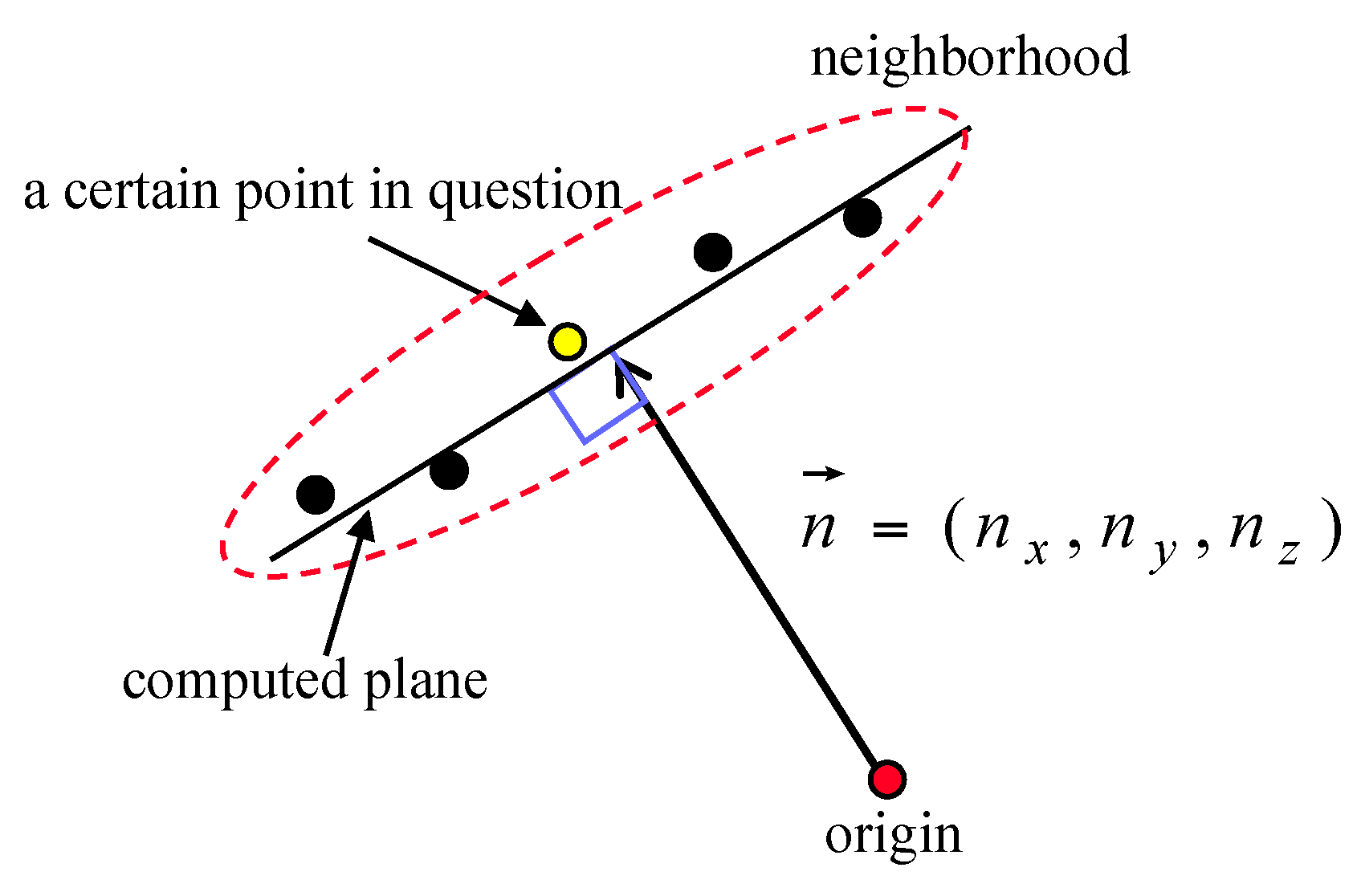
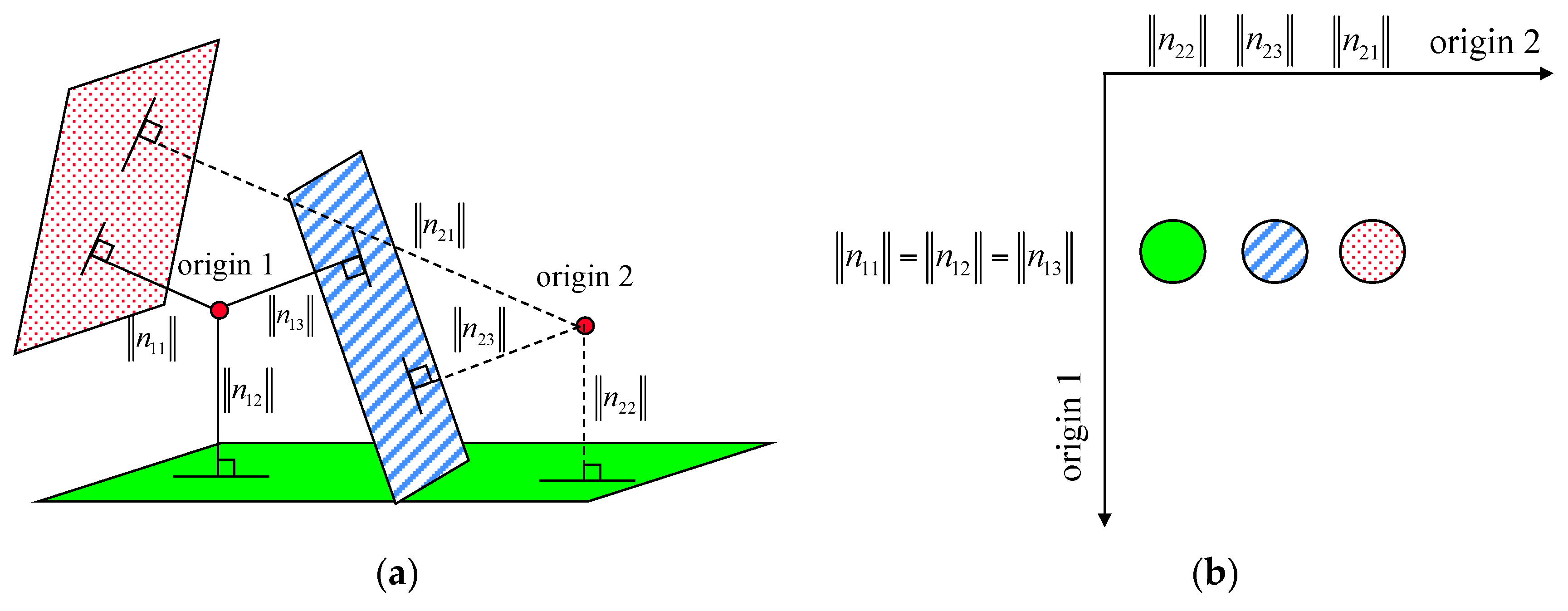
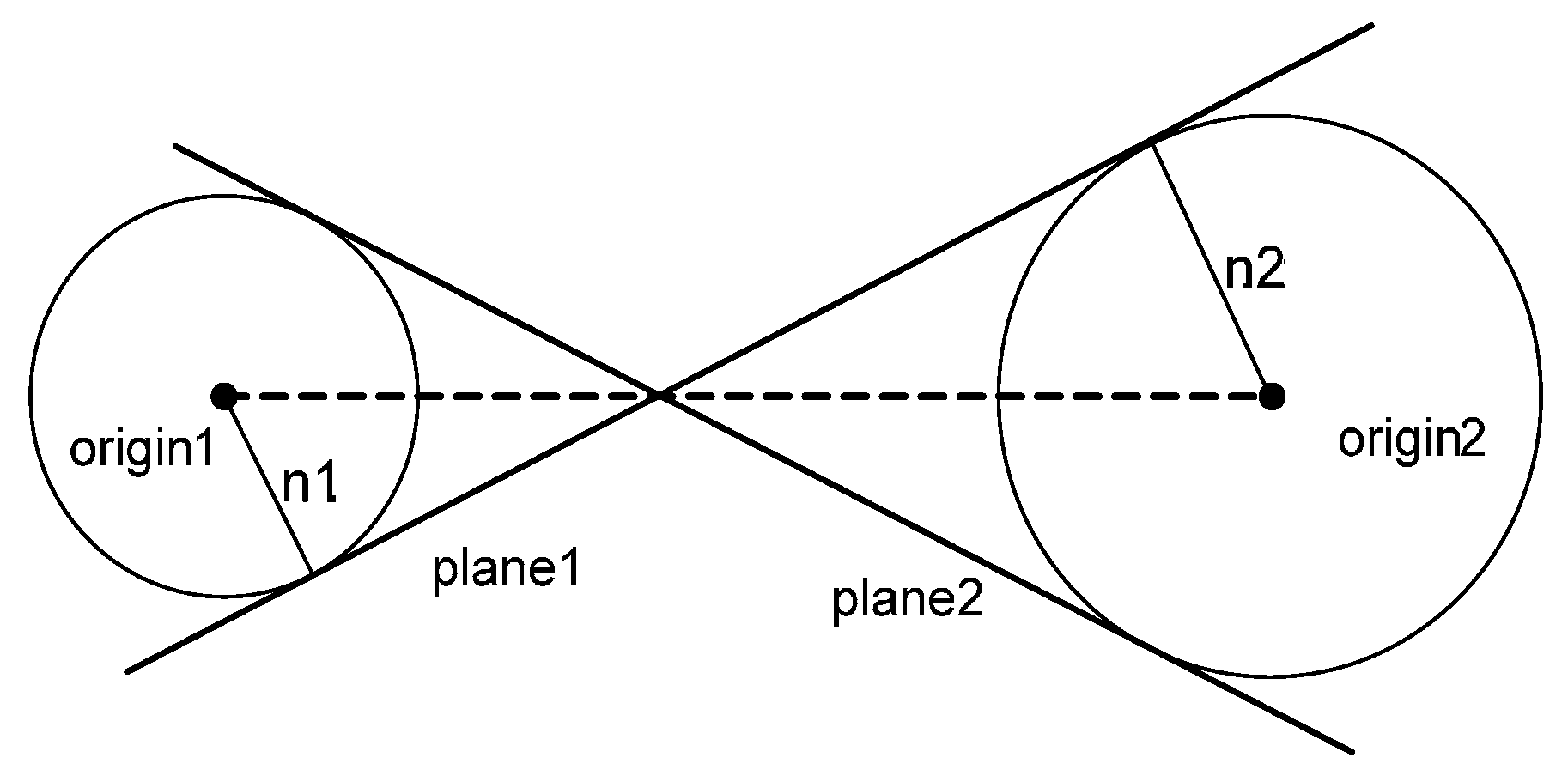
3.1. Analysis of the Effect of the Adaptive Cylindrical Neighborhood Definition
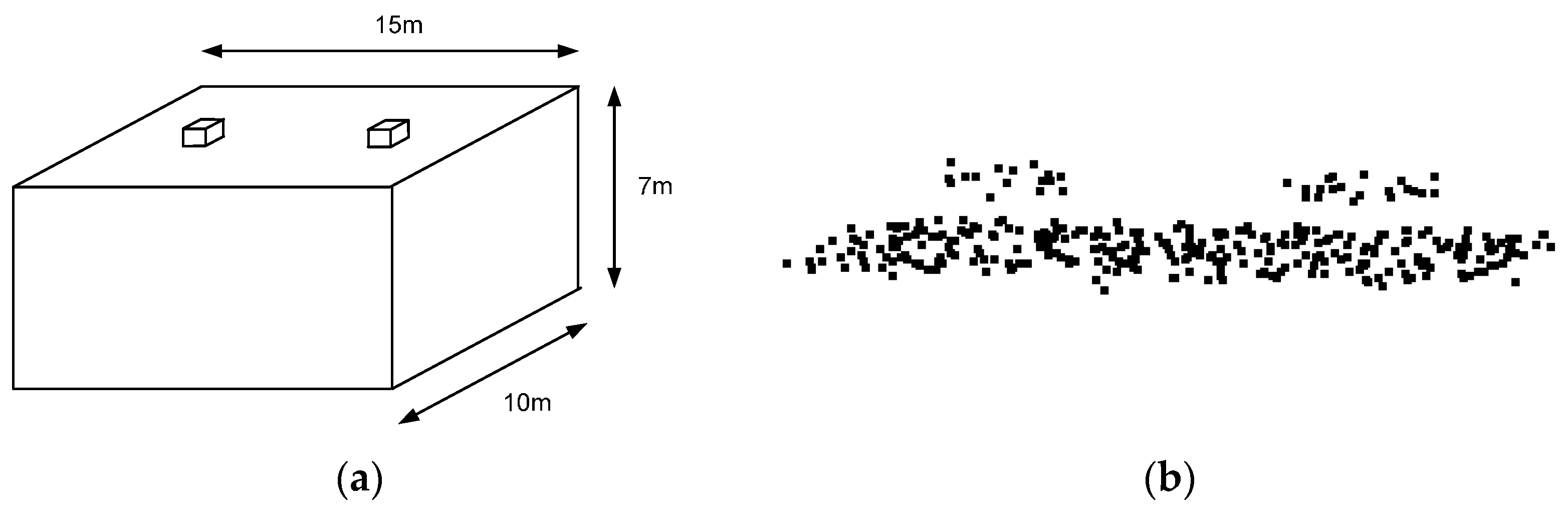
Laser points reflected from a structure of 15 m × 10 m × 7 m dimensions were, first, simulated for this analysis. The structure had two small objects on the rooftop (e.g., cooling towers of 3.0 m × 3.0 m × 1.5 m dimensions). The mean point density of the simulated data was 2.24 points/m
2 (~0.67 m point spacing), and the horizontal and vertical accuracies of the laser points were 0.5 m and 0.15 m, respectively. It should be emphasized that the simulated data followed the specifications of the real data acquired from OPTECH ALTM 3100, which was used by [
32].
