
Classification of Clouds in Satellite Imagery Using Adaptive Fuzzy Sparse Representation

Abstract
:1. Introduction
2. Satellite Data and Cloud Classification System
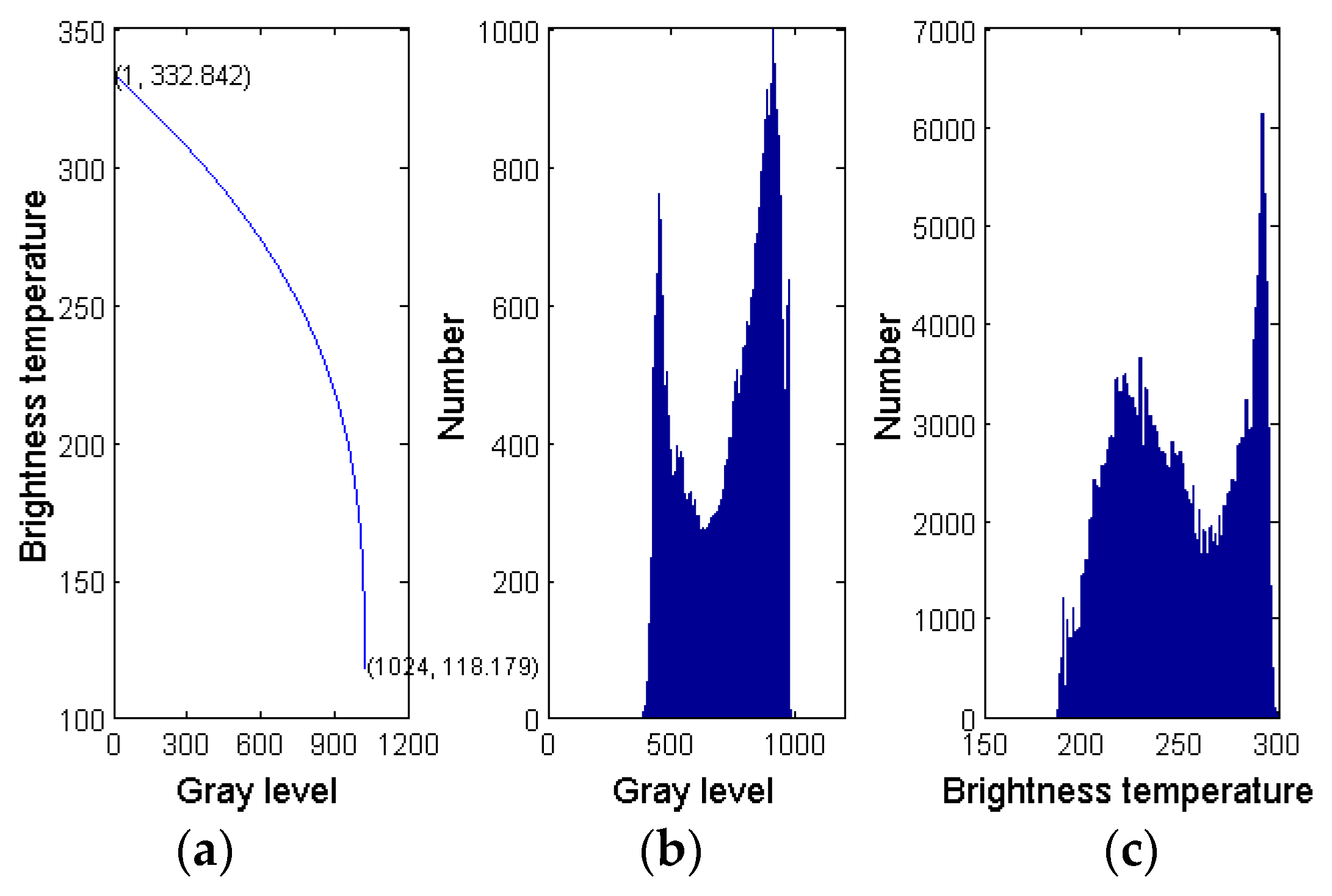
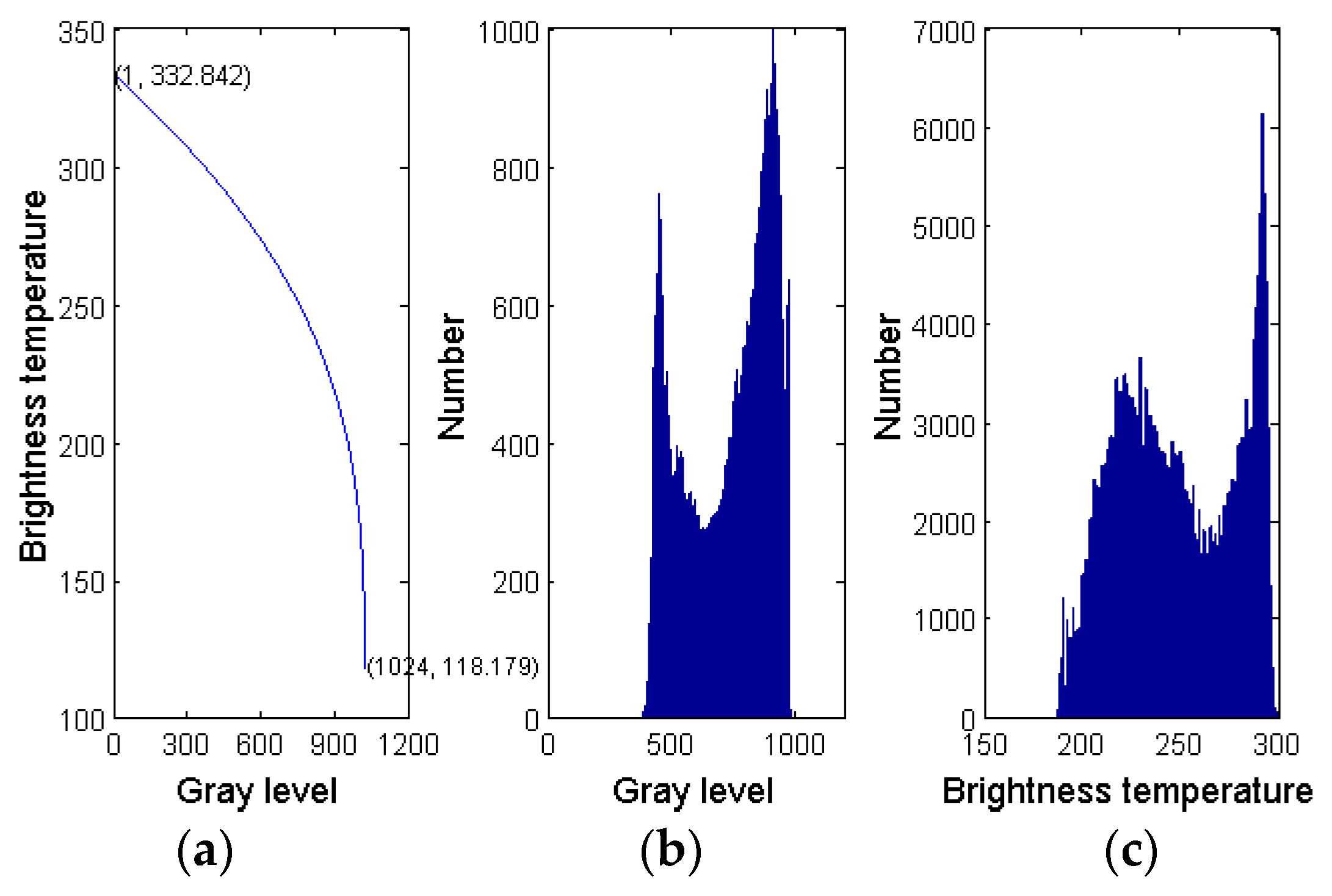
2.1. Satellite Data Feature Extraction
2.2. Cloud Classification System
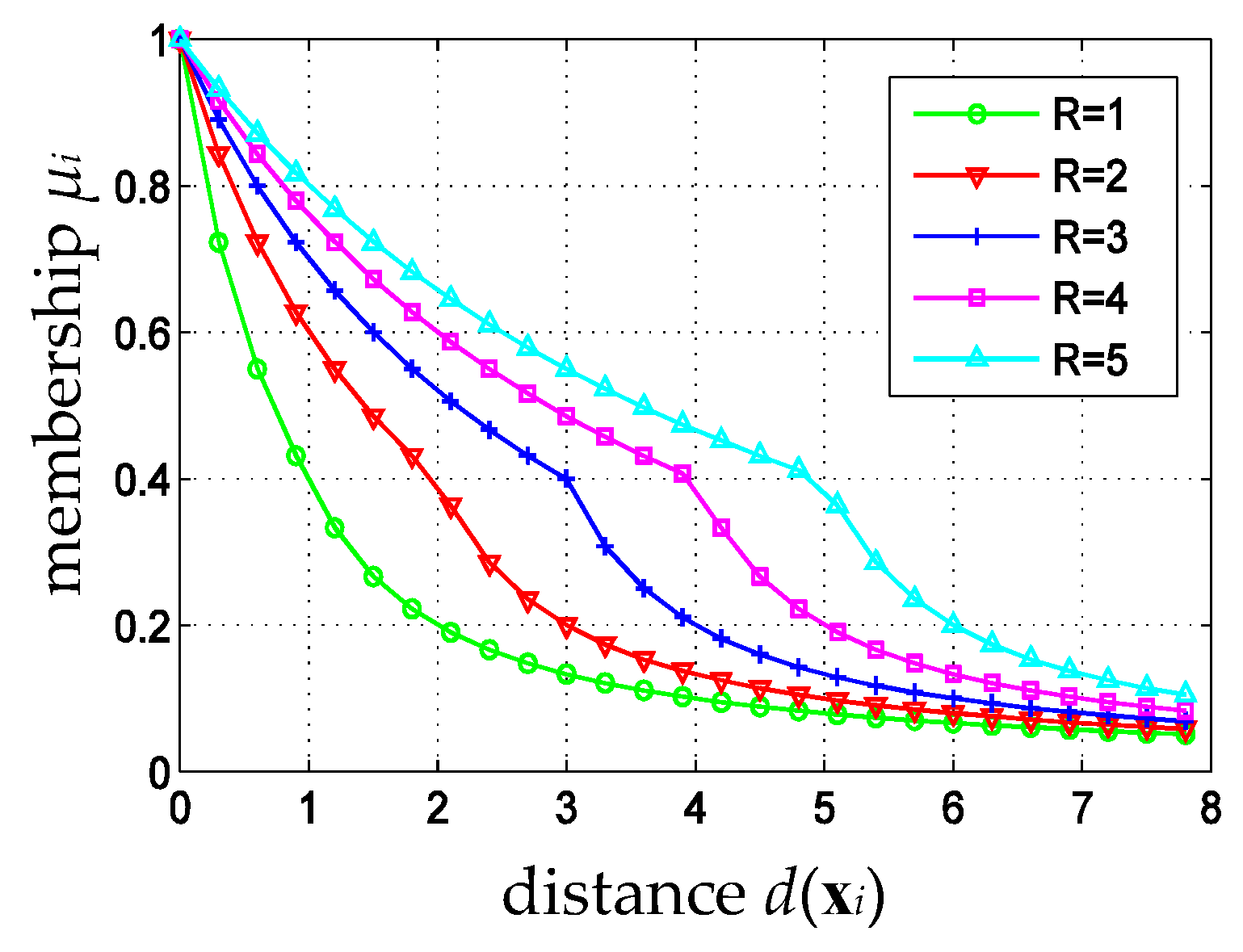
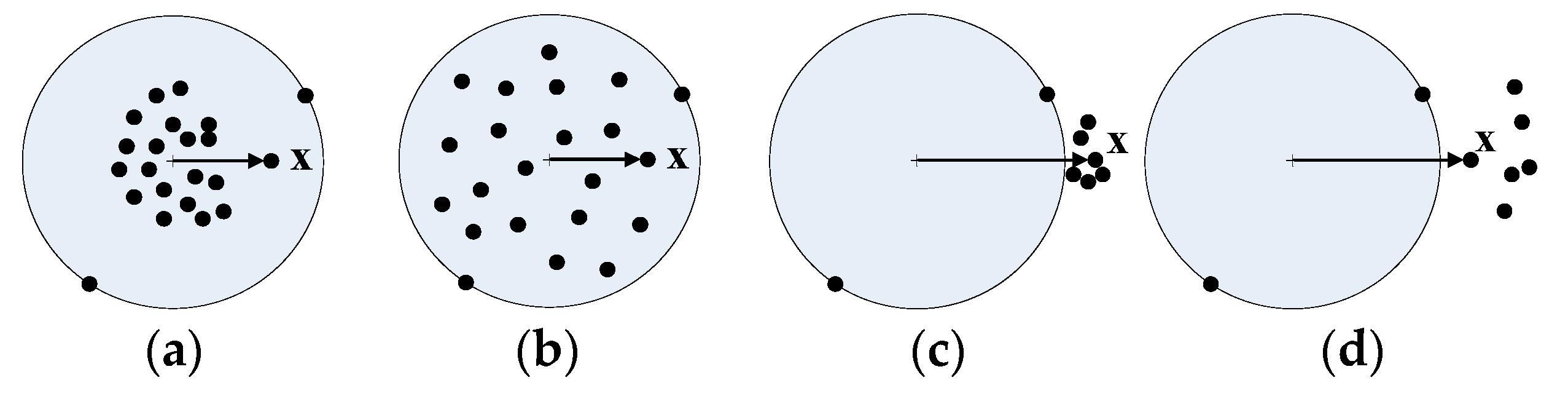
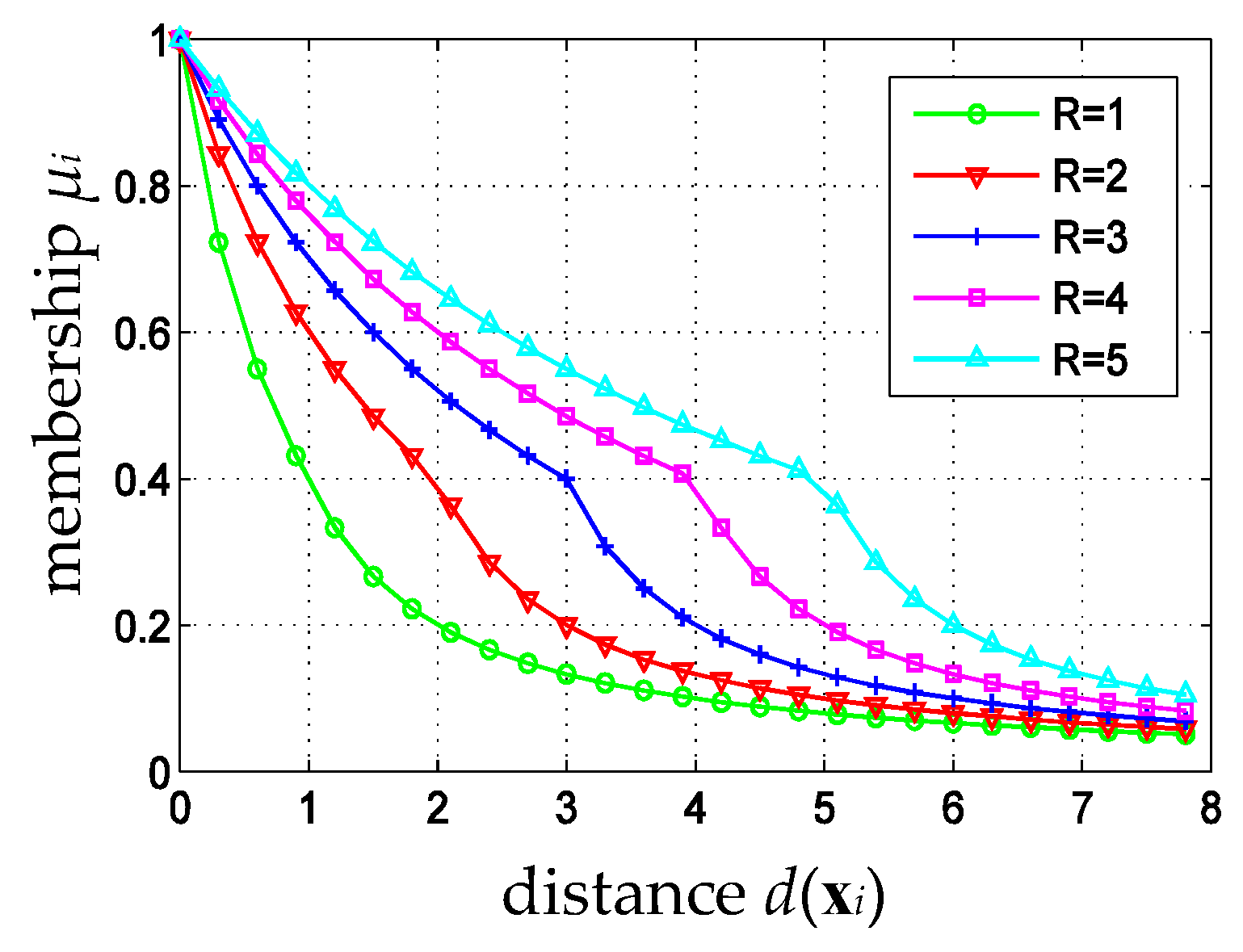
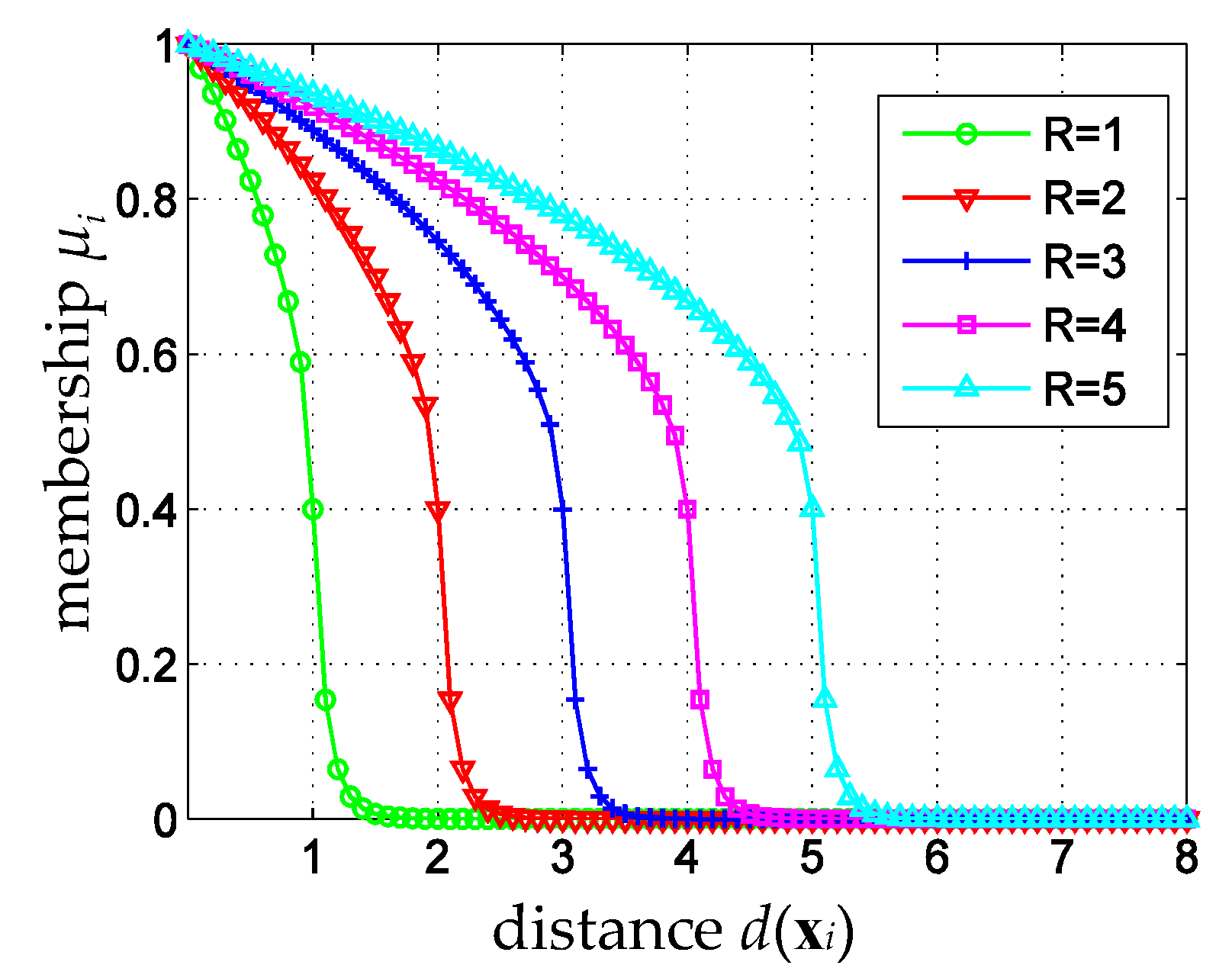
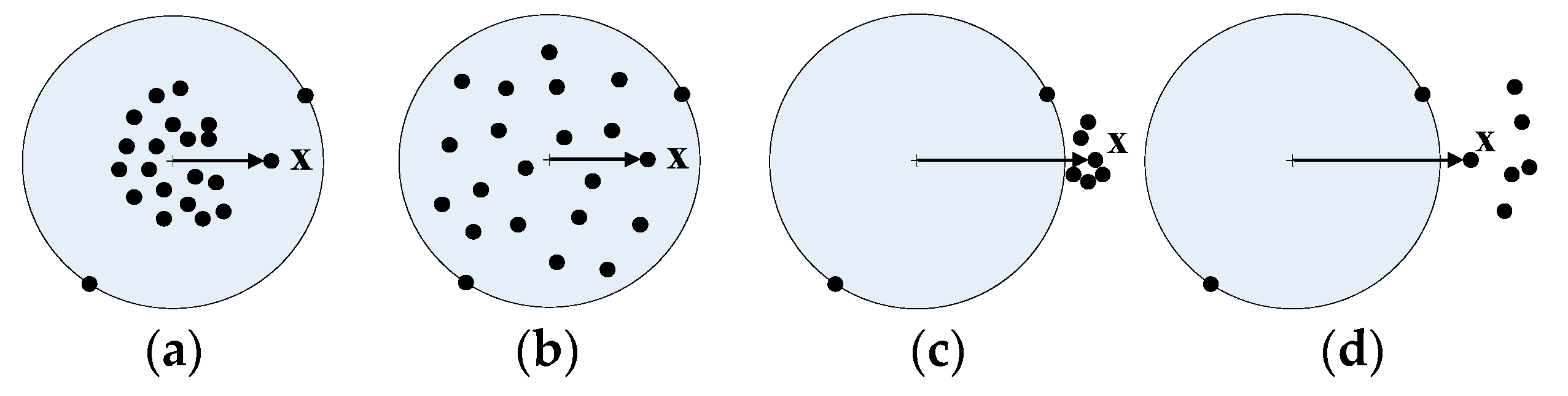
3. Fuzzy Membership for Cloud Classification
4. Adaptive Fuzzy Sparse Representation Classifier for Cloud Type Identification
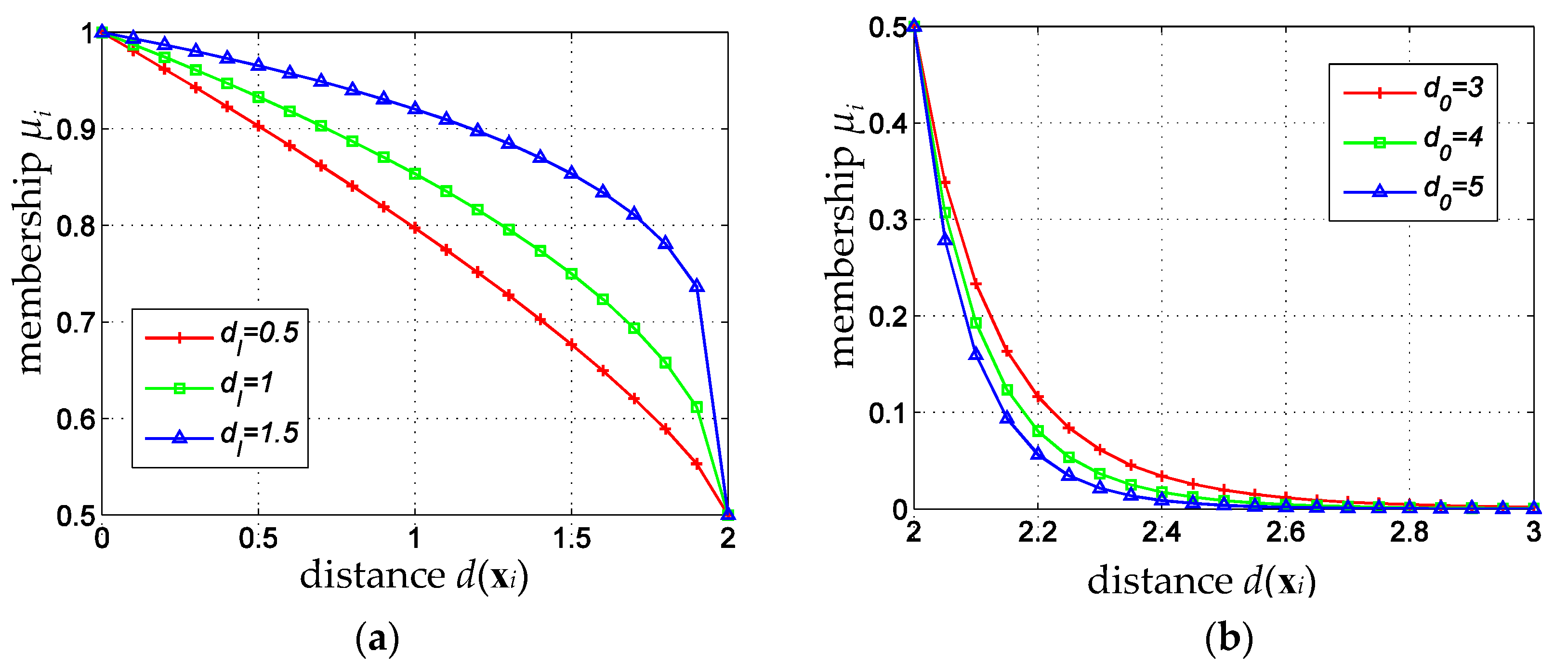
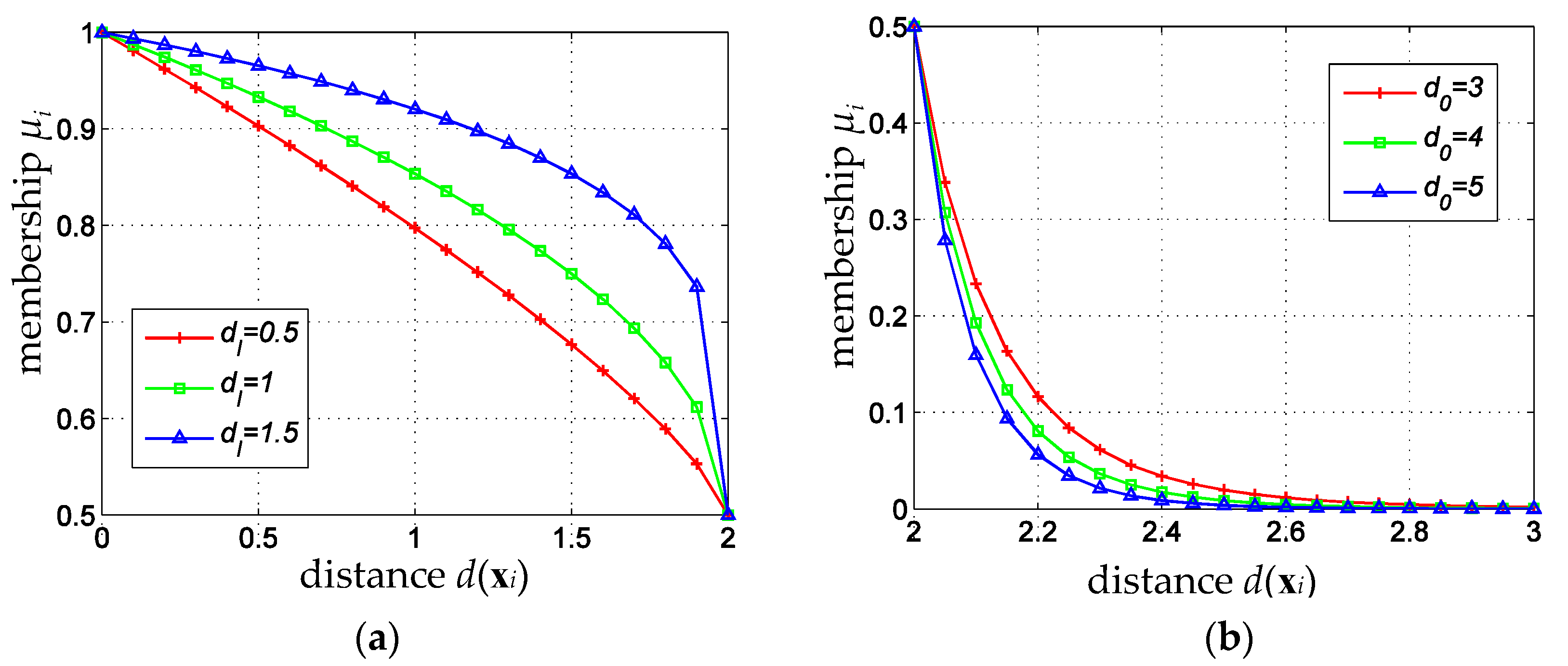
4.1. Adaptive Fuzzy Membership Function
4.2. Classification of Clouds in Satellite Imagery Using Adaptive Fuzzy Sparse Representation
| Algorithm 1: Classification of clouds in satellite imagery using adaptive fuzzy sparse representation |
|
5. Simulation Results and Analysis
