
Social Welfare Control in Mobile Crowdsensing Using Zero-Determinant Strategy

1
College of Information Science and Technology, Beijing Normal University, Beijing 100875, China
2
Department of Computer Science, George Washington University, Washington, DC 20052, USA
*
Author to whom correspondence should be addressed.
Sensors 2017, 17(5), 1012; https://doi.org/10.3390/s17051012
Submission received: 28 February 2017
/
Revised: 7 April 2017
/
Accepted: 11 April 2017
/
Published: 3 May 2017
(This article belongs to the Special Issue New Advances in Identification, Information & Knowledge in the Internet of Things)
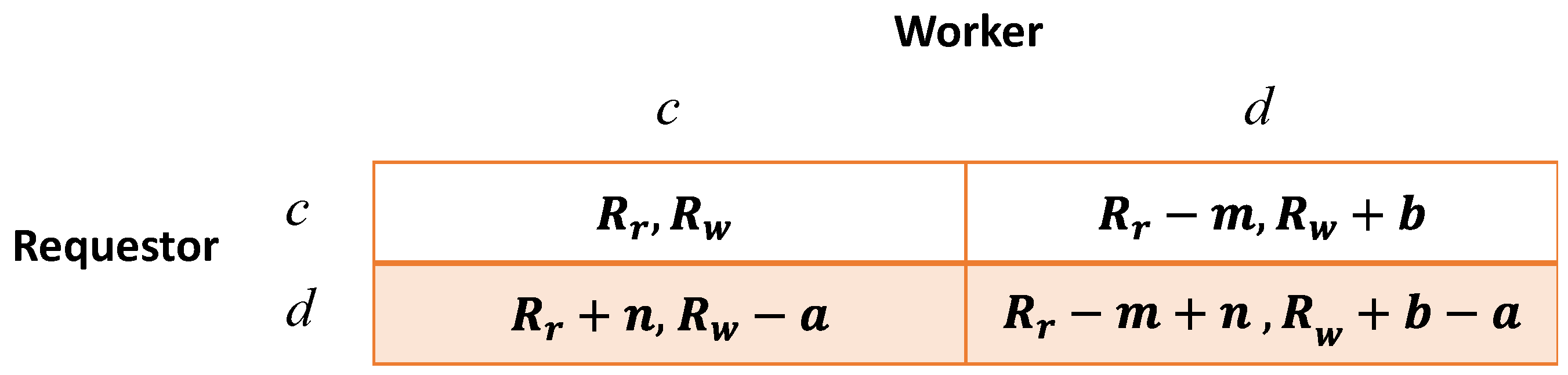{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:As a promising paradigm, mobile crowdsensing exerts the potential of widespread sensors embedded in mobile devices. The greedy nature of workers brings the problem of low-quality sensing data, which poses threats to the overall performance of a crowdsensing system. Existing works often tackle this problem with additional function components. In this paper, we systematically formulate the problem into a crowdsensing interaction process between a requestor and a worker, which can be modeled by two types of iterated games with different strategy spaces. Considering that the low-quality data submitted by the workers can reduce the requestor’s payoff and further decrease the global income, we turn to controlling the social welfare in the games. To that aim, we take advantage of zero-determinant strategy, based on which we propose two social welfare control mechanisms under both game models. Specifically, we consider the requestor as the controller of the games and, with proper parameter settings for the to-be-adopted zero-determinant strategy, social welfare can be optimized to the desired level no matter what strategy the worker adopts. Simulation results demonstrate that the requestor can achieve the maximized social welfare and keep it stable by using our proposed mechanisms.
1. Introduction
With the rapid development of micro-electro-mechanical systems and digital electronics, more and more functional sensors (e.g., accelerometers, cameras and compasses) are equipped in various kinds of mobile devices (e.g., smartphones and wearable devices). On the other hand, the development of wireless communication technologies (e.g., bluetooth and Wi-Fi) has stepped into a new era. These advances contribute substantially to the emergence of mobile crowdsensing [1,2,3]. Unlike traditional sensor networks with numerous static sensors [4,5], mobile crowdsensing takes advantage of the massive mobile-device owners (i.e., workers) and their mobility to obtain comprehensive and real-time sensing outcomes for requestors. However, since workers with different backgrounds and skills often undertake tasks without strict rules, they may provide low-quality data (e.g., fabricated or incomplete data) to get more profit. This situation is harmful to requestors in a short term and is disastrous to the whole crowdsensing system in a long term. Therefore, it is imperative to tackle the problem of low-quality data generated by the workers in mobile crowdsensing.
Recently, plenty of research focusing on data quality in mobile crowdsensing has been presented. Auction, a powerful tool in economics, has been widely adopted to ensure data quality. Accordingly, auctions are employed in the design of incentive mechanisms for mobile crowdsensing [6,7,8]. However, the negotiation process in an auction usually costs excessive time, which is redundant and cumbersome for lightweight mobile crowdsensing applications. History behaviorial information of the participants also has been utilized. Crowdsensing quality was improved by filtering out low-quality data providers in the reputation-based-schemes [9] and machine-learning-based-schemes [10]. Nevertheless, such an approach may fail due to the lack of sufficient training or history data.
To conquer the existing issues in mobile crowdsensing quality control, we devise a more cost-efficient and systematic approach in this paper. Our approach embeds a data quality improvement process into crowdsensing interaction. We first formulate the interaction between the requestor and any worker in mobile crowdsensing as an iterated game. In this game, the payment amount is regarded as the strategy of the requestor, and the submitted data quality is the action of the worker. Note that the worker’s bad actions can directly lower the requestor’s profit, and can bring damage to the total profit of the crowdsensing system. As the requestor is the victim of the low-quality data problem as well as the recruiter of the crowdsensing task, we consider that the requestor has the responsibility and capability to deal with the bad actions. Therefore, in order to warrant mobile crowdsing quality effectively and efficiently, we propose social welfare controlling schemes for the requestor to guarantee the whole interest of the crowdsensing system regardless of the workers’ actions.
More specifically, we analyze the problem under two situations with different types of strategies (i.e., discrete strategy and continuous strategy) a requestor and a worker may take. As a result, we propose a zero-determinant strategy that offers the possibility for the requestor to unilaterally control the social welfare in the iterated game. By solving a constrained optimization problem, we design social welfare control mechanisms for the two models. The requestor only needs to setup appropriate parameters for her (In this paper, we denote the requestor as “she” and the worker as “he” for better distinction) strategy, so as to obtain the desired social welfare instead of sparing any effort to deal with the workers’ actions. In other words, with the proposed schemes for the requestor, a worker’s strategy has no impact on the social welfare.
Concentrating on solving the above problem in mobile crowdsensing, we summarize the contributions of this paper as follows:
- We make use of two types of iterated games to formulate the interactions between the requestor and the worker in mobile crowdsensing when they adopt discrete strategies and continuous strategies.
- Based on the original zero-determinant strategy derived under the discrete model, we extend it with sufficient theoretic derivation to make it applicable for the continuous model. Note that this extension not only provides theoretical foundation for our proposed mechanism but also expands the application range of zero-determinant strategy.
- We propose two social welfare control mechanisms for the requestor under two different situations, which helps the requestor establish an overall control over the quality of the whole crowdsensing system so as to solve the low-quality data problem from the perspective of the ultimate goal.
The rest of the paper is organized as follows. Section 2 formulates the games between the requestor and any worker in mobile crowdsensing under the discrete-strategy and continuous-strategy situations. The mechanisms achieving social welfare control under two different models are proposed in Section 3. We simulate our proposed schemes in Section 4 to verify their effectiveness. Most related works are investigated in Section 5 and the whole paper is concluded in Section 6.
2. Game Formulation
In this paper, we consider the following crowdsensing scenario. As the initiator of mobile crowdsensing tasks, the requestor publishes jobs with the corresponding payments. The workers claim the jobs that they can accomplish in order to get payments. At each round, the requestor can distribute different payments to a certain job while the workers can choose to provide different levels of task quality to the claimed jobs. With the temptation of getting more profit, the workers may maliciously provide very low job quality. Because of the limitation on the resources of a requestor (e.g., computing power and detection time), we assume that the requestor has difficulty to discover the bad behavior of a worker in a timely manner. However, the requestor is able to find out a worker’s malicious behavior of providing low job quality after a certain number of rounds and then penalize the worker in future rounds. The above working scenario between the requestor and any one of the workers can be viewed as a game; and it turns out to be an iterated game if the same worker is recruited in multiple rounds.
For the iterated game mentioned above, the strategy of the requestor is considered to be the amount of payment she determines to offer to the worker for a specific job, while the strategy of the worker is the quality of the job he decides to provide in the following job completing process. Since the strategies of both players could be either simple or complicated, we consider them as either discrete or continuous. A discrete strategy means that both players adopt either an extremely amicable or a vicious action, while a continuous one refers to any action as long as it is in the corresponding continuous strategy space. The distinction on strategy types may result in totally different problem formulations and solutions in the iterated game; thus we model the above problem by considering a discrete model and a continuous model.
