
Sensing Urban Patterns with Antenna Mappings: The Case of Santiago, Chile †

Abstract
:1. Introduction
- We present “Antenna Virtual Placement” (AVP), a method to geolocate mobile devices connected to network antennas, based on the technology and orientation of the antenna, and a post-processing using Voronoi tessellation. This method decouples the antennas from the cell towers, which is the common spatial unit in the literature.
- We present a method to estimate two important places for a person using a mobile device: home and work. This method works reliably with the information of one day, and has potential to improve accuracy by considering more days.
- We present a method to cluster areas of the city based on floating population patterns measured through mobile connectivity. We use crowdsourced information to explain and characterize those clusters according to land use.
2. Background
3. Methods
- Given a set of antennas A and a network event e for a device m in a CDR dataset D, estimate a geographical position based on the corresponding antenna a (Section 3.1).
- Given a designed zoning Z, and the set of geographical positions P estimated during a day for all mobile devices, estimate the home and work zones and for a mobile device in (Section 3.2).
- Given a designed zoning Z, and the CDR dataset D, estimate the set of land-usage clusters C, where each cluster c contains a set of zones . Then, characterize each according to the Points of Interest (POIs) located in those zones (Section 3.3).
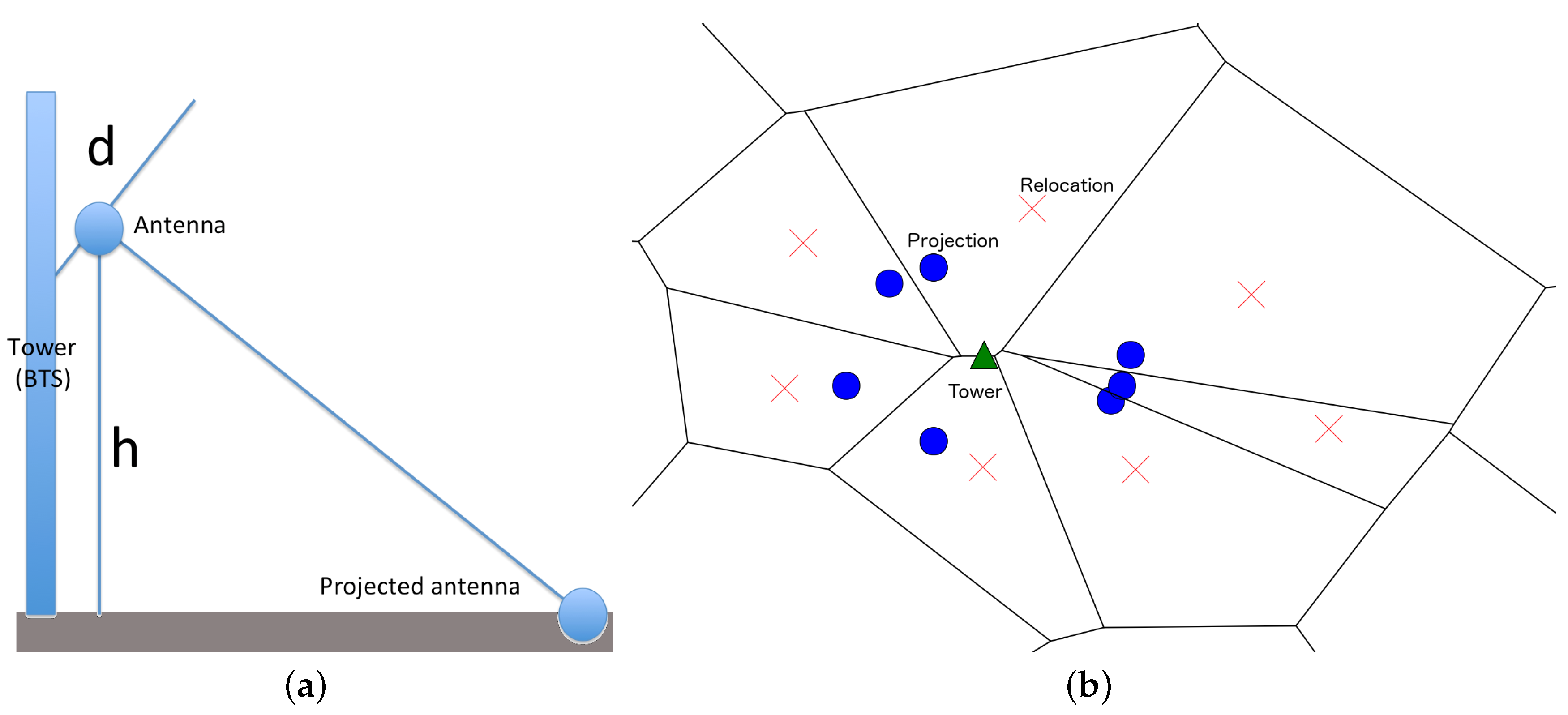
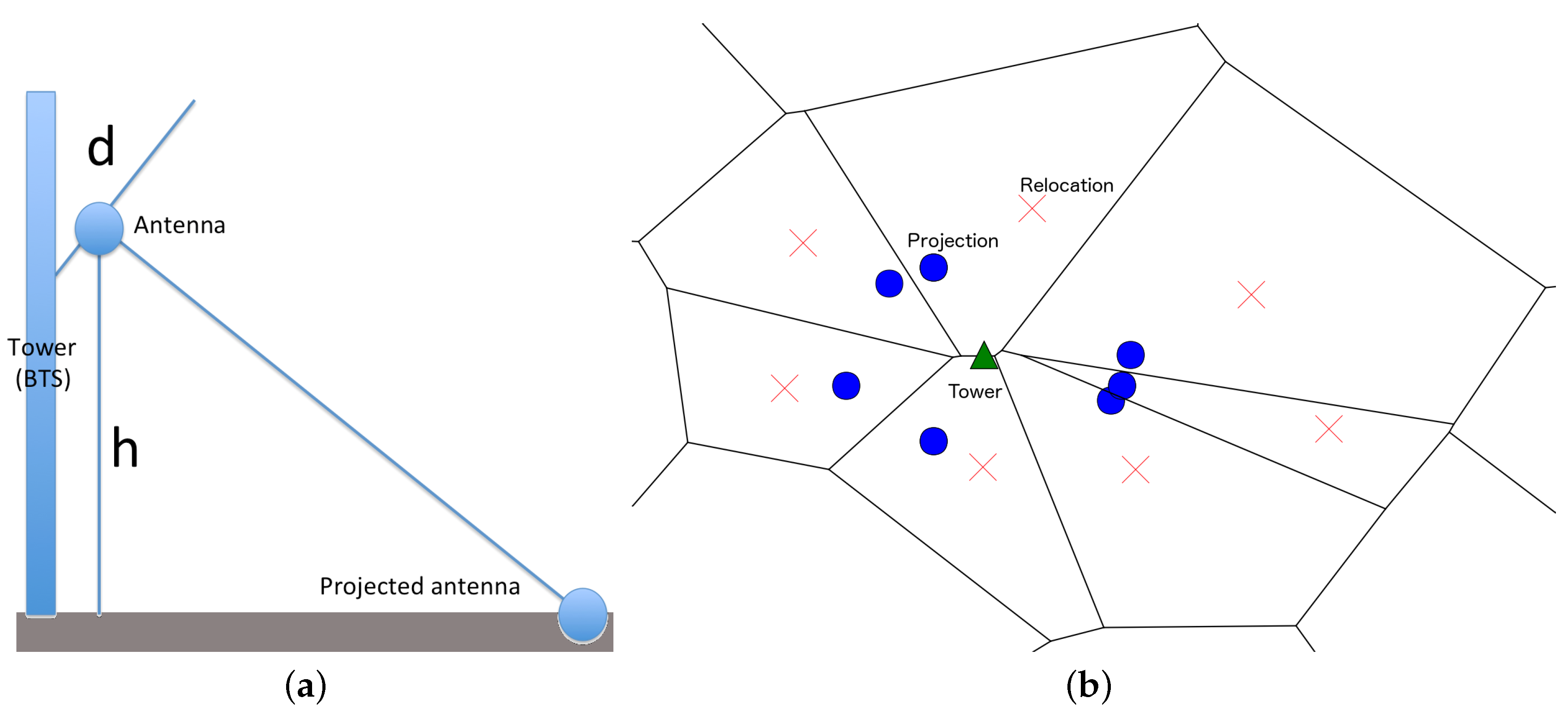
3.1. Antenna Virtual Placement
- Define the set of antennas A and towers , where each tower τ consists in a subset of antennas and a single antenna belongs to a unique tower. All antennas belonging to the same tower τ have the same geographical position of the tower, denoted . Using the same notation, we have for all .
- Obtain the projection of the antenna a, denoted , in the ground using the parameters with simple trigonometric rules. The projection will have the new position .
- Optionally, a relocation of the new positions can be obtained by moving the position to the centroid of the Voronoi polygon generated with the positions : . The relocated position is denoted Each position will belong to a unique Voronoi polygon, so the relocation can be viewed as a bijective map.
- For each network event e, where the active antenna is a, set the position of the mobile device m as .
3.2. Important Places at Individual Level
- Define time windows during the day that are likely to be related to home/work. For instance, to model home location we consider two time windows: one in the range 6:00 A.M. to 8:00 A.M., and one during 8:00 P.M. to 10:00 P.M.
- In all defined time windows, we weight network events using the exponential distribution:where x is the position of the network event in the time window, and the value of the parameter γ is determined according to the threshold given as confidence interval. If we consider a 95% interval, then , having N as the number of records under consideration. Thus, the sum of weights for all records in a given time window is always 1.
- For each mobile antenna a, we estimate as the sum of the weights of its corresponding records in a specific time window t.
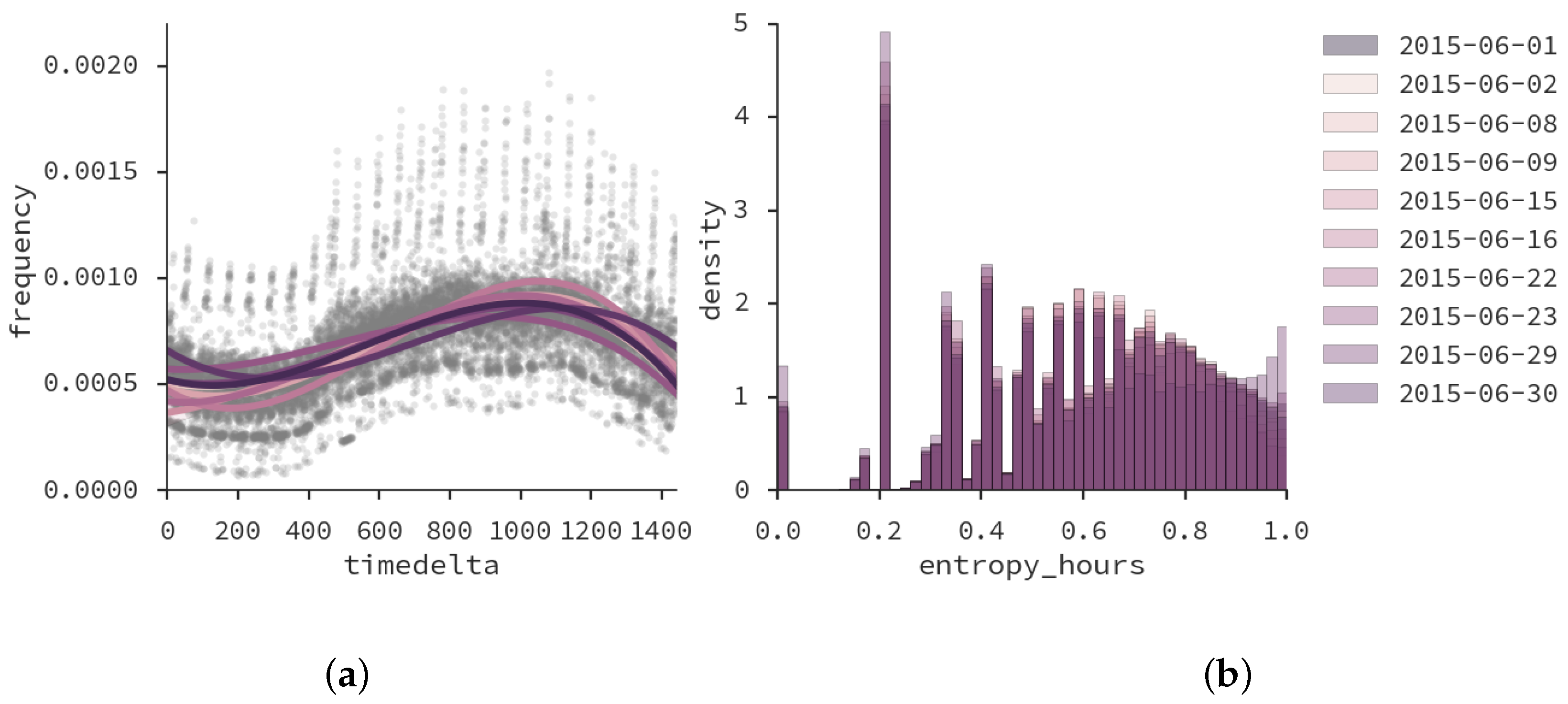
- To determine the regularity of citizen behavior in the different time windows, we use an intersection metric converted to a distance. To calculate this distance, we define a as an antenna and as its weight in the time window t:where A is the set of antennas. Note that d is 1 when there is no overlap or similarity between distributions, and 0 when all distributions are equal. Empirically, we have found that a is a good threshold for regularity.
- The device home/work locations are the weighted interpolations of the antenna positions (, estimated with AVP at Section 3.1) the mobile device was connected to in the corresponding time windows.
3.3. Determining Land-Usage Patterns
- We analyze network events at zone level. For each zone z (which may or not may be designed), we build a time-series :where M is the set of minutes of the day, starting from 00:00 and ending at 23:59, and is the number of mobile phones that generated network events at time t in the set of antennas assigned to zone z, using AVP (Section 3.1).
- For each time-series , we build a smoothed time-series using LOWESS (Locally Weighted Scatterplot Smoothing) interpolation. This allows us to smooth noise and drastic changes in the number of connections in consecutive intervals of time, as well as to interpolate the number of network events between minutes. This is needed because CDR data is sparse.
- To quantify how near (or similar) the time-series are we build a pairwise distance matrix M. Each element contains the correlation distance (as in [25]) between time-series u and v, defined as follows:where is the mean of the value of time-series u, and is the dot product between time-series x and y.
