T.; Zheng, R.; Han, Z. UMLI: An unsupervised mobile locations extraction approach with incomplete data. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Shanghai, China, 7–10 April 2013. [Google Scholar]
- Wu, C.S.; Yang, Z.; Liu, Y.H.; Xi, W. WILL: Wireless Indoor Localization without Site Survey. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 839–848. [Google Scholar]
- Wang, B.; Chen, Q.Y.; Yang, L.T.; Chao, H.C. Indoor smartphone localization via fingerprint crowdsourcing: challenges and approaches. IEEE Wirel. Commun. 2016, 23, 82–89. [Google Scholar] [CrossRef]
- Rai, A.; Chintalapudi, K.K.; Padmanabhan, V.N.; Sen, R. Zee: Zero-effort crowdsourcing for indoor localization. In Proceedings of the International Conference on Mobile Computing and Networking (MobiCom), Istanbul, Turkey, 22–26 August 2012. [Google Scholar]
- Yu, N.; Xiao, C.X.; Wu, Y.F.; Feng, R.J. A radio-map automatic construction algorithm based on crowdsourcing. Sensors 2016, 16, 504. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.D.; Li, Q.Q.; Mao, Q.Z.; Tu, W. A robust crowdsourcing-based indoor localization system. Sensors 2017, 17, 864. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Subbu, K.P.; Luo, J.; Wu, J.X. GROPING: Geomagnetism and cROwdsensing Powered Indoor NaviGation. IEEE Trans. Mob. Comput. 2015, 14, 387–400. [Google Scholar] [CrossRef]
- Robertson, P.; Frassl, M.; Angermann, M.; Doniec, M.; Julian, B.J.; Puyol, M.G.; Khider, M.; Lichtenstern, M.; Bruno, L. Simultaneous localization and mapping for pedestrians using distortions of the local magnetic field intensity in large indoor environments. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Montbeliard-Belfort, France, 28–31 October 2013. [Google Scholar]
- Kemppainen, A.; Vallivaara, I.; Röning, J. Magnetic field SLAM exploration: Frequency domain Gaussian processes and informative route planning. In Proceedings of the European Conference on Mobile Robots (ECMR), Lincoln, UK, 2–4 September 2015. [Google Scholar]
- Qian, J.C.; Pei, L.; Ma, J.B.; Ying, R.D.; Liu, P.L. Vector graph assisted pedestrian dead reckoning using an unconstrained smartphone. Sensors 2015, 15, 5032–5057. [Google Scholar] [CrossRef] [PubMed]
- Li, X.H.; Wei, D.Y.; Lai, Q.F.; Xu, Y.; Yuan, H. Smartphone-Based Integrated PDR_GPS_Bluetooth Pedestrian Location. Adv. Space Res. 2017, 3, 877–887. [Google Scholar] [CrossRef]
- Das, S.K.; Gupta, S.K.; Kauser, M. Micro aggregation Through DBSCAN for PPDM: Privacy-Preserving Data Mining. Int. J. Adv. Res. Sci. Eng. 2012, 2, 15–21. [Google Scholar]
- Deng, Z.A.; Wang, G.F.; Hu, Y.; Wu, D. Heading Estimation for Indoor Pedestrian Navigation Using a Smartphone in the Pocket. Sensors 2015, 15, 21518–21536. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Lee, J.; Cho, J.; Chang, N. Estimation of Heading Angle Difference between User and Smartphone Utilizing Gravitational Acceleration Extraction. IEEE Sens. J. 2016, 16, 3746–3755. [Google Scholar] [CrossRef]
Figure 1.
Comparison of stability between Wi-Fi and magnetic field at a simple location: (a) Time sequences for magnitude of magnetic field and Wi-Fi RSS of one AP measured on location 1 at the same time; (b) Stability index comparison between Wi-Fi and magnetic field for six test locations.
Figure 1.
Comparison of stability between Wi-Fi and magnetic field at a simple location: (a) Time sequences for magnitude of magnetic field and Wi-Fi RSS of one AP measured on location 1 at the same time; (b) Stability index comparison between Wi-Fi and magnetic field for six test locations.
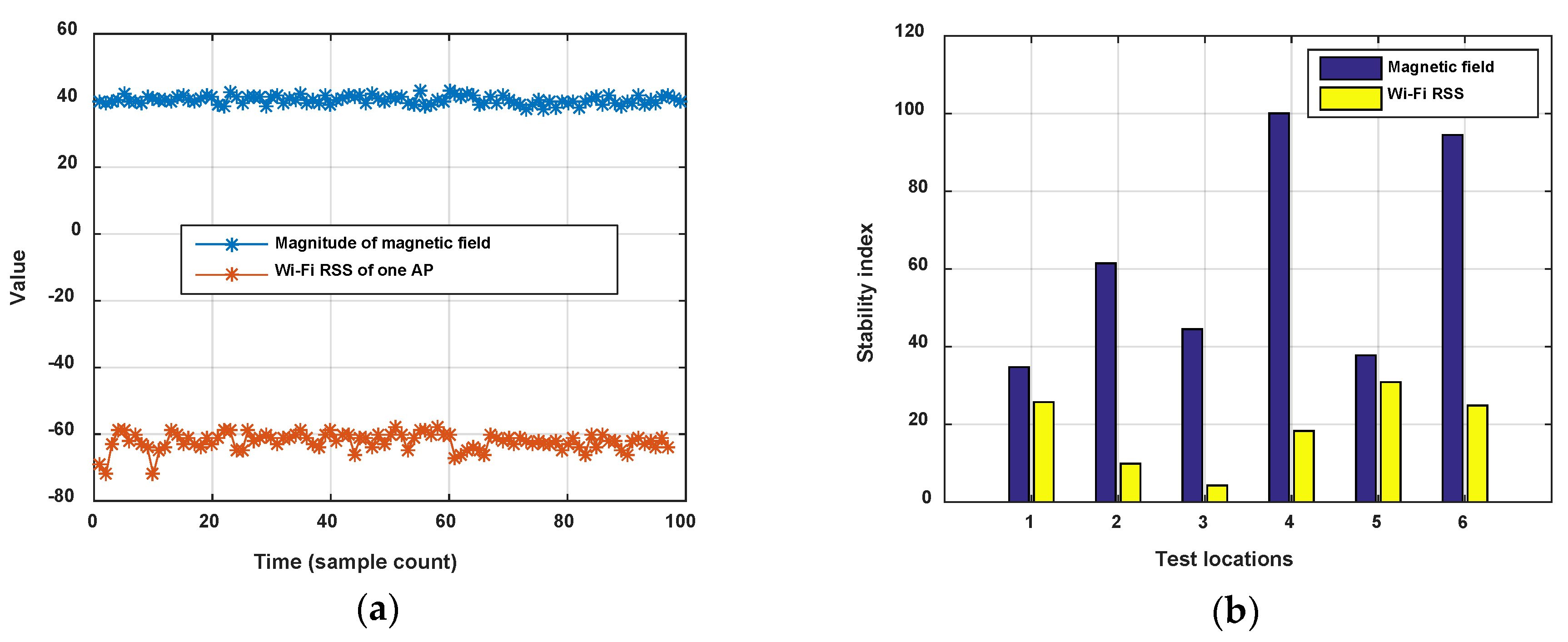
Figure 2.
Comparison of the stability between Wi-Fi and magnetic field in a corridor: (a) Time sequences for the magnitude of the magnetic field generated in a same corridor using forward and opposite directions; (b) Time sequences for Wi-Fi RSS of one AP generated in the same corridor using forward and opposite directions. The sequences generated in opposite directions have been reversed in these two figures.
Figure 2.
Comparison of the stability between Wi-Fi and magnetic field in a corridor: (a) Time sequences for the magnitude of the magnetic field generated in a same corridor using forward and opposite directions; (b) Time sequences for Wi-Fi RSS of one AP generated in the same corridor using forward and opposite directions. The sequences generated in opposite directions have been reversed in these two figures.
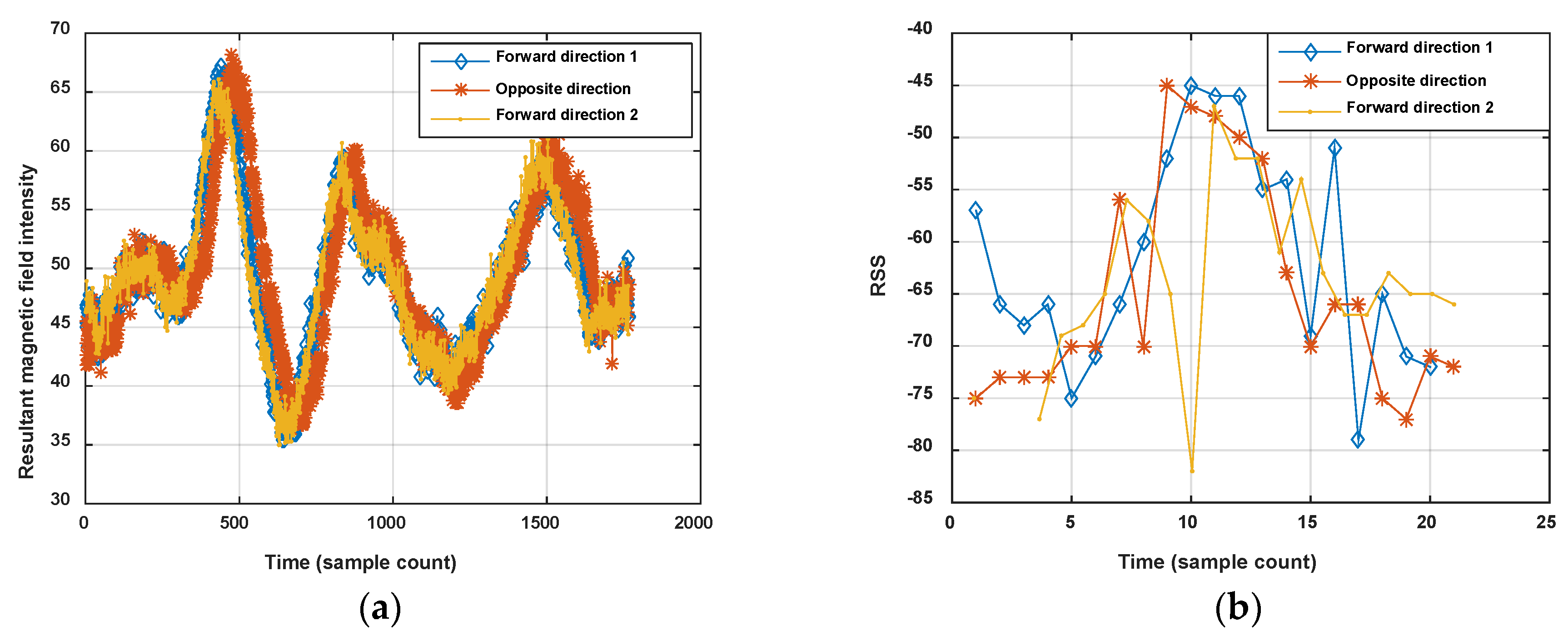
Figure 3.
Comparison of the ability of location differentiation between magnetic field and Wi-Fi RSS: (a) Sequence of resultant magnetic field intensity in a corridor, at location points 1, 2, 3 and 4, where the intensities are same; (b) Difference RSS vectors at location points 1, 2, 3 and 4.
Figure 3.
Comparison of the ability of location differentiation between magnetic field and Wi-Fi RSS: (a) Sequence of resultant magnetic field intensity in a corridor, at location points 1, 2, 3 and 4, where the intensities are same; (b) Difference RSS vectors at location points 1, 2, 3 and 4.
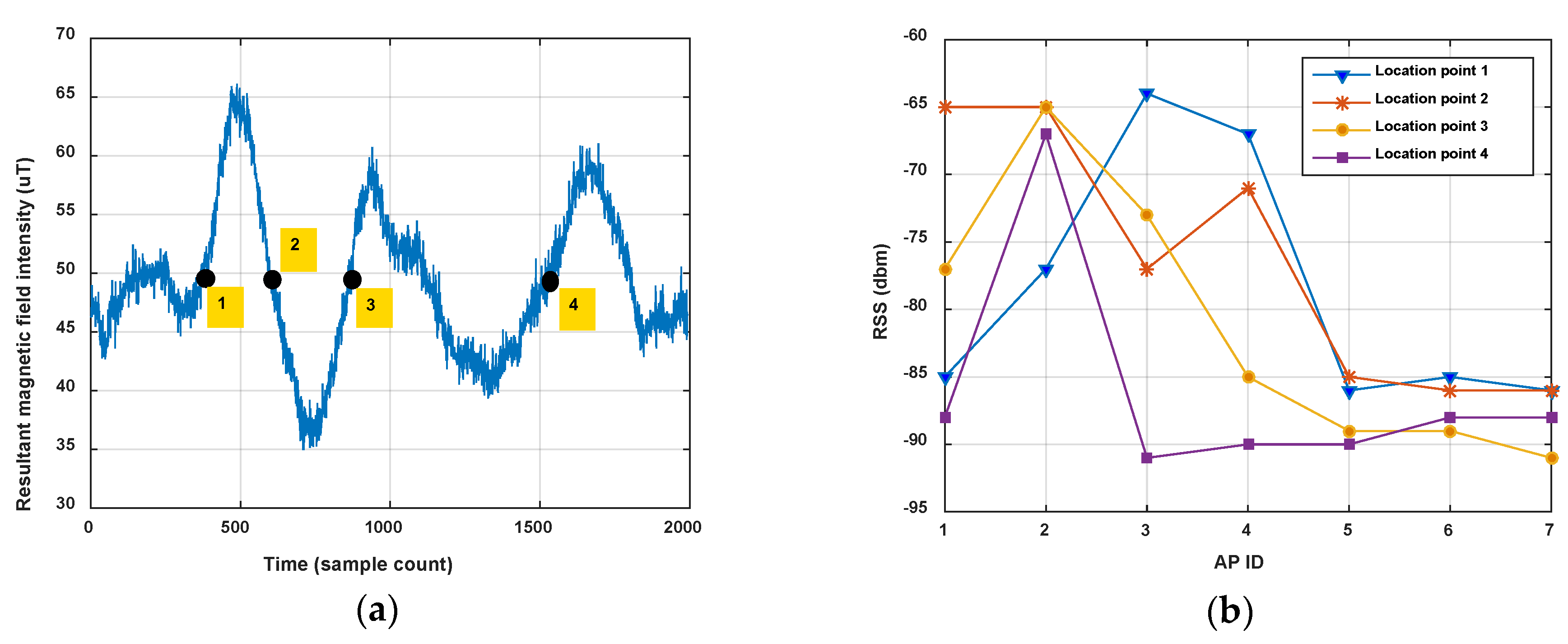
Figure 4.
Comparison of magnetism sequences measured in the same corridor and different corridors: (a) Smoothed magnetism sequences generated in the same corridor; (b) Smoothed magnetism sequences generated in different corridors.
Figure 4.
Comparison of magnetism sequences measured in the same corridor and different corridors: (a) Smoothed magnetism sequences generated in the same corridor; (b) Smoothed magnetism sequences generated in different corridors.

Figure 5.
The indoor map is handled as a pathway graph in this paper: (a) a floor plan of an underground parking, the blue line is the pathway; (b) pathway graph of the left floor plan, the edges represent roads and the vertexes represent connections between roads.
Figure 5.
The indoor map is handled as a pathway graph in this paper: (a) a floor plan of an underground parking, the blue line is the pathway; (b) pathway graph of the left floor plan, the edges represent roads and the vertexes represent connections between roads.
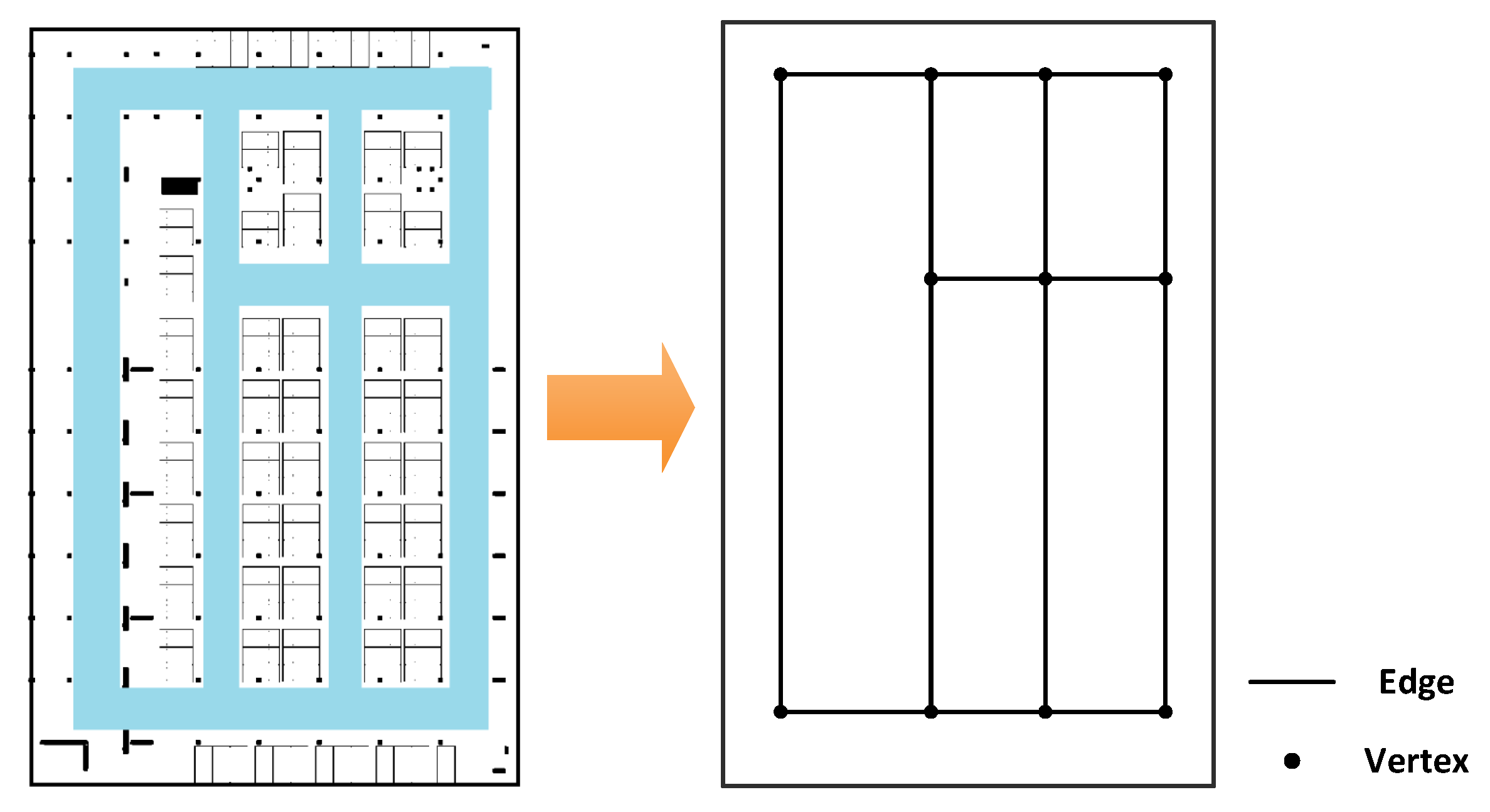
Figure 6.
Four kinds of connection type defined in this paper. represents a road segment, and represents a connection.
Figure 6.
Four kinds of connection type defined in this paper. represents a road segment, and represents a connection.