In the discrete model, the requestor can choose the strategy of providing the highest or the lowest payment for a certain job, and the worker determines his strategy on providing the highest or the lowest quality for accomplishing the claimed job. Here, the requestor’ strategy is defined as , where c is the abbreviation of cooperation denoting the highest payment and d means defection referring to the lowest payment; and the worker’s strategy is , where c refers to the highest job quality and d is the lowest. At each round, the strategy that any player adopts is private; thus there could be four outcomes of the game between the requestor and the worker, i.e., .
We define and as the payoff of the requestor and that of the worker when they mutually cooperate. Let b be the increase on payoff when the worker defects but the requestor cooperates, in which case the requester gets a decrease m on payoff; let n be the increase on payoff when the requestor defects but the worker cooperates, and thus the worker’s payoff will have a decrease a. Here, we consider because the lowest payment of the requestor and the lowest job quality of the worker could result in less payoff for both of them than that of the case when both cooperate. We denote the payoff vector of the requestor as and that of the worker as under the state , which are demonstrated in Figure 1. For the requestor, it is obvious that no matter what the worker’s strategy is, her best strategy is ; and, similarly, the worker can also derive that his best strategy is . Thus, this game has an equilibrium of , where the social welfare is certainly less than that of any other state.
In the continuous model, the requestor can choose any payment from her strategy space, while the worker can determine any job quality from his strategy domain. We denote the requestor’s strategy as , where and are respectively the lowest and the highest payment that the requestor can offer; and the worker’s strategy is denoted as , where and are respectively the lowest and the highest job quality the worker can provide.
We define the requestor’s utility as
where the first term is the profit that the accomplished job brings to the requestor and the second term refers to the payment she should assign to the worker; the scaling parameters and ; and monotonically increases with the worker’s strategy y.
With a similar composition, the worker’s utility can be expressed as
where the first term is the payment the worker can acquire by completing the sensing job, while the second term reflects the cost in the job completing process. The scaling parameters and ; and also monotonically increases with y.
To briefly examine the equilibrium of this continuous game, we make the following calculations. For the requestor, we have , which means that her utility decreases with x; thus the requestor’s best strategy is no matter what the worker’s strategy y is. On the other hand, since increases as y increases, we have . Combining with , we have , which means that the worker can get his best strategy regardless of the requestor’s strategy x. Therefore, the stable equilibrium of the continuous-model game is , which is clearly an unexpected outcome for the requestor.
3. Game Analysis and Mechanism Design
Based on the analysis in Section 2, one can see that the stable equilibrium states in both the discrete and the continuous models are unfavorable to the requestor. Moreover, these models are certainly inefficient for both the requestor and the worker in a short term, and it is potentially harmful to the stability and sustainability of the crowdsensing system. Thus, it is necessary for the requestor to address the issue as she is the sensing task employer who is assumed to have the responsibility and capability for solving such a problem. Therefore, in this section, we first provide a further analysis on the iterated games under these two different models and then propose mechanisms to help the requestor control the social welfare in mobile crowdsensing without considering the worker’s specific strategy.
3.1. Zero-Determinant Strategy Based Scheme in the Discrete Model
In this paper, we assume that all the players only have the memory of the state in the last round. As mentioned in [11], a short-memory player rather than a long-memory player determines the rules of the game. In our game, both players have mixed strategies at each round denoting the cooperation probabilities under the four possible states in the last round. Accordingly, we define the mixed strategy of the requestor as and that of the worker as . Here, and , , , are the probabilities of choosing c in round t when the outcome of round is . Additionally, we denote the possibilities of the four potential states at round t as , where ; thus the corresponding payoffs of the requestor and the worker are and , respectively.
With the definitions of and mentioned above, one can get the Markov state transition matrix as follows,
where each element denotes the probability of the state transferring from round to t. Here, each row of (3) corresponds to the state at round following the order and each column is corresponding to the state at round t following the same order. For example, denotes the transition probability from state at round to the state at round t.
We assume that the stable vector of the above transition matrix is denoted by ; thus we have
Inspired by the calculation in [11], we denote by the unitary matrix, and let ; thus we have Then, we can obtain according to the Cramer’s rule, in which denotes the adjugate matrix of . Comparing the above two equations, one can see that is proportional to every row of . Therefore, the dot product of the stable vector and any vector can be calculated as follows:
Notably, the second column of (5) can be determined by the requestor alone, which is denoted as . Hence, when , we have
where and are, respectively, the expected payoffs of the requestor and the worker in the final stable state; are scalars. Based on (5), we also have
Therefore, if the requestor selects strategy satisfying , the corresponding matrix’s second column is proportional to the fourth column, which implies that the above equation is equal to zero, i.e., . Therefore, the strategy adopted by the requestor is known as a zero-determinant strategy. Then the weighted social welfare of this game can be defined as
The above analysis indicates that when the requestor adopts a zero-determinant strategy, she can have a unilateral control over the social welfare, which can be fixed to a desired value no matter what strategy the worker adopts. This provides the requestor a powerful tool to maintain the stability and sustainability of the crowdsensing system.
In order to set the optimum and stable social welfare regardless of the worker’s strategy, the requestor needs to solve the following constrained optimization problem:
As mentioned in (8), it is equivalent to solve the following problem:
For the case of , when considering the constraint , one can get
while when considering the constraint condition , we have
Note that has a feasible solution only when it meets , i.e., . Considering that could be any positive value, we can obtain the minimum value of as follows,
For the case of , when considering that , we have ; while when considering that , we have . Then, is feasible when , i.e., . Finally, we can get the following result:
3.2. Zero-Determinant Strategy Based Scheme in the Continuous Model
In order to solve the problem under the continuous model, we also assume that both the requestor and the worker make their choices on strategies according to the outcome of the last round. Similarly, we define the mixed strategy of the requestor as the probability she chooses the payment x at round t when the state at round is , where and . Since the strategy x can be any value in the continuous domain, we have
In addition, the mixed strategy of the worker also refers to the conditional probability he provides job quality y when the state at the last round is , where and . There also exists the following relationship:
Next, we suppose that the joint probability that the requestor adopts strategy x and the worker adopts y at each round is . Considering the utility functions , one can get the expected utility of the requestor and that of the worker at round t as follows:
Similar to the state transition matrix in the discrete model, there is a transition function, denoted as , indicating the state transition probability from round to round t, which can be expressed as:
Then, the state probabilities at two sequential rounds have the following relationship:
With a similar analysis as the one for the zero-determinant strategy derived in the discrete model, we can figure out the zero-determinant strategy in the continuous model, which is summarized as follows.
Lemma 1.
When the requestor’s strategy satisfies , the requestor’s expected utility in a stable state and that of the worker meet the following relationship:
where is defined as
Proof.
We first divide the continuous strategy space into parts. Then the strategies of the requestor and the worker turn to be , and , respectively, where is sufficiently small while is sufficiently large, satisfying and . It is clear that when the strategy space is approximately continuous. Accordingly, the payoffs of the requestor and the worker are and , respectively.
Then, we define the requestor’s mixed strategy at round t as , which means that the probability of the requestor choosing at round t when the last state is ; similarly, the worker’s mixed strategy at round t is , where .
According to the above division on the strategy space and utility space, we have a Markov state transition matrix as follows:
where each element is a vector containing the transition probability from all the possible combinations of the last state to the current state and . More specifically, each element can be written as:
Suppose that the stable vector of is , we have , and the expected utilities of the requestor and the worker are and , respectively.
Assuming that , we have . With the same calculation as that under the discrete model, we obtain that is proportional to each row of . Therefore, for any vector , with the known condition , one can compute its dot product with as follows:
It is clear that the penultimate column of (26) can be decided only by the requestor, denoted as . When , we have . Therefore, if , we have . When the small number approaches to 0, the above lemma is proved. ☐
The weighted social welfare is defined as . Then according to Lemma 1, the requestor’s strategy is the only factor affecting the weighted social welfare , which can be regarded as the zero-determinant strategy in the continuous model. To be specific, the requestor can solve the following optimization problem to achieve a unilateral control on the social welfare without considering the worker’s strategy:
Let ; then the above problem can be converted into
For the case of , considering the constraint , we have
While considering the constraint condition , we have
When , has a feasible solution. In other words, . Since could be any positive number, we can get the minimum value of :
For the case of , when considering , we have ; while when considering , we have . Then, is feasible only when , i.e., . Thus, we can obtain the following result:
4. Evaluation of the Proposed Schemes
In this section, we evaluate the zero-determinant strategy based schemes proposed in Section 3 by simulations in Matlab. Considering the general definition of social welfare, we set First, we investigate the scheme proposed for the discrete model and report the results for the parameter settings , which implies that and . Note that we also simulate other parameter settings satisfying the relationship among these parameters mentioned in Section 2, and obtain very similar results, which are omitted due to page limit.
