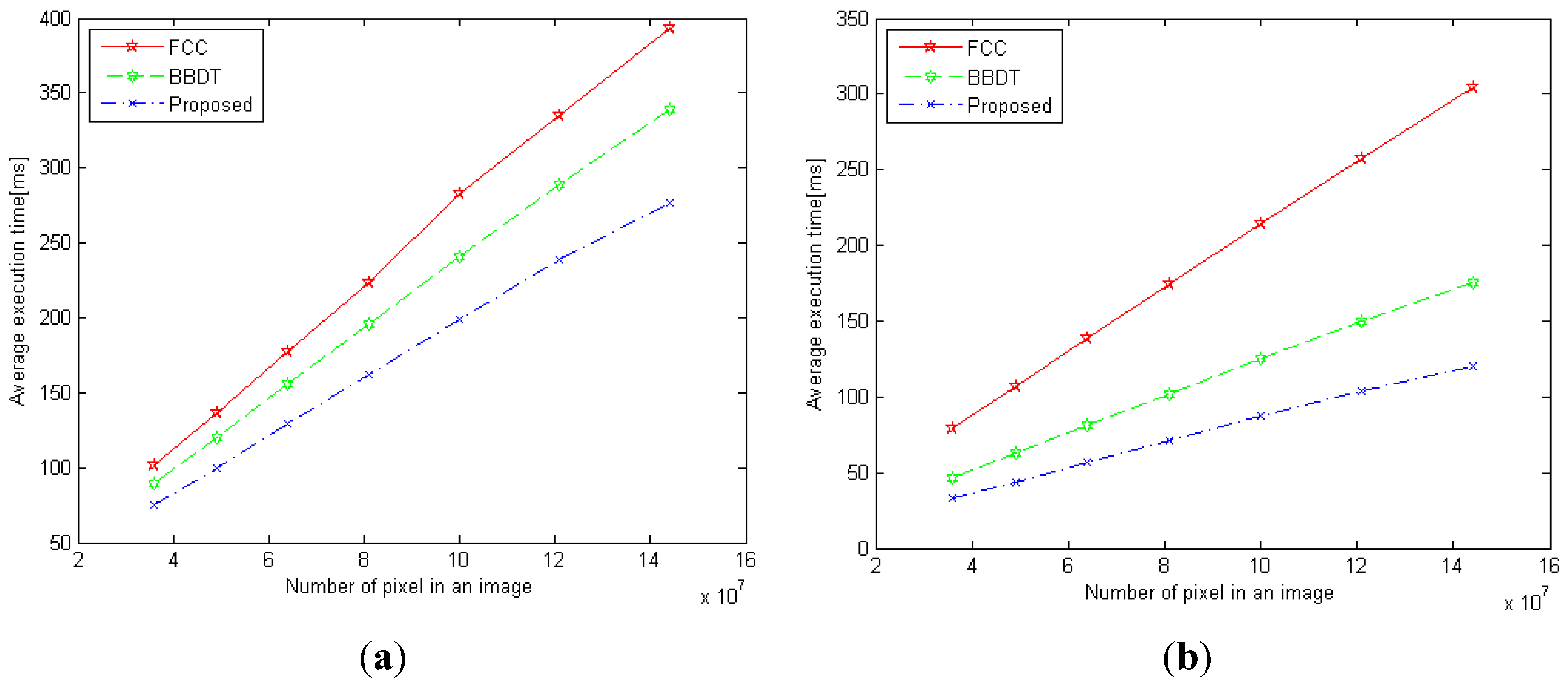
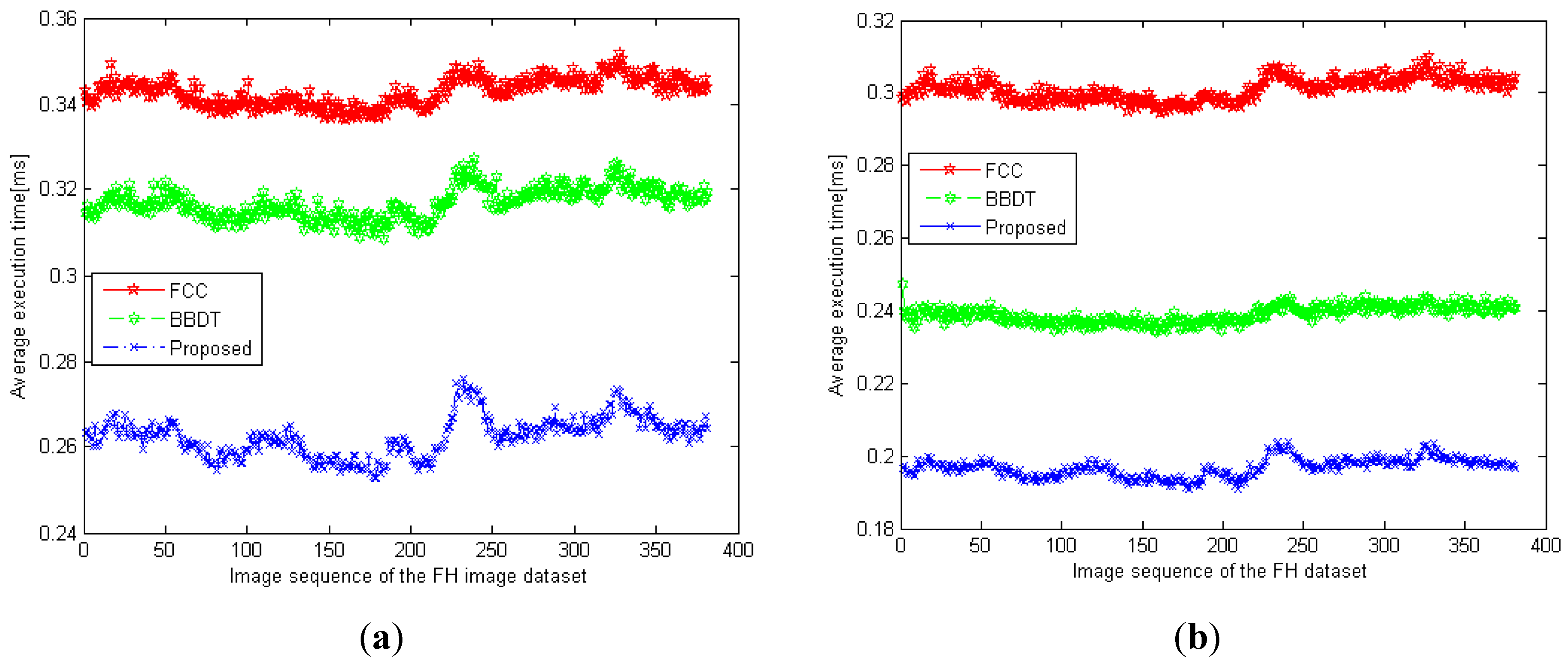
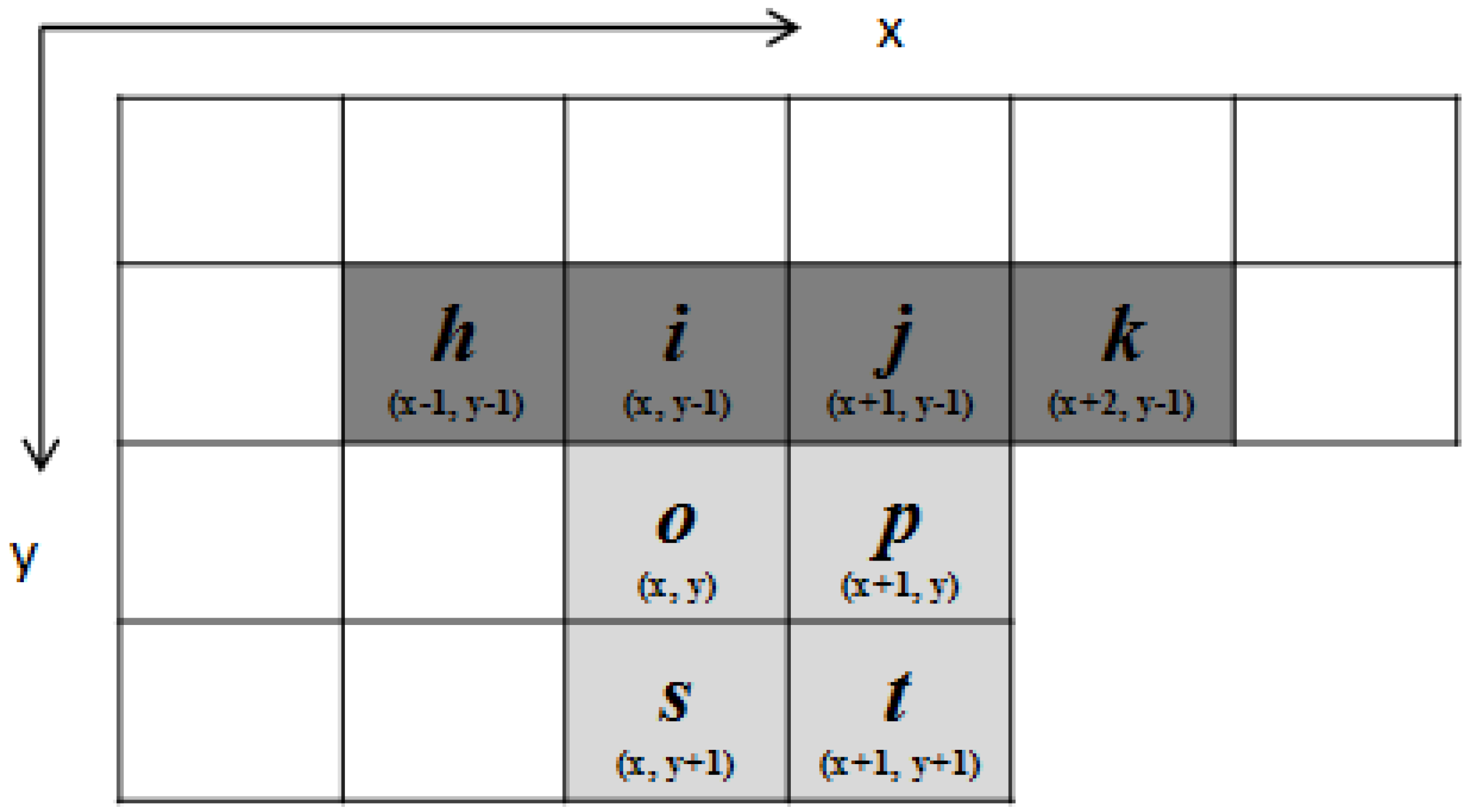
Our proposed algorithm uses the characteristics of block-connected relationships and the sequential raster scan to simplify the checking of pixels in the block-based scan mask. Unlike the BBDT algorithm, which checks this procedure and the decision tree using 16 pixels for each judgment, the proposed algorithm designs two procedures and binary decision trees in different block-connected situations. The proposed algorithm observes and chooses the necessary pixels from the 20 pixels obtained in the block-based scan mask according to block-connected relationships. It examines the block connectivity among blocks P, Q, R, S, and X to select the pixels necessary for labeling tasks. For the simplified block-based scan mask, the proposed algorithm determines the block-based relationship between the current block X and the other blocks P, Q, R, and S to minimize the use of the block-based scan mask. In checking pixels in blocks P and X of the block-based scan mask, the algorithm considers the connectivity of pixels o and h. The other pixels in block P are bypassed, because the connectivity of blocks P and Q, or of P and S, has dealt with neighboring processes in the previous block-based scan mask process. The subsequent selection of the necessary pixels is judged on the neighbor relationship between blocks Q and X, which requires pixels i, j, o, and p. Pixels c and d should be excluded from the simplified block-based scan mask. In selecting the necessary pixels, the proposed algorithm considers the neighbor relationship between blocks R and X. Pixels k and p are selected to join the simplified block-based scan mask. Pixels f and l cause unnecessary memory accesses in each judgment. The next selection focuses on pixel e, which is also bypassed by the simplified block-based scan mask because it has no connection with block X. The connectivity of blocks S and X is judged using pixels n, r, o, and s. Pixels m and q are bypassed because the neighbor operations concerning these have been processed in the previous block-based scan mask. Thus, our algorithm selects the 10 pixels h, i, j, k, n, o, p, r, s, and t from the 20 obtained in the block-based scan mask.
To simplify further, our proposed algorithm uses two procedures for different block-connected relationships. We design two checking sequences and two resulting binary decision trees, called “procedure 1,” and use “procedure 2” to apply suitable block-connected relationships individually. In terms of the block-connected relationship, the connectivity between blocks