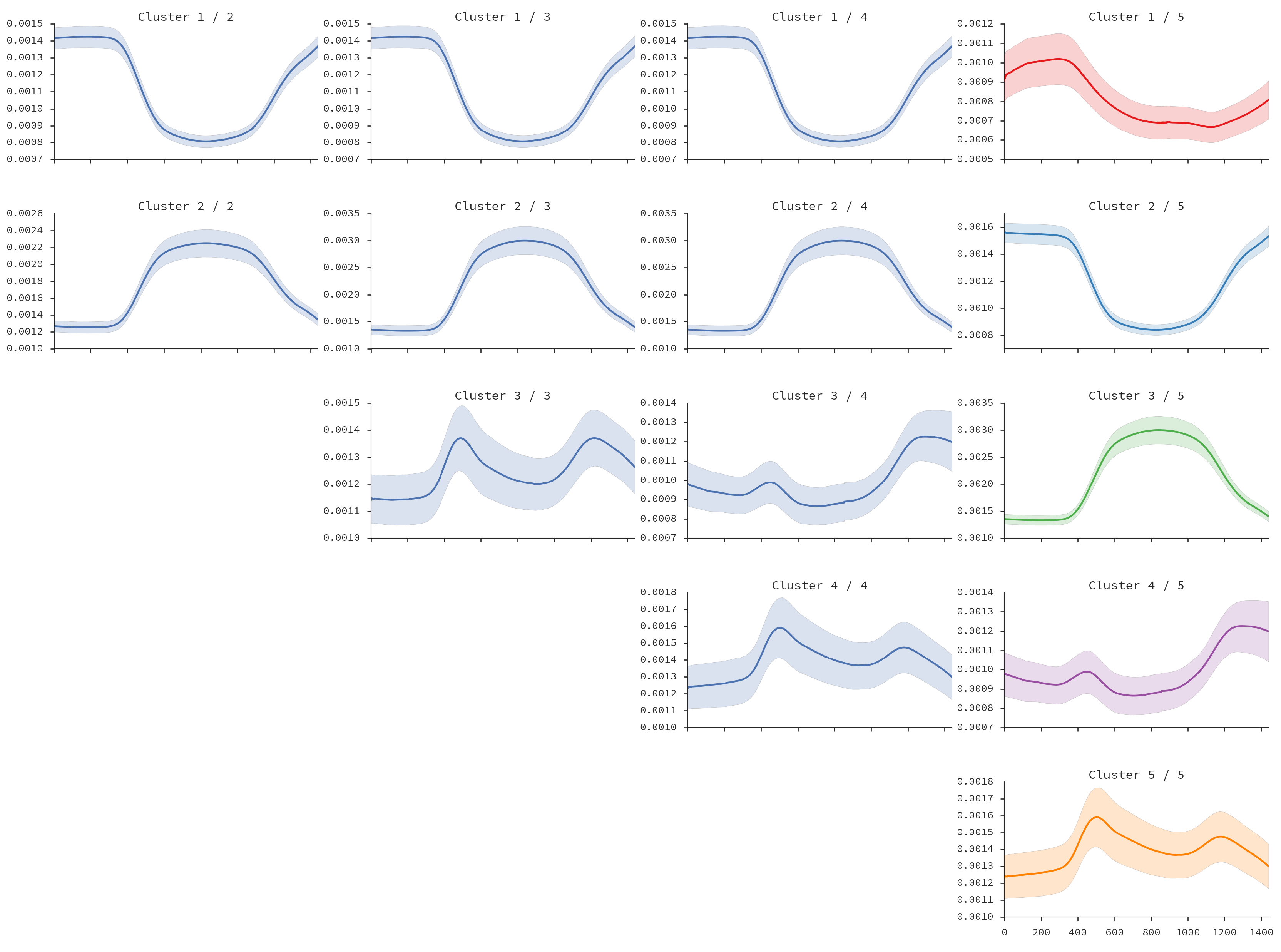
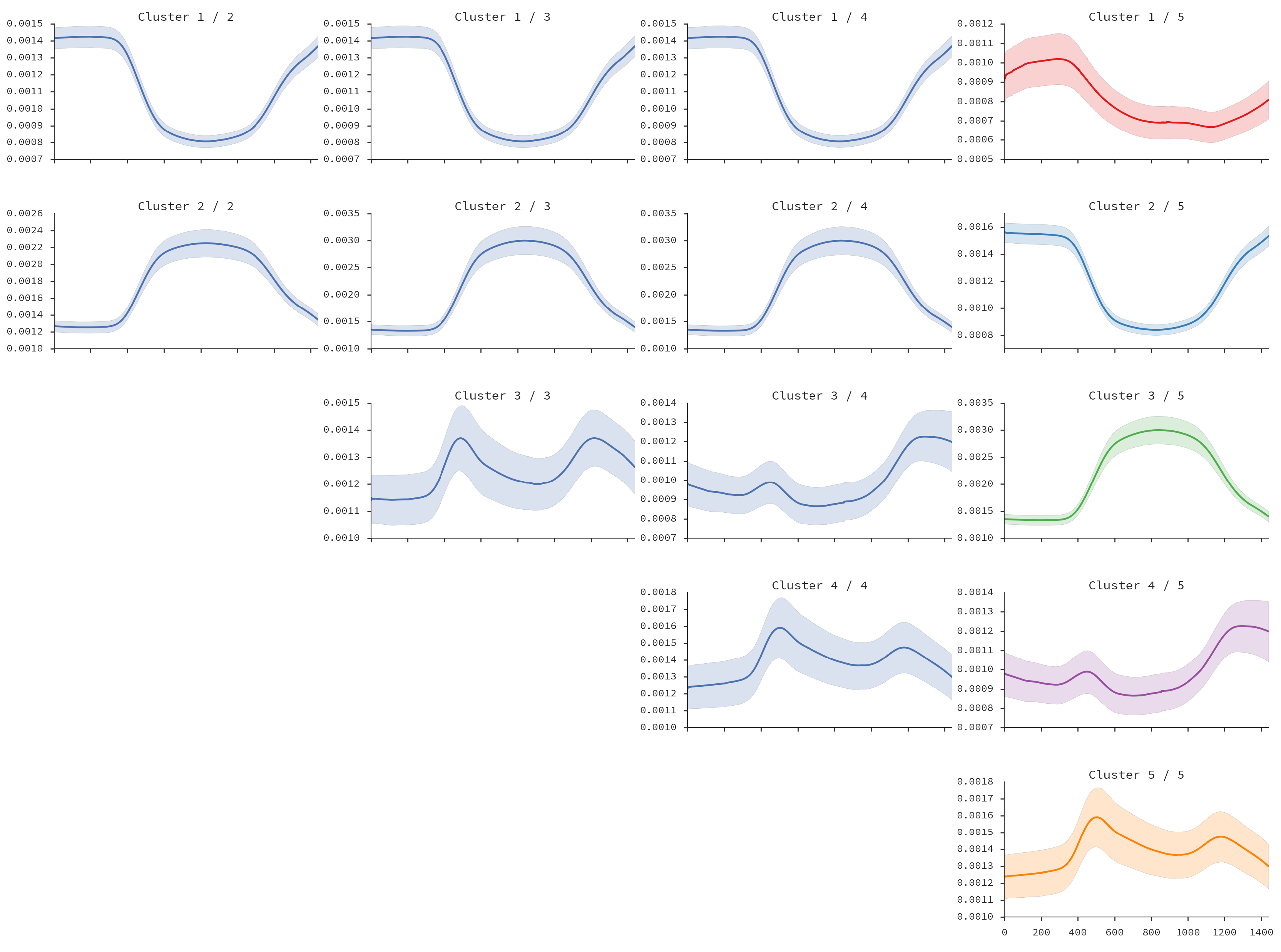
- Having the pairwise distance matrix between all smoothed zone time-series, we estimate agglomerative clustering using Ward variance minimization [27]. As result, we have a dendrogram of locations.
- We flatten the dendrogram of locations. If the number of desired clusters is known, the flattening can be performed based on cophenetic distance [42] between locations. This distance is the height of the dendrogram where the corresponding location branches merge into a single branch.
4. Materials
4.1. Santiago 2012 Travel Survey
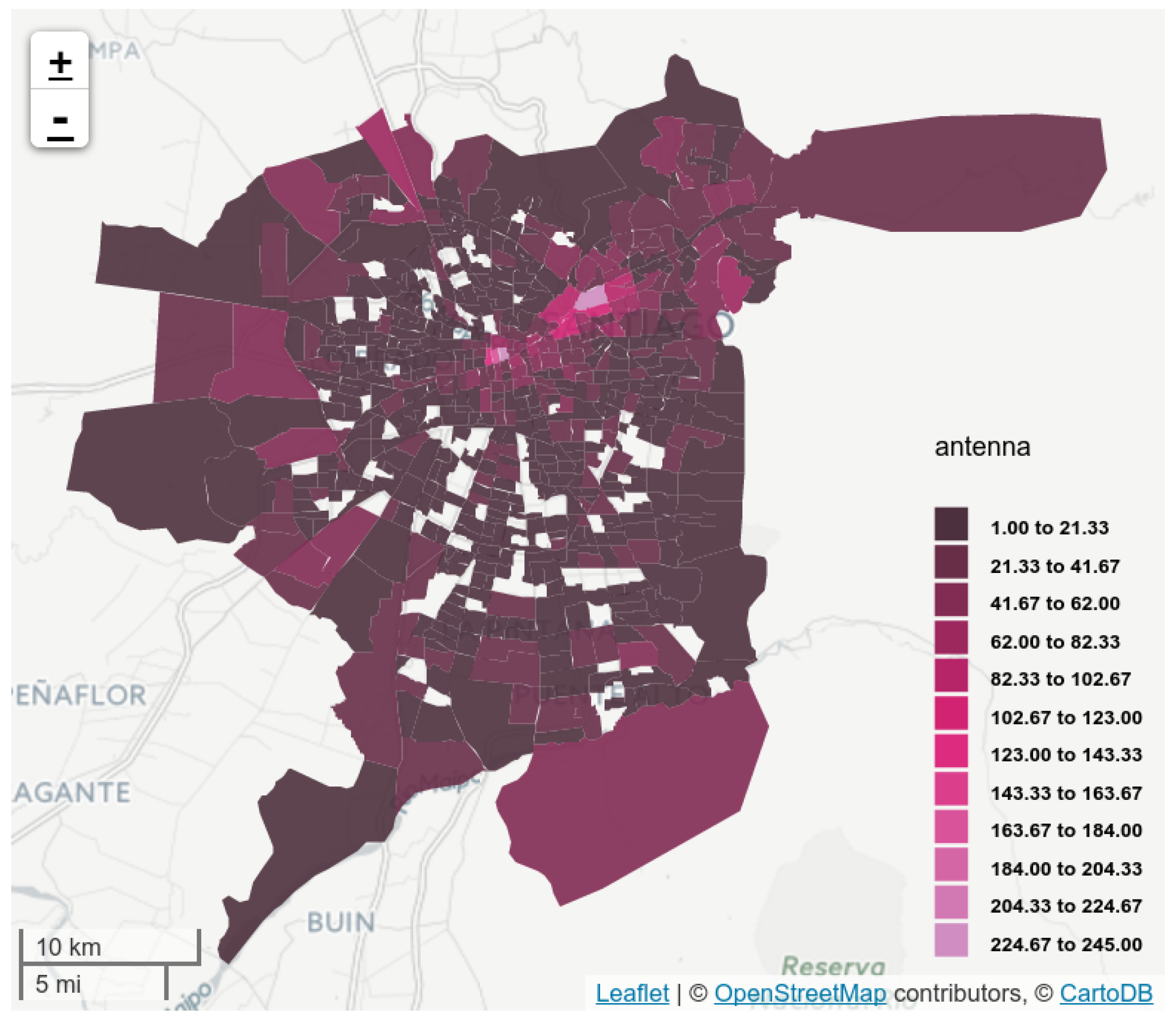
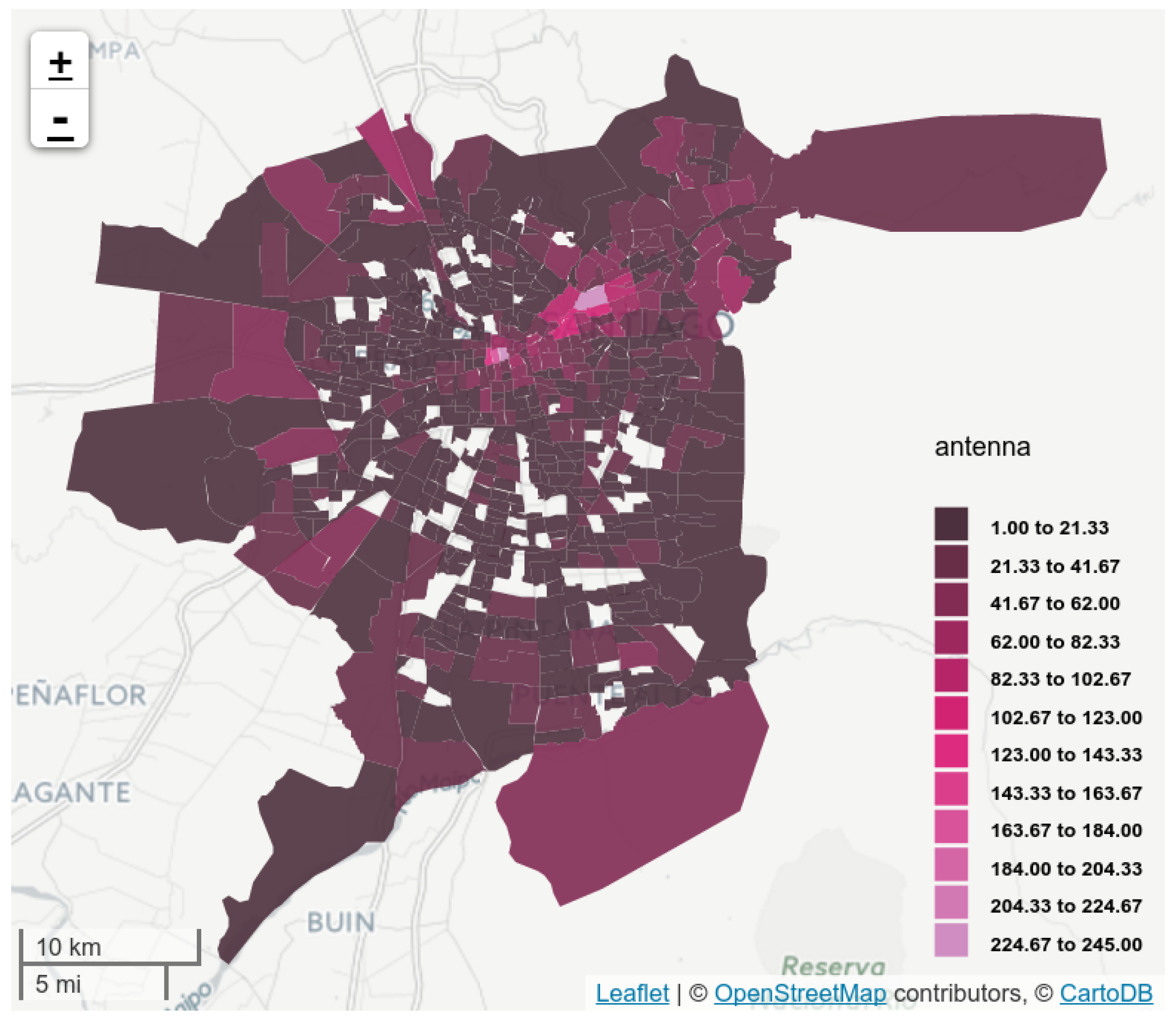
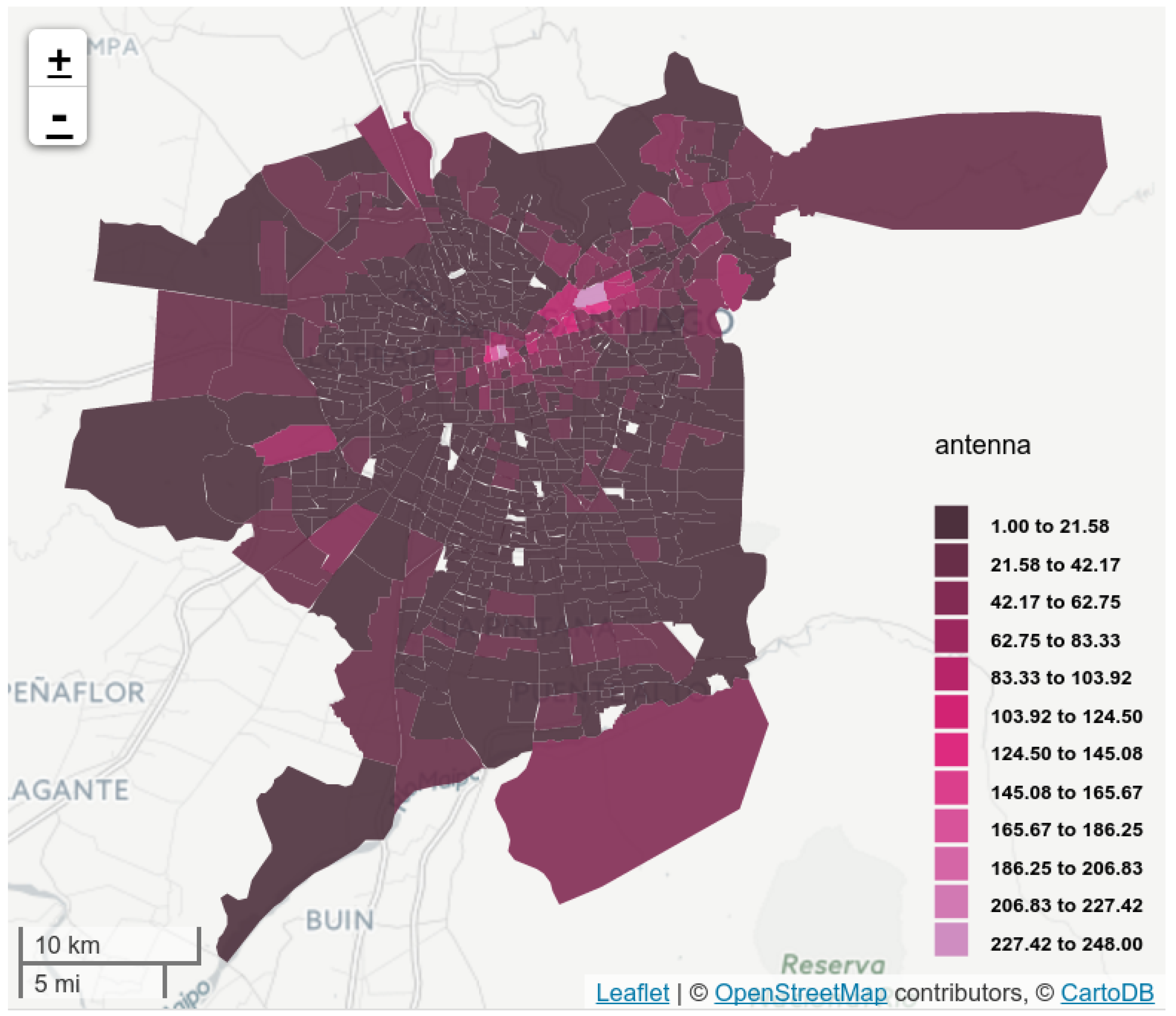
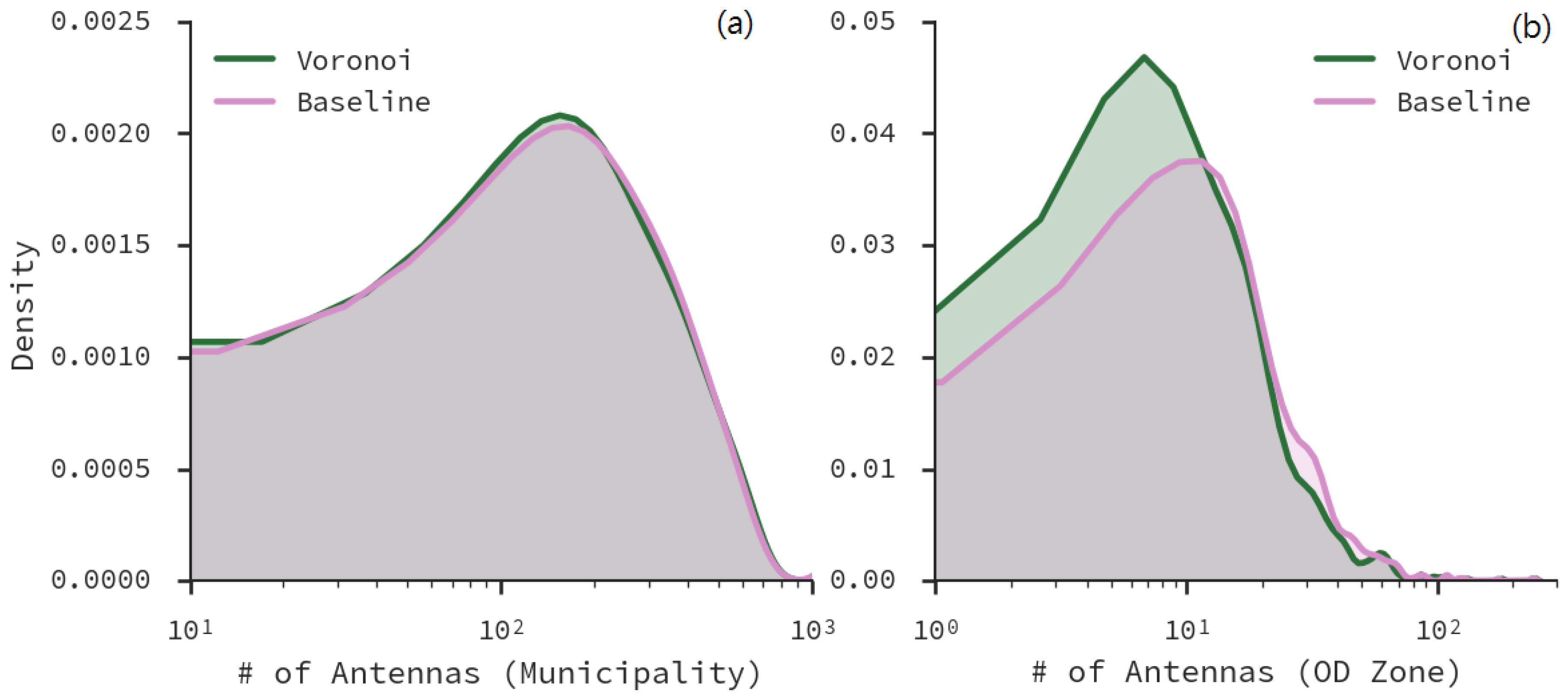
4.2. Mobile Antennas
4.3. Call Detail Records
