1. Introduction
Conventional wireless sensor networks (WSN) are always disposable systems, because sensors cannot be recharged due to random deployment and the entire network is invalid when the batteries of wireless sensors run out of energy [
1]. As the use of the WSN is strictly limited by the life span of the sensors’ batteries, energy consumption has become one of the biggest constraints of the wireless sensor node and has posed many challenges to WSNs [
2]. Energy has become one of the scarcest resources in WSN [
3]. Wireless power transfer (WPT) and other energy harvesting technologies provide solutions in such situations. Benefiting from microwave wireless power transfer, the wireless powered sensor networks (WPSN) can be used to reduce the operational cost, provide a stable energy supply, and achieve much longer operating lifetimes [
4].
WPSN has been widely researched in the recent literature [
5,
6,
7,
8]. Wireless sensors in WPSN can be powered through WPT in the downlink which is radio frequency enabled, and can use the harvesting energy for information transmission in the uplink. Compared to other energy harvesting technologies, WPT can achieve long-distance energy transfer and constant energy supplementation [
6]. However, in WPSN, the distance between the wireless sensors and energy nodes (ENs) may cause performance unfairness, because of the near-far effect. When wireless sensors are located far away from the ENs, they will receive less energy, because of power transmission attenuation. But they may need more energy for the uplink information transmission. Thus, communication and energy scheduling should be considered on this occasion. For the downlink energy transfer, energy beamforming technology is used for sensors which are located far away from energy sources, so that they can receive stronger energy beams [
7]. In this case, it is essential to research the uplink transmit power control problem, to balance throughput and energy performance among different sensors [
8].
When considering the literature, many studies have been completed in WPSN for power control problems. In [
9], the information relay nodes were working as energy beacon and information relays, and that energy and information can be transferred and transmitted through relay nodes. The protocol was divided into three phases. By jointly optimizing the duration and power allocation for transmission, the network throughput was maximized. In [
10], the authors researched the energy harvesting-based wireless networks and proposed an iterative method-based solution for the sub-channel and power allocation. The authors defined a logarithmic utility function, considering both the aggregated rate and the harvested energy. The sub-channel and power allocation are obtained through biconvex optimization. The convergence of the proposed algorithm is also proved.
Game theory solves the resource allocation problem of a system with conflicting components. It has recently received an increasing interest in the context of wireless sensor networks [
11,
12]. It can be used to solve the optimal energy management problems in wireless powered sensor networks, to meet the perceived QoS (Quality of Services) performance [
13]. In [
13], the wireless energy request policy was researched and analyzed, based on a constrained stochastic game model. A constrained Nash equilibrium solution was obtained, while meeting Qos requirements, and achieved an energy request cost minimization. In [
14], in WPSN, a Nash bargaining-based optimal power control approach was proposed, to balance the information transmission efficiency. The whole game process was simplified into three parts, and the power control and time allocation algorithm were proved to be quasiconcave.
Nevertheless, to the best of our best knowledge, all of the works above optimize the network performance, but do not consider the dynamic characteristics of a sensor’s energy which are exponent variables, and do not consider the optimization in given a time period. Differential Game, firstly proposed by Isaace [
15], is one of the most practical and complex branches of game theory and can be used to solve a class of resource allocation problems, under which the evolution of the state is described by a differential equation and the players act throughout a time interval [
