
An Online Continuous Human Action Recognition Algorithm Based on the Kinect Sensor

Abstract
:1. Introduction
2. Related Work
2.1. Segmented Human Action Recognition
2.2. Continuous Human Action Recognition
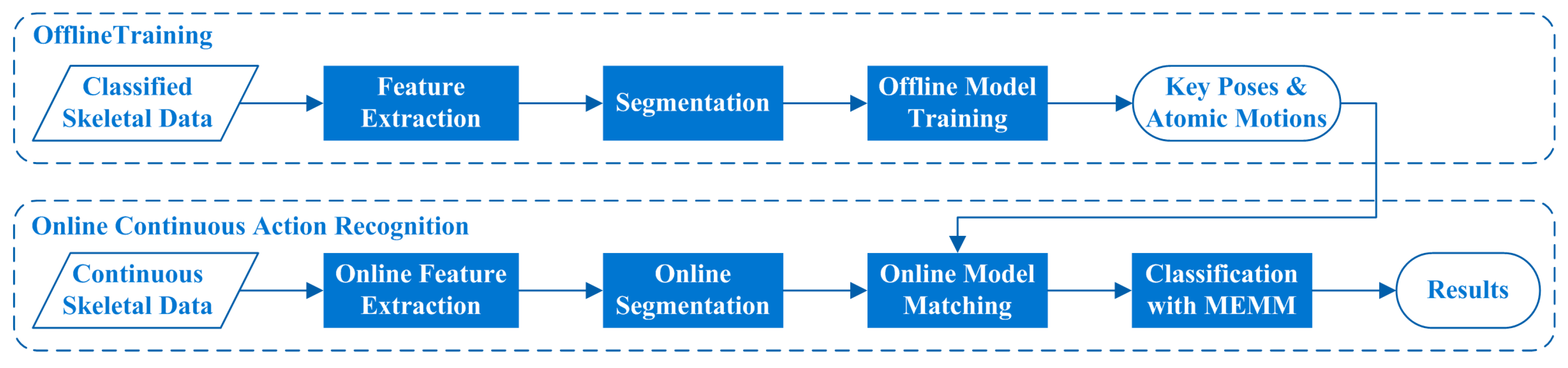
