1. Introduction
The technology implementation of multifunctional micro-sensor benefits from the rapid development of Micro-Electro-Mechanism System (MEMS) technology, wireless communications, and System on Chip [
1,
2,
3]. Emerging wireless sensor networks are distributed sensing network architectures constituted by many small, cheap micro-sensors deployed in a monitoring region. These emerging sensor networks have become more and more popular due to their ease of deployment, especially, mobile sensor networks, which include mobile nodes with sensing, communication capacity, and movement ability, are appealing for many applications, for instance, monitoring of animals living in the wild, tracking patients’ heart condition, etc. At the same time, the introduction of the mobile node can also broaden the sampling capacity in the network space [
4,
5,
6,
7,
8,
9], for example, mobile nodes are utilized as information collecting nodes to collect other static nodes’ data in applications [
10]. Today mobile wireless sensor networks have been extensively applied in all kinds of applicable fields. For example, mobile information systems with the two functions of mobile communication and mobile computing, are especially suitable for the military operational environment. The solution of the security requirements for mobile wireless sensor networks is highly desired. All kinds of different attacks could be launched by an adversary, which include capture attack, wormhole attack, sinkhole attack, eavesdropping, node clone attacks, etc. Node clone attacks have always been the key issue that affects the security of wireless sensor networks. Because the tiny sensor nodes are arbitrarily deployed and unprotected, generally speaking, these tiny sensor nodes are deployed in locations readily accessible to attackers.
The adversary can capture sensor nodes which lack hardware support for tamper-resistance, and can analyze the captured node for assorted information such as ID, code, key pairs, and then use the credentials of the compromised node to deploy cloned nodes in different strategic locations. The destructiveness would be indefinitely spread throughout the network. Clones with legitimate identities would be able to paralyze the network completely by the way of inside attack, for example, the replicas could not only capture correct data, but also inject false data. They could spy on network traffic, and capture data from the sensor networks. A more serious threat is that the clone could distribute false routing information or silence some nodes to control the network structure [
11]. A problem-solving method to avoid cloned nodes is to make nodes tamper-resistant, but the cost implications are prohibitive. Accordingly, detection of cloned nodes is one kind of way to solve the problem effectively.
As far as the location of witness nodes is concerned, there are two kinds of frameworks: centralized detection and decentralized detection. In centralized detection, the data packets including location information are usually forwarded to the base station for detection. To assure the accuracy of detection, the base station must be trusted and powerful. According to the principle of the centralized method, the system has some fatal drawbacks. Firstly, the base station undertaking the arduous task of detecting replicas must be a trusted third party. Once the trusted third party is compromised, a signal peer invalid will appear, and the centralized detection scheme fails. Secondly, nodes surrounding the base station possess undue data communication flaws. Once an adversary damages the communications networks around the witness node, the detection would fail. There is another dimension, which is the power supply of sensor node can easily run out, so the network lifetime is dramatically cut down. Finally the high cost of expensive trusted third parties makes it hard for the centralized detection to be widely used in many wireless sensor networks, so researchers have proposed a new method called distributed detection [
12].
In distributed detection, more than one sensor node in different locations acts as witness node, which avoids a possible stumbling block existing in centralized detection. In 2005, Parno et al. [
13] presented a distributed scheme called the Randomized Multicast Algorithm for replicas detection. In the presented scheme, the position information of sensor node is broadcast to
random witness nodes for detection. Parno et al. presented the other method called Line-Selected Multicast, in the presented scheme. The position information of sensor nodes is forwarded to witness nodes which are selected through the analysis of the routing topology. Meanwhile, geometric probability is applied for replica detection. The two protocols share one crucial feature in common, that is the witness nodes selected from networks for detection are random and distributed. In practice, it is hard to achieve the efficiency and security simultaneously in the design of a protocol due to the low success rate of detecting replicas or high communication cost. Therefore, how to select the witness nodes is a dilemma [
12]. In particular, it needs a large amount of multi-hop routing overhead to transmit the related information to the witness node for detection in mobile sensor networks. How to reduce routing overhead is another dilemma.
In our study, a novel distributed scheme is presented for detection of node clone attacks, which is called Encounter-based Sequential Hypothesis Testing protocol (ESHT). The basis of the ESHT protocol is the meeting of mobile nodes and the sequential hypothesis testing. In the ESHT scheme, random tracked nodes are pre-allocated to each mobile sensor, and every tracked node has witness nodes. When the tracked node and its witness node meet, the related location information is transmitted to the witness node, and the witness node judges whether the tracked node is a comprised node or a replica according to whether or not the measured speed ν is over the system-configured νmax. However, this can easily cause many more wrong judgments, if the judgment is made based on only one such observation. To improve the precision, a sequence of speed samples is collected and the Sequential Probability Ratio Test is applied to provide upper bounds for the false positive and false negative rates. Therefore, if two witness nodes with same tracked node encounter, the related detection information is forwarded to one of them and the sequential hypothesis testing method is applied to detect the replica. One major advantage of the ESHT protocol is that the overhead of maintaining a traditional multi-hop routing path is reduced to achieve energy saving effects, and an equally important benefit of the ESHT protocol is that the mobile replicas can be found quickly with a few samples for each tracked node.
The rest of the paper is organized as follows: we describe some of the related studies in
Section 2. The Random Waypoint Mobility Model is introduced, which is adopted in our scheme as the mobility mode in
Section 3.
Section 4 illustrates the system environment, while the encounter-based protocol for detecting mobile clones is presented, which utilizes sequential probability ratio testing.
Section 5 describes the theoretical analysis of security and efficiency, and shows our experimental investigation. Finally, the conclusions and guidelines for further research are drawn in
Section 6.
2. Related Works
In emerging sensor networks, as long as the tiny sensors are arrayed, the position of the sensor remains unchanged. This type of wireless sensor networks is called a static WSN. A commonly used detection principle of node clone attacks in static WSNs is that the same identity with different locations for a sensor node is impossible. This kind of scheme, called claimer-reporter-witness framework is widely adopted to detect static replicated nodes. Two kinds of basic detection methods are often used. One is centralized techniques [
14,
15,
16], the other is decentralized techniques [
17,
18,
19,
20,
21]. Yu et al. [
15] presented an approach utilizing the technology of compressive sensing to distinguish replicas from normal nodes in networks. Zhu et al. [
18] described a decentralized method applying Localized Multicast to complete the inspection task. In the study by Zeng et al. [
21] for clone detection, two kinds of frameworks called Random Walk and Improved Random Walk based on Table were presented.
Those schemes are not suitable for mobile scenarios due to the continuous movement. When the sensor nodes are mobile, the mobile sensor nodes are not fixed at any specific location. Moreover, it is even harder to forward location claim packets to some witness nodes in a mobile WSN.
In the study by Znaidi et al. [
22] a mechanism based on a three-tier hierarchical network structure was used. The principle of the scheme is based on the use of a Bloom filter. The process of detection can be split into three steps: first of all, cryptographic keying materials and some relative parameters are pre-distributed; and secondly, the cluster-head is determined by a relative algorithm; thirdly, the Bloom filter is utilized for the cluster-heads to exchange the ID information, and a node whose ID belongs to more than two clusters is detected as a cloned node. The storage cost of this protocol is significantly reduced. For the additional overhead of Bloom filter and clustering, the communication cost is relatively high. Based on the theory of similarity, the scheme presented in [
23] was proposed by utilizing the token-based authentication technology. In the scheme, the broadcast of a timestamp indicates the start of the detection process. Once the detection process starts, a mobile sensor node randomly selects a protected value
. When a mobile sensor node first encounters another node in the detection period, the two nodes will swap a token with each other, and then save it in their memories. When they meet again in the same detection period, each will request the token exchanged in advance. If the right token is provided, the provider is a genuine node, otherwise the provider is a cloned node. As long as the access between replicas and comprised node is set up by the smart attacker, the token is exposed to replicas, and the scheme fails. In order to prevent conspiracy attack which is launched by communicating with each other, Zhu et al. used a statistics method to detect mobile clones. This principle asserts that a moving node which encounters another node too regularly has probably been captured. Specific counters and lists for recording acquainted nodes are utilized to calculate the total amount of meeting times. The base station is used for centralized analysis.
In the study by Ho et al. [
24] the sequential probability ratio test (SPRT) is applied to detect cloned nodes. In the scheme, those mobile sensor nodes whose speed exceeds a predefined speed threshold are detected as replicas. A deadly vulnerability of the scheme introduces an invalid signal peer which is the inherent drawback of centralized techniques. Manickavasagam et al. [
25] proposed a distributed scheme based on the optimized SPRT. In the scheme, nodes’ speed is optimized to implement a sequential probability ratio test. At the same time, the message transmission paths are explored to position the intersection. The advantage of the scheme is that higher the node speed, the easier the detection is. Moreover, the presented protocol needs not explicit information packets, but periodic information packets are needed. Its communication cost and storage cost which reach
and
respectively, are relatively reasonable.
Deng et al. [
26] presented a method based on a polynomial based on the dispatches of key pairs. In the study, Bloom filters are utilized for verifiable authentication and collection of the total amount of key-pairs which is set up by each mobile node. If the total amount of pair-wise keys set up by the filters is more than the a predefined value, then the nodes are classified as replicas. However, this centralized protocol has a serious flaw. It guarantees nothing about whether the replicas report the right number of keys honestly. Deng et al. [
27] presented two decentralized approaches for clone detection in networks. Both of them are based on mobility-assistance. One approach is single storage of time-location claim and exchanges (UTLSE), the principle of the UTLSE protocol is that two nodes exchange related time-location information of the same monitored node until they meet with each other. Then one of the meeting witnesses is selected to detect the cloned node, and only one time-location claim is stored in the UTLSE protocol. Another scheme is called multi-time location storage and diffusion (MTLSD). The principle of MTLSD scheme is similar. The difference is that the second method stores more than one time-location for every monitored node and forwards the information among witnesses. As a result, a higher detection rate can be attained by the MTLSD scheme.
In order to find captured nodes, in the study by Conti et al. [
28] two distributed approaches were presented which were called History Information exchange Protocol (HIP) and its optimized version (HOP). Both algorithms are based on the communication with its one-hop neighbor and the mobility. Meanwhile, two kinds of attack modes were defined and their behavior discussed. Their differences are listed as follows: the HIP will keenly observe and analyze node capture attacks only by the information local to the node, but the HOP needs to analyze node cooperation to detect node capture attacks.
A study by Lou et al. [
29] depended on the neighborhood community, which can be characterized by the one-hop neighbor node list of the node to be detected. The rationale behind the scheme is that a node cannot appear in different neighborhood communities at any time. The first step of SHP is the fingerprint claim, where the neighbor node table is signed as the passport, and then the passport is broadcasted to one-hop neighbors. If the witnesses receive conflicting passports, there must be replicas present.
Wang et al. [
30] presented a study for detecting replicas deployed in wireless sensor networks, whereby some moving nodes act as patrolmen to finish the detection. For static clone nodes, when patrollers migrate to a new region, they spread their patrol information and receive the location messages from surrounding static nodes, and then apply the security thesis that “one benign node only has one location” to detect replicas which have different locations with the same ID. In another interval, the patrollers move to another zone to repeat the same operation. If the clones have been present in a zone, the cloned nodes can be found out once the second conflicting location message is received. In other cases, the cloned node’s answer messages are retrieved by different patrollers, and then they would be detected by the trusted third party or by exchanging information of patrol nodes after around. For the cloned patrol node, the basis of detection is that the speed of moving patrol node should never exceed the predefined maximum speed
Vmax. When the patroller broadcasts a patrol claim, there will be a static period interval of length T. Once the patroller broadcasts a patrol claim for a new location in time of [
T,
T +
interval], mobile cloned patrollers must exist.
In short, the existing detection schemes based on location confliction are not suitable for mobile wireless sensor networks. The research on detection of node clone attacks working in mobile environments must be different. Due to the mobility of mobile nodes, how to choose the distributed witness becomes a key issue. The cost and difficulty of forwarding related information to the designated witness node are the difficult problem for the solution design.
5. Performance Analysis
The detection probability is the probability that the replica nodes are accurately detected. The effect of different amount of epochs on the success rate has been an important performance index. Here an epoch is a random time interval, in this time interval a node keeps moving in the identical direction and at a constant velocity. The movement pattern adopted in the proposed protocol is Random Waypoint Mobility Model. Some random characteristics of RWP are adopted in the security analysis. In the following, the lower bound of detection probability would be analyzed.
Theorem 1. Assume node is a compromised node, and is a cloned node of , runs into one of its witness node with the time-location claim , encounters the same witness with the time-location claim , then the chance of the witness node detecting the node replication attacks by utilizing the two time-location claims is:
in which
.
Proof. Assume
is the probability density function that a node appears in a position
in the networks, and nodes in the network are uniformly distributed, therefore
. Node
is in the position
, the conditional probability that node
and node
are contradictory in their locations is:
where
, and:
□
Assume there are only two nodes with the same identity, they are the compromised node
and its cloned node
. Only one witness node is pre-distributed to detect the node replicas attacks. Let
denote the amount of epochs until the witness node detects the replica sensor.
indicates the number of epochs that is the only time the witness node encounters malicious node before the witness node detects the replica node, then:
where
is the probability that any two nodes encounter in one epoch.
