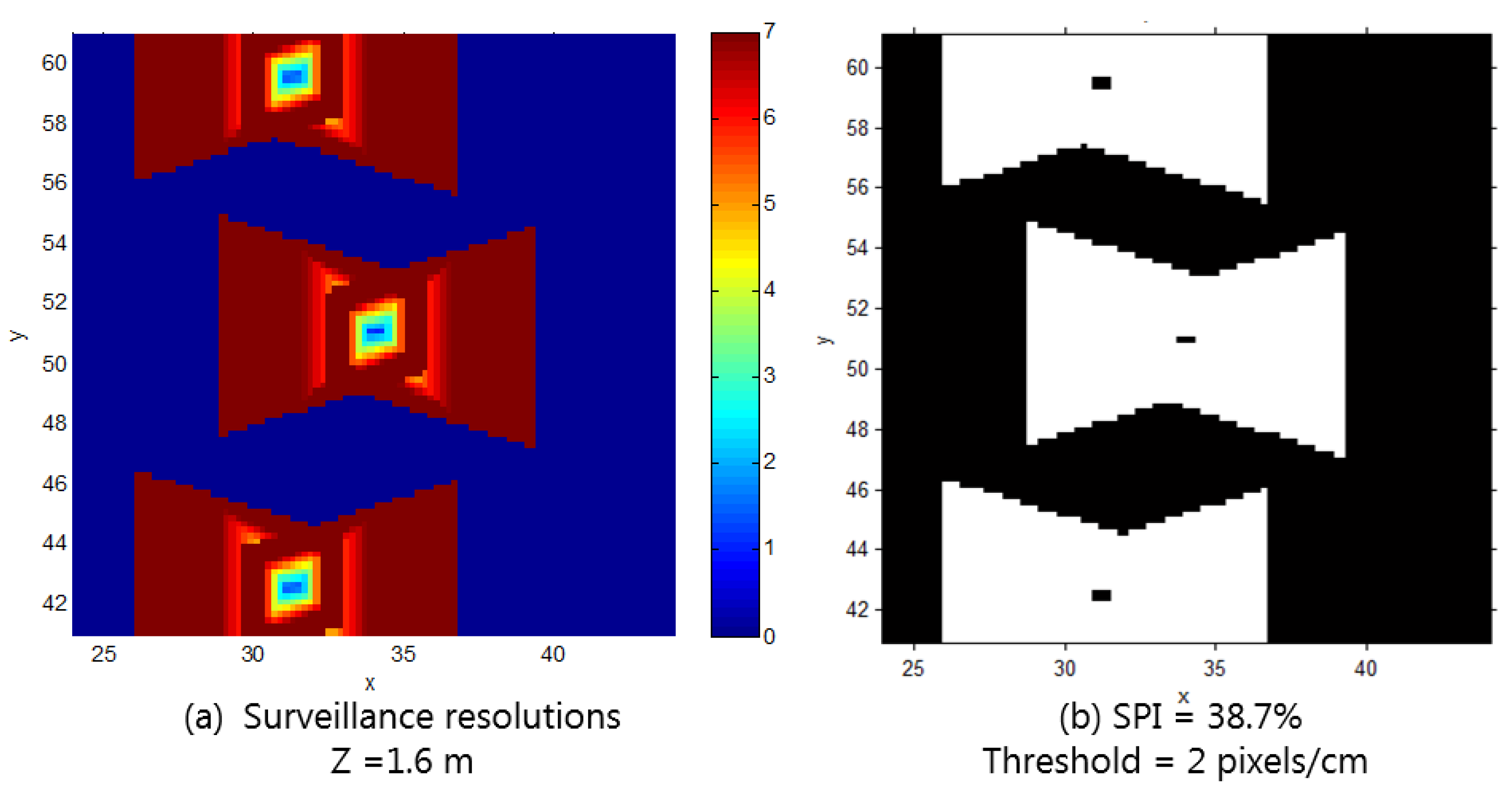
Surveillance performance indicates how effectively a target area is being monitored by a CCTV system. As quantitative measures of surveillance performance, we propose the following two indicators: surveillance resolution and surveillance coverage index. Surveillance resolution indicates how closely a specific object can be monitored with a CCTV system, depending on the location and orientation of the object as well as the cameras of the CCTV system. Surveillance coverage index focuses on a specific region rather than an object, indicating how completely a region of interest can be monitored with more than a specified surveillance resolution. The region can also be a path, an area, or a 3D space as a subset of the object space; for example, to what extent a pedestrian path in a parking lot, a crowded area in a mall, or the entire inner space of a building can be completely monitored may be of interest. The resolution threshold can be established according to its own application; for example, it can be two px/cm for facial recognition.
The evaluation process to derive the proposed performance indicators requires two kinds of inputs. The first group includes those with almost constant properties—at least during the evaluation process—which are a 3D geometric model of the object space, and the intrinsic and extrinsic parameters of all of the cameras of the CCTV system. The second group includes the changeable parameters, which are the resolution threshold and the regions of interest that are specified within the object space.
In this section, we first describe the definition and derivation of the proposed indicators, the surveillance resolution of an object with a specified location and orientation, and the surveillance coverage index for a specified region of interest. We then explain the proposed evaluation process to derive these indicators in an actual practical situation.
2.1. Surveillance Resolution and Coverage Index
The following four types of resolutions are used to define the quality of an image: geometric, radiometric, spectral, and temporal. Among these resolutions, the geometric resolution is the most effective when describing an object’s geometric properties such as position and shape. The geometric resolution is typically expressed in terms of Ground Sampling Distance (GSD), which refers to the distance of an object surface in a single pixel of an image. In this context, the surveillance performance of a CCTV can be evaluated by observing the minimum GSD required to monitor an object. An arbitrary length can therefore be set within the target area in the object space and the actual length projected on the CCTV image can be calculated; we define the latter value as the surveillance resolution and apply it when assessing the surveillance performance of a CCTV. The surveillance resolution depends on sensor’s physical characteristics, such as the focal length, the principle point, the pixel size, the projection type. It also varies according to the relative geometric relationship between the camera and the object. Even with an object at the same position, the resolution can be different in accordance with the orientation of the object surface. By considering these diverse factors affecting the resolution, we derive a formula to derive the resolution as follows.
