
An Effective 3D Shape Descriptor for Object Recognition with RGB-D Sensors

Abstract
:1. Introduction
2. Related Work
- (1)
- This study exploits the ability of popular shape features previously used for other purposes for object recognition. In order to have a strong discriminative power, as most other features used in object recognition, the shape features used were chosen to capture both local and global characteristics of a shape.
- (2)
- These features were concatenated in a simple way, resulting in a 10 dimensional vector as the final descriptor. The low-dimensional descriptor makes for effective computation and the further incorporation of other features.
3. Shape Feature Analysis
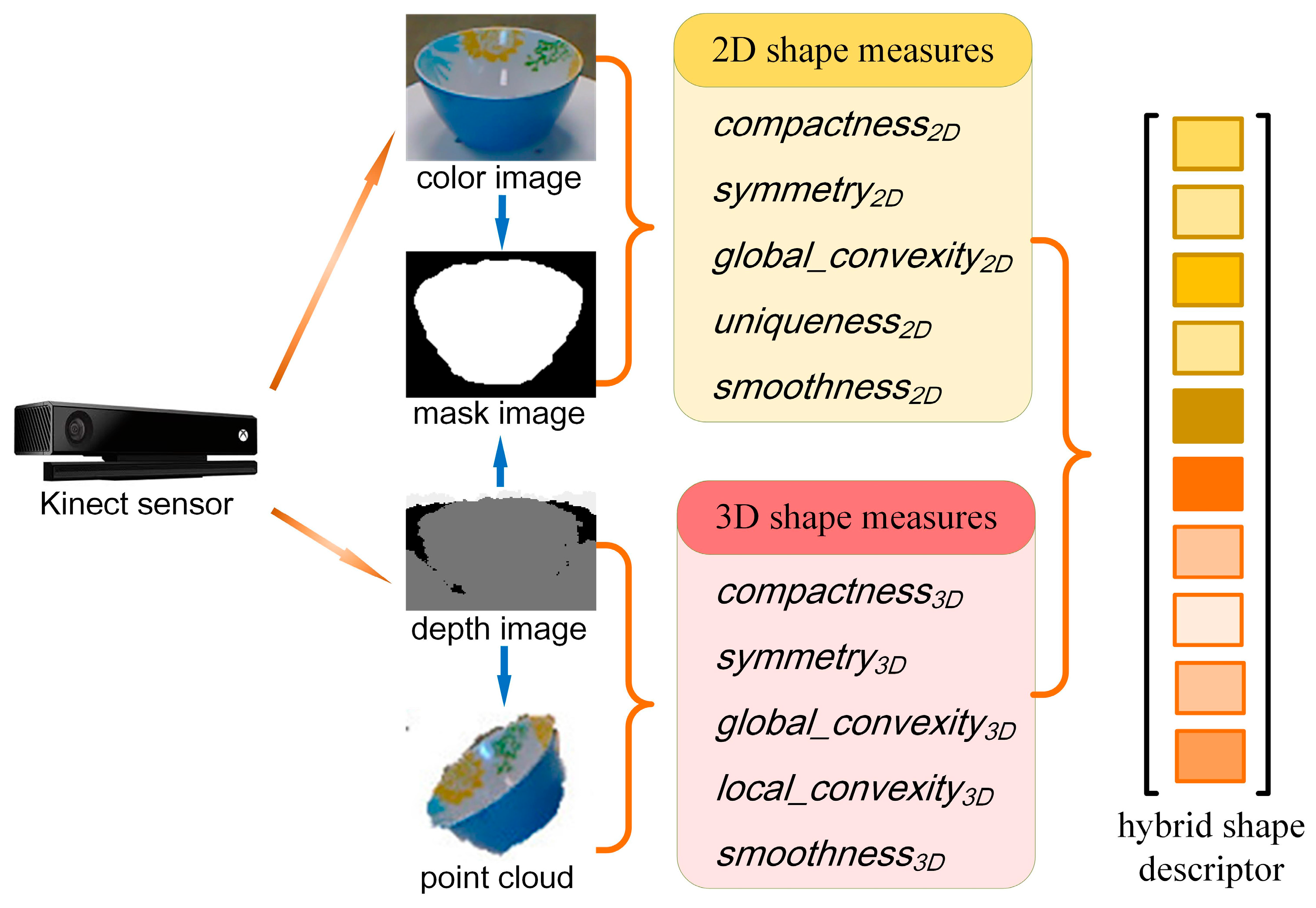
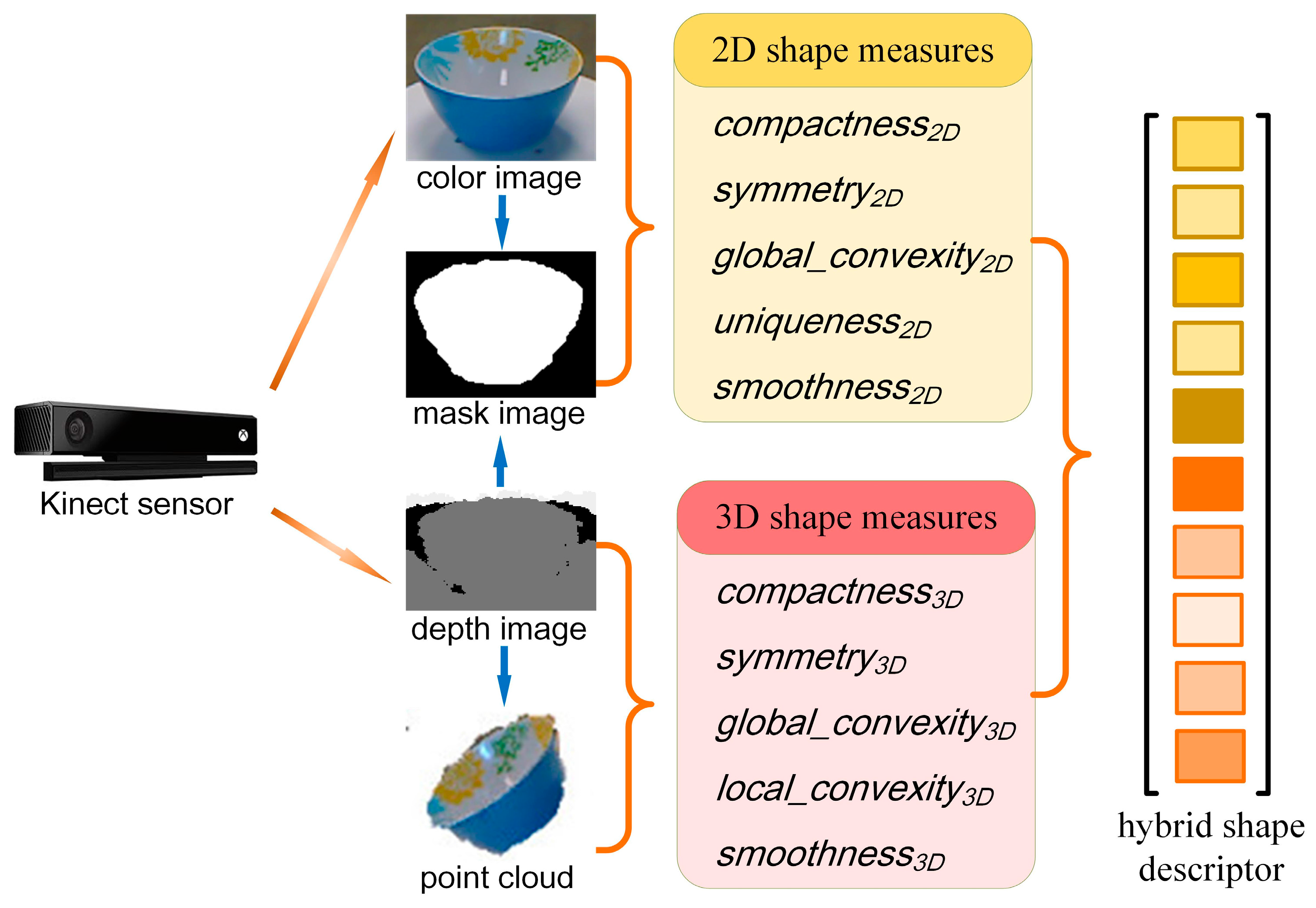
3.1. Algorithm Overview
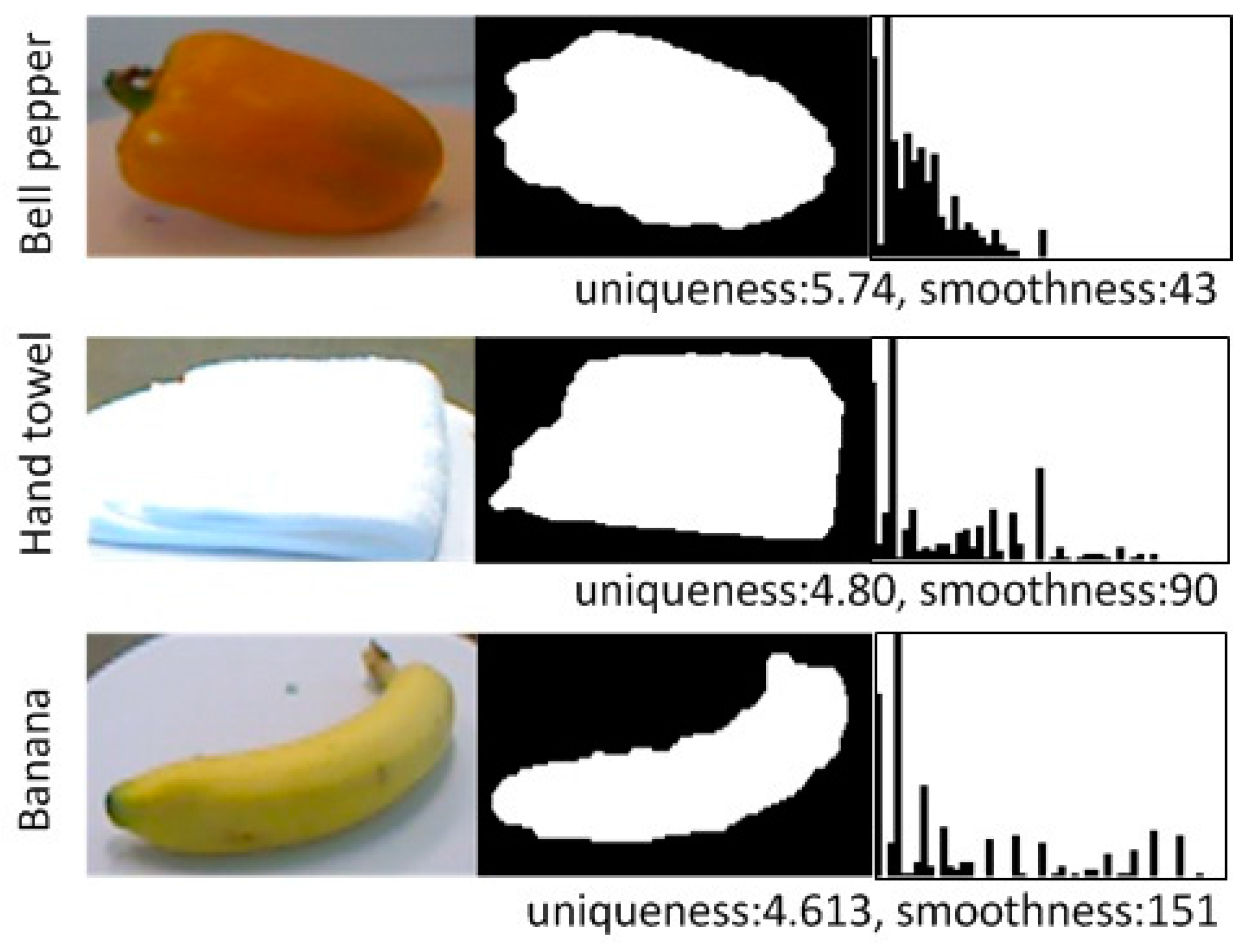