Let
indicate the chance that the node replication attacks are found out until the
kth epoch, only if the witness node receives two time-location claims coming from the different nodes with the same identity, the malicious nodes can be detected with a specified probability, and half time-location claims are useful. The probability:
where
denotes the probability that the witness node detects node replication attacks when the witness node encounters node
at
ith epoch and encounters node
at
jth epoch. According to Theorem 1,
represents the probability that the witnesses detect node replication attacks by utilizing the two time-location claims received from
and
respectively. When the two time-location claims are retrieved in different epoch,
is 0. In the meantime, the time
and
which are included in the two time-location claims are assumed to obey the uniform distribution in the same epoch, so the average difference of the two times is:
Then we substitute Equations (28) and (35) into Equation (33) to obtain:
After
epochs, the witness node detects the two malicious nodes with the following probability:
The real probability that one witness node detects replicas is larger than , since the witness nodes have some probability of sampling more than one measured speed before the kth epoch but until the kth epoch, the witness node detects the node replication attacks.
In the proposed scheme, each node has
witness nodes, the detection probability after
n epochs in step 2 is
:
When the node replication attacks are not detected at the second stage of the detection protocol, the protocol proceeds to the third phase. We assume there are only two witness nodes which would detect the compromised node
and its cloned node
. Let
denote the number of epochs before the malicious node is detected in the second phase of the protocol. Let
represent the probability that the node replication attacks are not detected until the
kth epoch in the second stage of the protocol, under the premise that there is one speed sample gained from the malicious nodes:
represents the maximum probability that the witness node detects the two malicious nodes in the third phase of the protocol after
epochs:
where
is the probability that any two mobile nodes encounter in an epoch. According to the principle of Sequential probability ratio test, we assume that
is the false positive rate and
is the false negative rate, in the light of Wald’s theory [
40], the predefined maximum boundary of
is computed by
. Similarly the truth, the predefined maximum boundary of
is computed by
. The sum of the false positive rate
and the false negative rate
meets the following inequality:
Since
is the false negative, therefore the detection probability for node replication attacks is
. The lower bound of
is given as follows:
Because each witness node has some probability to sample more than one measured speed before the
kth epoch, and the witness node detects the node replication attacks until the
kth epoch, so the real probability that one witness node detects replicas is larger than
. Let
denote the probability that the node replication attacks are detected in the third stage of the protocol when there are only two witness nodes. Then we can substitute the lower bound of replica detection probability into Equation (40) to obtain:
Considering the balance between storage cost and detection efficiency, every node has
witness nodes, and thus the detection probability after n epochs in step 3 is:
The metrics used to evaluate efficiency of the proposed protocol are:
Communication overhead: the average amount of packets which are transmitted and received by each node when the protocol for detecting node clone attacks works in networks, which is expressed as .
Storage overhead: the average amount of copies of the time-location claims or detection information that need to be stored in a sensor when the protocol for detecting node clone attacks works in networks, which is expressed as .
Computation overhead: the average amount of public key signing and verification operation for each node, which is denoted as .
In the ESHT scheme, the communication overhead
is calculated as:
where
is the communication overhead of receiving time-location claim requests from the encountered track nodes, and
is the communication cost of replying time-location claims to the track nodes,
is the communication cost of forwarding the detection information between the trace node.
The probability that each node encounters
trace nodes in one epoch is
:
where
is the chance that any two nodes encounter in one epoch,
denotes the amount of sensor nodes in the mobile wireless sensor networks,
denotes the average number of nodes which one sensor node encounters in one epoch . We assume a sensor node encounters
witnesses in one epoch, and then this sensor node would receive
time-location claim requests and reply
time-location claims to those witnesses. Assume
