Joint Probabilistic Data Association Filter with Unknown Detection Probability and Clutter Rate


School of Aerospace, Transport and Manufacturing, Cranfield University, MK43 0AL Cranfield, UK
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(1), 269; https://doi.org/10.3390/s18010269
Submission received: 15 December 2017
/
Revised: 10 January 2018
/
Accepted: 16 January 2018
/
Published: 18 January 2018
(This article belongs to the Section Sensor Networks)
Abstract
:This paper proposes a novel joint probabilistic data association (JPDA) filter for joint target tracking and track maintenance under unknown detection probability and clutter rate. The proposed algorithm consists of two main parts: (1) the standard JPDA filter with a Poisson point process birth model for multi-object state estimation; and (2) a multi-Bernoulli filter for detection probability and clutter rate estimation. The performance of the proposed JPDA filter is evaluated through empirical tests. The results of the empirical tests show that the proposed JPDA filter has comparable performance with ideal JPDA that is assumed to have perfect knowledge of detection probability and clutter rate. Therefore, the algorithm developed is practical and could be implemented in a wide range of applications.
1. Introduction
There has been increasing attention on utilisation of small autonomous systems in military and civil applications. The issue is that the operations of these small autonomous systems are constrained by limited payload, as well as limited operation time and endurance. This has led to proliferation of lightweight, low-cost and energy efficient on-board sensors.
Reliable and autonomous target tracking is a fundamental aspect of situation awareness for autonomous systems [1,2,3]. Applying low-cost and lightweight on-board sensors in target tracking imposes additional challenges to the tracking problem since they are likely to contain some degree of uncertainties. Low-cost sensors are generally subject to a high clutter rate and low detection probability. When combined with the inherent uncertainties and complexity of the problem, the poor performance issue with these sensors could be significantly exacerbated in target tracking, especially in multi-target tracking (MTT) [1].
It is known that data association in MTT is a challenging issue. With a high clutter rate, data association in MTT becomes even more challenging. One of the most popular data association approaches is the multiple hypothesis tracking (MHT) proposed in [4,5]. Given high computational power, MHT is known as a powerful MTT algorithm to address the problem of measurement uncertainty. Data, in MHT, are processed recursively with a delayed logic scheme and MHT intentionally expands parent track hypotheses with received measurements to form child track hypotheses in decision-making trees. These child track hypotheses are subsequently assessed and the ones with low scores are pruned by thresholding to keep feasibility. Although MHT is known as a theoretically optimal Bayesian estimator, the exact solution of MHT is computationally intractable and thereby requires approximated implementations [6,7].
JPDA is another widely used one-scan data association method. The basic assumption of JPDA is that each measurement can originate from several candidate targets in the valid gate. Therefore, JPDA never make any hard decisions on the measurement-to-target association and is a soft decision filter. The key part of JPDA is to enumerate all feasible joint events to calculate the marginal probability for the track update. Compared with the multi-scan MHT, JPDA can achieve reasonable results at lower computational burden [8,9,10,11,12,13]. Since JPDA forms tracks out of the marginal measurement-to-track association distributions, it is known as a track-oriented approach.
Despite its advantages, the JPDA filter, similar to most multi-target tracking algorithms, requires the knowledge of detection probability and clutter rate in implementation. These two parameters are of great importance for the JPDA filter as they determine the final estimation performance. Significant mismatches of these two key parameters could result in erroneous tracking outputs. Although the detection probability, dependent on the sensors and the scenarios, can be tested via offline experiments, it might not be cost-effective and they are typically unavailable for low-cost sensors. Furthermore, under dynamic environmental conditions or detection approaches, the clutter rate generated by the same sensor might change in a great deal: for example, in image-based target tracking, measurements are extracted from various detection algorithms [14], ranging from simple background subtraction [15] to complicated deep learning approach [16]. Obviously, the clutter rate and detection probability are different for different detection methods. Therefore, the usual assumption on the full knowledge of these two key parameters for MTT in advance might not be realistic and how to accommodate the unknown detection probability and clutter rate is of critical importance in practice. Although this issue is tackled in previous random finite set (RFS) filters [17,18], they cannot preserve the labels of the targets and thus might have limited applications.
Motivated by the above observations, this paper aims to propose an enhanced version of JPDA that can accommodate the unknown detection probability and clutter rate. The proposed algorithm is derived by integrating a JPDA filter with Poisson point process (PPP) birth model and a multi-Bernoulli filter. Note that the study in this paper is based on our previous work [19]: this paper refines the algorithm developed in [19] and extends the performance evaluation through extensive empirical tests. Unlike previous works, where the clutter rate estimation is decoupled from the multi-object tracking [14,20,21,22], the proposed approach utilises a closed feedback loop structure based on the property of the posterior of the JPDA estimations. More specifically, the multi-target JPDA filter leverages the information of estimated detection probability and clutter rate provided by the multi-Bernoulli filter. In the meantime, the multi-Bernoulli filter uses the estimation outputs of the main JPDA tracker since the posterior of JPDA estimations can be modelled by a multi-Bernoulli RFS.
The performance of the proposed approach is evaluated through extensive numerical simulations. The simulation results demonstrate that the proposed algorithm has comparable performance with the ideal JPDA, which is assumed to have perfect knowledge of detection probability and clutter rate.
The rest of the paper is organised as follows. Section 2 presents the system models utilised. Then, Section 3 briefly introduces the JPDA filter and provide the analysis on the effect of detection probability as well as the clutter rate on the tracking performance. Next, the details of the proposed JPDA filter is given in Section 4. Finally, some experiments and conclusions are offered.
2. System Models and Assumptions
This section addresses the system models that are used in the following sections. Throughout the paper, we use the symbol i to refer to a target index and j to refer to a measurement index.
The set of target states and measurements received at scan k are, respectively, defined as
where denotes the number of targets at scan k, the ith target at scan k, the number of measurements received at scan k, the jth measurement received at scan k, the dummy measurement for convenient representation of miss detection. We assume that the temporal evolution of each target is independent of others and follows a Markov transition model , then, the prediction of target state of scan k is governed by
As required for JPDA, we accept the assumption that each target can generate at most one measurement and each measurement can originate from at most one target. Each target-generated measurement is independent of each other and is detected with probability with measurement likelihood .
The additional assumptions made in the paper are as follows:
- The clutter distribution is assumed to be unknown a priori. When there is no prior knowledge regarding the clutter measurements, the MTT problem generally assumes that the number of clutters or false alarms is locally Poisson distributed [23]. Therefore, this paper utilises a Poisson distribution as the clutter distribution. Clutters or false alarms are modelled by a local PPP with intensity with being the average number of clutters of one scan and being the sensor volume. Clearly, if domain or environmental knowledge could be used to develop a more realistic clutter distribution in specific tracking tasks, the estimation performance could be improved.
- The detection probability is assumed to be independent of the target state in filter design. The detailed discussion will be presented in Section 4.1.
In standard JPDA filtering approach, a track is defined as a sequence of measurements that originate from the same target. The original JPDA filter assumes the number of targets is known a priori at each scan and utilise a wrapper heuristic logic for track initiation and deletion. In this paper, we resort to a PPP model, similar to [24], for target birth instead of the heuristic logic. In other words, we assume that target birth is modelled as a PPP with intensity and track is confirmed based on a random binary variable, target existence status, with being the existence of the ith target and being non-existence. Then, measurements that either from new targets or false alarms can be modelled by a PPP with intensity . Note that, by incorporating the PPP model into JPDA filter, the posterior multi-object PDF can then be represented by the multi-Bernoulli distribution. This fact enables the application of recently proposed multi-Bernoulli RFS to JPDA for joint detection probability and clutter rate estimation. Let denote the existence probability of the ith target at scan k. Then, the time evolution of can be formulated by the Markov Chain One model [9] and the Markov transition probability matrix is determined by the survival probability [9].
