
An Effective Massive Sensor Network Data Access Scheme Based on Topology Control for the Internet of Things


Abstract
:1. Introduction
2. Related Work
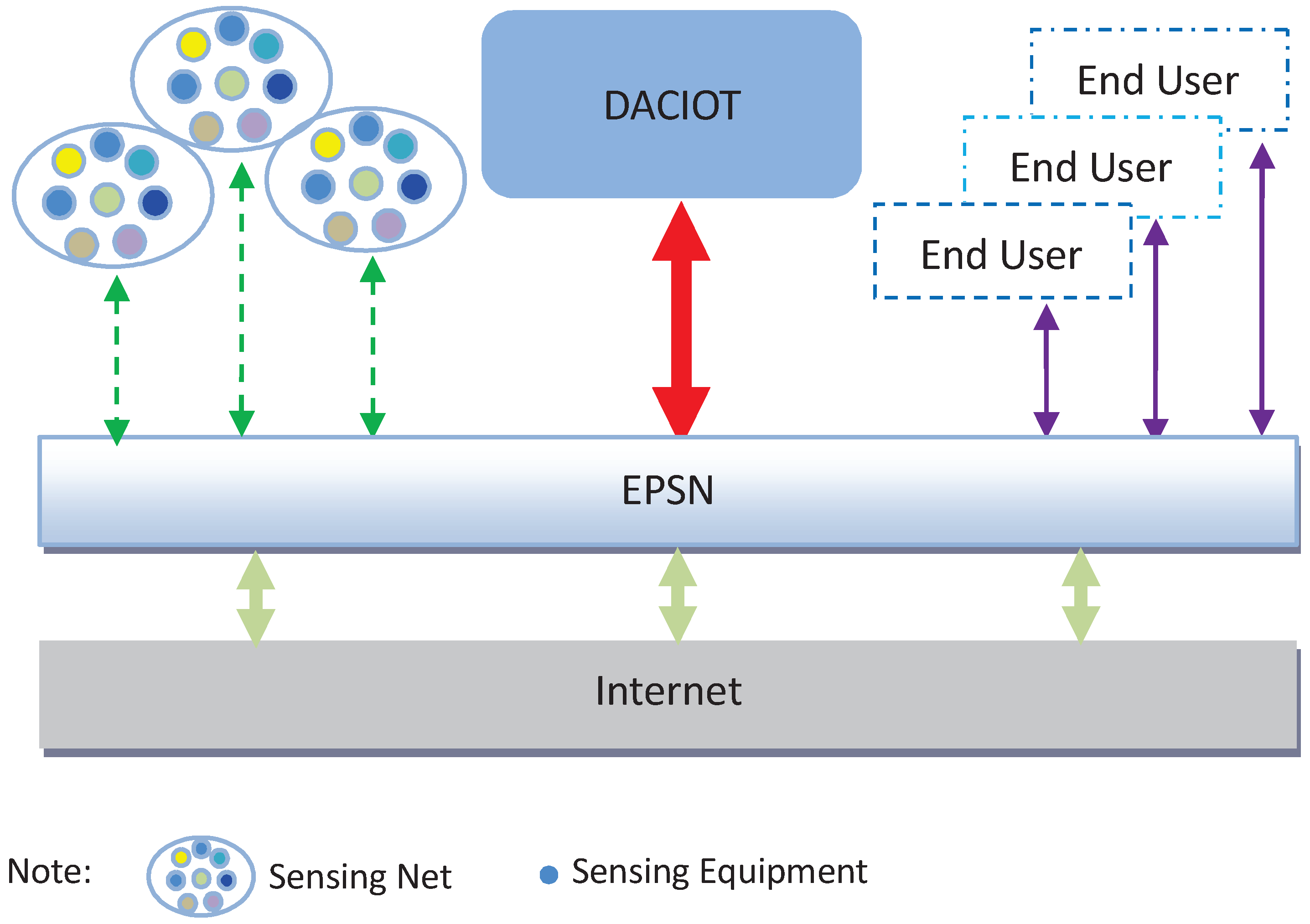
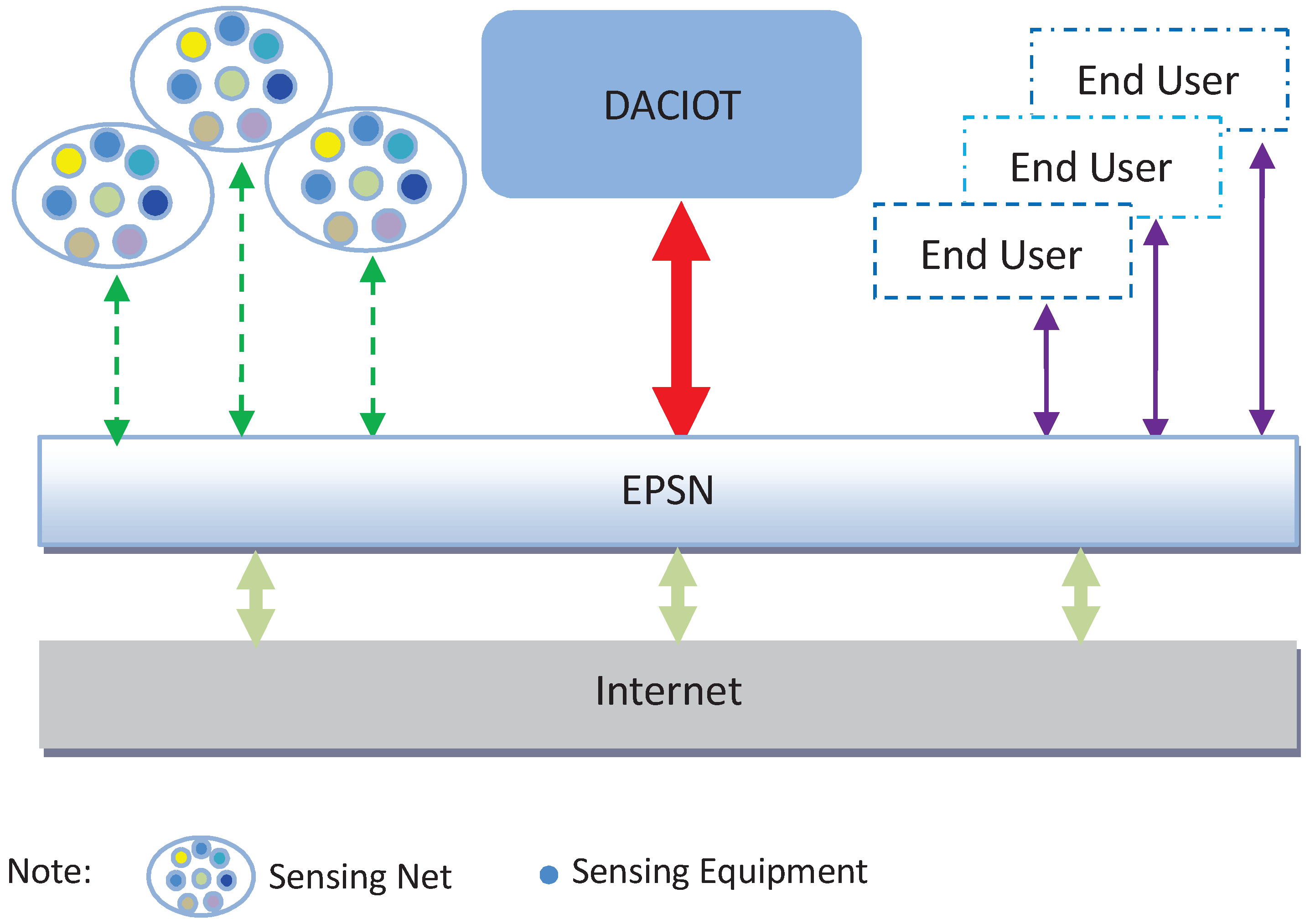
3. System Model and Definitions
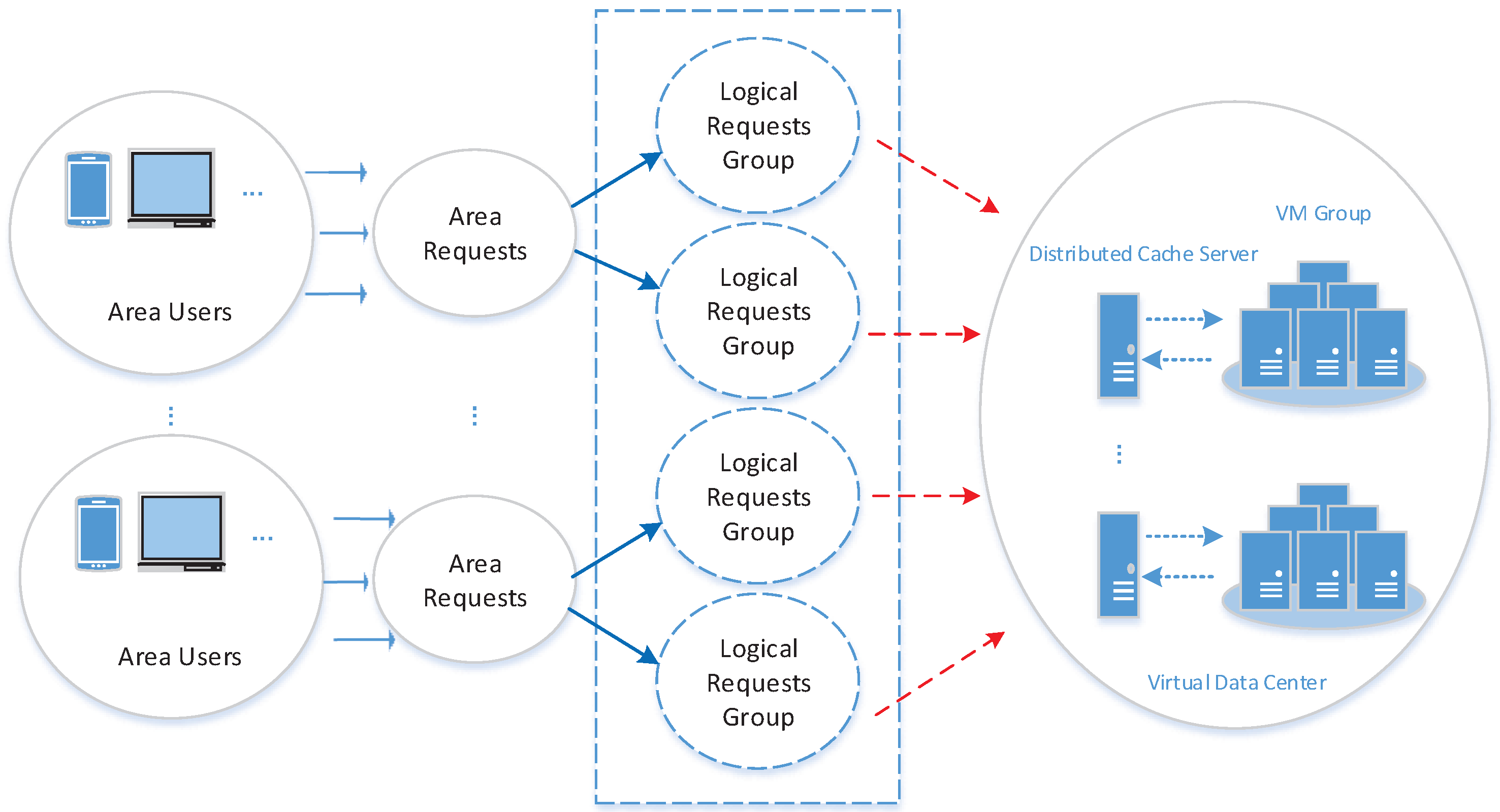
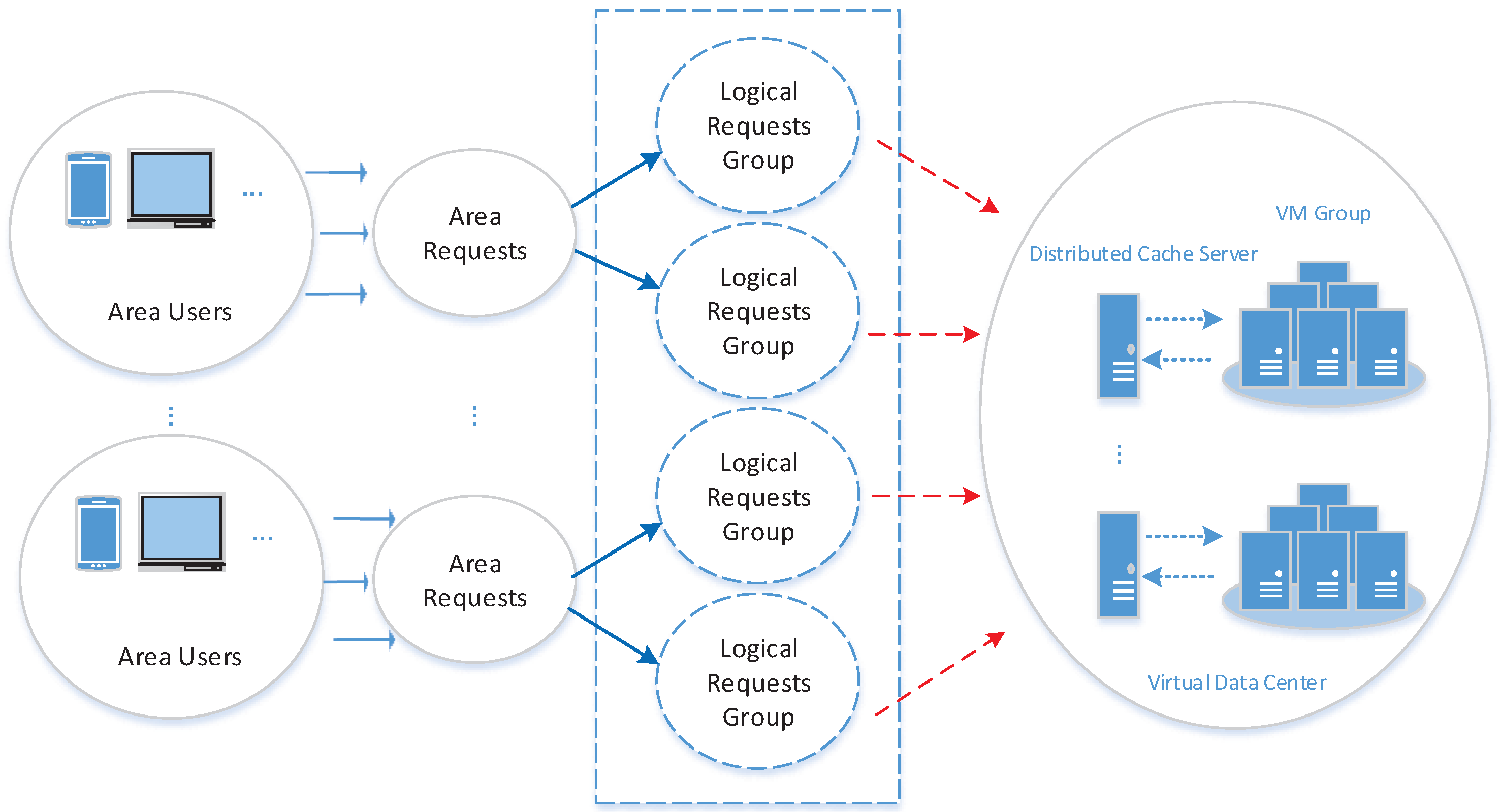
