Sparse Adaptive Iteratively-Weighted Thresholding Algorithm (SAITA) for
L
p
-Regularization Using the Multiple Sub-Dictionary Representation

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. The Non-Convex Penalties
1.2. The Iterative Thresholding Algorithm of Regularization
1.3. New Multiple-State Sparse Transform Based Regularization Algorithm
2. The Proposed Multiple Sub-Dictionary-Based Regularization
3. The Proposed SAITA- Algorithm
3.1. The Relationship of the SAITA- and Conventional Methods
3.2. The Thresholding Representation Theory for SAITA-Lp
3.3. The Proposed SAITA-Lp Algorithm
| Algorithm 1: The proposed SAITA- algorithm. |
| Problem: ; 1: Input:, , ; ; ; ; 2: Initialization: ; ; ; ; . 3: for 4: Calling the conventional analysis algorithm in (13): While not converged do Step 1: Compute in Equation (22); Step 2: Compute in Equation (21); Step 3: Update the value of using in Equation (31); Step 4: Update the solution in Equation (32); End 5: Updating: in Equation (29); 6: end 7: Output |
4. Performance Analysis and Discussion
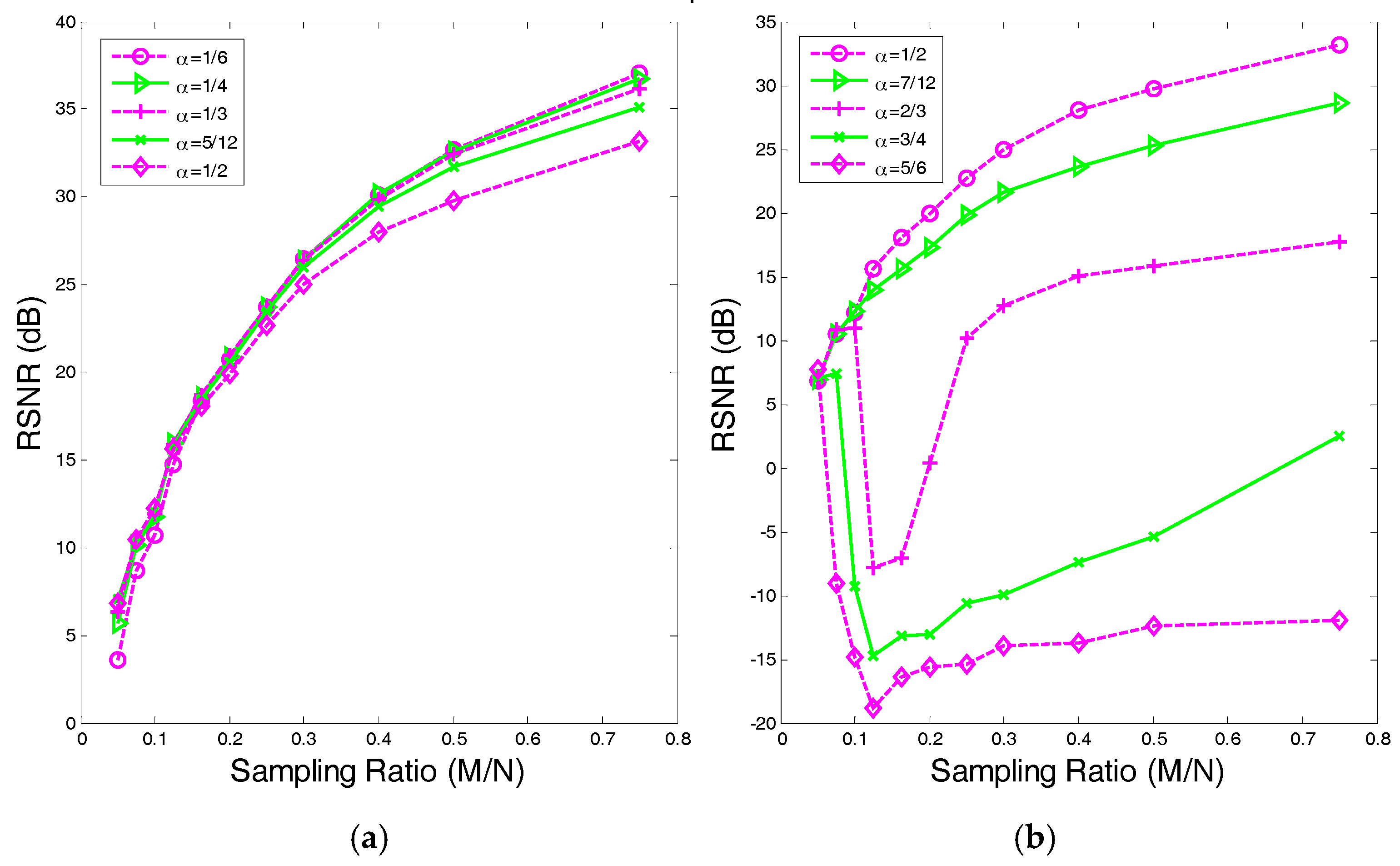
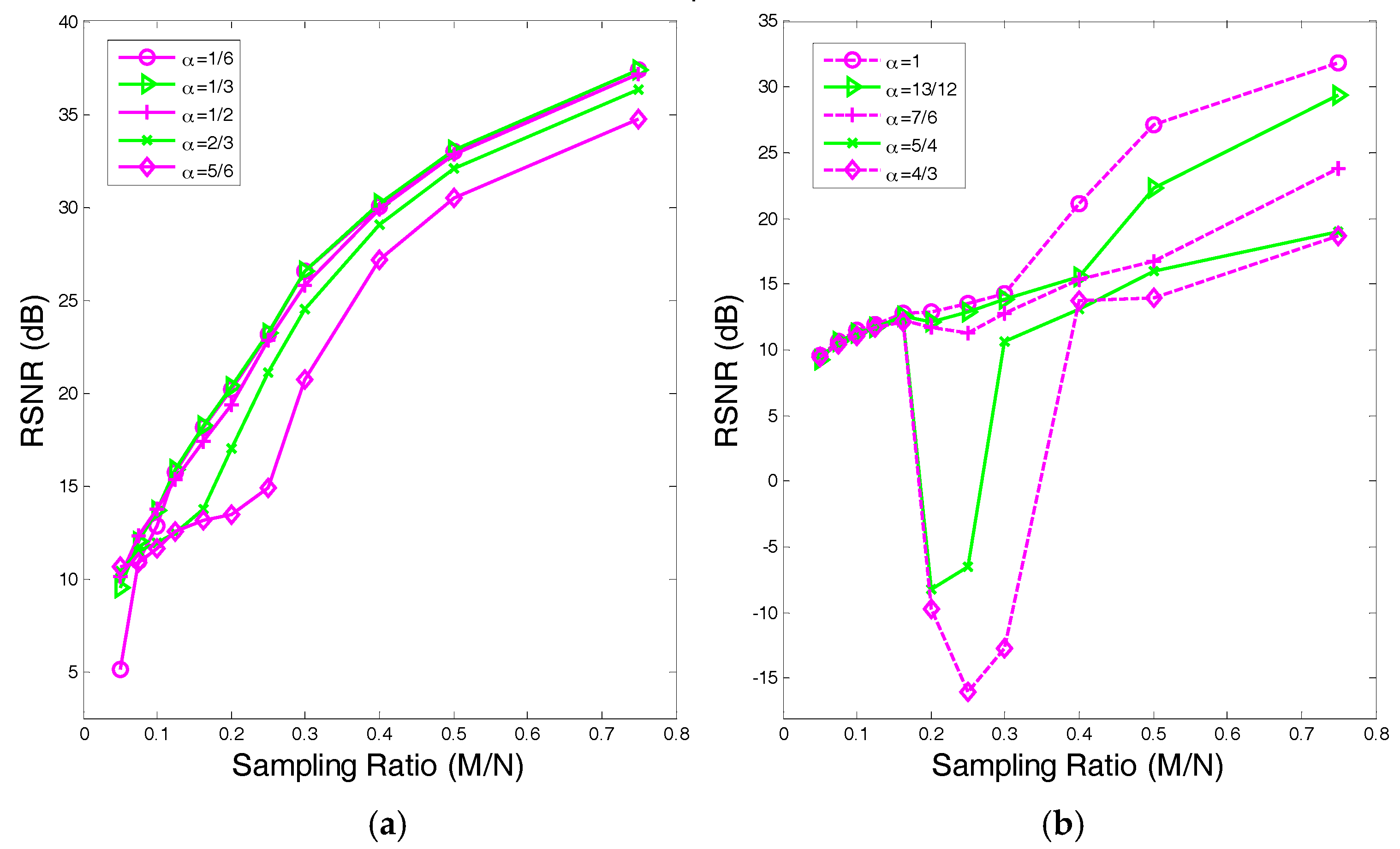
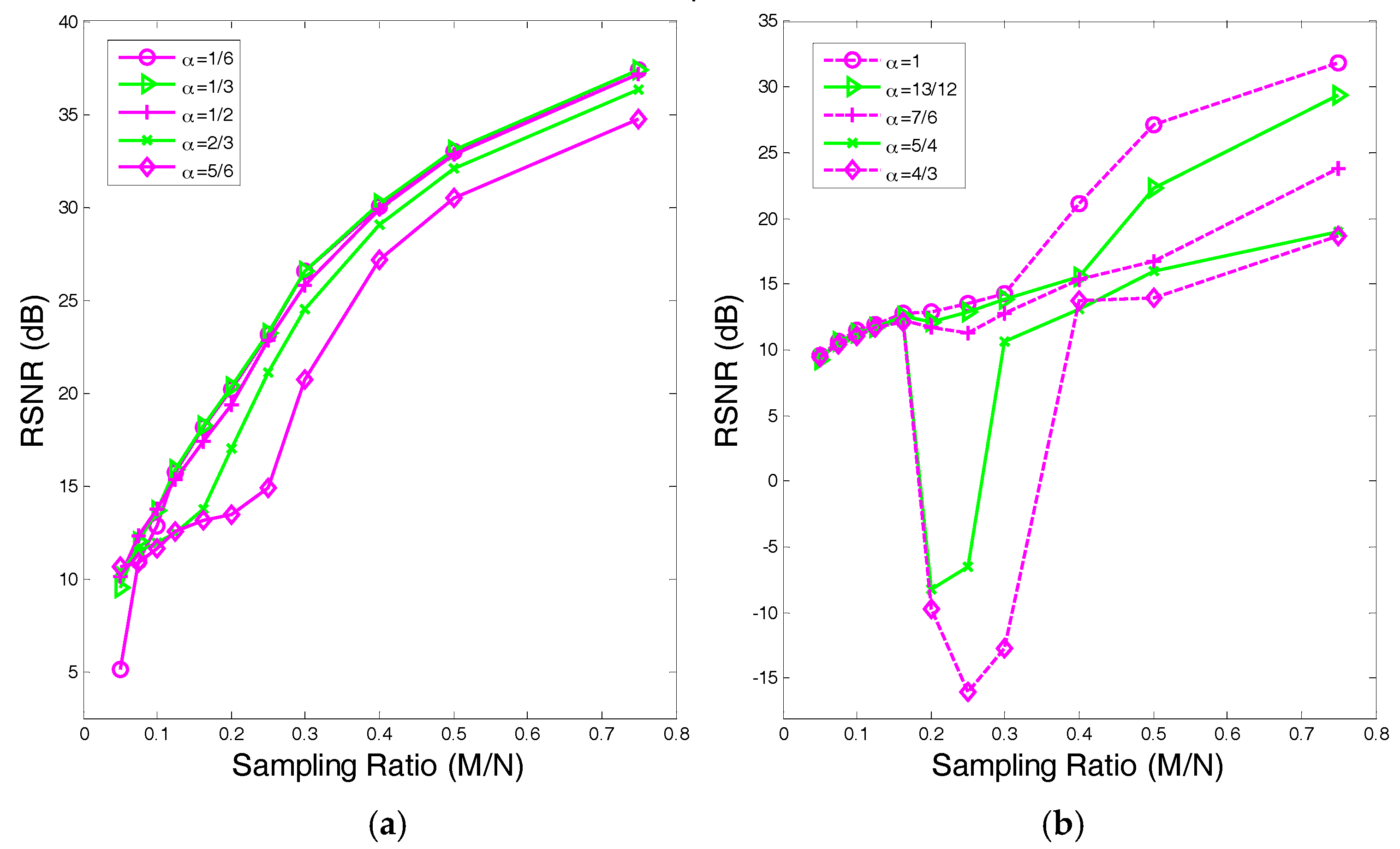
4.1. The Value Range of in
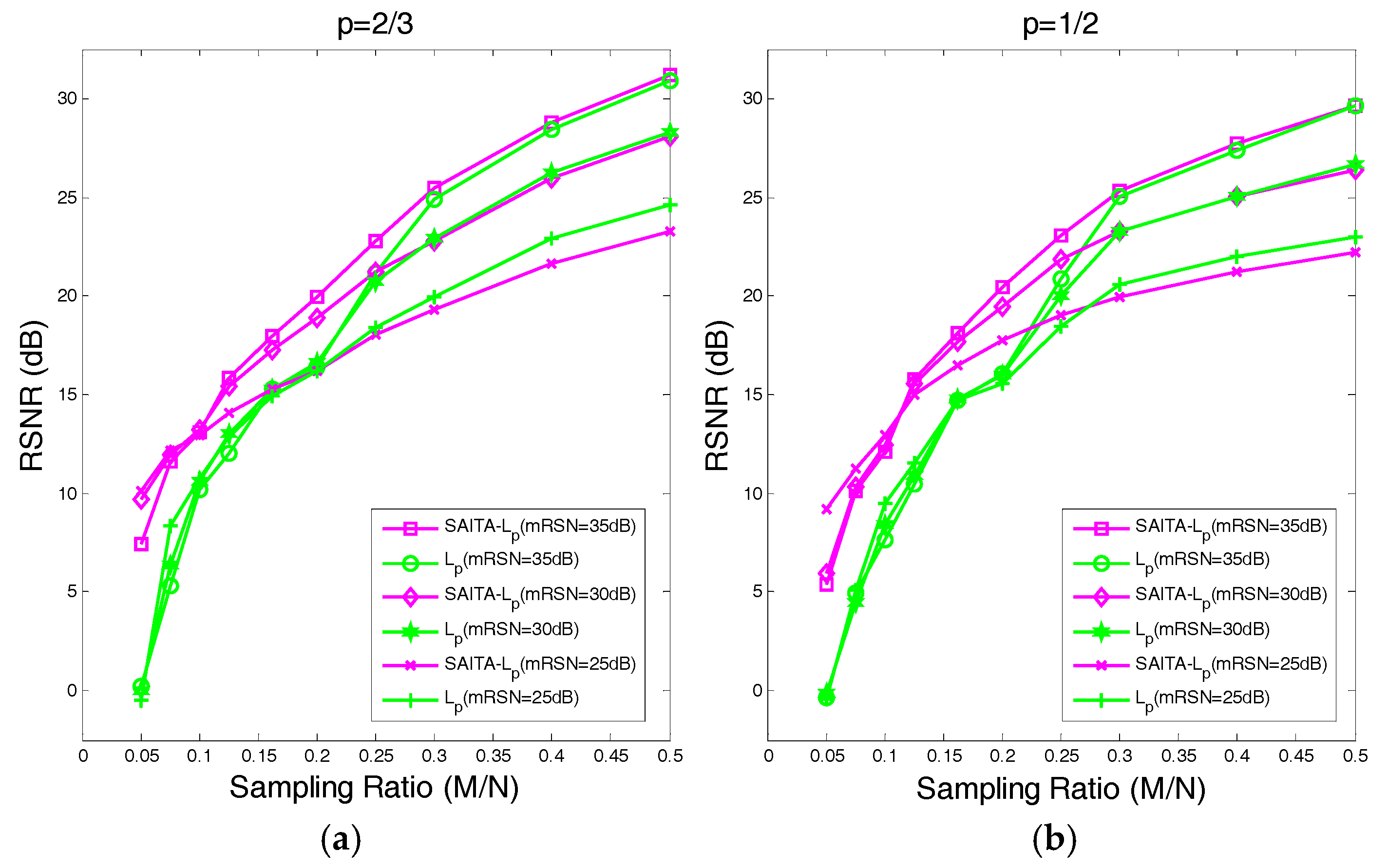
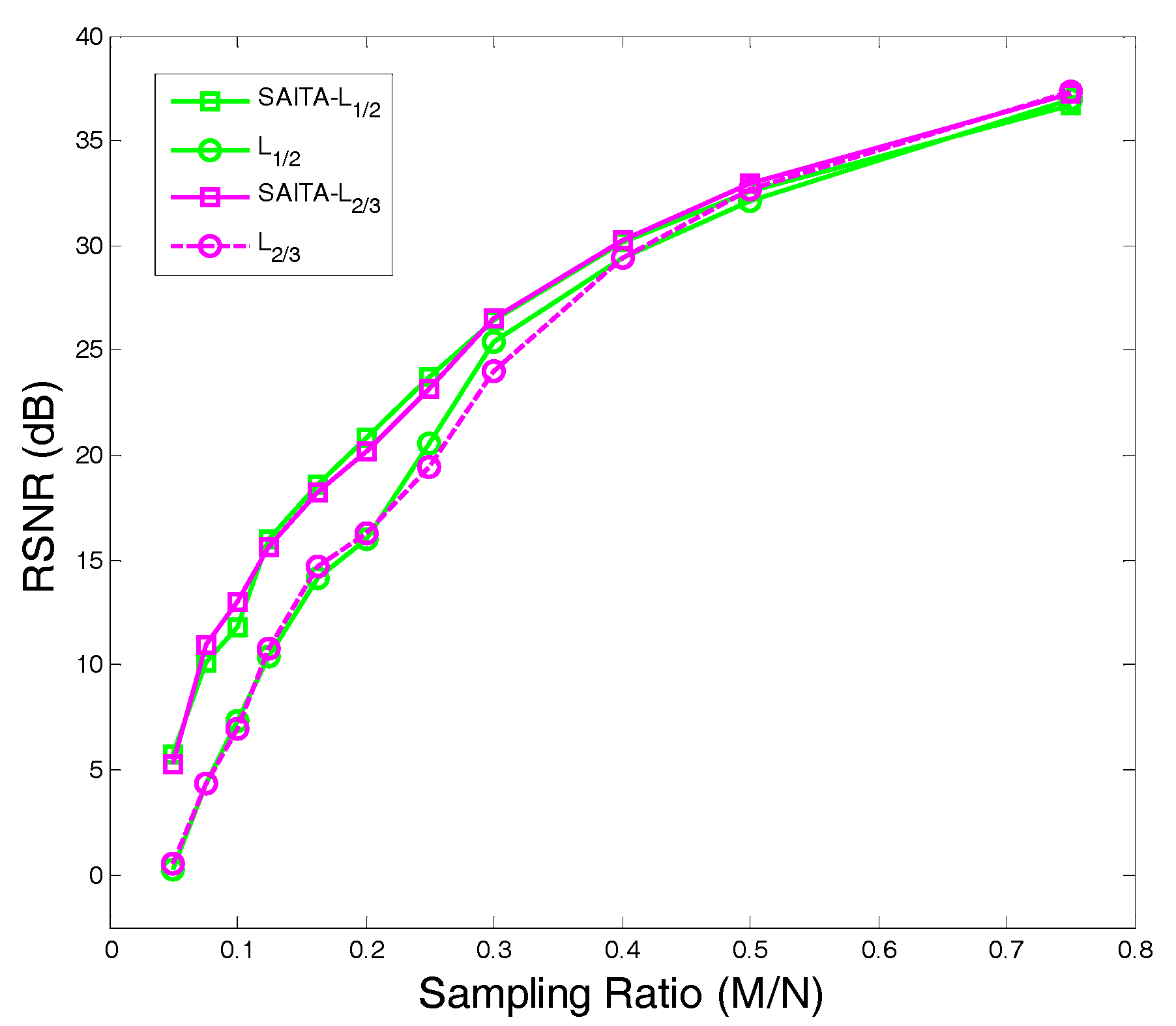
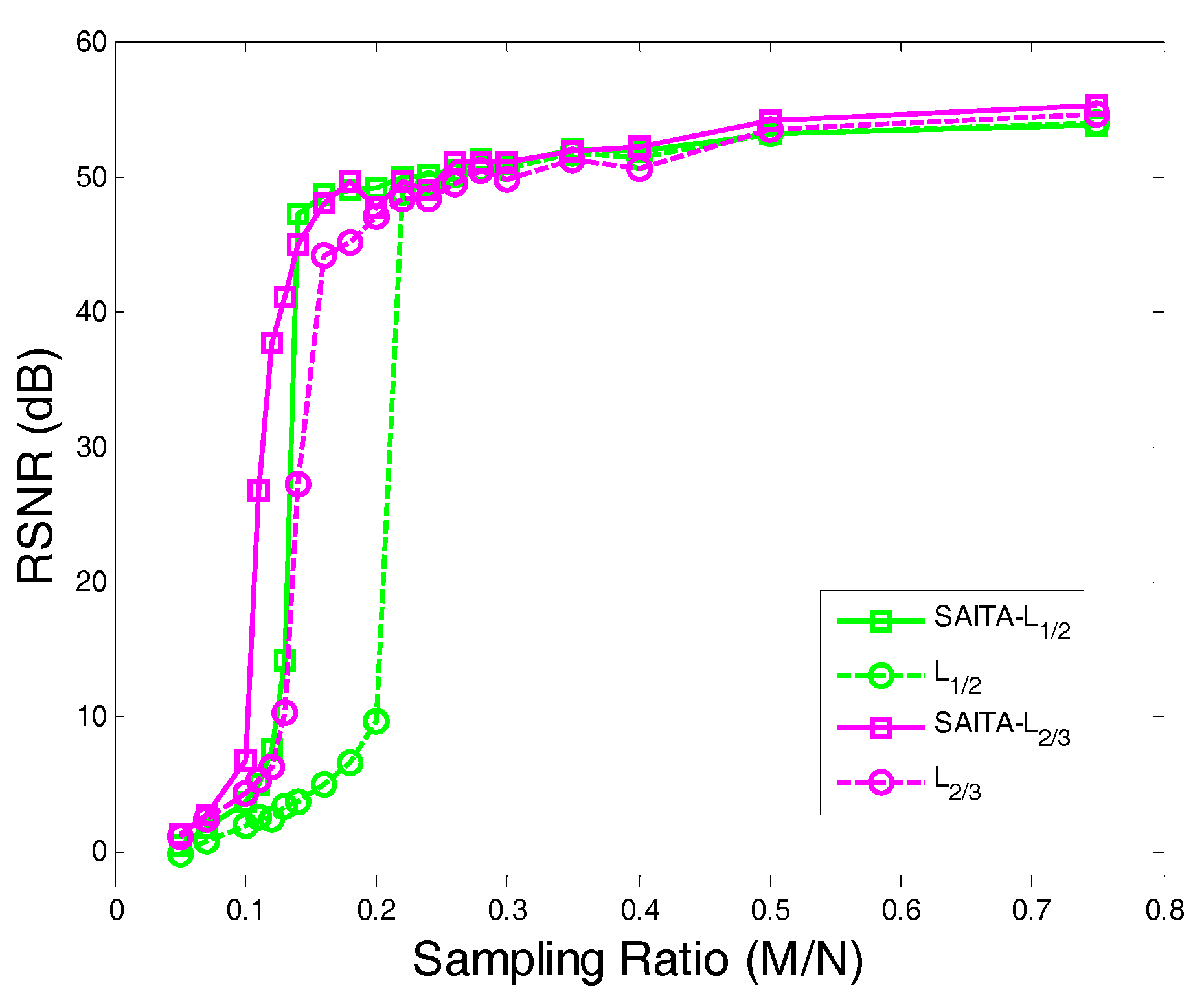
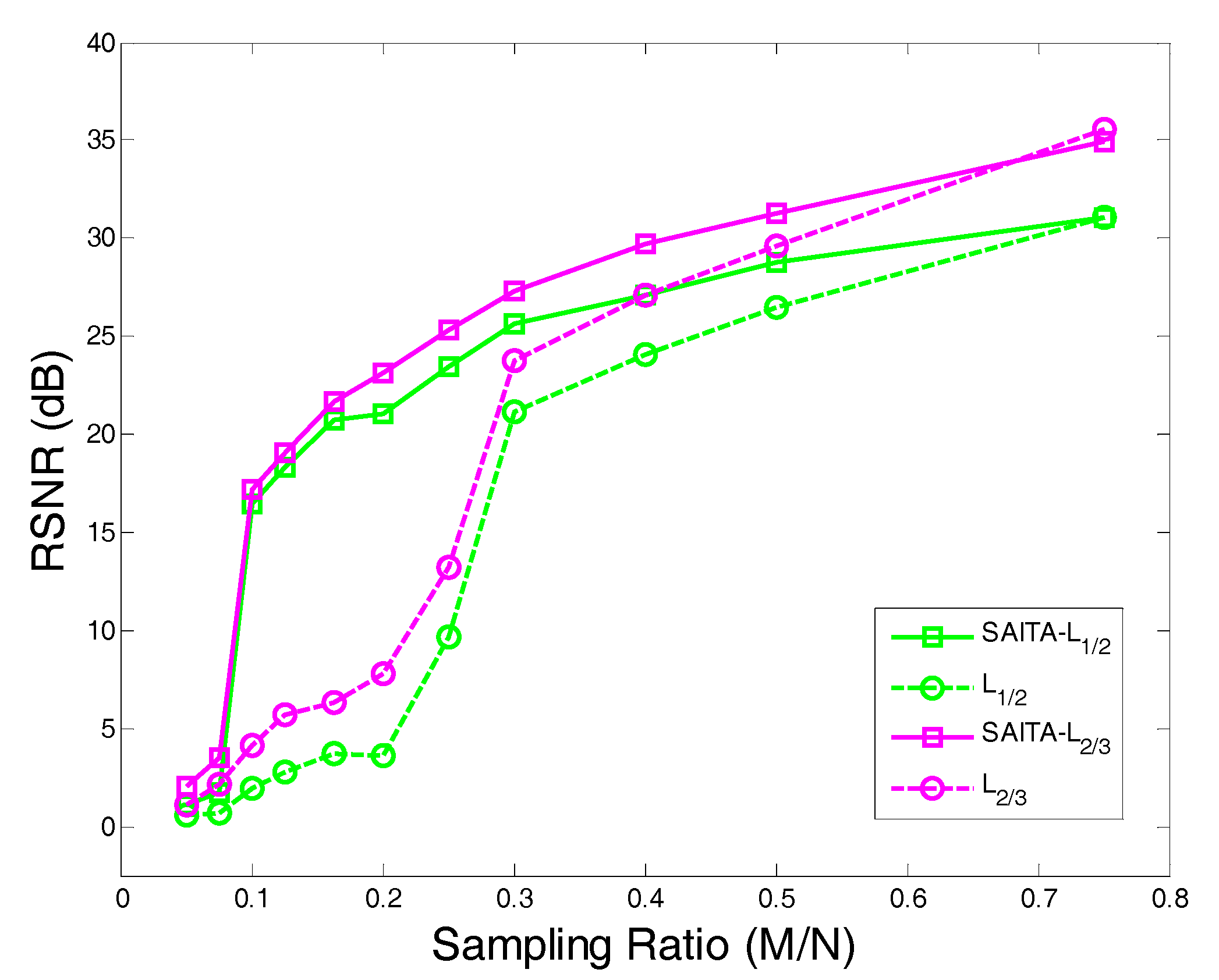
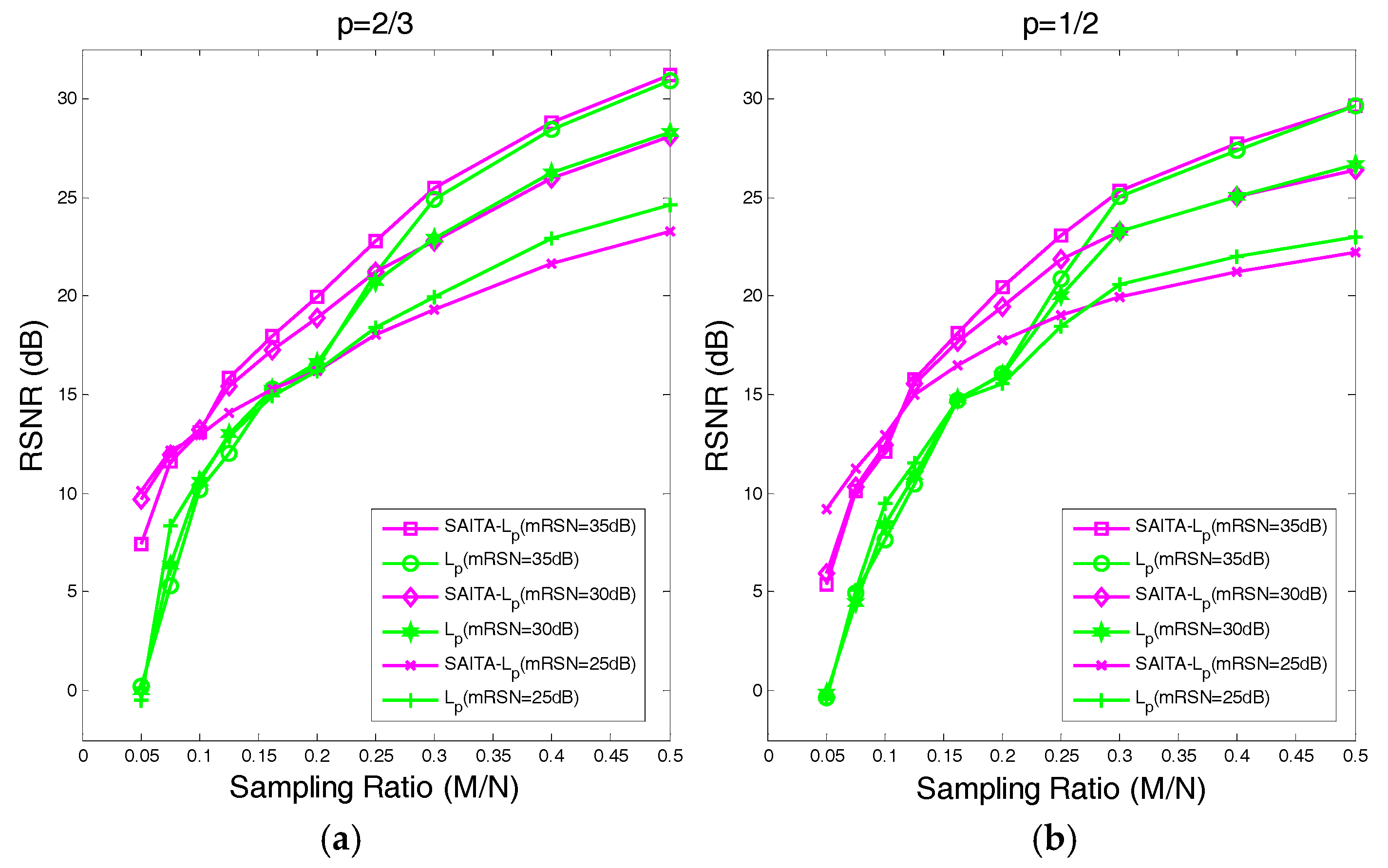
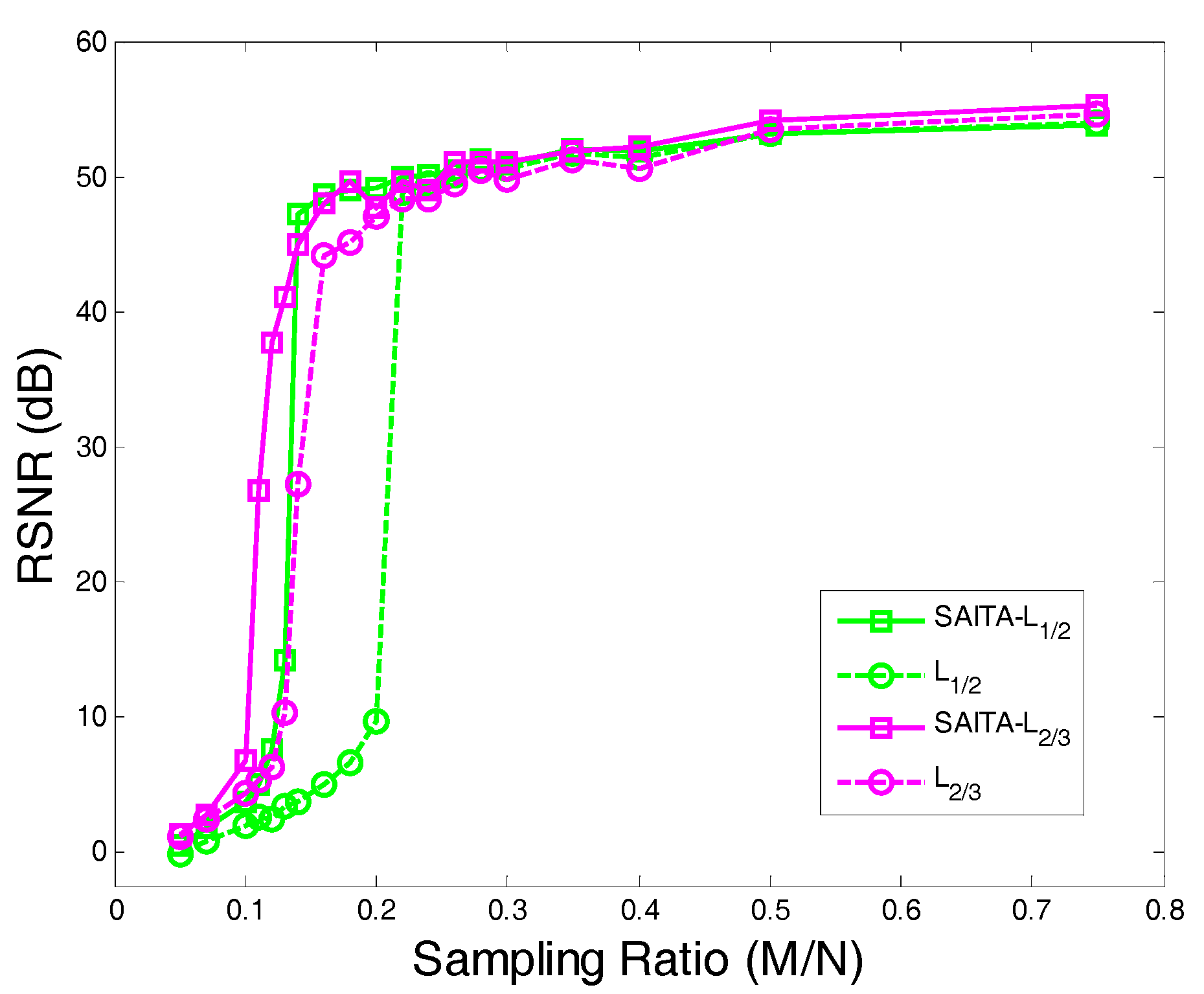
4.2. The Recovery SNR Performances Versus Sampling Ratio
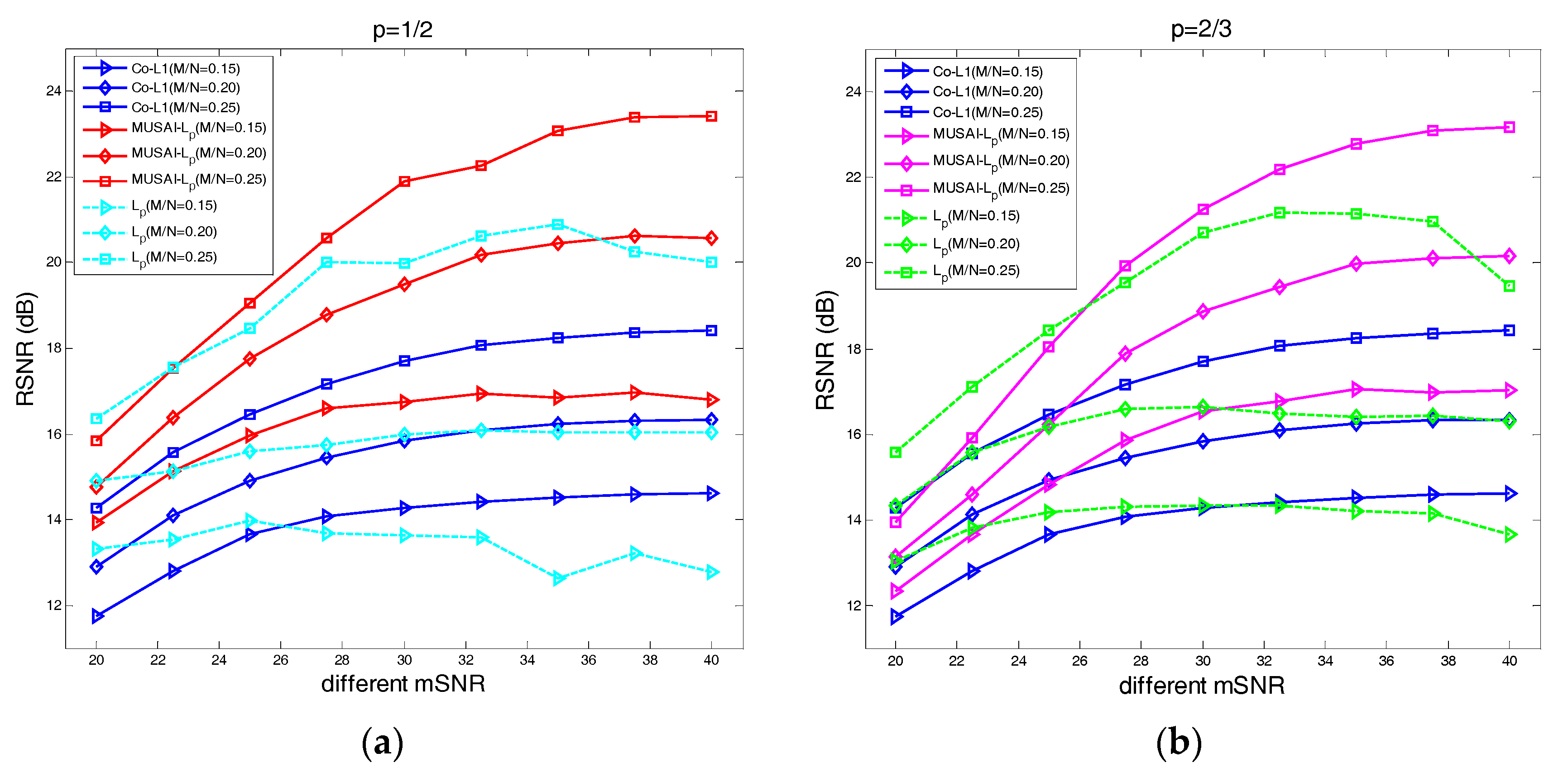