3. Joint Probabilistic Data Association Filter and Analysis
In this section, we first briefly review the basics of JPDA filter for the completeness and then give an intuitive analysis of the effect of the detection probability and clutter rate.
3.1. Joint Probabilistic Data Association Filter
JPDA algorithm aims to calculate the marginalized association probability based on all possible joint events for data association. A joint event is an allocation of all measurements to all tracks. In JPDA, a feasible joint event is defined as one possible mapping of the measurements to the tracks such that: (1) each measurement (except for the dummy one) is assigned to at most one target; and (2) each target is uniquely assigned to a measurement. Let , , denote the joint association event. For each pre-existed target , denotes the association event, where means the jth measurement is originated from the ith target and represents the dummy association in which the ith target is miss detected. JPDA assumes that each single association event is independent and the posterior of each target is characterised by a mixture as [5]
Generally, propagation of the mixture distribution is computationally intractable due to the explosion of mixture terms. JPDA approximates this mixture term by a single Gaussian distribution through first moment matching method. More specifically, the state correction for each pre-existed target and its corresponding covariance of JPDA is obtained as
where denotes the target estimates from associating the jth measurement to target i, the corresponding covariance. Note that can be obtained from . is the existence conditioned marginal association probability that the jth measurement is associated with the ith target.
The hypothesis-conditioned update can be calculated by standard Kalman filter algorithm. Therefore, the remaining part is how to obtain the marginal association probability in a tractable way as this is the most computationally part.
The posterior distribution of the joint association event consists of two parts: miss detection and detection [9]. Therefore, one can imply that
where
Note the term in is for the non-existence of the ith target and is for the existence but non-detection of the ith target.
Although full enumeration is intractable in real applications due to the high demand of computational power, the marginal probability can be approximated by best approximations, stochastic sampling or any other suitable approaches [10,11,12,25]. In this paper, we utilize the Gibbs sampling approach to approximate the marginal probability. This method enables fast calculation of the marginal probability with ignorable performance sacrifice. Detailed description of this algorithm can be found in our previous work [25]. For the completeness of the paper, a brief introduction to the Gibbs-JPDA implementation algorithm is provided in the Appendix.
After finding , the joint probability can be calculated using Bayesian rule as
Finally, the posterior probability of target existence and the existence-conditioned marginal probability used in the estimation update can be calculated as
Note that, except for the updates of pre-existed tracks, JPDA also creates new tracks for each measurement based on the birth model. After the track update, we use a similar approach, as shown in score-based approach [5], for track confirmation and deletion. A track is confirmed once its existence probability exceeds a pre-defined threshold and otherwise is still tentative and needs further test to be confirmed or deleted. Meanwhile, a track is immediately deleted if its existence probability is below a pre-defined threshold.
Remark 1.
Note that the utilisation of PPP birth model for target existence estimation is similar to the idea of joint integrated probabilistic data association (JIPDA) [9,26]. However, the difference lies in that the JIPDA filter assumes a stationary or constant intensity of extraneous sources, which include unknown targets and false alarms while the proposed JPDA with PPP birth model dynamically estimate this intensity. More specifically, in JIPDA derivation, Equation (7) reduces to [9]
Therefore, the standard JIPDA ignores the influence of the unknown targets in marginalisation. Clearly, leveraging the PPP birth model is beneficial and more realistic in initialisation and calculating the marginal association probability.
3.2. Effect of the Detection Probability and Clutter Rate
This subsection analyses the effect of detection probability and clutter rate on the performance of JPDA filter provided that they are given in advance.
The effect of the detection probability on the estimation are two folds. On the one hand, it follows from Equations (6) and (7) that the the detection probability influences the relative ratio or weighting between the target miss detection and target detection . Therefore, artificially lower detection probability will give more penalty on the target-absence , leading to the delayed track maintenance. However, lower detection probability might be useful in holding targets through temporary fades. On the other hand, the fact that also reveals that the detection probability also affects the track initialization process. Lower detection probability will force longer tentative tracks before a confirmation or deletion decision is made based on the score logic. This, in turn, will increase the workload of the tracking filter as more tracks remain tentative, which is especially severe in a high-clutter scenario.
From Equation (7), one can note that the clutter rate also plays an important role in the JPDA algorithm. Higher clutter rate will give more penalty on the external source term, i.e., false alarms or new targets, than the target-detection term . Therefore, artificially higher clutter rate provides an estimation result that more tracks will be considered as false alarms by the tracking system. Similarly, lower clutter rate usually generates overestimation of the real targets.
Consequently, significant mismatch of either detection probability or clutter rate will result in highly biased estimation. However, both and are difficult or not cost-effective to obtain in practice, especially for for low-cost sensors. Therefore, it is imperative to design an improved JPDA algorithm that can accommodate this issue.
4. Joint Probabilistic Data Association Filter with Unknown Detection Probability and Clutter Rate
In this section, we will propose a novel JPDA filter to adjust the unknown detection probability and clutter rate by leveraging the multi-Bernoulli filter.
4.1. Detection Probability and Clutter Rate Estimator
The recently proposed multi-Bernoulli filter [18,27,28,29] utilises the random finite set (RFS) theory to recursively propagate the posterior of multi-target state. This filter is known as a parametrised approximation of the Bayesian multi-target recursion. At each time instant k, the posterior PDF of the multi-target state is characterised as a multi-Bernoulli RFS. More specifically, each target is modelled as a single Bernoulli RFS, which is fully described by the existence probability and the probability density . A Bernoulli RFS is empty with probability and has only one element, whose distribution is described by , with probability . The multi-Bernoulli RFS is a simple union of single independent Bernoulli RFSs and thus can be completely characterised by the parameter set . The recursive multi-Bernoulli filter is given by two steps as [27,28]:
- (1)
- Prediction step. If the posterior multi-target density at time is characterised as a multi-Bernoulli RFS as , then, the prediction of the multi-target density is also a multi-Bernoulli aswhere the first part denotes the multi-Bernoulli RFS of the birth model and the second part represents the prediction of existing targets withwhere .
- (2)
- Update step. If the predicted multi-target density at time k is characterised as a multi-Bernoulli RFS as , then, the update of the multi-target density is also a multi-Bernoulli aswhere the legacy (miss detection) component is given byand the measurement updated component is given by
The advantage of the multi-Bernoulli filter is that it utilises the mathematically sound RFS theory and thus directly avoids the data association process in multi-target tracking, leading to computational efficiency. However, the target identity or the target label cannot be maintained during the filtering recursion. This means that the multi-Bernoulli filter cannot be used to support the target label management. Therefore, if the label information is required for practice, the application of multi-Bernoulli filter is limited. Fortunately, as our aim is to estimate the clutter rate as well as the detection probability using the multi-Bernoulli filter, there is no need to manage the clutter identity.
To apply the multi-Bernoulli filter to estimate the clutter rate, we consider each false alarm as a target with its own transition model, birth model and death model [18]. This consideration is motivated by the fact that the target and the clutter have totally different dynamics and thus can be treated separately in estimation. The true targets and clutters in recursive filtering are therefore labelled by a discrete space , where 1 is the label of real targets and 0 is for clutters. To further accommodate the detection probability estimation, we augment the state space as , where denotes the space of detection probability and × represents the Cartesian product. Since the new state space is a discrete one, the integration on this space is given by
In reality, the detection probability is related to the target state. This fact makes the system state propagation/prediction of the augmented system intractable. To address this problem, we further assume that the detection probability is independent of the target state, i.e.,
Note that the target detection probability used in JPDA is typically piecewise constant and thus the independence assumption is reasonable in filter design. Furthermore, the validation presented in the following section reveals that the proposed algorithm works well in the presence of time-varying detection probability.