Figure 12a,b show the designed structure for the simulation and the produced laser points on the rooftop of the structure, respectively. Three hundred and forty-five (345) laser points were generated, among which thirty-two (32) points were located on the two small objects, as seen in
Figure 12b.
Figure 12.
(a) Shape of a structure on which laser points are projected; and (b) the produced laser points on the rooftop of the structure.
Figure 12.
(a) Shape of a structure on which laser points are projected; and (b) the produced laser points on the rooftop of the structure.
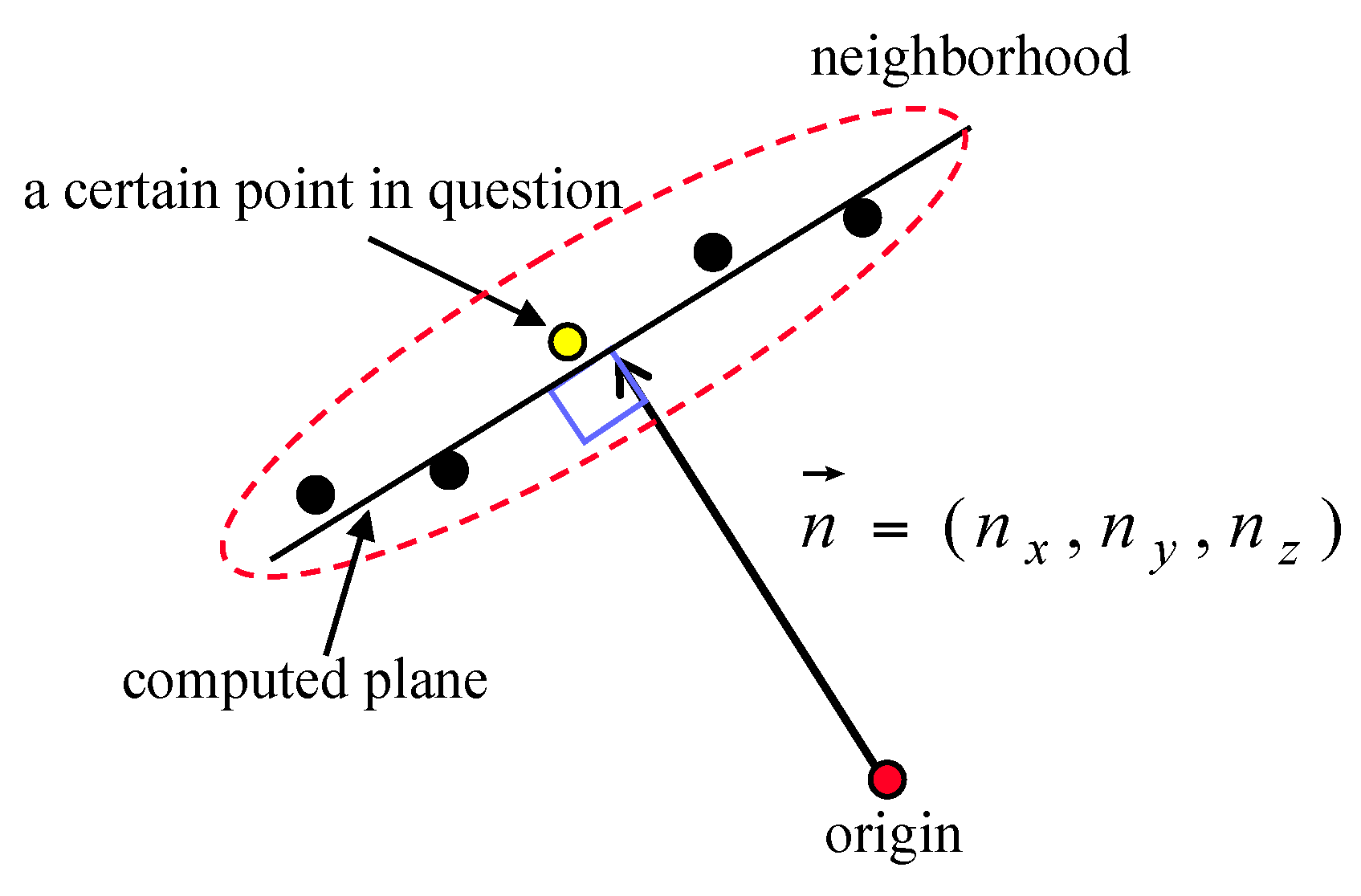
Based on the simulated laser points, the fitted plane was determined using the neighboring laser points around the target point; then, the surface normal vector of the plane was calculated. For this test, two neighborhood definition approaches, the adaptive cylindrical and spherical ones, were applied. The surface normal vectors calculated from the two approaches were then compared with the true one. Significantly, the components of the true unit normal vector were (0, 0, 1), because the laser points were reflected from the structure’s horizontal rooftop. Angle computation between the surface normal vector calculated and the true one was implemented for all of the points in the simulated dataset (refer to Equation (8)):
where
is the surface normal vector of the plane determined using the neighboring laser points around the
i-th point,
is the true unit normal vector (0, 0, 1), and
is the angle between the vectors
and
. In the test, the numbers of neighboring points were determined using four different searching radii: 2.0 m, 2.5 m, 3.0 m, and 3.5 m.