is the average amount of packets which are transmitted and received by each node when a sensor encounters its witnesses:
Substituting Equations (46) into (47) to obtain
:
The probability that each node encounters
traced nodes in one epoch is
:
In the same way, the communication cost of replying time-location claims to the track nodes is obtained as:
The probability that any two sensor nodes have k same tracked nodes in one epoch is
:
We assume two sensor nodes have
same tracked nodes. One of them would send or receive
detection information to another, so we assume
is the average number of detection requests:
Substituting Equation (51) into (52) to obtain
:
Since one sensor node encounters an average of
nodes, so the average number of sending or receiving packets including detection request and detection information is
:
Substituting Equations (48), (50) and (54) into (36) to obtain
:
so the communication cost of ESHT scheme is
. In our protocol, each node needs to use a digital signature when it sends a packet. Conversely, as soon as a node retrieves a claim, it is needed to verify up to the signature. So the computation cost is in proportion to the communication cost, the computation cost is
.
In the ESHT scheme, in order to detect replica attacks, each witness node need to obtain sample, a sample
is computed from two consecutive time-location claims of node
, according to Equation (3), when a sample
is retrieved, the former time-location claim
is abandoned, and only present time-location claim
is stored to wait for the next time-location claim
. At the same time, to detect replica attacks in the third stage, a queue in which the detection information is stored is maintained. So the fixed length of storage space including a time-location and a queue is required for each node. Every node has
tracked nodes. Conversely, every node has
trace nodes, so the storage cost of every node is
. The comparison of system overhead between [
15,
24,
25] and our proposed scheme is summarized in
Table 3.
An analogue test is carried out to test the feasibility and accuracy of the scheme by using OMNeT++ platform. OMNeT++ is a scalable, modular simulink and framework, mainly for constructing network emulators. In the testing,
sensor nodes distribution are relatively uniform within a square area of size 1000 m × 1000 m, where
varies from 100 to 1000. The communication range of each node varies from 50 m to 100 m. The Random Waypoint Mobility Model (RWP) is adopted as the movement model. We use the code of Ganeriwal et al. [
41] to construct the movement model based on Random Waypoint Mobility mode with steady-state distribution.
In the movement model, every node randomly selects a speed which is in the interval of 2~8 m/s to move toward a specific waypoint. At the close of each speech, a node stops for a random duration after moving for unit time, where varies from 0 s to 20 s.
In the simulation experiment, only one comprised node and its one replica are deployed in the network. The communication between different nodes applies the standard unit-disc two-way communication pattern. At the same time, the IEEE 802.11 protocol is adopted as the medium access control protocol for each node. Assume the user-configured false negative rate and the user-configured false positive rate . Every experiment is carried out for 1000 simulation seconds, and the average value of 10 experimental results is discussed.
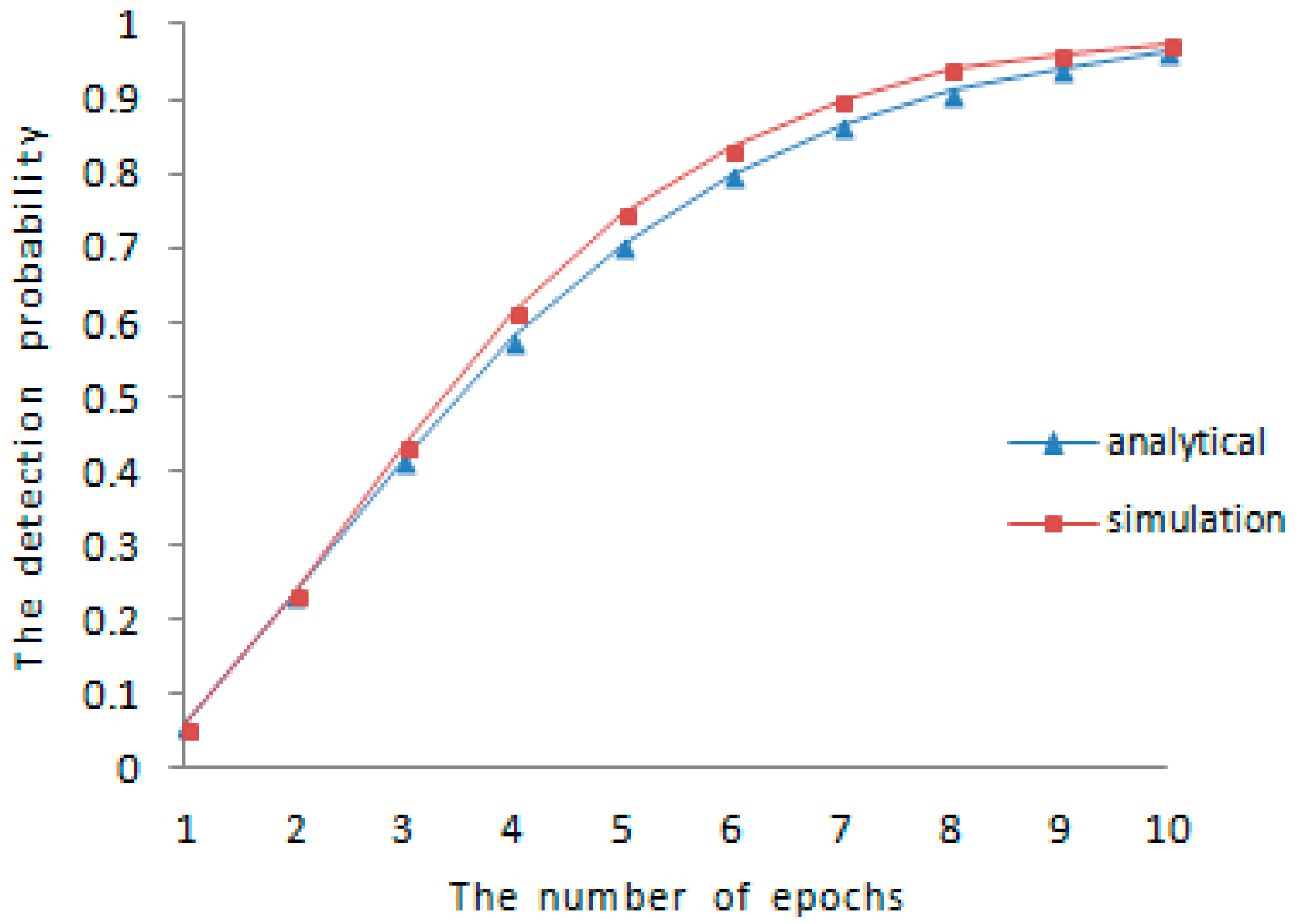
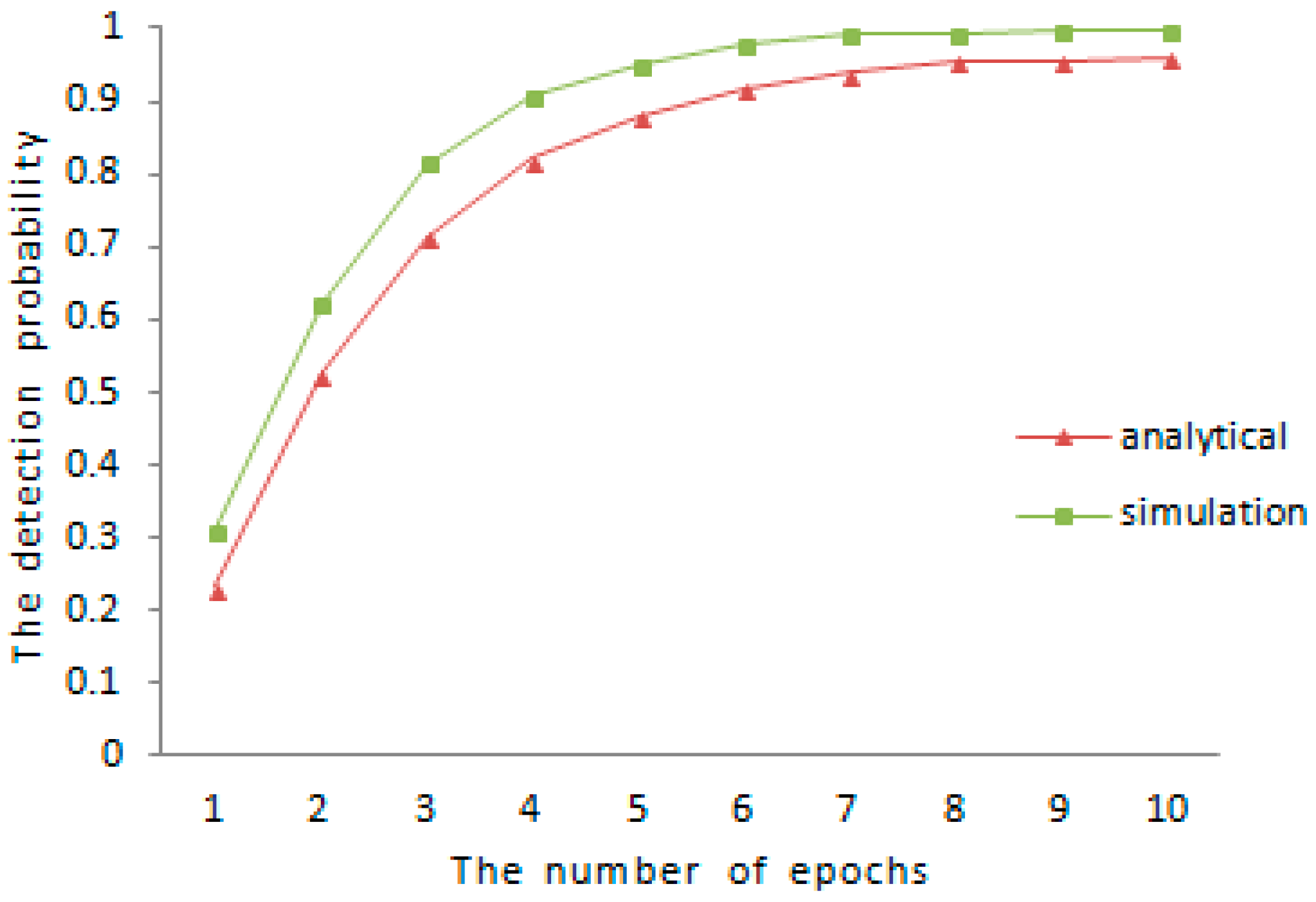
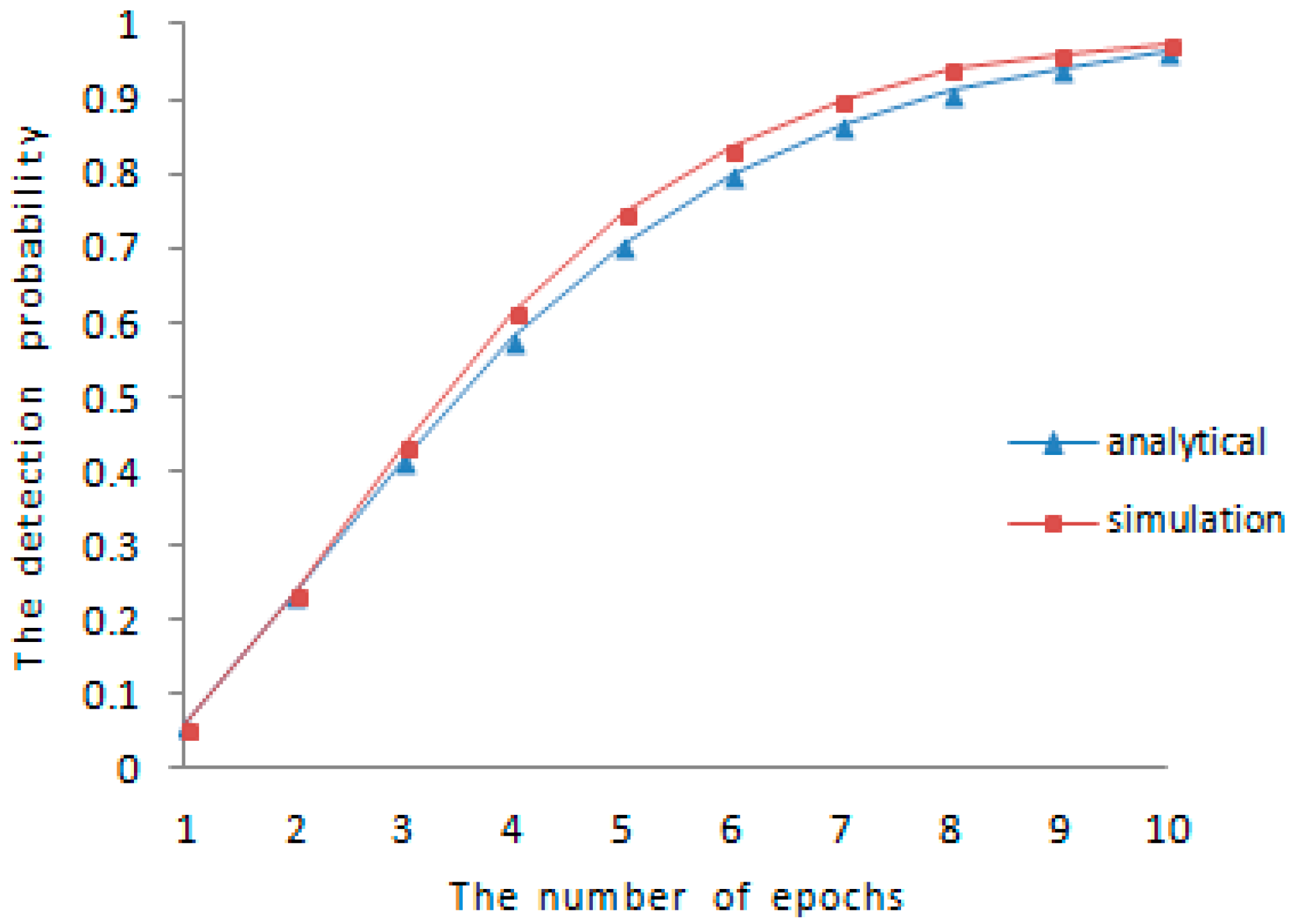
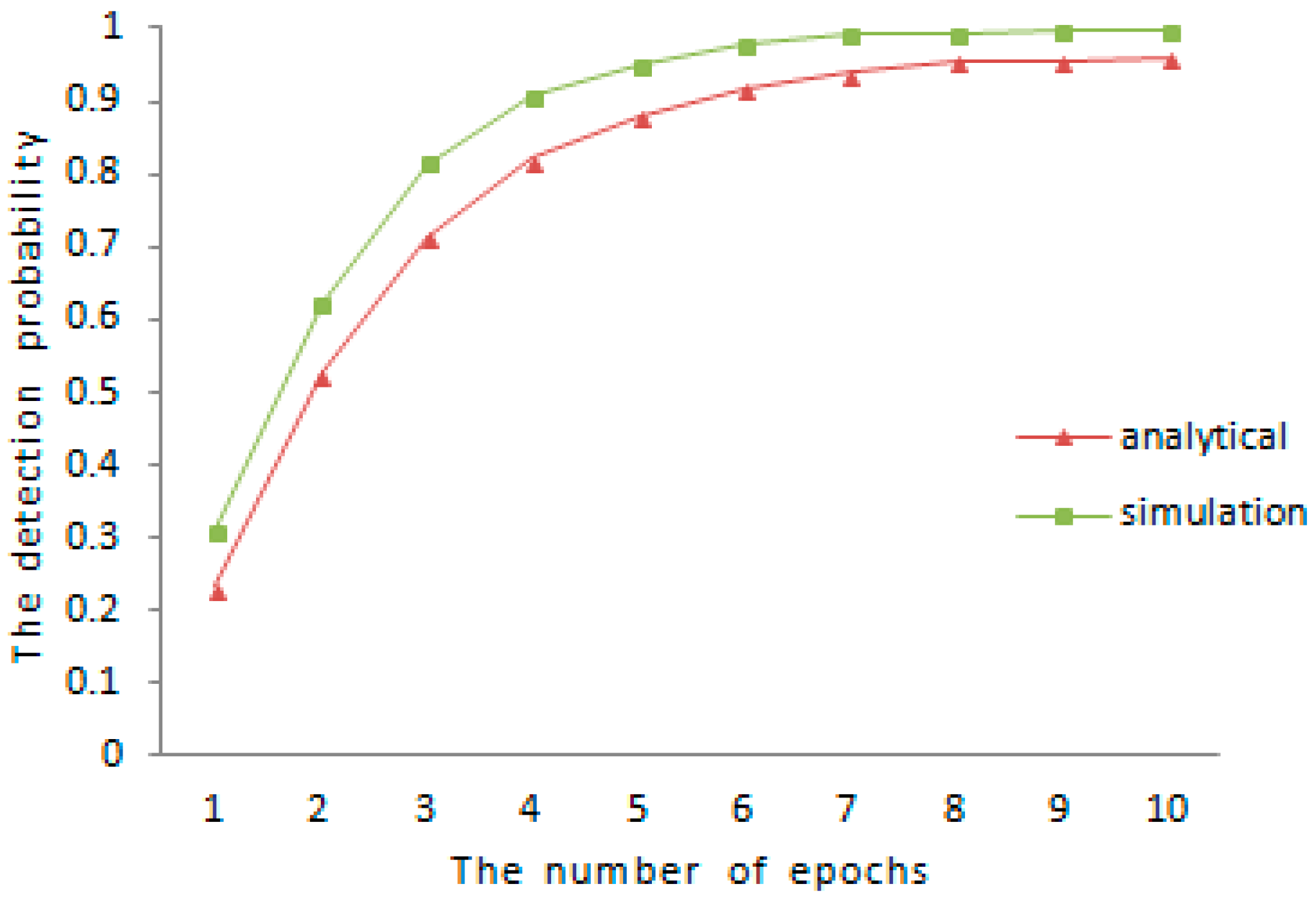
The lower bound of detection probability is analyzed in the earlier part of
Section 5, the comparison between theoretical analysis and experimental results for the detection probability is shown in
Figure 1 and
Figure 2, respectively. We vary the amount of mobile sensor nodes in sensor networks and the communication range between different sensor nodes. When
and
, the result of comparison is shown in
Figure 1. When
and
, the result of the comparison is shown in
Figure 2. As is shown in both of
Figure 1 and
Figure 2, the experimental detection probability is higher than the low bound of detection probability discussed before.
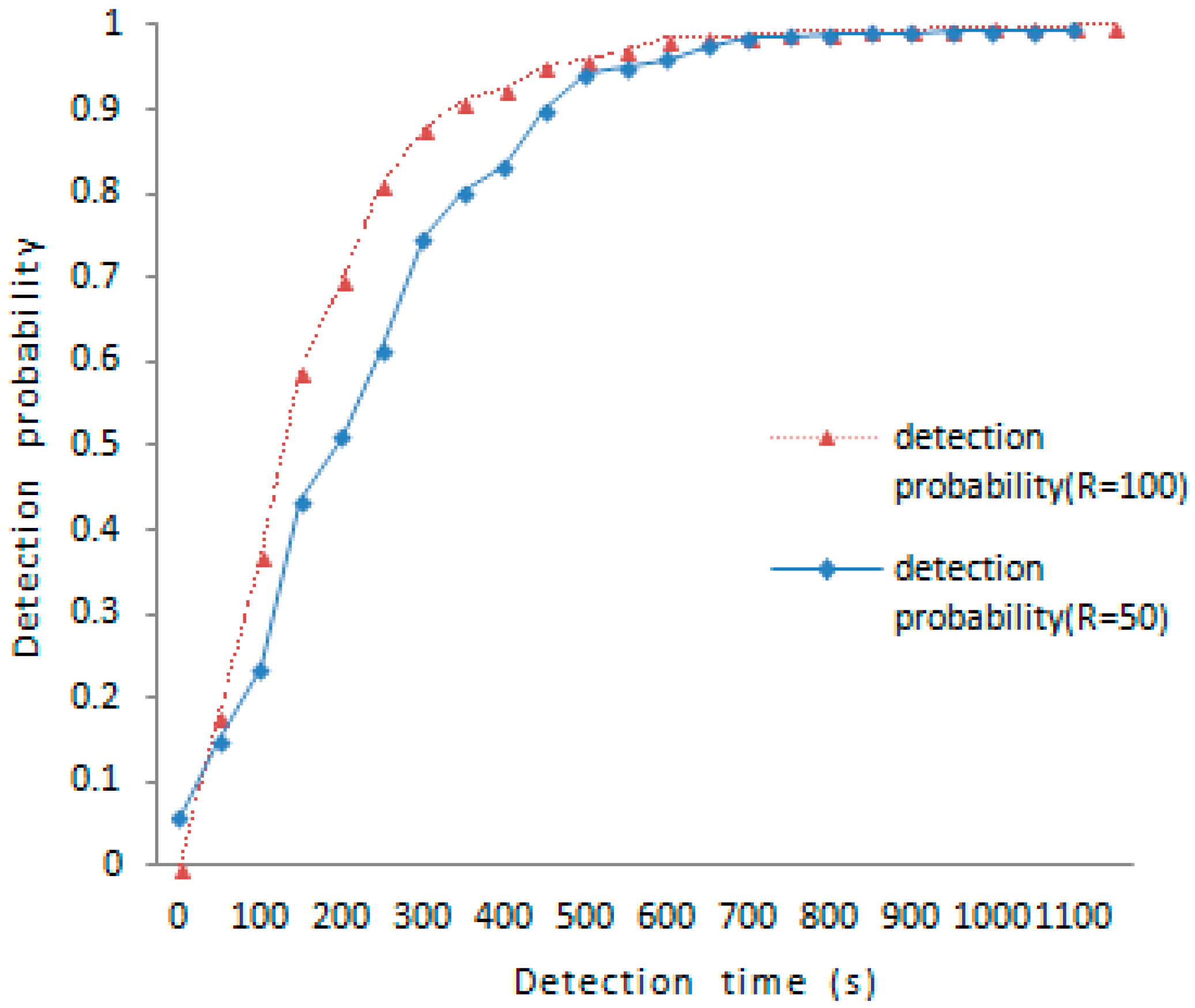
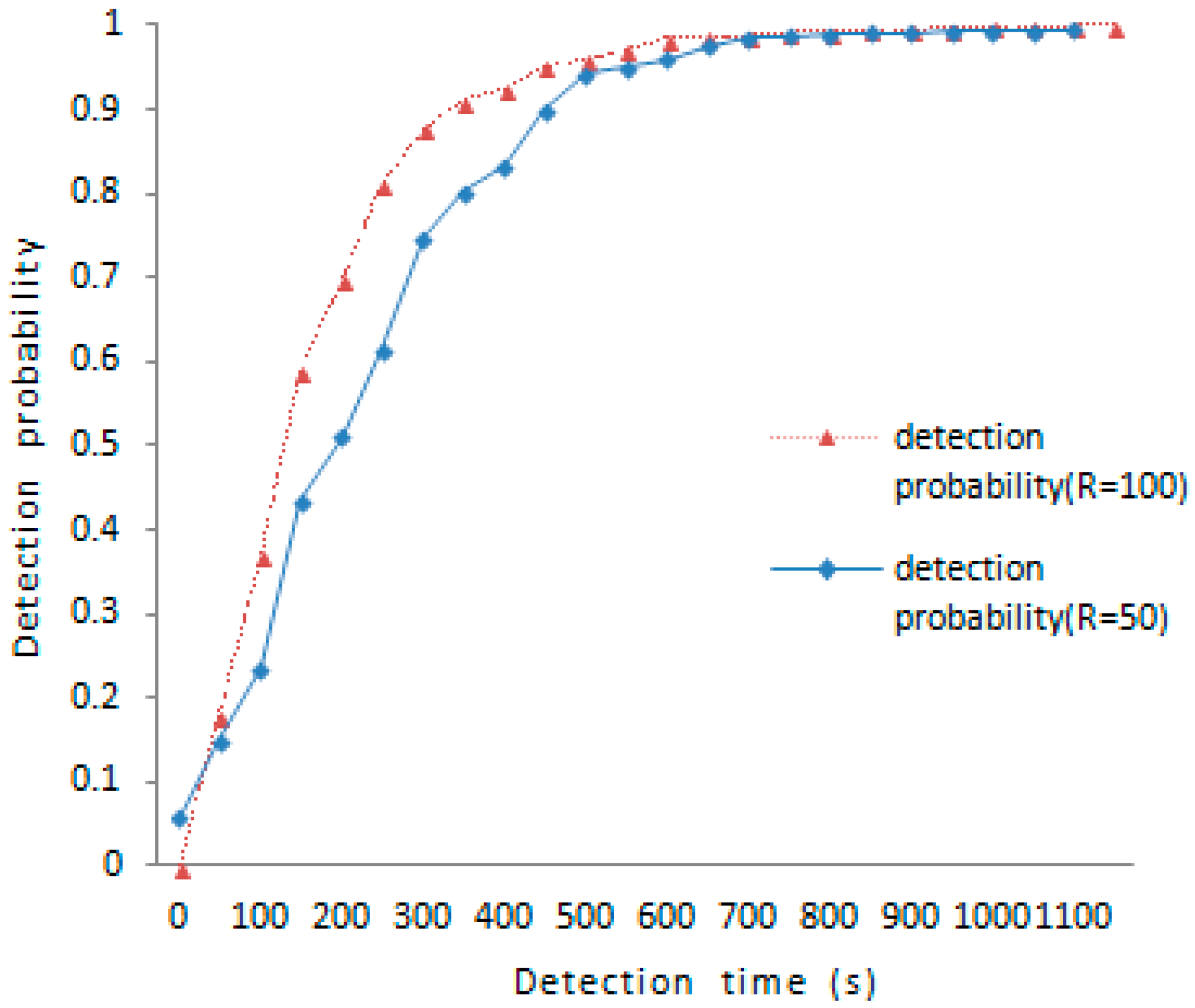
The detection time is an important metric to evaluate the proposed scheme. Because the communication range reflects the encounter probability, and the encounter probability decides the time elapsed between each meeting, so that we would discuss the change of detection probability with over time on the effects of different communication ranges. As is shown in
Figure 3, the detection probability under
is 51.1% and the detection probability under
is 82.1% about 250 s later; the detection probability under
is above 90% about 350 s later. To achieve the same result in the case of
, it takes at least 550 s to reach 90% detection probability. So the larger the communication range, the higher the detection probability.