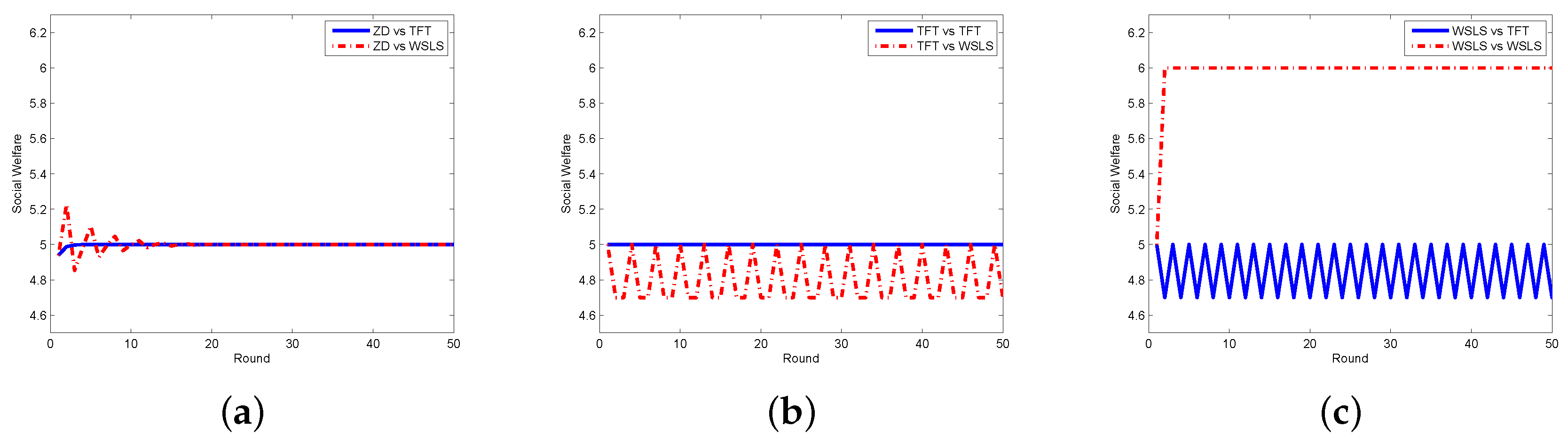
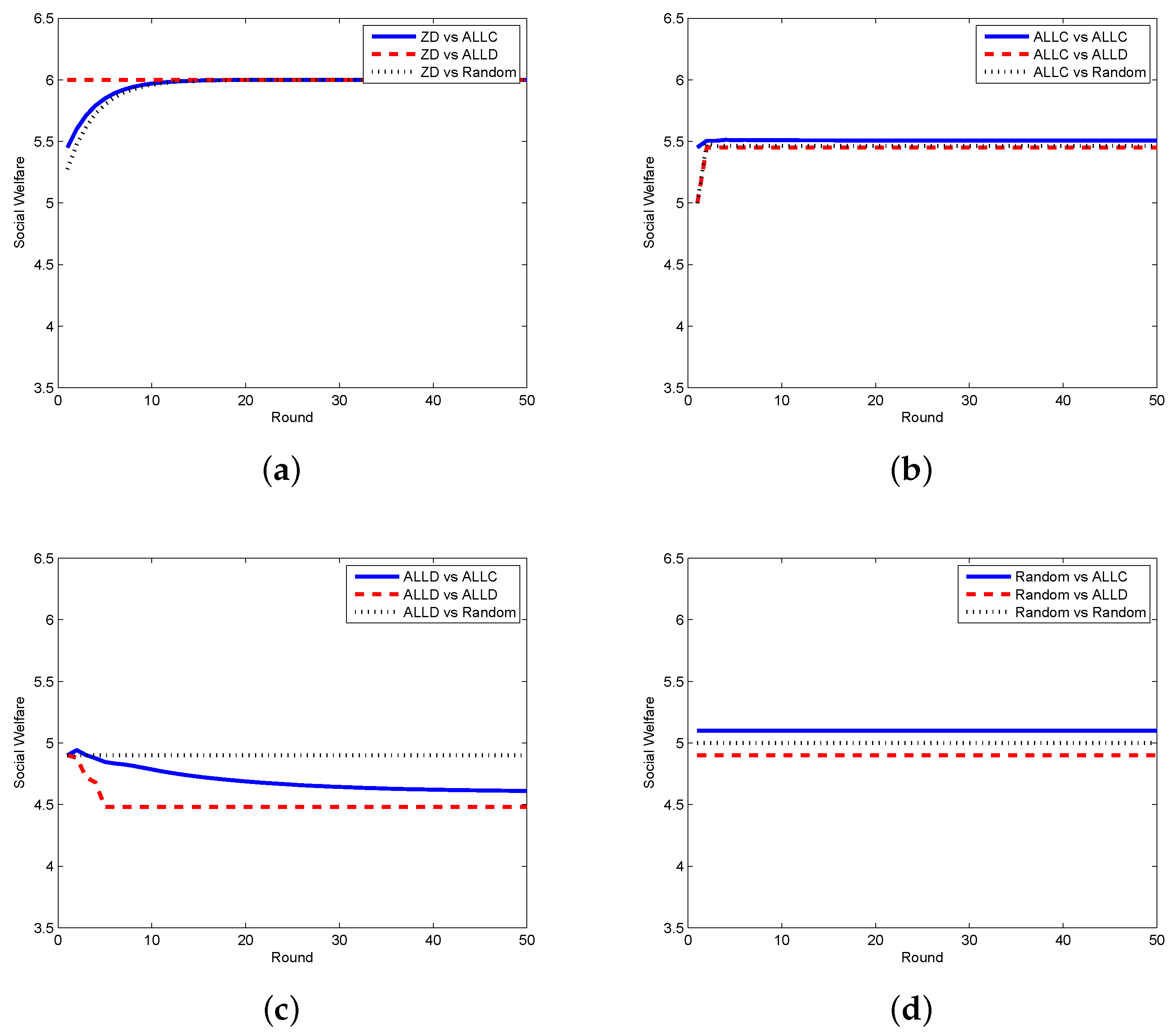
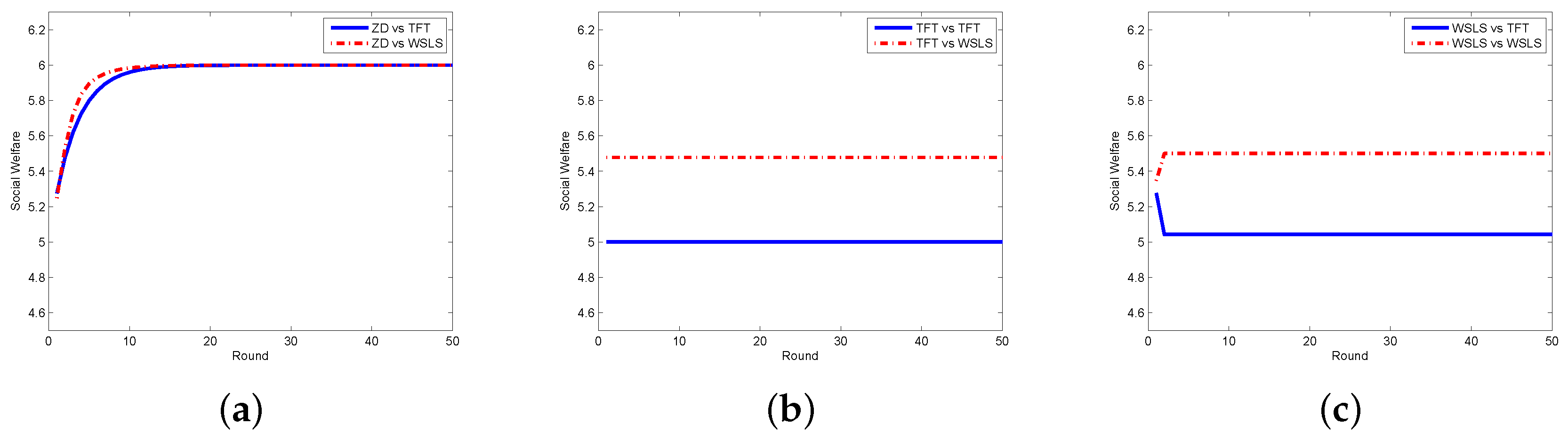
In order to testify the effectiveness of our proposed scheme, we compare the zero-determinant strategy with five other classical strategies that might be adopted by the requestor. In Figure 2, we display the results when the requestor adopts the proposed zero-determinant (ZD), all cooperation (, denoted as ALLC), all defection (, denoted as ALLD), and random (, denoted as Random) strategies while the worker adopts three strategies, i.e., ALLC, ALLD, and Random. It can be seen that the social welfare can be kept stable and can achieve its maximum value when the requestor adopts the ZD strategy and the worker adopts any strategy. However, when the requestor takes the other three strategies, the social welfare is determined by the strategies of both the requestor and the worker, which means that the requestor has no dominance on the control over the social welfare. The comparison results between the ZD strategy and two other classical strategies, i.e., tit-for-tat (TFT) and win-stay-lose-shift (WSLS), are presented in Figure 3. It is clear that when the requestor adopts the ZD strategy and the worker takes either TFT or WSLS, the social welfare is approximately the same and is stable; while when the requestor changes to any other strategy, the social welfare is fluctuated most of the time and is affected by the strategies of both parties.
