1. Introduction
Travel is an inevitable part of human life, required in order to perform an activity which is not possible at a current location. However, changing the perspective, travel itself can become an
activity in its own right, and again changing perspective, travel can be conceived as a
sequence of activities, each consisting of a segment travelled in a single mode. This paper focuses on the automatic interpretation of a travel as a sequence of activities, i.e., segments travelled in a single mode of travelling, from sensor traces collected on smartphones. In particular, the role of granularity will be highlighted (e.g., between
getting on board of a bus,
taking the bus, or
going to work), along with the ambiguity about the mode that comes along with it [
1]. The elementary trips of a travel are connected by transfers, at certain granularities. Travel can be mediated by moving objects in the form of different transport modes, but we explicitly include unsupported body movement (walking, running) as a mode. Since any mode is mixed with unrelated bodily movements, such as walking through a bus, taking a smartphone out of a pocket while sitting on a bus, or turning the head while cycling, the interpretation of sensor traces has to deal also with other noise than only from the sensor characteristics.
Identifying trips automatically is important for understanding the travel demand in a city, people’s movement behavior, modal preferences, route choice, patronage, and for enabling various customized services in the context of “Mobility as a Service” (MaaS) [
2]. With the emergence of context-aware computing in the light of MaaS, there is a need to develop a real-time mobility-based activity detection framework (e.g., real-time mode detection model): Only real-time detection can provide context-aware customer services such as providing car drivers with congestion-related routing information while protecting bus passengers from this to happen. Another instance could be activating auto-answering on the smartphone for a car driver (in order to avoid distraction) while ensuring that passengers on a tram remain unrestricted.
In order to understand people’s travel activities, traditional methods rely on paper-based, telephonic or face-to-face travel survey techniques in order to generate travel diaries. A travel diary contains the mobility information of a person in terms of trips, with their start time, end time, origin, destination and transport mode(s). Since there is a time gap between the actual travel and the reporting of the travel, such a reconstruction process often involves under-reporting, miss-reporting, and potentially bias. More recently, GPS-based travel surveys have been explored that collect movement data in the form of time-stamped coordinates along the travelled route [
3,
4]. Early GPS assisted travel surveys were based on in-vehicle tracking [
5,
6,
7], and only with the recent emergence of smartphones equipped with positioning and other location sensors along with inertial measuring units (IMU) it has been possible to continuously track an individual across any mode of travelling [
8].
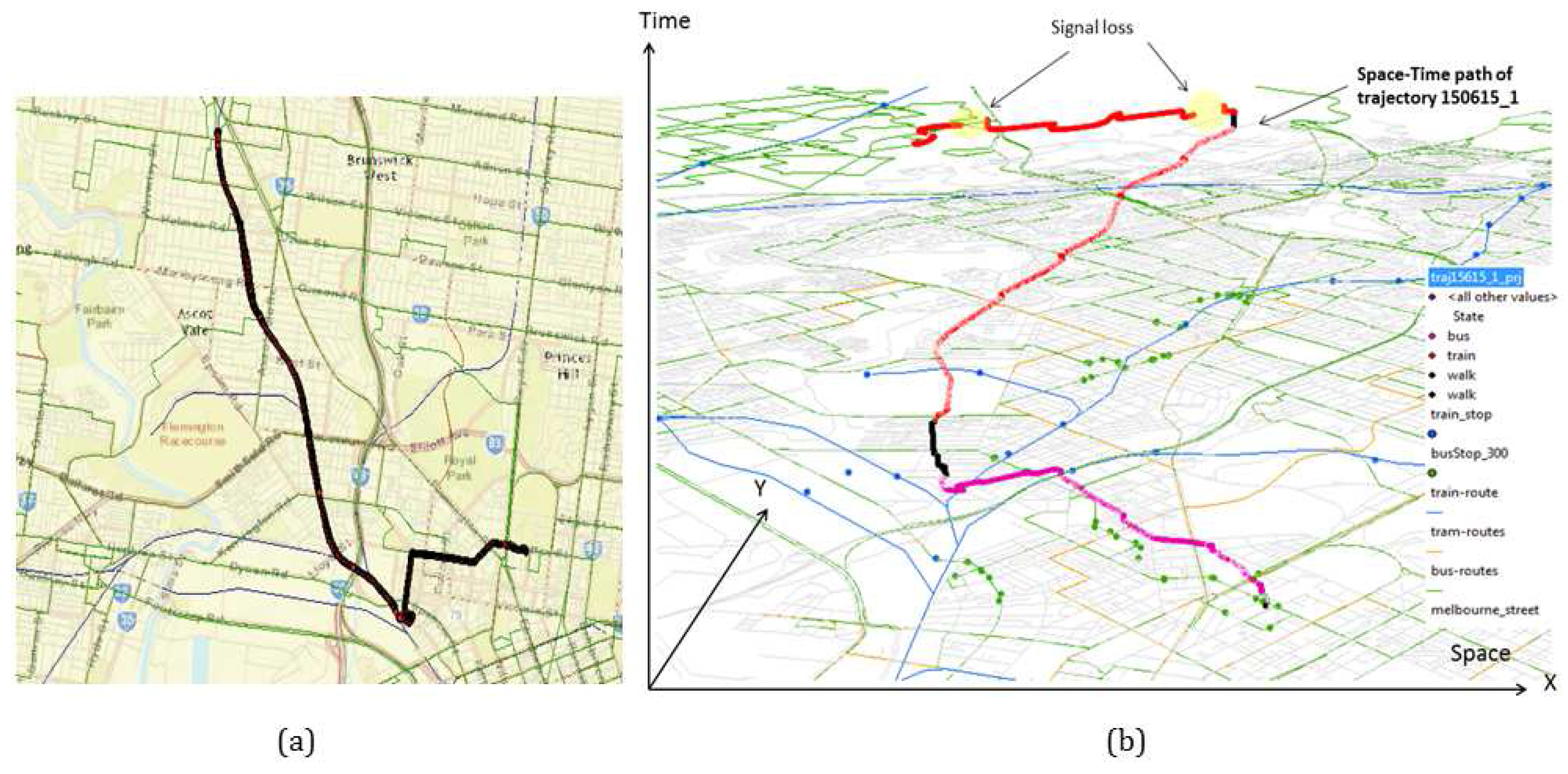
The remaining challenge is to automatically interpret these sensor traces for travel activities (single mode trips) and transfers. In the current state-of-the-art, a trajectory is top-down segmented based on some critical events (e.g., a drop in speed) and then activity states are detected for each segment [
9,
10]. However, segmenting a trajectory based on some heuristics is subjective and involves vagueness and uncertainty in activity transition in space and time, and thus, obscures the recognition and modelling of transfers. Prior work, discovering activities (including transfers) using clustering techniques, has to deal with clusters of any shape and any size, and hence comes with a significant uncertainty and ambiguity as to where a transfer begins and ends vis-á-vis a trip start and end. In contrast, the present work assumes that within a very fine grained space-time frame the activity state will remain same: A finer kernel involves less uncertainty than that of a longer segment, and the trip end of one segment becomes the trip start of the next segment. The common point in time defines a transfer precisely in space and time, and thus involves less ambiguity than that of a clustering-based approach. This paper hypothesizes that a state-based
bottom-up approach is more adaptive than any top-down approach, and in addition will be able to detect activity states in a progressive manner (i.e., in near-real time). This translates into the temporal uncertainty depending on the length of space-time kernel. The shorter the kernel the less is the uncertainty, but at a cost of overall detection accuracy.
In the state-based bottom up approach an atomic kernel is ran over the entire sensor trace and a particular activity state is detected iteratively. The assumption behind this approach is, shorter the temporal kernel more homogeneous the activity state will be. A transfer is then modelled with a given temporal uncertainty when there is a change in the activity state. The approach can be extended to a multi-grained atomic kernel approach to drill down the activity states, e.g., first detecting the travel activities, then the finer grained activity states during any transfer. The hypothesis has been tested on two different data sets: A trajectory data set of multi-modal inner-urban trips, and also a data set of inertial measurement unit (IMU) observations on-board a smartphone (without location information). The experiments prove that the new approach is not only more expressive in terms of richer travel information, but also capable of near-real time trip analysis as required for context-aware services. The contributions of this paper are as follows:
- (a)
Unlike the earlier approaches which are mostly behavior-based depend on a particular event(s) (say, drop in speed), this research presents a novel state-based bottom-up framework to segment the trajectories in a progressive way at different granularity.
- (b)
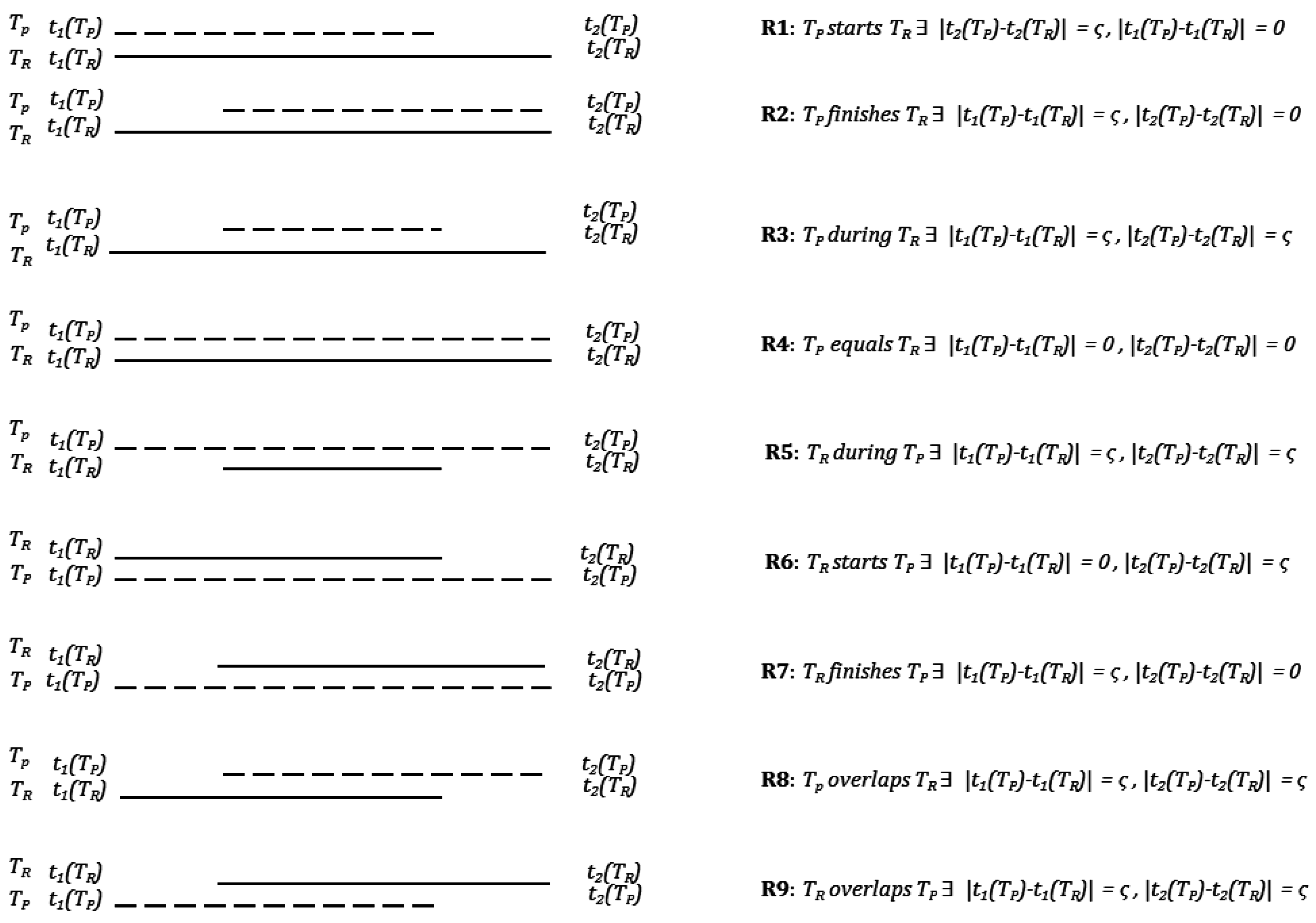
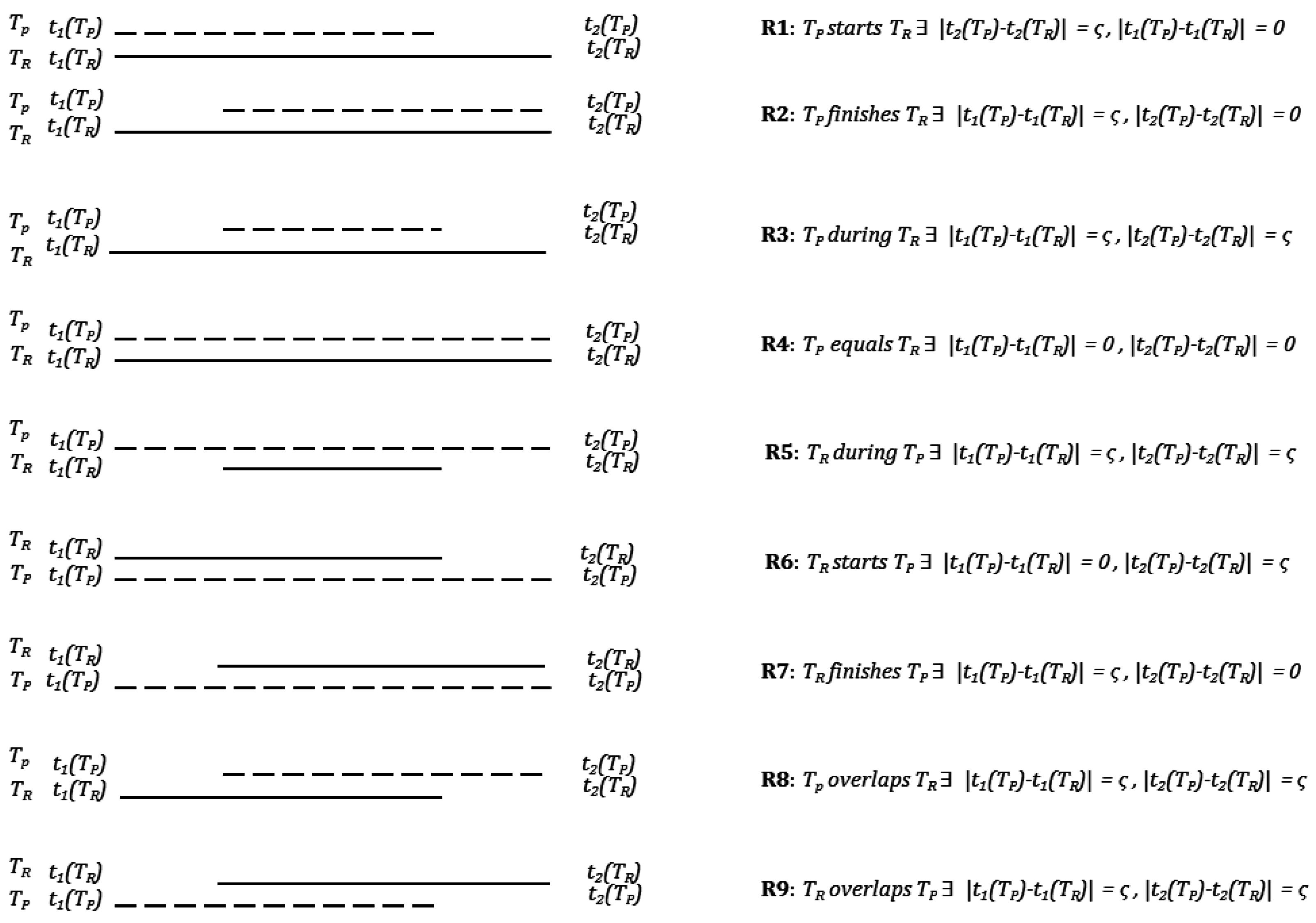
The aspect of temporal uncertainty in activity transition is explored and modelled using Allen’s temporal calculus [
11]—which was missing in the earlier trajectory segmentation, trip generation and transport mode detection research (
Figure 1).
- (c)
The framework presented in this paper is modular, adaptive, flexible and robust, and yet accurate. Since the framework uses an atomic kernel of definable length it can work in different granularities (e.g., for travel mode or transfer interpretation), and even in near-real time (defined by the kernel length). The framework can also handle varying data quality and richness in information content in the sensor trace.
Thus, in case of a top-down approach depending on a certain behavior or event, a trajectory is first segmented into a number of segments; and then an activity state is detected over each segment. On the other hand, for a bottom-up approach, a given activity state is detected within a short temporal kernel without considering any change in behavior of the moving object. Then the subsequent states are discovered iteratively, and a progressive segmentation takes place along the given trajectory.
The remainder of the paper is organized as follows.