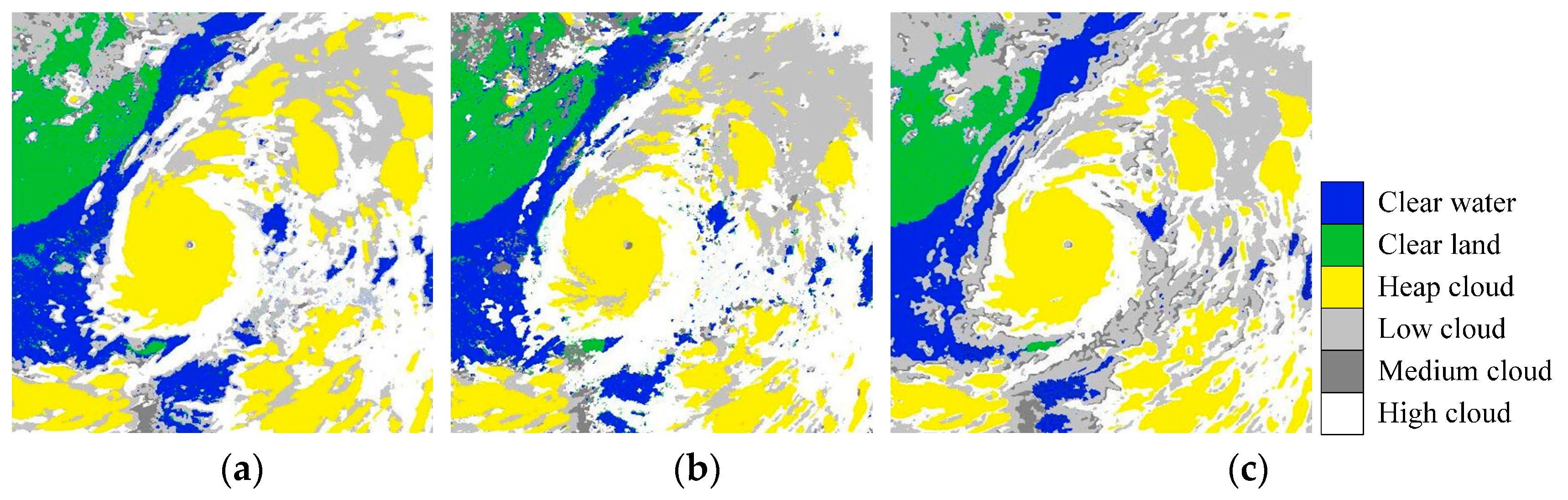
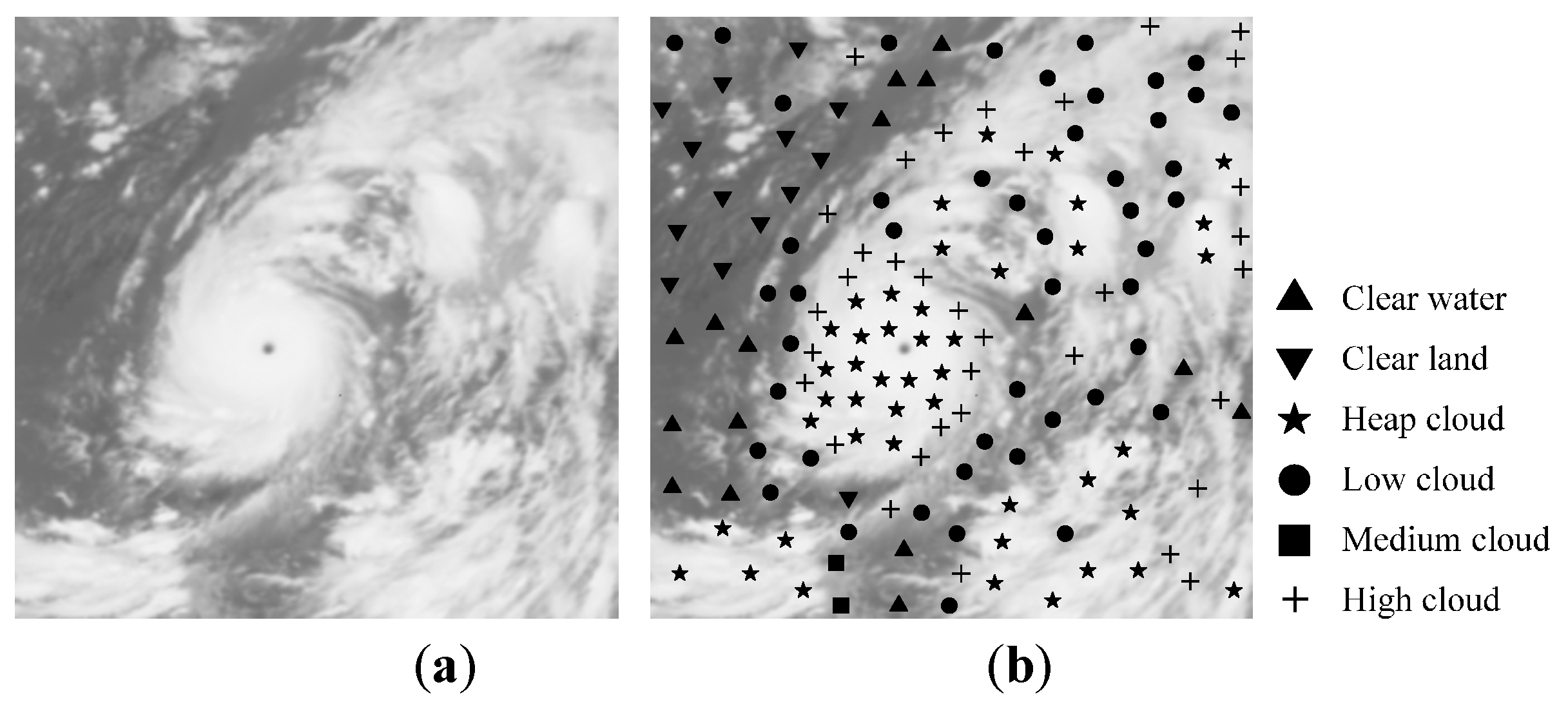
5.1. Accuracy Evaluation of AFSRC for FY-2G
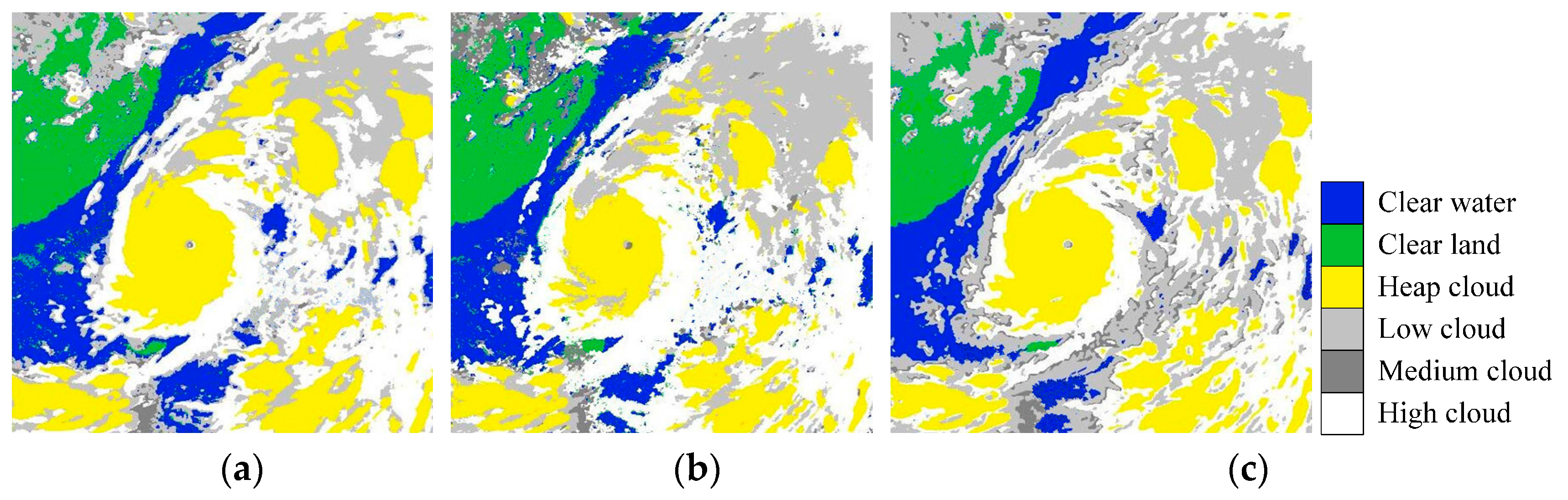
5.2. Comparisons with Existing Methods
5.3. Benchmarks on FY-2G Satellite Data
5.4. Running Time
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Roman, J.; Knuteson, R.; August, T.; Hultberg, T.; Ackerman, S.; Revercomb, H. A Global Assessment of NASA AIRS v6 and EUMETSAT IASI v6 Precipitable Water Vapor Using Ground-based GPS SuomiNet Stations: IR PWV Assessment. J. Geophys. Res. Atmos. 2016, 121, 8925–8948. [Google Scholar] [CrossRef]
- Jaiswal, N.; Kishtawal, C.M. Automatic Determination of Center of Tropical Cyclone in Satellite-Generated IR Images. IEEE Geosci. Remote Sens. Lett. 2011, 8, 460–463. [Google Scholar] [CrossRef]
- Tang, R.; Tang, B.; Wu, H.; Li, Z.L. On the Feasibility of Temporally Upscaling Instantaneous Evapotranspiration Using Weather Forecast Information. Int. J. Remote Sens. 2015, 36, 4918–4935. [Google Scholar] [CrossRef]
