1. Introduction
Computer vision (CV) has many possible utilizations and is one of the fastest growing research areas these days. Passive optical sensors have been used in the automotive industry for tasks such as management and off-board traffic observation [
1]. The CV technique is often used in driver assistance and traffic sign detection in onboard systems [
2]. Also, the augmented reality (AR) resulting from CV functions, improves the real environment by using virtual elements and allows diversified functions such as guided order picking or upkeep efforts [
3,
4].
Various light conditions, different views of an object, surface reflections and noise from image sensors are the challenging questions with which one has to deal when it comes to pose estimation and optical object detection. The solution to these problems to some extent can be achieved thanks to the use of SIFT or SURP algorithms as they compute the point features, which are invariant towards scaling and rotation [
5,
6]. However, these algorithms demand powerful hardware and consume high battery power because of their high computational complexity, making their use in automotive applications and in the field of mobile devices generally challenging.
The Nios II microprocessor has been widely used in many applications such as image processing, control, and mathematic acceleration. Low-cost sensors have been discussed in [
7]. They have accelerated block matching motion estimation techniques using the Altera C2H. Their processor can process 50 × 50 at 29.5 fps. Custom instructions in the Nios II were used for accelerating block matching algorithms [
8] where a 75% improvement was achieved by utilizing custom instructions. In [
9], customized Nios II multi-cycle instructions have been used to accelerate block matching techniques. A Nios II microprocessor was also used for image encryption and decryption. The AES algorithm was implemented using a Nios II soft core processor [
10]. The proposed implementation provides high security while retaining image quality. A MPPT controller for a hybrid wind/ photovoltaic system was developed using a Nios II microprocessor [
11]. In addition, a Nios II microprocessor was used to accelerate a quadratic sieve (QS) algorithm to factor RSA numbers [
12].
The task of camera pose estimation has been addressed by several algorithms. These algorithms can be categorized into two groups: iterative and analytical [
13,
14,
15]. Analytical algorithms utilize closed solutions with some assumptions in order to simplify this problem [
16,
17]. Iterative methods compare the projection with actual measured correspondences. Iterative methods are more used due to their accurate results and minimal number of iterations [
13,
14,
15,
18,
19,
20]. In this paper, the Nios II processor is used for estimating the pose based on [
19].
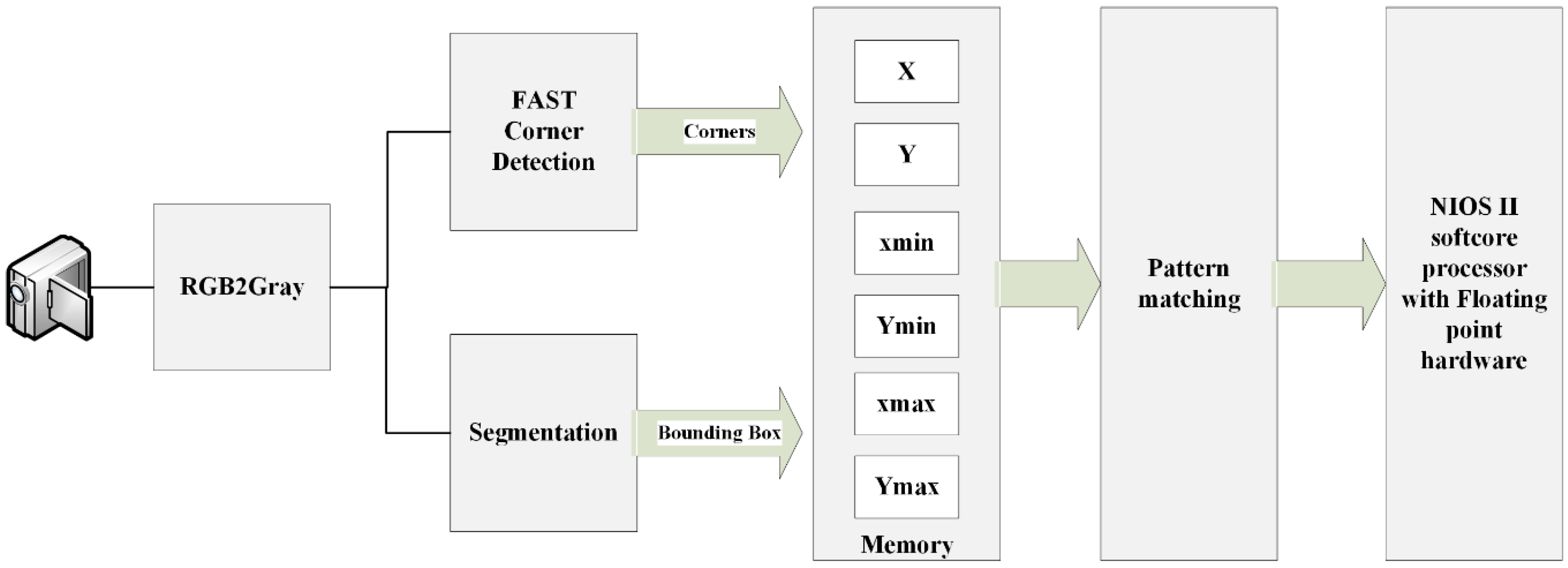
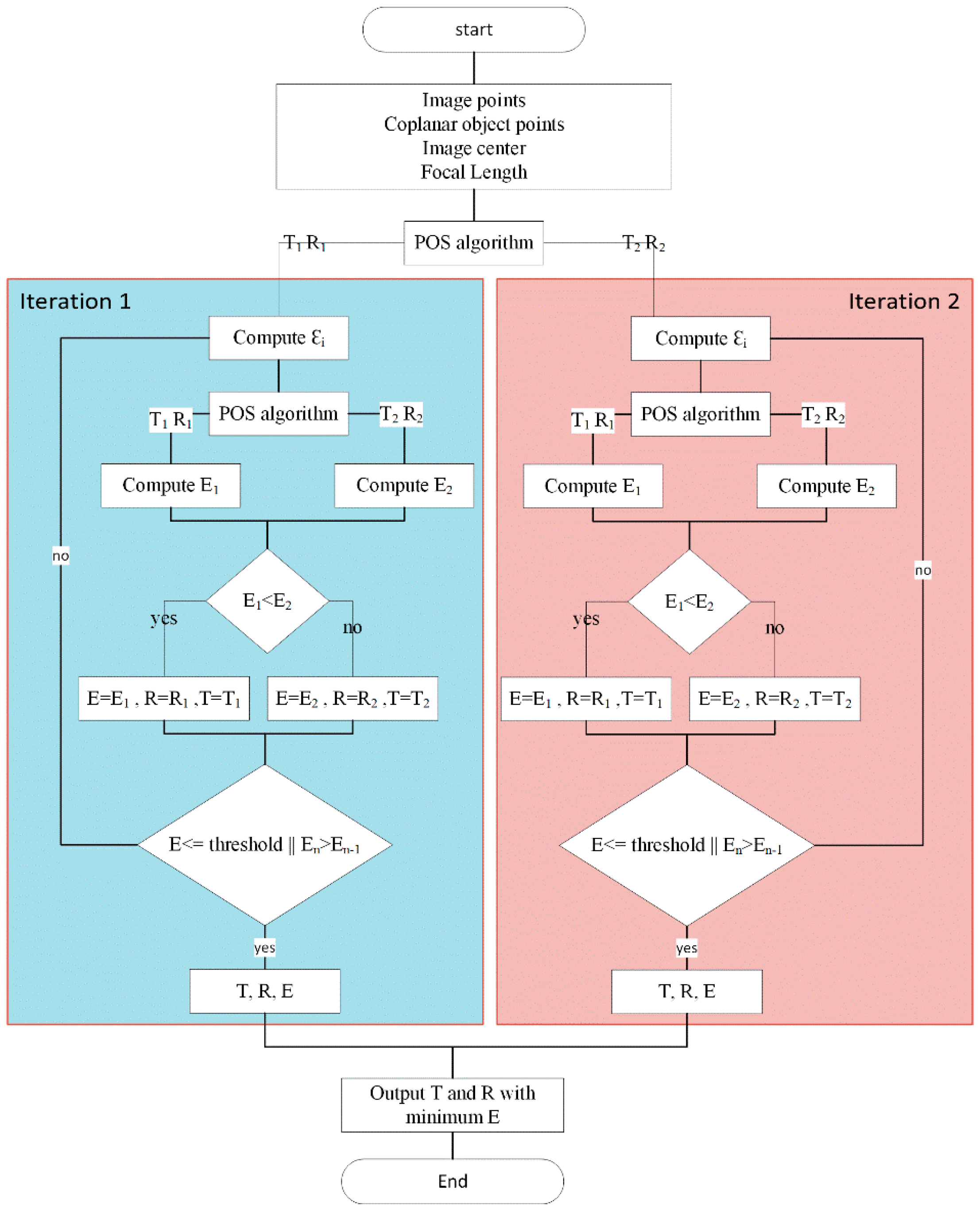
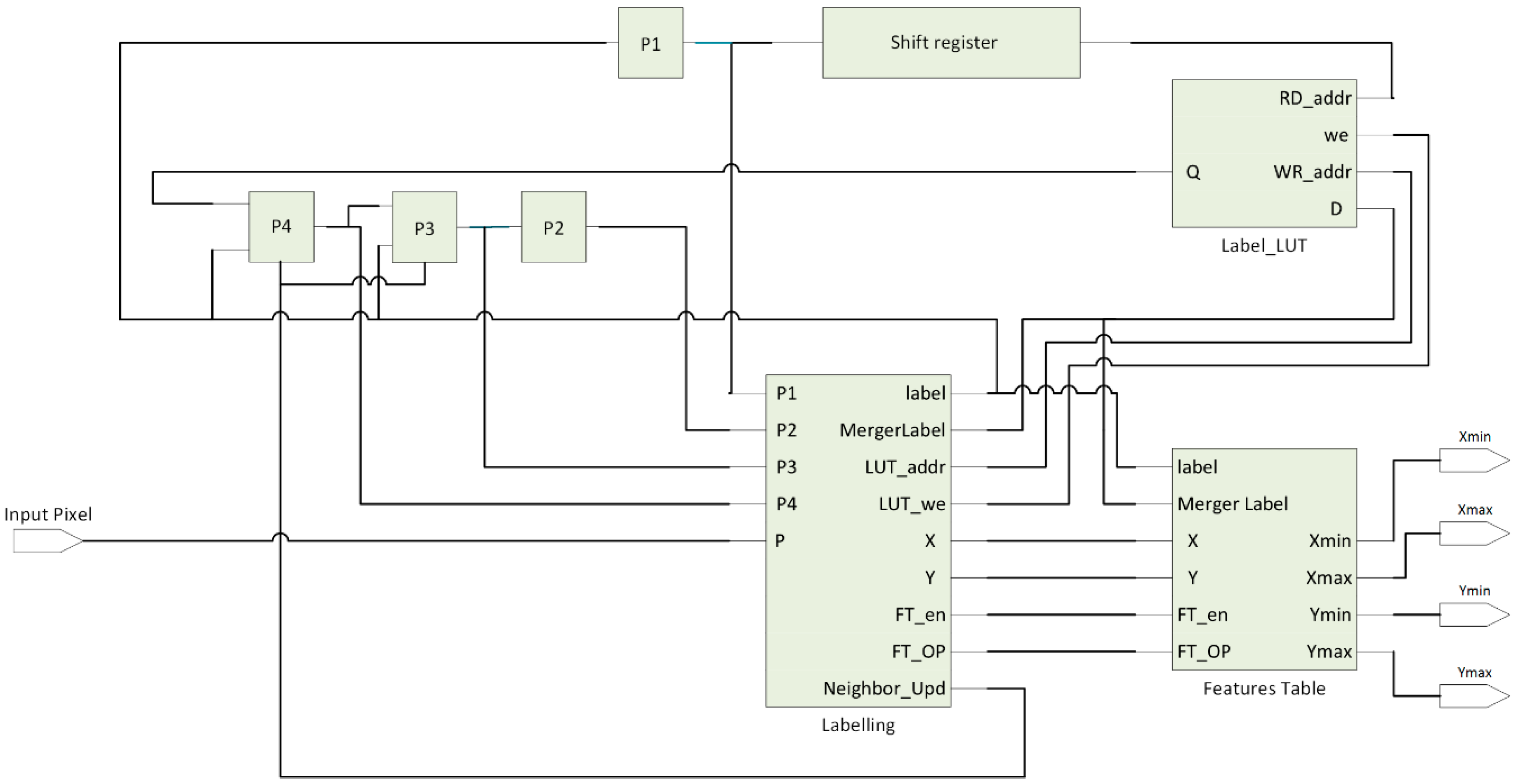
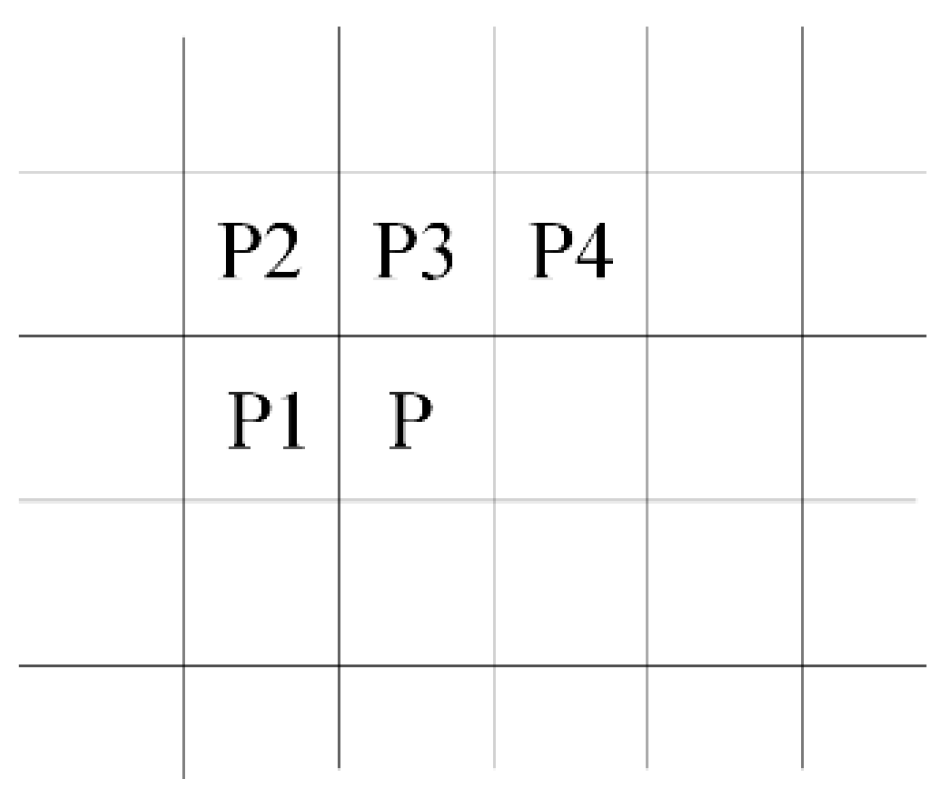
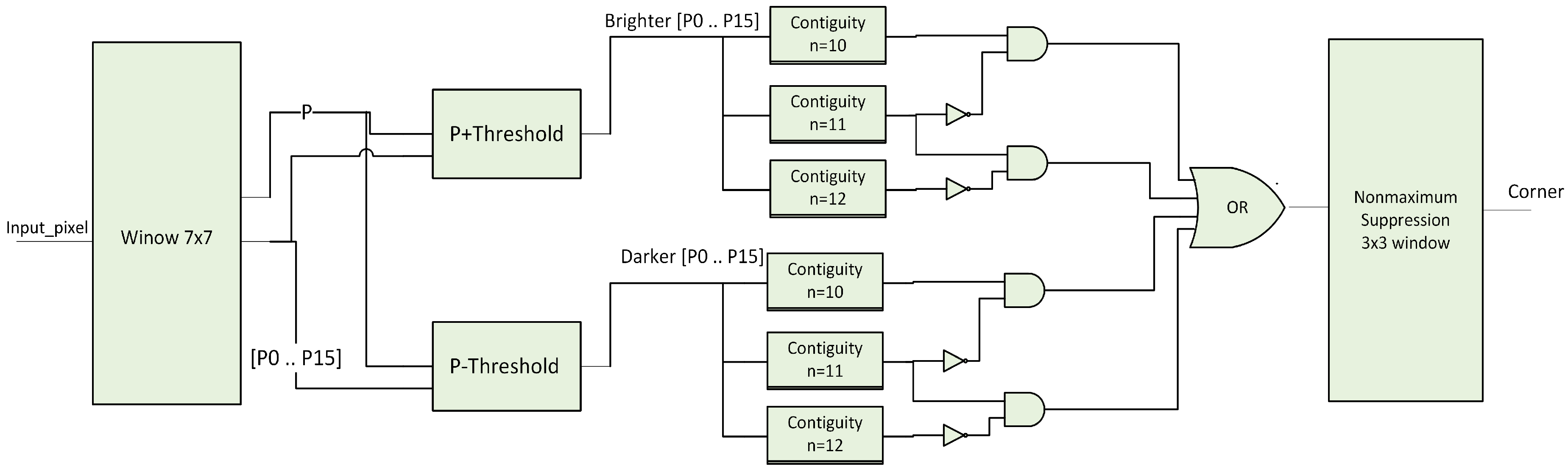
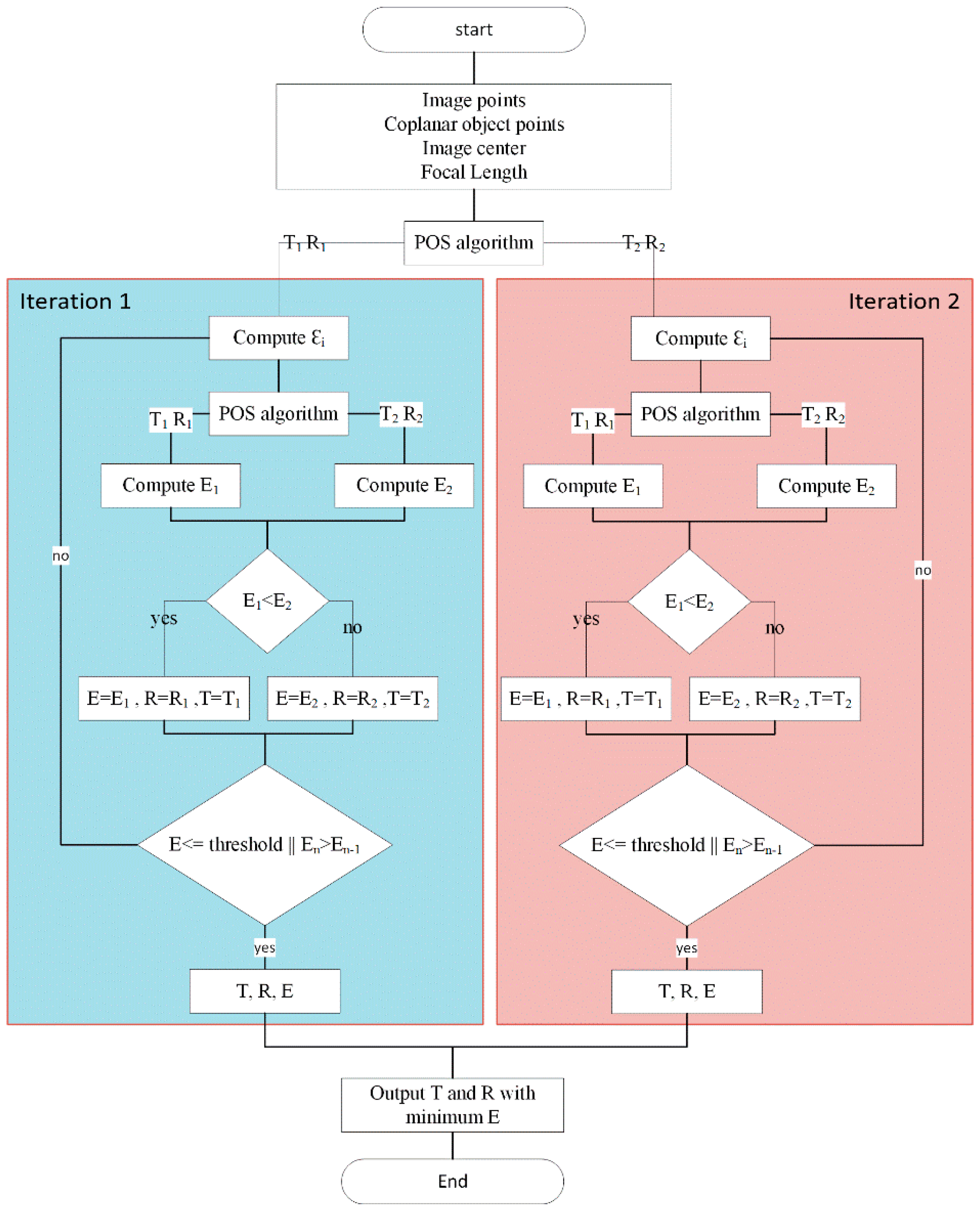