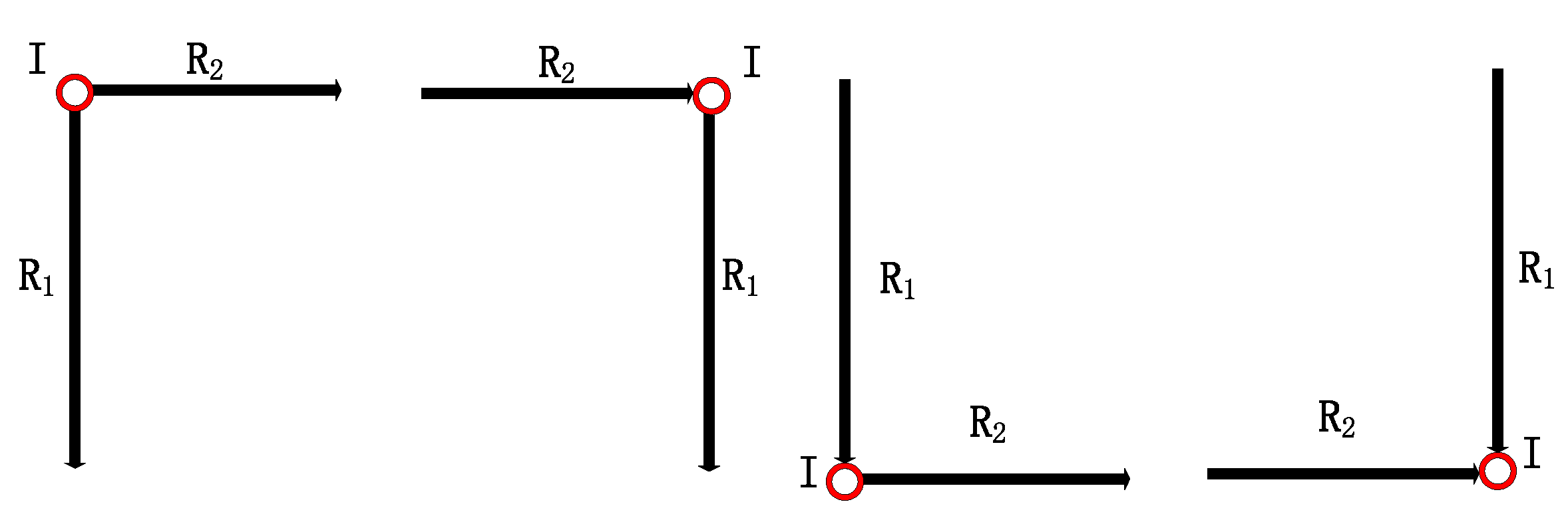
Figure 7.
Example of connections between road segments. The red line is a user trace in an underground parking. and are respectively the road segments and connections in this trace.
Figure 7.
Example of connections between road segments. The red line is a user trace in an underground parking. and are respectively the road segments and connections in this trace.
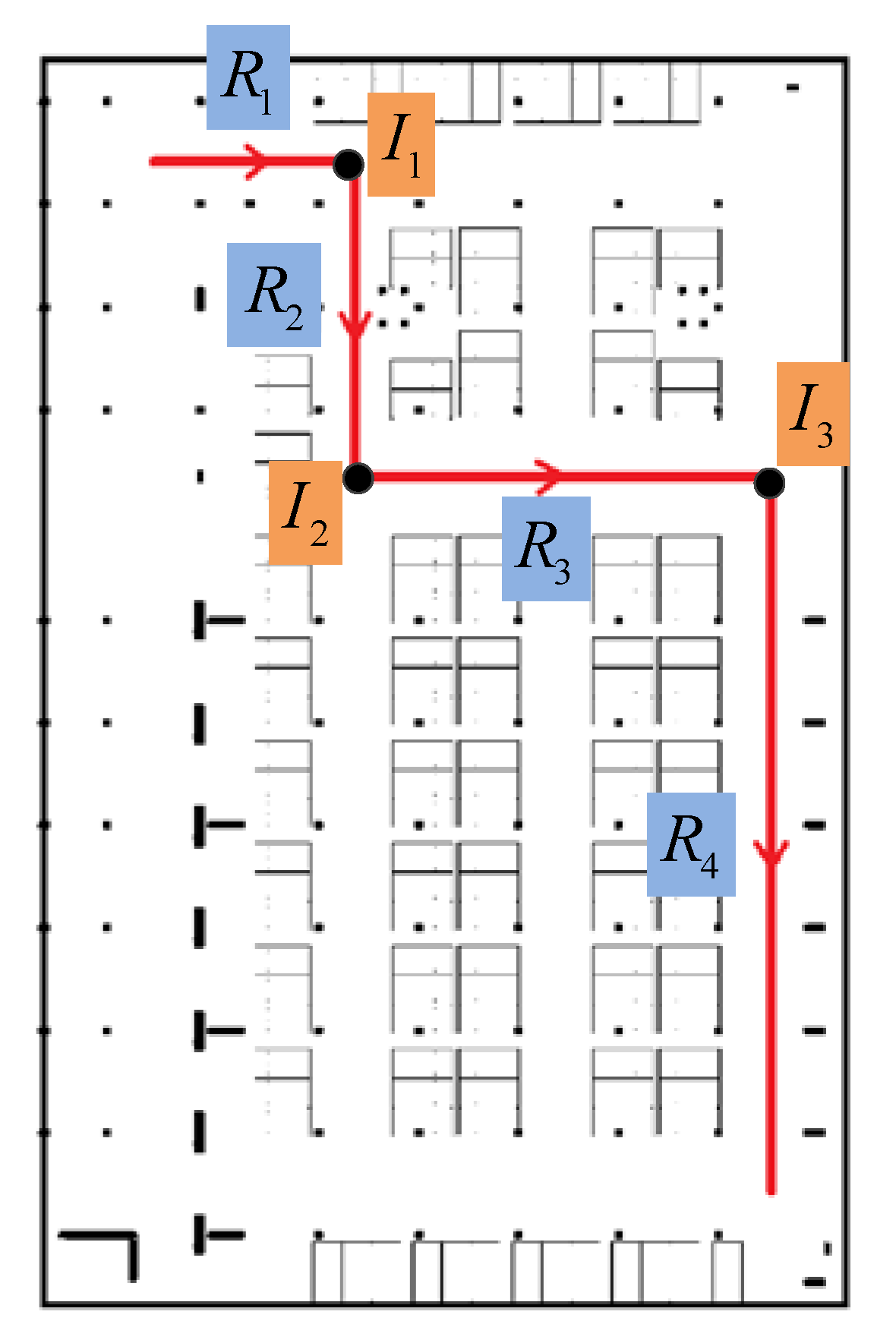
Figure 8.
Overview of the geomagnetism-aided indoor Wi-Fi radio map construction method via smartphone crowdsourcing.
Figure 8.
Overview of the geomagnetism-aided indoor Wi-Fi radio map construction method via smartphone crowdsourcing.
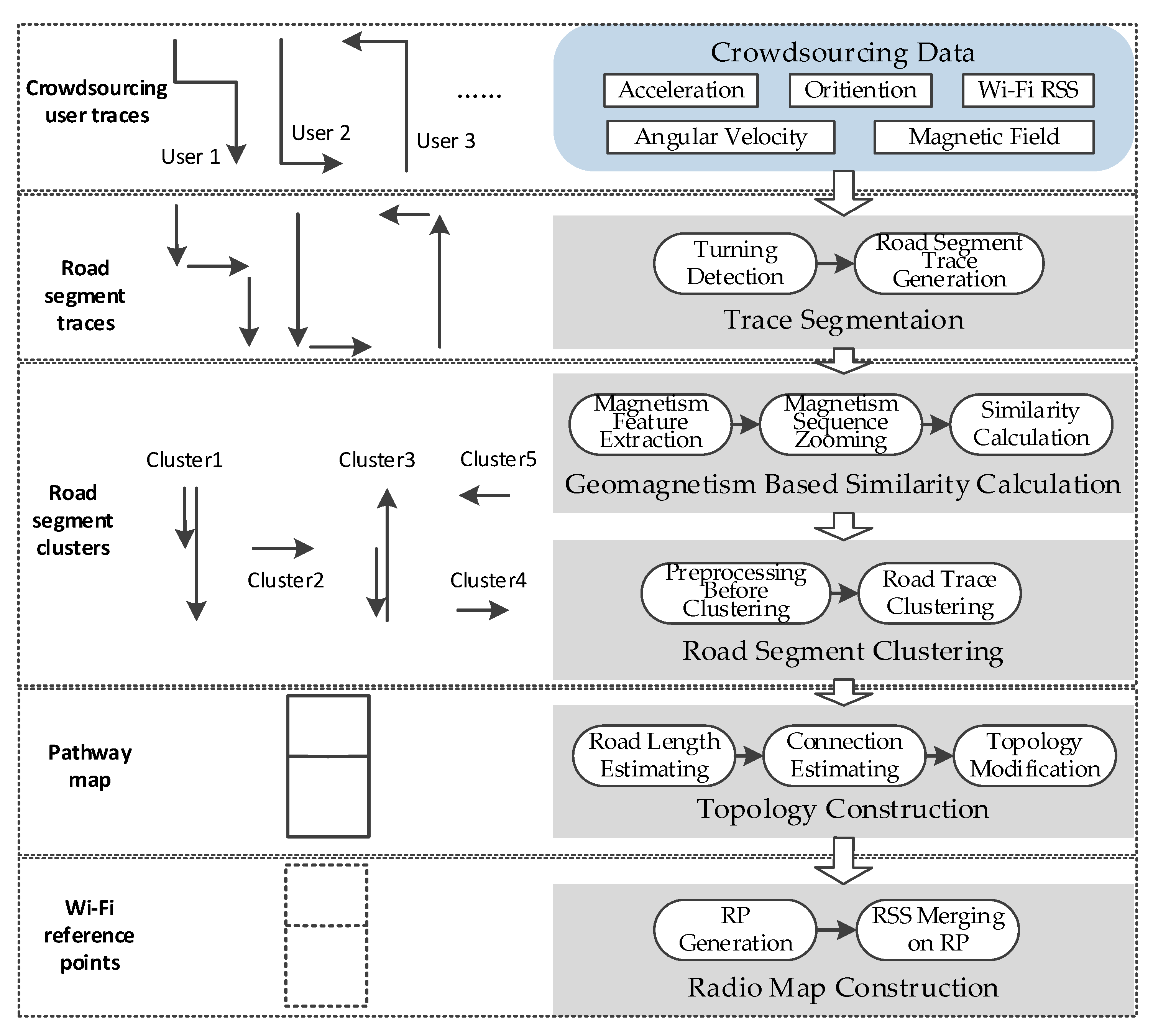
Figure 9.
User’s walking trace and the angular velocities measured by a smartphone gyroscope: (a) walking trace in an underground parking with three turns; (b) angular velocities (vertical component) of the smartphone measured with the walking trace.
Figure 9.
User’s walking trace and the angular velocities measured by a smartphone gyroscope: (a) walking trace in an underground parking with three turns; (b) angular velocities (vertical component) of the smartphone measured with the walking trace.
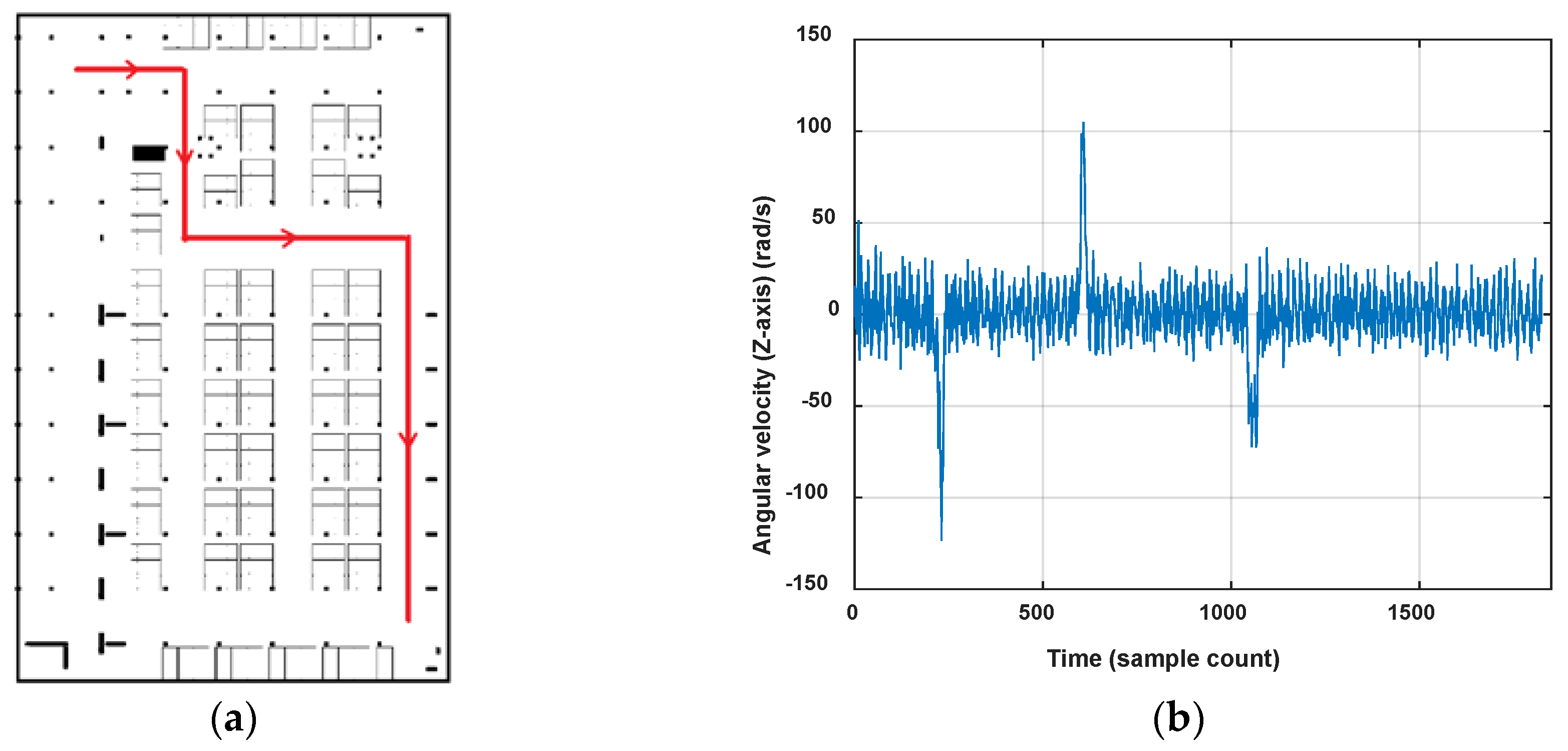
Figure 10.
Turn detection results using angular velocity: (a) vertical component of the angular velocities (smoothed) of the test trace and the detected start point, peak and end point of each turn; (b) four segmented road traces and the three connections between them.
Figure 10.
Turn detection results using angular velocity: (a) vertical component of the angular velocities (smoothed) of the test trace and the detected start point, peak and end point of each turn; (b) four segmented road traces and the three connections between them.
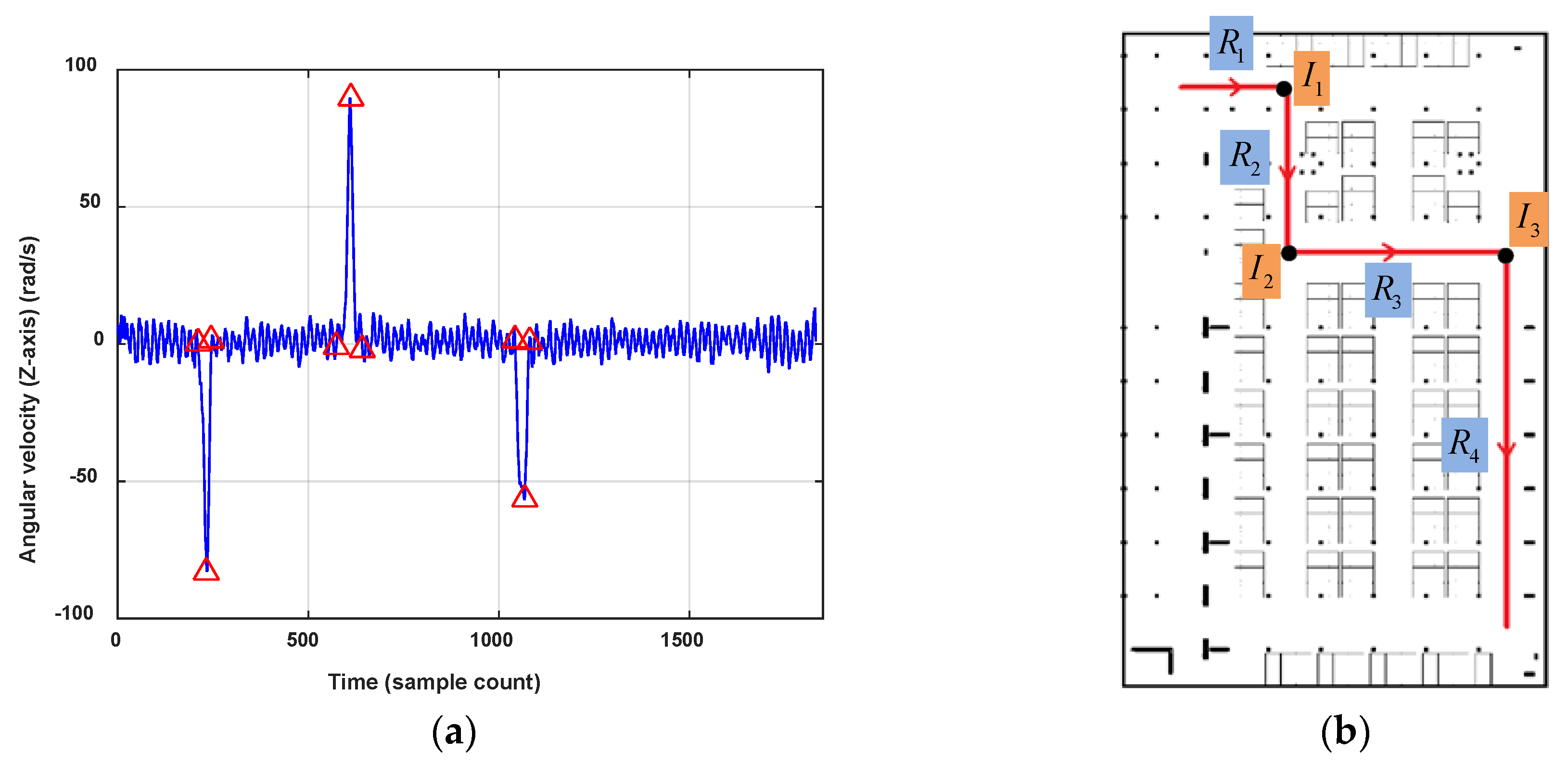
Figure 11.
Example for magnetism feature extraction: (a) sequence of resultant magnetism intensity generated with a user trace; (b) feature extraction result.
Figure 11.
Example for magnetism feature extraction: (a) sequence of resultant magnetism intensity generated with a user trace; (b) feature extraction result.