Section 2 gives an overview of the current state of knowledge and research gap.
Section 3 defines some key concepts used in this research.
Section 4 outlines the methodology used for data pre-processing and model building.
Section 5 discusses the data sets, experiments and results.
Section 6 reflects on the framework, which is followed by concluding remarks and an outlook in
Section 7.
2. Literature Review
Travel diaries are a record of people’s travel history and also other activities performed during the travel. This kind of information is important for understanding people’s travel and activity behavior, which is considered an input for different types of travel demand models within a given space and time. In order to collect such travel diaries, travel surveys are conducted, which are currently paper-based or telephonic in most of the places in the world [
12,
13]. As surveys rely on people’s ability to recall their past travel behavior accurately and at different granularities this approach is generally subject to quality issues such as
under-reporting—missing trips, missing transport mode annotation, missing transfers, unknown travel speeds—,
miss-reporting—wrong transport mode annotation, inaccurate trip start and end times and locations—, and
bias— deliberate manipulation of the provided information [
14].
In order to overcome these issues GPS assisted travel surveys have been developed, with a first proof-of-concept run in Lexington, Kentucky [
15,
16,
17]. GPS-based travel surveys can generate travel records in the form of a sequence of time ordered GPS points on the fly (trajectories) and thus are free from post-travel recall. However, the trajectories need to be interpreted as travel and other activities in order to fulfil the requirements of a household travel survey.
The efficacy of GPS-based surveys has proven that such in-situ sampled space-time information produces higher quality data than that of a paper-based travel diary [
18,
19,
20]. For the trajectory analysis generally a clustering-based approach is used to detect trip start and end times. However, GPS trajectories are subject to discontinuity due to signal loss, for example, in urban canyons, under dense foliage, in buildings, or when travelling underground. Signal loss produces semantic gaps in clustering-based approaches, and thus creates false origins or destinations. Especially trip end detection—i.e., the end of a single mode travel segment—and trip purpose identification are of interest [
7]. The trip end is detected based on a longer period of non-movement or longer dwell time at a given location. Prior studies suggested a threshold of 120 s to detect a trip end [
7,
18,
21,
22,
23]. Stopher and others detected a trip end using a rule-based algorithm that considers trip characteristics before and after possible GPS signal gaps [
24,
25]. In order to detect the trip purpose Wolf developed a ‘point-in-polygon’ approach that uses a number of pre-defined land use types and trip purpose classes and evaluates if a trip end falls within a given land use type [
6,
7].
With the advancement of information and communication technology (ICT) and miniaturization of location and IMU sensors on-board mobile phones, it has been possible to obtain travel and other activity information in the form of trajectories without burden, and across any mode of travelling and any form of environment [
26]. Asakura and Hato conducted a first mobile phone-based pilot survey in Japan [
27]. Following that, Ohmori and colleagues developed another mobile phone-based travel survey application with a manual intervention, with 10 min sampling intervals [
28]. Itsubo and Hato conducted a mobile phone-based travel survey on 31 respondents over five days with 30 s sampling intervals [
29]. However, the earlier mobile phone-based surveys require significant amount of user intervention and offer limited flexibility in phone usage and sampling rates, and thus the users cannot follow their true travel behavior. With recent emergence of smartphones researchers started coming up with more user-friendly applications. These smartphone-based travel survey techniques can generate high quality travel and activity information in the form of trajectories generated from GPS, Wi-Fi and 3G/4G localization, combined with traces from IMU. These raw trajectories and sensor traces reveal location information and geometric patterns of the user movements [
30,
31,
32]. In order to interpret the trajectories semantically, i.e., with regard of trips, travel modes, and activities, additional information relevant to the context and application domain is associated with raw trajectories [
33]. For this purpose, the trajectory is segmented into a number of segments where each segment is analyzed to detect a given activity state (e.g., transport mode) or kinematic behavior (e.g., travel speed).
Gonzalez and colleagues developed a smartphone-based travel survey and detected transport modes using a neural network model [
34]. Charlton and colleagues developed a similar application but focused on bicycle travel behavior [
35]. Recently, Cottrill and colleagues developed the Future Mobility Survey (FMS), a full-scale household travel survey that consists of four phases: registration, pre-survey, activity diary, and a follow-up feedback survey [
8,
36]. In the registration phase the participant registers on the FMS portal providing basic household information. In the pre-survey more information on the socio-demographic profile of the household members is provided. In the activity diary phase the actual travel behavior is recorded, and recorded trajectories are uploaded to the FMS platform for a backend mode detection model. Finally, the inferred trips, modes and activities are validated by the participants in the feedback survey, a web-based prompted recall survey [
37]. Similar applications have been developed elsewhere [
38] for detecting transport modes from smartphone trajectories.
In order to analyse the trajectories segmentation is performed. Spaccapietra and colleagues developed an episodic algorithm known as stop-and-move-on-trajectories (SMoT) from a top-down perspective: first the trajectory is segmented into a number of segments and then an activity state is detected over a particular segment using a machine learning approach or expert system-based model [
39]. This algorithm assumes a person will stop at a certain location for minimal amount of time in order to perform a certain activity and then start moving until reaching the next destination. Thus a raw trajectory is segmented into two different episodes and each episode is semantically enriched. A move episode reflects a person’s travel behavior, whereas a stop episode reveals a person’s activity behavior within a constrained space.
The SMoT algorithm was implemented in different forms. Alvares and colleagues developed an intersection-based approach (IB-SMoT) to model the stop and move episodes. IB-SMoT evaluates which spatio-temporal points of the trajectory intersect a given candidate region for a minimal time duration [
30]. If the respective points satisfy the spatio-temporal condition those points will be considered as stop points, and the points that do not fall within a candidate region will be considered as move points. Palma and colleagues developed clustering-based stops and moves (CB-SMoT) where a clustering kernel is run over a trajectory, and the clusters containing low speed points with respect to a predefined threshold are called potential stop clusters [
40]. Then each potential stop cluster is investigated if the cluster intersects any given region of interest and labeled as stop episode. Das and colleagues developed a density-based clustering algorithm based on the CB-SMoT approach but considering the speed, temporal duration and the proximity to nearest points of interests (POI) in order to detect the transfers [
41]. However, a density-based clusters can be of any shape and any size and hence the crisp activity (or trip) start and end is ambiguous. Following the same line, Rocha and colleagues developed a direction-based algorithm (DB-SMoT) based on change of directions of GPS points in a trajectory [
42]. Ashbrook and Starner developed a predefined clustering method to detect the stops from GPS trajectories [
42]. On the other hand, Zimmermann and colleagues developed a spatio-temporal clustering method to detect the stops and moves [
43]. In the same line, Andrienko and colleagues developed a stop detection framework by considering temporal duration and a user defined distance threshold [
44]. Gong and colleagues extended the traditional clustering based stop detection approach by incorporating a machine learning module. They have developed a two stage model for detecting stops and stop types. Gong and colleagues used an improved clustering algorithm (C-DBSCAN) to detect the stops based on the spatial proximity of the GPS points. Then they have used a SVM-based supervised machine learning technique to infer the stop type in terms of activity or non-activity [
45]. However clustering-based approaches work well on the dense GPS trajectories with good to moderate positional accuracy. During signal gap or in urban canyon clustering-based approach does not work well.
Assuming walking is necessary between two non-walking episodes, Zheng and colleagues proposed a walking-based segmentation approach in their transport mode detection research [
10]. Once the entire trajectory is segmented based on speed profile (potential walking episodes), other non-walking segments are fed into a number of machine learning models and a transport mode is detected. Zheng and colleagues used four popular machine learning models: decision tree (DT), Bayesian network (BN), conditional random fields (CRF) and support vector machine (SVM), with highest accuracy of 75% using a DT model. Zheng and colleagues used five kinematic features and four modal classes. Stenneth and colleagues developed another decision tree-based predictive model with 93.5% accuracy [
46]. A similar approach (walking-based segmentation) was adopted by Biljecki and colleagues who developed a Sugeno type fuzzy logic-based transport mode detection model with 91.6% accuracy [
47]. Xu and colleagues developed a similar fuzzy logic-based model that can detect four different modalities with 93.7% accuracy by adopting a walking-based segmentation approach [
48]. Yang and colleagues developed a two-stage approach for detecting modes with a core focus on distinguishing bus and car modality on a set of trajectories collected by handheld GPS devices [
14]. In the first stage a machine learning algorithm was used to distinguish walk, bicycle and motorized trips. Then in the second stage a motorized mode is further identified as bus or car using a critical point method [
14]. Mountain and Raper used a change in speed and direction for segmenting a trajectory [
49]. However, a low speed (or walking) based segmentation approach creates ambiguity in certain cases especially when a vehicle moves slowly in heavy traffic or due to bad weather condition. Xia and colleagues proposed a GPS and accelerometer-based model with 50 Hz sampling frequency without any walking-based or clustering-based segmentation approach. Xia and colleagues detected four activity states such as stationary, walking, bicycle, motorized modes using a SVM with 96.3% accuracy [
50].
However, such top-down segmentation approaches first segment the trajectory based on either a stop episode or a low speed or walking episode, and then attempt to detect a particular activity state or travel behavior over other segments. But as mentioned in
Section 1, this approach is subjective and creates spatial and temporal ambiguity [
51], and thus, if each of the segments is viewed as a specific trip then there is an uncertainty (or misalignment) of trip start and end (from segmentation perspective) and uncertainty of activity state (e.g., transport mode) along a given trip (from activity detection perspective). A vast majority of literature on transport mode detection and trip generation does not address this ambiguity during the trajectory inference process. Recently, from the transport mode detection perspective Prelipcean and colleagues developed a new error measure based on the quality of alignment of inferred segment to their ground truth counterpart to address such uncertainty during segmentation based on Allen’s temporal calculi [
52]. Prelipcean and colleagues modeled three types of error measures using a cardinality of the measurement and spatial and temporal discrepancy such as implicit, explicit-holistic, and explicit-consensus-based segmentation [
52]. However, their framework is limited and cannot model all the possible temporal relations in the context of trips. In this paper we have figured out four different types of trips that may possible during a single mobility-based action and their temporal inter-relationship.
In order to detect mobility-based activities in real time other researchers developed a temporal window-based approach. Hemminki developed an accelerometer-based transport mode detection model with a 1.2 s time window that can produce 84.2% accuracy [
53]. Reddy and colleagues integrated an accelerometer and a GPS sensor to detect the modality in 1 seconds and achieved 74% accuracy [
54]. Byon and colleagues used comparatively higher time window (10 min) to detect modalities without segmenting the GPS trajectories [
55].
A similar approach has also been developed in detecting micro-level activities involved with body parts movement or small scale locomotion in an indoor environment. Such micro-level activities are known as activities of daily living (ADL) such as running, walking, jogging, brushing teeth, talking on phone, hand washing and performing various travel related actions—to name a few [
56,
57,
58]. These activities are usually detected based on sensors, especially the CCTV installed in the environment and then analyzing the still images or video scenes [
59]. With the emergence of IMUs on smartphones now such micro-level activities are easily detected almost everywhere in offline as well online mode [
60,
61].
Thus the existing research in real time urban transport mode detection as well as most of the activity recognition research in public health and mobile computing attempt to detect the activity within a queried time window and do not attempt to model the uncertainty of the continuity of a given activity. That means, the existing activity recognition research lacks in providing the information on activity start and end.
In this research we use the existing temporal window (kernel)-based approach (but with an introduction of iterative temporal merging) in order to detect an activity in real to near real time as well as detecting activity transition at different granularity using different sensor combinations. Thus in contrast to the existing real time approaches [
53,
54,
55], where a time window is given and an activity state is to be detected, we have extended that approach and can detect an activity within a given time window as well, and given an activity the model can detect its start time and end time. In contrast to the offline approaches on trajectories where a subjective segmentation is performed, this paper presents a simple yet effective approach for segmenting the trajectory based on activity states in a fine grained time window. We also investigate how activity detection accuracy varies with different sensor combinations and different feature types.
4. Trajectory Segmentation Frameworks
In this section we will present the existing trajectory segmentation frameworks that detect the trips based on different criteria (see
Section 2). We then present our novel state-based trip detection framework, which detects the trips more adaptively along with rich behavioral information (e.g., transport mode state).
A trip can be modeled as a particular segment with a homogeneous state and distinct behavior. Trajectory segmentation approaches can be classified into two broad categories: behavior-based and state-based approaches. Behavior-based approaches segment a trajectory into meaningful parts and then infer a state for each segment. Thus, these approaches are top-down. The number and type of segmentation operations is context dependent. In contrast, the state-based approach developed in this paper extracts an atomic segment assuming the state will remain constant in that fine grain, and then the state is detected using a hybrid approach (machine learning and heuristic rules), whereupon homogenous segments are generated using an advanced merging operation, which will generate the trips. Thus, the second approach is richer in information content and more adaptive. This approach is bottom-up. This paper presents the novel state-based bottom-up approach, which is compared with the two state-of-the-art top-down approaches: a walking-based approach and a clustering-based approach (and its variants), which is basically a realization of the SMoT algorithm [
30,
39].
4.1. Trip Detection by a Walking-Based Approach
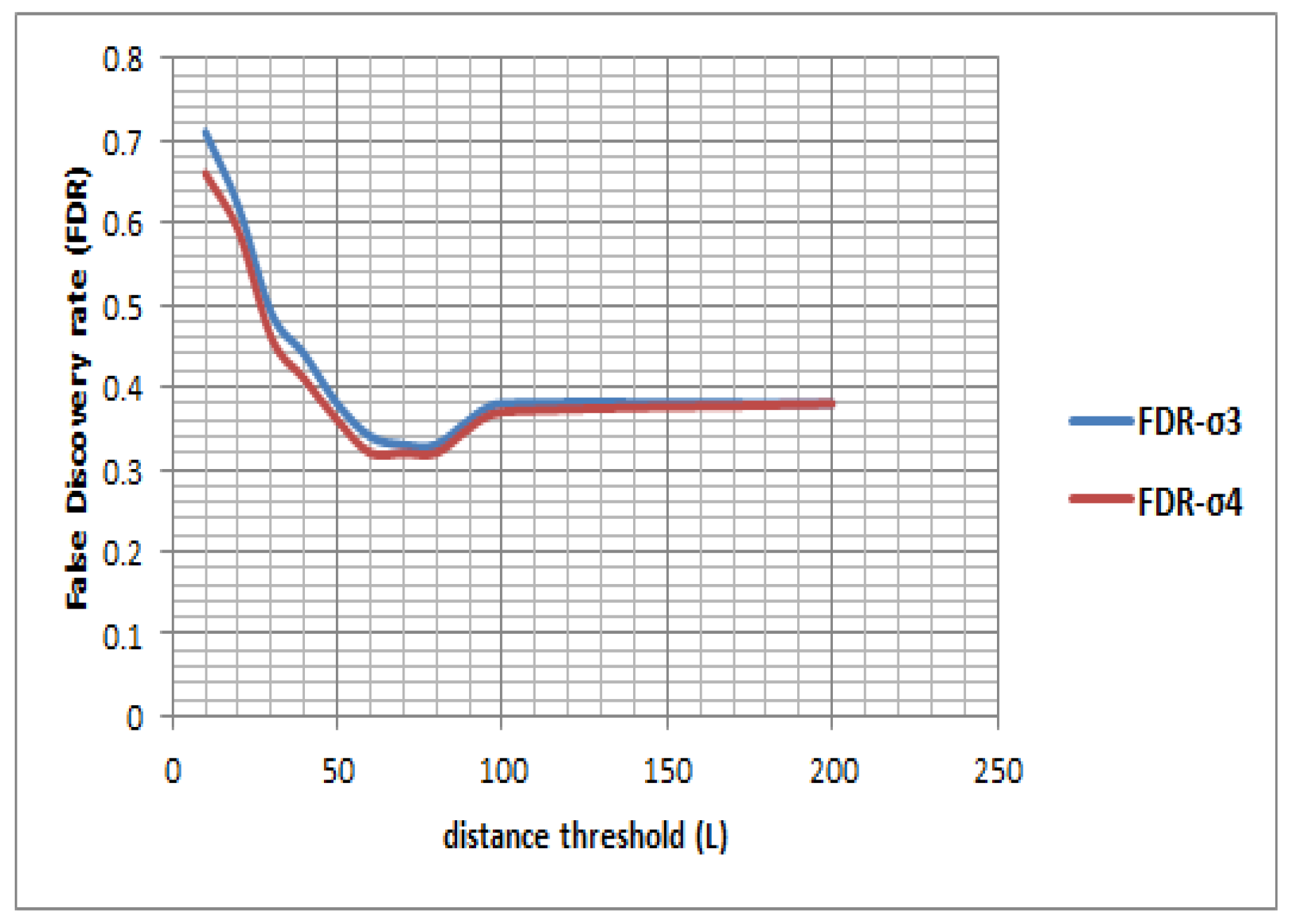
A walking-based approach is a variant of the behavior-based approaches where the behavior is attributed to drop in speed. It is generally used in order to segment a trajectory in the context of transport mode detection.