S and
X is judged according to pixels
n,
r,
o, and
s. When pixels
n and
r are background pixels, the proposed algorithm directly limits the consideration of the block-connected relationship between block
X and blocks
P,
Q, and
R in procedure 1. Otherwise, the proposed algorithm considers block-connected relationships between block
X and blocks
S,
P,
Q, and
R in procedure 2. Of the 10 checking pixels, pixels
n and
r are only used to choose the procedure for the current judgment. Procedure 1 or procedure 2 is selected for the current judgment according to the state of pixel
n or
r. When pixel
n or
r exists in the current judgment, procedure 2 is utilized to judge the block-connected relationships of block
X with blocks
S,
P,
Q, and
R. Otherwise, the judgment uses procedure 1 to reduce the number of relationships that need be considered, thus enhancing performance. Furthermore, the existence of pixels
n and
r allows the results for pixels
p and
t from the previous judgment to be used. Thus, the judgment of pixels
n and
r is simplified by the previous judgment. To summarize, the proposed algorithm judges the block-connected relationships using the eight selected pixels
h,
i,
j,
k,
o,
p,
s, and
t by applying two different procedures. The block-based scan mask of the proposed algorithm is shown in
Figure 2.
3.1. Procedure 1 of the Proposed Algorithm
When pixels
n and
r are both background pixels, the proposed algorithm chooses procedure 1 to determine the action for the current block
X. Procedure 1 is designed to judge the block-connected relationships between block
X and blocks
P,
Q, and
R. The state of pixels
n and
r indicates the existence of block
S. Thus, block
S has no connection with block
X. Block
X then considers fewer block-connected relationships, which enhances the performance of labeling tasks. For procedure 1, the proposed algorithm sequentially checks the pixels of block
X against pixels
o to
t. According to the values of the four pixels in the current block, there are 16 cases for pixels
o,
p,
s, and
t, which are denoted in binary digits as (
opst)
2. (
opst)
2 ranges from (0000)
2, (0001)
2, (0010)
2 … to (1111)
2. The proposed algorithm uses six cases, and simplifies the 10 redundant cases using the binary decision trees of procedure 1. The six cases can determine the final action for the current block depending on the binary number (
hijk)
2 of pixels
h,
i,
j, and
k by following the binary decision tree. (
hijk)
2 ranges from (0000)
2, (0001)
2, (0010)
2 … to (1111)
2. The six cases of procedure 1 in the proposed algorithm are summarized in
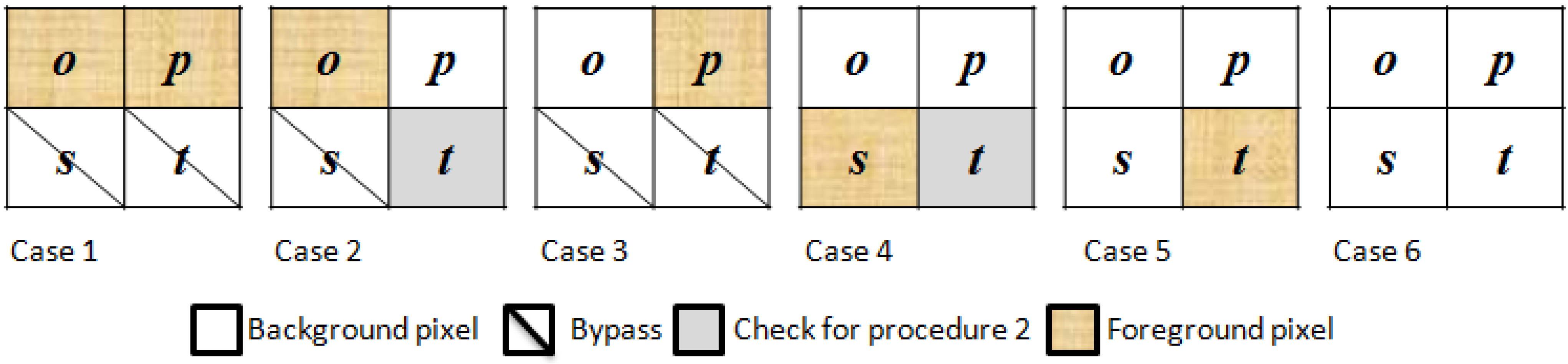
Figure 3.
