Defocus Blur Detection and Estimation from Imaging Sensors

School of Computer Science and Technology, Xidian University, Xi’an 710071, Shannxi, China
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(4), 1135; https://doi.org/10.3390/s18041135
Submission received: 10 March 2018
/
Revised: 30 March 2018
/
Accepted: 31 March 2018
/
Published: 8 April 2018
(This article belongs to the Special Issue Sensors Signal Processing and Visual Computing)
Abstract
:Sparse representation has been proven to be a very effective technique for various image restoration applications. In this paper, an improved sparse representation based method is proposed to detect and estimate defocus blur of imaging sensors. Considering the fact that the patterns usually vary remarkably across different images or different patches in a single image, it is unstable and time-consuming for sparse representation over an over-complete dictionary. We propose an adaptive domain selection scheme to prelearn a set of compact dictionaries and adaptively select the optimal dictionary to each image patch. Then, with nonlocal structure similarity, the proposed method learns nonzero-mean coefficients’ distributions that are much more closer to the real ones. More accurate sparse coefficients can be obtained and further improve the performance of results. Experimental results validate that the proposed method outperforms existing defocus blur estimation approaches, both qualitatively and quantitatively.
1. Introduction
Blur is an image degradation that commonly appears in consumer-level images obtained from a variety of image sensors [1,2,3,4]. Defocus blur is one type of blur degradation that results from defocus and improper depth of focus. For scenes with multiple depth layers, however, only the layer on a focal plane will focus on the camera sensor, which leads to others being out of focus. This phenomenon may sometimes strengthen a photo’s expressiveness, while, in most cases, it will lead to loss of texture details or incomprehensible information. In many scenarios, detecting and estimating the blur pixels can benefit a variety of image applications including but not restricted to image deblurring, image segmentation, depth estimation, objection recognition, scene classification and image quality assessment.
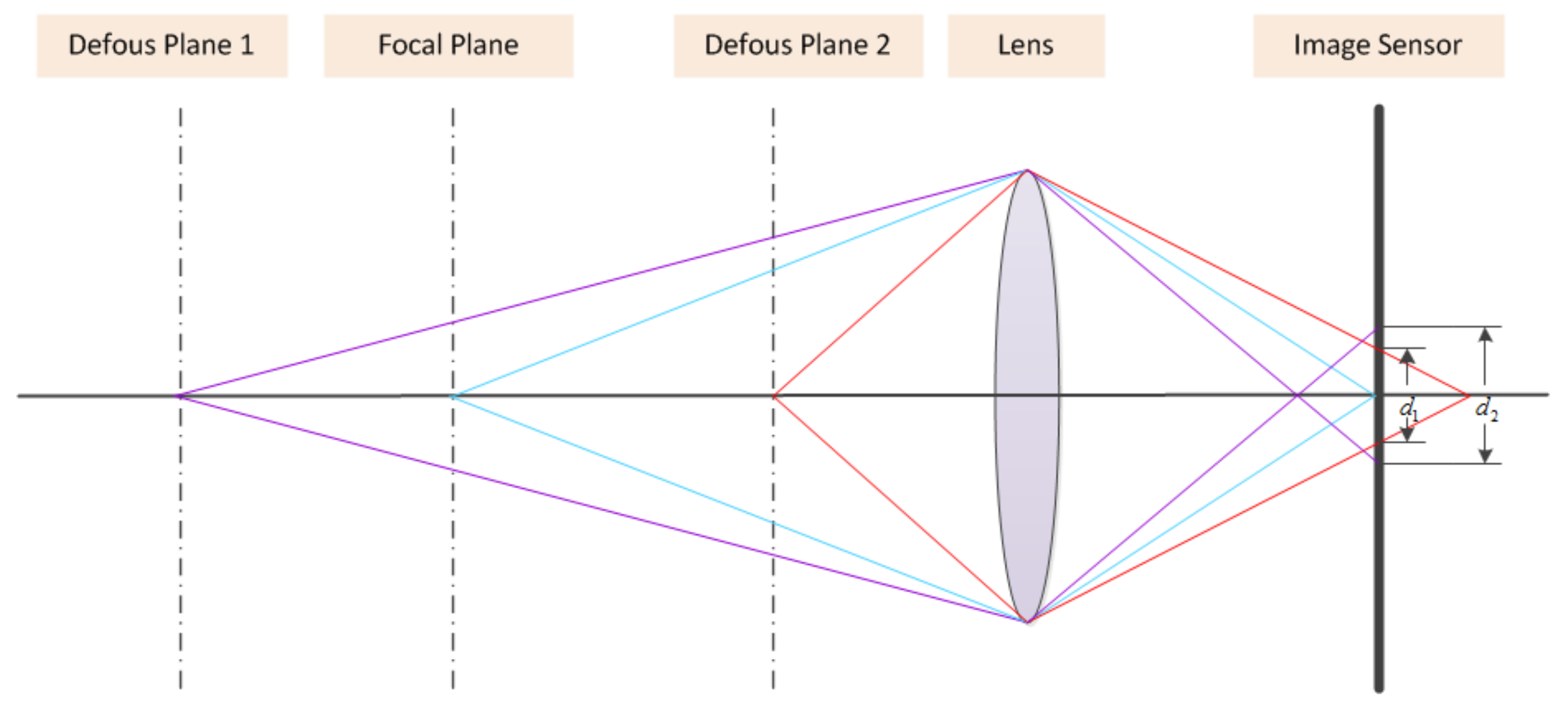
Assume that the defocus process can be modeled as a thin lens imaging system. Figure 1 illustrates the focus and defocus processes. Only the rays emitting from a focal plane will converge to a single point on a sensor plane and a sharp scene will appear, while the rays emitting from other planes will reach different points on a sensor plane and form circle regions. The circle region is called the circle of confusion (CoC) that results in defocus blur. From Figure 1, it is easy to verify that the larger the distance between the focal plane and the non-focal plane is, the greater the strength of defocus.
