
Exact Distributions of Finite Random Matrices and Their Applications to Spectrum Sensing

Abstract
:1. Introduction
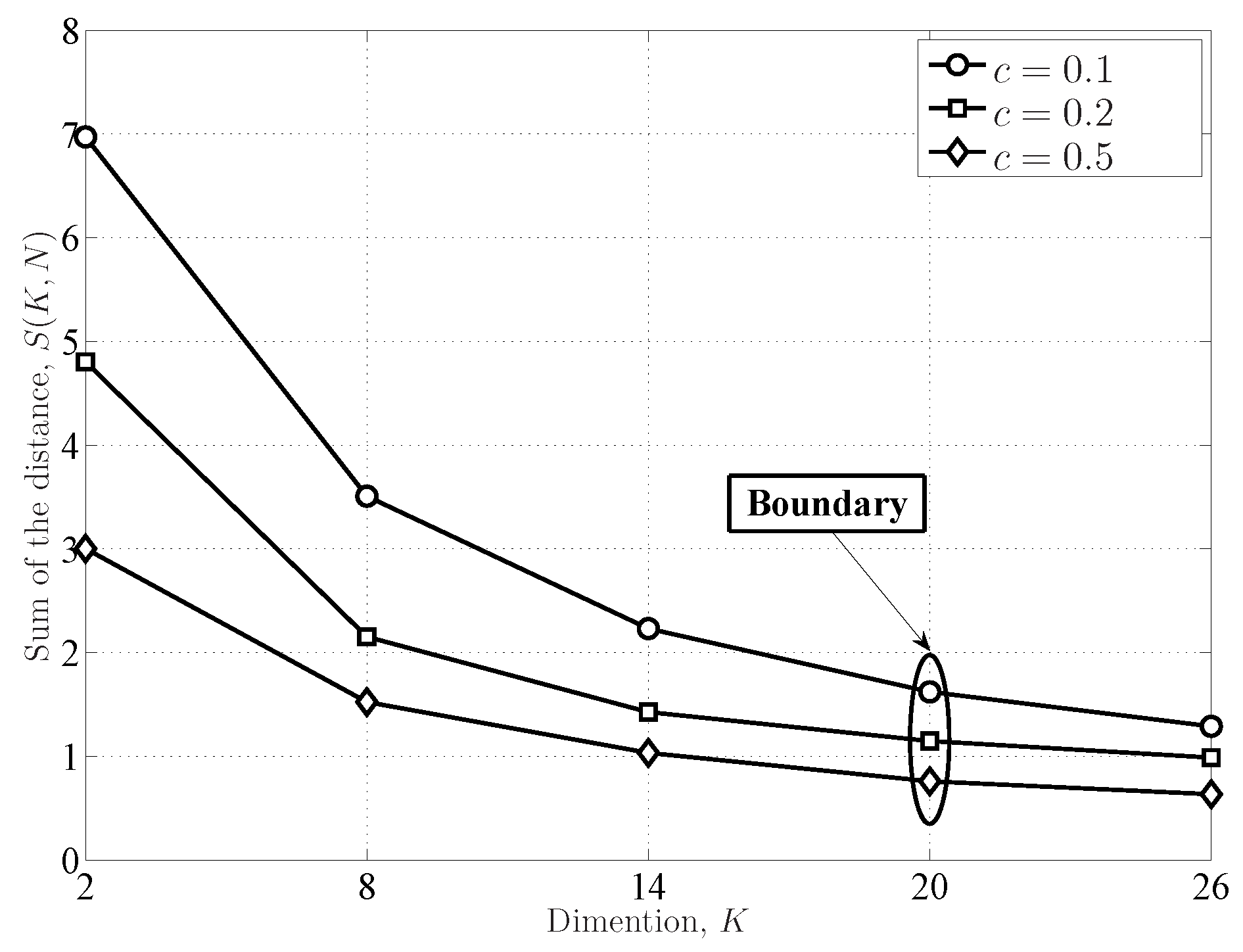
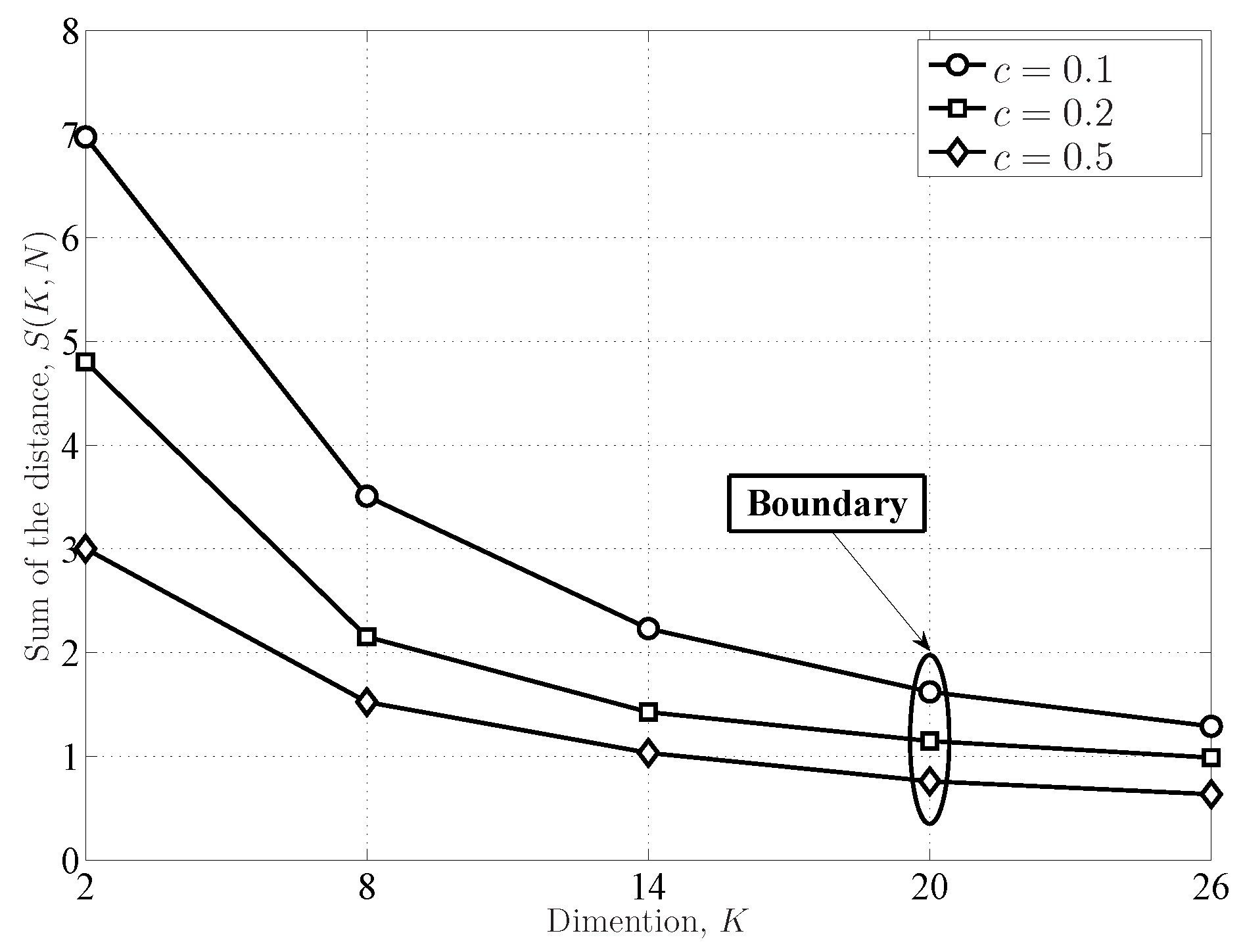
- The exact distributions of the FRMT are unified with the proposed coefficient matrices (vectors). The coefficient reuse mechanism is studied, i.e., the LE distributions and the SLE distributions can be formulated with the same coefficient matrices. Moreover, the SE distributions and the DCN distributions share the same coefficient vectors. In particular, a new and simple CDF of the DCN is formulated with the coefficient vector. The dimension boundary between the IRMT and the FRMT is defined by evaluating the theoretical and empirical eigenvalue distributions.