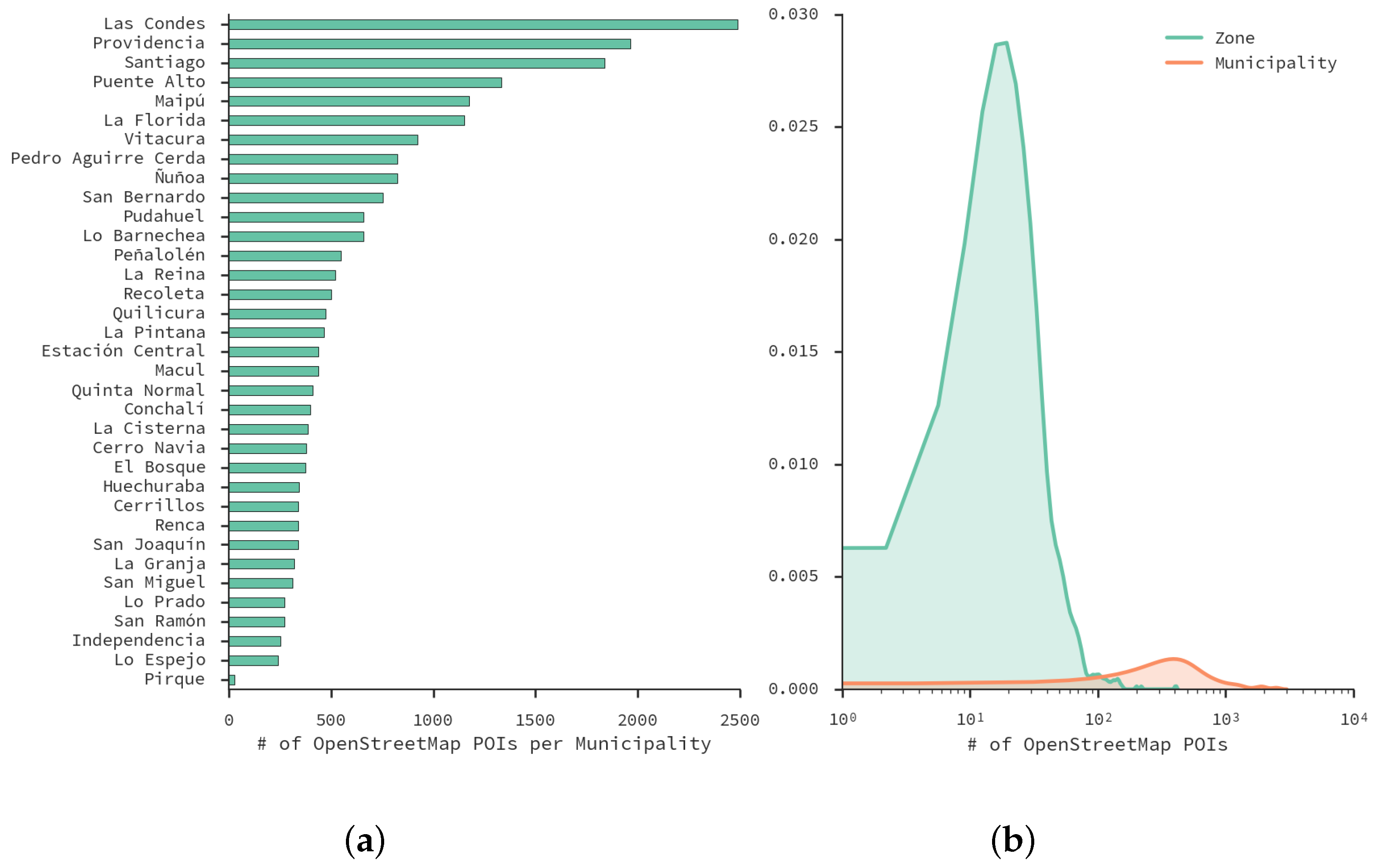
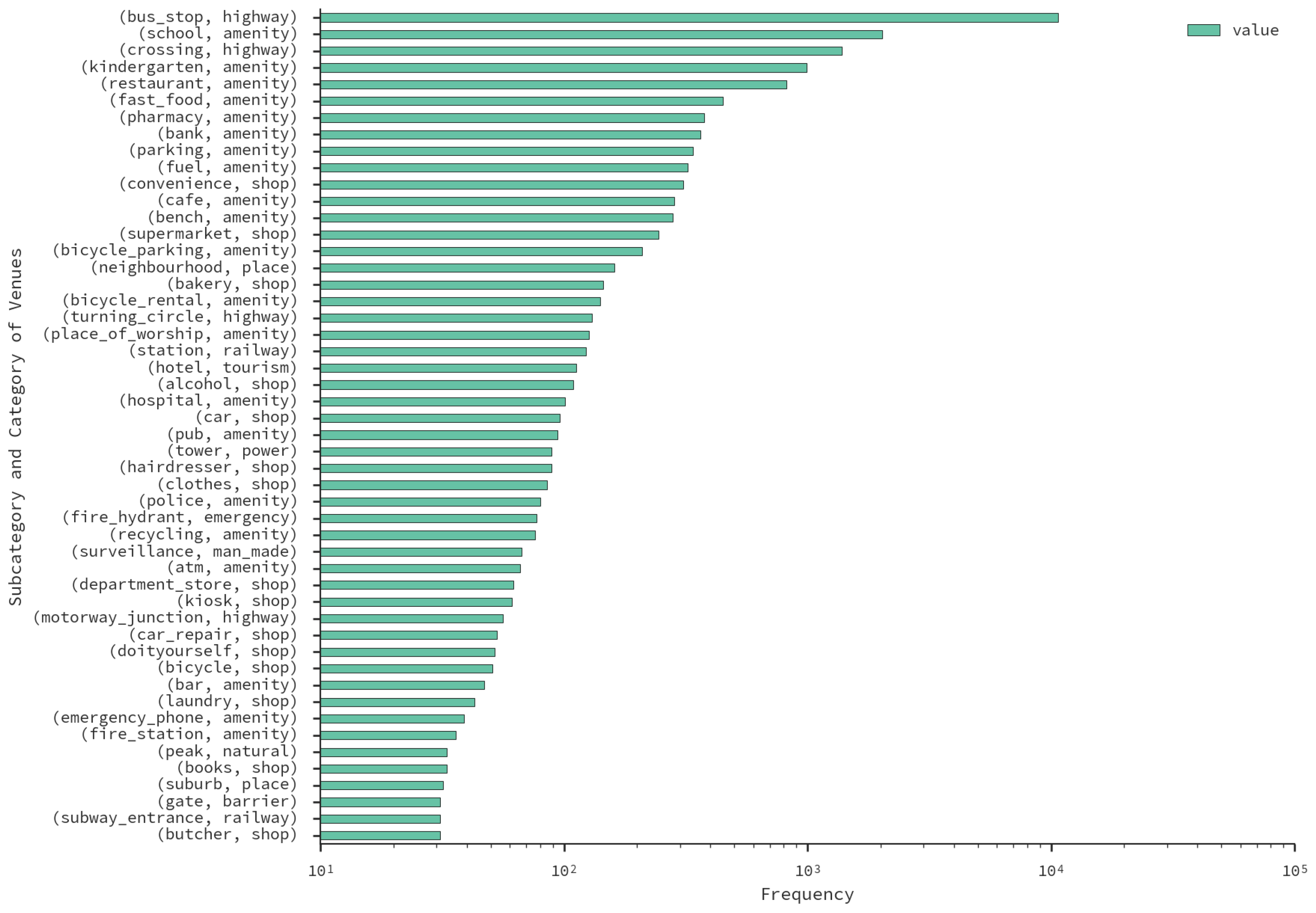
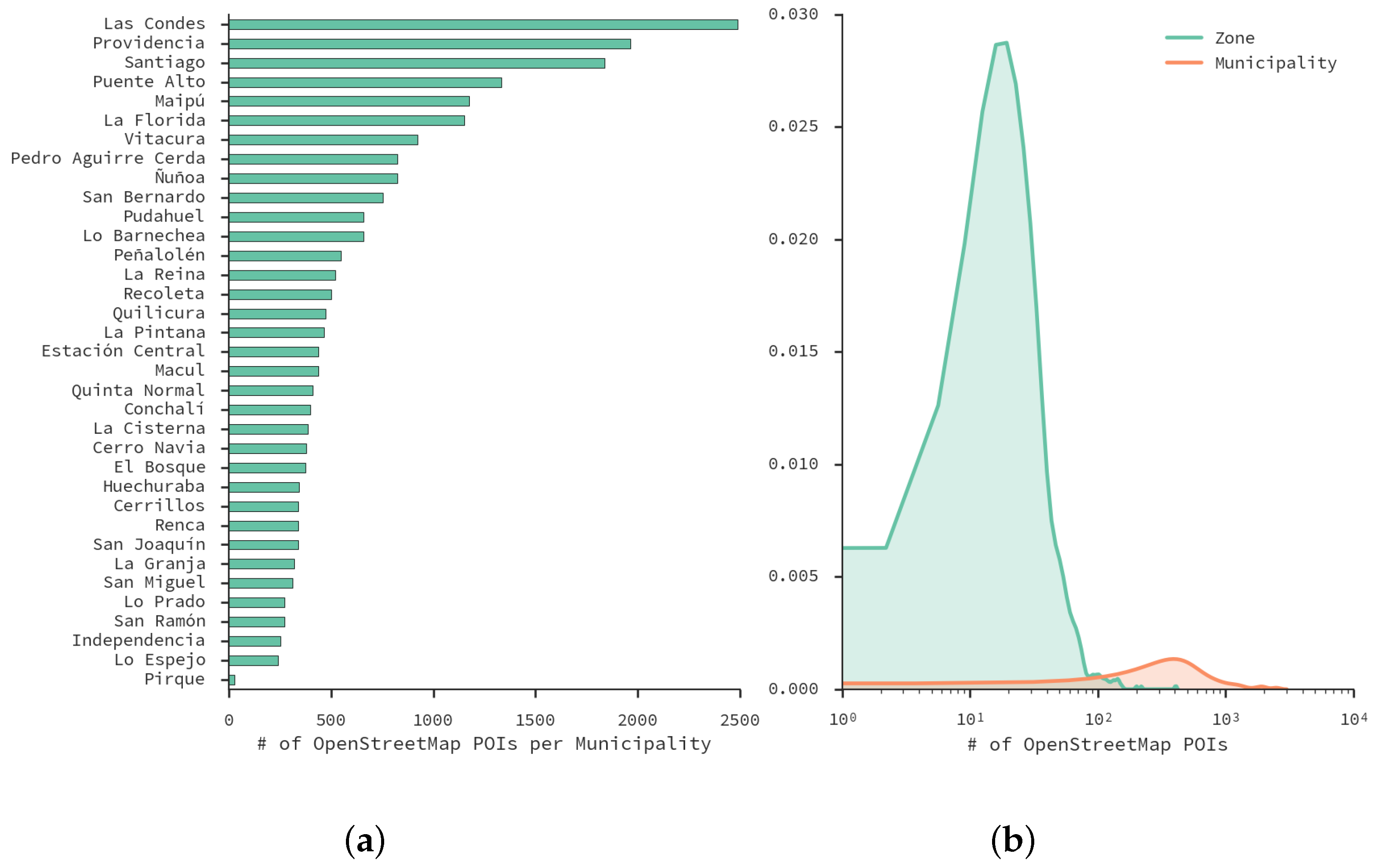
4.4. OpenStreetMap
5. Case Study: Santiago, Chile
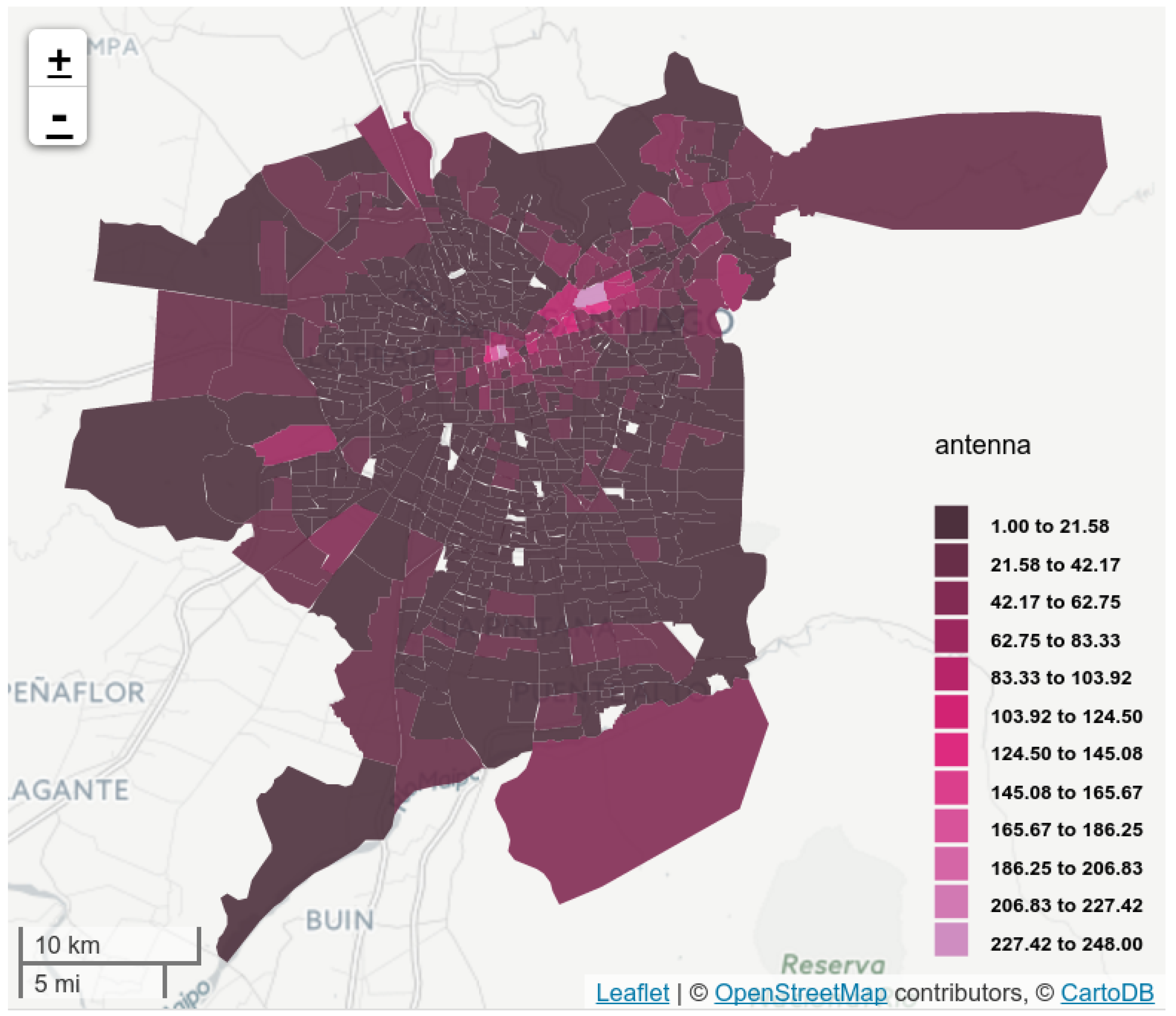
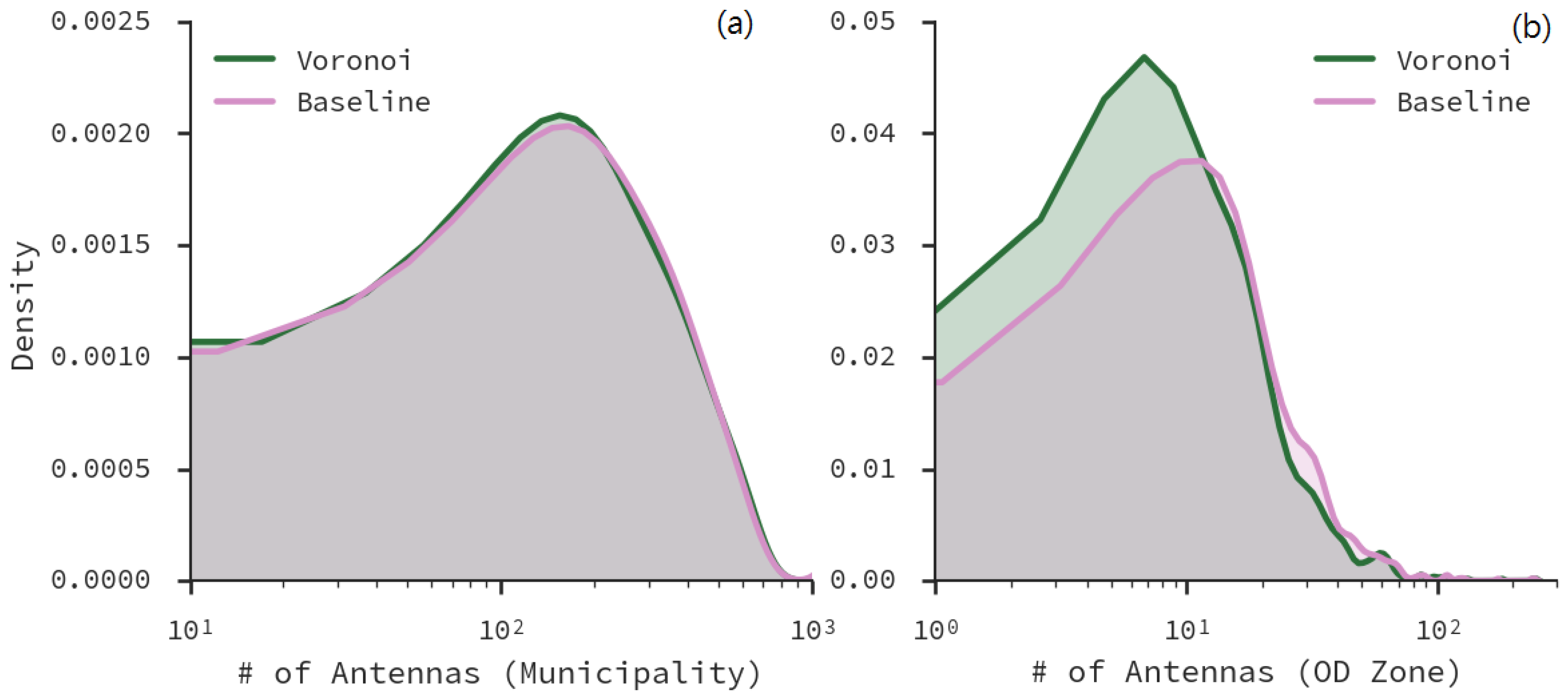
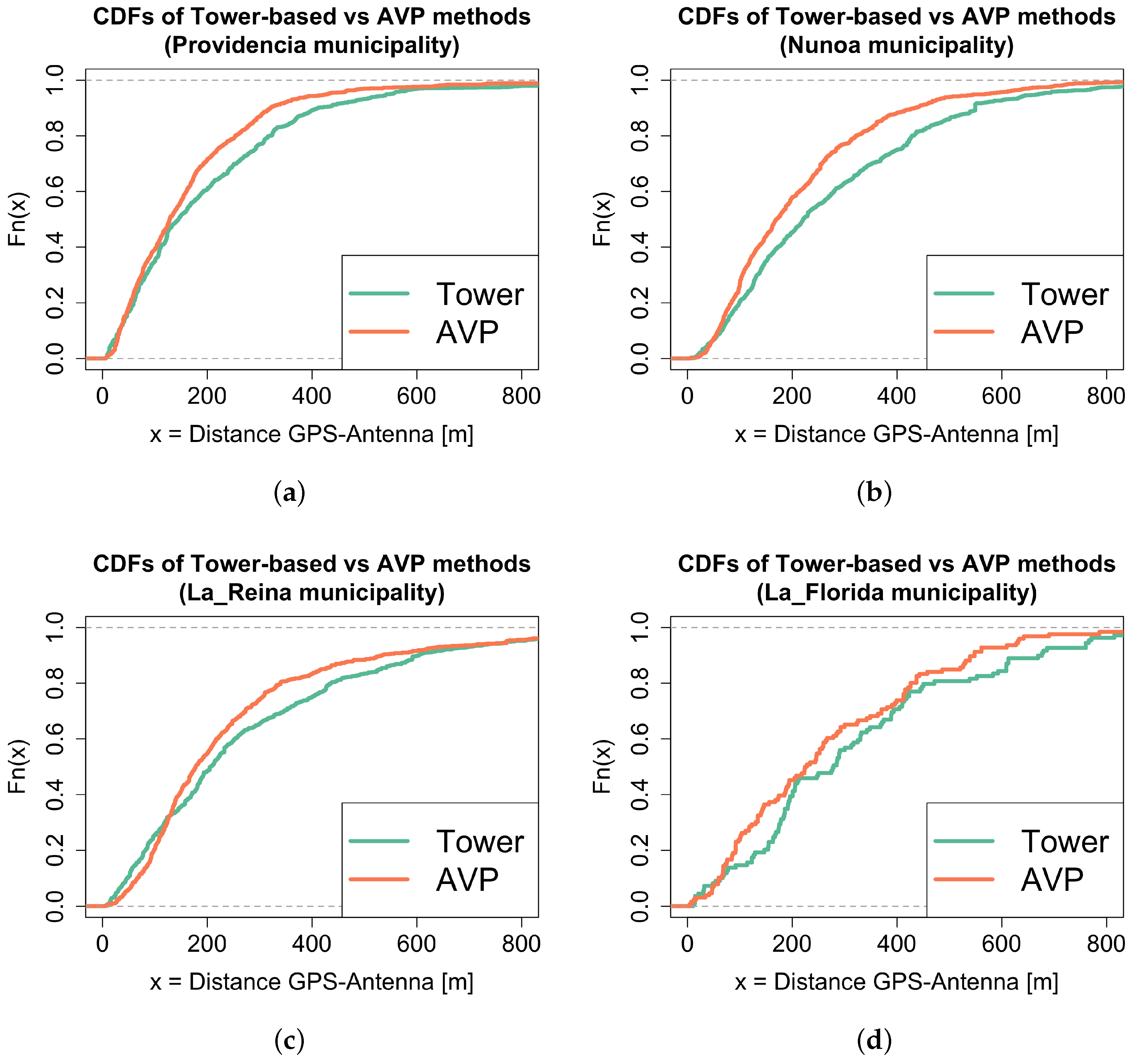
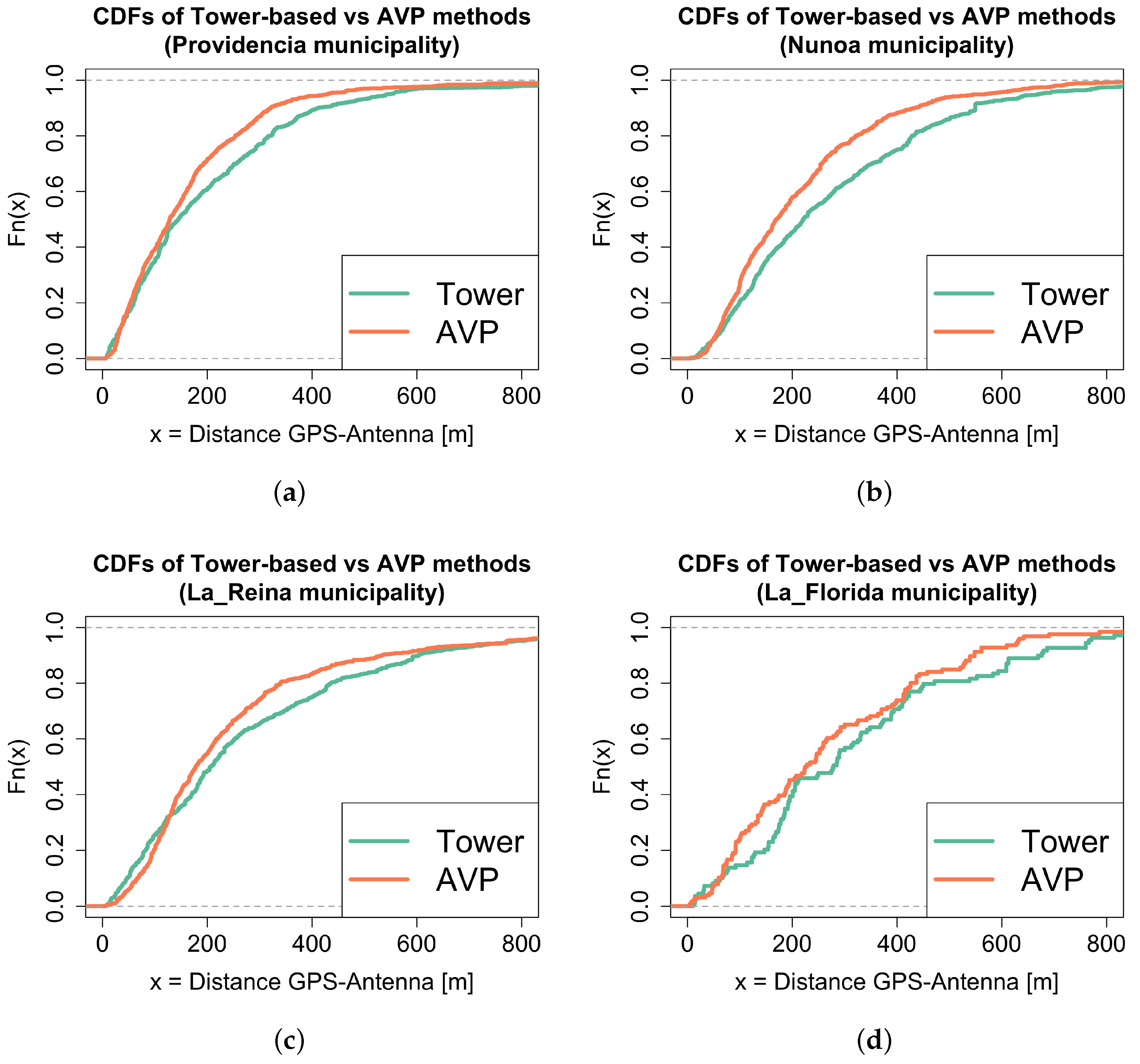
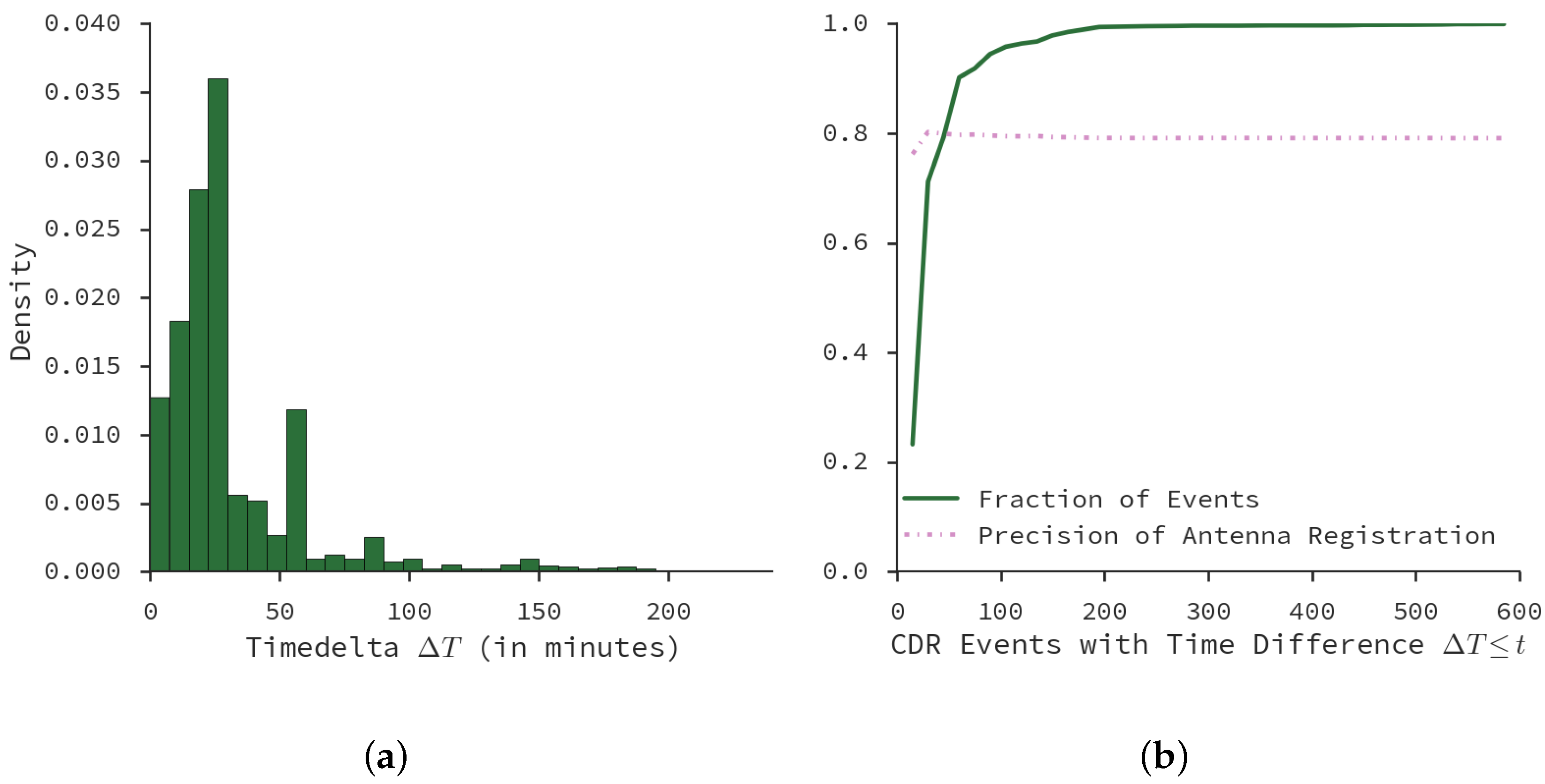
5.1. Antenna Virtual Placement
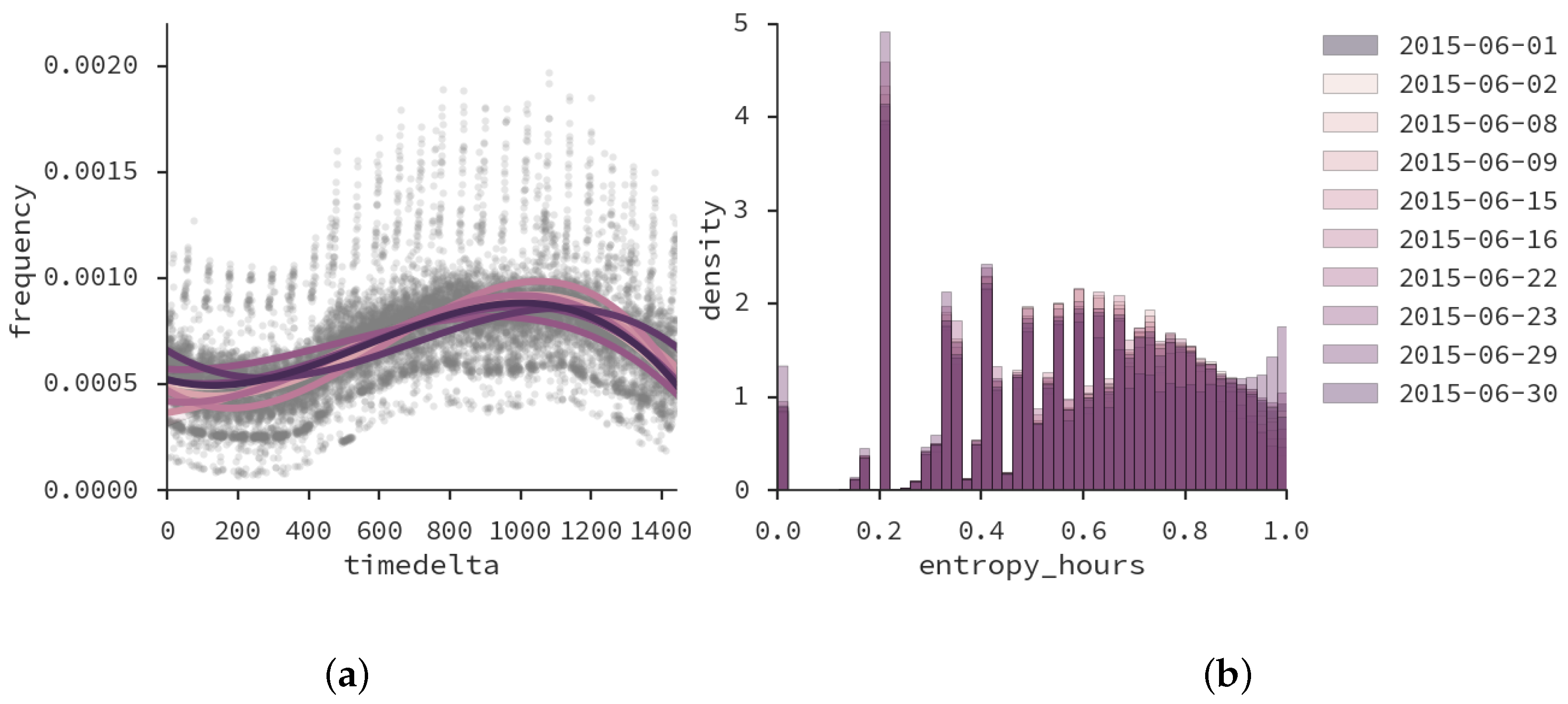
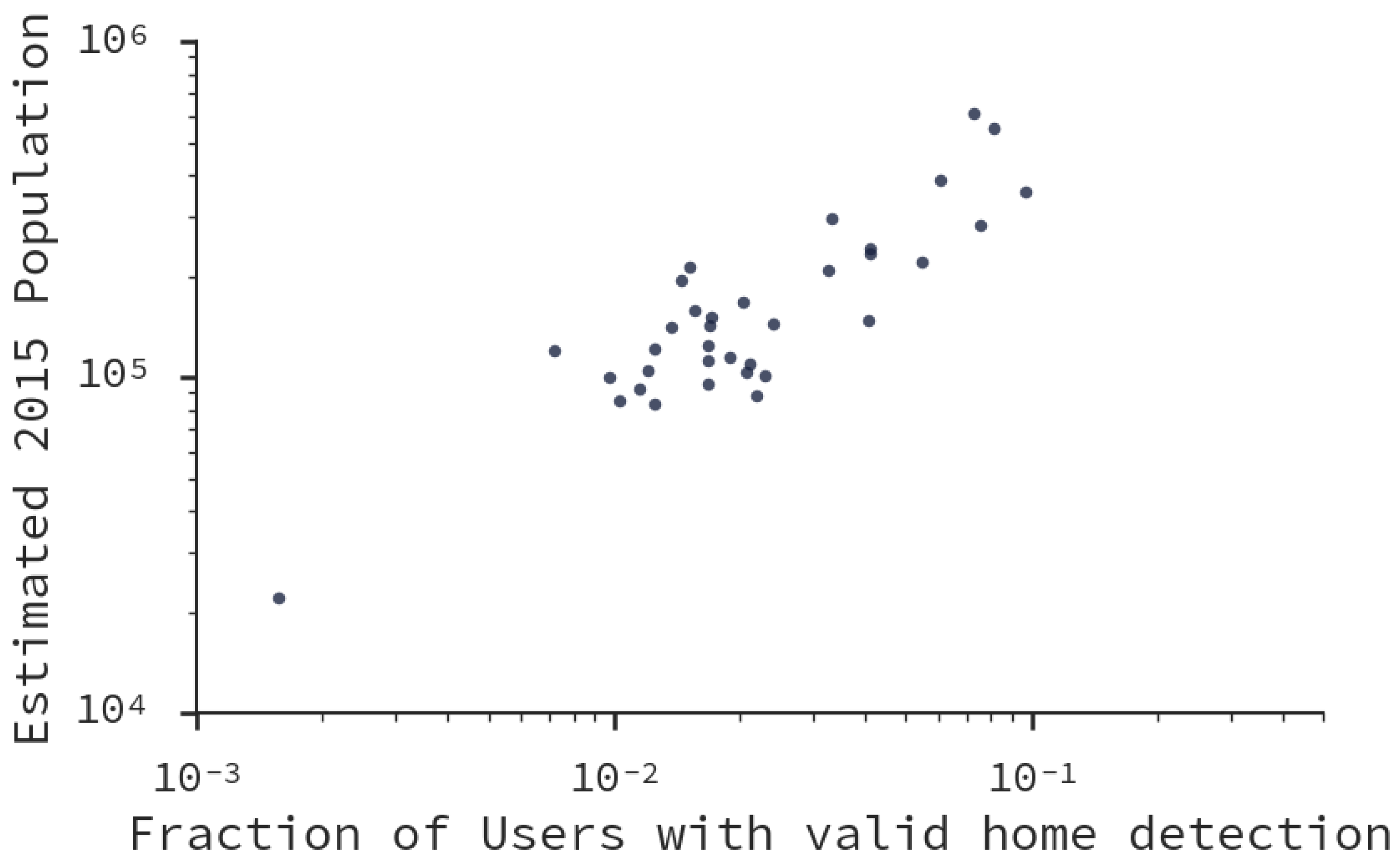
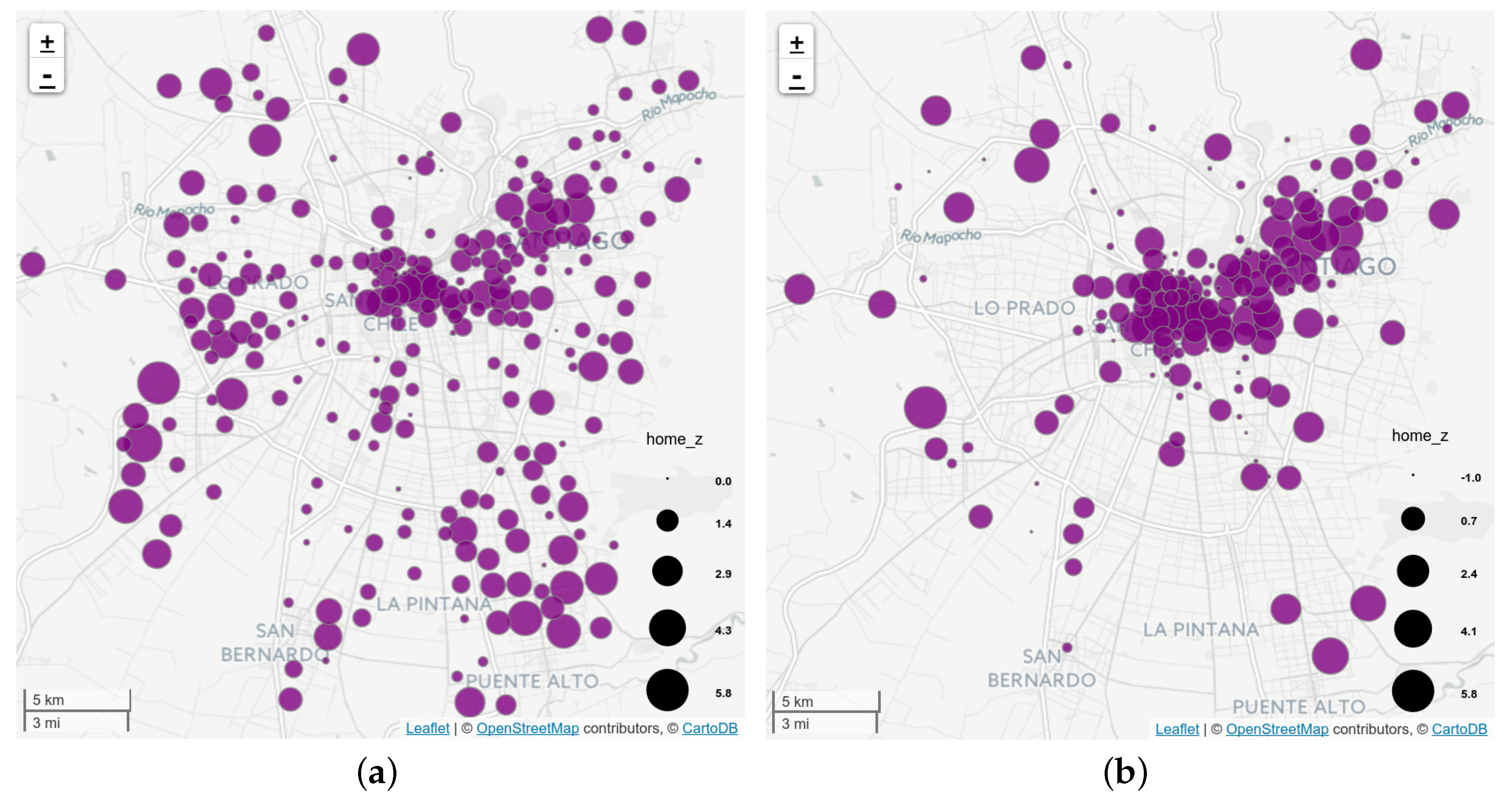
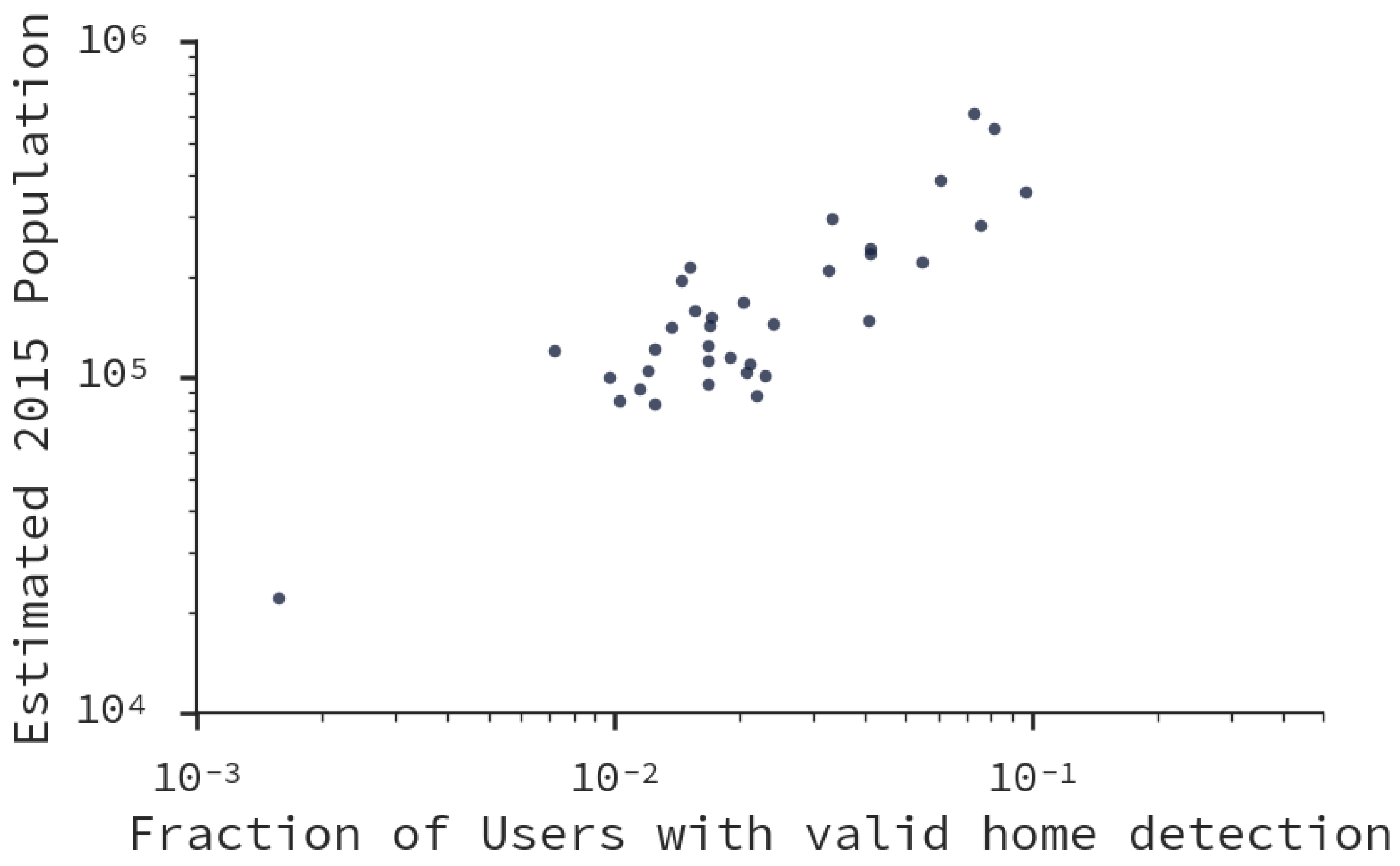
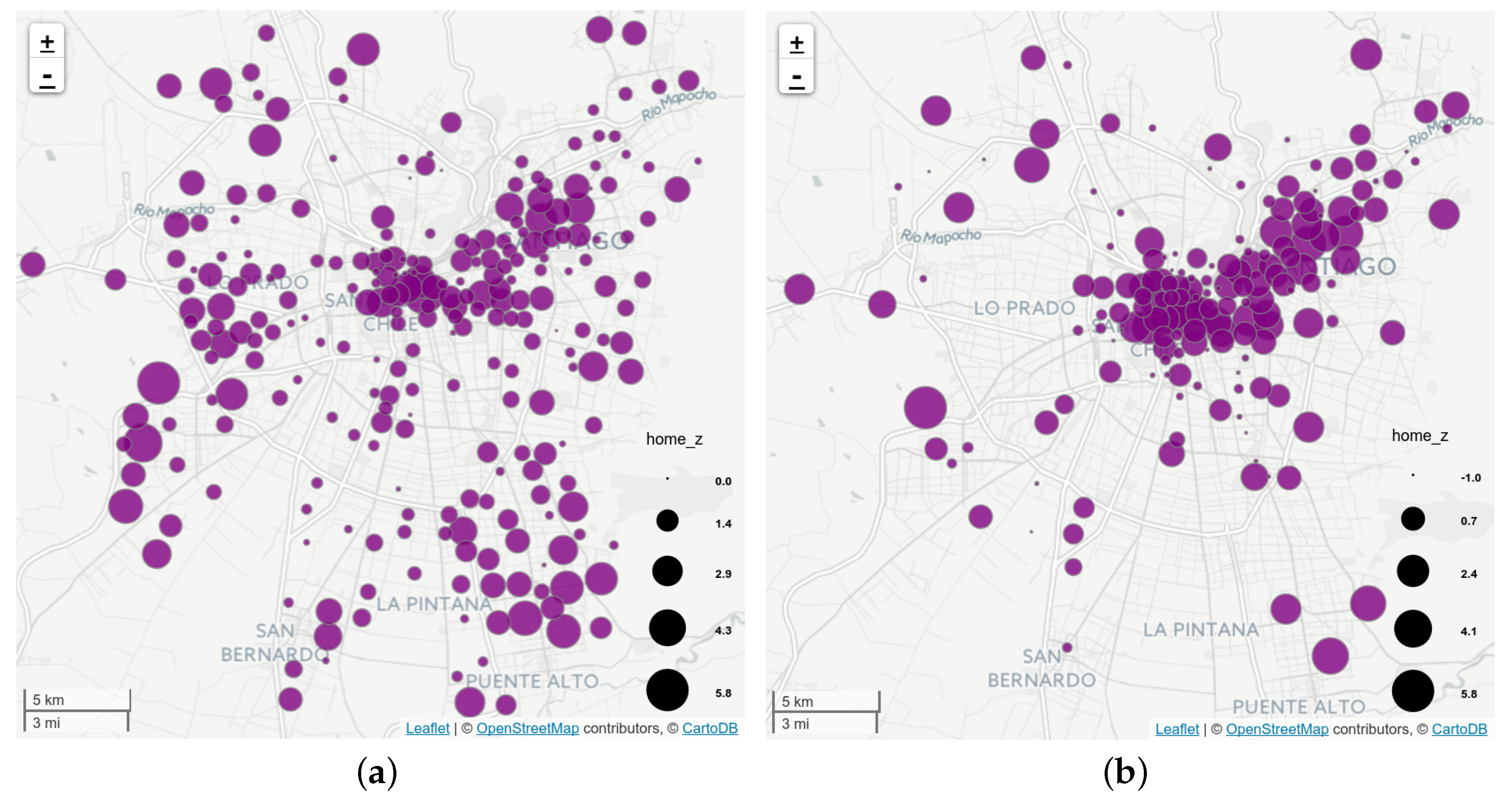
5.2. Important Places
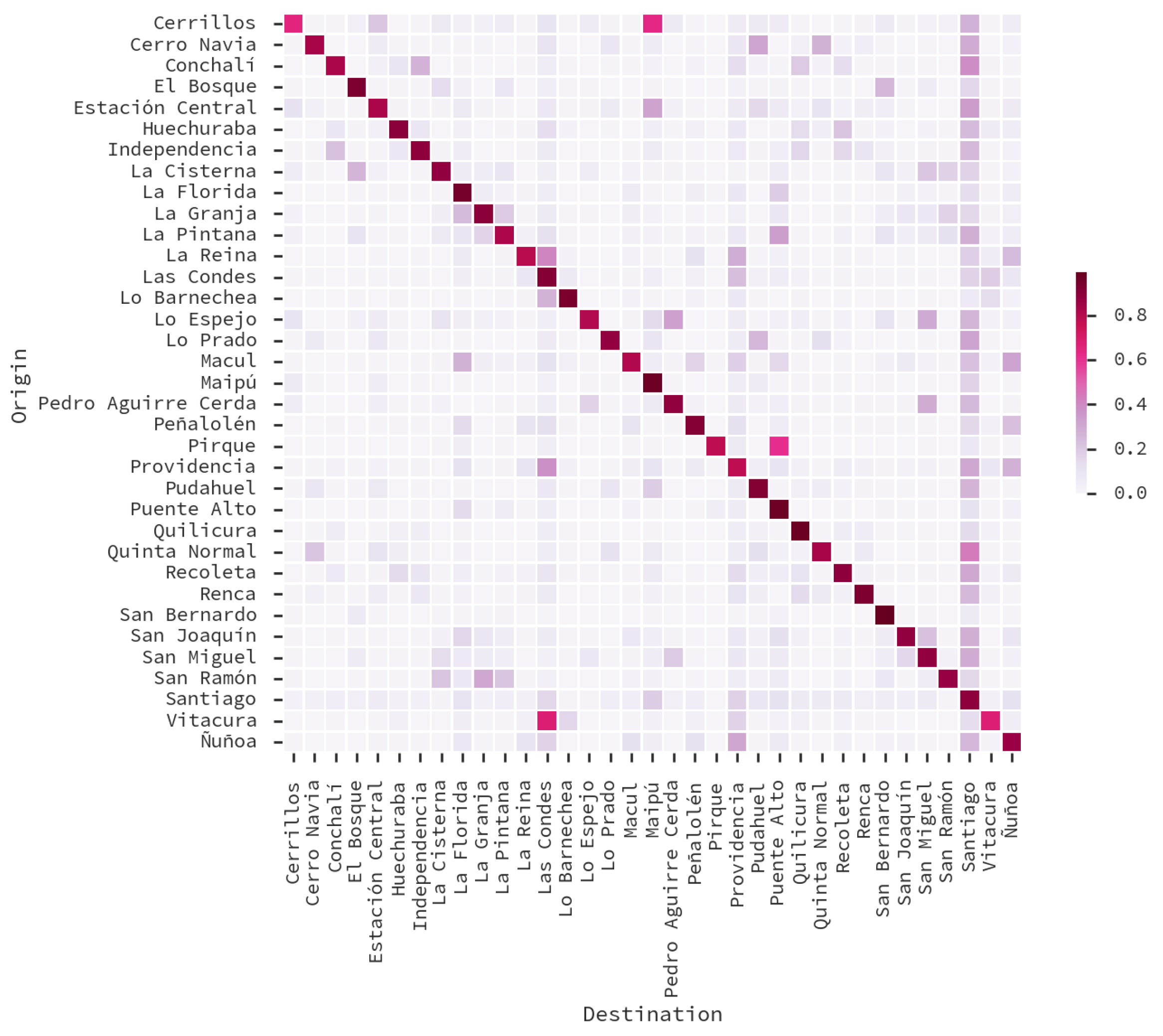
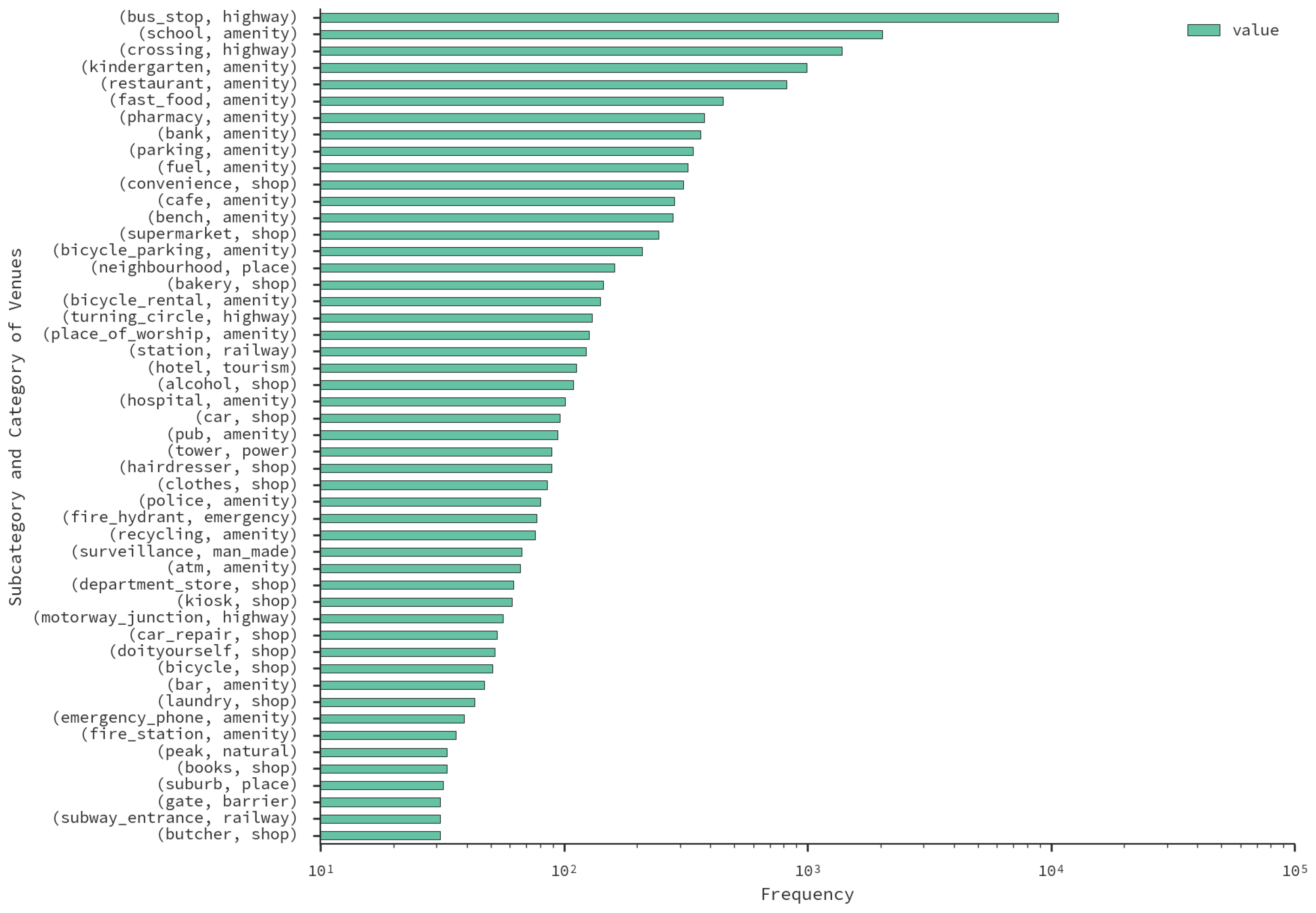
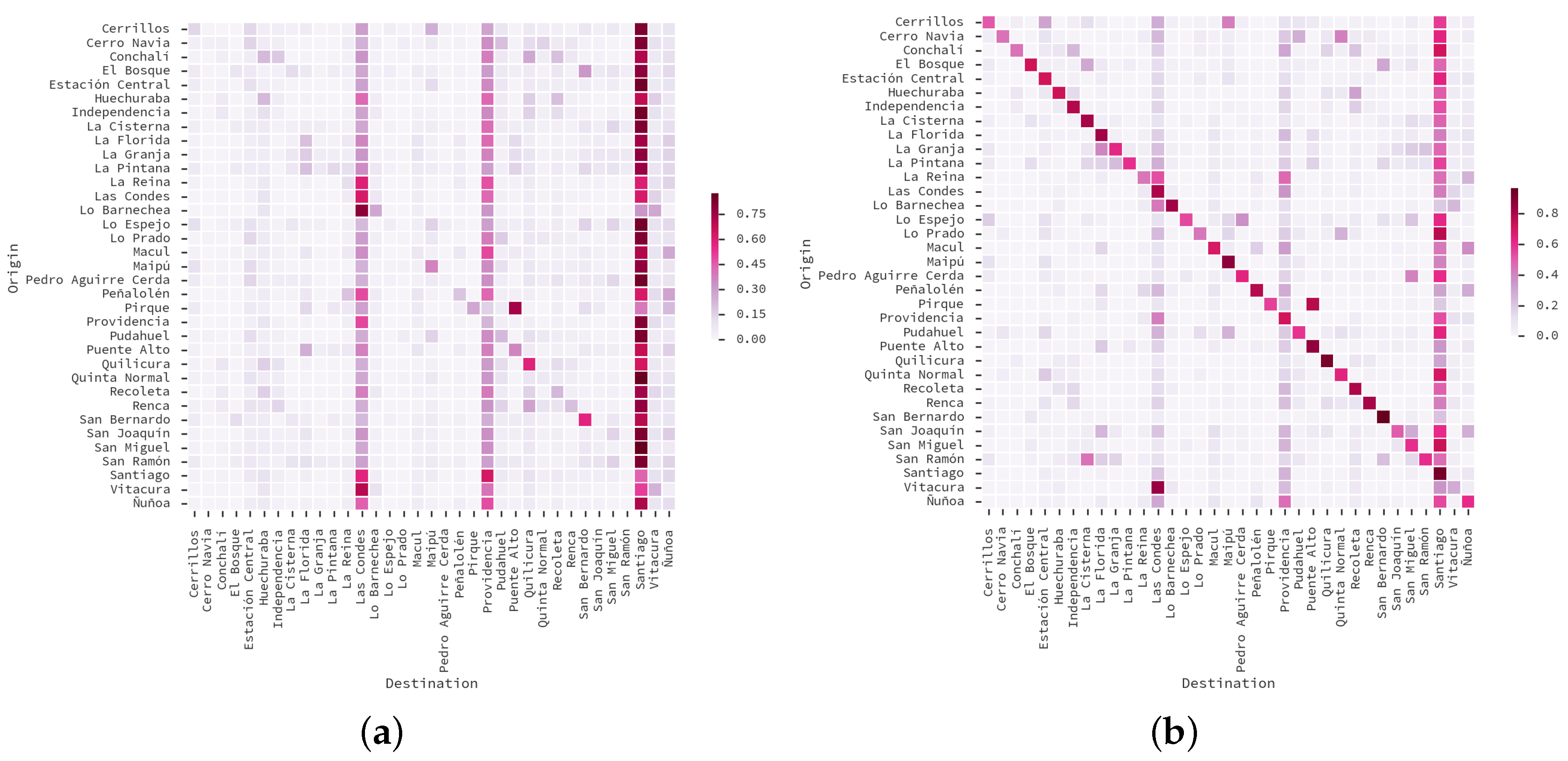
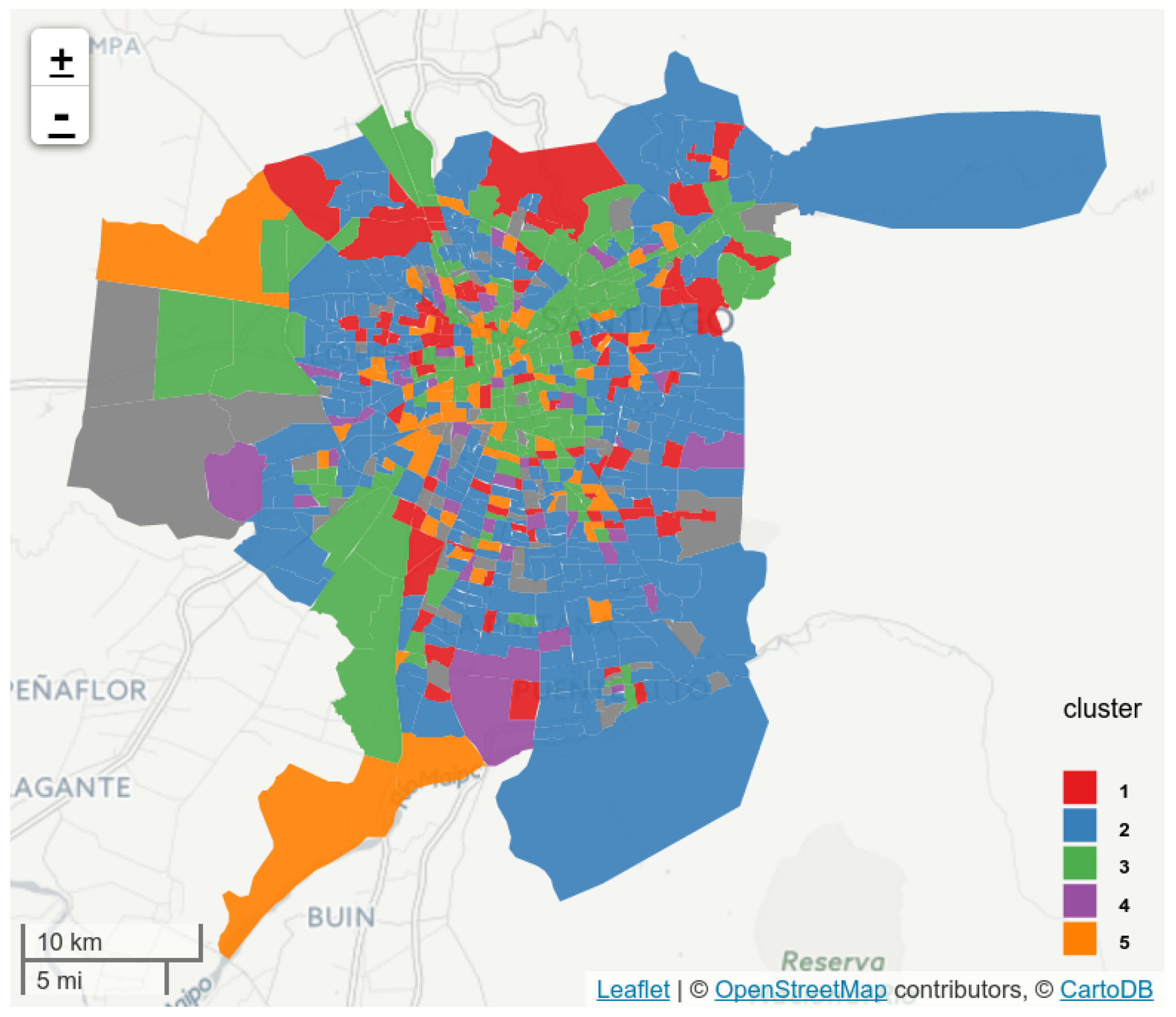
