2.2. GRID Data Storage Management Model
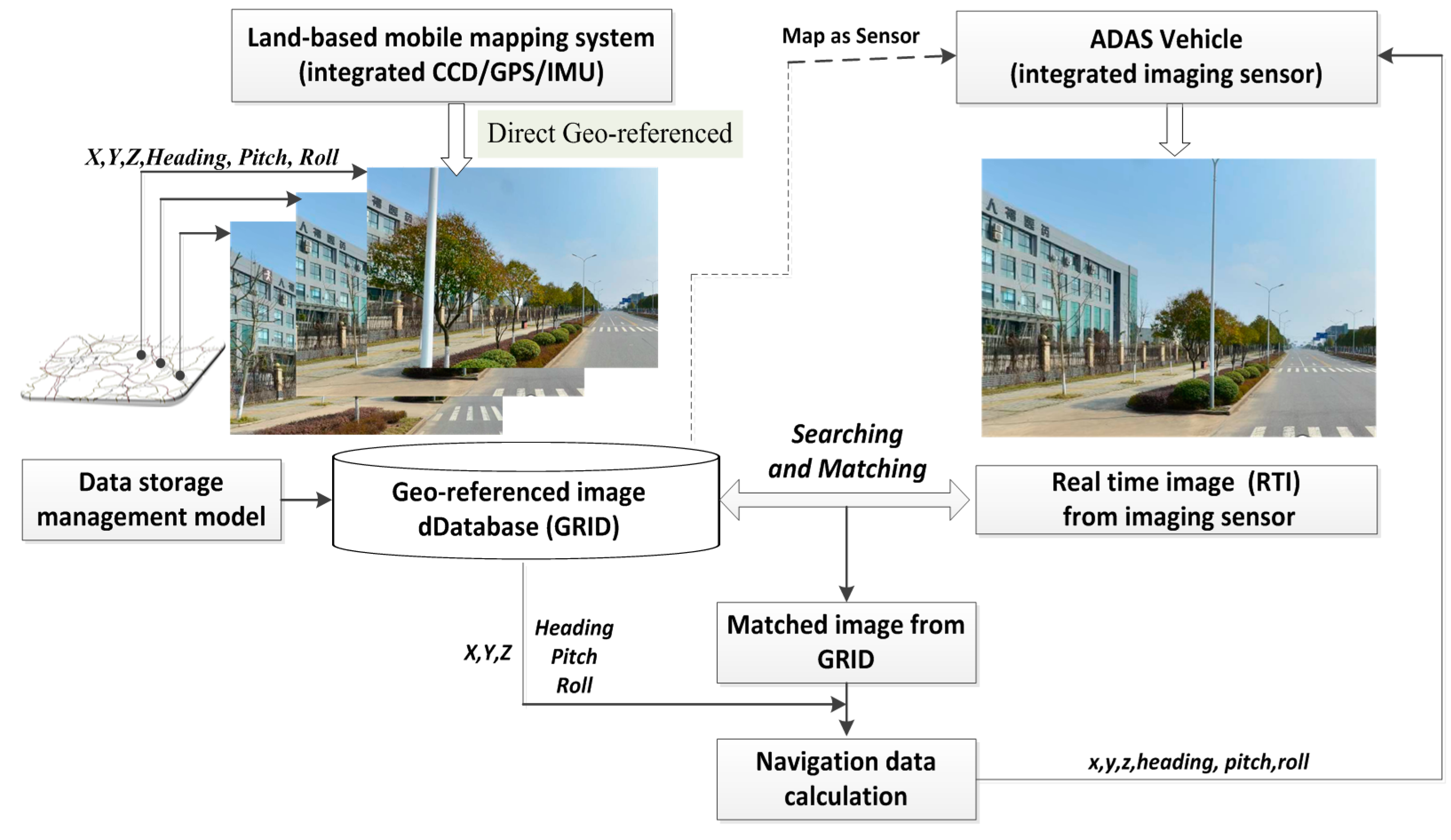
2.2.1. L-MMS for GRID Data Collection
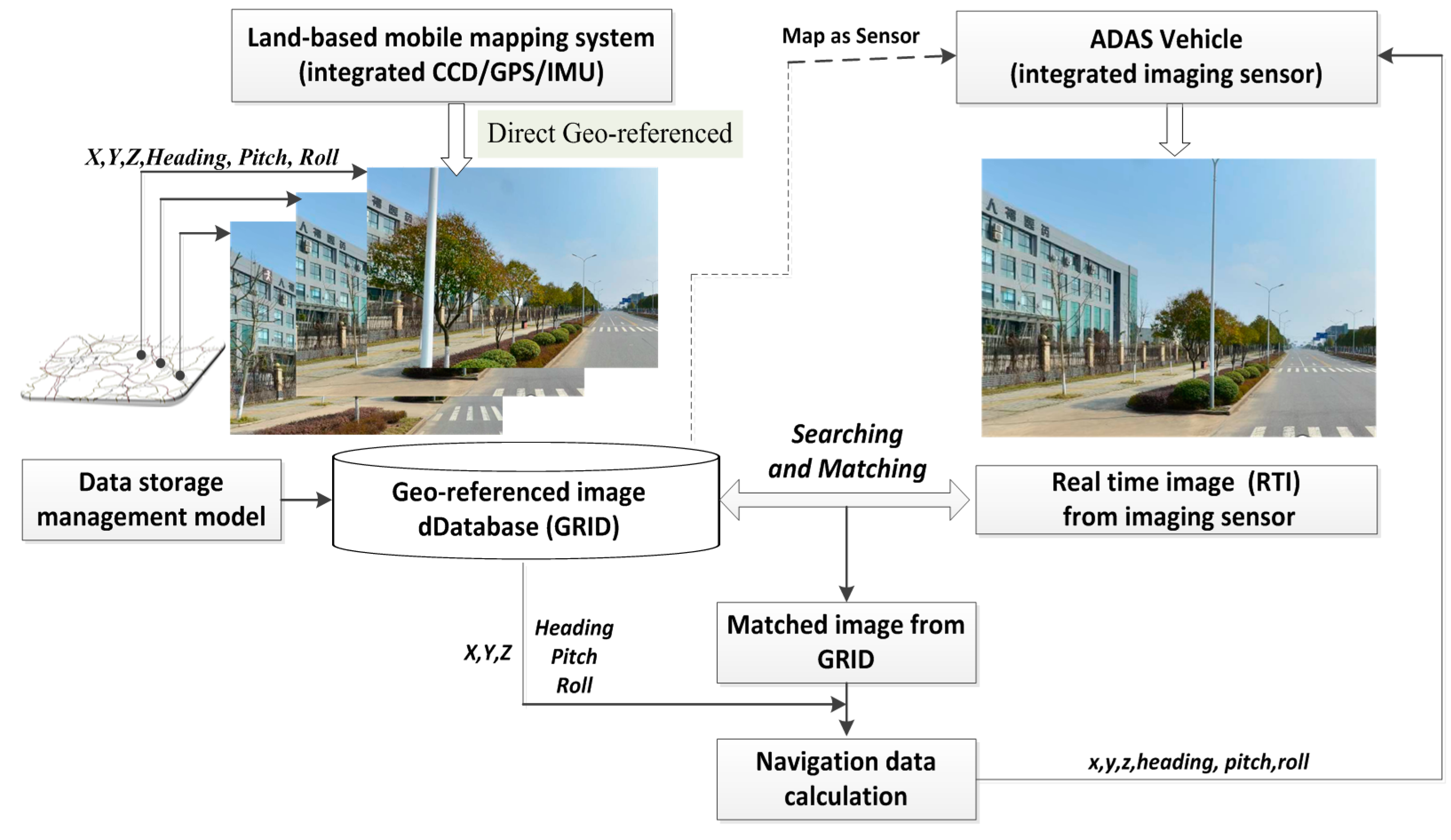
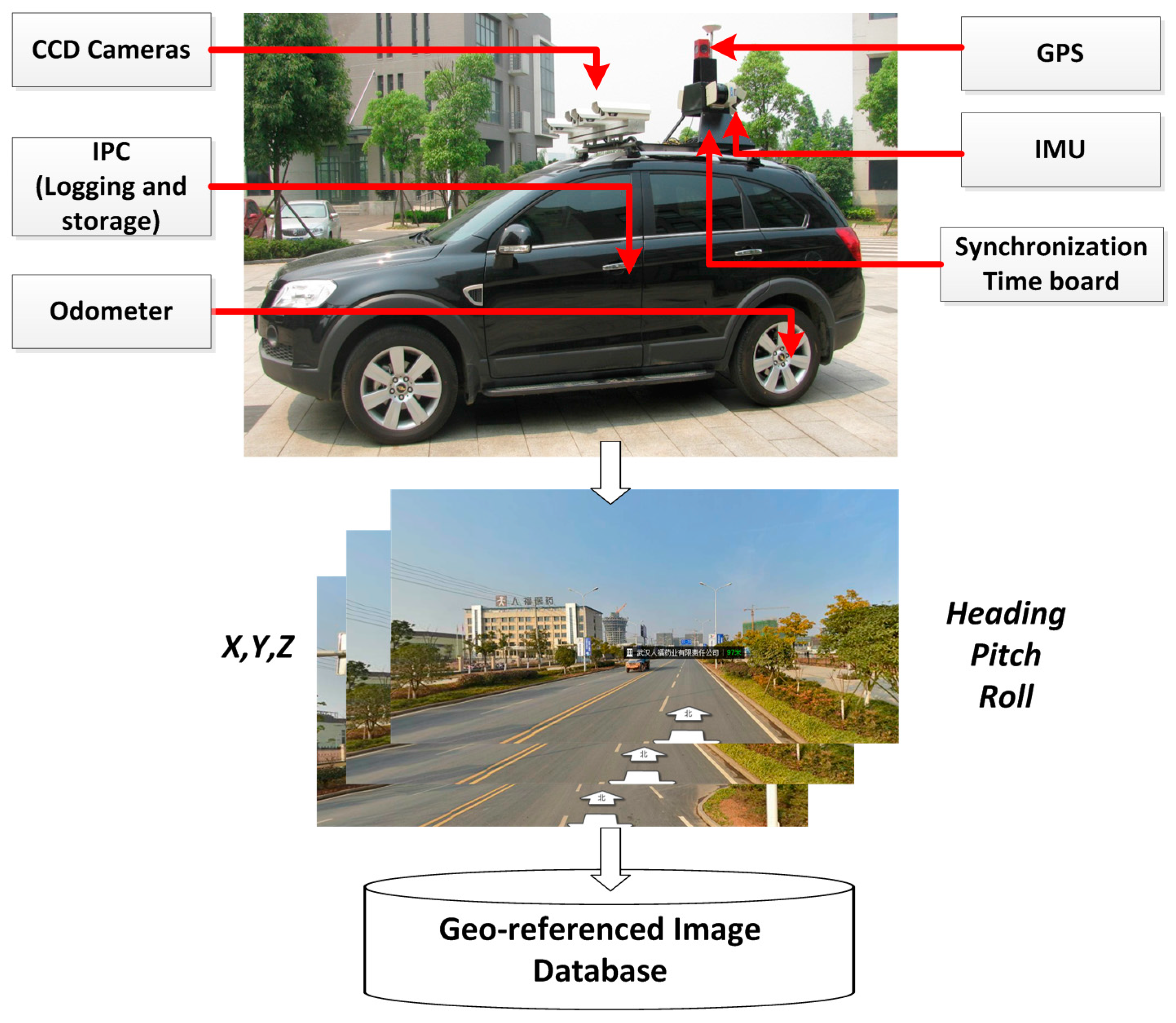
The GRID is compiled by multiple sensor-integrated, land-based mobile mapping systems, which were developed in the 1990s for rapid and efficient road surveying. Such systems include VISAT
TM, GPS Vision
TM, GI-EYE
TM, LD2000
TM, ON-SIGHT
TM, Topcon IP S2, and Hi-Target iScan [
2,
23,
24,
25]. L-MMS integrates geodetic quality GPS, an inertial navigation system (INS), an odometer, a synchronization time board, and digital cameras that are mounted on a land vehicle (as presented in
Figure 2). As a result, highly accurate GPS data can be logged along with INS orientation data and sequence images with high synchronized time in the process of running along defined routes at a speed of no more than 80 km/h.
Figure 2.
L-MMS for the data collection of geo-referenced database.
Figure 2.
L-MMS for the data collection of geo-referenced database.
Four or more cameras are installed in L-MMS to capture sequence images with a user-defined interval distance from 1 to 10 m. All the images are tagged with a time label by the synchronization time board, which adopts the GPS time as a time clock with an accuracy of less than 0.01 ms. The GPS/INS provides the orientation parameters for each sequence image based on the unique and unified GPS time. L-MMS is the most rapid, convenient, accurate, and economical surveying system for collecting and updating geo-information together with the GRID.
One L-MMS can obtain geo-referenced images for more than 200 km. Each image with a resolution of more than 2 MB in RGB mode has a data volume of approximately 5 MB. If the interval distance in image capturing is 5 m, then the number of images at 200 km will be 160,000 and the data volume will be 800,000 MB [
2,
26]. Determining the image number and the data volume are difficulties encountered in searching and matching RTI and GRID. The strategy and method of GRID design affects the efficiency of image searching and matching. To ensure the efficiency of the proposed vision navigation, we propose the indexing of a large number of images according to dynamic road section and the packing of images based on a large file storage model.
2.2.2. Dynamic Section Indexing of GRID Based on Road Networks
At present, the quad-tree index is commonly used as a data organization and indexing method (such as the KIWI data format developed in Japan) [
27,