- Tapakis, R.; Charalambides, A.G. Equipment and Methodologies for Cloud Detection and Classification: A Review. Sol. Energy 2013, 95, 392–430. [Google Scholar] [CrossRef]
- Dwi, P.Y.S.; Tomohito, J.Y. Two-dimensional, Threshold-based Cloud Type Classification Using MTSAT Data. Remote Sens. Lett. 2012, 3, 737–746. [Google Scholar]
- Fiolleau, T.; Roca, R. An Algorithm for the Detection and Tracking of Tropical Mesoscale Convective Systems Using Infrared Images from Geostationary Satellite. IEEE Trans. Geosci. Remote Sens. 2013, 7, 4302–4315. [Google Scholar] [CrossRef]
- Kärner, O. A Multi-dimensional Histogram Technique for Cloud Classification. Int. J. Remote Sens. 2000, 21, 2463–2478. [Google Scholar] [CrossRef]
- Ameur, S. Cloud Classification Using the Textural Features of Meteosat images. Int. J. Remote Sens. 2004, 25, 4491–4503. [Google Scholar] [CrossRef]
- Liu, Y.; Xia, J.; Shi, C.X.; Hong, Y. An Improved Cloud Classification Algorithm for China’s FY-2C Multi-Channel Images Using Artificial Neural Network. Sensors 2009, 9, 5558–5579. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Sun, D.; Li, S.; Yu, Y. A Stepwise Cloud Shadow Detection Approach Combining Geometry Determination and SVM Classification for MODIS Data. Int. J. Remote Sens. 2013, 34, 211–226. [Google Scholar] [CrossRef]
- Taravat, A.; Del Frate, F.; Cornaro, C.; Vergari, S. Neural Networks and Support Vector Machine Algorithms for Automatic Cloud Classification of Whole-Sky Ground-Based Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 666–670. [Google Scholar] [CrossRef]
- Lin, C.F.; Wang, S.D. Fuzzy Support Vector Machines. IEEE Trans. Neural Netw. 2002, 13, 464–471. [Google Scholar] [PubMed]
- Fu, R.; Tian, W.; Jin, W.; Liu, Z.; Wang, W. Fuzzy Support Vector Machines for Cumulus Cloud Detection. Opto-Electron. Eng. 2014, 41, 29–35. [Google Scholar]
- Zhang, X.; Xiao, X.L.; Xu, G.Y. Fuzzy Support Vector Machine based on Affinity among Samples. J. Softw. 2006, 17, 951–958. [Google Scholar] [CrossRef]