A number of methods for image blur analysis have been recently proposed; however, most of them focus on solving deblurring problems. On the contrary, there are a limited number of methods to explore defocus blur detection and estimation and the application is still far from practical. They assume that the defocus blur caused by multiple depth layers can be modeled by a latent image convolving with a spatial-variant kernel. In addition, the spatial-variant kernel is commonly assumed to be a disk or a Gaussian kernel. Therefore, the estimation of defocus blur map can be regarded as a deconvolution task. Cheong et al. [5] modeled a defocus blur kernel to be a Gaussian point-spread-function (PSF) and proved the amount of blur depends on the squared variance of the Gaussian PSF. In this method, the blur amount can be calculated from the first and second order derivatives. Oliveira et al. [6] defined the out-of-focus as a uniform disk kernel. This method is based on the assumption that the defocus blur kernel is characterized by its radius and can be provided by parametric models for each pixel efficiently. Zhang et al. [7] supposed that the defocus blur kernel to be a Gaussian function with standard and estimated the blur map by utilizing edges information. Then, a full blur map can be generated by utilizing a K nearest neighbors (KNN) matting method. The performances of these methods relay heavily on the accuracy of the PSFs, which is a challenging task in practical application.
There have been a series of methods proposed to handle a defocus blur problem. Conventional methods deal with defocus blur by utilizing a set of images of the same scene [8,9]. Using multiple focus settings, the defocus blur can be estimated during a deblurring process. Levin et al. [10] proposed modifying the aperture of the camera lens by inserting a patterned occluder so that they can recover a refocus image from a single input defocus image. Zhou et al. [11] used two coded apertures to complement each other and obtained a batter defocus blur measure for the two captured images. Xiao et al. [12] estimated a defocus blur kernel and restored a sharp image from time-of-flight depth camera. However, all of these methods require additional information or additional equipment that limit their applications in practice.
Since the level of defocus blur is intimately related with depth variation, depth information is of great value to defocus blur detection and estimation. A number of recently introduced methods aim at obtaining high quality in-focus images via scene depth from a single input image. Hu et al. [13] estimated and removed defocus blur from single images by utilizing depth estimation. However, the fine performance depended on the precisely separated depth layers and preassigned average depth of each layer, which may engender high computational cost and estimation error. Xiao et al. [12] proposed a joint optimization problem based on a model that the spatial-varying defocus blur kernel can be calculated for a given depth map. In this method, the defocus blur kernel matrix can be updated according to a currently estimated depth map.
In recent years, a variety of gradient and frequency based methods have been proposed to handle defocus blur analysis [14,15,16,17,18]. Elder and Zuker [19] firstly proposed a method for local blur estimation by utilizing the first and second order gradient information. Then, numerous methods have been proposed to detect and estimate defocus blur. Gradient-based methods [20,21,22] relied on a heavy-tailed distribution, which can be interpreted as an observation that the gradient distribution in a clear region should have more primarily small or zero gradient magnitudes. Frequency based methods [22,23] modeled defocus blur analysis exploiting the fact that the blur process decreases high-frequency components. Liu et al. [22] developed spectrum information and several blur features to classify blur images. Combining with the spectral and spatial domains, the method [24] utilized local power spectrum slope and total variation to assess image sharpness and estimate defocus blur. In [25], Shi et al. addressed the blur detection problem by constructing a combination of three local blur feature representations including image gradient distribution, Fourier domain descriptor, and local filters. Then, the blur map is formed in a discriminative way by utilizing a naive Bayesian classifier.
Sparse representation [26,27,28,29] has been known to be a very powerful statistical image modeling technique and successfully used in various low level restoration tasks. Shi et al. [30] has recently proposed a just noticeable defocus blur detection (JNB) method. However, it tends to inaccurately estimate the parametric distributions for the sparse coefficients and decrease the performance of defocus blur detection and estimation.
In this paper, a new method for blur detection and analysis is proposed. First, we use the principal component analysis (PCA) [31] technique to learn a set of compact dictionary and propose an adaptive domain selection scheme for sparse representation. Second, the proposed method learns nonzero-mean parametric distributions for coefficients based on the observation that nonzero-mean I.I.D Laplacian distributions do not fit the real coefficients’ distributions. Lastly, a blur strength measurement method is presented to evaluate the degree of defocus blur. Experimental results on various images show that the proposed method achieves better results than other approaches both in visual quality and evaluating indictor.
The paper is organized as follows. Section 2 introduces the general sparse representation models. Section 3 describes the details of adaptive domain selection, coefficient distributions learning and strength estimation for defocus blur detection and estimation, respectively. In Section 4, experimental results and comparison with other approaches are presented.
2. Blur Detection Model via Sparse Coding
Sparse representation is a powerful technique that has been widely used in signal processing or image restoration tasks. Recently, most of the approaches defined that natural images can be modeled with sparse representation over an over-complete dictionary. Using an over-complete dictionary that contains dictionary atoms, an image patch can be represented as a sparse liner combination of these atoms
where is a given image patch, is an over-complete dictionary, is a coefficient vector corresponding to and is a residual vector.
As illustrated above, is an over complete dictionary, which means that . This problem becomes untraceable because many different coefficients give rise to the same . Hence, additional information is required to constrain the solutions [32]. The sparsest representation coefficient has been proposed to be the solution
or
where is a norm that counts the number of the nonzero entries of vector and is a small constant controlling the approximation error.
Equations (2) and (3) use a norm in the constraint and this induces sparsity and indicates that any signal can be described by a sparse number of dictionary atoms. However, a norm is nonconvex, which results in -minimization of an NP-hard optimization problem. Thanks to [33], it has been proved that the norm is equivalent to the norm under certain conditions. Another sparse representation based method is proposed and can be expressed as
where is a norm.
Besides the sparse coefficient, the selection of the dictionary also influences the performance of sparse representation based methods. The constructions of dictionary can be generally categorized into iteratively updating dictionary [34] and the universal one [32]. In the iteratively update construction manner, the minimizing model of Equation (4) involves simultaneously computing two variables: and . It can be solved by the alternating minimization scheme, which is commonly adopted when dealing with multiple optimization variables. In each iteration, dictionary is fixed to estimate the coefficient of each image patch
where is the coefficient at iteration and is the dictionary at iteration .
Then, in the step of updating dictionary, each atom of dictionary can be updated
where is the residual component.
In the universal construction manner, the K-SVD algorithm [32] designed a learning method based on the K-means clustering process and obtained over-complete dictionaries to achieve sparse signal representation. Given a set of training image patches, the K-SVD algorithm iteratively updates the sparse coding of the current dictionary and atoms of the dictionary.