This paper describes a real time system to recognize a predefined marker with known geometries and calculate the pose of the detected markers in the frame. This system is divided into two main subsystems. The first one is carried out on FPGA and used for extracting the four vertices of the recognized markers which are required for pose estimation. The markers are recognized in the frame by using single pass image segmentation and a FAST algorithm. The second subsystem is a Nios II soft core processor based on RISC architecture. Using this processor, the Coplanar PosIT algorithm can be implemented. In order to achieve the fast use of floating point operations, additional floating point hardware was added to this processor. Moreover, the time required for running Coplanar PosIt has been reduced by approximating trigonometric functions using Taylor series and Lagrange polynomials. The entire system has been implemented on a Cyclone IVE EP4CE115 chip from Altera (San Jose, CA, USA) which operates at 50 MHZ. Quartus and Qsys were used for system building.
This paper is divided into the following sections:
Section 2 explores the related works.
Section 3 explains the top level architecture.
Section 4 presents the detailed architecture of the proposed system. Simulation results are discussed in
Section 5.
Section 6 gives the conclusions.
2. Related Works
Natural features of images, including global or local features, can been used in object recognition because of the increasing processing power of traditional PC hardware [
21]. Feature recognition techniques have been used in developing many applications such as autonomous systems and automotive systems [
22]. Harris Corner Detection, SIFT, and SURF are well-known algorithms for finding and describing point features [
5,
23]. SIFT and SURF extract local features which outperform global features [
6,
24]. However, the speed of SURF is faster than SIFT. The main drawback of the aforementioned algorithms is the need for high computational power which requires powerful PC-like hardware [
21], making the availability of high-speed platforms with such powerful PC-like hardware a necessity to implement these algorithms. A modern GPU hardware and programmable logic (FPGAs) have been used to meet the computational requirements of these algorithms [
25]. Histogram of Oriented Gradient (HOG) for object detection has been implemented using reduced bit width fixed point presentation in order to reduce required area resources. This implementation was able to process 68.2 fps for 640 × 480 image resolution on single FPGA [
26]. Another reduced fixed point bit width for human action recognition has been introduced in [
27] where hardware requirements have been reduced due to using a classifier with 8 bit-fixed-point. Bio-inspired optical flow has been implemented in reconfigurable hardware using a customizable architecture [
28,
29]. FPGA was used in order to enhance the performance of a localization algorithm. FAST corner detection has been accelerated using a FPGA-based grid approach in [
30]. Mirage pose estimation has been used for robot localization and trajectory tracking. Pose was estimated analytically without iterative solutions [
31]. A POSIT algorithm for non-coplanar feature points has been used for UAV localization in [
32].
A SURF-based object recognition and pose estimation embedded system was introduced in [
33]. This system is able to process images at five frames per second and recognize nine different objects. However, this system is not suitable for real-time systems due to the latency produced by the SURF algorithm implementation. On-board vision sensors have been designed and implemented using a linked list algorithm in [
34]. In this work, memory consumption had been minimized and the proposed algorithm is able to detect blobs in real-time.
5. Experimental Results
System experiments and simulations where carried out using an Altera DE2-115 board powered by a Cyclon IVE FPGA chip.
Figure 12 shows the experimental equipment used in this experiment.
