1. Introduction
Sleep is a physiological state comprising multiple stages. Electroencephalogram (EEG) analysis has indicated that typical patterns of activity are correlated with various stages of sleep, wakefulness, and certain pathophysiological processes, such as seizures. For many researchers, identifying sleep stages is important, for example, sleep stage identification is important sleep deprivation and seizure studies [
1,
2,
3,
4,
5]. Typically, sleep stages can be identified by combining EEG, electromyography (EMG), electrooculography (EOG), and visual behavioral monitoring. However, scoring these vigilance states manually is a time-consuming task, even when the analyzer is an expert.
The vigilance stages of rats are generally classified as three states [
6,
7,
8,
9]: the awake (AW) state, slow wave sleep (SWS) state, and rapid eye movement (REM) sleep state [
9]. During the AW state, the rats produced high-frequency EEG results. Several researchers have distinguished active awake from quiet awake based on high EMG activity. The spectrum of EEG in the AW state includes a high-power alpha wave (8–13 Hz) and gamma wave (20–50 Hz). The SWS state, which is defined by a high-amplitude and low-frequency EEG, begins with a sleep spindle and is dominated by a delta (0.5–4 Hz) wave. In the REM state, the rats produced high-frequency EEG results, which were similar to those produced in the AW state. However, the rats were atonic and demonstrated flat EMG activity. Alpha and gamma waves that display high activity are also characteristics of the REM state.
In our previous study [
9], we proposed a machine learning method to classify three vigilance stages of rats with a high accuracy rate. However, biological researchers are typically concerned with the crucial frequency bands used to classify these three vigilance states. The intuitive method used to extract crucial frequency bands is applying a feature selection algorithm to extract the features and identify the corresponding frequency bands based on these extracted features. To extract features, the EEG signal is first converted into frequency information by using fast Fourier transform (FFT) [
10,
11] (
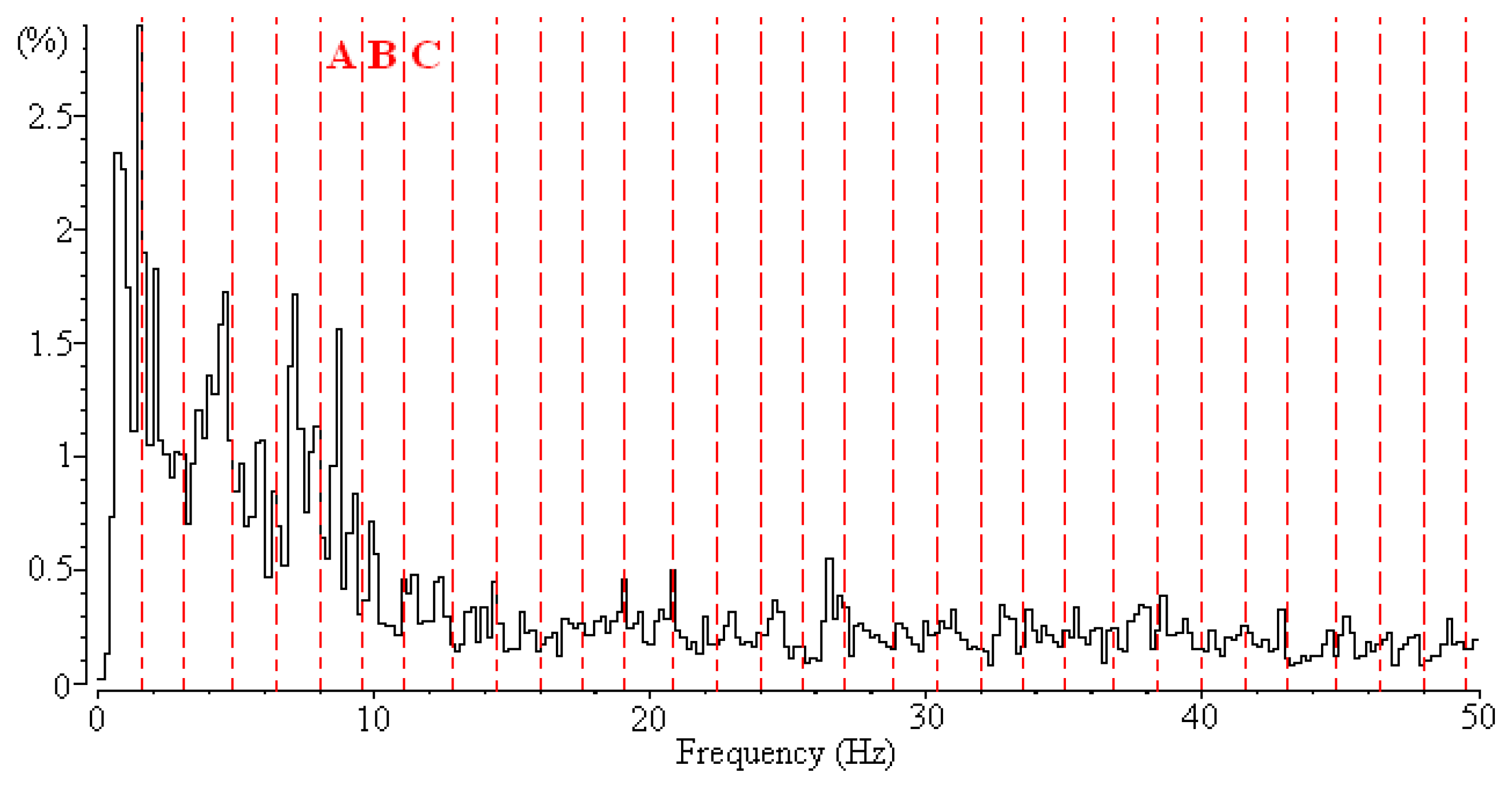
Figure 1). The EEG spectrum is generated using the FFT method with a frequency range from 0 to 50 Hz; then the EEG spectrum is uniformly divided into 32 nonoverlapping frequency bands (
