
Scene-Level Geographic Image Classification Based on a Covariance Descriptor Using Supervised Collaborative Kernel Coding

Abstract
:1. Introduction
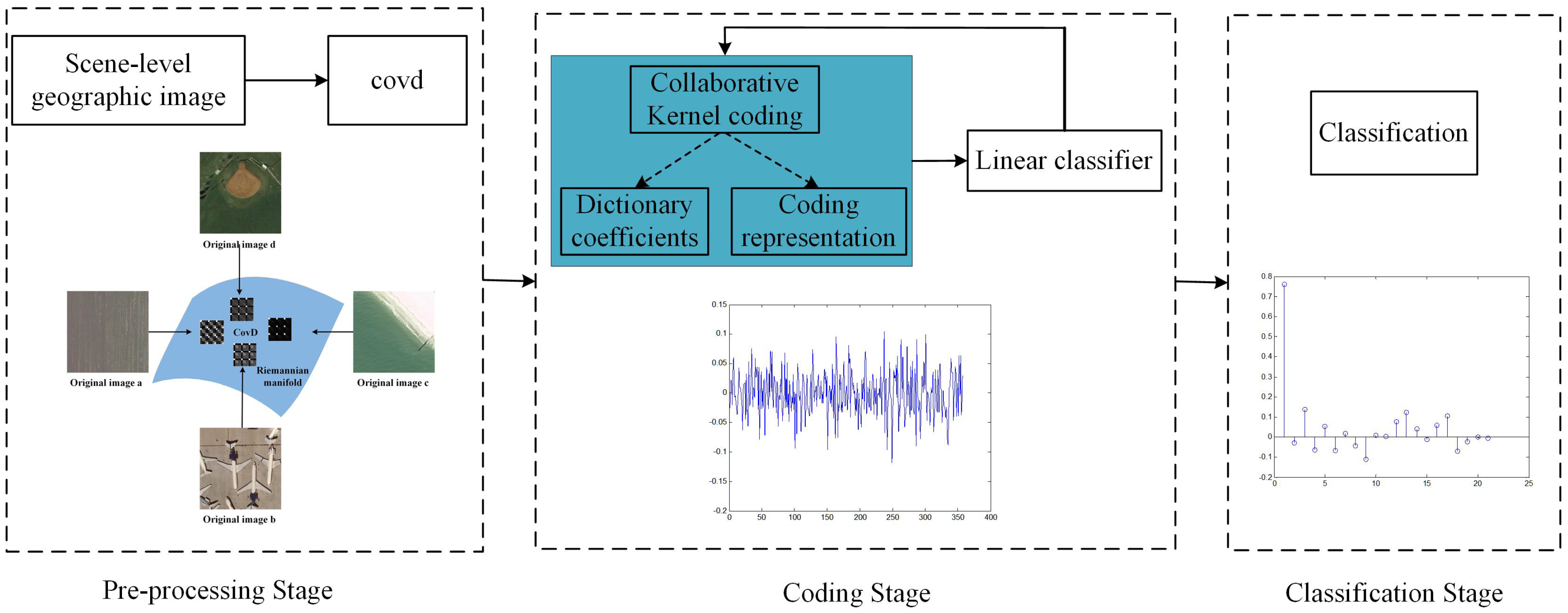
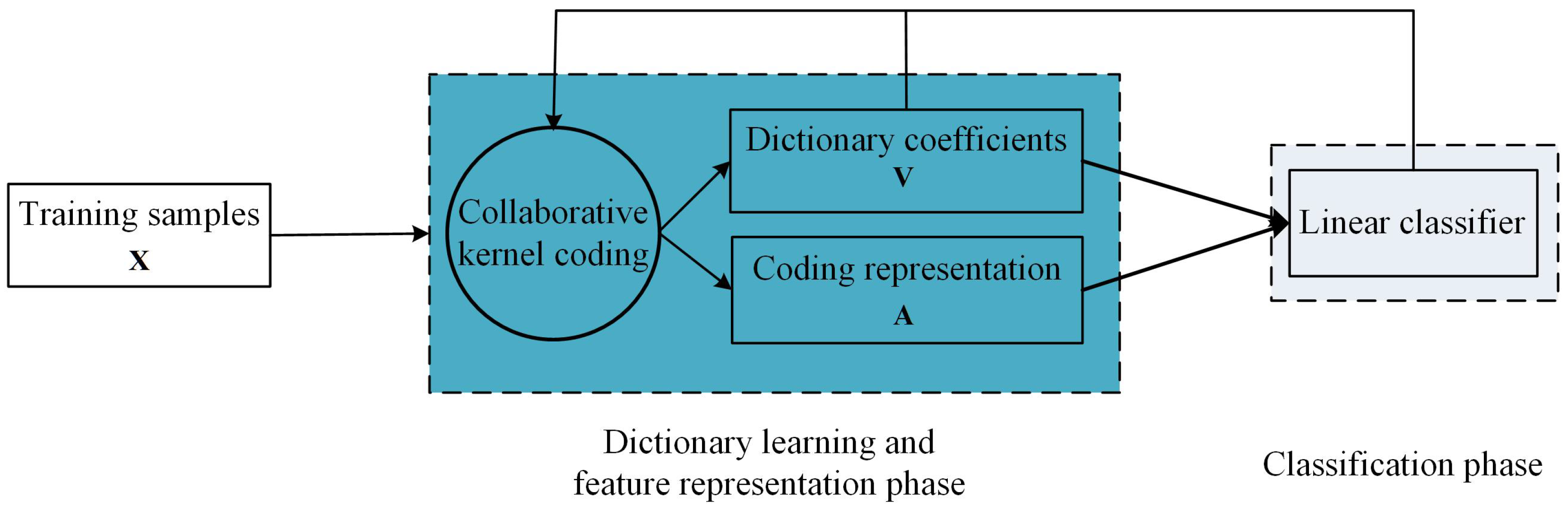
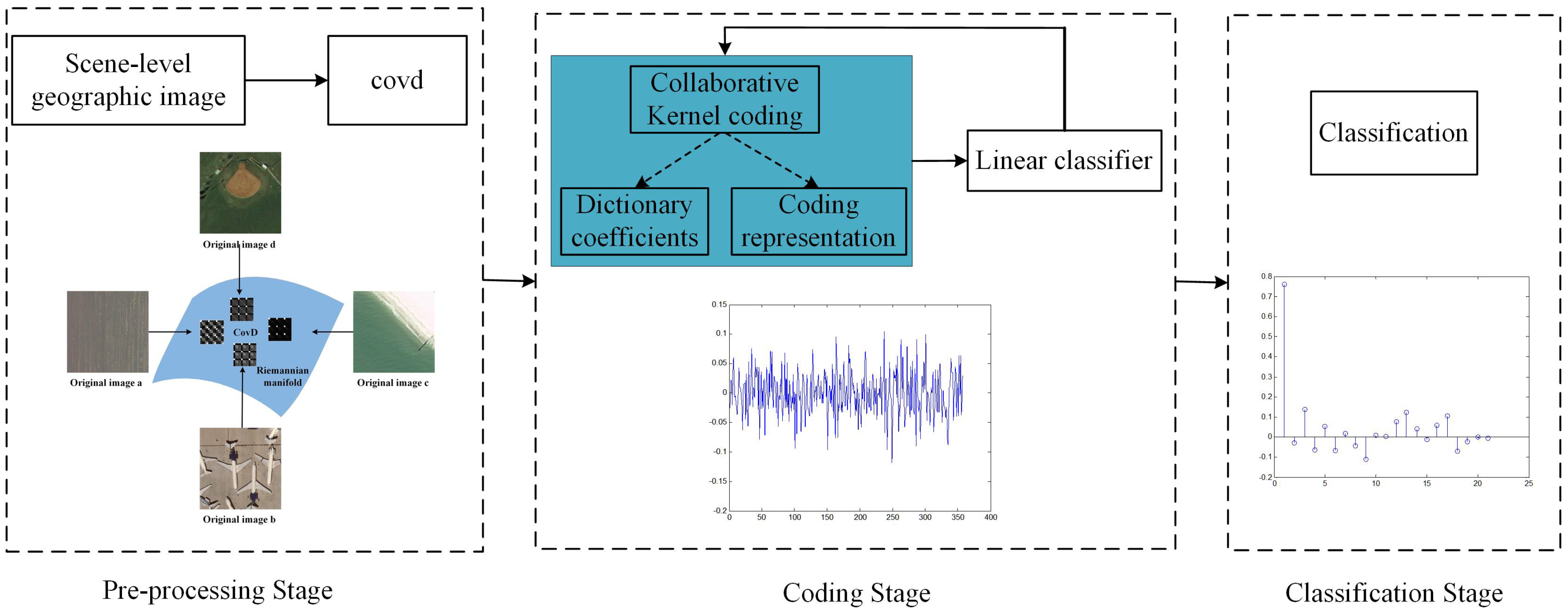
- A supervised collaborative kernel coding model, illustrated in Figure 2, is proposed. This model can not only transform the covd to a discriminative feature representation, but also can obtain the corresponding linear classifier.
- An iterative optimization framework is introduced to solve the supervised collaborative kernel coding model.
- Experiments on public high-resolution aerial image dataset validate that the proposed supervised collaborative kernel coding model derives a satisfying performance on the scene-level geographic image classification.
