Efficient Graph-Based Resource Allocation Scheme Using Maximal Independent Set for Randomly- Deployed Small Star Networks

1
School of Computer and Information, Hefei University of Technology, Hefei 230009, China
2
Key Laboratory of Universal Wireless Communications (Beijing University of Posts and Telecommunications), Ministry of Education, Beijing 100876, China
*
Author to whom correspondence should be addressed.
Sensors 2017, 17(11), 2553; https://doi.org/10.3390/s17112553
Submission received: 8 October 2017
/
Revised: 30 October 2017
/
Accepted: 2 November 2017
/
Published: 6 November 2017
(This article belongs to the Collection Smart Communication Protocols and Algorithms for Sensor Networks)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In future scenarios of heterogeneous and dense networks, randomly-deployed small star networks (SSNs) become a key paradigm, whose system performance is restricted to inter-SSN interference and requires an efficient resource allocation scheme for interference coordination. Traditional resource allocation schemes do not specifically focus on this paradigm and are usually too time consuming in dense networks. In this article, a very efficient graph-based scheme is proposed, which applies the maximal independent set (MIS) concept in graph theory to help divide SSNs into almost interference-free groups. We first construct an interference graph for the system based on a derived distance threshold indicating for any pair of SSNs whether there is intolerable inter-SSN interference or not. Then, SSNs are divided into MISs, and the same resource can be repetitively used by all the SSNs in each MIS. Empirical parameters and equations are set in the scheme to guarantee high performance. Finally, extensive scenarios both dense and nondense are randomly generated and simulated to demonstrate the performance of our scheme, indicating that it outperforms the classical max K-cut-based scheme in terms of system capacity, utility and especially time cost. Its achieved system capacity, utility and fairness can be close to the near-optimal strategy obtained by a time-consuming simulated annealing search.
1. Introduction
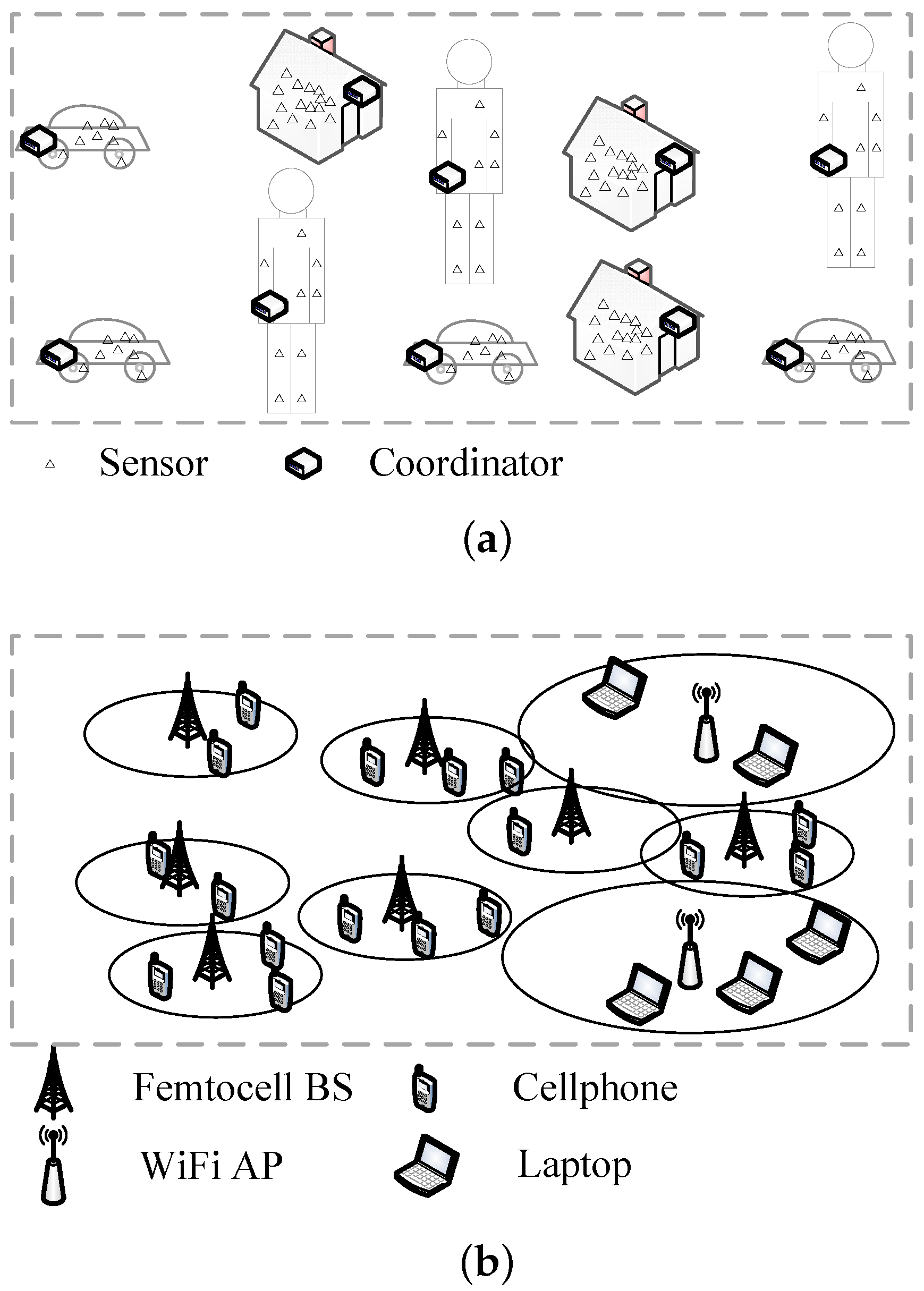
Heterogeneity and high density have been important trends for the research and development of wireless communication and networking in recent years toward 5G mobile communication systems supporting future promising applications, such as artificial intelligence, smart cities and telemedicine. This leads to the mission of deploying more small access points (APs), such as WiFi hotspots and femtocells, as well as clustering of sensors into small groups for the Internet of Things (IoT) [1,2]. Therefore, many studies involve scenarios with randomly-deployed small networks, each obeying a star topology. Three typical cases are identified, i.e., femtocell, WiFi hotspot and sensor cluster, as shown in Figure 1. The first sub-figure shows the clustering of wireless sensor networks, where clusterheads are voted on based on a certain clustering scheme and sensors are divided into clusters based on a certain rule [3,4]. This example can be also extended to body sensor network (BSN) scenarios, where a coordinator organizes a BSN in the center and a group of sensors on, in or around the body are connected to it [5,6]. The second sub-figure shows a number of femtocells covering many mobile user equipment (UEs) [7,8] and a number of WiFi hotspots covering many wireless terminals [9]. Both femtocell base stations (BSs) and WiFi APs are usually deployed to form indoor local area networks for high-speed wireless access. Meanwhile, clusterheads, femtocell BSs and WiFi APs all obey random deployment, which may be modeled as a Poisson point process (PPP) [10], and they all form small star networks (SSNs) with these equipment in the center. For overall management of radio resource among these networks, centralized resource allocation schemes might be used, and entities performing such schemes could be a macro BS in cellular networks, an access controller in WLAN and a monitoring and control center for telemedicine or transportation applications in IoT. The resource, once allocated, is mainly used for transmissions inside these networks, but interference between adjacent SSNs is unavoidable and becomes the main limitation for the performance of the whole system.
Traditional resource allocation schemes are not specifically designed for randomly-deployed SSNs, so they may not perform well in these scenarios. Resource allocation for homogeneous cellular networks has been widely studied [11,12], but the deployment of macrocells is almost regular, making their schemes also quite regular. For example, various fractional frequency reuse (FFR) schemes [13], also known as static resource allocation and interference coordination, allocate frequency bands based on the division of each macrocell into multiple circles to avoid severe inter-cell interference on cell edges, so this is obviously unsuitable for randomly-deployed SSNs due to the fact that these networks are too small to be further divided into multiple circles. There are also many dynamic or semi-static schemes for cellular networks in the literature [14], as well as optimization with some well-known ideas, such as cell range expansion (CRE) and almost blank subframe (ABS) [15,16], but they need much signaling and perform periodic resource allocation, making them too time consuming for future dense networks.
Frequency point allocation for WiFi hotspots does not seem to be a new issue, but existing studies mainly focus on the allocation of a single frequency point to each hotspot and mainly consider carrier sense multiple access with collision avoidance (CSMA/CA) within each hotspot instead of scheduling-based resource allocation [17]. Both of the features above make the interference relationship between wireless terminals of adjacent WiFi hotspots different from this study. Some traditional studies on the optimization of transmissions of randomly-deployed ad hoc nodes look also similar [18,19], but transmissions are between nodes, different from the new scenarios where transmissions are inside the SSNs (the smallest unit considered in our model). To sum up, those traditional studies basically focus on resource allocation to links or contention between adjacent nodes, which does not solve the problem in SSN scenarios.
There exists some recent studies on the allocation of frequency bands to femtocells. One method is to apply representative intelligent optimization algorithms, such as evolutionary algorithms, to search for an allocation solution with high performance [20,21], but these algorithms always need a very long time to find a near-optimal solution, which is unsuitable for usage in future networks with dense traffic and massive devices. Graph theory is a common tool for similar topics because it fits random deployment scenarios, and graph-based algorithms usually achieve much lower time complexity than intelligent optimization algorithms. Studies using graph theory are summarized as follows. Some studies built interference graphs and modeled the issue as max K-cut (MKC) problems. Sadr et al. considered resource allocation in femtocell networks as a graph coloring problem using the interference graph and proposed a scheme based on MKC [22]. Chang et al. also modeled downlink resource allocation as an MKC problem using the interference graph and proposed a two-phase scheme containing a greedy-like MKC searching in the first phase and a heuristic algorithm in the second phase [23]. The proposed scheme had relatively low complexity, but still too high for dense and massive networks. Moreover, the scenario studied in [23] was homogeneous networks, and the interference graph was established for users, while the scenarios considered in this article require building the interference graph for SSNs and consider transmissions inside SSNs. Pateromichelakis et al. studied resource allocation for small cell networks using the interference graph, obtained the optimal solution using the branch-and-cut approach and proposed a heuristic scheme based on a minimum path selection procedure [24].
Some papers, instead of using the interference graph, built the contention graph to solve the contention among links formed by randomly-deployed femtocells, and the maximum weighted independent set (MWIS) was used as a tool for a group of femtocells to separate the allocation of resources [25]. Chen et al. applied the contention graph and maximum independent set to study the opportunistic link scheduling, which achieved a distributed graph theory-based algorithm with the optimal policy for IEEE 802.11 CSMA/CA networks. The contention graph is suitable for solving the contention among links formed by randomly-deployed femtocells [26], but it may not be suitable for the issue studied in this article. That is because, each vertex in a contention graph represents a link, and an MWIS indicates a group of links that can simultaneously transmit, which is different from transmissions inside the SSNs in this issue. Moreover, the searching of MWIS is NP-hard [18], while the issue in this article demands a very low-complexity scheme.
The above discussion demonstrates that, along with the development of wireless communication systems toward heterogeneous networks with dense traffic and massive devices, instead of looking for the optimum or near-optimum, the main demand of resource allocation in these scenarios is a very low-complexity scheme with relatively good performance. Meanwhile, the consideration of interference for SSNs is different from existing studies for nodes. The allocated resource is mainly used for transmissions inside each SSN, so the transmission (also interference) range is relatively small. For example, sensors in a BSN transmit with low power, so they only interfere with a small number of BSNs quite close to them. By contrast, the interference range of a node in previous studies is usually large, depending on the distance to its destination, so it interferes with a large number of adjacent nodes. This difference affects the constructed interference graph, obviously leading to less edges. Therefore, resource reuse for SSNs is more prominent, which further stimulates our following consideration of the MIS-based design. In detail, existing MWIS-based ideas lead to too high of a time complexity in these scenarios, while MKC-based ideas are relatively faster. For example, in [23], a complete MKC-based scheme is proposed and evaluated, which is a quite representative work among similar studies and thoroughly compared with our proposed scheme later. To further improve the system performance, especially the time complexity, in this article, the interference graph is used to model the scenarios in Figure 1, and the unweighted maximal independent set (MIS) is applied, whose time complexity for one search is only ; see the detailed description in Section 3. Then, an MIS-based resource allocation scheme is proposed, which divides the vertices of the graph into multiple kinds of sets (such as leader set, leader adjacent set and MISs) and designs empirical resource allocation strategies for them. Extensive simulations show that the proposed scheme is very efficient compared with the MKC-based scheme. Its performances, in terms of system capacity and utility, are also significantly improved. Its achieved fairness, in terms of Jain’s fairness index, is not much worse, especially when a large parameter is set in empirical equations of the scheme. Meanwhile, the performance in terms of the above metrics is close to the near-optimal strategy obtained by a time-consuming simulated annealing search, further indicating that it is worth suffering a small possible decrement of fairness as long as a prominent increase of efficiency is achieved without obviously degrading system capacity and utility.
The remainder of this article is organized as follows. Section 2 provides the system model. Section 3 contains three subsections explaining interference graph construction, MIS searching and the proposed scheme. In Section 4, extensive simulations are performed to demonstrate the performance of our proposal in both dense and nondense scenarios. Finally, the article is concluded in Section 5.
2. System Model
Let us consider the scenarios in Figure 1. To unify the description in the following sections, sensor clusters, femtocells and WiFi hotspots are called SSNs uniformly (as defined in the previous section). These networks are the smallest units for resource allocation, while the consideration of further allocation inside these networks is not within the scope of this study. Therefore, a unified scenario containing N randomly-distributed SSNs in a square area is used for modeling the system. We only consider transmissions inside each SSN, while interference happens in between.
For the resource allocation issue, the resource could be time slots in the time domain and frequency points (or groups of subcarriers) in the frequency domain, accordantly called resource blocks (RBs). Given M RBs in a wireless communication system, each SSN is assigned a subset, written as:
where i indicates the index of the SSN, j indicates the index of the RB and is a binary variable indicating the usage status of RB j by SSN i, given by:
Let us consider the total interference on SSN i. Any other SSN using the same RBs might be an interferer, so the total interference received by SSN i is written as:
where is the point-to-point interference value between SSN i and SSN l, related to the distance in between. Note that interference from equipment outside of this system (such as from a macrocell to femtocells or from Bluetooth equipments to WiFi) is not integrated into this model. There are two reasons that force us to make this assumption: on the one hand, those equipment’s deployment can be considered independent of this system, so the interference effect tends to be equivalent to different SSNs; on the other hand, interference coordination among heterogeneous networks has been widely studied [15,16,27] and the modeling of such a kind of interference should be highly correlated with those coordination schemes, making it quite difficult to evaluate the real interference and to combine it in this model. Thus, the signal-to-interference-plus-noise ratio (SINR) of SSN i can be written as:
where is the transmitting power and is the variance of additive white Gaussian noise (AWGN). Hence, the capacity of SSN i is written as:
where is the minimum unit of bandwidth for allocation. Finally, the objective of this study is to optimize the total capacity of all the SSNs written as:
Taking fairness into consideration, the objective of the above optimization becomes:
where is the total utility of SSN i integrating fairness [28], given by:
fairness is a well-known generic way to integrate fairness consideration into an objective function. represents the previous objective function on capacity; represents proportional fairness; and represents max-min fairness. Note that the problem falls into the category of combinatorial optimization with variables indicating the assignment of RBs to the SSNs. In this issue, each SSN could use multiple RBs, and each RB could be used by multiple SSNs, so this optimization issue does not have any specific constraint except that (2) indicates the binary variables in the issue. Note that, instead of solving a specific optimization issue by a certain technique such as constraint relaxation, the purpose of this article is to propose a scheme that has very low complexity, so that it is fast for the scenarios with massive SSNs to reach a relatively good solution. Therefore, the optimization issue defined above is a generic issue of resource allocation for SSNs containing solutions. The optimality is highly related to the interference values . For any SSN i and SSN l, if is small enough, the two SSNs can use the same RBs. Moreover, since each SSN could use multiple RBs, all the RBs might be allocated to some SSNs under weak interference, resulting in an unfair allocation. Therefore, the usage of fairness in the objective function could lead to fairer allocation to the SSNs under severe interference.
3. The Proposed Graph-Based Scheme
3.1. Interference Graph
When two SSNs use exactly the same RBs for transmission, there might be interference between them. The strength of this interference highly depends on the distance between the two SSNs. When the distance is large enough, this interference might be ignored, so there might be a distance threshold to indicate whether the interference is ignorable or not. This threshold might be disparate for different scenarios or different objective functions of optimization, but this difference would not obviously affect the following study in this article. That is because, with different thresholds, the difference on the interference graph might be only a few edges added or removed. The changes usually happen at the places with dense deployment, which further causes only a very slight effect on the obtained MIS in the following subsection and the final performance, so the comparison of different ways to derive the distance thresholds and the discussion of the best distance threshold are out of the scope of this article. For the following examples and for performance evaluation, the distance threshold derived in the Appendix is used, which is obtained in a two-SSN scenario with the objective of maximizing their total capacity. Since this threshold is derived in a two-SSN scenario whose interference is less than dense scenarios, it can be considered as a relaxation that leads to an interference graph with more edges. Therefore, this relaxation only increases the time cost of the following procedures without changing its optimality feature.