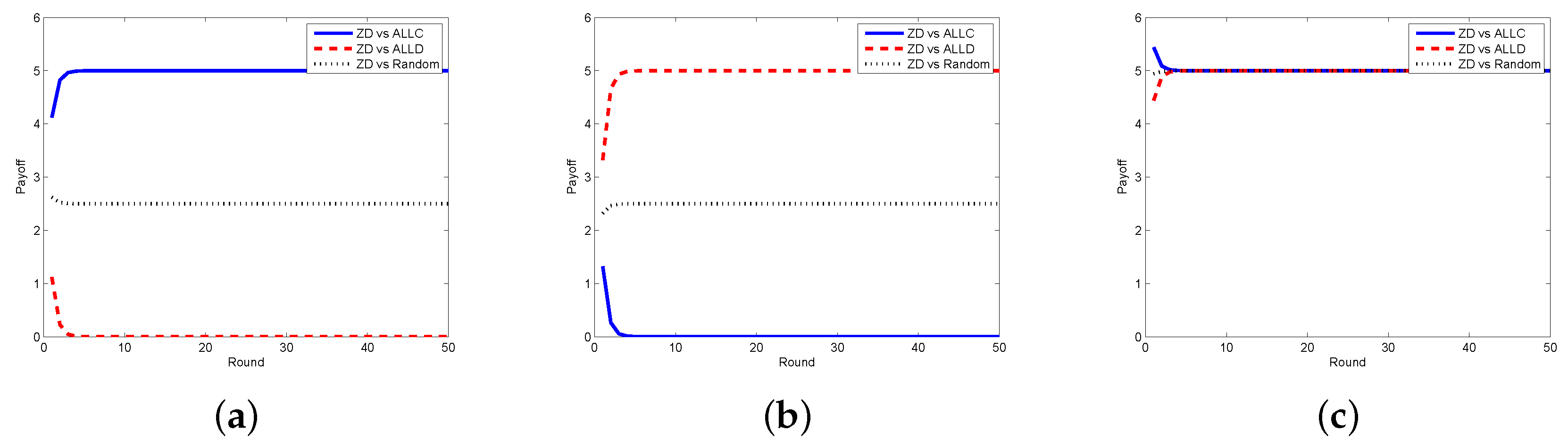
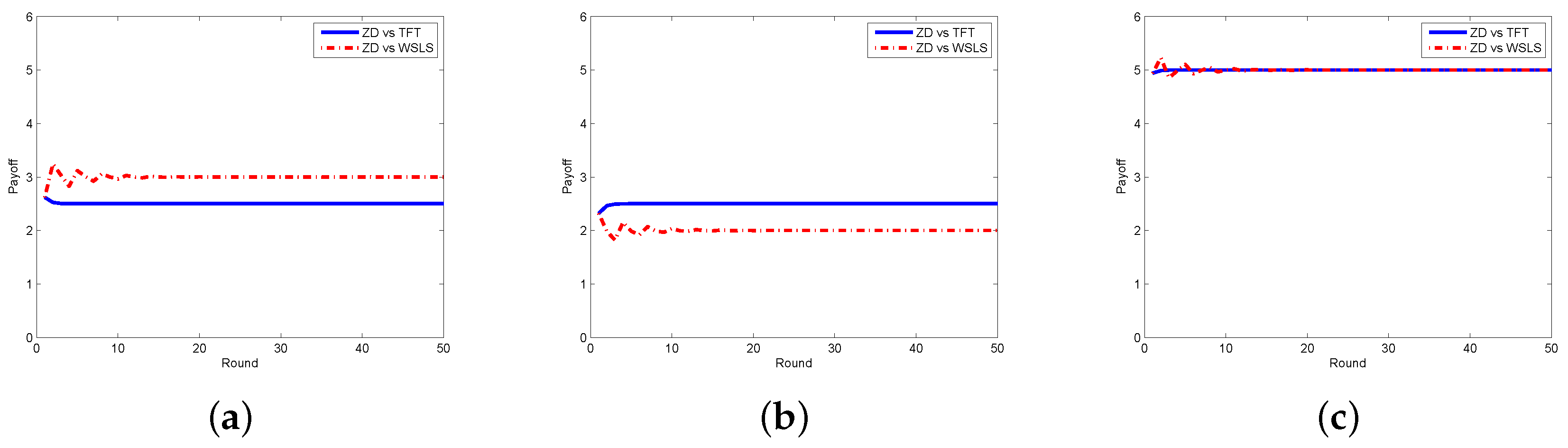
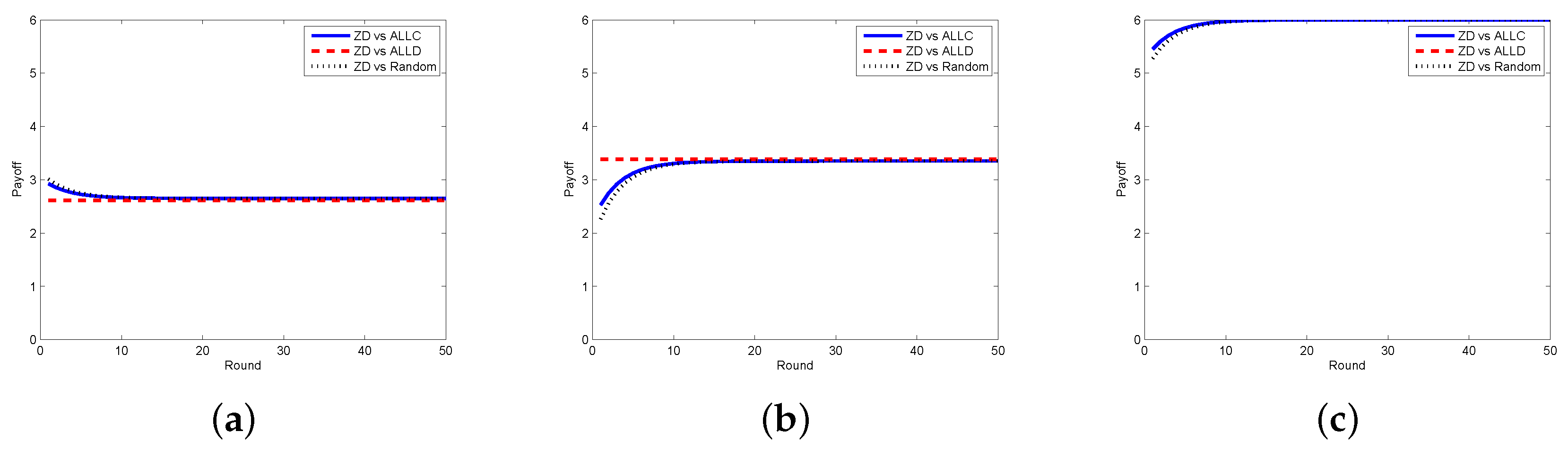
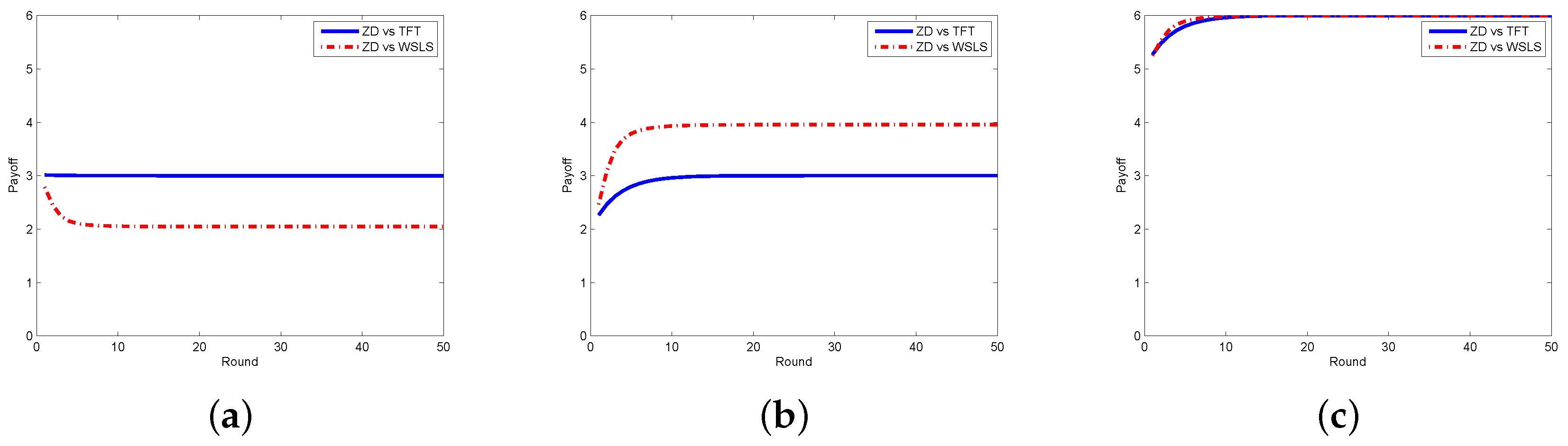
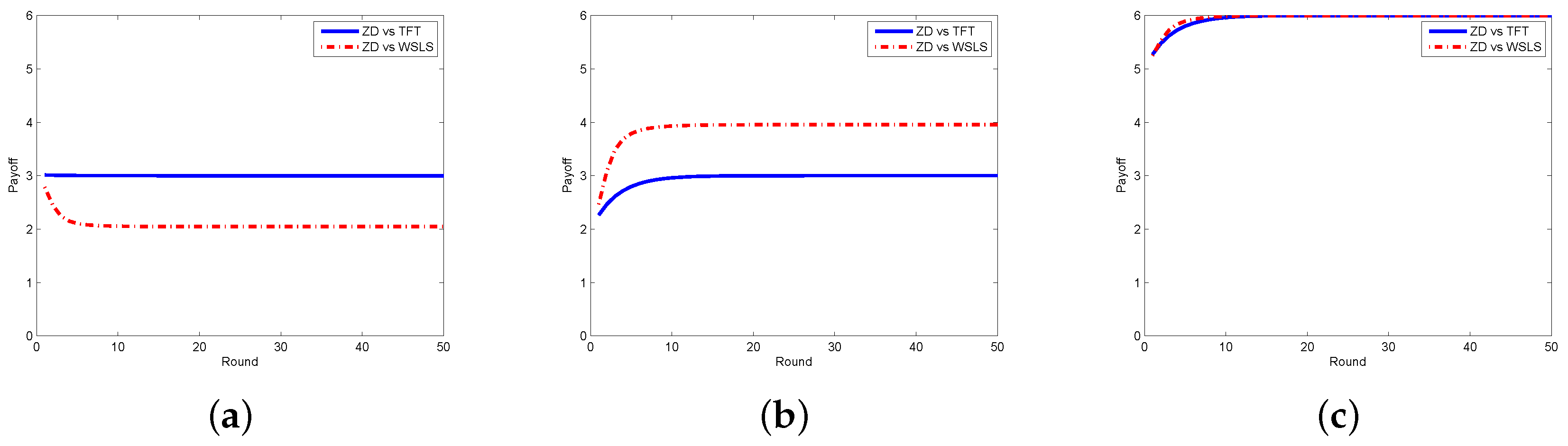
Next, we look at the respective payoffs of the requestor and the worker, depicted together with the total payoff (i.e., social welfare). The results when the requestor adopts the ZD strategy and the worker takes ALLC, ALLD, and Random strategies are shown in Figure 4, from which one can find out that the payoffs of the requestor and the worker are getting stable as the number of rounds increases, so does the social welfare. In Figure 5, we plot the payoffs of the requestor and the worker as well as the social welfare at each round under different strategy pairs, i.e., ZD versus TFT and ZD versus WSLS. The results indicate that the payoffs gradually become stable, which is consistent with the change of the social welfare. From the above two figures, one can also find out that the requestor’s payoff in stable state is no less than that of the worker in all strategy pairs except for the case when the requestor takes the ZD strategy while the worker takes the ALLD strategy, which seems to be unwise for a reasonable worker in practice.