4. The Proposed Massive Sensor Network Data Access and Control Mechanism (MSACM)
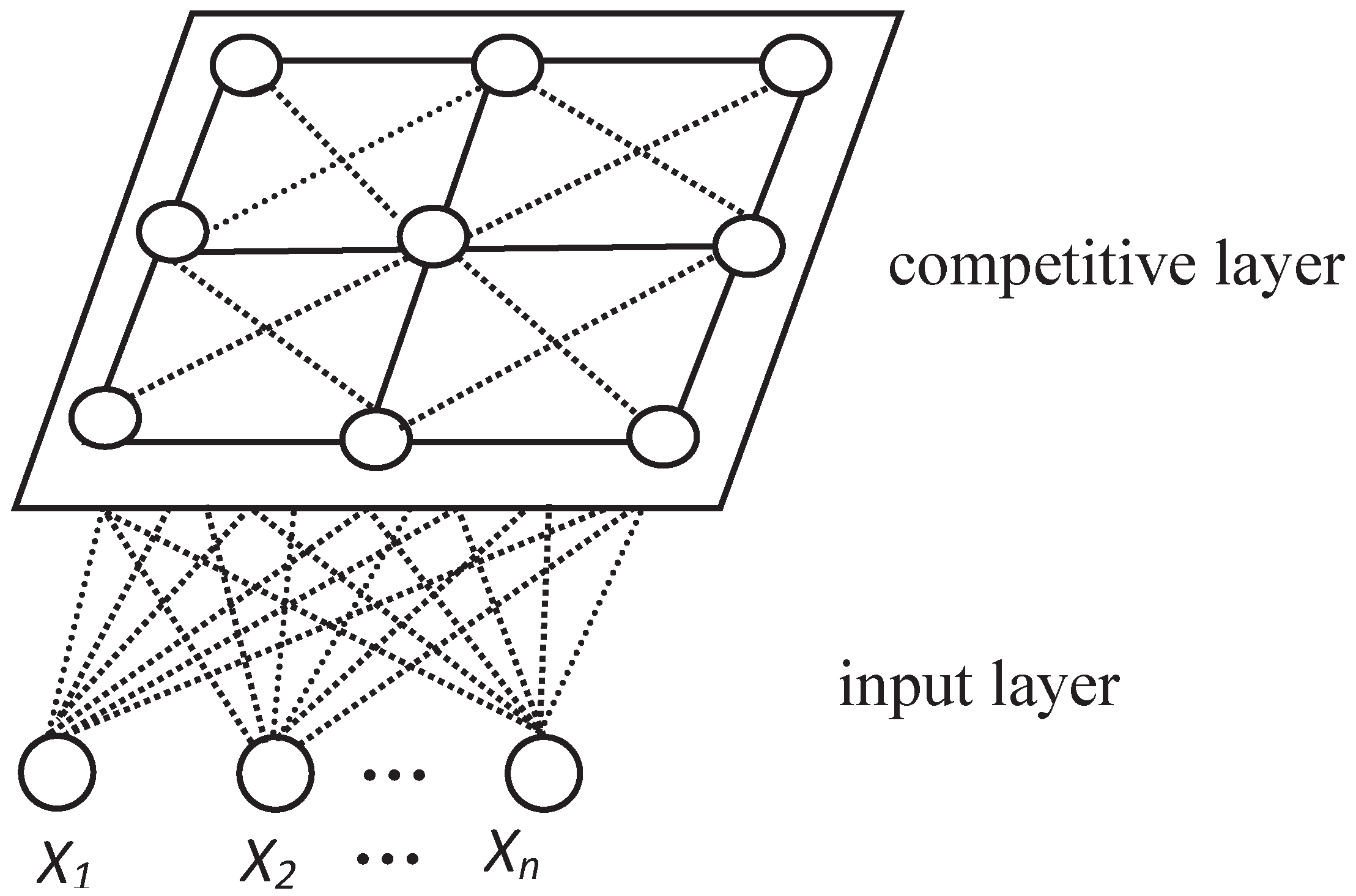
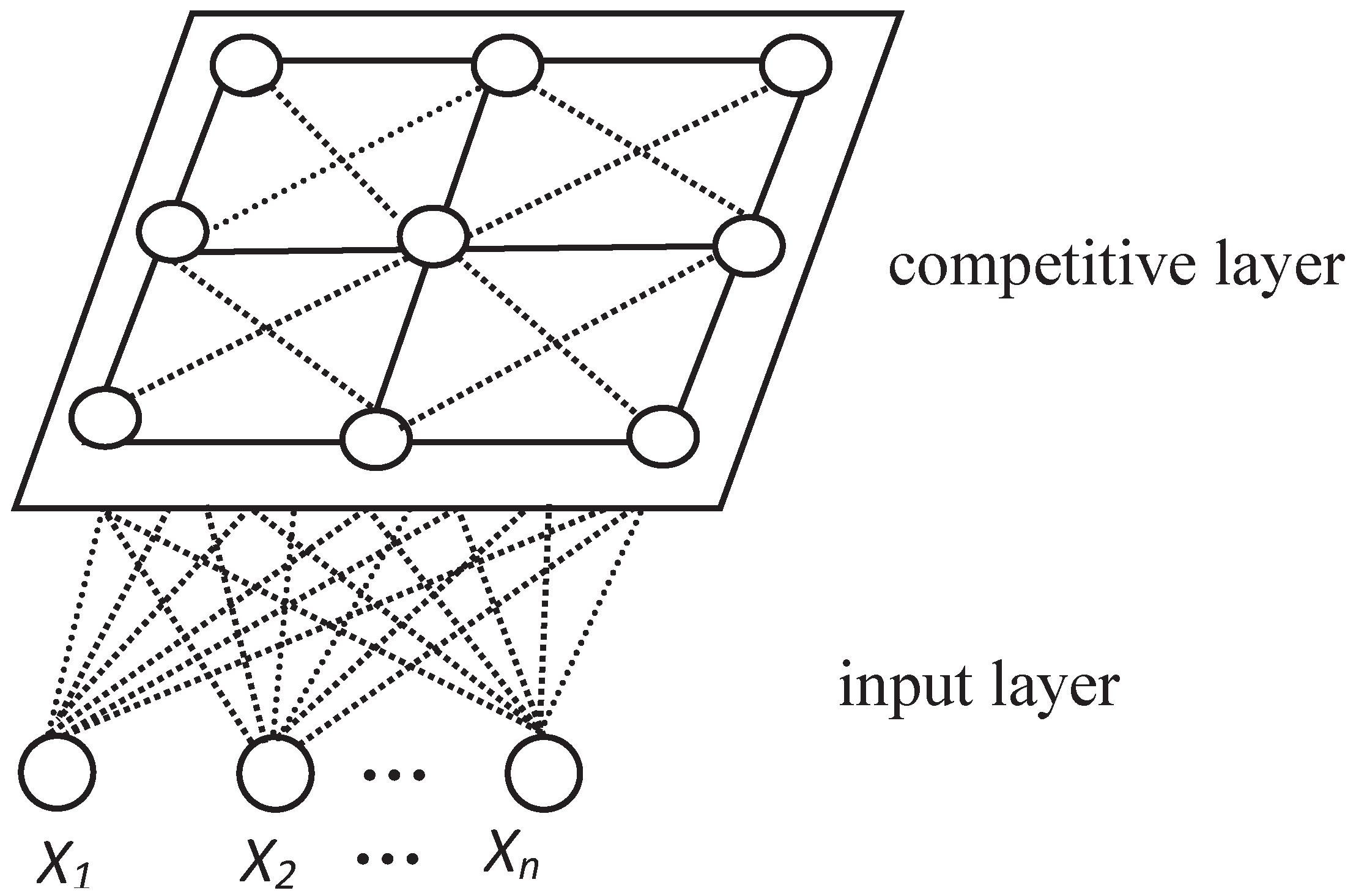
4.1. Optimized Dynamic Self-Organizing Feature Maps (ODSOFM)
4.1.1. ODSOFM Introduction
4.1.2. Description of Optimized Dynamic SOFM
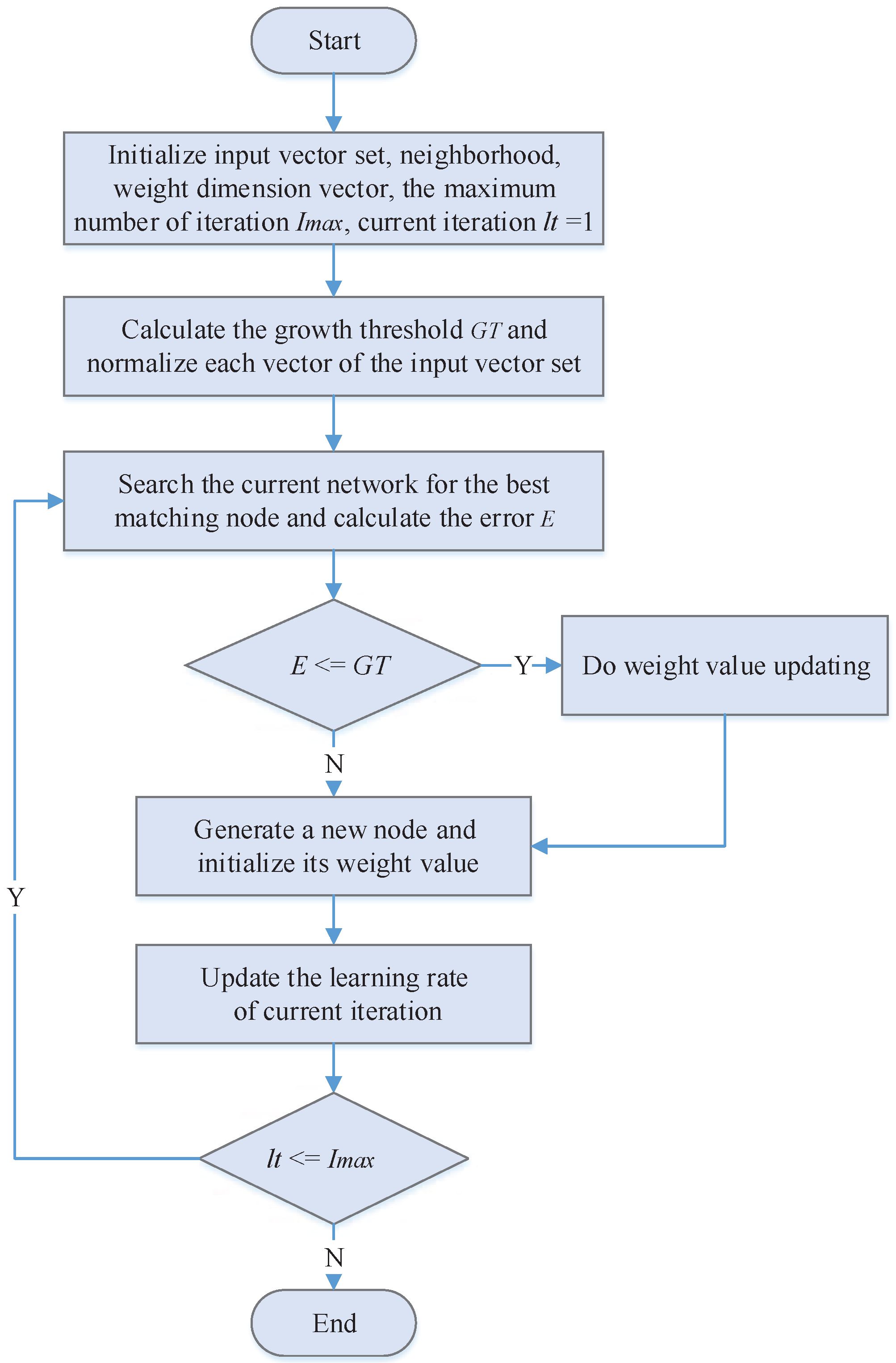
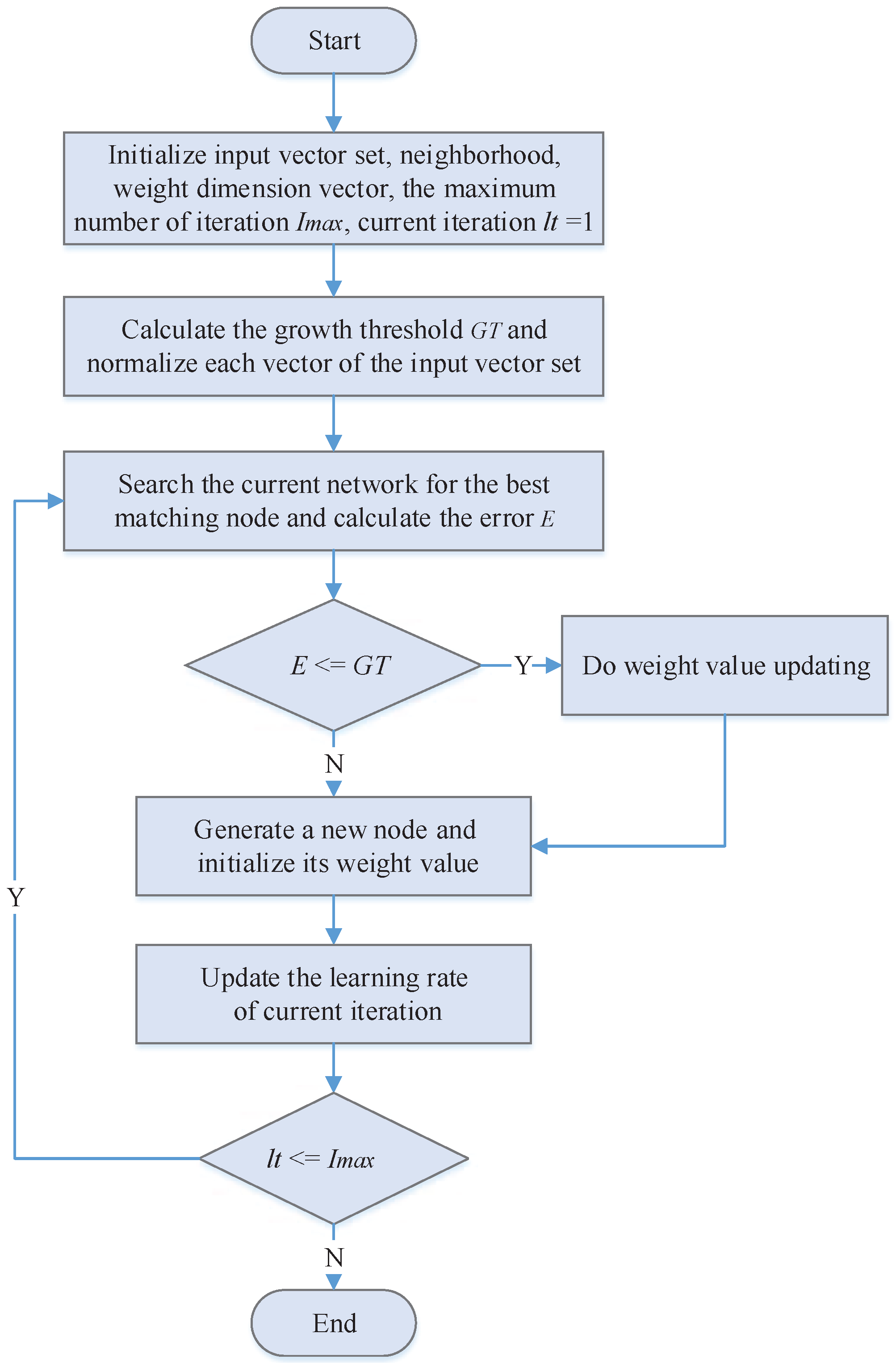
- Step 1:
- Initiate node , neighborhoods , weight dimension vector , the maximum number of iteration , and growth threshold , is a random value ranging from 0 to 1, at the initial period, , is calculated according to Equations (5) and (6), and then each vector of the input vector set is standardized between 0 and 1. When it is then the standardized is .