Figure 3.
Six selected cases of the current block for procedure 1.
Figure 3.
Six selected cases of the current block for procedure 1.
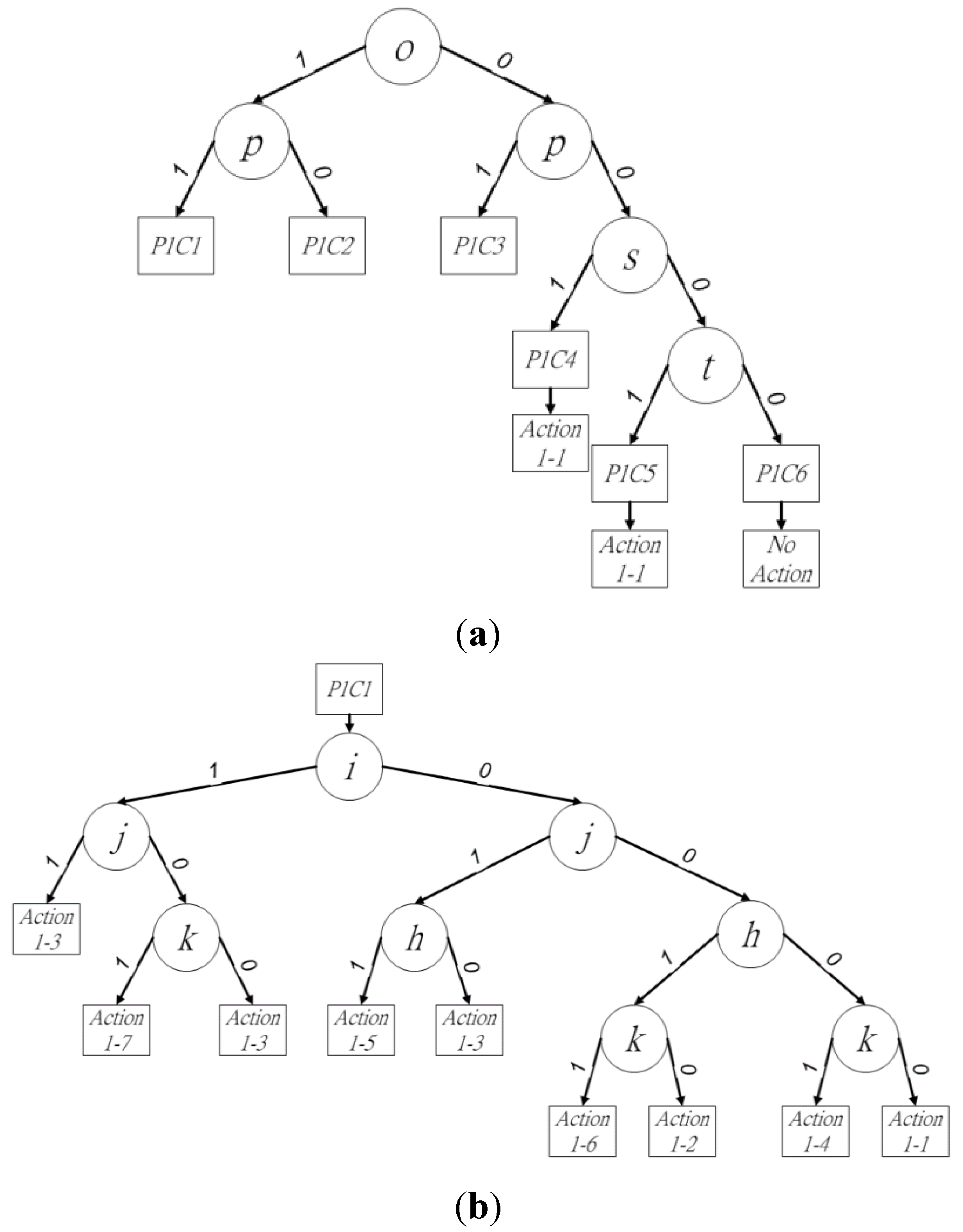
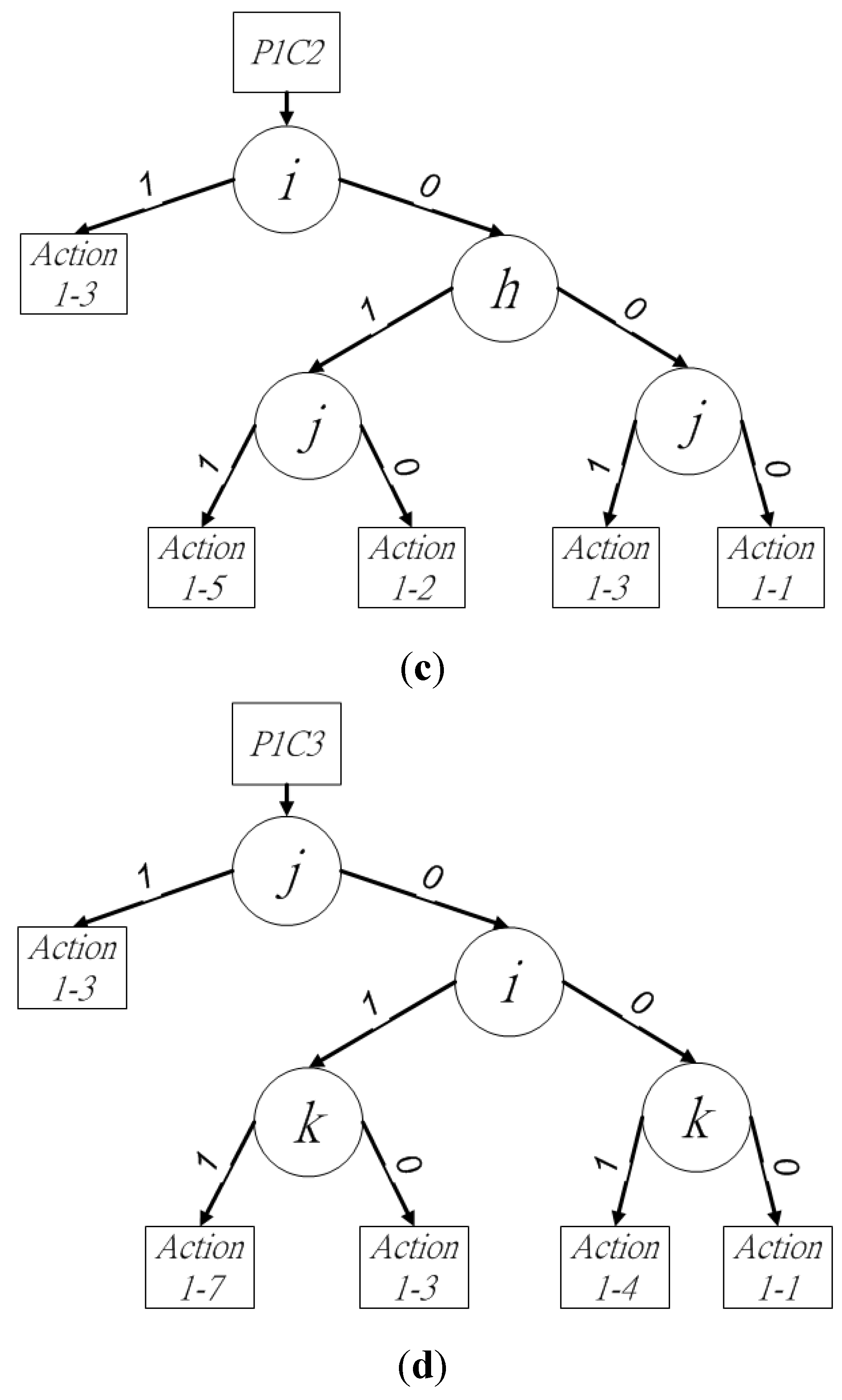
The binary decision trees of procedure 1 are shown in
Figure 4a. In the six cases for procedure 1, pixels
o and
p determine three cases and affect the other three, because the existence of pixels
o and
p determines the connectivity between block
X and blocks
P,
Q, and
R. Thus, these two pixels should be checked first to reduce redundant checking in the current block. To define the binary decision trees, case
w in procedure
u is denoted as
PuCw in this paper, where 1 ≦
u ≦ 2 and 1 ≦
w ≦ 7.