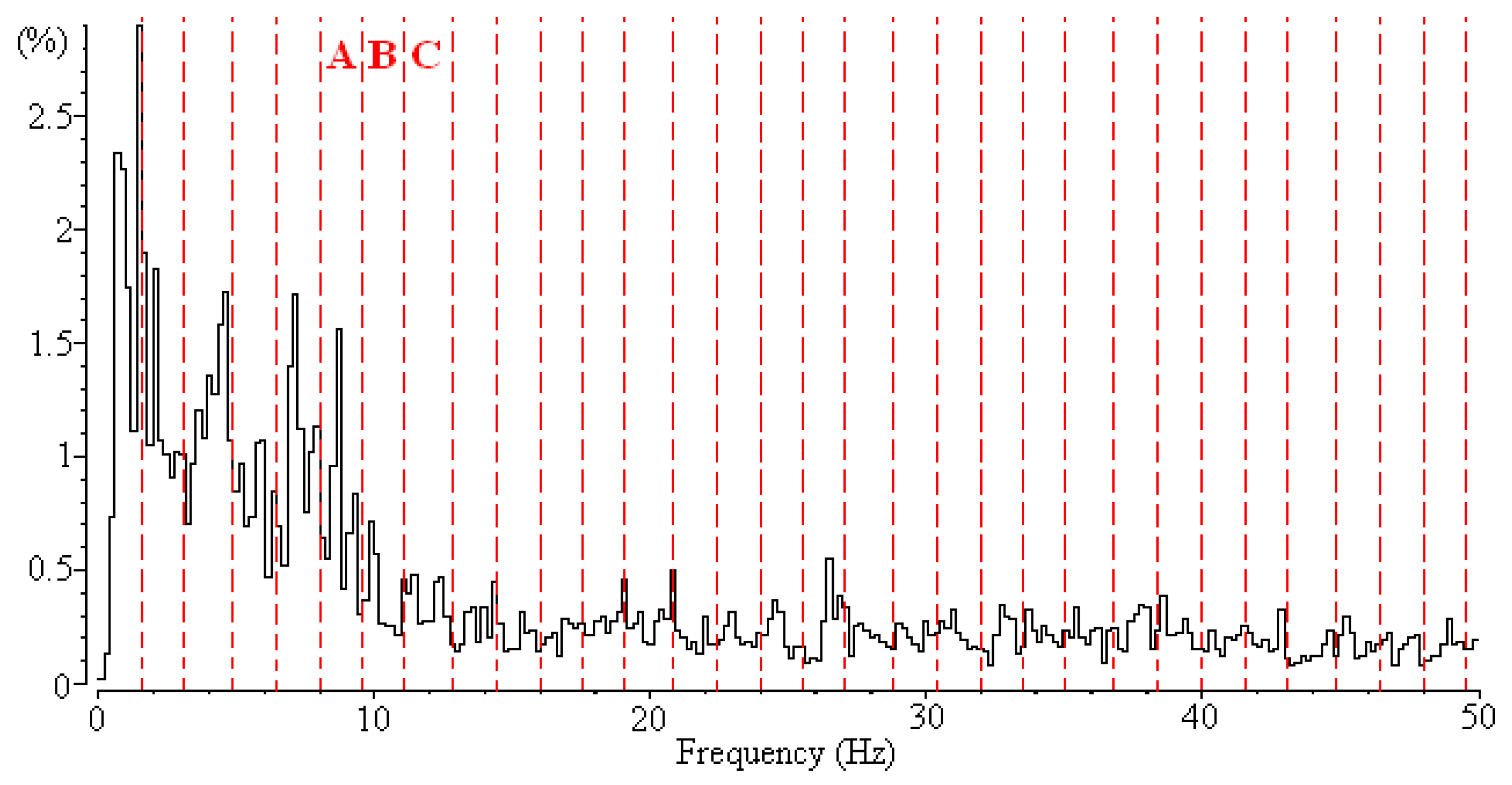
Figure 2). The frequency range of each frequency band is 1.6 Hz. The power of each frequency band is normalized according to the sum of the power of the frequency bands, and 32 numerical feature vectors are subsequently generated. A feature selection algorithm can then be used to extract a feature subset for classifying vigilance states. Examining the selected feature vectors in the feature subset reveals the crucial frequency bands.
Although a feature selection algorithm can be used to extract the crucial frequency bands of EEG signals, it creates a perplexed situation when applied to this problem. In the data set of EEG signals, each frequency feature vector may have a dependent relationship with neighboring feature vectors. For example (
Figure 2), the power of the alpha wave is the main characteristic used to classify vigilance states (e.g., the awake state), and the frequency bands A, B, and C belong to the alpha wave (8–13 Hz). Although these feature vectors (A, B, and C) denote different frequency bands, biological researchers have agreed that assuming that one feature vector is completely independent of the other two feature vectors is unreasonable. For example, if Feature B is selected as a crucial frequency band for identifying EEG signals, most biological researchers would agree that Features A and C are likely to be crucial frequency bands.
However, most feature selection algorithms are not designed for use in these types of scenarios; therefore, using these algorithms might produce unreasonable selection results. According to one of our simulation results, the information gain (IG) algorithm [
12] can be applied as the feature selection algorithm.
Figure 3 shows the feature subset selected by the IG algorithm. Eight feature vectors are selected. By examining the alpha wave, only Features A and C are selected by the IG algorithm, whereas Feature B is not selected. This means that the 8–9.6 Hz and 11.2–12.8 Hz frequency bands are important, but the 9.6–11.2 Hz frequency band is irrelevant. However, according the experience of biological researchers, the result makes it difficult to determine whether the alpha wave is the crucial frequency bands for identifying sleep stages.