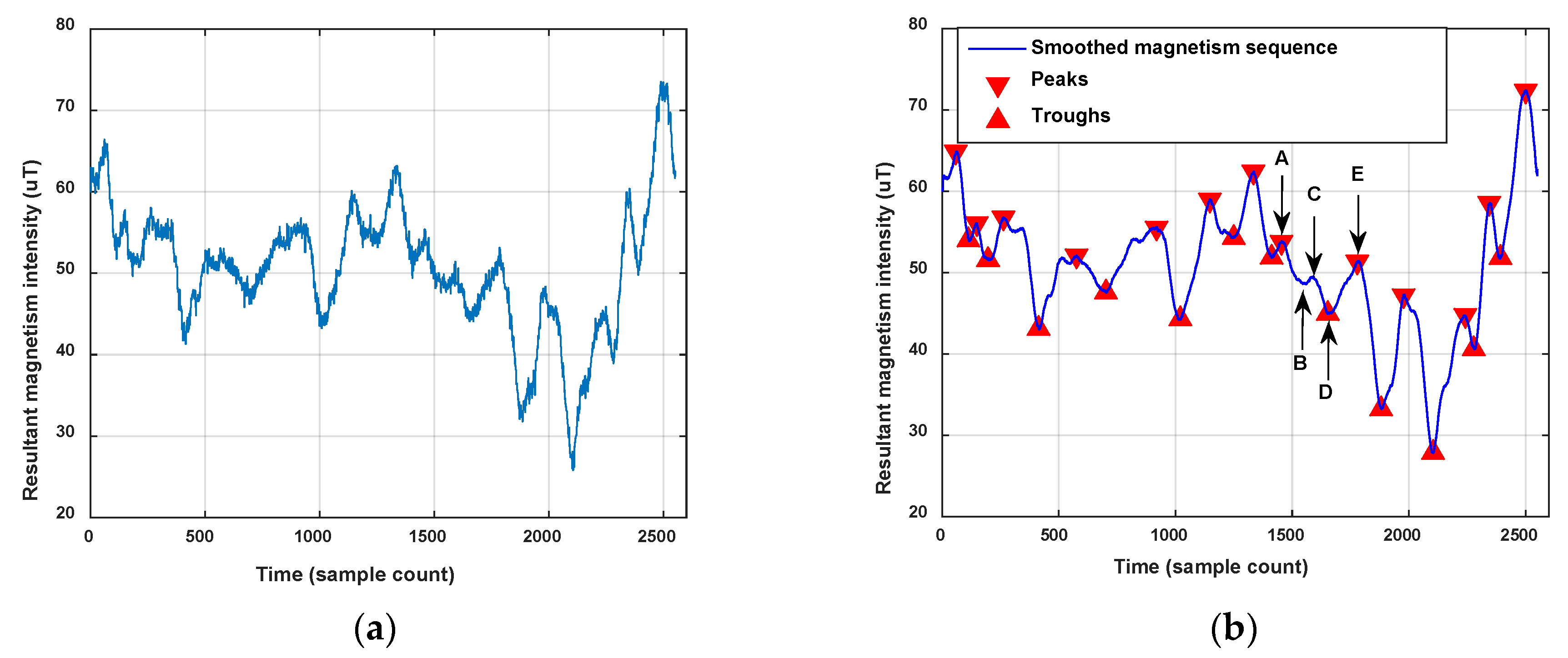
Figure 12.
Magnetism matching and similarity calculation results for two traces generated on the same road segment: (a) smoothed magnetism sequences and detected features marked by the initial estimated distance; (b) magnetism sequences after feature matching and sequence zooming, and the their calculated similarity.
Figure 12.
Magnetism matching and similarity calculation results for two traces generated on the same road segment: (a) smoothed magnetism sequences and detected features marked by the initial estimated distance; (b) magnetism sequences after feature matching and sequence zooming, and the their calculated similarity.
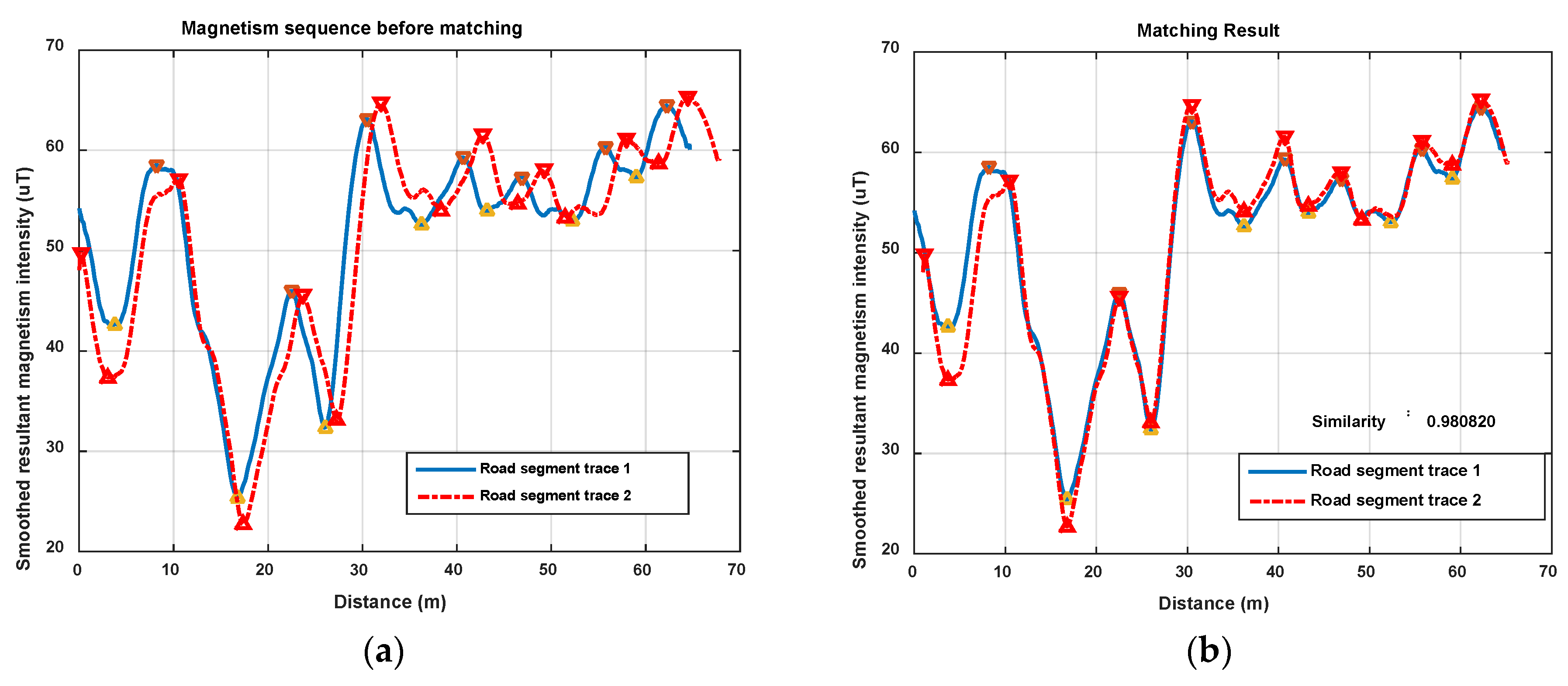
Figure 13.
Magnetism matching and similarity calculation results when trace 2 is partly generated on the same road segment that trace 1 was generated on: (a) smoothed magnetism sequences and detected features marked by the initial estimated distance; (b) magnetism sequences after feature matching and sequence zooming, and the calculated similarity between them.
Figure 13.
Magnetism matching and similarity calculation results when trace 2 is partly generated on the same road segment that trace 1 was generated on: (a) smoothed magnetism sequences and detected features marked by the initial estimated distance; (b) magnetism sequences after feature matching and sequence zooming, and the calculated similarity between them.
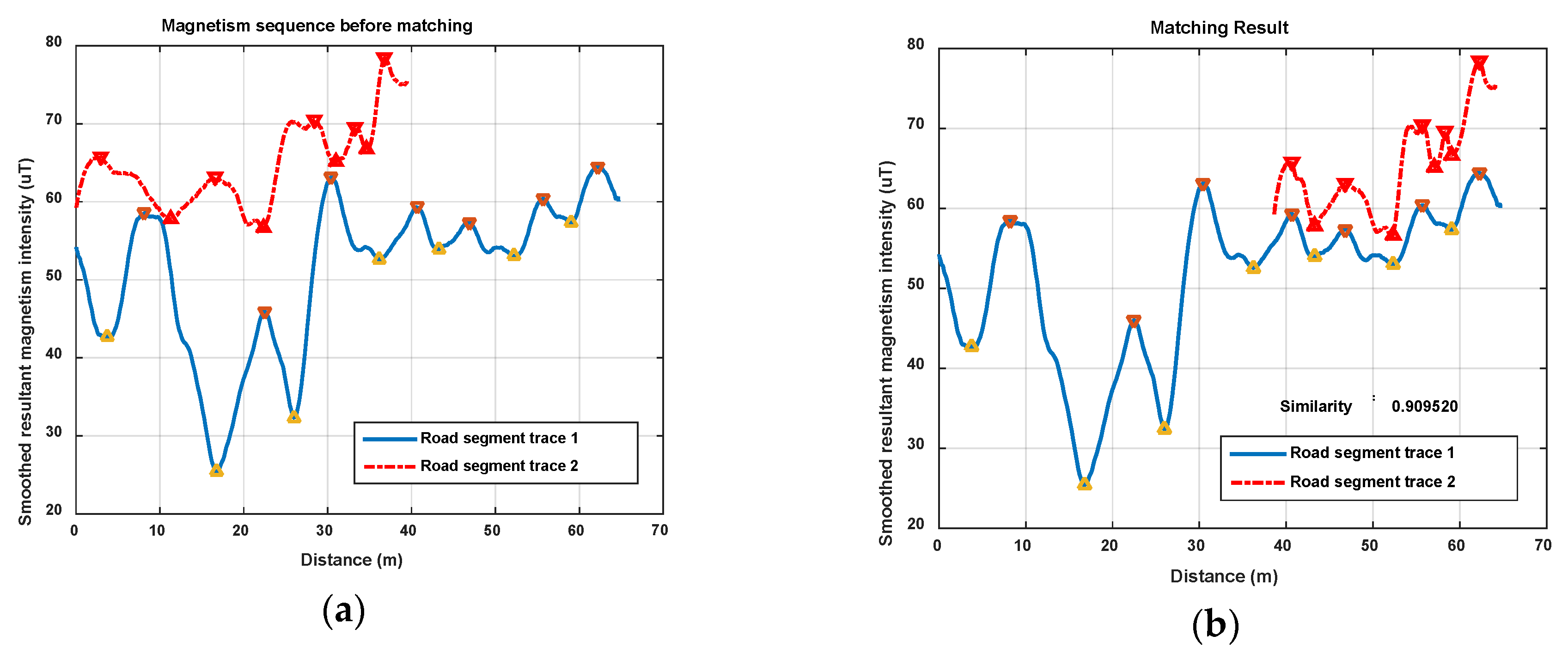
Figure 14.
Magnetism matching and similarity calculation results for two traces generated on different road segments: (a) smoothed magnetism sequences and detected features marked by the initial estimated distance; (b) magnetism sequences after feature matching and sequence zooming, and the calculated similarity between them.
Figure 14.
Magnetism matching and similarity calculation results for two traces generated on different road segments: (a) smoothed magnetism sequences and detected features marked by the initial estimated distance; (b) magnetism sequences after feature matching and sequence zooming, and the calculated similarity between them.
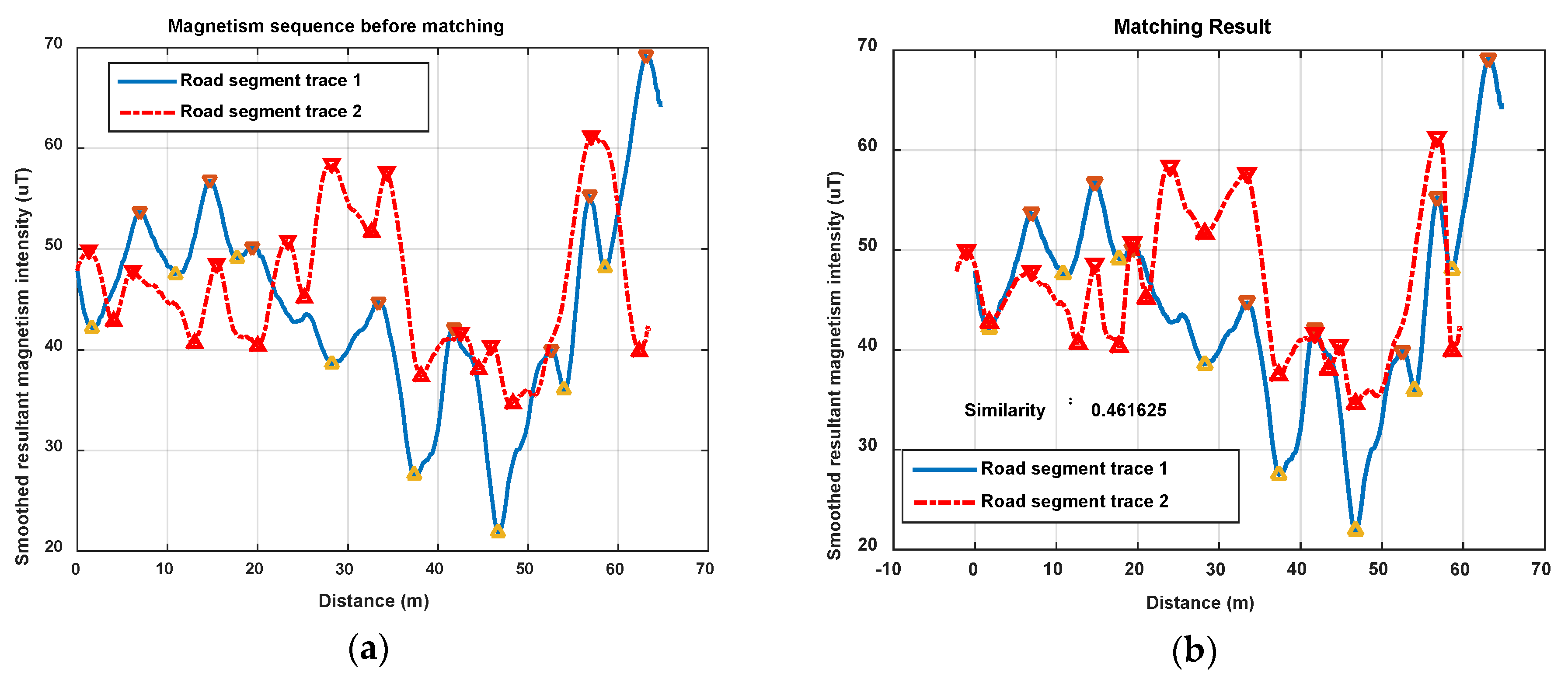
Figure 15.
Coordinate system for road orientation and the uncertainty () of shown in it.
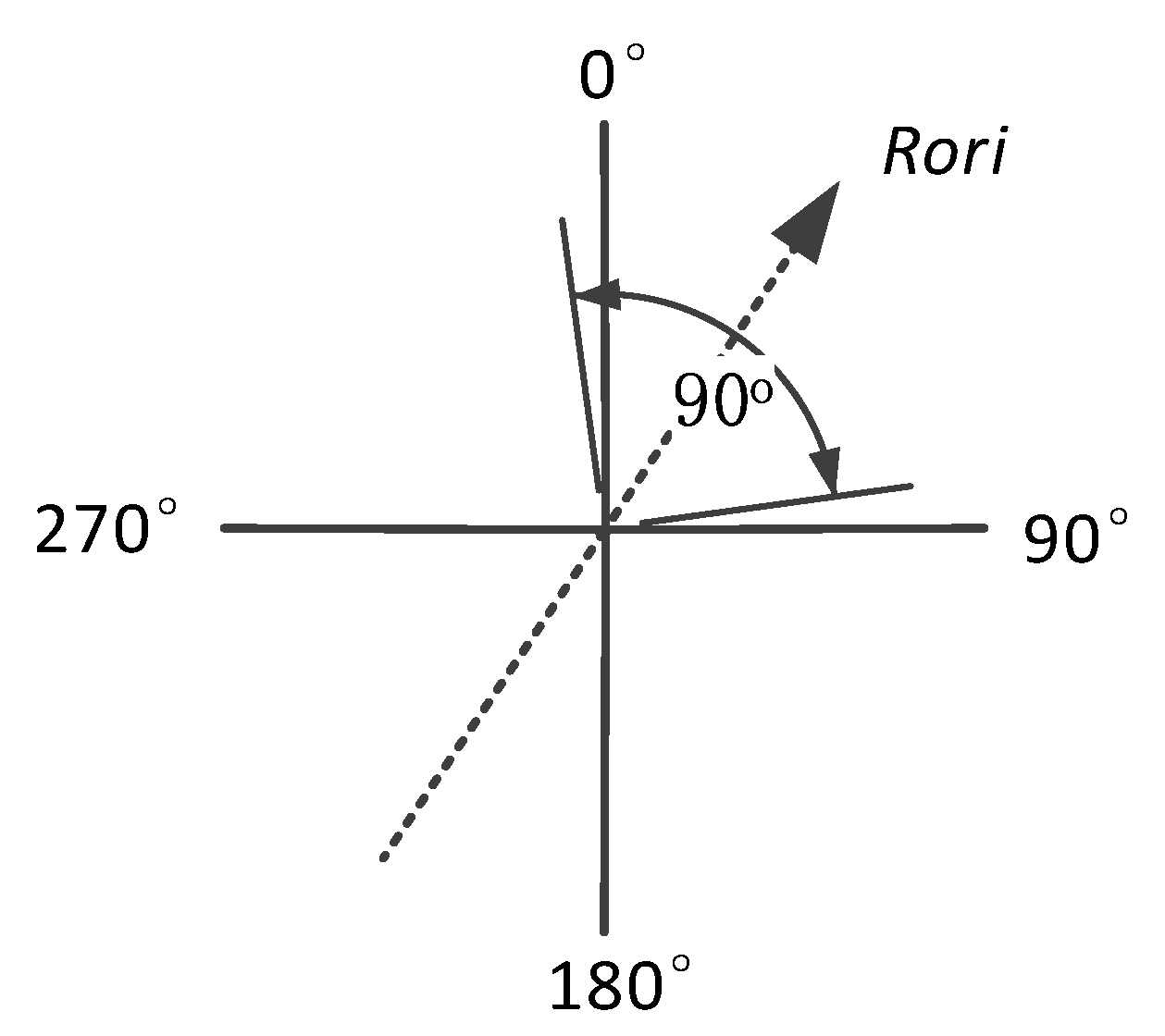
Figure 16.
The process to make distance scale of be identical with using the connections between them.
Figure 16.
The process to make distance scale of be identical with using the connections between them.
Figure 17.
The process for estimating connection angle between clusters and .
Figure 18.
A kind of topology error caused by inaccurate angles: (a) a rectangle and four calculated inner angles; (b) the topology result of the rectangle using inaccurate inner angles. C’ and C don’t overlap.
Figure 18.
A kind of topology error caused by inaccurate angles: (a) a rectangle and four calculated inner angles; (b) the topology result of the rectangle using inaccurate inner angles. C’ and C don’t overlap.