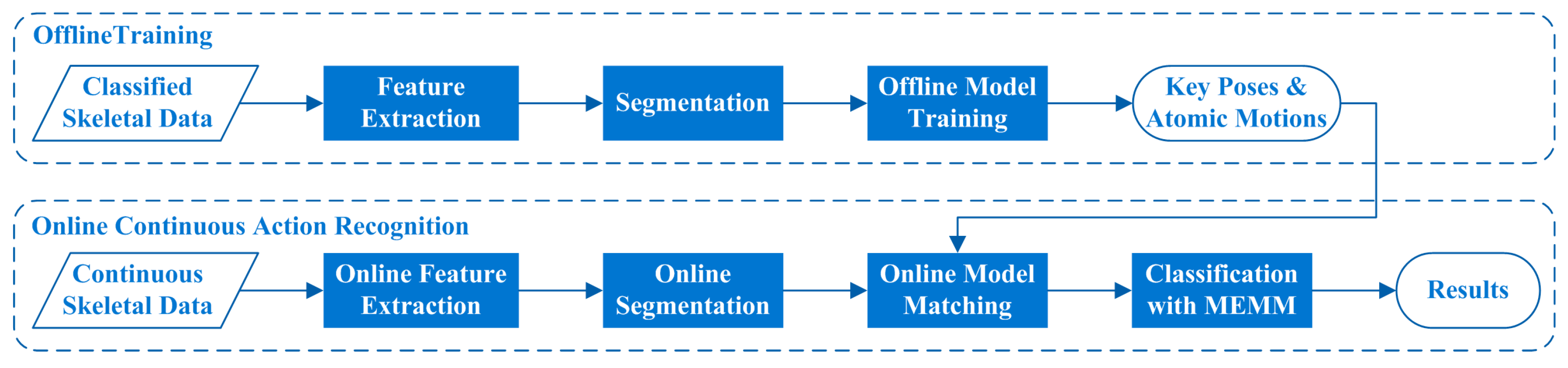
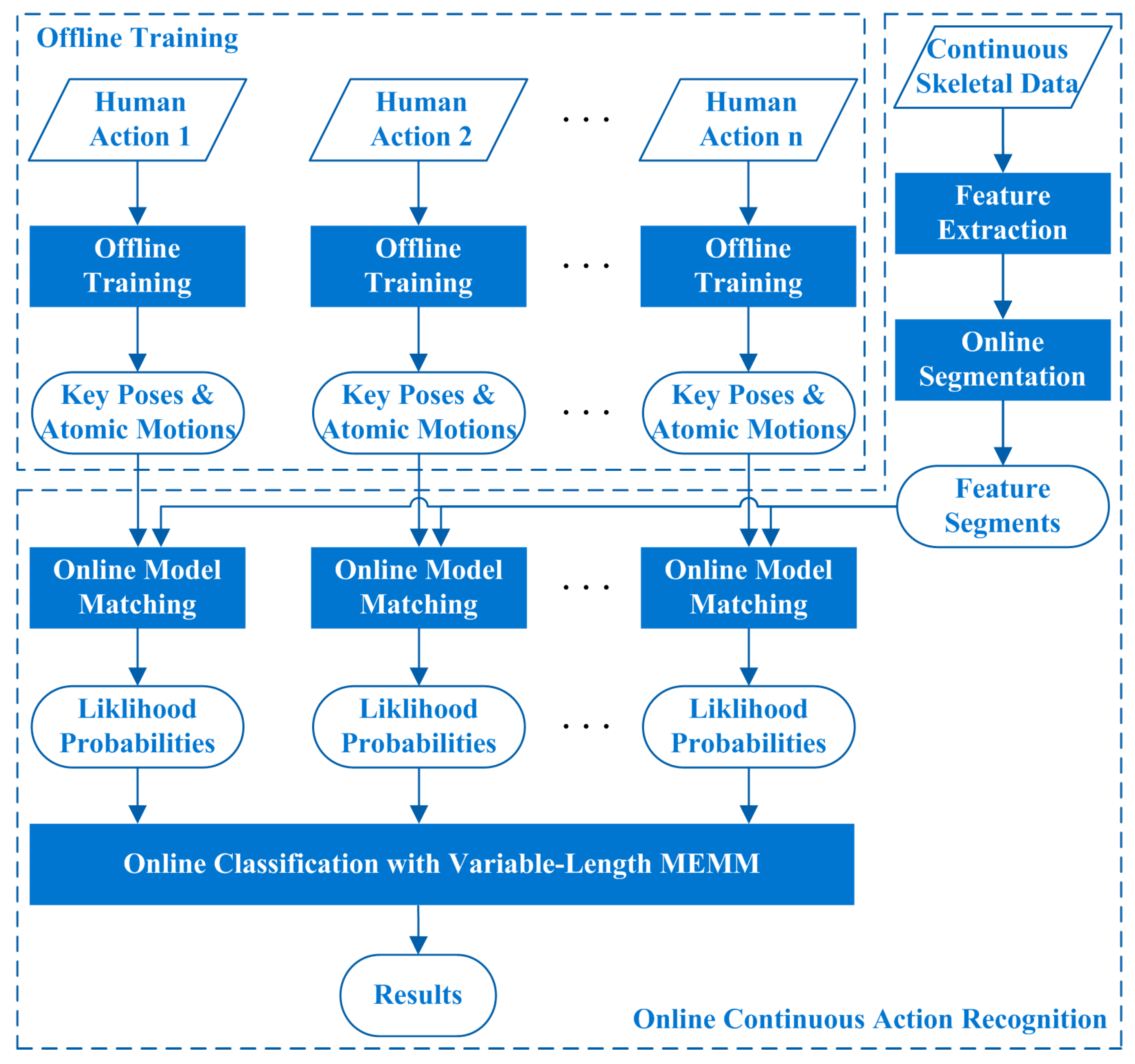
3. Proposed Algorithm
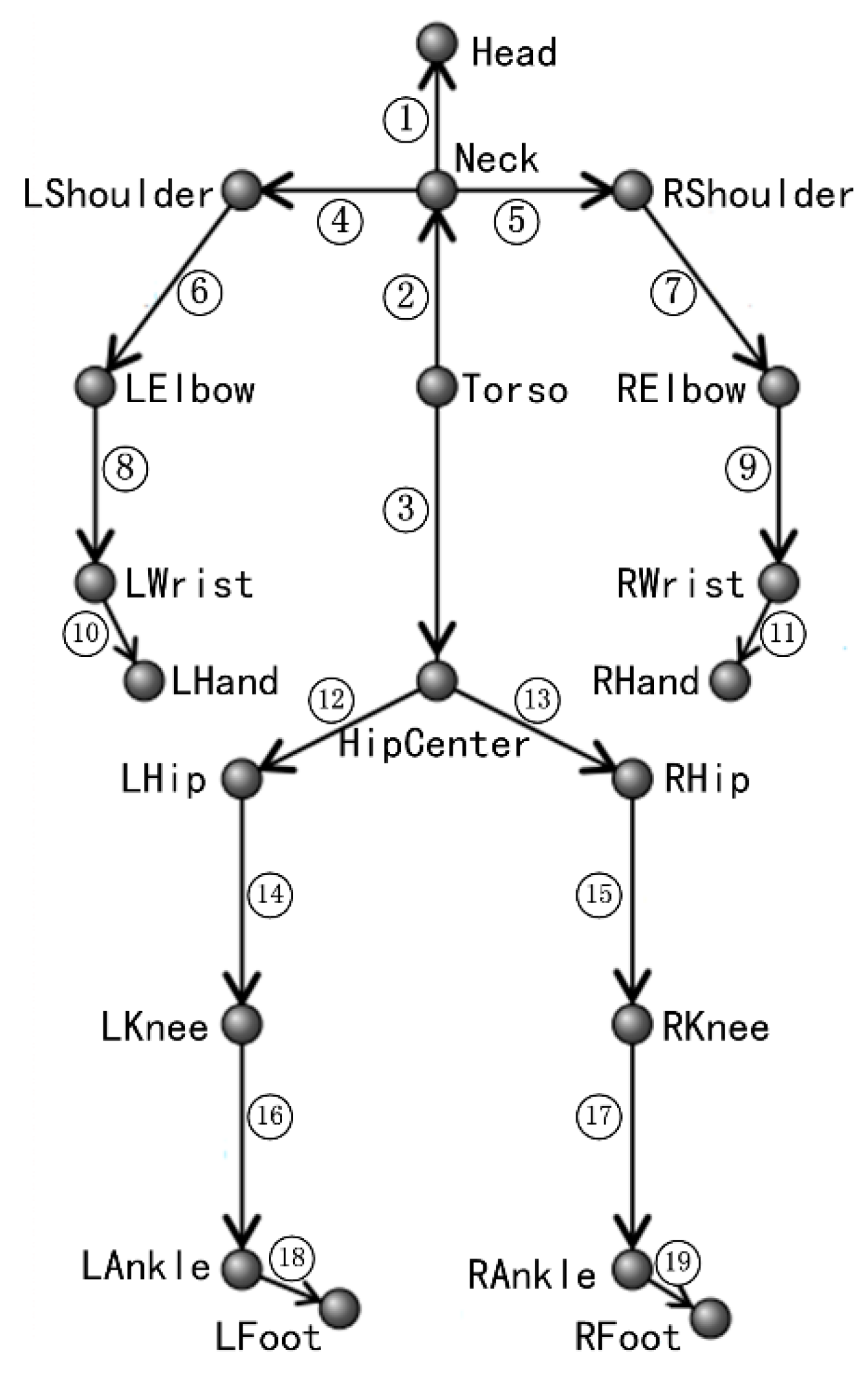
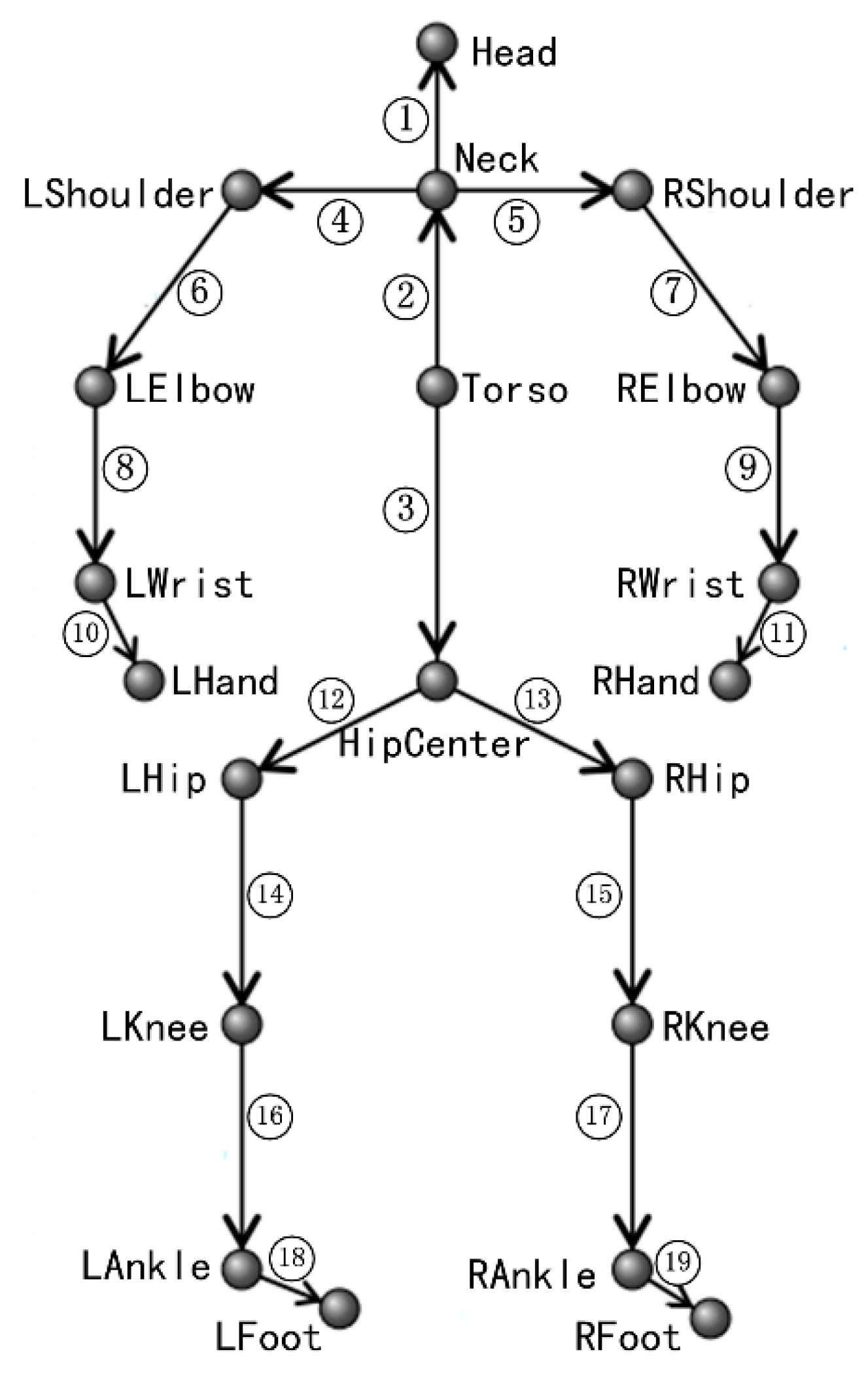
3.1. Feature Extraction
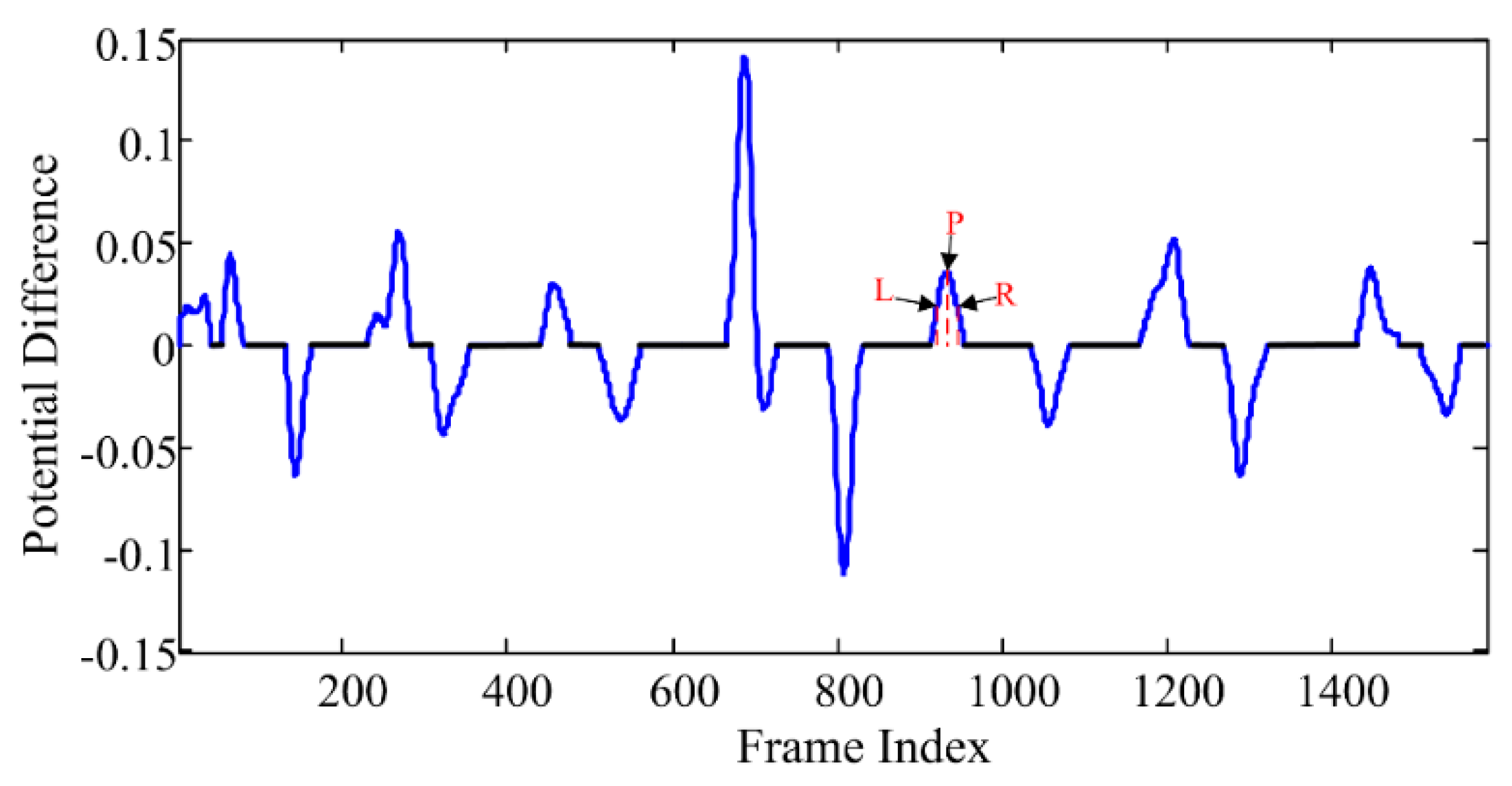