The assumption behind a walking-based approach is that people need to walk in between two different transport modes [
10]. In this regard, a walking segment is detected by deterministic rules where the key parameters are speed (
), merging distance (
), and total distance (L) traveled over a segment. However, by relying on these parameters this approach is subjective and thus it is difficult to set the threshold parameters.
Since a GPS trajectory is prone to signal loss and multipath effect a walking-based approach needs a thorough pre-processing of the raw trajectory. The trajectory is filtered in such a way that no high speed points remain in between two low speed points and vice-versa. The filtering process should also remove points with high DOP values (or spatial uncertainties). In this research the speed threshold is considered 9 km/hr based on prior research [
63], and the merging distance is 20 m based on trial and error. The total distance threshold for a segment to qualify as a walking segment is iteratively tested from 10 m to 200 m. Algorithm 1 presents a two stage pre-processing operation where a GPS trajectory is first filtered based on spatial uncertainty (Spatial_Filter) followed by speed outliers (Velocity_Filter). The walking-based technique is then presented in Algorithm 2.
| Algorithm 1 Pre-processing of a GPS trajectory in two stages |
- 1:
INPUT 1) rawTlist(), 2)lowSpeed: LST - 2:
OUPUT - 3:
PROCEDURE Spatial_Filter() - 4:
- 5:
for i=0 to −1 do - 6:
if then - 7:
# rawTlist.get(i)=, where is a GPS point in raw trajectory - 8:
end if - 9:
end for - 10:
END PROCEDURE - 11:
PROCEDURE Velocity_Filter() - 12:
- 13:
for i=1 to −1 do - 14:
if then - 15:
vfTlist.add() - 16:
else - 17:
if then - 18:
if then - 19:
vfTlist.add() - 20:
end if - 21:
end if - 22:
end if - 23:
end for - 24:
END PROCEDURE
|
| Algorithm 2 Trip generation using walking-based approach |
- 1:
INPUT 1) pTlist(), 2)lowSpeed: LST, 3)mergingDistance: , 4)totalDistance: L - 2:
OUPUT a set of trips - 3:
PROCEDURE Trajectory_Segmentation() - 4:
- 5:
for i=0 to −1 do - 6:
if then - 7:
templist.add() - 8:
else - 9:
if then - 10:
if then - 11:
- 12:
- 13:
end if - 14:
end if - 15:
end if - 16:
end for - 17:
END PROCEDURE - 18:
PROCEDURE getPotential_Walking_Segments() - 19:
if seglist.hasMergeableSegments() then - 20:
# merging all the mergeable short low speed segments - 21:
end if - 22:
- 23:
for i=0 to −1 do - 24:
if then - 25:
# walking segments are detected - 26:
end if - 27:
end for - 28:
# non walking segments are extracted - 29:
END PROCEDURE
|
4.2. Trip Detection Based on Clustering-Based Approach
A clustering-based technique is another popular approach for trajectory segmentation. Since a clustering technique is based on proximity of GPS points the clusters generated over a trajectory bear a semantic significance, for example, where the traveller has been stationary or had limited body movement for a certain time period. The notion behind a clustering-based approach is that during traveling on different modes people transfer or do some static activity (say, in a station, office, or home). In this research the clusters are assumed as the extent in space and time where a transfer takes place in order to change from one transport mode to another.
In this paper, a clustering-based algorithm is implemented using a spatial clustering application with noise (DBSCAN). DBSCAN is initialized with an arbitrary point () in the trajectory. The algorithm then searches for neighbor points (N) within an ϵ-neighborhood of point . If N ≥ minPts then is defined as core point. The parameter ‘minPts’ is the minimum number of points to be present in the neighborhood of any given point in order to qualify that point as a core point. The algorithm then evaluates the next point and grows the cluster(s) until all the points are visited.
Once the clustering operation is performed there may be a number of clusters of different shape and size. In order to extract the most potent clusters (in the context of trip detection) a merging operation is performed followed by a relevance measure check. The merging operation is performed based on inter-cluster spatial distance threshold (ICSD) and inter-cluster temporal duration threshold (ICTD). However, a spatial clustering may raise the risk of clustering the to and from points together and thus leading to erroneous trip modeling. In order to deal with this issue a temporal proximity (tdiff) is used along with the spatial proximity (ϵ) to modify the basic DBSCAN into spatio-temporal DBSCAN (ST-DBSCAN).
However, there may also be some clusters that form without characterizing a transfer, for example, due to vehicle stops for pickup or drop-off or at traffic lights, or over a walking trip where the speed of walking is low, such as a stroll in a park or moving in a crowd. In order to filter such irrelevant clusters a temporal relevance check is performed over all the clusters. If the duration (Φ) of the cluster is greater than or equals to a temporal threshold then that cluster qualifies as a relevant cluster or a potential transfer zone. That said, clusters can be of any shape and size and hence from ontological point of view it is difficult to model the trips with their start and end in space and time. Algorithm 3 demonstrates a spatio-temporal clustering on trajectories to retrieve the transfer information.
| Algorithm 3 Spatio-temporal clustering on trajectories |
- 1:
INPUT 1) rawTlist(), 2)Neighbors: minPts, 3)search radius: ϵ, - 2:
INPUT 4)temporal proximity: tdiff, 5)ICSD, 6)ICTD - 3:
OUPUTa set of clusters denoting possible transfers in a trajectory - 4:
PROCEDURE ST_Clustering() - 5:
clusterlist=getST_DBSCAN (rawTlist, minPts, ϵ, tdiff) - 6:
clusterlist.size()= - 7:
for i=0 to −1 do - 8:
if then - 9:
if then - 10:
- 11:
clusterlist.remove(i,i+1) - 12:
clusterlist.add() - 13:
end if - 14:
end if - 15:
end for - 16:
clusterlist.size()= - 17:
for i=0 to −1 do - 18:
if then - 19:
- 20:
transferlist.add() - 21:
end if - 22:
end for - 23:
END PROCEDURE
|
In this paper two existing top-down approaches (walking-based and clustering-based) have been implemented along with the proposed state-based approach for a comparative study. Although there could be different variations of the two above mentioned top-down approaches (see
Section 2), but in general such approaches are inadequate in certain circumstances. For example, the walking-based approach requires a consistent and good quality GPS signal, it cannot handle IMU information, and it completely fails when there is no GPS signal for a prolonged period of time. On the other hand the clustering-based approach is robust to GPS noise, but also cannot deal with the IMU information, and does not work very well on sparse GPS trajectory data. More significantly, the clustering-based approach suffers from the ontological ambiguity about start and end of a trip.