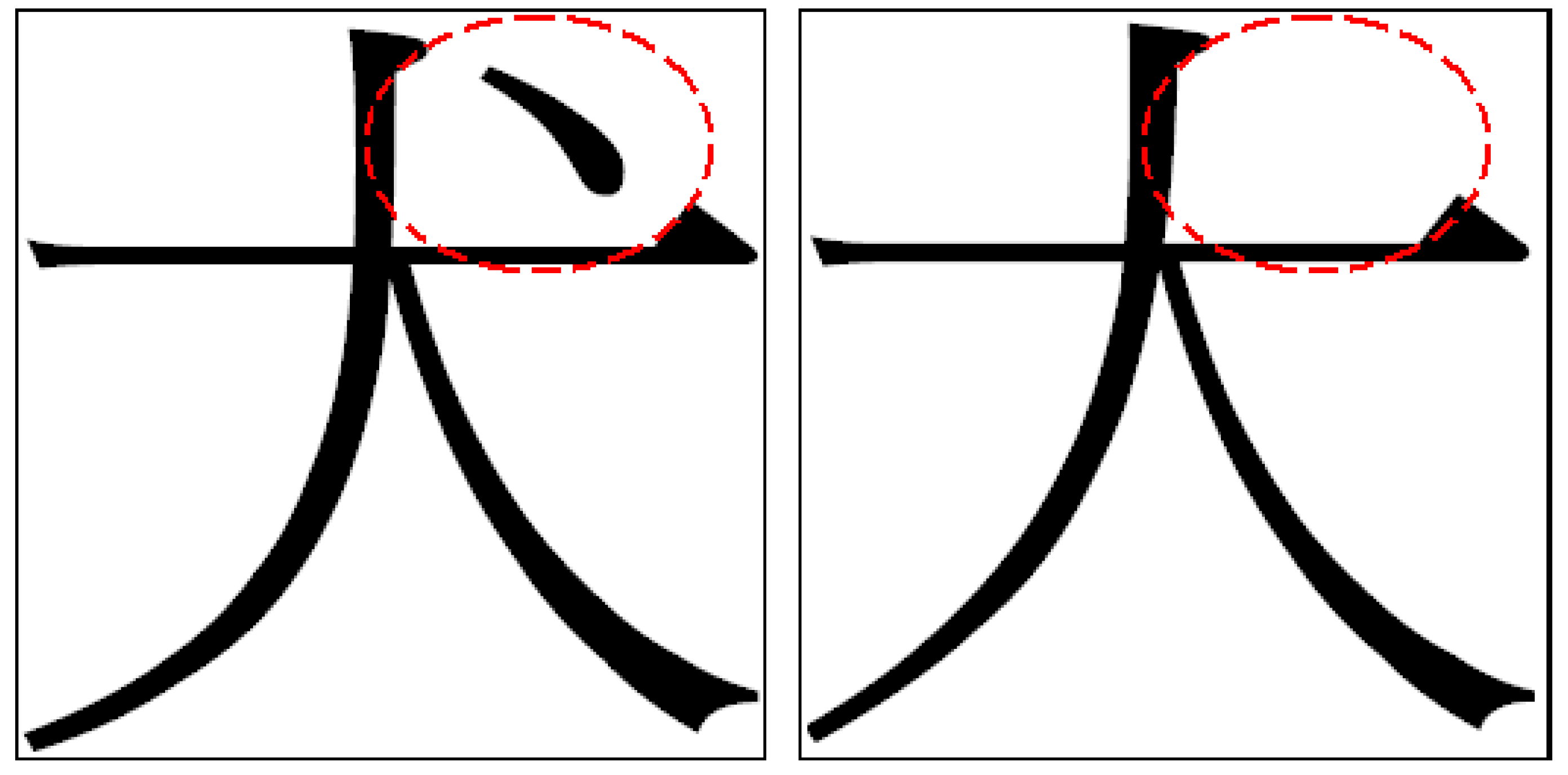
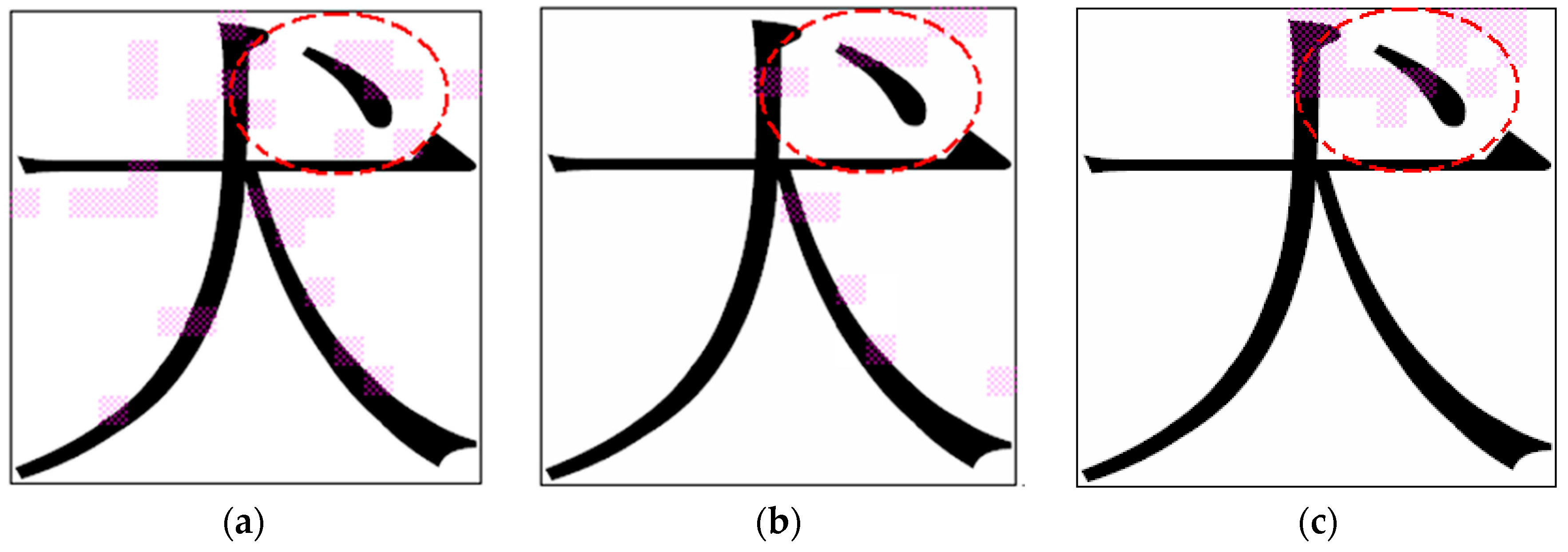
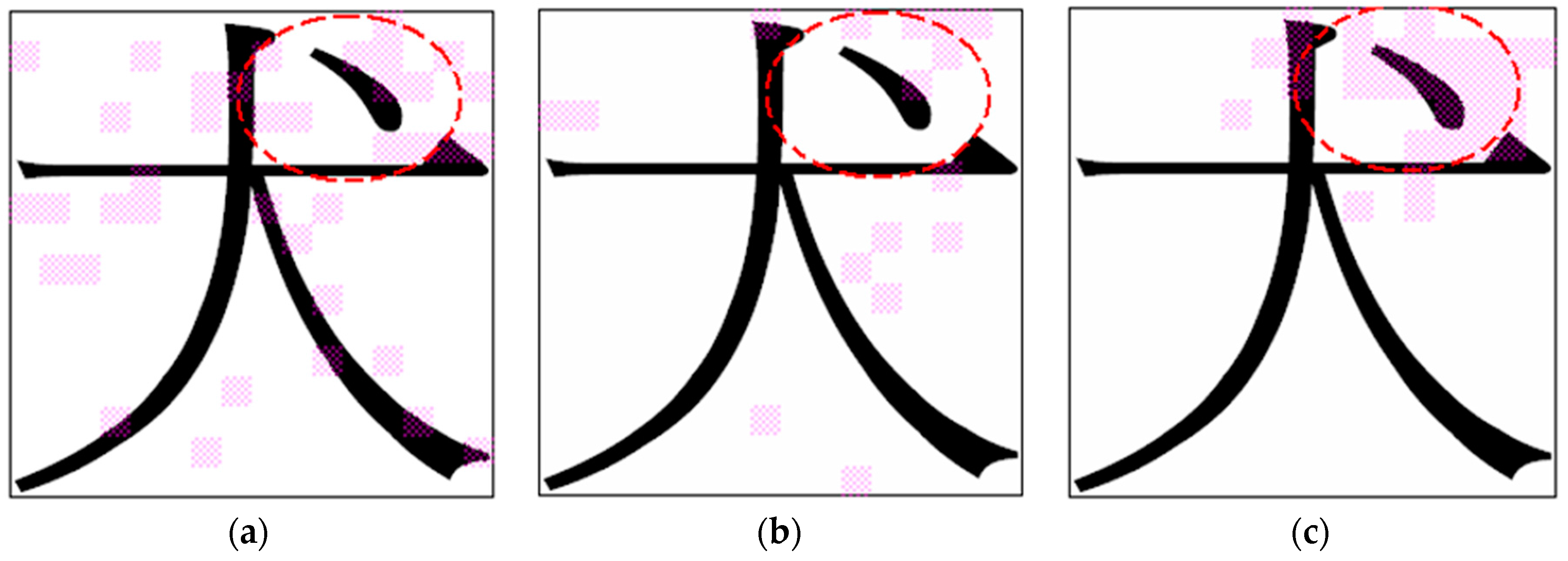
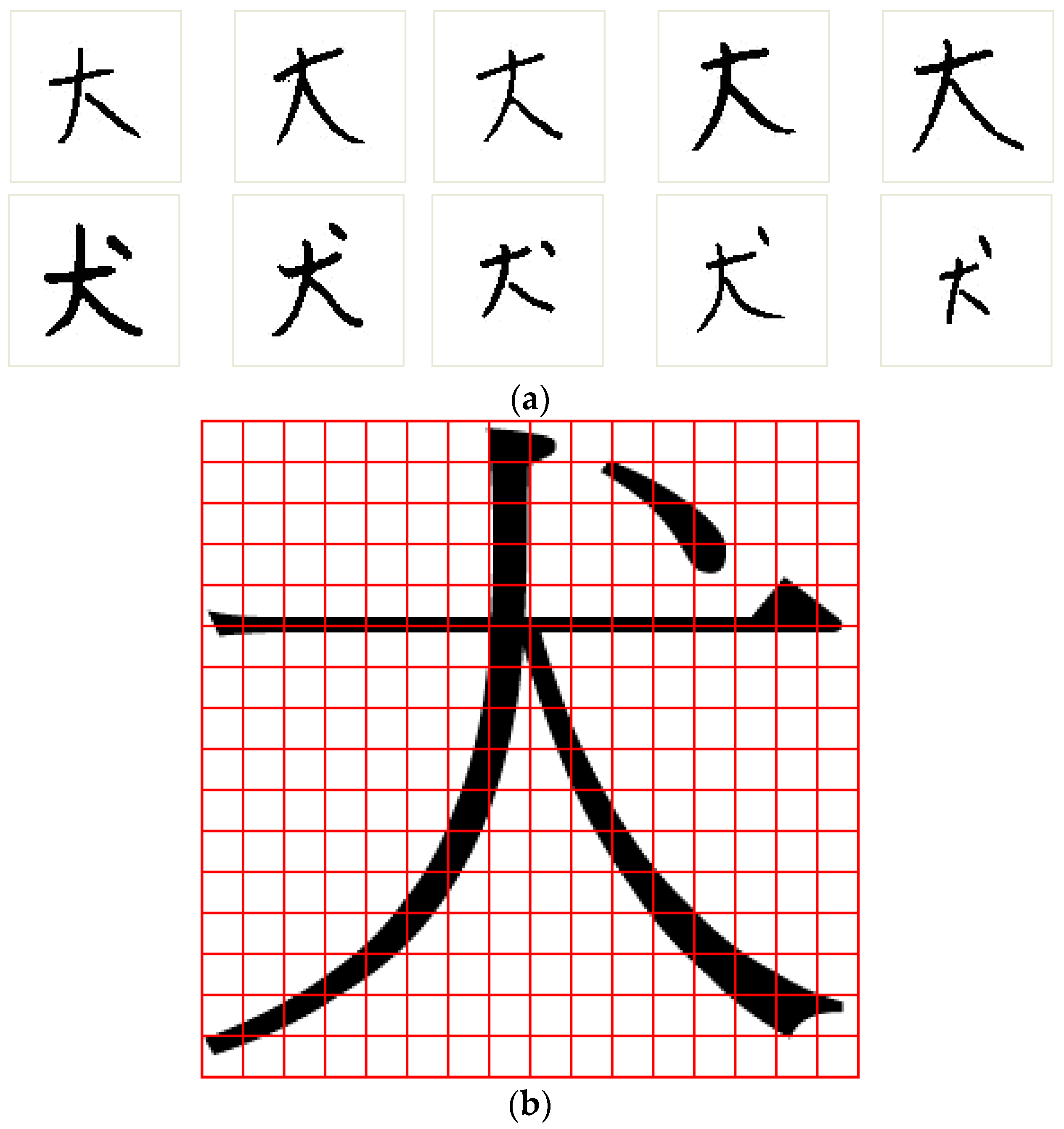
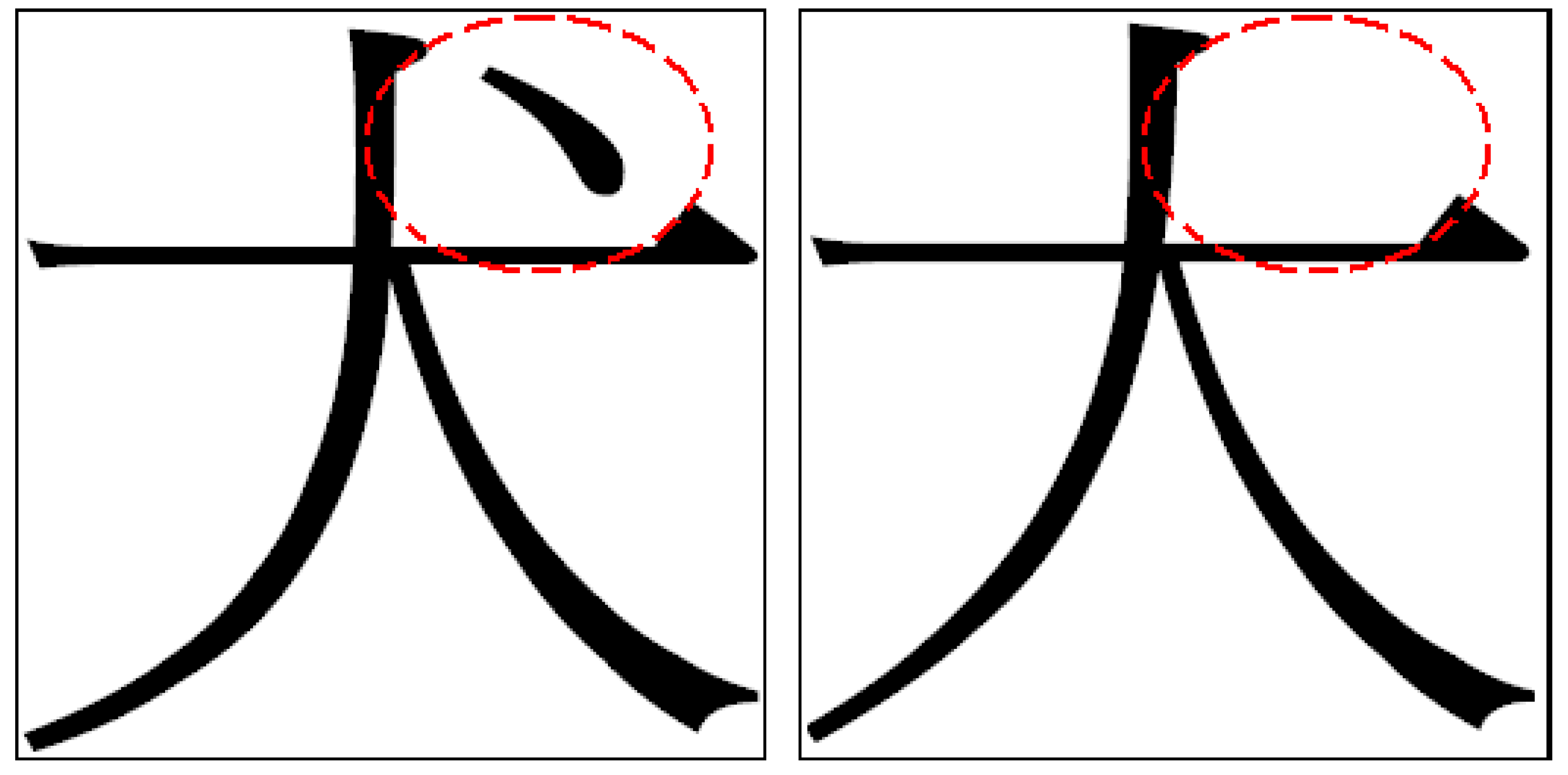
Regarding Chinese character recognition, a character image is typically normalized first using the nonlinear normalization technique and is then divided into several subimages. For each subimage, a numerical feature vector is obtained by calculating the specified image characteristics of this subimage. Each numerical feature vector represents the image information of the corresponding subimage in a character image. Similar to the feature vector of the EEG-signal data set, each Chinese-character feature vector has a dependent relationship with neighboring feature vectors (additional details are described in
Section 4.2). This situation may create more difficulties for applying a feature selection algorithm.
The aforementioned observations were the motivations of this study in which a novel feature selection scheme for EEG signal identification and Chinese character recognition is proposed. In the two applications, dependent relationships exist among the feature vectors and neighboring feature vectors. By applying the proposed algorithm, unselected feature vectors have a high priority of being