Learning Perfectly Secure Cryptography to Protect Communications with Adversarial Neural Cryptography

 , , , and
, , , and 
Abstract
:1. Introduction
2. Related Work
2.1. Neural Cryptography
2.2. Adversarial Neural Cryptography
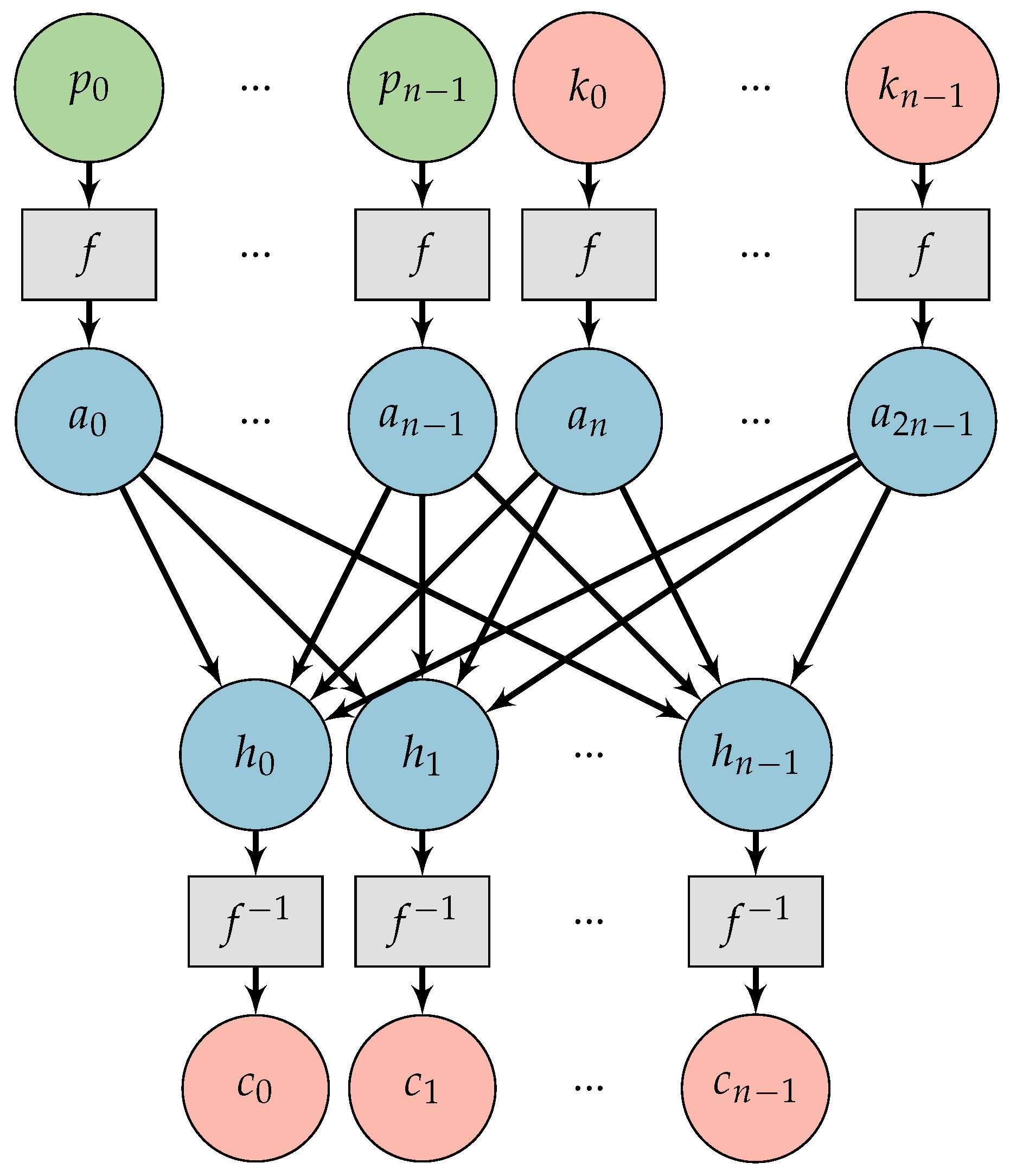
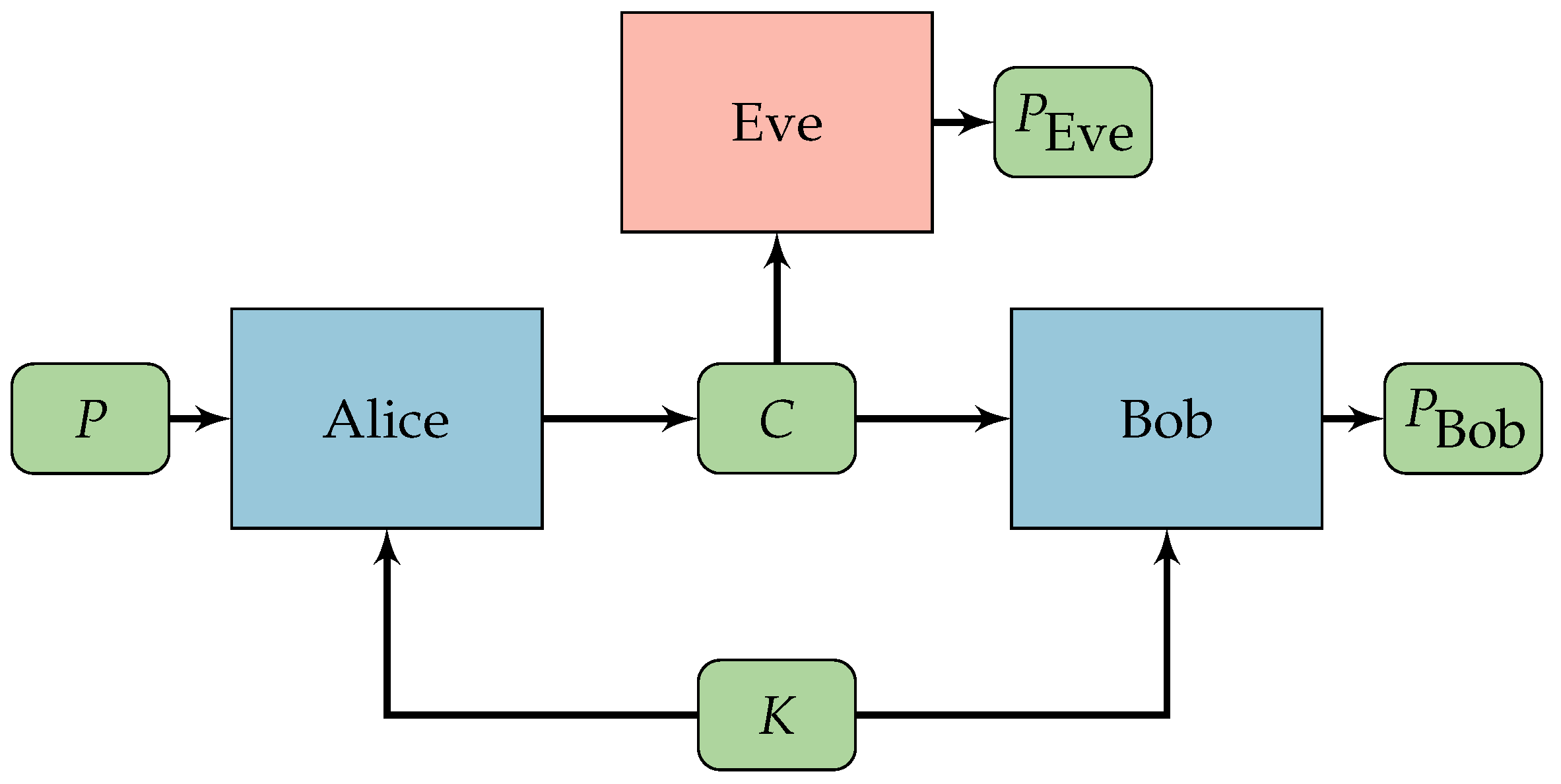
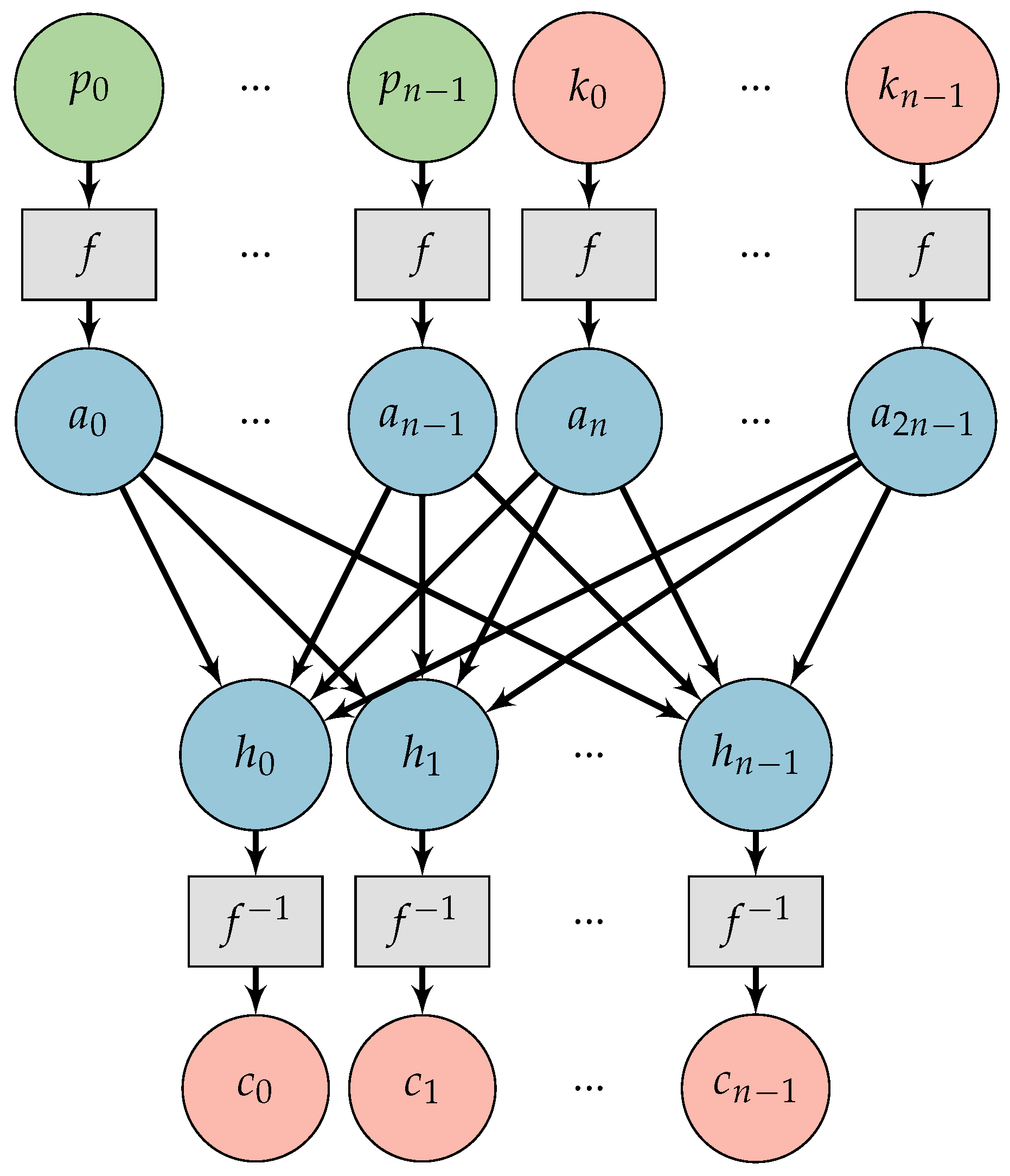
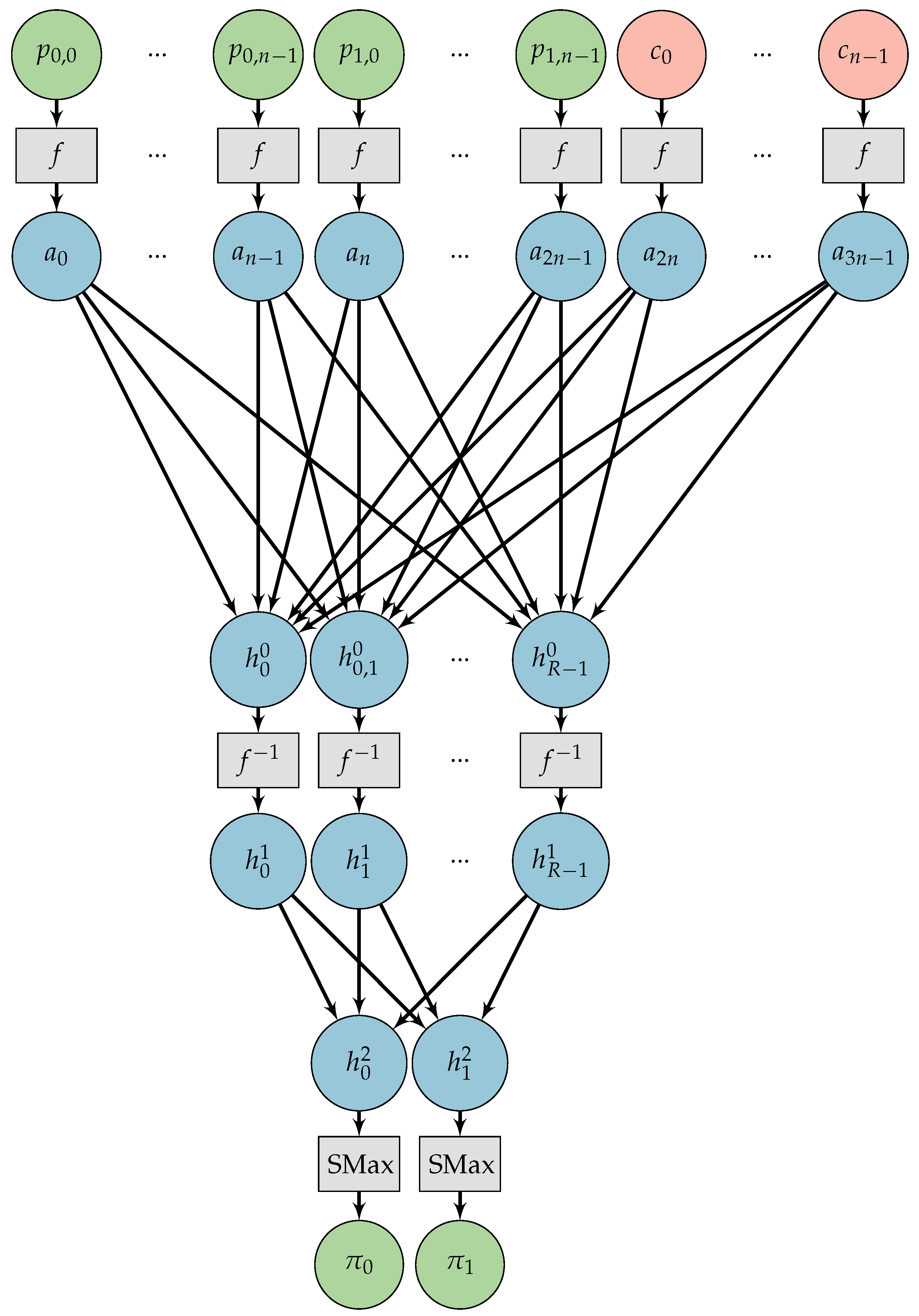
2.2.1. System Organization
2.2.2. Methodology
2.2.3. Training
3. Improvement to the ANC Methodology
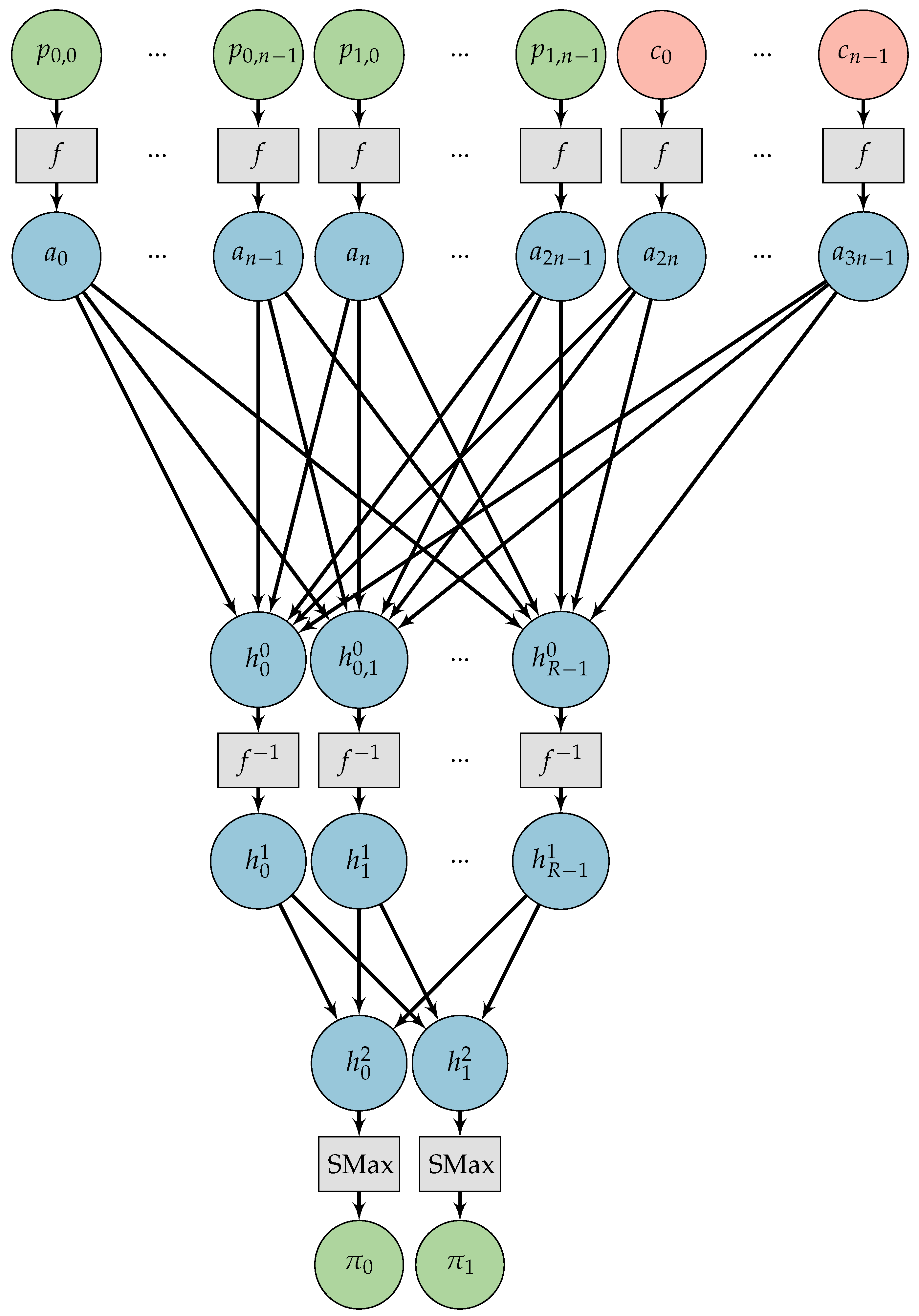
3.1. Chosen-Plaintext Attack Adversarial Neural Cryptography
3.2. A Simple Neural Network Capable of Learning the One-Time Pad
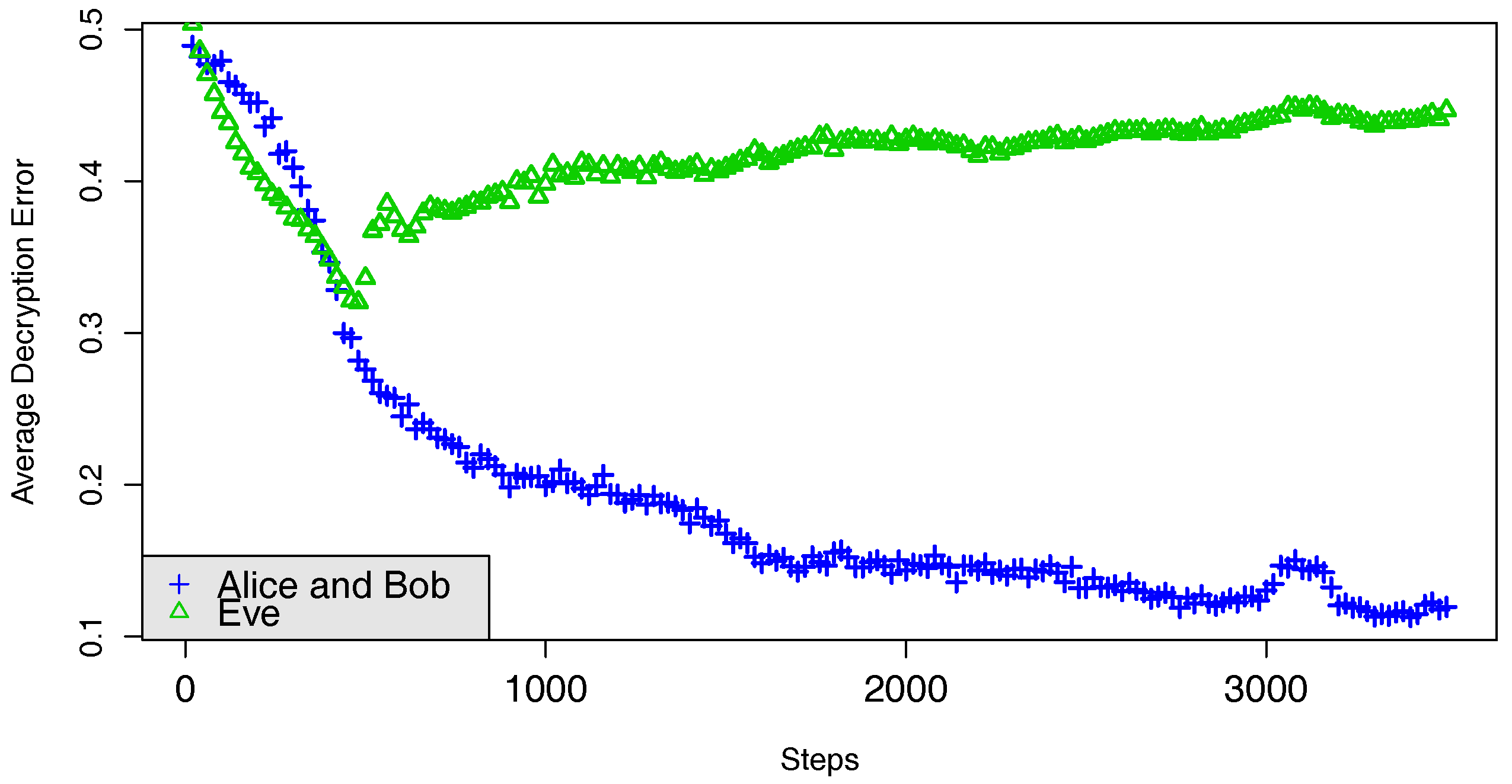
4. Results
4.1. Method
- If the decryption error of Bob is very close to zero and Eve’s attack are as bad as random guesses, then we stop. In this case, we say we had convergence or a success.