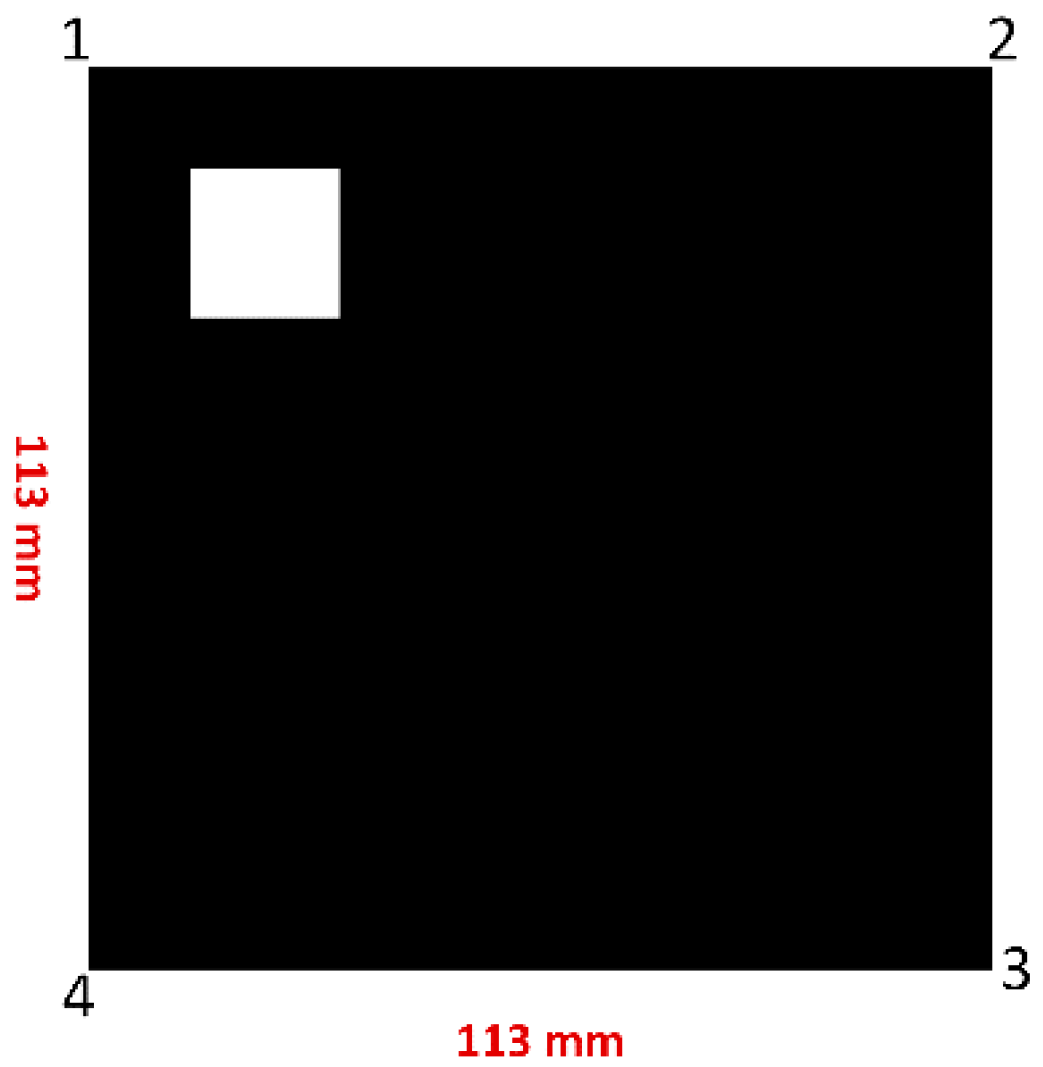
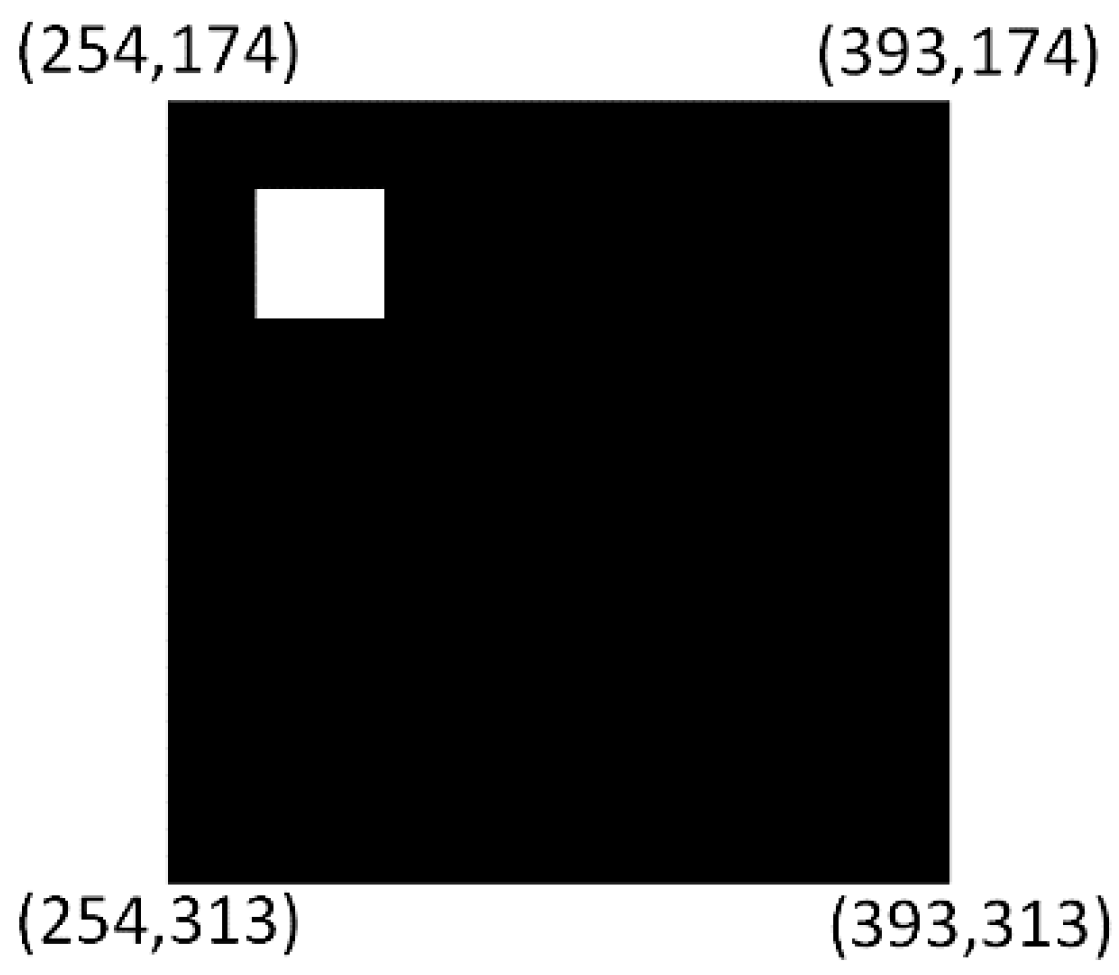
The simulation results for a frame containing one marker in the center of the frame will be introduced. The illustration of this frame is shown in
Figure 13.
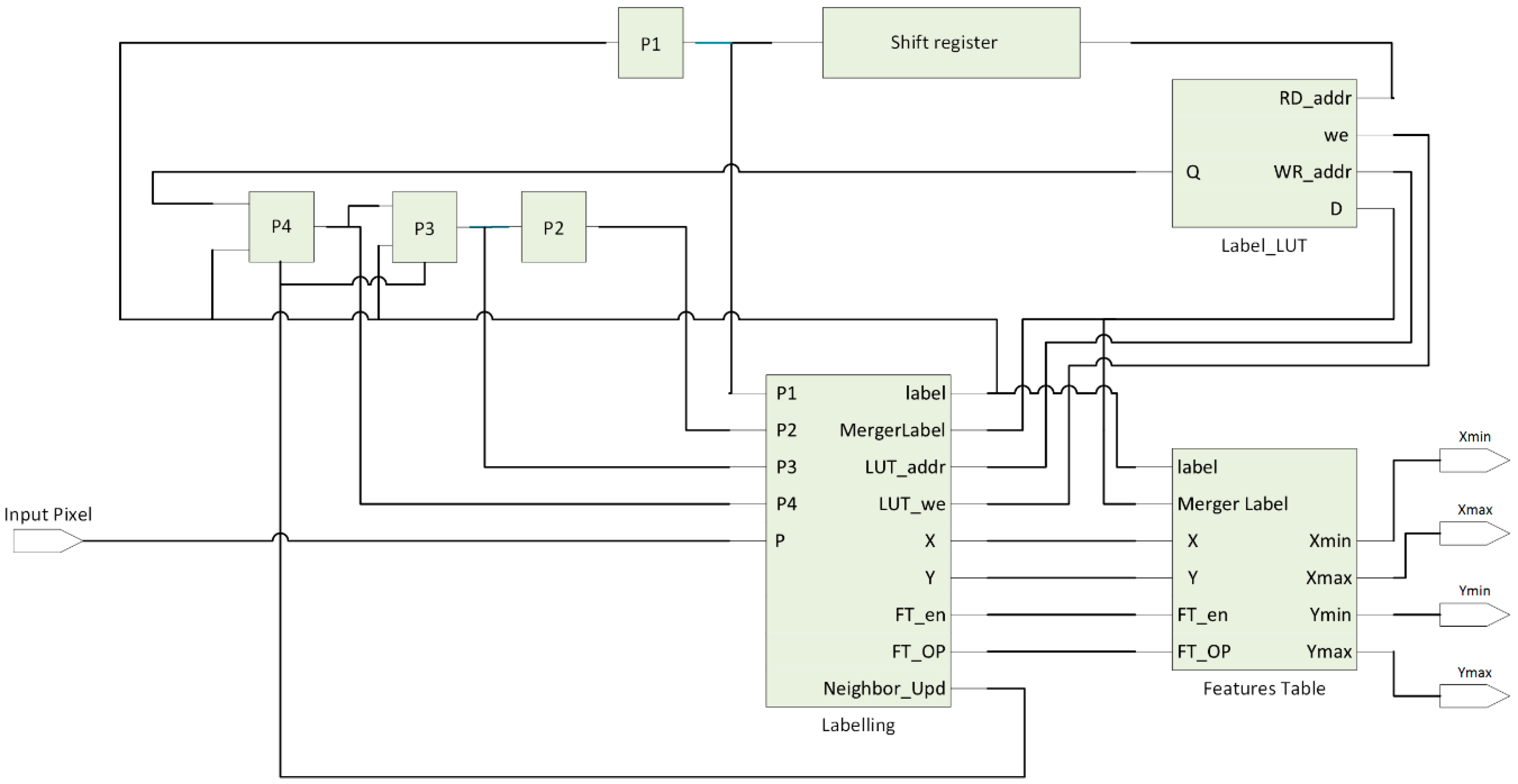
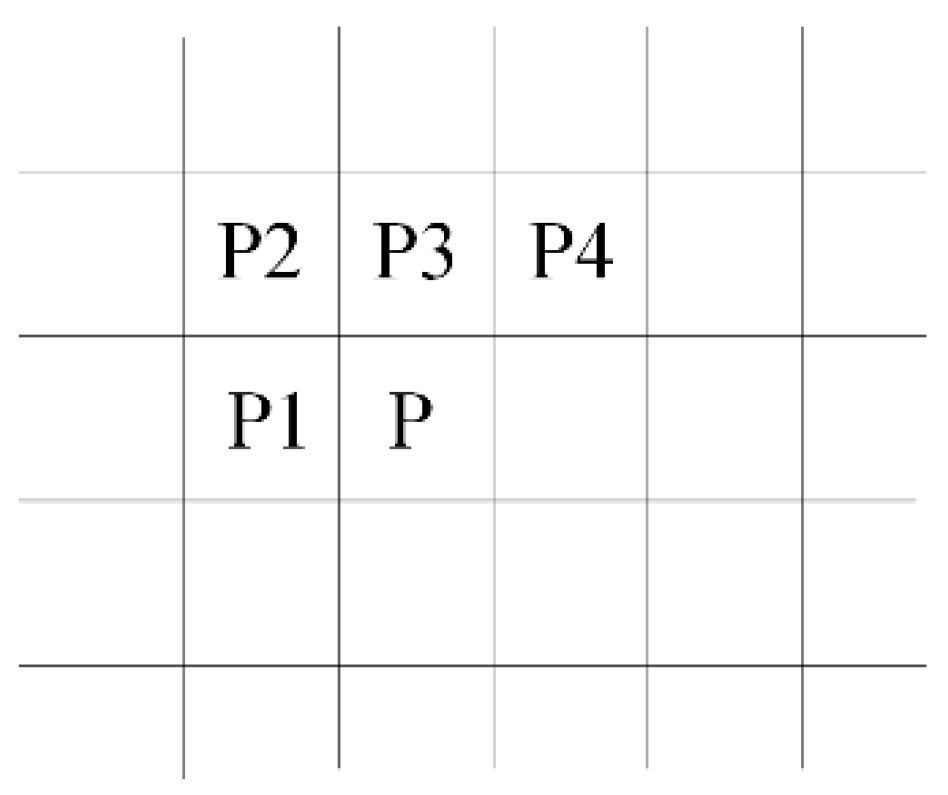
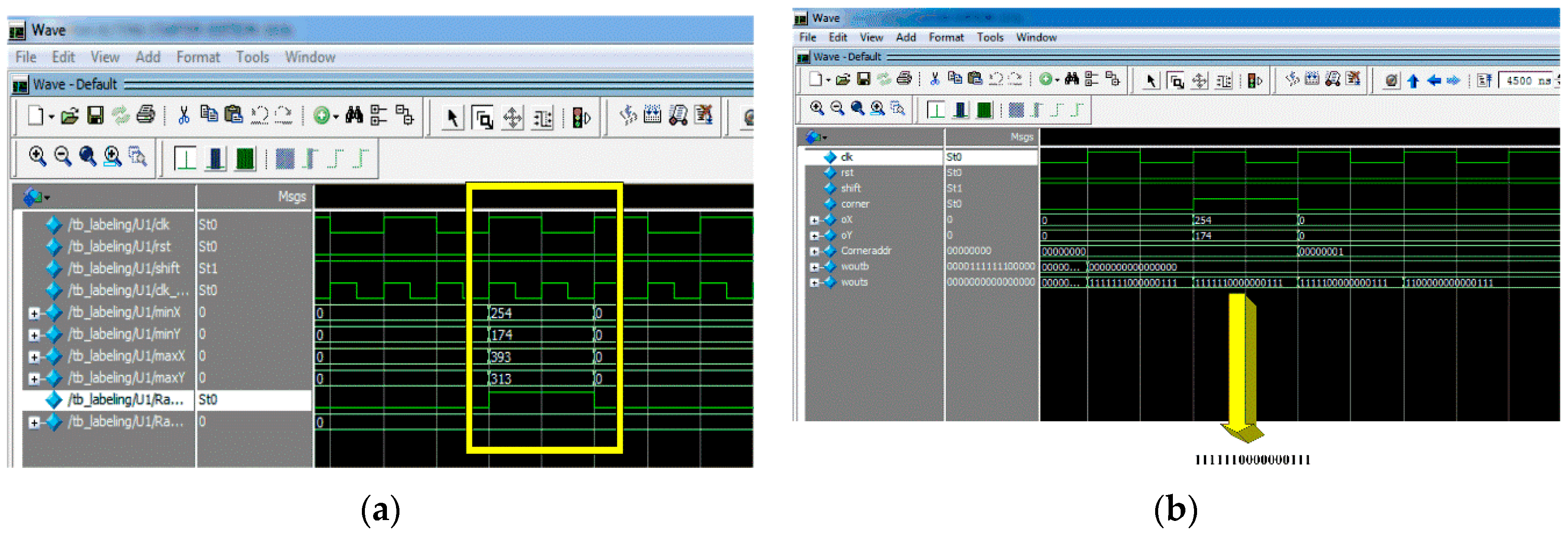
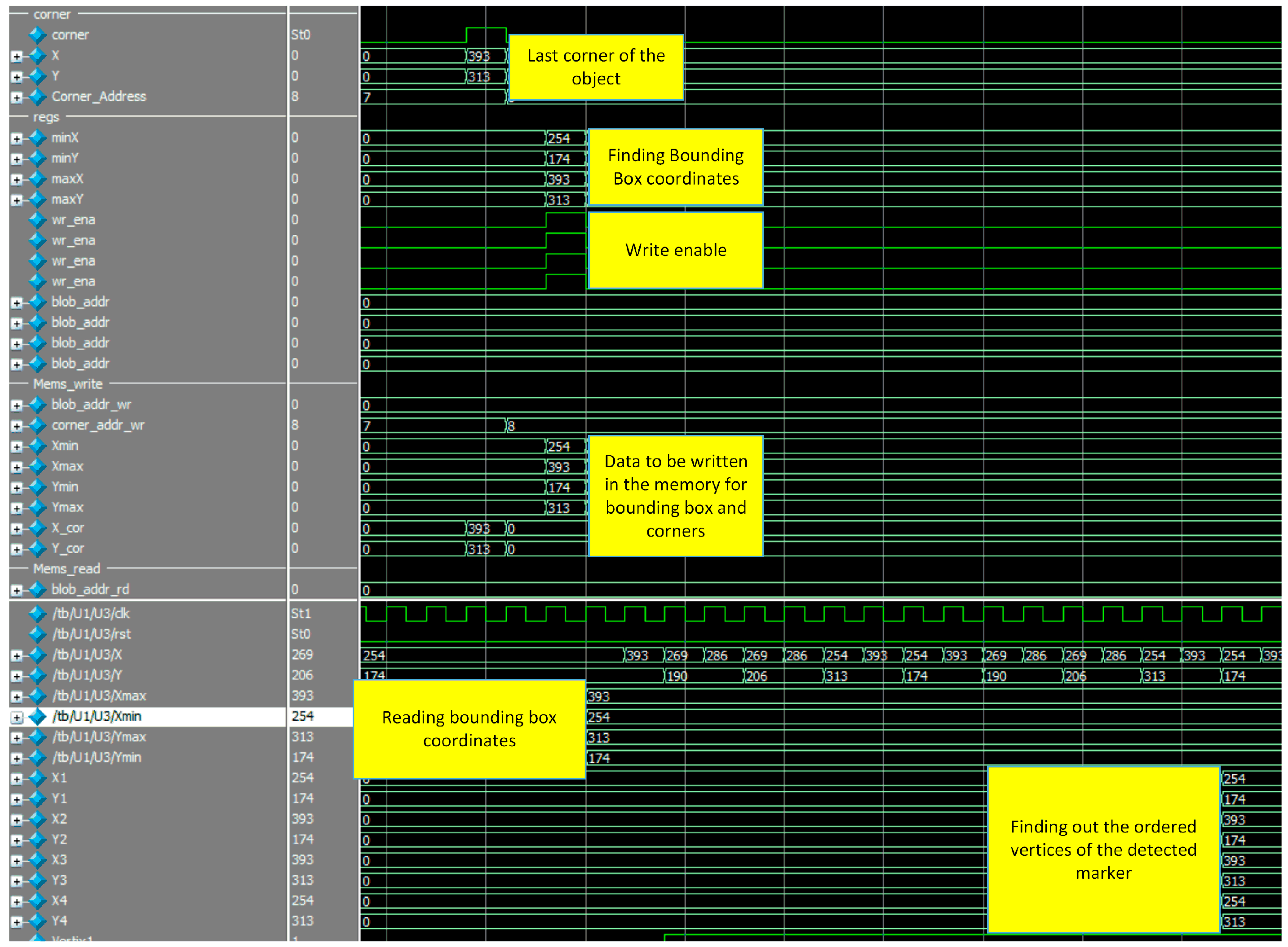