- An, W.J.; Liang, M. Fuzzy Support Vector Machine based on Within-class Scatter for Classification Problems with Outliers or Noises. Neurocomputing 2013, 110, 101–110. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Zhang, L.; Shiu, S.C.K.; Zhang, D. Gabor Feature based Robust Representation and Classification for Face Recognition with Gabor Occlusion Dictionary. Pattern Recognit. 2013, 46, 1865–1878. [Google Scholar] [CrossRef]
- Tang, X.; Feng, G.; Cai, J. Weighted Group Sparse Representation for Undersampled Face Recognition. Neurocomputing 2014, 145, 402–415. [Google Scholar] [CrossRef]
- Jin, W.; Wang, L.; Zeng, X.; Liu, Z.; Fu, R. Classification of Clouds in Satellite Imagery Using Over-complete Dictionary via Sparse Representation. Pattern Recognit. Lett. 2014, 49, 193–200. [Google Scholar] [CrossRef]
- Tax, D.M.; Duin, R.P. Support Vector Data Description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Donoho, D.L.; Tsaig, Y. Fast Solution of l1-norm minimization Problems When the Solution May be Sparse. IEEE Trans. Inf. Theory 2008, 54, 4789–4812. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Description |
|---|---|
| G1, G2, G3, G4, GV | Gray value of IR1, IR2, IR3, IR4, VIS |
| T1, T2, T3, T4 | Brightness temperature of IR1, IR2, IR3, IR4 |
| A | Albedo of VIS |
| T1-T2, T1-T3, T1-T4, T2-T3 | Brightness temperature difference IR1-IR2, IR1-IR3, IR1-IR4, IR2-IR3 |
| Component | Identification Characteristics |
|---|---|
| G1, G2, T1, T2 | Can be used to identify land, ocean, and clouds |
| G3, T3 | Can be used to measure the water vapor content of clouds |
| G4, T4 | Mainly represent the characteristics of under clouds over the ocean |
| GV, A | Mainly represent the thickness, height, and composition of clouds |
| T1-T2 | Mainly describe the characteristics of cirrus and cumulonimbus |
| T1-T3, T1-T4, T2-T3 | Indicate the height of clouds more precisely |
| Cloud Type | Classified as | |||||
|---|---|---|---|---|---|---|
| Clear Water | Clear Land | Heap Cloud | Low Cloud | Medium Cloud | High Cloud | |