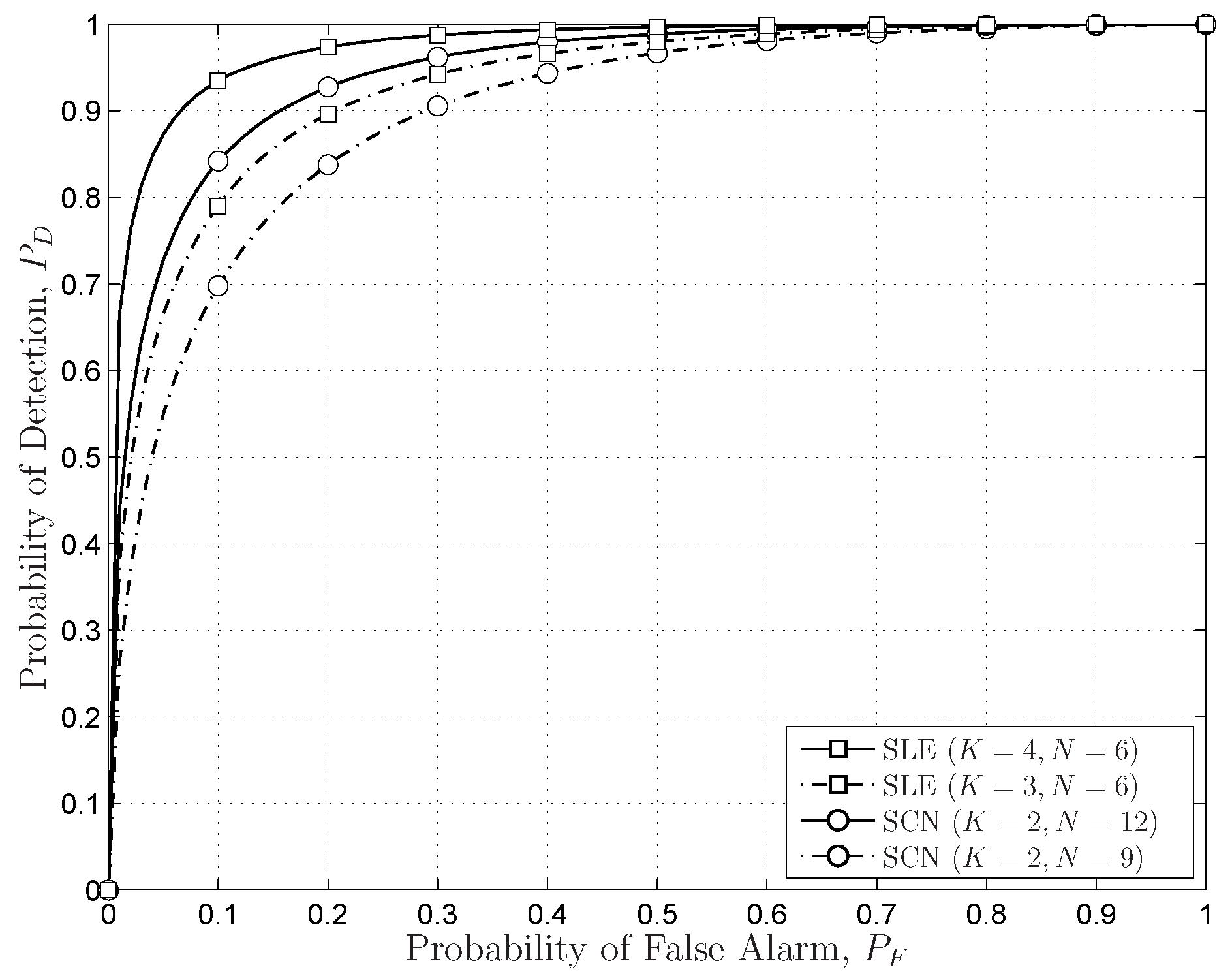
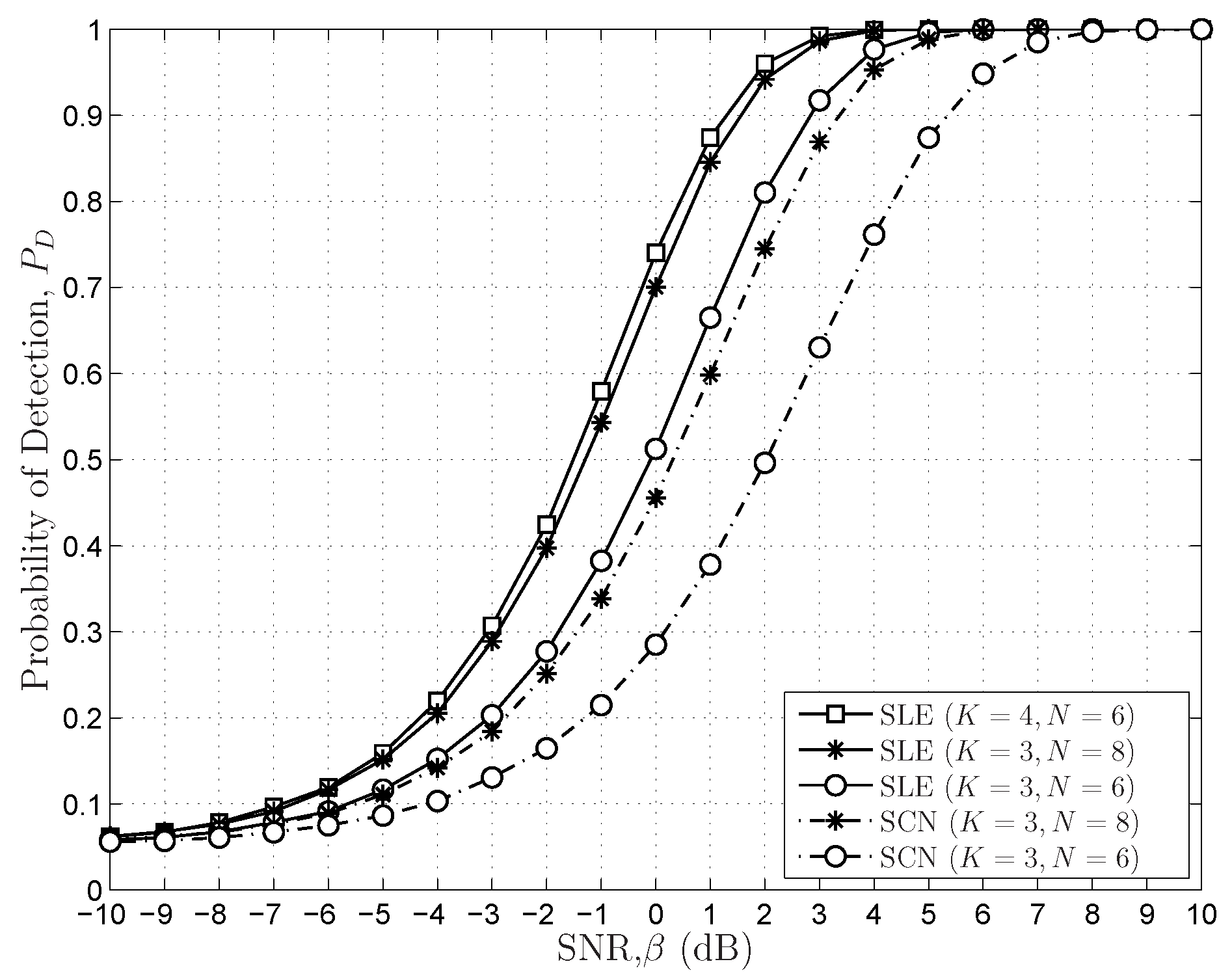
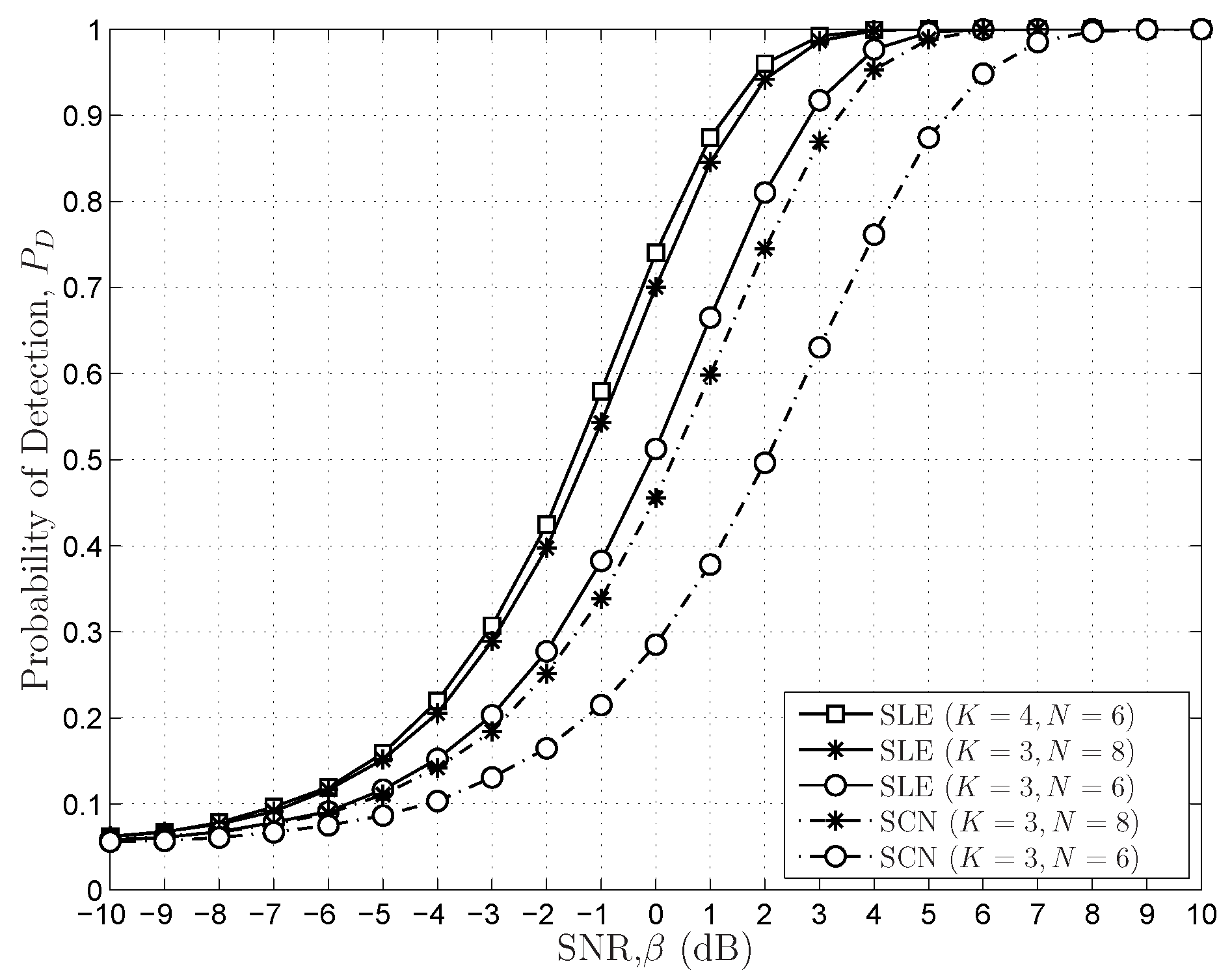
- The sensing performances of the FRMT-based SS schemes are analysed and evaluated. The asymptotical optimal SS schemes in the FRMT with varying dimensions are proposed. We demonstrate that the SLE-based scheme is asymptotically optimal when , and the SCN-based scheme possesses identical sensing performance with the SLE-based scheme when .