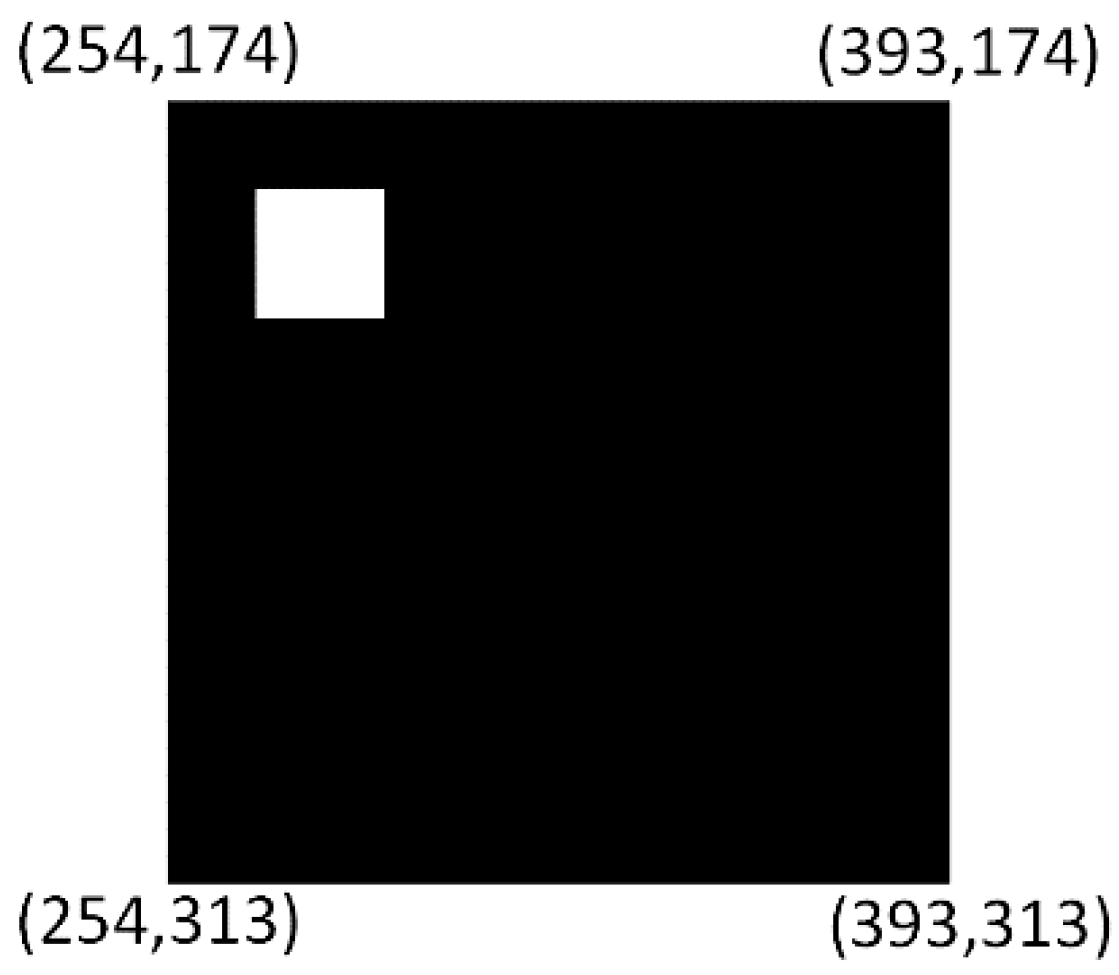
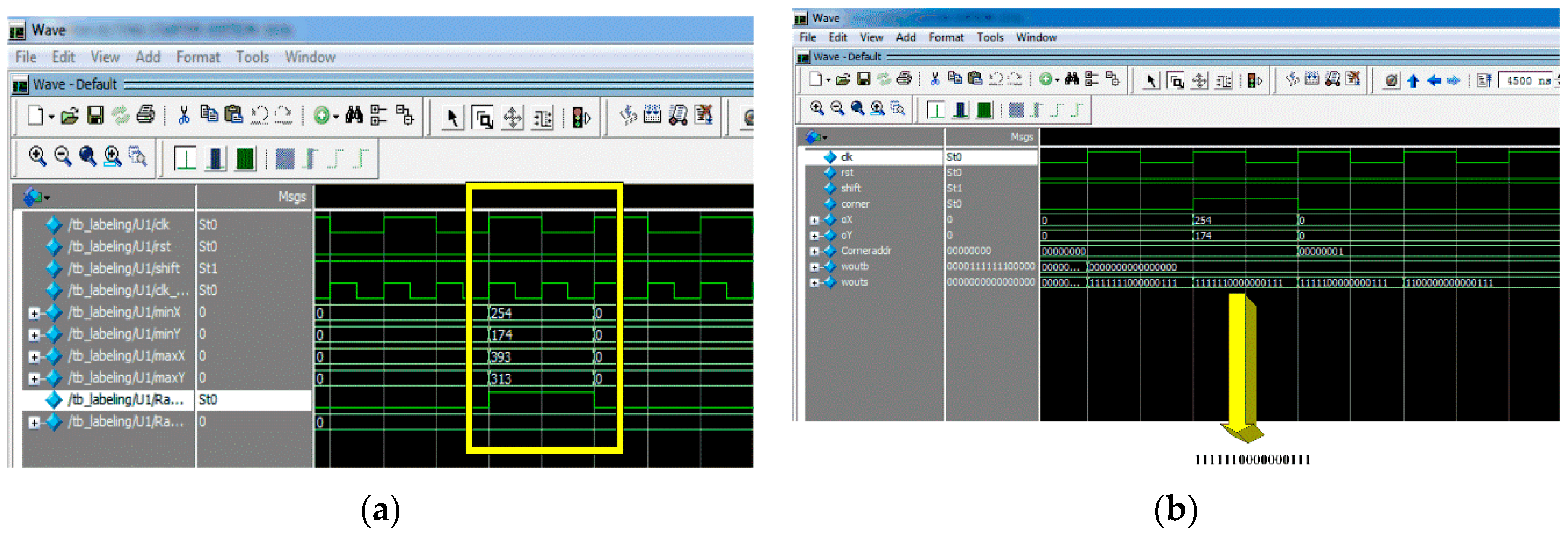
Figure 14a shows the bounding box coordinates of the detected marker. It can be seen from this figure that the coordinates of the bounding box [Xmin, Ymin, Xmax, Xmax] = [254, 174, 393, 313]. In addition, write enable is set to 1 in order to write these values in the corresponding memories.