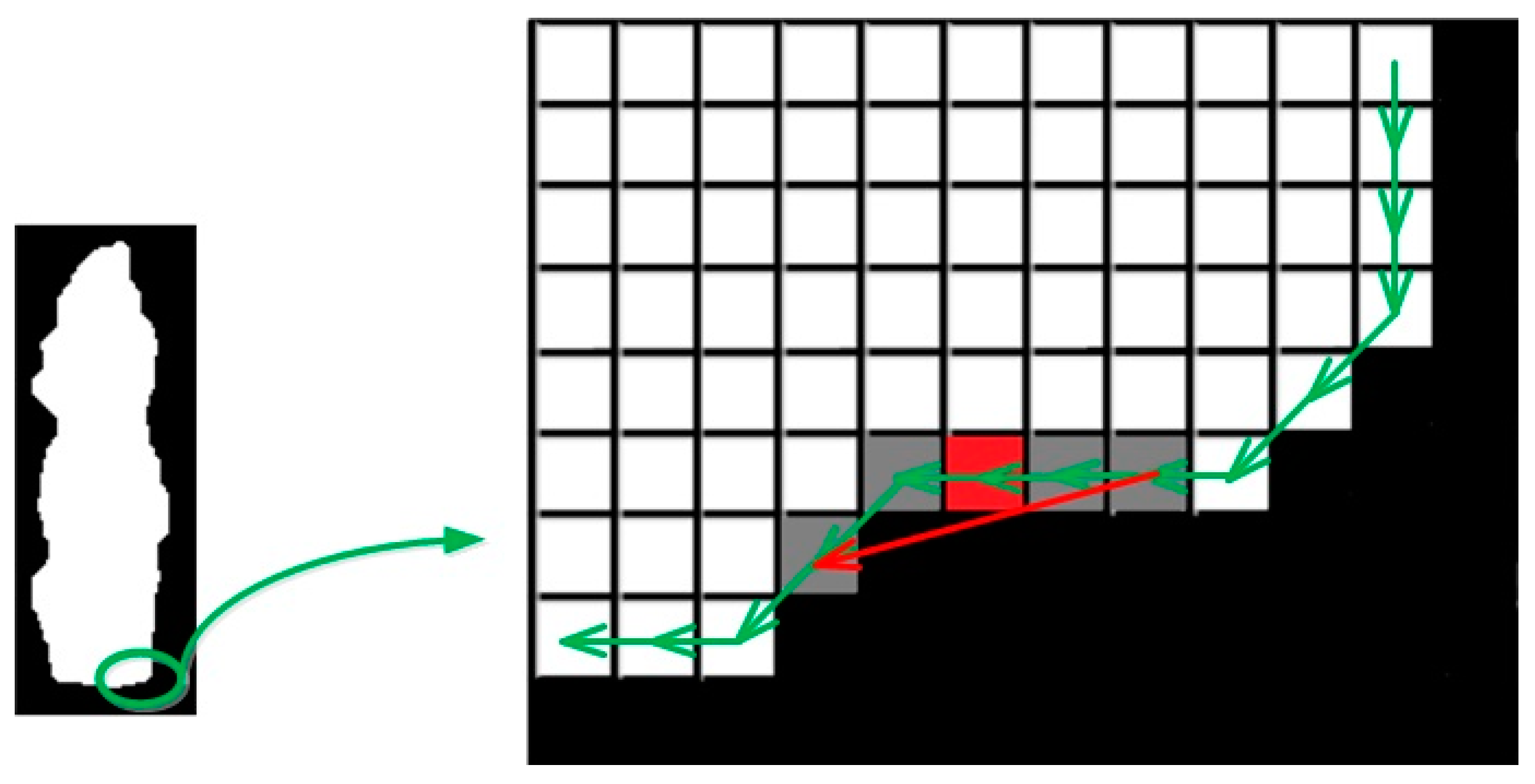
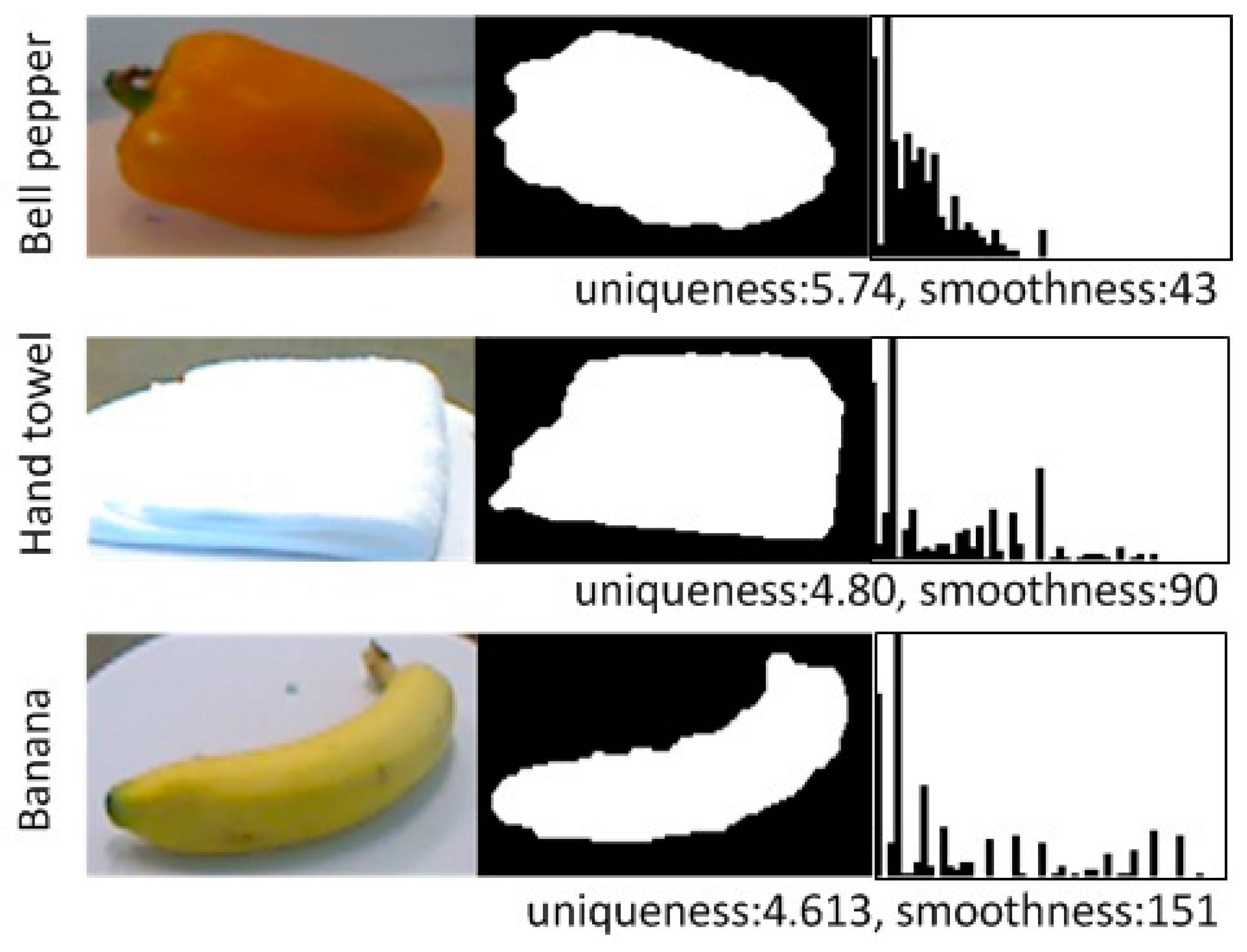
3.2. 2D Shape Measure
3.3. 3D Shape Measure
3.4. Computational Complexity Analysis
4. Experiment Results
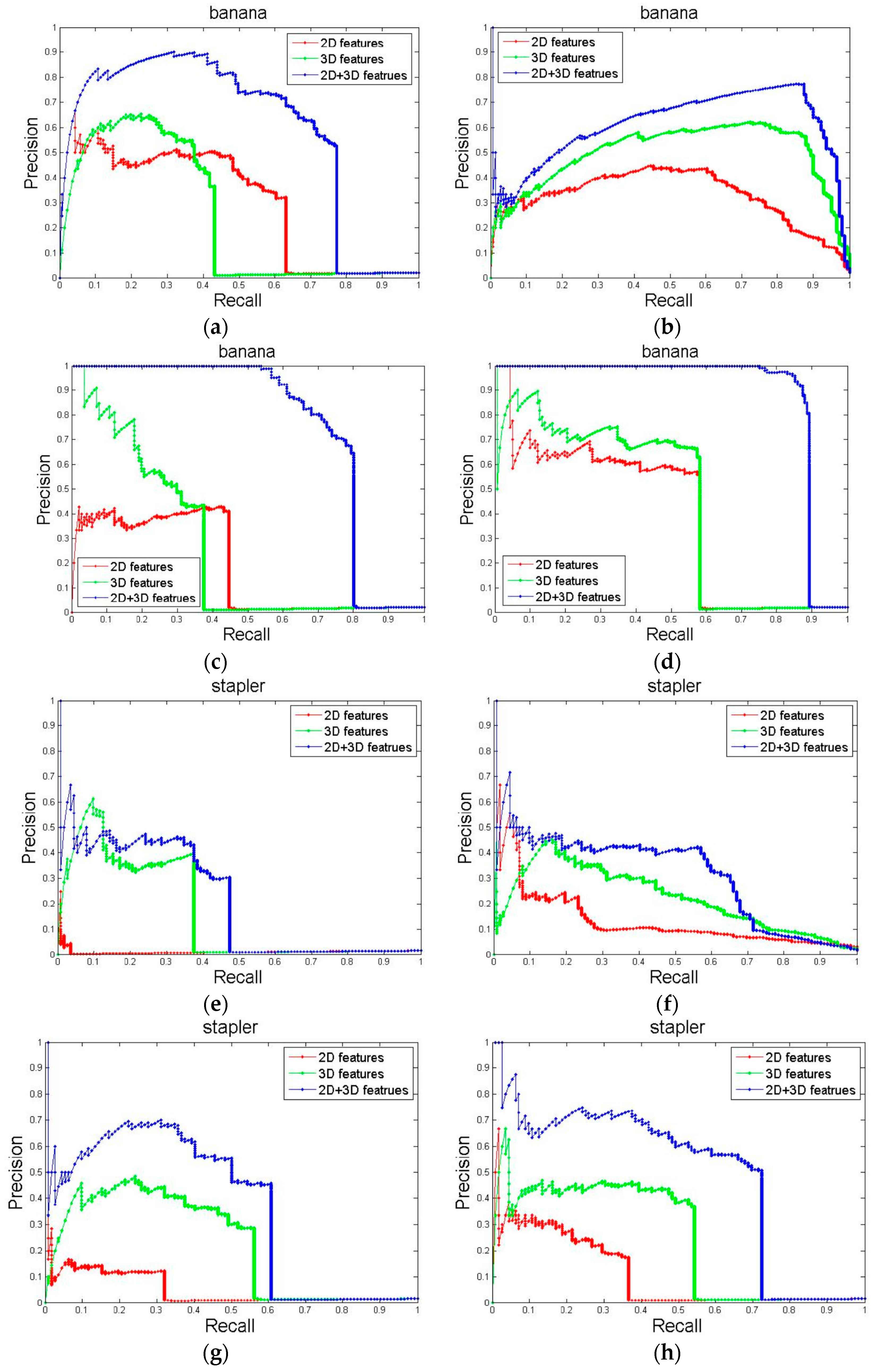
4.1. Comparison with Common Global-Based Shape Descriptors