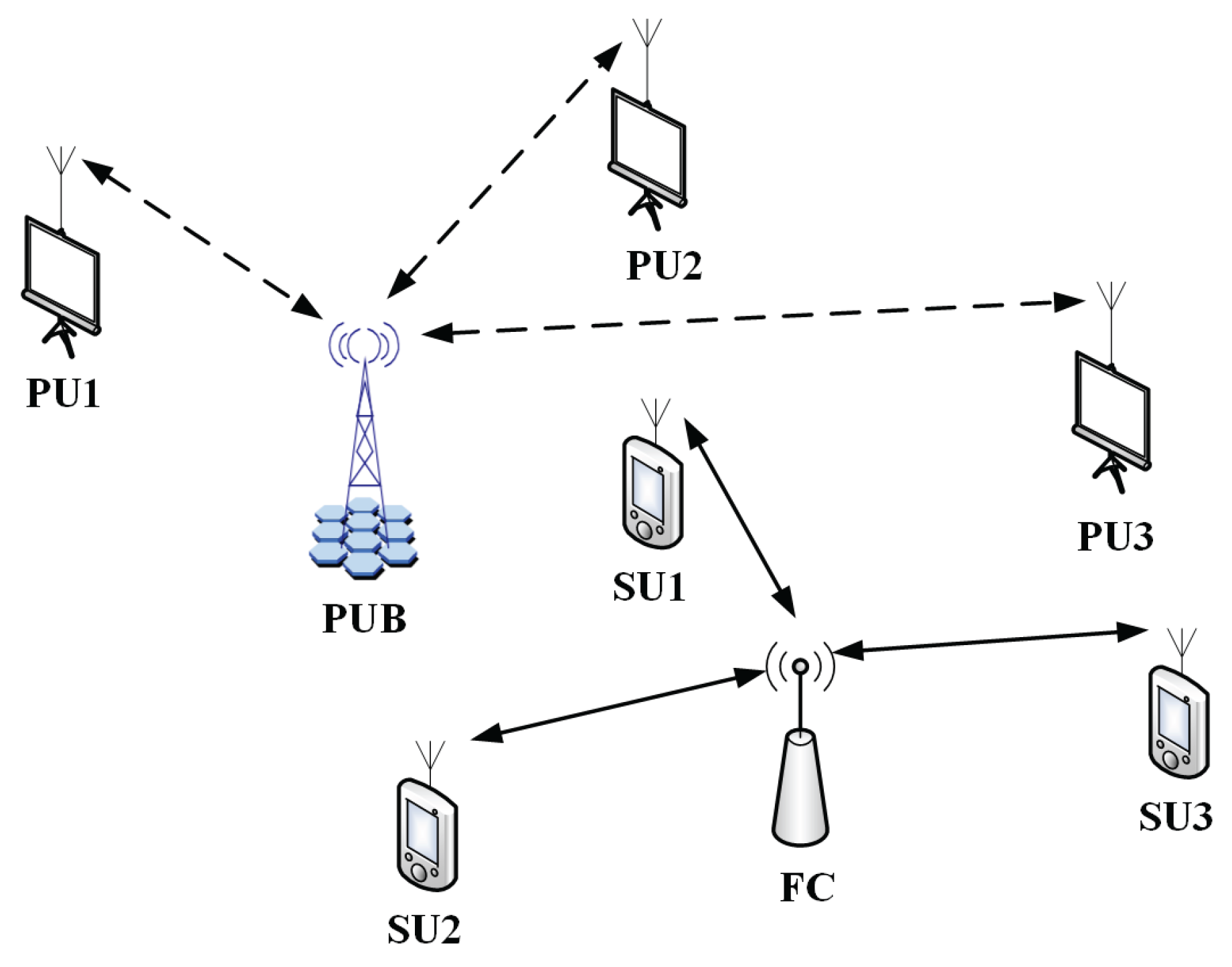
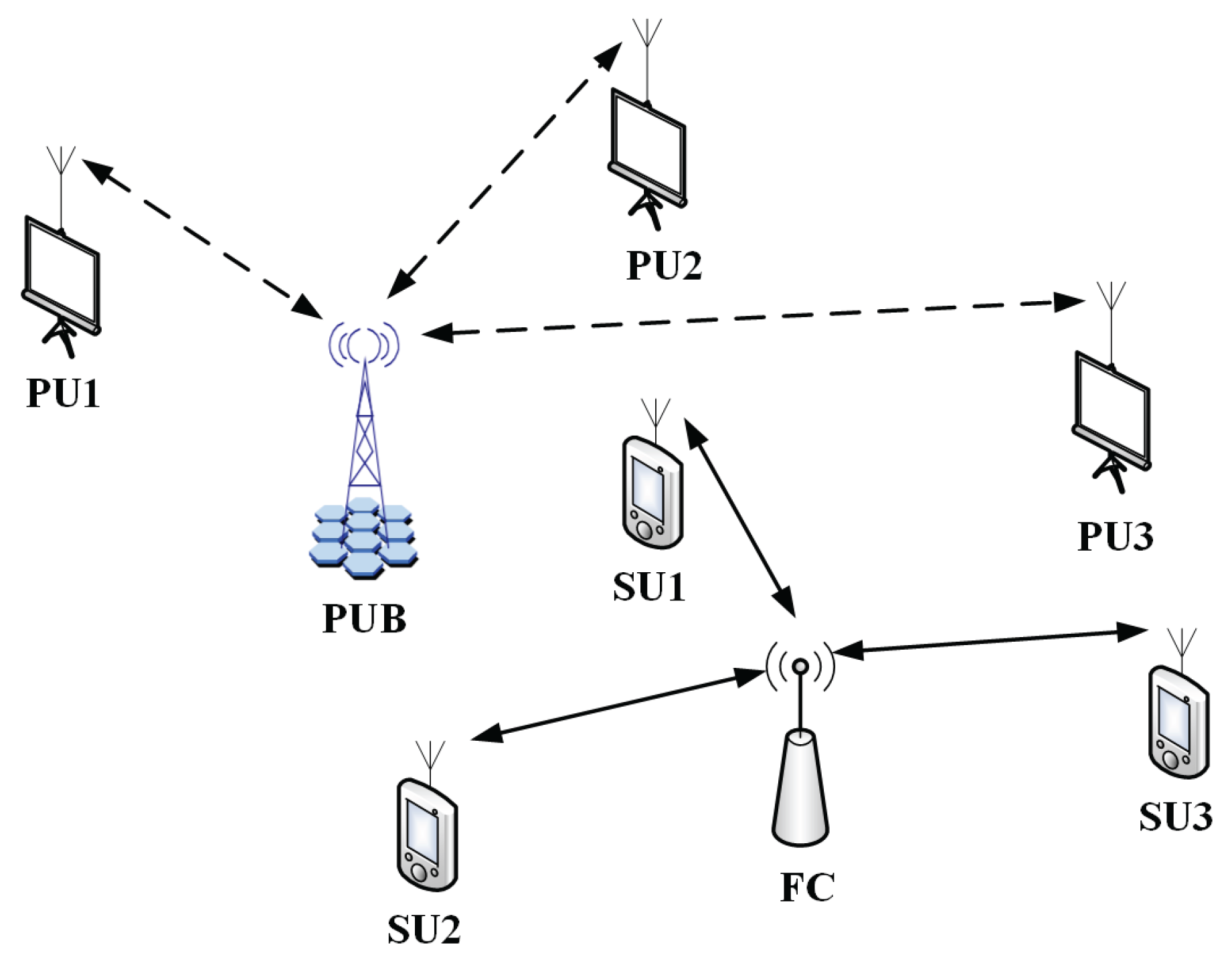
2. System Model
3. Asymptotic Distributions in the IRMT
3.1. Eigenvalue Distributions in the IRMT
3.1.1. General Eigenvalue Distributions in the IRMT
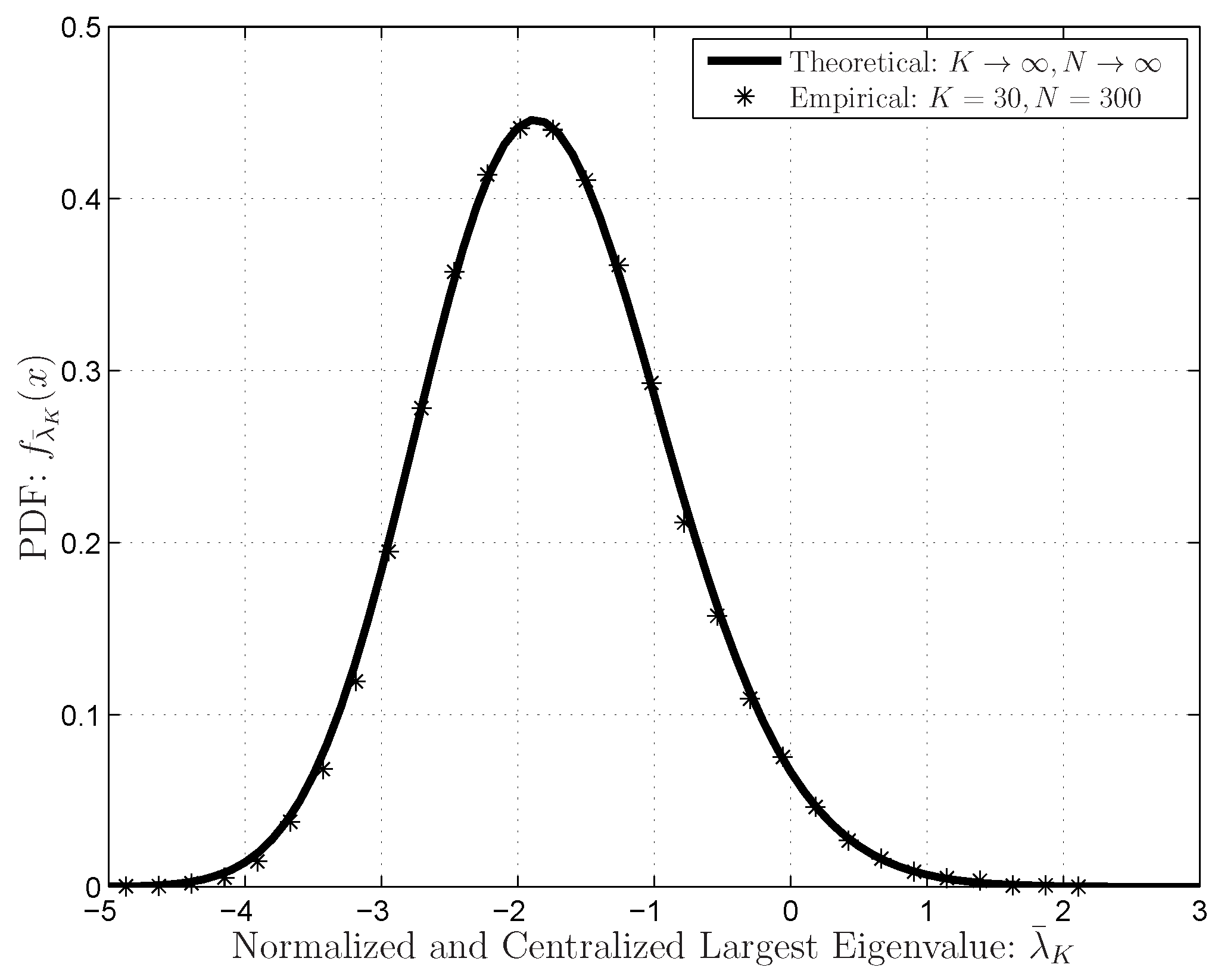
3.1.2. Extreme (Largest or Smallest) Eigenvalue Distributions in the IRMT
3.2. Standard Condition Number Distributions in the IRMT
3.3. Dimension Boundary between the IRMT and the FRMT
4. Exact Distributions in the FRMT