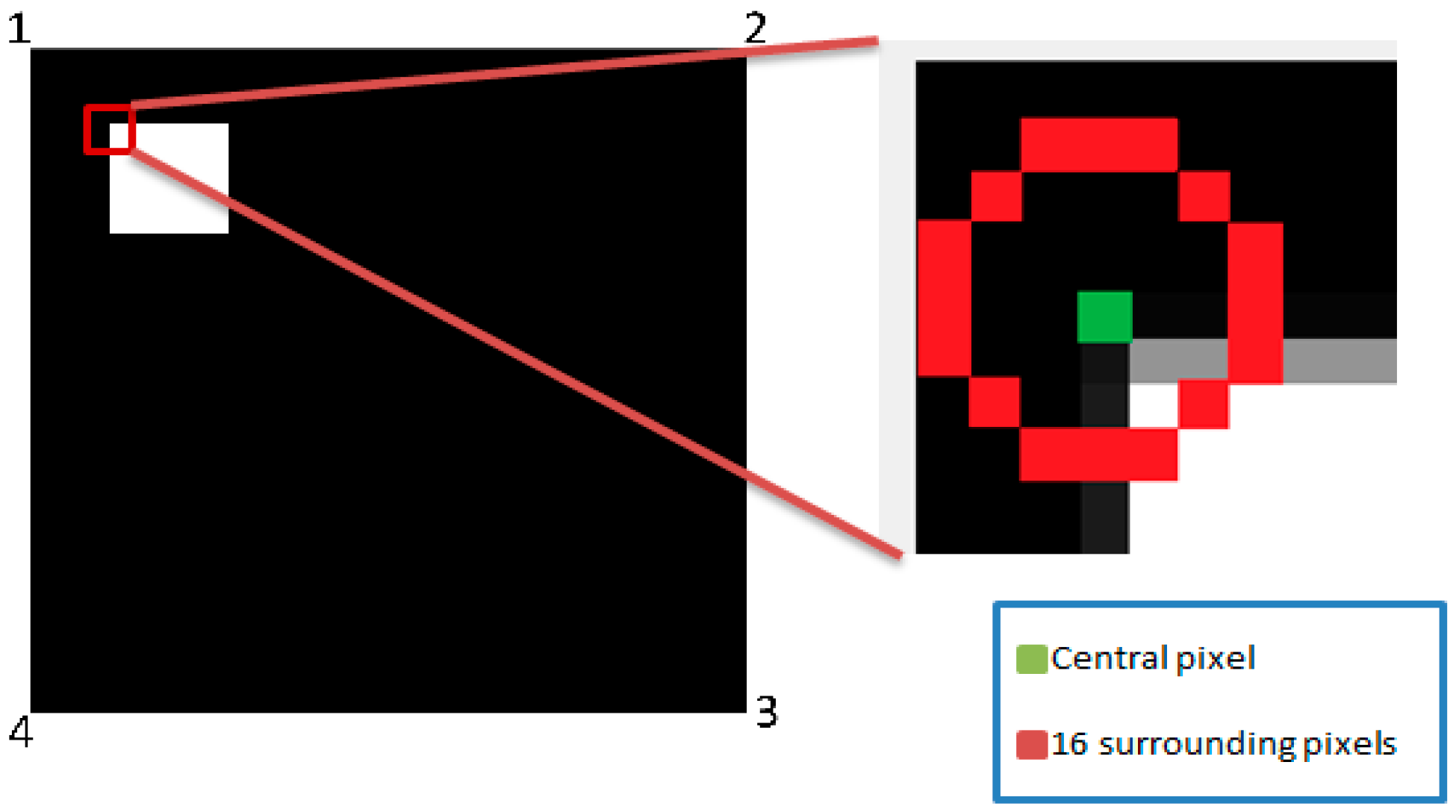
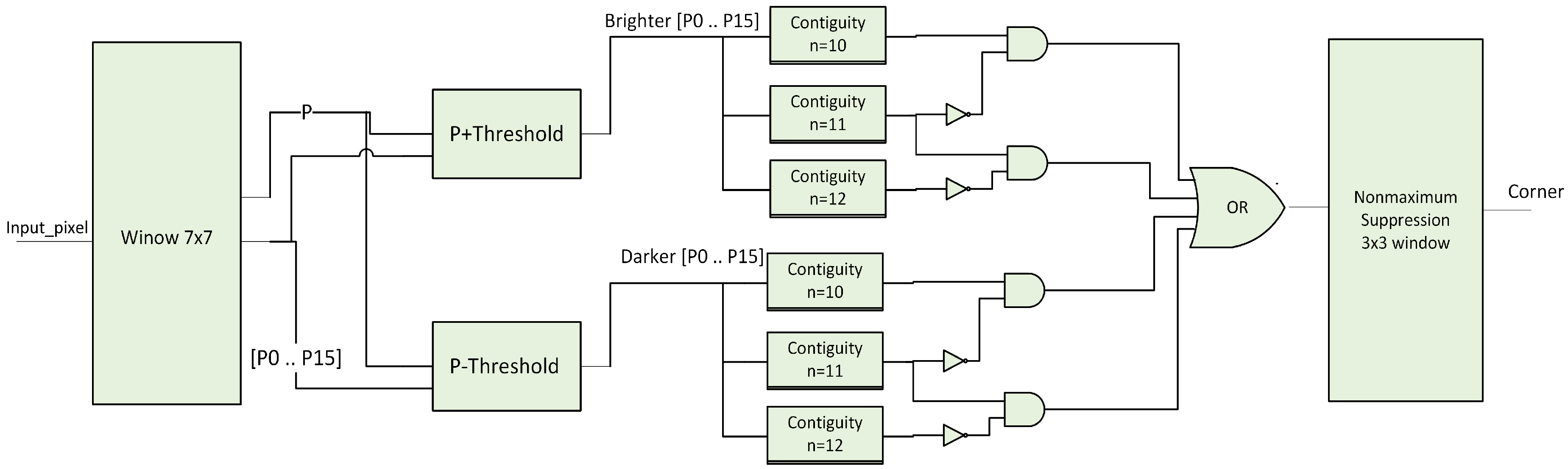
In addition, detected corners using FAST algorithm are shown in
Figure 14b. It can be seen that the ‘corner’ signal is set to one because there is a contiguity pattern equals to ‘1111111000000111’. In this case
n = 10. The detected corner at (X = 254, Y = 174) will be written at the address specified by ‘Coneraddr’.
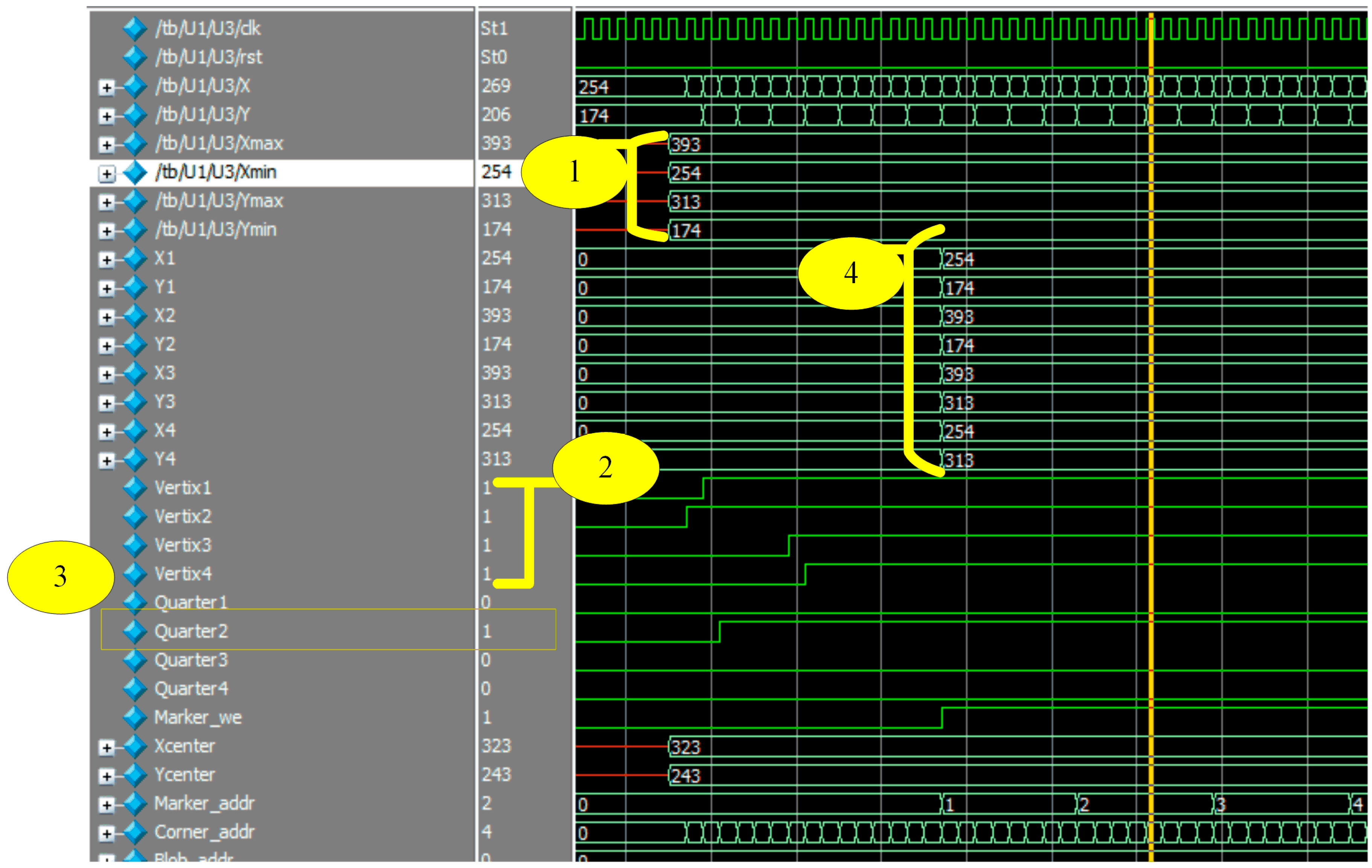
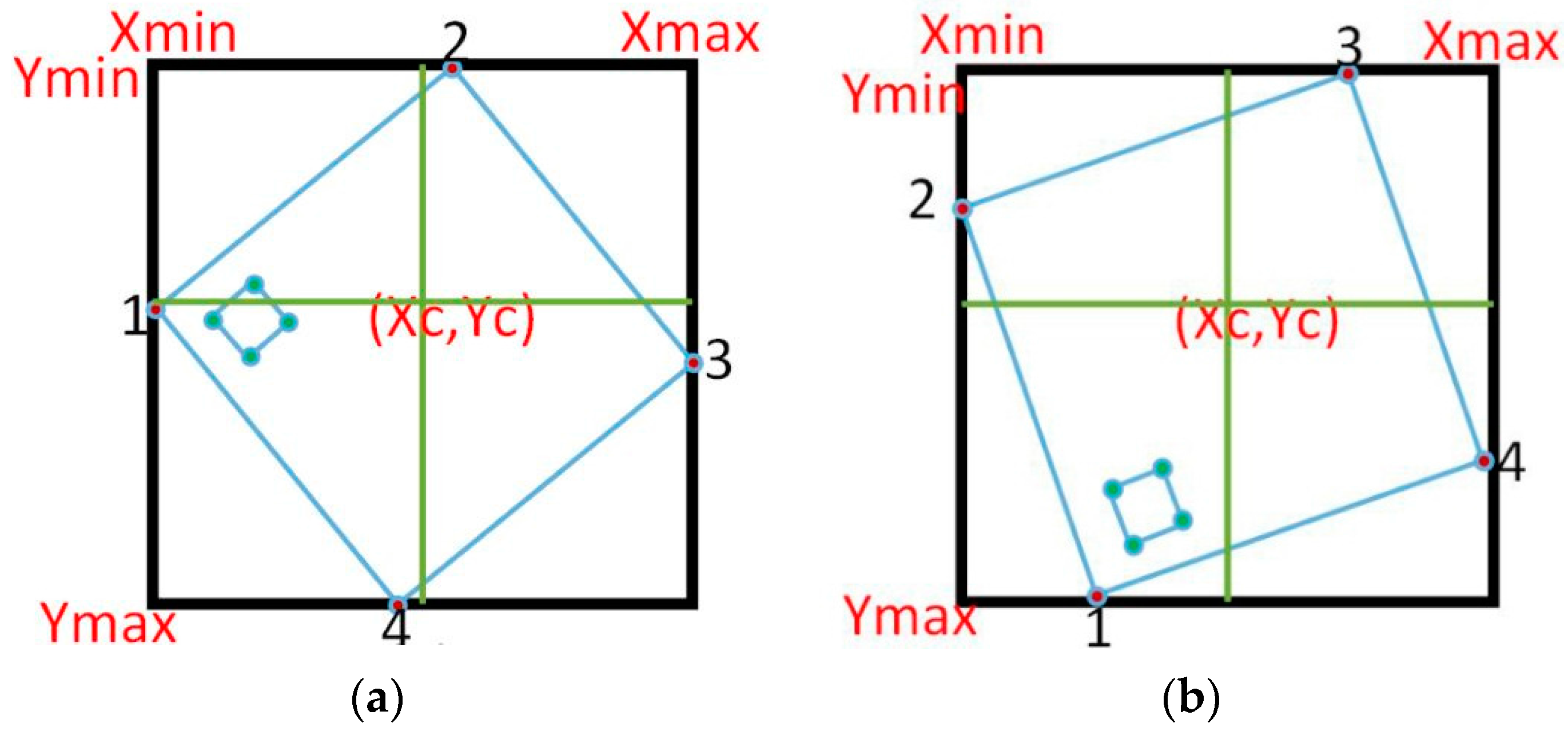
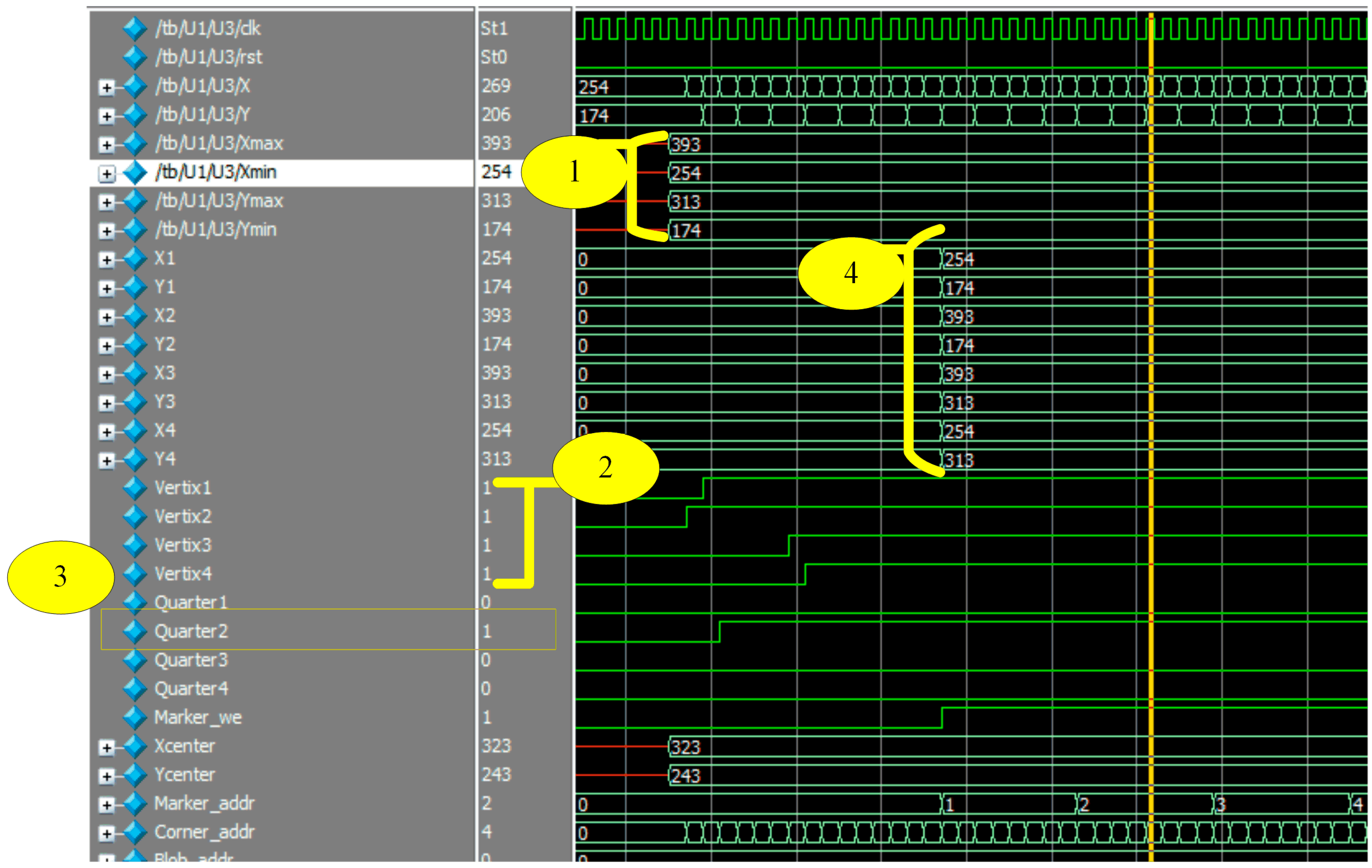
The matching process is illustrated in
Figure 15. This figure is marked from one to four. Step 1 represents reading coordinates of the bounding box. Step 2 shows how vertices signals became 1 during the reading of corner coordinates. Step 3 depicts that, the first vertex is located in the second quarter. Step 4 shows the output of the ordered vertices where [V1:(254,174), V2:(393,174), V3:(393,313), V4:(254,313)].