In the scenario of continuous strategies adopted by both the requestor and the worker, we assume that they can choose their strategies from [0,10], i.e., . Suppose that , and ; thus we have and . We first compare the ZD strategy with the ALLC strategy corresponding to , the ALLD strategy corresponding to , and the Random strategy corresponding to , applied by the requestor. As shown in Figure 6, when the requestor adopts the ZD strategy, the social welfare becomes stable no matter whether the worker adopts the ALLC strategy (), the ALLD strategy (), or the Random strategy (). However, when the requestor employs any other classical strategy, the social welfare is related to the strategies of both sides. When TFT and WSLS strategies are employed, the results are presented in Figure 7. It can be seen that when the requestor takes the ZD strategy, no matter what strategies (TFT or WSLS) the worker adopts, the social welfare stays in the same stable value. However, when the requestor adopts either TFT or WSLS , the social welfare is also affected by the worker’s strategy. Furthermore, from the above two figures, one can see that even though the social welfare with some other pairs of strategies can reach stability, it is always less than that can be achieved when the requestor adopts the ZD strategy.
We also examine the payoffs of the requestor and the worker, as well as the total payoff (i.e., social welfare), under different strategy pairs they adopt. When the requestor adopts the ZD strategy and the worker adopts ALLC, ALLD, or Random, the results are reported in Figure 8, which clearly shows that the payoffs of the requestor and the worker are getting stable when the number of rounds increases, so does the social welfare. Figure 9 reports the payoffs of the requestor and the worker as well as the social welfare in each round under different strategy pairs (i.e., ZD versus TFT and ZD versus WSLS). One can see that the payoffs and the social welfare are gradually becoming stable.
5. Related Work
Recently, a large number of works focusing on devising incentive schemes to motivate workers’ participation in mobile crowdsensing have been proposed. Generally speaking, there are three typical classes of incentives, i.e., entertainment, service, and money. Entertainment-based incentive schemes are always realized by delicately designing games with attractive rewarding and penalizing strategies. In [12], Jordan et al. developed a location-based game called Ostereiersuche to collect the landmark structural information by encouraging users to search for coupons with some navigation hints, which is certainly an entertainment based incentive mechanism. Hoh et al. [13] proposed TruCentive, a service incentive mechanism that employs the parking information as an incentive to stimulate the drivers to report available parking time and places, by which the reporters could obtain corresponding points for future parking information requests. Lan et al. [14,15] designed a virtual credit based incentive mechanism for collecting mobile surveillance data, by which a participant could download data only when he/she paid the amount of required virtual credit earned by uploading sensing data or sharing bandwidth with others. The monetary incentives mostly rely on an economics tool, i.e., auction. In [16], considering the opportunistic occurrences in the places of interest, several online reverse-auction-based incentive mechanisms were put forward to achieve desired computation efficiency, individual rationality, profitability, and truthfulness in mobile crowdsensing. Chen et al. in [17] also took account of the participants’ dynamic arriving, based on which they devised a truthful online auction mechanism with no requirement on the previous knowledge.
Considering that data quality is an essential factor affecting the performance of mobile crowdsensing, more and more literature have turned to tackling the challenges of low task quality offered by participants. In [7], a metric called quality of information (QoI) was considered in the design of the incentive mechanisms for mobile crowdsensing and a reverse combinatorial auction was adopted to realize a maximized social welfare for the requestor and all the participating workers. Each mobile crowdsensing task was distributed by the requestor according to the bids of the workers along with the sum of QoI they can provide, which was obviously an NP-hard (non-deterministic polynomial-time hard) problem and could be only approximately solved. Another auction based and data quality accounted research work was reported in [8], in which an algorithm based on reverse Vickrey auction was proposed to maximize the social welfare when choosing workers in mobile crowdsensing, where the concept of data quality was mainly determined by the data type provided by a specific worker. After the subset of winning workers was selected by the QDA algorithm, the independent payment for each winner could be derived, along with some extra rewards proportional to the number of requestors adopting the submitted sensing data. In order to further protect the crowdsensing system from fake data attack during the auction-based working process, Xiao et al. [18] utilized game theory to accommodate the data quality into the utility functions of the requestor and the workers, and then derived the Nash Equilibrium according to the best responses. To be specific, all the submitted sensing data were classified into several types indicating different data quality levels as well as different payment levels, where the fake-data providers would be rated to be the lowest level and given the lowest payment of zero.
Note that even though auction based schemes are effective for data quality sensitive situations, such an approach could be unnecessary and burdensome for some simple mobile crowdsensing applications with low limitations on budget or with strict requirement on promptness.
Different from the above schemes that evaluate the data quality after completing the receiving process, data quality can be estimated in advance to help determine the best subset of workers undertaking the sensing tasks. For example, an Expectation Maximization algorithm and Bayesian inference were jointly taken by [19] to achieve data quality assurance in mobile crowdsensing: with the estimated data quality, a relatively fair and appropriate payoff for each worker can be calculated through a contribution quantification process with a Information Theory based model; and at the end of each task round, the estimation of the data quality provided by each worker is updated so as to evaluate data quality more precisely in the next round.
With the historical execution behavior of workers, some reputation based methods were proposed to settle the low quality problem of submitted data in mobile crowdsensing. In [9], Ref. Amintoosi et al. put forward a reputation framework for social participatory crowdsensing systems, rating workers via a fuzzy inference system according to their contribution quality and social trustworthiness level. After earning this reputation score, they utilized the PageRank algorithm to filter out the low quality data contributors online.
In addition, historical records of the system feedback can also offer a possibility for some data analysis techniques to improve the data quality in mobile crowdsensing. Kawajiri et al. [10] proposed a framework named Steered Crowdsensing based on some commercial location-based services (LBSs) to directly increase the job quality provided by the workers in crowdsensing, especially in opportunistic crowdsensing scenario. A quality indicator was introduced into the machine learning settings to optimally determine the payment of each sensing task, corresponding to a specific location, in a feedback-system manner, and further determine the quality of services the whole crowdsensing system can offer. This implies that there is a clear display of payment for each subtask at different locations, and the workers only need to make decisions on whether or not to complete the data sensing task in the required places.
On the other hand, the embedded sensors in the workers’s devices can not only help collect data in mobile crowdsensing but also potentially leak private information of the workers, such as location privacy indicated by GPS. Thus, the tradeoff between privacy preservation and data contribution of the workers plays an important role in the stable and prosperous development of mobile crowdsensing, which has been widely investigated in recent years [20,21,22]. In [20], Alsheikh et al. proposed a mechanism based on Vickrey–Clarke–Groves auction, which can guarantee data accuracy of mobile crowdsensing applications and simultaneously protect the workers’ privacy according to their requirements. Furthermore, in [22], Gisdakis et al. extended their basic security and privacy framework called SPPEAR [21] to resist as many attacks as possible, which could support various incentive mechanisms for participants in mobile crowdsensing.