4.1. Eigenvalue Distributions in the FRMT
4.2. Extreme (Largest or Smallest) Eigenvalue Distributions in the FRMT

4.3. Condition Number Distributions in the FRMT
4.3.1. Standard Condition Number
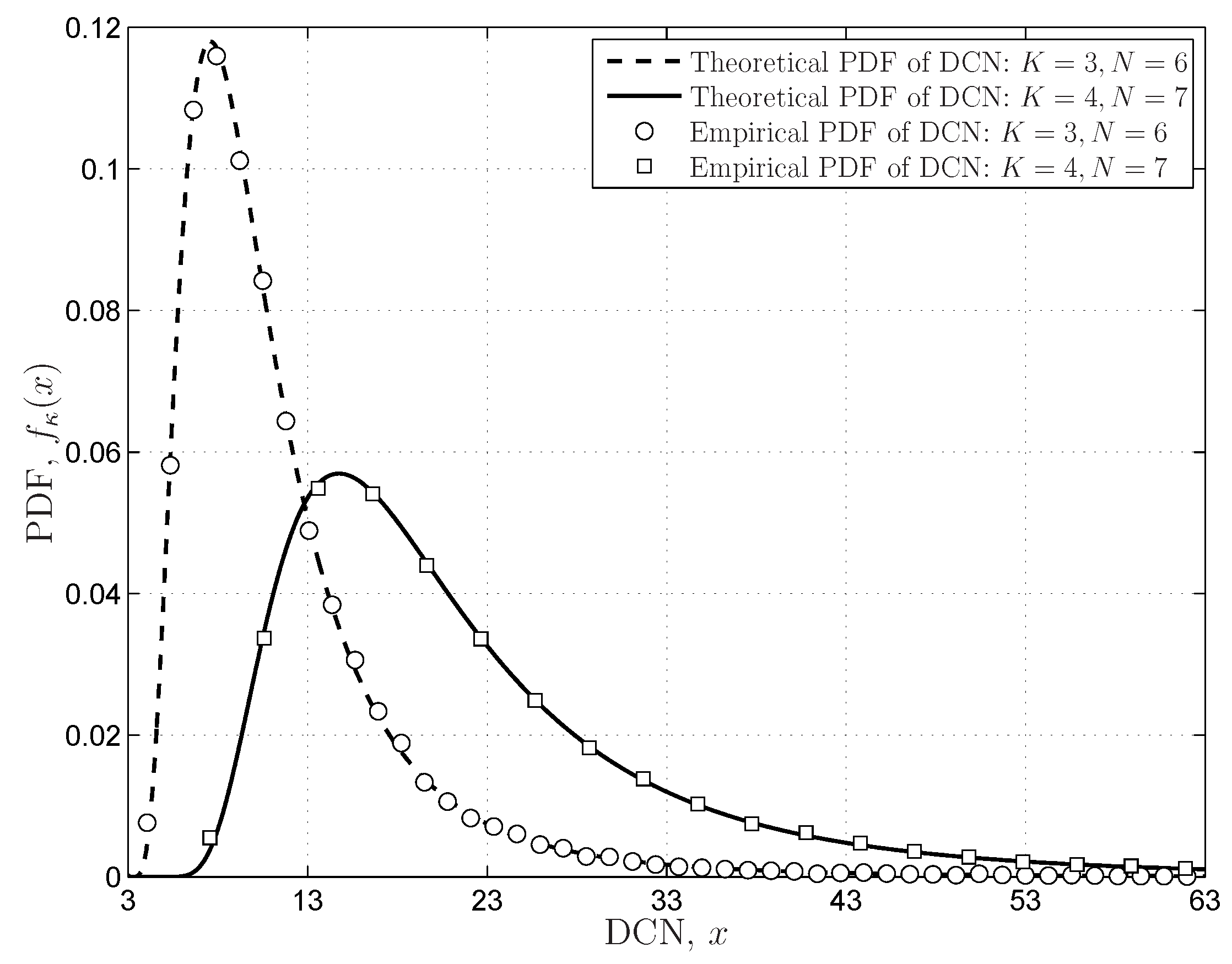
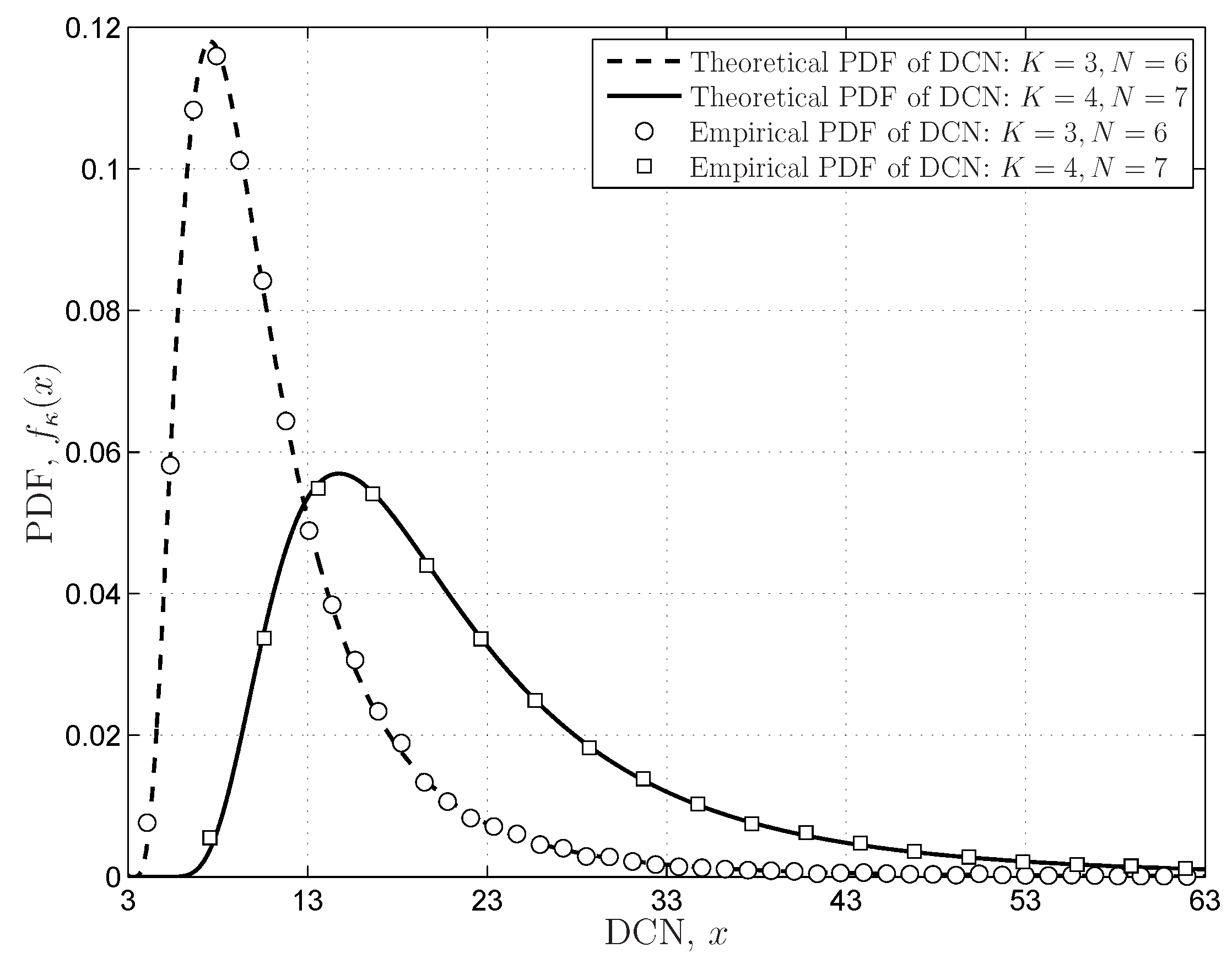
4.3.2. Demmel Condition Number
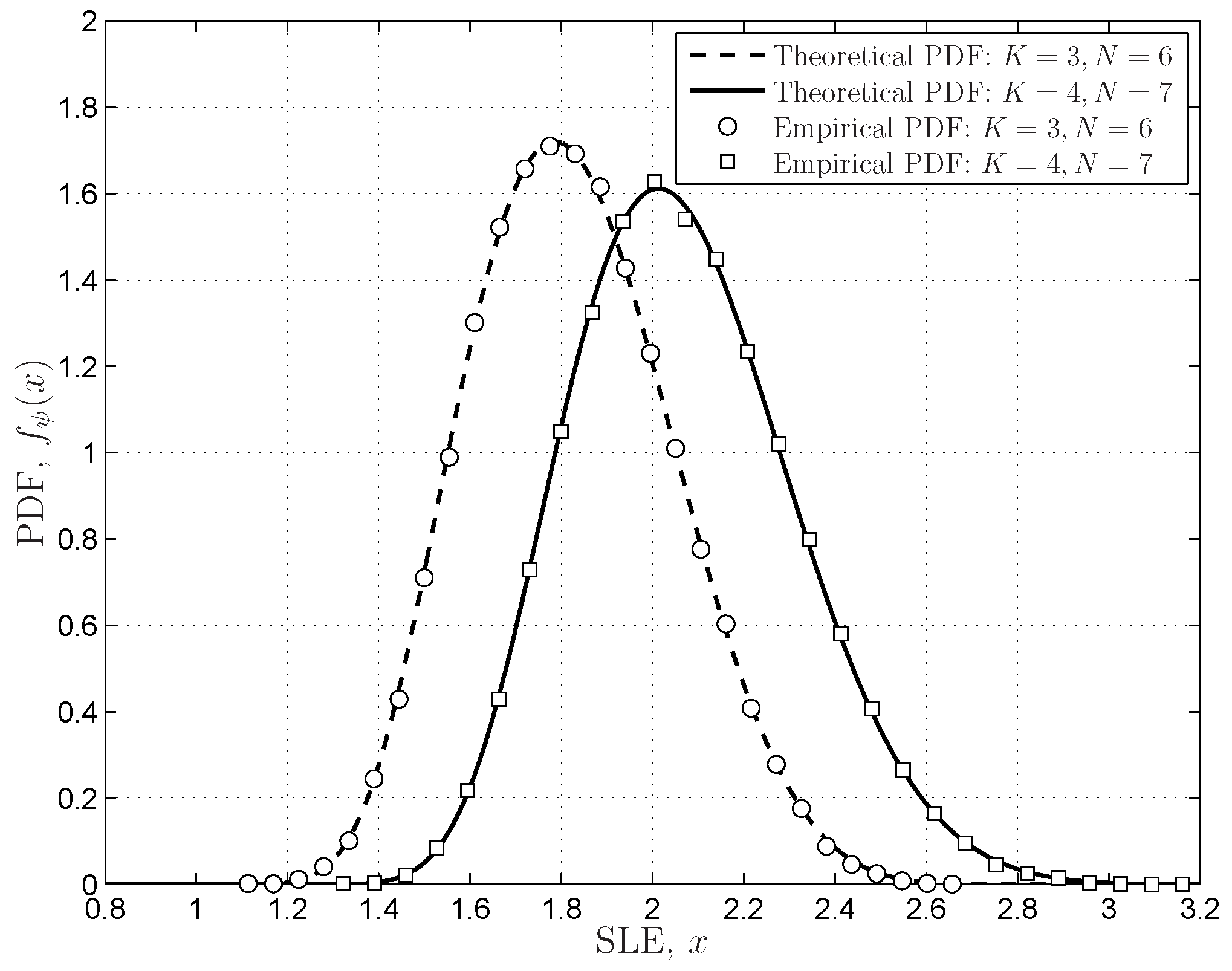
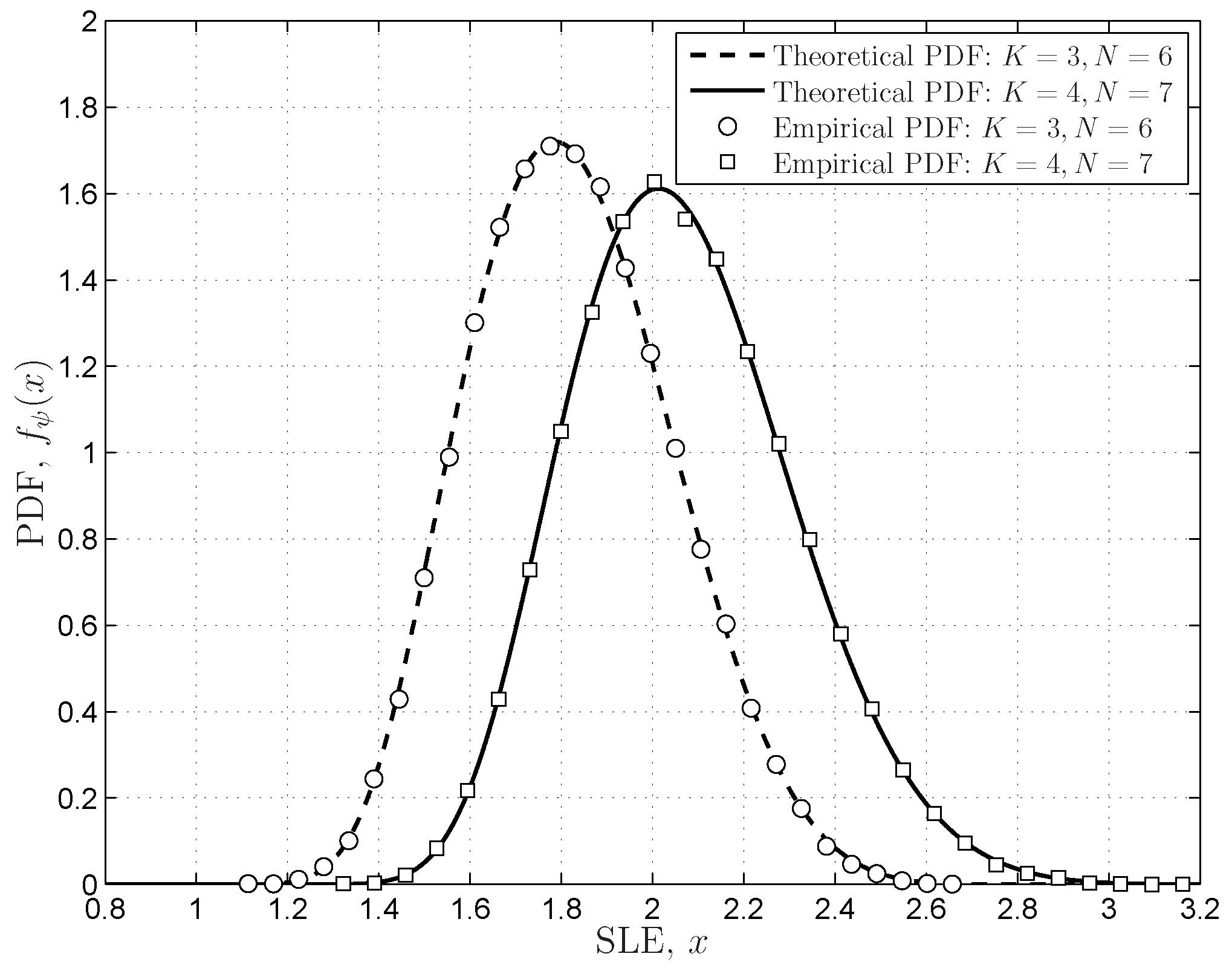
4.3.3. Scaled Largest Eigenvalue
5. SS Schemes Based on the FRMT
5.1. SS Schemes Based on Asymptotic GLRT
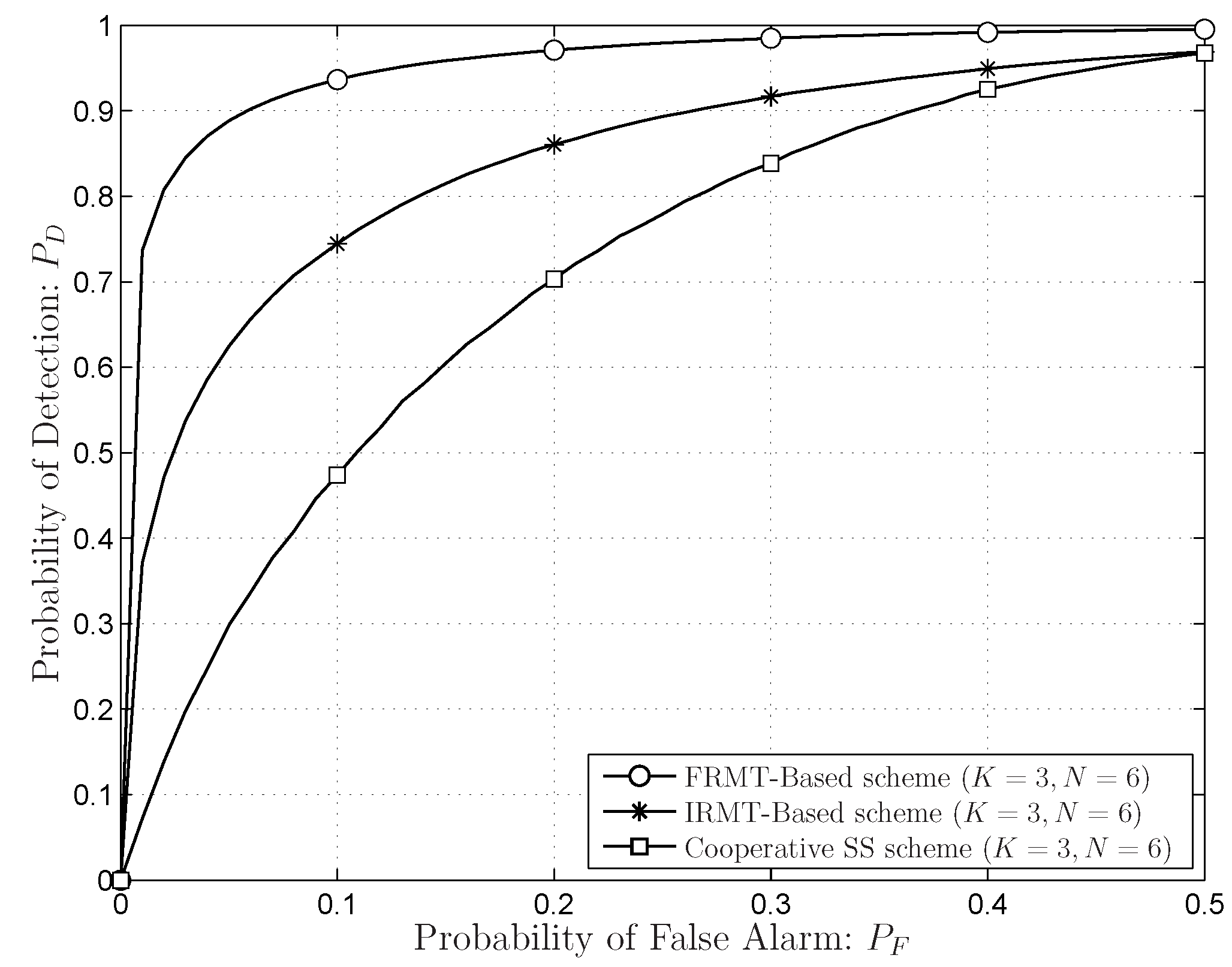
5.2. FRMT-Based SS Schemes
- Given the (), based on the CDF of ξ in Equation (33), the corresponding thresholds are generated by .
- Construct the sample matrix with PU samples from K sensors, each gathering N samples.
- Construct the covariance matrix ; calculate K ordered eigenvalues ; and let the SCN ξ denote the sensor T, that is .
- Compare T to the required threshold γ, and record the result if ; otherwise, .
- Repeat the above operations C times, , and evaluate the sensing performance by .