28] to navigate digital maps. The basic principle of this method is based on a quad-tree structure, and the geospace is divided into small grids. The map elements in the bottom grid to which the quad-tree leaf nodes correspond are packaged and stored according to location and size; furthermore, the map data are spatially separated into small blocks. The main advantage of the quad-tree index is its capability to quickly locate the current target area for a specified grid (block). The relevant target feature can also be extracted from an entire block. Nonetheless, obvious drawbacks are detected in GRID data indexing. GRID data are usually sampled along roads; therefore, data distribution in a quad-tree grid is uneven. As a result, the index data are redundant. In addition, all the images within the grid must be traversed and compared one by one in single-image retrieval (depending on the shooting location of the image), thereby lowering retrieval efficiency. Therefore, the GRID data indexing model in particular must be examined and designed.
GRID data indexing must satisfy two conditions. First, the traveling vehicle should be capable of quickly retrieving a recent image in a trend direction before reaching the current positioning point. Second, this approach should be capable of checking the image sequence in which the current positioning point of the region may be distributed during image matching and location retrieval. GRID data are linearly distributed along a road, unlike 2D GIS data with the geometrical features of point, line, and surface. Given this feature, a road-based dynamic segmentation (DS) index structure is designed in the linear referencing system to determine the spatial query speed of GRID and to ensure quick image matching.
The linear referencing system (LRS) constitutes a method of recording linearly distributed target position information. This system is widely used in the transport domain [
29,
30,
31,
32]. LRS can be expressed as (
R, M), which are also known as linear coordinates that indicate the position information of linear characteristics in an relative offset
M,
i.e., the distance to the starting point of the linear feature.
R denotes the linear characteristic. For example,
(320, 274) suggests that the distance from the starting point is
274 at road
320. Essentially, the proposed DS index method does not alter the position of image distribution (shooting position). Moreover, the image space coordinate in the 2D reference system is not associated with a road in the linear referencing system to establish the GRID data index depending on the road network. The specific approach adopts DS technology according to the image distribution position and location section, applies the offset from the starting point of each road section representing the image position, and converts the image position from 2D coordinates
(X, Y) to linear coordinates (
M). Meanwhile, road split (non-physical division) is realized, and the image is hooked with the corresponding road section. A DS index (DS) tree is also built into the linear benchmark for each linear feature (road).