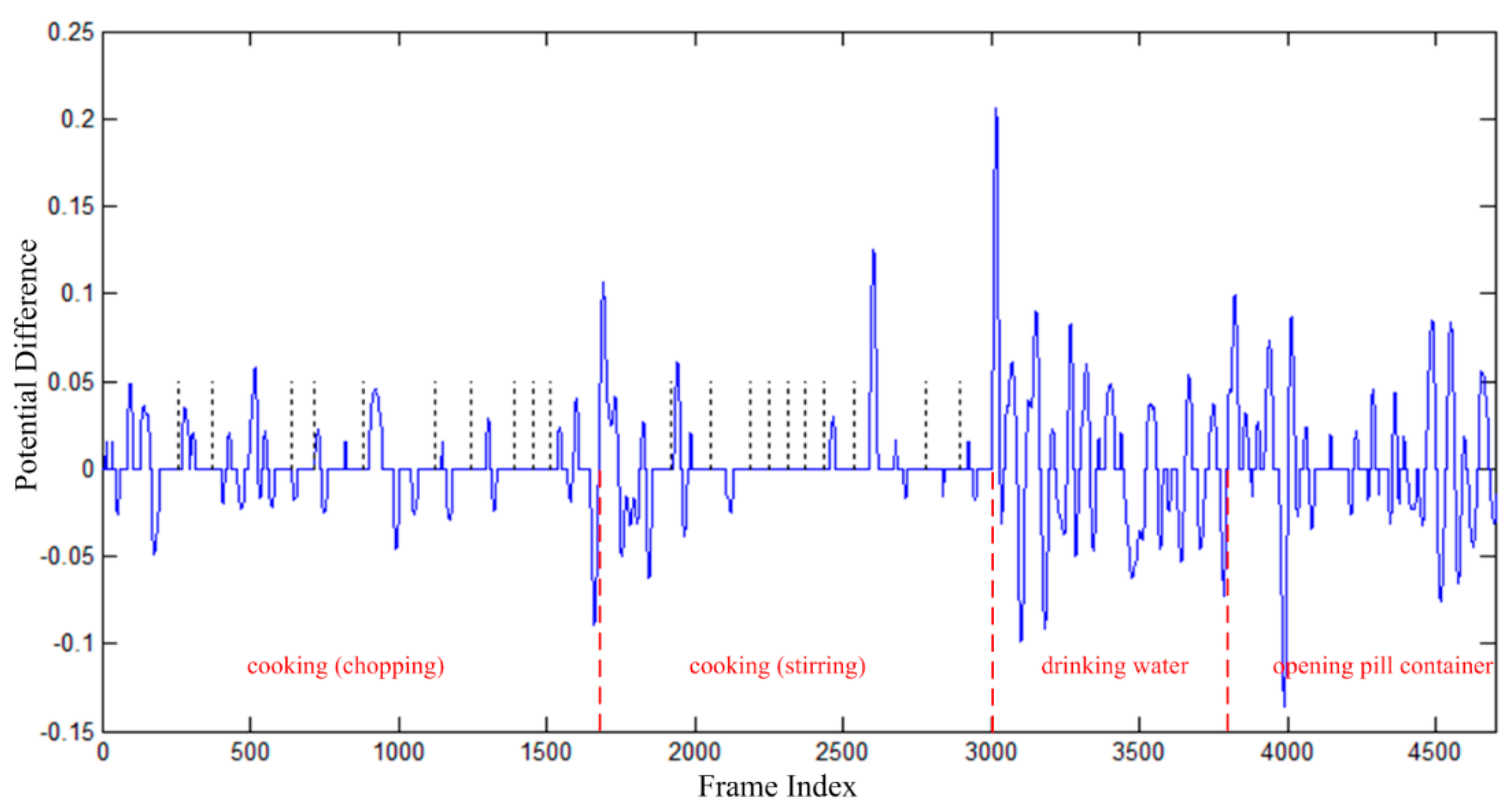
3.2. Online Segmentation
| Algorithm 1. The online segmentation process |
Initial: Start one segment from the frame , let and denote the feature vector of the frame and the sign of , respectively.