3. Defocus Blur Detection and Estimation by Adaptive Domain Selection and Learning Parametric Distributions for Coefficients
In this section, the proposed method first presents the dictionaries learning method, which learns a series of compact dictionaries and adaptively assigns the optimal dictionary to each local patch as the sparse domain. All compact dictionaries are learned offline, and the proposed method online selects the dictionary. Then, we introduce sparse parametric distributions by nonlocal structural similarity for sparse coefficients. The improved method can be modeled as
where is a patch extracted from an input defocus image and each patch is vectorized as a column vector of size . is the optimal compact dictionary that is adaptively selected for the given patch . The training method for is described in Section 3.1. is the sparse coefficient for patch over . and denote the mean and standard derivation for , respectively. In addition, is a small constant.
3.1. Sparse Representation by Adaptive Domain Selection
The sparse representation based approaches can achieve better performance in image restoration applications. However, many sparse decomposition models rely on learning an universal and over-complete dictionary to represent all image structures. The structures and contents vary remarkably across different images or different patches in a single image and the universal dictionary cannot satisfy all circumstances for defocus blur detection via sparse representation. In addition, it has been proved that sparse decomposition over a set of highly redundant basis is potentially unstable [35]. Therefore, an improved defocus blur estimation scheme, which prelearns a set of compact dictionaries, and adaptively assigning optimal dictionary to each local patch is proposed.
In order to learn the compact dictionary set for representing image structures, we first construct a dataset of blur local image patches by collecting images slightly blurred by Gaussian kernel with standard deviation and cropped from them a rich amount of patches with size . Let be selected blurred image patches. For better training performance, only pitches whose intensity variance, denoted by , that are within the range of and , i.e., , are selected.
In order to adaptively assign a dictionary to each local patch, the proposed method learns compact dictionaries from the patch set and generate clusters from the patch set by utilizing the K-means algorithm. Then, a dictionary can be learned from each of the clusters and represent distinctive patterns by the dictionaries. Denote by the clusters and the centroid of cluster . Meanwhile, subsets are obtained by partitioning , where is a matrix of dimension of and is the number of patches in .
Now, we aim to learn a dictionary from the cluster , which indicates that all the elements in can be exactly represented by . Typically, the learning model can be formulated as
where is Frobenius norm and denotes the coefficient matrix of over dictionary . denotes a parameter that balance the relationship between the data fidelity term and the regularization term. Minimizing model of Equation (8) involves simultaneously computing two variables: and . It can be solved by the alternating minimization scheme, which is commonly adopted when dealing with multiple optimization variables.
However, utilizing Label (8) to learn the dictionary is stopped by some major issues. First, the optimizing task in Equation (8) involves simultaneously computing two variables: and , which is computational challenging and time consuming. More importantly, the result of Equation (8) is commonly assumed to be an over-complete dictionary, which is redundant in the signal representing process and may not take advantage of similar patterns after K-means clustering. Specifically, is constructed via K-means clustering and can be treated as that all elements in share the similar patterns. Therefore, we prefer a compact dictionary rather than an over-complete one.