The shape of the DS tree is similar to those of the
R tree and quad-tree. However, the latter two indices are located in a 2D space, whereas the DS tree is indexed in a 1D linear space. In addition, the quad-tree and
R tree represent the position of an object in an index space given the spatial coordinates of object (
X, Y) or a minimum bounding rectangle, whereas the DS tree indicates the position of an object through offset M of the object. This tree is composed of root, intermediate, and leaf nodes. The 1D data set is divided recursively according to the nodes in each layer. In
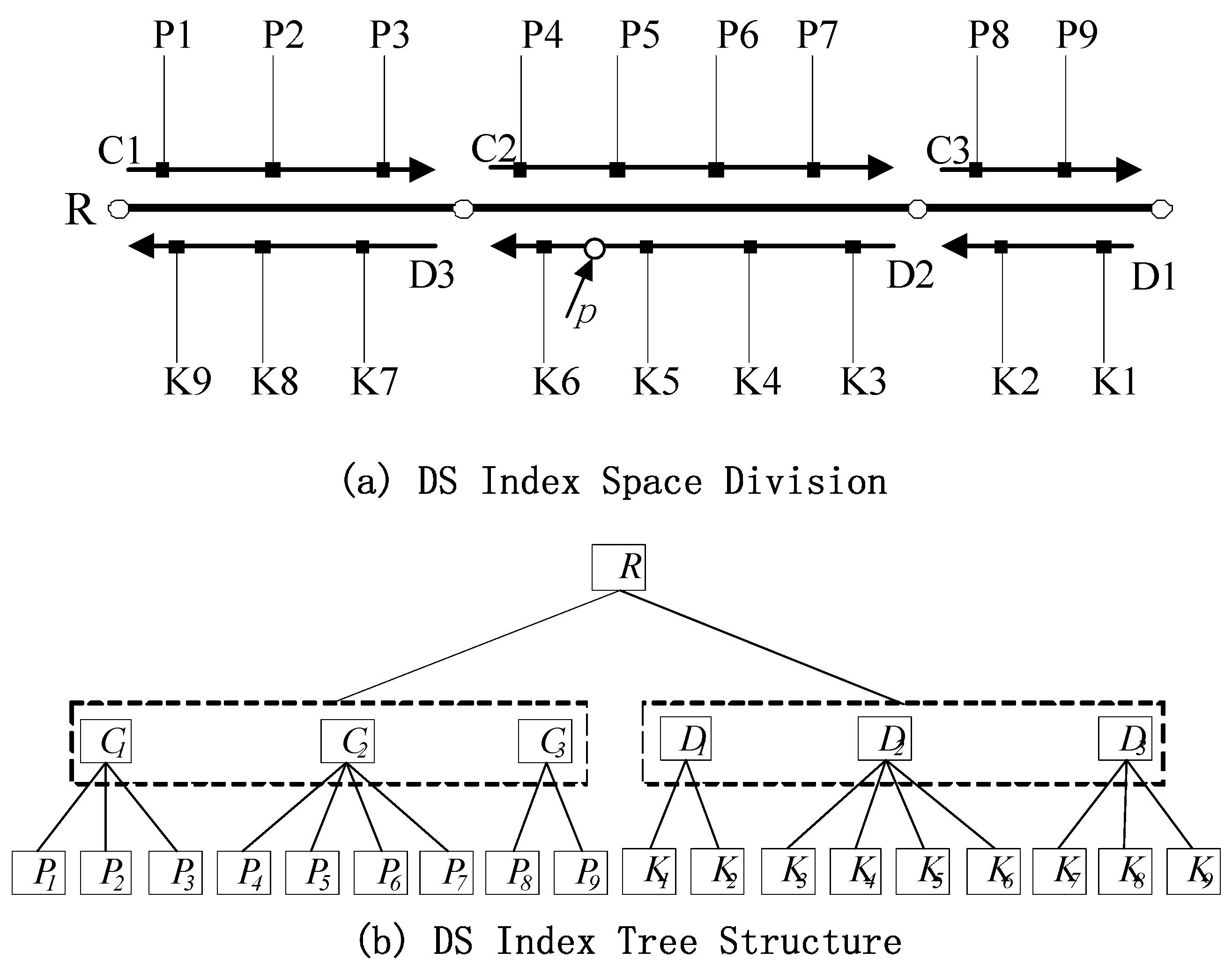
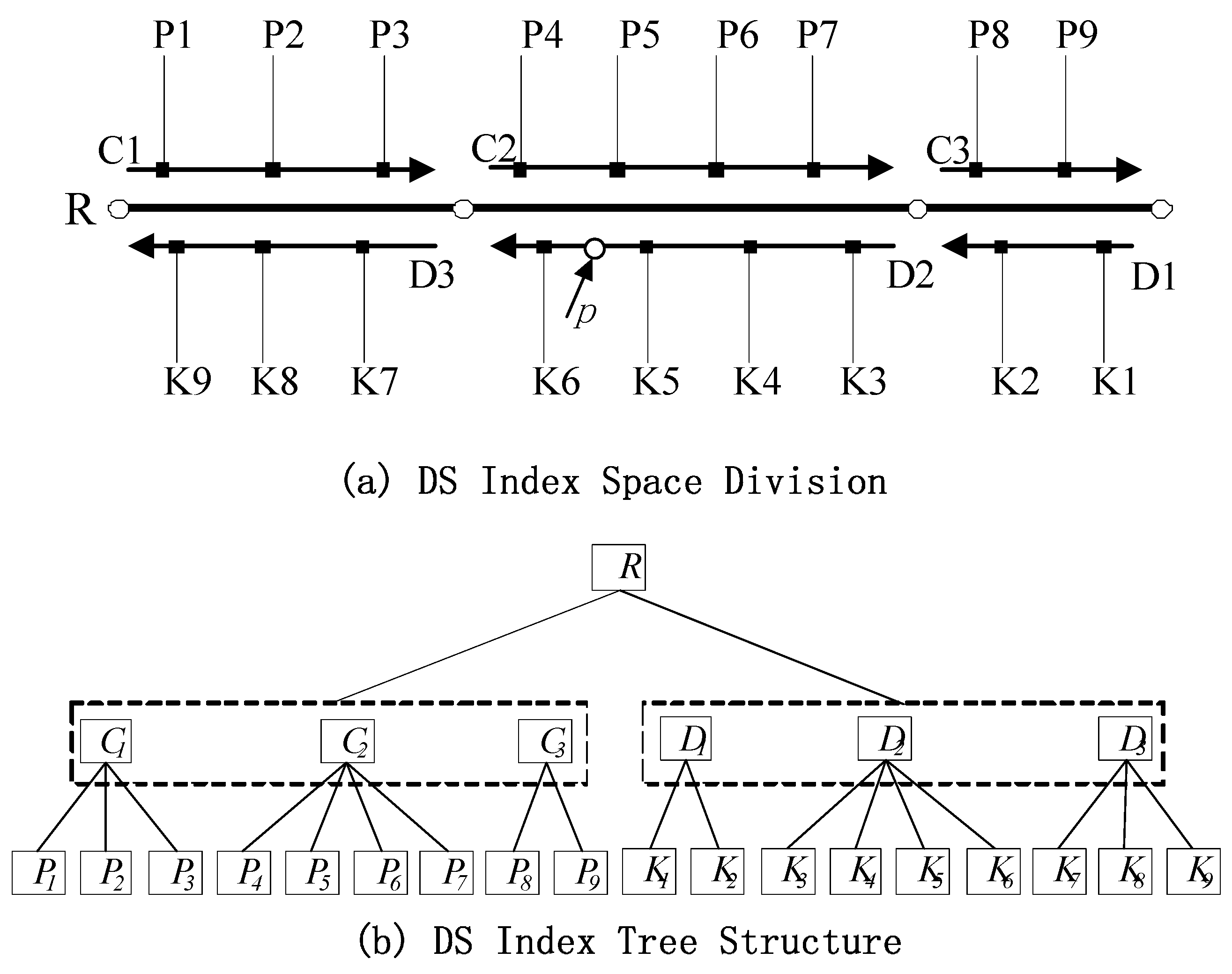
Figure 3, the two-direction road
R includes two road-width-flow centerlines
C and
D that correspond to two road section sequences in opposite directions:
C1, C2, C3 and
D1, D2, D3, respectively. These sequences comprise image sequences
P1, P2, …, P9 and
K1, K2, …, K9.
Figure 3a presents a schematic of the division of road R via DS index intervals.
Figure 3b illustrates the corresponding DS index tree structure, where R is the root node. The structure of R can be expressed as R(
RID, M1, M2). RID is the logical road index number.
M1 and
M2 are the beginning and ending offsets of the entire road. The starting offset of the road (
M1) is generally set to 0. Intermediate node
C or
D includes section sequences along two directions of the centerline of road way flow, and the related structure can be expressed as S(
SID, M1, M2).
SID is the section index number, and
M1 and
M2 are the beginning and ending offsets of the sections along road flow, respectively. The leaf node stores information on each image in the GRID image sequence, and its structure is
I (IID, M).
IID is the image index number, and M is the offset of the sections in which the image position is detected.
The data structure of the index tree node of GRID data is presented as follows:
struct NODE
{
Linear_Interval linear; //linear interval
NODE*Parent; //a pointer to the parent node
NODE**child; //a pointer to the child node
long*ObjID; //object ID within the linear interval
}
Figure 3.
Dynamic segment indexing of GRID based on the road network LRS: (a) division of DS index space; (b) structure of the DS index tree.
Figure 3.
Dynamic segment indexing of GRID based on the road network LRS: (a) division of DS index space; (b) structure of the DS index tree.