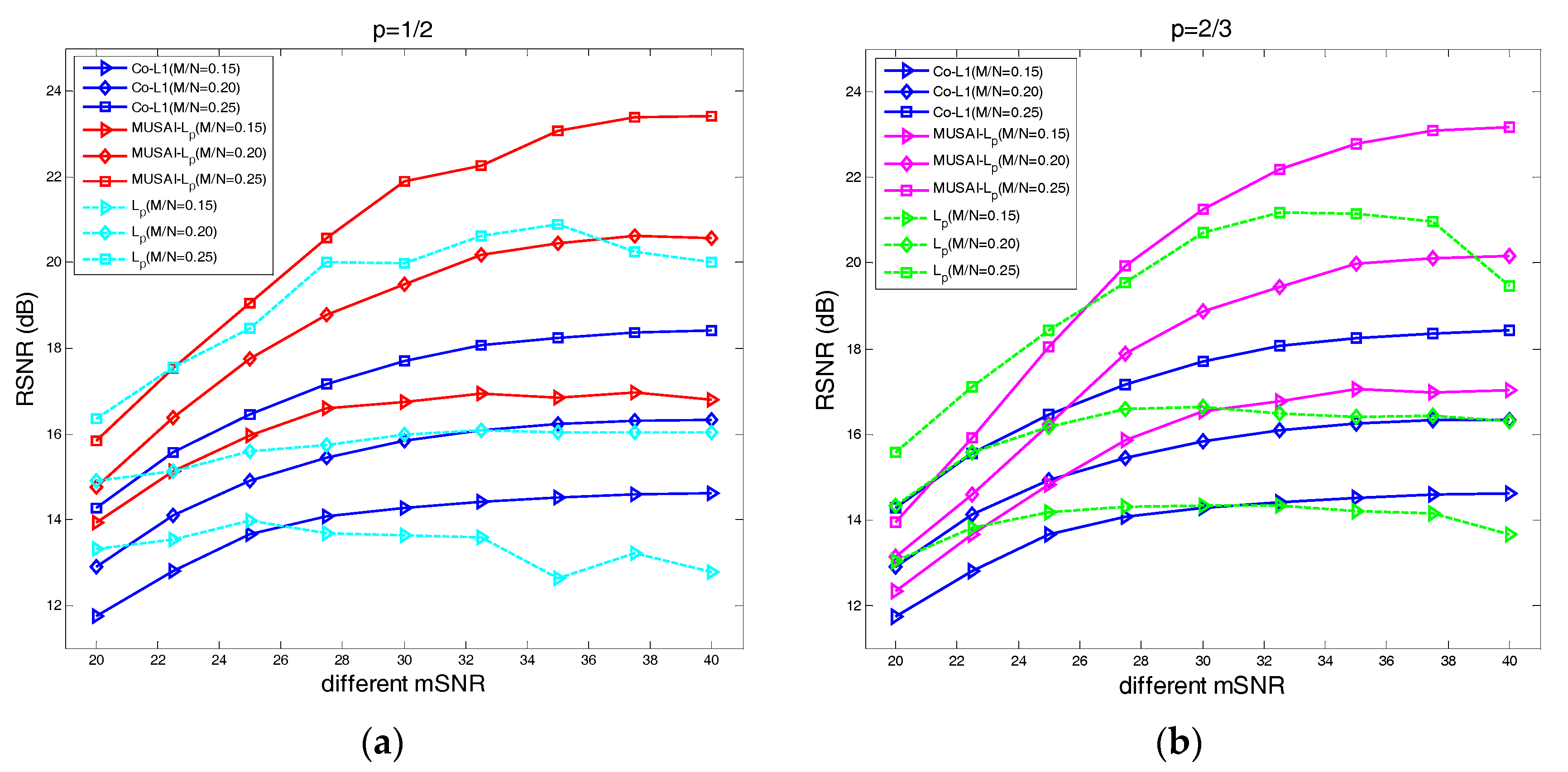
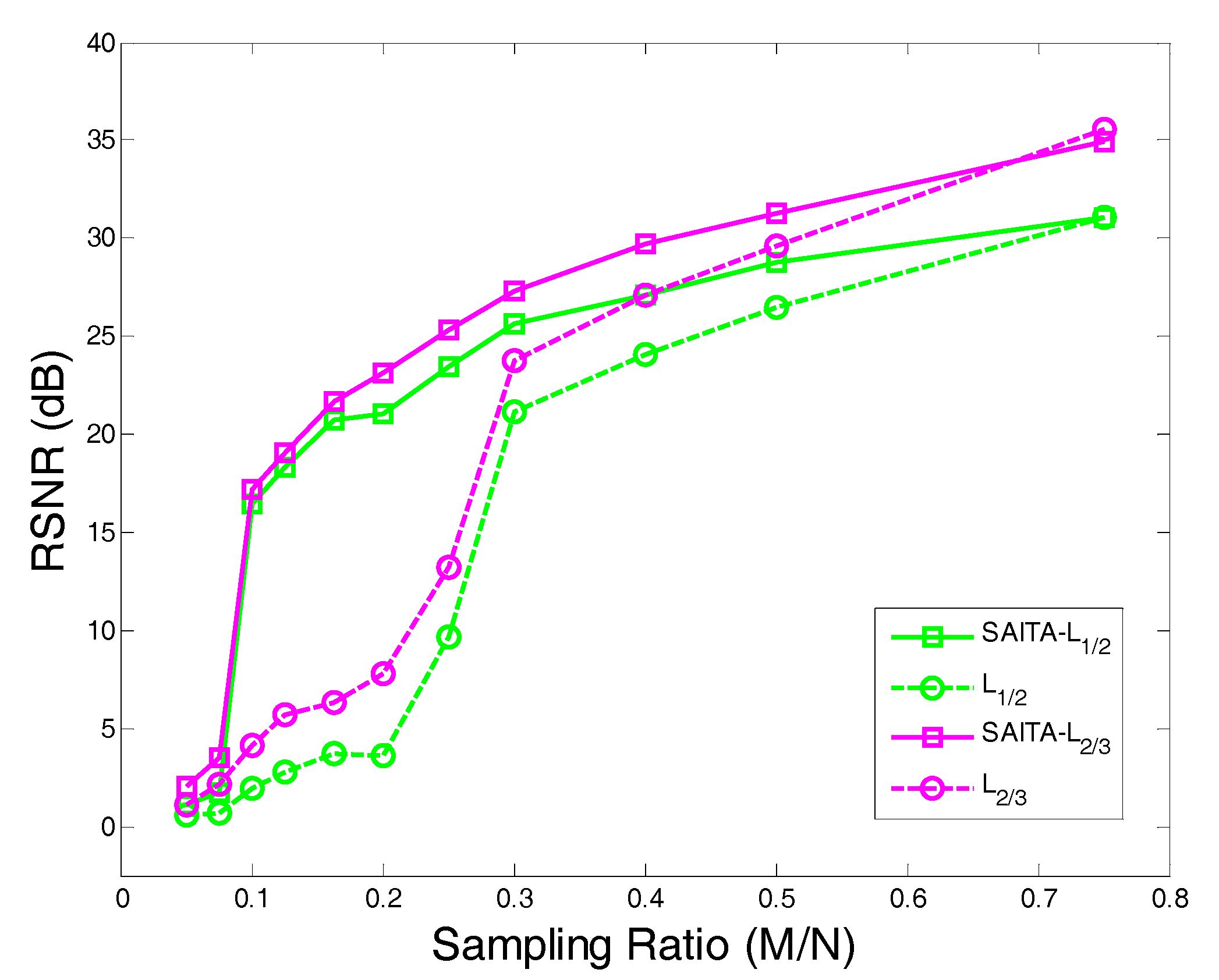
4.3. The Recovery SNR Performance Versus Measurement SNR
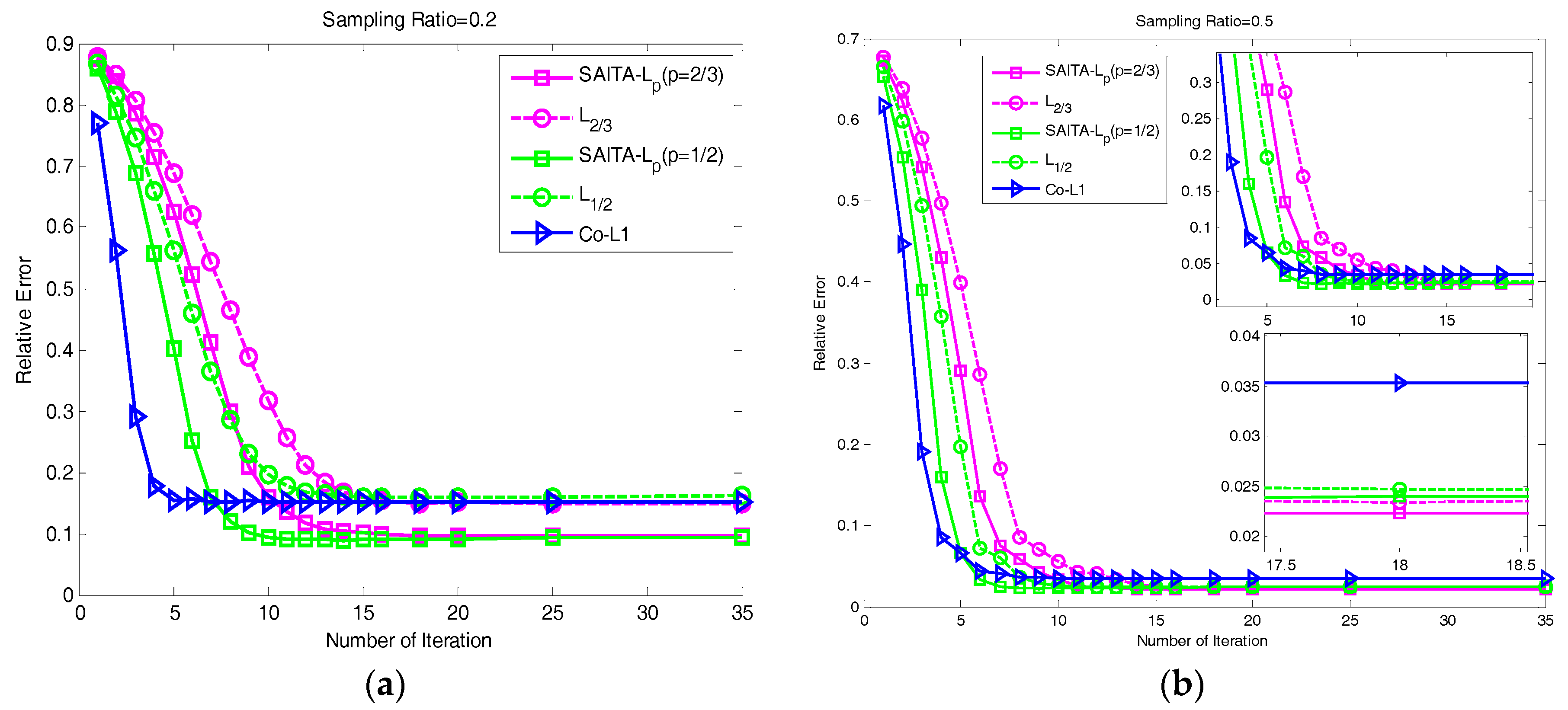
4.4. The Relative Error Performances Versus the Number of Iterations
5. Practical Experiments
5.1. Application 1: Image Sparse Restoration
5.2. Application 2: Medical Imaging
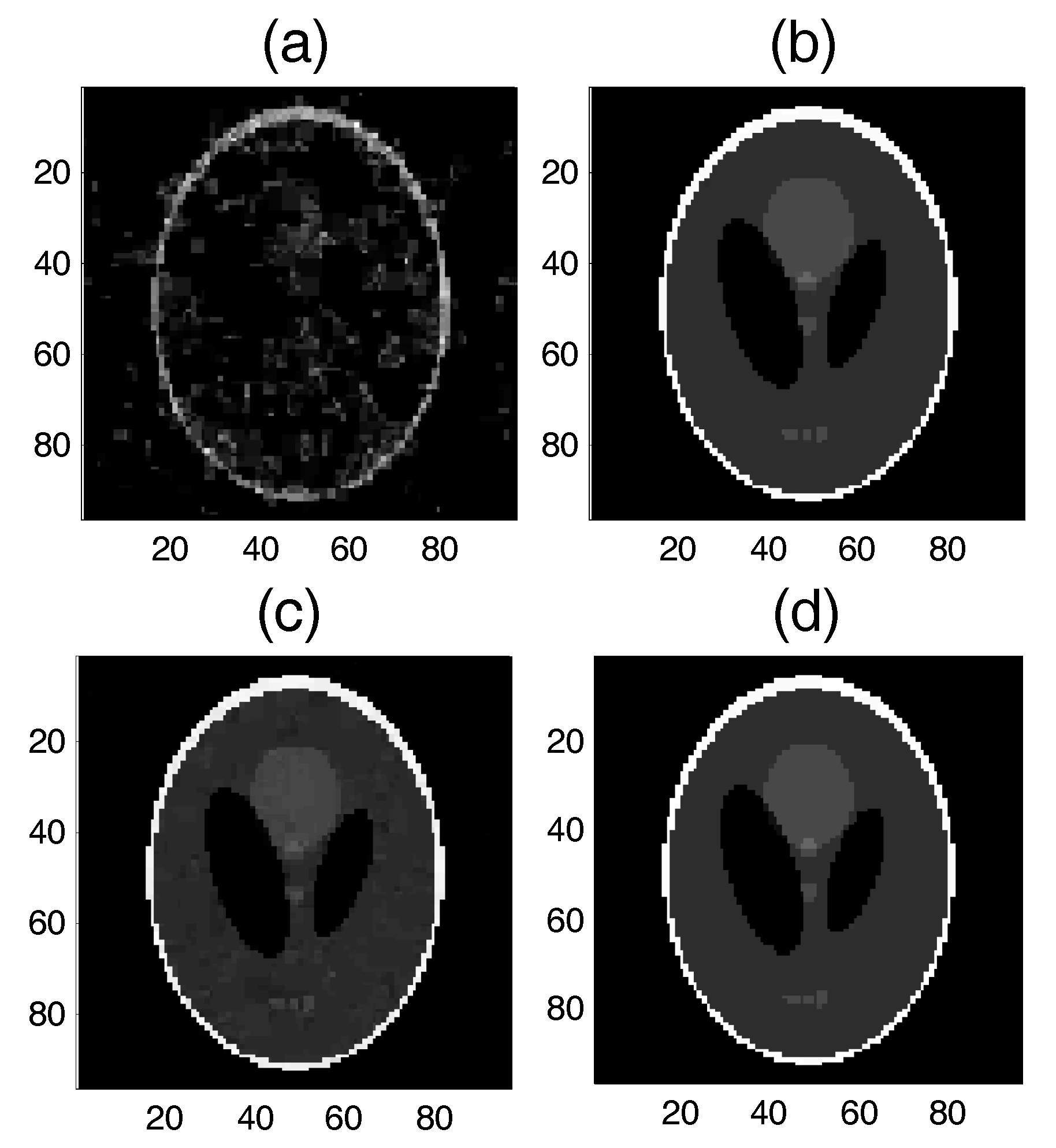
5.2.1. Test 1 for the Shepp-Logan Model
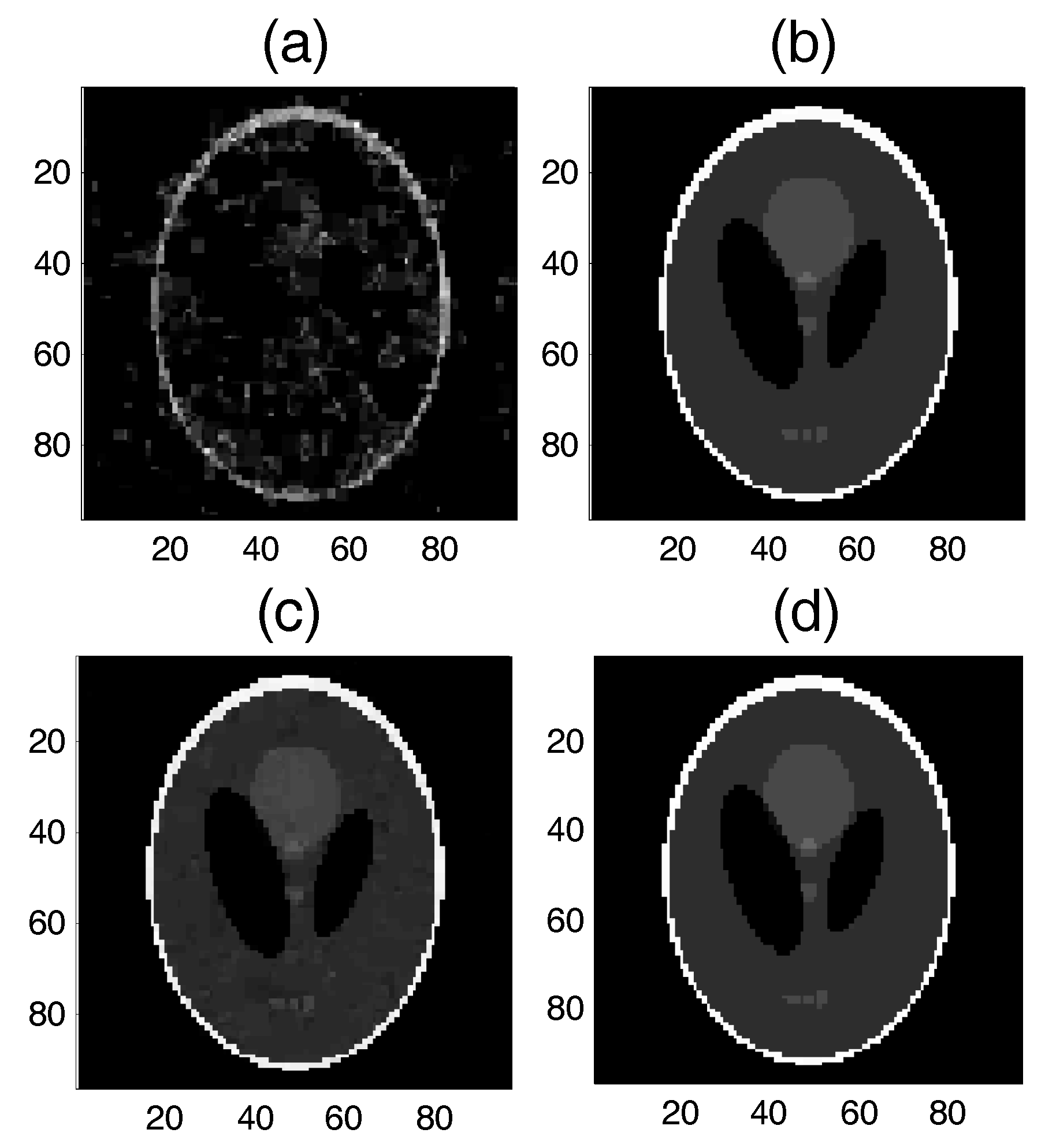
5.2.2. Test 2 for Real-World Data (2D MRI)
6. Conclusions