When an object locating at a location with its surface normal is monitored by a CCTV camera, it is projected to the image with a resolution. The defined surveillance resolution is represented as the ratio between the actual length
of an object and its projected length
on the image, which is defined as Equation (1). It consists of four terms that accurately model four steps of the projection process from the object space to the image space. The steps are computing (1) the projected length
of
on the surface where the object can be observed at a maximum resolution; (2) the incident angles
when the object is projected through the perspective center; (3) the projected length
of
on the image according to a lens formula without any distortion; and (4) the projected length
of
on the image considering distortions, respectively.
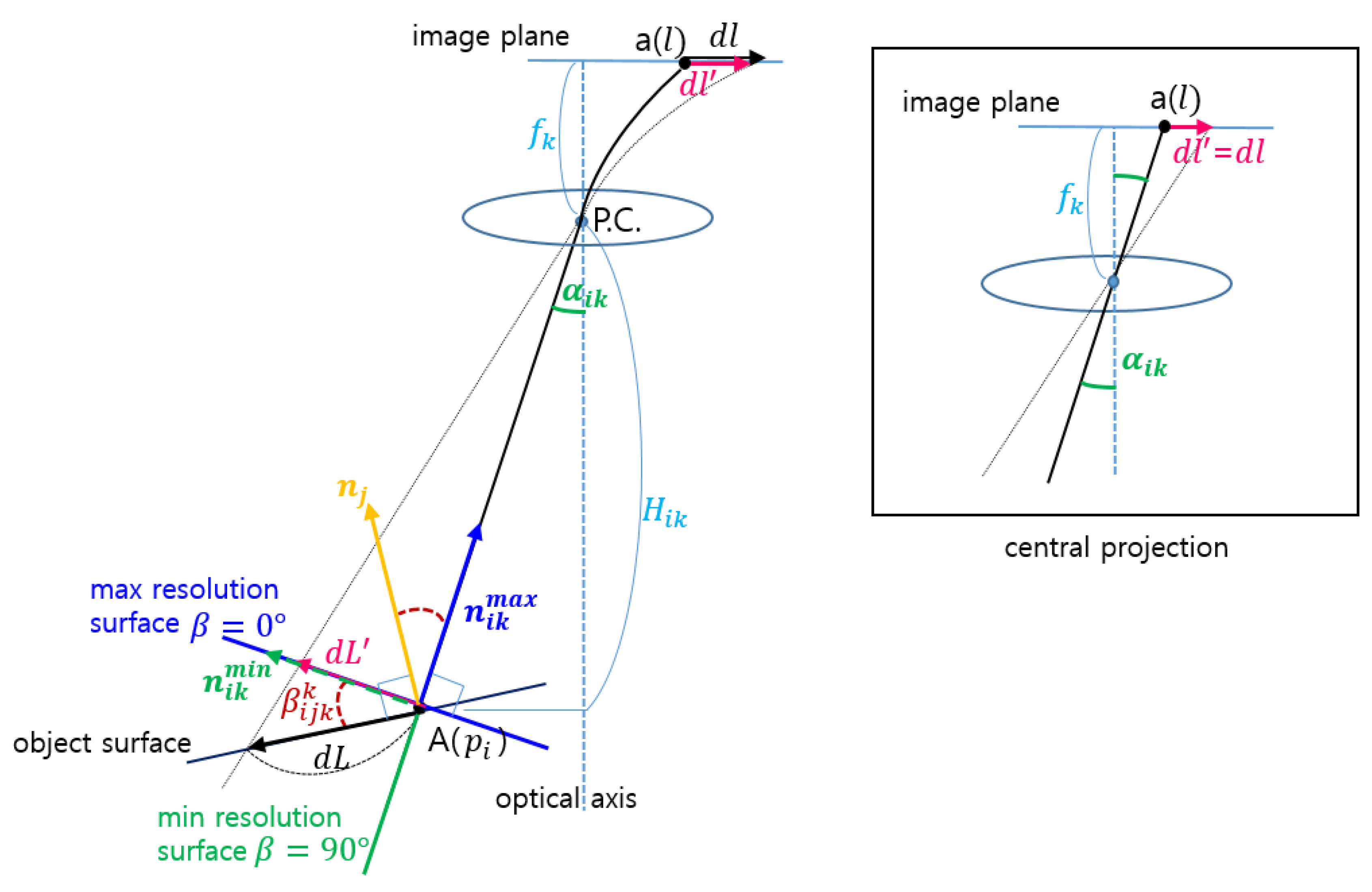
Figure 2 illustrates the geometric meanings of the main parameters associated with the derivation of the defined surveillance resolution.
Figure 2.
Definition of surveillance resolution.
Figure 2.
Definition of surveillance resolution.
The first term considers the orientation of the object surface. In spite of the same object position, the resolution of its projection can be different from the object’s orientation. The highest resolution can be achieved when the surface normal corresponds to the direction toward the perspective center. The length projected to the surface and directed to the perspective center can be derived as the following:
where is the angle between the actual orientation and the orientation resulting in the highest surveillance resolution.
The second term transforms the projected length
into the range of the incident angle
, which can be derived based on the arc length formula, as follows:
where is the distance from the object to the perspective center; and is its projected length to the optical axis, which is represented as .
The third term reflects a projection model. In a narrow angle system, it is usually assumed that the central projection model is available, whereas different models apply for wide angle systems, which are mostly utilized for CCTV systems. Some useful models are presented as Equation (4). Through a lens of a focal length (, an object point in the direction is projected to a position distant from the principal point. The first of the models in Equation (4) signifies the central projection model, while the last term models the distortion correction. If we consider only the radial distortion of the lens, the correction model can be expressed as Equation (5).