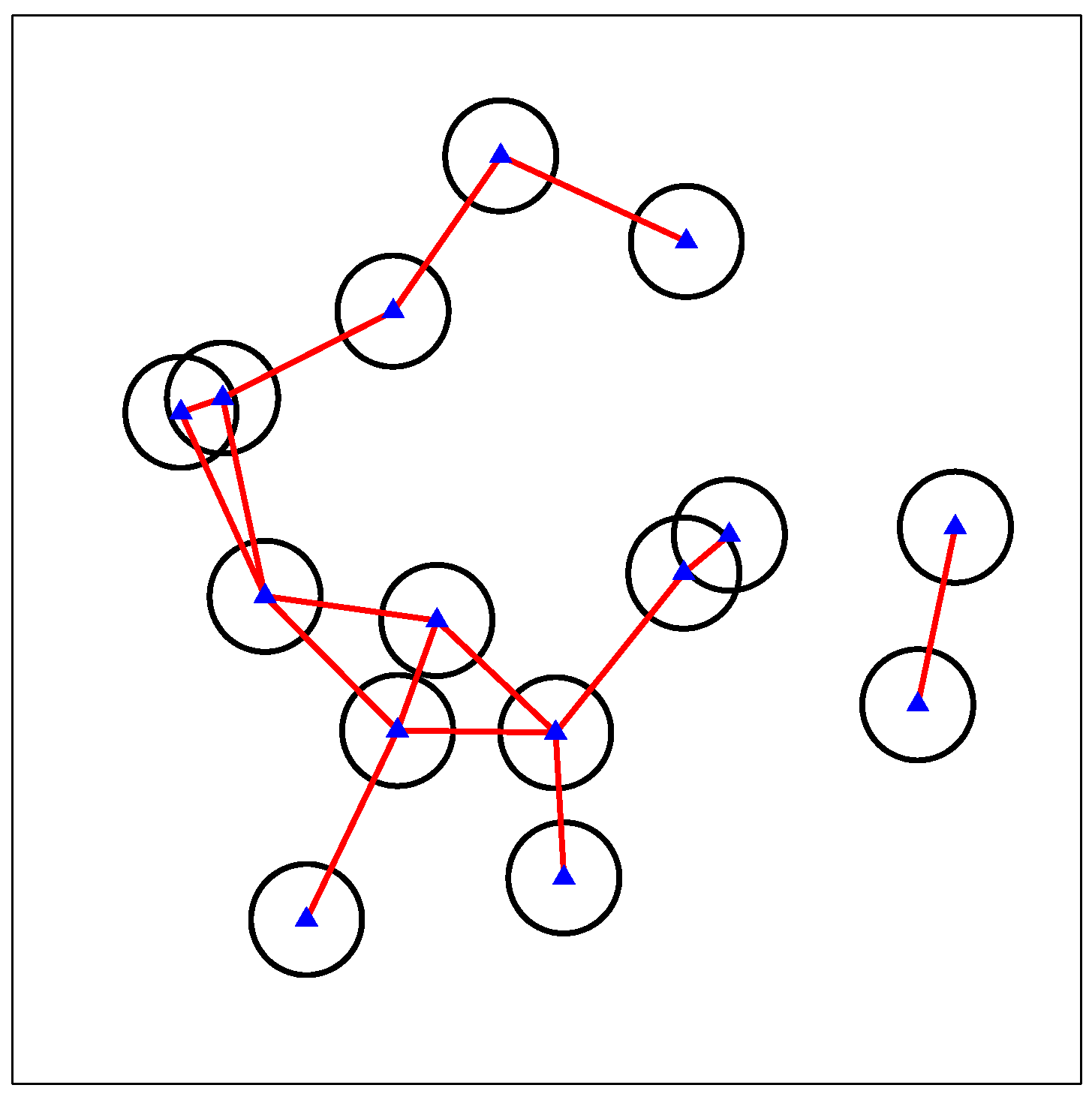
Once a distance threshold is given, an interference graph can be constructed for a certain scenario [29], whose vertices represent the SSNs. A matrix can be used to describe the edges, whose elements are defined as:
where is a binary variable with and , indicating whether the interference between SSN i and SSN l is ignorable () or not. If it is ignorable, no edge between vertex i and vertex l exists in the graph; otherwise, an edge connects the two vertices. Taking Figure 2 as an example, a number of randomly-deployed SSNs form an interference graph with edges connecting the vertices suffering un-ignorable interference. The graph might be divided into multiple isolated subgraphs due to the distances in between, but there is no difference for the following process. We can process each isolated subgraph separately or together during the calculation of MISs and the resource allocation proposed in the following section, leading to the same results.
3.2. MIS
For two SSNs far from each other, since their inter-SSN interference is small, the total capacity can be increased by using the same RBs repetitively. The interference graph described in the above subsection is a subset of the complete graph, whose edges corresponding to such a case are removed. Therefore, in order to increase the total capacity, vertices unconnected in an interference graph can use the same RBs. It is an MIS problem to find a maximal subset of vertices that are unconnected in an interference graph [30,31]. In this subsection, we describe two methods to obtain one or multiple MISs: (1) a theoretical method obtaining all the MISs; (2) a very efficient algorithm obtaining one MIS.
Given an interference graph , we use to represent the set of vertices, to represent the set of edges and to represent the number of vertices in the graph. An independent set is a subset of subject to the restriction that neither of any two vertices in this subset are connected by an edge.
Definition 1.
For an independent set of a graph , if it is not a subset of any other independent sets of , it is called a maximal independent set (MIS).
We say that an edge of a graph is covered by a subset of if at least one of the two vertices of this edge belongs to the subset. A subset of is called a cover set of if all the edges in are covered.
Definition 2.
For a cover set of a graph , if none of its subsets is a cover set of , it is called a minimal cover set.
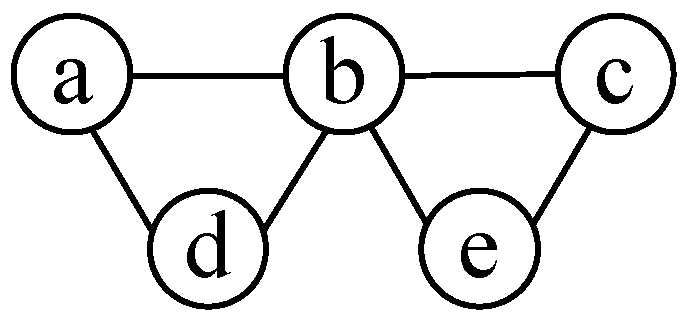
As basic knowledge in graph theory, MISs and minimal cover sets have a one-to-one complementary relationship, i.e., for any minimal cover set , is an MIS [32]. Therefore, one way to obtain all the MISs for a graph is to find all the minimal cover sets and to convert to their complementary sets. Given a graph, we firstly mark for each vertex the adjacent vertices connecting with it, called a connection indicator of this vertex. Secondly, connection indicators of all the vertices are multiplied and transformed into a polynomial of multiple terms by polynomial expansion, each term representing one minimal cover set. Thirdly, we take the inversion of each term to obtain all the MISs. We can also finally obtain the maximum independent set(s) by choosing the one(s) with the maximum number of vertices. Note that MIS and the maximum independent set are two different concepts. The latter corresponds to the MIS(s) with the largest number of vertices among all the MISs. Take the graph in Figure 3 as an example, the connection indicator of vertex a is written as , that of b is , and so on. The multiplication of all the connection indicators is given by:
There are five terms in the above polynomial, corresponding to five minimal cover sets, hence five MISs. For example, in (10) is a minimal cover set, and its inversion is b, an MIS. By comparing the number of vertices in each MISs, we find that the 2nd, 3rd, 4th and 5th terms in (10) all correspond to maximum ones, i.e., cd, ae, de and ac.
The above method obtains all the MISs, but the time cost is non-polynomial. Considering that our resource allocation scheme does not need all the MISs, the following very efficient algorithm will be used to obtain one MIS at once, which is an improvement from the algorithm described in [30] to make it faster for obtaining one random MIS. The algorithm starts from the set of vertices , and for each round, a random vertex i is chosen and put into the MIS. If it is not an isolated vertex, the adjacent vertices should be removed from the potential MIS, corresponding to Line 7 in the algorithm. The improvement is the removal of vertices’ profits and corresponding comparisons to choose vertices with lower profits during the form of an MIS. In detail, the original algorithm in [30] defines a profit value for each vertex, so that it will be used to choose the one with lower profit when any two adjacent vertices are compared. Therefore, that algorithm obtains an MIS with relatively low total profit for a weighted graph where vertices have profits. By contrast, the algorithm we need to use later for MIS searching in our proposed scheme is for a graph without vertex profits, so we simplify that algorithm by removing the considerations and comparisons of vertex profits to further save running time. This improvement concerns the implementation detail, which does not decrease its complexity.
| Algorithm 1 Obtaining one random MIS. |
| Input: , Output:
|
3.3. Proposed Scheme
In order to apply the MIS concept for designing an efficient scheme, we randomly generate extensive scenarios, use the simulated annealing algorithm to study their near-optima and summarize the following highlights:
(1) Adjacent SSNs (i.e., those connected by edges in the interference graph) should generally not use the same RBs; otherwise, severe interference decreases all their capacities. For each SSN, since its capacity is decreased, its utility integrating -fairness should be also decreased because of the monotonous feature of the -fairness function with regard to capacity. Since an MIS provides a set of unconnected vertices in a graph, we could allocate the same RBs to an MIS and repetitively use them for all the SSNs in it. Different MISs should not use the same RBs due to the fact that they are definitely connected by some edges.
(2) When we consider a small value, more RBs should be allocated to the SSNs under relatively slight interference, so that the total capacity of the whole system is high. Vertices on the border of an interference graph usually have only a small number of edges, so SSNs on the border of the scenario achieve high capacity on average and contribute more to the system capacity than those in the center.
Based on the above analysis, we believe that a certain ratio of SSNs on the border should be chosen and allocated more RBs than the others. However, due to the randomicity of the scenario, we cannot predict the features of interference to fix an allocation strategy. Therefore, to choose a number of vertices on the border, we set a vertex percentage parameter and gradually add the vertices to an alternative set starting from those with the smallest number of edges till the percentage of vertices in this set exceeds . Some vertices in this set might be connected by edges, indicating that they should not use the same RBs. To find a subset of vertices unconnected with one another from this set, an MIS is obtained as the chosen set of vertices on the border of the graph. Considering that SSNs corresponding to this set contribute significantly to the system capacity, we call it the leader set. Note that the search for this MIS starts from the vertices with a smaller number of edges, so that an MIS under almost the slightest interference is obtained.
For the ratio of RBs used by the leader set, we have the following observations. When , fairness is not considered, so the ratio is always 100% to maximize the system total utility. Along with the increment of -fairness, the ratio of the allocated RBs to the leader set decreases, and we find that the relationship between this ratio and is quite close to a sigmoidal function. When we use a large value, RBs will be allocated in a fairer way, but the ratio for the leader set has a maximum degradation around 1/4 due to the tradeoff between utility and fairness. That is because of its inherent low-interference feature, i.e., the interference for SSNs in the leader set is always less severe than the SSNs in the center of a scenario. Based on the above analysis, the following empirical equation and corresponding parameter values for the sigmoidal function are obtained to calculate the ratio of RBs for the leader set:
(3) Based on the first observation above, adjacent vertices should generally not use the same RBs. Adjacent vertices of the leader set include those in the above alternative set, but not chosen as leaders, and those connected with the leaders, but not in the alternative set. We put all these vertices into a set, called the leader adjacent set. Considering that these vertices are close to the border of a graph, they are on average under slighter interference than the vertices in the center, so they should use as much resource as possible. Since the leader set has occupied most of the RBs, we assign all the remaining RBs to the leader adjacent set without retaining any for other usage, but how to use the remaining RBs in the leader adjacent set should be considered carefully due to the fact that some vertices in the leader adjacent set might be connected (interfered) with one another.
On the one hand, since the vertices in the leader adjacent set themselves also form a complex graph, it is time consuming to find the optimal or a near-optimal allocation strategy of RBs in the leader adjacent set by certain combinatorial optimization approach or other optimization theories. Note that for all the other sets (leader set and the MISs in the central part of the graph), the optimization approach was not used either. We design their allocation strategies based on our experience with extensive empirical results, which is the main reason and merit to achieve a fast scheme. Therefore, we should not use certain optimization approaches to orthogonally assign the RBs to some connected (interfered) vertices in the leader adjacent set; otherwise, the time cost of this part may severely slow down the speed of the whole scheme.
On the other hand, even if a long-time search algorithm is used, the performance does not improve much compared with allocating all the remaining RBs to all the vertices. This phenomenon is more obvious when the number of vertices is moderate, i.e., when the vertices in this set are not severely interfering with one another. As we know, SSNs are networks, not devices, so the density of SSNs could be moderate even for a hyper-dense network. Each SSN may be connected with adjacent ones, but the coverage of an SSN does not usually span several layers of other SSNs. Therefore, for a hyper-dense network, the density of the interference graph formed by SSNs is moderate, not hyper-dense, while for a moderate graph, connected vertices in the leader adjacent set are not many. Meanwhile, for the case when two or more vertices are connected with one another, system fairness may be obviously decreased if we give up some of them, while the system capacity may only increase a little.
For all the reasons above, we find that a simple idea allocating all the remaining RBs to all the vertices in the leader adjacent set usually corresponds to high performance, so we do not use any specific algorithm to further separate the vertices in the leader adjacent set into different sets or design different strategies for different vertices in this set.
(4) Vertices in the center of a graph usually connect to multiple adjacent vertices, so they are generally all severely interfered. Meanwhile, they interconnect and are stochastically consistent with one another, making it not so meaningful to design a detailed, but time-consuming resource allocation strategy. Therefore, we design an efficient strategy based on MIS for the vertices besides the leader set and the leader adjacent set. Note that, in dense scenarios, the number of SSNs may be very large, leading to the division of a large number of groups for the central SSNs. To guarantee a low time cost, we set a predefined parameter to indicate the maximum number of MISs for central SSNs, so the unallocated SSNs exceeding this value will be put together as a final group and use all the remaining RBs repetitively. Since these groups contain different numbers of vertices, we design different strategies to allocate RBs to them. For the ratio of RBs used by the first group, the observations are basically the same as for the leader set, except that the parameters in the sigmoidal function are not the same. Meanwhile, we find that the ratio of RBs for the first group is also affected by the total number of groups, and the relationship can be represented by changing the degradation from 1/4 in (11) to , where q is the number of groups we finally obtain for central vertices during the running of the scheme. The following empirical equation and corresponding parameter values for the sigmoidal function are obtained to calculate the ratio of RBs for the first group:
indicating that the allocated RBs to the first group should decrease if there are more groups awaiting for resource. The -fairness index is used to adjust the allocation so that less RBs are allocated to the first group if is increasing. Denote the number of vertices in the m-th group as ; the ratio of RBs used by the m-th group is given by:
We can see that the total RBs used by the vertices in the center of the graph are those used by the leader set. The first group for the central vertices uses more RBs than the others based on (12), while the others proportionally use the remaining RBs according to their number of vertices based on (13). One reason to allocate more RBs to the first group is that its number of vertices is obviously larger than the others. Another important reason is that, for small , almost all the RBs tend to be allocated to the largest group, which could significantly improve the system capacity and utility.
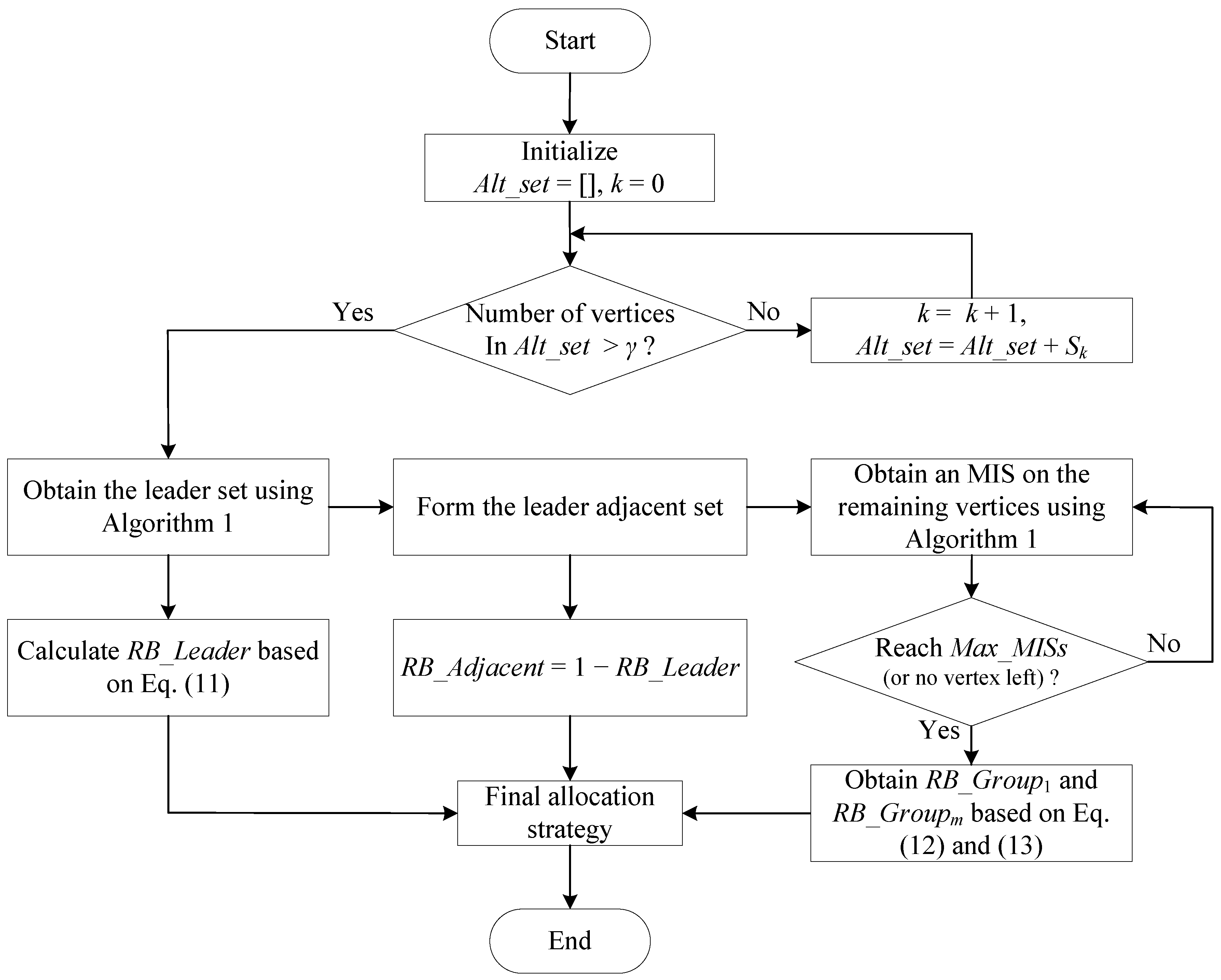
Combining all the above analysis and design, we propose an MIS-based resource allocation scheme for randomly-deployed dense SSNs as follows. Inputs of the scheme include the interference graph, the vertex percentage parameter for the leader set and the maximum number of MISs for central SSNs . Based on the interference graph, we count for each vertex the number of edges and obtain a series of sets of vertices, given by , where contains the vertices having k edges. The procedure of the scheme is shown in Figure 4.
Step 1: We initialize the alternative set as empty and the index , which will be used to help obtain the final .
Step 2: We form the alternative set by gradually adding vertices from those with the smallest number of edges, i.e., with k gradually increasing. A final alternative set is formed when the number of vertices in it is larger than the vertex percentage parameter .