4.3. Trip Detection Using a State-Based Bottom-up Approach
In order to address these issues a more robust and adaptive state-based bottom up approach is proposed. The proposed approach can handle GPS noise as well as IMU information. The proposed approach is less subjective than the walking-based approach, and at the same time tends to generate activity transitions with a clear provision of trip start and end, which is missing in the clustering-based approach. A state-based bottom-up approach also generates rich activity information (in terms of transport mode along a given trip) and thus this proposed approach is more effective in terms of generating travel diaries at different granularity with different level of uncertainty.
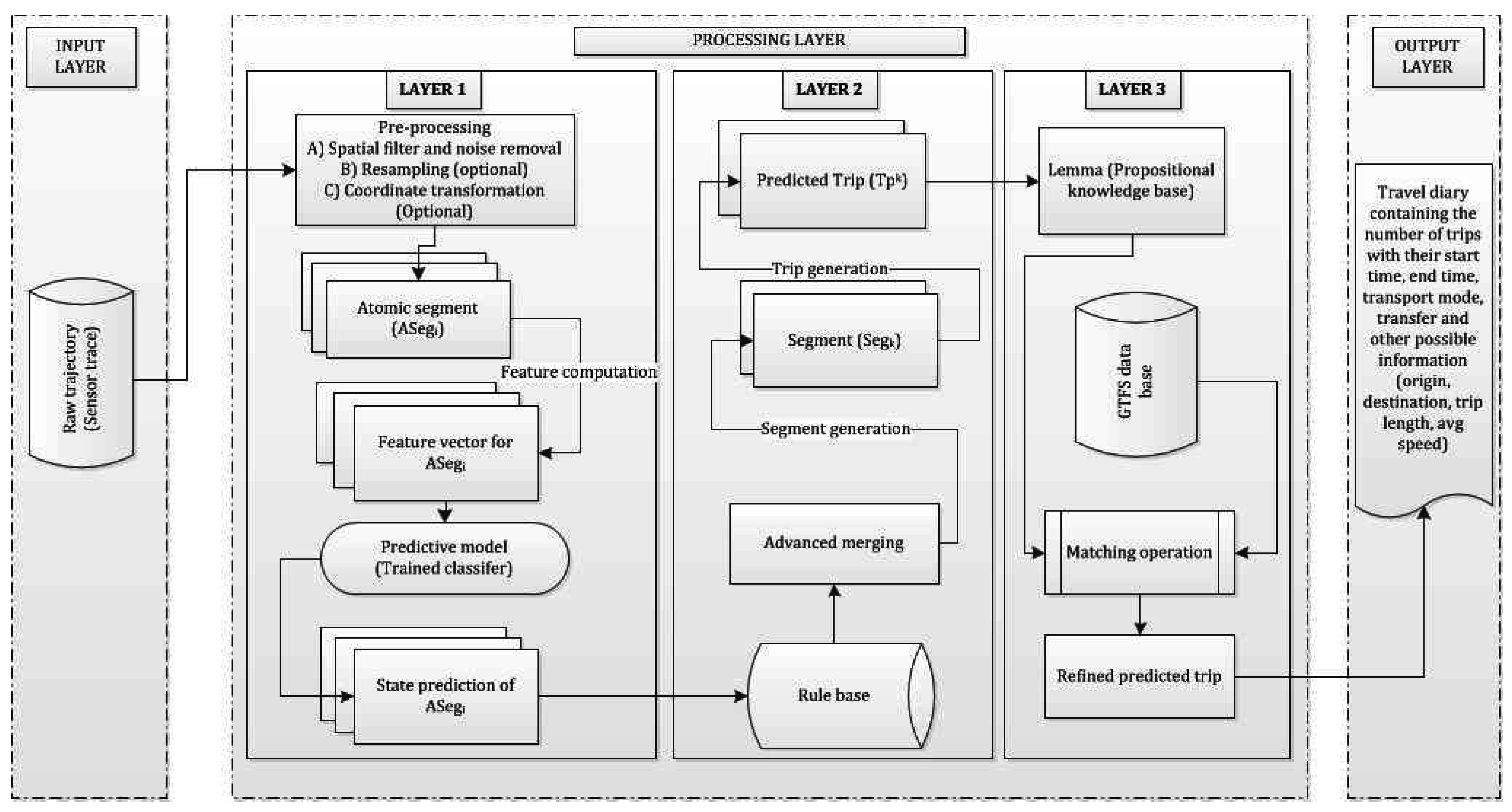
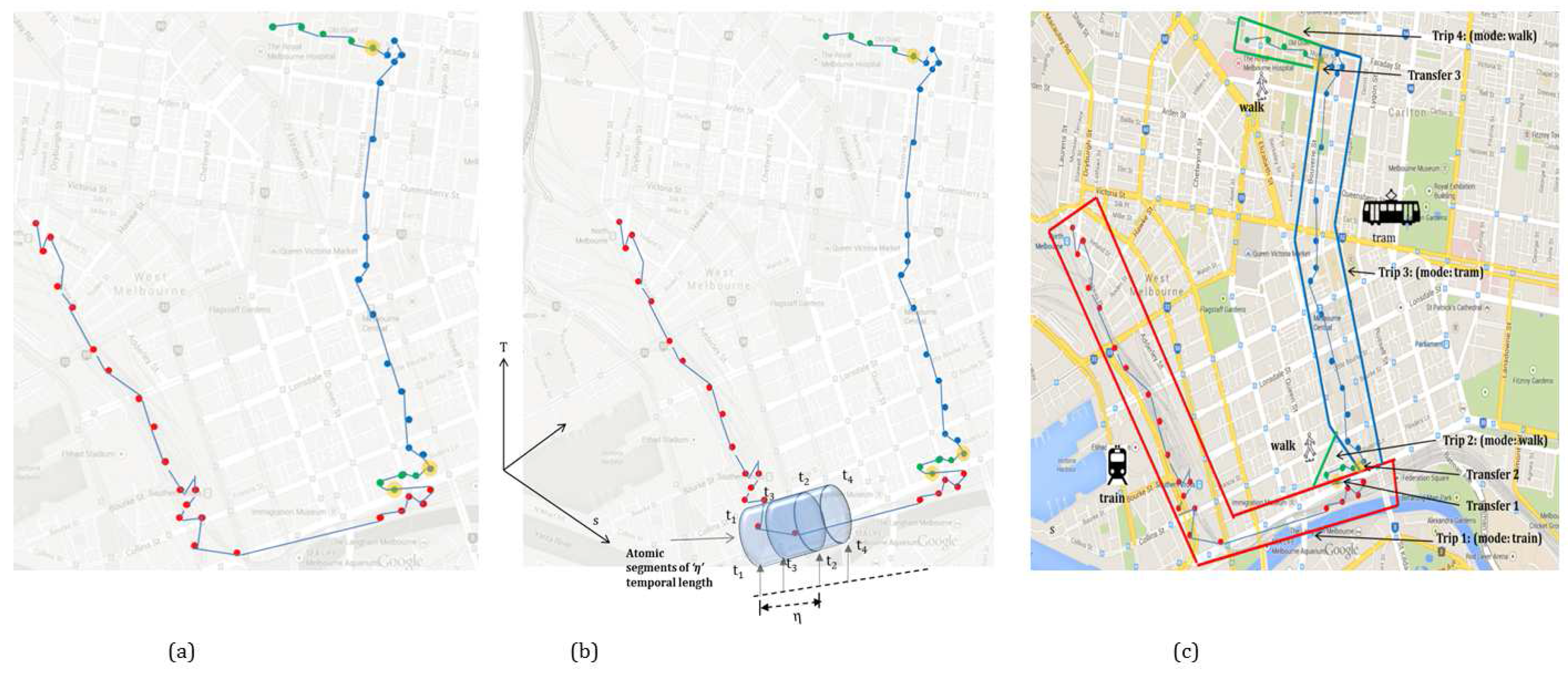
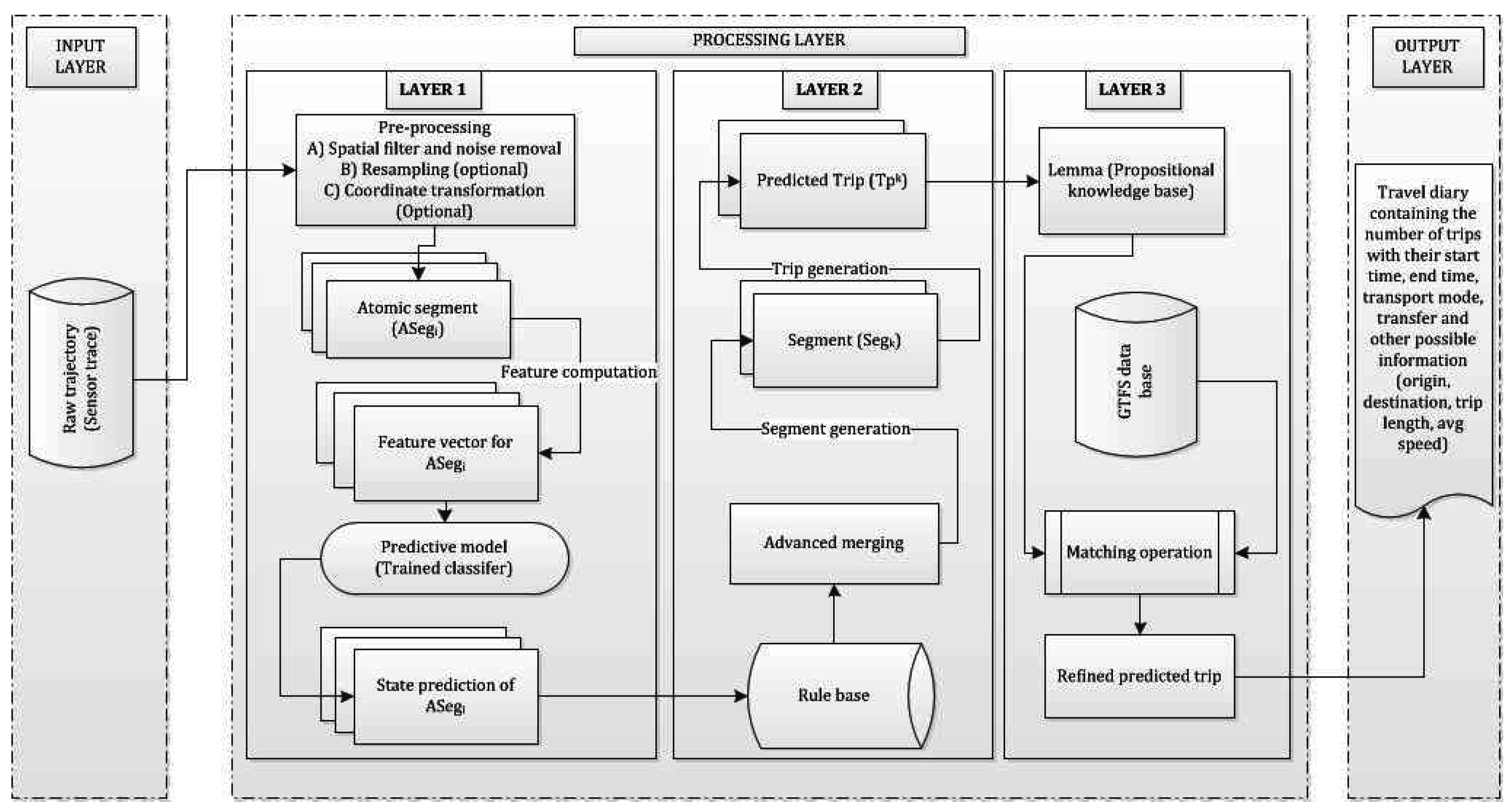
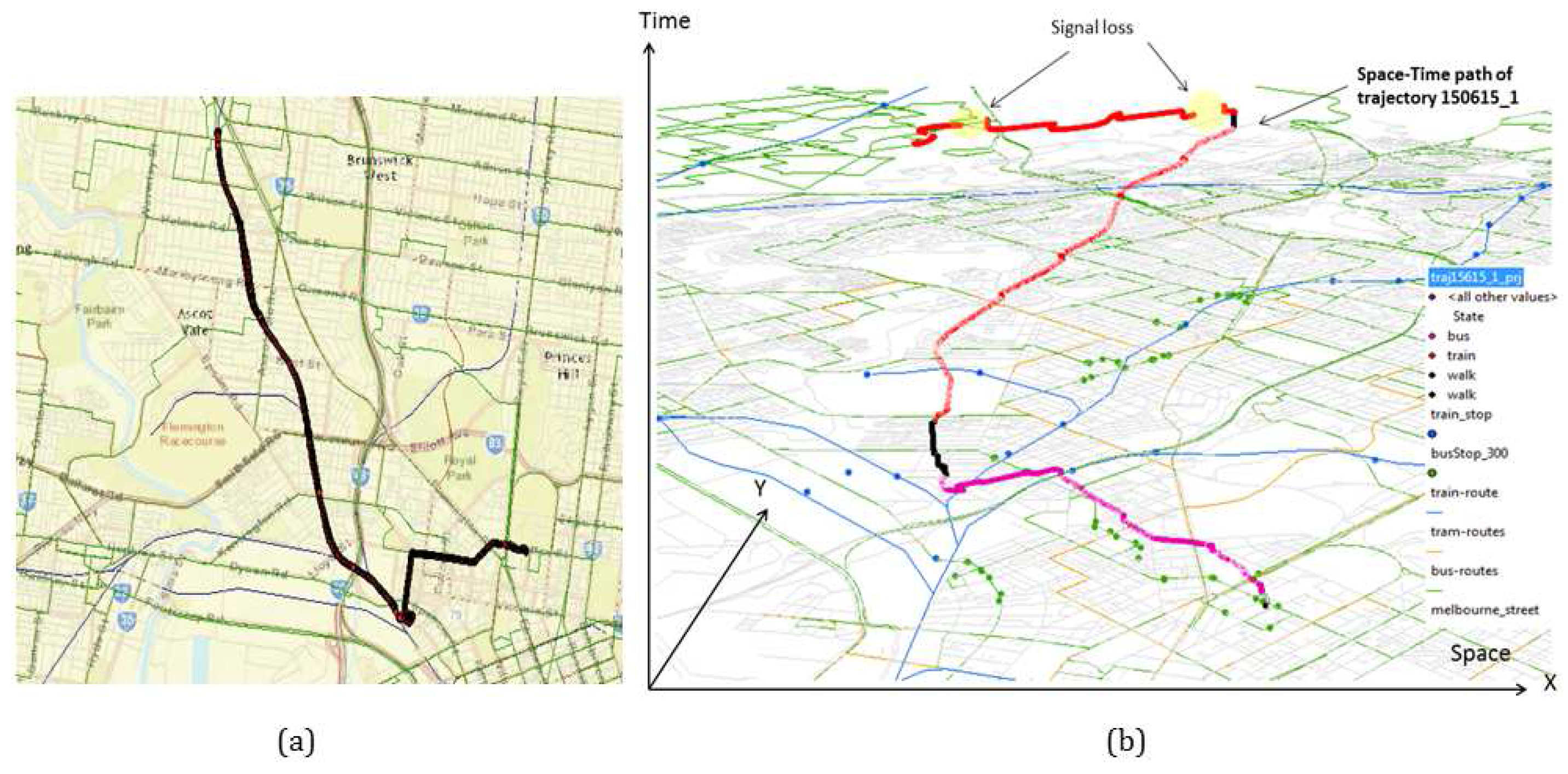
A state-based bottom-up approach is a hierarchical framework consisting of three layers (
Figure 3). The first layer is the input layer where a raw trajectory is fed in. The second layer is the processing layer that consists of further three sub-layers (LAYER 1, LAYER 2, LAYER 3), where the third layer is the output layer that generates the travel diary containing the trip information. In the first processing layer (LAYER 1) an atomic kernel is ran over the trajectory based on the query time that detects the activity states using a set of machine learning algorithms over each atomic segment. Thus, the first layer can also infer activity states (transport mode in this case) in near-real time. In the second processing layer (LAYER 2) an advanced merging operation is performed based on a set of heuristic rules. This will merge the consecutive atomic segments with similar activity states and predict the trips. In order to raise the confidence and strengthen the inference process, especially on trip start and trip end along with the transport mode used in that particular trip, a general transit feed specification (GTFS) information is used to evaluate the initial predicted trips in the third processing layer (LAYER 3).
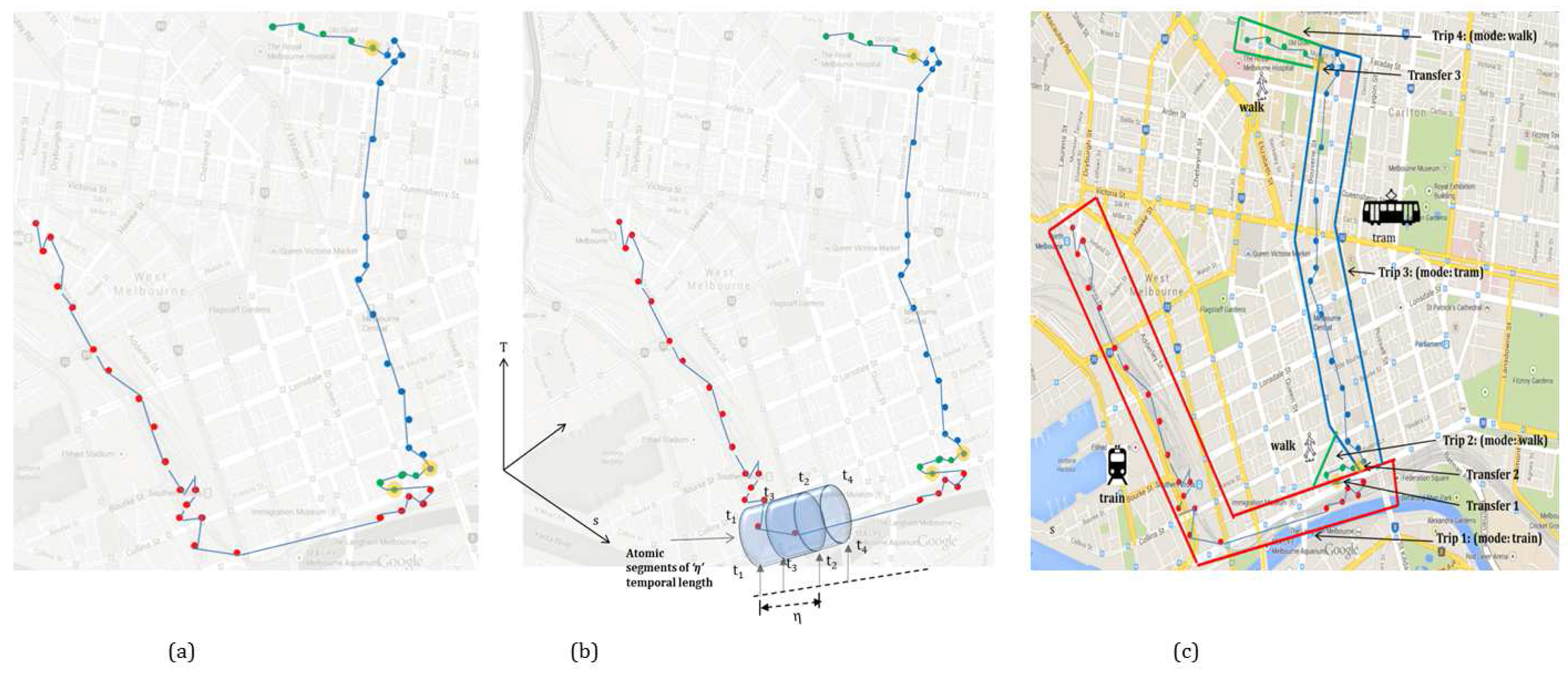
Figure 2 illustrates how the atomic kernel bounded in time [
,
] of duration (
−
=
η∣
) is ran over the trajectory and how different trips are inferred based on given transport modes. In the following section each layer is explained in detail. The model presented in this paper is a hybrid approach that leverages the machine learning algorithm(s) for the initial activity state prediction followed by processing the rule base.
4.3.1. LAYER 1: Near-Real Time Activity State Detection
Since a trip is characterized by a set of time-ordered homogeneous sensor data points (that may include GPS data points), in the first layer a predictive model is developed that will detect the activity state based on a classifier. In order to train the classifier different types of kinematic and spatial features are computed using sensor signals.
In this context the activity state is traveling on a given transport mode, and the transport mode is the mediation of this activity. In order to detect the transport mode an atomic kernel is applied (with 50% overlap) over the trajectory (or sensor trace) to extract a set of atomic segments. Then a number of features are computed within each atomic segment and a feature vector is created. Thus, if there are N atomic segments then there will be N feature vectors for a given trajectory. In some literature the atomic kernel is termed as sliding window or sliding kernel. The overlap is necessary in order to capture all the possible kinematic behavior especially during state transition and sudden change in behavior. Once the feature vectors are generated training is performed on a number of classifiers. Then all the classifiers are evaluated using testing trajectories separately. Once all the atomic segments are inferred (from all the test trajectories) an advanced merging operation is performed to generate longer segments of homogeneous activity states, which will turn into predicted trips. The six machine learning-based classifiers are chosen based on prior research in transport mode detection and trajectory analysis.
4.3.2. LAYER 2: Advanced Merging Operation and Potential Segment Generation for Trip Detection
In the second layer the atomic segments are merged sequentially based on similarity in their predicted transport mode (queried from Layer 1). The assumption behind such a merging operation is that all the points in a sensor trace or a portion of GPS trajectory that form a particular trip will bear a uniform activity state: traveling on one transport mode along one and the same trip from a given origin to a (temporary or final) destination. Thus, when there is a change in activity state, a new trip has started. The point in time and space where the transition occurs is the transfer point.
In the first stage in Layer 2 an initial merging is performed based on the initial transport mode inference. However, due to the diverse performance of classifiers and depending on the data quality and uncertainties in movement behavior there may be false positives. In order to address this issue a set of rules refines the merging operation of the consecutive atomic segments (Algorithm 4).
4.3.3. LAYER 3: Trip Refinement Using GTFS and Spatial Information
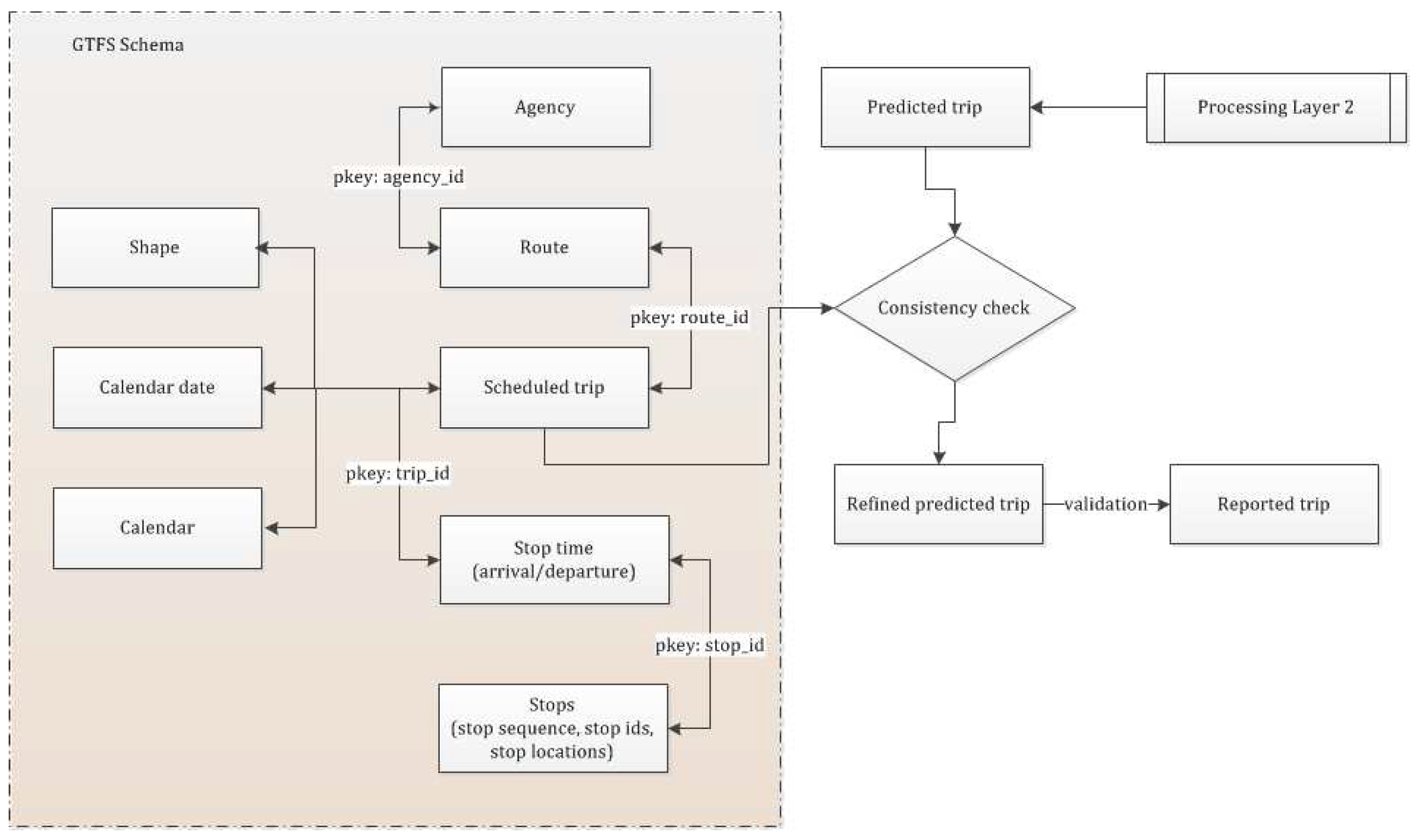
Once the merged segments (predicted trips) are generated from Layer 2 a further refinement operation is performed using GTFS and other spatial information realizing the following five lemmas. In this layer a matching is carried out that matches the predicted trips with the scheduled trips based on spatial and temporal information along with the trip start and trip end with the scheduled stop information. For the following lemmas an
predicted trip (
) is represented by a tuple of trip origin (
), trip destination (
), and predicted mode over trip
i (
). However, in order to match against the scheduled transit information the framework requires predicted stop and route information. Thus, a pair of stops at predicted trip origin (
) and destination (
) are queried using a variable search radius of 50 m, 100 m and 300 m progressively until at least one stop is retrieved around the trip origin point (
) and trip destination point (
). This information is then used to match the predicted trips with the scheduled trips and refine the prediction through the following lemmas.