From the above discussions, one can see that existing research related to mobile crowdsensing mainly focuses on incentive mechanism design and data quality control, as well as privacy and security protection. Incentive mechanisms are mostly based on providing entertainment, services, or money, where money based incentives always rely on auctions, while data quality control schemes mainly take advantage of auctions, game theory, data mining, and data analysis methods (e.g., Expectation Maximization algorithm, machine learning). The privacy and security issues are attracting more and more attention in recent years, which can be tackled by truthful actions and/or delicately designed security systems.
6. Conclusions
In this paper, we investigate the issue of social welfare control in crowdsensing. With the help of zero-determinant strategy, we propose a powerful approach for the requestor to unilaterally control the social welfare, i.e., the sum of the expected payoffs of the requestor and the worker, with no consideration on the strategy of the worker under both the discrete-strategy model and the continuous-strategy model. More specifically, with a delicate computation of her strategy, the requestor can achieve maximized and stable social welfare regardless of the worker’s strategy and complete the payment process at the same time. The simulation results validate the effectiveness of our proposed mechanisms, showing that the requestor adopting zero-determinant strategy can ensure the social welfare to stay at a desired level on her own.
Acknowledgments
This work has been supported by the National Natural Science Foundation of China (No. 61472044, No. 61272475, No. 61571049), and the Fundamental Research Funds for the Central Universities (No. 2014KJJCB32).
Author Contributions
Q.H., S.W., R.B. and X.C. conceived the main ideas of the paper; Q.H. and S.W. wrote the paper; R.B. designed the experiments; X.C. revised the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ganti, R.K.; Ye, F.; Lei, H. Mobile crowdsensing: Current state and future challenges. IEEE Commun. Mag. 2011, 49. [Google Scholar] [CrossRef]
- Ma, H.; Zhao, D.; Yuan, P. Opportunities in mobile crowd sensing. IEEE Commun. Mag. 2014, 52, 29–35. [Google Scholar] [CrossRef]
- Guo, B.; Wang, Z.; Yu, Z.; Wang, Y.; Yen, N.Y.; Huang, R.; Zhou, X. Mobile crowd sensing and computing: The review of an emerging human-powered sensing paradigm. ACM Comput. Surv. CSUR 2015, 48, 7. [Google Scholar] [CrossRef]
- Intanagonwiwat, C.; Govindan, R.; Estrin, D. Directed Diffusion: A Scalable and Robust Communication Paradigm for Sensor Networks. In Proceedings of the 6th Annual International Conference on Mobile Computing and Networking, Boston, MA, USA, 6–11 August 2000; pp. 56–67. [Google Scholar]
- Yu, J.; Wang, N.; Wang, G.; Yu, D. Connected dominating sets in wireless ad hoc and sensor networks—A comprehensive survey. Comput. Commun. 2013, 36, 121–134. [Google Scholar] [CrossRef]
- Sun, J.; Ma, H. A Behavior-Based Incentive Mechanism for Crowd Sensing with Budget Constraints. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, Australia, 10–14 June 2014; pp. 1314–1319. [Google Scholar]
- Jin, H.; Su, L.; Chen, D.; Nahrstedt, K.; Xu, J. Quality of Information Aware Incentive Mechanisms for Mobile Crowd Sensing Systems. In Proceedings of the 16th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Hangzhou, China, 22–25 June 2015; pp. 167–176. [Google Scholar]
- Wen, Y.; Shi, J.; Zhang, Q.; Tian, X.; Huang, Z.; Yu, H.; Cheng, Y.; Shen, X. Quality-driven auction-based incentive mechanism for mobile crowd sensing. IEEE Trans. Veh. Technol. 2015, 64, 4203–4214. [Google Scholar] [CrossRef]
- Amintoosi, H.; Kanhere, S.S. A reputation framework for social participatory sensing systems. Mob. Netw. Appl. 2014, 19, 88–100. [Google Scholar] [CrossRef]
- Kawajiri, R.; Shimosaka, M.; Kashima, H. Steered Crowdsensing: Incentive Design towards Quality-Oriented Place-Centric Crowdsensing. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 691–701. [Google Scholar]
- Press, W.H.; Dyson, F.J. Iterated Prisoner’s Dilemma contains strategies that dominate any evolutionary opponent. Proc. Natl. Acad. Sci. USA 2012, 109, 10409–10413. [Google Scholar] [CrossRef] [PubMed]
- Jordan, K.; Sheptykin, I.; Grüter, B.; Vatterrott, H.R. Identification of Structural Landmarks in a Park Using Movement Data Collected in a Location-Based Game. In Proceedings of the First ACM SIGSPATIAL International Workshop on Computational Models of Place, Orlando, FL, USA, 5–8 November 2013; pp. 1–8. [Google Scholar]
- Hoh, B.; Yan, T.; Ganesan, D.; Tracton, K.; Iwuchukwu, T.; Lee, J.S. Trucentive: A Game-Theoretic Incentive Platform for Trustworthy Mobile Crowdsourcing Parking Services. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems (ITSC), Anchorage, AK, USA, 16–19 September 2012; pp. 160–166. [Google Scholar]
- Lan, K.c.; Chou, C.M.; Wang, H.Y. An incentive-based framework for vehicle-based mobile sensing. Procedia Comput. Sci. 2012, 10, 1152–1157. [Google Scholar] [CrossRef]
- Chou, C.M.; Lan, K.c.; Yang, C.F. Using Virtual Credits to Provide Incentives for Vehicle Communication. In Proceedings of the 2012 12th International Conference on ITS Telecommunications (ITST), Taipei, Taiwan, 5–8 November 2012; pp. 579–583. [Google Scholar]
- Zhang, X.; Yang, Z.; Zhou, Z.; Cai, H.; Chen, L.; Li, X. Free market of crowdsourcing: Incentive mechanism design for mobile sensing. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3190–3200. [Google Scholar] [CrossRef]
- Chen, X.; Liu, M.; Zhou, Y.; Li, Z.; Chen, S.; He, X. A Truthful Incentive Mechanism for Online Recruitment in Mobile Crowd Sensing System. Sensors 2017, 17, 79. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.; Liu, J.; Li, Q.; Poor, H.V. Secure Mobile Crowdsensing Game. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 7157–7162. [Google Scholar]
- Peng, D.; Wu, F.; Chen, G. Pay as How Well You Do: A Quality Based Incentive Mechanism for Crowdsensing. In Proceedings of the 16th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Hangzhou, China, 22–25 June 2015; pp. 177–186. [Google Scholar]
- Alsheikh, M.A.; Jiao, Y.; Niyato, D.; Wang, P.; Leong, D.; Han, Z. The Accuracy-Privacy Tradeoff of Mobile Crowdsensing. arXiv, 2017; arXiv:1702.04565. [Google Scholar]
- Gisdakis, S.; Giannetsos, T.; Papadimitratos, P. Sppear: Security & Privacy-Preserving Architecture for Participatory-Sensing Applications. In Proceedings of the 2014 ACM Conference on Security and Privacy in Wireless & Mobile Networks, Oxford, UK, 23–25 July 2014; pp. 39–50. [Google Scholar]
- Gisdakis, S.; Giannetsos, T.; Papadimitratos, P. Security, Privacy, and Incentive Provision for Mobile Crowd Sensing Systems. IEEE Internet Things J. 2016, 3, 839–853. [Google Scholar] [CrossRef]
Figure 1.
Payoffs of the requestor and the worker at each round.
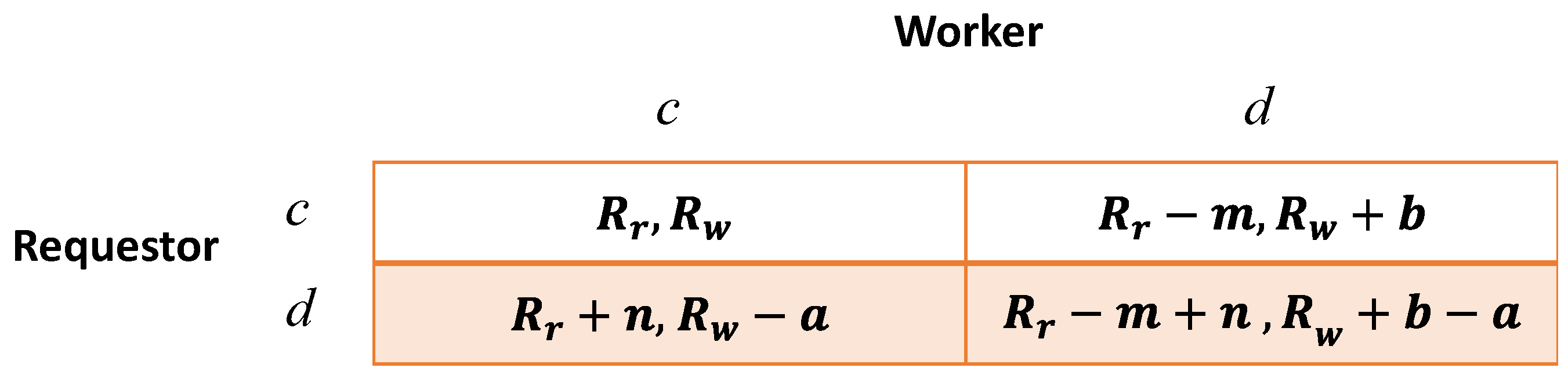
Figure 2.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, ALLC, ALLD, and Random in the discrete model. (a) requestor adopts the ZD strategy; (b) requestor adopts the ALLC strategy; (c) requestor adopts the ALLD strategy; (d) requestor adopts the Random strategy.