Step 3: Algorithm 1 is performed on to obtain an MIS as the leader set, and is calculated based on (11).
Step 4: The leader adjacent set is formed by adding all the vertices adjacent to the vertices in the leader set, and its RB ratio is obtained as .
Step 5: We run Algorithm 1 on the remaining vertices (that are not in the leader set or the leader adjacent set), so that they are divided into multiple groups. This division loop stops when the obtained number of MISs reaches (or when there is no vertex left, although this does not usually happen for dense scenarios).
4. Performance Evaluation
In this section, we simulate the proposed MIS-based scheme and compare it with several representative schemes. Based on the analysis in Section 1, the classical MKC-based scheme in [23] is considered as a milestone scheme for comparison due to its good system performance with low complexity, which is denoted as the “Classical MKC-based scheme” in the following figures. Meanwhile, it is very interesting to know the near-optimal solutions and to check the gap between our solution and the near-optimum. We use an optimum search algorithm for combinatorial optimization issues, i.e., the well-known simulated annealing algorithm, to reach a near-optimal solution by a very long-time search, denoted as “SA for near-optimal utility” in the figures. Random allocation, just as its literal meaning, is to randomly allocate resources without any specific concern, so it does not cost any time to do any computation for resource allocation. It is interesting to see whether the performance improvement of the proposed scheme from a random allocation is worth its time cost. We consider two types of scenarios: one is nondense with a limited number of SSNs to compare the performance of all the above schemes and also to show the effect of integrating -fairness into our proposal, while the other is dense with a large number of SSNs to compare the time cost between our proposal and the classical MKC-based scheme. One reason for considering two types of scenarios is to show the effectiveness of our scheme in both types of scenarios. Another reason is that the simulated annealing algorithm to search for a near-optimal strategy is intolerably time consuming to be used for comparison in dense scenarios. For both types of scenarios, the evaluated performance metrics include system capacity, utility and Jain’s fairness index. Moreover, we show 95% confidence intervals for most of the points in the following figures, excluding those whose confidence intervals are too small to be visible.
For the following simulations, the transmitting power of the SSNs is 21 dBm [33]; AWGN is watts; and the bandwidth for each SSN is set to a unit value of 1 MHz. Since SSNs are usually local and indoor networks, we choose the close-in free space reference distance path loss (CI-FSPL) model for propagation, given by [34]:
where b is the path loss exponent set to 3.19, represents the shadowing effect set to 8.29 dB and f is the carrier frequency set to 2.4 GHz in the simulations. in (14) represents the unit distance for the calculation of propagation, given by:
where c is the speed of light. By setting the receiver sensitivity to watts, also combining with the above propagation model and the transmitting power, the coverage radius of each SSN can be obtained as 44.76 m.
4.1. Results in Nondense Scenarios
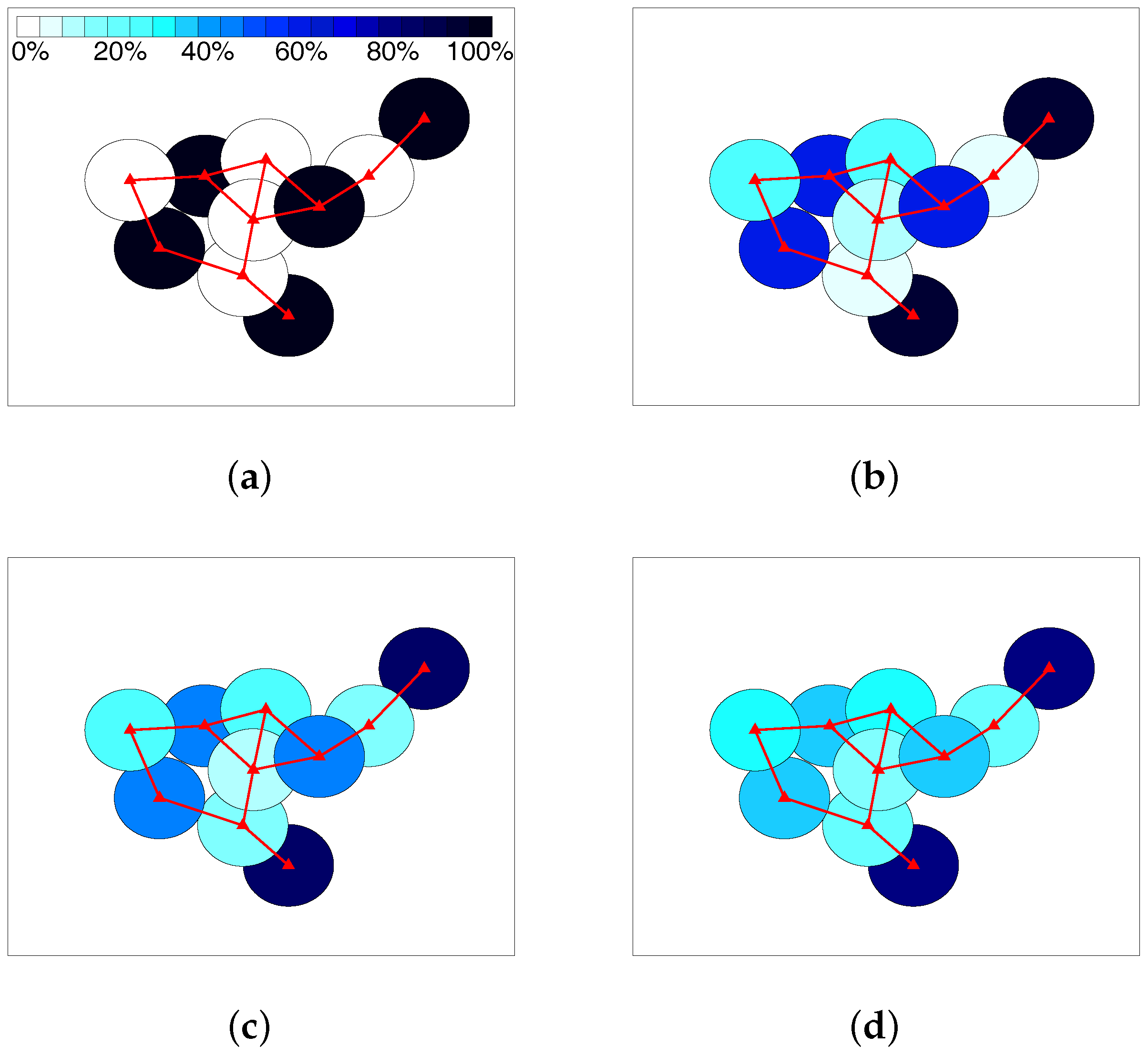
When -fairness is not considered, i.e., , the objective function in the system model becomes the maximization of system capacity. As is common knowledge, it will make the allocation unfair to the SSNs under strong interference. In other words, all the RBs tend to be allocated to the one under lower interference for any two SSNs connecting with each other. In Figure 5, allocation results in a randomly-generated scenario are visually shown for equaling 0, , and 1, respectively. The colors from light to dark represent the ratio of RBs used for a certain SSN, as shown by the color strip in Figure 5a. When , all the RBs are allocated to a number of SSNs unconnected with one another, which actually form an MIS of the graph. This allocation is unfair for the SSNs not in this MIS, but maximizing the system capacity. Along with the increment of , the ratio of used RBs by the SSNs in the MIS gradually decreases, while that of the SSNs not in the MIS gradually increases. When reaches one, i.e., the well-known proportional fairness position, the allocation becomes relatively balanced, although the SSNs under lower interference still tend to use more RBs.
We randomly generate 100 scenarios with the numbers of SSNs between 10 and 30. For each scenario, the proposed scheme, the classical MKC-based scheme and the random allocation scheme are simulated to obtain the average capacity, utility, Jain’s fairness index of average capacity and Jain’s fairness index of utility. For each metric above, each point in a curve is obtained by averaging for the 100 scenarios, so the curves are smooth and representative. Since the numbers of SSNs are variant for different scenarios, the average capacity and utility are calculated as average values per SSN. The MKC-based scheme requires dividing the SSNs into multiple groups. For each scenario, we first run our scheme and record the number of groups that our scheme obtains. Then, the same number of groups is set to the MKC-based scheme, which ensures the rationality of the comparison. For the simulated annealing search of a near-optimal utility, due to the fact that this optimization search is quite time consuming, we randomly choose 10 scenarios from the 100 generated scenarios above, and each point in its curves is obtained by averaging these 10 scenarios. Therefore, the confidence intervals for the curves of “SA for near-optimal utility” seem larger than the other schemes, but it does not affect the comparison between different schemes, especially between the proposed scheme and the classical MKC-based scheme.
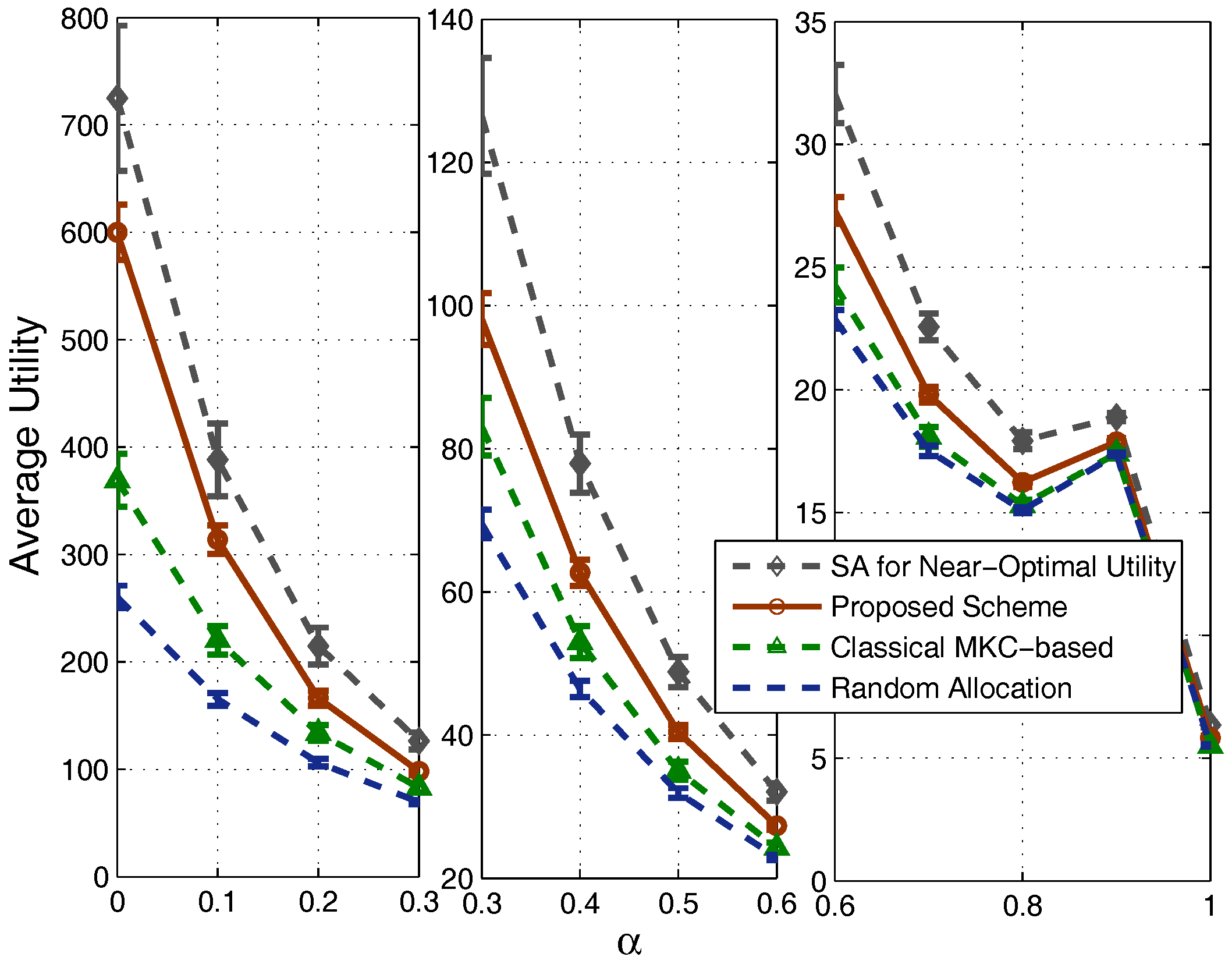
Comparisons of the system capacities and utilities of the four schemes are shown in Figure 6 and Figure 7, respectively. We can see that, along with the increment of , the utility value gradually decreases, and there is a fluctuation when is close to one. These are actually common features of the utility function defined by (8) in the system model. An interesting observation from this figure is that the utility of our scheme is quite close to the near-optimum obtained by the simulated annealing algorithm. Note that the simulated annealing algorithm uses quite a long period to search for this near-optimal strategy, while our scheme is a quite fast heuristic one, so the advantage of our scheme is obvious. Compared with the MKC-based scheme and the random allocation strategy, our scheme achieves a much higher utility. Note that, we divide the figure into three subparts, i.e., , and , so that the difference between the curves is still clear for the large case.
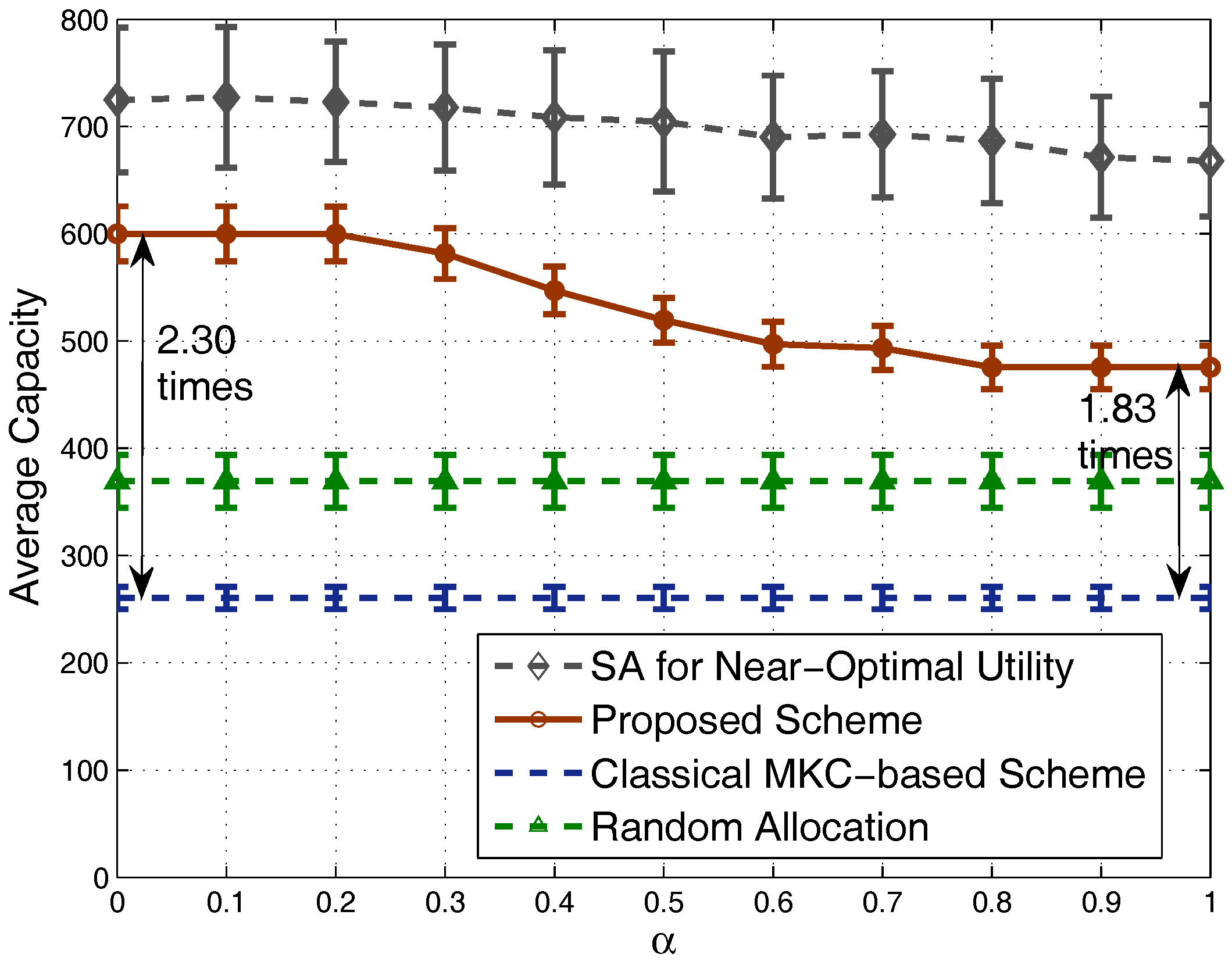
For the capacities shown in Figure 7, we can see that our scheme achieves a quite high system capacity, close to the performance of the strategy obtained by the simulated annealing algorithm especially when is small. Meanwhile, our scheme outperforms significantly the MKC-based scheme and the random allocation strategy. Specifically, when is small, our scheme’s achieved system capacity is around 2.30-times that of the MKC-based scheme. When we set a large value (e.g., ) to balance between system capacity and fairness, the achieved system capacity is lower than before, but still around 1.83-times that of the MKC-based scheme. Note that two of the evaluated schemes (MKC-based scheme and random allocation strategy), do not consider the -fairness factor, and capacity is independent of , so their achieved system capacities have a stable behavior for different values.