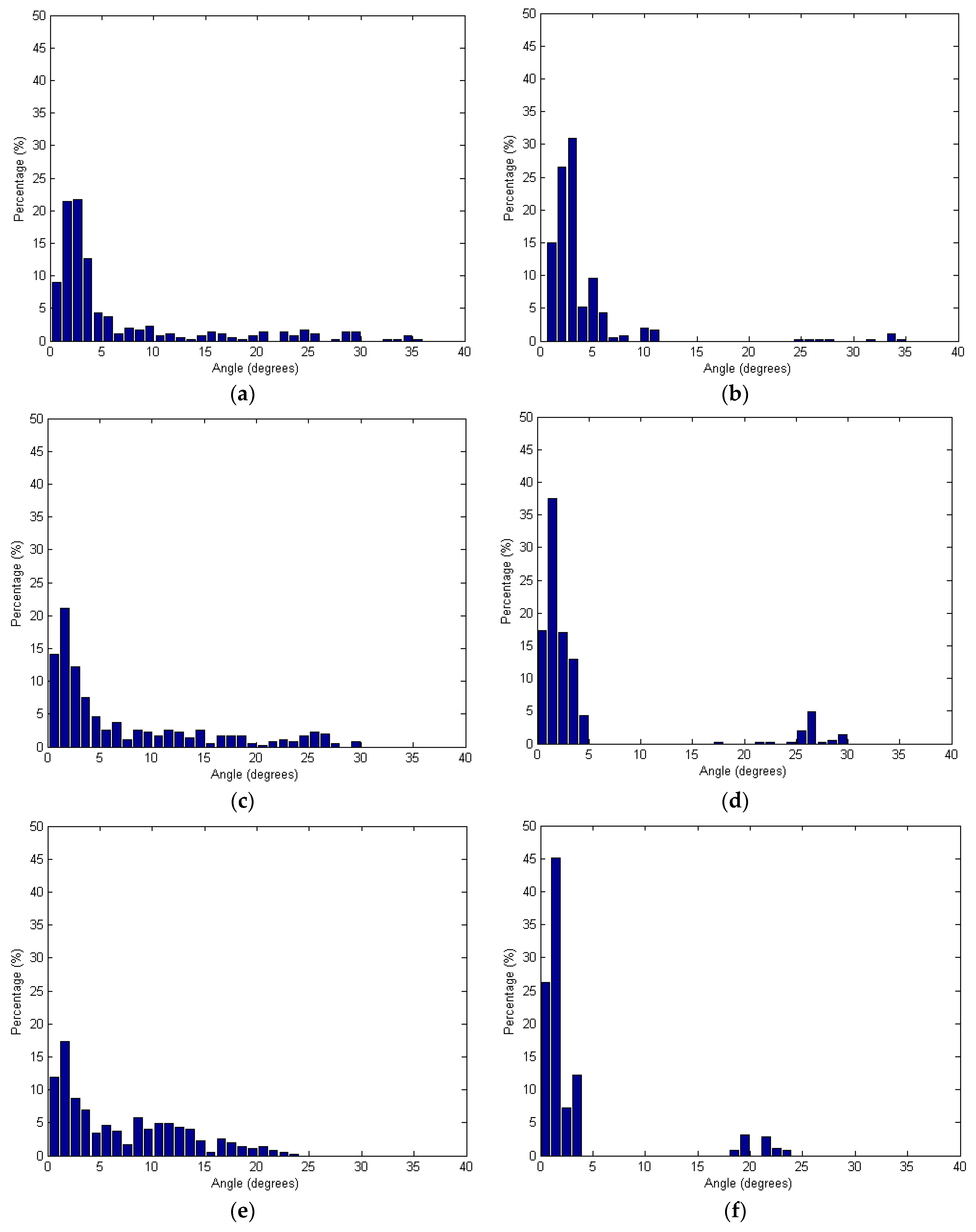
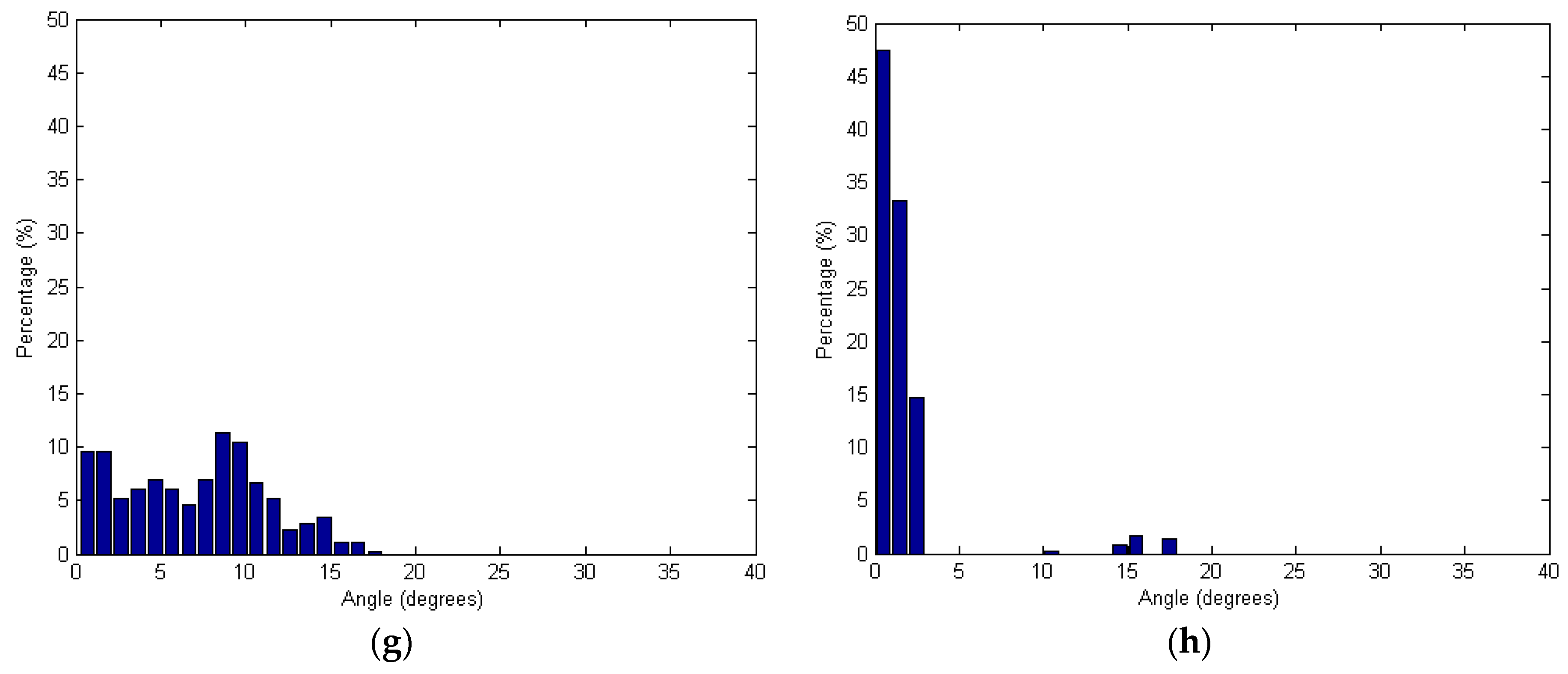
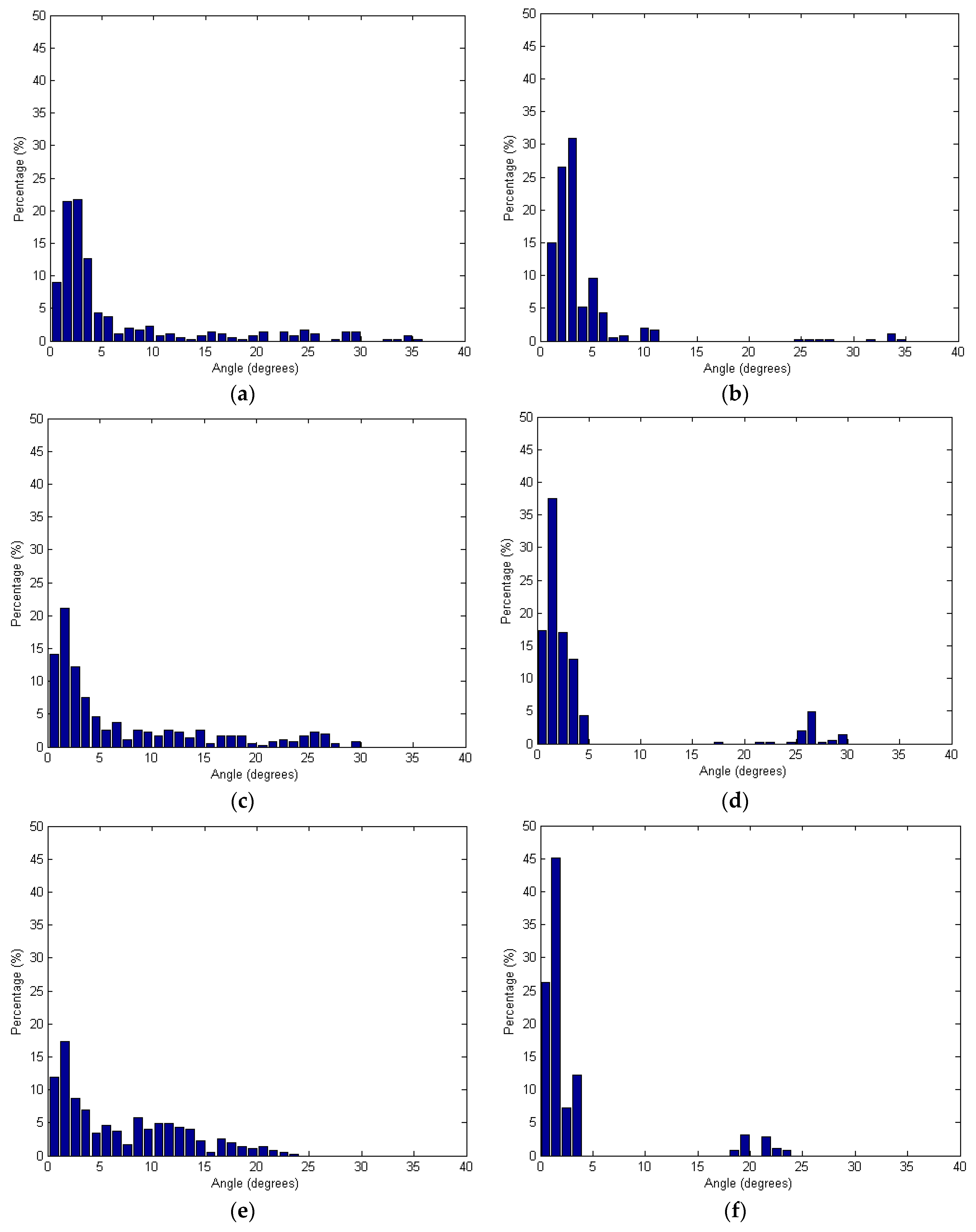
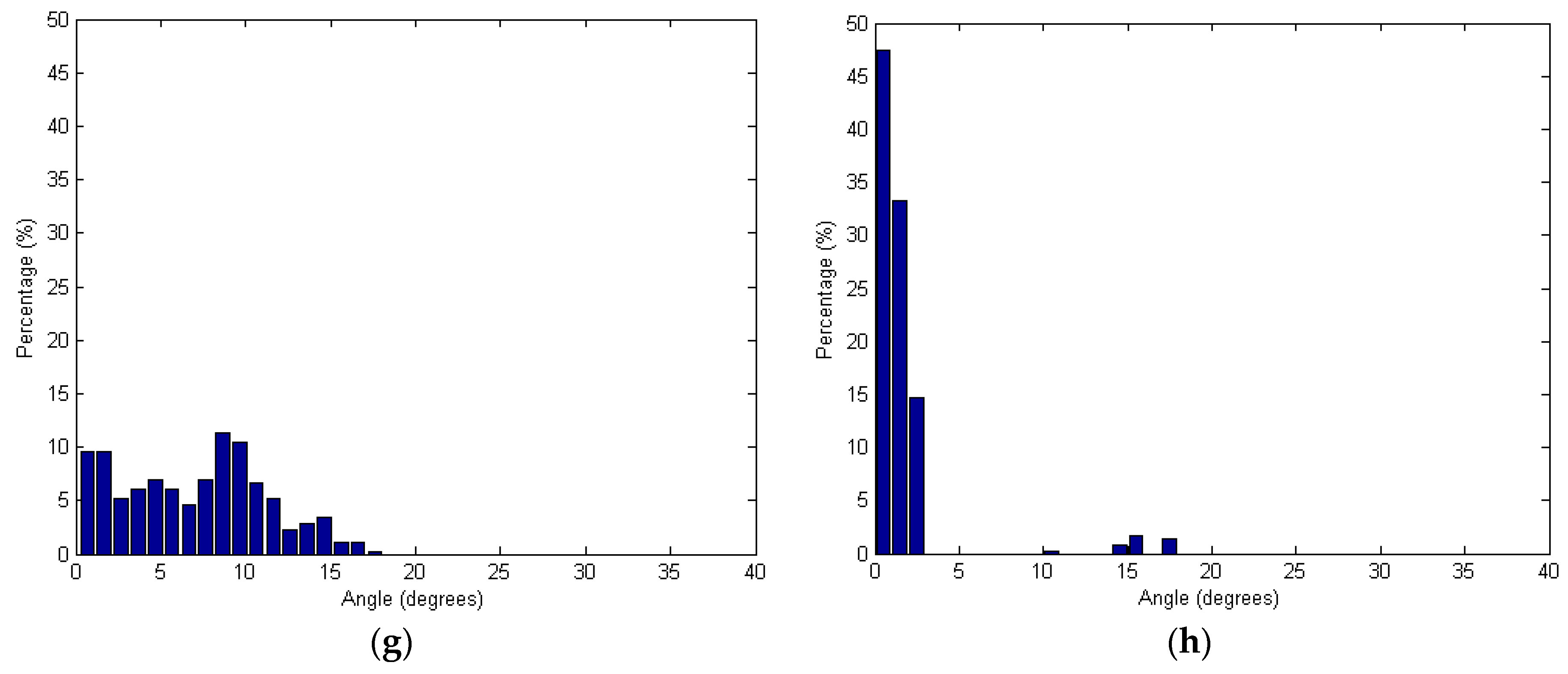
Figure 13 shows the angles based on the spherical and adaptive cylindrical approaches together with the searching radii. Additionally,
Table 1 lists the statistical evaluation data for the angles calculated.