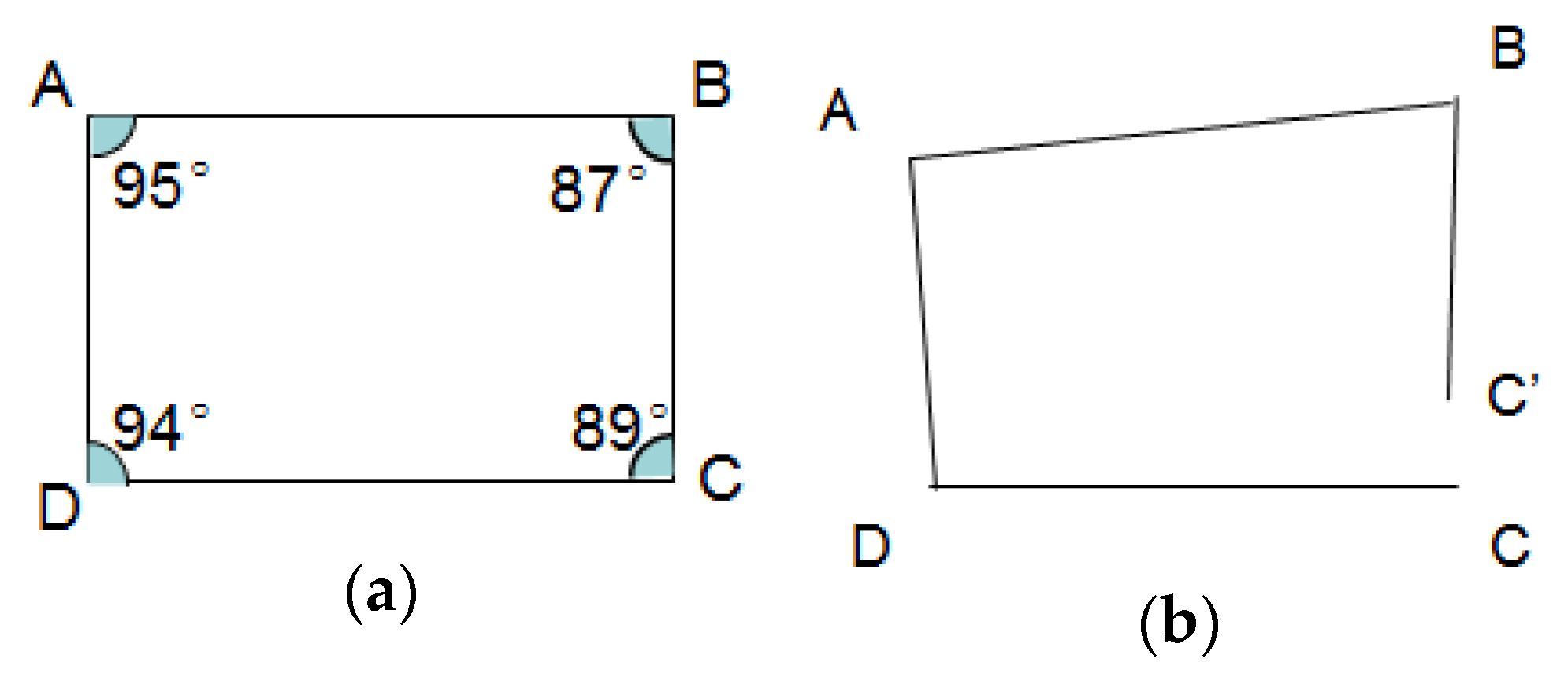
Figure 19.
Experimental area plan and examples for crowdsourcing traces: (a) the floor plan of the underground parking; (b) parts of test traces collected by crowdsourcing users in our experiment.
Figure 19.
Experimental area plan and examples for crowdsourcing traces: (a) the floor plan of the underground parking; (b) parts of test traces collected by crowdsourcing users in our experiment.
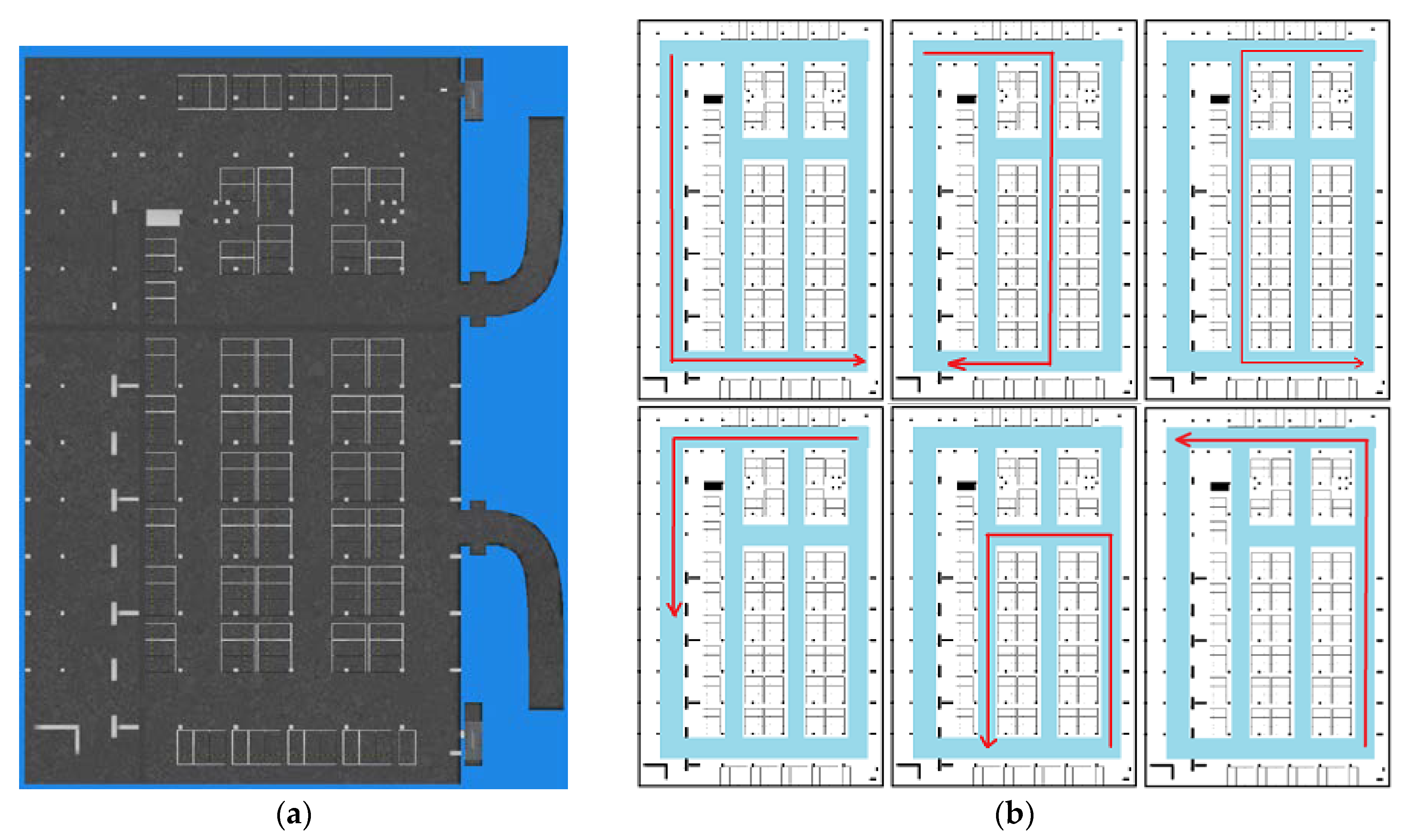
Figure 20.
Topology map construction results: (a) rough result after road length and connection estimations; (b) pathway map after topology modification; (c) final pathway map after orientation correction.
Figure 20.
Topology map construction results: (a) rough result after road length and connection estimations; (b) pathway map after topology modification; (c) final pathway map after orientation correction.

Figure 21.
Wi-Fi RPs generated in the constructed map.
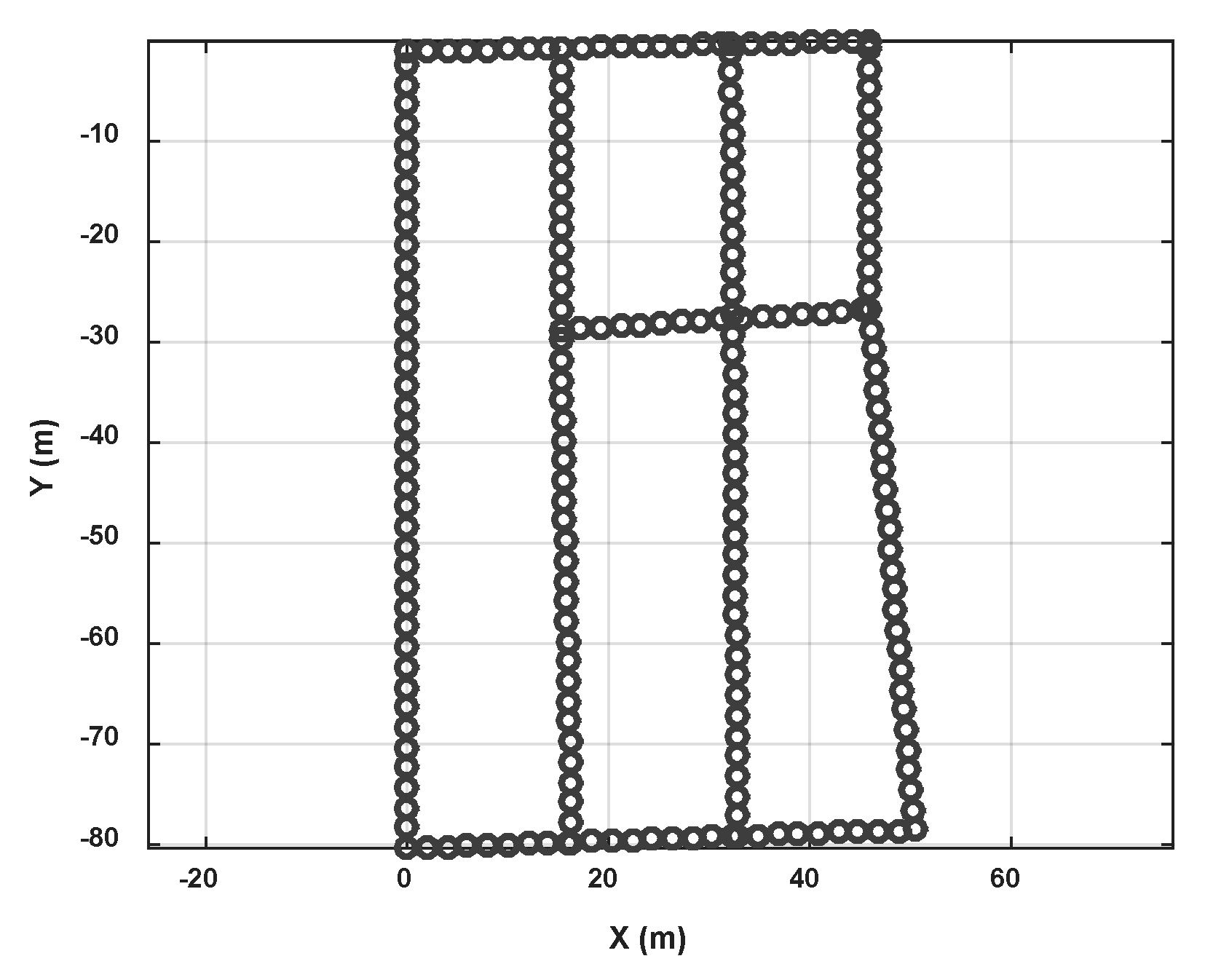
Figure 22.
Experiment results in an office floor: (a) floor plan and examples for test traces; (b) final pathway map constructed by proposed method; (c) labeled Wi-Fi sample points using the constructed pathway map.
Figure 22.
Experiment results in an office floor: (a) floor plan and examples for test traces; (b) final pathway map constructed by proposed method; (c) labeled Wi-Fi sample points using the constructed pathway map.
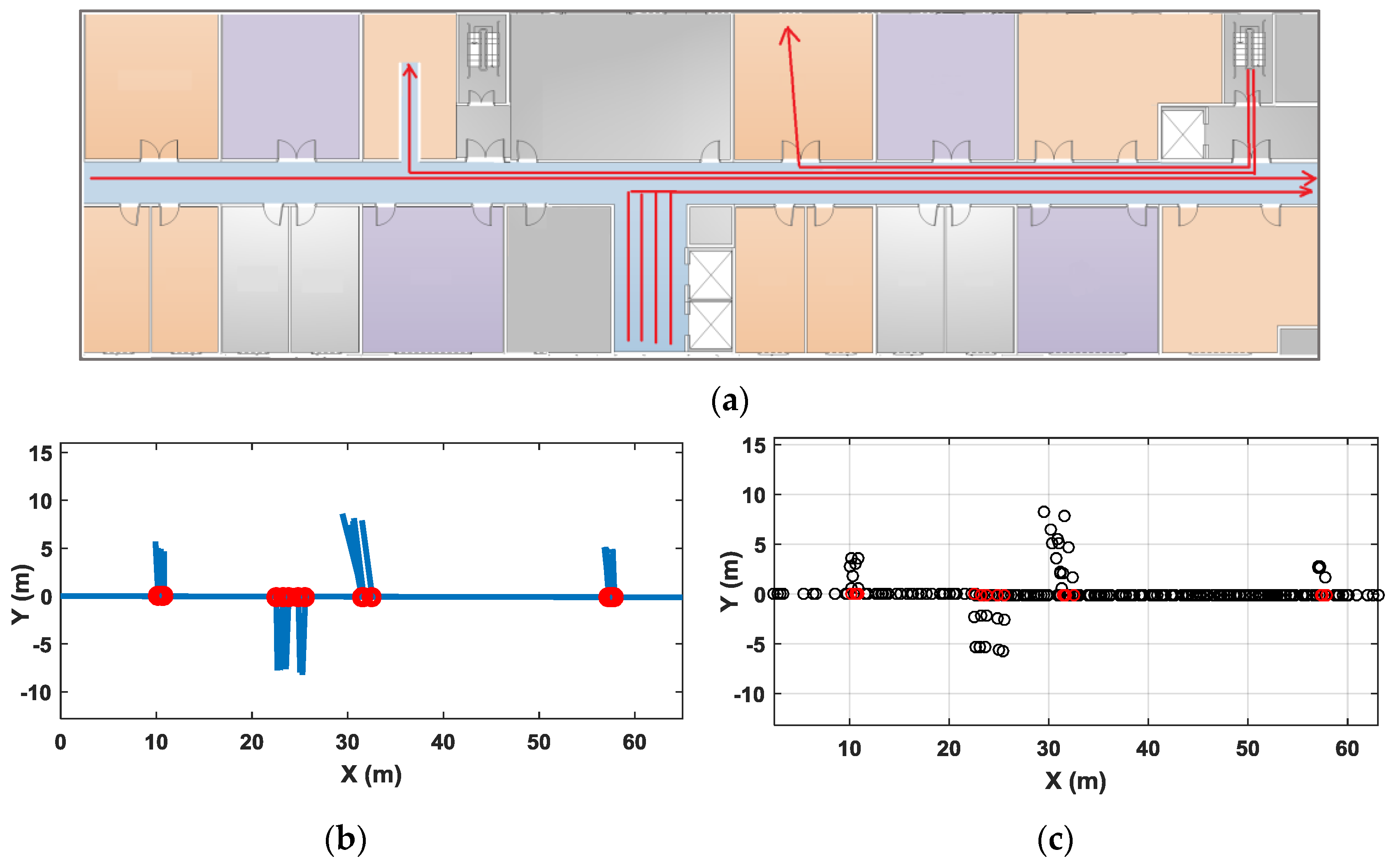
Figure 23.
Data comparison for road width influence. (a) seven test traces (red lines); (b) the measured magnetism sequence of them.
Figure 23.
Data comparison for road width influence. (a) seven test traces (red lines); (b) the measured magnetism sequence of them.
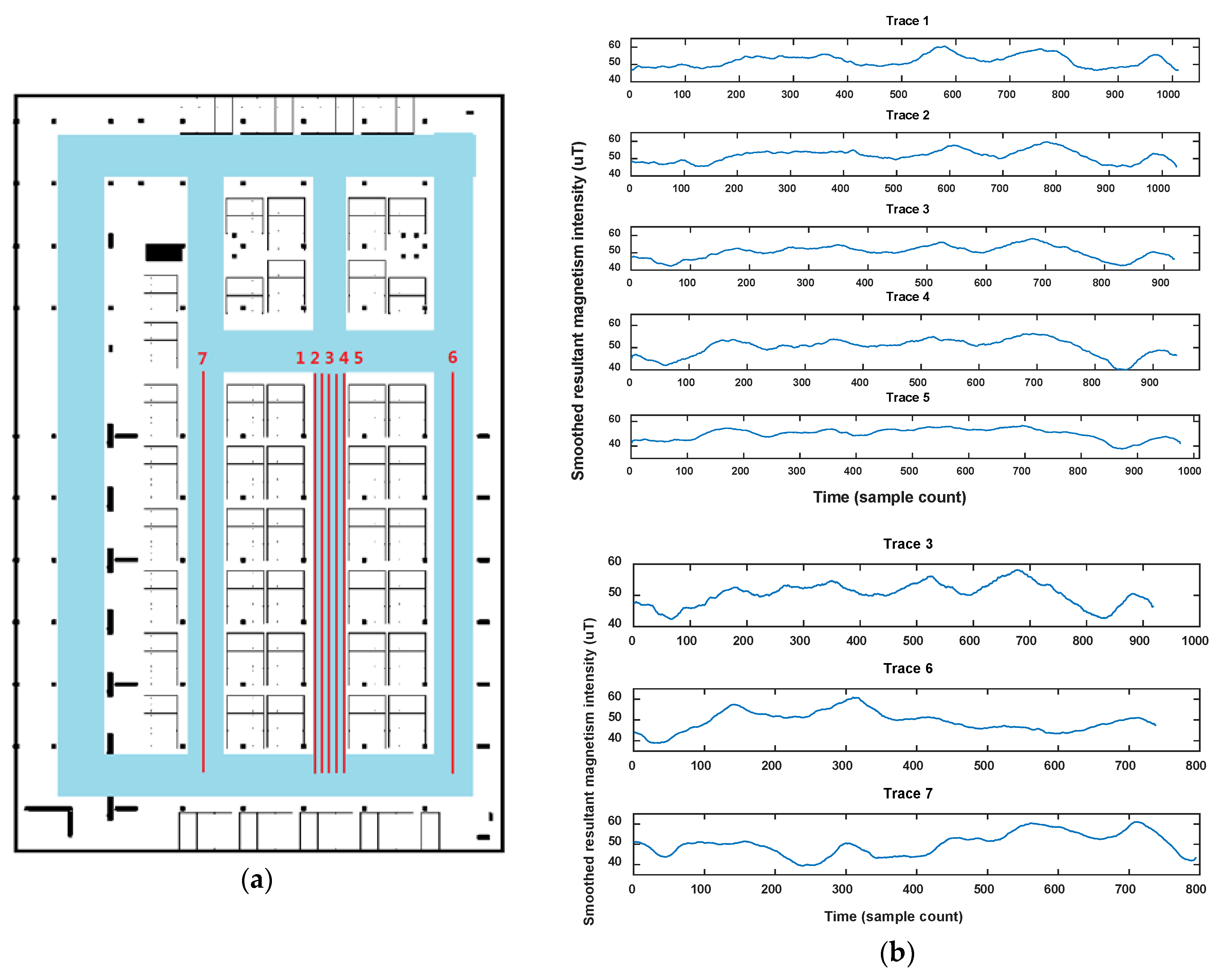
Figure 24.
Data comparison for different smartphone attitudes. (a) three type of postures when a pedestrian uses smartphone; (b) the measured magnetism sequence of them.
Figure 24.
Data comparison for different smartphone attitudes. (a) three type of postures when a pedestrian uses smartphone; (b) the measured magnetism sequence of them.