In general, the clutter dynamics is highly dependent on the sensors. If we have some prior information regarding the sensors, we can utilise such information to build the clutter dynamics model. Otherwise, general models can be leveraged, e.g., Gaussian distribution and random walk. Similarly, if there is no prior information, a typical choice of the detection probability model is the well-known beta distribution [30]. The beta distribution is a family of continuous distributions defined on the interval and has enough diversity to accommodate the changes of detection probability. By choosing different shaping parameters and , the beta distribution can accommodate different detection probability models.
By substituting the augmented state space into the original multi-Bernoulli filter, we can readily estimate the number of clutters at one scan by the summation of all confirmed targets with label 0 and the clutter rate estimation is then given by . As is part of the system states, it can directly obtained by the state estimation of multi-Bernoulli filter. Note that one can also apply the augmented system into JPDA to adapt to the unknown detection probability and clutter rate. However, the inherent data association process of JPDA will make practical implementation intractable.
4.2. Estimation Algorithm
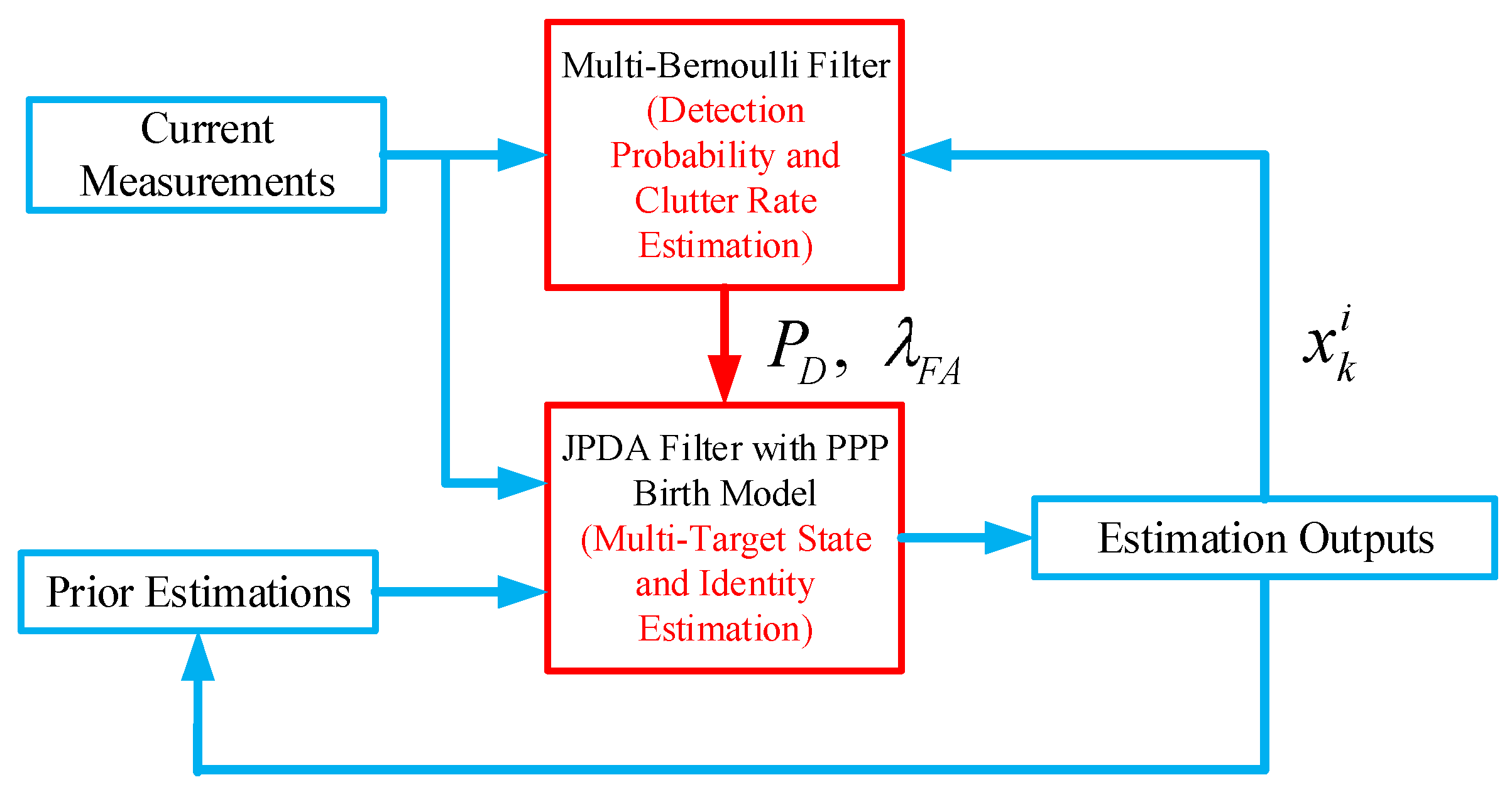
The proposed JPDA is shown in Figure 1. At each time instant k, we utilise the original JPDA with PPP birth model as the main tracker to provide the multi-target state estimation. The required detection probability and clutter rate is obtained from an one-step multi-Bernoulli filter. As discussed earlier, by incorporating the PPP model into JPDA, the posterior of JPDA estimation can be modelled as the multi-Bernoulli RFS and thus the estimated output of the JPDA is feedback to the multi-Bernoulli filter for its initialisation at every time instant. The advantage of the proposed parallel filtering scheme is that one can fully exploit the strengths of both approaches: using the JPDA for track management and obtaining fast estimation of detection probability as well as clutter rate by the multi-Bernoulli filter.
Remark 2.
The computational complexity of the proposed estimation algorithm comes from two main parts: JPDA and multi-Bernoulli filter. Although the original marginalisation in JPDA is a #P-complete problem, leading to the fact that the computational time increases exponentially with respect to the number of targets, the approximation by Gibbs-sampling is a polynomial-time algorithm, as detailed in [25]. Additionally, since the RFS-based multi-Bernoulli filter directly avoids the typical data association procedure in multi-target tracking, it also runs in a polynomial time.