The quad-tree index in the 2D reference system must calculate the Euclidean distance between the location point and the image position individually for image retrieval. Meanwhile, the DS index in the linear referencing system only needs to compare the location point offset with the image position offset. The retrieval calculations are performed in a 1D space. Thus, the computation amount is reduced, and the retrieval efficiency can be improved.
2.2.3. GRID Data Storage Based on Large Files
Many GRID images are collected by L-MMS. If 1 site includes four images and the distance between the two sites is 5 m, then the GRID data comprise more than 800,000 images given a city with 1000-km roads. If each image corresponds to a data file, then an excessive amount of files is produced, thus directly affecting data extraction efficiency. In addition, many small files induce frequent disk reading and writing, thereby resulting in straightforward disk damage. Therefore, the design of the data storage model for GRID must be optimized.
To effectively control the number of the generated GRID data files, a data storage model based on large files is proposed in this paper. The basic idea involves considering one road section as a unit to centrally store the image sequence in the section. This concept not only reduces the number of data files but also quickly determines the image sequence through a road section through the DS index and improves the efficiency of image retrieval.
The organization of GRID data based on large files is line with the following rules:
Rule 1: Images in one road section should be stored in one large data file as much as possible;
Rule 2: Cross-section images should be stored separately;
Rule 3: If the images in a section are so numerous that they constitute an excessively large image file (exceeding the set threshold), then this image file should be split and stored as multiple files.
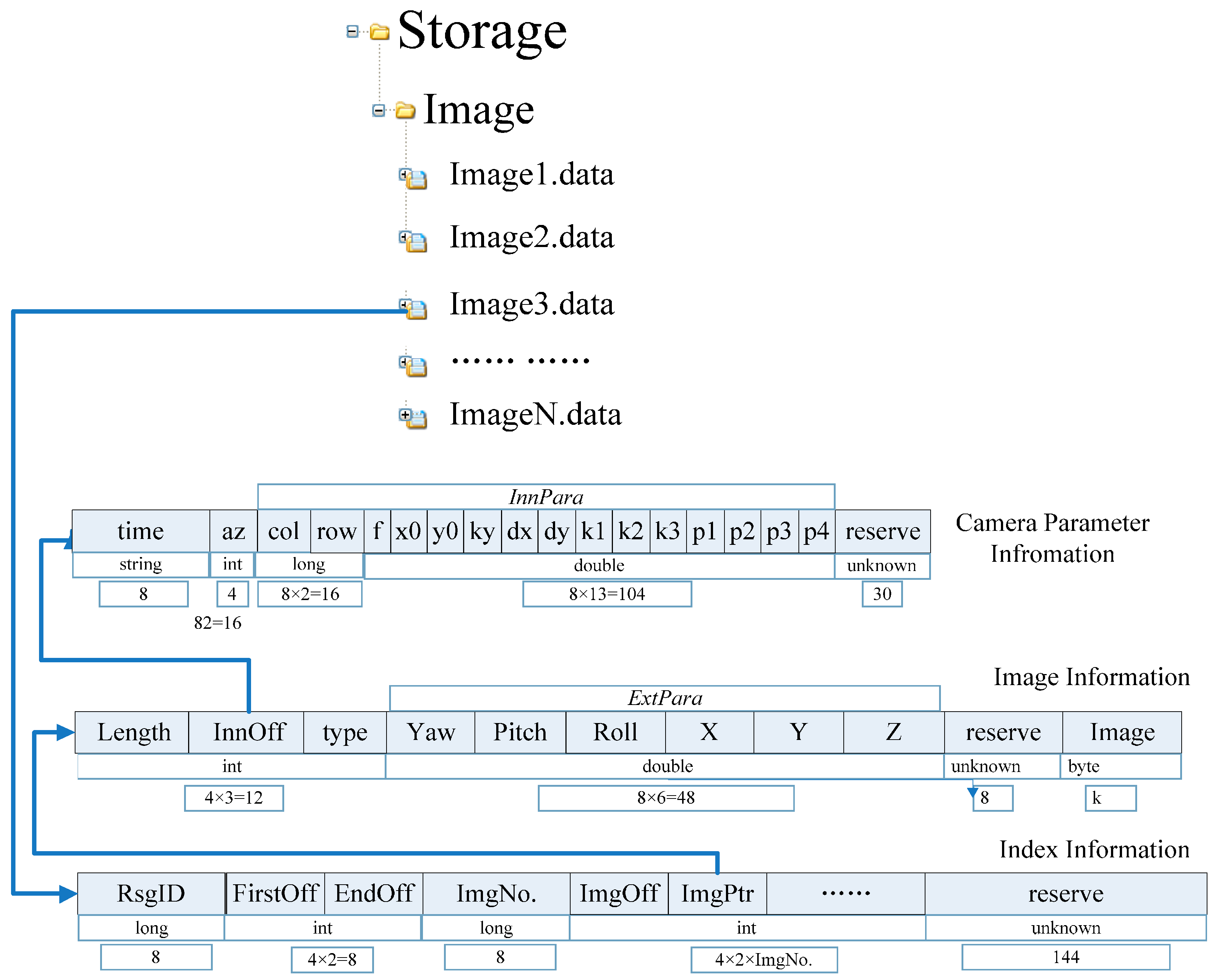
The proposed large file-based data storage model for GRID is established through compliance with the aforementioned rules, as shown in
Figure 4.
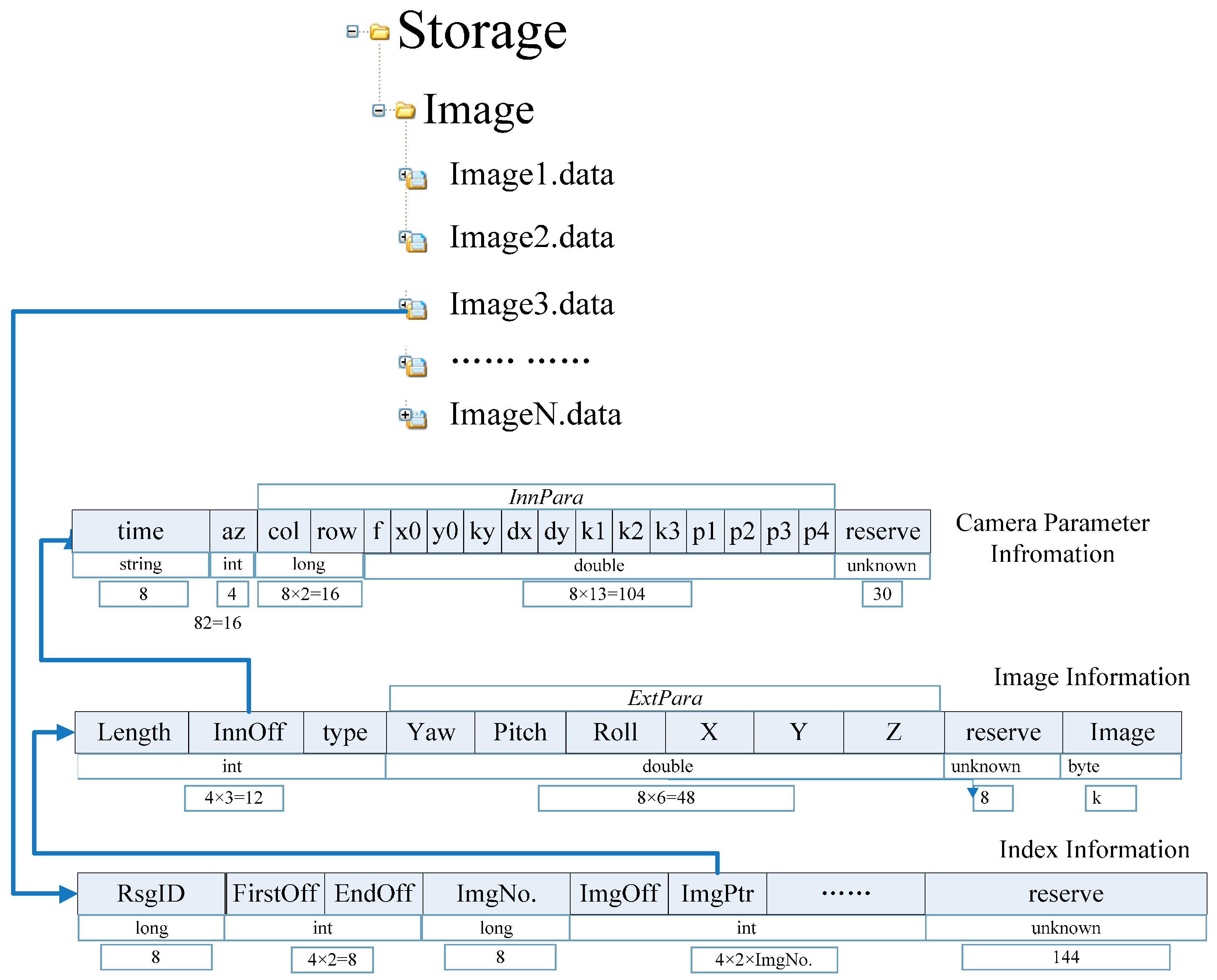
Figure 4.