- If the first stop criterion is not reached in 100.000 rounds, we stop. Here a round is completed when Alice and Bob are trained and then Eve is trained. If this happens we say we did not have convergence or a failure.
| Algorithm 1: Testing a discrete CryptoNet |
 |
4.2. Training without an Adversary
4.3. Training the network with Adversarial Neural Cryptography
4.4. Learning the One-Time Pad
5. Comparison with Related Work
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANC | Adversarial Neural Cryptography |
| OTP | One-Time Pad |
| CPA | Chosen-Plaintext Attack |
| NN | Neural Networks |
| PRNG | pseudo-random number generators |
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv, 2016; arXiv:1604.07316. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354. [Google Scholar] [CrossRef] [PubMed]
- Kanter, I.; Kinzel, W.; Kanter, E. Secure exchange of information by synchronization of neural networks. arXiv, 2002; arXiv:cond-mat/0202112. [Google Scholar]
- Lian, S.; Chen, G.; Cheung, A.; Wang, Z. A chaotic-neural-network-based encryption algorithm for JPEG2000 encoded images. Lect. Notes Comput. Sci. 2004, 3174, 627–632. [Google Scholar]
- Yu, W.; Cao, J. Cryptography based on delayed chaotic neural networks. Phys. Lett. A 2006, 356, 333–338. [Google Scholar] [CrossRef]
- Wang, X.Y.; Yang, L.; Liu, R.; Kadir, A. A chaotic image encryption algorithm based on perceptron model. Nonlinear Dyn. 2010, 62, 615–621. [Google Scholar] [CrossRef]
- Klimov, A.; Mityagin, A.; Shamir, A. Analysis of neural cryptography. In Advances in Cryptology— ASIACRYPT 2002, Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Queenstown, New Zealand, 1–5 December 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 288–298. [Google Scholar]