Here, the principal component analysis (PCA) [31] is applied to each subset , so that each compact dictionary can be constructed via elements with similar pattern. Let be the co-variance matrix of subset . Then, the proposed method can obtain an orthogonal matrix by applying PCA to . For the purpose of reducing dimensionality of dictionary , only the eigenvectors corresponding to the first largest eigenvalues in are selected to form the dictionary . Denote by the constructed dictionary and let . It is obvious that a decrease of will lead to an increase of data fidelity term and a decrease of sparse term . The optimal dimension of can be determined as
In addition, is the compact dictionary corresponding to subset .
Following this procedure, all compact dictionaries from subsets can be obtained. Figure 2 shows an example of the learned dictionary from a training dataset.
With each compact dictionary learned, the proposed method can continue to assign an example to the most relevant compact dictionary in the dictionary set. Recall that the centroid is available, and the most relevant dictionary can be selected by
3.2. Learning Coefficient Distributions with Nonlocal Structural Similarity
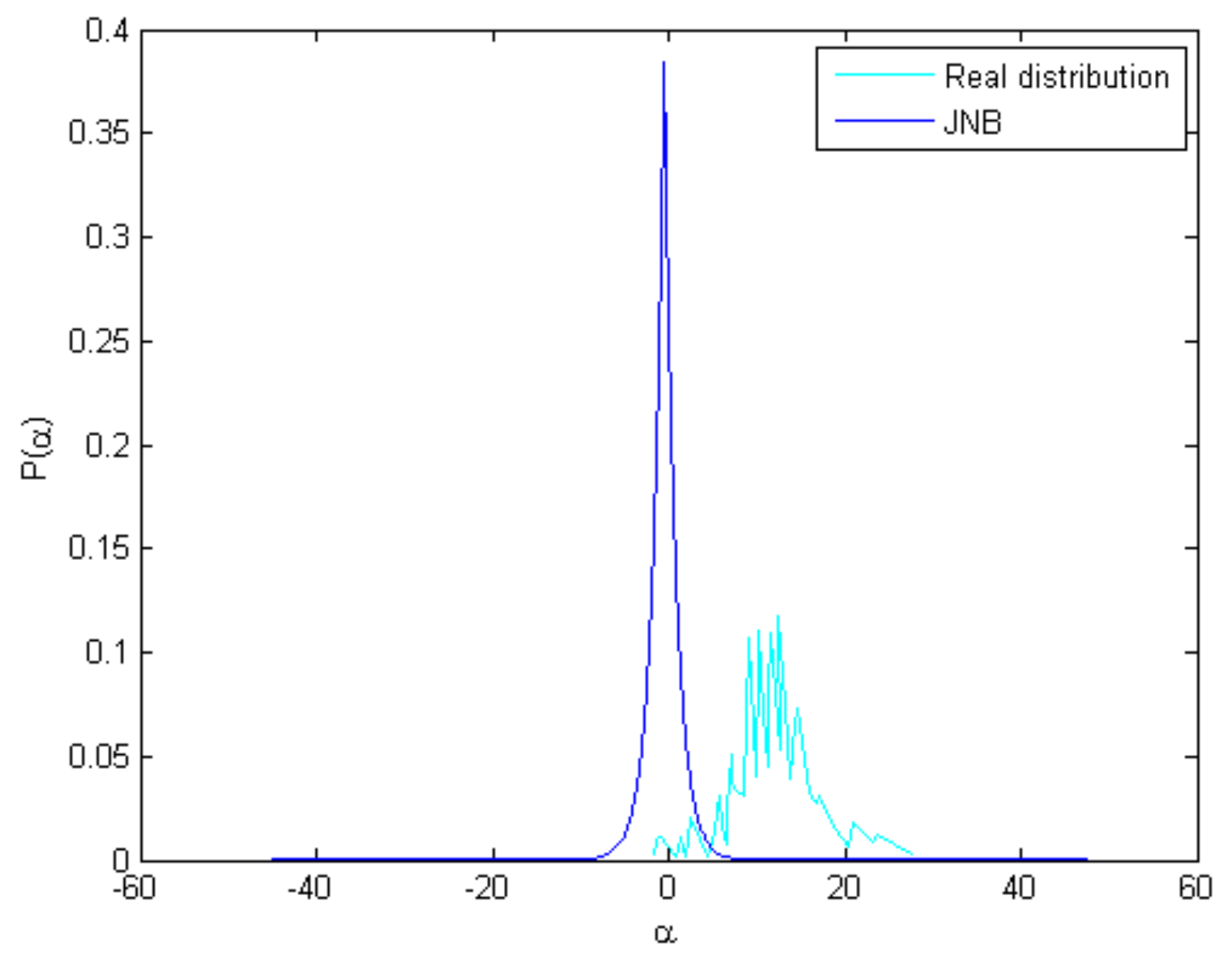
The JNB model [30] can achieve better results. However, due to the lack of nonlocal structural correlation [36], the JNB model tended to inaccurately estimate the parametric distributions for the sparse coefficients. It is easy to verify that the distribution of the common norm in Equation (4) equals an I.I.D zero-mean Laplaican distribution. Figure 3 shows the coefficients’ distributions obtained by the JNB method and real distribution of a test image. As illustrated in Figure 3, the I.I.D zero-mean Laplaican distribution can not fit the real coefficient distribution. Based on this observation, we generalise the nonlocal structural similarity and propose a nonzero-mean I.I.D Laplaican distribution to estimate the distribution of sparse coefficient for defocus blur detection.
First, the sparse model is extended based on the rich repetitive structures in blurred images. For each exemplar patch , a patch set is built via a patch matting algorithm in a larger window centered at to group patches similar to (including itself). Each column of corresponds to a patch similar to . As the patches share similar structures, hence, we characterize the sparse representation of each patch in as the same parametric distribution
where is the index from patch set . and represent the patch in patch set and the corresponding sparse coefficient, respectively. denotes the pre-trained compact dictionary that adaptively selected for , and can be obtained following Equation (10). is a small constant. and represent the mean and standard derivation, respectively.
Next, the nonlocal similar patches are used to accurately estimate the distribution parameters and . The expectation of patch is estimated by
where , wherein and denote the normalization coefficient and a predefined constant, respectively. Then, the more accurate mean is estimated as
With the grouped patch set and the mean estimated in Equation (13), the standard derivation for () can be estimated as
where , is a small positive number to ensure that is a non-zero value. Figure 4 shows the comparison of the coefficients’ distributions of the proposed method, the JNB method and the real distribution of the same test image. It is clear that the coefficients’ distributions learned by the proposed method is closer to the real distribution.
3.3. Strength Estimation for Defocus Blur
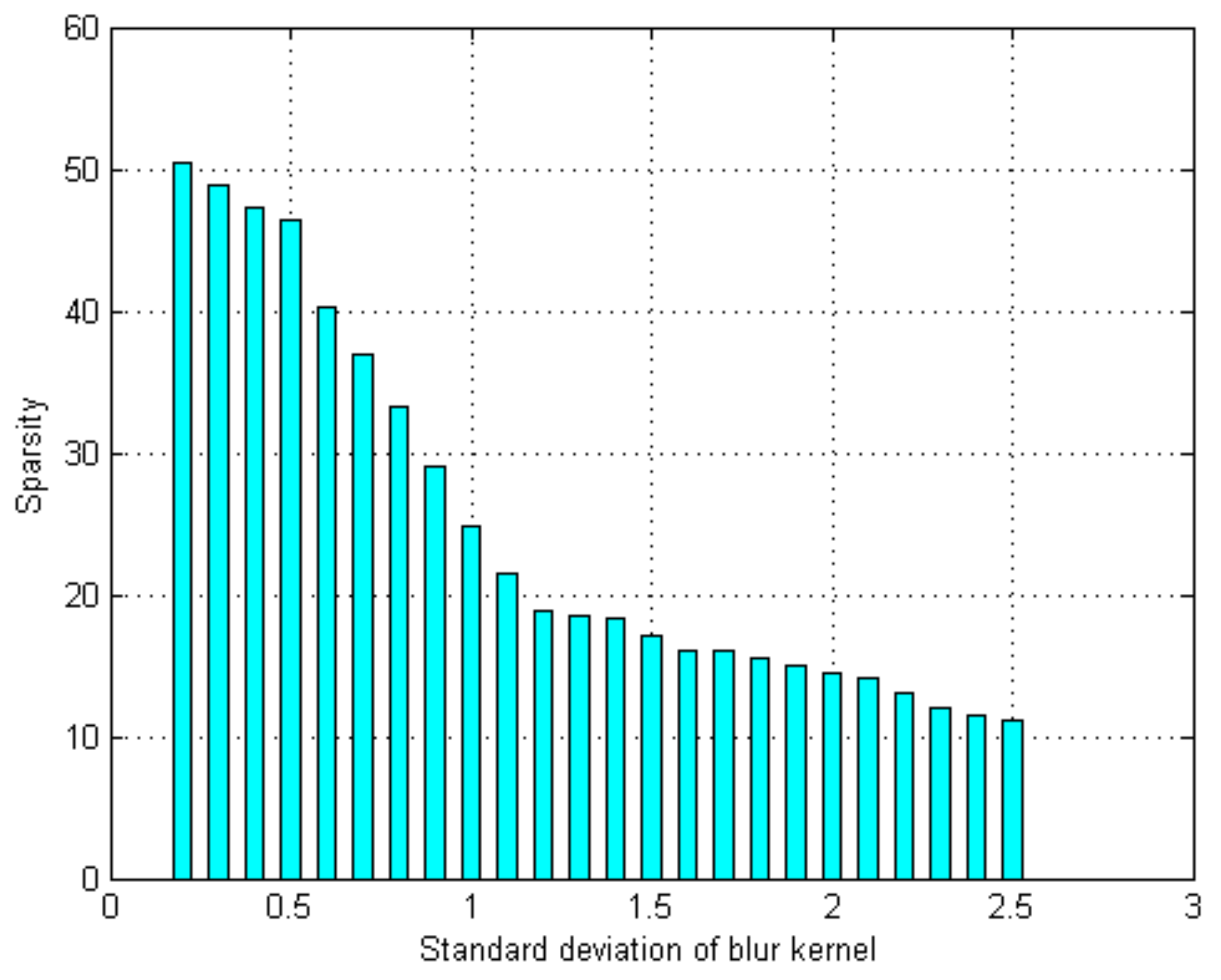
Denote by the sparse coefficient value. To estimate the strength of defocus blur, the proposed method first collects images with different blurriness levels. The images are blurred with the Gaussian kernel of standard deviation ranging from 0.2 to 2.5. Then, the statistical relationships between the sparse coefficient value and the corresponding blur standard deviation can be obtained and fitted into a logistic regression function
Figure 5 shows the statistical relationships between the sparse coefficient value and the corresponding blur standard deviation . With each sparse coefficient value calculated for an image patch, Equation (15) can be used to estimate the degree of defocus blur for each patch from a single defocus blur image.