5. Numerical Simulations
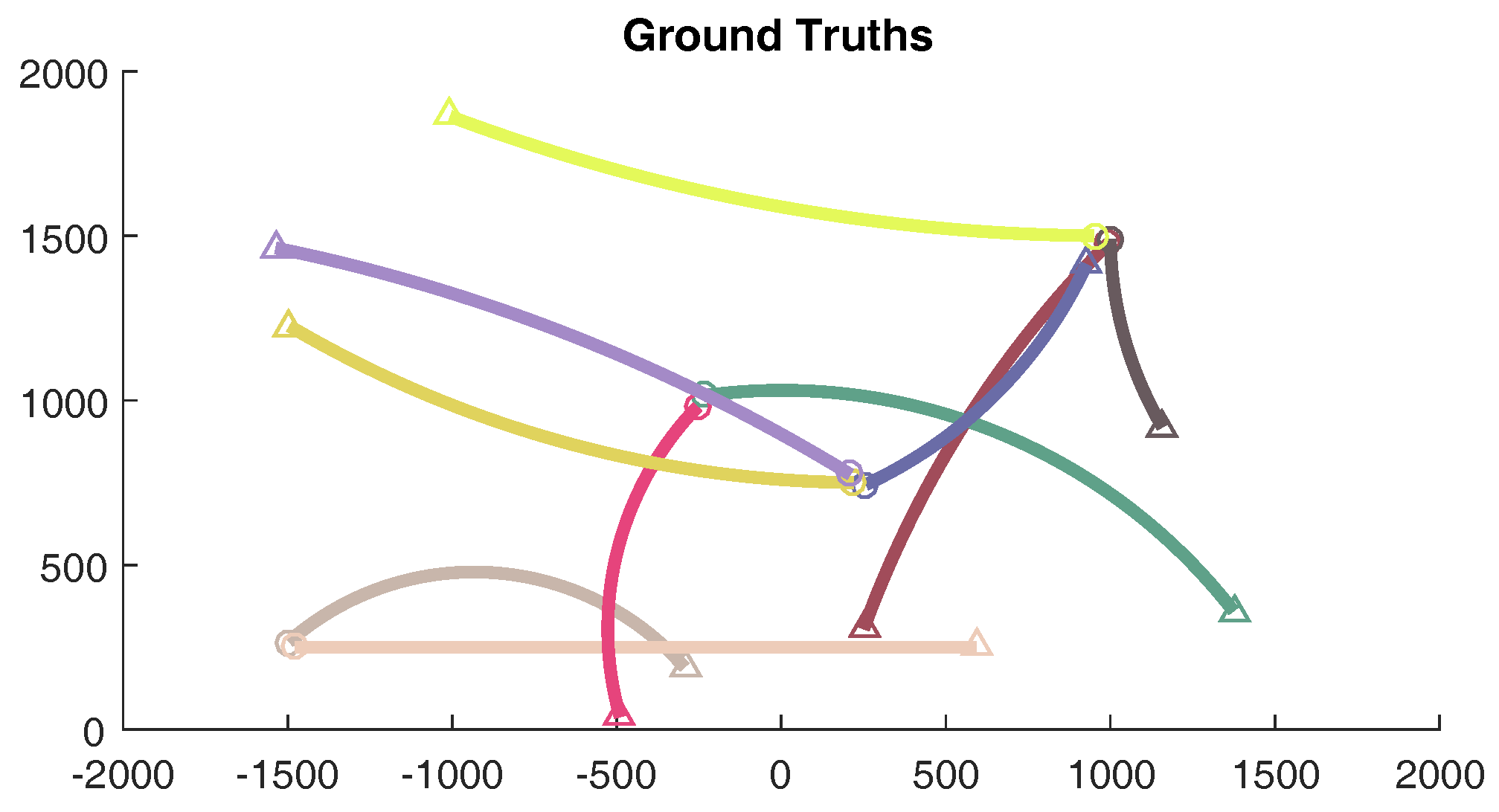
In this section, the effectiveness of the proposed JPDA filtering algorithm is investigated through numerical simulations in a cluttered environment. Our experiments explore a scenario, involving 10 manoeuvring targets with different birth time. The ground truth of the considered scenario is depicted in Figure 2.
5.1. Simulation Setup
The state vector contains planar position and velocity. We use the well-known constant velocity (CV) model for target prediction. The CV model is defined as
with
where denotes the identity matrix, T the sampling period, and the Gaussian process noise.
It is assumed that we use a radar for multiple targets tracking. The target-generated nonlinear range and bearing measurements are modelled by
where denotes target position, radar position, and the Gaussian measurement noise with .
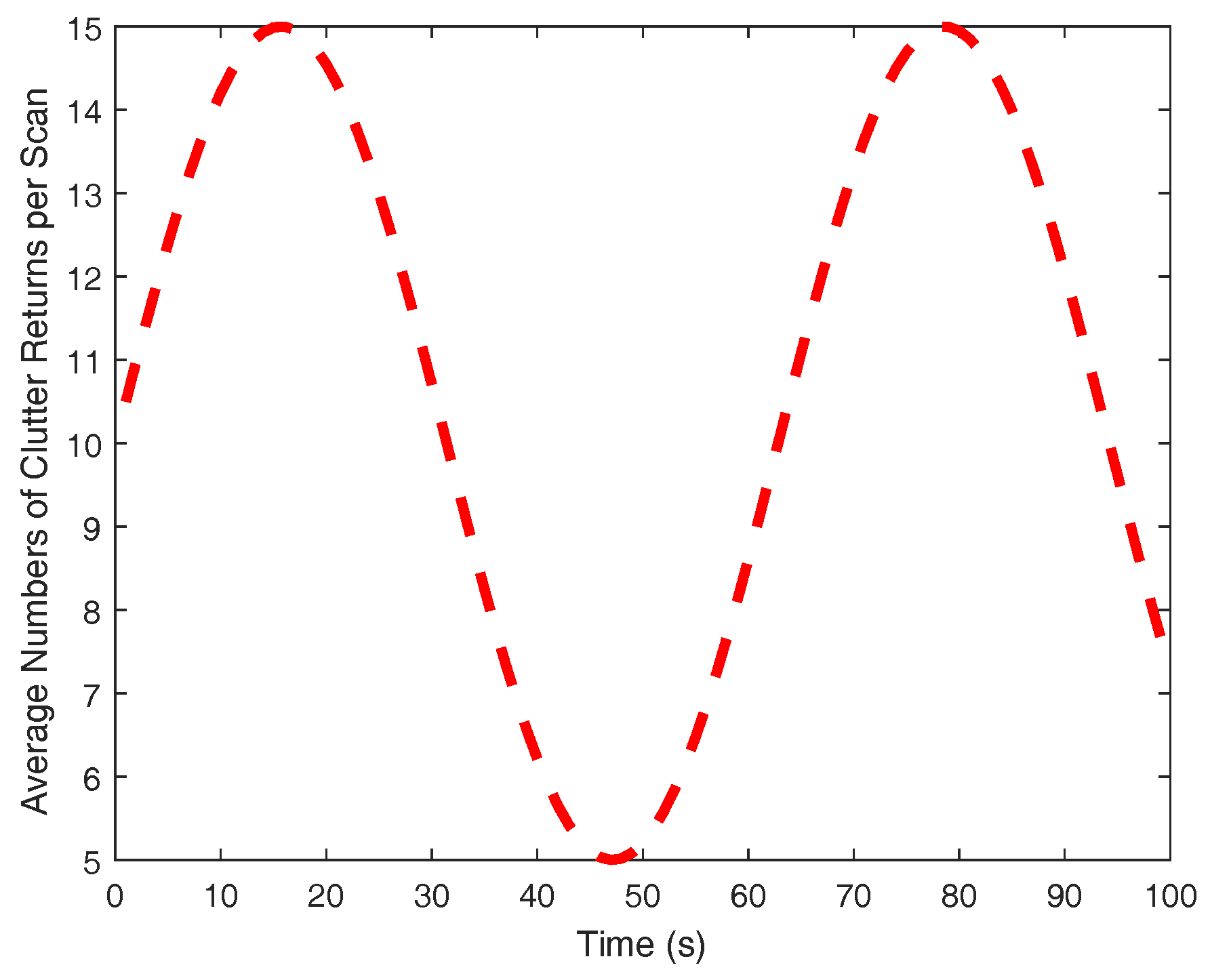
The clutter is assumed to be uniformly distributed in the surveillance region with its number being Poisson with average returns at each scan. To validate the proposed algorithm in dynamic scenarios, is given in a time-varying profile, as shown in Figure 3. Gating is performed with a threshold such that the gating probability is . The detection probability peaks at the sensor origin with and exponentially decreases to 0.8 at the boundary of the sensing field-of-view. This setting is reasonable as the received signal strength decreases when the target is far away from the sensor. A tentative track is confirmed if the existence probability satisfies and a confirmed track is deleted immediately once .