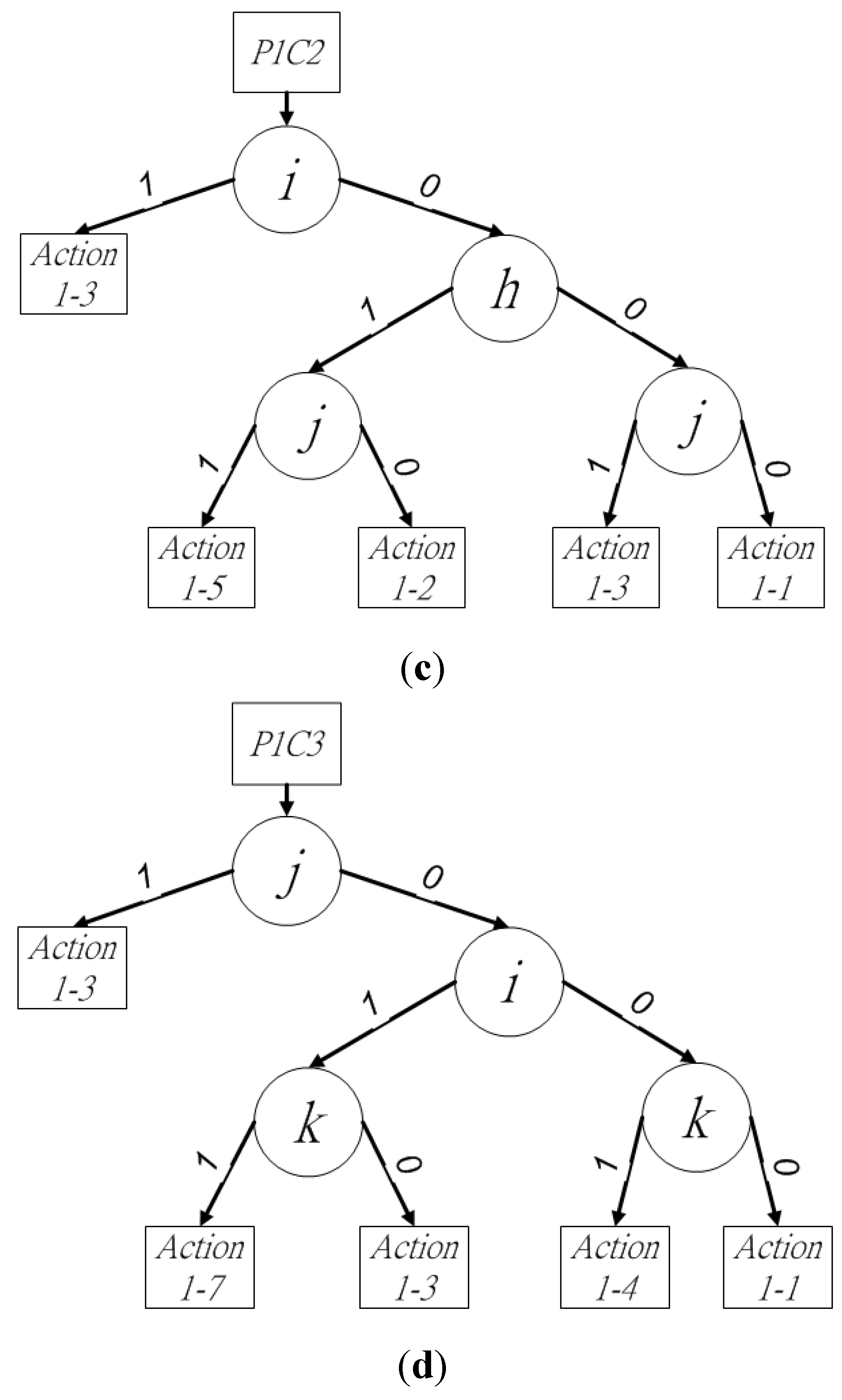
Figure 4.
Binary decision tree of (a) procedure 1, (b) P1C1, (c) P1C2 and (d) P1C3.
Figure 4.
Binary decision tree of (a) procedure 1, (b) P1C1, (c) P1C2 and (d) P1C3.
In
Figure 4a, the state of pixel
o is checked for the existence of the next leaf node. Following this, pixel
p is checked to choose the next leaf node. When the state of (
op)
2 is (11)
2, (10)
2, or (01)
2, the leaf node of
P1C1,
P1C2, or
P1C3 is used to judge the neighbor relationships between block
X and blocks
P,
Q, and
R, as shown in
Figure 4b–d, respectively. The state of pixel
s as either foreground or background determines whether leaf node
P1C4 is used or another leaf node should be checked. Pixel
t is checked last in the current block
X for the final leaf node
P1C5 or
P1C6, when pixels
o,
p, and
s are in the state (000)
2. For procedure 1, the six cases trigger seven different actions as leaf nodes in the binary decision trees. When the final leaf node of the binary decision tree has been obtained, the proposed algorithm follows the assigned actions for the neighbor operations. This step summarizes and assigns numbers to the final actions, including “a new provisional label,” “assign provisional label to block
P,
Q, or
R,” and “assign provisional label to block
P or
Q, and then merge blocks
P and
Q,
P and
R, or
Q and
R” in procedure 1. Action
w in procedure
u is denoted as
u-w in this paper, where 1 ≦
u ≦ 2 and 1 ≦
a ≦ 11. The necessary neighbor operations of each action in procedure 1 are summarized in
Table 1.
Table 1.
Actions of procedure 1.
Table 1.
Actions of procedure 1.
| Action Number | Neighbor Operations |
|---|
| 1-1 | Plus serial number and New a provisional label for block X as temporary label |
| 1-2 | Assign the same provision label as block P for the current block X |
| 1-3 | Assign the same provision label as block Q for the current block X |
| 1-4 | Assign the same provision label as block R for the current block X |
| 1-5 | Assign the same provision label as block P for the current block X.
Resolve the confliction with block Q by assigning the provisional label of block P |
| 1-6 | Assign the same provision label as block P for the current block X.
Resolve the confliction with block R by assigning the provisional label of block P |
| 1-7 | Assign the same provision label as block Q for the current block X.
Resolve the confliction with block R by assigning the provisional label of block Q |
In
P1C1, the state of pixels
o and
p is (11)
2. The block-connected relationships between block
X and blocks
P,
Q, and
R should be checked, which requires pixels
h,
i,
j, and
k to be considered
. The provisional label for the current block can be determined by following the binary decision sub-tree in
Figure 4b. Depending on the locations of all foreground pixels, action numbers 1-1 to 1-7 can be performed by the final leaf node. For the leaf nodes of the binary decision sub-tree, the proposed algorithm employs the strategy of “divide and conquer,” which ensures the connectivity of block
X with blocks
P,
Q, and
R for the elimination of redundant checks in the proposed algorithm. Block
Q should first check among blocks
P,
Q, and
R to reduce redundant judgments. Pixels
i and
j are checked first, because they indicate the existence of block
Q and its connectivity with block
X. Furthermore, pixels
h and
k indicate the connectivity of blocks
P and
R, respectively, with block
X. Thus, pixels
i and
j are first checked to ensure the existence of block
Q. The states of pixels
i and
j can be (11)
2, (10)
2, (01)
2, or (00)
2. The four states produce different actions for the current block
X. When pixels
i and
j are (11)
2, the relationships between blocks
X,
P,
Q, and
R can be described simply by assigning the provisional label for block
X using block
Q as action 1-3. The state (11)
2 of pixels
i and
j implies the existence of block
Q. Block
P or
R must be connected with block
Q in the previous two rows when either pixel
h or
k is the foreground pixel, respectively. Blocks
P,
Q, and
R retain the same provisional labels. Thus, the current block
X directly assigns the provisional label to block
Q. When pixels
i and
j are in state (10)
2, the leaf node of the decision tree performs either action 1-7 or 1-3, because blocks
Q and
R may have different provisional labels. When pixel
k is the foreground pixel, the neighbor operations assign the provisional label of block
Q to
X, and then merge blocks
Q and
R because they are connected by block
X. Otherwise, action 1-3 assigns the provisional label of block
Q to
X. The pixels
i and
j are in the state (01)
2, which triggers either action 1-5 or 1-3, because the disconnection between pixels
h and
j means that blocks
P and
R may not have the same provisional labels. In this state, blocks
P and
Q should be merged by action 1-5 when pixel
h is the foreground pixel. The neighbor operation following action 1-5 assigns the provisional label of block
Q to
X. Otherwise, action 1-3 assigns the provisional label for block
Q to the current block
X. The final state of pixels
i and
j is (00)
2. This state triggers four different actions, 1-1, 1-2, 1-4, and 1-6, depending on the four states of (
hk)
2. Pixels
h and
k represent blocks
P and
R. The four states of (
hk)
2 indicate the existence of blocks
P and
R. The first state of (
hk)
2 is (11)
2. The neighbor operations assign the provisional label of block
Q to block
X, and then merge blocks
P and
R as action 1-6
. The second state of (
hk)
2 is (10)
2, in which only block
P exists in the upper row of the current block
X. The neighbor operation assigns the provisional label of block
P to
X as action 1-2. The next state of (
hk)
2 is (01)
2. In the upper row of block
X, only block
R exists
. The provisional label of block
R is assigned to the current block
X as action 1-4. The final state of (
hk)
2 is (00)
2. The neighbor operation requires a new provisional label for block
X, as action 1-1. Because the provisional label has already been assigned by the leaf node of
P1C1, pixels
s and
t are bypassed to improve labeling performance. The bypassing of pixels
s and
t simplifies the consideration of the four cases into one in the current block of procedure 1. At the end of
P1C1, the binary decision tree of the next judgment chooses procedure 2, because pixel
p is the foreground pixel representing the existence of block
Q.