added into the feature subset if the neighboring feature vectors have been selected. In addition, selected feature vectors have a high priority of being eliminated if neighboring feature vectors are not selected. Additional details are described in
Section 3. The remainder of this paper is organized as follows:
Section 2 presents a brief review of feature selection algorithms. In
Section 3, the proposed feature selection algorithm is presented.
Section 4 introduces the method for generating experimental data sets. In
Section 5, the experimental results are presented to demonstrate the effectiveness of the proposed algorithm. In
Section 6, the discussions of the proposed algorithm are given.
Section 7 concludes the paper.
2. Brief Review of Feature Selection Algorithms
A successful feature selection algorithm can extract specific features with which users are concerned [
13,
14,
15,
16,
17]. For example, researchers can identify the genes that may lead to certain diseases by using feature selection algorithms to analyze the microarray data [
13]. In analyzing DNA sequences, feature selection algorithms have been applied to locate segments on the sequence or identify types of amino acids [
14,
15]. Feature selection algorithms also facilitate the extraction of keywords in text classification [
16,
17].
Researchers have proposed numerous feature selection methods in recent years [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34]. Guyon and Elisseeff [
18] categorized feature selection algorithms as wrappers, filters, and hybrid algorithms. The following discussion provides a brief introduction on these feature selection algorithms.
Filters: In the filters method, the importance of the features is ranked according to statistical criteria or information-theoretic criteria [
19,
20,
21,
22]. IG or the X2 statistic is typically used to extract the features in text categorization [
21,
22].
Wrappers: The wrappers method involves the extraction of the optimal feature subset by adopting a specific searching strategy and performing continual evaluations [
23,
24,
25,
26]. These strategies include the sequential floating search [
23], adaptive floating search [
24], branch and bound [
25], and genetic algorithm [
26] methods.
Hybrid: The hybrid method extracts several feature subsets by combining both filters and wrappers using an independent feature evaluation method. In addition, the optimal feature subset is extracted by processing the classification algorithm. This strategy is performed repeatedly until obtaining any more favorable feature subsets is not possible [
27,
28].