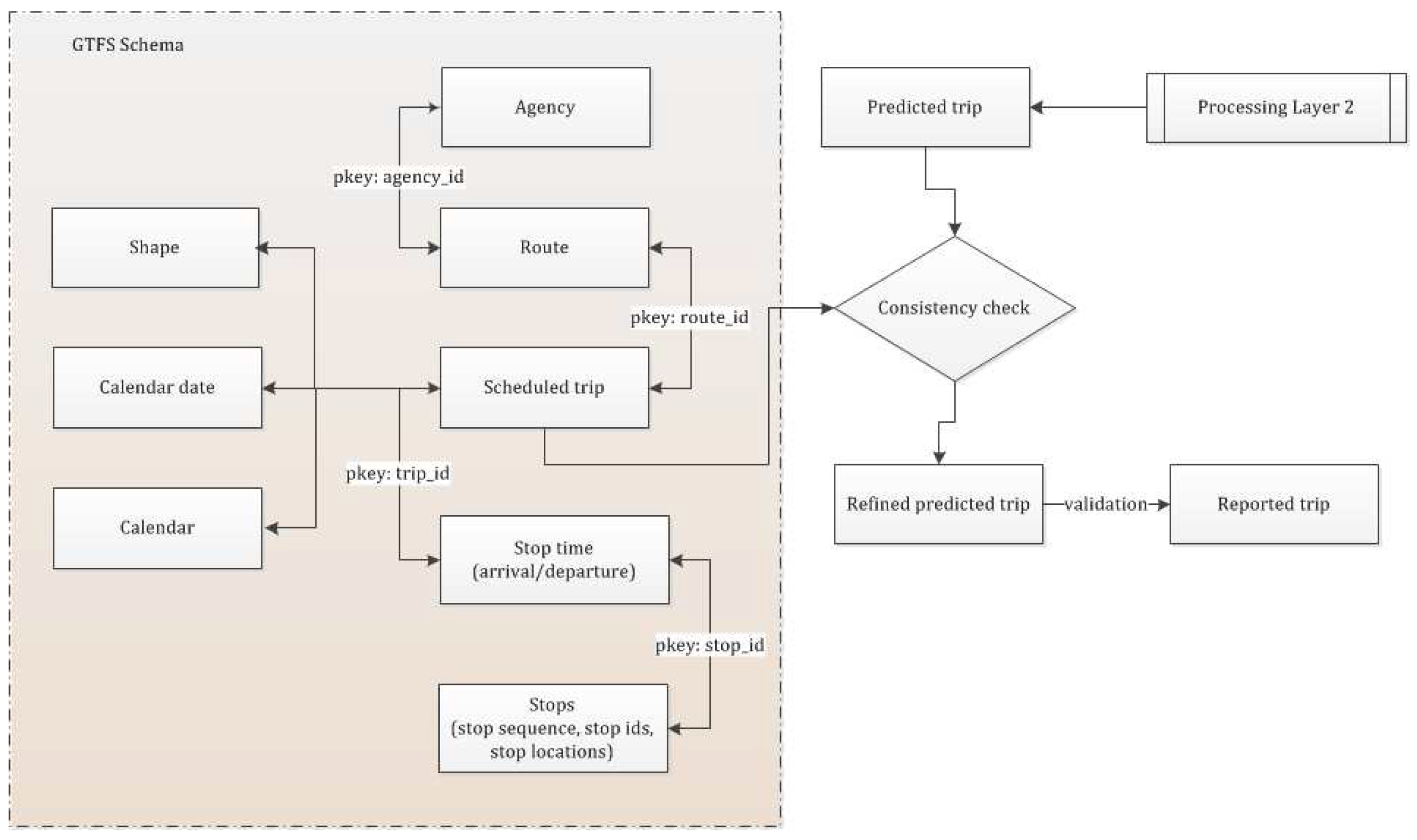
Figure 4 shows different component tables of GTFS schema with their common primary keys (
pkey) and a consistency check between the predicted trip generated from Layer 2 in processing layer (with stop information at trip start and end) and a suitable scheduled trip, which is retrieved from the GTFS data.
| Algorithm 4 Rules for segment merging |
- 1:
INPUT All the atomic segments in a given trajectory (seglist), temporal threshold: Ψ - 2:
OUPUT a set of merged segments (mergedSeglist) - 3:
PROCEDURE Segment_Merging() - 4:
- 5:
boolean - 6:
for i=0 to k−2 do - 7:
- 8:
- 9:
RULE 1: - 10:
if then - 11:
- 12:
- 13:
- 14:
end if - 15:
RULE 2: - 16:
if then - 17:
- 18:
- 19:
- 20:
end if - 21:
RULE 3: - 22:
if then - 23:
- 24:
- 25:
- 26:
end if - 27:
RULE 4: - 28:
if then - 29:
- 30:
- 31:
end if - 32:
end for - 33:
END PROCEDURE
|
Lemma 1: Stop type similarity
Since a trip is a segment of the trajectory, which consists of sensor data points that bear the same transport mode state (
), the stops at trip start and end must be of type (
). For example if a trip is made by a tram then the start stop and end stop of this trip must be two tram stops.
Lemma 2: Disjoint stop relationship
Since the GPS signal is prone to multipath effects and occasional signal loss due to obstruction must be expected, not all GPS points are recorded, and instead of updates in the GPS feed successive points will be recorded as the last known point. However, technically the stop at the trip start and end must be spatially different if it is not a return trip.
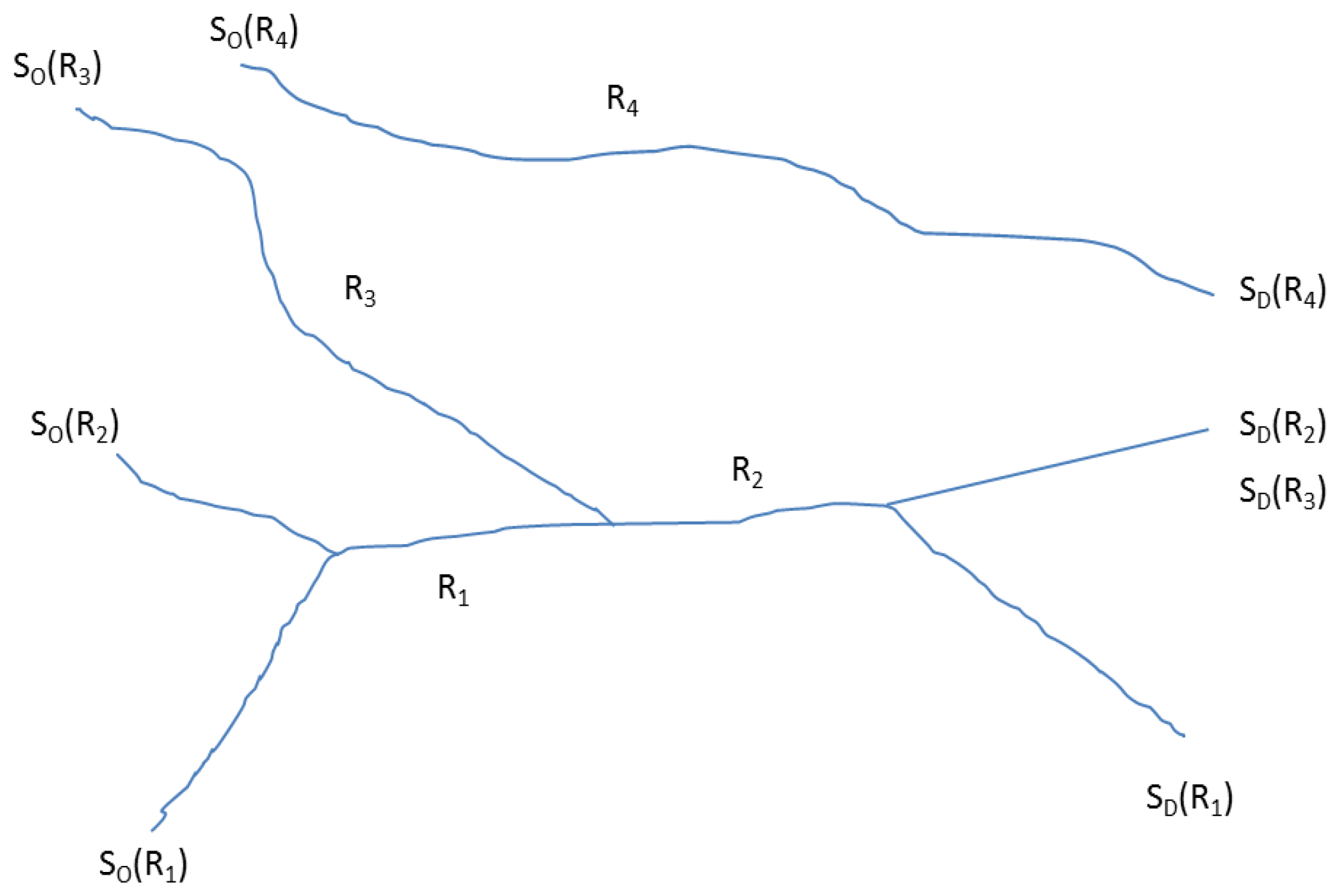
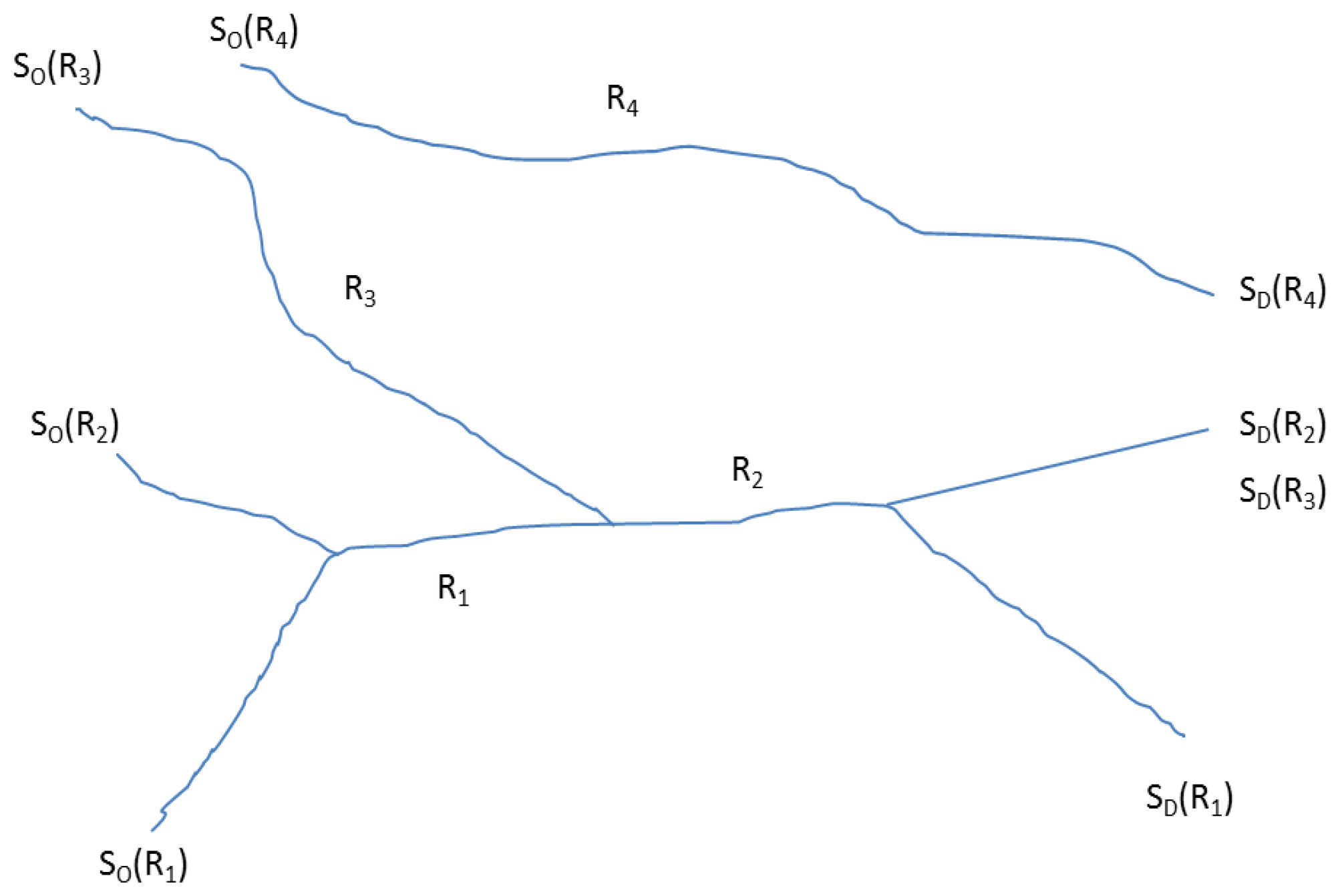
Lemma 3: Stop sequence (un)ambiguity
No pair of trip origin and destination stop may be the members of more than one scheduled trip. That said, two scheduled trips may have a portion of their routes overlapping with each other. There may also be two routes with the same pair of origin and destination stops but in reverse order (which is a typical case in a return travel along the same route but in different direction). In this case routes may overlap.
Figure 5 illustrates some of these ambiguities in stop sequences for different routes.
For the time being we will ignore the first case in lemma 3. In order to address the latter case the following proposition should be followed.
Proposition L3.1: The end stop or destination stop (
) should occur after start or origin stop (
) in terms of time of visit (t).
Lemma 4: Closest time selection
The arrival and departure time at predicted origin and destination stops should be close to the scheduled stops in that location. However, there always exists a temporal uncertainty that makes the predicted trip start and end time deviate from the scheduled trip start and end time. For this purpose a temporal threshold (
) is used. For origin stops this can be expressed as follows, and similarly for destination stops. This will also conform with the first case in Lemma 3.
Lemma 5: Use of OD information
Due to signal loss and uncertainties in the inference process in Layer 1, some (predicted) non-walking trips may have wrong trip start and end time. And these trip origin and destination stops may not have any scheduled trips in common within a given temporal threshold (). To address this issue following proposition is made.
Proposition L5.1: If there is no scheduled trip () found in the GTFS data base that matches a predicted trip i () in terms of the mode type (M) or temporal information (arrival/departure time) then the mode type () at the destination stop of the previous predicted trip () or mode type () at the origin stop of the next predicted trip () stops are considered, whichever is a walking trip (WT) in between and .
The lemmata developed in this paper are not complete. Depending on the situation new lemmata can be added. However the lemmata presented in this paper are sufficient enough to deal with different spatio-temporal and predictive uncertainties of trip patterns. That said, the thresholds set to quantify the lemmata and length of the temporal kernel depend on the type of data quality, sampling frequency and mode types to be distinguished. For temporal kernels the length has been evaluated starting with the shortest possible duration depending on the sampling frequency. Empirically the length of the temporal kernel must be greater than the minimum sampling rate used to capture the sensor trace.
4.3.4. Feature Computation for Detecting Near-Real Time Activity States in Layer 1
In order to construct the predictive model, a number of features are generated using different machine learning classifiers, inferring the activity state on a queried trajectory using a given kernel length (
η) over
number of data points. Three different case studies are presented (Context 1 Scenario 1, Context 1 Scenario 2, and Context 2) depending on the quality and granularity of data using different sensor combinations (e.g., GPS, 3-axis accelerometer, gyroscope and gravity sensor). Prior work has investigated the aspects of sensor calibration in the context of activity recognition [
64]. However, in real to near-real time scenario the sensor information can come from different (unknown) smartphone sources owned by different users to a centralized server where the inference model is running. In such situation it is not always possible to get the hardware type, or mobile manufacturer information and thus poses difficulty in calibrating the particular source(s). To emulate the real world condition, thus in this paper no attempt has been made to calibrate the sensors. However, a low pass filter has been used to remove the noise present in the IMU signals used in the proposed framework (see
Section 5).