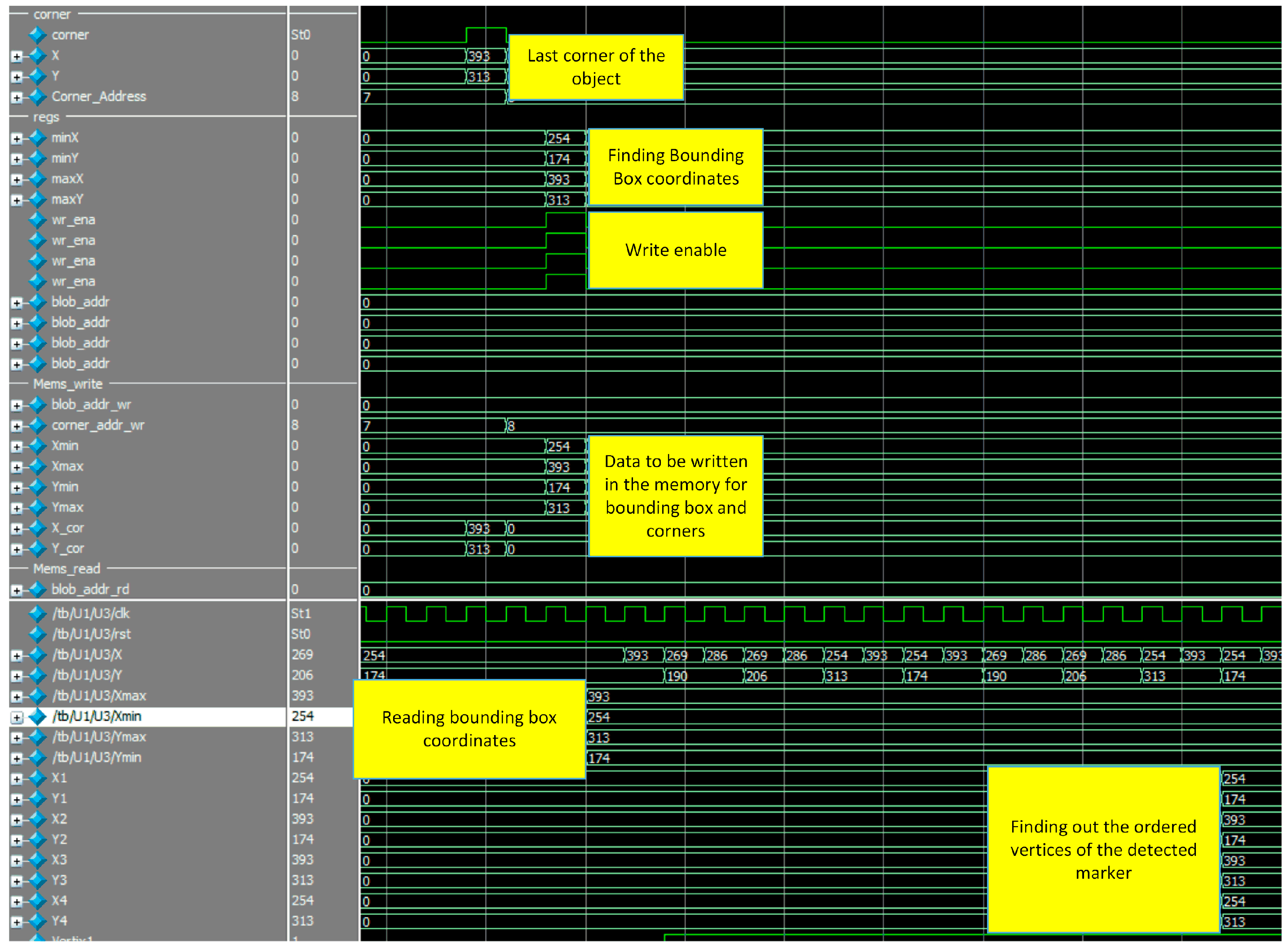
The complete system simulation is shown in
Figure 16. Features such as detected corners, bounding box coordinates of the marker, writing these coordinates in the memory block and finally, matching process which gives the ordered vertices of the detected markers are illustrated in this figure. These vertices are sent to the designed soft core processor in order to find out the pose of the detected markers.
The pose estimation using coplanar PosIt running on the designed processor is , whereas the result of coplanar PosIt without approximation is .
Another example of a rotated marker is shown in
Figure 17.
The whole system simulation for extracting the ordered vertices of the detected marker is shown in
Figure 18. The pose estimation using coplanar PosIt running on the designed processor is
whereas the result of coplanar PosIt without approximation is given by
.
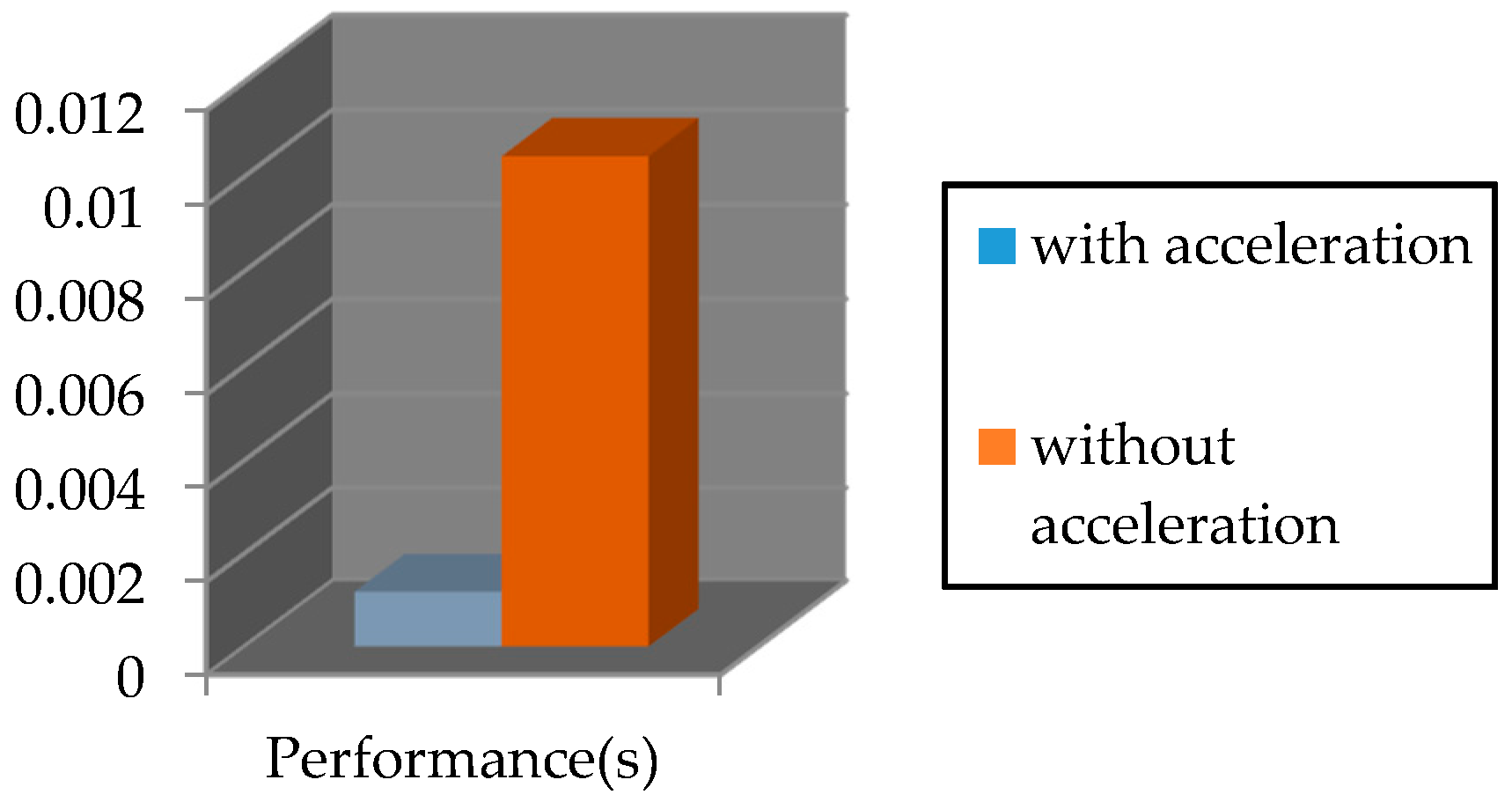
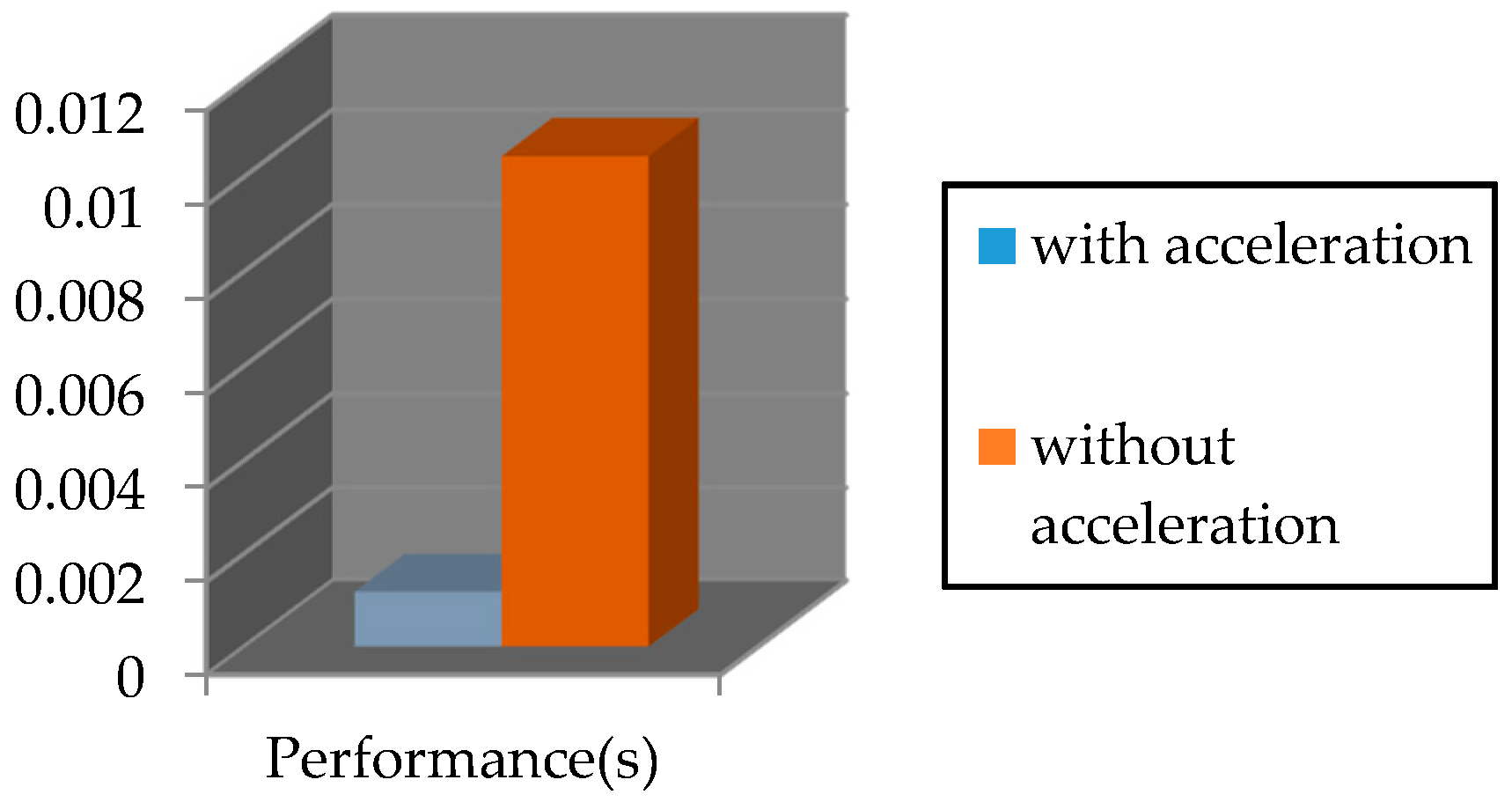
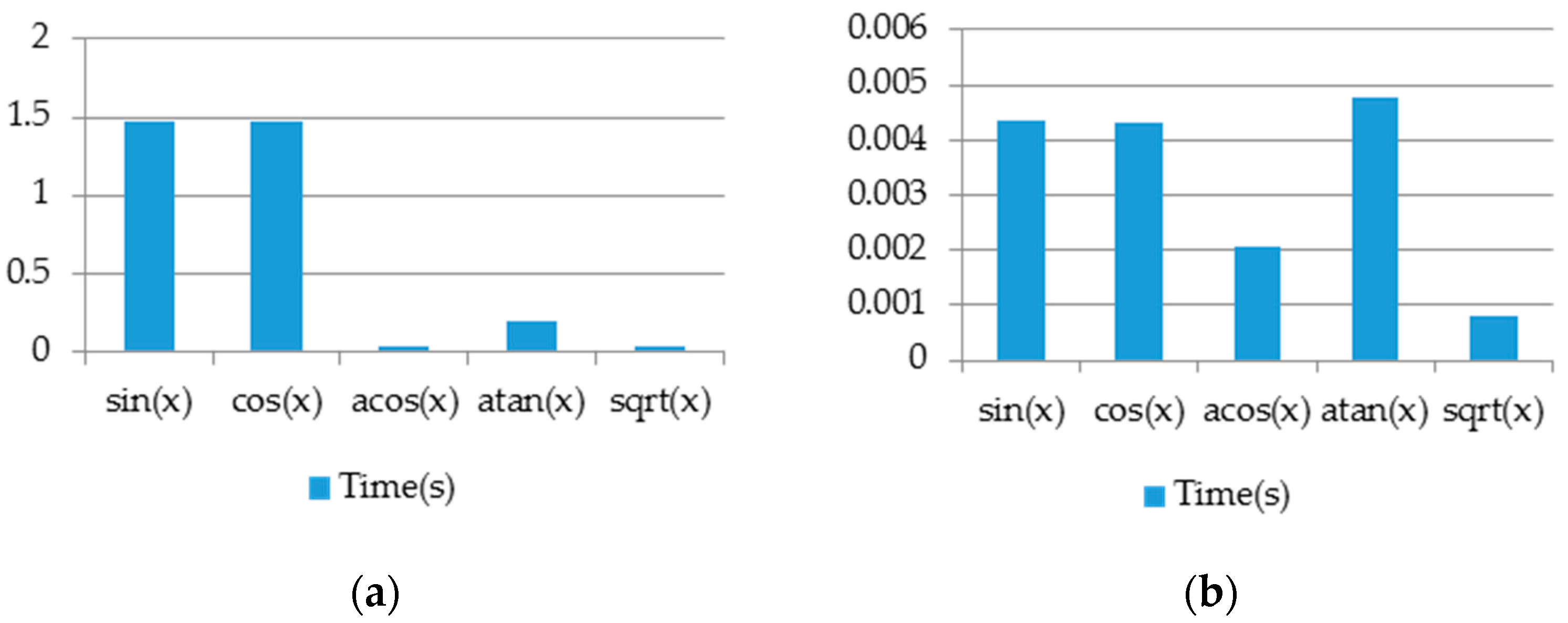
The required time for executing the PosIt algorithm on Nios II soft-core processor by using FPCI and functions approximation is 0.00118 s. However, the time required for running this algorithm without acceleration is 0.01043 s. This is illustrated in