Information Gain (IG) [
12] is a general feature selection algorithm for evaluating the measurement of informational entropy, it measures decreases in entropy when the feature value is given. This method is widely applied in applications of text categorization and classification of microarray data. On the other hand, the sequential forward floating search (SFFS) algorithm [
23] is also a well-known method. The SFFS algorithm starts with an empty feature set. In each step, the best feature that satisfies some criterion function is included with the current feature set. In addition, while some feature is excluded, the SFFS algorithm also verifies the possibility of improving the criterion. Therefore the SFFS algorithm proceeds dynamically increasing and decreasing the number of features until the desired target is reached. In this paper, we compared the IG and SFFS algorithms with our method.
3. The Proposed Neighborhood-Relationship Feature Selection Algorithm
This section presents the proposed neighborhood-relationship feature selection (NRFS) algorithm, which consists of two main stages: adding features and eliminating features. The SFFS algorithm [
23] was applied to generate an initial feature subset from the original feature set. At Stage 1 of the NRFS algorithm, the weight value of each unselected feature is calculated according to neighboring selected features. Subsequently, unselected features are added into the feature subset iteratively based on their weight value to generate a more favorable feature subset. At Stage 2 of the NRFS algorithm, a new weight value for each selected feature is calculated, and selected features are subsequently eliminated based on the new weight value. To evaluate the recognition rate of the selected feature subset, the classification method used in this study for the authentication method was the k-nearest neighbor (
kNN) method [
35,
36]. The steps of the NRFS algorithm are described in detail as follows.
Use the SFFS algorithm to generate the initial feature subset for the NRFS algorithm.
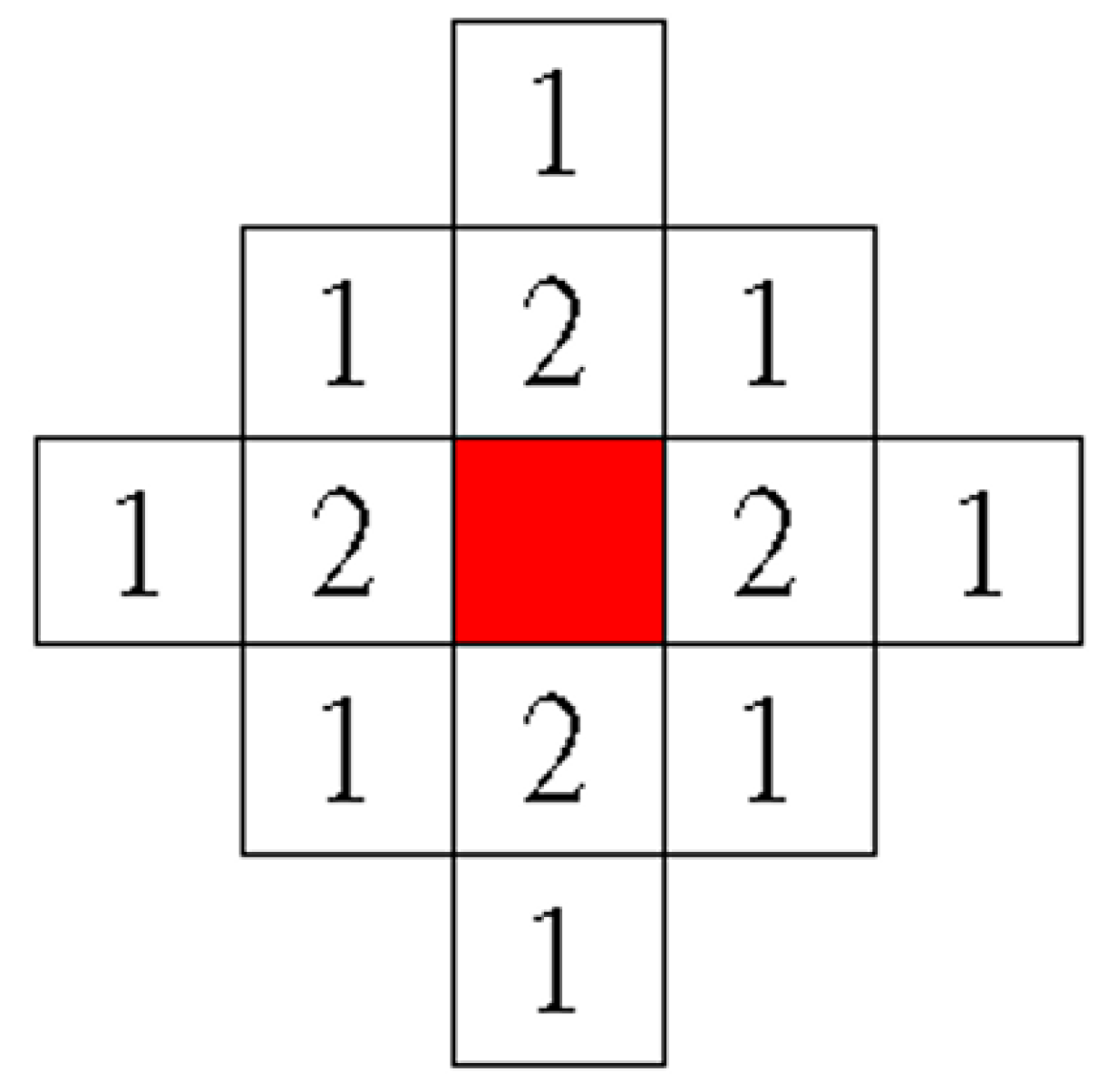
To add the unselected features (the candidate features for being added) into the feature subset, the weight value of each unselected feature should first be calculated to represent the number of neighboring features that have been selected.