4. Experimental Results
The performance of the proposed method was tested on defocus images dataset from [25]. The blurry regions in all tested images are masked out as ground-truth, which indicates the clear regions with respect to the defocus blur regions. In addition, the proposed method is also tested on 150 natural defocus blur images taken by consumer-level cameras or from the Internet with different defocus blur regions. Then, we compared the proposed method with several approaches including the JNB method [30], Vu’s method [24] and Shi’s method [25]. All the comparisons are performed by directly utilizing the public codes. In the experiments, each image patch is extracted with size to form a 64D vector. The compact dictionary set is learned over 125,000 patches cropped from 1250 blurry images, which blurred by a Gaussian kernel with . The parameters of the proposed algorithm are set as follows: , , = 125,000, and .
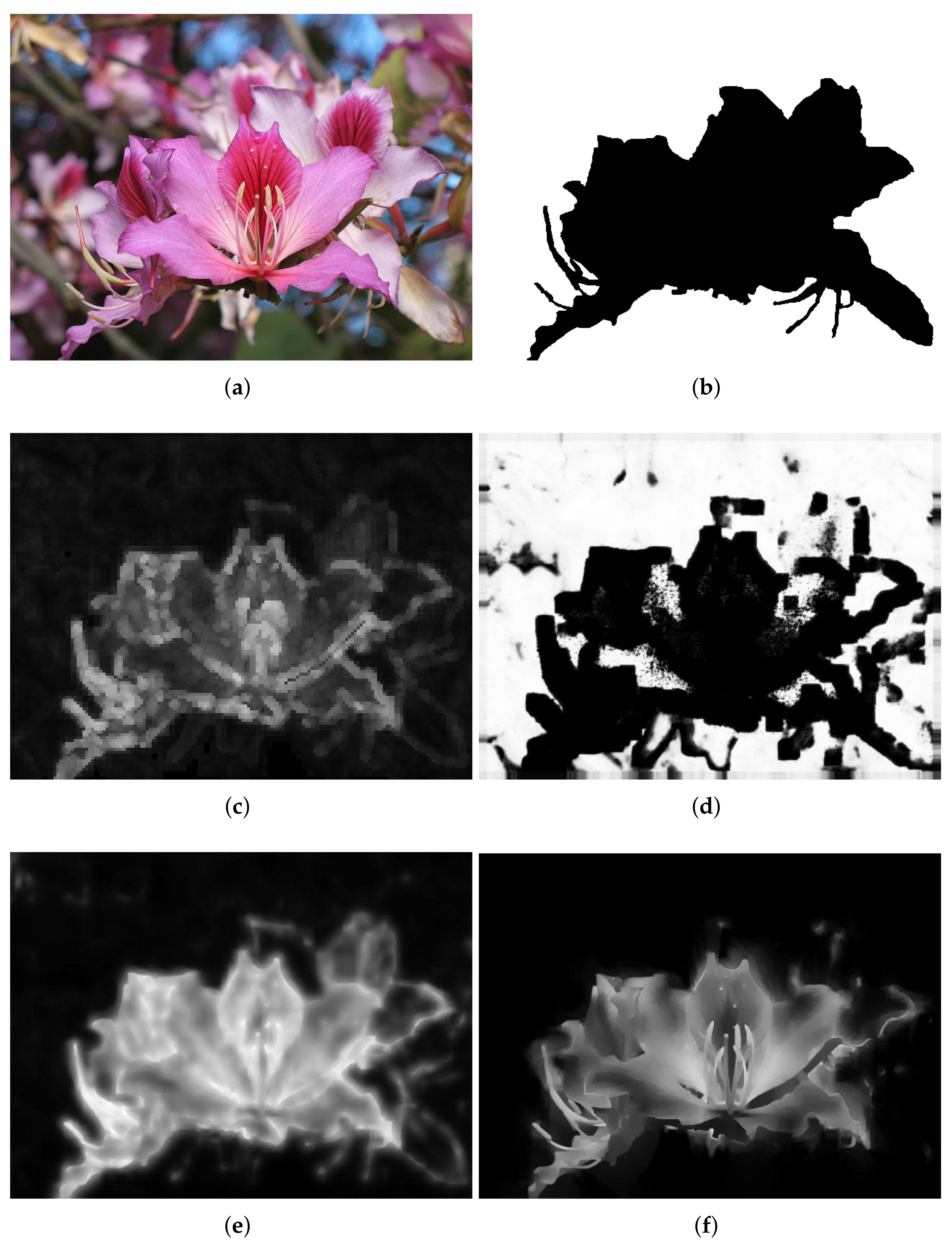
The performance of the proposed method was evaluated on the visual quality, the precision–recall (PR) and execution time. In the comparisons of visual quality, all of the compared results are normalized to [0, 1]. Figure 6 shows a set of experimental results using an input defocus blur image in which blur amount changes continuously. Vu’s method [24] combines both spectral and spatial sharpness to assess image sharpness. As shown in Figure 6c, Vu’s method [24] can roughly separate in-focus foreground from defocus background. However, it cannot handle flat regions and intends to smooth the boundaries because of total variation, such as facula and grass. Shi’s method [25] constructs a combination of three local blur feature representations including image gradient distribution, Fourier domain descriptor, and local filters. Then, the blur map is formed in a discriminative way by utilizing a naive Bayesian classifier. From Figure 6d, it shows that the results of Shi’s method [25] contain several estimation errors, which lead to a difficulty in separating the clear regions from the blur regions. In addition, a much longer processing time is required because of the combination of three local features, which cannot be satisfied in practical. Although the JNB method [30] can achieve a better result in detecting flat regions as shown in Figure 6e, it cannot detect defocus blur at strong edges’ regions and results in clear errors. The performance of the proposed method is shown in Figure 6f. The proposed method can result in much less artifacts and clear errors. Therefore, the proposed method performs better than the others both in separating clear regions from blur regions and representing details.