4.1.1. Experimental Setup
4.1.2. Results
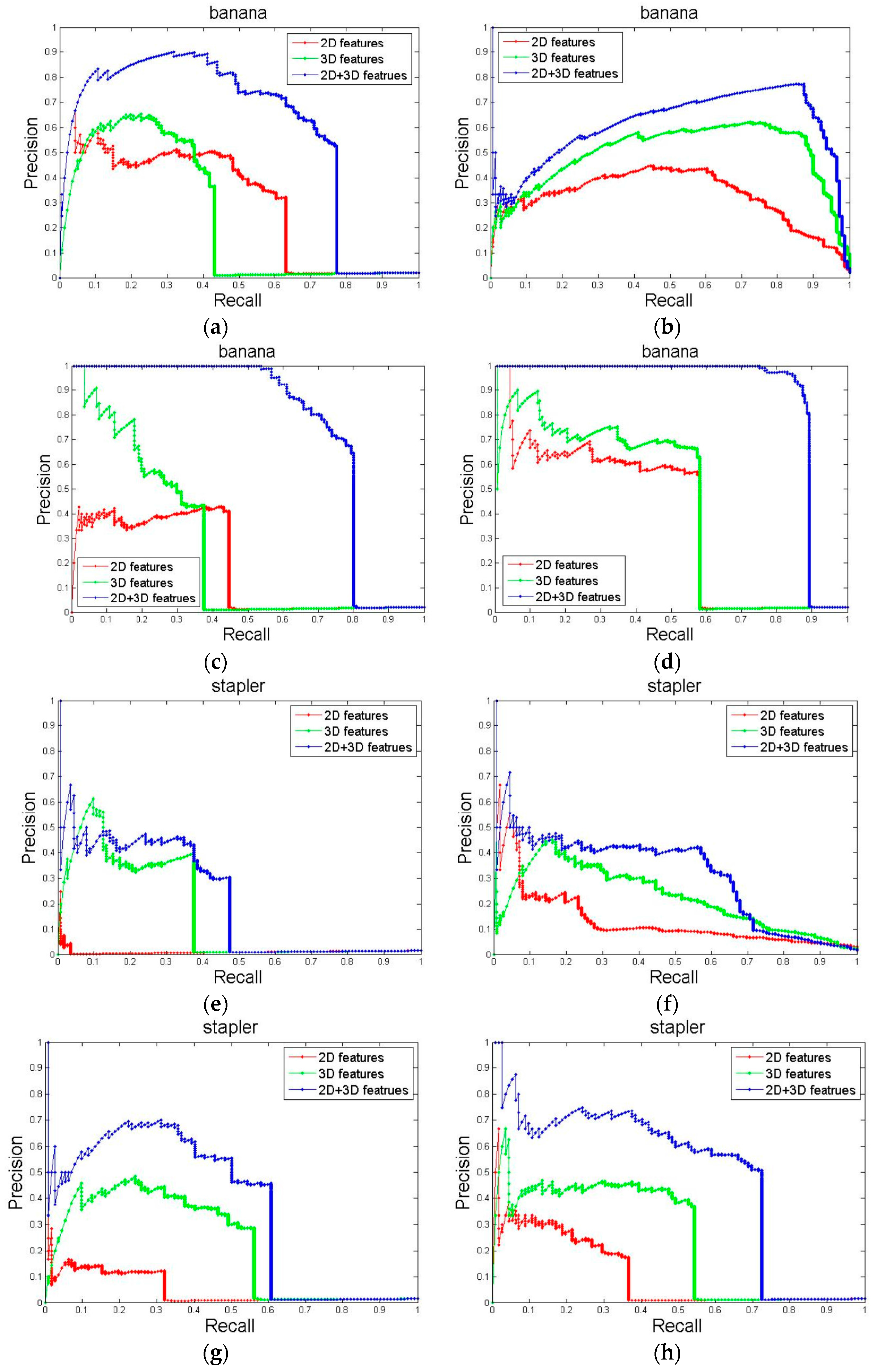
4.2. Comparison with Some Local-Based Shape Descriptors
4.2.1. Experimental Setup
4.2.2. Results
4.3. Contributions of Partial Features
4.4. Computational Time Comparisons
4.4.1. Feature Extraction Phase
4.4.2. Classifier Training and Testing Phase
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1529–1537.
- Song, H.O.; Xiang, Y.; Jegelka, S.; Savarese, S. Deep metric learning via lifted structured feature embedding. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016.