- (1)
- Using the proposed multiple sub-dictionary sparsifying transforms strategy, we construct a multiple sub-dictionary based regularization method to exploit more priori knowledge of images for the sparse image recovery problem. By multiplying by the proposed adaptive weighting parameter , we can gain more control of weighting the contribution of each sub-dictionary based regularizer. Experiments show that the proposed algorithms appear to perform better than the conventional single-dictionary algorithms, especially when the sampling rate is very low (e.g., 0.1~0.3);
- (2)
- Compared with the -norm regularization based work, the nonconvex -norm penalty can more closely approximate the -norm minimization over the -norm, which gives a sparser solution and needs fewer measurement data.
- (3)
- In our experiments, we find that the recovery performances between the and are close, even when the corresponding algorithm can obtain a better performance over the . Hence, a proper need to be selected in practical applications.
- (4)
- Moreover, the proposed SAITA- method also indicates that it is feasible to improve the recovery performance by exploiting the signal inner sparse structure and designing a proper sparse representation dictionary. Thus, it is beneficial to exploit the signal sparse structure with a dictionary learning method, which will be the subject of future work.
- (5)
- The proposed SAITA- algorithm can be extended to other non-convex penalties include smoothly clipped absolute deviation (SCAD) and minimax concave penalty (MCP).