The optimal sub-pattern assignment (OSPA) distance metric [31] is considered here for overall performance evaluation, namely, cardinality and position estimation errors. Let X and Y be the position estimation set and true target position set, respectively. The cardinality of these two sets are m and n, respectively. Then, for and , the OSPA distance is defined as [31],
where denotes the set of all permutations on for any positive integer n. is the cut-off Euclidean distance between two vectors as with being the Euclidean distance. The order parameter p determines the sensitivity of in penalizing estimation outliers, while the cut-off parameter c determines the relative weighting of the penalties allocated to cardinality and localization errors. In all simulations, these two parameters are set as , .
5.2. Simulation Results
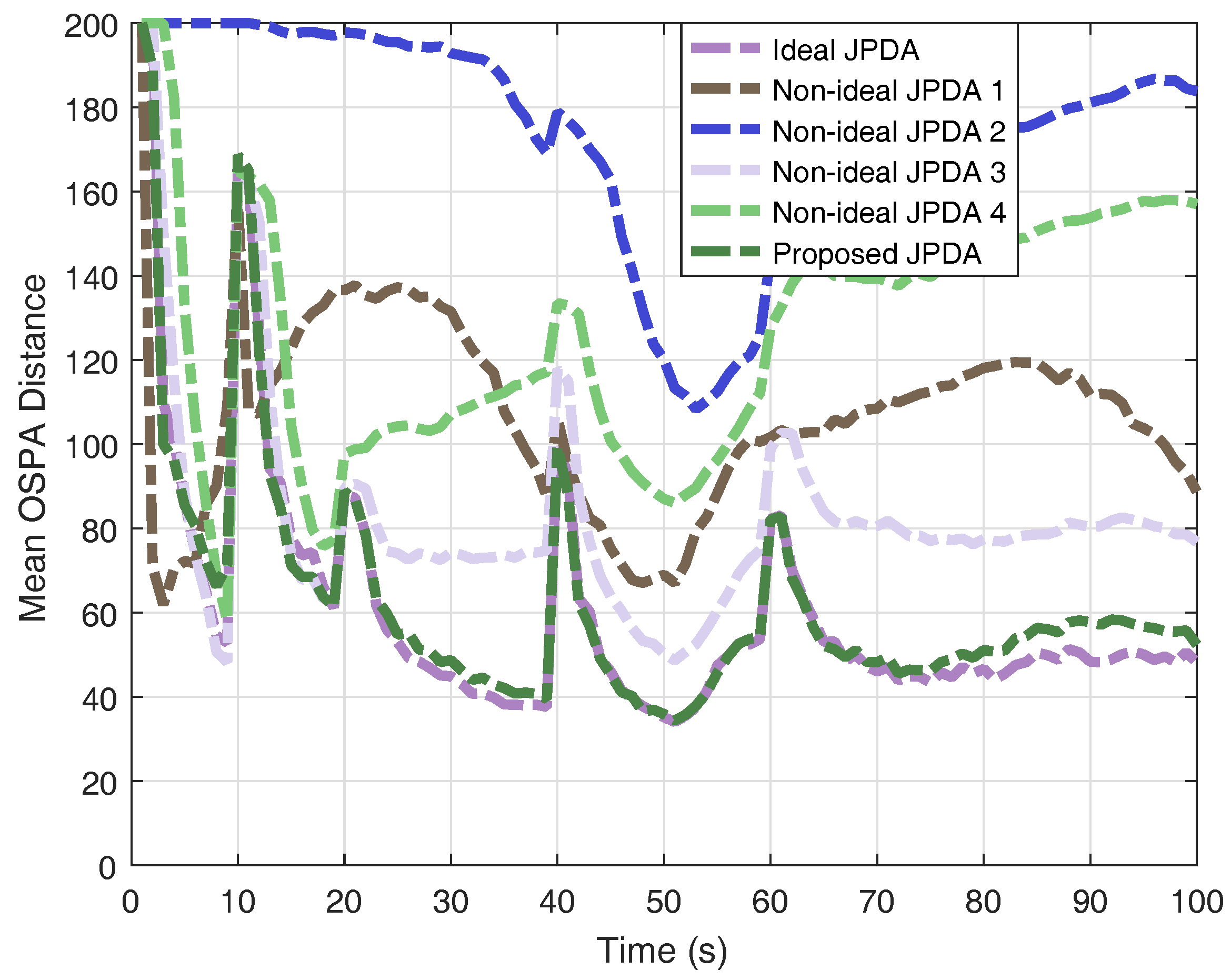
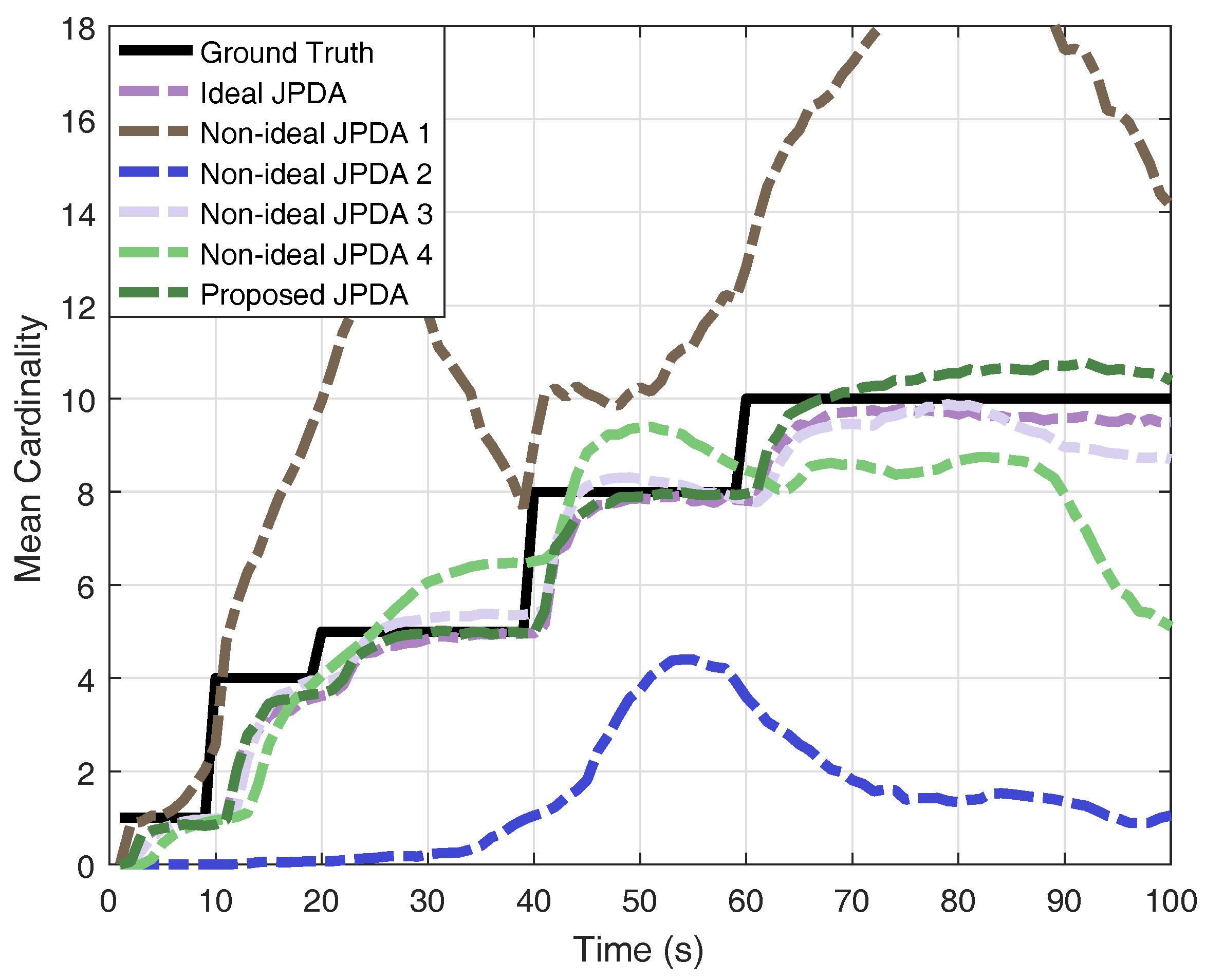
For the purpose of comparison, we also perform the ideal JPDA filter with perfect knowledge of detection probability and clutter rate, the following four non-ideal JPDA filters: (1) ideal , ; (2) ideal , ; (3) , ideal ; and (4) , ideal .