P1C2 occurs when pixels
o and
p are in state (10)
2. The block-connected relationships between block
X and blocks
P and
Q should be checked, which requires pixels
h,
i, and
j to be examined
. The provisional label for the current block can be determined by following the binary decision sub-tree in
Figure 4c. The first pixel to be checked is the middle pixel among
h,
i, and
j. Thus, when pixel
i is the foreground pixel, action 1-3 is performed, because pixels
h and
j have the same provisional label as
i. Otherwise, pixels
h and
j are checked. They have four different states. The first state is (11)
2 for (
hj)
2. This indicates the existence of blocks
P and
Q, but they may have different provisional labels because of the disconnection between pixels
h and
j. Action 1-5 is used as the neighbor operation. The second state of (
hj)
2 is (10)
2, in which only block
P exists above block
X. Action 1-2 is thus applied to assign the provisional label of
P to
X. The third state of (
hj)
2 is (01)
2, representing the existence of block
R in the upper row of block
X. The provisional label of block
X is assigned as the label of block
R by action 1-3. The final state of (
hj)
2 is (00)
2, whereby a new provisional label is required by block
X as action 1-1. At the end of
P1C2, it is necessary to check pixel
t to determine between procedures 1 and 2 for the next judgment. Pixel
s should be bypassed, because the provisional label of the current block
X has been determined by the aforementioned states.
In
P1C3, pixels
o and
p are in state (01)
2. The block-connected relationships between block
X and blocks
Q and
R should be checked, which requires the consideration of pixels
i,
j, and
k. The provisional label for the current block
X can be determined by following the binary decision sub-tree in
Figure 4d. As in
P1C2, the middle pixel of
i,
j, and
k is first checked. Thus, action 1-3 is directly applied when pixel
j is the foreground pixel, because pixels
i and
k have the same provisional label as
j. Otherwise, pixels
i and
k are checked. Pixels
i and
k have four different states. The first state is (11)
2 for (
ik)
2. Blocks
Q and
R may have different provisional labels because of the disconnection between pixels
i and
k in the first state. Action 1-7 is thus applied for the neighbor operations of assigning the provisional label of block
Q to
X, and merging blocks
Q and
R. The second state of (
hj)
2 is (10)
2. Action 1-3 is directly applicable here, because only block
Q exists above the current block
X. The next state of (
hj)
2 is (01)
2. Action 1-4 is performed for the current block
X, because blocks
P and
Q do not exist above
X. At the end of
P1C3, pixels
s and
t are bypassed, because the provisional label of block
X has already been assigned by the binary decision tree. Because block
S exists in the following judgment, procedure 2 is chosen next.
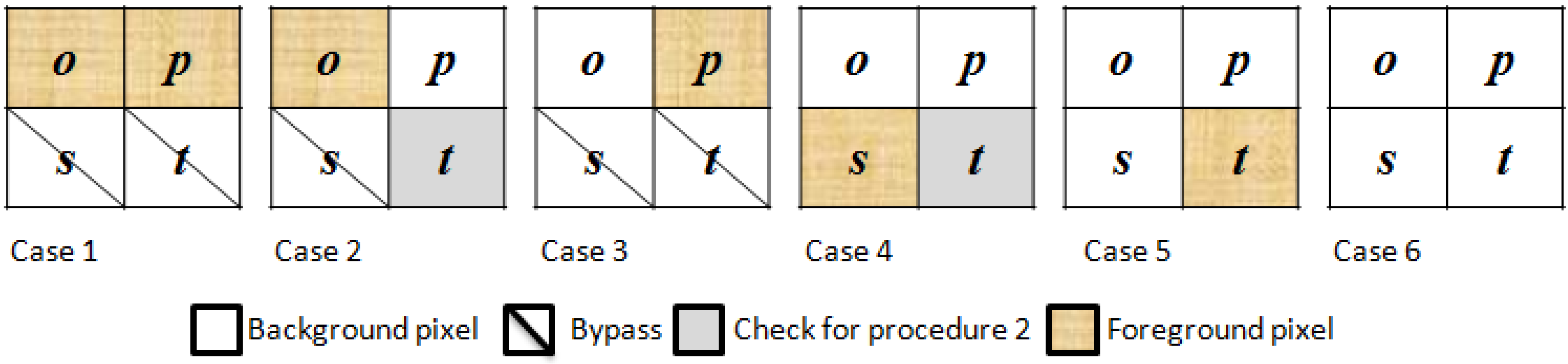
In P1C4–P1C6, block X has no connection with blocks P, Q, and R. In P1C4, pixels s and t are (11)2 or (10)2. Action 1-1 is used to obtain a new provisional label for block X. When pixel p is a background pixel, pixel t should be checked to ensure the existence of block S for the next judgment and choose the appropriate procedure. P1C5 of the current block only has one foreground pixel at location t. Action 1-1 is therefore utilized to obtain a new provisional label for block X. Pixel t determines that procedure 2 is chosen in the next judgment. The final case is P1C6, in which there are no foreground pixels in block X. In this case, all neighbor operations should be bypassed, and the binary decision tree of procedure 1 should be chosen for the next judgment. The pseudo-code for procedure 1 of the first scan in the proposed method is given in Algorithm 1.
| Algorithm 1 Procedure 1 of the First-Scan Method in the Proposed Algorithm |
Begin
1. if(o!=0){
2. if(p!=0)
3. {P1C1;}
4. else
5. {P1C2;}
6. }else if(p!=0)
7. {P1C3;}
8. else if(s!=0)
9. {P1C4;}
10. else if(t!=0)
11. {P1C5;}
12. else
13. {P1C6;}
end
|
3.2. Procedure 2 of the Proposed Algorithm
When pixel
n or
r is the foreground pixel in the current judgment, the proposed algorithm chooses procedure 2 to determine the actions for block
X. There are seven different cases in procedure 2,
P2C1–
P2C7, as shown in
Figure 5. All seven cases must consider the block-connected relationship with block
S. The judgments and actions of procedure 2 become more complex than those in procedure 1. Considering
P2C1 as an example, the neighbor operations are “assign the same provisional label as block
S to block
X, and then resolve the conflict among blocks
S,
Q, and
R” when the state of (
ijk)
2 is (101)
2. To compare the same locations of the foreground pixel in
P1C1,
P2C1 must deal with conflicts regarding the provisional labels of blocks
S,
Q, and
R. Although the leaf nodes and the depth levels of the binary decision tree in
P2C1 are the same as those of
P1C1, the final actions of
P2C1 are more complex.
Figure 5.
The seven selected cases of the current block for procedure 2.
Figure 5.
The seven selected cases of the current block for procedure 2.