As shown in
Figure 2, when an object
locating at location
with its surface normal
is monitored by a CCTV camera
, it is projected to a CCTV image with a resolution
. The defined surveillance resolution is represented as the ratio between the actual length
of an object
and its projected length
, which is formulated as Equation (6). Here, it is assumed that the camera follows the central projection without any distortion:
The vertical distance between the object and center of projection and the offset angle from the optical axis are determined based on ’s location , and the camera’s position and attitude. According to the orientation , the angle between the actual orientation of and the orientation resulting in the highest surveillance resolution is decided. The and represent the normal vector of on the object surface and the normal vector of on the image plane at the maximum surveillance resolution possible, respectively. In addition, focal length is computed from the camera modeling process.
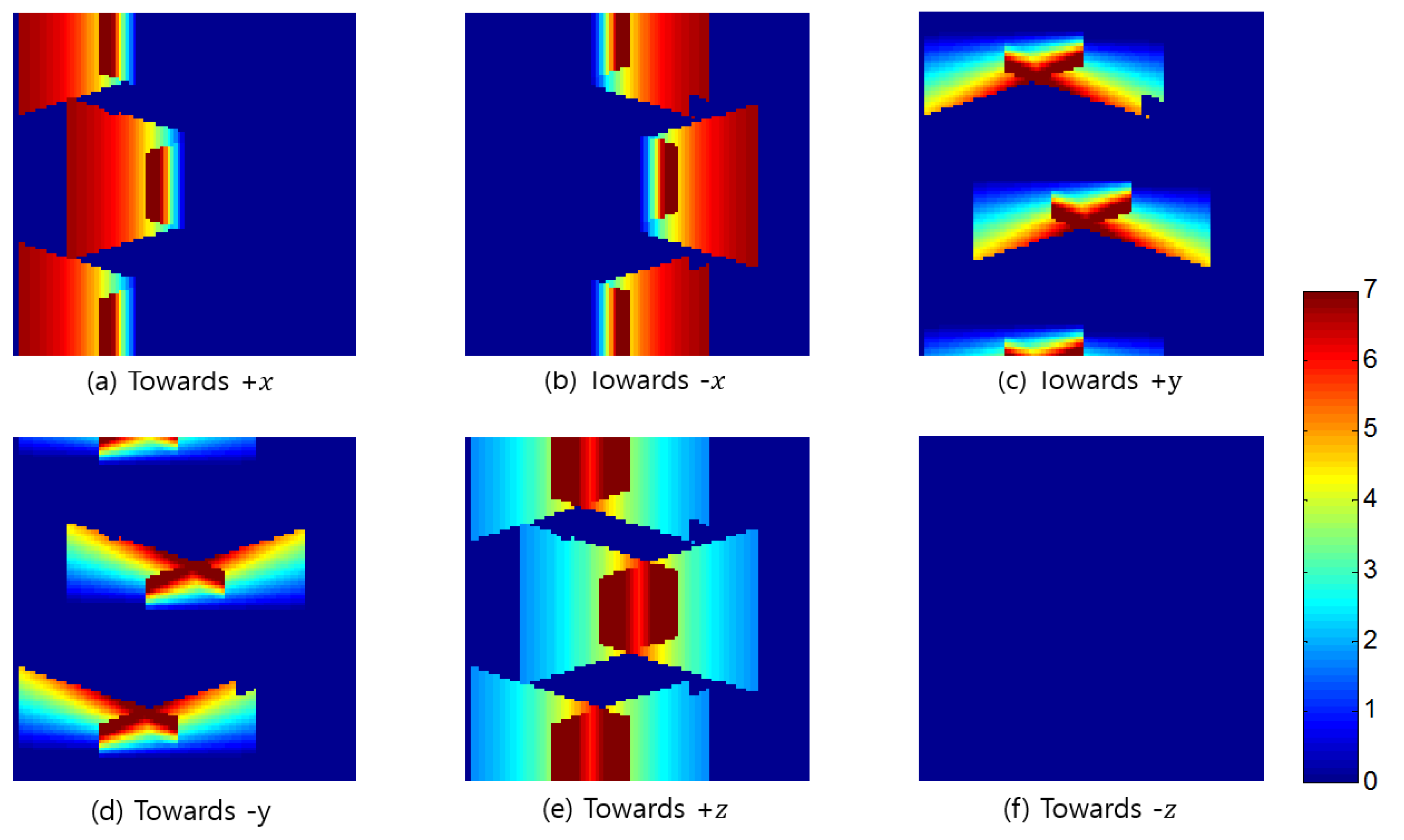
Although CCTV cameras will acquire images at a maximum resolution of if the object orientation is facing , the resulting image resolution will be lower when the object is placed on the surface tilted by . When the angle of increases to 90°, the object will not be identifiable in the images. Moreover, the surveillance resolution will have a negative value when is larger than 90°, and this is the case when the opposite side of the object is projected to the image; for example, only the back of a suspect is captured in the CCTV image when the intention was to observe the facial features of the suspect. The negative surveillance-resolution value is not useful information in this case and it is therefore replaced by 0.
The camera parameters describe its projection characteristics. The intrinsic parameters are focal length, principal point, and distortion coefficients, whereas the extrinsic parameters are the position and orientation of the camera in an object coordinate system. As the camera parameters can be estimated through a camera modeling process, such as self-calibration using the acquired CCTV images and reference data, the intrinsic and extrinsic parameters can be assumed as known. In addition, the same camera parameters can be applied in cases where the coverage originates from an identical camera. The surveillance resolution of a camera is therefore derived from an object in a specific location and orientation in a target space.