16]. In this paper, we propose a new method for uplink transmit power control, based on a differential game. Each sensor node can be satisfied with a constant wireless energy transfer from a hybrid access point, and the hybrid access point has an energy transfer function and information transmission function. The energy dynamic of sensors is considered as the state of the system, which is denoted by differential equations. We suppose that all sensors are rational players and the combination of energy and throughput revenues are interpreted as the optimization objectives for different players. We will obtain individual feedback Nash equilibriums for the sensors in a finite time horizon and those in an infinite time horizon, and an iterative algorithm is presented to achieve optimal solutions for uplink power control. The numerical results will be given, to present the correctness of the differential game analysis.
The remainder of the paper is organized as follows.
Section 2 introduces the system model of WPSN and the uplink power control problem in a differential game.
Section 3 provides feedback Nash equilibrium solutions for each wireless sensor and a differential game-based iterative algorithm. Numerical simulations are given in
Section 4. Finally, we conclude the work in
Section 5.
2. System Model and Problem Formulation
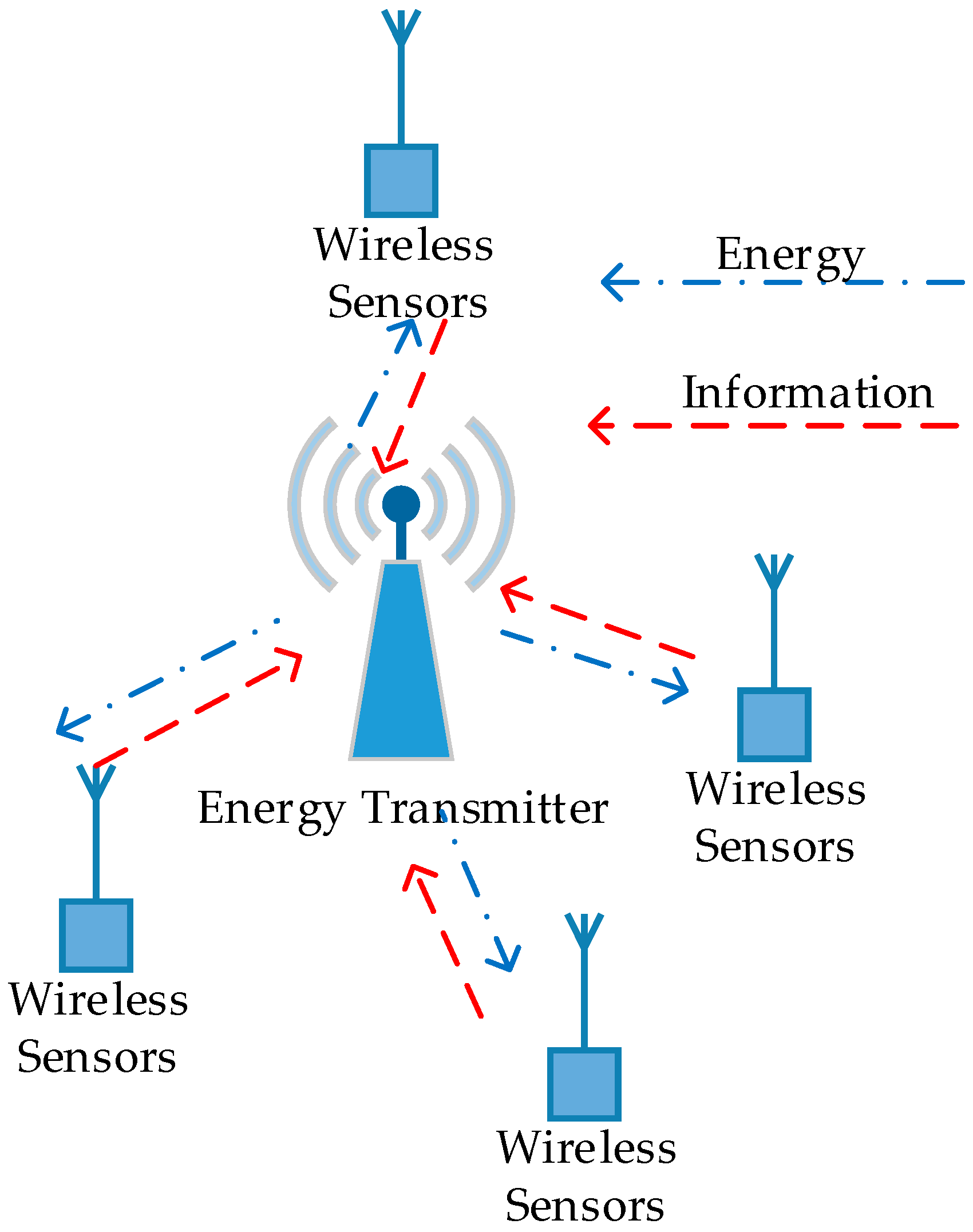
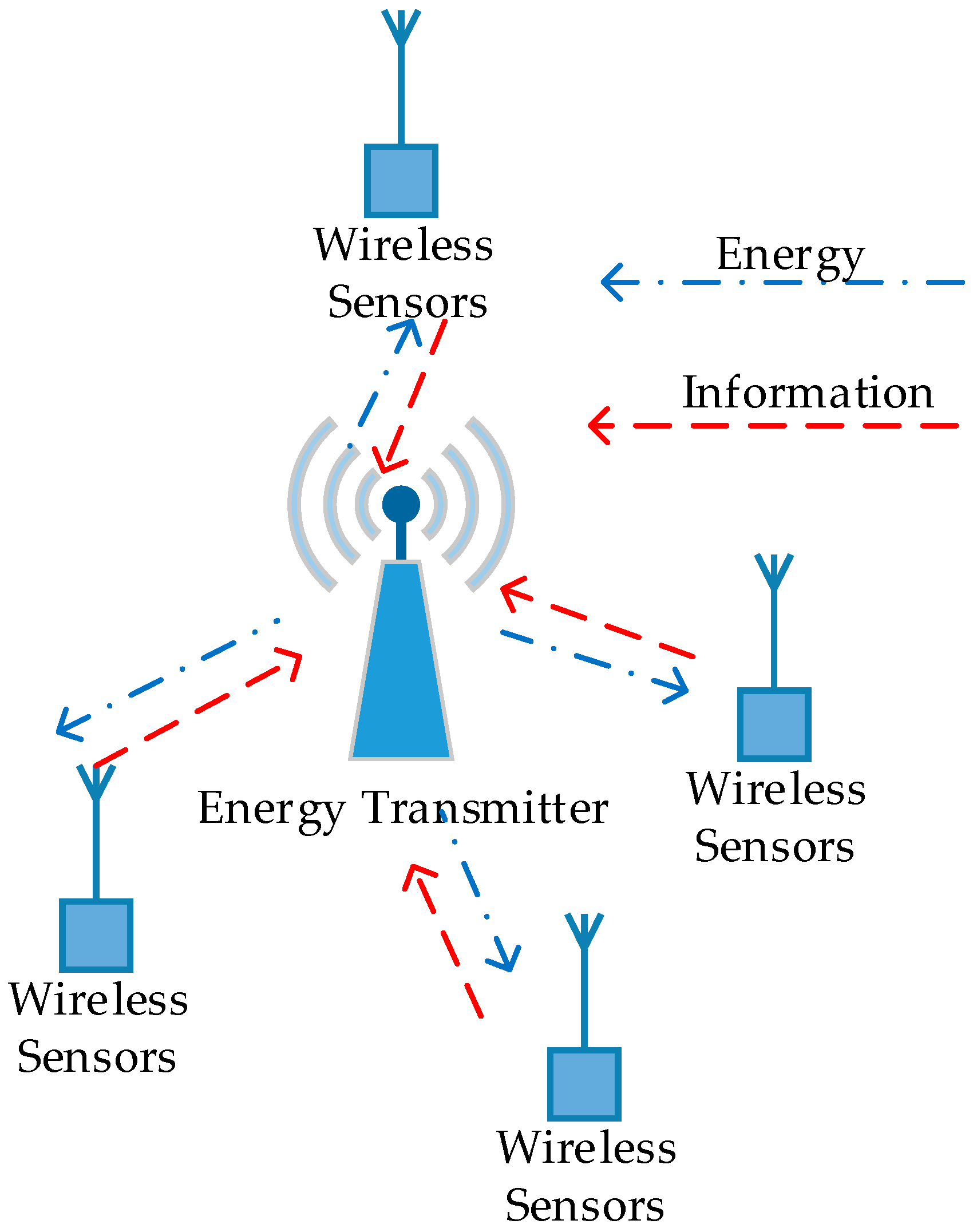
In this section, we propose a differential game model for uplink transmit power control in wireless powered sensor networks (WPSN). We consider a WPSN where there is one wireless energy transmitter serving several wireless sensors in its coverage area (as shown in
Figure 1). The wireless energy transmitter can achieve a constant power supply in the downlink and can work as an access point for information transmission in the uplink, receiving signals from distributed wireless sensors. Thus, the wireless energy transmitter can be considered as a hybrid access point (H-AP) for energy and information transmission. All of the devices (including wireless energy transmitters and wireless sensors) in WPSN are assumed to work on orthogonal frequency bands, and work in the half-duplex mode. The wireless sensors use the energy harvested from H-AP for information transmission [
17]. The energy harvested by each sensor is stored in a rechargeable battery and then used for wireless information transmission (WIT). Moreover, the wireless sensors control their uplink transmit power to extend the working hours, meanwhile improving their own QoS, which is a distributed optimization problem and leads to a dynamic game that can be modeled by a non-cooperative differential game.
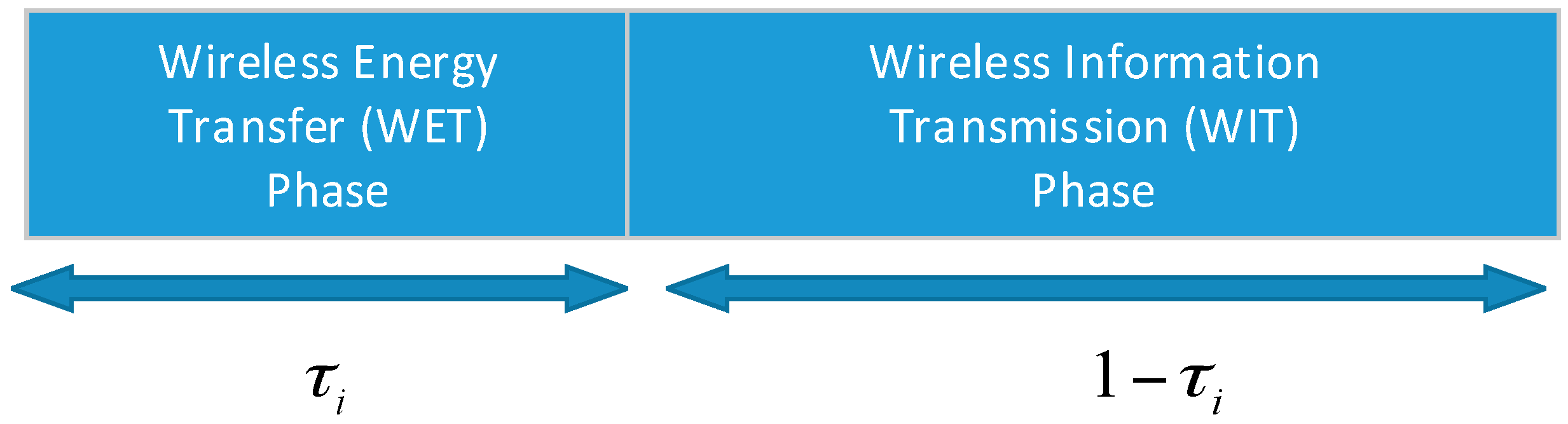
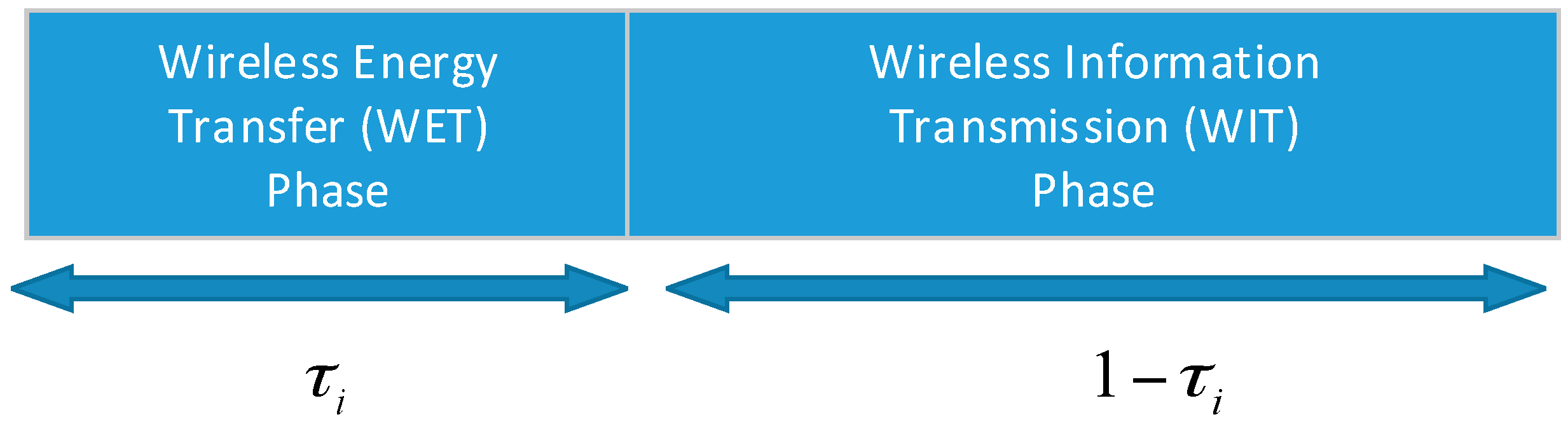
In this paper, the “harvest-then-transmit” protocol [
18] is considered. The time duration of transmission is assumed to be a different block transmission time with a normalized duration. Energy and information are transmitted from block to block. For each transmission block, it can be divided into two phases (as shown in
Figure 2). The first phase is the time duration of wireless energy transfer (WET), which is denoted by
, and the second phase is the time duration of wireless information transmission (WIT), which is represented as
.
Our target is to control the uplink transmit power of sensors in WPSN, to maximize the sensors’ own economic revenue during the time period
. A differential game-based model is constructed to describe the revenue maximization problem. Through the optimal power control, the wireless sensors in WPSN can achieve a balance between energy consumption and QoS improvement. In order to simplify the system, we will consider a WPSN with one H-AP and
wireless sensors, where
is the set of wireless sensors (players). During the first phase of wireless energy transfer, let
denote the transfer power from H-AP to sensor
. It is assumed that
satisfies a maximum power constraint
(i.e.,
) [
19]. The harvesting energy in sensor
is given by [
20]:
where
is the energy conversion efficiency of player
, and
.
is the downlink channel gain. Let
denote the power level of player
, which can be interpreted as the state variables of a system. State variables are dynamic variables over different time periods that are influenced by the uplink transmit power, as well as by exiting levels of the state variables. Let
denote the uplink transmit power of player
, which is viewed as the control variable. The dynamic of the power level can be characterized as a linear differential equation, i.e.:
where
is the energy loss coefficient.
, is the initial state, which means that there is no energy transmission at the beginning of the game.