For each feature vector (The subscript indicate the frame index)
Step 1: Compute the potential difference and its sign .
Step 2:
If
If /* is the maximal length of pose feature segments. */
Complete the segment at the frame i–1; /* Pose feature segments. */
Else
Continue;
End
Else /* */
If /* is the minimal length of motion feature segments. */
; /* Eliminate tiny motion feature segments. */
Continue;
Else
Complete the segment at the frame ; /* The segment type is decided by . */
If /* Two adjacent motion feature segments */
Insert one pose feature segment which is only composed of the features and ;
End
End
End
Step 3: Start one new segment from the frame i, let and ;
End |

3.3. Model Training and Matching
3.3.1. Offline Model Training
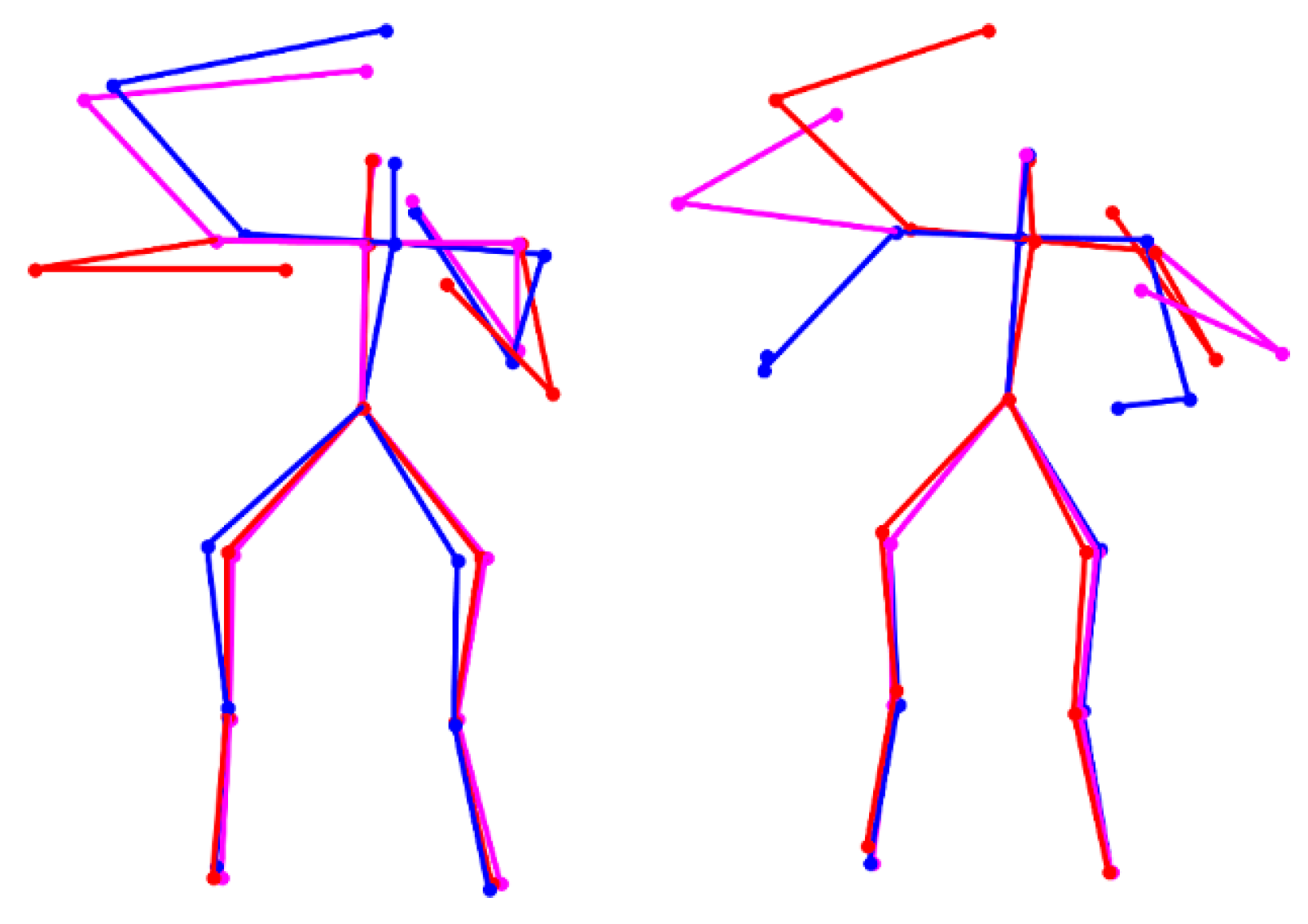
(1) Key Pose Extraction and Transition Probability Calculation
(2) Atomic Motion Extraction
3.3.2. Online Model Matching
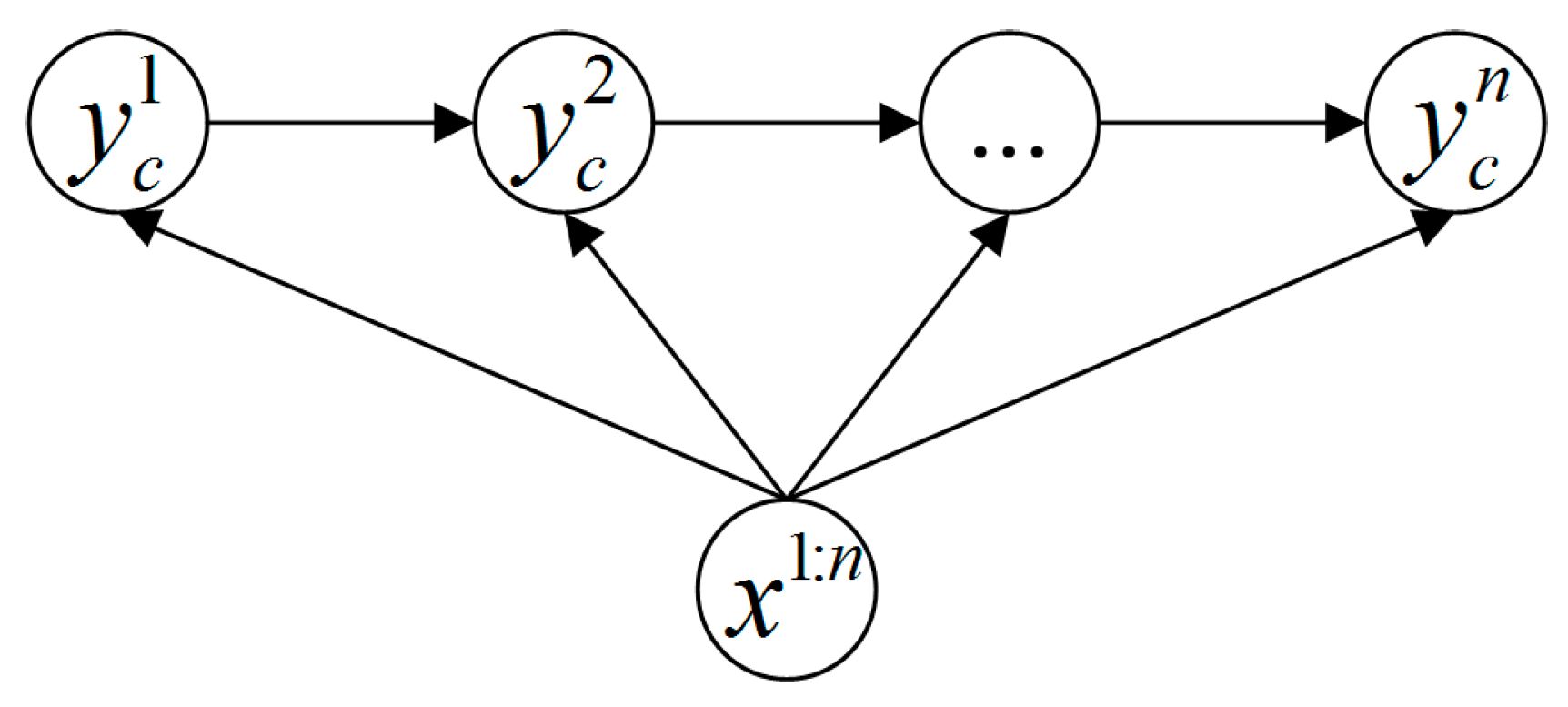
3.4. Classification with Variable-Length MEMM
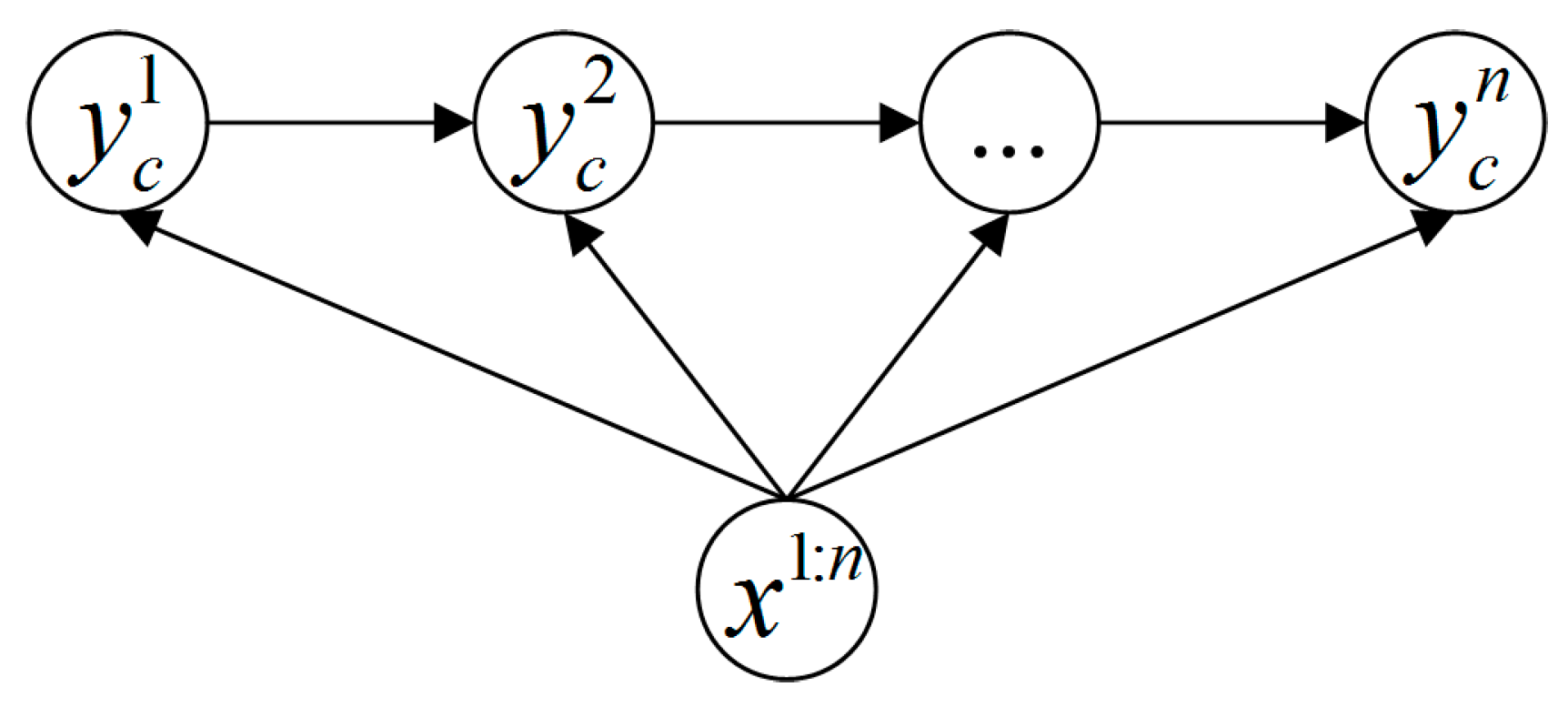
| Algorithm 2. The variable-length MEMM process |