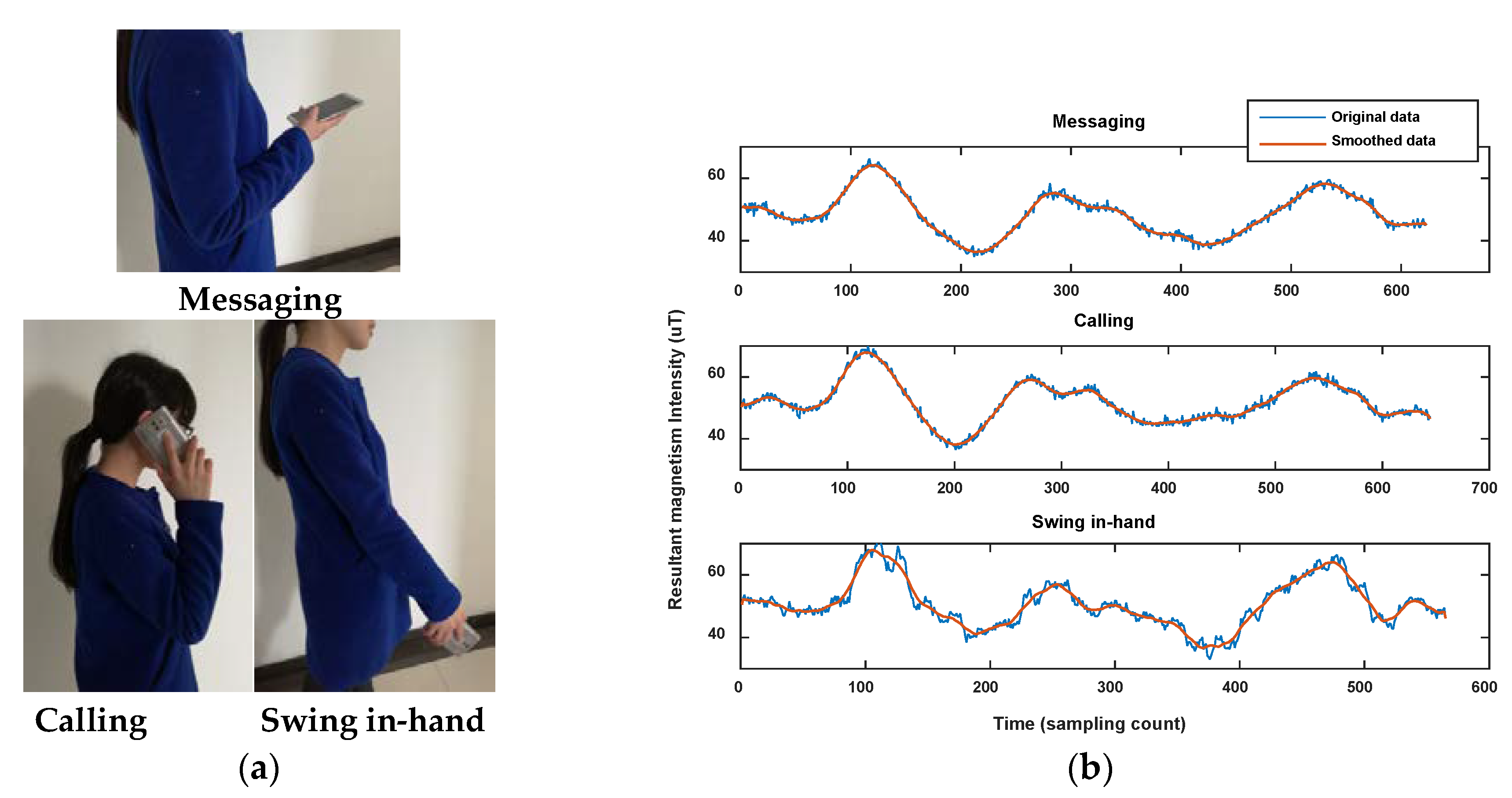

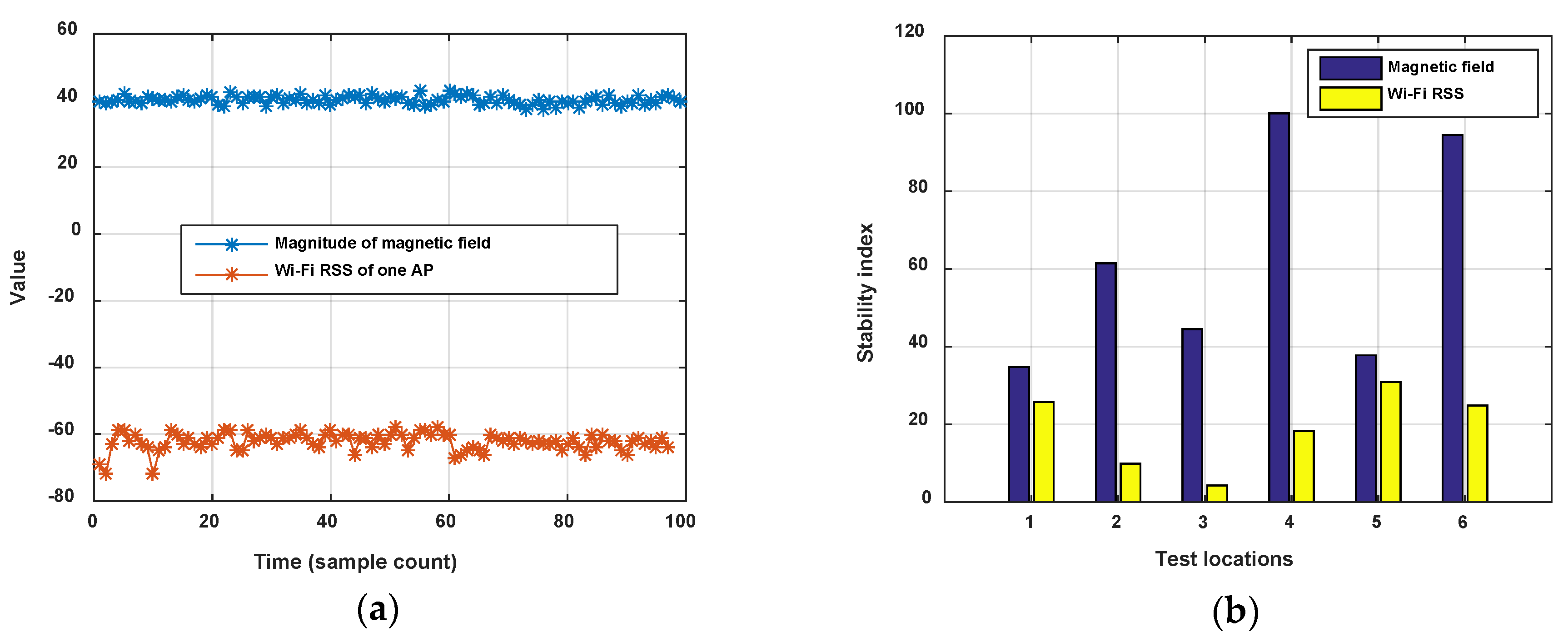{kind=link}
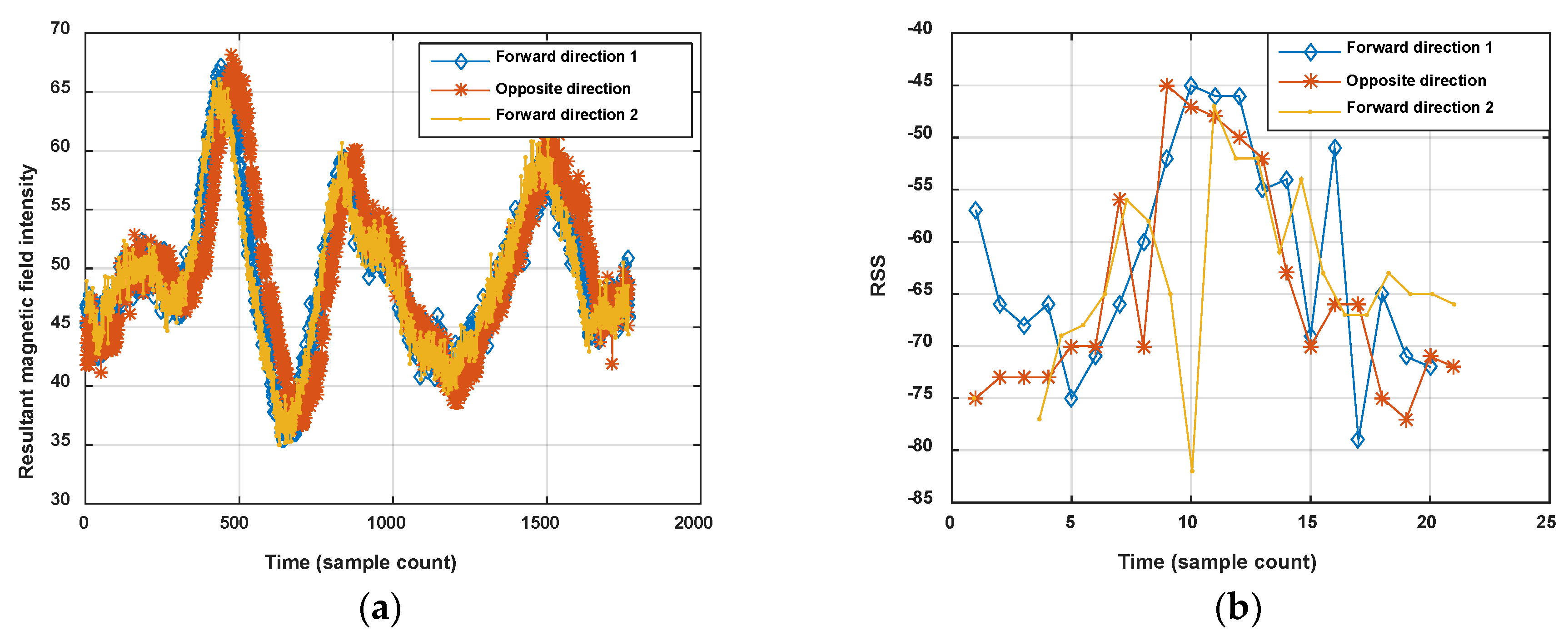{kind=link}
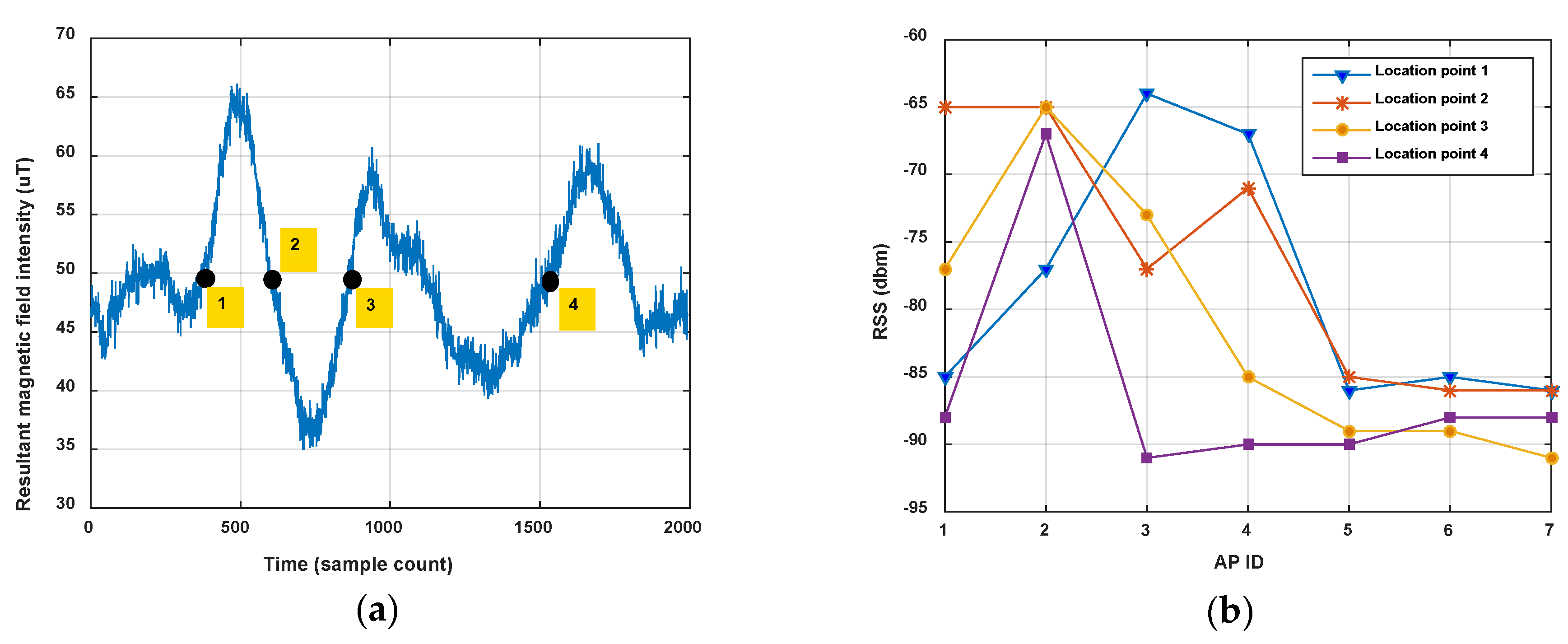{kind=link}
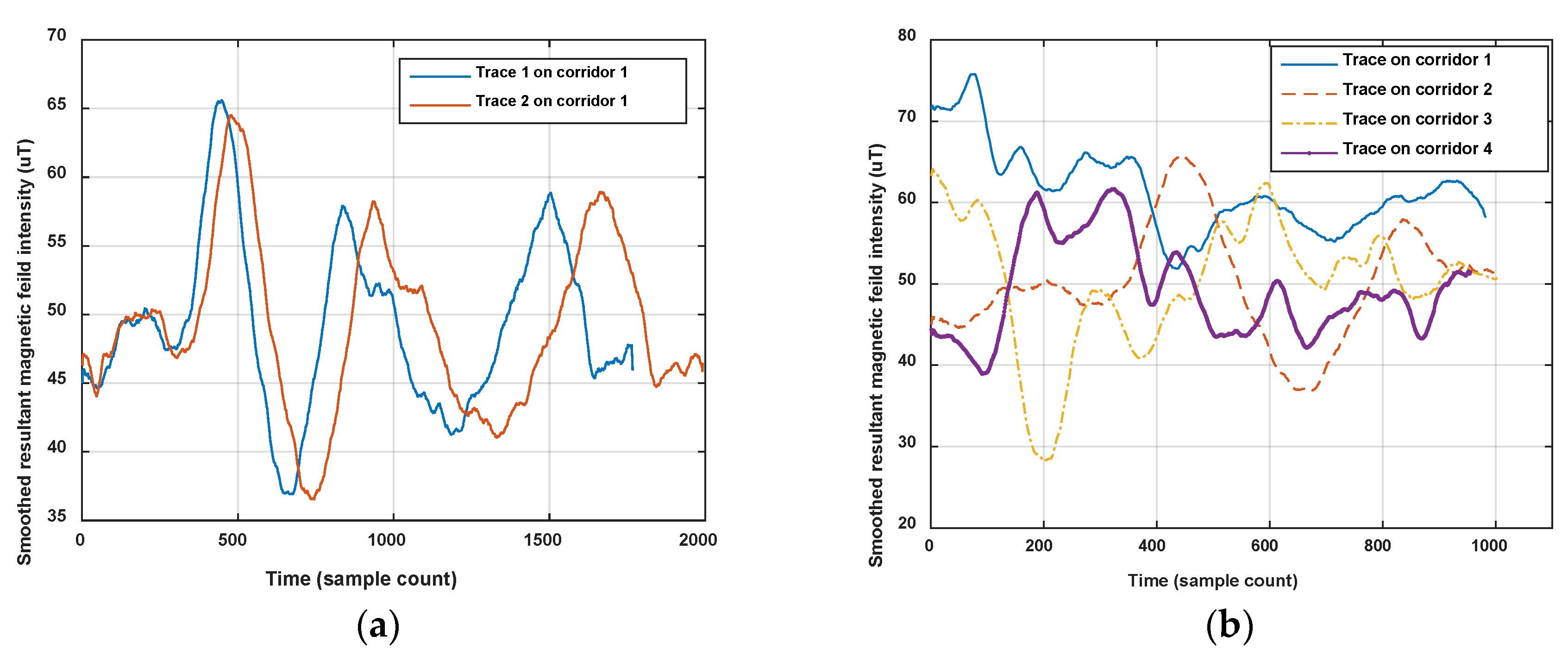{kind=link}
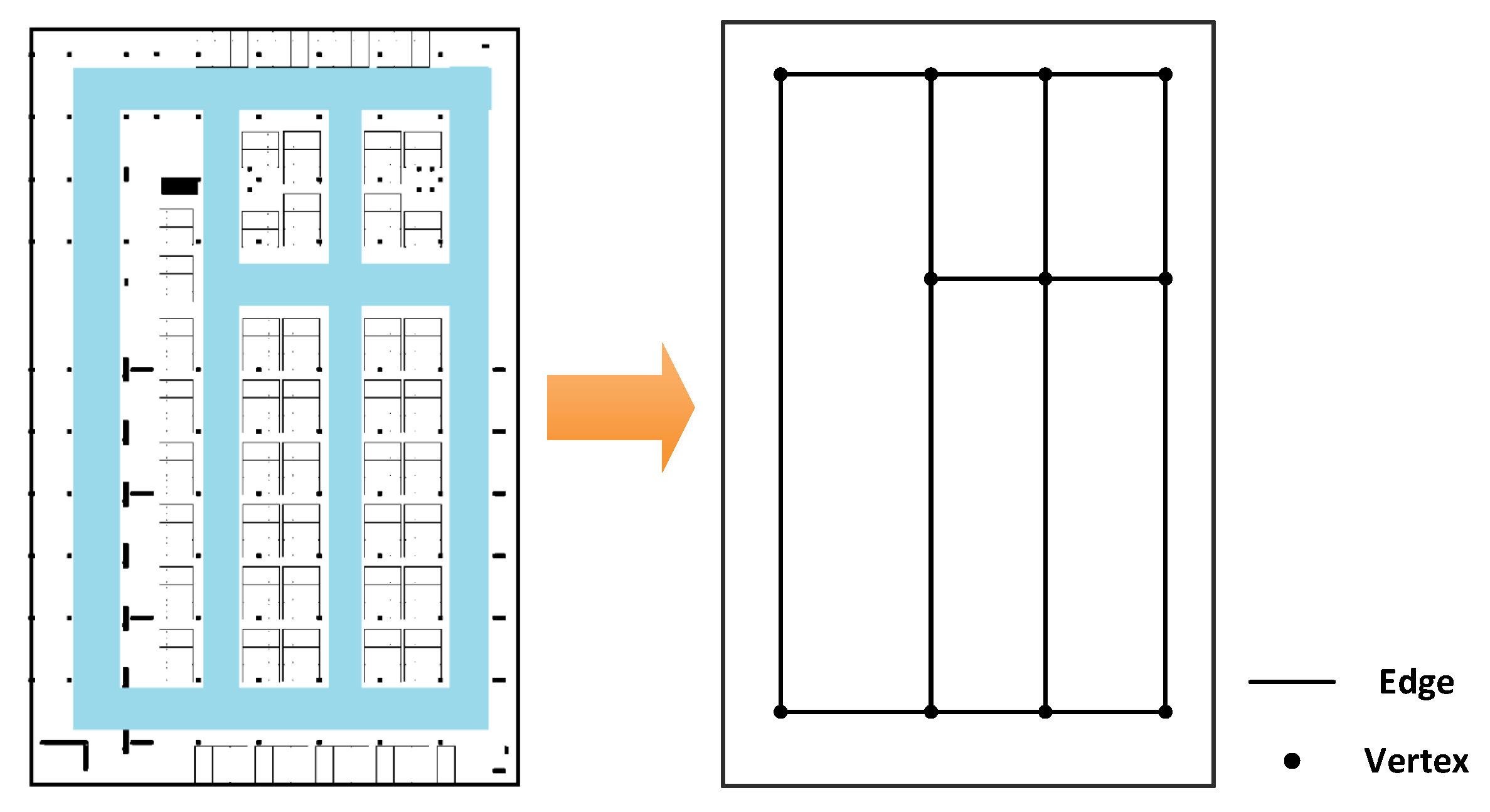{kind=link}
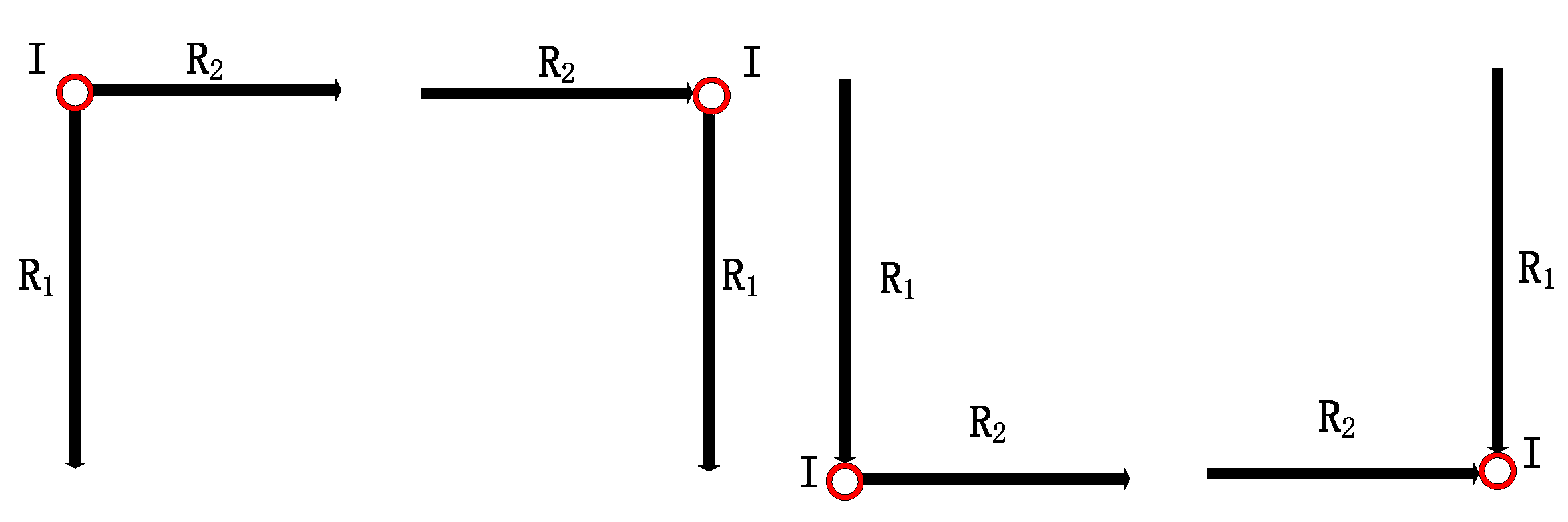{kind=link}
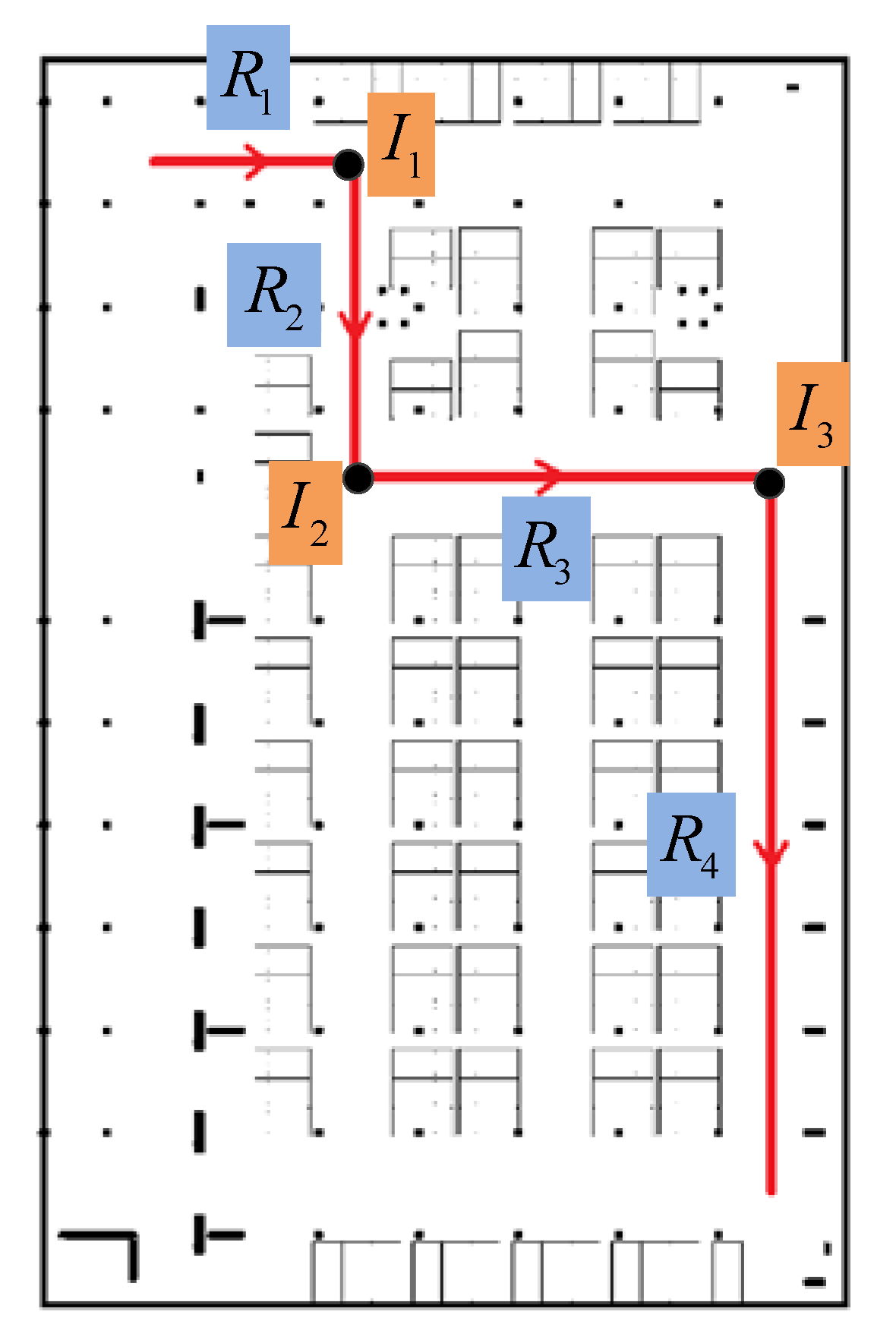{kind=link}
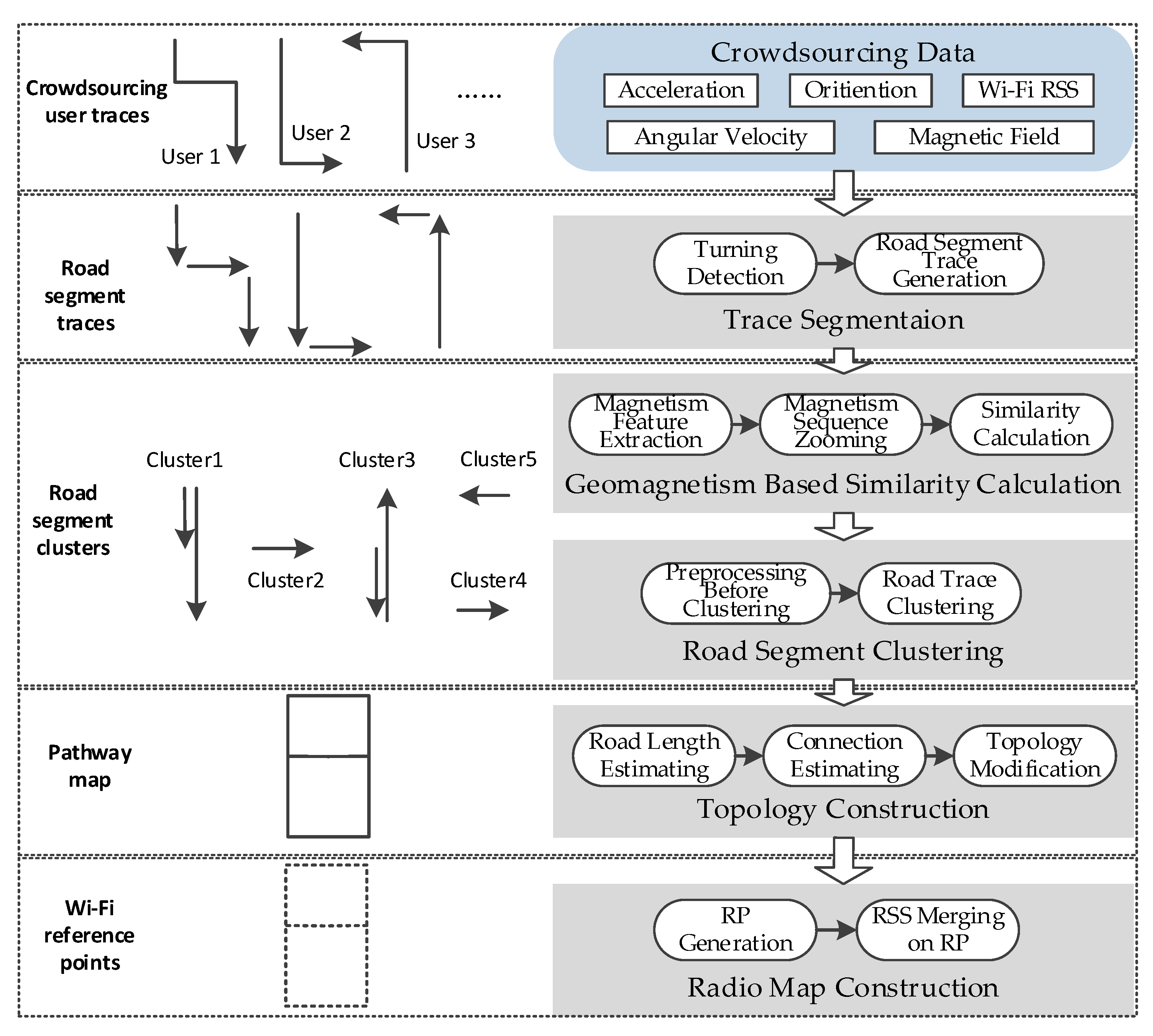{kind=link}
{kind=link}
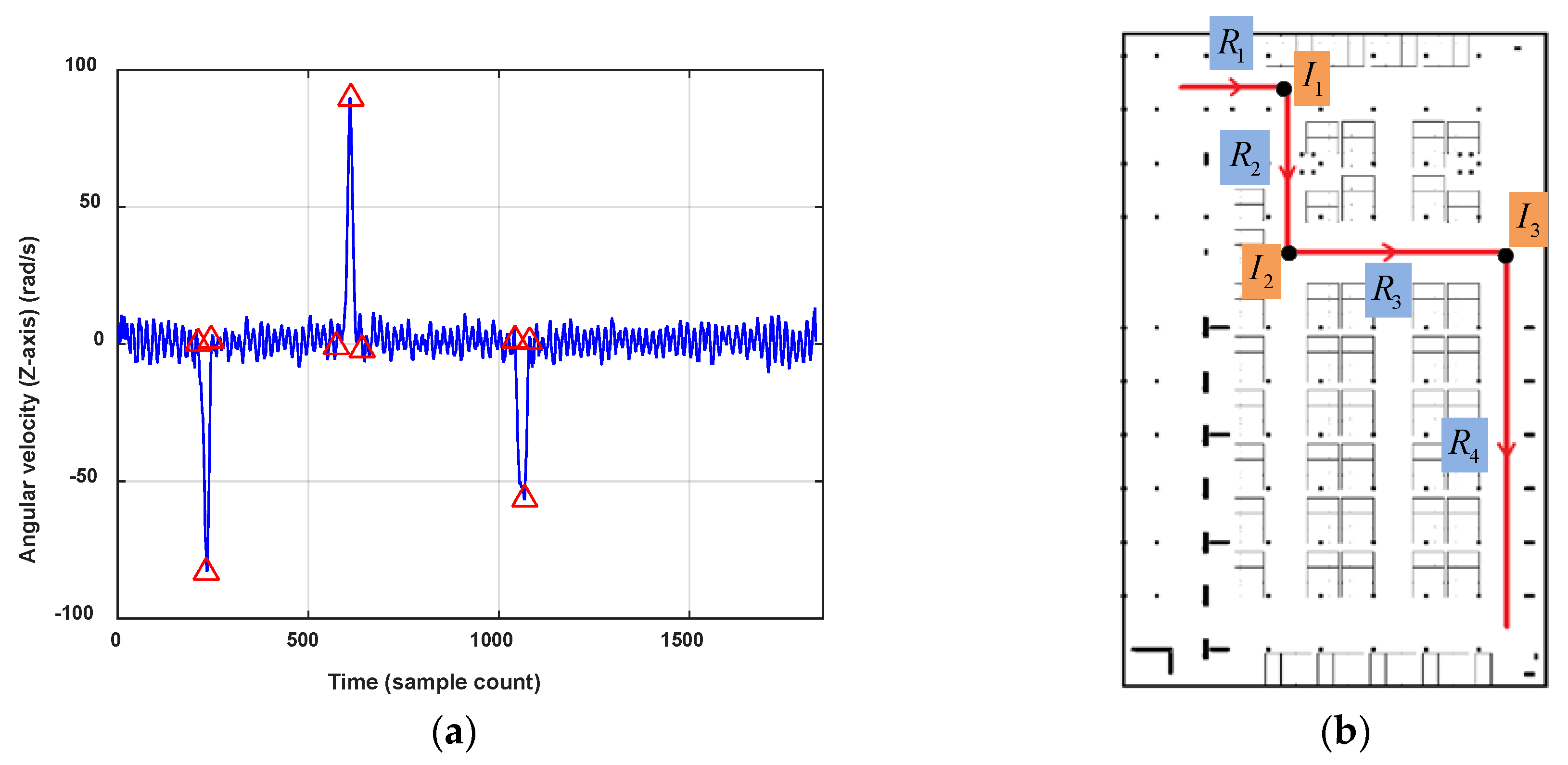{kind=link}
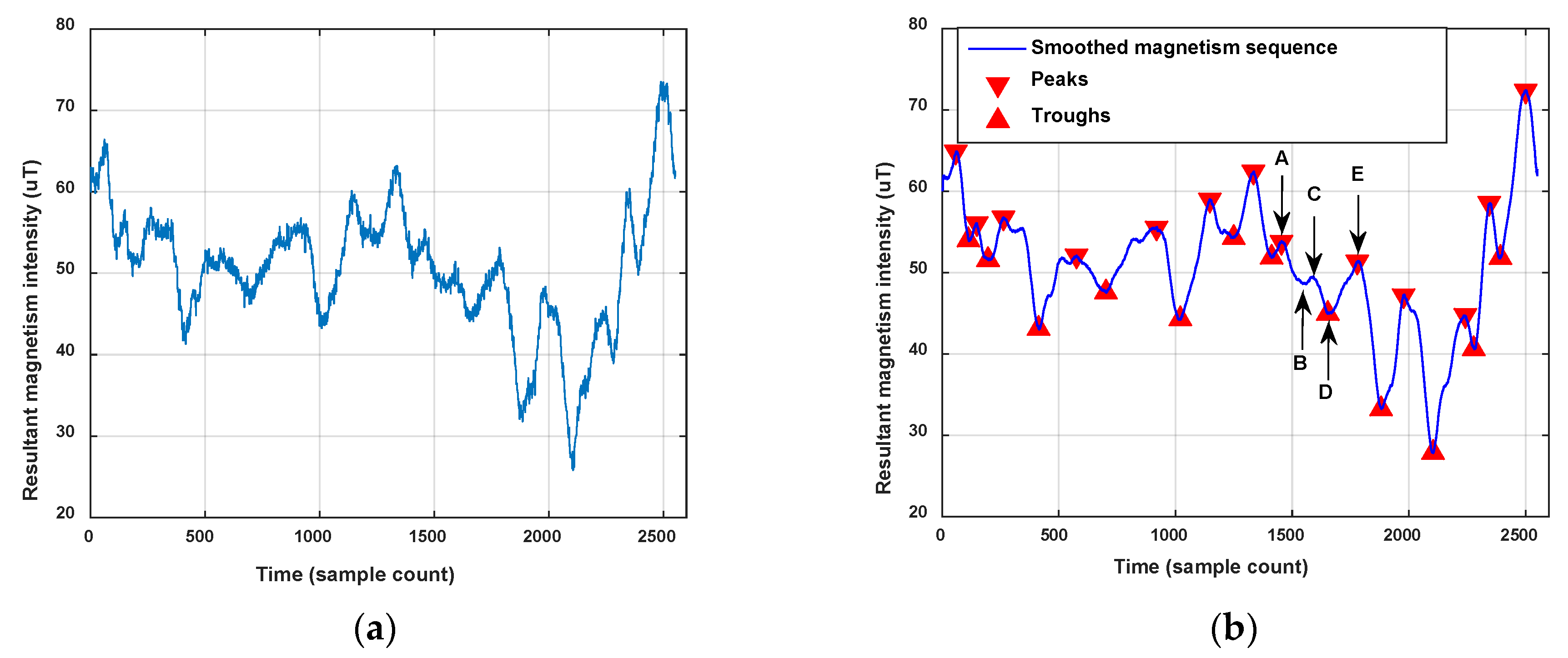{kind=link}
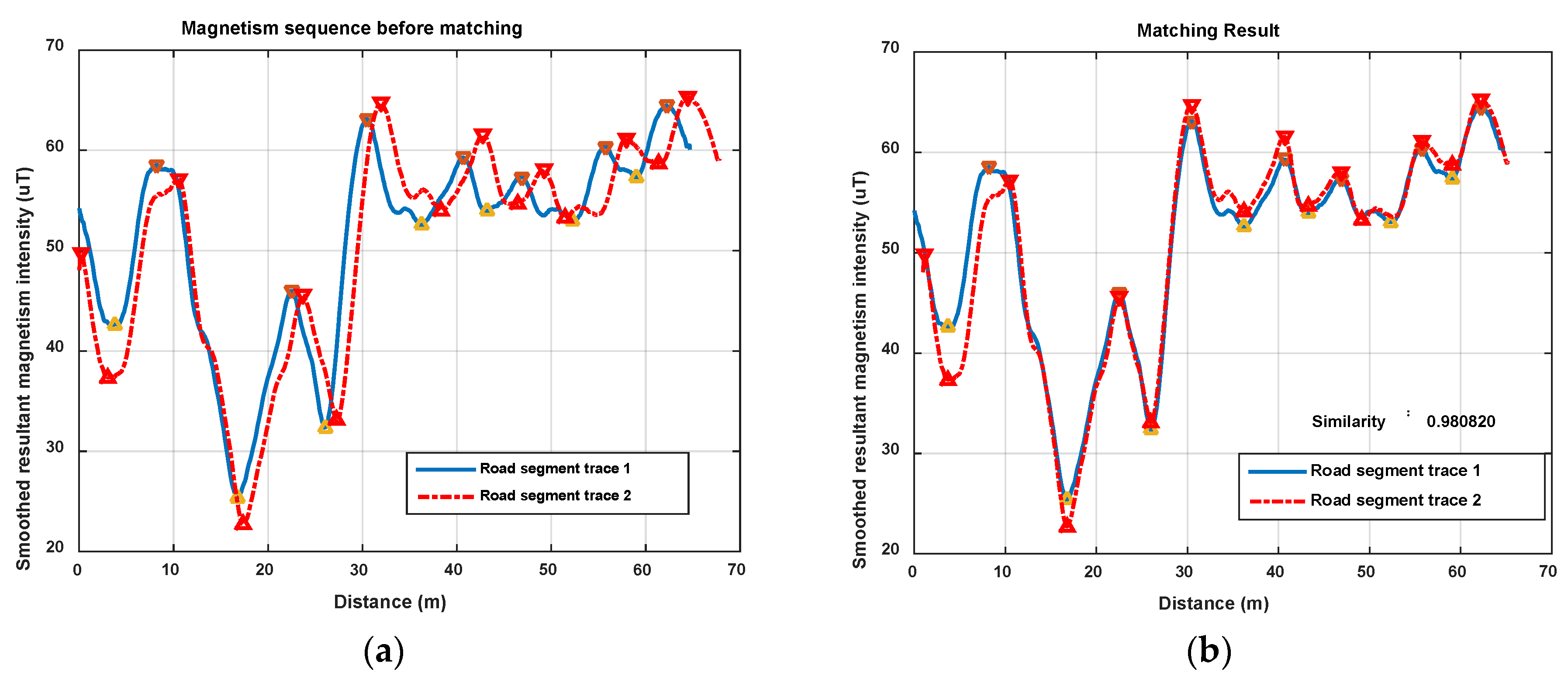{kind=link}
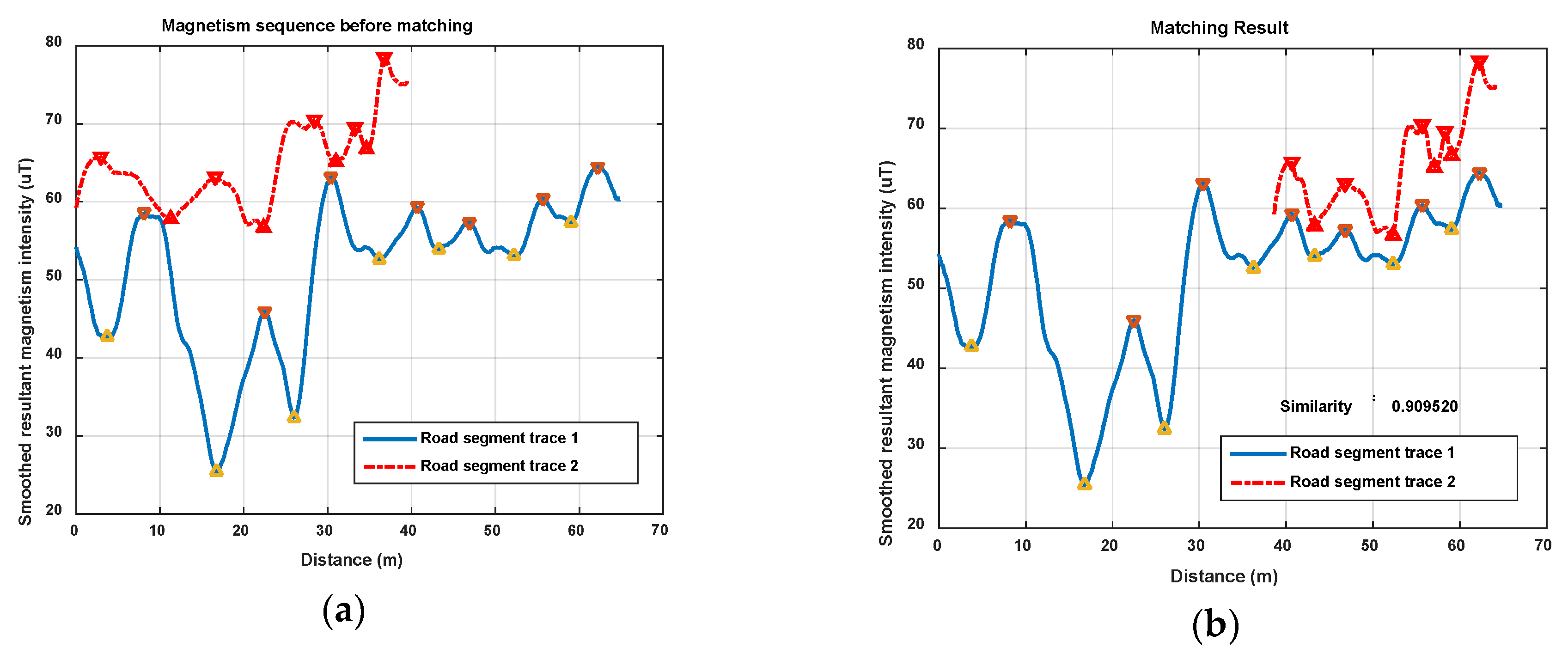{kind=link}
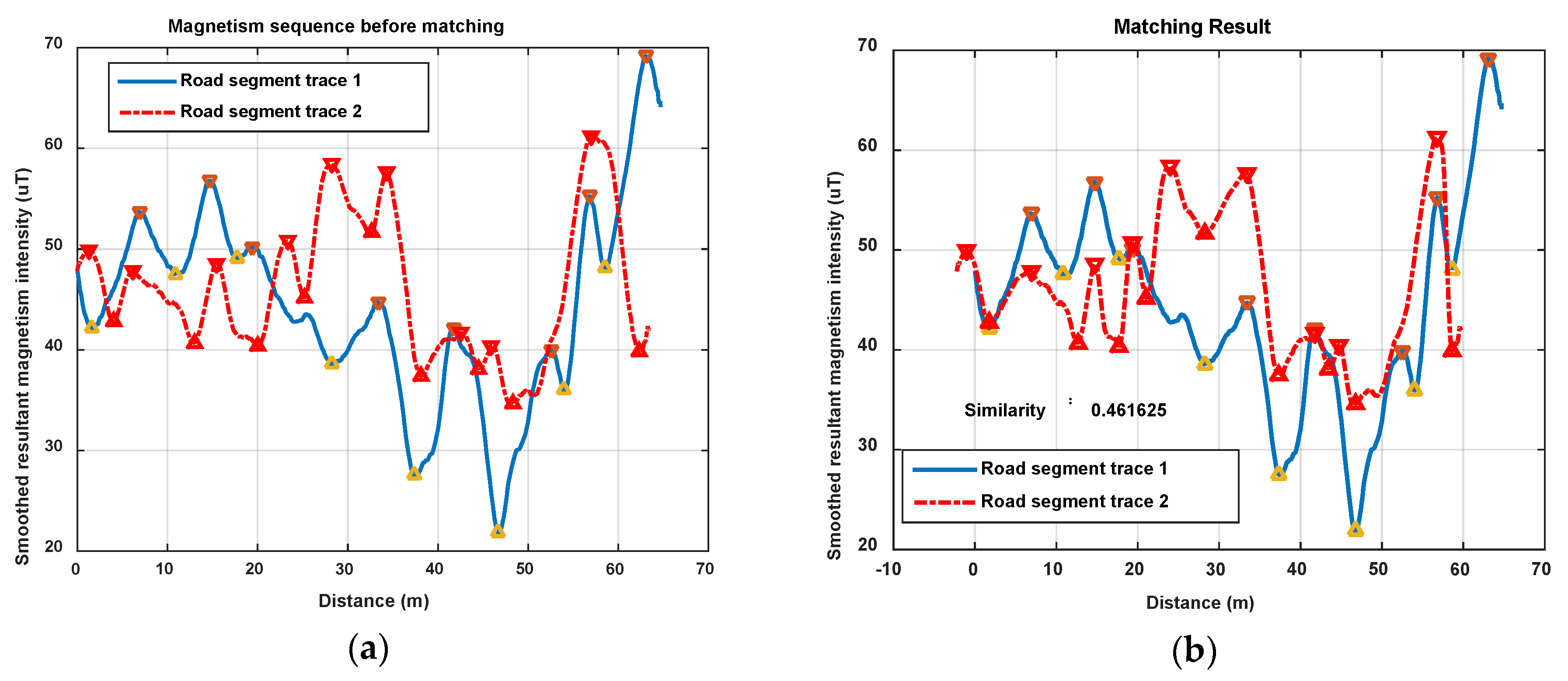{kind=link}
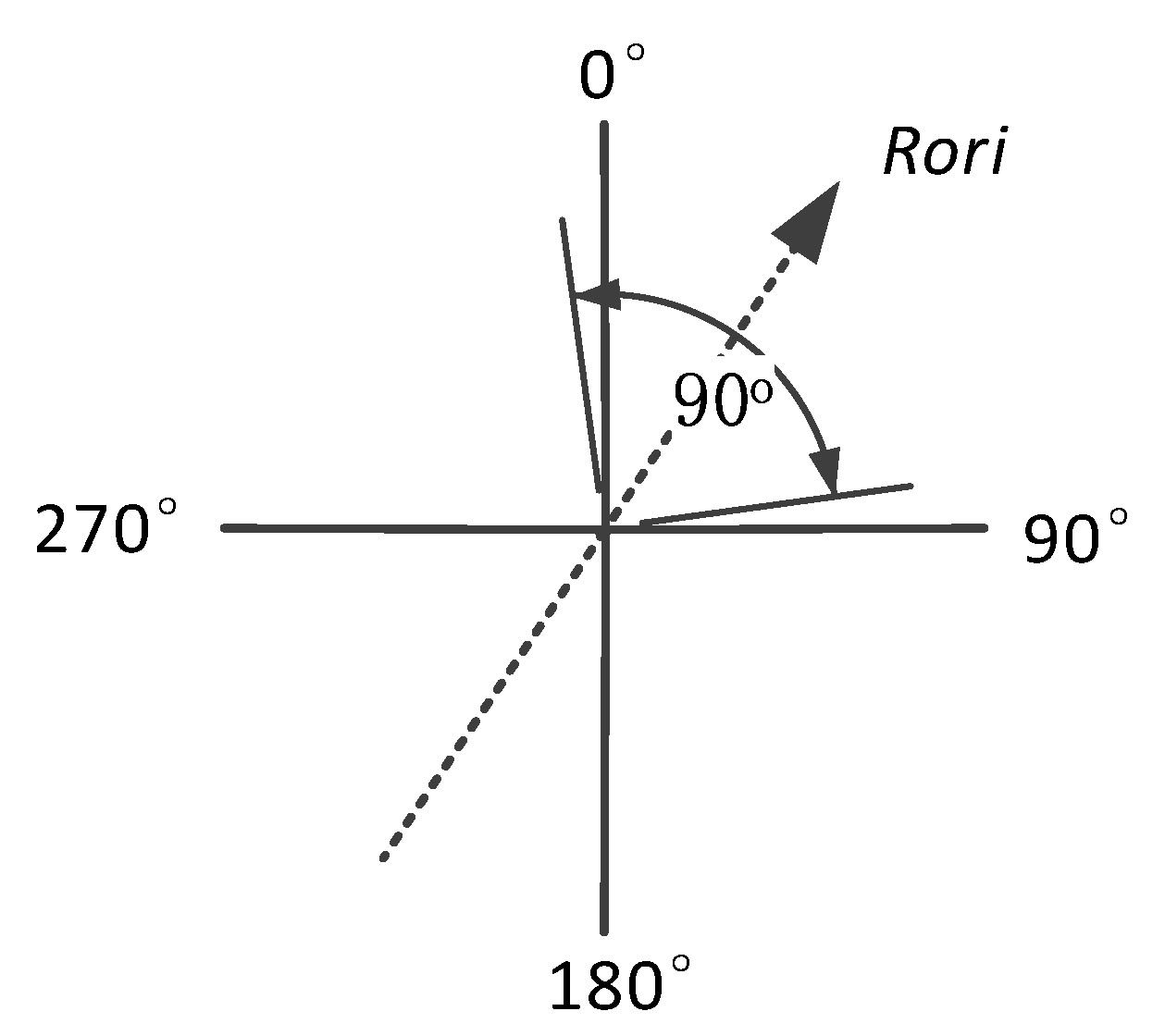{kind=link}
{kind=link}
{kind=link}
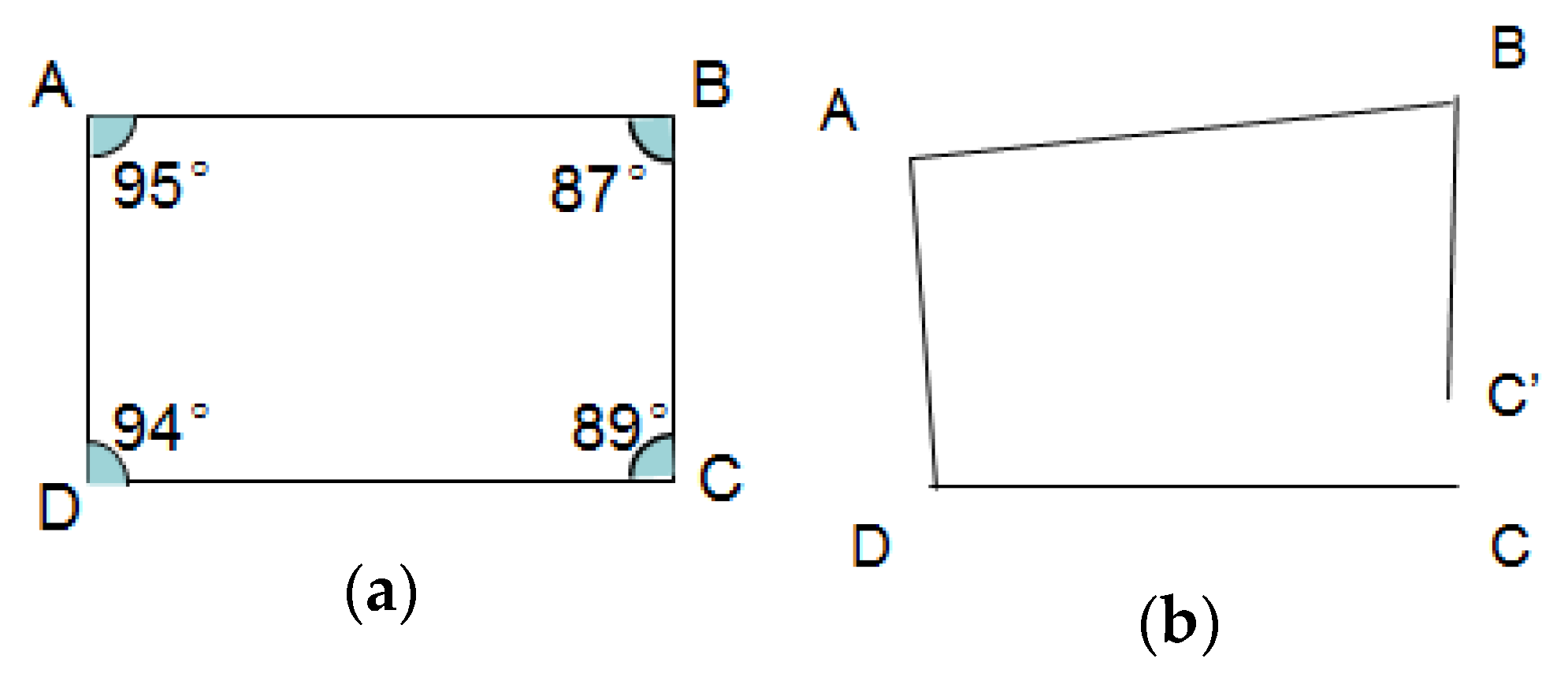{kind=link}
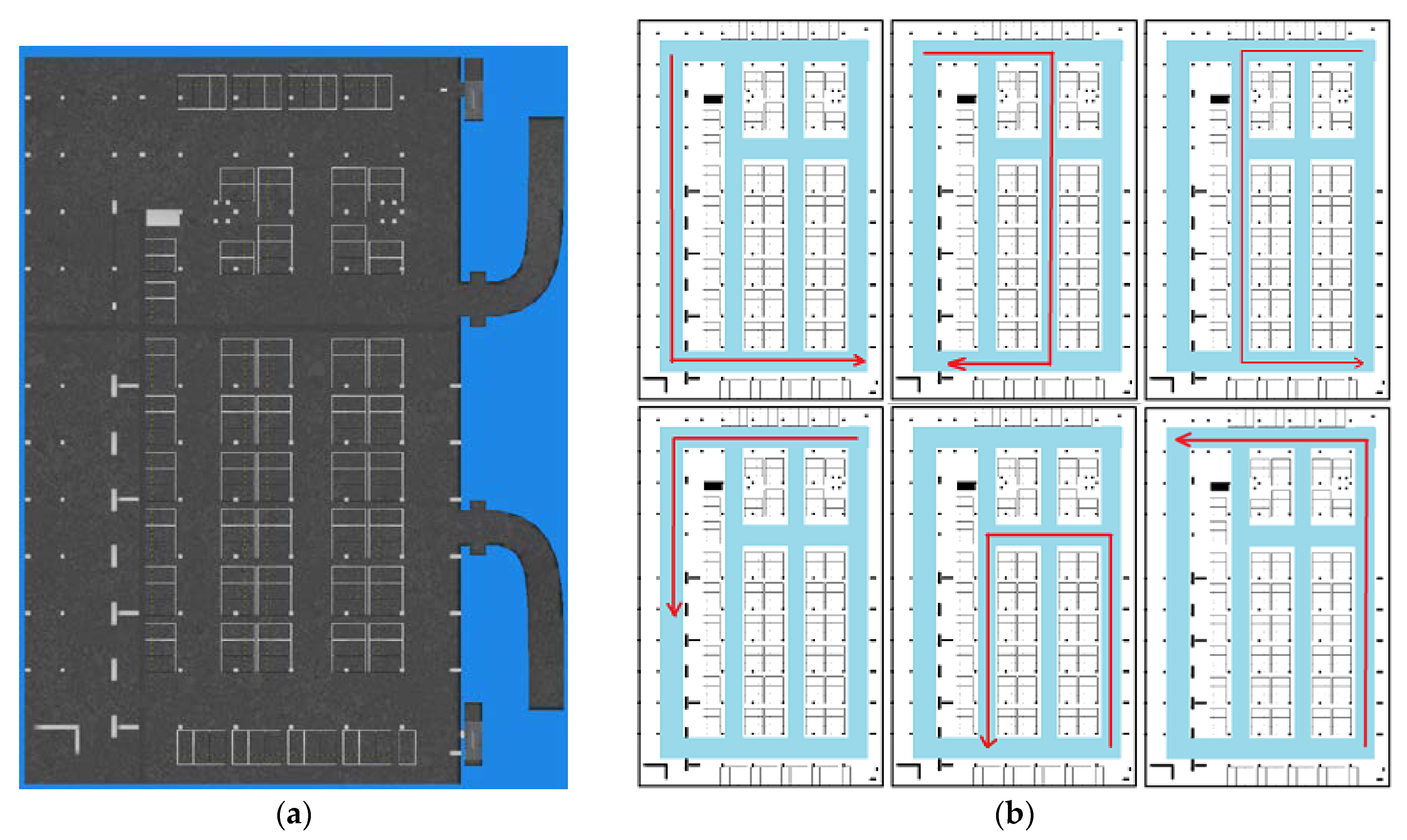{kind=link}
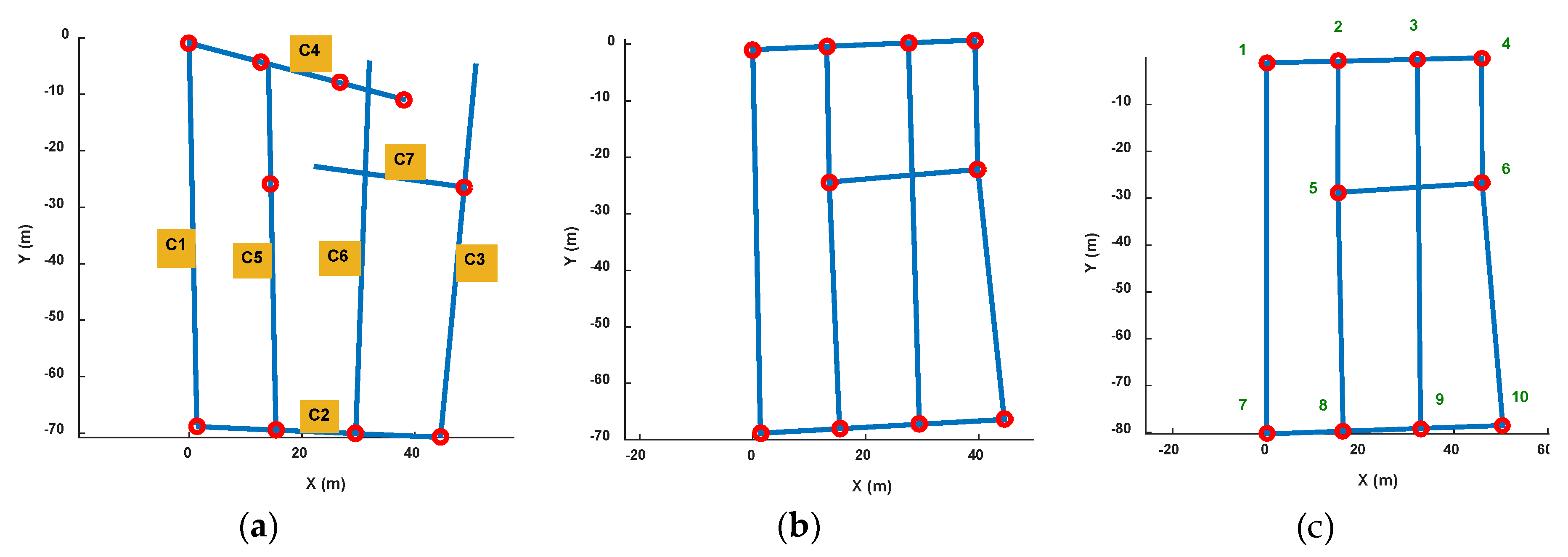{kind=link}
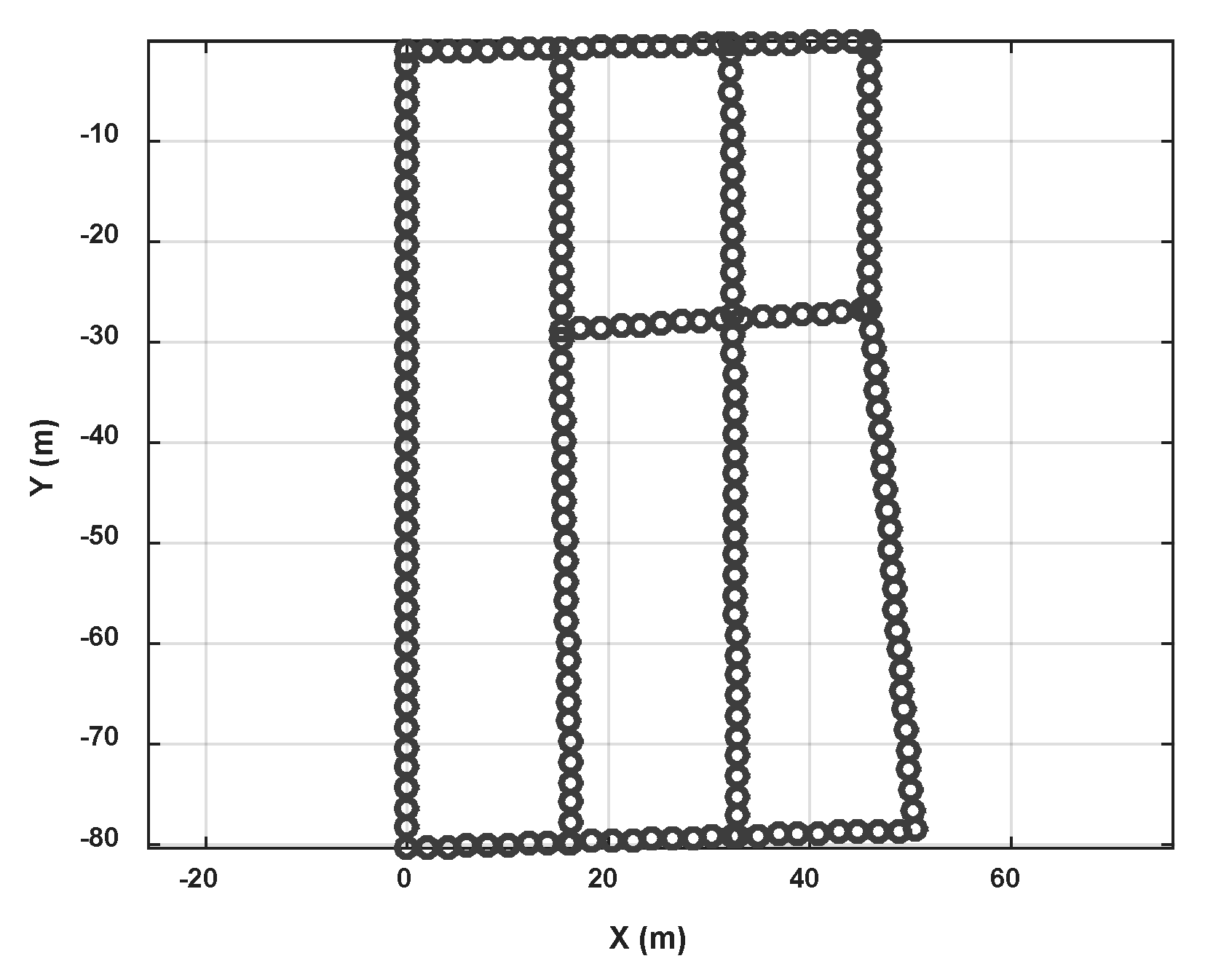{kind=link}
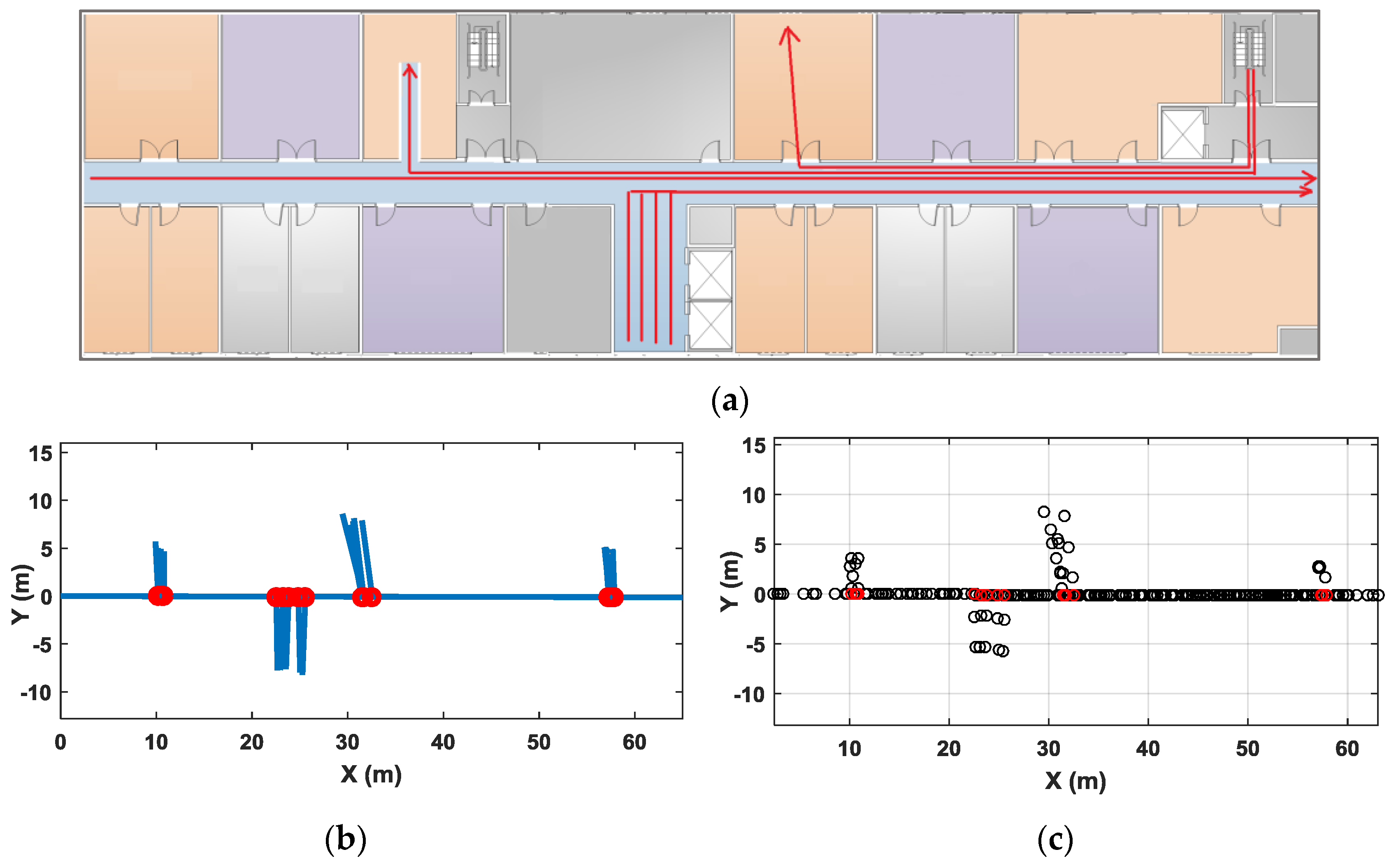{kind=link}
{kind=link}
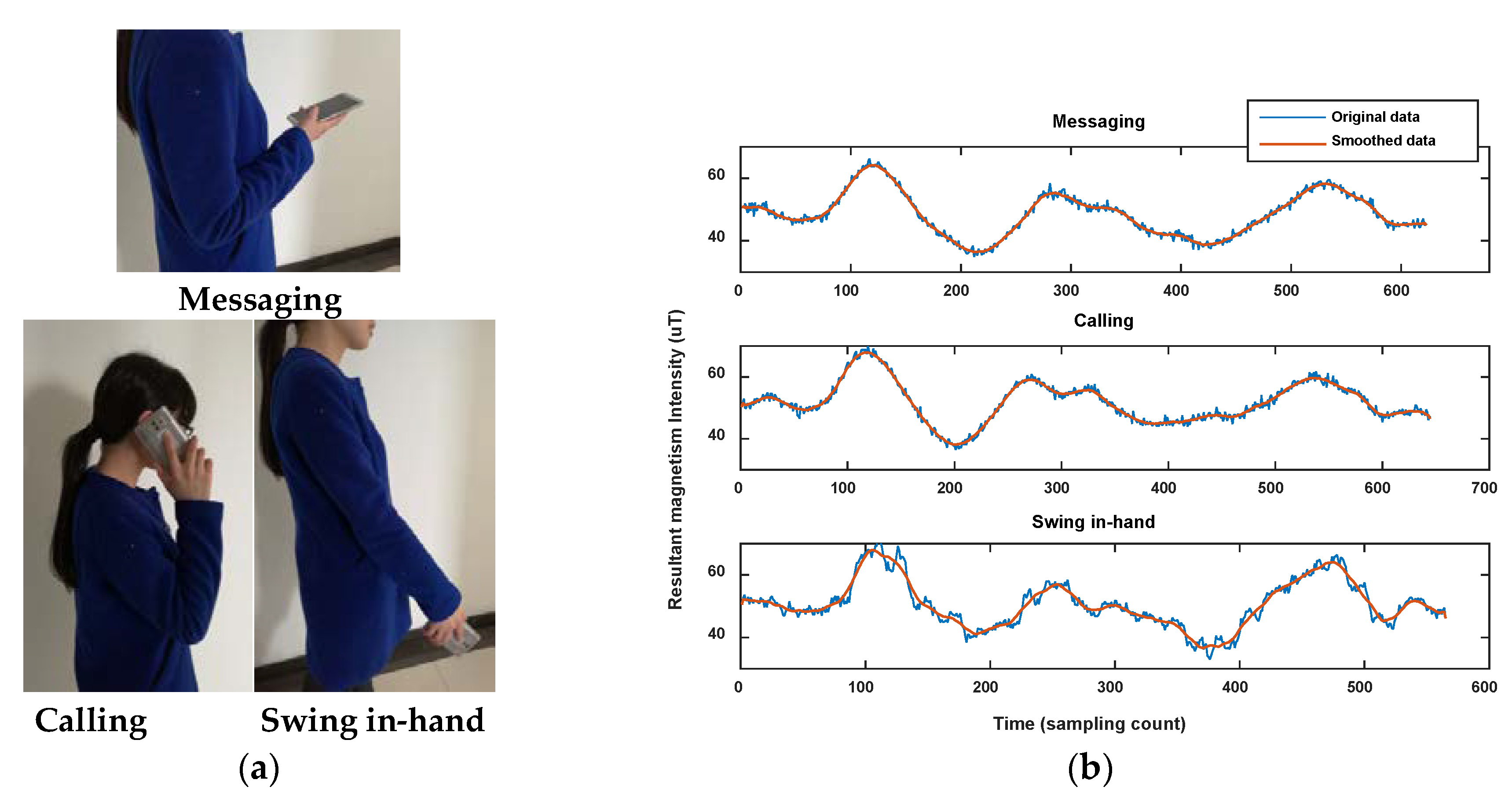{kind=link}
Table 1.
Comparison of fingerprint localization methods without site surveys via passive crowdsourcing data.