2. Overview of the Methodology
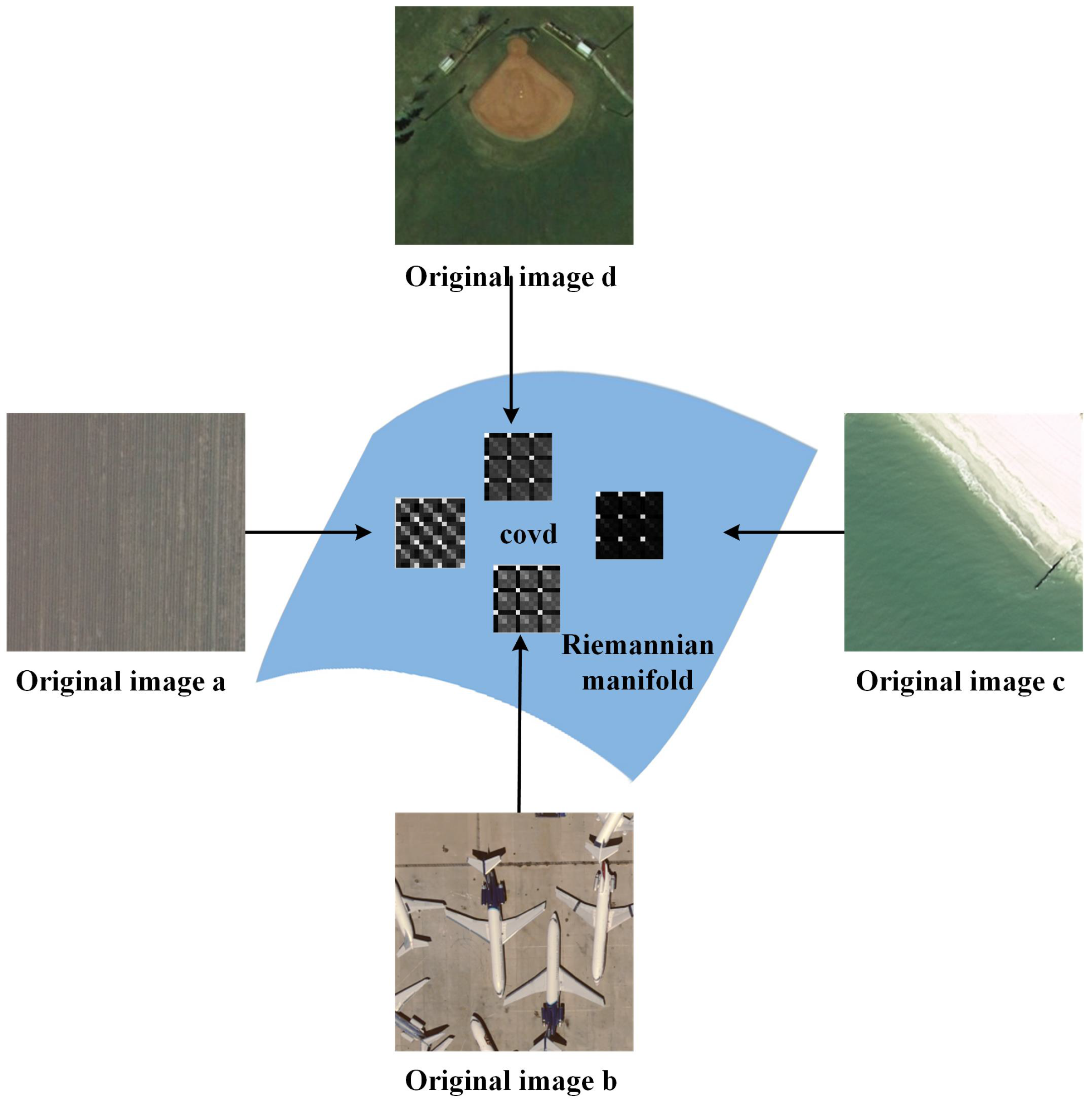
2.1. Covariance Descriptor
2.2. Supervised Collaborative Kernel Coding Model
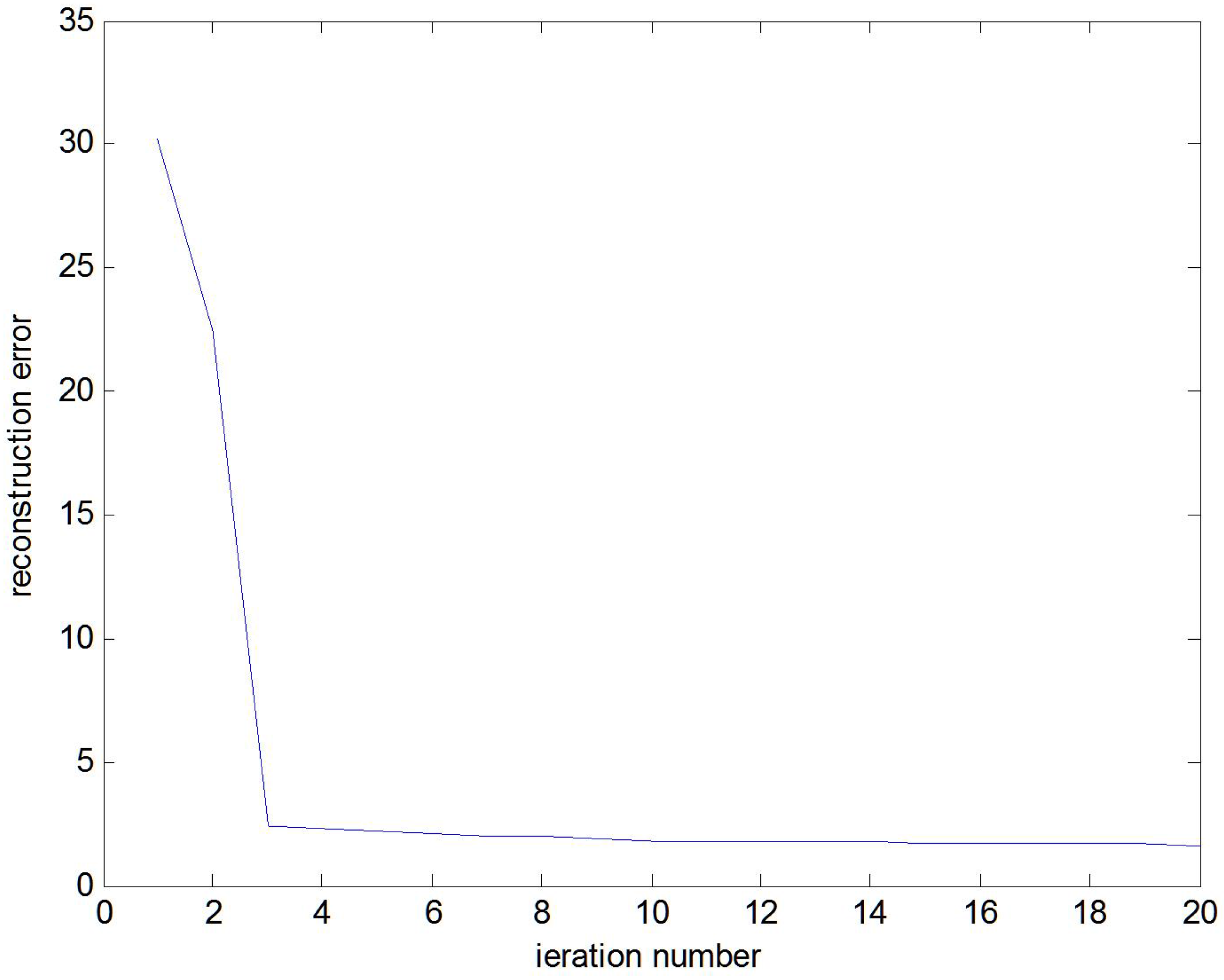
3. Optimization Algorithm
| Algorithm 1. The Iteration Optimization Procedure. |
| : |
| : |
| , , |
| 1. Initialization: Randomly set with appropriate dimensions and obtain initial according to Equation (8). |
| 2. Not convergent |
| 3. Fixing , update according to Equation (10) |
| 4. Fixing and , update according to Equation (12) |