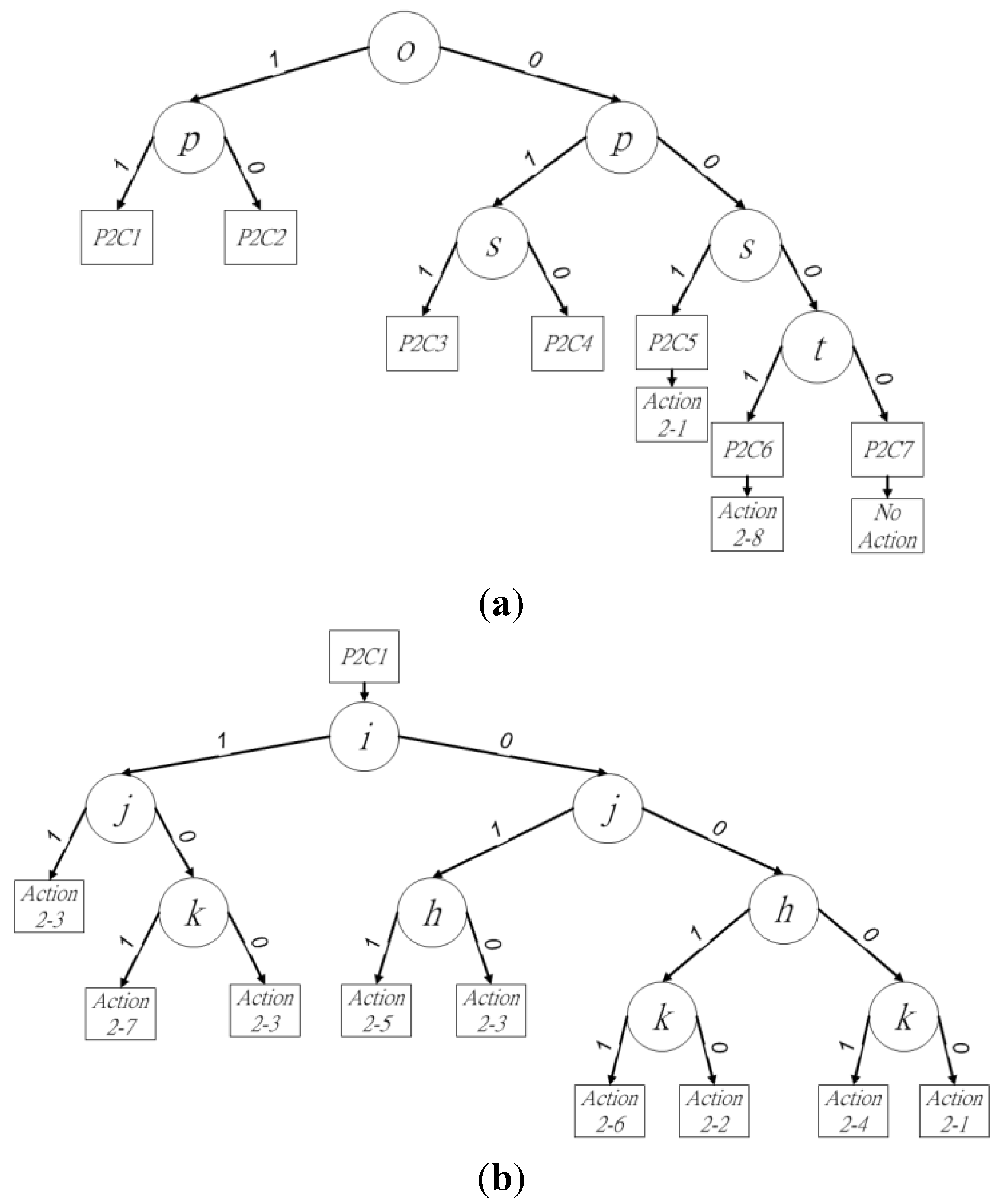
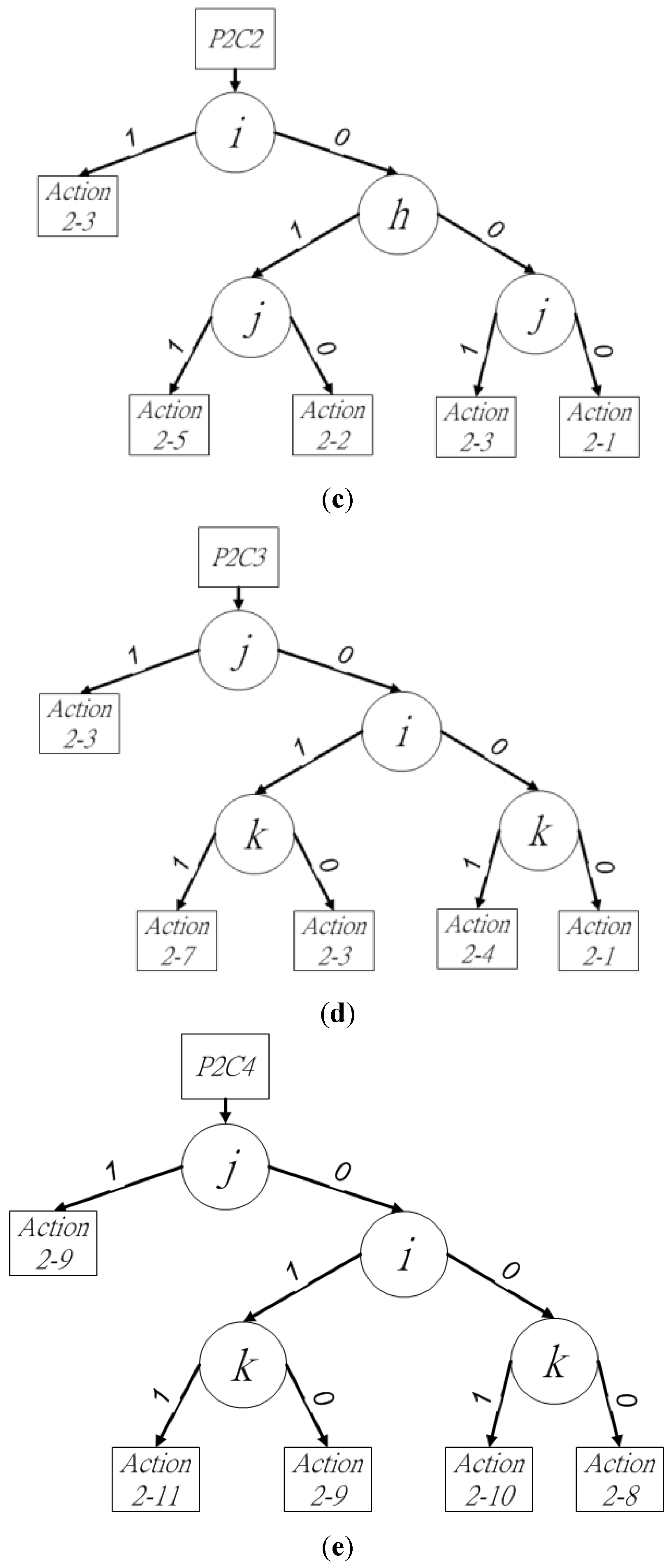
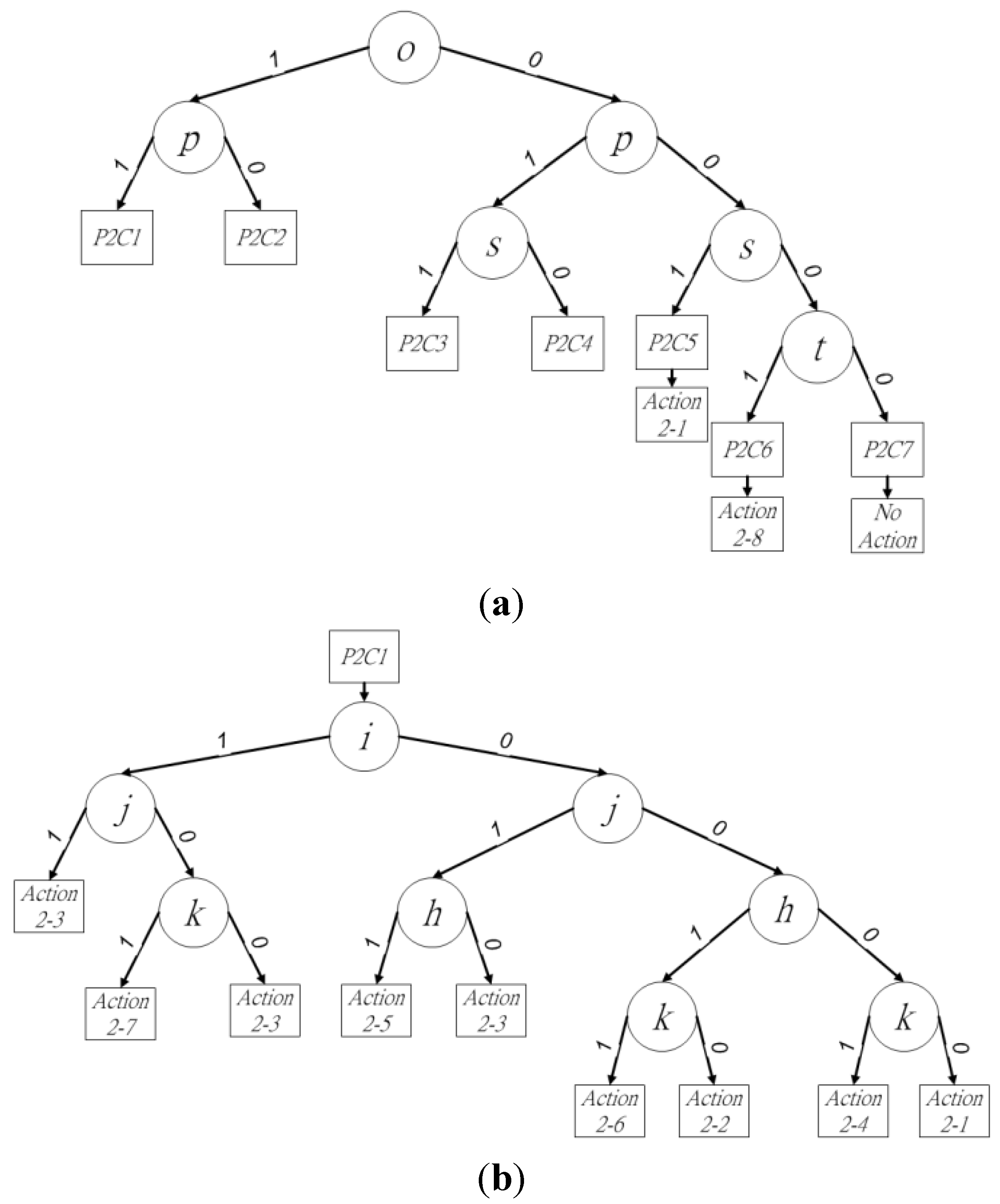
The binary decision trees for procedure 2 are shown in
Figure 6a. Pixels
o and
p determine four cases and affect the other three cases, because the existence of pixels
o and
p determines the connectivity between block
X and adjacent blocks
P,
Q, and
R. Thus, pixels
o and
p should be checked first to improve the labeling performance in block
X. When (
op)
2 = (11)
2 or (10)
2, leaf nodes from
P2C1 or
P2C2 are chosen for further judgment. Pixel
s is then checked when (
op)
2 = (01)
2 or (00)
2, because the connectivity between blocks
X and
Q must be ensured when pixel
o is the background pixel. Leaf nodes from
P2C3,
P2C4, or
P2C5 are used for more judgments when (
ops)
2 = (011)
2, (010)
2, or (001)
2. The final pixel to be checked in current block
X by procedure 2 is
t, which determines the selection of
P2C6 or
P2C7 by (
opst)
2 = (0001)
2 or (0000)
2. To summarize the seven cases and their leaf nodes,
P2C1–
P2C4 have more judgments for block
X and blocks
P,
Q, and
R than the other cases in procedure 2. The binary decision sub-trees for these four cases are shown in
Figure 6b–e.
The seven cases of procedure 2 trigger 11 different actions as leaf nodes in the binary decision trees of procedure 2. The leaf nodes of the binary decision tree in procedure 2 include “assign the same provisional label as block
S to block
X,” “assign the same provisional label as block
S to block
X, and resolve the conflict among blocks
S and
P,
S and
Q,
S and
R,
S,
P, and
Q,
S,
P, and
R, or
S,
Q, and
R,” “a new provisional label,” “assign the provisional label of block
P,
Q, or
R,” and “assign the provisional label of block
P or
Q, and merge blocks
P and
Q,
P and
R, or
Q and
R.” The action numbers are summarized in
Table 2.
Figure 6.
Binary decision tree of (a) procedure 2, (b) P2C1, (c) P2C2, (d) P2C3, and (e) P2C4.
Figure 6.
Binary decision tree of (a) procedure 2, (b) P2C1, (c) P2C2, (d) P2C3, and (e) P2C4.
Table 2.
Actions of procedure 2.
Table 2.
Actions of procedure 2.
| Action Number | Neighbor Operations |
|---|
| 2-1 | Assign the same provision label as block S for the current block X |
| 2-2 | Assign the same provision label as block S for the current block X.
Resolve the confliction with block P by assigning the provisional label of block S |
| 2-3 | Assign the same provision label as block S for the current block X.
Resolve the confliction with block Q by assigning the provisional label of block S |
| 2-4 | Assign the same provision label as block S for the current block X.
Resolve the confliction with block R by assigning the provisional label of block S |
| 2-5 | Assign the same provision label as block S for the current block X.
Resolve the confliction with blocks P and Q by assigning the provisional label of block S |
| 2-6 | Assign the same provision label as block S for the current block X.
Resolve the confliction with blocks P and R by assigning the provisional label of block S |
| 2-7 | Assign the same provision label as block S for the current block X.
Resolve the confliction with blocks Q and R by assigning the provisional label of block S |
| 2-8 | Plus serial number and New a provisional label for block X as temporary label |
| 2-9 | Assign the same provision label as block Q for the current block X |
| 2-10 | Assign the same provision label as block R for the current block X |
| 2-11 | Assign the provisional label by block Q then merge blocks Q and R |
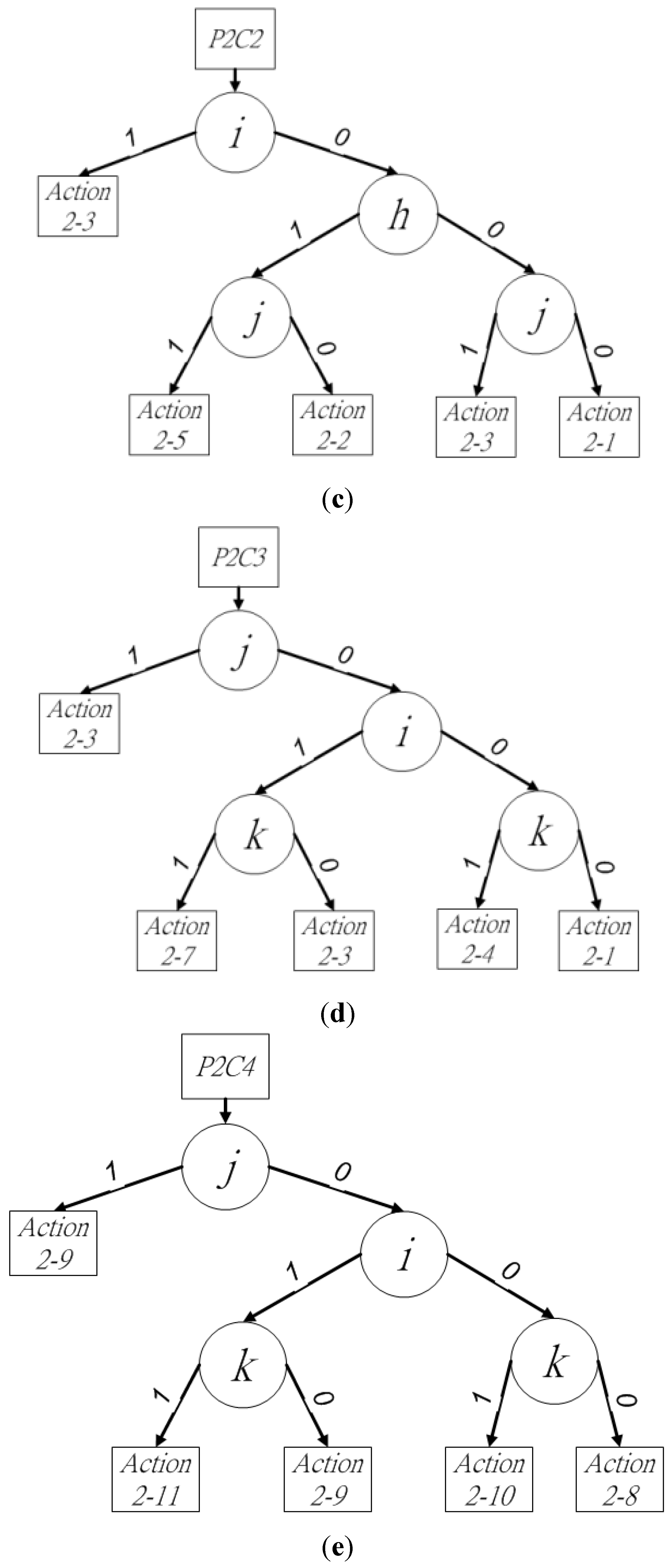
In
P2C1, pixels
o and
p are in state (11)
2. The block-connected relationships between block
X and blocks
S,
P,
Q, and
R should be checked, which requires pixels
h,
i,
j, and
k to be considered
. The final action can be determined by following the binary decision sub-tree in
Figure 6b. According to the locations of all foreground pixels, action numbers 2-1 to 2-7 can be used in the final decision. The first pixels to be checked are