Large file-based data storage model for GRID.
Figure 4.
Large file-based data storage model for GRID.
A large file for GRID can be divided into three parts: an image index table, a file body, and an image parameter file. The index table records the current file section ID (long type, eight bytes), first section offset of the image position in the file (int type, four bytes), final section offset of the image position (int type, four bytes), number of images (long type, eight bytes), section offset of each next image in turn (int type, four bytes), and stored address of the image in the file (int type, four bytes). The file body accounts for each image information record (44 bytes plus the space occupied by the image sequence). The image parameter file stores the interior and exterior orientations of the GRID. The size of each large file for this database should be controlled to below 200 MB for one road section. When the file size exceeds this recommendation, a new large file should be generated automatically. One record should not be stored in two separate files. If the current storage space is not enough to store an entire piece of data, then this information should be transferred to a new large file for storage. All large GRID files are labeled “Image” + n + “. data”.
The proposed GRID data storage based on large files can be organized in a database system or file directory, and this step is similar to image retrieval. In database storage, the generation of a large file can be regarded as the storage of sequence images related to a road section via a memory block. Meanwhile, the single file model can be treated as individual image storage.
2.3. Fast Image Searching and Matching
The RTI from a global GRID is impossible to search for and match efficiently or accurately. A navigation system typically has GPS and IMU sensors, which play the most important role in determining the position and orientation parameters of a moving platform. Imaging sensor-based vision navigation is adopted to enhance navigation reliability and accuracy for a moving platform in a harsh GPS or IMU-failed environment. Thus, the vision navigation module generates an initial navigation parameter from GPS/IMU. The initial position can restrict the range of GRID searching and matching, which can induce fast image searching and accurate matching. The proposed method to search and match the RTI from GRID includes three steps: searching for and locating large GRID files, extracting image features, and image matching.
2.3.1. Searching for and Locating Large GRID Files
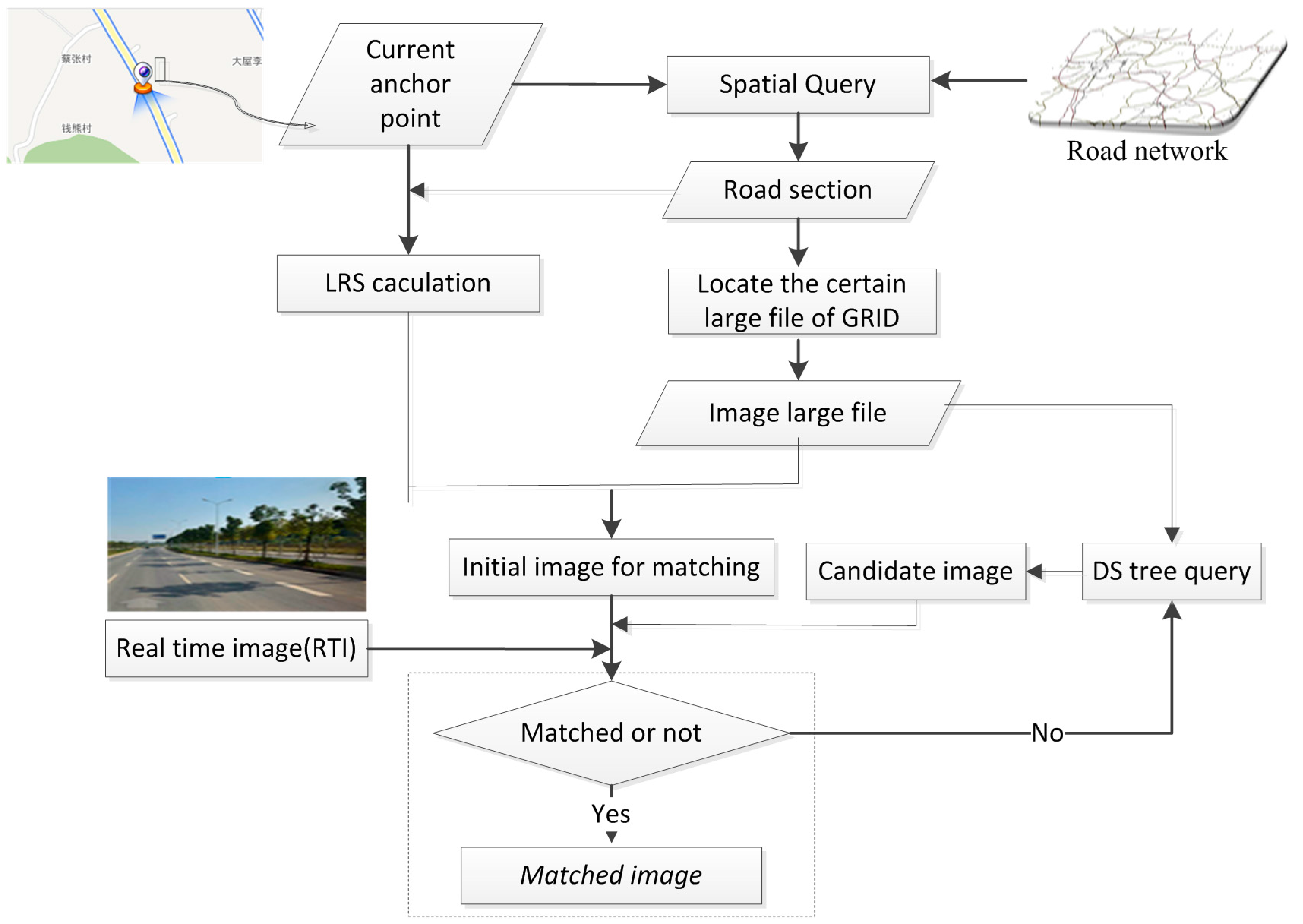
To obtain a fast and reliable search result from a high-volume GRID, a spatial query is implemented before image retrieval based on image understanding. Although the worst position accuracy of GPS/IMU is 100–500 m, it can restrict image searching and matching in a road section or a street block. This restriction can significantly reduce the workload of blind searching and matching over a wide range. Thus, a fast search that conducts a spatial query of the initial position can be performed through the proposed dynamic section indexing of GRID based on a road network. The road section of the initial position can be determined to locate a certain large GRID file for accurate matching.
Figure 5 illustrates the proposed concept of fast searching based on spatial query to locate a large GRID file.
Figure 5.
Fast search and large file location based on spatial query.
Figure 5.
Fast search and large file location based on spatial query.
The current anchor point from GPS/IMU is considered as the spatial query input within the road network to determine the current road section. A large file can be located through the road section based on the proposed GRID data model. Meanwhile, the anchor point is converted into a 1D coordinate based on the LRS model to obtain the initial image from a large file as the candidate image for matching with the RTI. The candidate image is identified based on the DS tree; the process stops until the image is well matched with the RTI, as explained in the subsequent part.
2.3.2. Extracting Image Features
RTI and GRID are the images captured in different environments of the same scene. Feature selection and extraction are the key issues in achieving highly reliable image matching. Lowe [
33,
34] proposed an efficient scale invariant feature transform (SIFT) algorithm that is widely used in image matching. The local features of SIFT include invariance in rotation, scaling, affine transformation, and a view angle, which is suitable for matching images captured at different times, distances, and viewing angles [
33,
34,
35,
36]. In the proposed approach, we adopt a 128-dimensional SIFT feature vector to describe the key feature point. The geometric distortion influence of scale and rotation can be reduced by this vector, and its normalization can eliminate the effect of illumination change. Thus, the SIFT vector of an image local feature can result in robust matching between RTI and GRID.
The SIFT 128-dimensional feature vector in GRID is time consuming to extract, particularly in real-time processing applications. To decrease the duration of matching between RTI and GRID, the SIFT feature vectors of each image in GRID are extracted in advance and linked to GRID.