Experimental results for defocus blur images whose blur amounts change abruptly are shown from Figure 7, Figure 8 and Figure 9. Vu’s method [24] assigns incorrect clear regions in the defocus blur regions of the background. The JNB method [30] contains too many clear errors and cannot produce significant differences between clear and blur regions. The proposed method is superior and the results of the proposed method are much closer to the ground-truth than that of others.
In additional, experimental results for defocus blurred image generated with a HUAWEI mobile phone are shown in Figure 10. Our method provides better detection and estimation performance than the others. Although successfully extracting the ground-truth from the blur regions, the method in Figure 10c also has errors in outliers’ regions. Figure 10d shows that the estimated local blur results have clear errors in separating the ground-truth from the blur regions. In Figure 10e, there are some artifacts in the result and the outline does not produce a significant difference to separate the ground-truth from the blur background. In contrast, Figure 10f shows that the proposed method produces favourable results in distinguishing ground-truth from the blur background regions and representing image details.
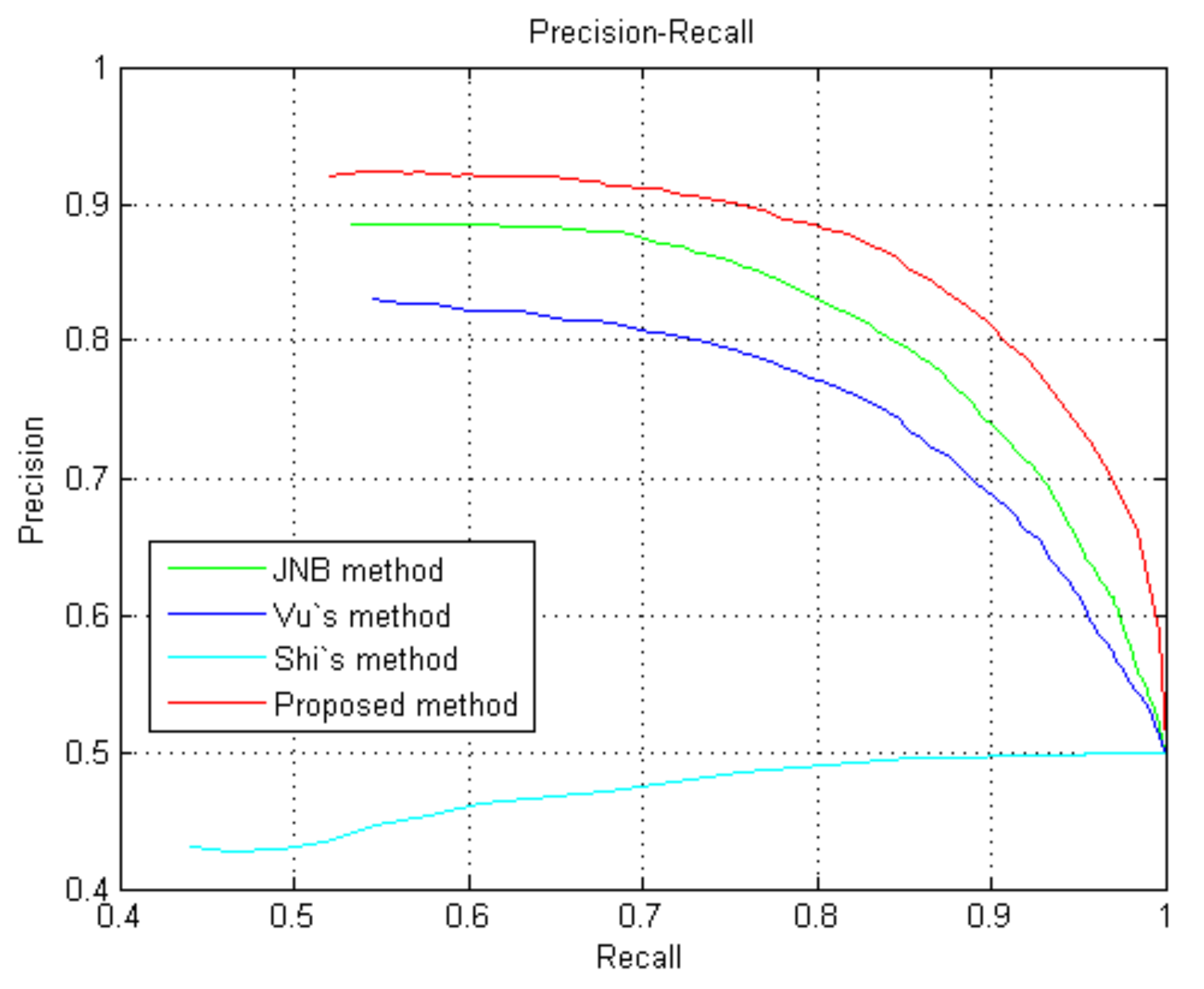
To further evaluate the effectiveness of the proposed method, we compare our method with other approaches via precision–recall (PR) in Figure 11. Forty defocus blur images (20 from dataset [25] and 20 from the naturally blurred images) are collected to test the proposed method. Figure 11 shows that the proposed method achieves the highest precision within almost the entire range of recall in [0, 1].