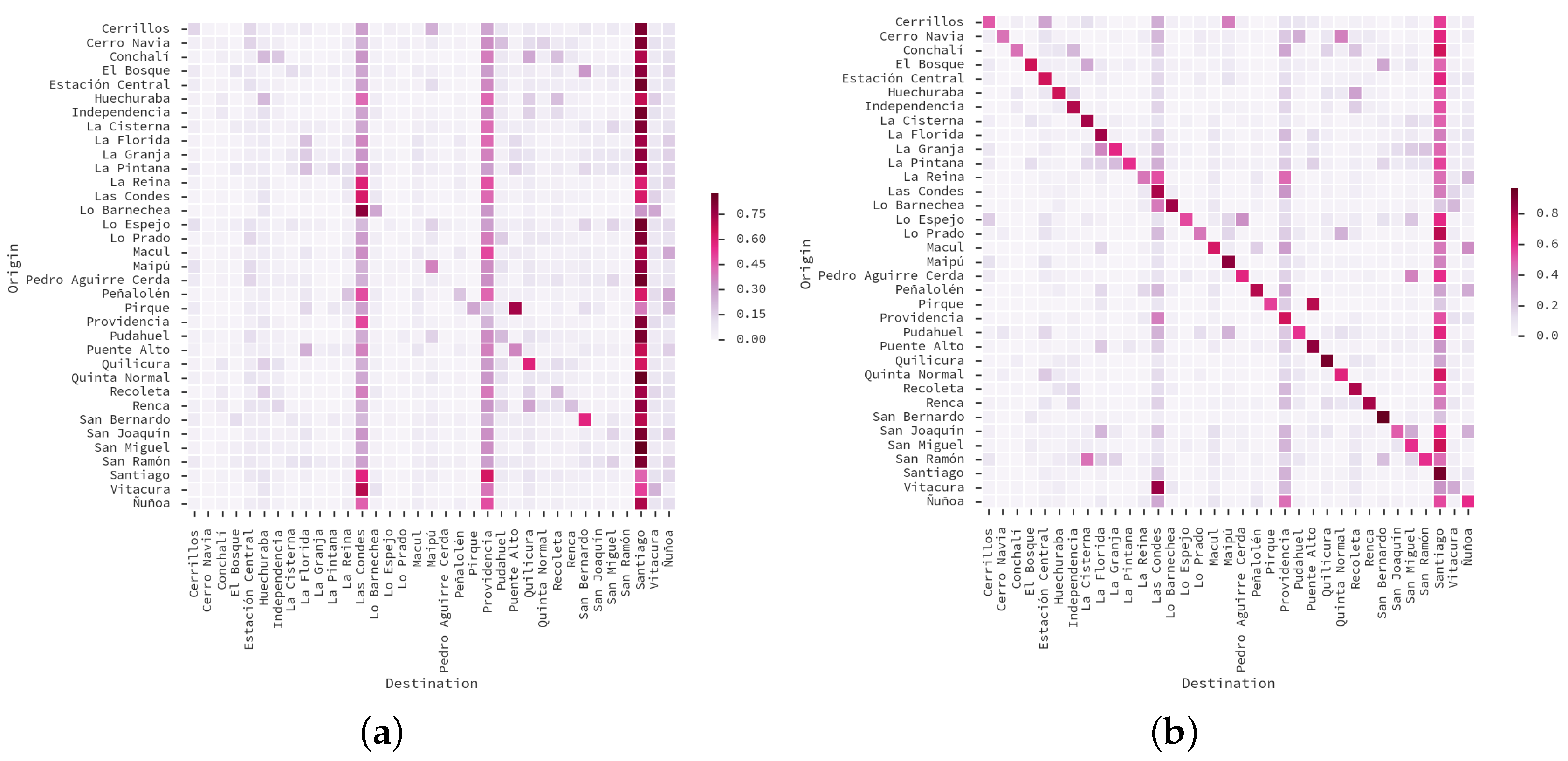
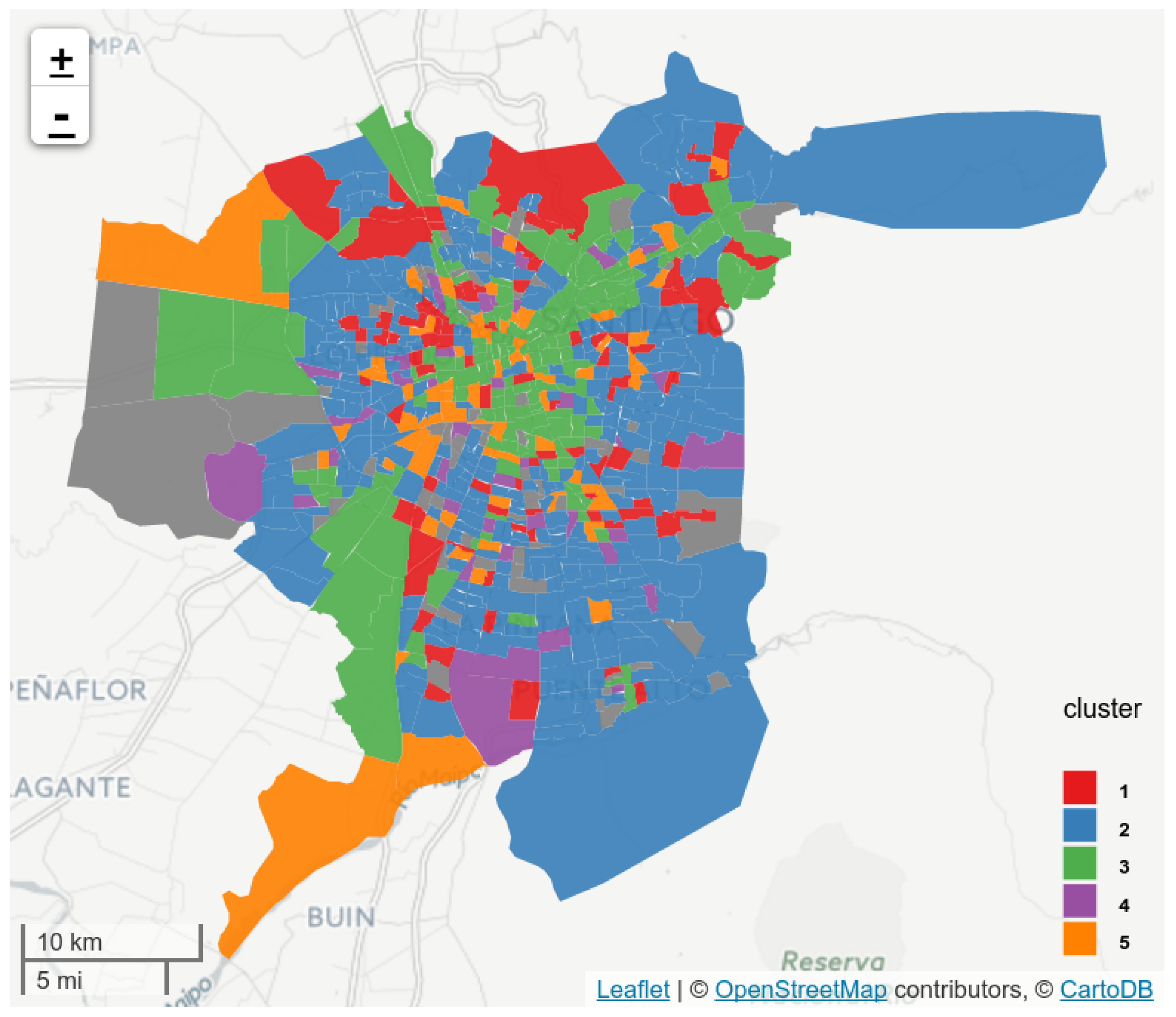
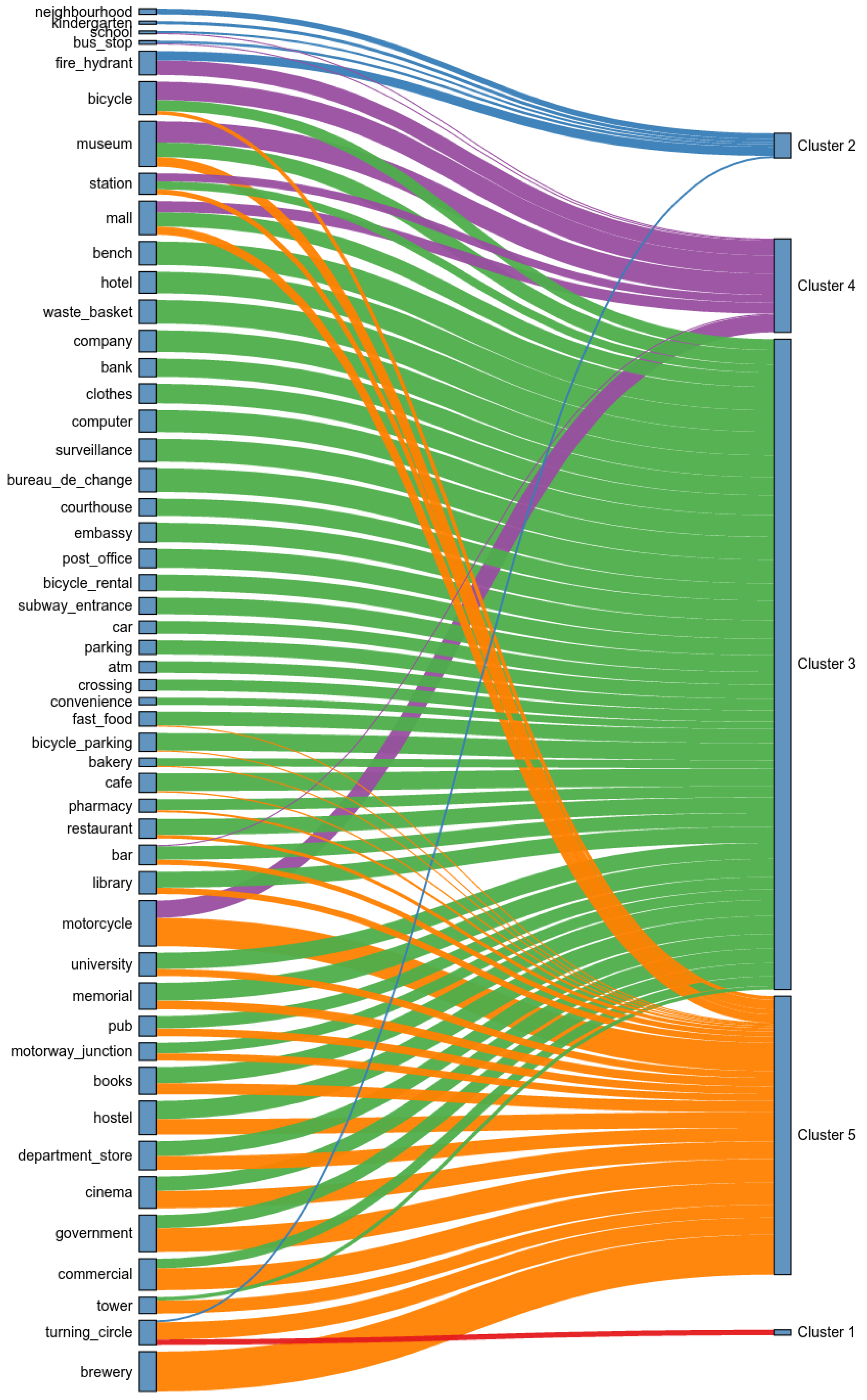
5.3. Land-Use Results
6. Discussion and Conclusions
6.1. Implications
6.2. Limitations and Future Work
6.3. Concluding Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AVP | Antenna Virtual Placement |
| BTS | Base Transceiver Station |
| CDF | Cumulative Distribution Function |
| CDR | Call Detail Records |
| KDE | Kernel Density Estimation |
| OD | Origin-Destiny |
| ODS | Origin-Destiny Survey |
| OSM | OpenStreetMap |
| PMI | Pointwise Mutual Information |
| POI | Point of Interest |
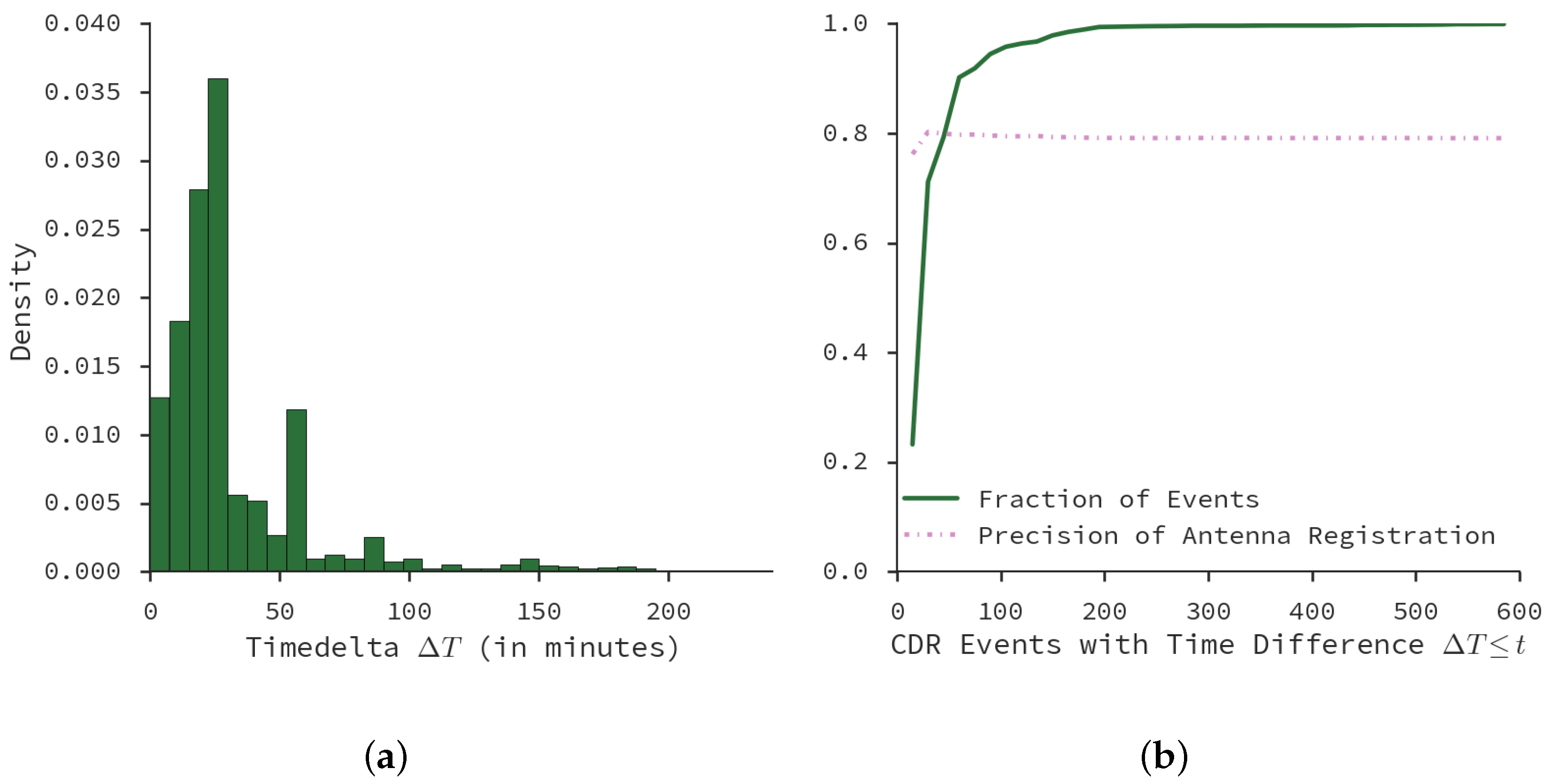
Appendix A. Data Events in Call Detail Records
References
- Groves, R.M. Nonresponse rates and nonresponse bias in household surveys. Public Opin. Q. 2006, 70, 646–675. [Google Scholar] [CrossRef]