2.3.3. Image Matching
Image matching between RTI and GRID is implemented based on the SIFT feature. As this process runs during the image search, SIFT matching should be as fast as possible. The SIFT feature vectors of RTI can be extracted before matching because we have identified these vectors for each image in the GRID in advance. Thus, image matching is conducted only to calculate the similarity among the SIFT feature vectors of RTI and GRID. The SIFT matching algorithm usually adopts Euclidean distance as the similarity measurement of the key point. If the ratio of two key points with the closest Euclidean distance to the candidate key point for matching is less than a certain threshold (always taken as 0.9–1.0), then one of these two key points is considered a successful match. The number of matching points can be reduced by lowering the threshold ratio, thus stabilizing the SIFT matching process. In the proposed approach, the matching between RTI and GRID is simplified as the calculation of the Euclidean distance in the set of key points between RTI and GRID. A best-bin-first matching search algorithm with a 128-dimensional feature vector is presented as well, and all these strategies reduce the duration of searching and matching.
The correlation calculation based on Euclidean distance exhibits gross error. Handling mismatch is another important process during SIFT matching; normally, the SIFT matching algorithm follows a robust random sample consensus (RANSAC) [
37,
38] algorithm to address the gross error in SIFT matching.
The image searching and matching processes intersect, as depicted in
Figure 5. We can determine the match status according to the number of the matched key points between RTI and GRID. The number of matched points can be used to guide the search direction based on the LRS in a large file.
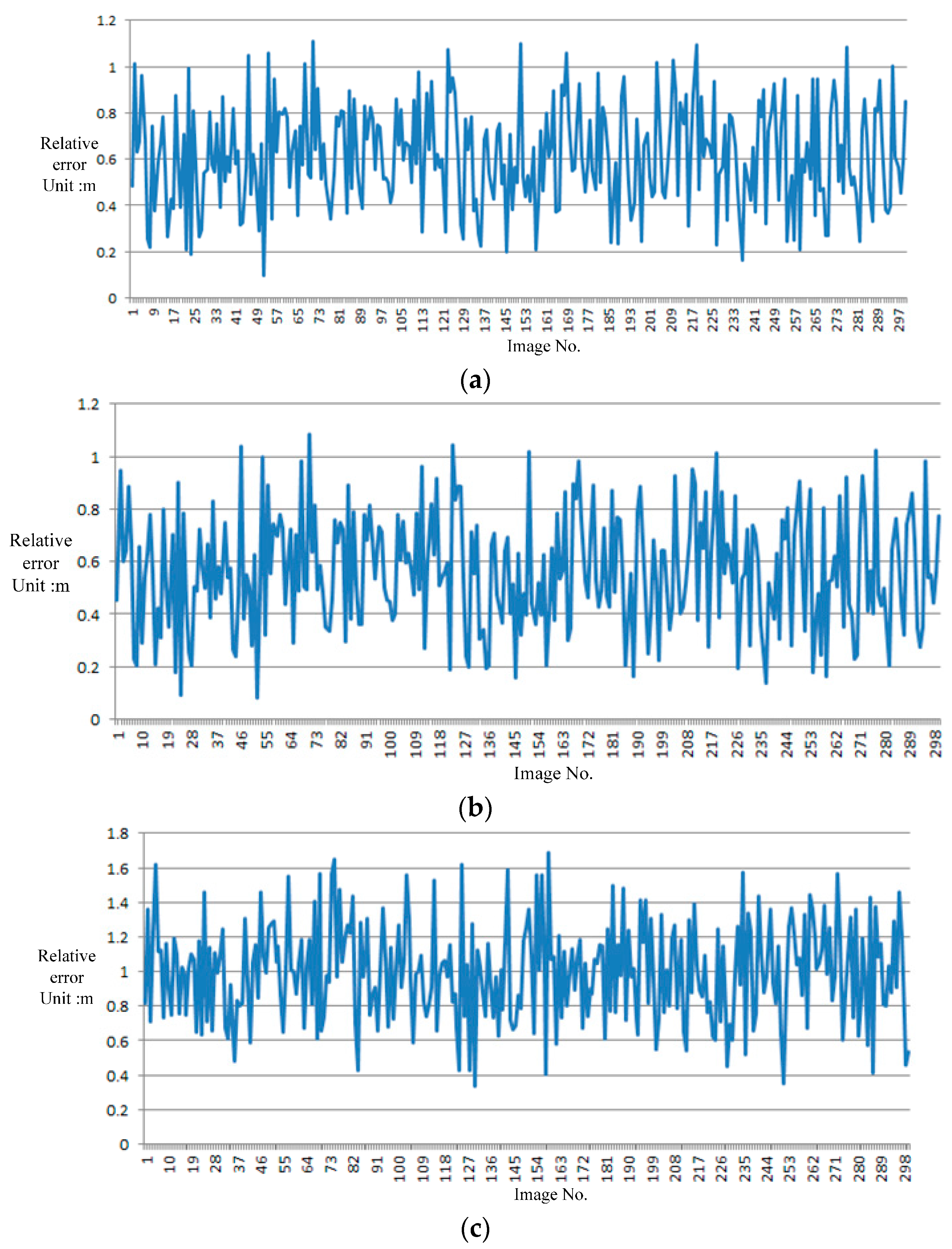
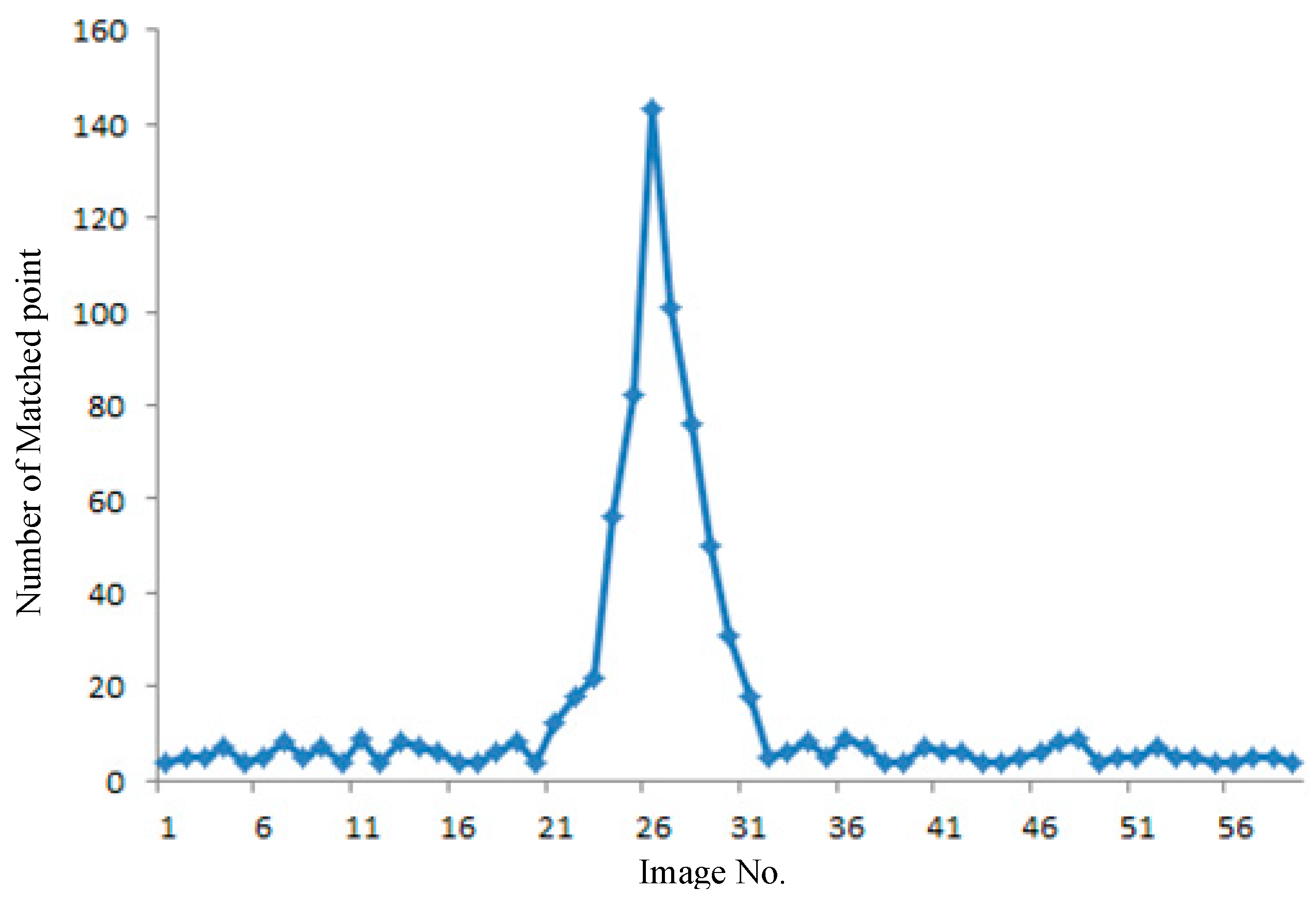
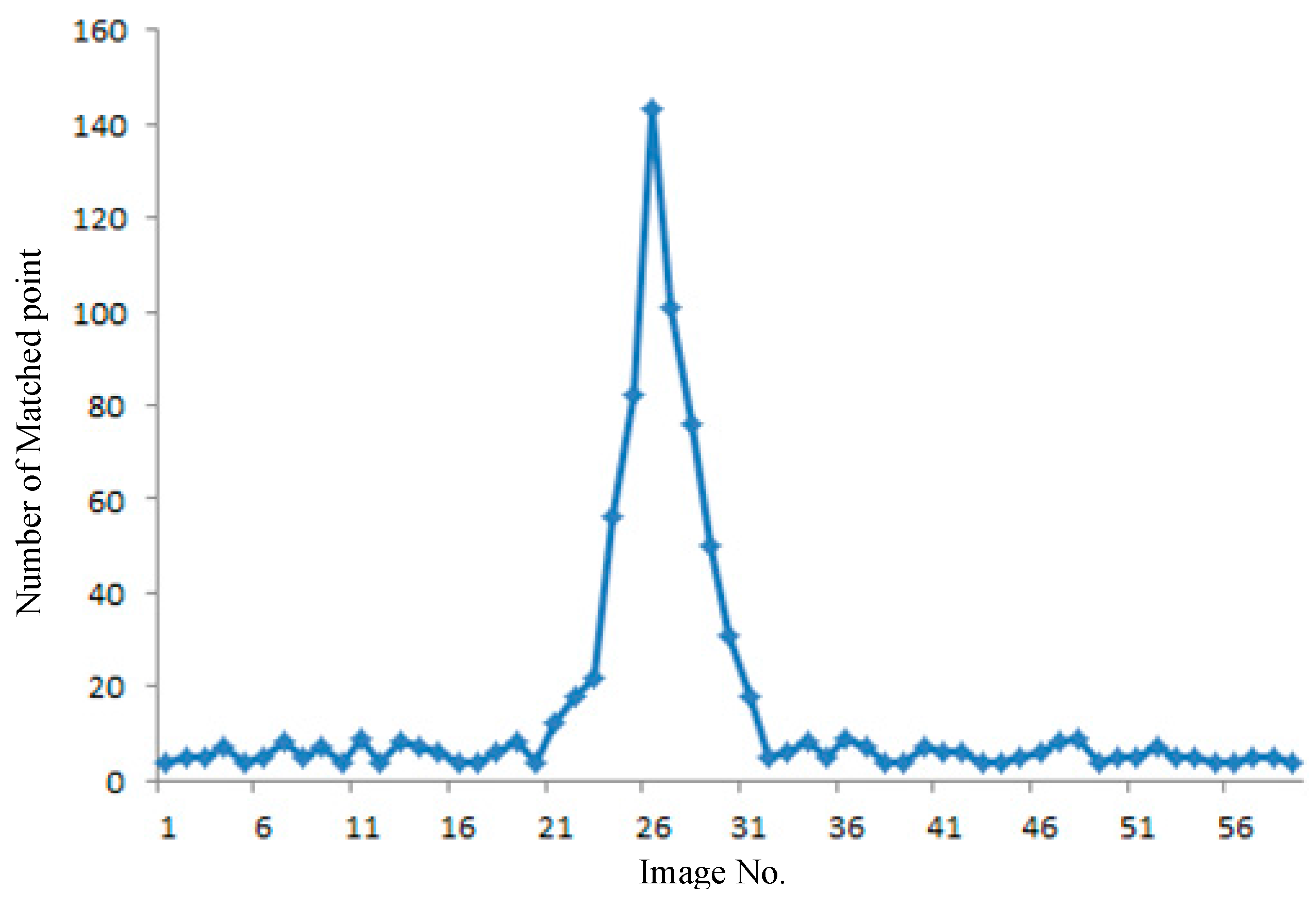
Figure 6 presents an example of the number variance of the matched points. A total of 59 images from GRID are considered candidate images to match RTI.
The number of matched points increases when the GRID image is close to RTI. The entire matching process uses the same parameter of the SIFT algorithm and RANSAC. Thus, the matched image has the highest number of matching points. The number of matched points increases rapidly when the candidate image is in view of RTI; this step also helps determine the direction of image searching. The searching and matching time in all 59 images is 0.43 s; in real-time processing, these procedures stop after the image either matches well or fails. The searching and matching time is shorter than that of the SIFT matching of all the candidate images. The 59 GRID images cover a distance of approximately 300 m, which can be considered the largest error in the GPS/IMU position serving as the initial input for image interval retrieval.
Figure 6.