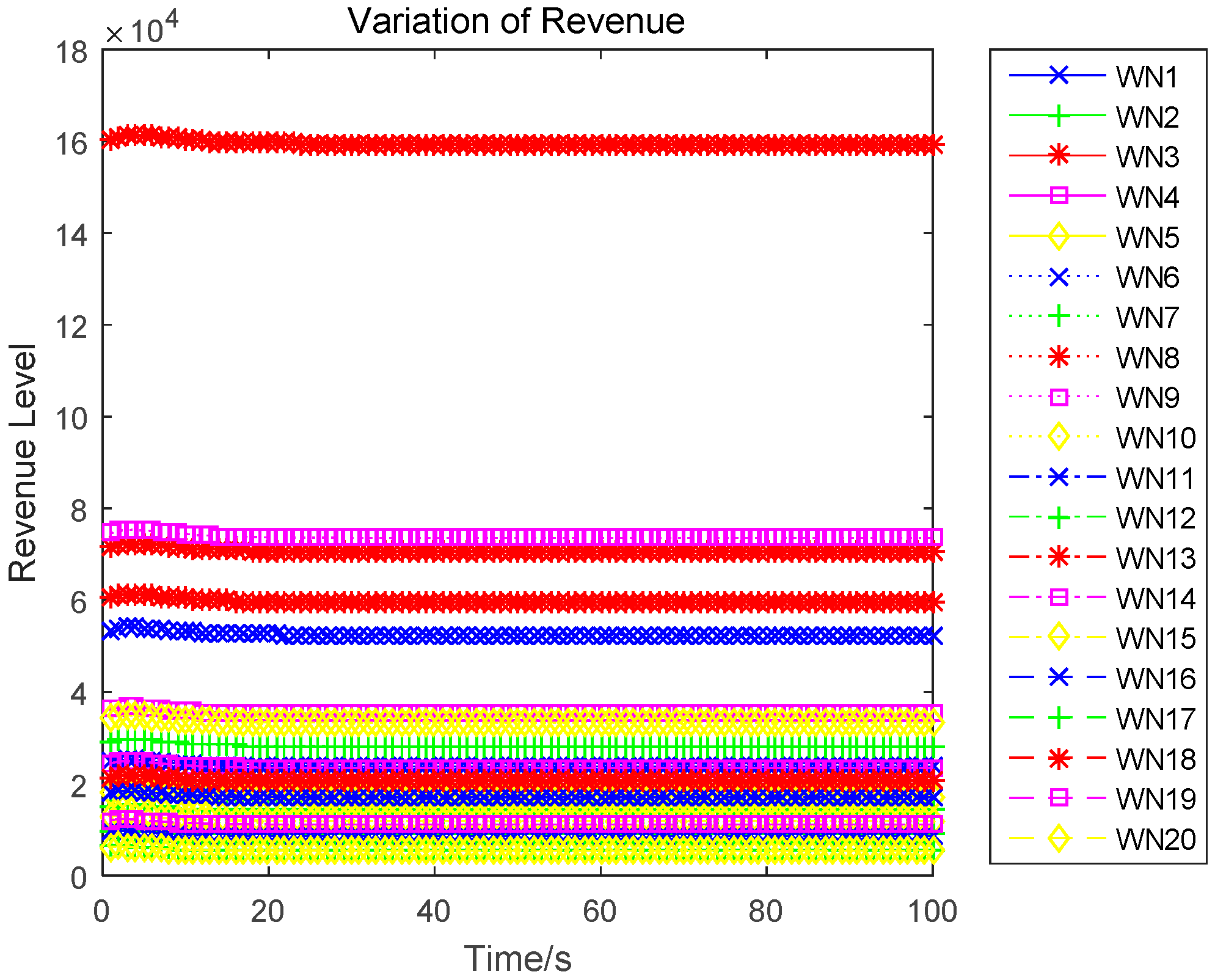
Now, we discuss how wireless sensors control their uplink transmit power to achieve revenue maximization, to reach an equilibrium between energy consumption and an achievable throughput. Subject to the limited energy, each sensor aims to minimize the uplink transmit power to extend the working hours, but may result in less information transmission and a low QoS. Therefore, each sensor needs to balance the conflict between energy consumption and an achievable throughput. Generally speaking, there will be a queue length or buffer size for each H-AP. When the buffer size of the H-AP is full, it will refuse to provide the service for any uplink information transmission. Therefore, in our game, we suppose that there are enough buffer sizes for information transmission and only consider how to control the uplink transmission power to achieve revenue maximization. The structure of the optimization model will consist of energy revenue specifications and QoS revenue specifications.
Firstly, we give the energy revenue definition. The energy revenue depends on the energy storage in the sensors and the energy’s unit price. Assuming the unit price is
, the instantaneous energy revenue is defined as a linear form, as follows:
In perfect competition, each sensor will use the lowest power possible, to reduce the energy consumption and increase the energy revenue, given by Equation (2). However, less transmission power may cause a low transmission rate and low QoS. Thus, we introduce a QoS revenue to describe the conflict between energy consumption and QoS requirements. As the “harvest-then-transmit” protocol is considered, there is no interference from the energy transmission. Let the achieve rate of sensor
denote the QoS revenue, where the QoS revenue specifications are obtained as:
where
,
is the uplink transmit power and the control variables of the game.
is the uplink channel power gain.
is a constant parameter that denotes the unit rate revenue.
Based on the above assumption, the total revenue of wireless sensor
is denoted as follows:
In this paper, we use the noncooperative differential game theory [
21] to analyze the optimal uplink transmit power and to achieve revenue maximization for each sensor. Let the target QoS level for each sensor be denoted by
. We evaluate the balance between energy consumption and QoS over the time interval
, using the term
, where
is a constant parameter and
is the end of the control. Let
denote the discount rate, where the dynamic game of the power control for each sensor noncooperatively chooses its uplink transmit power as:
Subject to the deterministic dynamics:
Now, we formulate the optimal power control for all sensors in WPSN as a differential game, as follows.
Players : All wireless sensors in the WPSN.
Strategy space: All wireless sensors can noncooperatively choose their uplink transmit power , to maximize the revenue.