- Supancic, J.S.; Rogez, G.; Yang, Y.; Shotton, J.; Ramanan, D. Depth-based hand pose estimation: Methods, data, and challenges. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1868–1876.
- Pieroni, L.; Rossi-Arnaud, C.; Baddeley, A.D. What can symmetry tell us about working memory? In Spatial Working Memory; Psychology Press: Hove, UK, 2011. [Google Scholar]
- Rosselli, F.B.; Alemi, A.; Ansuini, A.; Zoccolan, D. Object similarity affects the perceptual strategy underlying invariant visual object recognition in rats. Front. Neural Circuits 2015, 9. [Google Scholar] [CrossRef] [PubMed]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 1817–1824.
- Karpathy, A.; Miller, S.; Fei-Fei, L. Object discovery in 3D scenes via shape analysis. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 2088–2095.
- Eitz, M.; Richter, R.; Boubekeur, T.; Hildebrand, K.; Alexa, M. Sketch-based shape retrieval. ACM Trans. Graph. 2012, 31, 31. [Google Scholar] [CrossRef]
- Yumer, M.E.; Chaudhuri, S.; Hodgins, J.K.; Kara, L.B. Semantic shape editing using deformation handles. ACM Trans. Graph. 2015, 34, 86. [Google Scholar] [CrossRef]
- As’ari, M.; Sheikh, U.U.; Supriyanto, E. 3D shape descriptor for object recognition based on kinect-like depth image. Image Vis. Comput. 2014, 32, 260–269. [Google Scholar] [CrossRef]
- Berg, A.C.; Berg, T.L.; Malik, J. Shape matching and object recognition using low distortion correspondences. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 26–33.
- Heisele, B.; Rocha, C. Local shape features for object recognition. In Proceedings of the 19th International Conference on Pattern Recognition (ICPR), Tampa, FL, USA, 8–11 December 2008; pp. 1–4.
- Toshev, A.; Taskar, B.; Daniilidis, K. Shape-based object detection via boundary structure segmentation. Int. J. Comput. Vis. 2012, 99, 123–146. [Google Scholar] [CrossRef]
- Liang, C.W.; Juang, C.F. Moving object classification using local shape and hog features in wavelet-transformed space with hierarchical SVM classifiers. Appl. Soft Comput. 2015, 28, 483–497. [Google Scholar] [CrossRef]
- Bo, L.; Ren, X.; Fox, D. Depth kernel descriptors for object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 821–826.
- Bronstein, M.M.; Bronstein, A.M. Shape recognition with spectral distances. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 5, 1065–1071. [Google Scholar] [CrossRef] [PubMed]
- Prautzsch, H.; Umlauf, G. Parametrizations for triangular g(k) spline surfaces of low degree. ACM Trans. Graph. 2006, 25, 1281–1293. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Aligning point cloud views using persistent feature histograms. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3384–3391.
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217.
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D recognition and pose using the Viewpoint Feature Histogram. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162.
- Bo, L.; Sminchisescu, C. Efficient match kernel between sets of features for visua recognition. In Proceedings of the Advances in Neural Information Processing Systems 22: 23rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 135–143.
- Han, E.J.; Kang, B.J.; Park, K.R.; Lee, S. Support vector machine–based facial-expression recognition method combining shape and appearance. Opt. Eng. 2010, 49, 117202. [Google Scholar] [CrossRef]
- Ekman, W.F.P. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: San Francisco, CA, USA, 2010. [Google Scholar]
- Qian, F.; Zhang, B.; Yin, C.; Yang, M.; Li, X. Recognition of interior photoelectric devices by using dual criteria of shape and local texture. Opt. Eng. 2015, 54, 123110. [Google Scholar] [CrossRef]
- Ning, X.; Wang, Y.; Zhang, X. Object shape classification and scene shape representation for three-dimensional laser scanned outdoor data. Opt. Eng. 2013, 52, 024301. [Google Scholar] [CrossRef]
- Carolina, H.A.; Clara, G.; Jonathan, C.; Ramón, B. Object detection applied to indoor environments for mobile robot navigation. Sensors 2016, 16, 1180. [Google Scholar]
- Wagemans, J.; Elder, J.H.; Kubovy, M.; Palmer, S.E.; Peterson, M.A.; Singh, M.; von der Heydt, R. A century of gestalt psychology in visual perception: I. perceptual grouping and figure–ground organization. Psychol. Bull. 2012, 138, 1172–1217. [Google Scholar] [CrossRef] [PubMed]
- Hauagge, D.C.; Snavely, N. Image matching using local symmetry features. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 206–213.
- Sun, Y. Symmetry and Feature Selection in Computer Vision. Ph.D. Dissertation, University of California, Riverside, CA, USA, 2012. [Google Scholar]
- Huebner, K.; Zhang, J. Stable symmetry feature detection and classification in panoramic robot vision systems. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Beijing, China, 9–15 October 2006; pp. 3429–3434.