5. Conclusions
In this paper, we integrate the sparse representation model with adaptive domain selection and learning coefficient distribution for defocus blur detection and estimation. Compared with other defocus blur detection and estimation methods that rely on learning a universal and over-complete dictionary, the proposed method is helpful in adaptively selecting the optimal compact dictionary for each local patch and thus can much improve the accuracy and execution time of the defocus blur estimation. Based on the observation that the distributions of coefficients generally cannot be fitted with a I.I.D zero-mean Laplaican distribution, the proposed method learns parametric distributions from the gathered similar patches via nonlocal structural similarity. More accurate sparse coefficients can be obtained and further improve the the quality of the defocus blur detection. To estimate the strength of defocus blur, a criterion is defined to estimate the degree of defocus blur for each patch. Extensive experimental results show the superiority of the proposed method, both in visual quality and evaluation indexes.
Acknowledgments
This research has been partially supported by the National Natural Science Foundation of China (No. 61173091).
Author Contributions
J.L. and Z.L. conceived and designed the experiments; J.L. performed the experiments; Y.Y. analyzed the data; and J.L. and Y.Y. wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- El-Sallam, A.A.; Boussaid, F. Spectral-Based Blind Image Restoration Method for Thin TOMBO Imagers. Sensors 2008, 8, 6108–6123. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Quan, W.; Guo, L. Blurred Star Image Processing for Star Sensors under Dynamic Conditions. Sensors 2012, 12, 6712–6726. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhang, B.; Shi, Y. Scattering Removal for Finger Vein Image Restoration. Sensors 2012, 12, 3627–3640. [Google Scholar] [CrossRef] [PubMed]
- Manfredi, M.; Bearman, G.; Williamson, G.; Kronkright, D.; Doehne, E.; Jacobs, M.; Marengo, E. A New Quantitative Method for the Non-Invasive Documentation of Morphological Damage in Painting Using RTI Surface Normals. Sensors 2014, 14, 12271–12284. [Google Scholar] [CrossRef] [PubMed]
- Cheong, H.; Chae, E.; Lee, E.; Jo, G.; Paik, J. Fast Image Restoration for Spatially Varying Defocus Blur of Imaging Sensor. Sensors 2015, 15, 880–898. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, J.; Figueiredo, M.; Bioucas-Dias, J. Parametric Blur Estimation for Blind Restoration of Natural Images: Linear Motion and Out-of-Focus. IEEE Trans. Image Process. 2014, 23, 466–477. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Wang, R.; Jiang, X.; Wang, W.; Gao, W. Spatially variant defocus blur map estimation and deblurring from a single image. J. Vis. Commun. Image R. 2016, 35, 257–264. [Google Scholar] [CrossRef]
- Favaro, P.; Soatto, S.; Burger, M.; Osher, S. Shape from defocus via diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 518–531. [Google Scholar] [CrossRef] [PubMed]
- Favaro, P.; Soatto, S. A geometric approach to shape from defocus. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 406–417. [Google Scholar] [CrossRef] [PubMed]
- Levin, A.; Fergus, R.; Durand, F.; Freeman, W. Image and depth from a conventional camera with a coded aperture. ACM Trans. Graph. 2007, 26, 70–78. [Google Scholar] [CrossRef]
- Zhou, C.; Lin, S.; Nayar, S. Coded aperture pairs for depth from defocus and defocus deblurring. Int. J. Comput. Vis. 2011, 93, 53–72. [Google Scholar] [CrossRef]
- Xiao, L.; Heide, F.; O’Toole, M.; Kolb, A.; Hullin, M.; Kutulakos, K.; Heidrich, W. Coded aperture pairs for depth from defocus and defocus deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 657–665. [Google Scholar]
- Hu, Z.; Xu, L.; Yang, M. Joint Depth Estimation and Camera Shake Removal from Single Blurry Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2893–2900. [Google Scholar]
- Pang, Y.; Zhu, H.; Li, X.; Li, X. Classifying discriminative features for blur detection. IEEE Trans. Cyber. 2016, 46, 2220–2227. [Google Scholar] [CrossRef] [PubMed]
- Yi, X.; Eramian, M. LBP-based segmentation of defocus blur. IEEE Trans. Image Process. 2016, 25, 1626–1638. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.J.; Chen, H.T.; Chang, L.W. Fast defocus map estimation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3962–3966. [Google Scholar]
- Xu, G.; Quan, Y.; Ji, H. Estimating Defocus Blur via Rank of Local Patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 22–29 October 2017; pp. 5371–5379. [Google Scholar]
- Karaali, A.; Jung, C.R. Edge-Based Defocus Blur Estimation With Adaptive Scale Selection. IEEE Trans. Image Process. 2018, 27, 1126–1137. [Google Scholar] [CrossRef] [PubMed]
- Elder, J.; Zucker, S. Local scale control for edge detection and blur estimation. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 699–716. [Google Scholar] [CrossRef]
- Pan, J.; Hu, Z.; Su, Z.; Yang, M. Deblurring Text Images via L0-Regularized Intensity and Gradient Prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2901–2908. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M. Blind Image Deblurring Using Dark Channel Prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Liu, R.; Li, Z.; JiaBlind, J. Image partial blur detection and classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhu, X.; Cohen, S.; Schiller, S.; Milanfar, P. Estimating spatially varying defocus blur from a single image. IEEE Trans. Image Process. 2013, 22, 4879–4891. [Google Scholar] [CrossRef] [PubMed]
- Vu, C.; Phan, T.; Chandler, D. S3: A Spectral and Spatial Measure of Local Perceived Sharpness in Natural Images. IEEE Trans. Image Process. 2012, 21, 934–945. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Xu, L.; Jia, J. Discriminative Blur Detection Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2965–2972. [Google Scholar]
- Dong, W.; Shi, G.; Ma, Y.; Li, X. Image Restoration via Simultaneous Sparse Coding: Where Structured Sparsity Meets Gaussian Scale Mixture. Int. J. Comput. Vis. 2015, 114, 217–231. [Google Scholar] [CrossRef]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2012, 21, 3850–3864. [Google Scholar] [CrossRef]
- Dong, W.; Li, G.; Shi, G.; Li, X.; Ma, Y. Low-Rank Tensor Approximation with Laplacian Scale Mixture Modeling for Multiframe Image Denoising. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 442–449. [Google Scholar]
- Dong, W.; Shi, G.; Li, X. Nonlocal Image Restoration With Bilateral Variance Estimation: A Low-Rank Approach. IEEE Trans. Image Process. 2013, 22, 700–711. [Google Scholar]