Simulations are conducted to demonstrate the impact of time synchronization and localization errors on the proposed protocol. We use ideal temporal synchronization and positioning method to measure the speed, and then the measured speed
v is modified as
v′,
v′ is selected uniformly at random from the range of
and
, where
is defined as the maximum speed error rate.
and
are set in accordance with the maximum speed error rate.
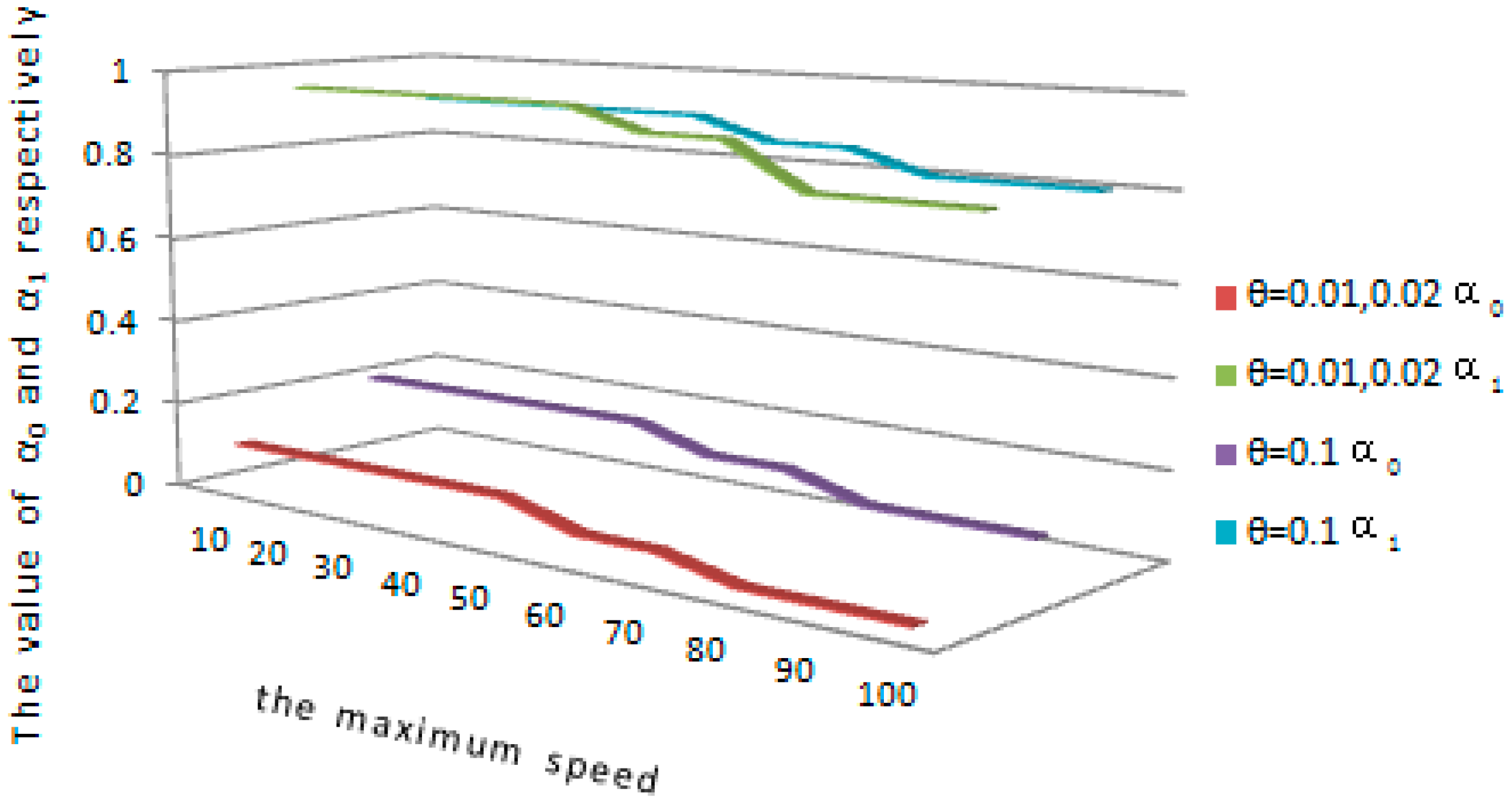
Figure 4 shows how to take different values of
and
according to the maximum speed
which is scientifically configured by the system. As shown in
Figure 4, when the system-configured maximum speed
is in the interval of 10~60 m/s, and the maximum speed error rate is 0.01 or 0.02.
and
are set to 0.1 and 0.95 respectively. When the predefined maximum value
is in the interval of 60~80 m/s and the maximum speed error rate is 0.01 or 0.02,
and
are set to 0.05 and 0.9 respectively. When the system-configured maximum speed
is in the interval of 80~100 m/s and the maximum speed error rate is 0.01 or 0.02,
and
are set to 0.01 and 0.8 respectively. When the system-configured maximum speed
is in the interval of 10~60 m/s and the maximum speed error rate is 0.1,
and
are set to 0.2 and 0.9 respectively. When the predefined maximum value
is in the range of 60 to 80 and the maximum speed error rate is 0.1,
and
are set to 0.15 and 0.85 respectively. When the system-configured maximum speed
is in the interval of 80~100 m/s and the maximum speed error rate is 0.1,
and
are set to 0.1 and 0.8 respectively. So it is deduced that the configurations of
and
are inversely proportional to variety in the system-configured maximum speed