- Burges, C. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Osada, R.; Funkhouser, T.; Chazelle, B.; Dobkin, D. Shape distributions. ACM Trans. Graph. 2002, 21, 807–832. [Google Scholar] [CrossRef]
- Huang, P.; Hilton, A.; Starck, J. Shape similarity for 3d video sequences of people. Int. J. Comput. Vis. 2010, 89, 362–381. [Google Scholar] [CrossRef]
- Ankerst, M.; Kastenmüller, G.; Kriegel, H.P.; Seidl, T. 3D shape histograms for similarity search and classification in spatial databases. In Advances in Spatial Databases; Springer: Berline/Heidelberg, Germany, 1999; Volume 1651, pp. 207–226. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | SD | GSI | SH | Our Work |
|---|---|---|---|---|
| Category Recognition | ||||
| NB | 35.1 ± 0.03 | 38.2 ± 0.03 | 33.4 ± 0.03 | 54.5 ± 0.01 |
| NN | 43.8 ± 0.01 | 47.0 ± 0.02 | 42.9 ± 0.01 | 59.2 ± 0.02 |
| LinSVM | 47.4 ± 1.89 | 53.7 ± 2.42 | 38.2 ± 1.41 | 63.2 ± 2.69 |
| kSVM | 56.9 ± 2.19 | 54.3 ± 3.49 | 46.7 ± 1.29 | 68.7 ± 3.60 |
| Instance Recognition | ||||
| NB | 19.8 | 27.9 | 19.4 | 36.3 |
| NN | 20.1 | 28.8 | 18.4 | 25.2 |
| LinSVM | 31.5 | 37.2 | 20.0 | 45.7 |
| kSVM | 35.5 | 35.4 | 21.0 | 46.0 |
| Shape Features | Category | Instance |
|---|---|---|
| KPCA [19] | 50.2 ± 2.9 | 29.5 |
| Spin KDES [19] | 64.4 ± 3.1 | 28.8 |
| SF+LinSVM [10] | 53.1 ± 1.7 | 32.3 |
| SF+Ksvm [10] | 64.7 ± 2.2 | 46.2 |
| Our work | 66.3 ± 1.8 | 45.8 |
| Steps | Normal Estimation | PCA | GSI | SD | SH |
|---|---|---|---|---|---|
| time (s) | 8.6138 | 0.0291 | 0.0119 | 0.0782 | 0.0034 |
| Steps | Compactness 3D | Symmetry 3D | Global convexity 3D | Local convexity 3D | Smoothness 3D |
| time (s) | - | 0.4034 | 0.7222 | 0.4366 | - |
| Steps | Compactness 2D | Symmetry 2D | Global convexity 2D | Uniqueness 2D | Smoothness 2D |
| time (s) | - | 0.0013 | 0.0145 | - | - |
| Methods | GSI | SD | SH | Our Work |
|---|---|---|---|---|
| Total time (s) | 8.6548 | 8.7211 | 8.6463 | 10.2209 |
| p (%) | 99.53 | 98.77 | 99.62 | 84.28 |
| Training (s) | GSI (1600D) | SD (1024D) | SH (100D) | Our Work (10D) |
| Linear SVM | 295.5 ± 6.3 | 1178.2 ± 18.1 | 98.0 ± 2.9 | 25.1 ± 0.2 |
| Kernel SVM | 2529.3 ± 16.9 | 4224.2 ± 20.8 | 94.4 ± 1.6 | 31.9 ± 0.2 |
| Testing (s) | GSI (1600D) | SD (1024D) | SH (100D) | Our work (10D) |
| Linear SVM | 77.9 ± 0.7 | 84.5 ± 0.6 | 11.1 ± 0.1 | 9.4 ± 0.1 |
| Kernel SVM | 128.9 ± 0.9 | 97.5 ± 0.6 | 13.1 ± 0.1 | 12.3 ± 0.2 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Zhao, C.; Wu, X.; Chen, W. An Effective 3D Shape Descriptor for Object Recognition with RGB-D Sensors. Sensors 2017, 17, 451. https://doi.org/10.3390/s17030451
Liu Z, Zhao C, Wu X, Chen W. An Effective 3D Shape Descriptor for Object Recognition with RGB-D Sensors. Sensors. 2017; 17(3):451. https://doi.org/10.3390/s17030451
Chicago/Turabian StyleLiu, Zhong, Changchen Zhao, Xingming Wu, and Weihai Chen. 2017. "An Effective 3D Shape Descriptor for Object Recognition with RGB-D Sensors" Sensors 17, no. 3: 451. https://doi.org/10.3390/s17030451