Figure 13.
Angles between the surface normal vector calculated and the true one: (a,c,e,g) Spherical and (b,d,f,h) Adaptive cylindrical approaches applying different radii of 2.0 m (a,b); 2.5 m (c,d); 3.0 m (e,f); and 3.5 m (g,h).
Figure 13.
Angles between the surface normal vector calculated and the true one: (a,c,e,g) Spherical and (b,d,f,h) Adaptive cylindrical approaches applying different radii of 2.0 m (a,b); 2.5 m (c,d); 3.0 m (e,f); and 3.5 m (g,h).
Table 1.
Statistical evaluations of the angles between the surface normal vector calculated and the true one.
Table 1.
Statistical evaluations of the angles between the surface normal vector calculated and the true one.
| Radius (m) | Spherical Approach (Degrees) | Adaptive Cylindrical Approach (Degrees) |
|---|
| Mean | STD | Mean | STD |
|---|
| 2.0 | 6.738 | 8.240 | 4.058 | 4.991 |
| 2.5 | 7.399 | 7.872 | 4.484 | 7.605 |
| 3.0 | 7.116 | 5.894 | 3.257 | 5.582 |
| 3.5 | 7.018 | 4.252 | 1.738 | 3.067 |
Figure 13 shows that the angles provided by the adaptive cylindrical approach are more concentrated than the values provided by the spherical one. Considering
Table 1 results, it is also clear that the mean and standard deviation values of the angles were much lower for the adaptive cylindrical method than for the spherical one. Therefore, the adaptive cylindrical method can be considered robust against random noises and outliers in the laser point cloud when compared to those using spherical neighborhoods. In other words, the adaptive cylindrical neighborhood approach increases the homogeneity of the laser point attributes. To see the impact of the neighborhood definition on the segmentation results, the qualitative and qualitative comparison between the results from the spherical and adaptive cylindrical approaches is added in
Section 3.3, Segments extracted and evaluations.
3.3. Segments Extracted and Evaluations
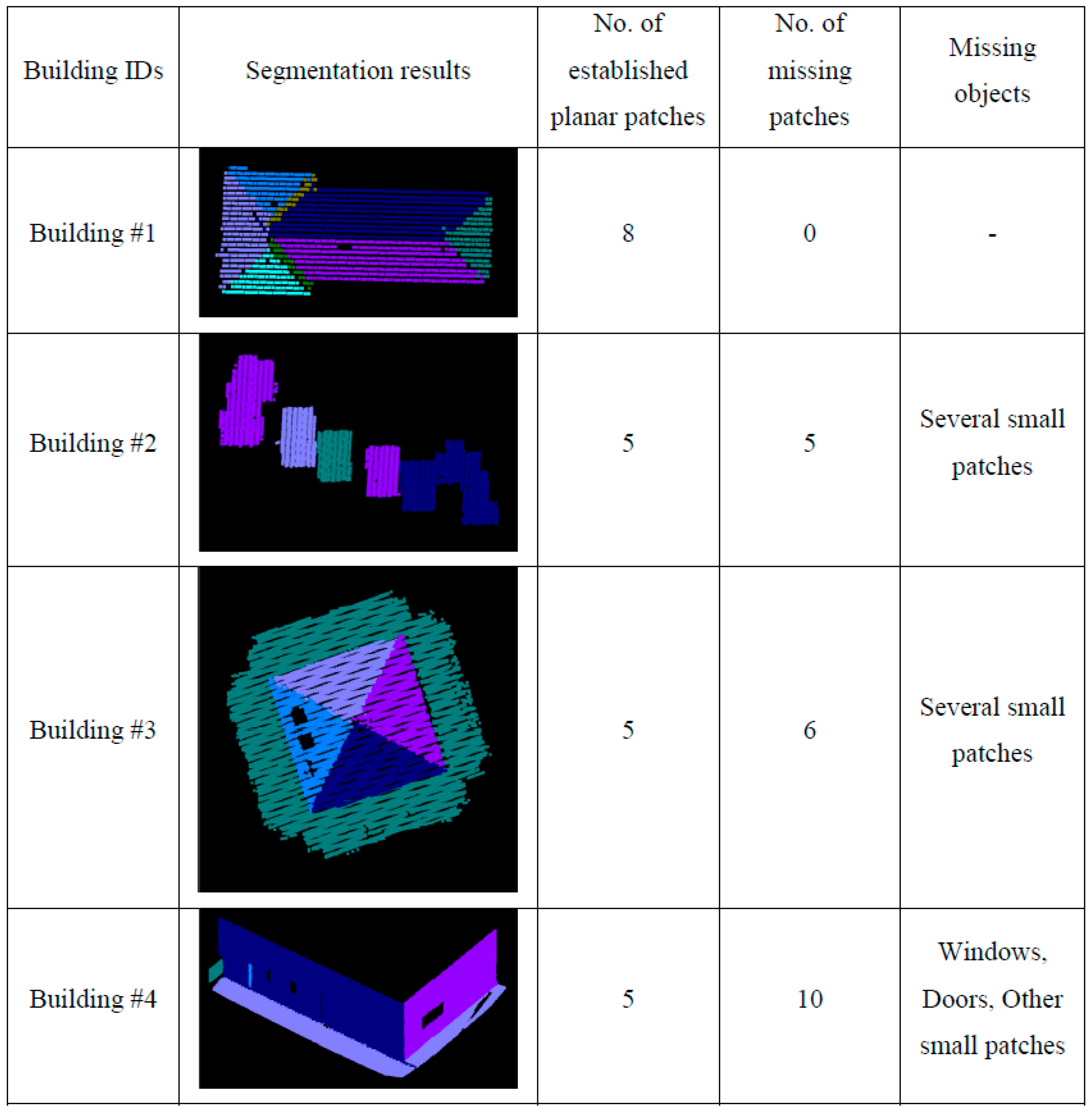
An automated segmentation process based on the proposed methodology was, first, carried out using four different datasets. The flatness of the surfaces, the roughness of the materials, and the instrumental accuracies were considered when the accuracies of the laser datasets in the depth direction were determined. The values from the Vaihingen, Toronto, and Seoul datasets, respectively, were 0.15 m, 0.15 m, and 0.10 m. Descriptions, values, and justifications for the thresholds used in the segmentation process for four buildings are provided in
Table 3.
Table 3.
Descriptions, values, and justifications for the thresholds used in the segmentation process.
Table 3.
Descriptions, values, and justifications for the thresholds used in the segmentation process.
| Threshold | Description | Value (Building #1/#2/#3/#4) | Justification |
|---|
| Searching radius | Radius of the spherical neighborhood centered at a point | 2.00 m/2.00 m/2.00 m/0.30 m | Including sufficient number of points to define reliable attributes |
| Buffer threshold | Buffer defined above and below the final fitted plane | 0.30 m/0.30 m/0.30 m/0.20 m | Two times the accuracy of the laser data in the depth direction |
| Co-planarity test threshold | Threshold for testing the co-planarity of points at the peak of the accumulator array | 0.30 m/0.30 m/0.30 m/0.20 m | Two times the accuracy of the laser data in the depth direction |
| Proximity threshold | Maximum distance for determining the proximity among points in the object space | 0.50 m/0.50 m/0.50 m/0.15 m | Approximately equal to the average point spacing of the laser data |
| Minimum size of detectable peak | Minimum size of the detected points at the highest peak | 4.00 m2/4.00 m2/4.00 m2/0.50 m2 | Prior knowledge about building planar patch size within the area of interest |
| Accumulator Cell resolution | Cell size of the accumulator array | 0.30 m/0.30 m/0.30 m/0.20 m | Two times the accuracy of the laser data in the depth direction |
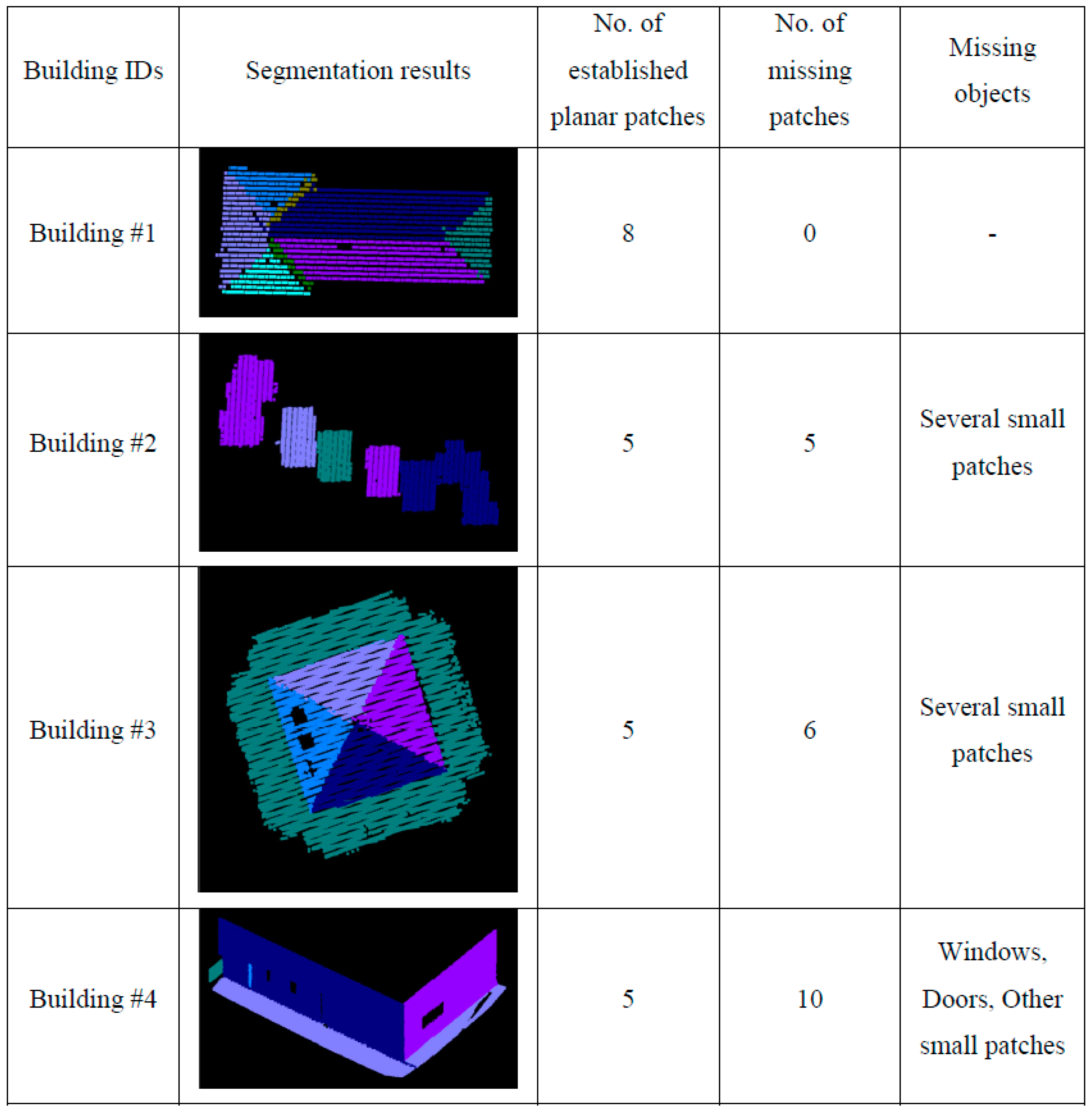
To see the impact of the neighborhood definition on the segmentation results, the adaptive cylindrical and spherical approaches were carried out and compared with each other. More specifically, two different attribute files are generated separately based on the adaptive cylindrical and spherical neighborhood definitions. Afterwards, the exactly same remaining segmentation procedures were applied to those attributes. The final segmentation results based on the adaptive cylindrical and spherical neighborhood definitions are provided in
Figure 16 and
Figure 17, respectively. Each color indicates a planar patch of different slope and aspect.