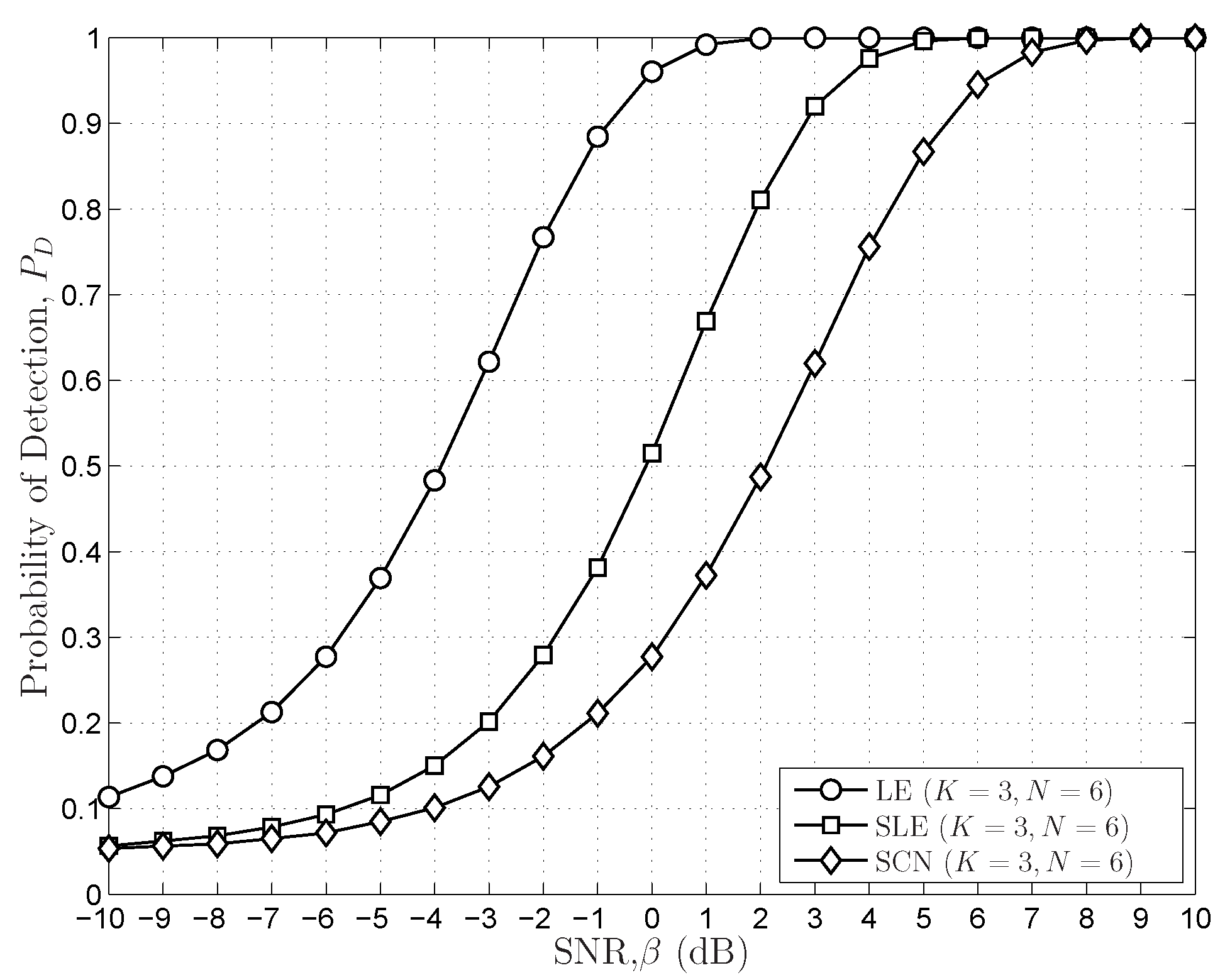
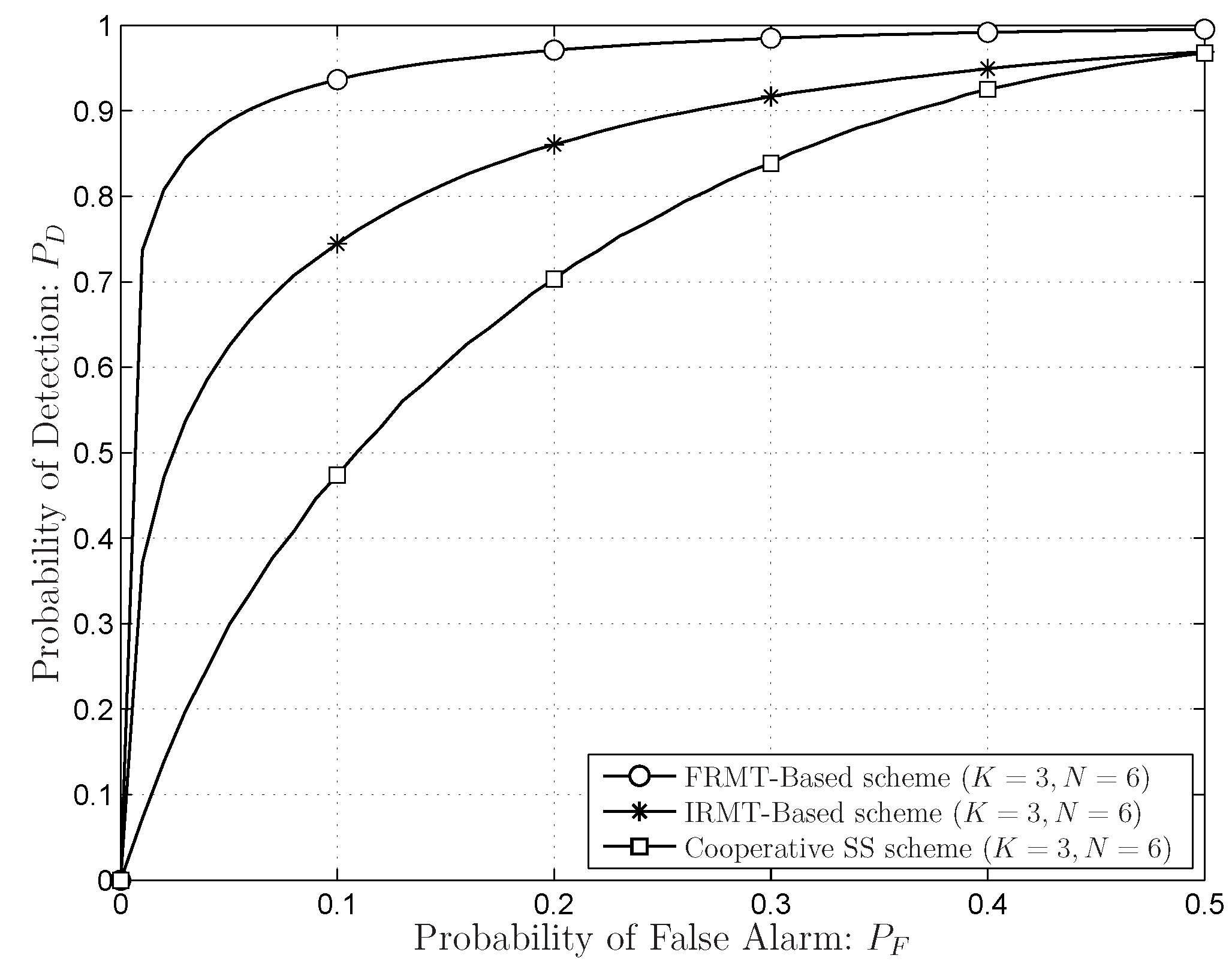
- Compared to the SS schemes based on the SCN or the DCN, all eigenvalue information under the hypothesis are included;
- The compact and closed-form distributions of the SLE in the FRMT are available, and the exact thresholds can be generated.
6. Numerical Results and Analysis
6.1. Theoretical Results’ Verifications
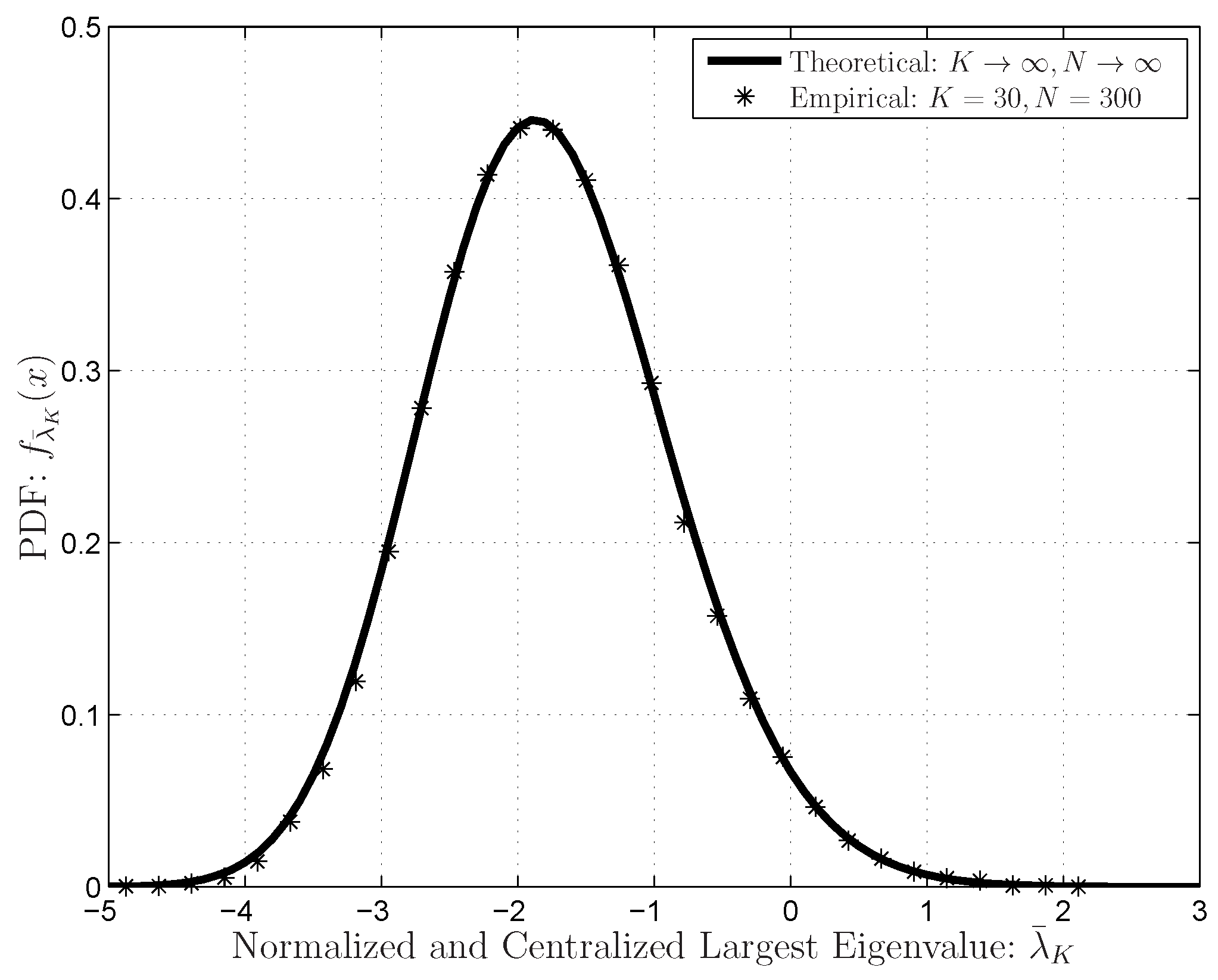
6.1.1. IRMT Verifications
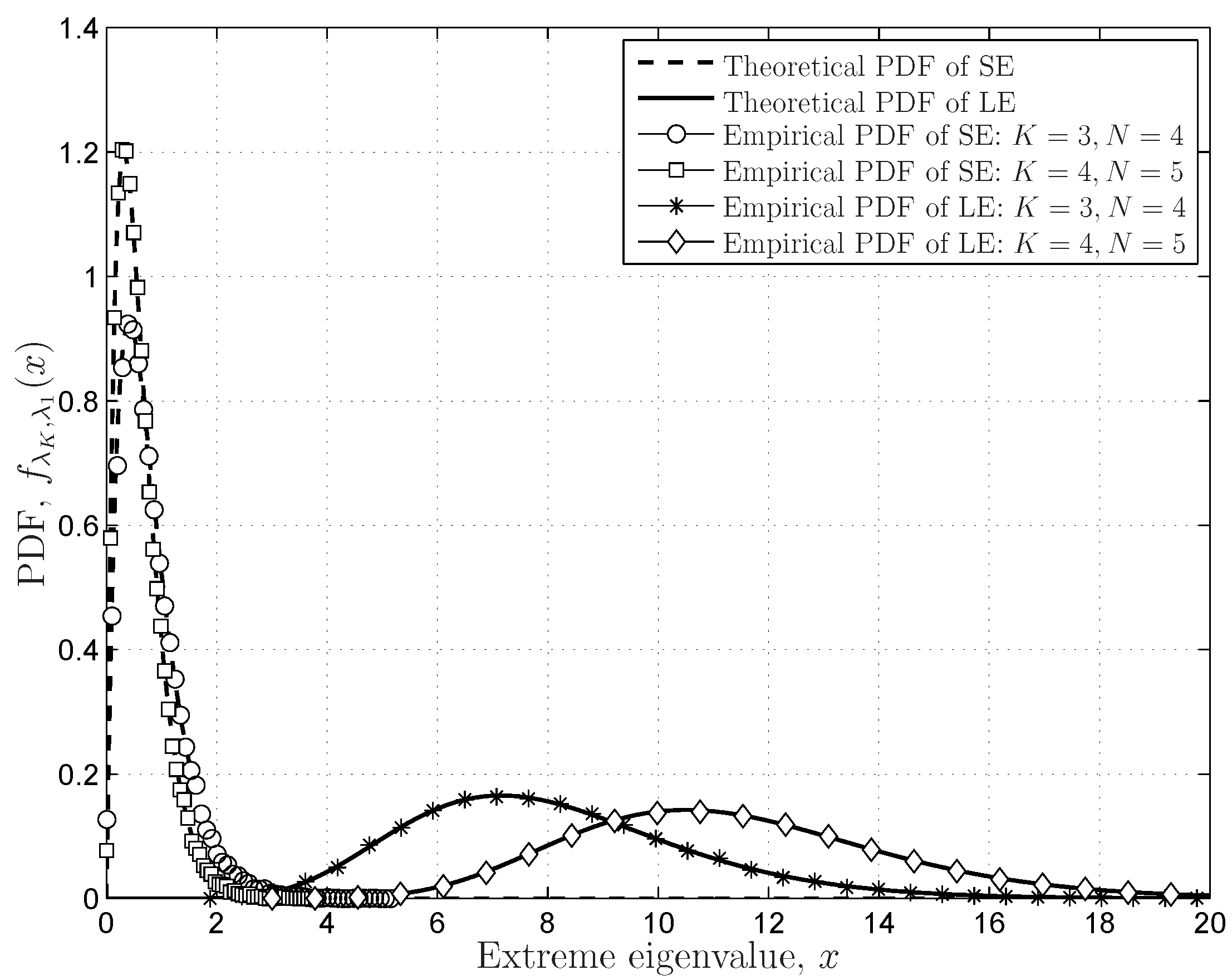
6.1.2. FRMT Verifications
6.2. Simulations Results for Sensing Performances
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
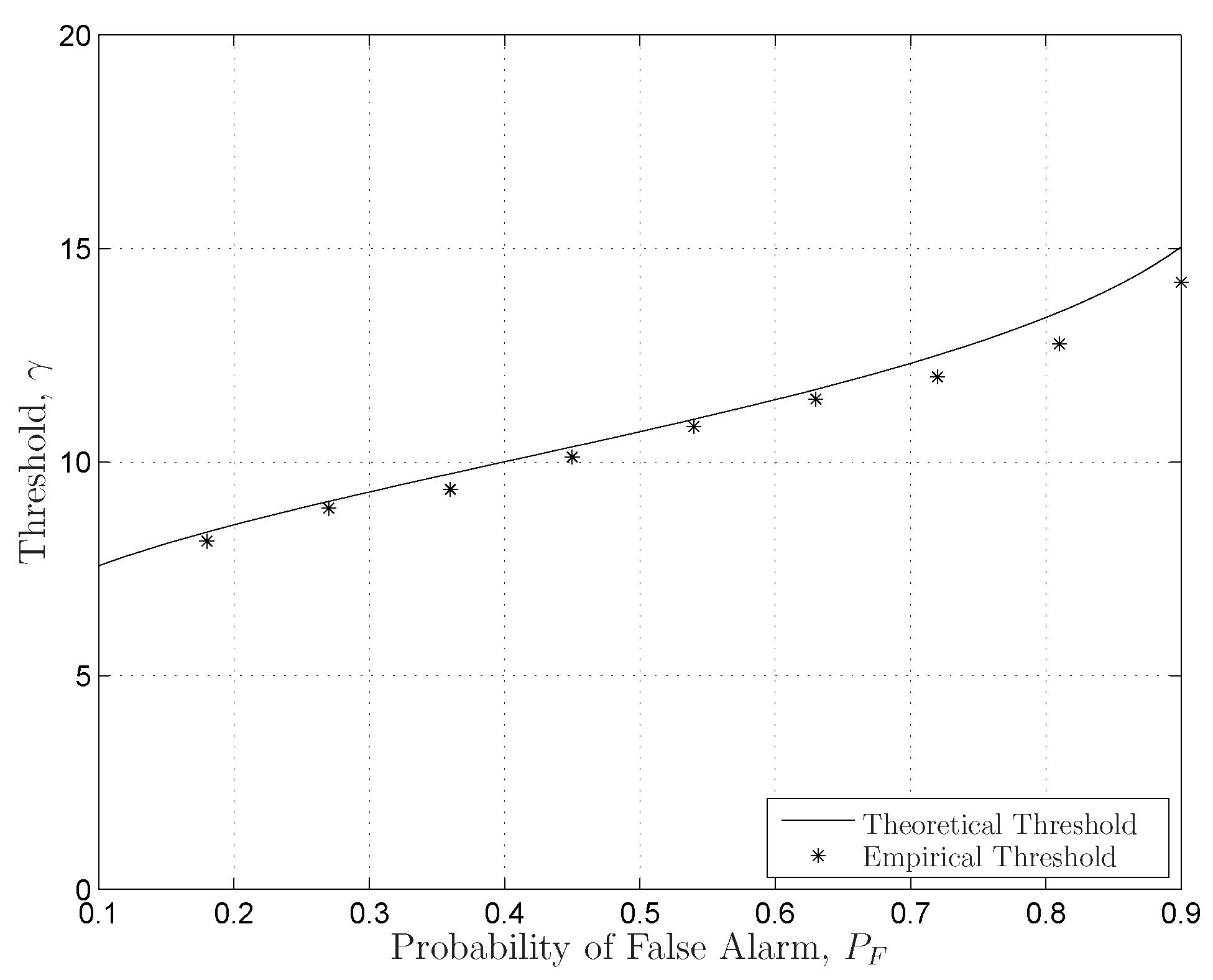{kind=link}
| N = 3 | N = 4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| −3 | −6 | 6 | −2 | 6 | −8 | −1 | 0 | |||
| −6 | 6 | −3 | −1 | −12 | 4 | 1 | −1 | |||
| 3 | 0 | 0 | 0 | 0 | 6 | 4 | 0 | 0 | 0 | |
| N = 5 | ||||||||||
| 5 | −5 | 2 | 0 | 0 | ||||||
| −10 | 0 | 1 | 0 | 0 | ||||||
| 5 | 5 | 2 | 0 | 0 | ||||||
| N = 6 | ||||||||||
| −2 | 0 | 0 | 0 | |||||||
| −5 | −1 | |||||||||
| 3 | 0 | |||||||||
| N= 3 | N= 4 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| −3 | 0 | −3 | 1 | −3 | −3 | 0 | |||||
| 3 | 0 | 3 | 1 | 3 | 6 | 0 | |||||
| −1 | 0 | 0 | 0 | 0 | −1 | −3 | 0 | 0 | 0 | ||
| N = 5 | |||||||||||
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||
| −3 | −3 | 0 | 0 | ||||||||
| 3 | 6 | 6 | |||||||||
| −1 | −3 | 0 | 0 | ||||||||
| N = 6 | |||||||||||
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| −3 | −3 | 0 | 0 | 0 | |||||||
| 3 | 6 | 6 | 4 | ||||||||
| −1 | −3 | 0 | |||||||||
Appendix B
| Coefficient Matrices p | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| N = 3 | N = 4 | N = 5 | |||||||
| 3 | 6 | 4 | 5 | 5 | 2 | ||||
| N = 6 | |||||||||
| 3 | |||||||||
| Coefficient Matrices c | |||||||||
| N = 3 | N = 4 | ||||||||
| −1 | −1 | −3 | |||||||
| N = 5 | |||||||||
| −1 | −3 | ||||||||
| N = 6 | |||||||||
| −1 | −3 | ||||||||
References
- Haykin, S. Cognitive radio: Brain-empowered wireless communications. IEEE J. Select. Areas Commun. 2005, 23, 201–220. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Lee, W.-Y.; Vuran, M.C.; Mohanty, S. Next generation/dynamic spectrum access/cognitive radio wireless networks: A survey. Comput. Netw. J. 2006, 50, 2127–2159. [Google Scholar] [CrossRef]