| Clear water | 198 | 2 | 0 | 0 | 0 | 0 |
| Clear land | 3 | 196 | 0 | 1 | 0 | 0 |
| Heap cloud | 0 | 0 | 198 | 1 | 0 | 1 |
| Low cloud | 0 | 0 | 0 | 199 | 1 | 0 |
| Medium cloud | 0 | 0 | 0 | 1 | 198 | 1 |
| High cloud | 0 | 0 | 0 | 3 | 0 | 197 |
| K | Clear Water | Clear Land | Heap Cloud | Low Cloud | Medium Cloud | High Cloud | Overall Accuracy |
|---|---|---|---|---|---|---|---|
| K = 0.5 | 98.50 | 98.00 | 94.50 | 90.00 | 88.00 | 92.50 | 93.58 |
| K = 1 | 98.00 | 97.00 | 96.00 | 89.00 | 92.50 | 96.00 | 94.75 |
| K = 3 | 99.00 | 97.50 | 95.00 | 95.00 | 97.00 | 95.50 | 96.50 |
| K = 5 | 99.00 | 98.00 | 99.00 | 99.50 | 99.00 | 98.50 | 98.83 |
| K = 7 | 98.00 | 98.50 | 96.50 | 99.00 | 93.00 | 95.00 | 96.67 |
| K = 9 | 97.00 | 97.00 | 97.50 | 98.50 | 93.00 | 95.50 | 96.42 |
| K = 11 | 97.50 | 97.00 | 96.50 | 98.00 | 94.00 | 96.50 | 96.58 |
| Method | Clear Water | Clear Land | Heap Cloud | Low Cloud | Medium Cloud | High Cloud | Overall Accuracy |
|---|---|---|---|---|---|---|---|
| FSVM | 97.50 | 99.50 | 98.50 | 90.50 | 91.50 | 97.50 | 95.83 |