Fast search and large file location based on spatial query.
Figure 6.
Fast search and large file location based on spatial query.
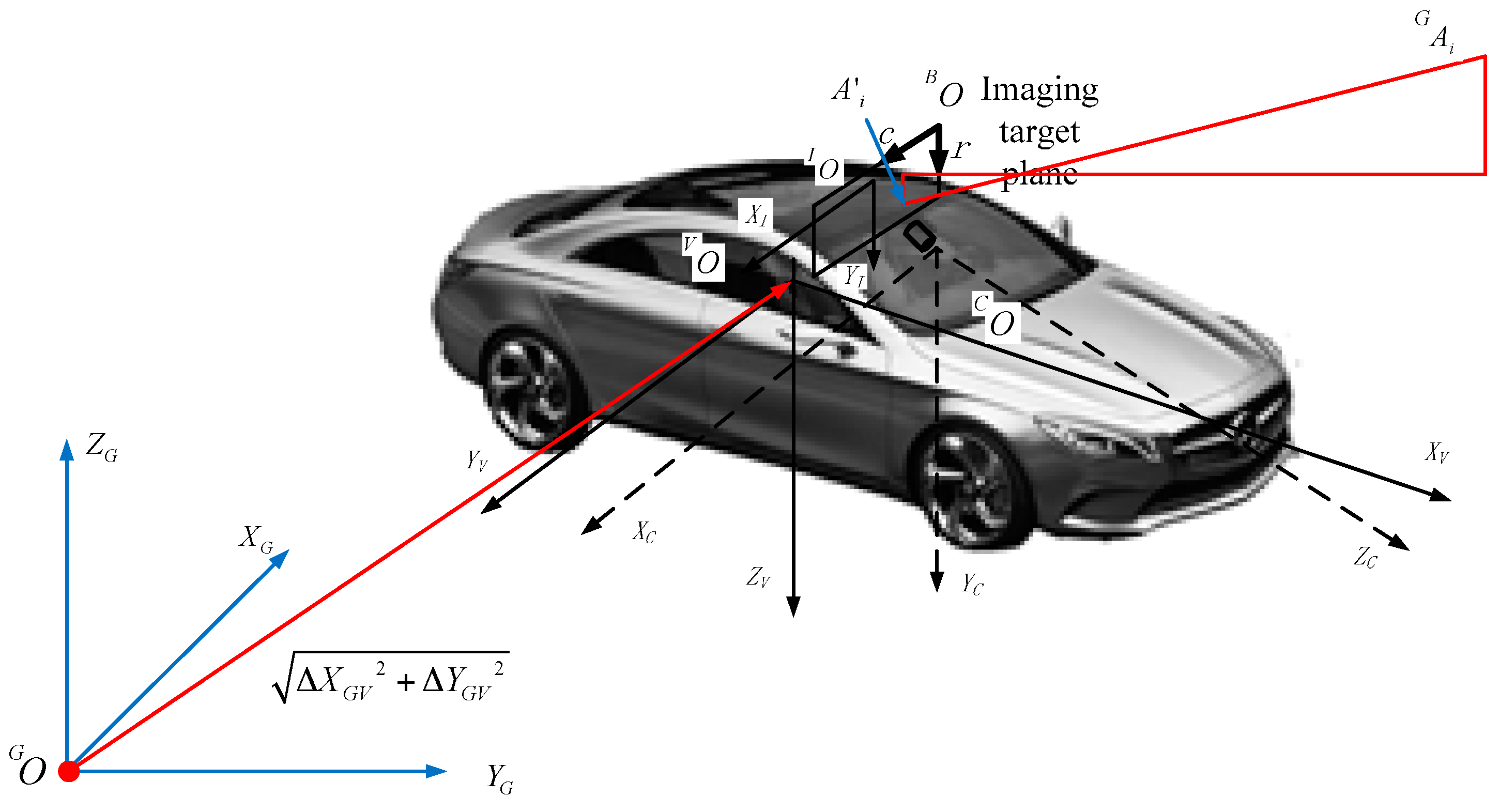
2.4. 3D Navigation Calculation: From GRID to RTI
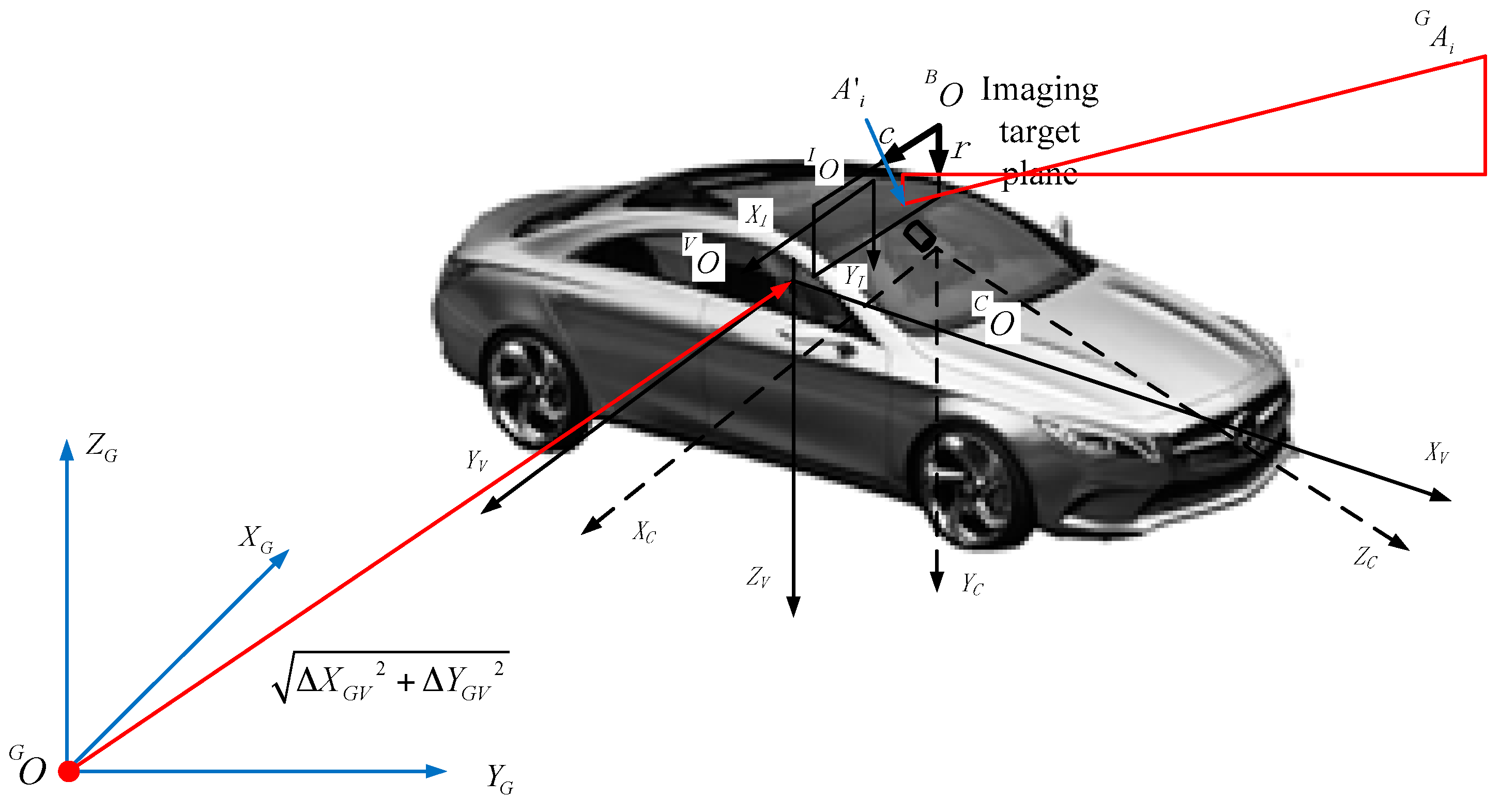
In the proposed imaging sensor-aided vision navigation system, a camera is fixed to the body of a moving vehicle, as described by a right-handed coordinate system. We define five coordinate systems to derive the navigation parameters from GRID to RTI, as shown in
Figure 7.
Figure 7.
Definition of a coordinate system.
Figure 7.
Definition of a coordinate system.
is the Cartesian coordinate of the geodetic coordinate system(GCS).
is the coordinate origin and its coordinates in GCS are
, which is adopted by the GRID and the moving platform.
is the body coordinate system(BCS) of a moving platform where the coordinate origin
is defined as the intersection of two perpendicular lines of the cut planes through the center of gravity and the body; its coordinates in BCS are
. The
axis is parallel to the longitudinal axis of the body, which is the forward direction of the vehicle. The
axis is perpendicular to the longitudinal axis of the vehicle body and parallel to the cutting plane, which is located to the right of the vehicle. The
axis is downward perpendicular to the cut plane.
is the camera coordinate system(CCS), where coordinate origin
is the projection center of the camera, and its coordinates in CCS are
. The
axis is parallel to the direction of the camera scan lines and to the direction of the increasing scan pixels. The
axis is perpendicular to the direction of the camera scan lines and to the direction of the increasing scan lines. The
axis is perpendicular to the silicon target plane and to the gaze direction of camera imaging system.
is the image coordinate system (ICS) that defines the location coordinates of the optical imaging plane of the internal camera image, where coordinate origin
is the focus on the image plane of the imaging system; its coordinates in ICS are
. The
axis is parallel to the direction of the camera scan lines and to the direction of the increasing scan pixels. The
axis is perpendicular to the direction of the camera scan lines and to the direction of the increasing scan lines.
is the pixel coordinate system(PCS) that defines the pixel coordinate, where coordinate origin
is located in the top-left corner of the image; its coordinates in PCS are
. The
axis is parallel to the direction of the camera scan lines and to the direction of the increasing scan pixels. The
axis is perpendicular to the direction of the camera scan lines and to the direction of the increasing scan lines.
Figure 7 indicates that
,
,
,
,
, and
are considered to define the installation status of imaging cameras in the camera coordinate system.
The following paragraphs describe a few of the main transformations of the aforementioned coordinate system.
(
1)