- Hong, X.; Wang, J.; Wang, C.-X.; Shi, J. Cognitive radio in 5g: A perspective on energy-spectral efficiency trade-off. IEEE Commun. Mag. 2014, 52, 46–53. [Google Scholar]
- Yücek, T.; Arslan, H. A survey of spectrum sensing algorithms for cognitive radio applications. IEEE Commun. Surv. Tutor. 2009, 11, 116–130. [Google Scholar]
- Sun, H.; Nallanathan, A.; Wang, C.-X.; Chen, Y. Wideband spectrum sensing for cognitive radio networks: A survey. IEEE Wirel. Commun. 2013, 20, 74–81. [Google Scholar]
- Tulino, A.M.; Verdu, S. Random Matrix Theory and Wireless Communications; Now Publishers Inc.: Hanover, MA, USA, 2004; pp. 1–182. [Google Scholar]
- Couillet, R.; Debbah, M. Random Matrix Methods for Wireless Communications; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Kang, M.; Alouini, M.-S. Largest eigenvalue of complex Wishart matrices and performance analysis of MIMO MRC systems. IEEE J. Select. Areas Commun. 2003, 21, 418–426. [Google Scholar]
- Matthaiou, M.; McKay, M.; Smith, P.; Nossek, J. On the condition number distribution of complex wishart matrices. IEEE Trans. Commun. 2010, 58, 1705–1717. [Google Scholar]
- Zanella, A.; Chiani, M.; Win, M. On the marginal distribution of the eigenvalues of wishart matrices. IEEE Trans. Commun. 2010, 57, 1050–1060. [Google Scholar]
- Jin, S.; McKay, M.; Gao, X.; Collings, I. MIMO multichannel beamforming: SER and outage using new eigenvalue distributions of complex noncentral wishart matrices. IEEE Trans. Commun. 2010, 56, 424–434. [Google Scholar]
- Edelman, A. Eigenvalues and Condition Numbers of Random Matrices. Ph.D. Thesis, MIT, Cambridge, MA, USA, May 1989. [Google Scholar]
- Baik, J.; Silverstein, J.W. Eigenvalues of large sample covariance matrices of spiked population models. J. Multivar. Anal. 2006, 97, 1382–1408. [Google Scholar]
- Bai, Z.; Silverstein, J.W. Spectral Analysis of Large Dimensional Random Matrices; Springer: New York, NY, USA, 2010. [Google Scholar]
- Marchenko, V.A.; Pastur, L.A. Distributions of eigenvalues for some sets of random matrices. Math. USSR Sb. 1967, 1, 457–483. [Google Scholar]
- Tracy, C.; Widom, H. On orthogonal and sympletic matrix ensembles. Commun. Math. Phys. 1996, 177, 727–754. [Google Scholar]
- Abreu, G.; Zhang, W.; Sanada, Y. Finite random matrices for blind spectrum sensing. In Proceedings of the Forty Fourth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 7–10 November 2010; pp. 116–120.