i and
j to ensure the existence of block
Q. The state of pixels
i and
j is (11)
2, (10)
2, (01)
2, or (00)
2, producing different actions for the current block
X. When pixels
i and
j are in state (11)
2, the block-connected relations among
X,
P,
Q, and
R are simplified to assign the provisional label for block S to block
X and resolve the conflict between blocks
S and
Q as action 2-3. When pixels
i and
j are in state (10)
2, the leaf node for the decision tree has two options, action 2-7 or 2-3, because blocks
S,
Q, and
R may have different provisional labels. When pixel
k is the foreground pixel, the neighbor operations assign the provisional label of block
S to
X, and resolve the conflict among blocks
S,
Q, and
R. In contrast, action 2-3 assigns the provisional label of block
S to
X, and resolves the conflict between blocks
S and
Q when pixel
k is 0
. Either action 2-5 or 2-3 is triggered when pixels
i and
j are in state (01)
2, because blocks
P and
R may not have the same provisional labels. Blocks
P and
Q must resolve their conflict via action 2-5 when pixel
h is the foreground pixel. The next neighbor operation, action 2-5, assigns the provisional label of block
S to
X. Otherwise, action 2-3 is applied when pixel
h is 0. Four different actions, actions 2-1, 2-2, 2-4, and 2-6, are triggered when pixels
i and
j are in state (00)
2. The actions are determined by the four states of (
hk)
2. When (
hk)
2 is in state (11)
2, blocks
Q and
R do not exist in the upper row of the current block
X. Action 2-6 then assigns the provisional label of block
S to block
X, and resolves blocks
S,
P, and
R. When the state of (
hk)
2 is (10)
2, action 2-2 performs the neighbor operations of assigning the provisional label of block
S to
X and resolving the conflict between blocks
S and
P. When the state of (
hk)
2 is (01)
2, block
R exists and is connected to block
X. Action 2-4 is used to assign the provisional label of block
S to
X, and resolve the conflict between block
S and
R. The final state of (
hk)
2 is (00)
2. The neighbor operation assigns the provisional label of block
S to block
X as action 2-1 when blocks
P,
Q, and
R do not exist. Pixels
s and
t are bypassed, because block
X has already been assigned a provisional label by the leaf node of
P2C1. Bypassing two checking pixels in procedure 2 eliminates three redundant cases. At the end of
P2C2, the binary decision tree of the next judgment retains procedure 2, because pixel
p is the foreground pixel representing the existence of block
Q.
Pixels
o and
p in state (10)
2 represent
P2C2. The block-connected relationships between block
X and blocks
S,
P, and
Q must be checked by pixels
h,
i, and
j. Figure 6c shows the binary decision sub-tree. The middle pixel of pixels
h,
i, and
j is checked first. Action 2-3 is performed, because pixels
h and
j have the same provisional label as
i when pixel
i is the foreground pixel. Otherwise, pixels
h and
j are checked when pixel
i is 0. Pixels
h and
j have four different states that produce four different actions. Blocks
P and
Q may have different provisional labels when (
hj)
2 has the state (11)
2. The leaf node performs action 2-5 as the neighbor operation. The second state of (
hj)
2 is (10)
2, which indicates that block
P is connected to block
X. Action 2-2 is used to assign the provisional label of
S to
X, and resolve the conflict between
S and
P. The third state of (
hj)
2 is (01)
2. Block
Q is the only block in the upper row of block
X. Action 2-3 is thus performed, assigning the provisional label of block
S to
X and resolving the conflict between blocks
S and
Q. The final state of (
hj)
2 is (00)
2. Action 2-1 is used to assign the provisional label of block
S to block
X. The last neighbor operation of
P2C2 checks pixel
t to determine which of procedures 1 and 2 should be used for the next judgment. Pixel
s is bypassed, because the provisional label of block
X has been acquired by following the binary decision tree.
For
P2C3, pixels
o,
p, and