| For /* is the largest step count */ For Calculate ; End If is significantly larger than others return ; End End return ; |

4. Experimental Results and Discussion
4.1. Experimental Setup
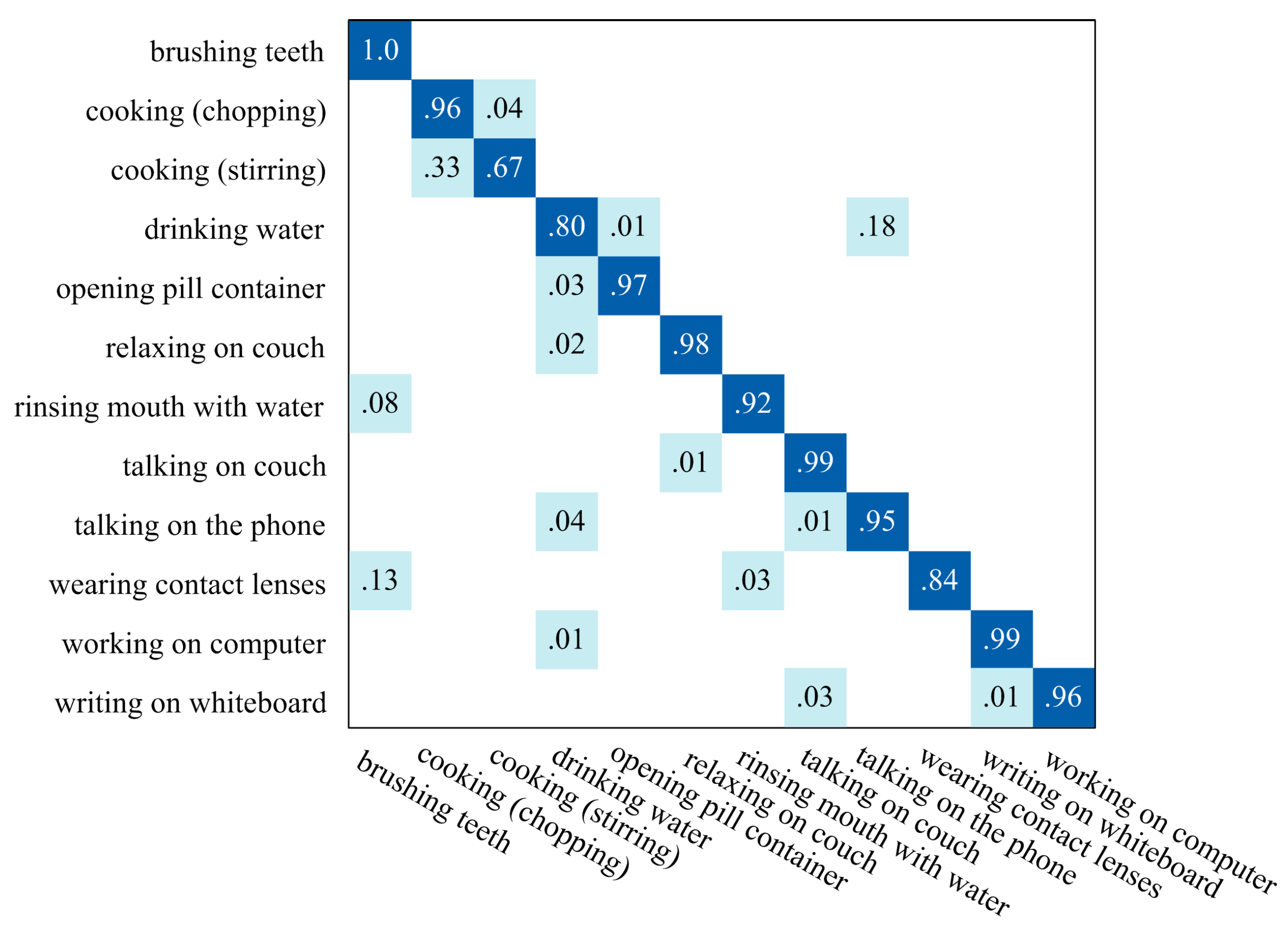
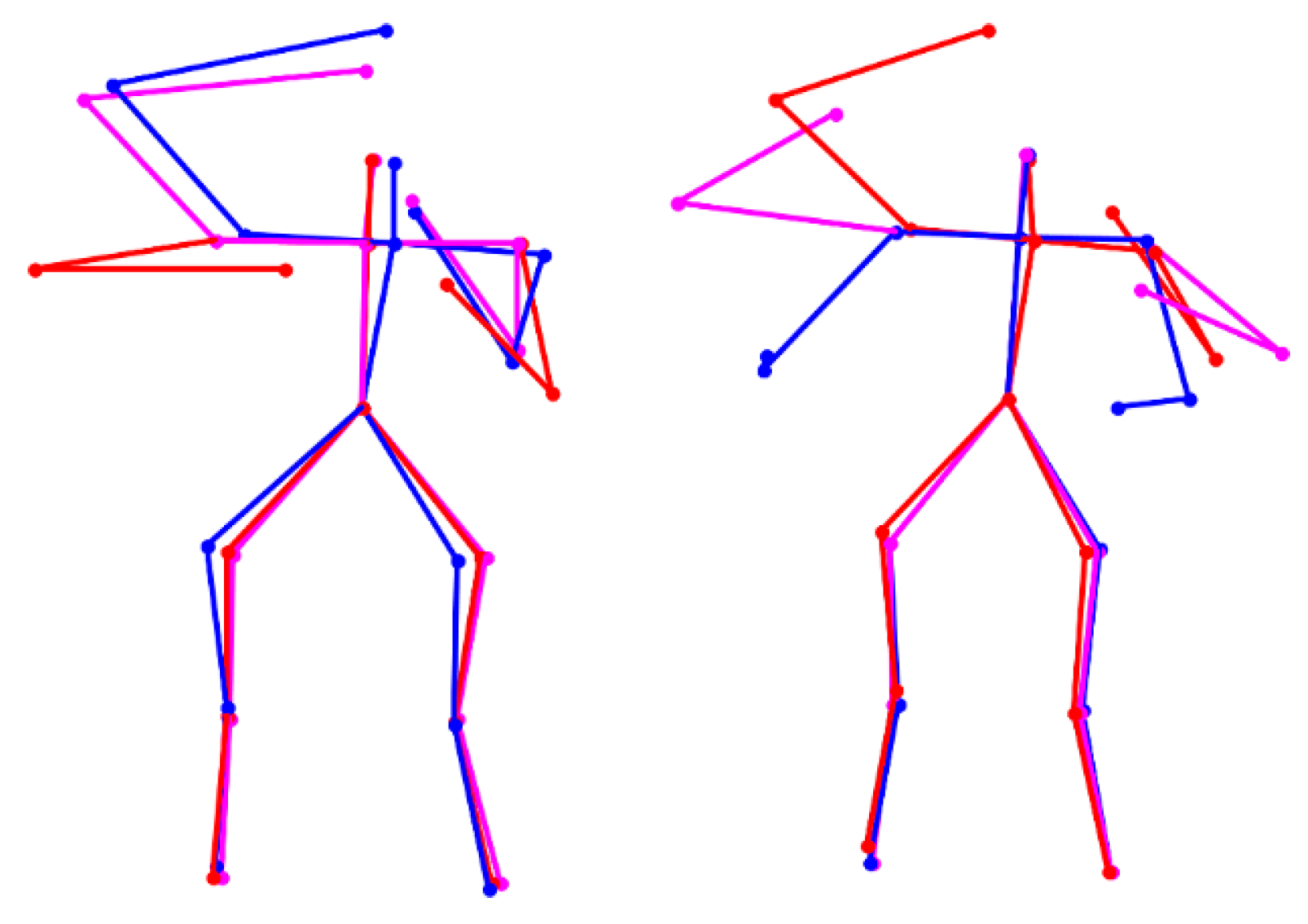
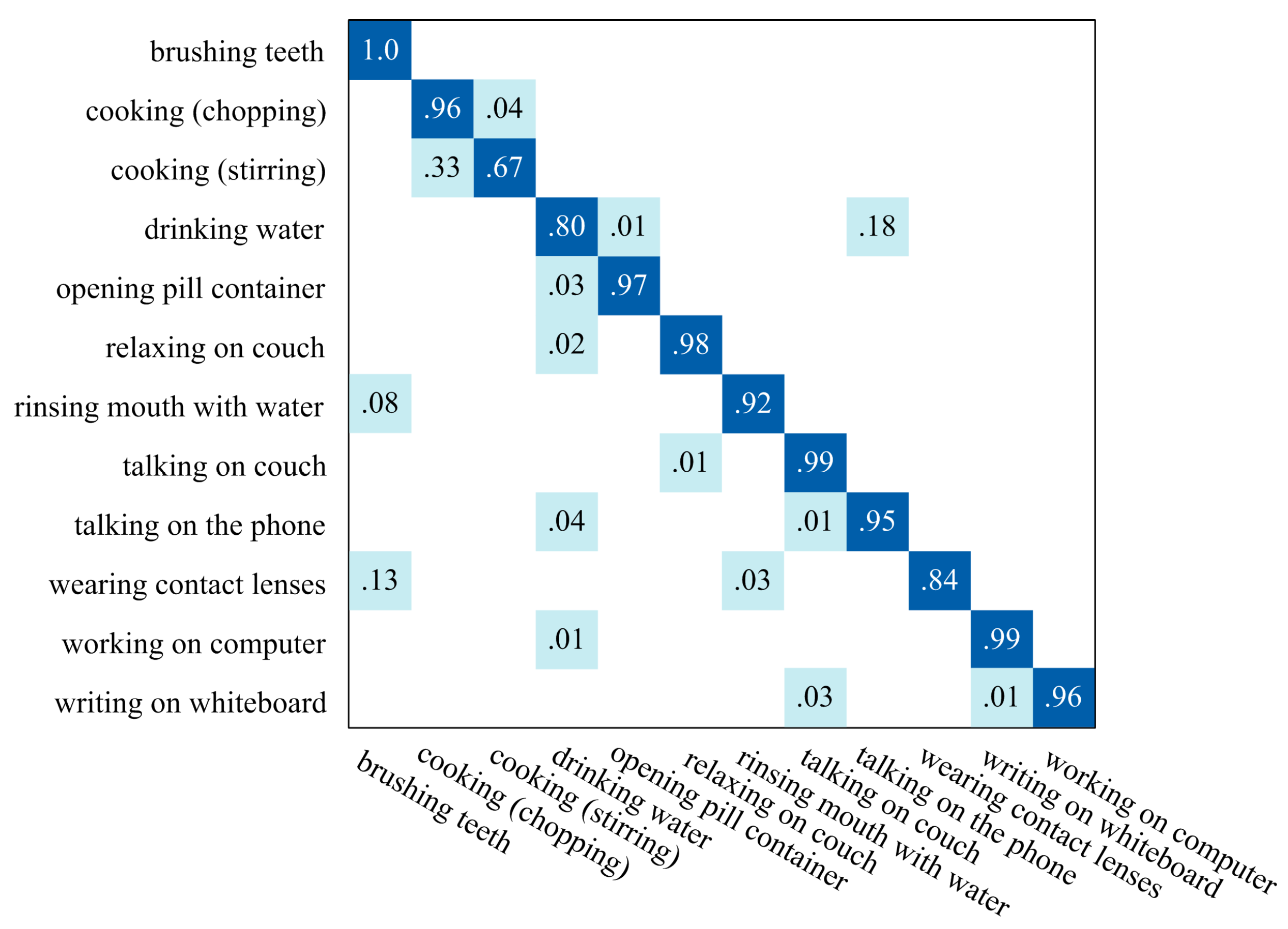
4.2. Segmentation Evaluation on CAD-60

4.3. Recognition Evaluation on CAD-60

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy |
|---|---|
| Our algorithm | 92.0% |
| Pose Kinetic Energy [41] | 91.9% |
| Actionlet [44] | 74.7% |
| Sparse Coding [45] | 65.3% |
| Result | Correct Recognition | Delayed Recognition | Error Recognition |
|---|---|---|---|
| Count | 27 | 36 | 2 |
4.4. Recognition Evaluation on MSR Daily Activity 3D
| Method | Accuracy |
|---|---|
| Our algorithm | 54.7% |
| Discriminative Orderlet [37] | 60.1% a |
| DSTIP + DCSF [46] | 24.6% |
| EigenJoints [47] | 47.0% |
| Moving Pose [30] | 45.2% |
4.5. Efficiency Evaluation