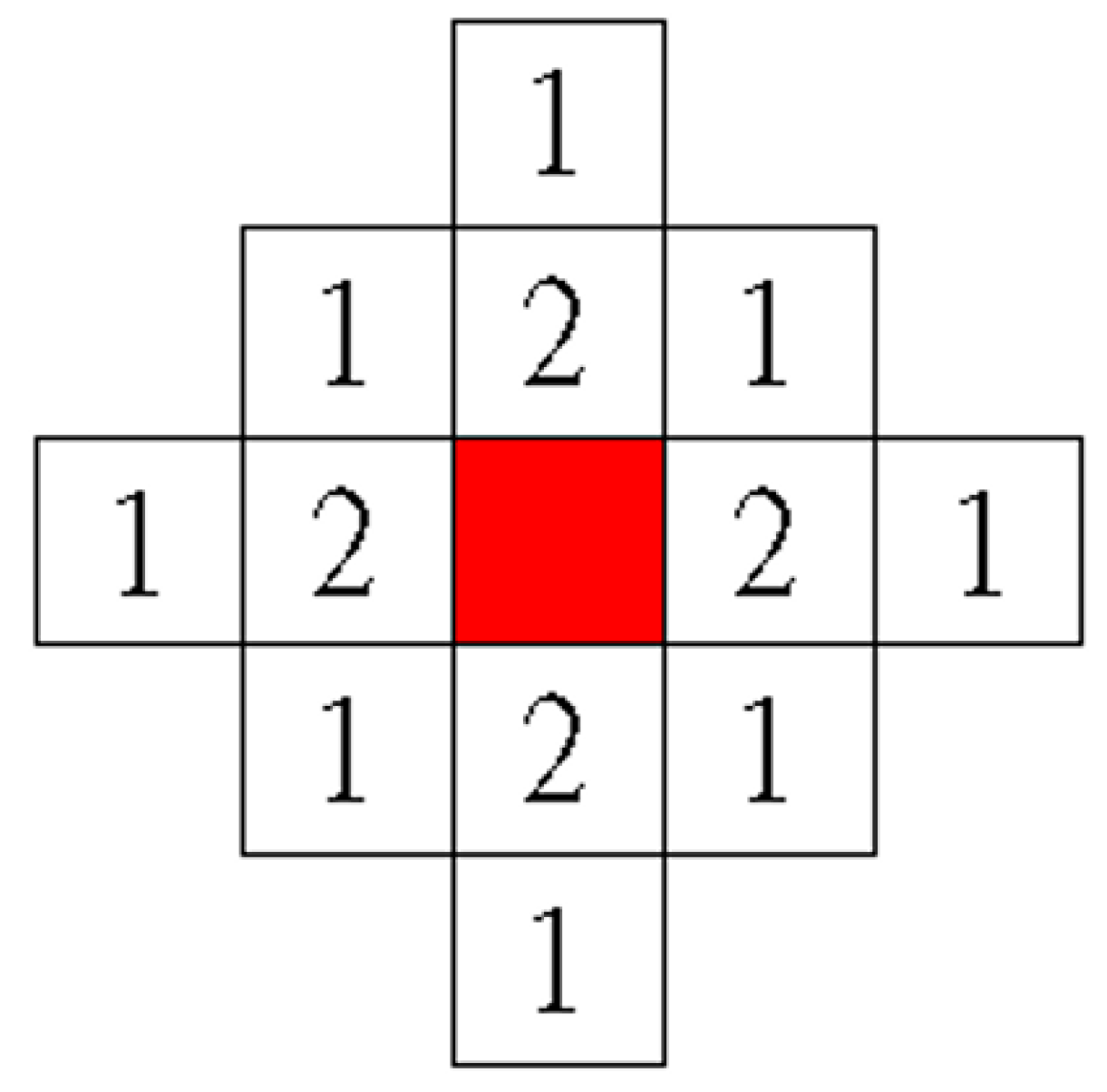
Figure 4 shows the diagram of the weight values applied in this study. The red block in this figure denotes a feature that has been selected in the feature subset, and the neighboring unselected features are represented by the white blocks. The unselected features are assigned weight values (1 or 2) when they are located in the neighborhood of the selected feature (red block).
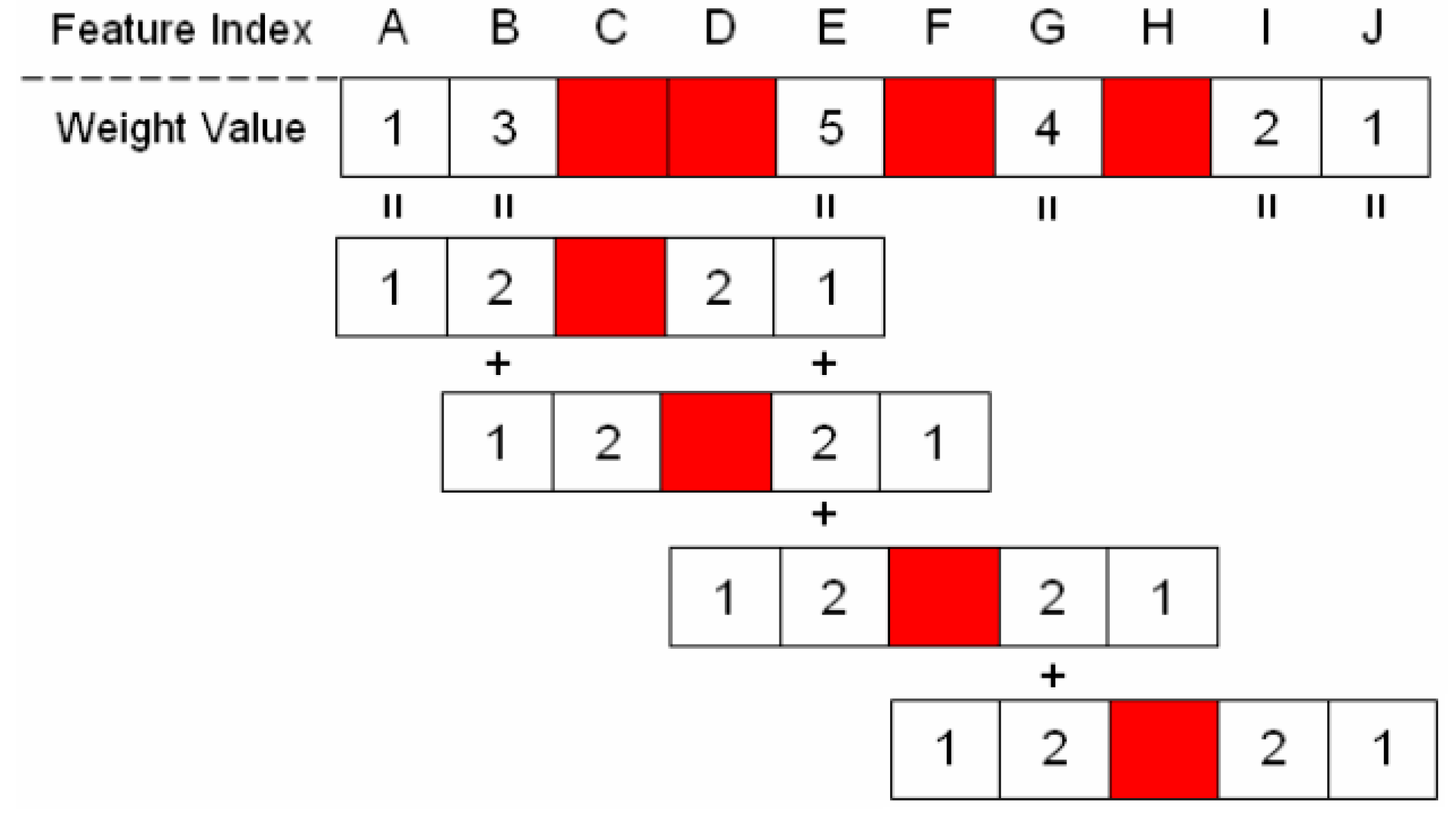
Figure 5 shows an example calculation of the weight value of these unselected features. In this example, four features (feature indices C, D, F, and H) were selected in the feature subset. Subsequently, each unselected feature accumulated weight values that were based on neighboring selected features. As shown in
Figure 5, Feature E obtained the highest weight value of 5 because it accumulated the weight values of three neighboring selected features (Features C, D, and F), whereas Feature J exhibited a weight value of only 1, which was obtained from the selected Feature H.