.
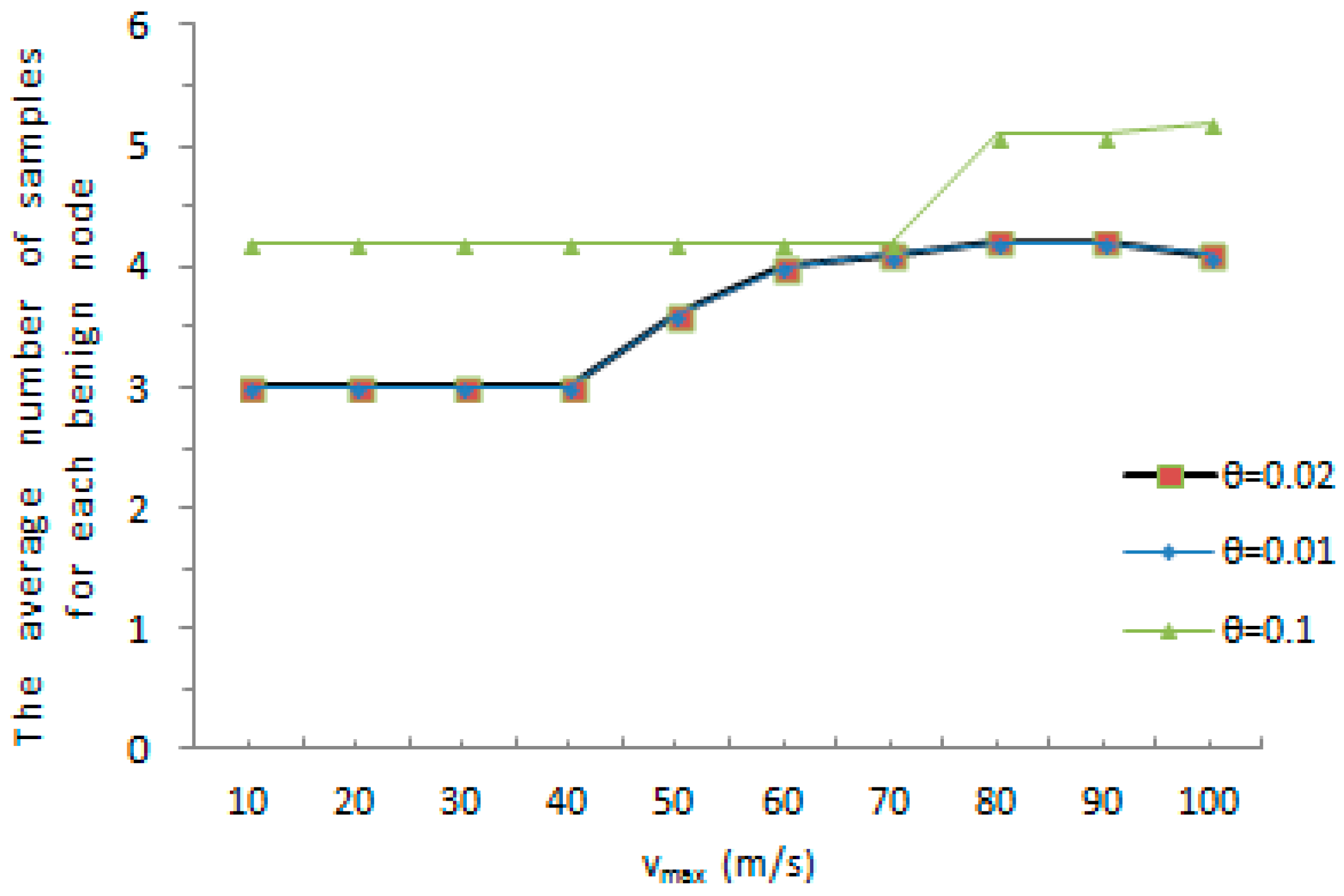
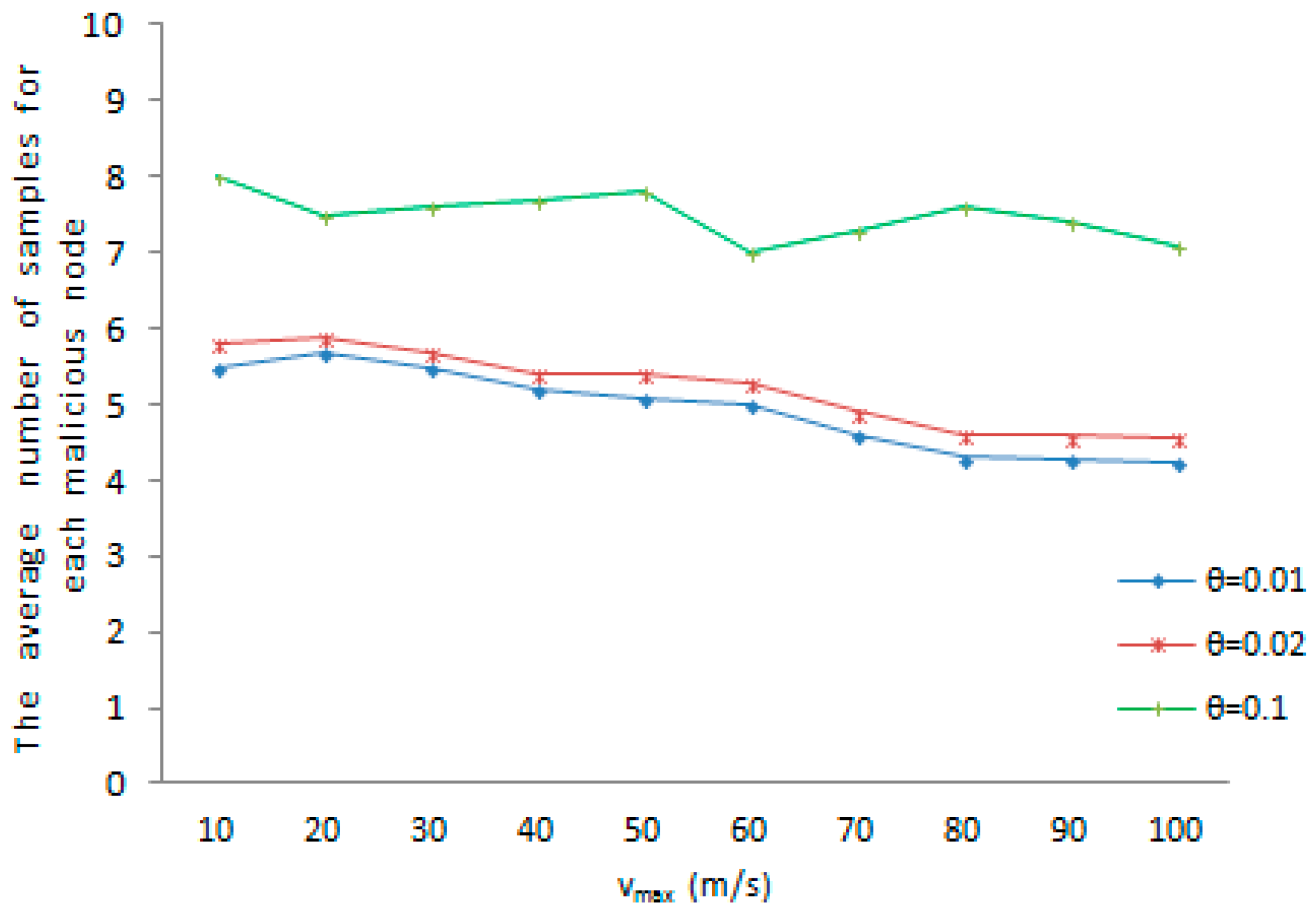
The average amount of samples for every tracked node is the amount of samples required for the witness node to judge whether a node has been cloned or not. We evaluate the average number of samples for each tracked node under different system-configured maximum speed when a malicious node is accurately found out as cloned node. As shown in
Figure 5, the average amount of samples achieves a maximum value at 8, when the maximum speed
and the maximum speed error rate
. The average number of samples reaches a minimum value at 4.25 when the predefined maximum value
and the maximum speed error rate
. There is another dimension,
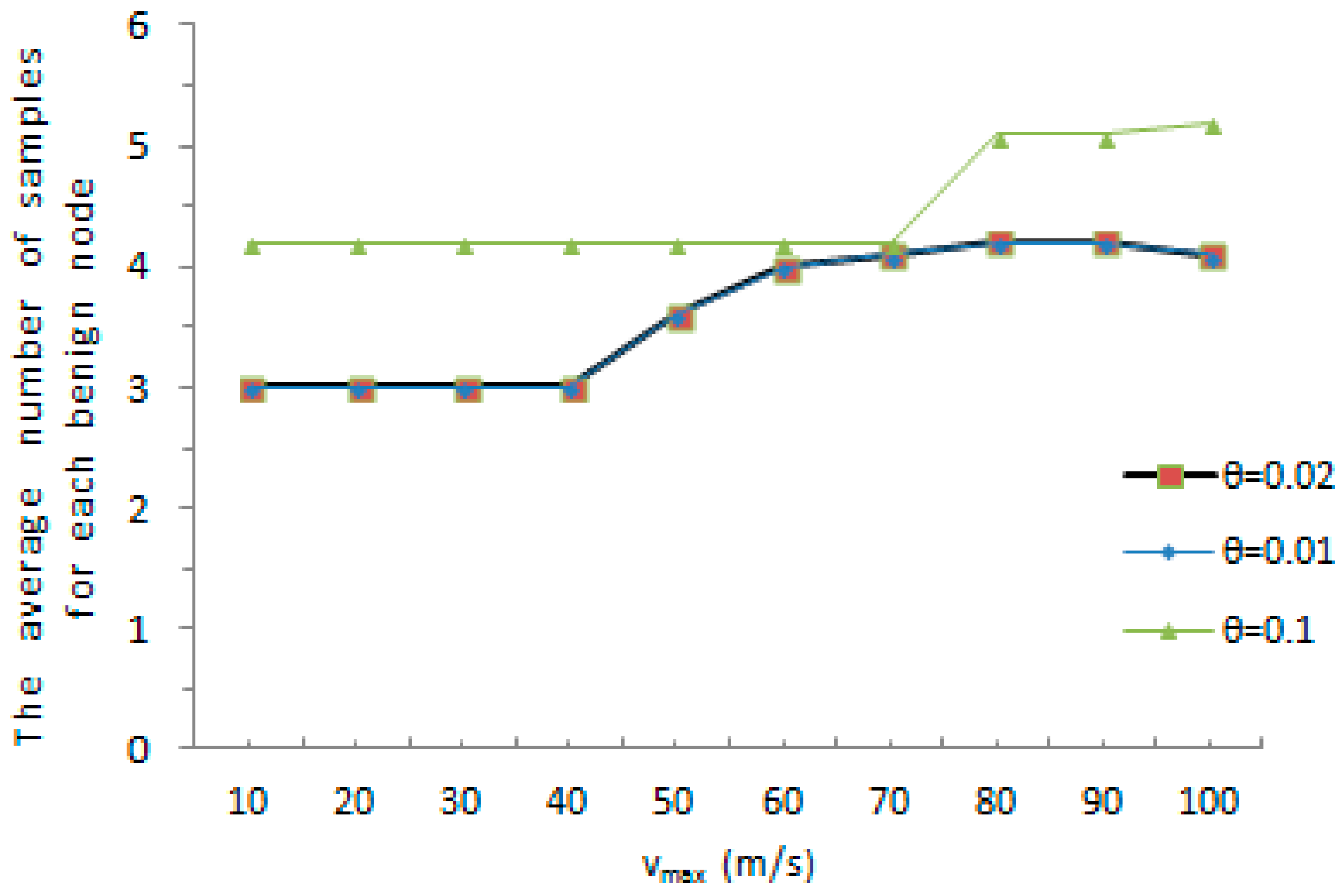
Figure 6 shows the average amount of samples for each tracked node under different maximum speed when a benign node is accurately detected as a normal node. As shown in
Figure 6, the average amount of samples achieves a maximum value at 5.2, when the predefined maximum speed
and the maximum speed error rate
. The average amount of samples reaches a minimum value at 3 when the predefined maximum speed
and the maximum speed error rate
. As the whole, with the increase of the predefined maximum value, the average number of samples for each tracked node rises or drops slightly. The witness node would detect whether a mobile sensor node has been replicated or not with a smaller number of samples in both cases. Meanwhile, it is obvious that an increase of the maximum speed error rate