Referring back to Equation (6), and must be known to determine the surveillance resolution at a certain location and orientation. As it is assumed that the CCTV camera’s intrinsic and extrinsic parameters and the object’s location and orientation are known, the following equations can be used to compute and . First, the distance from the object location to the center of the projection and the unit vector of the optical axis in a 3D coordinate system defined by the camera’s extrinsic parameters are calculated. Then, the normal vector of the surface where the CCTV camera can monitor at maximum resolution can be calculated using Equation (7), as follows:
Next, the off-axis angle from the CCTV camera’s optical axis is determined by Equation (8) and Equation (9) is used to compute . In addition, the angle created by the actual surface where the object exists, and the surface at which the CCTV camera can observe the object at maximum resolution can be calculated with the relation shown in Equation (10), as follows:
The values of
vary with respect to the local reference frame defined by the CCTV camera and the object as expressed in Equations (8)–(10), and these values will determine the surveillance resolution defined by Equation (6). Nonetheless, in general, multiple cameras are installed over the target area and one object may appear in many camera images. As the relative position and orientation differ between each CCTV camera and the particular object, each image will attain different surveillance resolutions. Although there may be different surveillance resolutions for a given object, the largest value will be assigned as the object’s surveillance resolution. Consequently, the surveillance resolution of an object in a CCTV system with multiple cameras
can be expressed as the following, where
is the total number of cameras in a CCTV system:
The surveillance resolution
is calculated with
, which are obtained with respect to the object’s position and orientation in a space. To assess the surveillance coverage
, the surveillance resolution at every possible position and orientation in a given space is produced. Then, the percentage of the surveillance resolution that exceeds over a pre-defined threshold can be computed by Equation (12), as follows:
where
is the total number of positions sampled;
is the total number of orientations sampled at each position; and
is the number of samples that meet the requirement in the bracket.
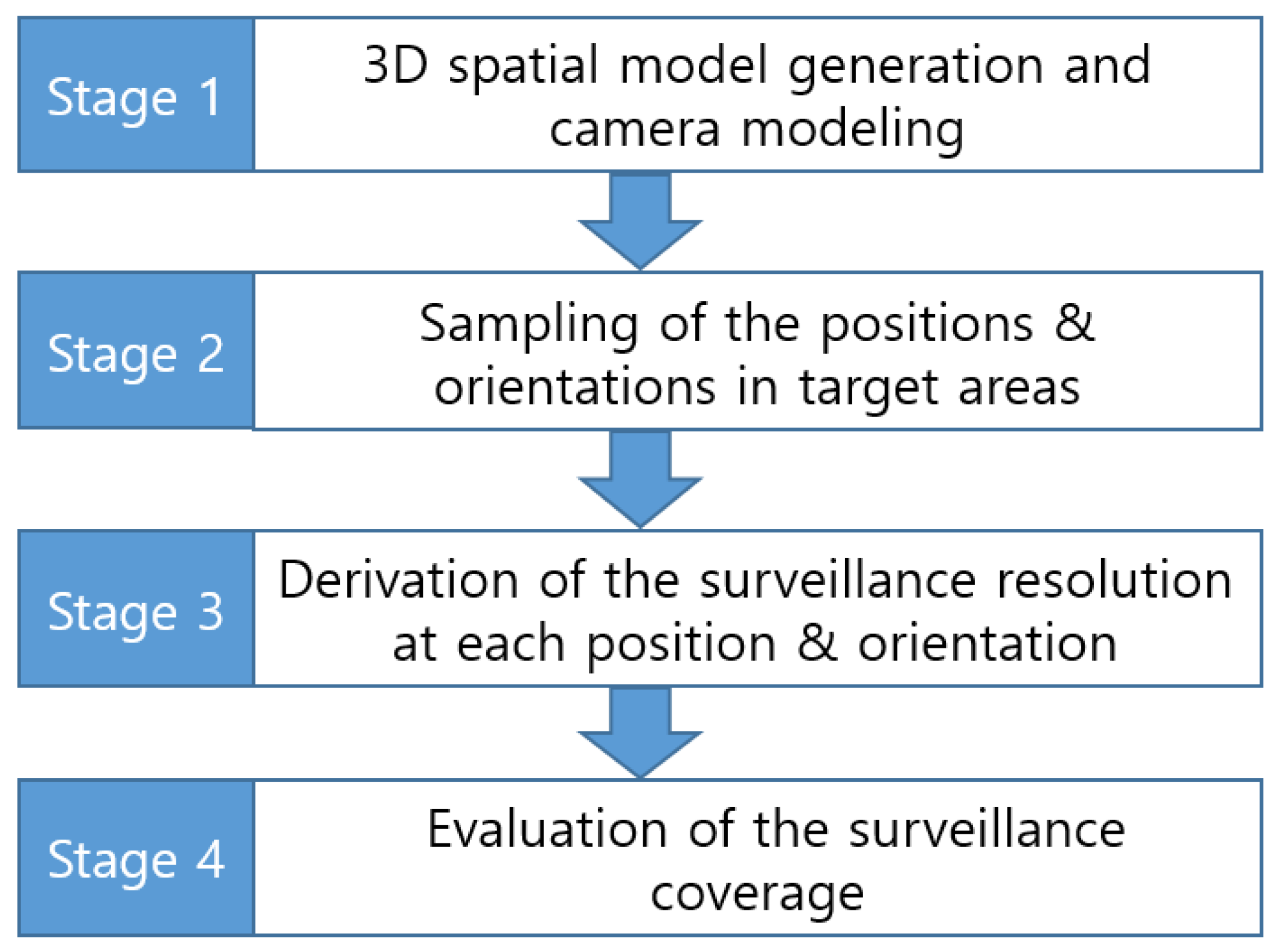
2.2. Coverage Evaluation Procedure