Since the -fairness factor is integrated into our utility function, fairness should be improved if a large is used, so the well-known Jain’s fairness index is used to evaluate the achieved fairness of our proposal. Jain’s fairness index is defined as [35]:
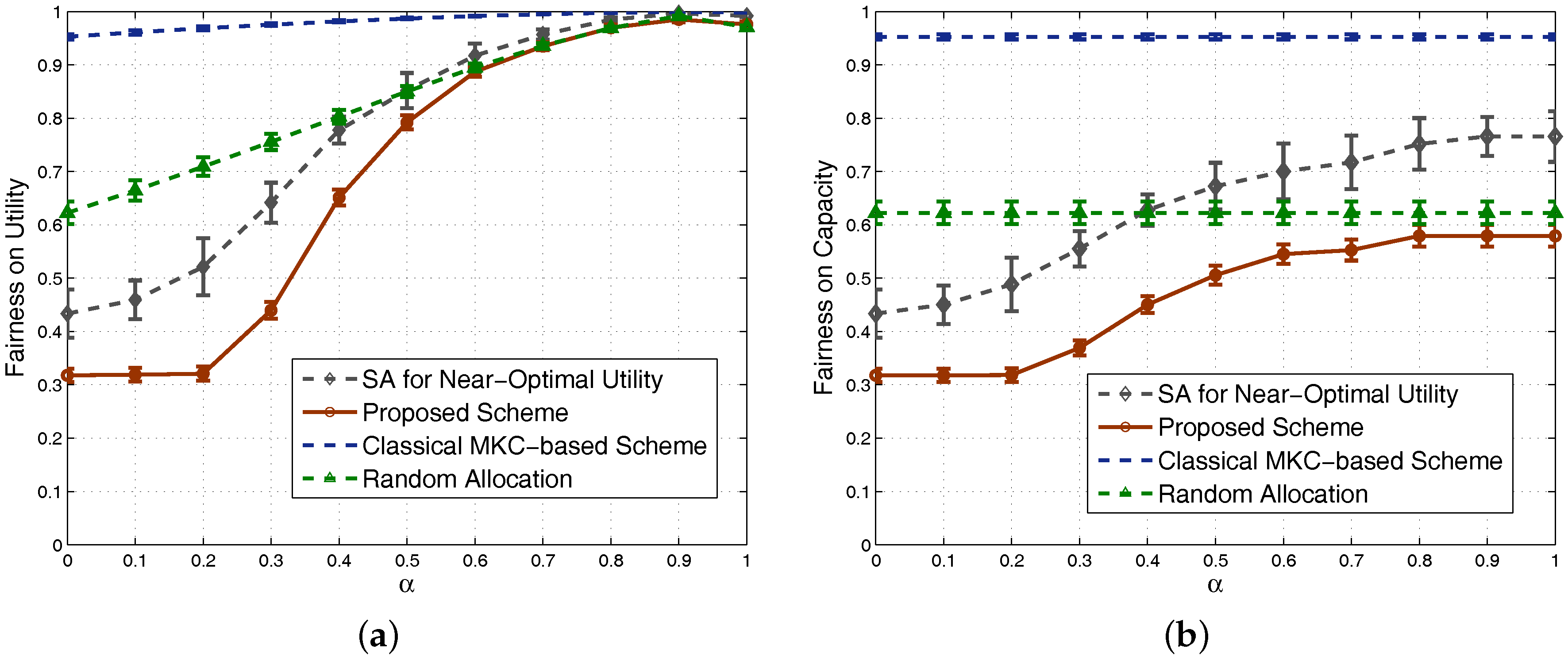
where is the performance of the ith SSN, such as its capacity or utility. Based on this equation, we see that fairness is proportional to J, a value between zero and one. We calculate Jain’s fairness values for both utility and capacity, shown in Figure 8a,b, respectively. The classical MKC-based scheme achieves very high fairness, which is an important reason for us to integrate the -fairness factor into our proposed scheme. We can see that, by using a large , the achieved Jain’s fairness of our scheme can be significantly improved. Especially for the fairness of utility in Figure 8a, it is finally quite close to the MKC-based scheme for a large . Combined the truth that our scheme achieves higher system capacity and utility than the MKC-based scheme shown in Figure 6 and Figure 7, our scheme has obvious benefits. Note that the main purpose of this study is to design a very fast scheme achieving relatively high performance, and we will show that our scheme significantly saves time compared with the MKC-based scheme in the simulations of Section 4.2 later. Moreover, considering the sigmoidal functions used in the proposed scheme for calculating the ratios of RBs used, the obtained ratios are close to one another when is too small or too large, so the curves of our scheme in Figure 7 and Figure 8 all look like a sigmoidal form.
4.2. Results in Dense Scenarios
This subsection focuses on the dense scenarios where 30–100 SSNs are randomly deployed in a small simulation area. Since the coverage radius is set to 44.76 m based on the settings described at the beginning of the section, we set the simulation area to 500 m × 500 m, so that the SSNs could severely overlap with one another. To obtain relatively smooth curves, we generate 50 random scenarios for each given number of SSNs, and each point on a curve below is obtained by averaging the performance of the 50 scenarios. Since the time cost of the simulated annealing algorithm dramatically increases when the number of SSNs is large, the purpose of this subsection is to compare our proposal with the MKC-based scheme to demonstrate the benefits of our proposal in dense scenarios.
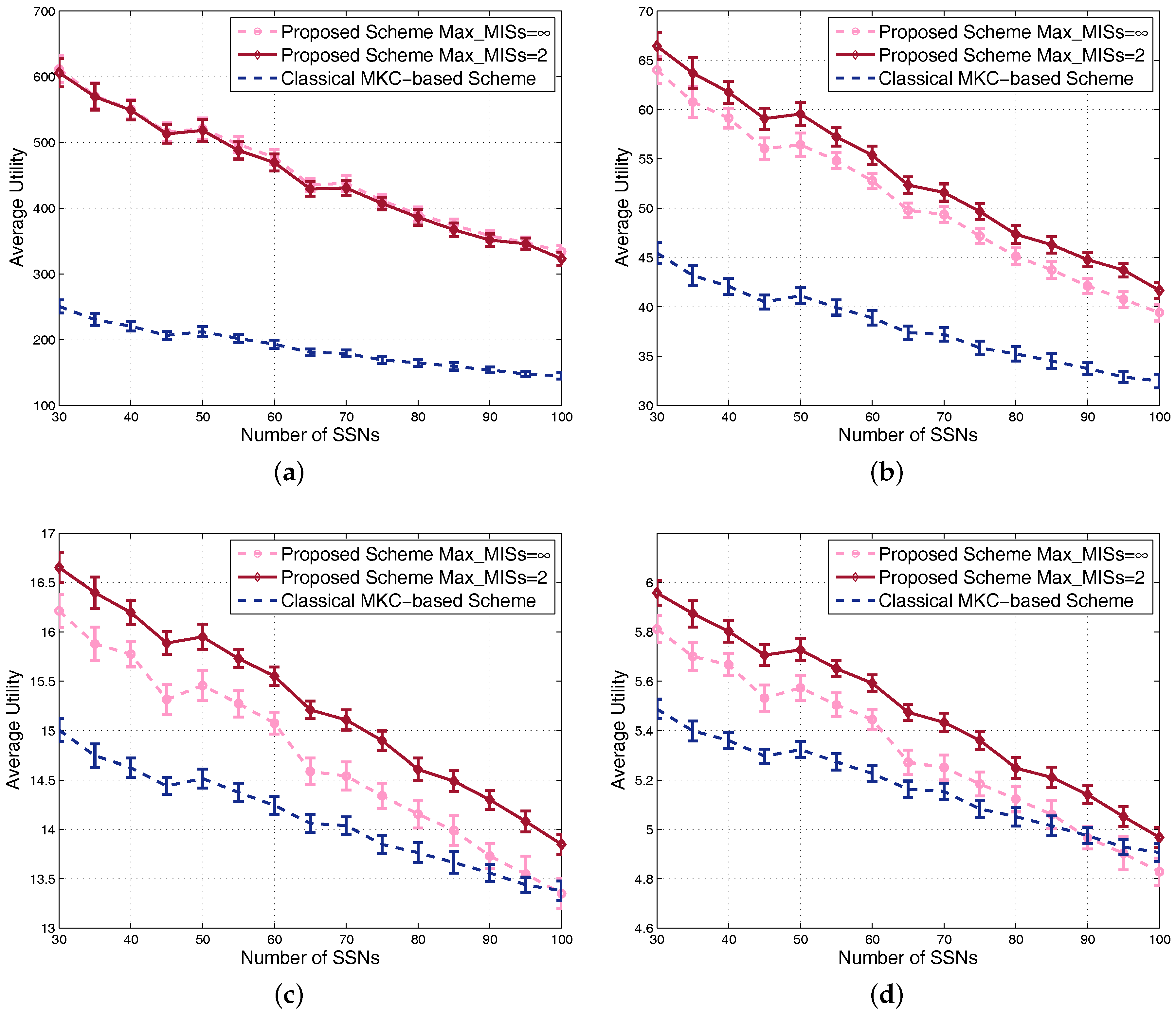
Firstly, we compare the utilities of the two schemes along with the increment of the number of SSNs. For different values, the utilities might be different in the orders of magnitude, so we draw the curves for in the four sub-figures in Figure 9 to clearly show the gap between the two schemes. For each sub-figure, we can see that the utilities gradually decrease along with the increment of system density, because the increment of the density brings about more interference. When is small, our scheme obviously outperforms the MKC-based scheme, especially for dense scenarios. When is large, our scheme degrades utility to guarantee fairness, so the curves of the two schemes become close. Meanwhile, we also compare the curves with different values and draw the curves with and in the figures. means searching for two MISs in the central part, so there are at most five groups, i.e., leader set, leader adjacent set, two MISs and the rest. means dividing the central part into multiple MISs until no vertex is left.
We can see that the performance may not increase by dividing the vertices into more groups. The reason is mainly as follows: more divided MISs correspond to the division of the whole resource into more portions. A group with only a few vertices can only get a small amount of resource leading to very poor performance. By contrast, a group with a large number of vertices can get a large amount of resource, and they are not interfered by their neighbors because their neighbors are not in the same MIS, which leads to much better performance for them than putting them together with their neighbors in the same MIS. In a word, dividing the vertices into more MISs makes the performance difference among vertices increase, hence decreasing the fairness of the system. Since the calculation of system utility integrates fairness consideration, it is not difficult to understand that the achieved system utility may decrease when becomes large. Actually, we also evaluate the performance for equal to different values, such as four and six, but we find that the obtained curves almost overlap with the curves of , indicating that the latter corresponds actually to a sufficient number of groups for the case with 30–100 SSNs. An important reason for us to choose is that, the smaller the value, the shorter the simulation time cost required. Based on the above results and analysis, we conclude that, as long as a proper is set, the proposed scheme would be almost better than the classical MKC-based scheme in terms of system average utility.
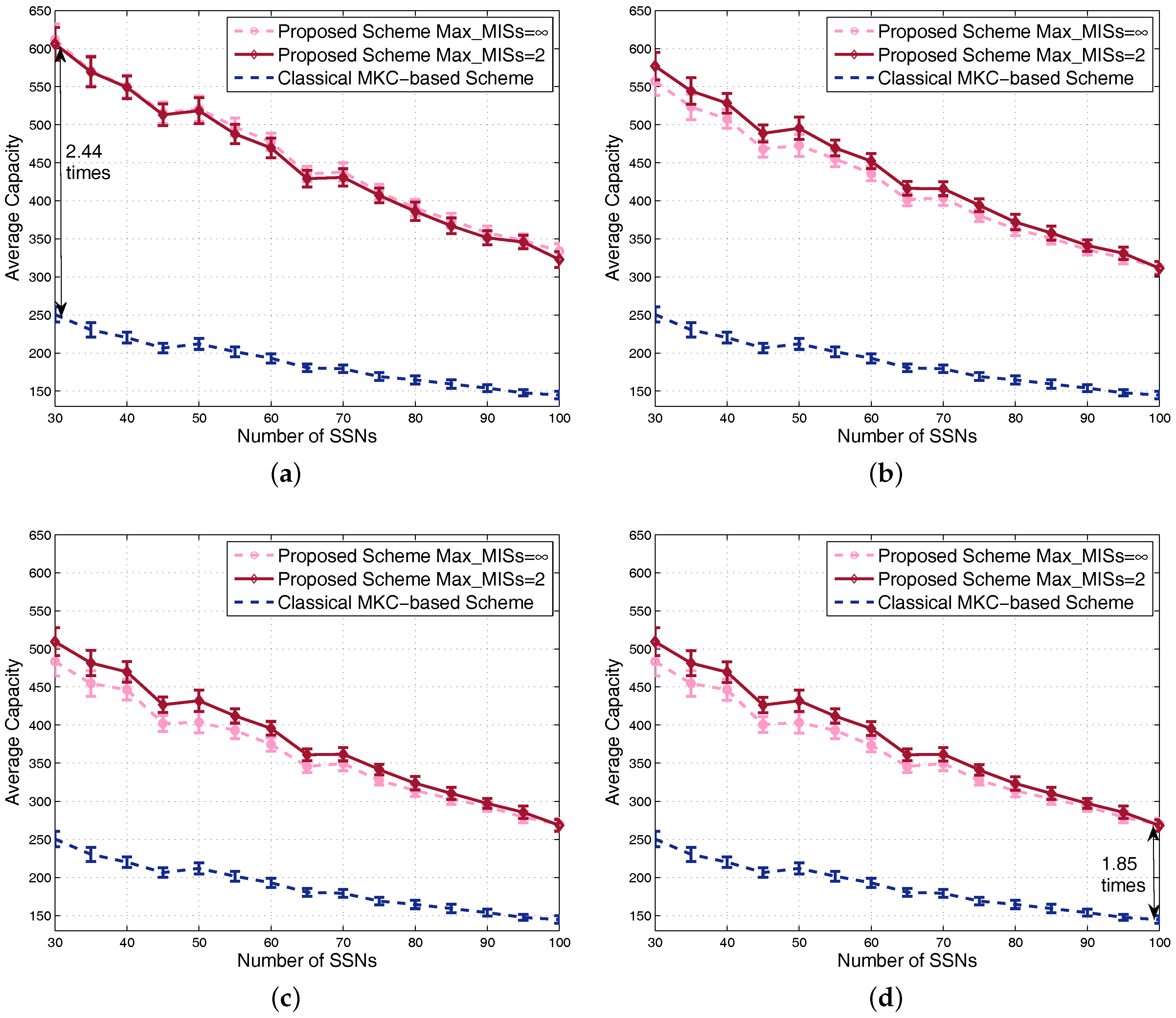
Capacity is evaluated and shown by the four sub-figures of Figure 10. Along with the increment of the number of SSNs, system average capacity decreases due to the increment of interference, which is similar to the feature of utility. Due to the fact that the classical MKC-based scheme is unrelated to the -fairness factor, its achieved capacity is the same for different values, so the curves of this scheme in different subfigures are the same. By contrast, the achieved capacity of our proposed scheme gradually decreases with regard to the increment of because of the increasing tradeoff affect between capacity and fairness. Seen from these subfigures, we conclude that the proposed scheme achieves always better system average capacity than the classical MKC-based scheme, for various , and numbers of SSNs. For example, the almost worst case of our scheme is at and the number of SSNs equal to 100, but our scheme still achieves around 1.85-times the system capacity of the classical MKC-based scheme. For the almost best case of our scheme at and the number of SSNs equal to 30, the achieved capacity of our scheme is around 2.44-times the classical MKC-based scheme. Note that, although the number of scenarios for each point is only half of the previous figures, the confidence intervals in Figure 9 and Figure 10 are not wider than those in previous figures; that is because the scenarios averaged for each point here have the same number of SSNs leading to similar performance results.
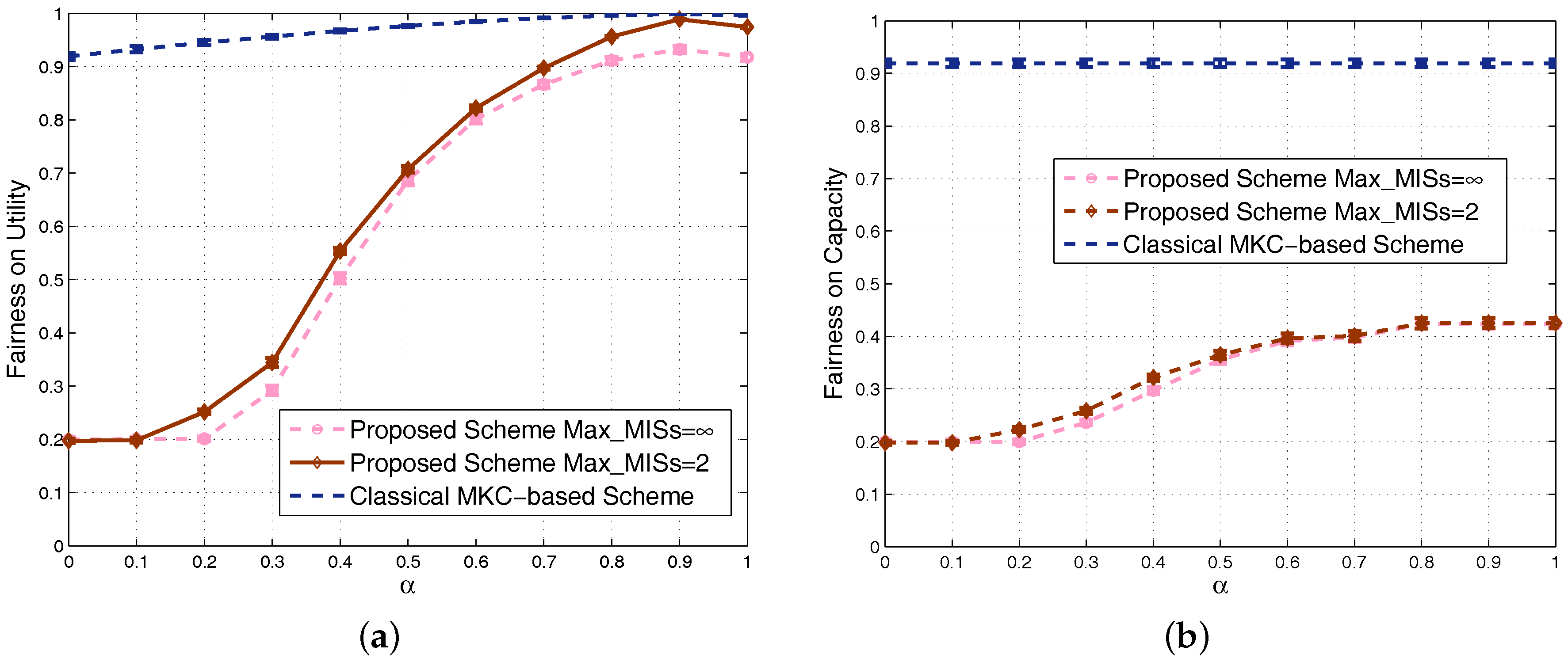
We also study the Jain’s fairness index in dense scenarios and obtain Figure 11a,b for fairness based on utility and capacity, respectively. To show the fairness feature in dense scenarios, each point on any curve is obtained by averaging the results of 100 randomly-generated scenarios with 80–100 SSNs. The trends of the curves are similar to the nondense scenarios. Since different sets have the same number of SSNs in the classical MKC-based scheme, its achieved fairness is still high in dense scenarios. Our proposed scheme allocates more resources to the groups with more SSNs, so its achieved fairness becomes obviously low in dense scenarios. By increasing the fairness factor , our scheme’s fairness on utility could increase to almost the same as the classical MKC-based scheme, but the fairness on capacity cannot be close to it due to the fact that capacity is a metric not integrating -fairness. One of our future works is to look for schemes to further improve the fairness on capacity. As we know that system capacity and its fairness are two metrics usually opposite of each other, so this future work generally lead to a totally different scheme satisfying fairness and time cost requirements, but sacrificing system capacity, which is out of the scope of this article. Since the 100 scenarios generated between 80 and 100 SSNs for this figure are dense, their achieved performance results are relatively closer than the 100 scenarios in Figure 8. Therefore, the confidence intervals in this figure become much narrower and even almost invisible for many points.