Figure 2.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, ALLC, ALLD, and Random in the discrete model. (a) requestor adopts the ZD strategy; (b) requestor adopts the ALLC strategy; (c) requestor adopts the ALLD strategy; (d) requestor adopts the Random strategy.
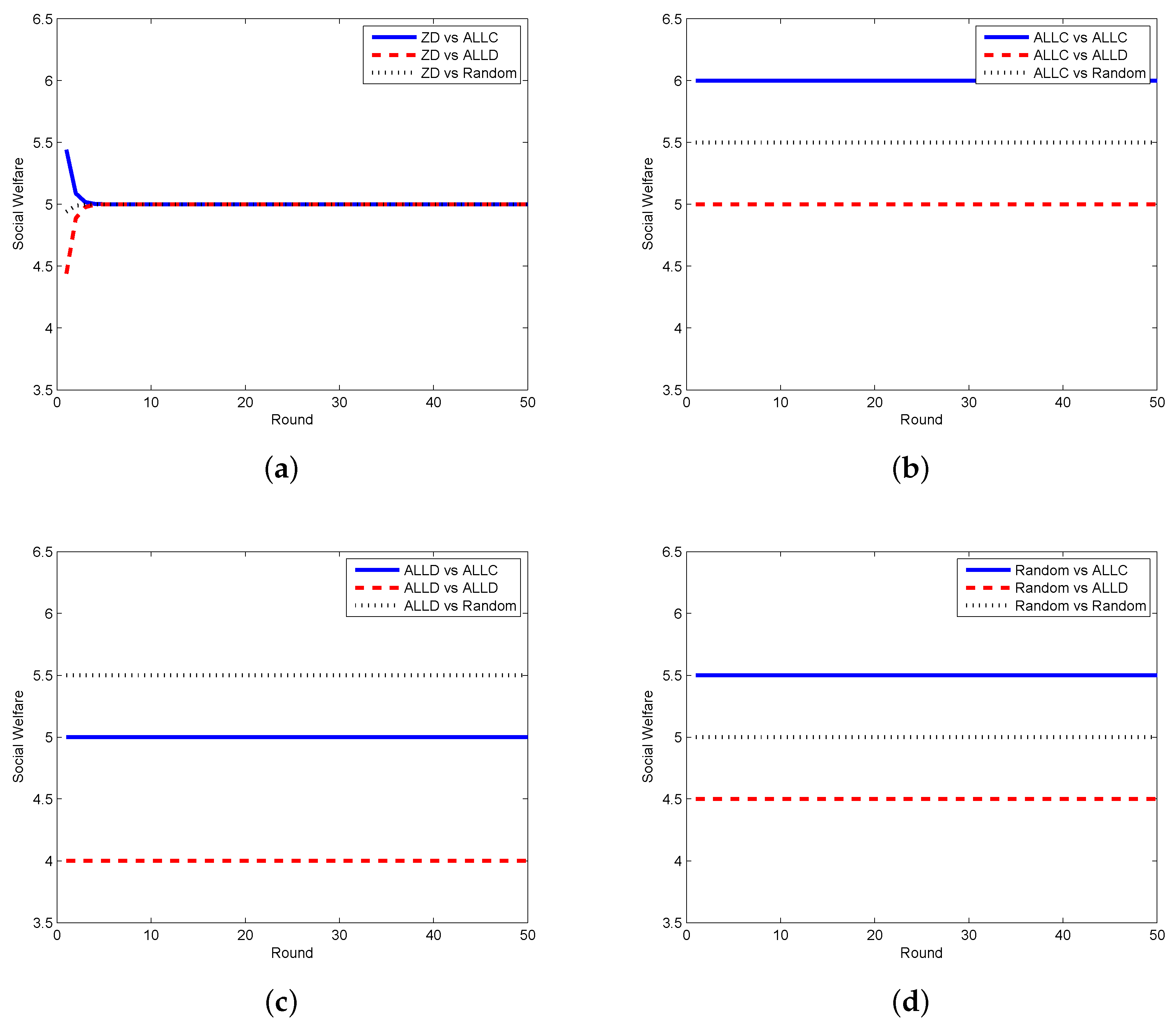
Figure 3.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, TFT, and WSLS in the discrete model. (a) requestor adopts the ZD strategy; (b) requestor adopts the TFT strategy; and (c) requestor adopts the WSLS strategy.
Figure 3.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, TFT, and WSLS in the discrete model. (a) requestor adopts the ZD strategy; (b) requestor adopts the TFT strategy; and (c) requestor adopts the WSLS strategy.
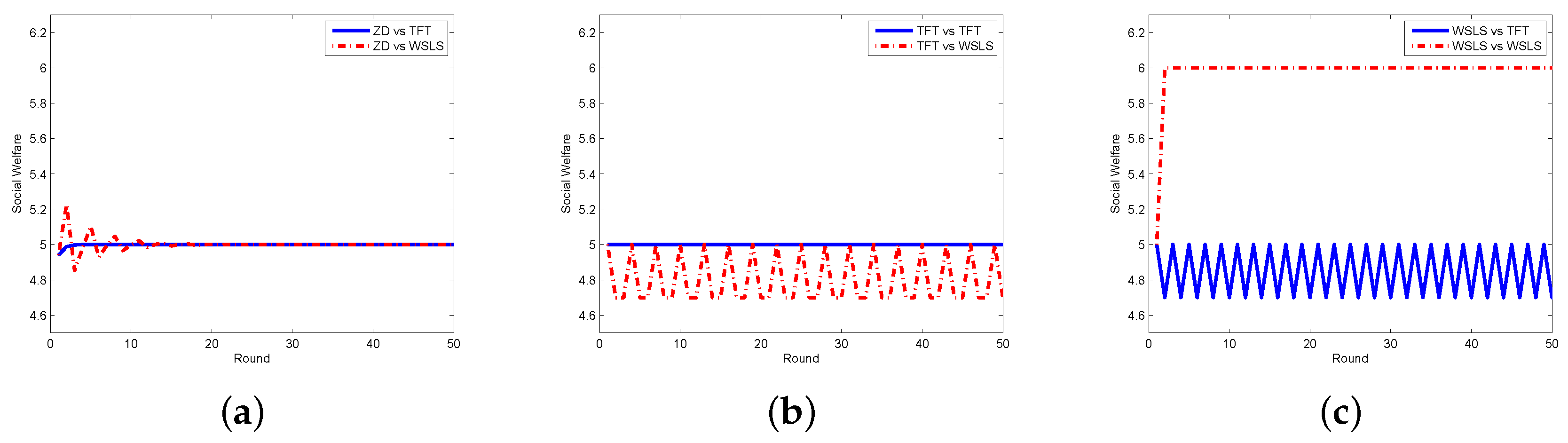
Figure 4.
Payoffs with ZD vs. ALLC/ALLD/Random in the discrete model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.
Figure 4.
Payoffs with ZD vs. ALLC/ALLD/Random in the discrete model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.

Figure 5.
Payoffs with ZD vs. TFT/WSLS in the discrete model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.
Figure 5.
Payoffs with ZD vs. TFT/WSLS in the discrete model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.
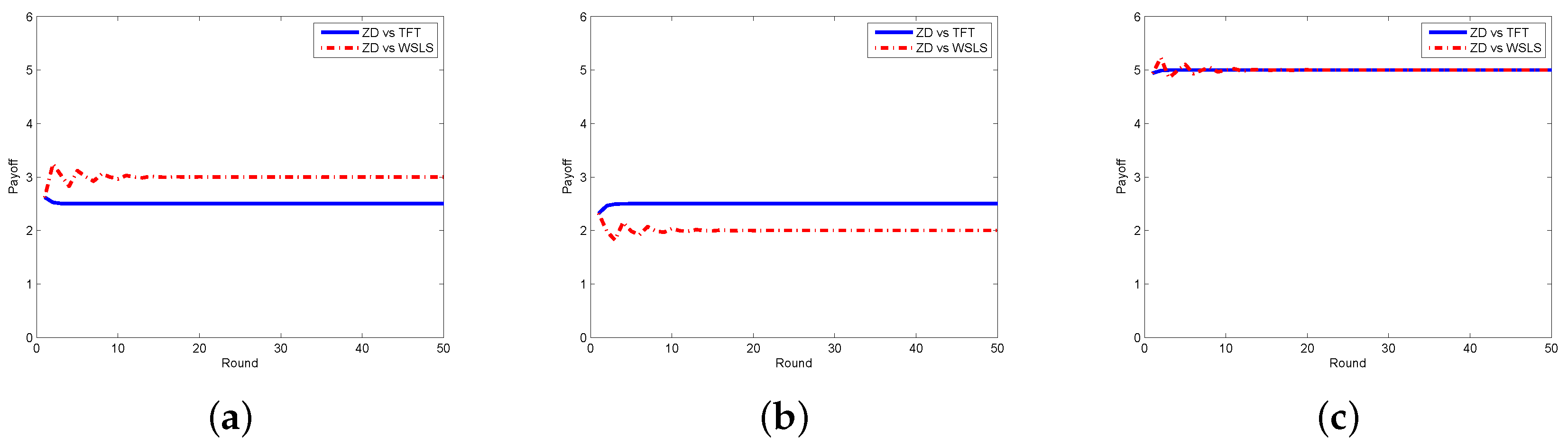
Figure 6.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, ALLC, ALLD, and Random in the continuous model. (a) requestor adopts the ZD strategy; (b) requestor adopts the ALLC strategy; (c) requestor adopts the ALLD strategy; (d) requestor adopts the Random strategy.