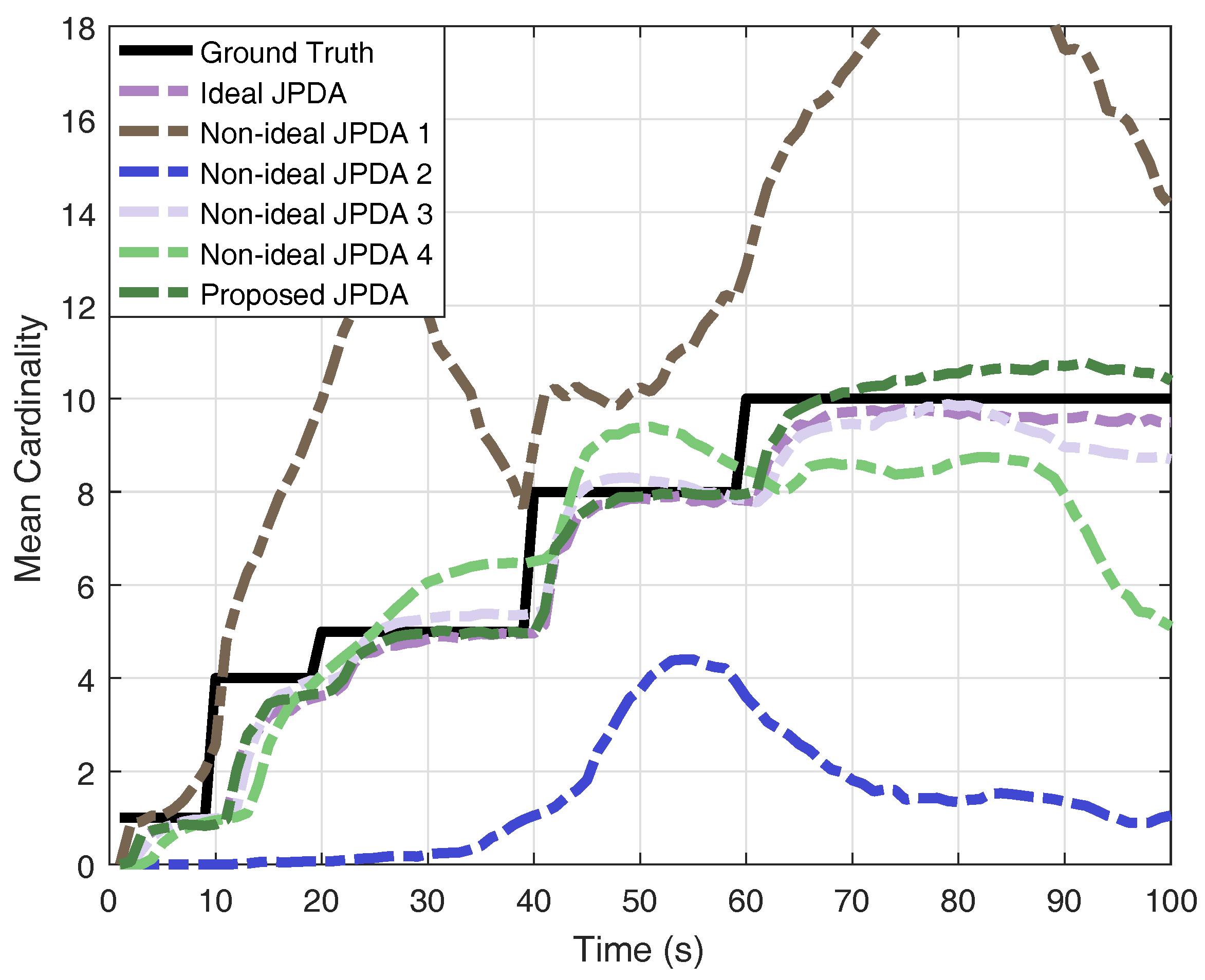
The results of OSPA distance and cardinality estimation obtained by 200 Monte-Carlo runs are shown in Figure 4 and Figure 5. The obtained mean OSPA distances from different JPDAs in simulations are summarised in Table 1. The peaks of mean OSPA distance in Figure 4 are resulted from track confirmation for target birth. If the clutter rate is set lower than the real value, the JPDA filter overestimate the multi-target state and thus generating more ’confirmed’ targets, leading to larger OSPA distance (e.g., non-ideal JPDA filter 1). If the clutter rate is set higher than the real value, the JPDA filter gives an underestimation the multi-target state (e.g., non-ideal JPDA filter 2). Although the results, shown in Figure 4, reveal that the JPDA filter is somewhat robust against the detection probability (e.g., non-ideal JPDA filter 3), lower detection probability gives a delayed confirmation, as we stated earlier. Moreover, when the detection probability is highly mismatched with its real value (e.g., non-ideal JPDA filter 4), the estimation is unreliable. As a comparison, the results clearly verify that the proposed JPDA filter has comparable performance as the ideal JPDA filter by utilising the multi-Bernoulli estimator in a feedback loop.
6. Conclusions
This paper developed an enhanced version of JPDA by incorporating with the multi-Bernoulli filter to accommodate the unknown detection probability and clutter rate. By utilising the PPP birth in JPDA filter, the multi-target estimation output can be characterised as a multi-Bernoulli RFS. This enables the application of the multi-Bernoulli filter in a feedback loop to estimate the unknown detection probability and clutter rate. Simulation results confirm that the proposed algorithm exhibits the advantages of the original JPDA filter and can correct the biased estimations induced by the unknown detection probability and clutter. Under the condition where detection probability and clutter rate are difficult to be obtained, the proposed JPDA filter can be a practical solution, providing performance comparable to the ideal JPDA filter.
Acknowledgments
The authors acknowledge Cranfield University for the support of open access publication.
Author Contributions
Hyo-Sang Shin conceived and designed the research; Shaoming He and Hyo-Sang Shin developed the algorithm, performed simulations, analysed the results and drafted the manuscript; Antonios Tsourdos supervised the data analysis and discussion.
Conflicts of Interest
The authors declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Appendix A. Approximated Marginalisation by Gibbs Sampling
According to Equation (5), the posterior distribution of the joint event can be formulated as
where denotes the un-normalised PDA probability of given by
and
which ensure that one measurement (except for the dummy measurement) can only be allocated to one target.
It is clear that determining the marginal joint association probability requires full enumeration of all possible joint association events, which is a well-known #P-complete problem. To tackle the combinatorial nature of this problem, our previous work suggested a sampling based, especially Gibbs sampling-based, algorithm [25]. The key idea of utilising Gibbs sampling in JPDA is to consider each joint association event as a random variable that satisfies a distribution . To ensure that the joint events with higher probability are more easily to be sampled, the sampling proposal is constructed proportional to the joint posterior probability as
The issue is that direct sampling from Equation (A5) is very difficult as enumerating all possible joint events is impossible for real-time applications. Therefore, Gibbs sampling to applied for generating the samples. The transition kernel from one joint event to another joint event is
where can be obtained as
“Proportion to” in Equation (A7) highlights the dependence of individual conditional distribution on , while rest parts are formed as the normalisation constant. Given the joint event , a joint event can be obtained by recursive sampling according to the following individual conditional distributions
Using Gibbs sampling, we could generate a sufficient number of samples of . From the samples, it is straightforward to approximate the marginal probability by the event occurrence.