s are in state (011)
2. The block-connected relationships between block
X and blocks
S,
P, and
Q are checked by pixels
h,
i, and
j. Figure 6d shows the binary decision sub-tree. Pixel
j must be checked first, because it is the middle pixel of
i,
j, and
k. If pixel
j is a foreground pixel, pixels
i and
k have the same provisional label. In this state, action 2-3 is applied to assign the provisional label of block
X. Otherwise, pixels
i and
k are checked when pixel
j is (0)
2. The four different states of pixels
i and
k generate four different actions. The first state of (
ik)
2 is (11)
2. Blocks
S,
P, and
Q may have different provisional labels, which requires action 2-7. In the second state, (
ik)
2 is (10)
2, whereby blocks
Q and
X are connected. Action 2-3 hence assigns the provisional label of
S to
X and resolves the conflict between
S and
Q. The third state of (
ik)
2 is (01)
2. Block
R is the only existing block in the upper row of block
X. Action 2-4 thus assigns the provisional label of block
S to
X and resolves the conflict between blocks
S and
R. The final state of (
ik)
2 is (00)
2, in which action 2-1 assigns the provisional label of block
S to block
X. The next judgment uses procedure 2, because pixel
s is the foreground pixel. Pixel
t is bypassed because the binary decision tree of the next judgment and the provisional label of block
X have already been determined.
Pixels
o,
p, and
s are in state (010)
2 in
P2C4. For block
X and blocks
Q and
R, the block-connected relationships must be checked, which requires an examination of pixels
i,
j, and
k. From
Figure 6e, it is apparent that the current block
X can determine the provisional label by following the binary decision sub-tree. In
P2C3, the middle pixel of
i,
j, and
k is first checked. However, blocks
S and
X have no connection with each other in
P2C4. The assignment of the provisional label for block
X by
Q is applied as action 2-9 when pixel
j is the foreground pixel. Pixels
i and
k are checked if pixel
j is the background pixel. There are four different states for pixels
i and
k. The first state of (
ik)
2 is (11)
2, where blocks
Q and
R may have different provisional labels. Action 2-11 is applied to the neighboring operations to assign the provisional label of block
Q to
X and resolve the conflict between blocks
Q and
R. The second state of (
hj)
2 is (10)
2, whereby action 2-9 is applied to assign the provisional label of block
Q to
X. The third state of (
hj)
2 is (01)
2. In this case, action 2-10 assigns the provisional label of block
R to
X. The binary decision tree for the next judgment chooses procedure 2, because pixel
p is the foreground pixel. At the end of
P2C4, pixel
t is bypassed because it is connected to pixel
p, and the provisional label has already been determined by the above process.
For P2C5, P2C6, and P2C7, the judgment focuses on the block-connected relationships of blocks S and X. In P2C5, pixels s and t have two states: (11)2 or (10)2. Action 2-1 is used to assign the provisional label of block S to block X. To select the correct procedure for the next judgment, pixel t must be checked to ensure the existence of block S. P2C6 in procedure 2 has one foreground pixel at location t. Action 2-8 is thus performed to add and assign a new provisional label to block X. Pixel t has a value of 1, which ensures the next judgment retains the binary decision tree for procedure 2. P2C7 involves no foreground pixels in block X. In this case, neighbor operations are avoided, and the binary decision tree of procedure 1 is chosen for the next judgment. The pseudo-code for procedure 2 of the first scan is given in Algorithm 2.
| Algorithm 2 Procedure 2 of the First-Scan Method in the Proposed Algorithm |
Begin
1. if(o!=0){
2. if(p!=0)
3. {P2C1;}
4. else
5. {P2C2;}
6. }else if(p!=0)
7. if(s!=0)
8. {P2C3;}
9. else
10. {P2C4;}
11. else if(s!=0)
12. {P2C5;}
13. else if(t!=0)
14. {P2C6;}
15. else
16. {P2C7;}
end
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}