By applying the surveillance resolution and coverage index described in
Section 2.1, the evaluation of surveillance coverage can be conducted using the steps shown in
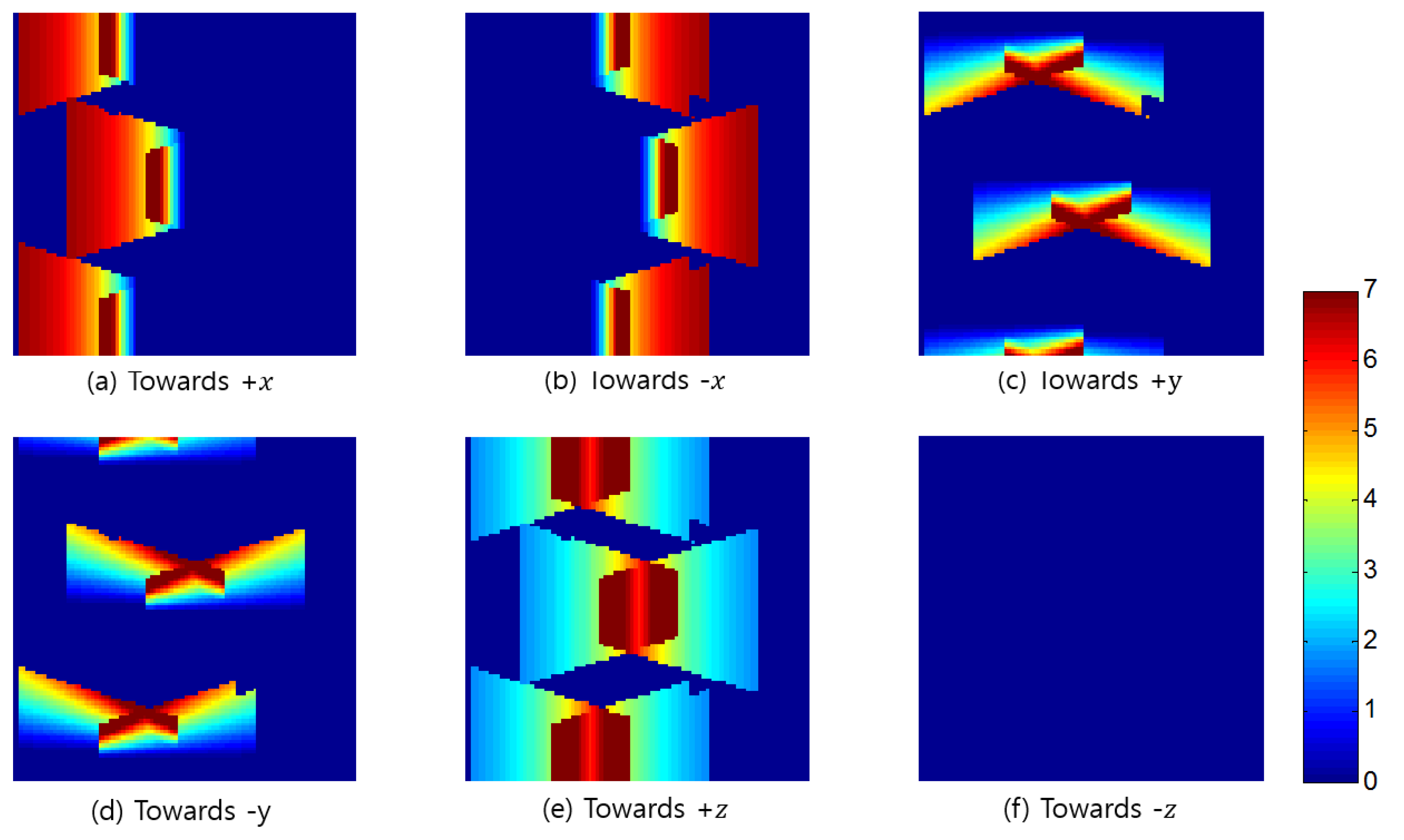
Figure 3. First, we need to generate 3D spatial models of the target surveillance area and determine the CCTV camera’s extrinsic and intrinsic parameters. Next, samples are selected at each location, whereby the object is visible from different orientations. Then, the surveillance resolutions at each of the sampled locations and orientations are derived from Equation (1). Finally, the completeness of the surveillance coverage is evaluated by computing the surveillance coverage index based on Equation (12).
Figure 3.
Surveillance Coverage Evaluation Procedure.
Figure 3.
Surveillance Coverage Evaluation Procedure.
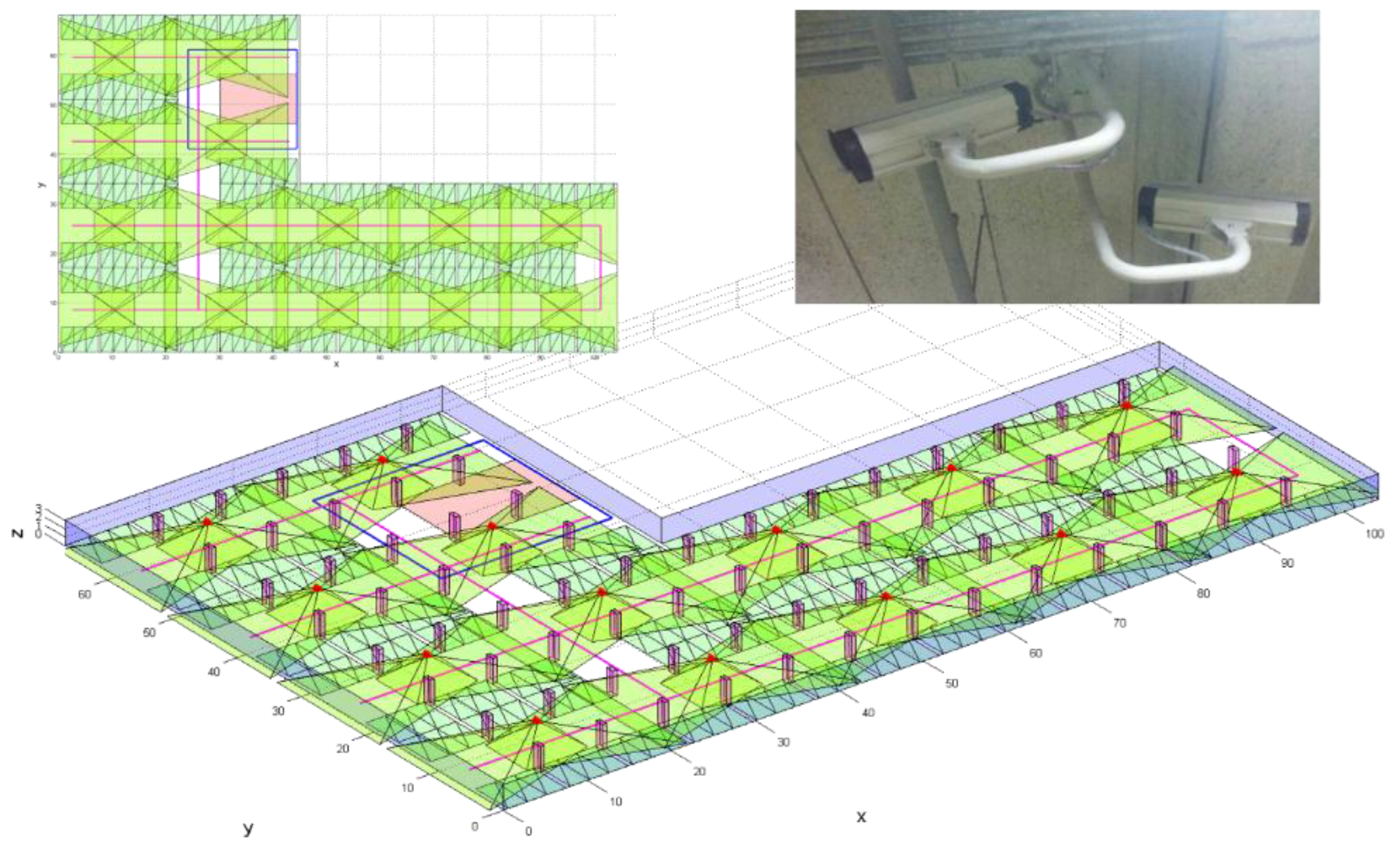
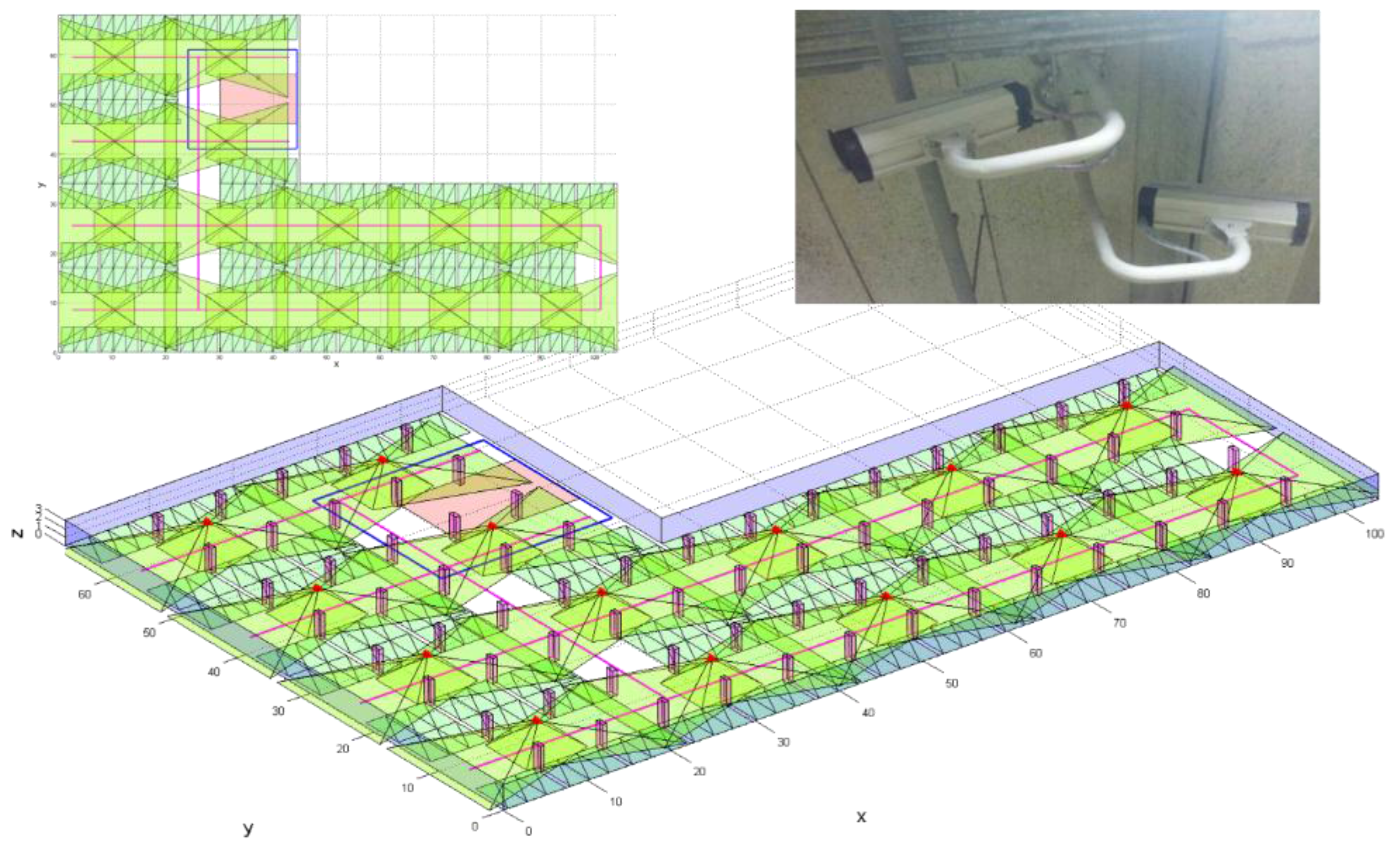
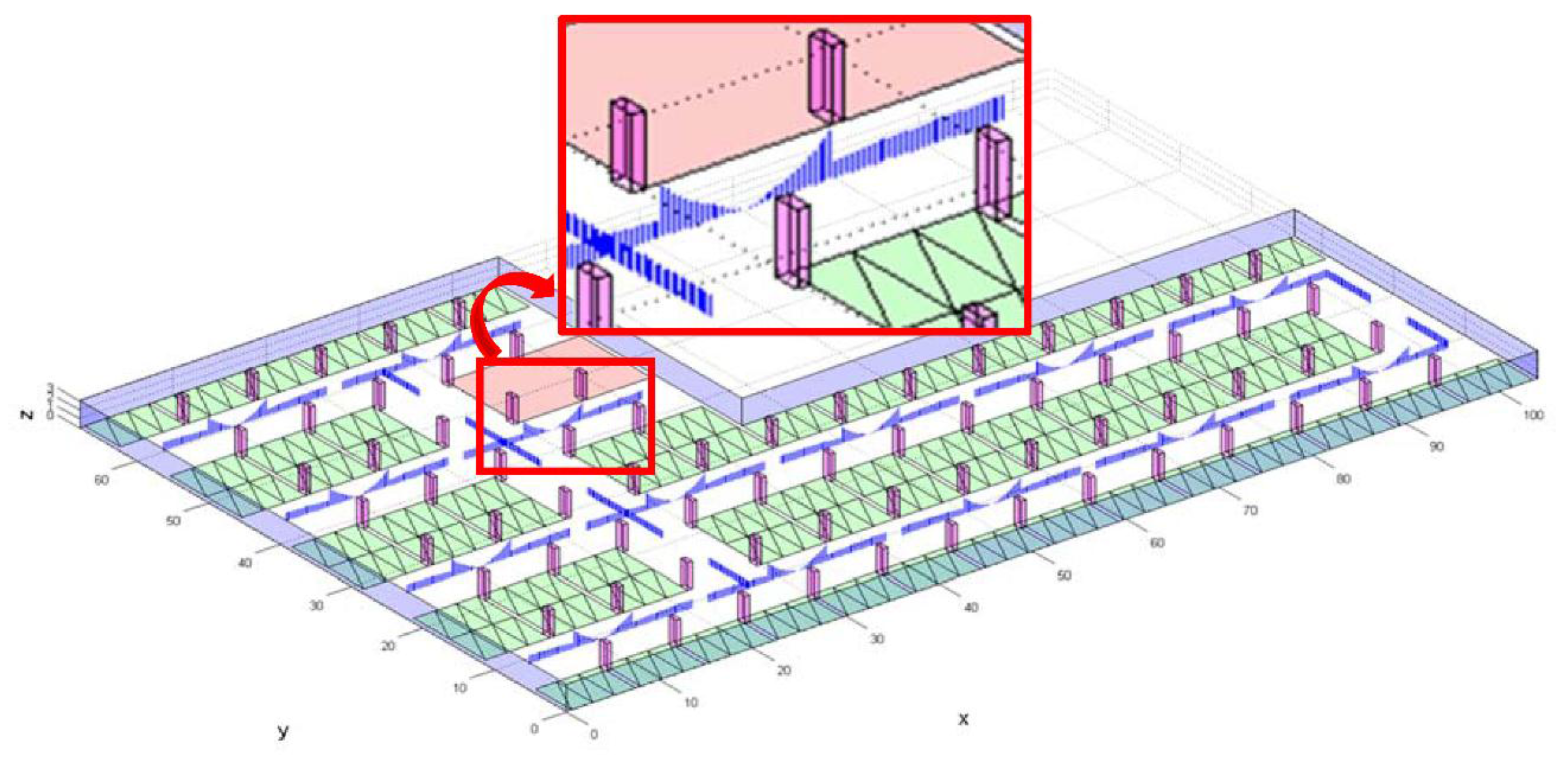
In the first stage, we need to generate polyhedral models of the area from existing 2D architectural floor plans or newly acquired sensory data. If we use the floor plans, rather than using other sensory data, it is easier to create the corresponding 3D model of the building; however, floor plans contain the detailed architectural design of a building, and inconsistencies between the designed model and the actual building construction may exist. To accurately model the physical building, we need to acquire the sensory data of the area, such as images and laser-scanning data; then, the polyhedral model can be generated manually from stereo images or semi-automatically from point clouds. With the 3D polyhedral model, we need to know the camera’s extrinsic and intrinsic parameters. For extrinsic parameters, we have the location of the camera’s perspective center, expressed by three coordinates, and its attitude, expressed by three independent rotation angles. To obtain the parameter values, we distribute GCPs (Ground Control Point) in the area and perform bundle adjustment with images including the GCPs. The intrinsic parameters describe the metric characteristics of a camera, and can be determined through a camera-calibration process using a specially designed calibration target. The position of principal point, focal length, distortion amount, and pixel size are the main intrinsic parameters. In this case, unlike most, we cannot change the camera’s position and attitude, so we must position the calibration target on the floor in various directions and acquire images of the target.