- Shi, J.; Xu, L.; Jia, J. Just Noticeable Defocus Blur Detection and Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 657–665. [Google Scholar]
- Zhang, L.; Lukac, R.; Wu, X.; Zhang, D. PCA-Based Spatially Adaptive Denoising of CFA Images for Single-Sensor Digital Cameras. IEEE Trans. Image Process. 2009, 18, 797–821. [Google Scholar] [CrossRef] [PubMed]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Singal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Donoho, D.L. For most large underdetermined systems of linear equations the minimal l1-norm solution is also the sparsest solutions. Commun. Pure Appl. Math. 2006, 797–829. [Google Scholar] [CrossRef]
- Hu, Z.; Huang, J.; Yang, M. Single image deblurring with adaptive dictionary learning. In Proceedings of the 2010 17th IEEE International Conference on Image Processing (ICIP), Hong Kong, China, 26–29 September 2010; Volume 119, pp. 1169–1172. [Google Scholar]
- Protter, M.; Yavneh, I.; Elad, M. Closed-form MMSE estimation for signal denoising under sparse representation modeling over a unitary dictionary. IEEE Trans. Singal Process. 2010, 58, 3471–3484. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J. A non-local algorithm for image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
Figure 1.
Focus and defocus for thin lens imaging sensors.

Figure 2.
One example of the compact dictionaries learned by PCA.

Figure 3.
The observation of coefficients’ distributions between the JNB method and real distribution of a test image. The coefficients’ distributions are plotted by associating with the 4th atom of the dictionary that is learned by the K-SVD algorithm.
Figure 3.
The observation of coefficients’ distributions between the JNB method and real distribution of a test image. The coefficients’ distributions are plotted by associating with the 4th atom of the dictionary that is learned by the K-SVD algorithm.

Figure 4.
Comparison of the coefficients’ distributions of proposed method, the JNB method and the real distribution of the same test image; (a) the coefficients’ distributions associated with the 4th atom; (b) the coefficients’ distributions associated with the 6th atom.
Figure 4.
Comparison of the coefficients’ distributions of proposed method, the JNB method and the real distribution of the same test image; (a) the coefficients’ distributions associated with the 4th atom; (b) the coefficients’ distributions associated with the 6th atom.

Figure 5.
The association between sparsity of coefficient and blur strength.

Figure 6.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes continuously. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation results by Vu’s method; (d) the detection and estimation results by Shi’s method; (e) the detection and estimation results by the JNB method; (f) the detection and estimation results by the proposed method.
Figure 6.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes continuously. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation results by Vu’s method; (d) the detection and estimation results by Shi’s method; (e) the detection and estimation results by the JNB method; (f) the detection and estimation results by the proposed method.

Figure 7.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes abruply. (a) the input blur image (Image source: originally posted to Flickr as Hong Kong Orchid tree flower); (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; and (f) the detection and estimation results by the proposed method.
Figure 7.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes abruply. (a) the input blur image (Image source: originally posted to Flickr as Hong Kong Orchid tree flower); (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; and (f) the detection and estimation results by the proposed method.

Figure 8.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes abruply. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; (f) the detection and estimation results by the proposed method.
Figure 8.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes abruply. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; (f) the detection and estimation results by the proposed method.

Figure 9.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes abruptly. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; (f) the detection and estimation results by the proposed method.
Figure 9.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes abruptly. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; (f) the detection and estimation results by the proposed method.

Figure 10.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes continuously. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; (f) the detection and estimation results by the proposed method.
Figure 10.
Comparison of different defocus blur detection and estimation using an input image form dataset [25], whose blur amount changes continuously. (a) the input blur image; (b) the ground-truth mask; (c) the detection and estimation result by Vu’s method; (d) the detection and estimation result by Shi’s method; (e) the detection and estimation result by the JNB method; (f) the detection and estimation results by the proposed method.

Figure 11.
PR for different methods tested on defocus images from the dataset and naturally blurred images.
Figure 11.
PR for different methods tested on defocus images from the dataset and naturally blurred images.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison of execution time (/s).
| Data | Vu’s Method | Shi’s Method | JNB Method | Proposed Method |
|---|---|---|---|---|
| out_of _ focus0010 | 16.344 | 241.352 | 7.626 | 5.473 |
| out_of _ focus0015 | 19.298 | 282.467 | 22.762 | 16.251 |
| out_of _ focus0047 | 26.712 | 325.757 | 20.586 | 19.329 |
| out_of _ focus0070 | 21.760 | 288.181 | 7.794 | 8.257 |
| out_of _ focus0092 | 12.063 | 186.534 | 2.965 | 2.019 |
| out_of _ focus0120 | 22.271 | 275.451 | 8.256 | 5.060 |
| out_of _ focus0150 | 26.838 | 334.250 | 23.193 | 14.225 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, J.; Liu, Z.; Yao, Y. Defocus Blur Detection and Estimation from Imaging Sensors. Sensors 2018, 18, 1135. https://doi.org/10.3390/s18041135
AMA Style
Li J, Liu Z, Yao Y. Defocus Blur Detection and Estimation from Imaging Sensors. Sensors. 2018; 18(4):1135. https://doi.org/10.3390/s18041135
Chicago/Turabian StyleLi, Jinyang, Zhijing Liu, and Yong Yao. 2018. "Defocus Blur Detection and Estimation from Imaging Sensors" Sensors 18, no. 4: 1135. https://doi.org/10.3390/s18041135
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.