Figure 16 and
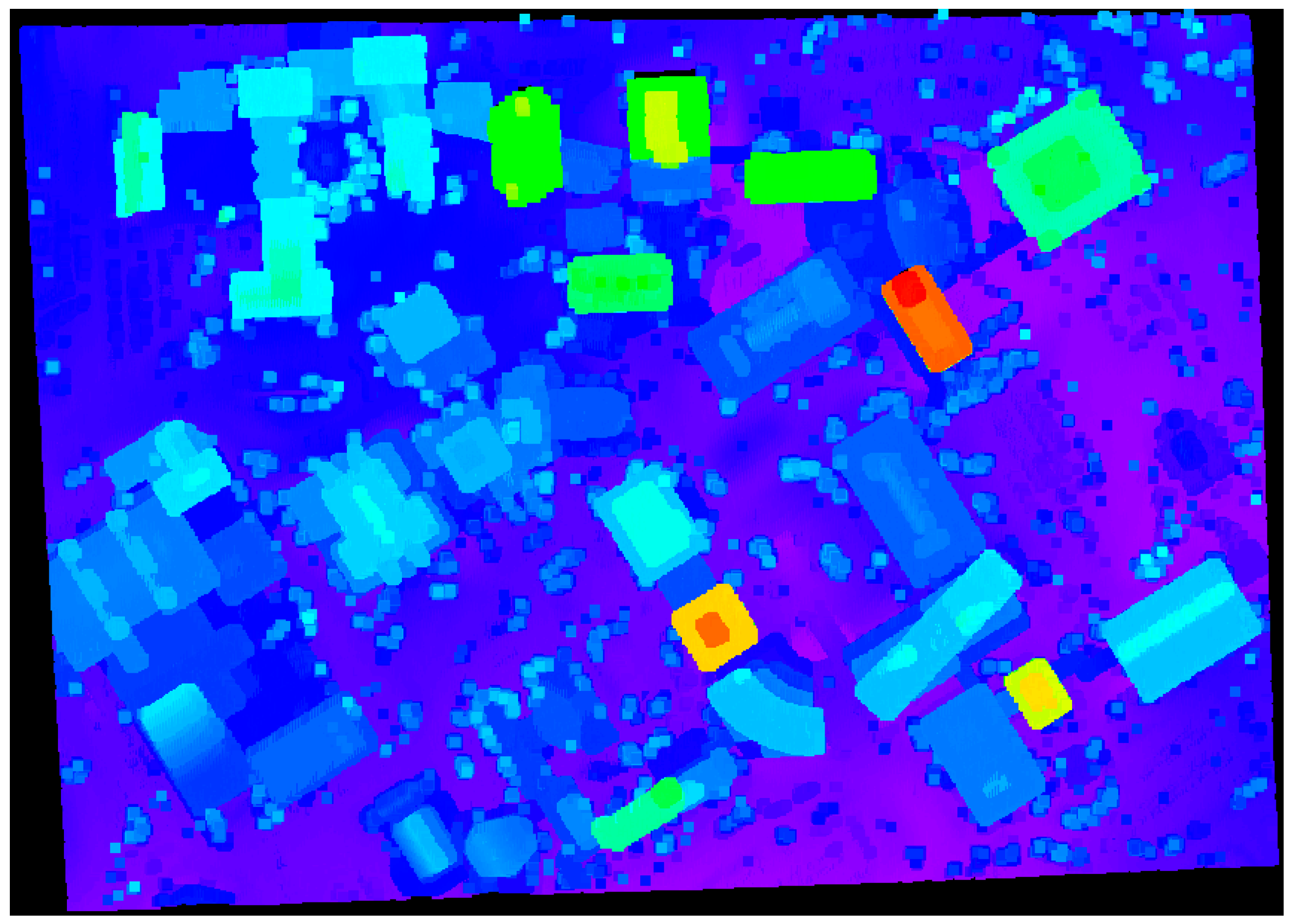
Figure 17 also show a number of extracted planar patches, a number of missing patches, and the missing object types. When the segmentation results were visually checked for
Figure 16, most of the planar patches had been correctly extracted, excepting a very small object and three windows. The missing objects could be accounted for by the facts that the small patch belonging to building #2 had just very few points and that the windows belonging to building #4 have very noisy and few laser points. On the other hand, the segmentation results based on the spherical neighborhood have many missing objects as seen in
Figure 17. Several small patches, windows, and doors are not detected in the segmentation results except for building #1.
Figure 16.
Segmentation results based on the adaptive cylindrical neighborhood definition.
Figure 16.
Segmentation results based on the adaptive cylindrical neighborhood definition.
For more detailed quantitative evaluations of the experimental results, the automatically extracted patches (
i.e., from adaptive cylindrical and spherical approaches) were compared with those manually derived by experienced operators. The manually derived patches functioned in this research as references. Since this research focused on planar segmentation, the laser points belonging to non-planar surfaces were not considered when the manually derived patches were prepared. The correctness, completeness, plane fitting precision, plane fitting precision difference, centroid difference, and angle difference were considered as quantitative measures. The correctness and completeness measures were, first, computed point-by-point, automatic-to-manual comparison of the clustered point IDs. In computing these measures, the total number of laser points with matching IDs, between the automatic and manual clusters, was calculated. The correctness measure in Equation (9) evaluates the percentage of the matched laser points among the established ones (
i.e., the automatically detected ones). On the other hand, the completeness measure in Equation (10) provides an indication of the percentage of the matched points among the actual ones (
i.e., the manually detected ones).
Table 4 and
Table 5 list the correctness and completeness values computed from the adaptive cylindrical and spherical approaches for the four buildings, respectively.
Figure 17.
Segmentation results based on the spherical neighborhood definition.
Figure 17.
Segmentation results based on the spherical neighborhood definition.
Table 4.
Correctness and completeness values of four buildings (Adaptive cylindrical approach).
Table 4.
Correctness and completeness values of four buildings (Adaptive cylindrical approach).
| | No. of Points Detected Manually | No. of Points Detected Automatically | No. of Points Matched | Correctness (%) | Completeness (%) |
|---|
| Building #1 | 1490 | 1475 | 1367 | 92.68 | 91.74 |
| Building #2 | 2988 | 3007 | 2946 | 97.97 | 98.59 |
| Building #3 | 11,394 | 10,509 | 10,378 | 98.75 | 91.08 |
| Building #4 | 33,778 | 34,117 | 32,892 | 96.41 | 97.38 |
| Minimum | - | - | - | 92.68 | 91.08 |
| Maximum | - | - | - | 98.75 | 98.59 |
| Overall | 49,650 | 49,108 | 47,583 | 96.89 | 95.84 |
Table 5.
Correctness and completeness values of four buildings (Spherical approach).
Table 5.
Correctness and completeness values of four buildings (Spherical approach).
| | No. of Points Detected Manually | No. of Points Detected Automatically | No. of Points Matched | Correctness (%) | Completeness (%) |
|---|
| Building #1 | 1490 | 1495 | 1368 | 91.51 | 91.81 |
| Building #2 | 2988 | 2632 | 2624 | 99.70 | 87.82 |
| Building #3 | 11,394 | 10,305 | 10,133 | 98.33 | 88.93 |
| Building #4 | 33,778 | 35,660 | 31,097 | 87.20 | 92.06 |
| Minimum | - | - | - | 87.20 | 87.82 |
| Maximum | - | - | - | 99.70 | 92.06 |
| Overall | 49,650 | 50,092 | 45,222 | 90.43 | 91.08 |
In case of adaptive cylindrical approach (as seen in
Table 3), the minimum and maximum values of the correctness measure were 92.68%, and 98.75%, respectively. The minimum and maximum values of the completeness measure were 91.08%, and 98.59%, respectively. In terms of the overall correctness and completeness measures, the adaptive cylindrical segmentation algorithm provided 96.89% and 95.84% values, respectively. On the other hand, the spherical approach (as seen in
Table 4) showed worse segmentation results compared to the adaptive cylindrical one. In this case, the minimum and maximum values of the correctness measure were 87.20%, and 99.70%, respectively. The minimum and maximum values of the completeness measure were 87.82%, and 92.06%, respectively. In terms of the overall correctness and completeness measures, the spherical segmentation algorithm provided 90.43% and 91.08% values, respectively. Those values mostly affected by the results from buildings #2 and #4. As seen in
Table 4, building #2 has much less number of points detected automatically than the points detected manually. This caused the maximum value of the correctness (
i.e., 99.70%) and the minimum value of the completeness (
i.e., 87.82%). However, it is the other way around in case of building #4. There are much more automatically detected points than the manually detected ones. This caused the minimum value of the correctness (
i.e., 87.20%) and the maximum value of the completeness (
i.e., 92.06%).