- Li, C. Cryptanalyses of Some Multimedia Encryption Schemes. Master’s Thesis, Zhejiang University, Hangzhou, China, May 2005. [Google Scholar]
- Qin, K.; Oommen, B.J. On the cryptanalysis of two cryptographic algorithms that utilize chaotic neural networks. Math. Probl. Eng. 2015, 2015, 9. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, C.; Li, Q.; Zhang, D.; Shu, S. Breaking a chaotic image encryption algorithm based on perceptron model. Nonlinear Dyn. 2012, 69, 1091–1096. [Google Scholar] [CrossRef]
- Abadi, M.; Andersen, D.G. Learning to protect communications with adversarial neural cryptography. arXiv, 2016; arXiv:1610.06918. [Google Scholar]
- Shannon, C.E. Communication theory of secrecy systems. Bell Labs Techn. J. 1949, 28, 656–715. [Google Scholar] [CrossRef]
- Katz, J.; Lindell, Y. Introduction to Modern Cryptography; Chapman & Hall: London, UK, 2007. [Google Scholar]
- Desai, V.; Deshmukh, V.; Rao, D. Pseudo random number generator using Elman neural network. In Proceedings of the IEEE Recent Advances in Intelligent Computational Systems (RAICS), Trivandrum, India, 22–24 September 2011; pp. 251–254. [Google Scholar]
- Desai, V.; Patil, R.; Rao, D. Using layer recurrent neural network to generate pseudo random number sequences. Int. J. Comput. Sci. Issues 2012, 9, 324–334. [Google Scholar]
- Yayık, A.; Kutlu, Y. Improving Pseudo random number generator using artificial neural networks. In Proceedings of the IEEE 21st Signal Processing and Communications Applications Conference (SIU), Haspolat, Turkey, 24–26 April 2013; pp. 1–4. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint, 2014; arXiv:1412.6980. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 19 April 2018).
- Borges de Oliveira, F. Analytical comparison. In On Privacy-Preserving Protocols for Smart Metering Systems: Security and Privacy in Smart Grids; Springer International Publishing: Cham, Switzerland, 2017; pp. 101–110. [Google Scholar]