| 5. Fixing and , update according to Equation (14) |
| 6. |
4. Experiments
4.1. Dataset and Experiment Setup
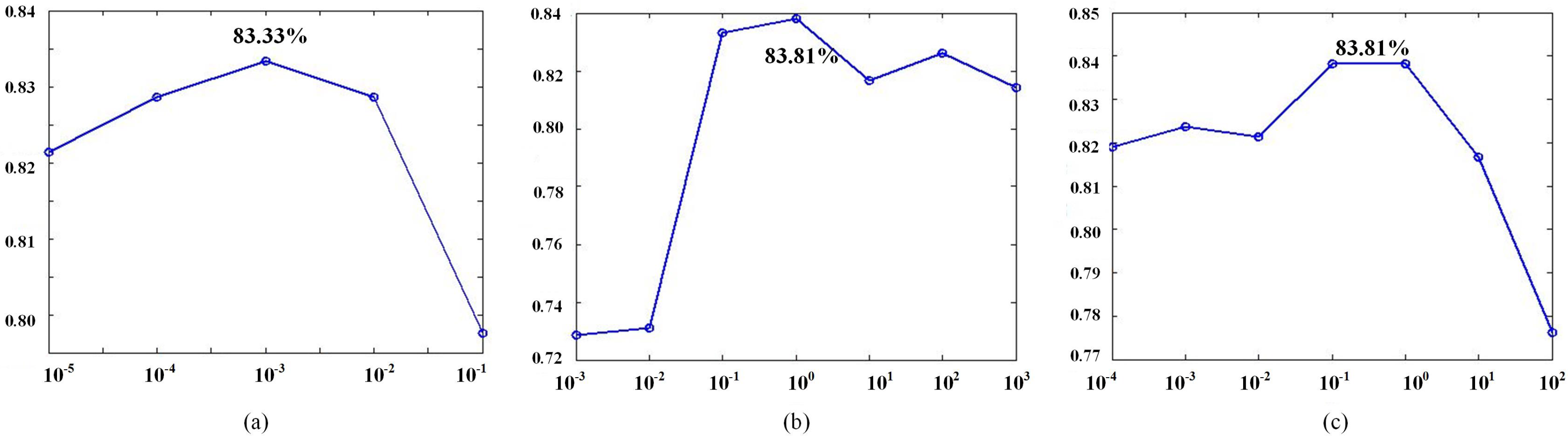
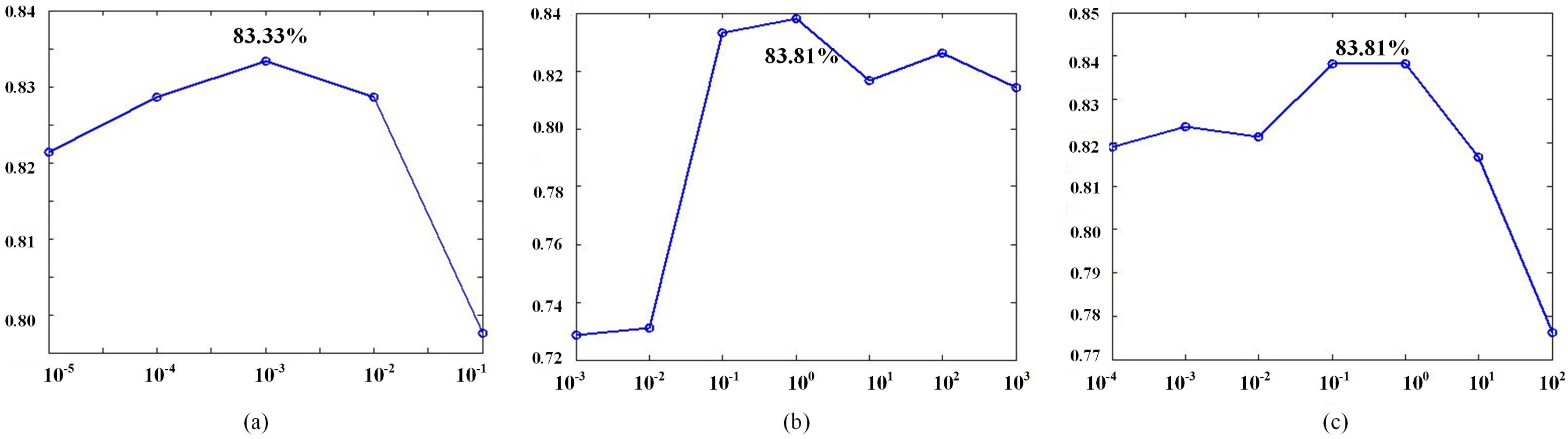
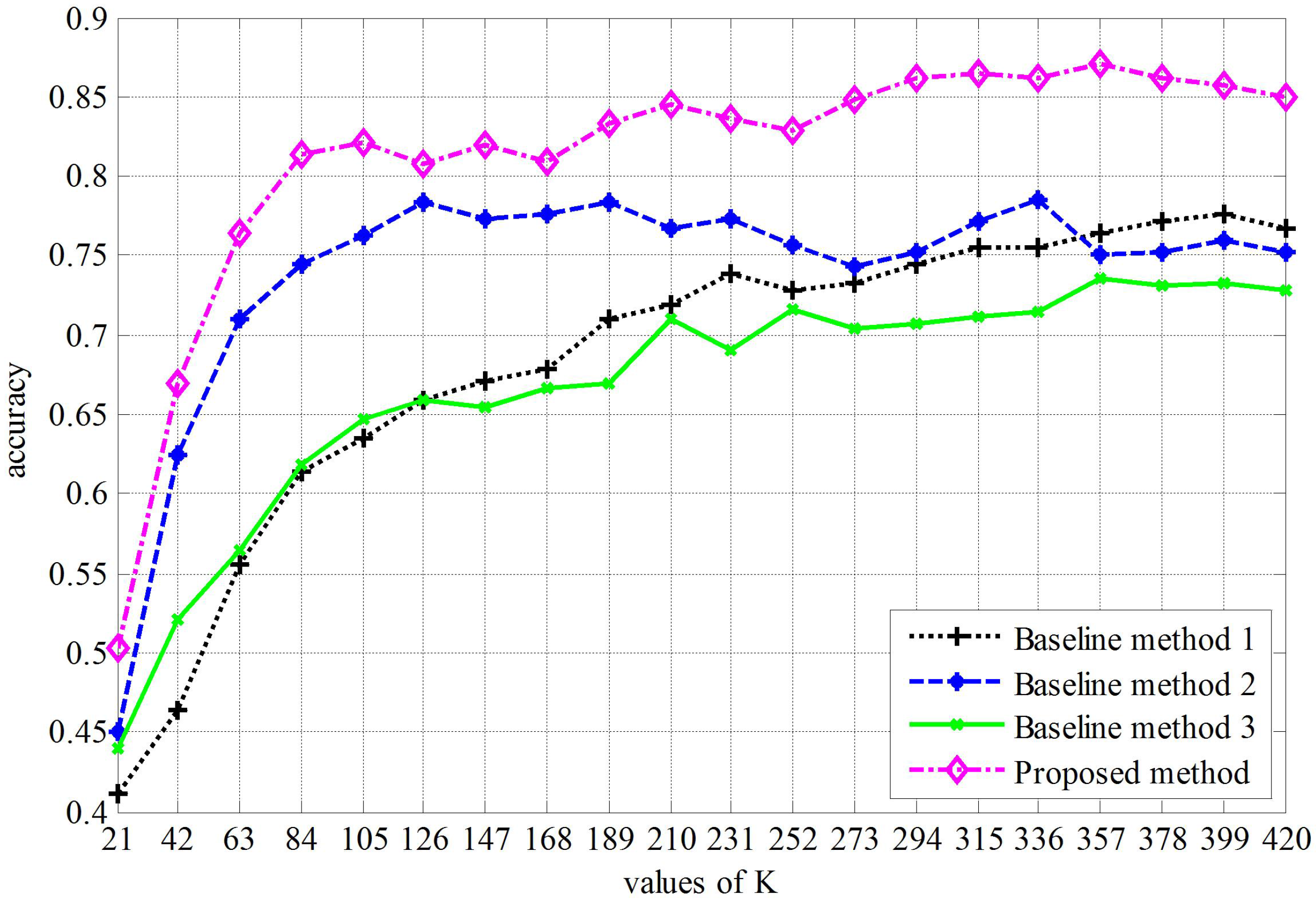
4.2. Parameter Analysis
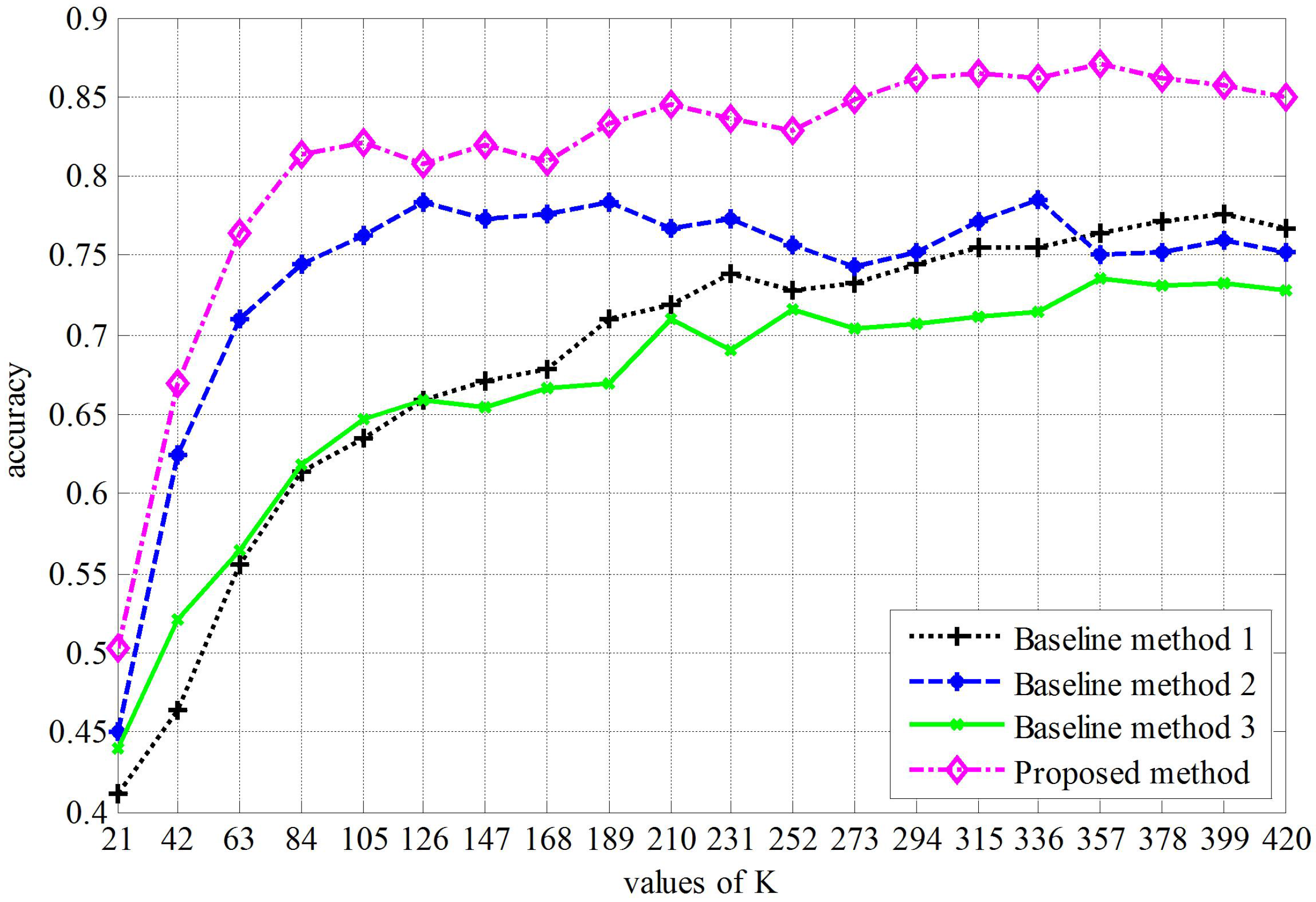
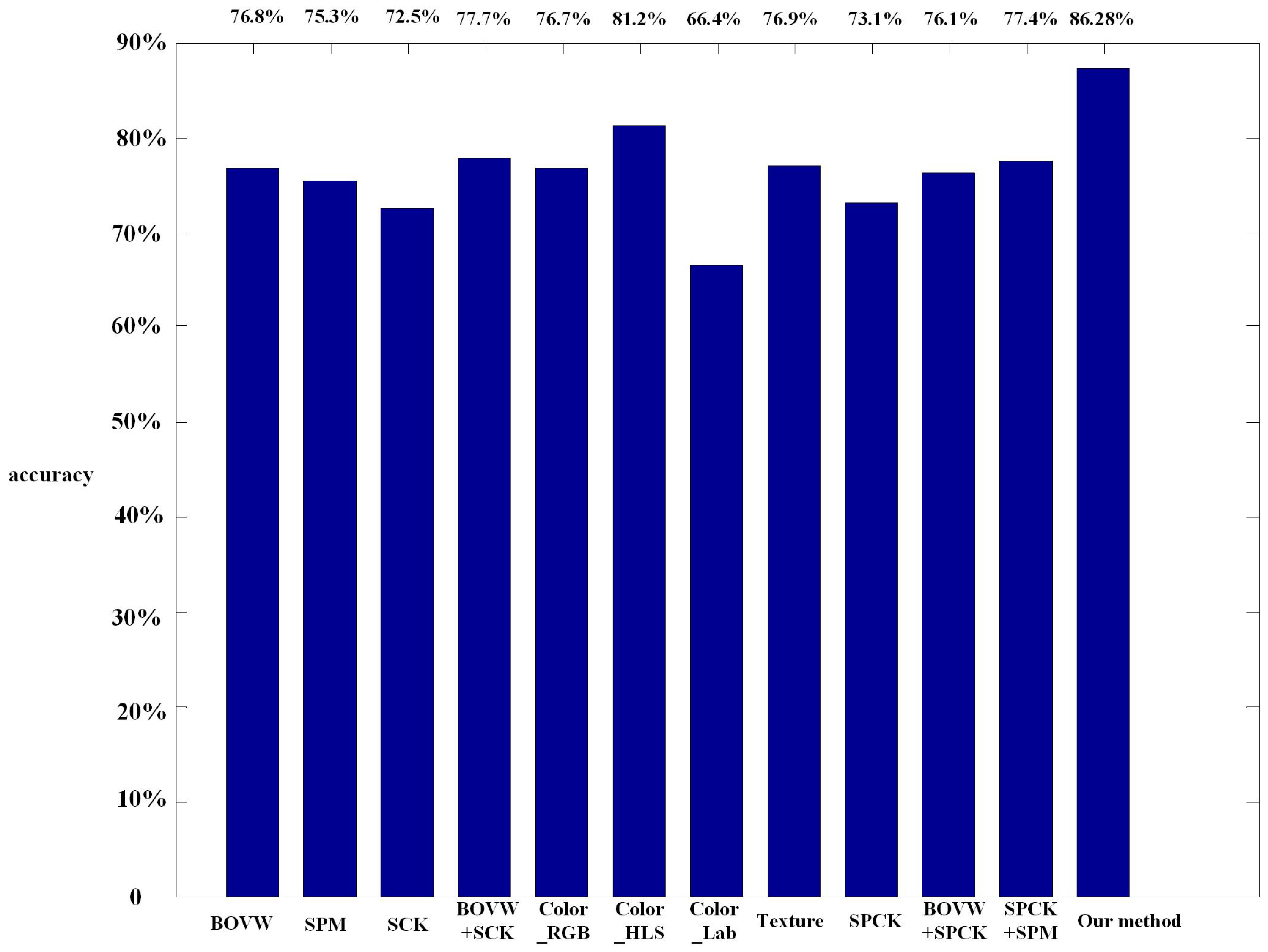
4.3. Experiment Results and Comparison
- This method isolates the feature representation and classification process, which means that is used as the feature representation and that is used as the linear classifier.
- This method is the same as the proposed method, except that the covd is established based on image intensities and the magnitude of the first and second gradients. Namely, and .
- This method is the same as baseline Method 1, except that the covd is a 9 × 9 matrix, which is the same as baseline Method 2.
- Our approach is always better than the three baseline methods, and when , our approach obtains the best performance ().
- Comparing to baseline Method 1, our proposed method obtains a higher classification accuracy, which indicates the effectiveness of the optimization algorithm.
- Comparing the proposed method to baseline Method 2, the only difference is the covd. The former uses a 15 × 15 matrix, which is a covariance format of intensity of each channel and the norms of the first and second gradients of intensities, while the covd of the latter is a 9 × 9 covariance format of the intensity of each channel and the magnitude of the first and second gradients. It is clear that both covds are not rotationally invariant, especially that the former covd is not direction invariant. However, the proposed method obtains a higher classification accuracy. This may indicate that the covariance format offsets the rotations to some extent.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279.
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the 7th IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1465–1472.