References
- Wenzl, K.; Ruser, H.; Kargel, C. Performance evaluation of a decentralized multitarget-tracking algorithm using a LIDAR sensor network with stationary beams. IEEE Trans. Instrum. Meas. 2013, 62, 1174–1182. [Google Scholar] [CrossRef]
- He, S.; Shin, H.S.; Tsourdos, A. Track-Oriented Multiple Hypothesis Tracking Based on Tabu Search and Gibbs Sampling. IEEE Sens. J. 2017, 18, 328–339. [Google Scholar] [CrossRef]
- Zhang, Q.; Song, T.L. Improved Bearings-Only Multi-Target Tracking with GM-PHD Filtering. Sensors 2016, 16, 1469. [Google Scholar] [CrossRef] [PubMed]
- Reid, D. An algorithm for tracking multiple targets. IEEE Trans. Autom. Control 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Blackman, S.; Popoli, R. Design and Analysis of Modern Tracking Systems; Artech House: Norwood, MA, USA, 1999. [Google Scholar]
- Cox, I.J.; Hingorani, S.L. An Efficient implementation of Reid’s multiple hypothesis tracking algorithm and its evaluation for the purpose of visual tracking. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 138–150. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4696–4704. [Google Scholar]
- Fortmann, T.E.; Bar-Shalom, Y.; Scheffe, M. Sonar tracking of multiple targets using joint probabilistic data association. IEEE Eng. Ocean. Eng. 1983, 8, 173–184. [Google Scholar] [CrossRef]
- Challa, S. Fundamentals of Object Tracking; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Roecker, J.A.; Phillis, G.L. Suboptimal Joint Probabilistic Data Association. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 510–517. [Google Scholar] [CrossRef]
- Roecker, J.A. A Class of Near Optimal JPDA Algorithms. IEEE Trans. Aerosp. Electron. Syst. 1994, 30, 504–510. [Google Scholar] [CrossRef]
- Rezatofighi, S.H.; Milan, A.; Zhang, Z.; Shi, Q.; Dick, A.; Reid, I. Joint probabilistic data association revisited. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3047–3055. [Google Scholar]
- Lee, E.H.; Zhang, Q.; Song, T.L. Markov Chain Realization of Joint Integrated Probabilistic Data Association. Sensors 2017, 17. [Google Scholar] [CrossRef] [PubMed]
- Kim, W.C.; Song, T.L. Spatial clutter measurement density estimation in nonhomogeneous measurement spaces. In Proceedings of the 18th IEEE International Conference on Information Fusion (Fusion), Washington, DC, USA, 6–9 July 2015; pp. 1772–1777. [Google Scholar]
- Elgammal, A.; Duraiswami, R.; Harwood, D.; Davis, L.S. Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. Proc. IEEE 2002, 90, 1151–1163. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Mahler, R.P.; Vo, B.T.; Vo, B.N. CPHD filtering with unknown clutter rate and detection profile. IEEE Trans. Signal Proc. 2011, 59, 3497–3513. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Hoseinnezhad, R.; Mahler, R.P. Robust multi-Bernoulli filtering. IEEE J. Sel. Top. Signal Proc. 2013, 7, 399–409. [Google Scholar] [CrossRef]
- He, S.; Shin, H.S.; Tsourdos, A. Joint Probabilistic Data Association Filter with Unknown Detection Probability and Clutter Rate. In Proceedings of the IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Daegu, Korea, 16–18 November 2017; pp. 559–564. [Google Scholar]
- Li, X.R.; Li, N. Integrated real-time estimation of clutter density for tracking. IEEE Trans. Signal Proc. 2000, 48, 2797–2805. [Google Scholar] [CrossRef]
- Song, T.L.; Musicki, D. Adaptive clutter measurement density estimation for improved target tracking. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 1457–1466. [Google Scholar] [CrossRef]
- Chen, X.; Tharmarasa, R.; Kirubarajan, T.; McDonald, M. Online clutter estimation using a Gaussian kernel density estimator for multitarget tracking. IET Radar Sonar Navig. 2014, 9, 1–9. [Google Scholar] [CrossRef]
- Smith, F.W.; Malin, J.A. Models for radar scatterer density in terrain images. IEEE Trans. Aerosp. Electron. Syst. 1986, AES-22, 642–647. [Google Scholar] [CrossRef]
- Williams, J.L. Hybrid Poisson and multi-Bernoulli filters. In Proceedings of the 2012 15th IEEE International Conference on Information Fusion (FUSION), Singapore, 9–12 July 2012; pp. 1103–1110. [Google Scholar]
- He, S.; Shin, H.S.; Tsourdos, A. Distributed Multiple Model Joint Probabilistic Data Association with Gibbs Sampling-Aided Implementation. IEEE Trans. Autom. Control 2018. under review. [Google Scholar]
- Mušicki, D.; Evans, R. Joint Integrated Probabilistic Data Association—JIPDA. IEEE Trans. Aerosp. Electron. Syst. 2004, 40, 1093–1099. [Google Scholar] [CrossRef]
- Vo, B.T.; Vo, B.N.; Cantoni, A. The cardinality balanced multi-target multi-Bernoulli filter and its implementations. IEEE Trans. Signal Proc. 2009, 57, 409–423. [Google Scholar]
- Ouyang, C.; Ji, H.; Li, C. Improved multi-target multi-Bernoulli filter. IET Radar Sonar Navig. 2012, 6, 458–464. [Google Scholar] [CrossRef]
- Mahler, R.P. Statistical Multisource-Multitarget Information Fusion; Artech House, Inc.: Norwood, MA, USA, 2007. [Google Scholar]
- Kennedy, H.L. Powerful test statistic for track management in clutter. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 207–223. [Google Scholar] [CrossRef]
- Schuhmacher, D.; Vo, B.T.; Vo, B.N. A consistent metric for performance evaluation of multi-object filters. IEEE Trans. Signal Proc. 2008, 56, 3447–3457. [Google Scholar] [CrossRef]
Figure 1.
JPDA with unknown detection probability and clutter rate.