results in the growth of the average amount of samples for each tracked node. It can be further reasoned that the faster the movement speed, the higher the chance that the measured speed of a normal node is erroneous detected to be over the predefined maximum speed. On the contrary, the faster the movement speed, the less chance that the measured speed of a malicious node is erroneous detected to be below the system-configured maximum speed.
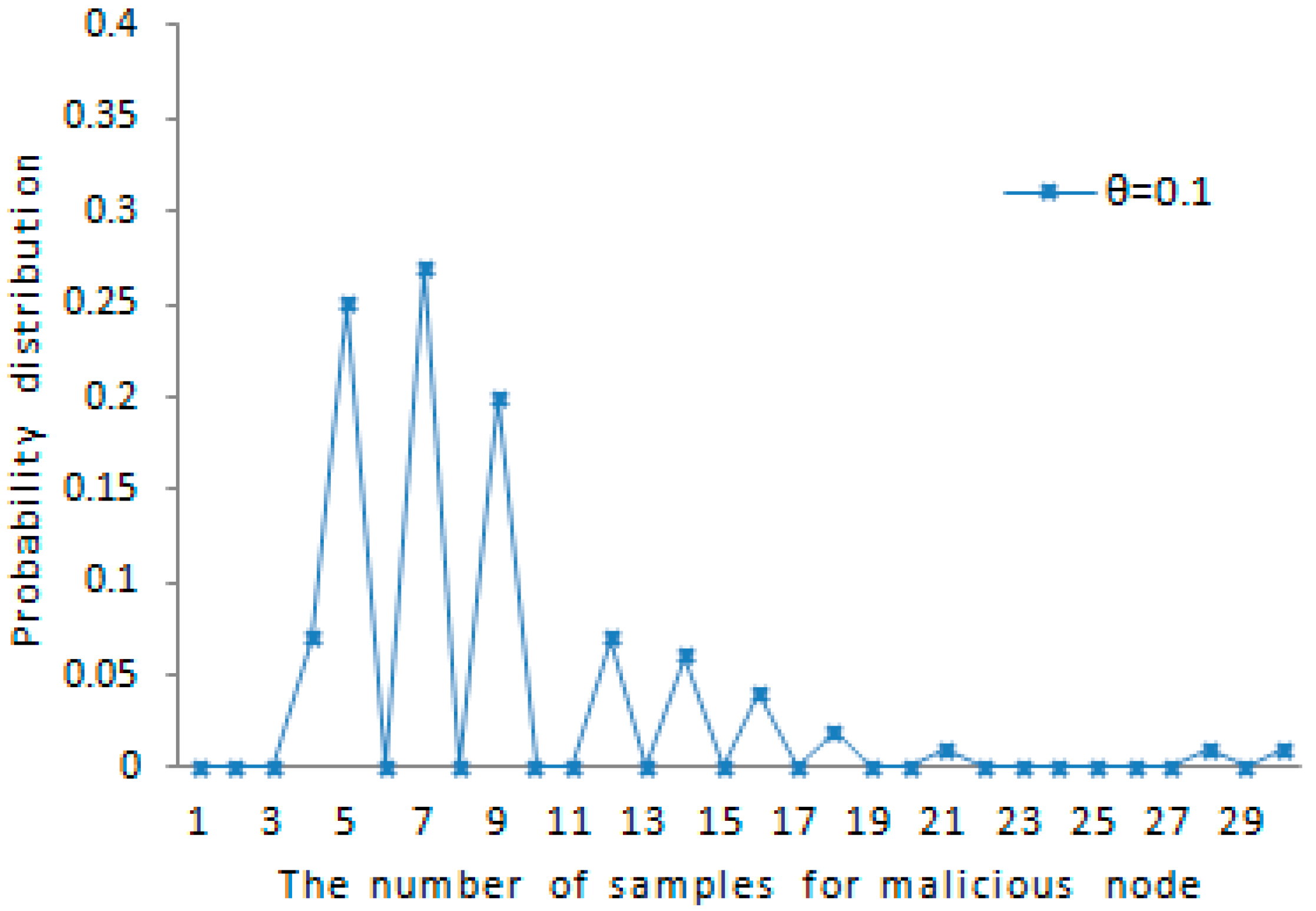
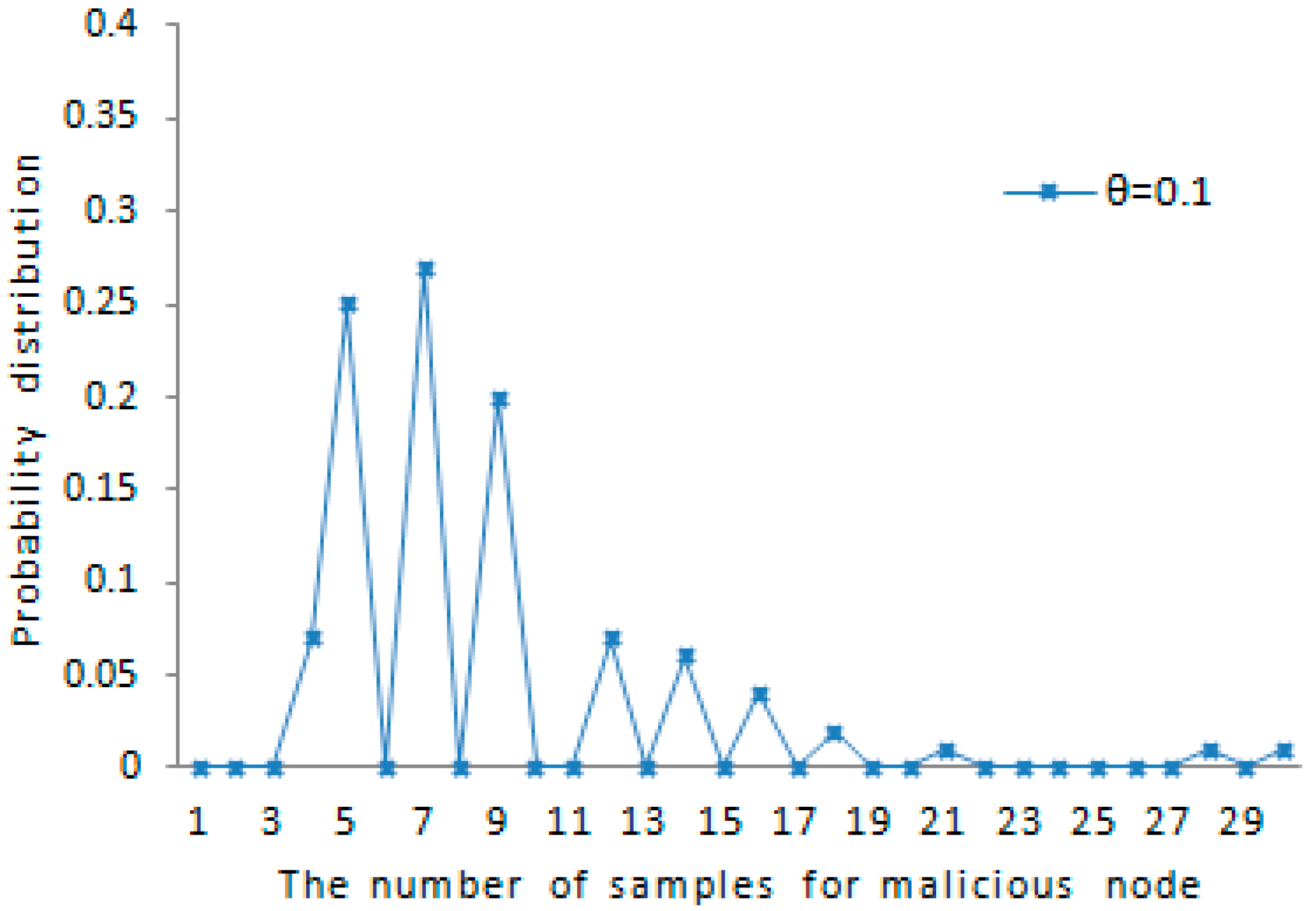
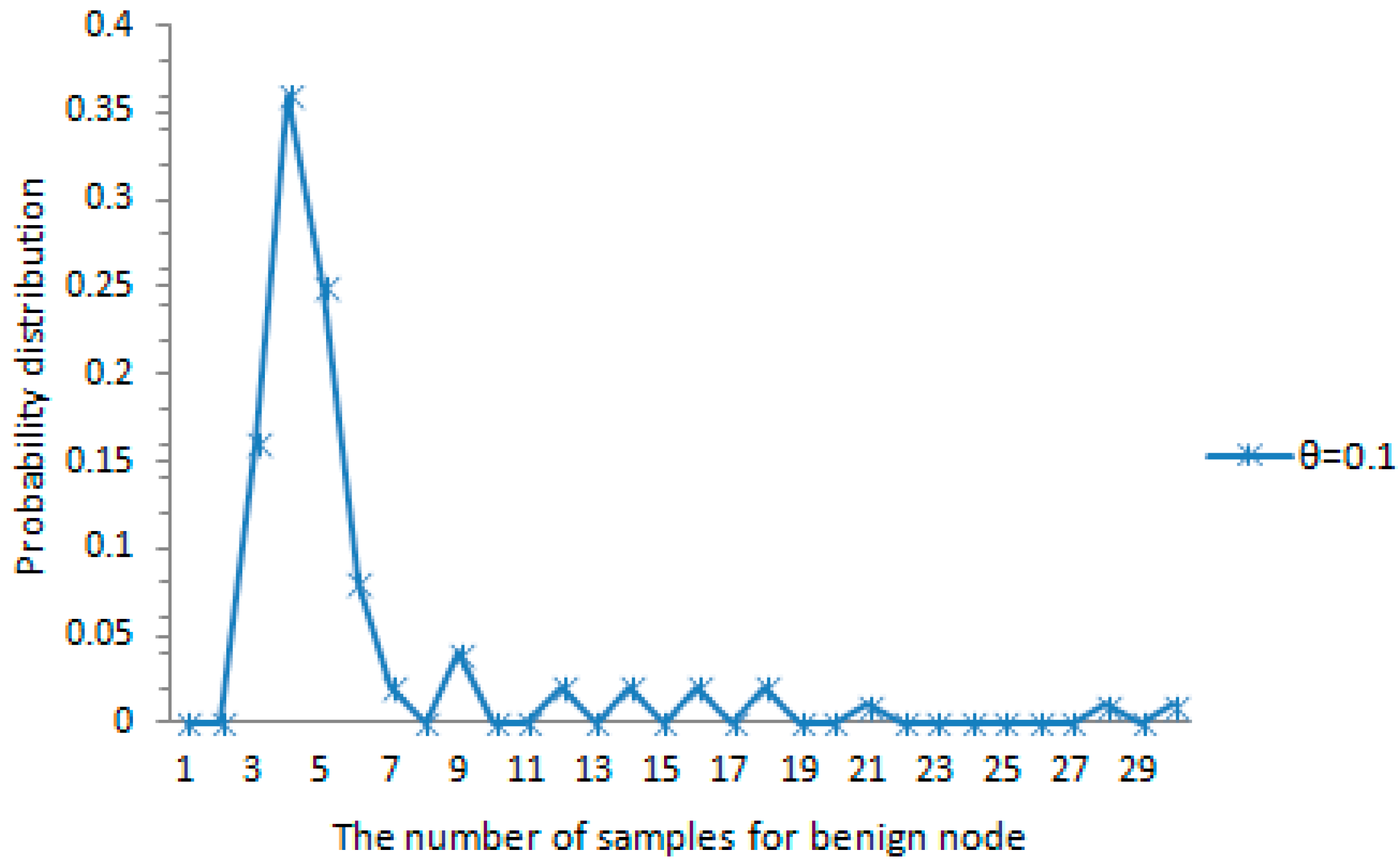
The probability distribution of the amount of samples for each malicious node detected accurately is shown in
Figure 7. When the maximum speed error rate
and the maximum speed
, about 79% of all the case falls in the range of
as shown in the figure. This also indicates that the probability distribution of the amount of samples satisfies the rule reflected in
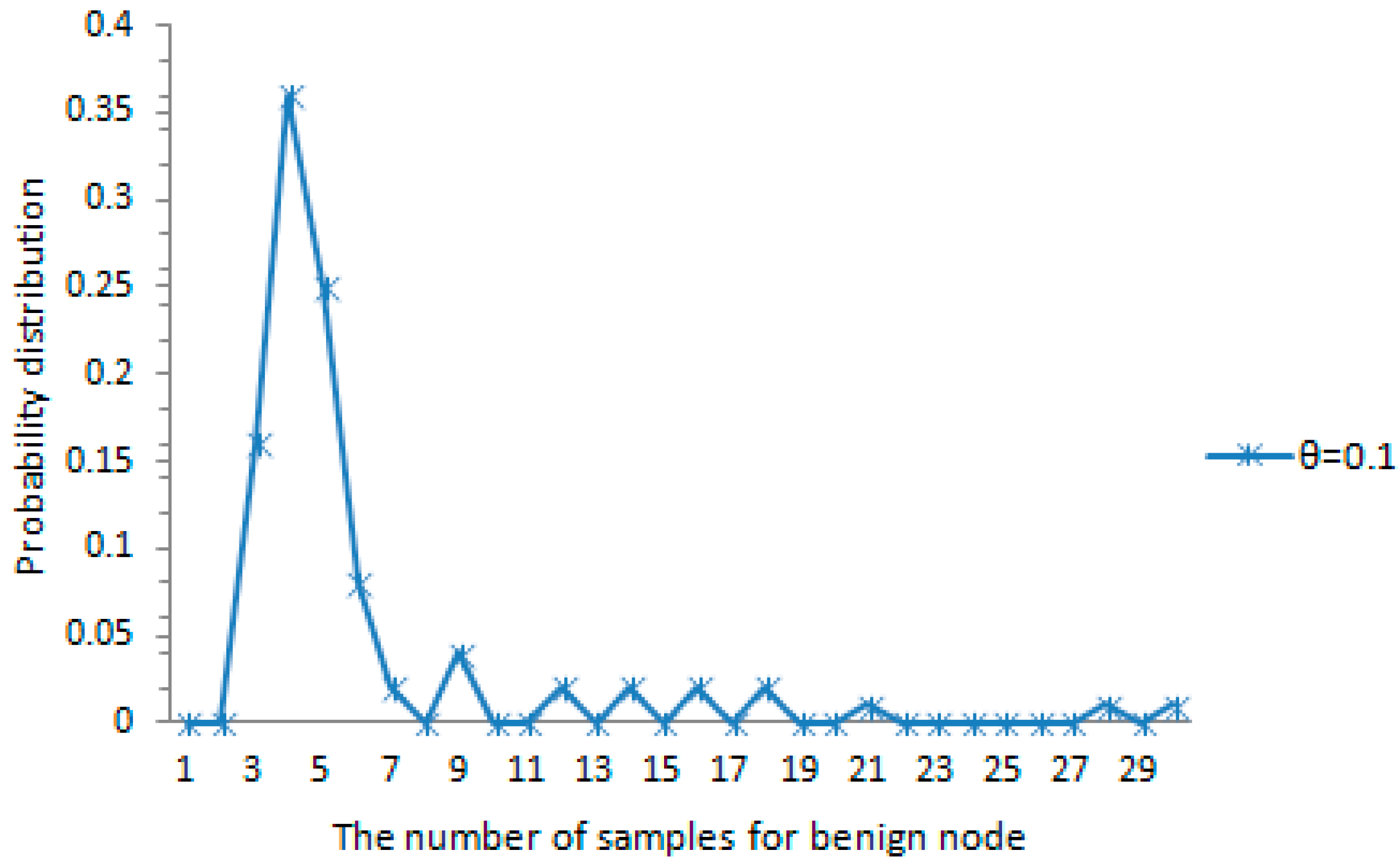
Figure 5. The amount of samples for each tracked node is less than or close to the average amount for each tracked node. The probability distribution of the amount of samples for each benign node detected accurately is shown in
Figure 8. When the maximum speed error rate
and the system-configured maximum speed
, about 87% of all the case falls in the range of
as shown in the figure. This also indicates that the probability distribution of the amount of samples satisfies the rule reflected in
Figure 6. The amount of samples for each benign node is below or close to the average amount for each benign node. As we can see from
Figure 5 and
Figure 6, it is obvious that whether a mobile sensor node is malicious node can be decided quickly with a few samples for each tracked node.