- Kuwahara, M.; Sullivan, E.C. Estimating origin-destination matrices from roadside survey data. Transp. Res. Part B Methodol. 1987, 21, 233–248. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Järv, O.; Ahas, R.; Witlox, F. Understanding monthly variability in human activity spaces: A twelve-month study using mobile phone call detail records. Transp. Res. Part C Emerg. Technol. 2014, 38, 122–135. [Google Scholar] [CrossRef]
- Calabrese, F.; Diao, M.; Di Lorenzo, G.; Ferreira, J.; Ratti, C. Understanding individual mobility patterns from urban sensing data: A mobile phone trace example. Transp. Res. Part C Emerg. Technol. 2013, 26, 301–313. [Google Scholar] [CrossRef]
- Accesos a Internet en Chile Registran Crecimiento Histórico en 2014. Available online: http://www.subtel.gob.cl/accesos-a-internet-registran-crecimiento-historico-en-2014/ (accessed on 7 July 2016). (In Spanish)
- Puertas, O.L.; Henríquez, C.; Meza, F.J. Assessing spatial dynamics of urban growth using an integrated land use model. Application in Santiago Metropolitan Area, 2010–2045. Land Use Policy 2014, 38, 415–425. [Google Scholar] [CrossRef]
- Calabrese, F.; Ferrari, L.; Blondel, V.D. Urban sensing using mobile phone network data: A survey of research. ACM Comput. Surv. (CSUR) 2015, 47, 25. [Google Scholar] [CrossRef]
- Calabrese, F.; Di Lorenzo, G.; Liu, L.; Ratti, C. Estimating origin-destination flows using mobile phone location data. IEEE Pervasive Comput. 2011, 10, 36–44. [Google Scholar] [CrossRef]
- Alexander, L.; Jiang, S.; Murga, M.; González, M.C. Origin–destination trips by purpose and time of day inferred from mobile phone data. Transp. Res. Part C Emerg. Technol. 2015, 58, 240–250. [Google Scholar] [CrossRef]
- Iqbal, M.S.; Choudhury, C.F.; Wang, P.; González, M.C. Development of origin–destination matrices using mobile phone call data. Transp. Res. Part C Emerg. Technol. 2014, 40, 63–74. [Google Scholar] [CrossRef]
- Frias-Martinez, V.; Soguero, C.; Frias-Martinez, E. Estimation of urban commuting patterns using cellphone network data. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12–16 August 2012. [CrossRef]
- Traag, V.A.; Browet, A.; Calabrese, F.; Morlot, F. Social Event Detection in Massive Mobile Phone Data Using Probabilistic Location Inference. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2011 IEEE Third International Conference on Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; pp. 625–628.