| SRC | 83.50 | 70.50 | 91.00 | 62.50 | 52.00 | 58.50 | 69.67 |
| CCSI-ODSR | 98.50 | 96.00 | 91.50 | 88.00 | 97.00 | 91.50 | 93.75 |
| AFSRC | 99.00 | 98.00 | 99.00 | 99.50 | 99.00 | 98.50 | 98.83 |
| Method | FSVM | SRC | CCSI-ODSR | AFSRC |
|---|---|---|---|---|
| Training time (s) | 1.92 | Null | 8.61 | 1.01 |
| Testing time (ms) | 0.13 | 4.47 | 10.06 | 3.82 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, W.; Gong, F.; Zeng, X.; Fu, R. Classification of Clouds in Satellite Imagery Using Adaptive Fuzzy Sparse Representation. Sensors 2016, 16, 2153. https://doi.org/10.3390/s16122153
Jin W, Gong F, Zeng X, Fu R. Classification of Clouds in Satellite Imagery Using Adaptive Fuzzy Sparse Representation. Sensors. 2016; 16(12):2153. https://doi.org/10.3390/s16122153
Chicago/Turabian StyleJin, Wei, Fei Gong, Xingbin Zeng, and Randi Fu. 2016. "Classification of Clouds in Satellite Imagery Using Adaptive Fuzzy Sparse Representation" Sensors 16, no. 12: 2153. https://doi.org/10.3390/s16122153