- Step 2:
- Select the input dimension vector sequentially from and search the current network node collection N for the best matching node () of the vector , calculated by Equation (7);
- Step 3:
- Calculate the error between and v as E according to Equation (8). If , skip to Step 4 for weight value updating, if not, go to Step 5 for the node growth operation;
- Step 4:
- Adjust neighborhood’s weight value via Equation (9).In the above equation, is the learning rate, when , and are the weight values of respectively prior and post adjustment. is the neighborhood when is at times of iteration.
- Step 5:
- Generate a new node of , and make ;
- Step 6:
- , α is the regulating factor of , ;
- Step 7:
- Repeat Step 2 to Step 6 till all input dimension vectors in V have been trained completely;
- Step 8:
- Make , repeat Step 2 to Step 7 and enter into the next iteration period till no more new nodes are generated in the network.
4.2. Group Migration Bee Colony Optimization Scheduling Algorithm (GMBCOS)
4.2.1. Basic Principle of the Artificial Bee Colony Algorithm
- (1)
- Searching for honey source, in which the employed bee and onlooker bee search for a honey source in the manner shown in Equation (10):In the equation, refers to the new honey source location searched by Number i bee responding to Number j dimension, while refers to the honey source location searched by current Number i bee responding to Number j dimension. refers to Number j location of the randomly selected honey source k, , and . is the disturbance factor with a value being random between and 1, which determines the search range for .
- (2)
- Onlooker bee selects honey source. If the honey content of the new source is no less than that of the old one, then the employed bee accepts the location of the new source location, otherwise, it will continue to explore the old source. This can be understood as the employed bee determining a honey source by applying a greedy selection. When all the employed bees finish searching, they convey the information on the honey source to the onlooker bees, which will select the honey source based on the honey content and by means of Round Robin (RR). The equation for the selection probability is as follows:In the equation, refers to the selection probability for Number i solution, and is the fitness value for Number i solution. This value corresponds to the honey mass at this point.
- (3)
- Given the honey source and new solution is generated randomly, in case a specific solution is still not improved after times of recycling the iteration threshold, and the benefit degree of the honey source is not the global optimal solution, this indicates that the solution falls into a locally optimal solution and the solution should be given up. The employed bees responding to the solution should be changed to scout bees, which work to generate a new solution randomly to replace the old one as Equation (12) shows.In the equation, refers to the random numbers generated between 0 and 1, while and respectively refer to the upper and lower limits of Number i honey source of j-dimension component.
4.2.2. Group Migration Bee Colony Optimization Scheduling Algorithm (GMBCOS)
- (1)
- Chaos features randomness, ergodic property and regularity, enabling ergodicity of all kinds of status unrepeatedly within a specific rand and based on its own rule. With these characteristics, it is easy for chaos optimization to appear to be a locally optimal solution; and, if a specific solution is still not improved after times of recycling in ABC, this indicates that the solution falls into a locally optimal solution. In such a case, the scout bees will not select a new solution anymore according to Equation (12), but will generate a chaos sequence by utilizing the ergodic property of the chaos movement and based on the solution of the currently stagnant search. The optimal location in such a chaos sequence is going to replace the original location, causing the solution of the stagnant search to continue evolving, thus enhancing convergence speed and accuracy. The detailed steps are as follows:
- (a)
- To initialize a typical chaos system:where r refers to the sequential length, and μ refers to the control parameter. When , the system is in the status of chaos. By the time the value of μ is determined, an explicit chaos sequence can be iterated from an arbitrary initial value .
- (b)
- To assume that the solution for the current search stagnancy is , which is mapped into the domain of definition of the chaos system mentioned above as in the following equation:An iteration based on Equation (13) results chaos variable sequence (), in which refers to the maximum number of iteration for bee colony local search.
- (c)
- To bring chaos sequence back to the original solution space via inverse mapping , resulting in , and to calculate the adaptive value and compare it to the original, and maintain the optimal solution.
- (d)
- To complete the process of optimization if the local maximum number of iteration , otherwise, return to Step b.
- (2)
- In the process of searching for honey sources, employed bees and onlooker bees are merely searching through single-dimensional variables, and ignore the impact from variables of other dimensions, causing the convergence speed of the algorithm to reduce. Comparatively, in a particle algorithm, particles are update based on a globally optimal solution so that a better convergence speed can be maintained.
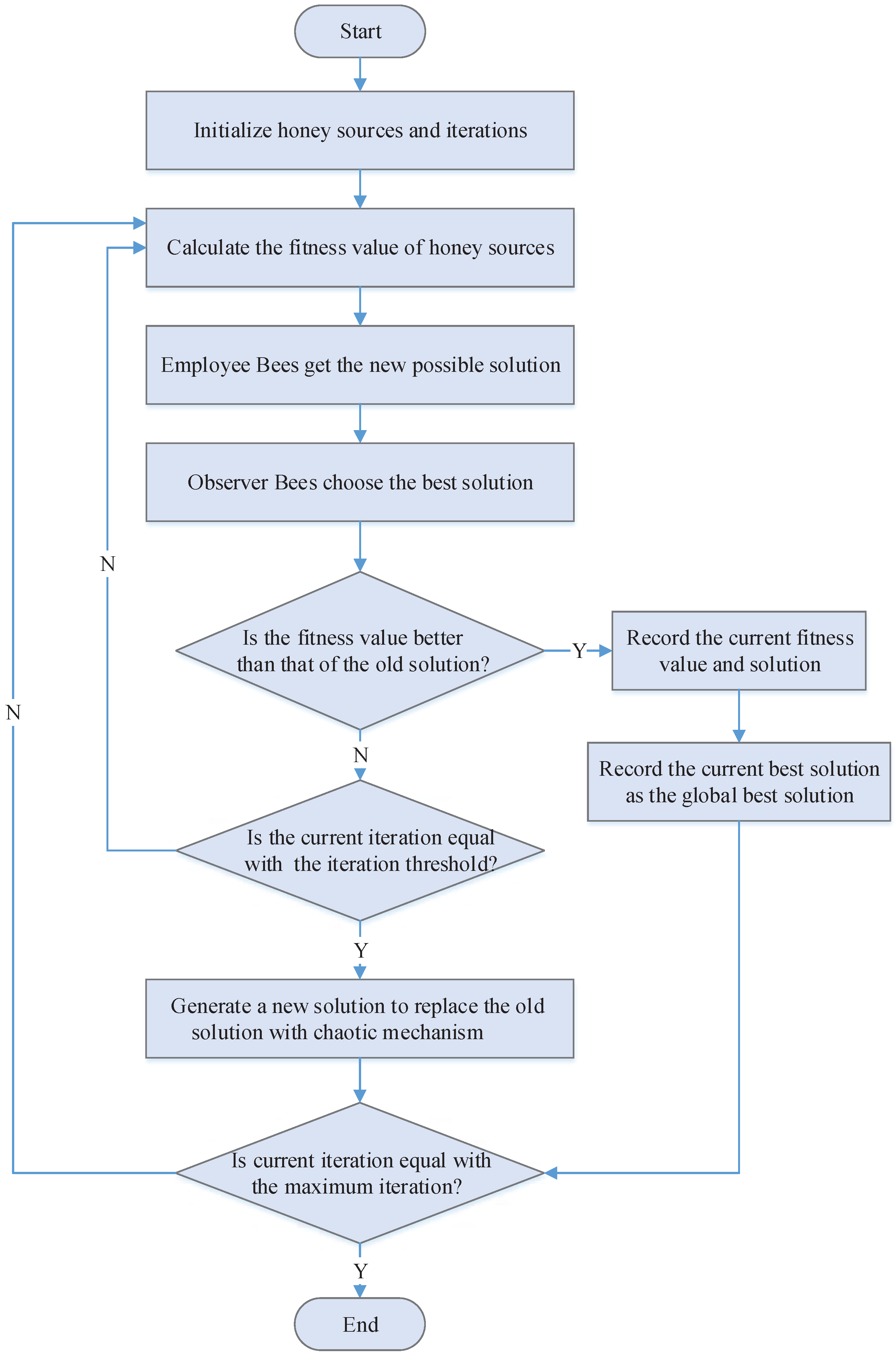
- Step 1:
- Initiation, to carry out logical grouping and efficiency verification of the users’ requests from different geographical locations;
- Step 2:
- Randomly generate a number of initiative solution collection , with the problem dimension as D, as the iteration threshold, N as the total number of honey sources, as the maximum number of iteration, and ;
- Step 3:
- Calculate the fitness value of honey sources, , and record the current optimal fitness value as ;
- Step 4:
- Generate new locations according to Equation (15), and the employed bees select honey sources with the greedy selection mechanism;
- Step 5:
- Onlooker bees select honey sources according to Equation (11);
- Step 6:
- Onlooker bees generate new locations according to Equation (15) and select honey sources with the greedy selection mechanism;
- Step 7:
- Give up the solution when it is still not improved (falls into locally optimal) after times of recycles continuously, and convert the employed bees corresponding to the solution to scout bees, which will generate a new solution to replace the old one according to the given chaos search mechanism;
- Step 8:
- Record the optimal solution so far;
- Step 9:
- ; judge if the condition for termination is met-if yes, terminate and output the optimal solution; and if not, go back to Step 3 for re-search.
4.3. Steps to Realize MSACM
- Step 1:
- Initialize the DAPVDC problem, relevant functions and parameters, set the value of the relevant measurement parameters and constraint conditions for the DAPVDC problem, and move onto Step 2;
- Step 2:
- Initialize the synergistically distributed buffer access model according to the parameters relevant to the DAPVDC problem, and move onto Step 3;
- Step 3:
- According to the synergistically distributed buffer access model, use the ODSOFM algorithm to divide the massive access requests into dynamic groups based on the location characteristics;
- Step 4:
- Use the GMBCOS algorithm to compute the model result regarding virtual logical requests, and move onto Step 5;
- Step 5:
- Save the computed result and exit.