- Calabrese, F.; Colonna, M.; Lovisolo, P.; Parata, D.; Ratti, C. Real-Time Urban Monitoring Using Cell Phones: A Case Study in Rome. IEEE Trans. Intell. Transp. Syst. 2011, 12, 141–151. [Google Scholar] [CrossRef]
- Ahas, R.; Silm, S.; Järv, O.; Saluveer, E.; Tiru, M. Using mobile positioning data to model locations meaningful to users of mobile phones. J. Urban Technol. 2010, 17, 3–27. [Google Scholar] [CrossRef]
- Ahas, R.; Aasa, A.; Silm, S.; Tiru, M. Daily rhythms of suburban commuters’ movements in the Tallinn metropolitan area: Case study with mobile positioning data. Transp. Res. Part C Emerg. Technol. 2010, 18, 45–54. [Google Scholar] [CrossRef]
- Kang, J.H.; Welbourne, W.; Stewart, B.; Borriello, G. Extracting places from traces of locations. ACM SIGMOBILE Mobile Comput. Commun. Rev. 2005, 9, 58–68. [Google Scholar] [CrossRef]
- Liao, L.; Fox, D.; Kautz, H. Extracting places and activities from gps traces using hierarchical conditional random fields. Int. J. Robot. Res. 2007, 26, 119–134. [Google Scholar] [CrossRef]
- Isaacman, S.; Becker, R.; Cáceres, R.; Kobourov, S.; Martonosi, M.; Rowland, J.; Varshavsky, A. Identifying Important Places in People’s Lives From Cellular Network Data. In Pervasive Computing; Springer: Berlin, Germany, 2011; pp. 133–151. [Google Scholar]
- Noulas, A.; Mascolo, C. Exploiting Foursquare and cellular data to infer user activity in urban environments. In Proceedings of the 2013 IEEE 14th International Conference on Mobile Data Management (MDM), Milan, Italy, 3–6 June 2013; Vol. 1, pp. 167–176.
- Lenormand, M.; Picornell, M.; Cantú-Ros, O.G.; Louail, T.; Herranz, R.; Barthelemy, M.; Frías-Martínez, E.; San Miguel, M.; Ramasco, J.J. Comparing and modelling land use organization in cities. Royal Soc. Open Sci. 2015, 2, 150449. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Toole, J.L.; Ulm, M.; González, M.C.; Bauer, D. Inferring land use from mobile phone activity. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12–16 August 2012; pp. 1–8.
- Reades, J.; Calabrese, F.; Ratti, C. Eigenplaces: Analysing cities using the space–time structure of the mobile phone network. Environ. Plan. B Plan. Des. 2009, 36, 824–836. [Google Scholar] [CrossRef]
- Soto, V.; Frías-Martínez, E. Automated Land Use Identification Using Cell-phone Records. In Proceedings of the 3rd ACM International Workshop on MobiArch, Bethesda, MD, USA, 28 June–1 July 2011; pp. 17–22.
- Lanzendorf, M. Key events and their effect on mobility biographies: The case of childbirth. Int. J. Sustain. Transp. 2010, 4, 272–292. [Google Scholar] [CrossRef]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Church, K.W.; Hanks, P. Word association norms, mutual information, and lexicography. Comput. Linguist. 1990, 16, 22–29. [Google Scholar]
- Carmel, D.; Roitman, H.; Zwerdling, N. Enhancing Cluster Labeling Using Wikipedia. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 139–146.
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194.
- Vaca, C.K.; Quercia, D.; Bonchi, F.; Fraternali, P. Taxonomy-Based Discovery and Annotation of Functional Areas in the City. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015.
- Hecht, B.; Stephens, M. A Tale of Cities: Urban Biases in Volunteered Geographic Information. ICWSM 2014, 14, 197–205. [Google Scholar]
- Quattrone, G.; Capra, L.; De Meo, P. There’s no such thing as the perfect map: Quantifying bias in spatial crowd-sourcing datasets. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015; pp. 1021–1032.
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Candia, J.; González, M.C.; Wang, P.; Schoenharl, T.; Greg, M.; Barabási, A.L. Uncovering individual and collective human dynamics from mobile phone records. J. Phys. A Math. Theor. 2008, 41, 224015. [Google Scholar] [CrossRef]
- Song, C.; Koren, T.; Wang, P.; Barabasi, A.L. Modelling the scaling properties of human mobility. Nat. Phys. 2010, 6, 818–823. [Google Scholar] [CrossRef]
- Horanont, T.; Shibasaki, R. An implementation of mobile sensing for large-scale urban monitoring. In Proceedings of the UrbanSense’ 08, Raleigh, NC, USA, 4 November 2008.
- Horanont, T. A Study on Urban Mobility and Dynamic Population Estimation by Using Aggregate Mobile Phone Sources (CSIS Discussion Paper No. 115); Technical Report; Center for Spatial Information Science, The University of Tokyo: Tokyo, Japan, 2012. [Google Scholar]
- White, J.; Wells, I. Extracting origin destination information from mobile phone data. In Proceedings of the 11th International Conference on Road Transport Information and Control, London, UK, 19–21 March 2002; pp. 30–34.
- Holleczek, T.; Yu, L.; Lee, J.K.; Senn, O.; Ratti, C.; Jaillet, P. Detecting weak public transport connections from cellphone and public transport data. In Proceedings of the 2014 International Conference on Big Data Science and Computing (BigDataScience ’14), Beijing, China, 4–7 August 2014. [CrossRef]
- Graells-Garrido, E.; García, J. Visual Exploration of Urban Dynamics Using Mobile Data. In Ubiquitous Computing and Ambient Intelligence. Sensing, Processing, and Using Environmental Information; Proceedings of the 9th International Conference (UCAmI 2015), Puerto Varas, Chile, 1–4 December 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 480–491. [Google Scholar]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Actualización y Recolección de Información del Sistema de Transporte Urbano, IX Etapa: Encuesta Origen Destino Santiago 2012. Encuesta Origen Destino de Viajes 2012. Available online: http://www.sectra.gob.cl/biblioteca/detalle1.asp?mfn=3253 (accessed on 7 July 2016). (In Spanish)
- Graells-Garrido, E.; Saez-Trumper, D. A Day of Your Days: Estimating Individual Daily Journeys Using Mobile Data to Understand Urban Flow. 2016; arXiv:1602.09000. [Google Scholar]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Demográficas y Vitales: Productos Estadísticos. Available online: http://www.ine.cl/canales/chile_estadistico/familias/demograficas_vitales.php (accessed on 7 July 2016). (In Spanish)
- Kujala, R.; Aledavood, T.; Saramäki, J. Estimation and monitoring of city-to-city travel times using call detail records. EPJ Data Sci. 2016, 5, 1. [Google Scholar] [CrossRef]
- Amini, A.; Kung, K.; Kang, C.; Sobolevsky, S.; Ratti, C. The impact of social segregation on human mobility in developing and industrialized regions. EPJ Data Sci. 2014, 3, 1–20. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
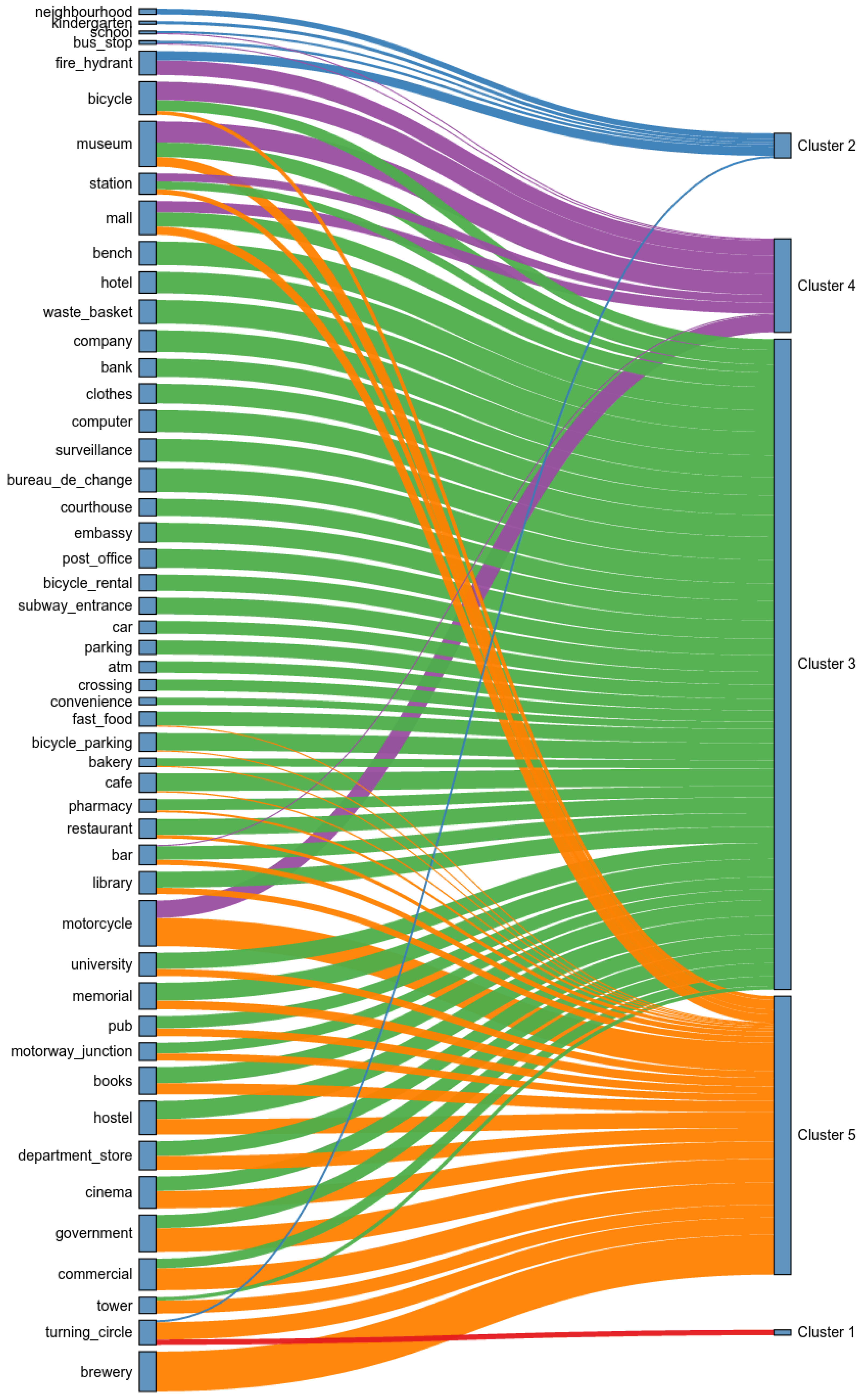
| Cluster ID | % of City Surface | Top-15 Venues | Label |
|---|---|---|---|
| Cluster 1 | 13.34 | turning_circle (0.32) | Transition |
| Cluster 2 | 46.60 | fire_hydrant (0.54), neighbourhood (0.34), kindergarten (0.19), bus_stop (0.15), school (0.13), turning_circle (0.12) | Dormitory |
| Cluster 3 | 24.66 | waste_basket (1.40), bureau_de_change (1.40), bench (1.39), surveillance (1.35), computer (1.29), company (1.28), hotel (1.27), clothes (1.17), embassy (1.16), post_office (1.11), bank (1.08), memorial (1.07), hostel (1.06), cafe (1.04), bicycle_parking (1.03) | Business |
| Cluster 4 | 5.96 | museum (1.25), bicycle (1.08), motorcycle (1.03), fire_hydrant (0.87), mall (0.66), station (0.47), bar (0.07), bus_stop (0.06), school (0.05) | Leisure Activities After Working Hours |
| Cluster 5 | 4.43 | brewery (2.36), motorcycle (1.67), government (1.41), commercial (1.30), cinema (1.03), turning_circle (1.02), hostel (0.93), department_store (0.81), tower (0.76), books (0.66), museum (0.57), memorial (0.50), mall (0.49), pub (0.46), university (0.41) | Civic Districts and Recreation Activities Before Working Hours |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Graells-Garrido, E.; Peredo, O.; García, J. Sensing Urban Patterns with Antenna Mappings: The Case of Santiago, Chile. Sensors 2016, 16, 1098. https://doi.org/10.3390/s16071098
Graells-Garrido E, Peredo O, García J. Sensing Urban Patterns with Antenna Mappings: The Case of Santiago, Chile. Sensors. 2016; 16(7):1098. https://doi.org/10.3390/s16071098
Chicago/Turabian StyleGraells-Garrido, Eduardo, Oscar Peredo, and José García. 2016. "Sensing Urban Patterns with Antenna Mappings: The Case of Santiago, Chile" Sensors 16, no. 7: 1098. https://doi.org/10.3390/s16071098