After the segmentation process completed, plane fitting was carried out for all of the automatically and manually derived planar patches. In this process, the plane fitting precisions are determined by calculating the RMS errors of the planes. Also, the centroids of the fitted planes and angles of the normal position vectors are calculated. Afterwards, the differences between the automatically derived planes and the corresponding manual ones are computed in terms of the plane fitting precisions, the centroids of the fitted planes, and the angles of the normal position vectors. For the case of the adaptive cylindrical approach,
Table 6,
Table 7,
Table 8 and
Table 9 show the values of these measures for buildings #1 to #4, respectively.
Table 10,
Table 11,
Table 12 and
Table 13 also show the evaluation results for the spherical approach. It needs to be noted that the bottom of building #4, because it is not planar, was not considered in the evaluation process. As
Figure 16 illustrates, the bottom of the building consists of several patches, not a single patch.
Table 6.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #1 (Adaptive cylindrical approach).
Table 6.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #1 (Adaptive cylindrical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.025 | 0.051 | 0.026 | 0.304 | 0.685 |
| P2 | 0.027 | 0.030 | 0.003 | 0.381 | 0.052 |
| P3 | 0.032 | 0.033 | 0.002 | 0.140 | 0.173 |
| P4 | 0.032 | 0.031 | −0.001 | 0.133 | 0.086 |
| P5 | 0.026 | 0.029 | 0.003 | 0.149 | 0.100 |
| P6 | 0.022 | 0.022 | 0.000 | 0.130 | 0.064 |
| P7 | 0.037 | 0.020 | −0.017 | 0.675 | 0.347 |
| P8 | 0.031 | 0.016 | −0.014 | 1.298 | 1.588 |
| Mean | 0.029 | 0.029 | 0.000 | 0.401 | 0.387 |
Table 7.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #2 (Adaptive cylindrical approach).
Table 7.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #2 (Adaptive cylindrical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.020 | 0.027 | 0.007 | 0.017 | 0.020 |
| P2 | 0.023 | 0.032 | 0.009 | 0.025 | 0.016 |
| P3 | 0.052 | 0.053 | 0.001 | 0.015 | 0.002 |
| P4 | 0.019 | 0.037 | 0.019 | 0.038 | 0.069 |
| P5 | 0.016 | 0.068 | 0.052 | 0.169 | 1.973 |
| P6 | 0.016 | 0.031 | 0.015 | 0.196 | 0.847 |
| P7 | 0.021 | 0.012 | −0.009 | 0.415 | 0.285 |
| P8 | 0.017 | 0.046 | 0.028 | 0.148 | 1.575 |
| P9 | 0.015 | 0.073 | 0.058 | 0.885 | 7.901 |
| Mean | 0.022 | 0.042 | 0.020 | 0.212 | 1.410 |
Table 8.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #3 (Adaptive cylindrical approach).
Table 8.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #3 (Adaptive cylindrical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.027 | 0.049 | 0.022 | 0.072 | 0.086 |
| P2 | 0.034 | 0.035 | 0.002 | 0.227 | 0.029 |
| P3 | 0.035 | 0.042 | 0.007 | 0.436 | 0.025 |
| P4 | 0.025 | 0.024 | −0.001 | 0.136 | 0.017 |
| P5 | 0.115 | 0.086 | −0.029 | 0.280 | 0.003 |
| P6 | 0.095 | 0.091 | −0.004 | 0.145 | 0.906 |
| P7 | 0.070 | 0.074 | 0.005 | 0.131 | 1.233 |
| P8 | 0.094 | 0.046 | −0.048 | 0.039 | 1.471 |
| P9 | 0.101 | 0.085 | −0.016 | 0.265 | 1.530 |
| P10 | 0.021 | 0.020 | −0.001 | 0.629 | 0.040 |
| P11 | 0.080 | 0.044 | −0.036 | 1.267 | 7.960 |
| Mean | 0.063 | 0.054 | −0.009 | 0.330 | 1.209 |
Table 9.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #4 (Adaptive cylindrical approach).
Table 9.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #4 (Adaptive cylindrical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.005 | 0.006 | 0.002 | 0.053 | 0.017 |
| P2 | 0.002 | 0.002 | 0.000 | 0.066 | 0.001 |
| P3 | 0.009 | 0.007 | −0.002 | 0.371 | 0.135 |
| P4 | 0.001 | 0.001 | 0.000 | 0.015 | 0.020 |
| P5 | 0.004 | 0.002 | −0.002 | 0.063 | 0.196 |
| P6 | 0.002 | 0.002 | 0.000 | 0.018 | 0.034 |
| P7 | 0.002 | 0.001 | 0.000 | 0.008 | 0.031 |
| P8 | 0.002 | 0.002 | 0.001 | 0.017 | 0.398 |
| P9 | 0.001 | 0.005 | 0.004 | 0.123 | 2.477 |
| P10 | 0.001 | 0.007 | 0.006 | 0.035 | 3.365 |
| Mean | 0.003 | 0.004 | 0.001 | 0.077 | 0.667 |
Table 10.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #1 (Spherical approach).
Table 10.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #1 (Spherical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.025 | 0.049 | 0.024 | 0.366 | 0.690 |
| P2 | 0.027 | 0.027 | 0.000 | 0.358 | 0.021 |
| P3 | 0.032 | 0.034 | 0.003 | 0.047 | 0.122 |
| P4 | 0.032 | 0.029 | −0.002 | 0.107 | 0.085 |
| P5 | 0.026 | 0.018 | −0.008 | 0.182 | 0.168 |
| P6 | 0.022 | 0.041 | 0.019 | 0.541 | 0.676 |
| P7 | 0.037 | 0.031 | −0.006 | 0.220 | 2.225 |
| P8 | 0.031 | 0.027 | −0.004 | 0.578 | 2.594 |
| Mean | 0.029 | 0.032 | 0.003 | 0.300 | 0.823 |
Table 11.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #2 (Spherical approach).
Table 11.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #2 (Spherical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.020 | 0.022 | 0.002 | 0.182 | 0.026 |
| P2 | 0.023 | 0.019 | −0.004 | 0.014 | 0.008 |
| P3 | 0.052 | 0.052 | 0.000 | 0.024 | 0.007 |
| P4 | 0.019 | 0.019 | 0.001 | 0.021 | 0.020 |
| P5 | 0.016 | N.A. | N.A. | N.A. | N.A. |
| P6 | 0.016 | N.A. | N.A. | N.A. | N.A. |
| P7 | 0.021 | N.A. | N.A. | N.A. | N.A. |
| P8 | 0.017 | N.A. | N.A. | N.A. | N.A. |
| P9 | 0.015 | N.A. | N.A. | N.A. | N.A. |
| Mean | 0.022 | N.A. | N.A. | N.A. | N.A. |
Table 12.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #3 (Spherical approach).
Table 12.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #3 (Spherical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.027 | 0.057 | 0.030 | 0.221 | 0.105 |
| P2 | 0.034 | 0.044 | 0.010 | 0.476 | 0.103 |
| P3 | 0.035 | 0.032 | −0.003 | 0.586 | 0.040 |
| P4 | 0.025 | 0.022 | −0.004 | 0.186 | 0.031 |
| P5 | 0.115 | 0.094 | −0.022 | 0.210 | 0.017 |
| P6 | 0.095 | N.A. | N.A. | N.A. | N.A. |
| P7 | 0.070 | N.A. | N.A. | N.A. | N.A. |
| P8 | 0.094 | N.A. | N.A. | N.A. | N.A. |
| P9 | 0.101 | N.A. | N.A. | N.A. | N.A. |
| P10 | 0.021 | N.A. | N.A. | N.A. | N.A. |
| P11 | 0.080 | N.A. | N.A. | N.A. | N.A. |
| Mean | 0.063 | N.A. | N.A. | N.A. | N.A. |
Table 13.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #4 (Spherical approach).
Table 13.
Plane fitting precision, plane fitting precision difference, centroid difference, and angle difference values for building #4 (Spherical approach).
| Patch | Precision-Manual (m) | Precision-Auto (m) | Precision Difference (m) | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| P1 | 0.005 | 0.027 | 0.022 | 0.098 | 0.179 |
| P2 | 0.002 | 0.004 | 0.002 | 0.104 | 0.011 |
| P3 | 0.009 | N.A. | N.A. | N.A. | N.A. |
| P4 | 0.001 | 0.001 | 0.000 | 0.023 | 0.008 |
| P5 | 0.004 | N.A. | N.A. | N.A. | N.A. |
| P6 | 0.002 | 0.011 | 0.009 | 0.205 | 4.072 |
| P7 | 0.002 | N.A. | N.A. | N.A. | N.A. |
| P8 | 0.002 | N.A. | N.A. | N.A. | N.A. |
| P9 | 0.001 | N.A. | N.A. | N.A. | N.A. |
| P10 | 0.001 | N.A. | N.A. | N.A. | N.A. |
| Mean | 0.003 | N.A. | N.A. | N.A. | N.A. |
Upon close examination of
Table 6,
Table 7,
Table 8 and
Table 9 for the adaptive cylindrical approach, it is evident that building #2 has the maximum value of mean precision difference (
i.e., around 0.02 m) compared with the other three buildings. As for the centroid difference, the mean value for building #1 (
i.e., around 0.4 m) is greater than those of the other buildings. In the case of the angle difference, buildings #2 and #3 show around 1.4 and 1.2 degrees, respectively. Among the four buildings’ 38 patches, P8 in building #1, P9 in building #2, and P11 in building #3 significantly affected the values of three measures: precision difference, centroid difference, and angle difference. The numbers of laser points belonging to the three patches (the manually derived ones) were quite small (
i.e., 40, 42, and 84, respectively). It should be emphasized that the plane fitting quality of patches having a small number of points can be more affected by missing points than is the case for patches having a large number of points. On the other hand, building #4 showed quite good values for the three measures.
In case of
Table 10,
Table 11,
Table 12 and
Table 13 for the spherical approach, there are many missing patches (
i.e., which are expressed as N.A.) except for building #1. The three measures, which are plane fitting precision, precision difference, and centroid difference for building #1 in
Table 10, are similar to the values from the adaptive cylindrical one in
Table 6. However, the angle difference between the approaches is a bit different due to P7 and P8. Building #2 in
Table 11 shows a slightly better result than that in
Table 7. It is also evident that the evaluation results for buildings #3 and #4 in
Table 12 and
Table 13 are worse than those in
Table 8 and
Table 9.