4.4. Analysis of MSACM Performance
5. Performance Evaluation
5.1. Experiment Environment and Parameter Setting
5.2. MSACM Performance Test
- (1)
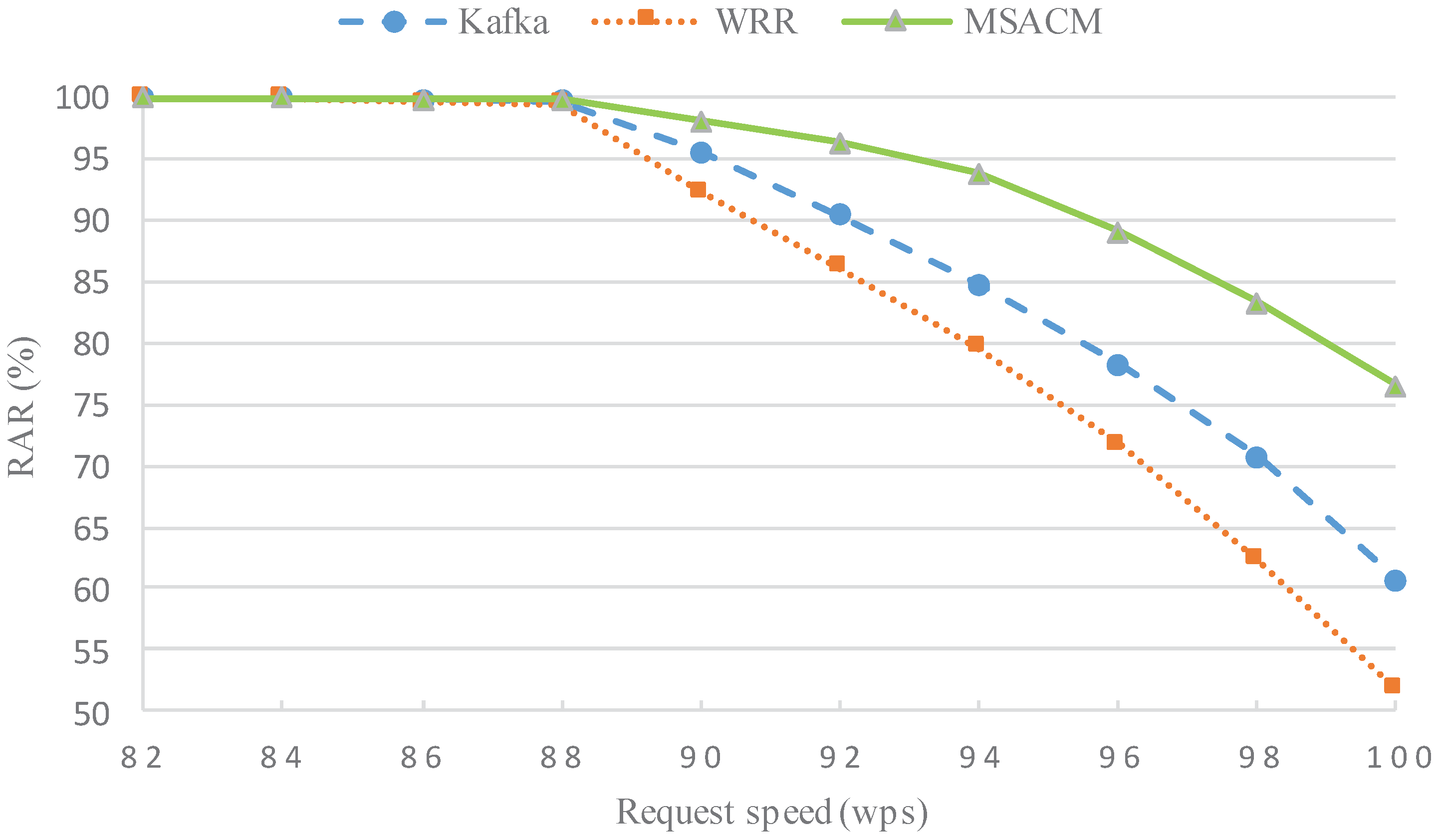
- In the situation of steadily increasing service request speed, the request arrival rate (RAR) is compared between MSACM and the other algorithms. RAR is defined as: RAR = number of service requests with successful arrival/total number of service requests;
- (2)
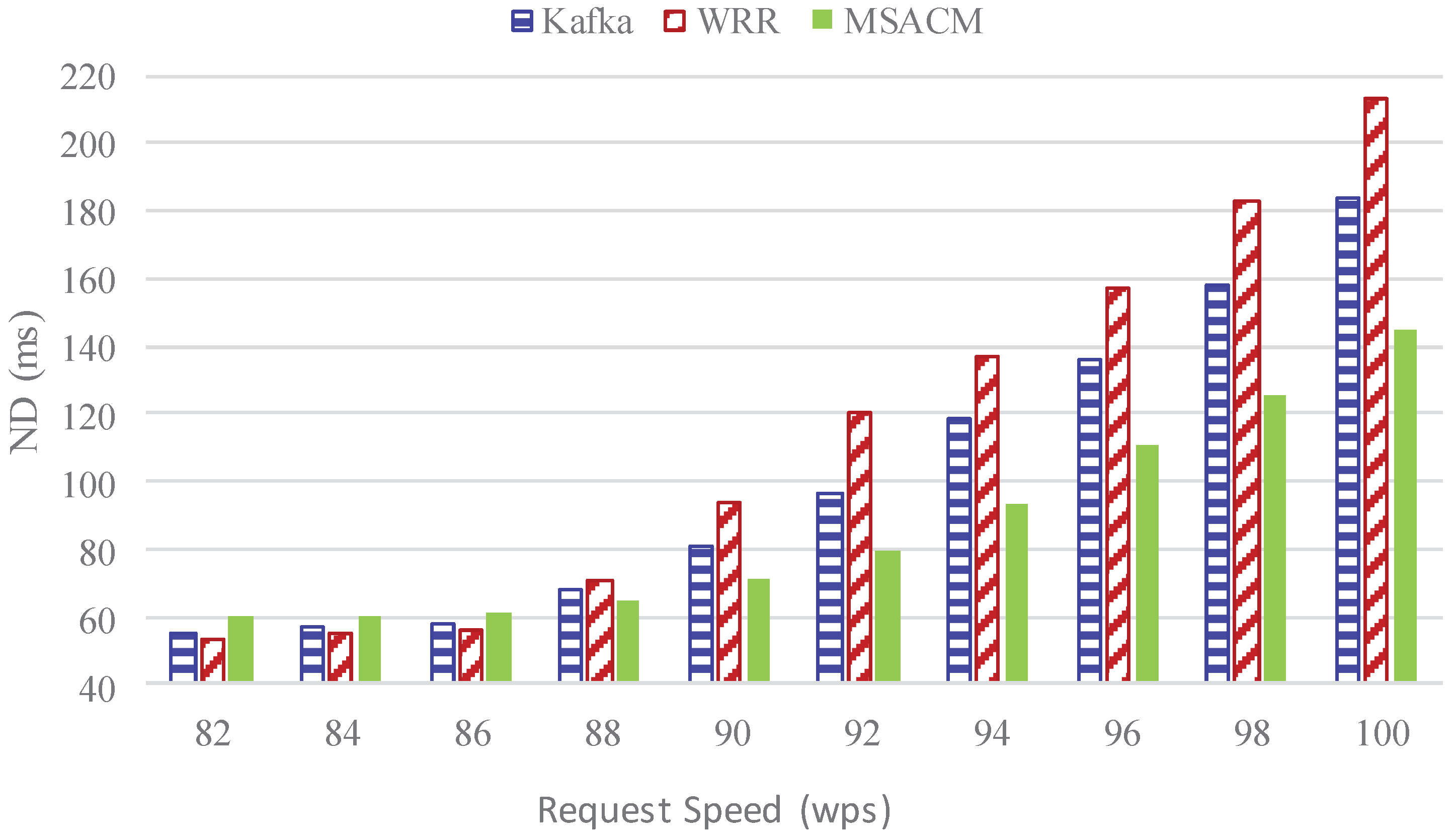
- In the situation of steadily increasing service request speed, network delay (ND) is compared between MSACM and other algorithms. ND herein refers to the average network delay;
- (3)
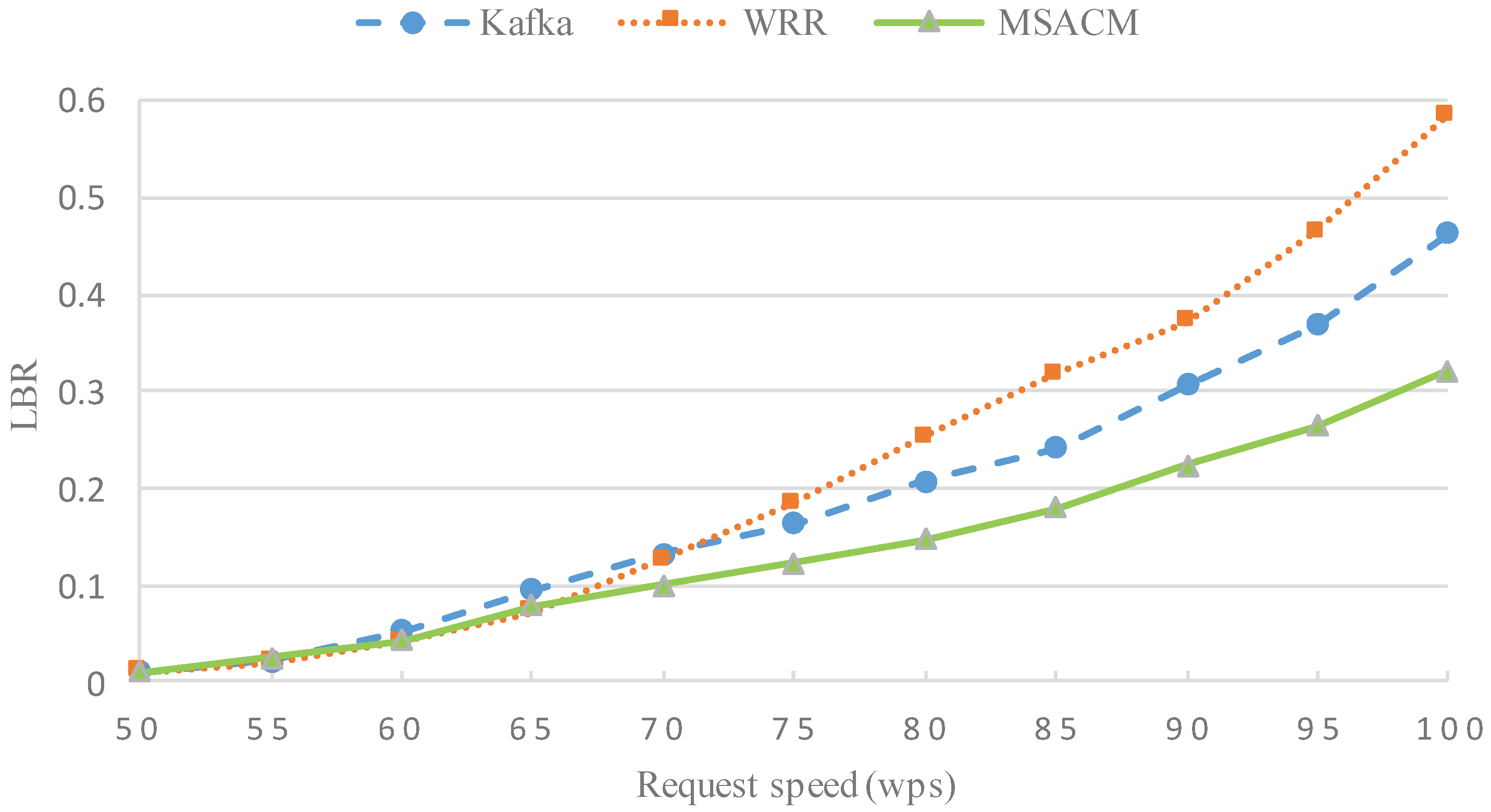
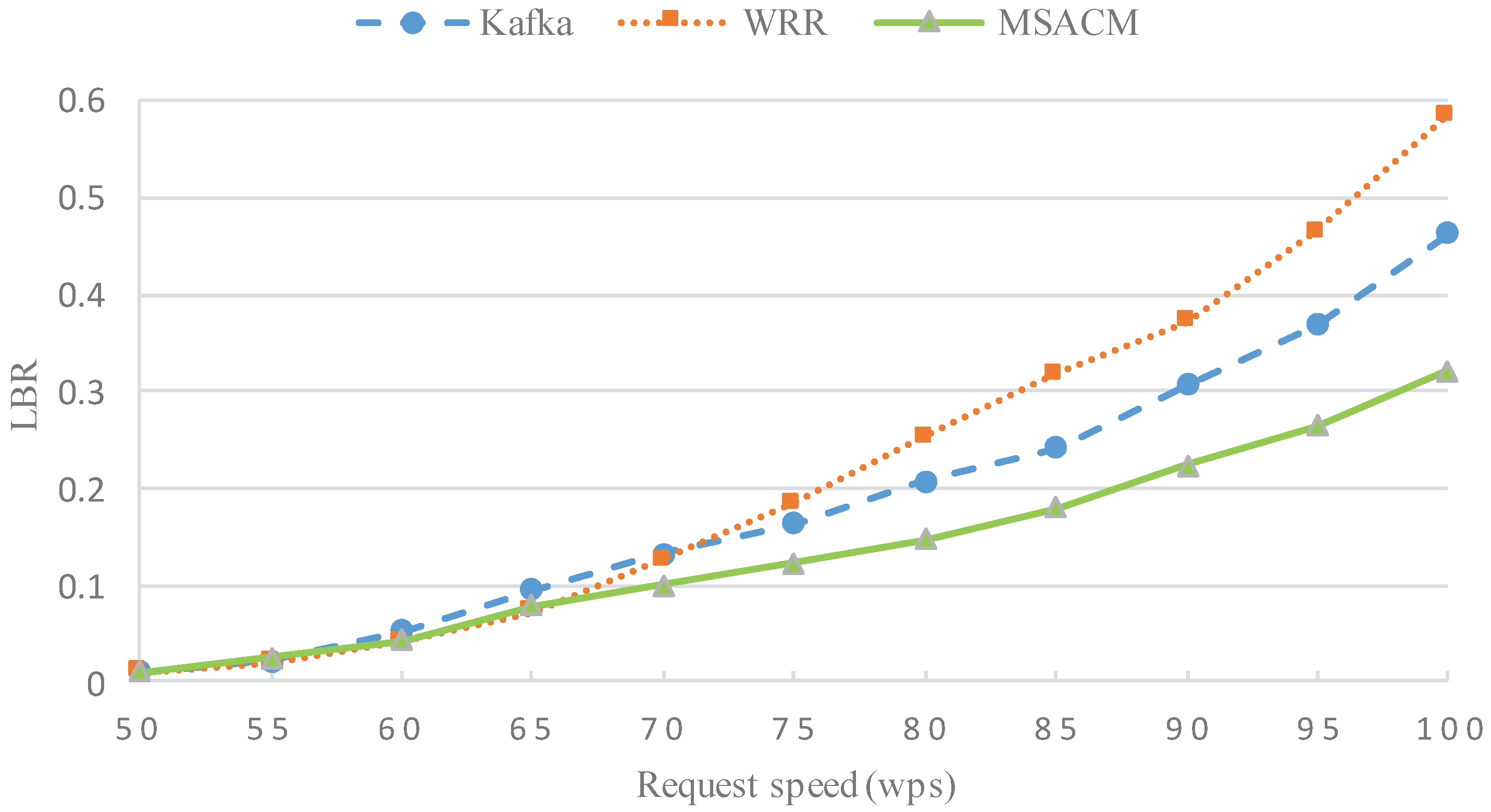
- In the situation of steadily increasing number of access service requests, the load balance rate (LBR) is compared between MSACM and other algorithms. The load of Number i access server at the moment of t is set as , the total number of online virtual machines is κ, the average load of the access cluster is , and the load balance rate is defined as ;
- (4)
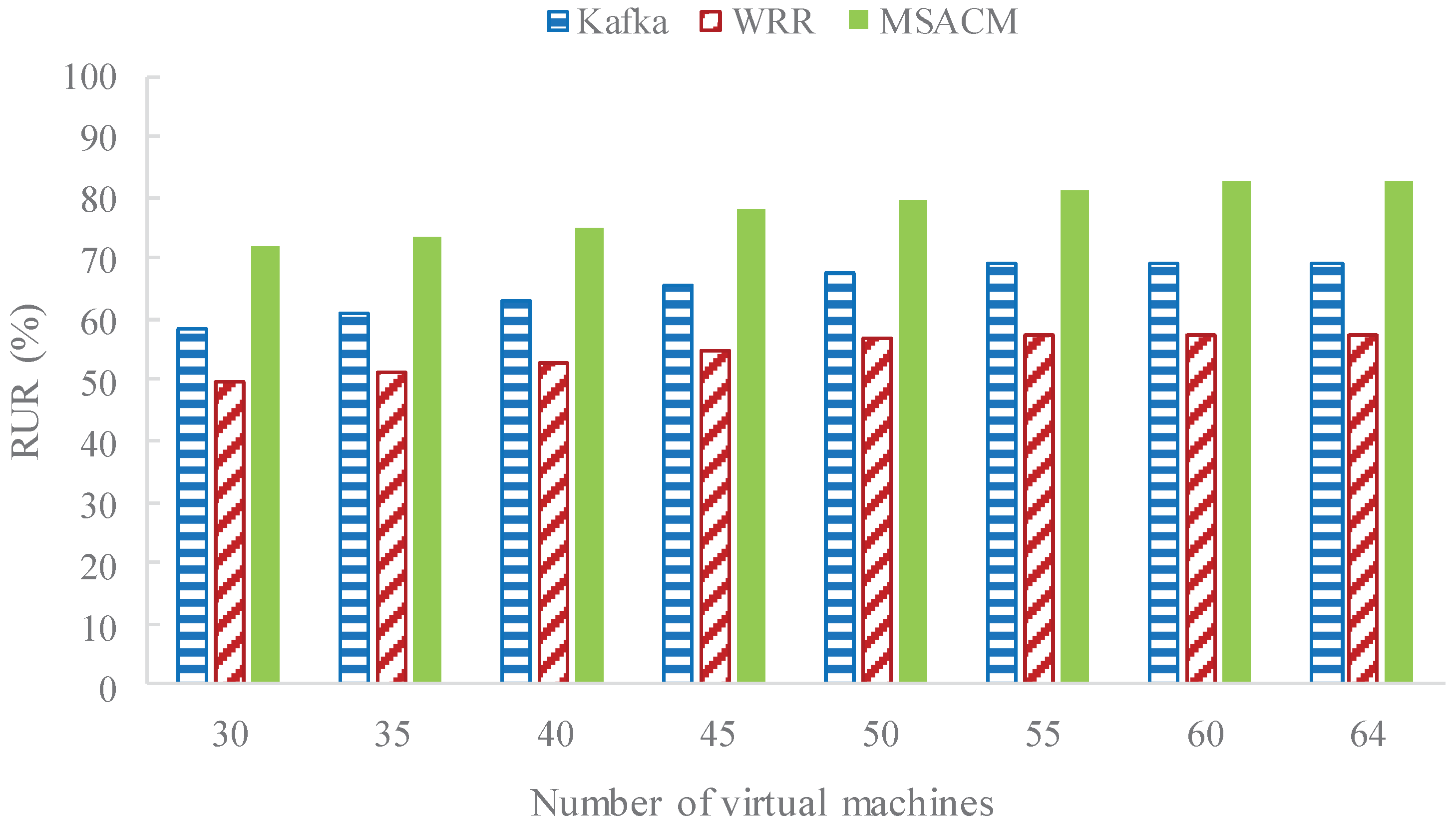
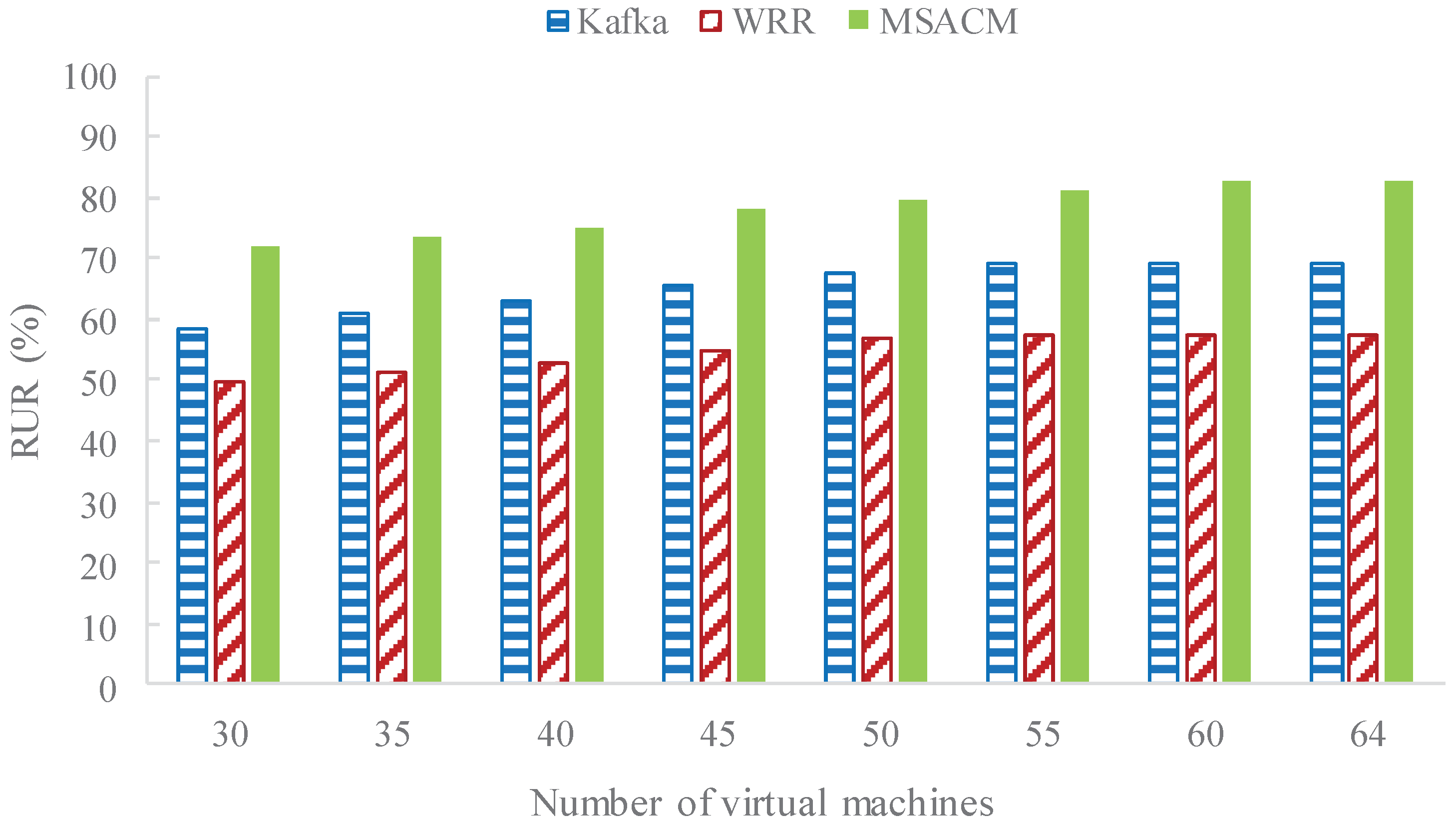
- In the process of a gradually growing number of virtual servers, the resource utilization rate (RUR) is compared between MSACM and other algorithms. The number of online virtual machines is set as κ, the time consumed by Number j access servers when requesting access is , the real occupation time of Number j access servers is , then RUR is defined as ;
- (5)
- In the situation of a steadily growing number of service requests, the migrating cost rate (MCR) is compared between MSACM and other algorithms. The number of online virtual machines is set as κ, the migrating time consumed by Number j access servers when requesting access is , and the time consumed by Number j access servers when requesting access is , then MCR of the access server cluster is defined as .
5.2.1. Experiment 1: RAR Performance with Different Request Rate
5.2.2. Experiment 2: ND Performance with Different Request Rate
5.2.3. Experiment 3: LBR Performance with Variable Request Scale
5.2.4. Experiment 4: RUR Performance with Variable Access Servers
5.2.5. Experiment 5: MCR Performance with Variable Request Scale
5.2.6. Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lazarescu, M.T. Design and field test of a WSN platform prototype for long-term environmental monitoring. Sensors 2015, 15, 9481–9518. [Google Scholar] [CrossRef] [PubMed]
- Chi, Q.; Yan, H.; Zhang, C.; Pang, Z.; Xu, L.D. A reconfigurable smart sensor interface for industrial WSN in IoT environment. IEEE Trans. Ind. Inform. 2014, 10, 1417–1425. [Google Scholar]
- Ananad, N.; Varma, S. Scrutinizing localized topology control in WSN using rigid graphs. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; pp. 1712–1715.