- Oliveira, L.B.; Pereira, F.M.Q.; Misoczki, R.; Aranha, D.F.; Borges, F.; Liu, J. The computer for the 21st century: Security privacy challenges after 25 years. In Proceedings of the 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–10. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size of Key | Number of Trials | Successful Communications | Secure Algorithm Learned (OTP) |
|---|---|---|---|
| 4-bit | 10 | 10 | 0 |
| 8-bit | 10 | 10 | 0 |
| 16-bit | 10 | 10 | 0 |
| Size of Key | Number of Trials | Successful Communications | Secure Algorithm Learned (OTP) |
|---|---|---|---|
| 4-bit | 20 | 20 | 2 |
| 8-bit | 20 | 18 | 2 |
| 16-bit | 20 | 11 | 0 |
| Size of Key | Number of Trials | Successful Communications | Secure Algorithm Learned (OTP) |
|---|---|---|---|
| 4-bit | 20 | 19 | 19 |
| 8-bit | 20 | 20 | 20 |
| 16-bit | 20 | 20 | 19 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coutinho, M.; De Oliveira Albuquerque, R.; Borges, F.; García Villalba, L.J.; Kim, T.-H. Learning Perfectly Secure Cryptography to Protect Communications with Adversarial Neural Cryptography. Sensors 2018, 18, 1306. https://doi.org/10.3390/s18051306
Coutinho M, De Oliveira Albuquerque R, Borges F, García Villalba LJ, Kim T-H. Learning Perfectly Secure Cryptography to Protect Communications with Adversarial Neural Cryptography. Sensors. 2018; 18(5):1306. https://doi.org/10.3390/s18051306
Chicago/Turabian StyleCoutinho, Murilo, Robson De Oliveira Albuquerque, Fábio Borges, Luis Javier García Villalba, and Tai-Hoon Kim. 2018. "Learning Perfectly Secure Cryptography to Protect Communications with Adversarial Neural Cryptography" Sensors 18, no. 5: 1306. https://doi.org/10.3390/s18051306