In the process of detection, one queue for each tracked node in the tracking set is maintained, which can hold more than two corresponding detection information. Because the more samples are measured, the more accurate the detection, the length of the queue denoted as
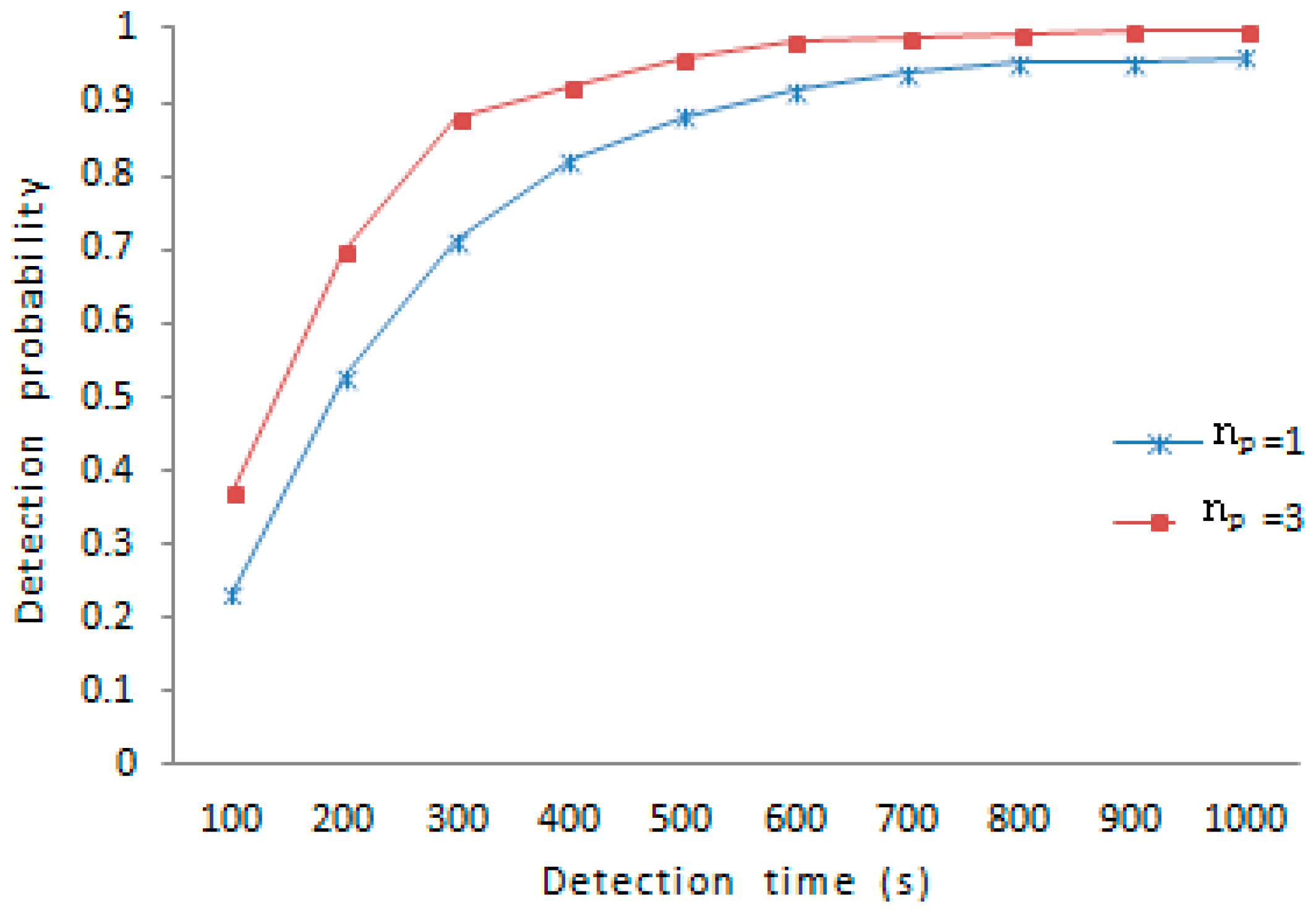
is set to a higher value to accelerate the speed of detection. But the longer the queue, the more space costs, to avoid overload for the tracking node, therefore making the size of each queue equal to 3 is meeting demand. As is shown in
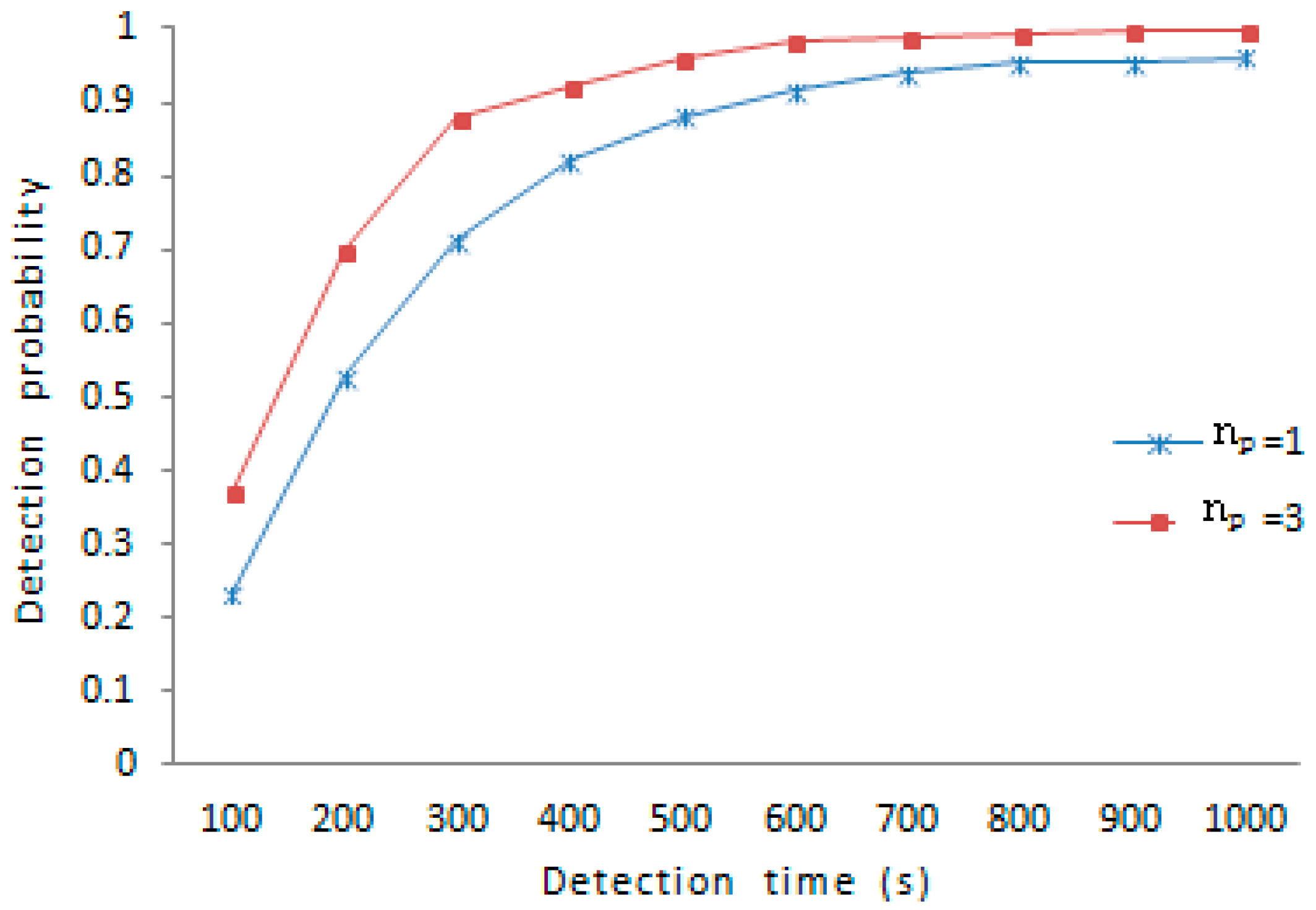
Figure 9, under the same amount of nodes compromised, the scheme with
shows stronger resilience than the scheme with
. For example, the detection probability under
is 37.1% and the detection probability under
is 23.3%, when the detection time is 100 s; the detection probability under
is 95.9% and the detection probability under
is 88.1%, when the detection time is 500 s. At the beginning of detection, the growth rate of detection probability under
is higher than that of detection probability under
. About 400 s later, the growth rate of detection probability under
is gradually slower than that of detection probability under
. Generally speaking, the detection probability under
is higher than the detection probability under
just as shown in
Figure 9.
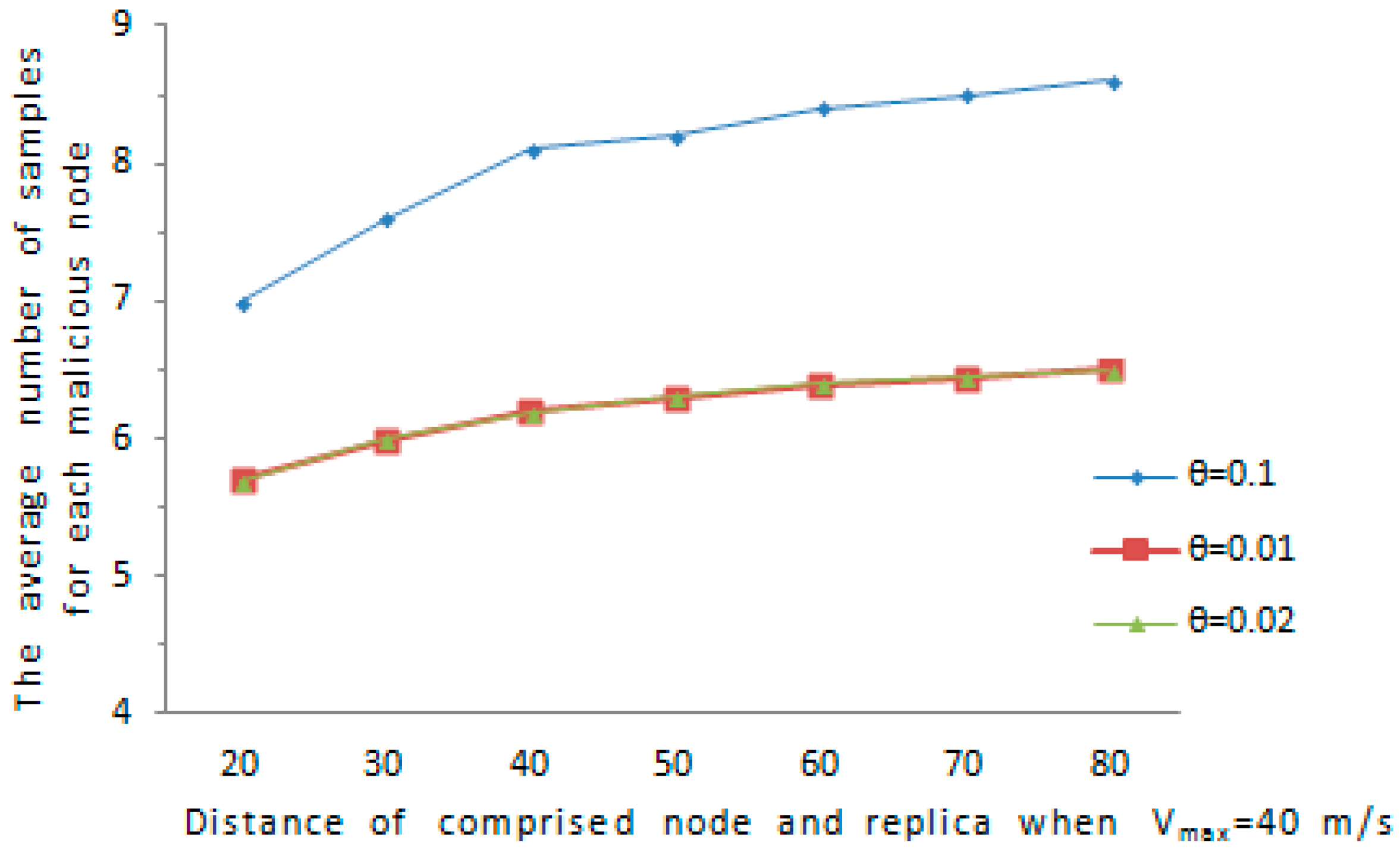
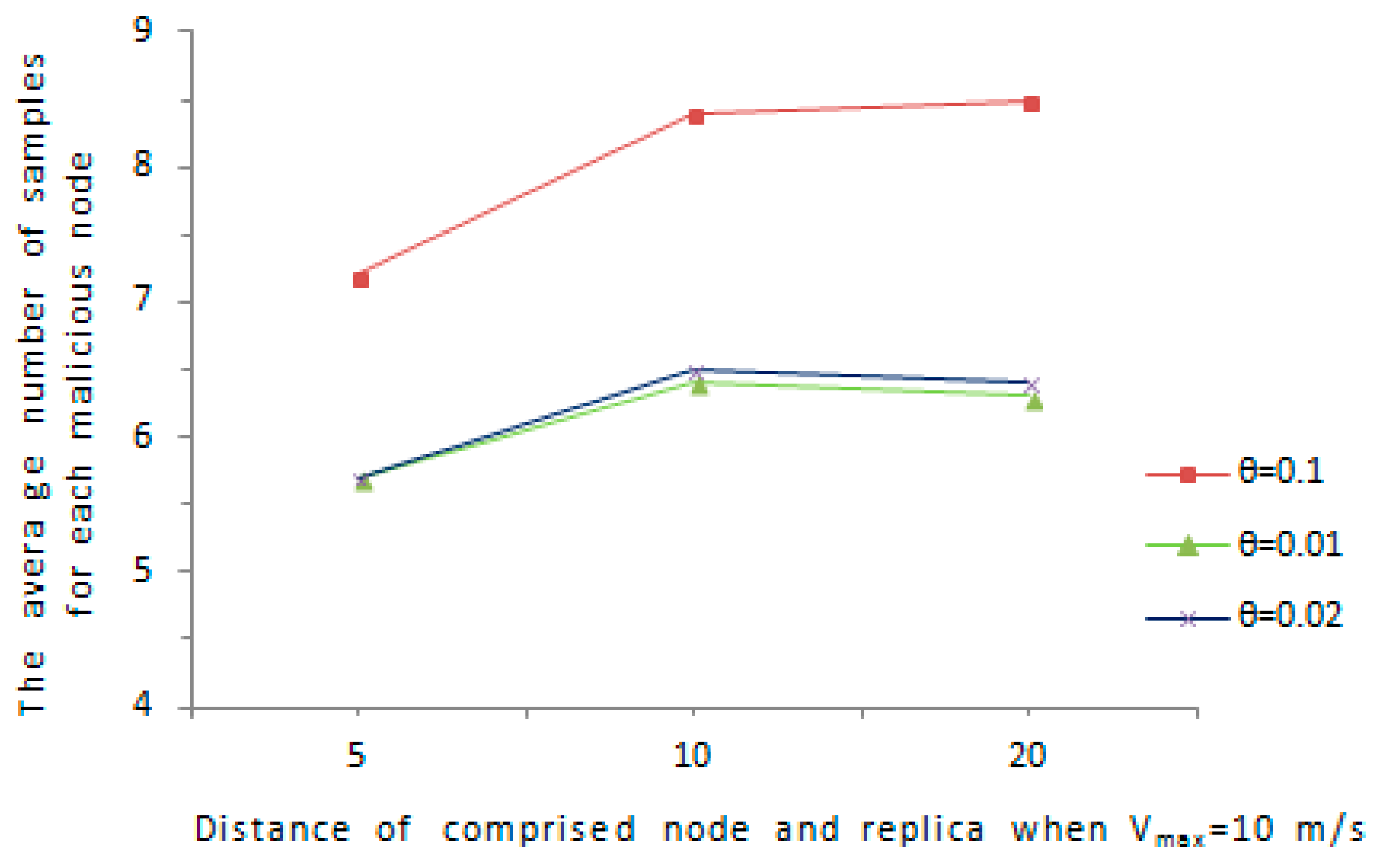
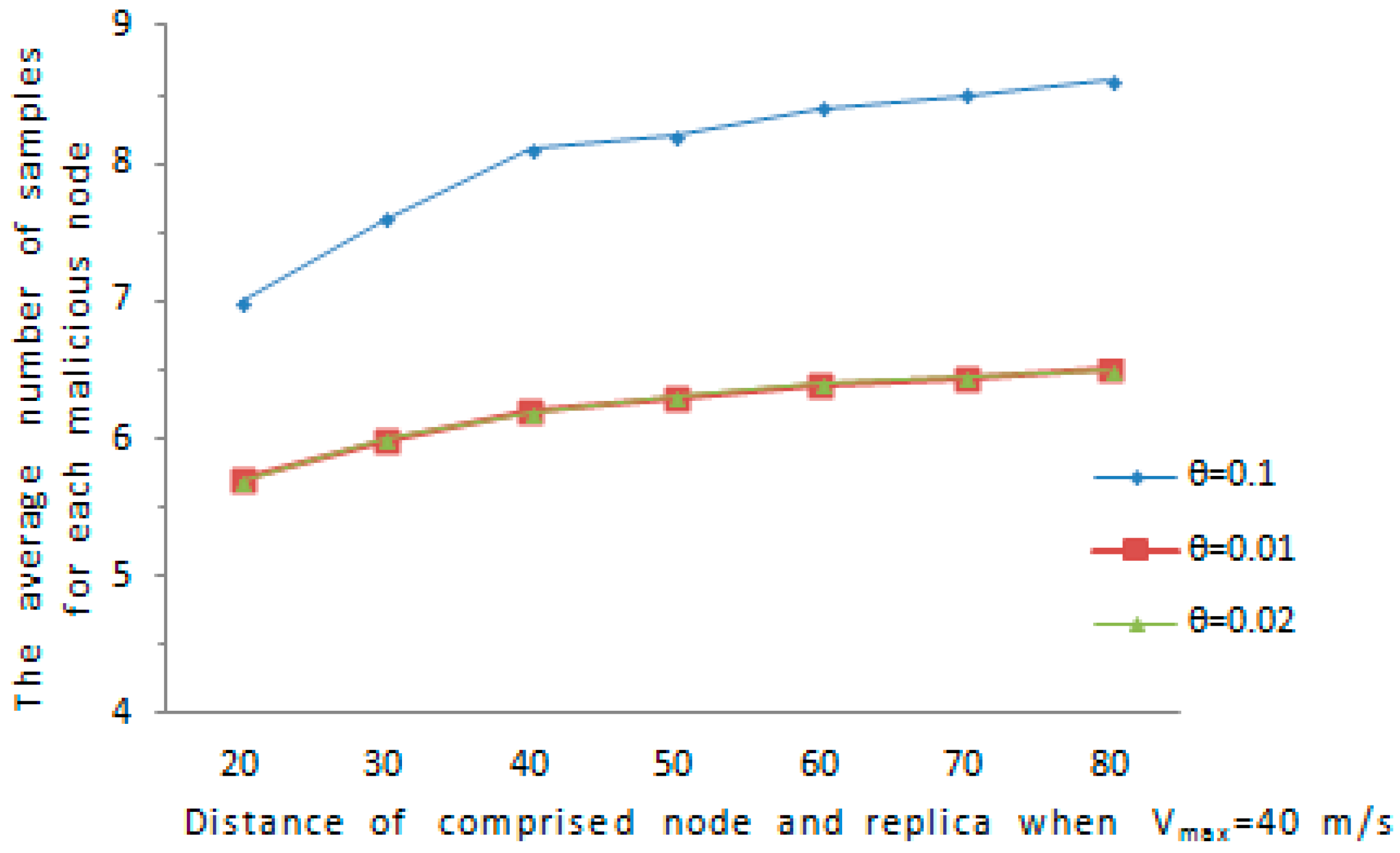
We further consider a special case, if the comprised node and its replica remain static at a certain distance, it is possible for the malicious node to avoid being discovered, for example, the comprised node and its replica are not detected with high probability when
and
, because the detection is based on speed. Assume
indicates the distance between the comprised node and the cloned node, we evaluate the distance
in such a way that
varies from
to
, where
is set according
. We evaluate the detection ability of our proposed protocol in the case of