- Prinsloo, J.; Malekian, R. Accurate vehicle location system using RFID, an Internet of Things approach. Sensors 2016, 16, 825. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Chen, Q.K. Group command transmission model based on effective path statistics network. Chin. J. Electron. 2015, 43, 1826–1832. [Google Scholar]
- Chowdhury, N.M.K.; Boutaba, R. A survey of network virtualization. Comput. Netw. 2010, 54, 862–876. [Google Scholar] [CrossRef]
- Chowdhury, N.M.K.; Boutaba, R. Network virtualization: State of the art and research challenges. IEEE Commun. Mag. 2009, 47, 20–26. [Google Scholar] [CrossRef]
- Hwang, J.; Ramakrishnan, K.; Wood, T. NetVM: High performance and flexible networking using virtualization on commodity platforms. IEEE Trans. Netw. Serv. Manag. 2015, 12, 34–47. [Google Scholar] [CrossRef]
- Drutskoy, D.; Keller, E.; Rexford, J. Scalable network virtualization in software-defined networks. IEEE Internet Comput. 2013, 17, 20–27. [Google Scholar] [CrossRef]
- Bari, M.F.; Boutaba, R.; Esteves, R.; Granville, L.Z.; Podlesny, M.; Rabbani, M.G.; Zhang, Q.; Zhani, M.F. Data center network virtualization: A survey. IEEE Commun. Surv. Tutor. 2013, 15, 909–928. [Google Scholar] [CrossRef]
- Tian, W.; Zhao, Y.; Xu, M.; Zhong, Y.; Sun, X. A toolkit for modeling and simulation of real-time virtual machine allocation in a cloud data center. IEEE Trans. Autom. Sci. Eng. 2015, 12, 153–161. [Google Scholar] [CrossRef]
- Espadas, J.; Molina, A.; Jiménez, G.; Molina, M.; Ramírez, R.; Concha, D. A tenant-based resource allocation model for scaling Software-as-a-Service applications over cloud computing infrastructures. Future Gener. Comput. Syst. 2013, 29, 273–286. [Google Scholar] [CrossRef]
- Ren, Y.; Zhou, M.; Li, G.; Shen, Z. Hierarchically coordinated ultra-short term load forecasting for load aggregator. In Proceedings of the 2015 5th International Conference on Electric Utility Deregulation and Restructuring and Power Technologies (DRPT), Changsha, China, 26–29 November 2015; pp. 141–146.
- Chen, X. Decentralized computation offloading game for mobile cloud computing. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 974–983. [Google Scholar] [CrossRef]
- Ferragut, A.; Paganini, F. Network resource allocation for users with multiple connections: Fairness and stability. IEEE/ACM Trans. Netw. 2014, 22, 349–362. [Google Scholar] [CrossRef]
- Kuehn, E.; Fischer, M.; Jung, C.; Petzold, A.; Streit, A. Monitoring data streams at process level in scientific big data batch clusters. In Proceedings of the 2014 IEEE/ACM International Symposium on Big Data Computing (BDC), London, UK, 8–11 December 2014; pp. 90–95.
- Bertaux, L.; Medjiah, S.; Berthou, P.; Abdellatif, S.; Hakiri, A.; Gelard, P.; Planchou, F.; Bruyere, M. Software defined networking and virtualization for broadband satellite networks. IEEE Commun. Mag. 2015, 53, 54–60. [Google Scholar] [CrossRef]