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candès, E.J.; Romberg, J.; Tao, T. Robust Uncertainty Principles : Exact Signal Frequency Information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Mairal, J.; Elad, M.; Sapiro, G. Sparse representation for color image restoration. IEEE Trans. Image Process. 2008, 17, 53–69. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Dai, L.; Qi, C.; Yuen, C.; Wang, Z. Near-Optimal Signal Detector Based on Structured Compressive Sensing for Massive SM-MIMO. IEEE Trans. Veh. Technol. 2016, 9545, 1–5. [Google Scholar] [CrossRef]
- Gao, Z.; Dai, L.; Wang, Z.; Member, S.; Chen, S.; Hanzo, L. Compressive Sensing Based Multi-User Detector for the Large-Scale SM-MIMO Uplink. IEEE Trans. Veh. Technol. 2015, 9545, 1–14. [Google Scholar]
- Gui, G.; Xu, L.; Adachi, F. Variable step-size based sparse adaptive filtering algorithm for estimating channels in broadband wireless communication systems. EURASIP J. Wirel. Commun. Netw. 2014, 2014, 1–10. [Google Scholar] [CrossRef]
- Herman, M.; Strohmer, T. Compressed sensing radar. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Las Vegas, NV, USA, 30 March–4 April 2008; pp. 1509–1512. [Google Scholar]
- Chen, G.; Gui, G.; Li, S. Recent results in compressive sensing based image inpainiting algorithms and open problems. In Proceedings of the 2015 8th International Congress on Image and Signal Processing, Liaoning, China, 14–16 October 2015. [Google Scholar]
- Oh, P.; Lee, S.; Kang, M.G. Colorization-based RGB-white color interpolation using color filter array with randomly sampled pattern. Sensors 2017, 17, 1523. [Google Scholar] [CrossRef] [PubMed]
- Candès, E.J. The restricted isometry property and its implications for compressed sensing. C. R. Math. 2008, 346, 589–592. [Google Scholar] [CrossRef]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A.T. Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 2010, 19, 2345–2356. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhang, Y. Alternating Direction Algorithms for L1 Problems in Compressive Sensing. SIAM J. Sci. Comput. 2009, 33, 250–278. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Becker, S.; Bobin, J.; Candes, E. NESTA: A Fast and Accurate First-order Method for Sparse Recovery. SIAM J. Imaging Sci. 2009, 4, 1–39. [Google Scholar] [CrossRef]
- Borgerding, M.; Schniter, P.; Vila, J. Generalized Approximate Message Passing for Cosparse Analysis compressive sensing. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 3756–3760. [Google Scholar]
- Chartrand, R. Exact reconstruction of sparse signals via nonconvex minimization. IEEE Signal Process. Lett. 2007, 14, 707–710. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef]
- Chartrand, R.; Yin, W. Iteratively reweighted algorithms for compressive sensing. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Las Vegas, NV, USA, 1 March–4 April 2008; pp. 3869–3872. [Google Scholar]
- Blumensath, T.; Davies, M.E. Iterative hard thresholding for compressed sensing. Appl. Comput. Harmon. Anal. 2009, 27, 265–274. [Google Scholar] [CrossRef]
- Fornasier, M.; Rauhut, H. Iterative thresholding algorithms. Appl. Comput. Harmon. Anal. 2008, 25, 187–208. [Google Scholar] [CrossRef]
- Marjanovic, G.; Solo, V. On Lq Optimization and Matrix Completion. IEEE Trans. Signal Process. 2012, 60, 5714–5724. [Google Scholar] [CrossRef]
- Xu, Z.; Chang, X.; Xu, F.; Zhang, H. L 1/2 Regularization : A Thresholding Representation Theory and a Fast Solver. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1013–1027. [Google Scholar] [CrossRef] [PubMed]
- Cao, W.; Sun, J.; Xu, Z. Fast image deconvolution using closed-form thresholding formulas of L q (q = 1/2, 2/3) regularization. J. Vis. Commun. Image Represent. 2013, 24, 31–41. [Google Scholar] [CrossRef]
- Ma, J.; März, M.; Funk, S.; Schulz-Menger, J.; Kutyniok, G.; Schaeffter, T.; Kolbitsch, C. Shearlet-based compressed sensing for fast 3D cardiac MR imaging using iterative reweighting. arXiv, 2017; arXiv:1705.00463. [Google Scholar]
- Ma, J.; März, M. A multilevel based reweighting algorithm with joint regularizers for sparse recovery. arXiv, 2016; arXiv:1604.06941. [Google Scholar]
- Ahmad, R.; Schniter, P. Iteratively Reweighted L1 Approaches to Sparse Composite Regularization. IEEE Trans. Comput. Imaging 2015, 1, 220–235. [Google Scholar] [CrossRef]
- Tan, Z.; Eldar, Y.C.; Beck, A.; Nehorai, A. Smoothing and decomposition for analysis sparse recovery. IEEE Trans. Signal Process. 2014, 62, 1762–1774. [Google Scholar]
- Zhang, Y.; Ye, W. L2/3 regularization: Convergence of iterative thresholding algorithm. J. Vis. Commun. Image Represent. 2015, 33, 350–357. [Google Scholar] [CrossRef]
- Lim, W.Q. The discrete shearlet transform: A new directional transform and compactly supported shearlet frames. IEEE Trans. Image Process. 2010, 19, 1166–1180. [Google Scholar] [PubMed]
- Zhang, W.; Gao, F.; Yin, Q. Blind Channel Estimation for MIMO-OFDM Systems with Low Order Signal Constellation. IEEE Commun. Lett. 2015, 19, 499–502. [Google Scholar] [CrossRef]
- Daubechies, I. Ten Lectures on Wavelets; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1992. [Google Scholar]
- Zeng, J.; Lin, S.; Wang, Y.; Xu, Z. L1/2 regularization: Convergence of iterative half thresholding algorithm. IEEE Trans. Signal Process. 2014, 62, 2317–2329. [Google Scholar] [CrossRef]
- Puy, G.; Vandergheynst, P.; Gribonval, R.; Wiaux, Y. Universal and efficient compressed sensing by spread spectrum and application to realistic Fourier imaging techniques. EURASIP J. Adv. Signal Process. 2012, 2012. [Google Scholar] [CrossRef] [Green Version]
- Liu, A.; Zhang, Q.; Li, Z.; Choi, Y.J.; Li, J.; Komuro, N. A green and reliable communication modeling for industrial internet of things. Comput. Electr. Eng. 2017, 58, 364–381. [Google Scholar] [CrossRef]
- Li, H.; Dong, M.; Ota, K.; Guo, M. Pricing and Repurchasing for Big Data Processing in Multi-Clouds. IEEE Trans. Emerg. Top. Comput. 2016, 4, 266–277. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, A.; Li, Z.; Choi, Y.J.; Sekiya, H.; Li, J. Energy-efficient broadcasting scheme for smart industrial wireless sensor networks. Mob. Inform. Syst. 2017. [Google Scholar] [CrossRef]
- Wu, J.; Ota, K.; Dong, M.; Li, J.; Wang, H. Big data analysis based security situational awareness for smart grid. IEEE Trans. Big Data 2016, 99, 1–11. [Google Scholar] [CrossRef]
- Hu, Y.; Dong, M.; Ota, K.; Liu, A.; Guo, M. Mobile target detection in wireless sensor networks with adjustable sensing frequency. IEEE Syst. J. 2016, 10, 1160–1171. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, A.; Li, Z.; Choi, Y.J.; Li, J. Distributed Duty cycle control for delay improvement in wireless sensor networks. Peer-to-Peer Netw. Appl. 2017, 10, 559–578. [Google Scholar] [CrossRef]
- Kato, N.; Fadlullah, Z.M.; Mao, B.; Tang, F.; Akashi, O.; Inoue, T.; Mizutani, K. The Deep Learning Vision for Heterogeneous Network Traffic Control: Proposal, Challenges, and Future Perspective. IEEE Wirel. Commun. 2017, 24, 146–153. [Google Scholar] [CrossRef]







© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhang, J.; Fan, S.; Yang, J.; Xiong, J.; Cheng, X.; Sari, H.; Adachi, F.; Gui, G.
Sparse Adaptive Iteratively-Weighted Thresholding Algorithm (SAITA) for
Li Y, Zhang J, Fan S, Yang J, Xiong J, Cheng X, Sari H, Adachi F, Gui G.
Sparse Adaptive Iteratively-Weighted Thresholding Algorithm (SAITA) for
Li, Yunyi, Jie Zhang, Shangang Fan, Jie Yang, Jian Xiong, Xiefeng Cheng, Hikmet Sari, Fumiyuki Adachi, and Guan Gui.
2017. "Sparse Adaptive Iteratively-Weighted Thresholding Algorithm (SAITA) for