State: The power level state is denoted by vector , where the state is controlled by the dynamic constraint in Equation (2).
Objective function: All of the wireless sensors act to maximize their discounted revenues over a time interval , respectively.
3. Game Analysis
In this section, we analyse the optimal uplink transmit power for each wireless sensor. In the following subsections, we first discuss the optimal uplink transmit power in a finite horizon. Then, the optimal strategy will be considered under an infinite horizon. An uplink power control algorithm based on the differential game will be given in the third subsection.
3.1. Analysis of Differential Game in Finite-Horizon
The finite horizon differential game will be solved, based on the dynamic optimization program technique, which was developed by Bellman [
22,
23]. According to Bellman’s dynamic programming principle, the uplink transmit power should be optimal for the given time duration.
Lemma 1. For the optimization Equations (6) and (7), an n-tuple of strategies constitutes a feedback Nash equilibrium solution if there exists a functional , defined on the time interval and satisfying the following relations for each [
22,
23]:
where the time interval : For all , if the strategies provide a feedback Nash equilibrium to the differential game problem on the time interval , it can provide a feedback Nash equilibrium for the same problem on the time interval .
Lemma 2. A feedback Nash equilibrium solution to the games (6) and (7) has to satisfy the following conditions: Lemma 3. In the wireless information phase, the optimal uplink transmit power for each sensor in WPSN, satisfies: 3.2. Analysis of Infinite-Horizon Differential Game
Consider the infinite-horizon autonomous game problem with constant discounting, in which
approaches infinity and where the objective functions and state dynamics are both autonomous. Now consider the alternative game to (6) and (7):
Subject to the deterministic dynamics:
The infinite-horizon autonomous game is independent of the choice of t and only dependent upon the state at the starting time, which is 0. Then, a feedback Nash equilibrium solution for the infinite-horizon autonomous games (14) and (15) can be characterized as follows:
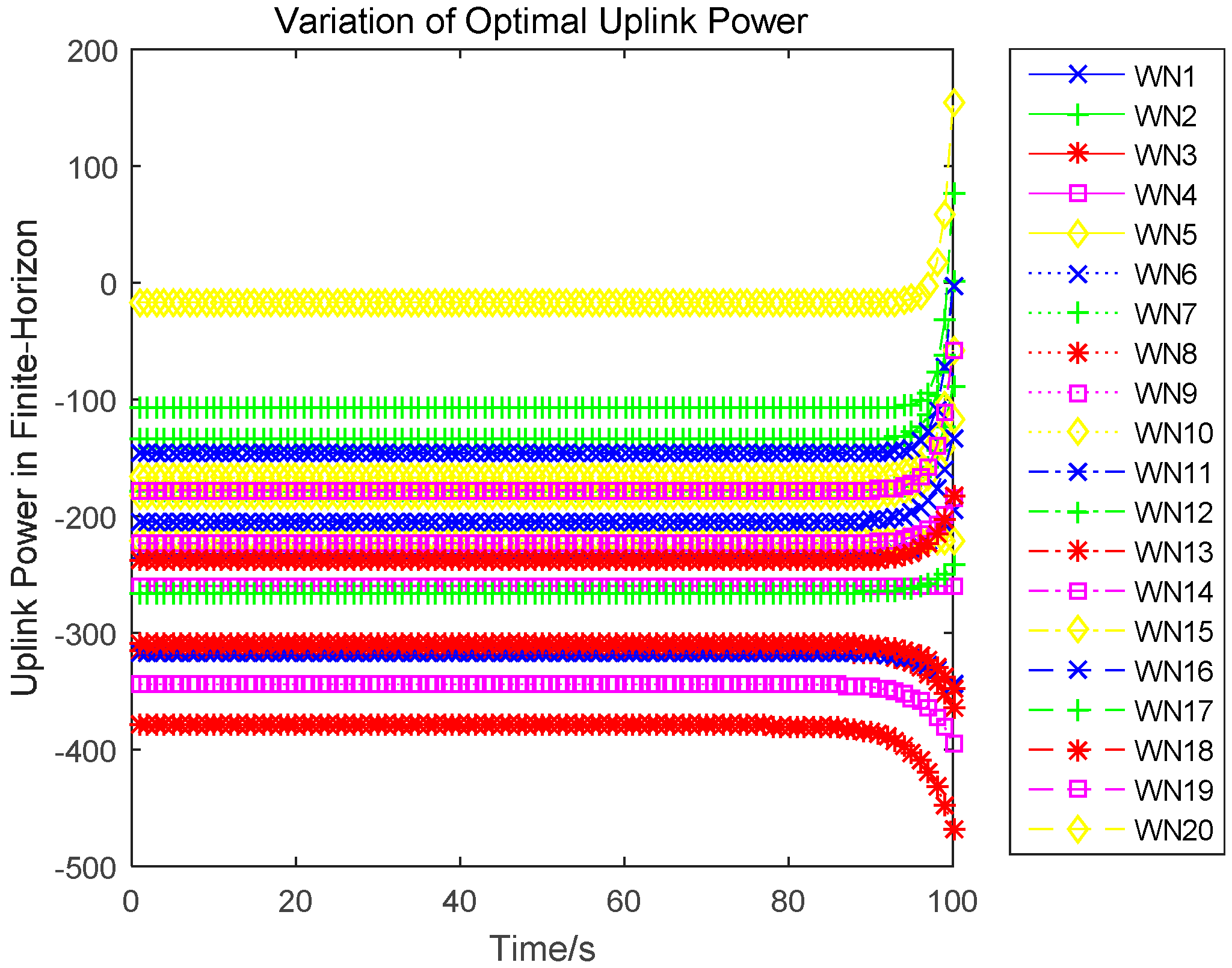
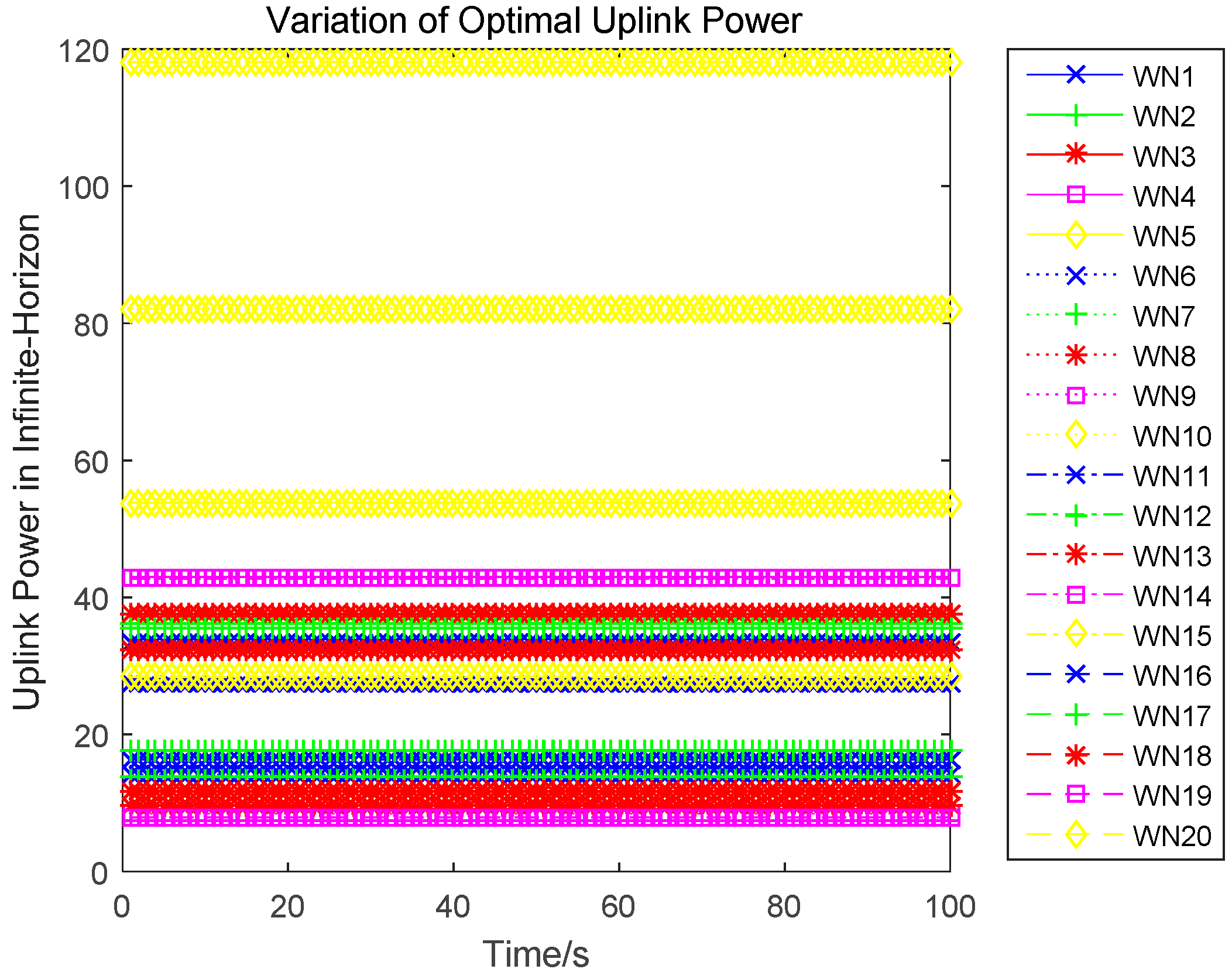
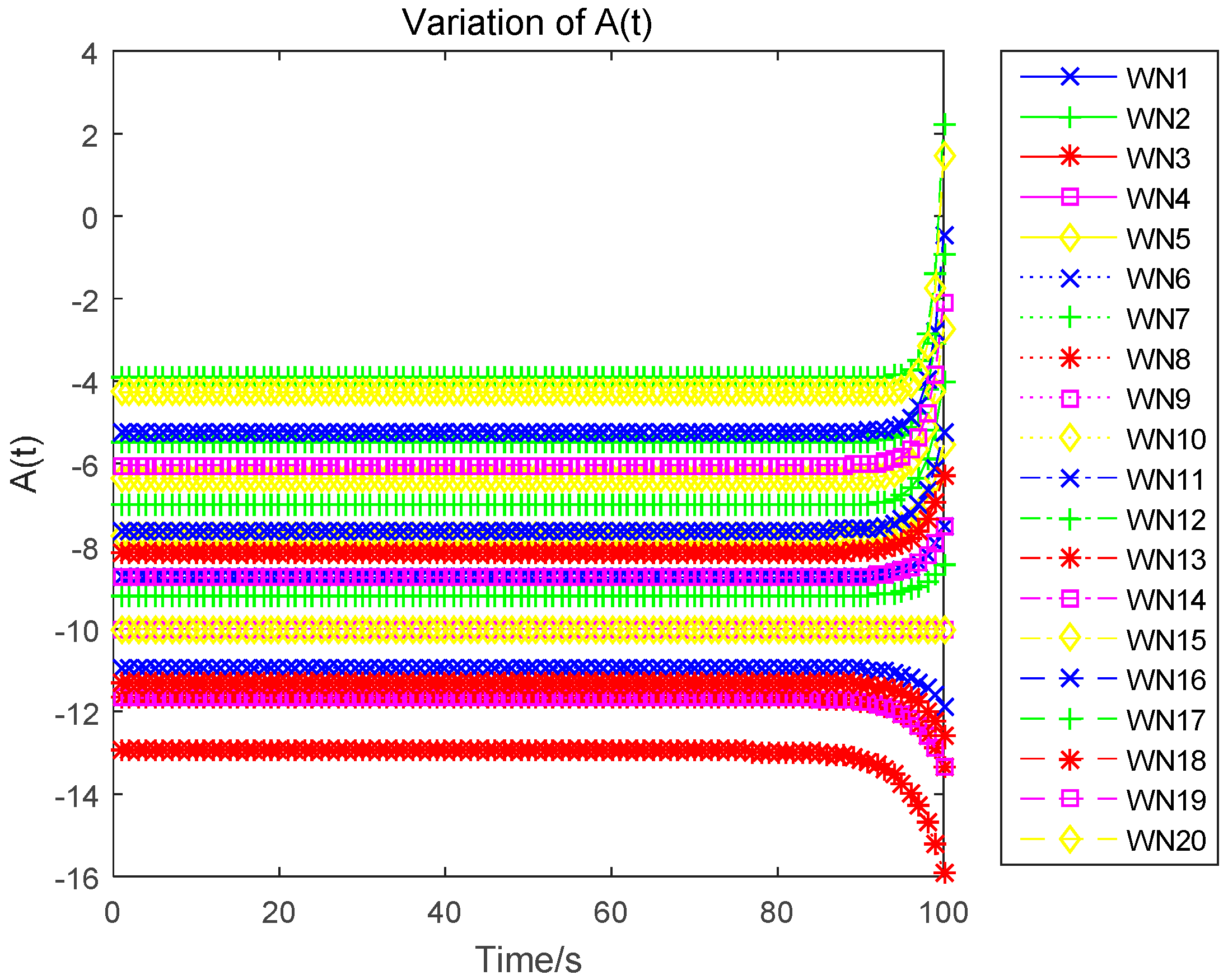
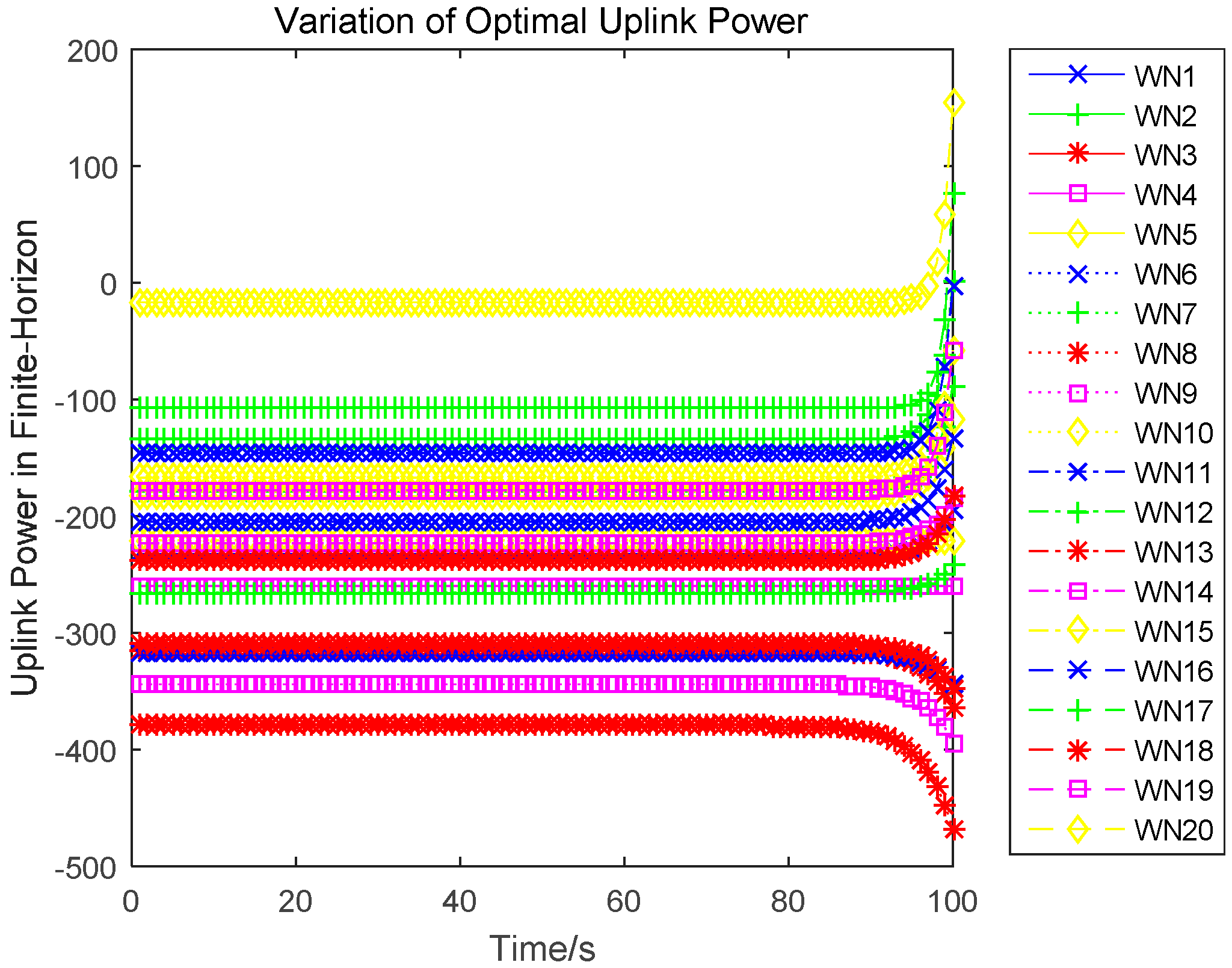
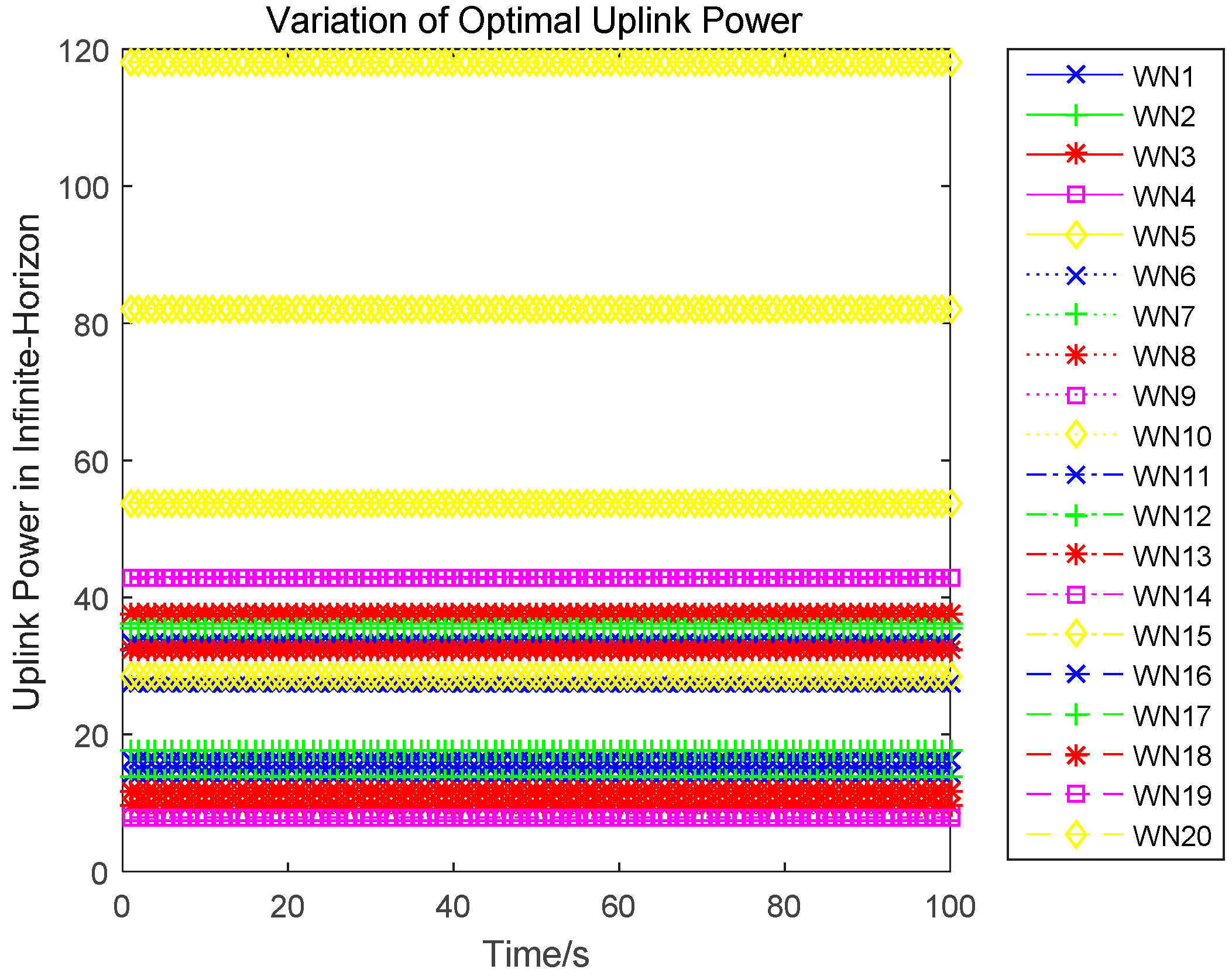
Lemma 4. An n-tuple of strategies constitutes a feedback Nash equilibrium solution if there exists a functional , defined on the time interval and satisfying the following set of partial differential equations for each : Lemma 5. The optimal uplink power for each wireless sensor is independent of the time, which is the game equilibrium strategy and can be expressed as:
Lemma 6. The optimal strategy for the infinite-horizon differential game satisfies:
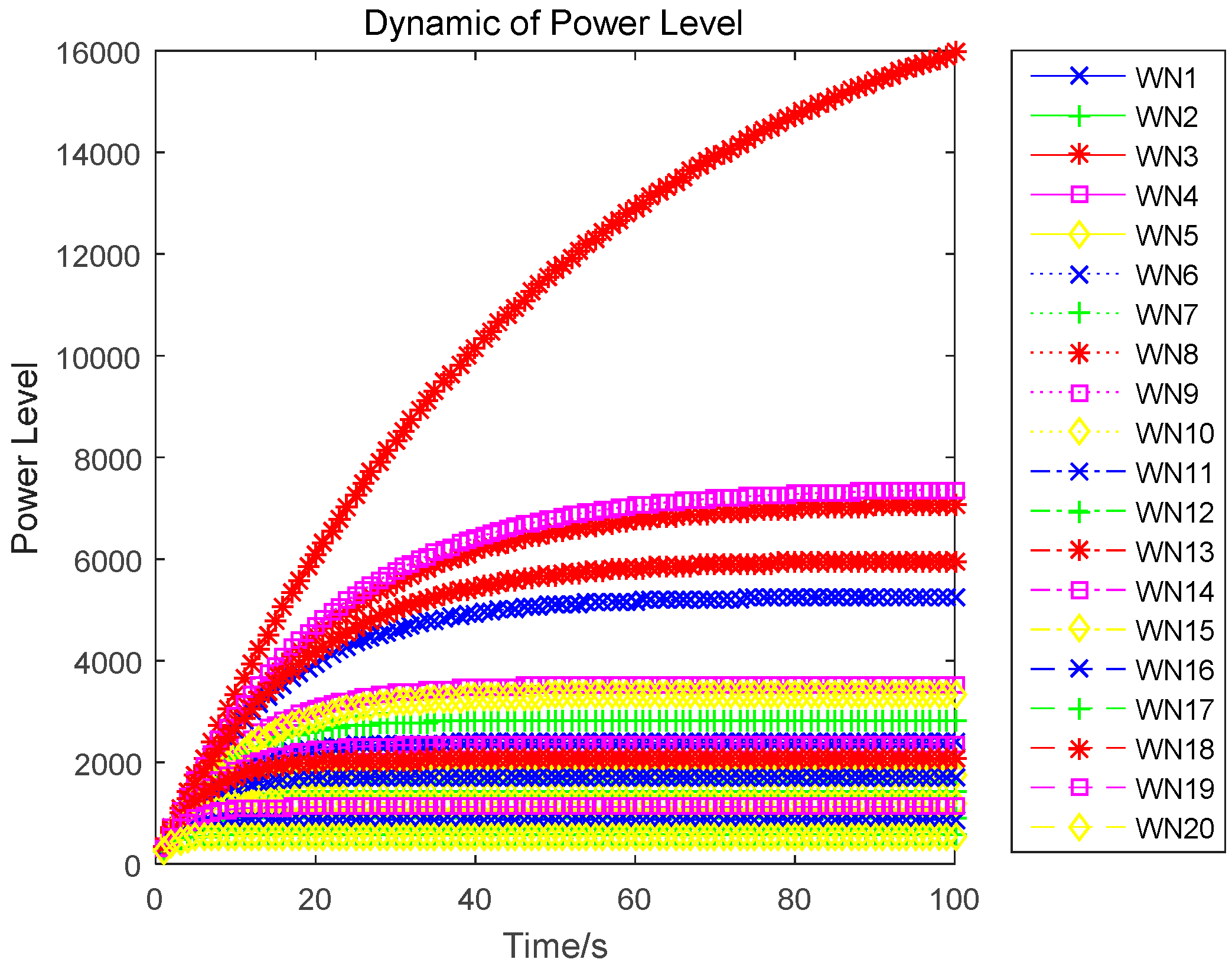