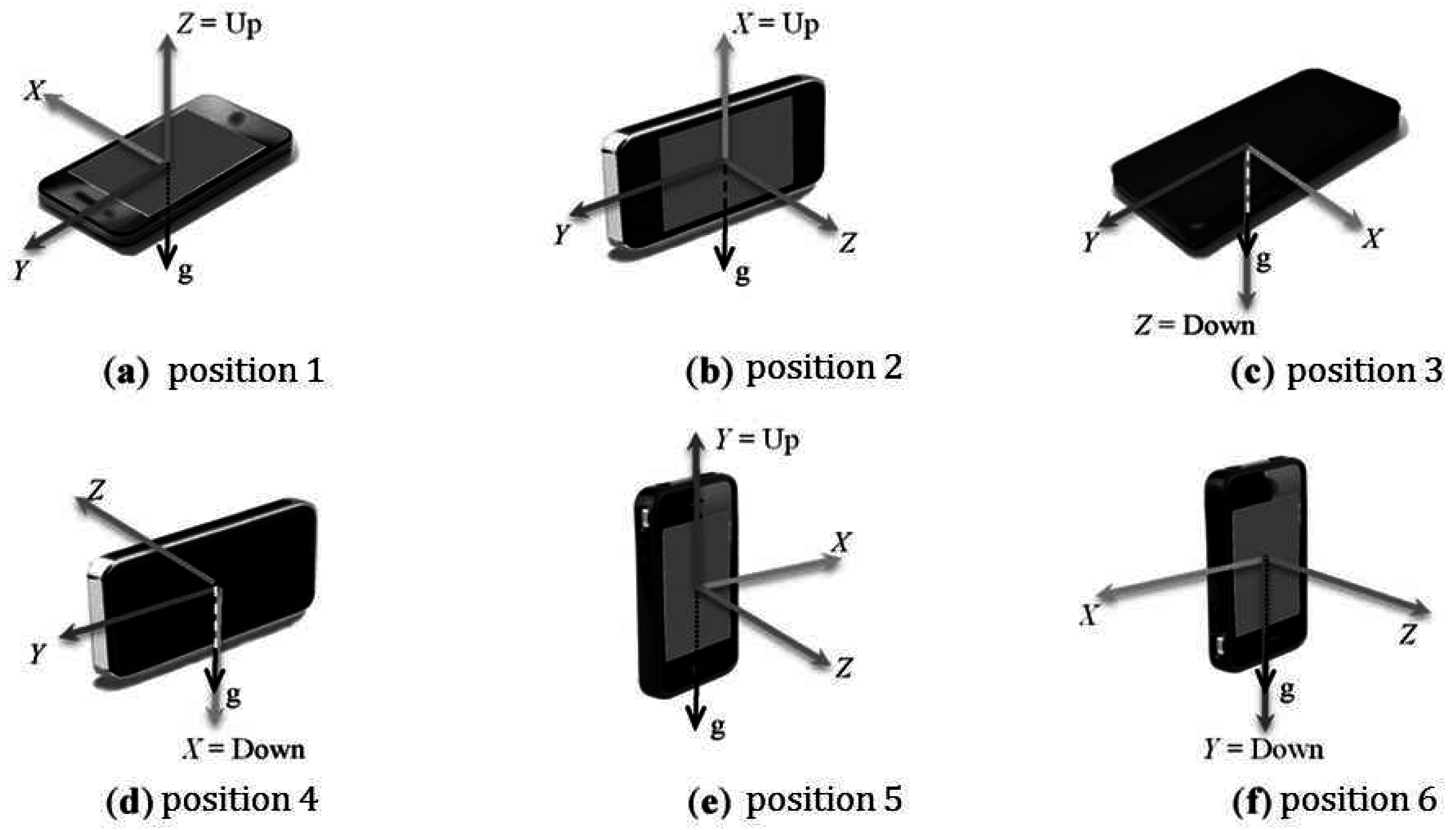
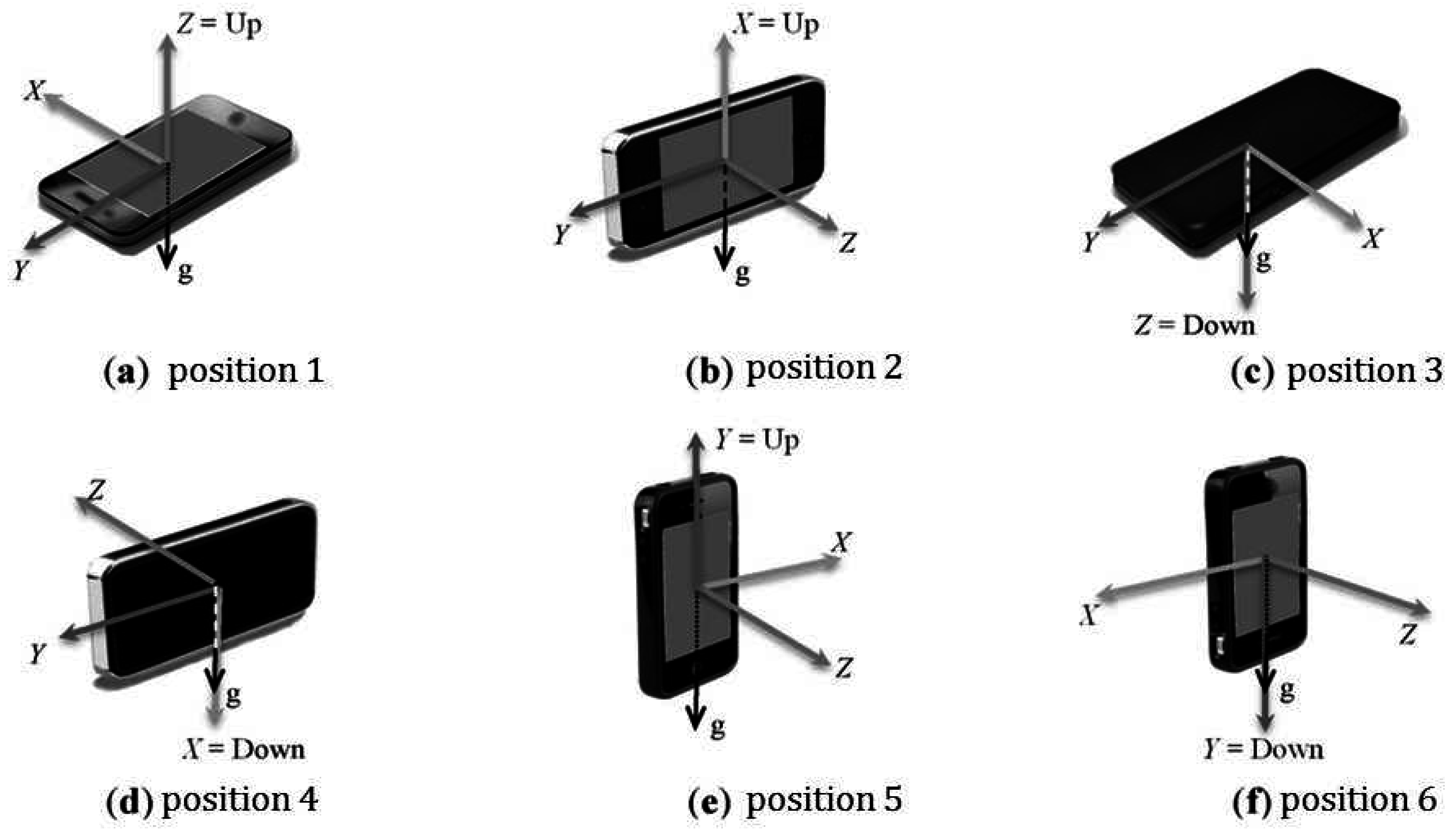
Figure 6 shows different axes of a smartphone in different positions [
64]. Conventionally the axes will remain constant irrespective of the phone’s orientation.
A total of 34 features are computed using different sensor signals, based on acceleration in three directions such as (X:
, Y:
, Z:
), rotational vectors in three directions (X:
, Y:
, Z:
), pitch (
), yaw (
), roll (
), speed (
v), and spatial proximity to the nearest route network using latitude, longitude information from a GPS sensor. In order to eliminate the gravity component a linear acceleration in three axes is chosen (X:
, Y:
, Z:
). The features generated are as follows:
Average of linear acceleration in X-direction (
), Y-direction (
) and Z-direction (
)
Average of resultant linear acceleration (
)
Average of resultant rotational vector (
)
Average of rotational vectors in X-direction (
), Y-direction (
) and Z-direction (
)
Variance of linear acceleration in X-direction (
), Y-direction (
), Z-direction (
) and resultant linear acceleration (
)
Variance of rotational vector in X-direction (
), Y-direction (
), Z-direction (
) and resultant rotational vectors (
)
Signal magnitude area in 2-channels (
) and 3-channels (
) respectively
Average of Fourier coefficients of the resultant acceleration (
) over kernel length
ηAverage of Fourier coefficients of the resultant acceleration (
) over kernel length
ηNumber of zero crossings along in linear acceleration over η in X-direction (), Y-direction (), Z-direction ()
Average speed () and 95th percentile of maximum speed ()
Correlation of linear acceleration in X-Y direction (), Y-Z direction () and X-Z direction ()
Entropy of resultant rotational vector (
) and linear acceleration (
) based on normalized power spectrum density (PSD) of resultant rotational vectors (
) in the time domain and normalized PSD of resultant acceleration (
)
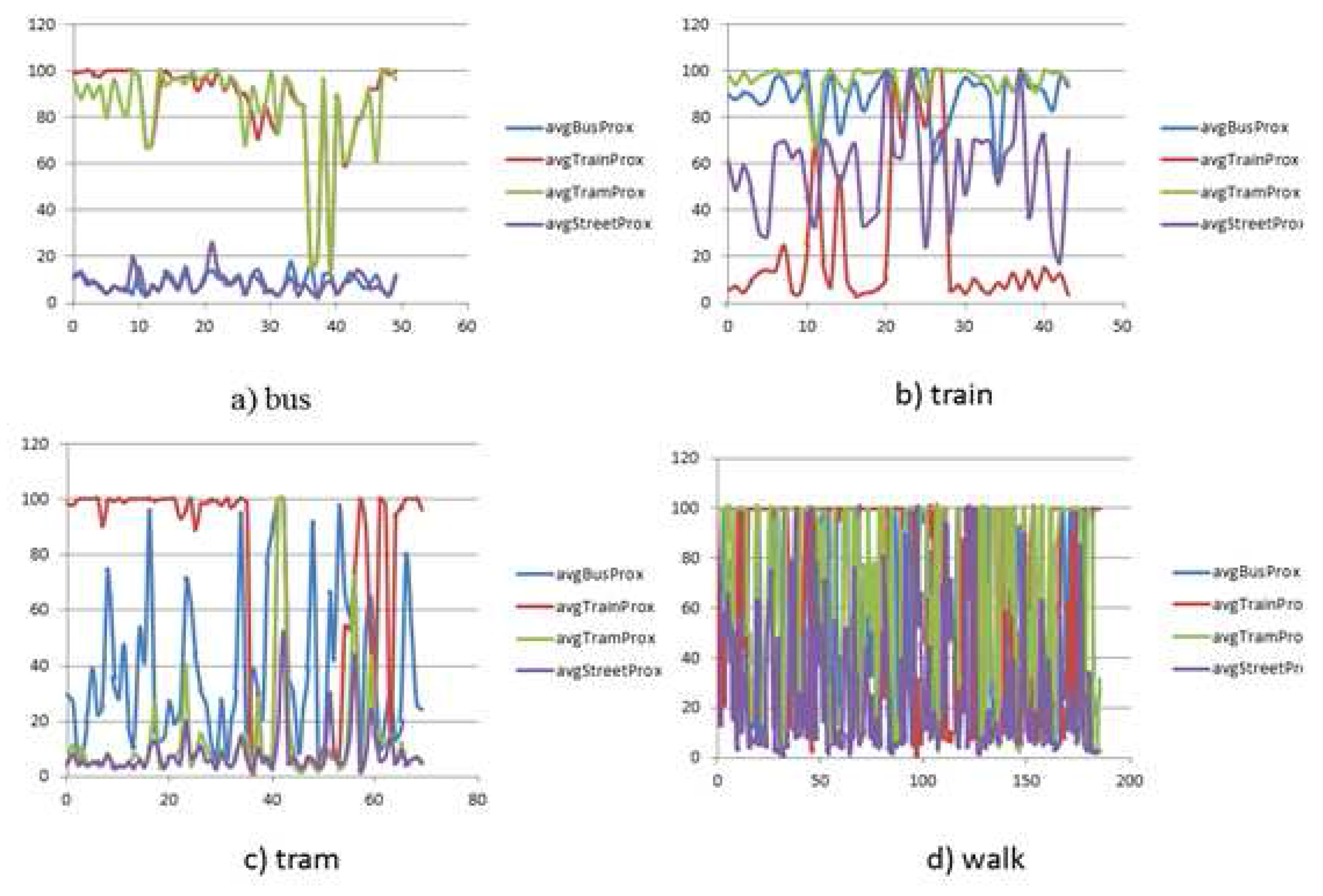
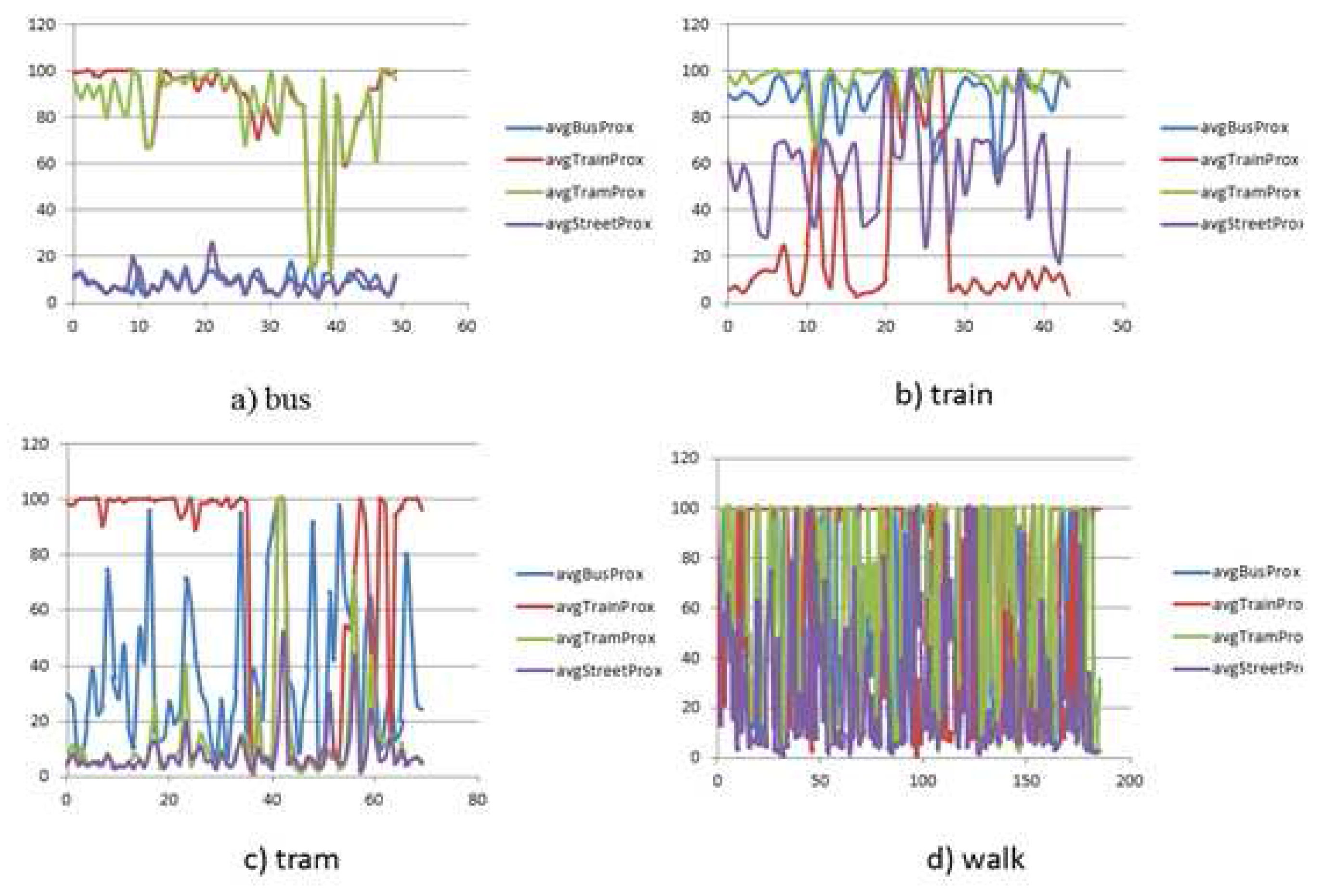
Average spatial proximity (Euclidean distance) to the bus network (), tram network (), train network (), street network ()
Table 1 gives an overview of the different features that are used in different contexts to detect the activity states over atomic segments that leads to trip detection after further merging and refinement.
6. Discussion
In this paper a novel state-based bottom-up framework is proposed that can interpret a raw sensor trace and can generate an automated travel diary containing a rich travel information from smartphone based sensor information. A travel diary generated through this framework contains the number of trips, their start and end time, and the particular transport mode used during that trip(s). The model presented in this paper is adaptive and modular in nature. The model is adaptive because it can be applied in different contexts with different types of sensor data and different granularity. The model can generate the activity state information based on a user defined kernel length. The model consists of three phases: an input phase, a processing phase and an output phase. The core of this model is the processing phase which consists of three layers. Depending on the situation each of the layers can be activated or deactivated. For example, if the interest lies in near-real time activity detection (transport mode in this case) then the Layer 1 will be activated and the subsequent layers (Layer 2 and Layer 3) can be deactivated. On the other hand, if one is interested in trip detection from GPS trajectory all three layers can be activated. However, if the same task (trip detection) is to be performed based on IMU only then the third layer is no longer required—thus the model can adapt depending on the requirements and workload effectively.