Table 1.
Comparison of fingerprint localization methods without site surveys via passive crowdsourcing data.
| Method | Floor Plan | Assistant Sensors | Reported Accuracy |
|---|---|---|---|
| WILL [22] | with | Acc. | Average 86% (room-level) |
| Wang [23] | with | None | 95% (subarea-level) |
| Zee [24] | with | Acc., gyro., comp. | 1.2 m (50%), 2.3 m (80%) |
| RACC [25] | with | Acc., gyro., comp. | 1.7 m (50%), 2.2 m (80%) (fingerprint density: 1 m) |
| 2.9 m (50%), 4.3 m (80%) (fingerprint density: 2 m) | |||
| RCILS [26] | with | Acc., gyro., mag., bar. | Median error ~1.6 m |
| PiLoc [15] | without | Acc., gyro., comp. | Average 1.5 m |
Table 2.
Road segment clustering result using C-neighborhood DBSCAN.
| Number of Test Traces | Number of Corridors | Number of Obtained Clusters | Number of Correct Clustering Traces | Number of Incorrect Clustering Traces | Correct Ratio | Incorrect Ratio |
|---|---|---|---|---|---|---|
| 100 | 5 | 9 | 100 | 0 | 100% | 0 |
Table 3.
Different pedestrians who collected crowdsourcing data in our experiment.
| Height/cm | Weight/kg | |
|---|---|---|
| Pedestrian 1 | 172 | 68 |
| Pedestrian 2 | 168 | 75 |