- Zou, S.; Zhang, Y.; Tang, Y. Resource allocation mechanism based on two-step mapping for saving energy in wireless network virtualization. In Proceedings of the 2015 IEEE 9th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 25–27 September 2015; pp. 150–154.
- Tao, D.; Wang, B.; Lin, Z. Resource Scheduling and Data Locality for Virtualized Hadoop on IaaS Cloud Platform. In Big Data Computing and Communications, Proceedings of the International Conference on Big Data Computing and Communications, Shenyang, China, 29–31 July 2016; Springer: Cham, Switzerland, 2016; pp. 332–341. [Google Scholar]
- Endo, P.T.; de Almeida Palhares, A.V.; Pereira, N.N.; Goncalves, G.E.; Sadok, D.; Kelner, J.; Melander, B.; Mangs, J.E. Resource allocation for distributed cloud: Concepts and research challenges. IEEE Netw. 2011, 25, 42–46. [Google Scholar] [CrossRef]
- Han, B.; Gopalakrishnan, V.; Ji, L.; Lee, S. Network function virtualization: Challenges and opportunities for innovations. IEEE Commun. Mag. 2015, 53, 90–97. [Google Scholar] [CrossRef]
- Kreps, J.; Narkhede, N.; Rao, J. Kafka: A distributed messaging system for log processing. In Proceedings of the Networking Meets Databases Workshop (NetDB), Athens, Greece, 12–16 June 2011; pp. 1–7.
- Ranjan, R. Streaming big data processing in datacenter clouds. IEEE Cloud Comput. 2014, 1, 78–83. [Google Scholar] [CrossRef]
- Ranjan, R.; Wang, L.; Zomaya, A.Y. Advances in methods and techniques for processing streaming big data in datacentre clouds. IEEE Trans. Emerg. Top. Comput. 2016, 4, 262–265. [Google Scholar] [CrossRef]
- Patel, D.; Khasib, F.; Sadooghi, I.; Raicu, I. Towards in-order and exactly-once delivery using hierarchical distributed message queues. In Proceedings of the 2014 14th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), Chicago, IL, USA, 26–29 May 2014; pp. 883–892.
- Razaque, A.; Elleithy, K.M. Energy-efficient boarder node medium access control protocol for wireless sensor networks. Sensors 2014, 14, 5074–5117. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Ng, T.E. The impact of virtualization on network performance of Amazon EC2 data center. In Proceedings of the 2010 IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9.
- Yang, H.; Zhang, J.; Zhao, Y.; Han, J.; Lin, Y.; Lee, Y. SUDOI: Software defined networking for ubiquitous data center optical interconnection. IEEE Commun. Mag. 2016, 54, 86–95. [Google Scholar] [CrossRef]
- Guo, C.; Lu, G.; Wang, H.J.; Yang, S.; Kong, C.; Sun, P.; Wu, W.; Zhang, Y. SecondNet: A data center network virtualization architecture with bandwidth guarantees. In Proceedings of the 6th International Conference on Emerging Networking Experiments and Technologies (CoNEXT), Philadelphia, PA, USA, 30 November–3 December 2010; p. 15.