Proof. Substituting the optimal uplink power obtained in Equation (17), which is also the game equilibrium strategy, into the state function, yields:
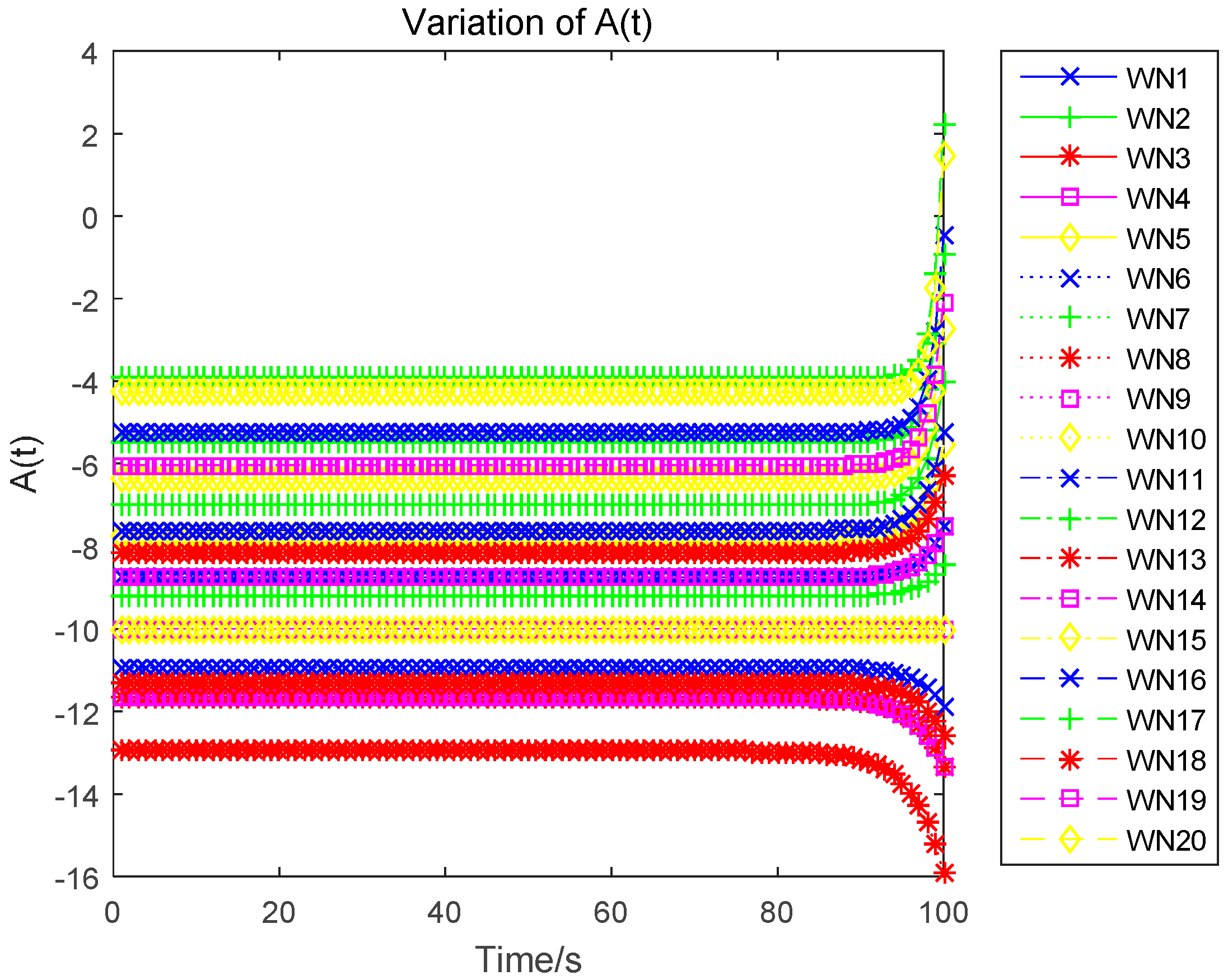
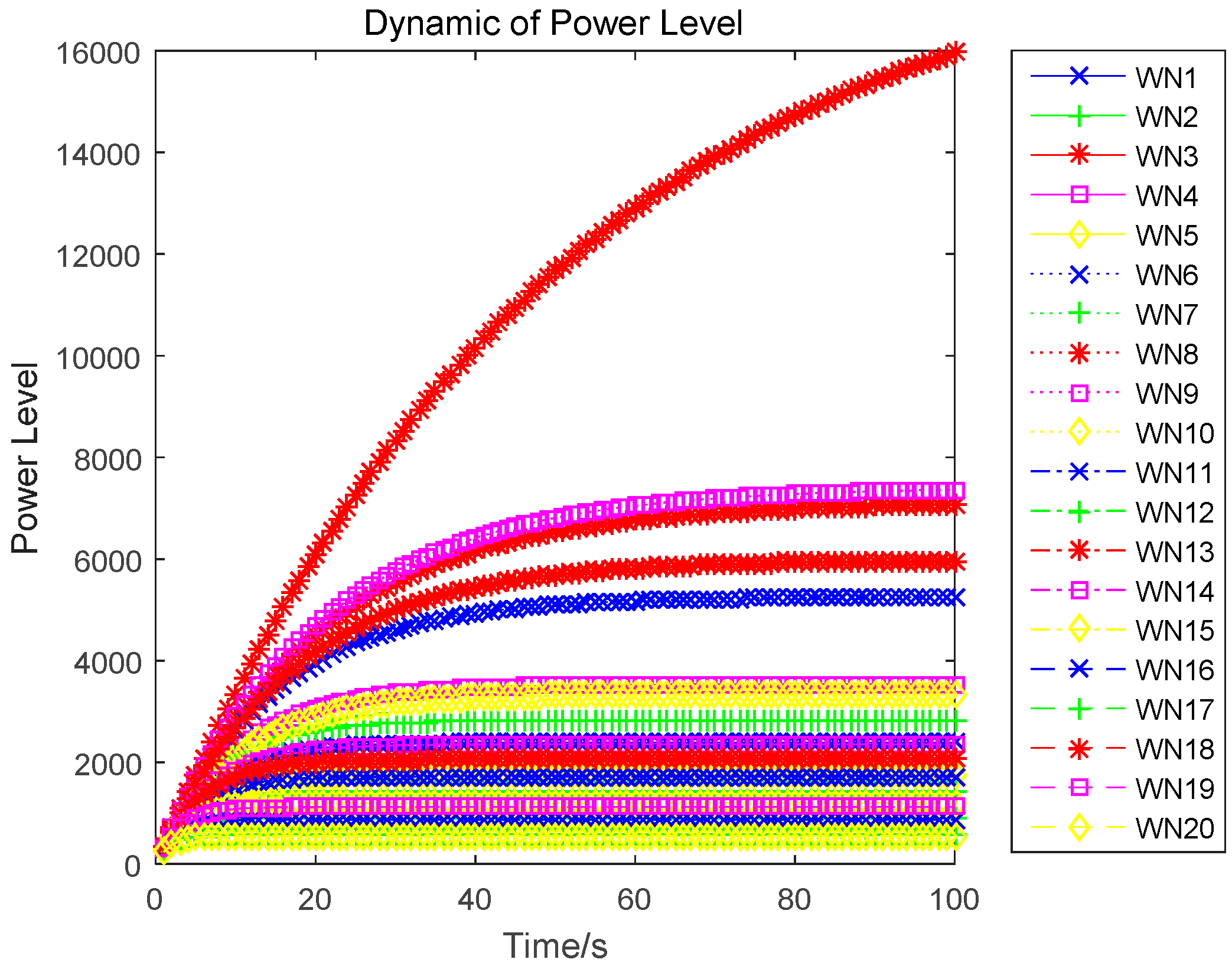
The optimal state trajectory can be obtained through solving the above dynamics, and is denoted as:
3.3. Uplink Power Control Algorithm
In this subsection, we present an uplink power control algorithm (Algorithm 1) in wireless powered sensor networks, based on the infinite-horizon solutions presented in
Section 3.2, which is as follows:
| Algorithm 1. The strategy for each sensor to determine the optimal uplink transmit power |
| 1: | Initially, sensor set the power level as 0, there is no energy transmission at the beginning of the game. |
| 2: | for sensor do |
| 3: | Start game, initial parameters ,, for the game; |
| 4: | Based on the QoS requirements, set the final rate revenue level as |
| 5: | while , do |
| 6: | Calculate the optimal uplink power based on Equation (17); |
| 7: | Calculate the optimal strategy of power level based on Equation (20); |
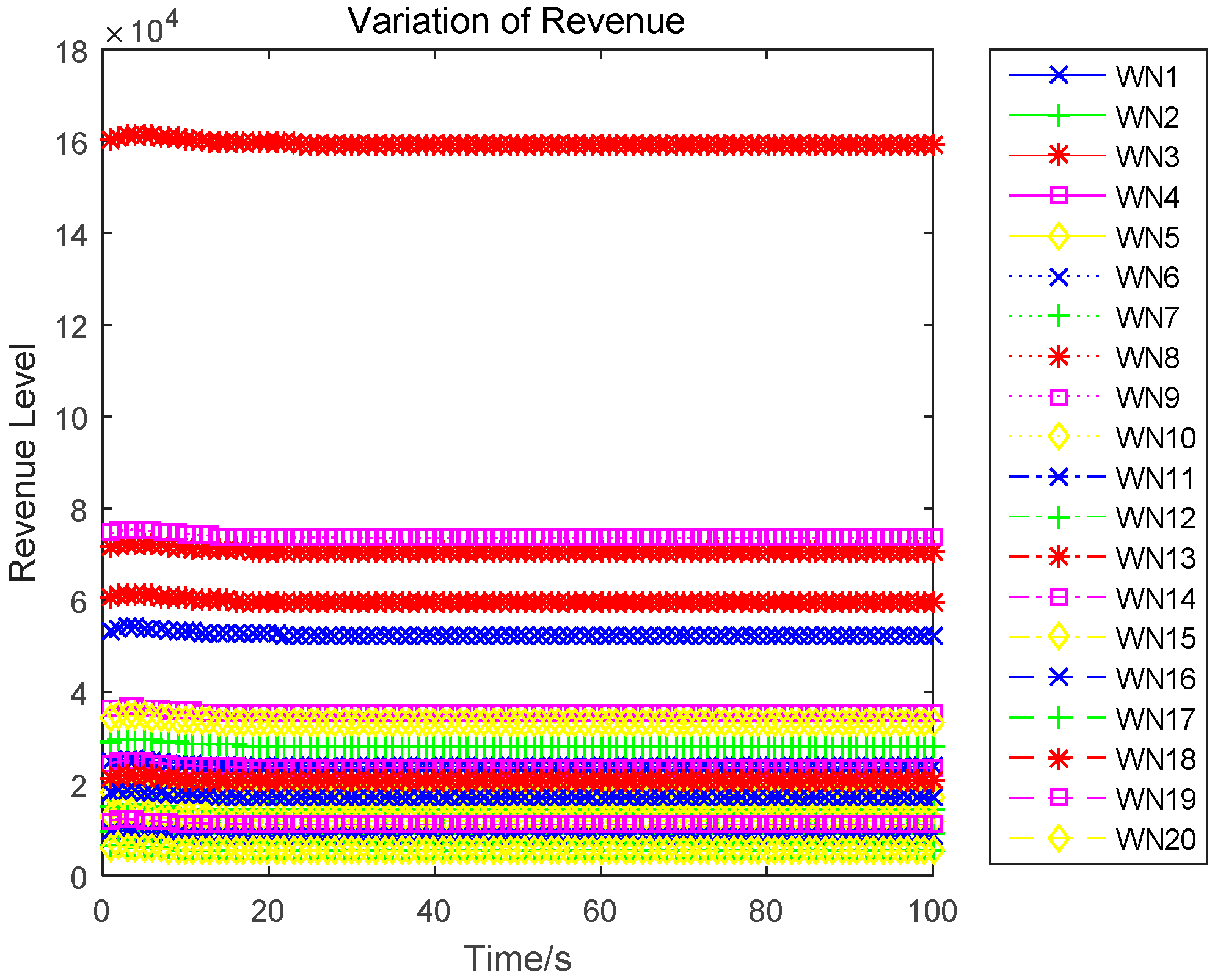
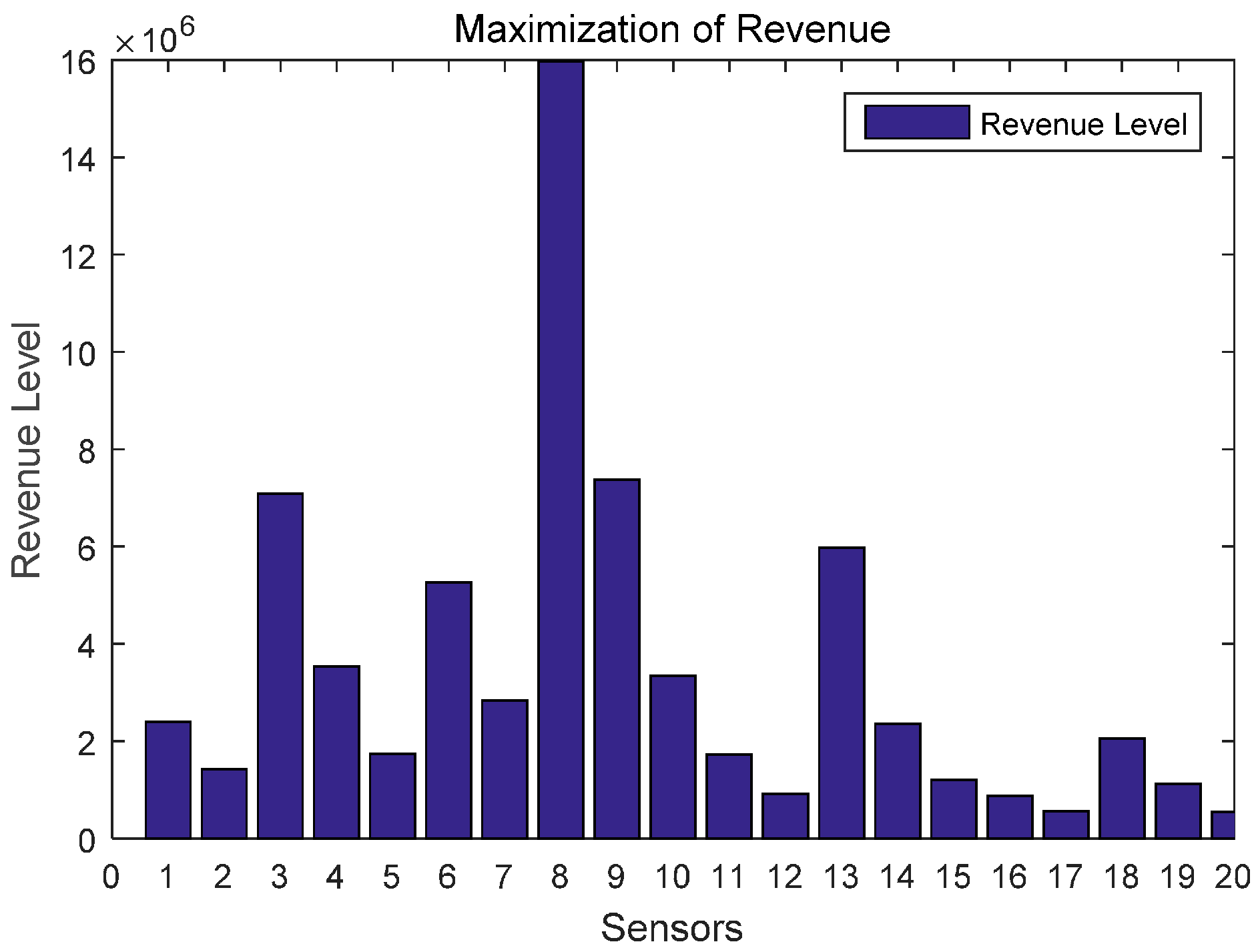
| 8: | Calculate the maximized revenue for each sensor based on Equations (14), (17) and (20); |
| 9: | Updata power level for each sensor; |
| 10: | end while |
| 11: | end for |
In the above algorithm, each sensor continues to calculate the optimal uplink transmit power, until there is no energy left in the sensor’s batteries for information transmission.