From the body coordinate system into the camera coordinate system: the body coordinate system can be transformed into the pixel coordinate system. The transition from the former into the camera coordinate system includes translation and rotation, as indicated in Equation (1)
where
is the coordinates of
in the body coordinate system.
is the rotation matrix, as per Equation (2)
(
2)
From the camera coordinate system into the image coordinate system: this transformation is based on the principle of perspective projection, where the object distance is far greater than the focal length. Thus, the pinhole imaging model can replace the perspective projection model. The image coordinate can be calculated with Equation (3)
(
3)
From the image coordinate system into the pixel coordinate system: the pixel coordinate system can be calculated from the image coordinate system through a 2D scale and translation, as indicated in Equation (4)
where
and
are the numbers of rows and columns of width and length in the image coordinate system, respectively.
is the offset of the main point position in the column and row directions.
In the transformation from Equations (1) to (4) explained above, , , , , , and are usually called the outer orientation elements of an imaging camera. , , , , and are known as the inner orientation elements of such a camera.
(4) From the body coordinate system into the geodetic Cartesian coordinate system: the matched image is geo-referenced in the geodetic Cartesian coordinate system. All the matched key points have Cartesian coordinates
that are transferred to the corresponding points in RTI. Thus, we can convert
to
in the body coordinate system of the moving platform with Equation (5):
where
and
are unknown quantities, and
is the heading of the moving platform. Then, we can convert
to
in the camera coordinate based on Equations (1) and (2). We can also transform
into
in the image coordinate system and
in the pixel coordinate system on the basis of Equations (3) and (4). We finally complete the transformation of the key points
in the camera coordinate system to
in the pixel coordinate system, as shown in Equation (6):
The in the pixel coordinate system of RTI is determined through SIFT matching, and the corresponding in the geodetic Cartesian coordinate system is also identified from the GRID. Both outer orientation elements (, , , , , and ) and inner orientation elements (, , , , and ) can be effectively calibrated in a high-precision calibration site. Each pair of matched key points can generate two equations based on Equation (6), and we can build the equations with all the matched key points with unknown elements , , and . Thus, we can employ least squares’ adjustment to solve these unknown elements, which are the navigation parameters of the moving platform in the geodetic Cartesian coordinate system. To obtain a robust result, at least five key points should be used in the solving process.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}