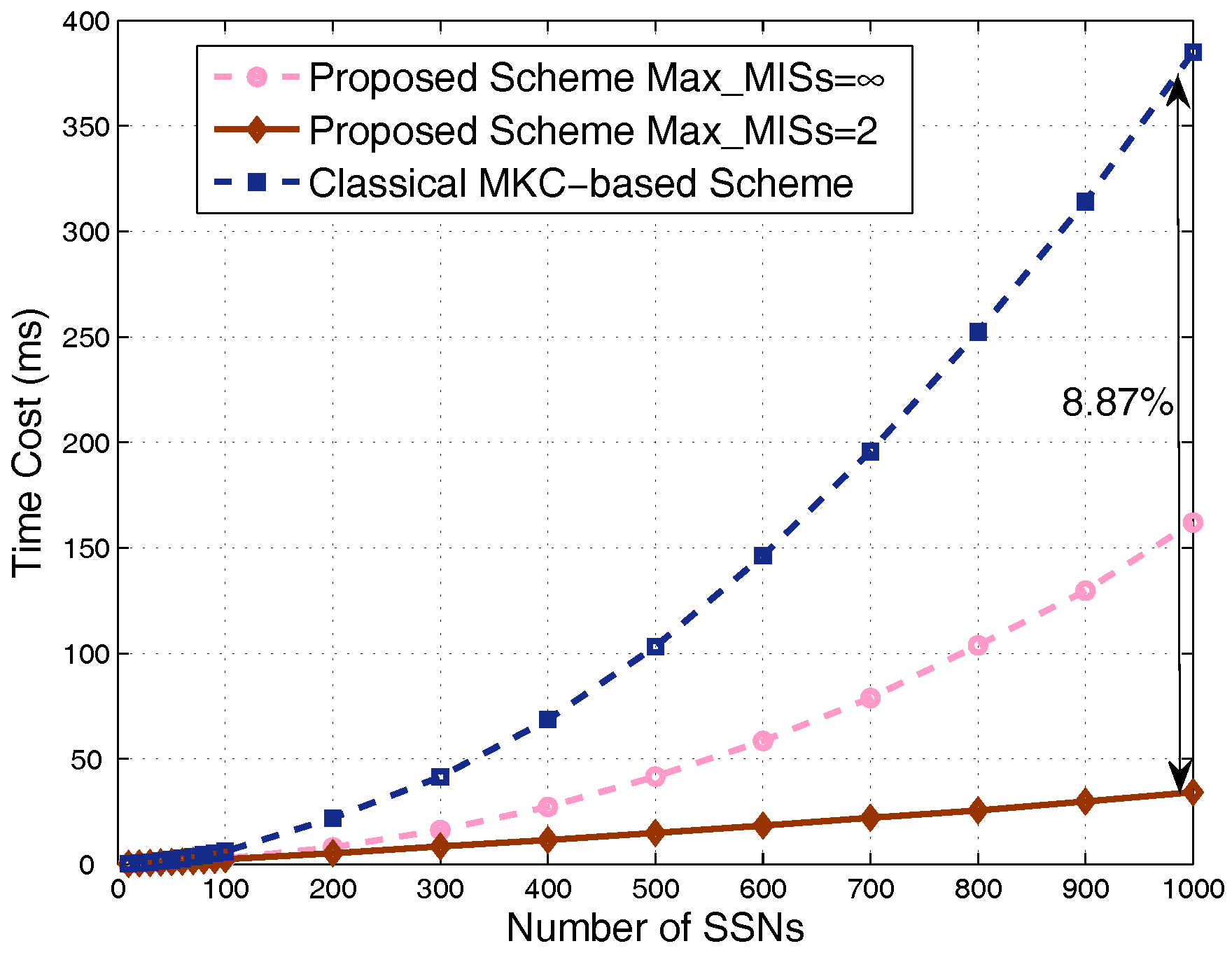
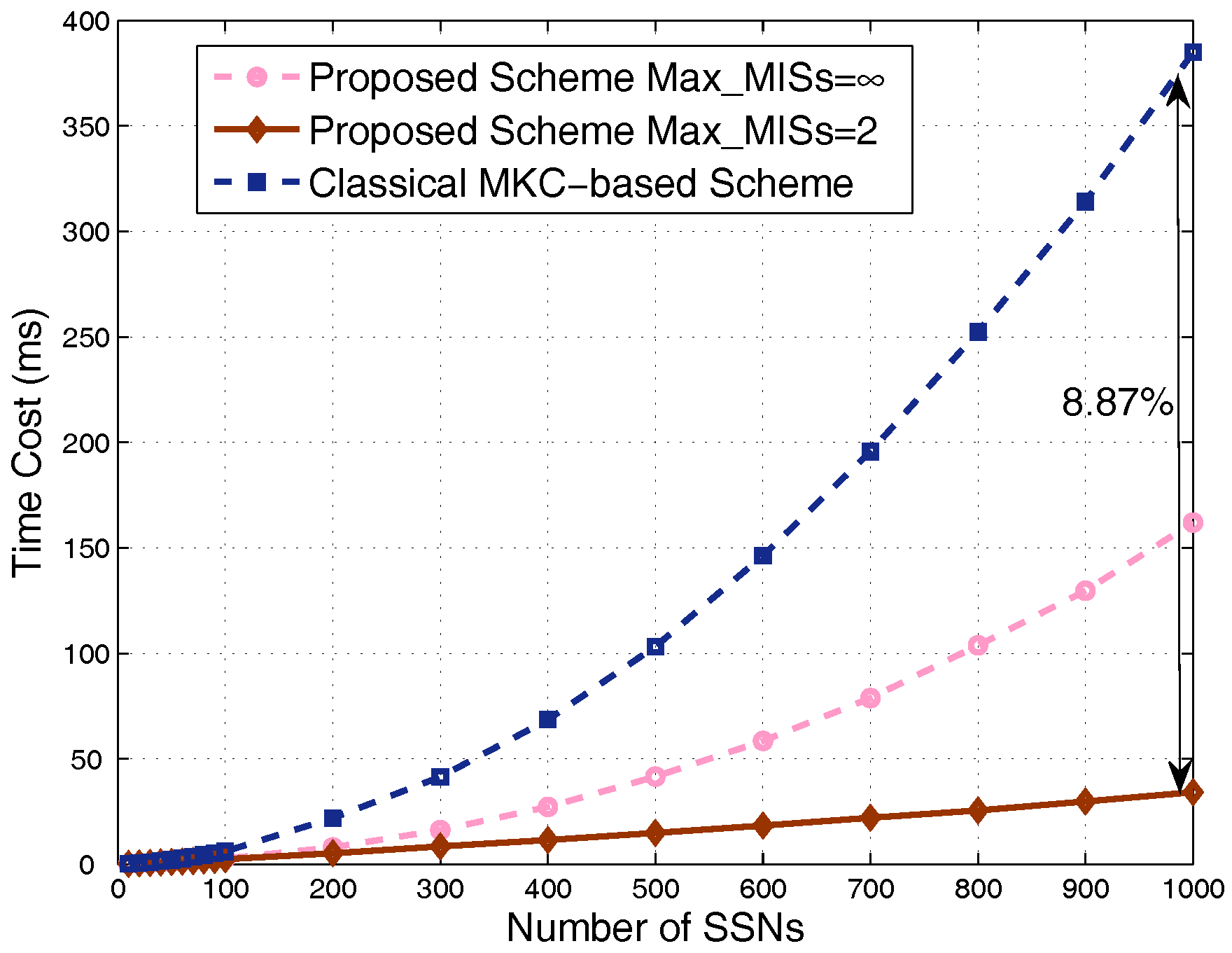
Finally, comparison of the time cost is shown in Figure 12. We can see that our scheme is obviously faster than the MKC-based scheme, especially for dense scenarios. By taking , corresponding to the largest simulation time cost of our scheme (the worst case in terms of time cost), the proposed scheme is still obviously faster than the classical MKC-based scheme. We also take , the proper value corresponding to the case where the proposed scheme significantly outperforms the classical MKC-based scheme in terms of utility and capacity based on the simulation results above; the time cost dramatically decreases to a very low value, around 8.87% of the time cost of the classical MKC-based scheme in hyper-dense scenarios.
By carefully analyzing the time costs of various parts of the two schemes in the simulation codes, we explicitly see that the key part deciding the complexity of the proposed scheme is the removal operation of nodes in an obtained MIS from the current graph. The complexity of this operation is , leading to a complexity of for the proposed scheme with , which repeats this removal operation only for limited times. For the proposed scheme with , the original graph is divided into many MISs until no node is left. The computational cost is calculated as the sum of arithmetic series when the numbers of nodes in different MISs are identical, although they are generally different. Therefore, its computational complexity can be approximately obtained as . The complexity of the classical MKC-based scheme is mainly decided by the interference calculation and comparison process because the total interference of each node put into any of the K sets should be calculated, and this total interference includes interference from all the nodes in other sets. This process makes the complexity of the scheme , and K is related to N because we consider the same number of sets for this scheme as the number of MISs for the proposed scheme to guarantee a fair performance comparison. To summarize, in dense scenarios, our scheme achieves a much lower time cost and obviously higher average capacity and utility, without degrading much of the fairness.
5. Conclusions
The upcoming application requirements, such as artificial intelligence, smart cities and telemedicine, bring about new networking paradigms for future wireless and mobile communication systems, i.e., the clustering of sensors and the deployment of dense WiFi hotspots and femtocells, uniformly called SSNs in this article. These scenarios require a very fast resource allocation scheme, which guarantees a relatively good system total capacity and utility for transmissions of these applications, while existing schemes, such as the classical MKC-based scheme evaluated in the simulations, do not satisfy this requirement, especially due to their high time cost. A graph-based scheme was proposed in this article, which applied the MIS concept to divide the SSNs into interference-free groups, and resources were allocated to these groups based on a procedure containing the search of several MISs with empirical parameter settings. Simulations demonstrated that the proposed scheme outperformed many other schemes. Because of the low time cost feature of Algorithm 1 for obtaining one random MIS, the proposed scheme achieves the most important advantage (i.e., low time cost), making it quite suitable for usage in future dense networks. Meanwhile, its achieved system capacity and utility are also higher than the classical MKC-based scheme and almost close to the near-optimum obtained by a time-consuming simulated annealing search. By setting a large -fairness value in the proposed scheme, its achieved fairness of utility can be guaranteed. Our work in the near future is to derive more distance thresholds for various scenarios as the Appendix because suitable distance thresholds could further decrease the time cost. Another future work may be research on new fast schemes with high fairness on capacity to fit both the fairness and time cost requirements.
Acknowledgments
The project was supported by Key Laboratory of Universal Wireless Communications (Beijing University of Posts and Telecommunications), Ministry of Education, China, under Grant No. KFKT-201603, including the costs to publish in open access. This research was also supported by the National Natural Science Foundation of China under Grant Nos. 61501160 and 61471156 at the beginning of this study. The work of Q.Z. was also supported by Science and Technology Planning Project of Guangdong Province, China, under Grant No. 2016B010108002.
Author Contributions
L.W. and J.Z.were the main designers of the proposed scheme. J.Z. performed the experiments. W.W. focused on the guidance of the research, part of the paper writing and also the funding for publication, Q.Z. worked on the paper writing and verification of the derivation.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
This Appendix explains the derivation of the distance threshold between two adjacent SSNs. Each of them forms a circular coverage with the network equipment in the center. When the distance is larger than this threshold, they can use the same resource and tolerate the interference. Otherwise, to maximize the total capacity of the two SSNs, it is better to use orthogonal resources for them.
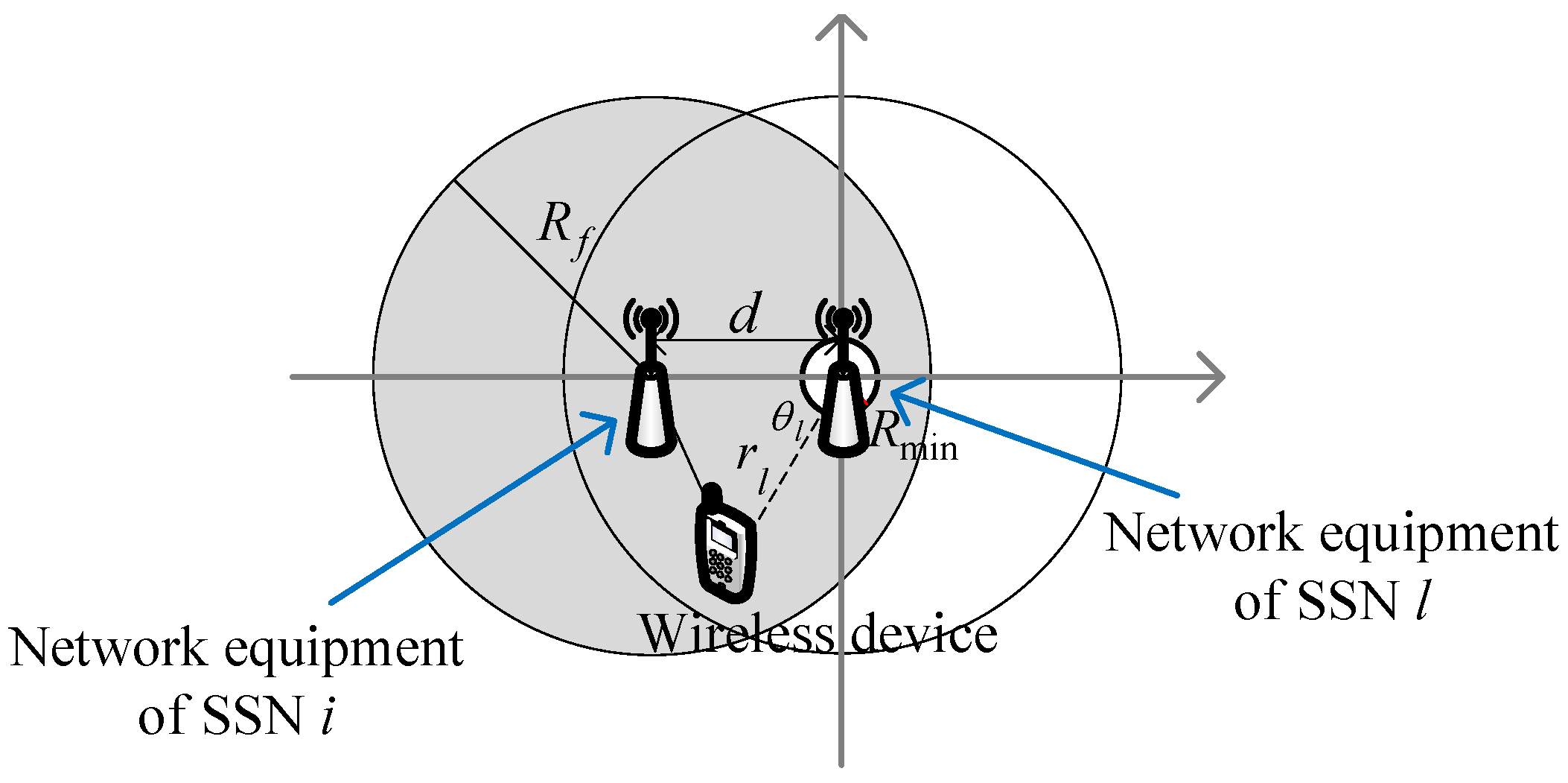
Let us consider the case in Figure A1, where the network equipments of the two SSNs and have a distance d and the coverage radius of each SSN is R. To calculate the downlink interference from to , the receiving device of the interference could be anywhere in the coverage area of , so we should take the integral of this coverage area. To complete this derivation, we denote the distance as between the network equipment of and a given wireless device accessing it, while the distance between this device and the network equipment is . The angle between and d is , while the angle between and d is .
Figure A1.
Two-SSN scenario with .