In this step, sequentially add unselected features to the feature subset according to their weight values. An unselected feature with a high weight value has a high priority of being added.
Table 1 shows the ranking of the unselected features in
Figure 5. The example in
Table 1 shows that Feature E was the first feature to be added to the feature subset. If the recognition rate of the new feature subset can be improved or remains equal to the original recognition rate, then Feature E is added to the feature subset. Subsequently, proceed to Step 2 to recalculate the weight values. Otherwise, the next unselected feature is added, depending on its ranking. If no features can be added at this step, then go to Step 4.
At this step, to explore additional feature subset combinations, sequentially add two unselected features to the feature subset in each trial. Following the example in
Table 1, create all possible combinations of any two unselected features and calculate the sum of their weight values. Because the amount of possible combinations of any two unselected features may be too numerous, we set a threshold T
Add to filter the combinations. If the weight-value sum of two selected features is larger than the threshold T
Add (the threshold T
Add was 7 in this study), then this combination of two features is a candidate combination for being added. As
Table 2 shows, the weight sums of three combinations exceed the threshold T
Add. In this scenario, sequentially add the unselected features of each combination to the feature subset. If the recognition rate of the new feature subset can be improved, or remains the same as the original recognition rate, then add the two features comprising the test combination to the feature subset. Subsequently, proceed to Step 2 to recalculate the weight values. Otherwise, add the next combination, depending on its ranking. If no features can be added at this step, go to Step 5.
Before eliminating the selected features from the feature subset, recalculate the weight values of these candidate features. At this step, calculate only the weight values of the selected features for elimination in the following step. The calculation method applies the same diagram of weight values shown in
Figure 4.
Figure 6 shows an example of the method used to calculate the weight values of these selected features. In this example, five features (feature indices C, D, E, F, and H) were selected in the feature subset. Each selected feature exhibited a weight value that was based on neighboring selected features. For example, Feature D exhibited the highest weight value of 5 because it accumulated the weight values of three neighboring selected features (Features C, E, and F), whereas Feature H exhibited a weight value of only 1, which was obtained from the selected Feature F.
At this step, sequentially eliminate selected features from the feature subset if they have low weight values.
Table 3 lists the ranking of the selected features shown in
Figure 6. In the example shown in this table, Feature H was the first candidate feature for elimination from the feature subset. If the recognition rate of the new feature subset can be improved by eliminating this feature, then Feature H is removed from the feature subset. Otherwise, the next selected feature is removed, depending on its ranking, and the recognition rate is examined again. If no features can be eliminated in this step, go to Step 7.
Similar to Step 4, sequentially eliminate two selected features from the feature subset in each trial of this step. Following the example in
Table 3, create all possible combinations of any two selected features and calculate the sum of their weight values. Subsequently, examine whether the weight-value sum of the two selected features is smaller than the threshold TDel (which was 3 in this study). In this scenario, the sum of Features C and H was smaller than the threshold TDel. Attempt to eliminate the selected Features C and H, and then examine the recognition rate. If the recognition rate of the new feature subset can be improved, eliminate the two features comprising the test combination from the feature subset and perform Step 5 to recalculate the weight values. If no other features can be eliminated at this step, then end the NRFS algorithm.
6. Discussion
In Experiment A-1, the NRFS algorithm was applied to select the critical frequency bands in classifying three vigilance stages of rats. Finally, the frequency bands of the selected feature vectors were at alpha band (8–12.8 Hz) and lower gamma band (22.4–35.2 Hz) for these two main regions. According to research results of Westbrook [
6] and Louis
et al. [
8], they considered that the major difference of spectrum pattern in the delta (0.5–4 Hz), alpha (8–13 Hz), and gamma (20–50 Hz) bands were the key features for classifying three vigilance stages. In addition, they also suggest distinguishing active awake from quiet awake by observing high EMG activity. Compared with their research results, the NRFS algorithm selected feature vectors at alpha and gamma bands, however, it did not select any feature vector at delta band. To explain this result, we have following observations.
The proposed NRFS algorithm uses the SFFS algorithm to generate the initial feature subset. If the initial feature subset does not include any feature vector in the delta band, the NRFS algorithm usually cannot have a change to extract any feature vector from the delta band. This means the performance of the NRFS algorithm is sensitive to its initial feature subset.
By further examining the data patterns in the EEG signal dataset, in the REM state, the data patterns have high amplitude in the lower gamma band. Additionally, in the lower gamma band, the data patterns show median amplitude for the AW state and show lower amplitude for the SWS state, respectively. It means that the feature vectors at the low gamma band can be the key features to identify three vigilance stages. To our collected EEG-signal data set, when the NRFS algorithm selects enough feature vectors from the lower gamma band into the feature subset, this feature subset can usually achieve a high accuracy rate. This situation also reduces the possibility to select feature vectors in the delta band for the NRFS algorithm.
Although the NRFS algorithm achieves good performance in identifying the crucial frequency band for classifying vigilance stages, however, in this paper, the EEG-signal data set was collected by a single rat. As a result, the generalizability of the NRFS algorithm is limited. In the future, we would collect more EEG-signal data sets to further examine the performance of the NRFS algorithm.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}