In this paper we have also introduced the concept of temporal uncertainty (ς), while modeling the trips using Allen’s temporal calculus [
11]. The upper bound of ς is considered to vary from 3 min to 4 min depending on the observation for this particular research. The quantification of such temporal uncertainty is done from the fuzziness in traveler and driver behavior, uncertainties in hardware performance (sensors and clock), and the uncertainty present in user’s perceptions of activities while reporting the trips. Since in this research the precision used in temporal information on reported trips is limited to minutes and not seconds, there is always an uncertainty of at least 59 s. Thus, the minimum temporal uncertainty that can be improved in future research will be 2 min by shortening the 3 min minimum uncertainty modelled in this research, which can be further improved if a finer temporal precision is available while recording the ground truth.
In order to illustrate the efficacy and performance of the proposed model for trajectory segmentation and trip generation, it has been compared with two state-of-the-art approaches (walking-based and clustering-based). A walking-based approach is subjective and context-sensitive and thus subject to proper functioning in different situations and for different users. The success of a walking-based approach depends on proper selection of walking speed, distance merging threshold and total distance threshold, which are difficult to set. On the other hand a clustering-based approach depends on the minimum number of points to form a potential cluster based on their spatial proximity. A potential cluster can be treated as a stop or slow walking trip depending on the chosen ϵ. The relevance of a cluster can be measured based on the dwell time and other contextual information. In this paper, the clusters formed are simple geometric clusters without any semantic enrichment. The clusters can be of any shape and size, thus raising more uncertainty especially when there is frequent signal gap and randomness in GPS locations. Since both the methods work only when there is a consistent location information (say from a GPS feed) with reasonable accuracy they do not perform well in sparse GPS trajectory data (Context 1) and cannot cope without location information (Context 2). However, the state-based bottom-up method presented in this research can incorporate different IMU information, and hence can work in diverse situations with a reasonable accuracy for mode detection as well as trip detection. The proposed model can also work on a low frequency GPS, combination of GPS and IMU signals, and a high frequency IMU only signal. The model can be made more robust and more intelligent by extending the layers in its processing phase to deal with more diverse and challenging situations, for example, detecting trips and modes on a GSM trajectory, which is generally coarser and more uncertain than that of a GPS trajectory depending on the distribution of cell phone towers.
Despite of the richness in mobility-based activity information the proposed model has some limitations. For example, in Layer 3 while performing the consistency checking an alternate possibility checking is missing at this moment, and that is due to the fact that machine learning algorithms cannot generate an alternate prediction in a human understandable format.
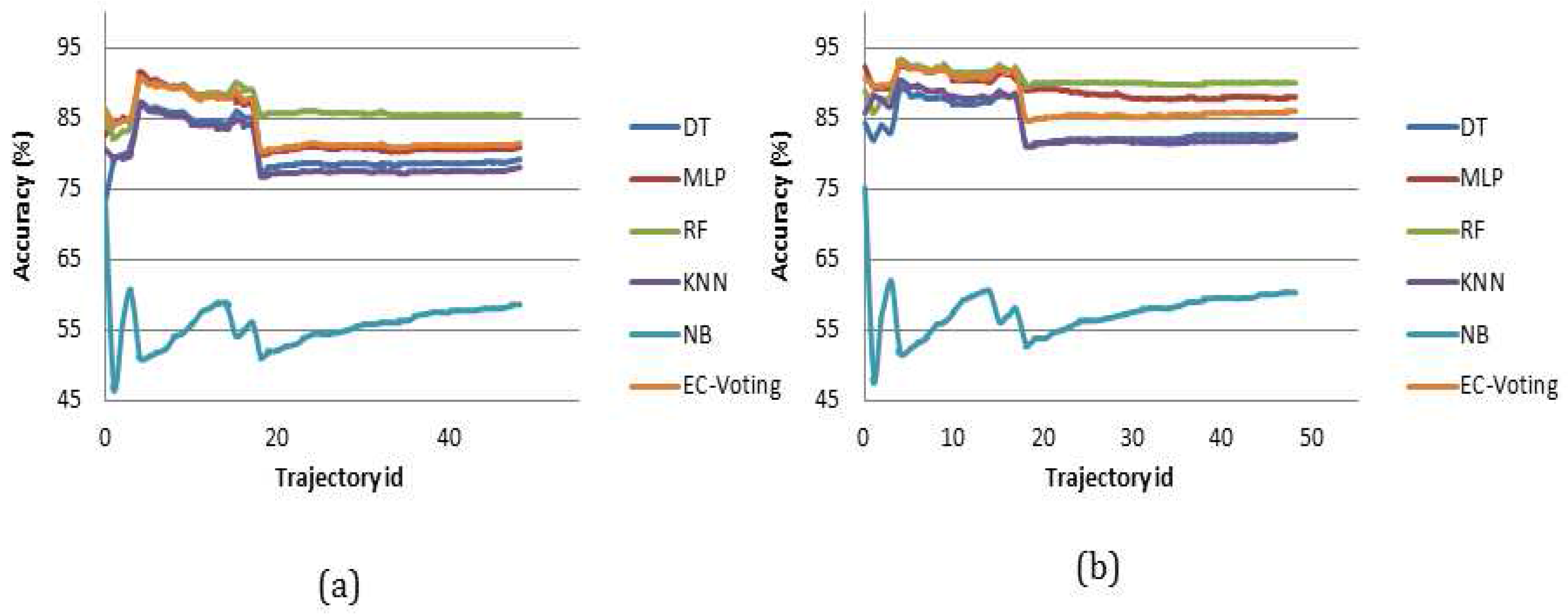
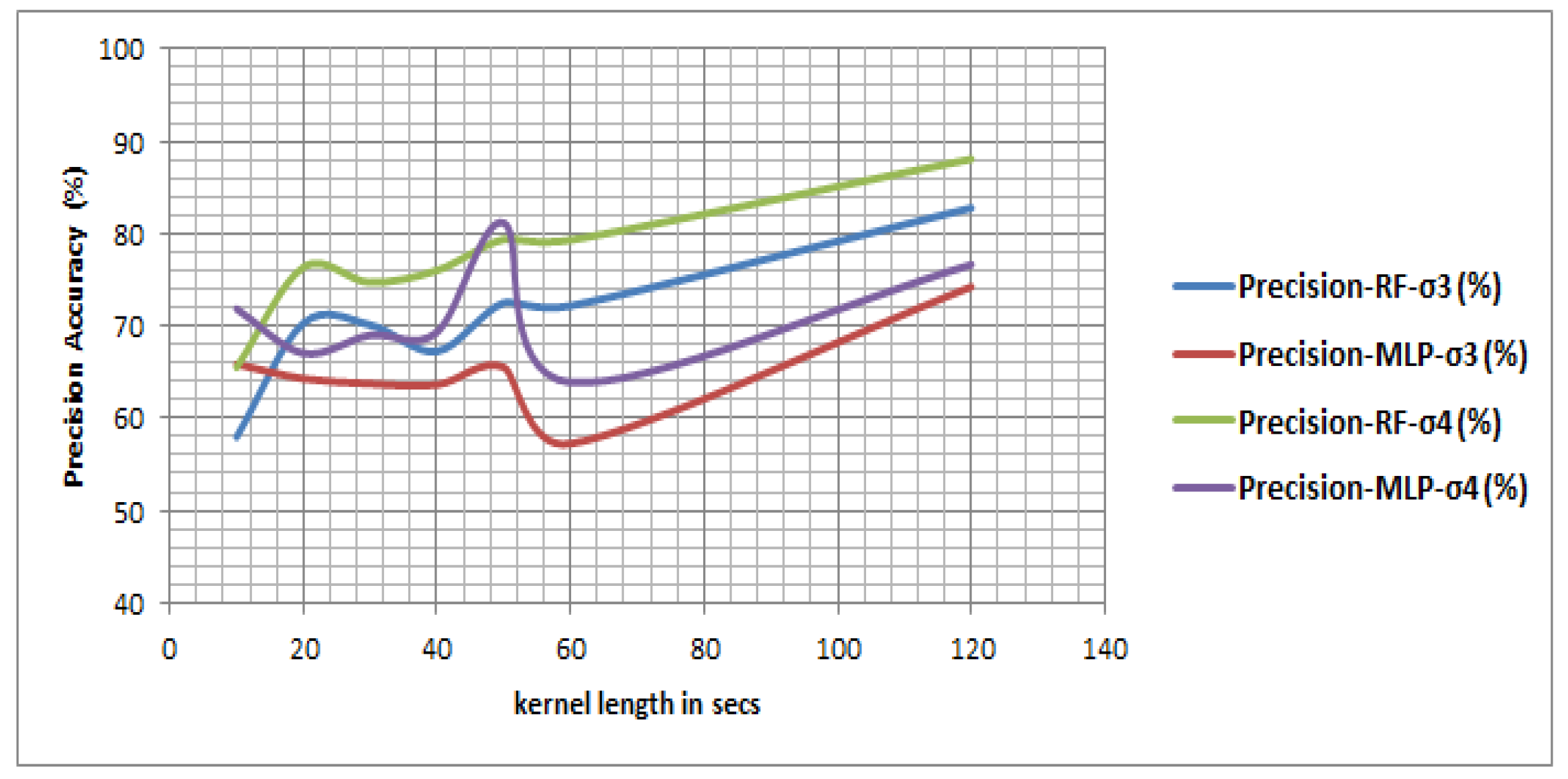
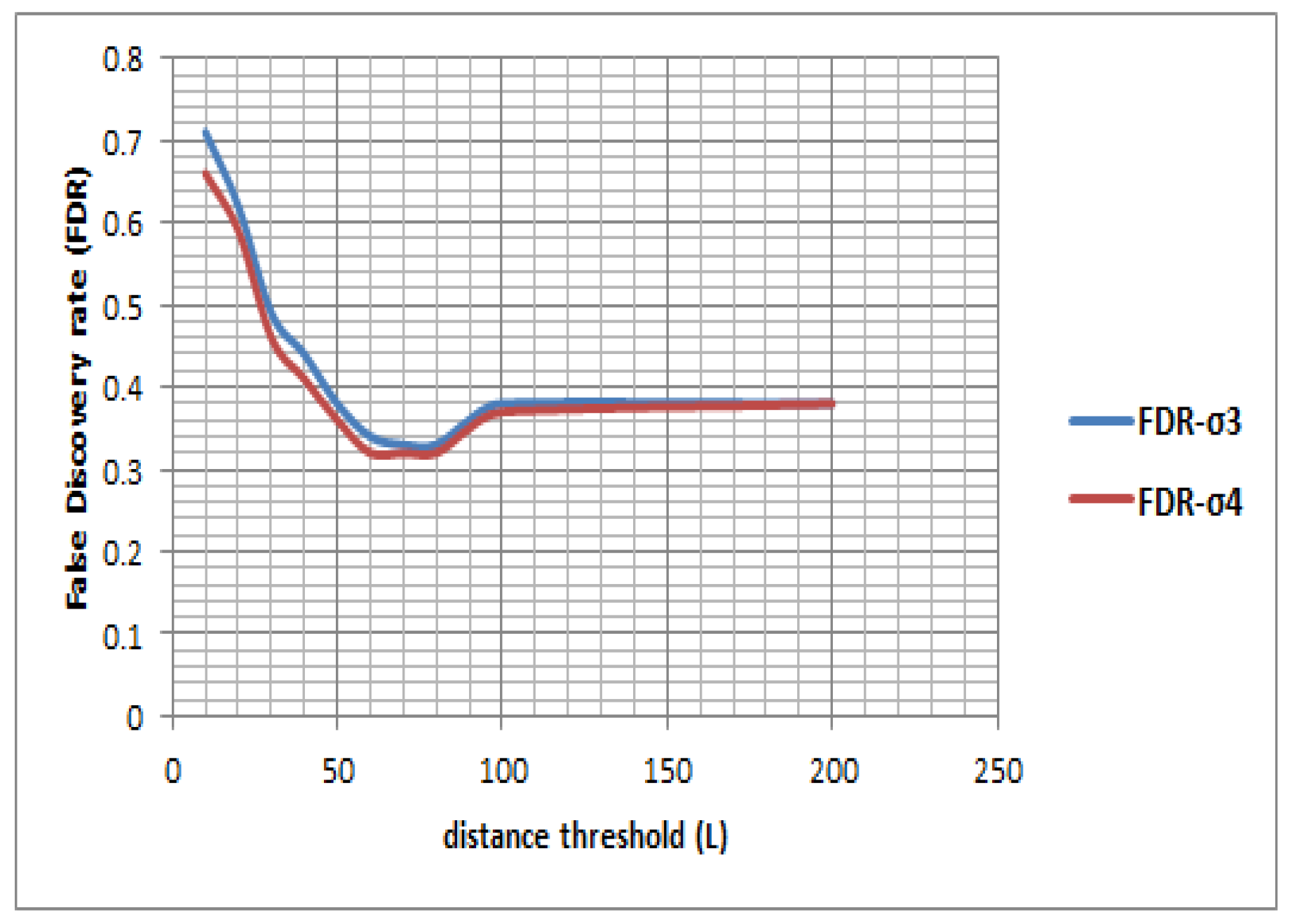
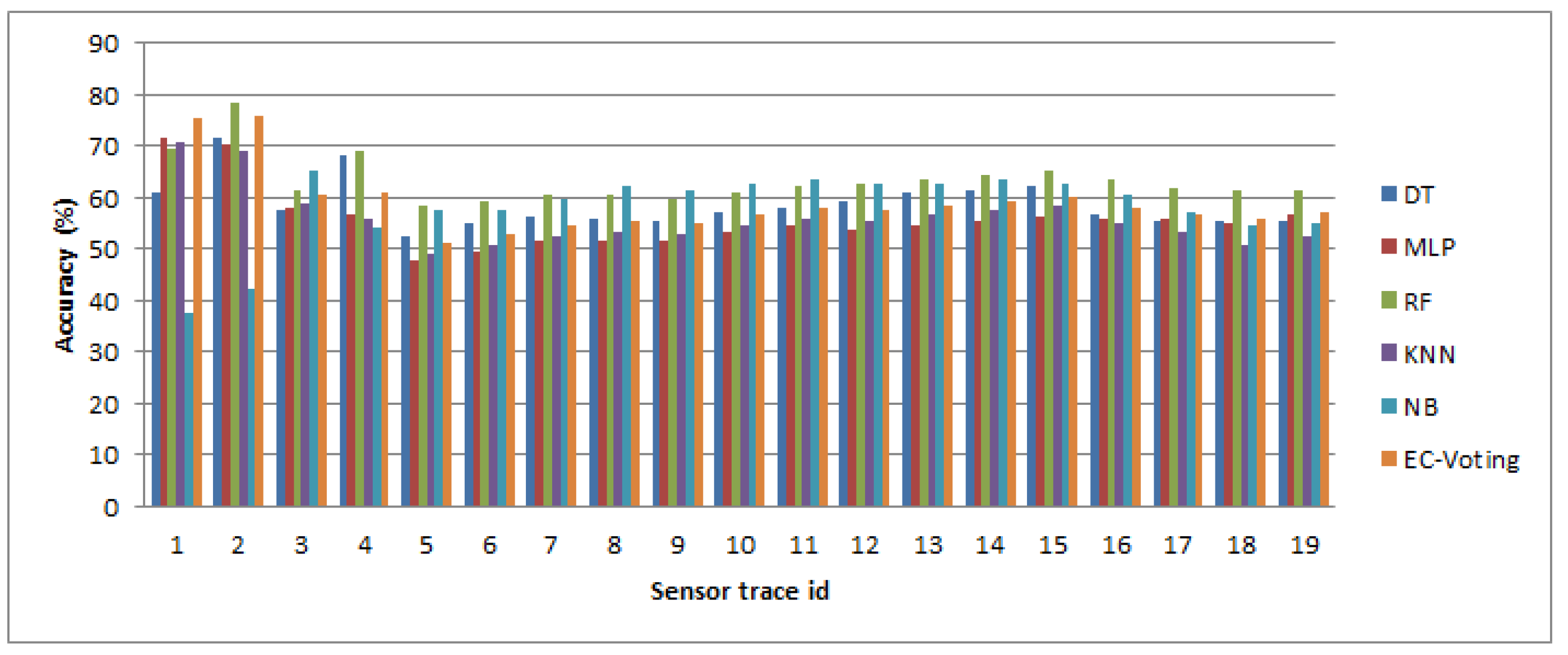
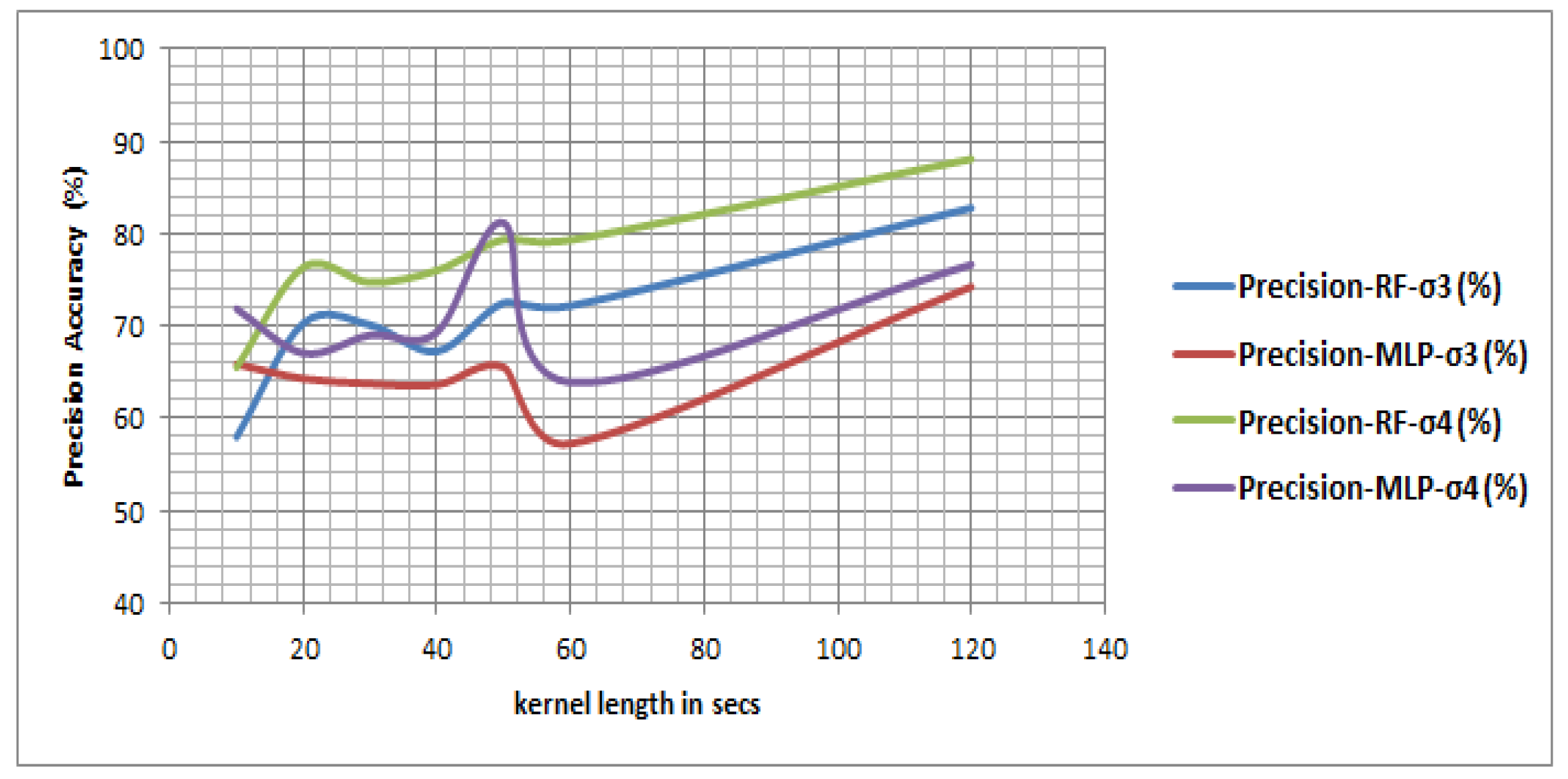
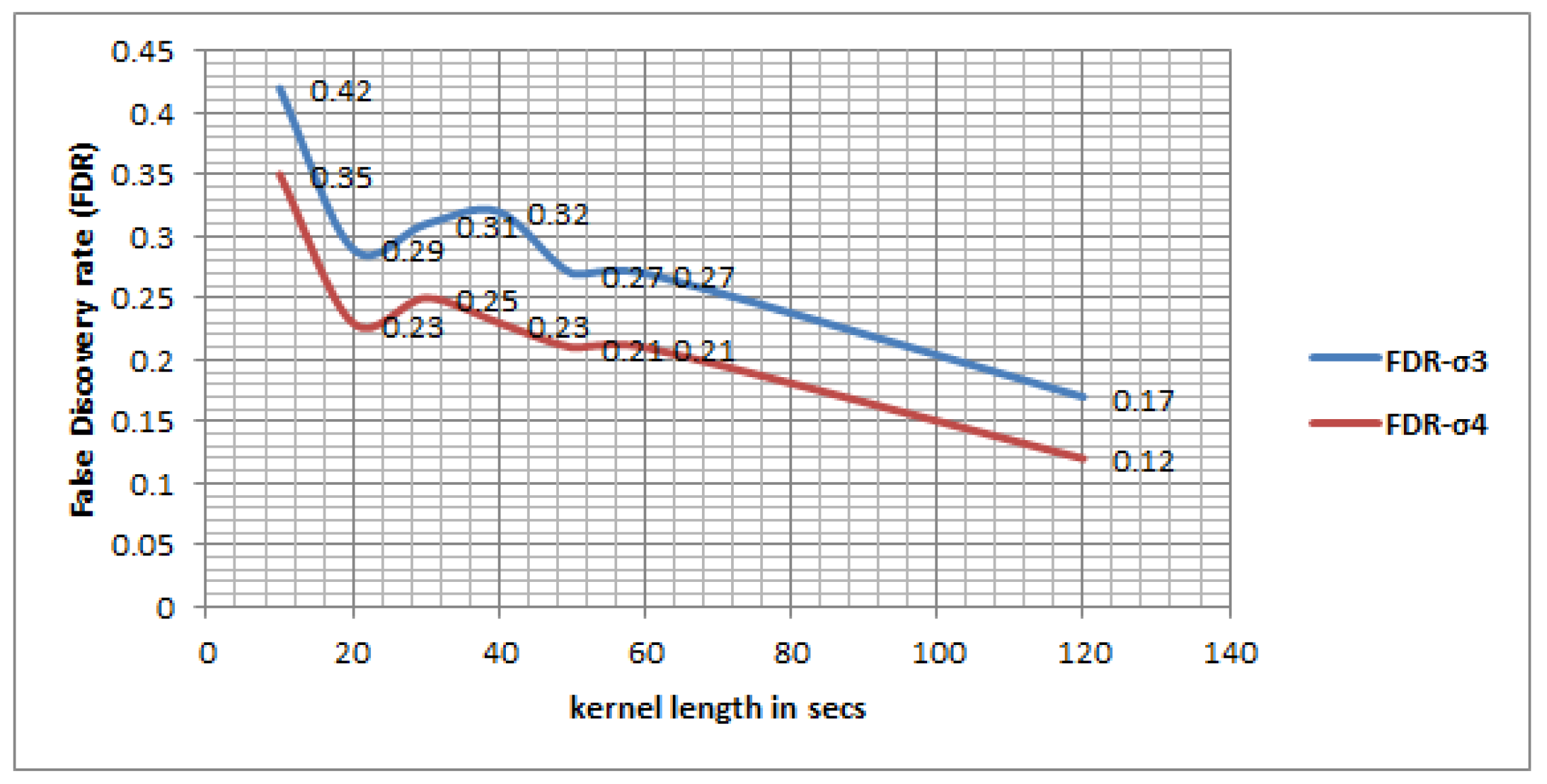
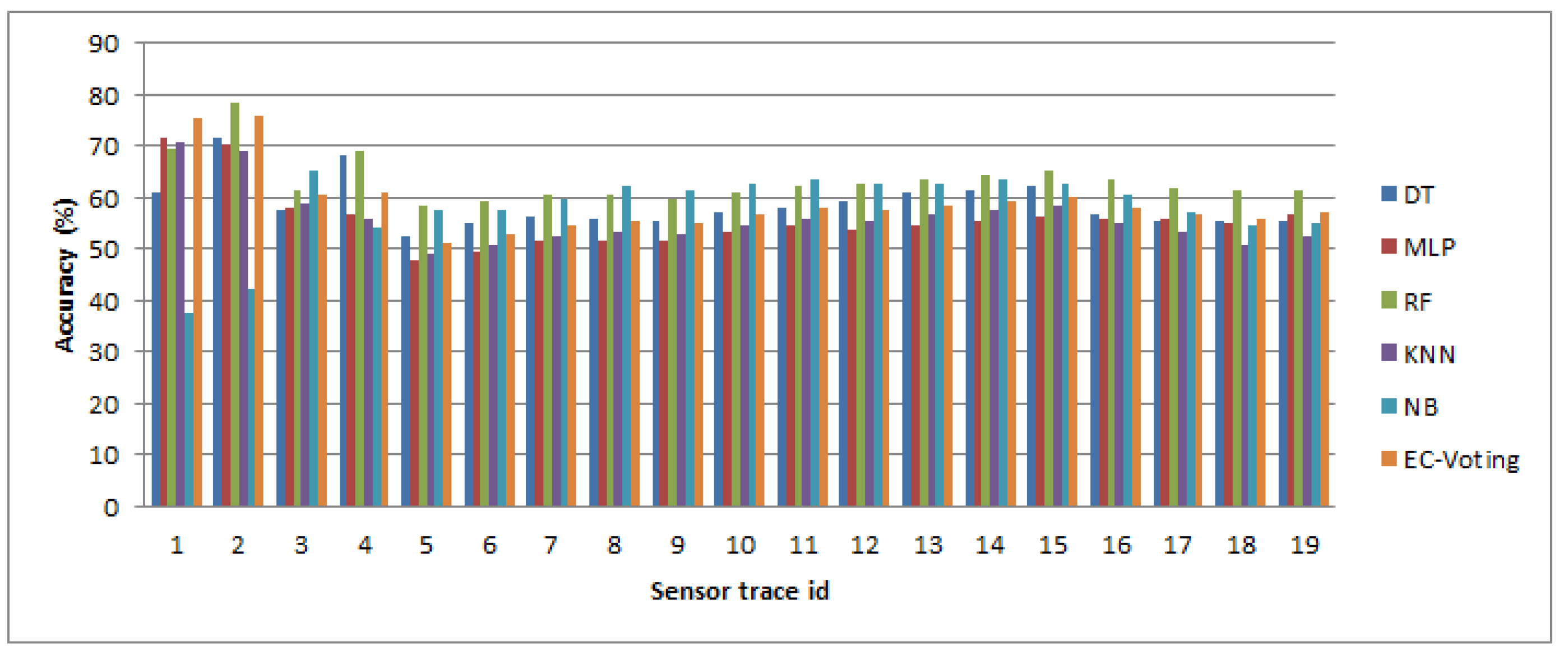
We also investigated the optimal kernel length for detecting transport mode in near-real time. The length of kernels ranging from 5 s to 300 s conforms with the prior studies that attempt to detect mobility-based activities from different perspectives [