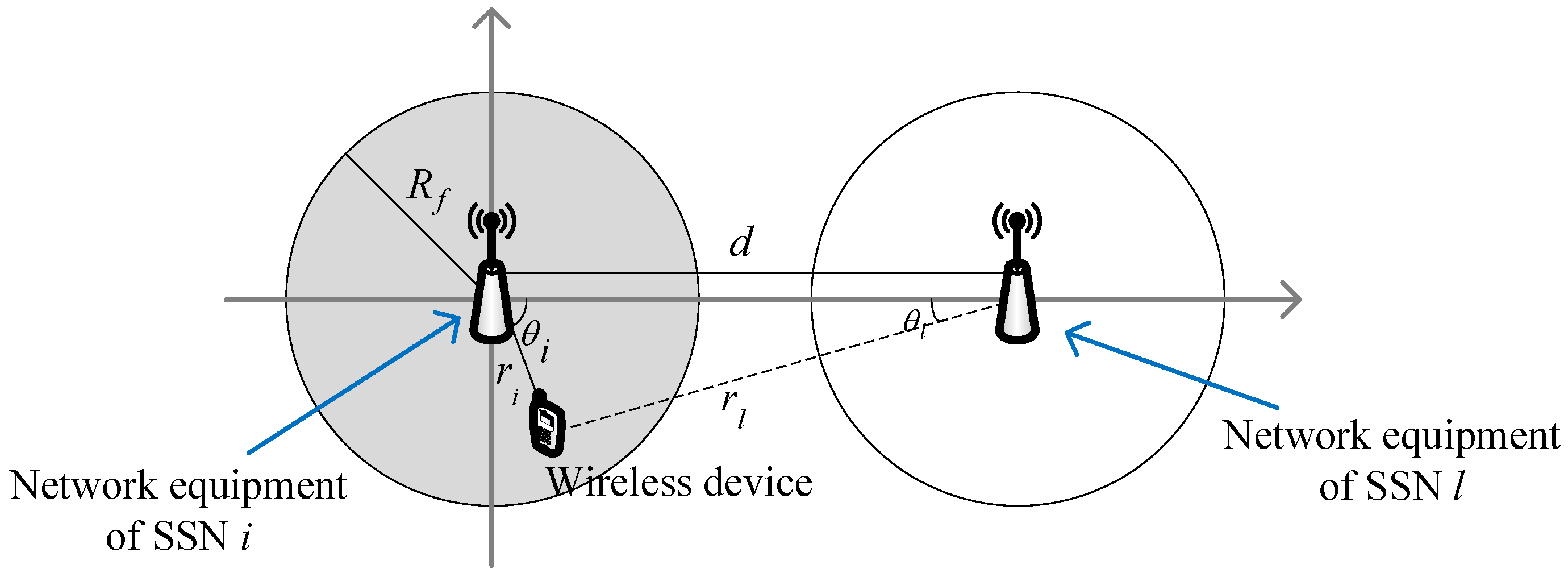
Based on the relationship between d and R, the derivation of the interference from to can be divided into two cases as follows. In case , as shown by Figure A1, is not within the coverage of , so the integral for calculating the interference can be written in a normal way. We set the original point of the coordinate system at the network equipment of , so the average interference is calculated by taking the integral within the coverage area of , given by:
Let ; the above integral becomes:
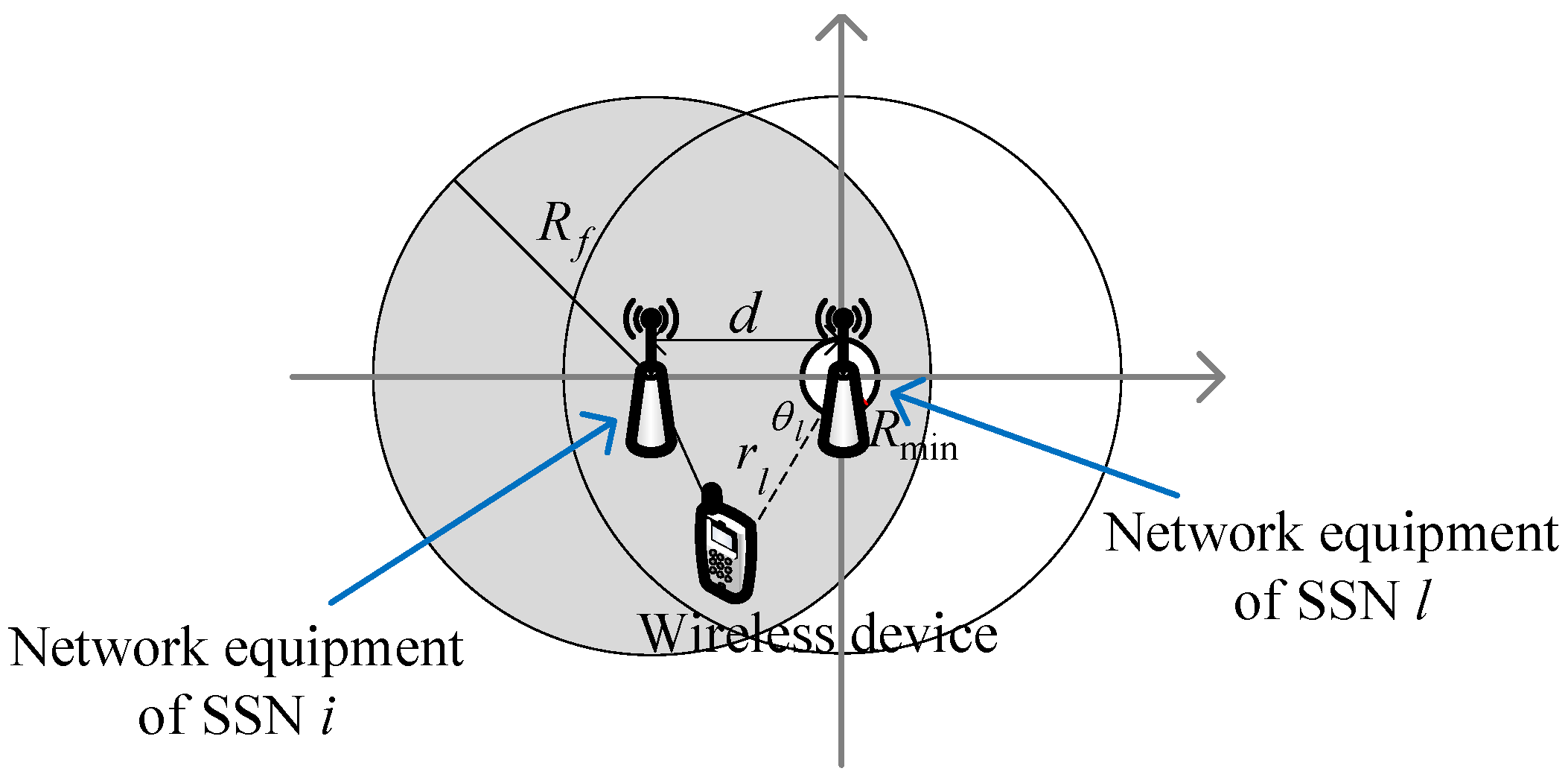
In the case , as shown in Figure A2, is within the coverage of , so the method of integral used in the above case is no longer suitable. One reason is that the interference source inside the coverage of making the integral trend be infinite, so we should consider a reference distance as the minimum possible distance between the network equipment and any device. Note that, in wireless communication theory, it is quite common to define such a reference distance when calculating the channel propagation. Another reason is that the usage of reference distance forms a small circle within the coverage of , making it difficult to take the integral using the previous coordinate system even through the subsection integral may be used. Therefore, for the second case, we build a coordinate system with the original point at the network equipment of and derive the average interference as follows. Note that, although the case is for , it is actually equivalent to , due to the fact that should be a very small value compared with R, so our discussion in this Appendix covers all the cases.
Figure A2.
Two-SSN scenario with .
The edge of is a circle whose equation under the polar coordinate system can be written as:
which is a quadratic equation with one unknown and can be solved as:
Note that the other solution has a negative value, which cannot be used to represent distance. Up to now, we could describe the integral for the average interference as:
Let ; we have:
Let ; we take into and obtain:
To derive the thresholds for the two cases, the average receiving power of the useful signal from to its devices is needed. A reference distance around the network equipment of is also needed; otherwise, this maximal power becomes infinite. Then, we obtain the average receiving power as:
After obtaining the expressions for the average useful power and the average interference, we can now derive the distance threshold, which is the distance with equal total capacities by orthogonal and non-orthogonal resource allocations, given by:
where represents the total capacity of the two SSNs using orthogonal resource allocation and represents the usage of non-orthogonal resource allocation. The two total capacities can be written as:
where , , and B represents the total bandwidth of each SSN can use. Taking (A12) and (A13) into (A11), we obtain:
By taking (A14) into (A2) and (A9), respectively, we obtain the thresholds for the first and the second cases as follows:
where . Note that is a very small value, so H should be slightly larger than one. We have:
which is a paradox for the initial condition of this case . Therefore, (A16) is not a solution to the distance threshold. To sum up, the second case discussed does not reach a solution, so (A15) obtained in the first case is the only solution for the derivation of the distance threshold.
References
- Andrews, J. Seven ways that HetNets are a cellular paradigm shift. IEEE Commun. Mag. 2013, 15, 136–144. [Google Scholar] [CrossRef]
- Kamel, M.; Hamouda, W.; Youssef, A. Ultra-dense networks: A survey. IEEE Commun. Surv. Tutor. 2016, 18, 2522–2545. [Google Scholar] [CrossRef]
- Lin, H.; Wang, L.; Kong, R. Energy efficient clustering protocol for large-scale sensor networks. IEEE Sens. J. 2015, 15, 7150–7160. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Han, D.; Wu, H.; Zhou, R. Fuzzy-logic based distributed energy-efficient clustering algorithm for wireless sensor networks. Sensors 2017, 17, 1554. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Quek, T. On constructing interference free schedule for coexisting wireless body area networks using distributed coloring algorithm. In Proceedings of the IEEE International Conference on Wearable and Implantable Body Sensor Networks, Cambridge, MA, USA, 9–12 June 2015; pp. 1–6. [Google Scholar]
- Cheng, S.; Huang, C. Coloring-based inter-WBAN scheduling for mobile wireless body area networks. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 250–259. [Google Scholar] [CrossRef]
- Lin, P.; Zhang, J.; Chen, Y.; Zhang, Q. Macro-femto heterogeneous network deployment and management: From business models to technical solutions. IEEE Wirel. Commun. 2011, 18, 64–70. [Google Scholar] [CrossRef]
- Patel, C.; Yavuz, M.; Nanda, S. Femtocells: Industry perspectives. IEEE Wirel. Commun. 2010, 17, 6–7. [Google Scholar] [CrossRef]
- Omar, H.; Abboud, K.; Cheng, N.; Malekshan, K.; Gamage, A.; Zhuang, W. A survey on high efficiency wireless local area networks: Next generation WiFi. IEEE Commun. Surv. Tutor. 2016, 18, 2315–2344. [Google Scholar] [CrossRef]
- Dhillon, H.; Ganti, R.; Baccelli, F.; Andrews, J. Modeling and analysis of k-tier downlink heterogeneous cellular networks. IEEE J. Sel. Areas Commun. 2012, 30, 550–560. [Google Scholar] [CrossRef]
- Kosta, C.; Hunt, B.; Auddus, A.; Tafazolli, R. On interference avoidance through inter-cell interference coordination (ICIC) based on OFDMA mobile systems. IEEE Commun. Surv. Tutor. 2013, 15, 973–995. [Google Scholar] [CrossRef]
- Hamza, A.S.; Khalifa, S.S.; Hamza, H.S.; Elsayed, K. A survey on inter-cell interference coordination techniques in OFDMA-based cellular networks. IEEE Commun. Surv. Tutor. 2013, 15, 1642–1670. [Google Scholar] [CrossRef]
- Wang, L.; Fang, F.; Cottatellucci, L.; Nikaein, N. An analytical framework for multilayer partial frequency reuse scheme design in mobile communication systems. IEEE Trans. Veh. Technol. 2016, 65, 7593–7605. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Y.; Chen, W.; Kai, C.; Wu, L. Dynamic interference coordination with analytical near-optimum of power allocation toward high user fairness. China Commun. 2016, 13, 37–48. [Google Scholar] [CrossRef]
- Lopez-Perez, D.; Guvenc, I.; Roche, G.; Kountouris, M.; Quek, T.; Zhang, J. Enhanced intercell interference coordination challenges in heterogeneous networks. IEEE Wirel. Commun. 2011, 18, 22–30. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, S.; Li, X.; Ji, H.; Du, X. Interference management for heterogeneous networks with spectral efficiency improvement. IEEE Wirel. Commun. 2015, 22, 101–107. [Google Scholar] [CrossRef]
- Chieochan, S.; Hossain, E.; Diamond, J. Channel assignment schemes for infrastructure-based 802.11 WLANs: A survey. IEEE Commun. Surv. Tutor. 2010, 12, 124–136. [Google Scholar] [CrossRef]
- Joo, C.; Lin, X.; Ryu, J.; Shroff, N. Distributed greedy approximation to maximum weighted independent set for scheduling with fading channels. IEEE/ACM Trans. Netw. 2016, 24, 1476–1488. [Google Scholar] [CrossRef]
- Bai, S.; Che, X.; Bai, X.; Wei, X. Maximal independent sets in heterogeneous wireless ad hoc networks. IEEE Trans. Mob. Comput. 2016, 15, 2023–2033. [Google Scholar] [CrossRef]
- Marshoud, H.; Otrok, H.; Barada, H.; Estrada, R.; Dziong, Z. Genetic algorithm based resource allocation and interference mitigation for OFDMA macrocell-femtocells networks. In Proceedings of the 6th Joint IFIP WMNC, Dubai, United Arab Emirates, 23–25 April 2013; pp. 1–7. [Google Scholar]
- Li, H.; Chen, X.; Xiang, X. An intelligent optimization algorithm for joint MCS and resource block allocation in LTE femtocell downlink with QoS guarantees. In Proceedings of the International Conference on Game Theory for Networks, Beijing, China, 25–27 November 2014; pp. 1–6. [Google Scholar]
- Sadr, S.; Adve, R. Hierarchical resource allocation in femtocell networks using graph algorithms. In Proceedings of the IEEE ICC, Ottawa, ON, Canada, 10–15 June 2012; pp. 4416–4420. [Google Scholar]
- Chang, Y.; Tao, Z.; Zhang, J.; Kuo, C.J. Multicell OFDMA downlink resource allocation using a graphic framework. IEEE Trans. Veh. Technol. 2009, 58, 3494–3507. [Google Scholar] [CrossRef]
- Pateromichelakis, E.; Shariat, M.; Quddus, A.U. Graph-Based multicell scheduling in ofdma-based small cell networks. IEEE Access 2014, 2, 897–908. [Google Scholar] [CrossRef]
- Li, Y.; Luo, J.; Xu, W.; Vucic, N.; Pateromichelakis, E.; Caire, G. A joint scheduling and resource allocation scheme for millimeter wave heterogeneous networks. In Proceedings of the IEEE WCNC, San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Chen, Q.; Zhang, Q.; Niu, Z. A graph theory based opportunistic link scheduling for wireless ad hoc network. IEEE Trans. Wirel. Commun. 2009, 8, 5075–5085. [Google Scholar] [CrossRef]
- Pang, Q.; Leung, V.C.M. Channel clustering and probabilistic channel visiting techniques for WLAN interference mitigation in Bluetooth devices. IEEE Trans. Electromagn. Compat. 2007, 49, 914–923. [Google Scholar] [CrossRef]
- Lan, T.; Kao, D.; Chiang, M.; Sabharwal, A. An axiomatic theory of fairness in network resource allocation. In Proceedings of the IEEE InfoCom, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Yang, J.; Draper, S.; Nowak, R. Learning the interference graph of a wireless networks. IEEE Trans. Signal Inf. Process. Netw. 2017, 3, 631–646. [Google Scholar] [CrossRef]
- Luby, M. A simple parallel algorithm for the maximal independent set problem. SIAM J. Comput. 1986, 15, 1036–1053. [Google Scholar] [CrossRef]
- Alon, N.; Babai, L.; Itai, A. A fast and simple randomized parallel algorithm for the maximal independent set problem. J. Algorithm. 1986, 7, 567–583. [Google Scholar] [CrossRef]
- Bondy, J.; Murty, U. Independent sets and cliques. In Graph Theory with Applications; Macmillan Press Ltd.: London, UK, 1976; pp. 101–113. [Google Scholar]
- Weber, A.; Agyapong, P.; Rosowski, T.; Zimmerman, G.; Fallgren, M.; Sharma, S.; Kousaridas, A.; Yang, C.; Karls, I.; Maternia, M.; et al. Performance Evaluation Framework. Deliverable 2.1, METIS Project: Mobile and Wireless Communications Enablers for the Twenty-Twenty Information Society-II. 2016. Available online: http://www.metis2020.com (accessed on 25 July 2017).
- Special Interest Group (SIG) on 5G Channel Model, 5G Channel Model for Bands up to 100 GHz. IEEE Globecom White Paper. 2015. Available online: http://www.5gworkshops.com/5GCM.html (accessed on 25 July 2017).
- Jain, R.; Chiu, D.; Hawe, W. A Quantitative Measure of Fairness and Discrimination for Resource Allocation in Shared System; DEC Research Report TR-301; Digital Equipment Corporation: Hudson, MA, USA, 1984. [Google Scholar]
Figure 1.
Scenarios for randomly-deployed small star networks (SSNs): (a) sensor clusters; (b) femtocells and WiFi hotspots.
Figure 1.
Scenarios for randomly-deployed small star networks (SSNs): (a) sensor clusters; (b) femtocells and WiFi hotspots.
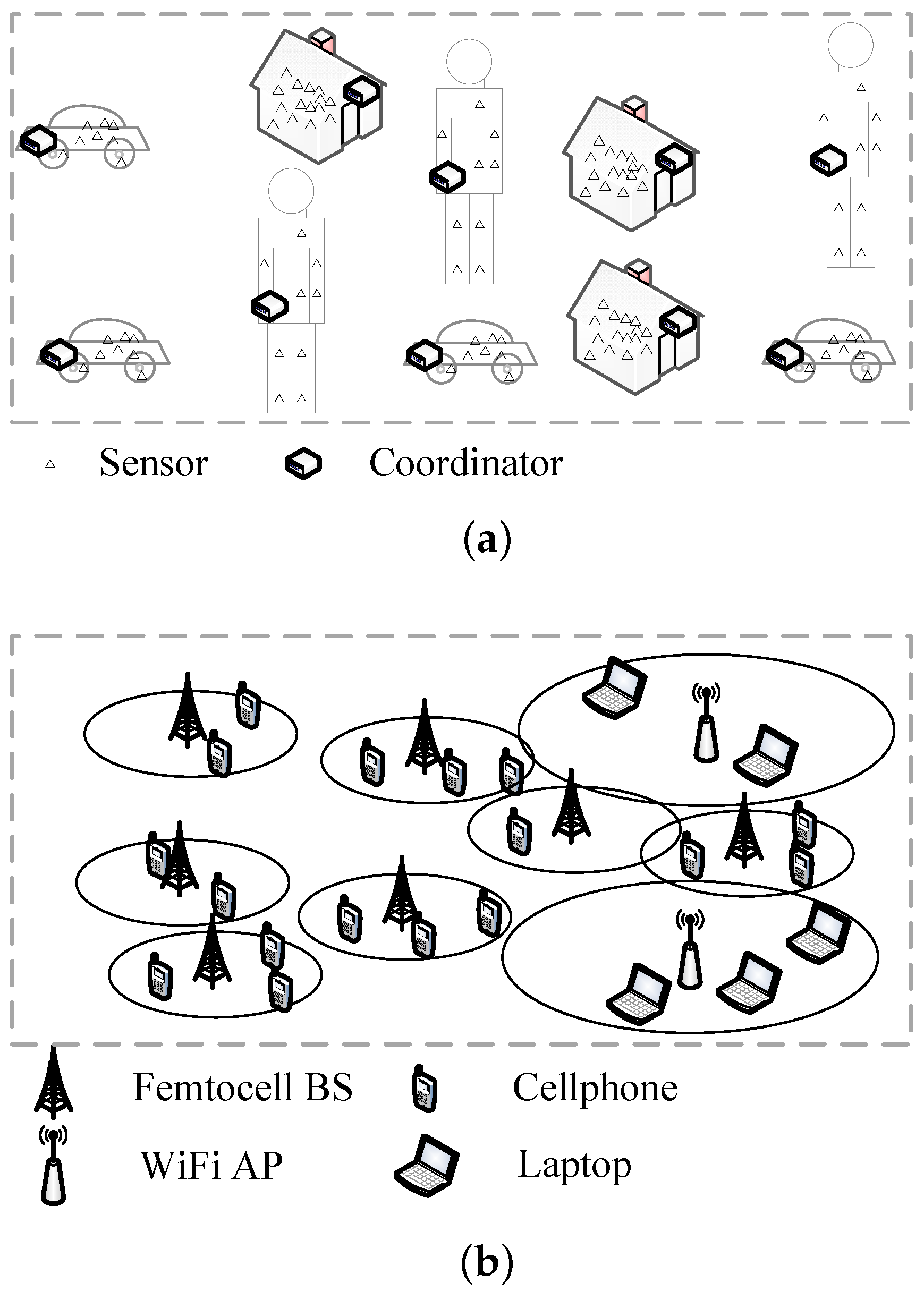
Figure 2.