4.6. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. 2011, 43, 1–43. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Padilla-Lopez, J.R.; Ferrandez-Pastor, F.J.; Nieto-Hidalgo, M.; Florez-Revuelta, F. A vision-based system for intelligent monitoring: Human behaviour analysis and privacy by context. Sensors 2014, 14, 8895–8925. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saxena, A. Anticipating human activities using object affordances for reactive robotic response. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 1, 1–14. [Google Scholar]
- Zhang, C.; Tian, Y. RGB-D camera-based daily living activity recognition. J. Comput. Vision Imag. Process. 2012, 2, 1–7. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Xia, L. Human activity recognition from 3D data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with Microsoft Kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Zatsiorsky, V.M. Kinetics of Human Motion; Human Kinetics: Champaign, IL, USA, 2002. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3D skeletons as points in a lie group. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 588–595.
- Shan, Y.; Zhang, Z.; Huang, K. Learning skeleton stream patterns with slow feature analysis for action recognition. In Proceedings of the Computer Vision-ECCV 2014 Workshops, Zurich, Switzerland, 6–7 and 12 September 2014; pp. 111–121.
- Ofli, F.; Chaudhry, R.; Kurillo, G.; Vidal, R.; Bajcsy, R. Sequence of the most informative joints (SMIJ): A new representation for human skeletal action recognition. J. Vis. Commun. Image Represent. 2014, 25, 24–38. [Google Scholar] [CrossRef]
- Yoon, S.M.; Kuijper, A. Human action recognition based on skeleton splitting. Expert Syst. Appl. 2013, 40, 6848–6855. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14.
- Fothergill, S.; Mentis, H.; Kohli, P.; Nowozin, S. Instructing people for training gestural interactive systems. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 1737–1746.
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Unstructured human activity detection from RGBD images. In Proceedings of the IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 842–849.
- Hu, Y.; Cao, L.; Lv, F.; Yan, S.; Gong, Y.; Huang, T.S. Action detection in complex scenes with spatial and temporal ambiguities. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 128–135.