50,
55]. The results show that an RF-based classifier performs better than the other classifiers, and an optimal kernel length can be 60 s to 120 s. However, since some activities, e.g., a transfer, can take place within a 120 s interval, the kernel length can further be reduced to 10 s with the given accuracy. The experimental results show that the performance of the model drops in high frequency IMU only information. This is because the public transport modes (bus, train and tram) can stop at different locations due to traffic signals, congestion, passenger drop off and pick up. During all these events the traveler was most likely being stationary and sitting (or standing) in the vehicle, and the acceleration profile would show a momentary drop during that period. But while reporting the trips, it is difficult to get such a fine ground truth information including how many times a vehicle stopped during a given trip and why. The reported trip is generally annotated as trip start and end time with origin, destination information with a single trip mode type. Thus, if a reported trip mode is
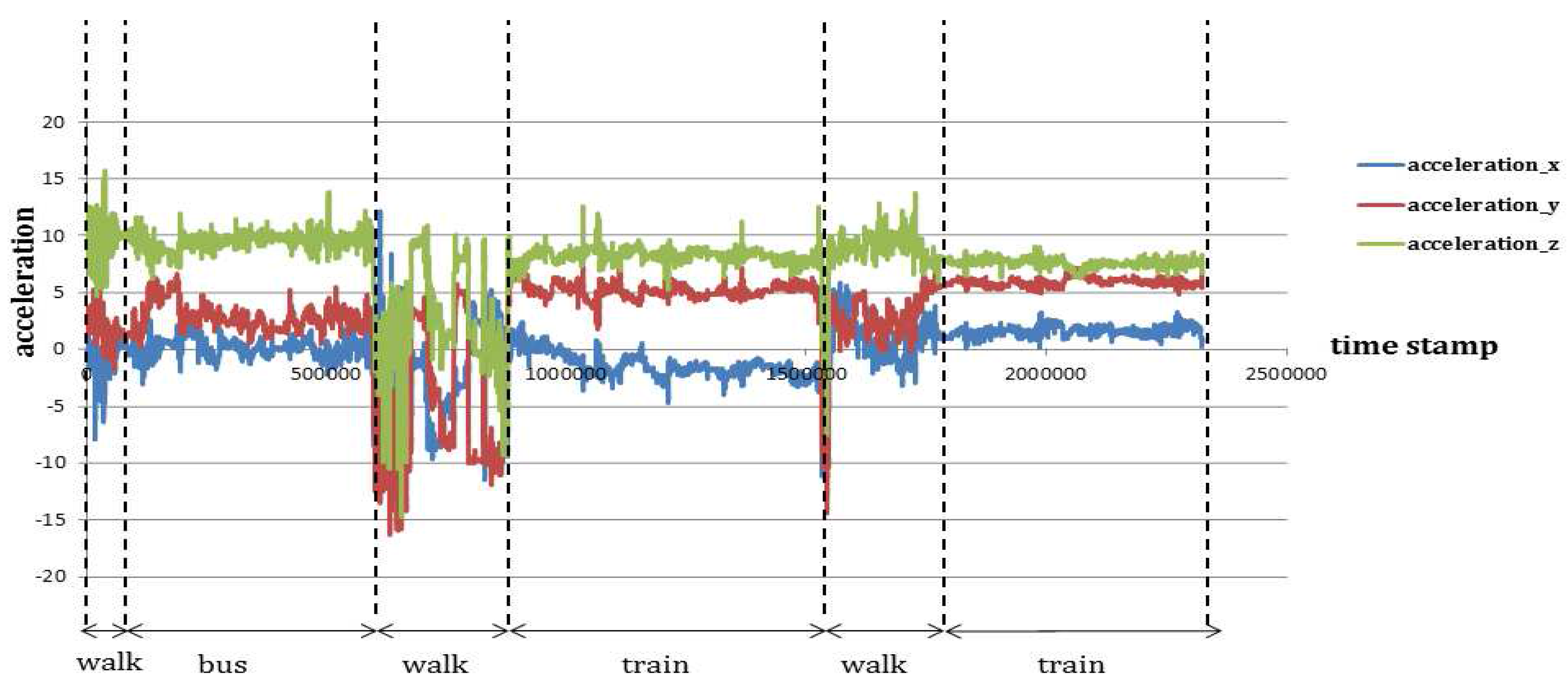
bus, all atomic segments of the trip are labeled so, although some of them may be actually stationary. This can cause missclassification as well when the predictive model is wrongly trained and detects some of the stationary atomic segment as
bus and others as
train or
tram. When merging the segments in Layer 2, due to this issue some of the trajectories show unreasonable travel behavior, especially Trip ID 1 to 3 (
Table 14), where a
bus mode has been detected in between two
tram modes, which is not realistic due to the two reasons: (a) if the trip duration (
) is very short that means it was actually a continuation of tram trip, but some portion of that particular tram trip has been wrongly detected as
bus; (b) For some reason if the given trip (Trip ID: 2) is a bus trip then there has to be two walking trips before and after the bus trip as walking can only connect two motorized (or bicycle) modes, which is missing in this case (
Table 14).
Such ambiguity can be resolved in a number of ways. In the first approach all the consecutive non-walk trips can be merged together until a discontinuity in activity state occurs or a walk trip is encountered (assuming walking is necessary between two non-walking modes). The first approach is used in this research. However, there may be some cases when a quick transfer may take place shorter than the kernel length, which will generate a Type I error, and wrongly detects a trip with its end time higher than the end time in reported trip. The second approach is collecting even finer ground truth data that should contain intermittent stationary states at different locations (stop, traffic light, congestion, driver fatigue), while traveling in a particular mode in order to train the classifier accordingly. Then while predicting the trips, all the consecutive stationary atomic segments will be merged together until a non-stationary atomic segment is found. The merged segment will be labeled as the immediate non-stationary mode found. However, this approach is tedious, puts cognitive burden on the travelers keeping records for ground truthing, and also deviates these travelers from their normal travel behavior. The third approach can be using a phased sampling strategy (whenever a there is a drop in speed a higher sampling rate can be deployed to record the movement behavior). And lastly the IMU information can be supplemented by speed information from a GPS sensor. Prior studies show using speed information along with the acceleration profile improves mode detection accuracy [
54].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}