| Pedestrian 3 | 155 | 55 |
| Pedestrian 4 | 180 | 75 |
Table 4.
Distance errors of vertex points in the constructed pathway map.
| Vertex ID | Error/m | Vertex ID | Error/m |
|---|---|---|---|
| 1 | 1.0982 | 6 | 0.8173 |
| 2 | 0.7739 | 7 | 0.3158 |
| 3 | 1.4769 | 8 | 0.8829 |
| 4 | 0.0548 | 9 | 2.2865 |
| 5 | 2.8184 | 10 | 4.6869 |
Table 5.
Results comparison with method proposed by other researchers.
| Method | Floor Plan | Assistant Sensors | Reported Accuracy |
|---|---|---|---|
| Zee [24] | with | Acc., gyro., comp. | 1.2 m (50%), 2.3 m (80%) |
| RACC [25] | with | Acc., gyro., comp. | 2.9 m (50%), 4.3 m (80%) |
| PiLoc [15] | without | Acc., gyro., comp. | Average 1.5 m |
| This paper | without | Acc., gyro., comp., mag. | 1.8 m (50%) and 5 m (70%) |
Table 6.
Calculated similarities between seven test traces.
| Trace 1 | Trace 2 | Trace 3 | Trace 4 | Trace 5 | Trace 6 | Trace 7 | |
|---|---|---|---|---|---|---|---|
| Trace 1 | 1 | 0.9577 | 0.8982 | 0.8610 | 0.7445 | 0.6791 | 0.6979 |
| Trace 2 | 0.9577 | 1 | 0.9517 | 0.9162 | 0.8502 | 0.6595 | 0.7100 |
| Trace 3 | 0.8809 | 0.9517 | 1 | 0.9690 | 0.9205 | 0.5916 | 0.7929 |
| Trace 4 | 0.8603 | 0.9162 | 0.9690 | 1 | 0.9603 | 0.6744 | 0.6795 |