Additionally, the mean values of the centroid and angle differences were computed, as listed in
Table 14, using all of the patches (
i.e., 38 patches) belonging to the four buildings, so as to confirm the overall performance of the adaptive cylindrical segmentation algorithm. At this stage, one should note that the results from the spherical approach are not considered for the overall mean values of the centroid and angle differences since it produced many missing patches. It is also important to note that neither the plane fitting precision nor the plane fitting precision difference are included in
Table 14, since the characteristics of the laser points (
i.e., the degree of laser point accuracy) in building #4 differ so markedly from those in the other three datasets. Overall, the mean value of centroid difference was 0.25 m, and the angle difference was less than 1°, as can be seen in
Table 14.
Table 14.
Overall mean values of centroid difference and angle difference measures (Adaptive cylindrical approach).
Table 14.
Overall mean values of centroid difference and angle difference measures (Adaptive cylindrical approach).
| | Centroid Difference (m) | Angle Difference (Degree) |
|---|
| Overall mean | 0.250 | 0.941 |
Additional experiment using the proposed approach (
i.e., the adaptive cylindrical approach) with a large dataset taken over University of Calgary, Canada (refer to
Figure 15) was carried out while comparing the result from the region growing approach [
4,
5,
6,
7,
8,
28], which is well-known as a segmentation algorithm.
Figure 18 and
Figure 19 illustrate the segmentation results from the region growing and the proposed approach, respectively. As seen in
Figure 18, the segmentation procedure based on the region growing approach produced 2718 different patches. Moreover, many circular patches can be detected in the figure. Such result shows that the region growing approach causes the significant over-segmentation and there is sensitivity to the choice of seed points. On the other hand, the proposed approach produced a better segmentation results (with 1499 patches) compared to the region growing one as illustrated in
Figure 19. A few patches which are over-segmented are found in the figure; however, most ones are segmented correctly. The ones with irregular shapes are planar patches extracted from the terrain or roads.
Figure 18.
Segmentation results based on the region growing approach over University of Calgary.
Figure 18.
Segmentation results based on the region growing approach over University of Calgary.
Figure 19.
Segmentation results based on the proposed approach over University of Calgary.
Figure 19.
Segmentation results based on the proposed approach over University of Calgary.
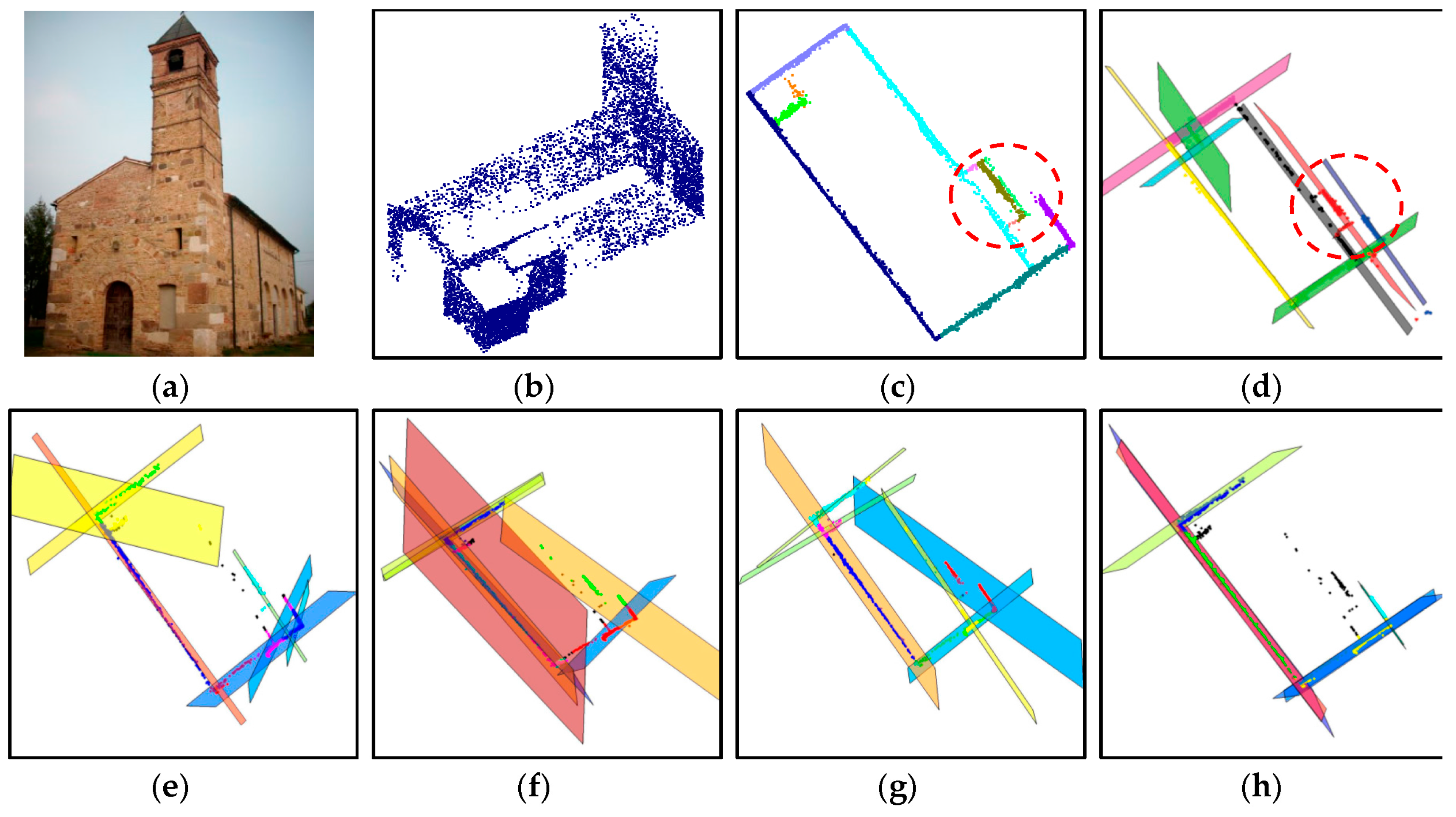
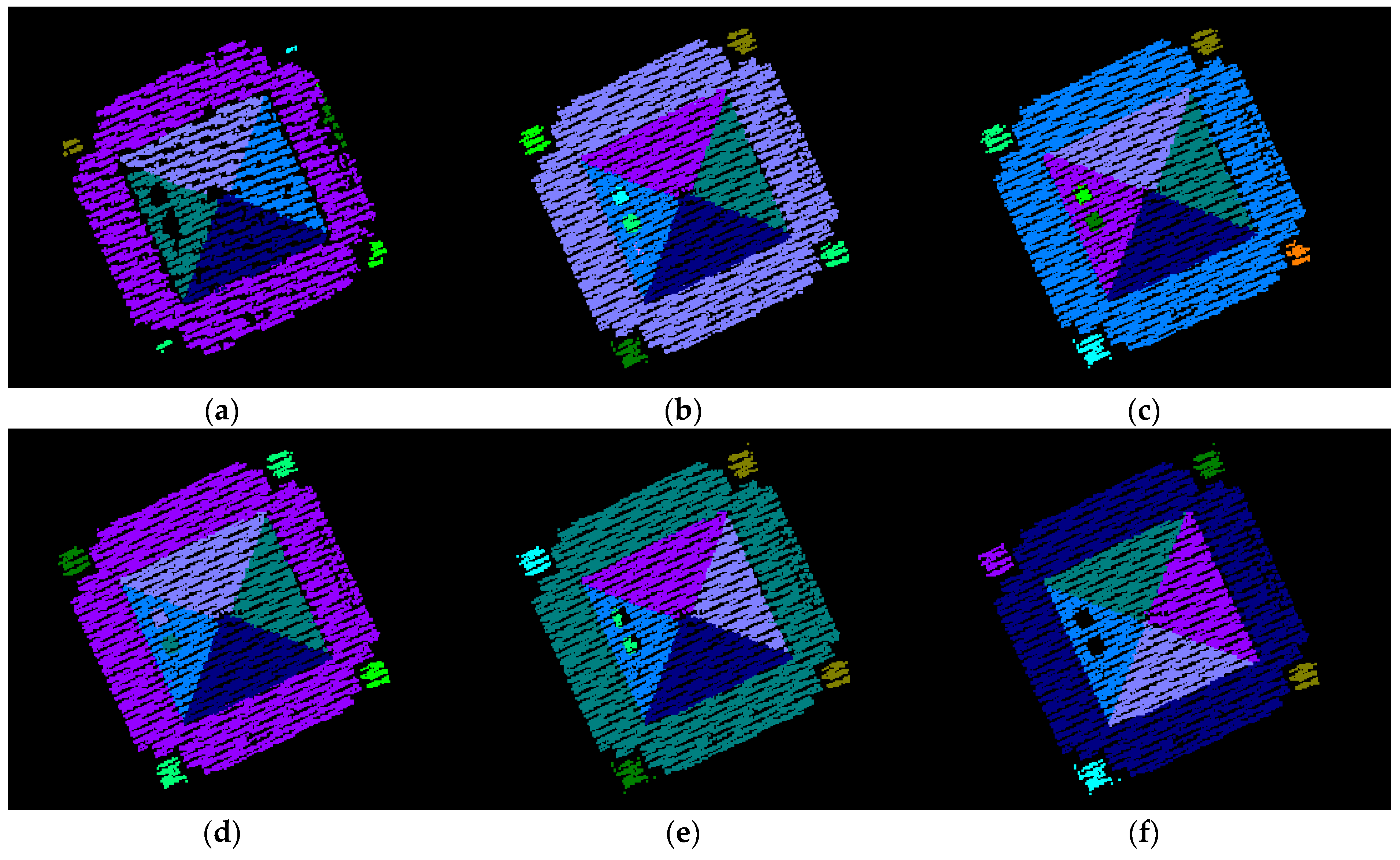
The segmentation performance of the proposed approach is also compared with J-linkage, RHA, multiRANSAC, sequential RANSAC, and mean-shift. The comparisons are carried out by using the same dataset as [
14] (
i.e., a 3D point cloud data of Pozzoveggiani church, Italy; see
Figure 20a,b). One should note that the 3D point data of the church is actually derived from a set of images. The 3D plane extraction results using the above-mentioned algorithms are taken from [
14] and shown in
Figure 20d–h. As seen in
Figure 20c, the proposed approach derived 11 planar surface segments. J-linkage also has 10 planar surfaces as seen in
Figure 20d. Except for the proposed approach and J-linkage, the other approaches extract the surfaces incorrectly or have missing ones as seen in the figures.
Figure 20.