Figure 6.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, ALLC, ALLD, and Random in the continuous model. (a) requestor adopts the ZD strategy; (b) requestor adopts the ALLC strategy; (c) requestor adopts the ALLD strategy; (d) requestor adopts the Random strategy.
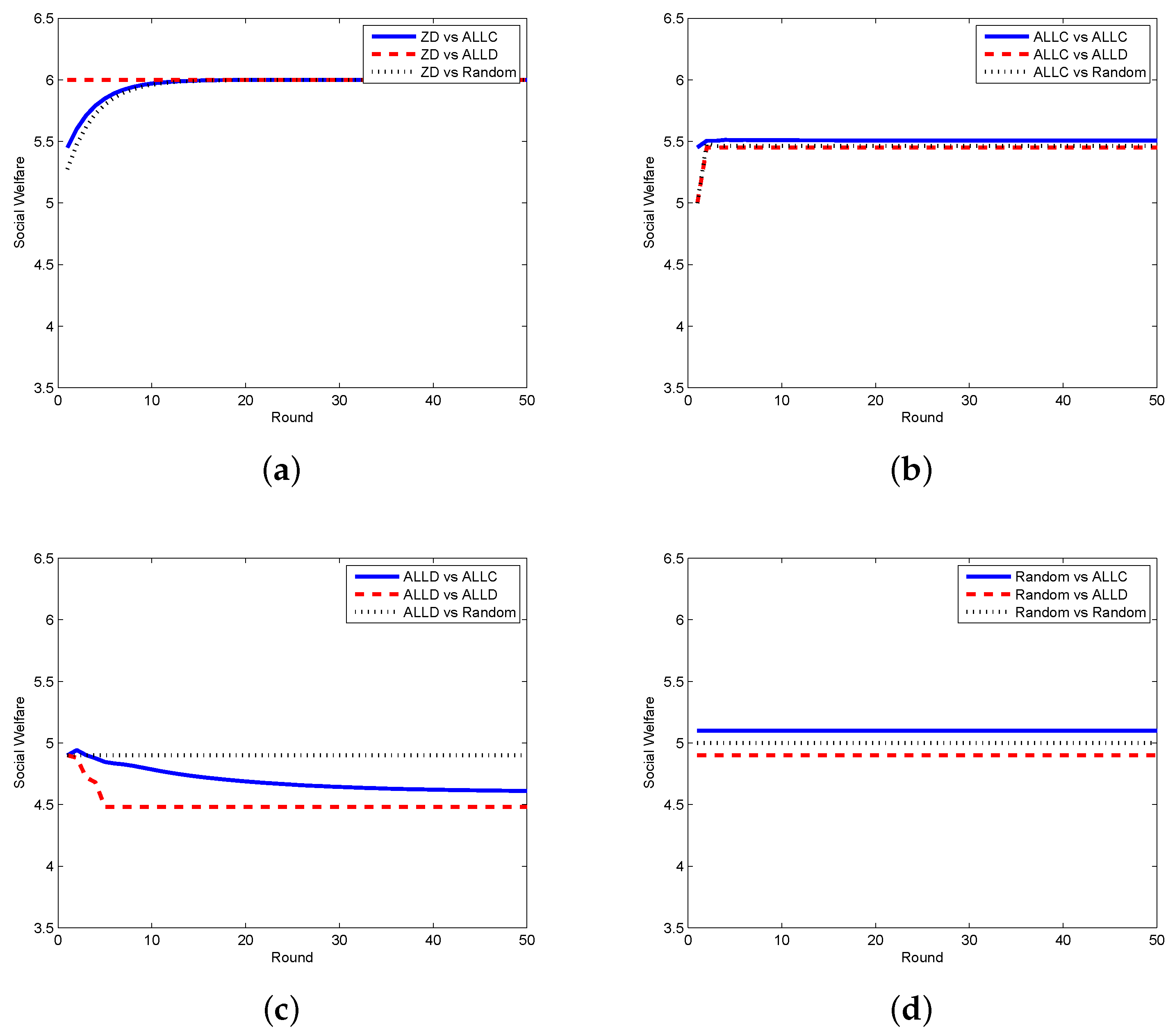
Figure 7.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, TFT, and WSLS in the continuous model. (a) requestor adopts the ZD strategy; (b) requestor adopts the TFT strategy; and the (c) requestor adopts the WSLS strategy.
Figure 7.
Social welfare with different strategy pairs (requestor vs. worker) among ZD, TFT, and WSLS in the continuous model. (a) requestor adopts the ZD strategy; (b) requestor adopts the TFT strategy; and the (c) requestor adopts the WSLS strategy.
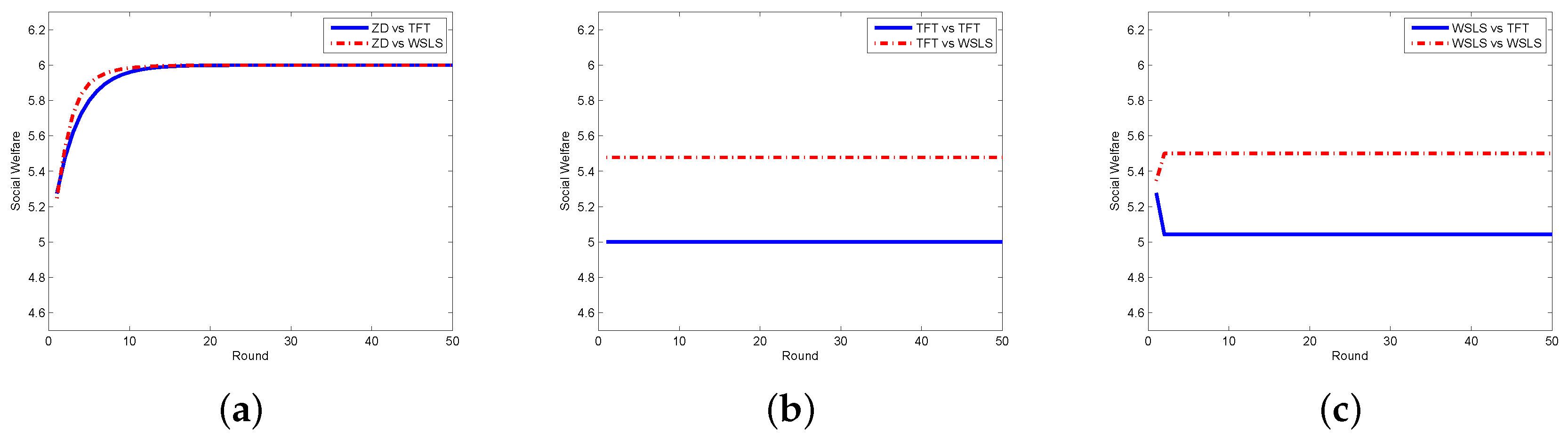
Figure 8.
Payoffs with ZD vs. ALLC/ALLD/Random in the continuous model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.
Figure 8.
Payoffs with ZD vs. ALLC/ALLD/Random in the continuous model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.

Figure 9.
Payoffs with ZD vs. TFT/WSLS in the continuous model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.
Figure 9.
Payoffs with ZD vs. TFT/WSLS in the continuous model. (a) requestor’s payoff; (b) worker’s payoff; (c) social welfare.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hu, Q.; Wang, S.; Bie, R.; Cheng, X. Social Welfare Control in Mobile Crowdsensing Using Zero-Determinant Strategy. Sensors 2017, 17, 1012. https://doi.org/10.3390/s17051012
AMA Style
Hu Q, Wang S, Bie R, Cheng X. Social Welfare Control in Mobile Crowdsensing Using Zero-Determinant Strategy. Sensors. 2017; 17(5):1012. https://doi.org/10.3390/s17051012
Chicago/Turabian StyleHu, Qin, Shengling Wang, Rongfang Bie, and Xiuzhen Cheng. 2017. "Social Welfare Control in Mobile Crowdsensing Using Zero-Determinant Strategy" Sensors 17, no. 5: 1012. https://doi.org/10.3390/s17051012
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.