| Trace 5 | 0.7445 | 0.8502 | 0.9205 | 0.9603 | 1 | 0.6261 | 0.6002 |
| Trace 6 | 0.6941 | 0.6595 | 0.7118 | 0.6744 | 0.7339 | 1 | 0.6751 |
| Trace 7 | 0.7191 | 0.7100 | 0.7829 | 0.7839 | 0.7614 | 0.6751 | 1 |
Table 7.
Calculated similarities between three test traces collected using different poses.
| Trace 1 | Trace 2 | Trace 3 | |
|---|---|---|---|
| Trace 1 | 1 | 0.9531 | 0.9537 |
| Trace 2 | 0.9531 | 1 | 0.8632 |
| Trace 3 | 0.9537 | 0.8632 | 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, W.; Wei, D.; Lai, Q.; Li, X.; Yuan, H. Geomagnetism-Aided Indoor Wi-Fi Radio-Map Construction via Smartphone Crowdsourcing. Sensors 2018, 18, 1462. https://doi.org/10.3390/s18051462
AMA Style
Li W, Wei D, Lai Q, Li X, Yuan H. Geomagnetism-Aided Indoor Wi-Fi Radio-Map Construction via Smartphone Crowdsourcing. Sensors. 2018; 18(5):1462. https://doi.org/10.3390/s18051462
Chicago/Turabian StyleLi, Wen, Dongyan Wei, Qifeng Lai, Xianghong Li, and Hong Yuan. 2018. "Geomagnetism-Aided Indoor Wi-Fi Radio-Map Construction via Smartphone Crowdsourcing" Sensors 18, no. 5: 1462. https://doi.org/10.3390/s18051462
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.