is relatively short. We consider the
is in the interval of
and
is in the range of
. As is shown in
Figure 10 and
Figure 11, the average amount of samples for malicious node increases with the maximum speed error rate
. As far as the affect of
on the amount of samples for a abnormal node, when
grows from
to
, the average amount of samples for an abnormal node increases obviously. Overall, the average amount of samples for an abnormal node is below 9.5 in all cases, and the comprised node and its replica can be detected with a reasonable amount of samples.
In our scheme, the average amount of messages that each node transmitted and received in one epoch is utilized to estimate the communication overhead.
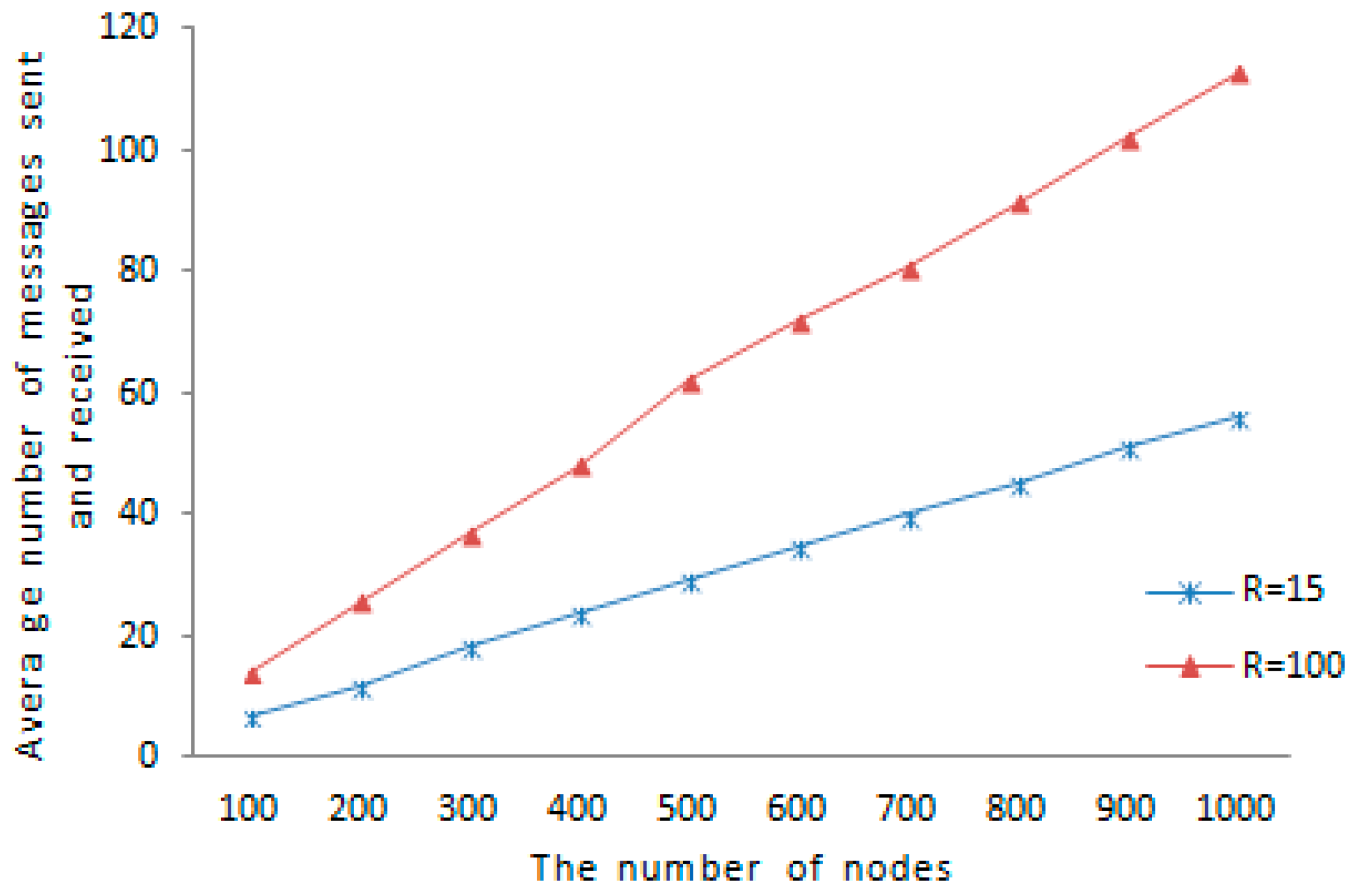
Figure 10 shows that the communication overhead changes over the number of nodes uniformly distributed in wireless sensor networks. The communication overheads under different communication ranges are compared. When the communication range of sensor node increases, the set of node’ one-hop neighbors enlarges. The probability that two tracking nodes with same tracked node encounter increases, and the detection information forwarded to witness node for detection increases accordingly, so the communication overhead becomes higher. As is shown in
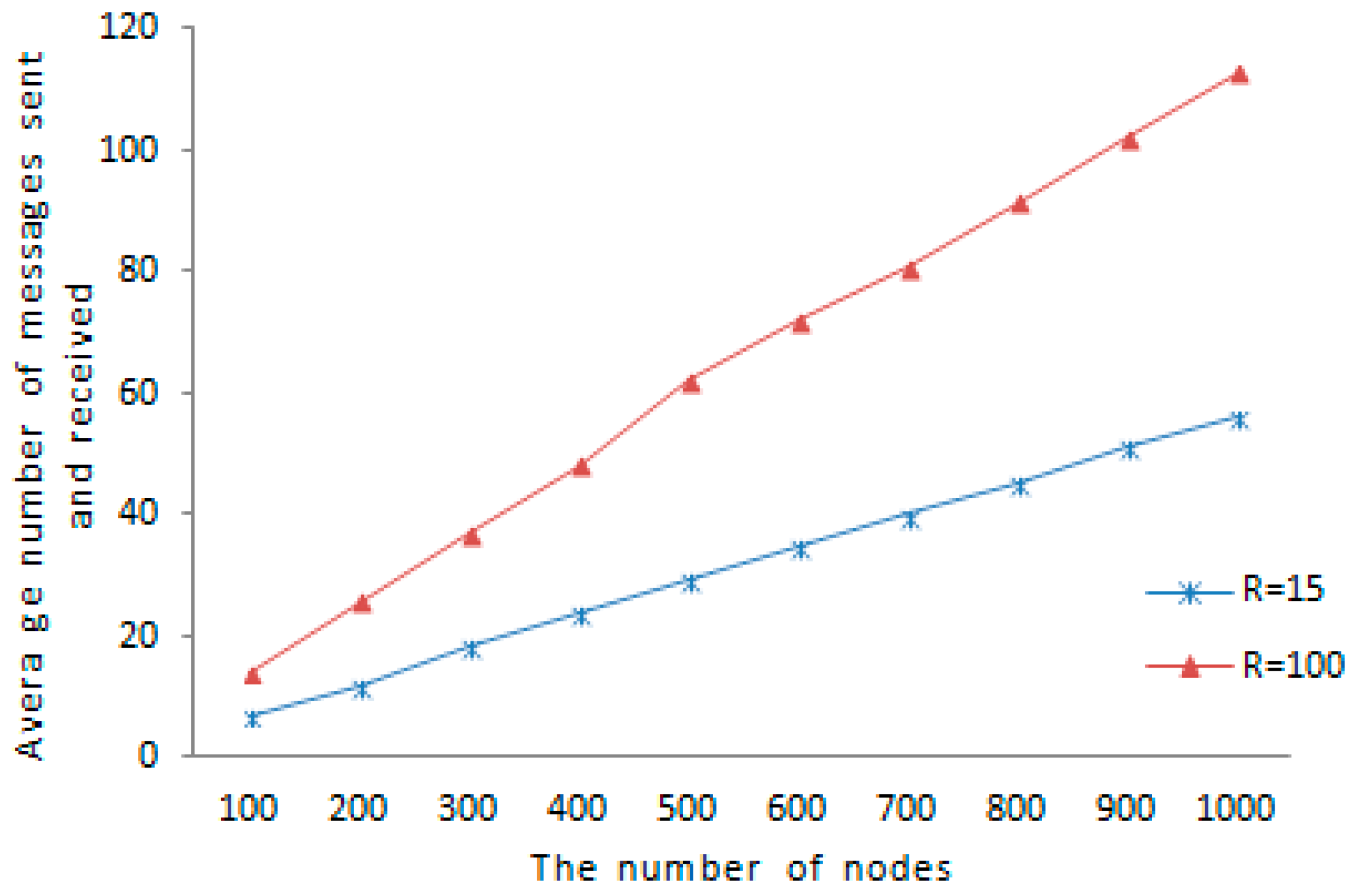
Figure 12, the average amount of messages sent and received under
is 62, and the average amount of messages sent and received under
is 29, as the network size is 500 nodes. The average amount of messages sent and received under
is 113 and the average amount of messages transmitted and received under
is 56 when the network size is 1000 nodes, so the larger the communication range, the higher the communication overhead, further a gap of the average amount of messages transmitted and received under the two communication range becomes more and more large with the network pattern’s augmentation.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}