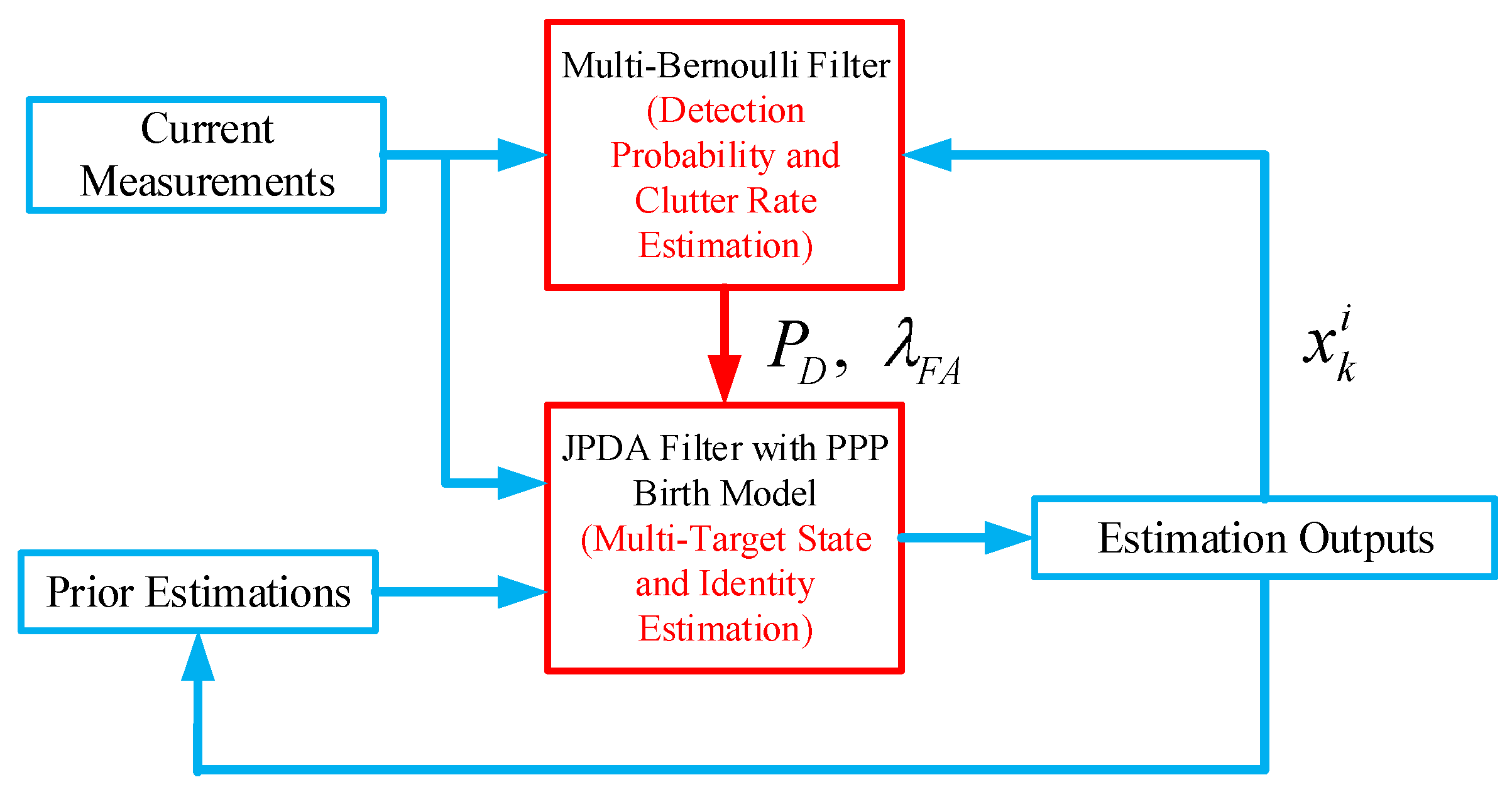
Figure 2.
Ground truth of the considered scenario.

Figure 3.
Clutter profile.

Figure 4.
Monte-Carlo results of mean OSPA distance.
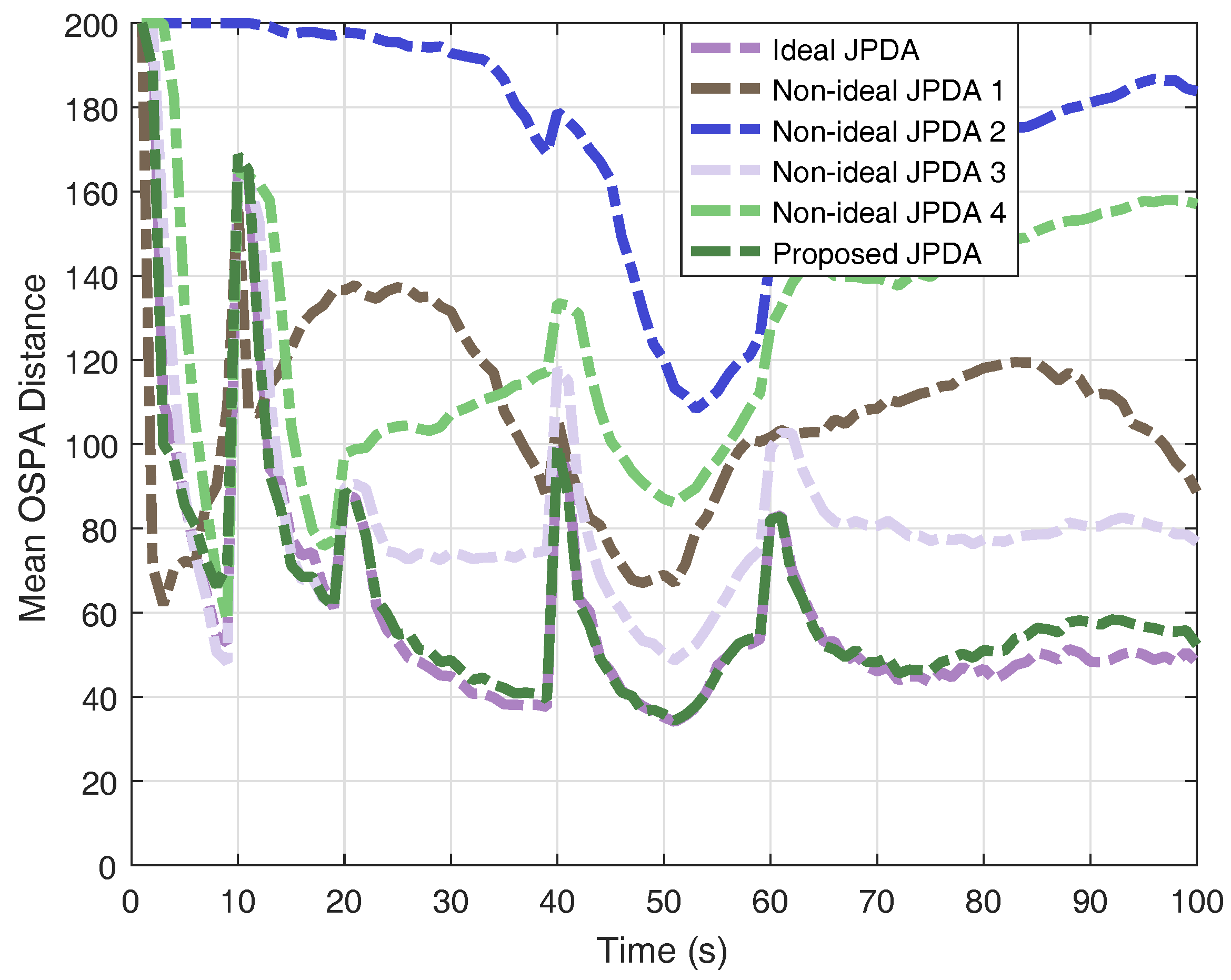
Figure 5.
Monte-Carlo results of mean cardinality estimation.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Mean OSPA distance of 200 Monte-Carlo runs.
| Ideal JPDA | JPDA 1 | JPDA 2 | JPDA 3 | JPDA 4 | Proposed JPDA | |
|---|---|---|---|---|---|---|
| Mean OSPA distance |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
He, S.; Shin, H.-S.; Tsourdos, A. Joint Probabilistic Data Association Filter with Unknown Detection Probability and Clutter Rate. Sensors 2018, 18, 269. https://doi.org/10.3390/s18010269
AMA Style
He S, Shin H-S, Tsourdos A. Joint Probabilistic Data Association Filter with Unknown Detection Probability and Clutter Rate. Sensors. 2018; 18(1):269. https://doi.org/10.3390/s18010269
Chicago/Turabian StyleHe, Shaoming, Hyo-Sang Shin, and Antonios Tsourdos. 2018. "Joint Probabilistic Data Association Filter with Unknown Detection Probability and Clutter Rate" Sensors 18, no. 1: 269. https://doi.org/10.3390/s18010269
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.