5. Conclusions
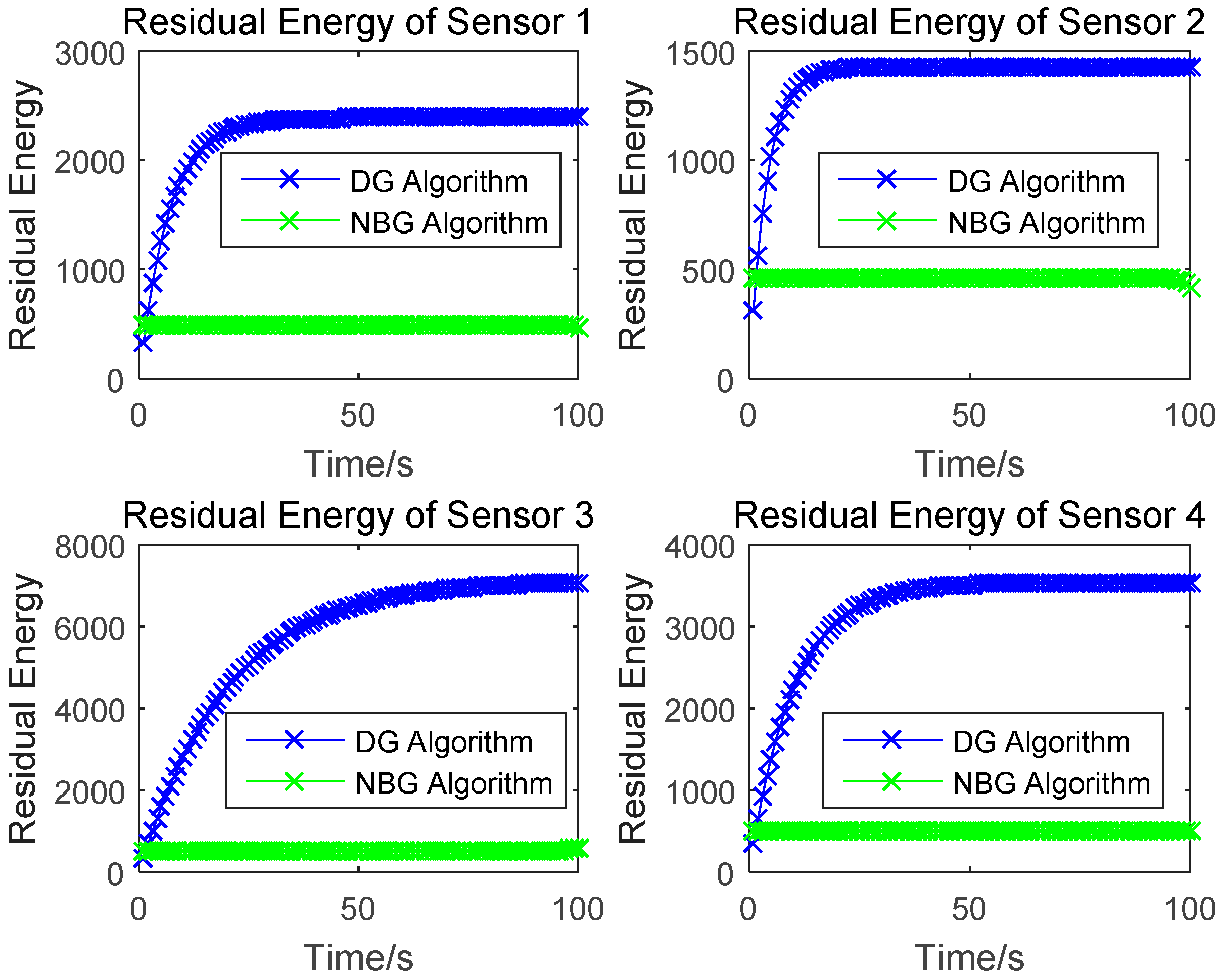
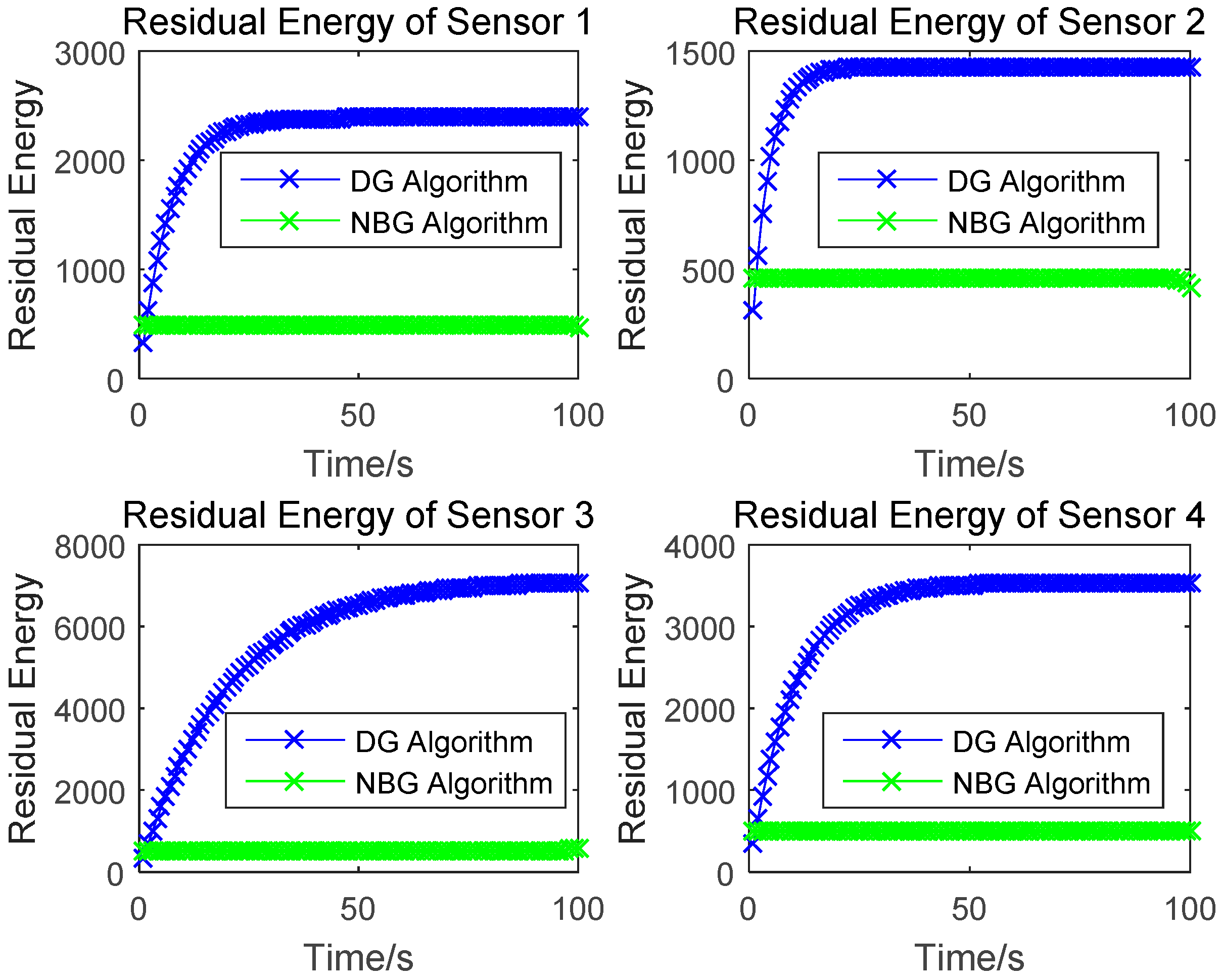
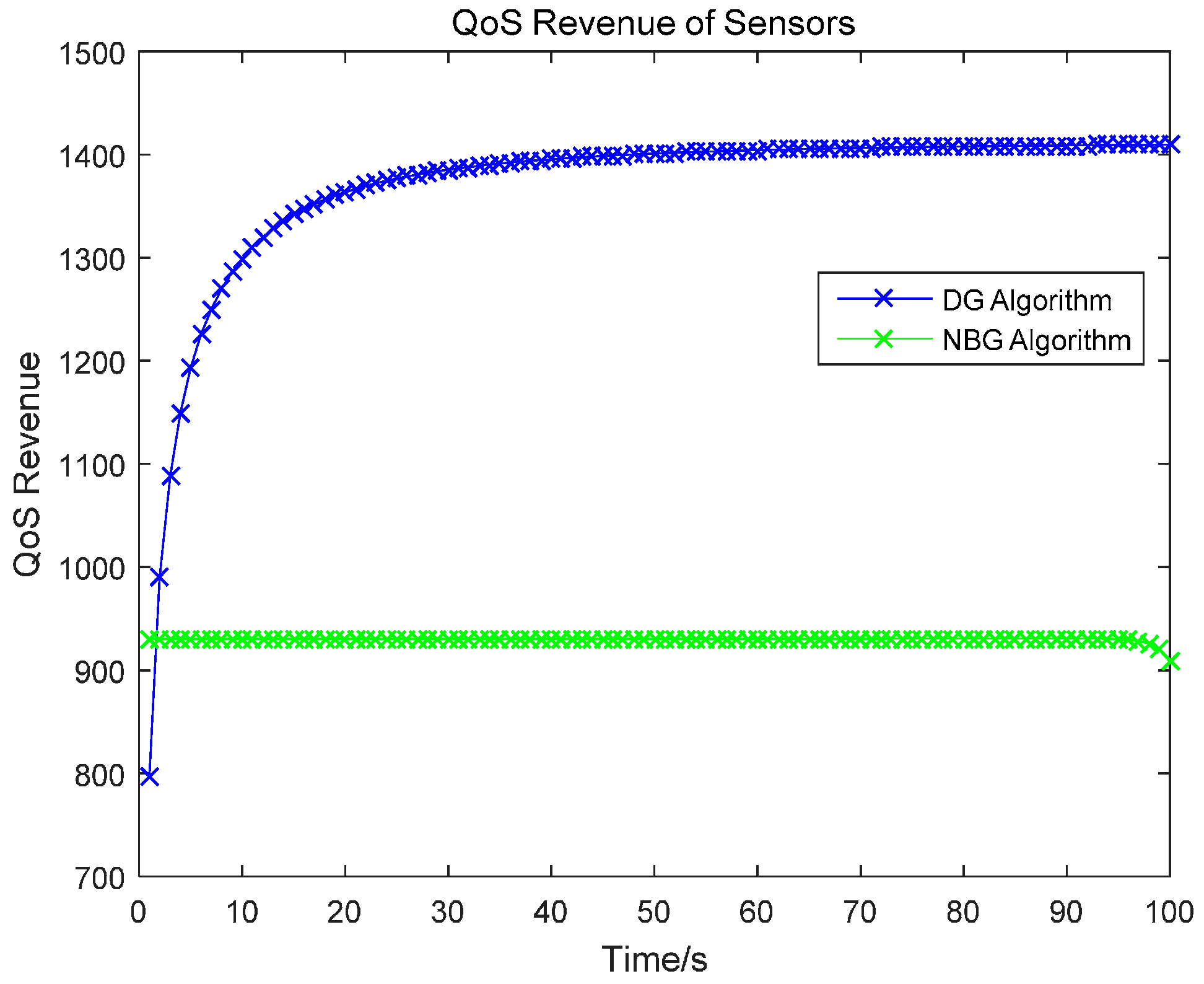
In this paper, we research the uplink transmit power control problem in wireless powered sensor networks. We propose a non-cooperative differential game model to analyze the optimal transmission power for the energy harvesting sensors. In the game, each sensor determines the uplink transmit power, to maximize the utility combination of energy revenue and QoS revenue in a time horizon. According to the Bellman dynamic programming, we can individually obtain the Nash equilibrium (NE) solutions under a finite-horizon and an infinite-horizon. When all sensors achieve NE, the optimal trajectory of the power level can be derived and the maximized revenue can be obtained. The correctness and convergence of the proposed algorithm is proved through numerical simulations.
In future work, we will attempt to combine the power control problem and time scheduling problem, in order to analyse the buffer size influences in our model, which is more practical for the limited network resource. Then, the way in which we can achieve optimal power control under an appropriate MAC algorithm can be ascertained. Finally, the whole revenue can be maximized, based on this solution.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}