- Kortun, A.; Ratnarajah, T.; Sellathurai, M.; Liang, Y.; Zeng, Y. On the eigenvalue-based spectrum sensing and secondary user throughput. IEEE Trans. Veh. Technol. 2014, 63, 1480–1486. [Google Scholar]
- Huang, L.; Fang, J.; Liu, K.; So, H.; Li, H. An eigenvalue-moment-ratio approach to blind spectrum sensing for cognitive radio under sample-starving environment. IEEE Trans. Veh. Technol. 2015, 64, 3465–3480. [Google Scholar]
- Dighe, P.; Mallik, R.; Jamuar, S. Analysis of transmit-receive diversity in rayleigh fading. IEEE Trans. Commun. 2003, 51, 694–703. [Google Scholar]
- Park, C.S.; Lee, K.B. Statistical multimode transmit antenna selection for limited feedback MIMO systems. IEEE Trans. Wirel. Commun. 2008, 7, 4432–4438. [Google Scholar]
- Wei, L.; Tirkkonen, O. Analysis of scaled largest eigenvalue based detection for spectrum sensing. In Proceedings of the IEEE International Conference on Communications (ICC), Kyoto, Japan, 5–9 June 2011; pp. 1–5.
- Wei, L.; Tirkkonen, O.; Dharmawansa, K.D.P.; McKay, M.R. On the exact distribution of the scaled largest eigenvalue. In Proceedings of the IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 2422–2426.
- Kortun, A.; Sellathurai, M.; Ratnarajah, T.; Zhong, C. Distribution of the ratio of the largest eigenvalue to the trace of complex wishart matrices. IEEE Trans. Signal Process. 2012, 60, 5527–5532. [Google Scholar]
- Abreu, G.; Zhang, W. Extreme eigenvalue distributions of finite random wishart matrices with application to spectrum sensing. In Proceedings of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2004; pp. 772–776.
- Cabric, D.; Mishra, S.; Brodersen, R. Implementation issues in spectrum sensing for cognitive radios. In Proceedings of the Thirty Eighth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 7–10 November 2004; pp. 772–776.
- Unnikrishnan, J.; Veeravalli, V. Cooperative sensing for primary detection in cognitive radio. IEEE J. Sel. Areas Commun. 2008, 21, 418–426. [Google Scholar]
- Li, Z.; Yu, F.; Huan, M. A cooperative spectrum sensing consensus scheme in cognitive radios. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 2546–2550.
- Ding, G.; Wang, J.; Wu, Q.; Zhang, L.; Zou, Y.; Yao, Y.; Chen, Y. Robust spectrum sensing with crowd sensors. IEEE J. Select. Areas Commun. 2014, 62, 3129–3143. [Google Scholar]
- Huang, X.; Hu, F.; Chen, H.; Wang, G.; Jiang, T. Intelligent cooperative spectrum sensing via hierarchical Dirichlet process in cognitive radio networks. IEEE J. Select. Areas Commun. 2015, 33, 771–787. [Google Scholar]
- Zhang, Z.; Zhang, W.; Zeadally, S.; Wang, Y.; Liu, Y. Cognitive radio spectrum sensing framework based on multi-agent architecture for 5G networks. IEEE Wirel. Commun. 2015, 22, 34–39. [Google Scholar]
- Cardoso, L.S.; Debbah, M.; Bianchi, P.; Najim, J. Cooperative spectrum sensing using random matrix theory. In Proceedings of the 3rd International Symposium on Wireless Pervasive Computing (ISWPC), Santorini, Greece, 7–9 May 2008; pp. 334–338.
- Zeng, Y.; Liang, Y.-C. Eigenvalue-based sectrum sensing algorithms for cognitive radio. IEEE Trans. Wirel. Commun. 2009, 57, 1784–1793. [Google Scholar]
- Penna, F.; Garello, R.; Spirito, M. Cooperative spectrum sensing based on the limiting eigenvalue ratio distribution in wishart matrices. IEEE Commun. Lett. 2009, 13, 507–509. [Google Scholar]
- Bianchi, P.; Debbah, M.; Maida, M.; Najim, J. Performance of statistical tests for single-source detection using random matrix theory. IEEE Trans. Inform. Theory 2011, 57, 2400–2419. [Google Scholar]
- Zhang, W.; Abreu, G.; Inamori, M.; Sanada, Y. Spectrum sensing algorithms via finite random matrices. IEEE Trans. Commun. 2012, 60, 164–175. [Google Scholar]
- Goldsmith, A.; Jafar, S.; Maric, I.; Srinivasa, S. Breaking spectrum gridlock with cognitive radios: An information theoretic perspective. Proc. IEEE 2009, 97, 894–914. [Google Scholar]
- Edelman, A. On the distribution of a scaled condition number. Math. Comput. 1992, 58, 185–190. [Google Scholar]
- Dieng, M. Distribution functions for edge eigenvalues in orthogonal and symplectic ensembles: Painlevé representations. Ph.D. Thesis, University of California, Davis, CA, USA, 2005. [Google Scholar]
- Curtiss, J.H. On the distribution of the quotient of two chance variables. Ann. Math. Statist. 1941, 12, 409–421. [Google Scholar]
- James, A.T. Distributions of matrix variates and latent roots derived from normal samples. Ann. Math. Statist. 1964, 35, 475–501. [Google Scholar]
- Wei, L.; McKay, M.; Tirkkonen, O. Exact demmel condition number distribution of complex wishart matrices via the mellin transform. IEEE Commun. Lett. 2011, 15, 175–177. [Google Scholar]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products, 7th ed.; Academic Press: Burlington, MA, USA, 2007. [Google Scholar]
- Nadler, B. On the distribution of the ratio of the largest eigenvalue to the trace of a wishart matrix. J. Multivar. Anal. 2011, 102, 363–371. [Google Scholar]
- Maaref, A.; Aissa, S. Closed-form expressions for the outage and ergodic Shannon capacity of MIMO MRC systems. IEEE Trans. Commun. 2005, 53, 1092–1095. [Google Scholar]
- Johnstone, M. On the distribution of the largest eigenvalue in principal components analysis. Ann. Stat. 2001, 29, 295–327. [Google Scholar]
- Zeitouni, O.; Ziv, J.; Merhav, N. When is the generalized likelihood ratio test optimal? IEEE Trans. Inform. Theory 1992, 38, 1597–1602. [Google Scholar]





| Variable | IRMT | FRMT | ||
|---|---|---|---|---|
| CDF | CDF | |||
| Largest Eigenvalue: | Equation (12) | Equation (13) | Equation (26) | Equation (27) |
| Smallest Eigenvalue: | Equation (12) | Equation (13) | Equation (30) | Equation (31) |
| SCN: ξ | Equation (18) | Equation (19) | Equation (32) a | Equation (33) a |
| DCN: κ | PDF of b | Equation (37) | Equation (38) | |
| SLE: ψ | no results c | Equation (42) | Equation (43) | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Wang, C.-X.; Tao, X.; Patcharamaneepakorn, P. Exact Distributions of Finite Random Matrices and Their Applications to Spectrum Sensing. Sensors 2016, 16, 1183. https://doi.org/10.3390/s16081183
Zhang W, Wang C-X, Tao X, Patcharamaneepakorn P. Exact Distributions of Finite Random Matrices and Their Applications to Spectrum Sensing. Sensors. 2016; 16(8):1183. https://doi.org/10.3390/s16081183
Chicago/Turabian StyleZhang, Wensheng, Cheng-Xiang Wang, Xiaofeng Tao, and Piya Patcharamaneepakorn. 2016. "Exact Distributions of Finite Random Matrices and Their Applications to Spectrum Sensing" Sensors 16, no. 8: 1183. https://doi.org/10.3390/s16081183