A constructed interference graph.
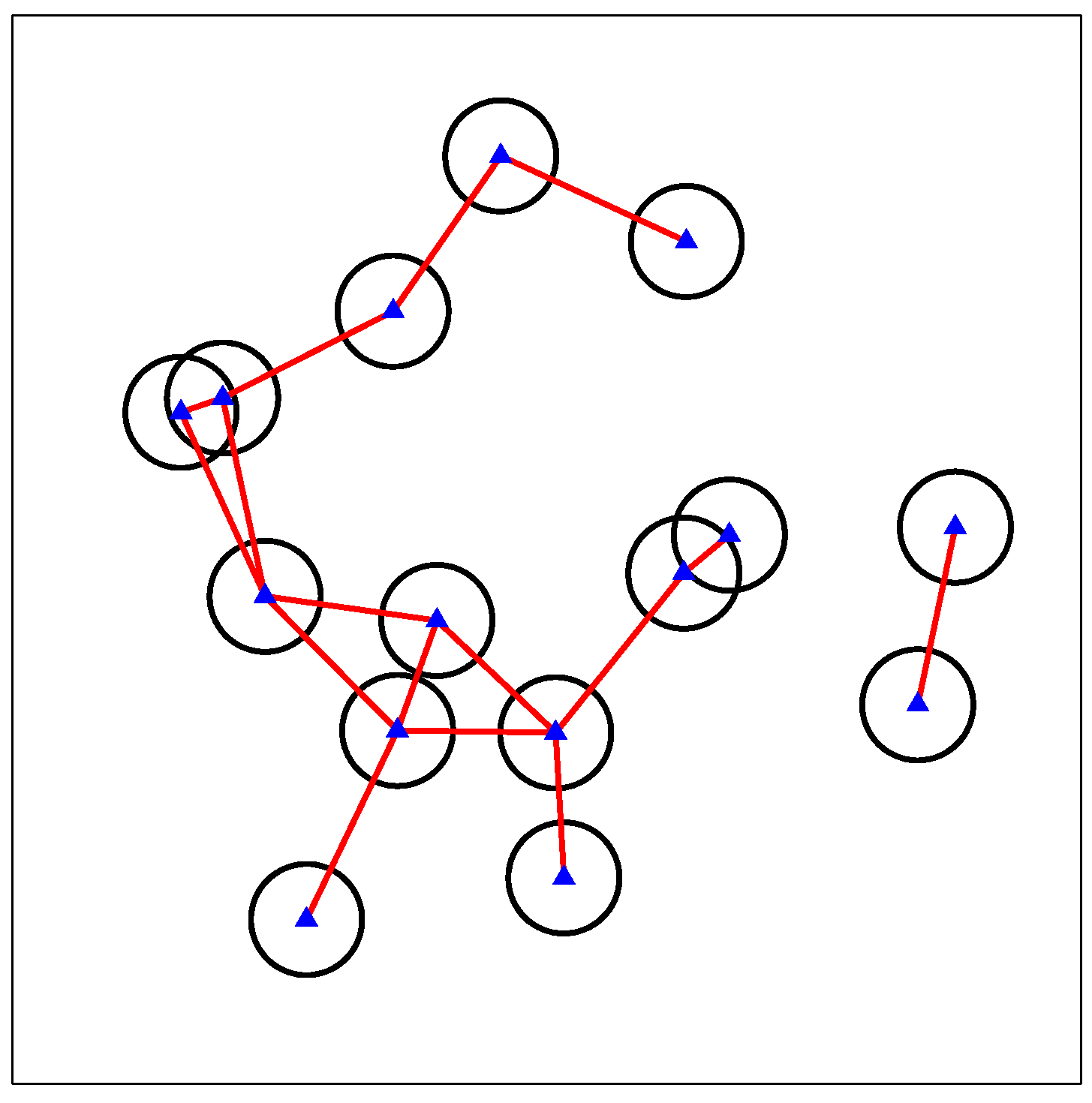
Figure 3.
An example for maximal independent set (MIS) calculation.
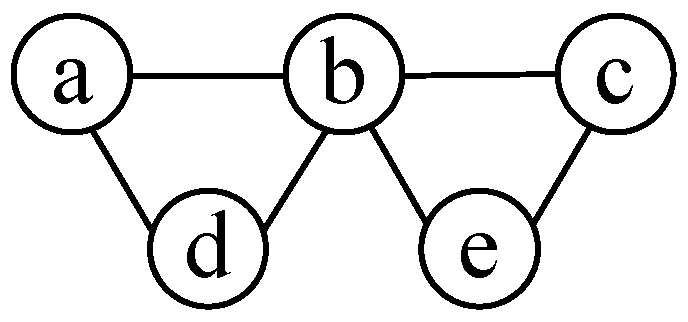
Figure 4.
Flowchart of the proposed scheme.
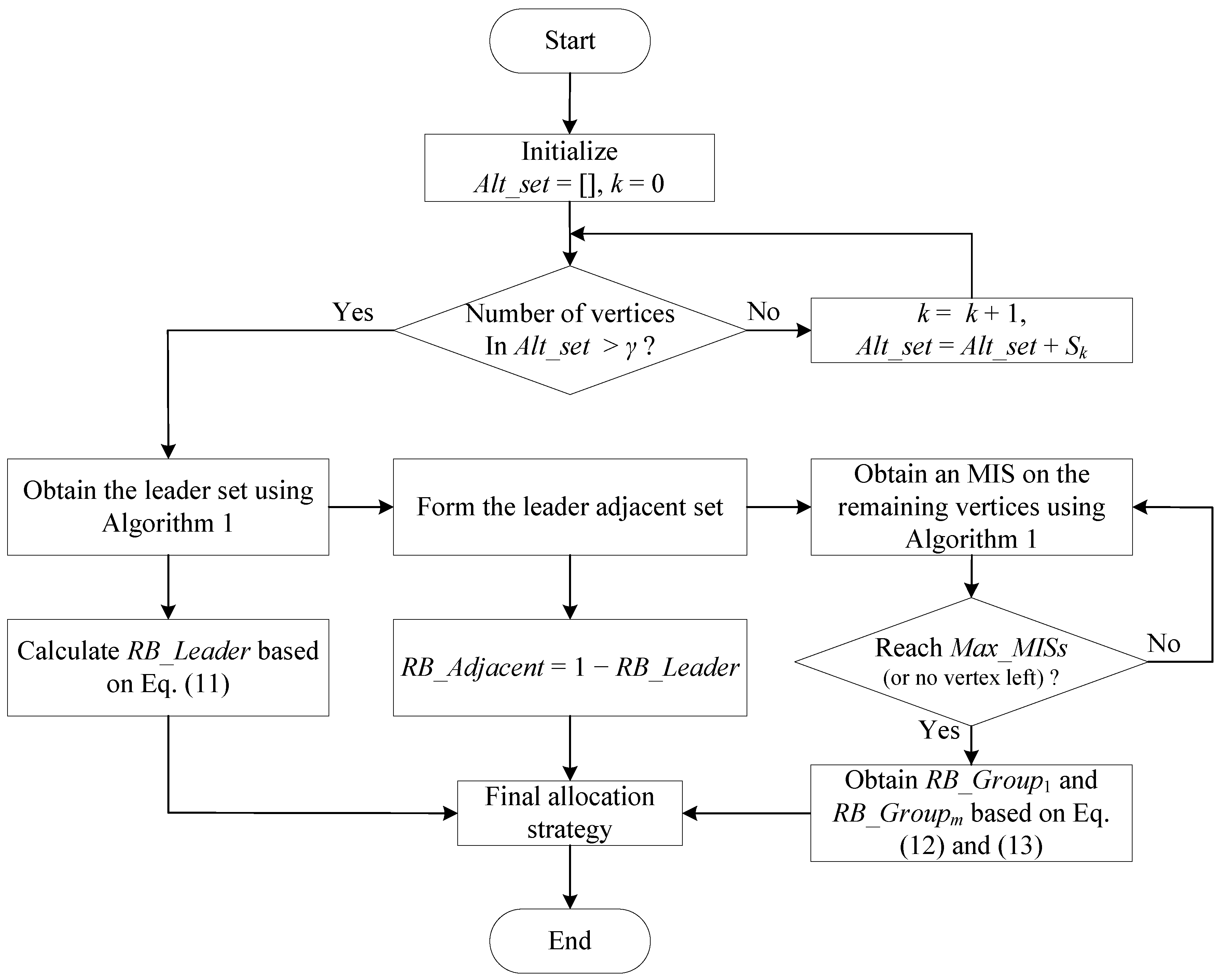
Figure 5.
Allocation example using a randomly-generated scenario: (a) ; (b) ; (c) ; (d) .
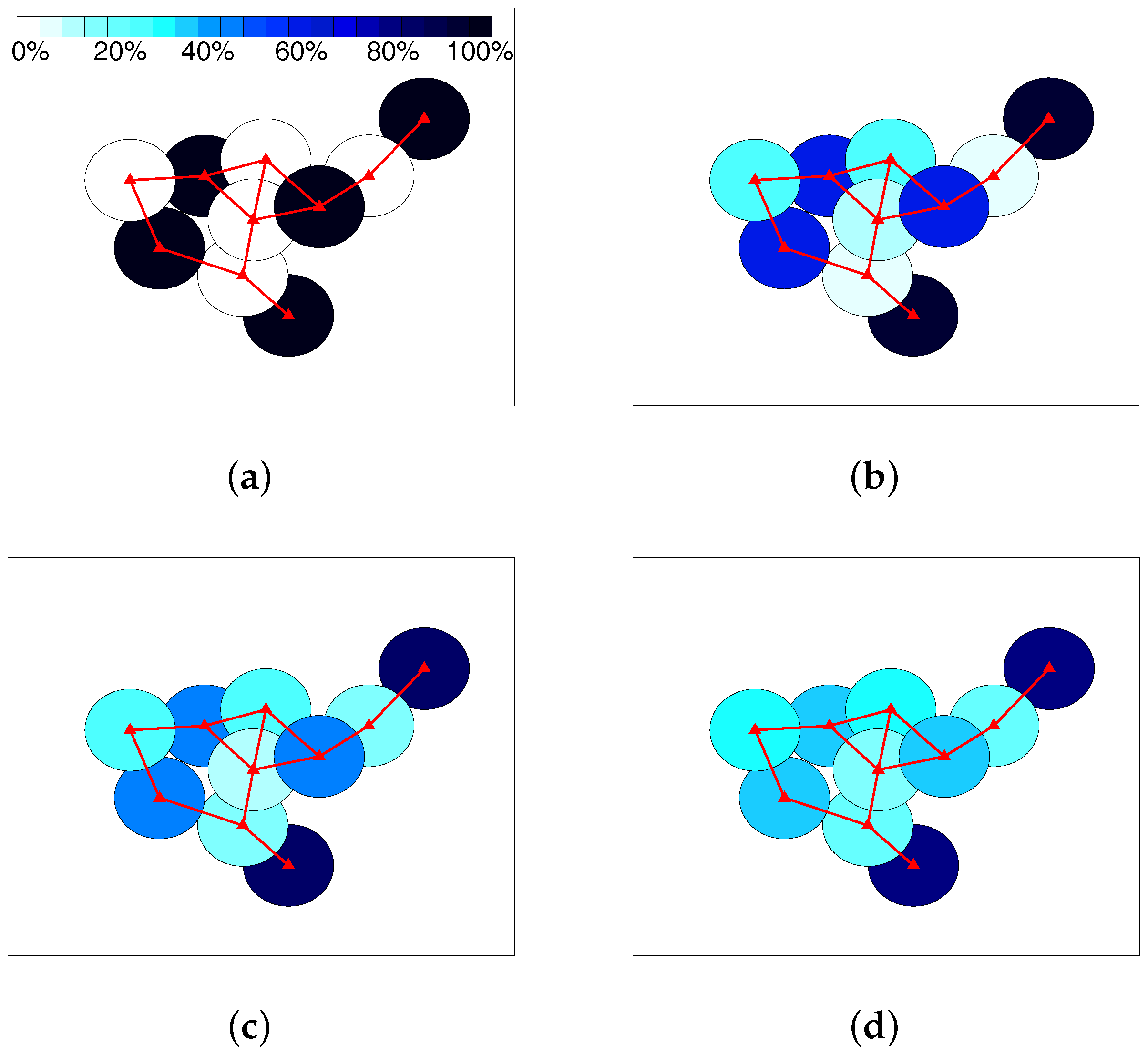
Figure 6.
Comparison of utility.
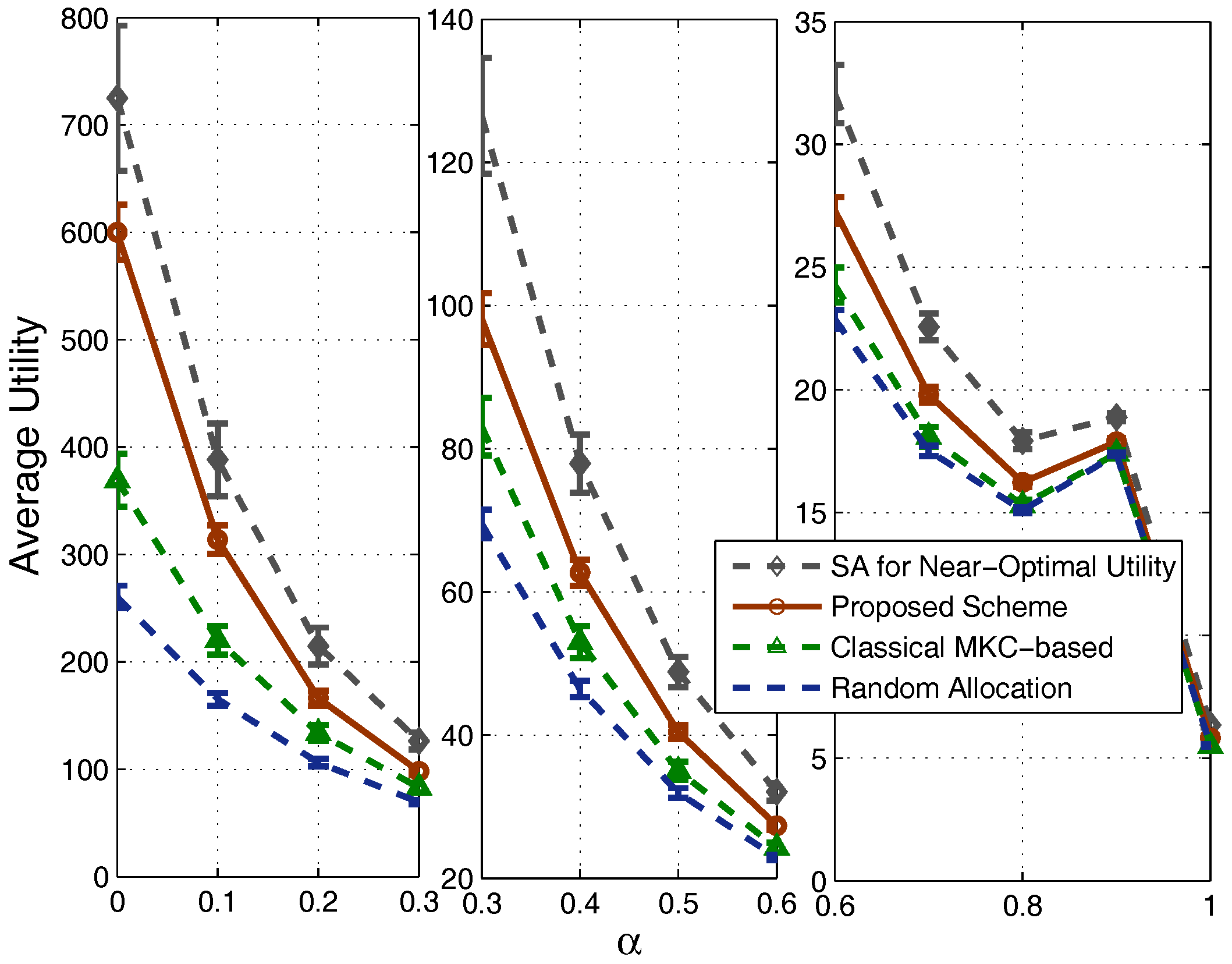
Figure 7.
Comparison of average capacity.