- Xu, J.W.; Zhang, W.B.; Wang, T.; Huang, T. A genetic algorithm based adaptive strategy for image backup of virtual machines. Chin. J. Comput. 2016, 39, 351–363. [Google Scholar]
- Guzek, M.; Kliazovich, D.; Bouvry, P. A holistic model for resource representation in virtualized cloud computing data centers. In Proceedings of the 2013 IEEE 5th International Conference on Cloud Computing Technology and Science (CloudCom), Bristol, UK, 2–5 December 2013; pp. 590–598.
- Palmieri, F.; Fiore, U.; Ricciardi, S.; Castiglione, A. Grasp-based resource re-optimization for effective big data access in federated clouds. Future Gener. Comput. Syst. 2016, 54, 168–179. [Google Scholar] [CrossRef]
- Alicherry, M.; Lakshman, T.V. Optimizing data access latencies in cloud systems by intelligent virtual machine placement. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 647–655.
- Dong, M.; Lit, H.; Ota, K.; Zhu, H. HVSTO: Efficient privacy preserving hybrid storage in cloud data center. In Proceedings of the 2014 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 27 April–2 May 2014; pp. 529–534.
- Wang, Y.D.; Yang, J.H.; Xu, C.; Ling, X.; Yang, Y. Survey on access control technologies for cloud computing. J. Softw. 2015, 26, 1129–1150. [Google Scholar]
- Singh, A.; Korupolu, M.; Mohapatra, D. Server-storage virtualization: Integration and load balancing in data centers. In Proceedings of the 2008 ACM/IEEE Conference on Supercomputing, Austin, TX, USA, 15–21 November 2008; p. 53.
- Lin, W.; Liang, C.; Wang, J.Z.; Buyya, R. Bandwidth-aware divisible task scheduling for cloud computing. Softw. Pract. Exp. 2014, 44, 163–174. [Google Scholar] [CrossRef]
- Ebrahimirad, V.; Goudarzi, M.; Rajabi, A. Energy-aware scheduling for precedence-constrained parallel virtual machines in virtualized data centers. J. Grid Comput. 2015, 13, 233–253. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, H.; Yang, L.T.; Yin, S. Energy-aware rolling-horizon scheduling for real-time tasks in virtualized cloud data centers. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing (HPCC_EUC), Zhangjiajie, China, 13–15 November 2013; pp. 1119–1126.
- Baccarelli, E.; Cordeschi, N.; Mei, A. Energy-efficient dynamic traffic offloading and reconfiguration of networked data centers for big data stream mobile computing: Review, challenges, and a case study. IEEE Netw. 2016, 30, 54–61. [Google Scholar] [CrossRef]
- Wen, Y.; Meng, D.; Zhan, J.F. Adaptive virtualized resource management for application’s SLO guarantees. J. Softw. 2013, 24, 358–377. [Google Scholar] [CrossRef]
- Zou, S.; Wen, X.; Chen, K.; Huang, S.; Chen, Y.; Liu, Y.; Xia, Y.; Hu, C. VirtualKnotter: Online virtual machine shuffling for congestion resolving in virtualized datacenter. Comput. Netw. 2014, 67, 141–153. [Google Scholar] [CrossRef]
- Choi, D.; Chung, K.S.; Shon, J. An Improvement on the Weighted Least-Connection Scheduling Algorithm for Load Balancing in Web Cluster Systems. In Grid and Distributed Computing, Control and Automation; Springer: Berlin/Heidelberg, Germay, 2010; pp. 127–134. [Google Scholar]
- Tasdemir, K.; Merényi, E. Exploiting data topology in visualization and clustering of self-organizing maps. IEEE Trans. Neural Netw. 2009, 20, 549–562. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Wang, C.; Li, L. Distributed adaptive output consensus tracking of higher-order systems with unknown control directions. Neurocomputing 2016, 203, 129–138. [Google Scholar] [CrossRef]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Technical Report-tr06; Engineering Faculty, Computer Engineering Department, Erciyes University: Kayseri, Turkey, 2005. [Google Scholar]
- Karaboga, D.; Gorkemli, B.; Ozturk, C.; Karaboga, N. A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 2014, 42, 21–57. [Google Scholar] [CrossRef]
- Faigl, J.; Kulich, M.; Vonásek, V.; Přeučil, L. An application of the self-organizing map in the non-Euclidean Traveling Salesman Problem. Neurocomputing 2011, 74, 671–679. [Google Scholar] [CrossRef]
- Karaboga, D.; Akay, B. A modified artificial bee colony (ABC) algorithm for constrained optimization problems. Appl. Soft Comput. 2011, 11, 3021–3031. [Google Scholar] [CrossRef]
- Goodhope, K.; Koshy, J.; Kreps, J.; Narkhede, N.; Park, R.; Rao, J.; Ye, V.Y. Building LinkedIn’s real-time activity data pipeline. IEEE Data Eng. Bull. 2012, 35, 33–45. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
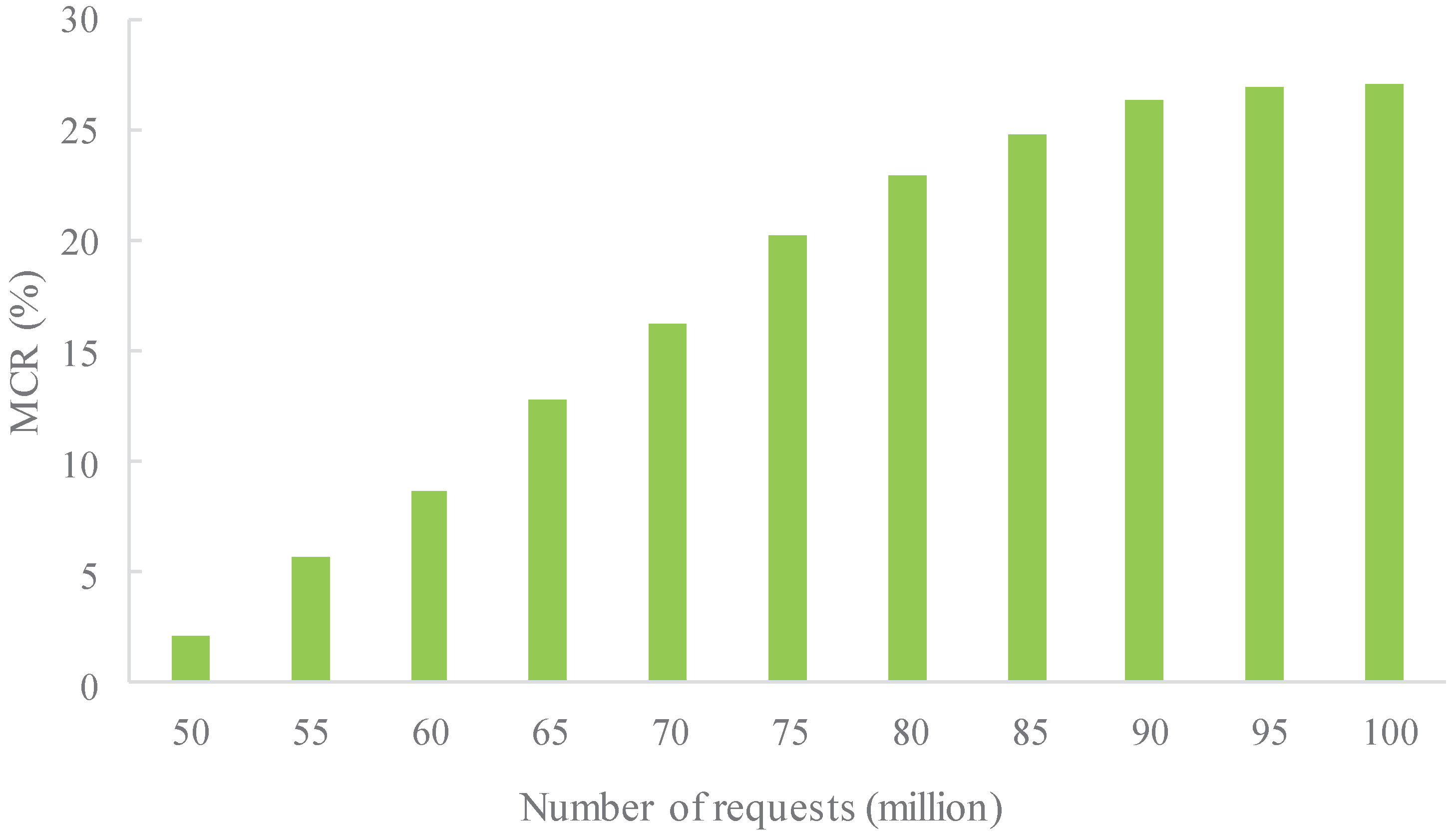{kind=link}
| Parameters | Descriptions |
|---|---|
| G | Collection of virtual logic groups of user’s requests |
| V | Collection of virtual machine groups in data center |
| P | Collection of physical servers in data center |
| L | Collection of network links in data center |
| The number a of physical servers | |
| If the physical server works well | |
| s | Number of physical servers |
| The number i logic groups of users’ requests | |
| The number u groups of virtual machines | |
| Number of virtual machines in the group of virtual machines | |
| The number j virtual machines in the group of virtual machines | |
| Amount of resources needed by virtual machine | |
| Gross resources of physical server | |
| Communication resources between virtual machines and in the time of | |
| Network communication resources consumed when request group is accessed by virtual machine | |
| If request group is successfully accessed by virtual machine | |
| If request group migrates from virtual machine to | |
| Measurement of size of request group | |
| λ | Adjusting factor that balances impact of other resources on request migration |
| Viable access means of request group |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, M.; Chen, Q.; Xiong, N.N. An Effective Massive Sensor Network Data Access Scheme Based on Topology Control for the Internet of Things. Sensors 2016, 16, 1846. https://doi.org/10.3390/s16111846
Yi M, Chen Q, Xiong NN. An Effective Massive Sensor Network Data Access Scheme Based on Topology Control for the Internet of Things. Sensors. 2016; 16(11):1846. https://doi.org/10.3390/s16111846
Chicago/Turabian StyleYi, Meng, Qingkui Chen, and Neal N. Xiong. 2016. "An Effective Massive Sensor Network Data Access Scheme Based on Topology Control for the Internet of Things" Sensors 16, no. 11: 1846. https://doi.org/10.3390/s16111846