- Xu, S.; Fang, T.; Wang, S. Object classification of aerial images with bag-of-visual words. IEEE Geosci. Remote Sens. Lett. 2010, 7, 366–370. [Google Scholar]
- Aksoy, S.; Koperski, K.; Tusk, C.; Marchisio, G.; Tilton, J.C. Learning bayesian classifiers for scene classification with a visual grammar. IEEE Trans. Geosci. Remote Sens. 2005, 43, 581–589. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Trans. Geosci. Remote Sens. 2013, 51, 818–832. [Google Scholar] [CrossRef]
- Schroder, M.; Rehrauer, H.; Seidel, K.; Datcu, M. Interactive learning and probabilistic retrieval in remote sensing image archives. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2288–2298. [Google Scholar] [CrossRef]
- Shyu, C.; Klaric, M.; Scott, G.J.; Barb, A.S.; Davis, C.H.; Palaniappan, K. GeoIRIS: Geospatial information retrieval and indexing system-content mining, semantics modeling and complex queries. IEEE Trans. Geosci. Remote Sens. 2000, 45, 839–852. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.; Madden, M.; Warner, T.A. Forest type mapping using object-specific texture measures from multispectral Ikonos imagery: Segmentation quality and image classification issues. Photogramm. Eng. Remote Sens. 2000, 75, 819–829. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, L.; Neggaz, N.; Wang, S.; Wei, G. Remote-sensing image classification based on an improved probabilistic neural network. Sensors 2009, 9, 7516–7539. [Google Scholar] [CrossRef] [PubMed]
- Cheriyadat, A. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Du, P.; Xia, J.; Zhang, W.; Tan, K.; Liu, Y.; Liu, S. Multiple classifier system for remote sensing image classification: A review. Sensors 2012, 12, 4764–4792. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRC J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Li, J.; Du, Q.; Li, W.; Li, Y. Optimizing extreme learning machine for hyperspectral image classification. J. Appl. Remote Sens. 2015, 8, 097296:1–097296:13. [Google Scholar] [CrossRef]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the ECCV International Workshop on Statistical Learning in Computer Vision, Prague, Czech Republic, 11–14 May; 2004. [Google Scholar]
- Cao, Y.; Wang, C.; Li, Z.; Zhang, L.Q.; Zhang, L. Spatial-bag-of-features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3352–3359.
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178.
- Yang, J.; Yu, K.; Gong, Y.; Huang, T. Linear spatial pyramid matching suing sparse coding for image classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1794–1801.
- Tuzel, O.; Porikli, F.; Meer, P. Region covariance: A fast descriptor for detection and classification. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006.
- Erdem, E.; Erdem, A. Visual saliency estimation by nonlinearly integrating features using region covariances. J. Vis. 2013, 13, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Tuzel, O.; Porikli, F.; Meer, P. Pedestrian detection via classification on riemannian manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1713–1727. [Google Scholar] [CrossRef] [PubMed]
- Porikli, F.; Tuzel, O.; Meer, P. Covariance tracking using model update based on lie algebra. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 728–735.
- Wang, R.; Guo, H.; Davis, L.; Dai, Q. Covariance discriminative learning: A natural and efficient approach to image set classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2496–2503.
- Wang, L.; Liu, H.; Sun, F. Dynamic texture video classification using extreme learning machine. Neurocomputing 2016, 174, 278–285. [Google Scholar] [CrossRef]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Geometric means in a novel vector space structure on symmetric positive-definite matrices. SIAM J. Matrix Anal. Appl. 2006, 29, 328–347. [Google Scholar] [CrossRef]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Log-euclidean metrics for fast and simple calculus on diffusion tensors. Magn. Reson. Med. 2006, 56, 411–421. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Wang, Q.; Zhang, L. Log-euclidean kernels for sparse representation and dictionary learning. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 8–15 December 2013.
- Bo, L.; Sminchisescu, C. Efficient match kernels between sets of features for visual recognition. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, B.C., Canada, 7–12 December 2009; pp. 135–143.
- Gao, S.; Tsing, I.; Chia, L. Sparse representation with kernels. IEEE Trans. Image Process. 2013, 22, 423–434. [Google Scholar] [PubMed]
- Harandi, M.; Salzmann, M. Riemannian coding and dictionary learning: Kernels to the rescue. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3926–3935.
- Van Nguyen, H.; Patel, V.M.; Nasrabadi, N.M.; Chellappa, R. Design of non-linear kernel dictionaries for object recognition. IEEE Trans. Image Process. 2013, 22, 5123–5135. [Google Scholar] [CrossRef] [PubMed]
- Kim, M. Efficient kernel sparse coding via first-order smooth optimization. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1447–1459. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subset Number | 1 | 2 | 3 | 4 | 5 | Average |
|---|---|---|---|---|---|---|
| baseline Method 1 | 78.10% | 79.29% | 76.90% | 78.81% | 71.90% | 77.00% |
| baseline Method 2 | 78.33% | 75.48% | 74.29% | 75.71% | 74.29% | 75.62% |
| baseline Method 3 | 73.10% | 71.43% | 70.00% | 73.33% | 69.05% | 71.38% |
| proposed Method |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Liu, H.; Wang, S.; Liao, S. Scene-Level Geographic Image Classification Based on a Covariance Descriptor Using Supervised Collaborative Kernel Coding. Sensors 2016, 16, 392. https://doi.org/10.3390/s16030392
Yang C, Liu H, Wang S, Liao S. Scene-Level Geographic Image Classification Based on a Covariance Descriptor Using Supervised Collaborative Kernel Coding. Sensors. 2016; 16(3):392. https://doi.org/10.3390/s16030392
Chicago/Turabian StyleYang, Chunwei, Huaping Liu, Shicheng Wang, and Shouyi Liao. 2016. "Scene-Level Geographic Image Classification Based on a Covariance Descriptor Using Supervised Collaborative Kernel Coding" Sensors 16, no. 3: 392. https://doi.org/10.3390/s16030392