Figure 19.
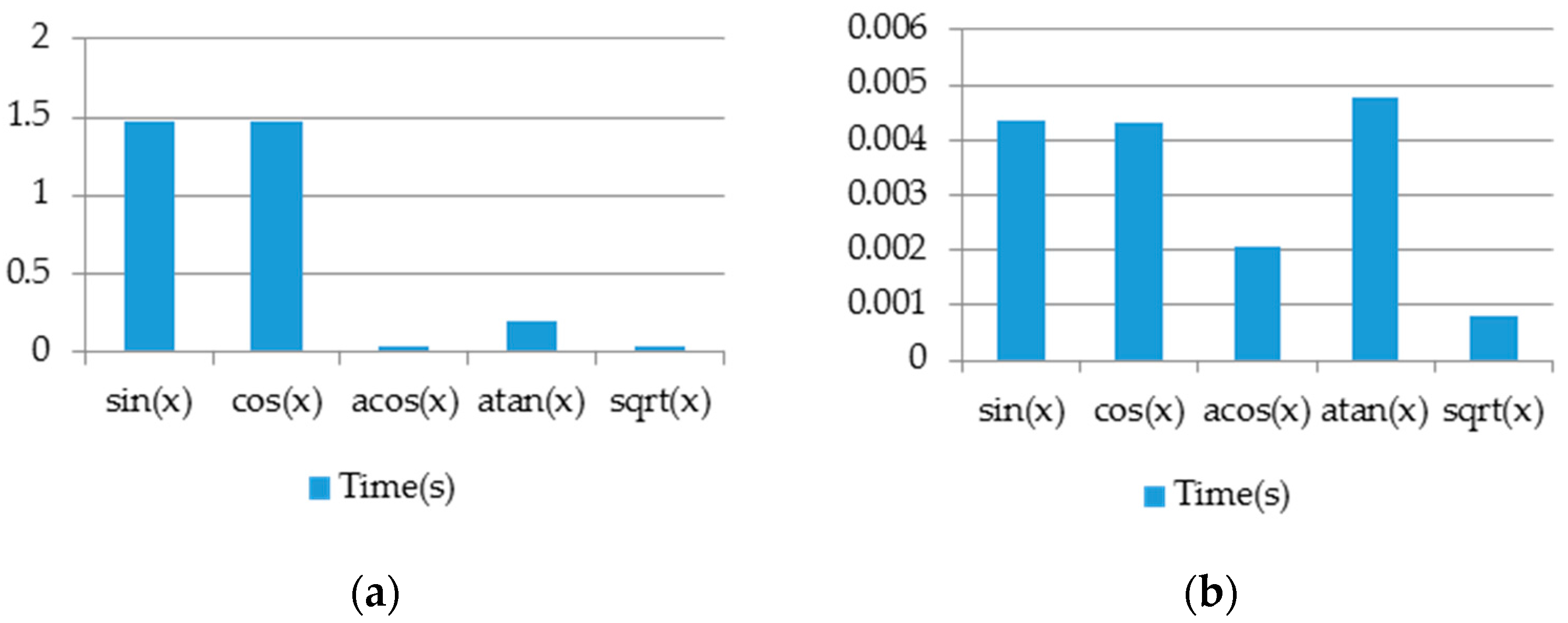
Figure 20 shows a comparison between the trigonometric functions supported by FPCI and the approximated ones. These functions have been tested on an array with 1000 random float-number elements and have run on the designed processor.
In order to test the performance of proposed pose estimation algorithm on Nios II, two scenarios have been considered. In the first scenario, we study the performance of translation and orientation at predefined locations. For instance, the robot moves on the X-axis and all other degrees of freedom are fixed. In other words, the target is either translated or rotated with respect to one axis only.
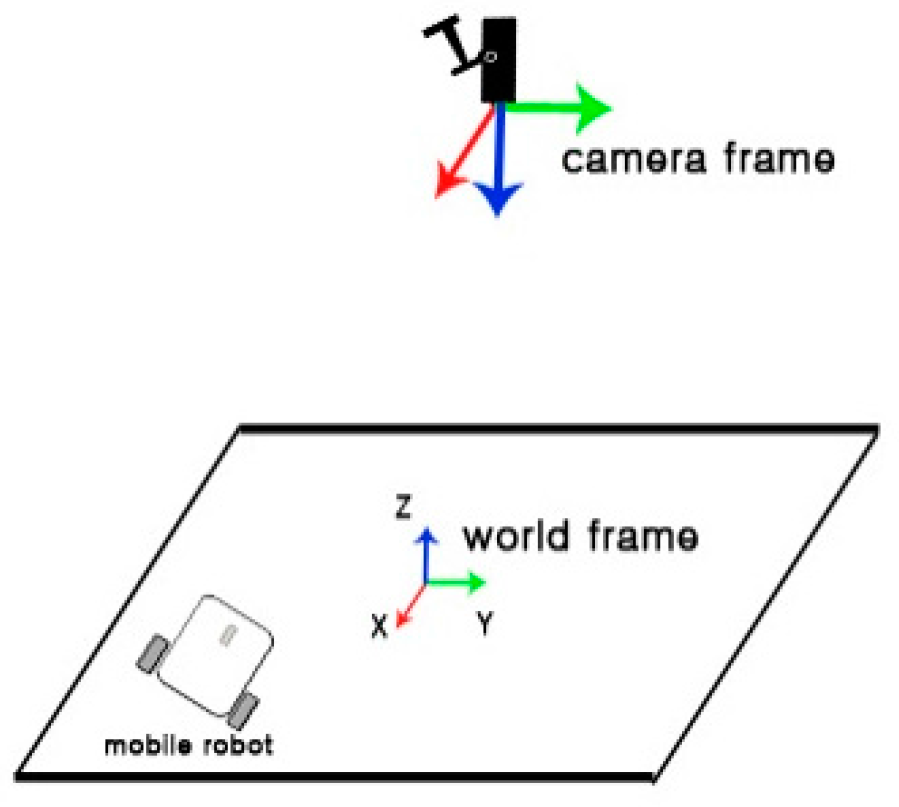
Figure 21 illustrates the pose of the camera and target.
Figure 22 illustrates the comparison of estimated pose with the real pose.
The minimum, maximum, and mean error of x, y, and z coordinates and roll-yaw-pitch angles are shown in
Table 2.
In the second scenario, the marker traveled on a predefined trajectory and the estimation error has been recorded and compared with [
31].