Result comparison using Pozzoveggiani dataset: (a) image of Pozzoveggiani church; (b) 3D points of Pozzoveggiani church; (c) top view of the result from the proposed approach; (d) result from J-linkage; (e) result from Residual Histogram Analysis (RHA); (f) result from MultiRANSAC; (g) result from sequential RANdom SAmple Consensus (RANSAC); and (h) result from mean-shift.
Figure 20.
Result comparison using Pozzoveggiani dataset: (a) image of Pozzoveggiani church; (b) 3D points of Pozzoveggiani church; (c) top view of the result from the proposed approach; (d) result from J-linkage; (e) result from Residual Histogram Analysis (RHA); (f) result from MultiRANSAC; (g) result from sequential RANdom SAmple Consensus (RANSAC); and (h) result from mean-shift.
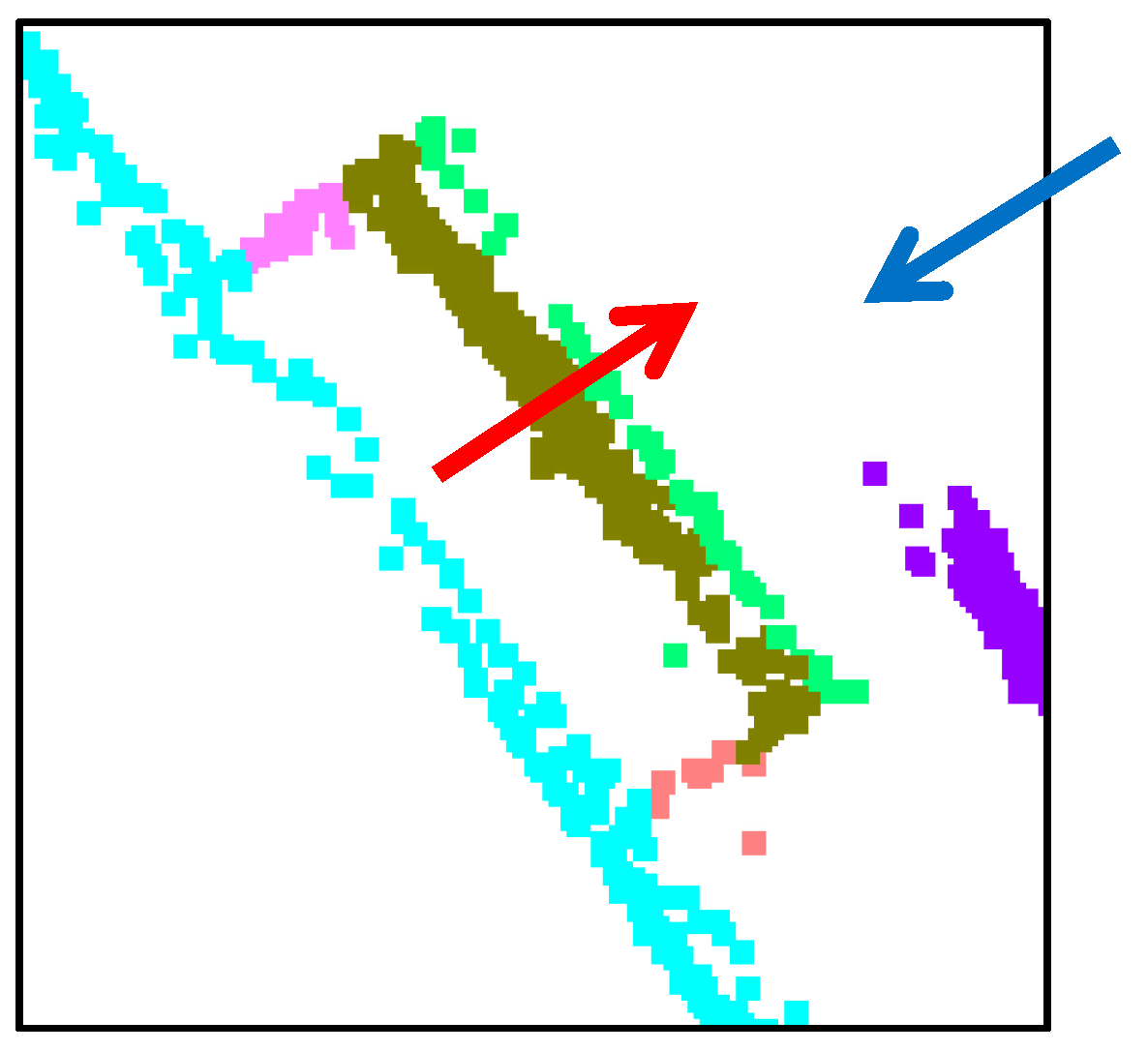
The only difference between the proposed approach and J-linkage is on the areas enclosed by the red dashed circles in
Figure 20c–d. To take a closer look at the area in
Figure 20c, it is enlarged as seen in
Figure 21. Two segments indicated by the red and blue arrows are separated and derived using the proposed approach; however, J-linkage does not have two separated planes. The result comparison shows that the proposed approach works well with the 3D point data derived even from a set of images. Moreover, the result from the proposed approach is a bit better than the J-linkage and superior to the other approaches (
i.e., RHA, MultiRANSAC, Sequential RANSAC, and mean- shift).
Figure 21.
Enlarged area which is enclosed by the red dashed circles in
Figure 20c.
Figure 21.
Enlarged area which is enclosed by the red dashed circles in
Figure 20c.
3.4. Evaluation of the Sensitivity of the Thresholds
The proposed approach uses several thresholds in the segmentation process such as (1) searching radius; (2) buffer threshold; (3) co-planarity test threshold; (4) proximity threshold; (5) minimum size of detectable peak; and (6) accumulator cell resolution (please refer to the justifications of these thresholds in
Table 3). First of all,
proximity threshold is defined as the value which is approximately equal to the average point spacing of the laser data. The average point spacing of the laser data is, usually, provided by a data vendor or can be simply calculated. The other threshold,
minimum size of detectable peak, is defined as the value which is based on prior knowledge about building planar patch size within the area of interest. This threshold can be changed according to the minimal planar patch size that the user wants to derive for his or her purpose of work. Hence, at this stage, the authors can mention that the two thresholds,
proximity threshold and
minimum size of detectable peak are not significant values and can be determined easily.
The other three thresholds, which are
buffer threshold,
co-planarity test threshold, and
accumulator cell resolution are all defined as the same value which is two times the accuracy of the laser data in the depth direction (refer to the justification in
Table 3). Hence, knowing the accuracy of the laser data is significantly important to determine these three thresholds. Similar to the average point spacing of the laser data, the accuracy of the laser data is usually known or provided by a data vendor. For example, as addressed in
Section 3.3, the values from the Vaihingen, Toronto, and Seoul datasets, respectively, were given as 0.15 m, 0.15 m, and 0.10 m. On the other hand, the remaining threshold,
searching radius, is defined as the value which is for including sufficient number of points to define reliable attributes. Even though the values of the four thresholds (
i.e., buffer threshold, co-planarity test threshold, accumulator cell resolution, and searching radius) can be determined properly and easily as above-mentioned, the additional analyses are carried out in this section to evaluate the sensitivity of the thresholds while changing the values of the accuracy of the laser data and searching radius.
Figure 22.
Segmentation results according to changing the threshold, searching radius, from 0.5 m to 5.0 m (the accuracy of the laser data is 0.15 m for all cases). Searching radius: (a) 0.5 m; (b) 1.0 m; (c) 2.0 m; (d) 3.0 m; (e) 4.0 m; (f) 5.0 m.
Figure 22.
Segmentation results according to changing the threshold, searching radius, from 0.5 m to 5.0 m (the accuracy of the laser data is 0.15 m for all cases). Searching radius: (a) 0.5 m; (b) 1.0 m; (c) 2.0 m; (d) 3.0 m; (e) 4.0 m; (f) 5.0 m.
For this analysis, building #3 in Toronto data (see
Figure 14) is utilized. The first analysis is about the threshold, searching radius while changing the values from 0.5 m to 5 m. When radius is 0.5 m, the segmentation process missed several patches located at the four corners and the left roof side of the building as can be seen in
Figure 22a. Moreover, the segmented patches do have less number of points compared to the other cases (
i.e., the cases of Radius of 1.0 m to 5.0 m). This comes from the small searching radius which causes unreliable attribute computation due to the insufficient number of points for neighborhood definition. On the other hand, the good segmentation results are acquired and they are almost similar to each other when the radius is increased (
i.e., 1.0 m to 3.0 m, also see
Figure 22b–d). However, in case of too large searching radius (more than 4.0 m), the results were losing two small patches at the left roof side of the building (
Figure 22e–f). Also, large searching radius increases the computational load since the number of points in the neighborhood is too large. In summary, searching radius can be determined to include sufficient number of points to define reliable attributes. Moreover, the thresholds from 1.0 m to 3.0 m derived good segmentation results; which means that the range of the proper searching radius threshold is wide enough in the proposed approach.
Figure 23.
Segmentation results according to changing the accuracy of the laser data from 0.02 m to 0.30 m (searching radius is 2.0 m for all cases). The accuracy of the laser data: (a) 0.02 m; (b) 0.05 m; (c) 0.10 m; (d) 0.15 m; (e) 0.20 m; (f) 0.30 m.
Figure 23.
Segmentation results according to changing the accuracy of the laser data from 0.02 m to 0.30 m (searching radius is 2.0 m for all cases). The accuracy of the laser data: (a) 0.02 m; (b) 0.05 m; (c) 0.10 m; (d) 0.15 m; (e) 0.20 m; (f) 0.30 m.
The second analysis is about the accuracy of the laser data which determines the three thresholds such as buffer threshold, co-planarity test threshold, and accumulator cell resolution. Recall that the accuracy of the laser data is usually known or provided by a data vendor (0.15 m for this dataset). However, the segmentations are carried out for this analysis while intentionally changing the accuracy values in the process from 0.02 m to 0.3 m. When the laser data accuracy is set to 0.02 m, over-segmentation occurs; hence, lots of planar patches are acquired from the segmentation process (in
Figure 23a). Similar but less segments are acquired for the case of the value of 0.05 m (
Figure 23b). The phenomenon of the over-segmentation is reduced when the value applied is increased. On the other hand, almost same segmentation results are acquired when the values of 0.10 m to 0.30 m are applied (
Figure 23c–f). With a closer look at the segmentation results in these figures, the size of the small planar patch at the right corner of the building is slightly increasing when the value of the applied accuracy is increasing. This means that it will be fine to apply the value of the accuracy from 0.10 m to 0.30 m. In other words, the range of the proper value of the laser data accuracy can be from little bit less than to greater than the value provided (
i.e., 0.15 m for this dataset). However, one should note that the large value of the applied laser data accuracy causes more computational load since the number of points in the neighborhood will increases. Hence, to avoid the over-segmentation and keep the computational efficiency, the value of the laser data accuracy can be set close to the one provided.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}