- Zhu, G.; Zhang, L.; Shen, P.; Song, J.; Zhi, L.; Yi, K. Human action recognition using key poses and atomic motions. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (IEEE-ROBIO), Zhuhai, China, 6–9 December 2015. (in press).
- McCallum, A.; Freitag, D.; Pereira, F.C. Maximum entropy Markov models for information extraction and segmentation. In Proceedings of the International Conference on Machine Learning (ICML), Stanford, CA, USA, 29 June–2 July 2000; pp. 591–598.
- Guo, P.; Miao, Z.; Shen, Y.; Xu, W.; Zhang, D. Continuous human action recognition in real time. Multimed. Tools Appl. 2014, 68, 827–844. [Google Scholar] [CrossRef]
- Eum, H.; Yoon, C.; Lee, H.; Park, M. Continuous human action recognition using depth-MHI-HOG and a spotter model. Sensors 2015, 15, 5197–5227. [Google Scholar] [CrossRef] [PubMed]
- Chaaraoui, A.A.; Florez-Revuelta, F. Continuous human action recognition in ambient assisted living scenarios. In Proceedings of the 6th International ICST Conference on Mobile Networks and Management, Wuerzburg, Germany, 22–24 September 2014; pp. 344–357.
- Theodorakopoulos, I.; Kastaniotis, D.; Economou, G.; Fotopoulos, S. Pose-based human action recognition via sparse representation in dissimilarity space. J. Vis. Commun. Image Represent. 2014, 25, 12–23. [Google Scholar] [CrossRef]
- Ballan, L.; Bertini, M.; Del Bimbo, A.; Seidenari, L.; Serra, G. Effective codebooks for human action categorization. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops (ICCV Workshops), Kyoto, Japan, 29 Sepember–2 October 2009; pp. 506–513.
- Raptis, M.; Sigal, L. Poselet key-framing: A model for human activity recognition. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2650–2657.
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Human activity detection from RGBD images. In Proceedings of the AAAI Workshop—Technical Report, San Francisco, CA, USA, 7–11 August 2011; pp. 47–55.
- Lu, G.; Zhou, Y.; Li, X.; Kudo, M. Efficient action recognition via local position offset of 3D skeletal body joints. Multimed. Tools Appl. 2015. [Google Scholar] [CrossRef]
- Lu, G.; Zhou, Y.; Li, X.; Lv, C. Action recognition by extracting pyramidal motion features from skeleton sequences. Lect. Notes Electr. Eng. 2015, 339, 251–258. [Google Scholar]
- Evangelidis, G.; Singh, G.; Horaud, R. Skeletal quads: Human action recognition using joint quadruples. In Proceedings of the 2014 22nd International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 4513–4518.
- Hussein, M.E.; Torki, M.; Gowayyed, M.A.; El-Saban, M. Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2466–2472.
- Yang, X.; Tian, Y. Effective 3D action recognition using eigenjoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Zanfir, M.; Leordeanu, M.; Sminchisescu, C. The moving pose: An efficient 3D kinematics descriptor for low-latency action recognition and detection. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 3–6 December 2013; pp. 2752–2759.
- Jung, H.-J.; Hong, K.-S. Enhanced sequence matching for action recognition from 3D skeletal data. In Proceedings of the 12th Asian Conference on Computer Vision (ACCV 2014), Singapore, 1–5 November 2014; pp. 226–240.
- Gowayyed, M.A.; Torki, M.; Hussein, M.E.; El-Saban, M. Histogram of oriented displacements (HOD): Describing trajectories of human joints for action recognition. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1351–1357.
- Lu, X.; Chia-Chih, C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, RI, USA, 16–21 June 2012; pp. 20–27.
- Oreifej, O.; Liu, Z. Hon4D: Histogram of oriented 4D normals for activity recognition from depth sequences. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 716–723.
- Song, Y.; Demirdjian, D.; Davis, R. Continuous body and hand gesture recognition for natural human-computer interaction. ACM Trans. Interact. Intell. Sys. 2012, 2. [Google Scholar] [CrossRef]
- Evangelidis, G.D.; Singh, G.; Horaud, R. Continuous gesture recognition from articulated poses. In Proceedings of the Computer Vision-ECCV 2014 Workshops, Zurich, Switzerland, 6–7 and 12 September 2014; pp. 595–607.
- Yu, G.; Liu, Z.; Yuan, J. Discriminative orderlet mining for real-time recognition of human-object interaction. In Proceedings of the 12th Asian Conference on Computer Vision (ACCV 2014), Singapore, 1–5 November 2014; pp. 50–65.
- Kulkarni, K.; Evangelidis, G.; Cech, J.; Horaud, R. Continuous action recognition based on sequence alignment. Int. J. Comput. Vis. 2015, 112, 90–114. [Google Scholar] [CrossRef] [Green Version]
- Ke, S.R.; Thuc, H.L.U.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. Human Action Recognition Based on 3D Human Modeling and Cyclic HMMs. ETRI J. 2014, 36, 662–672. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Xiao, J.; Lin, K.H.; Huang, T. Substructure and boundary modeling for continuous action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1330–1337.
- Shan, J.; Srinivas, A. 3D human action segmentation and recognition using pose kinetic energy. In Proceedings of the 2014 IEEE Workshop on Advanced Robotics and its Social Impacts (ARSO), Evanston, IL, USA, 11–13 September 2014; pp. 69–75.
- Sempena, S.; Maulidevi, N.U.; Aryan, P.R. Human action recognition using dynamic time warping. In Proceedings of the 2011 International Conference on Electrical Engineering and Informatics (ICEEI), Bandung, Indonesia, 17–19 July 2011; pp. 1–5.
- Piyathilaka, L.; Kodagoda, S. Gaussian mixture based HMM for human daily activity recognition using 3D skeleton features. In Proceedings of the 2013 8th IEEE Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; pp. 567–572.
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning actionlet ensemble for 3D human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 914–927. [Google Scholar] [CrossRef] [PubMed]
- Ni, B.; Moulin, P.; Yan, S. Order-preserving sparse coding for sequence classification. In Proceedings of Computer Vision–ECCV, Firenze, Italy, 7–13 October 2012; pp. 173–187.
- Xia, L.; Aggarwal, J.K. Spatio-temporal depth cuboid similarity feature for activity recognition using depth camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2834–2841.
- Yang, X.; Tian, Y. Eigenjoints-based action recognition using Naive-Bayes-Nearest-Neighbor. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, RI, USA, 16–21 June 2012; pp. 14–19.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, G.; Zhang, L.; Shen, P.; Song, J. An Online Continuous Human Action Recognition Algorithm Based on the Kinect Sensor. Sensors 2016, 16, 161. https://doi.org/10.3390/s16020161
Zhu G, Zhang L, Shen P, Song J. An Online Continuous Human Action Recognition Algorithm Based on the Kinect Sensor. Sensors. 2016; 16(2):161. https://doi.org/10.3390/s16020161
Chicago/Turabian StyleZhu, Guangming, Liang Zhang, Peiyi Shen, and Juan Song. 2016. "An Online Continuous Human Action Recognition Algorithm Based on the Kinect Sensor" Sensors 16, no. 2: 161. https://doi.org/10.3390/s16020161