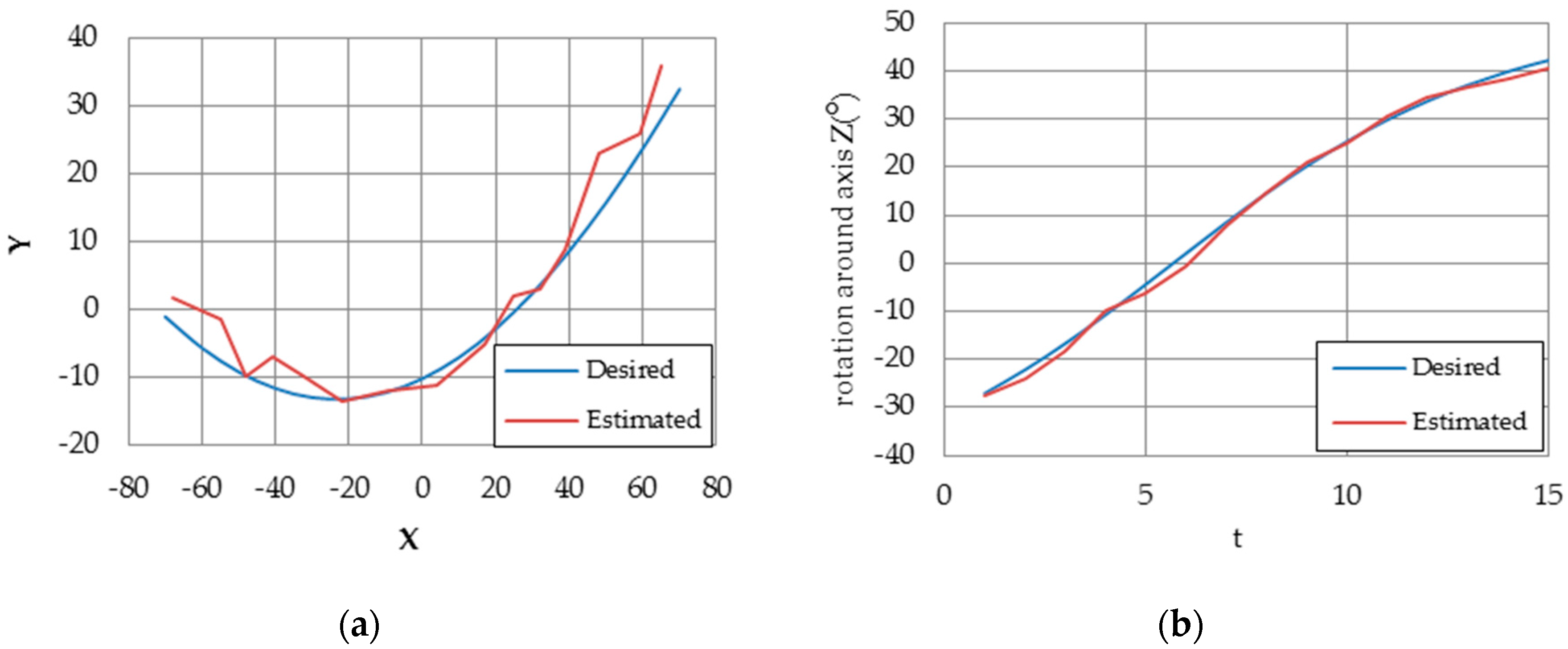
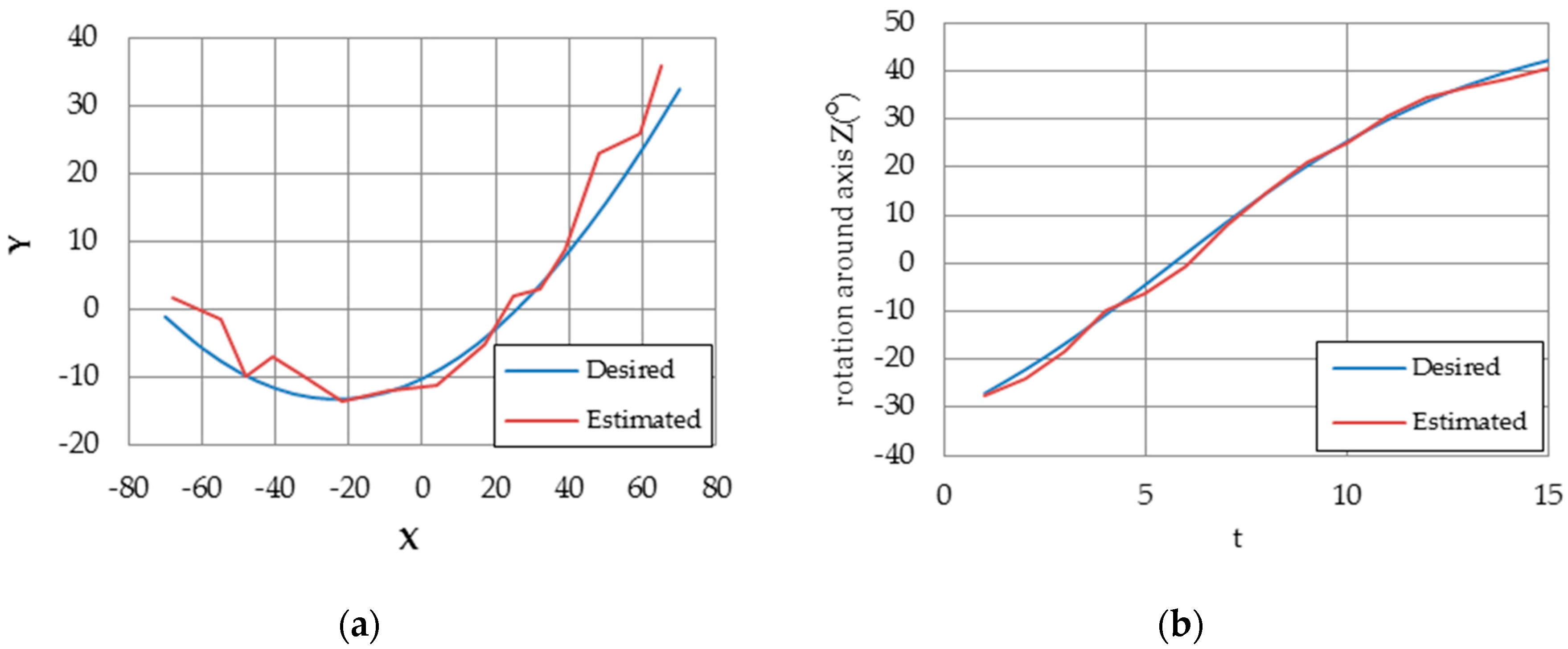
Figure 23 shows pose estimation and rotation angle results. In [
31], the estimation performance was studied with respect to the number of target points (4, 20, 50, 100). However, we estimate the pose using four coplanar target points only.
Table 3 shows the comparison of pose estimation error between implemented coplanar Posit algorithm and [
31] results. The results shows that our proposed design outperforms the method introduced in [
31].
The algorithm mentioned in [
34] is used for object tracking, the extracted foreground objects are sent to CPU where simple motion-based tracker is used for object tracking. On the other hand, our proposed algorithm extracts the blobs and corners simultaneously. These information are sent to on-board soft-core processor NIOS II to estimate the pose of the extracted objects using Coplanar-Posit algorithm. Coplanar-Posit algorithm was accelerated by approximating trigonometric functions to achieve real-time results. The performance comparison of the proposed method with reference method is shown in
Table 4.
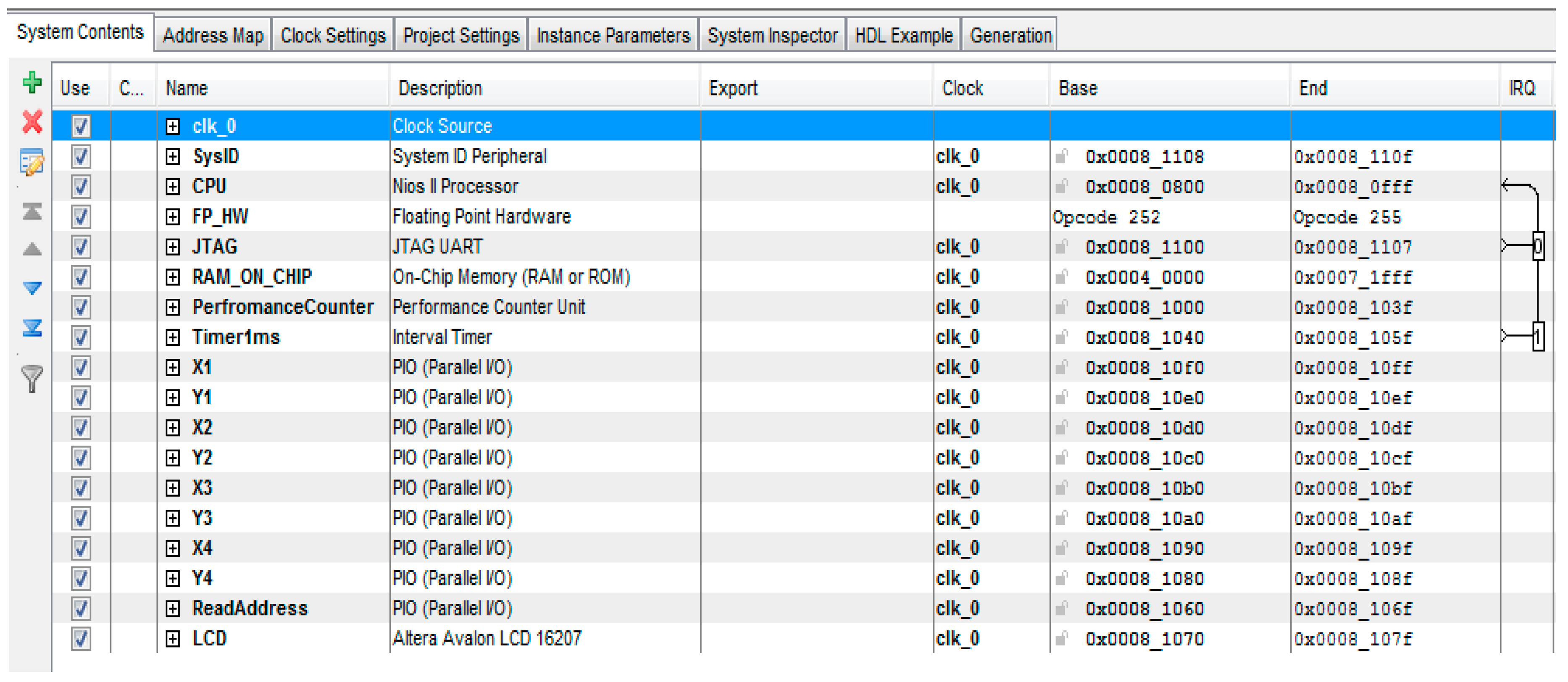
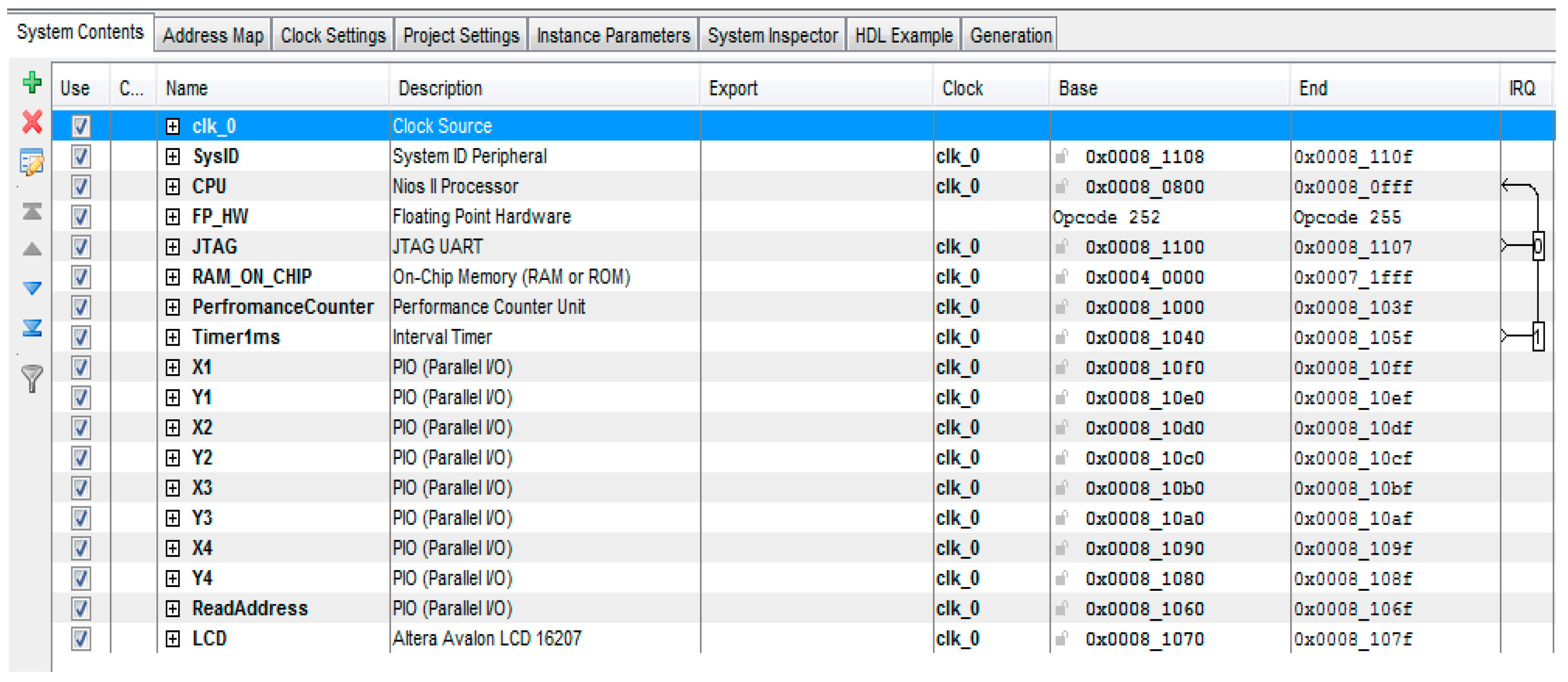
Hardware resources used for building this system are shown in the
Table 5. The Cyclone IVE EP4CE115F29C7 has been used for implementing the proposed system.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}