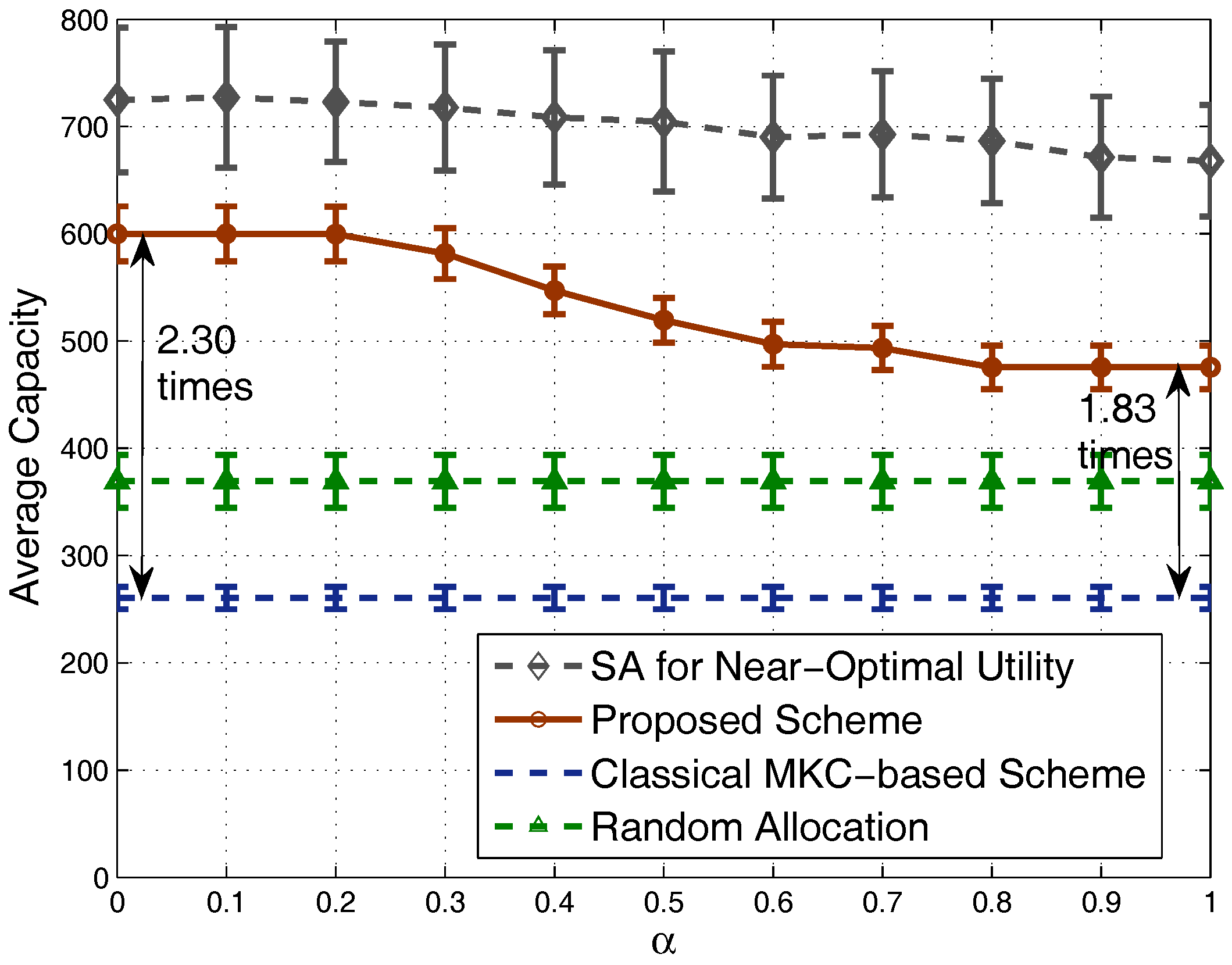
Figure 8.
Comparison of fairness: (a) based on utility; (b) based on capacity.
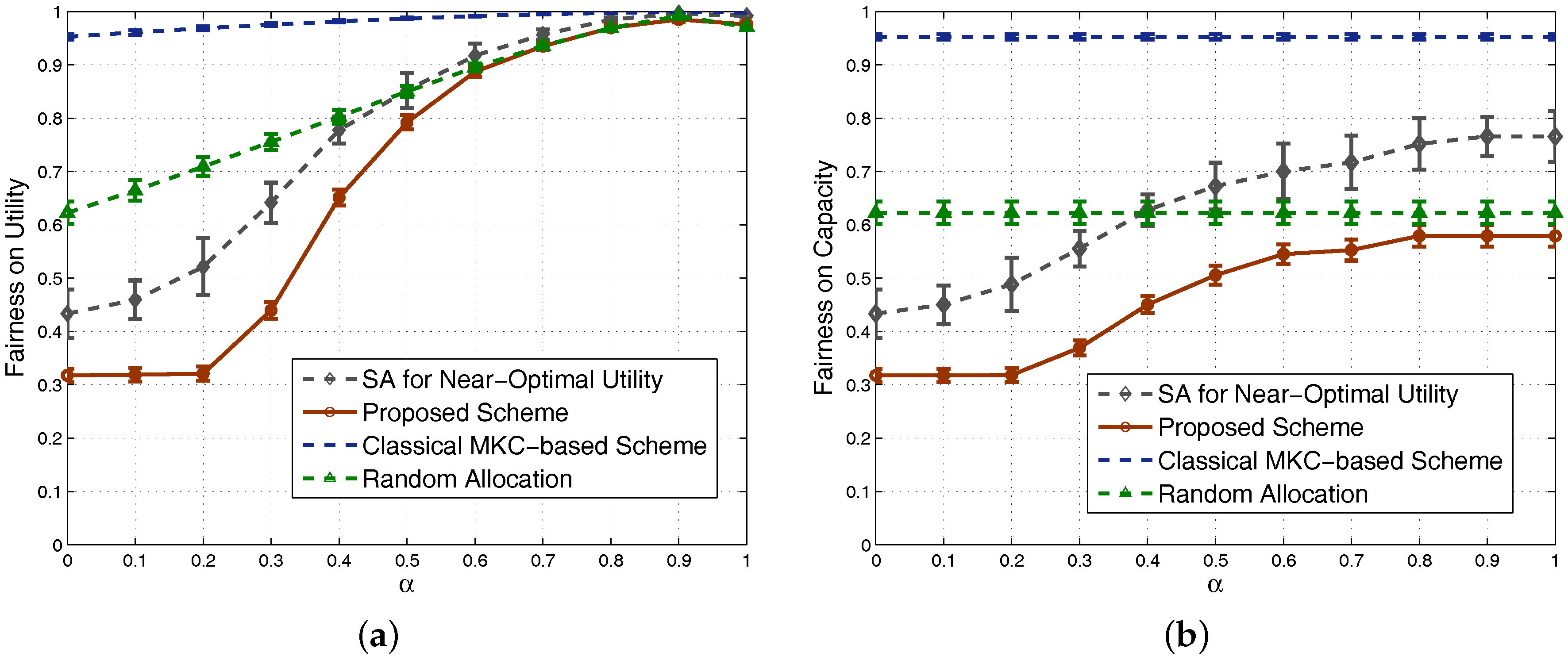
Figure 9.
Comparison of utility in dense scenarios: (a) ; (b) ; (c) ; (d) .
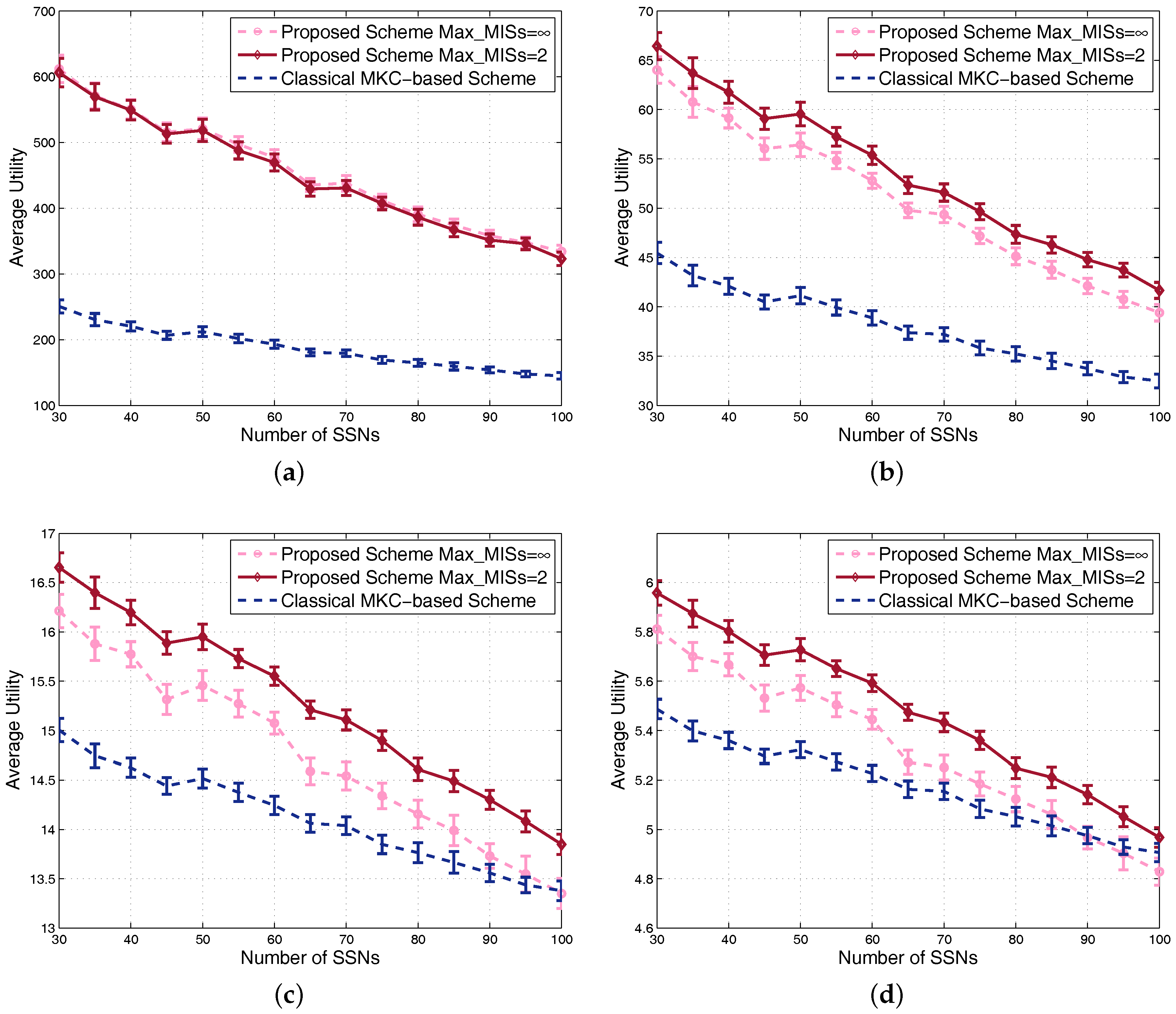
Figure 10.
Comparison of capacity in dense scenarios: (a) ; (b) ; (c) ; (d) .
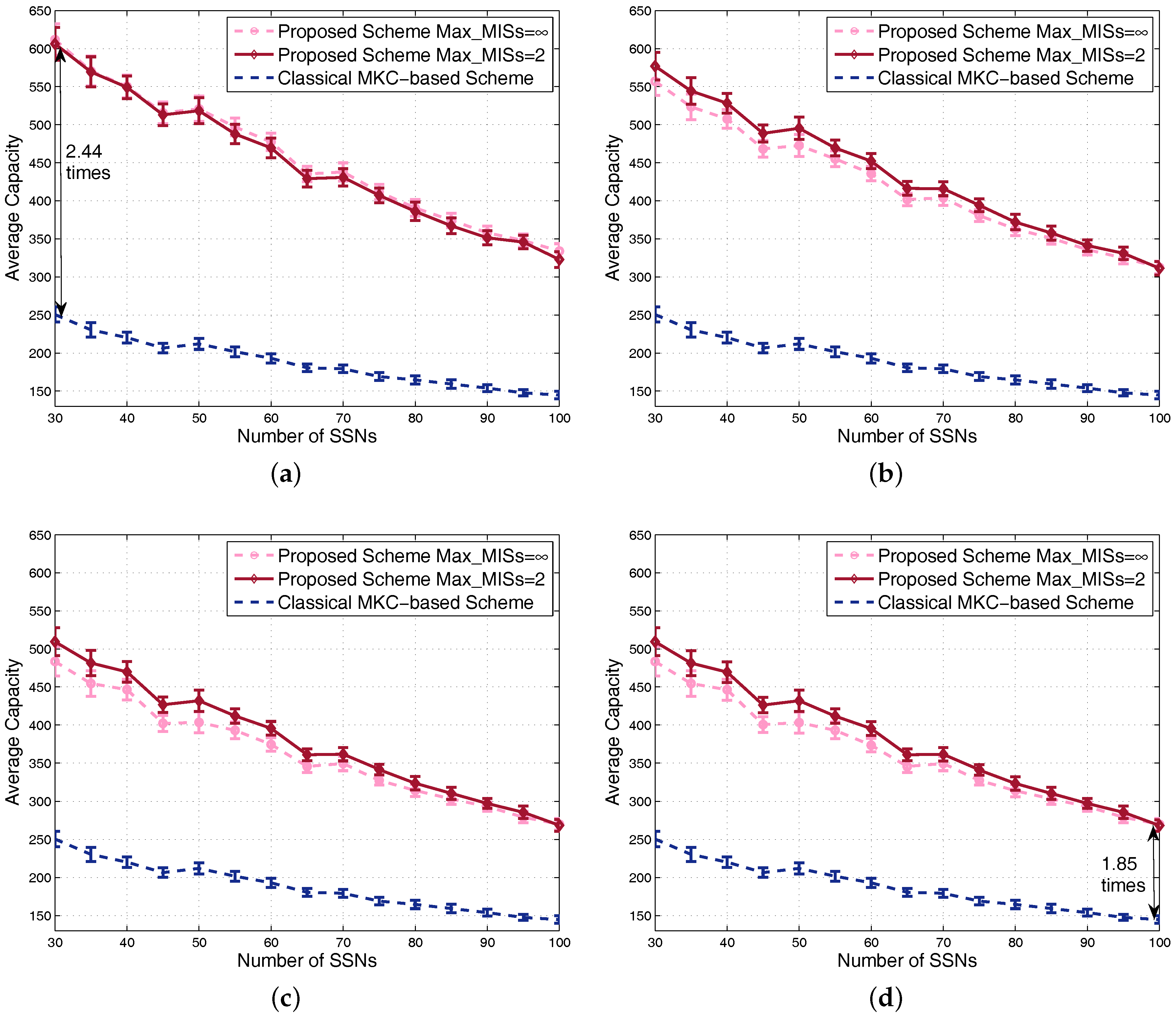
Figure 11.
Comparison of fairness in dense scenarios: (a) based on utility; (b) based on capacity.
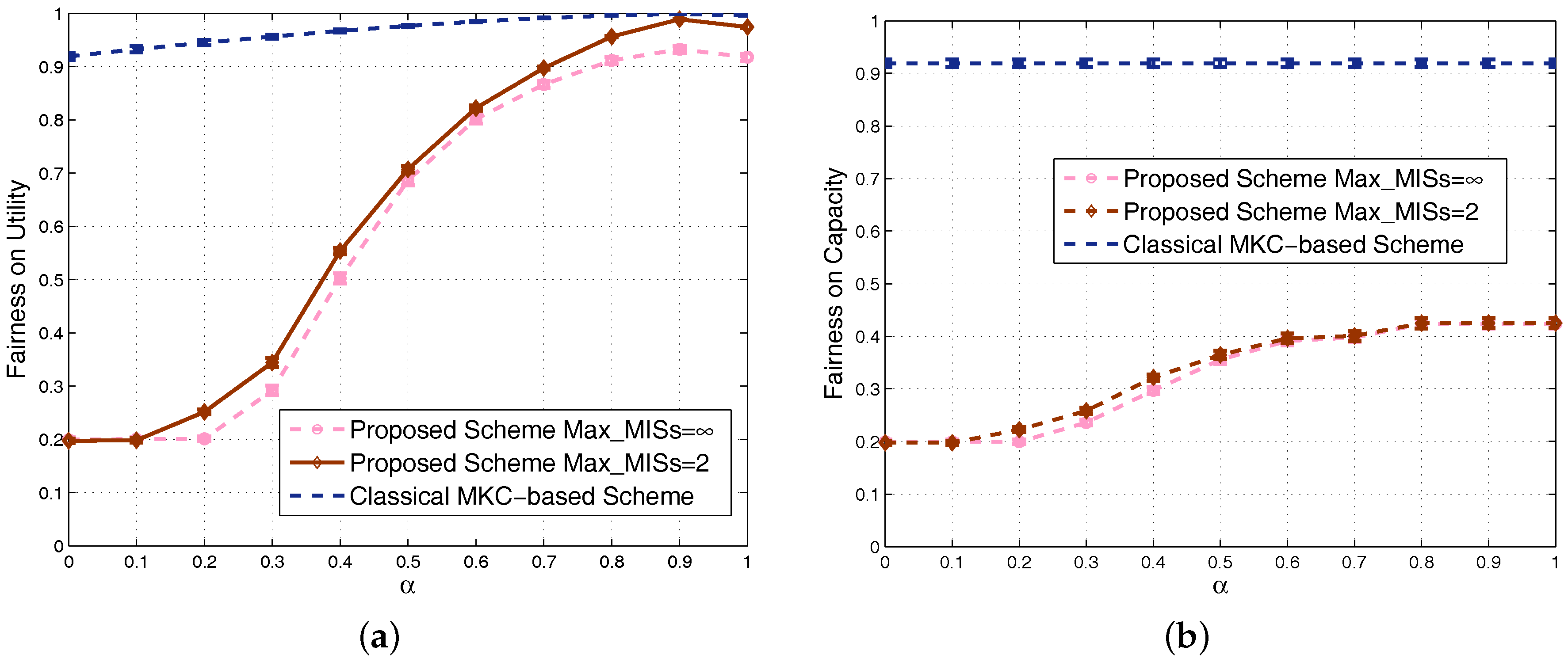
Figure 12.
Comparison of time cost in dense scenarios.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhou, J.; Wang, L.; Wang, W.; Zhou, Q. Efficient Graph-Based Resource Allocation Scheme Using Maximal Independent Set for Randomly- Deployed Small Star Networks. Sensors 2017, 17, 2553. https://doi.org/10.3390/s17112553
AMA Style
Zhou J, Wang L, Wang W, Zhou Q. Efficient Graph-Based Resource Allocation Scheme Using Maximal Independent Set for Randomly- Deployed Small Star Networks. Sensors. 2017; 17(11):2553. https://doi.org/10.3390/s17112553
Chicago/Turabian StyleZhou, Jian, Lusheng Wang, Weidong Wang, and Qingfeng Zhou. 2017. "Efficient Graph-Based Resource Allocation Scheme Using Maximal Independent Set for Randomly- Deployed Small Star Networks" Sensors 17, no. 11: 2553. https://doi.org/10.3390/s17112553
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.