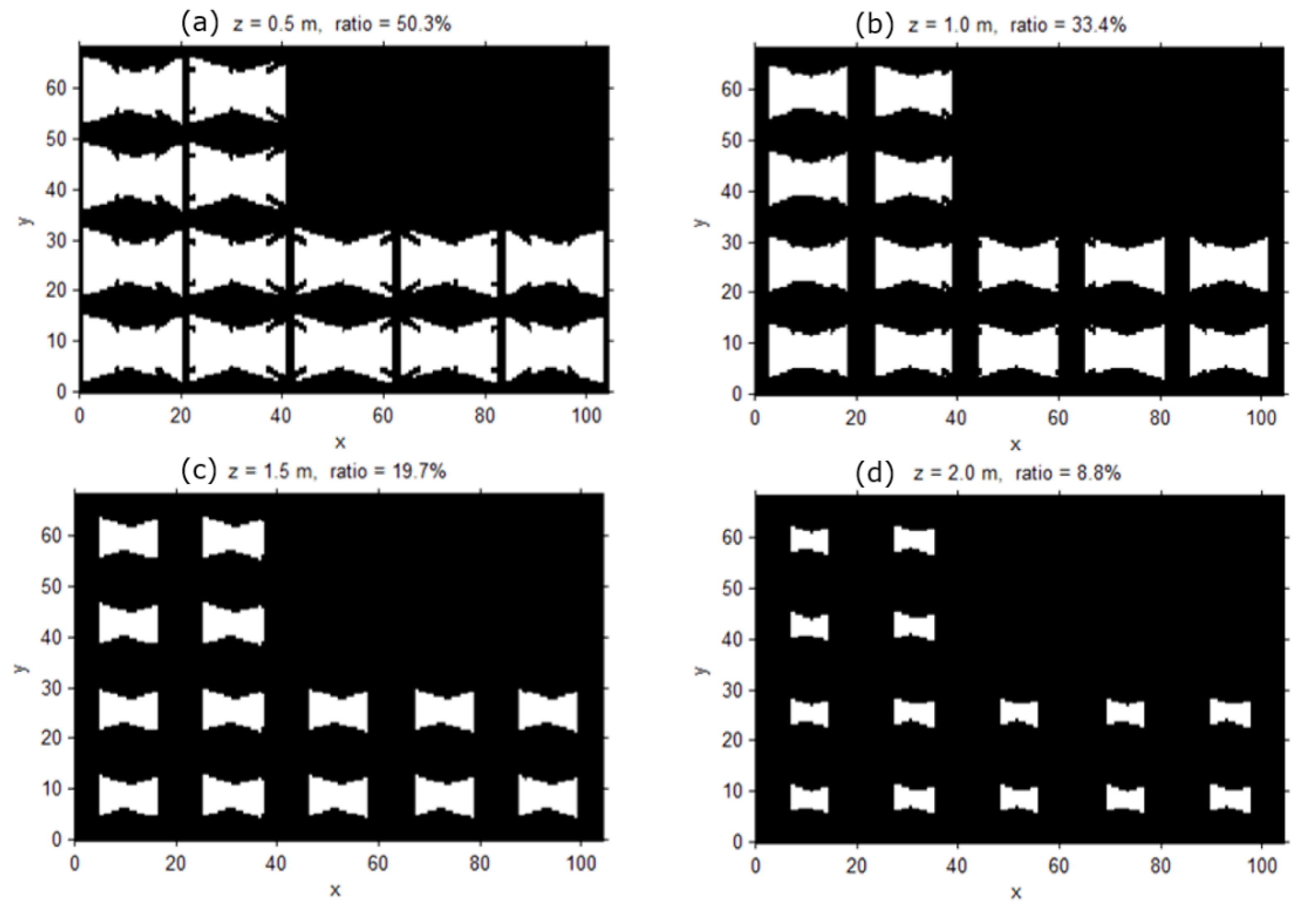
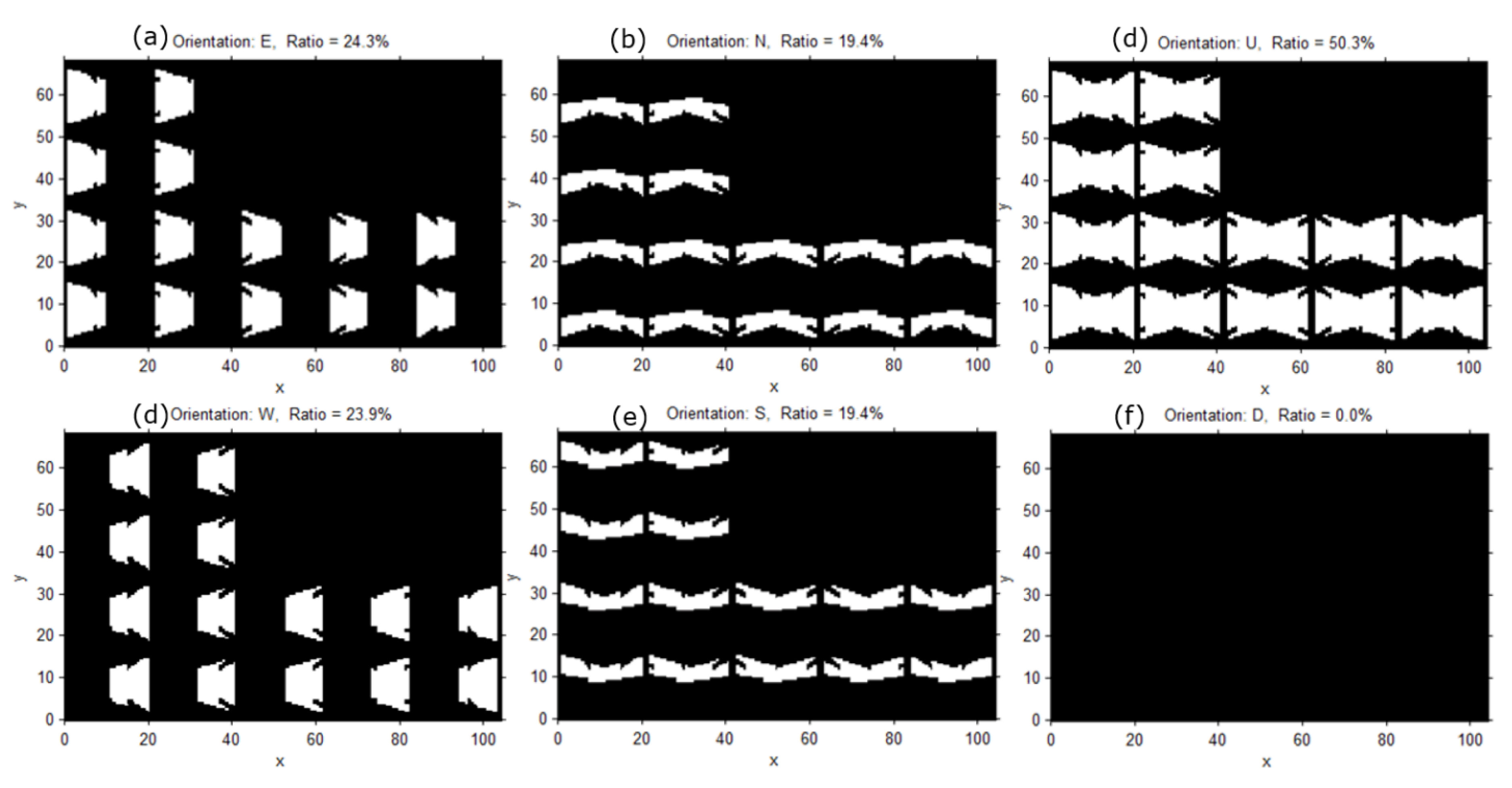
In the second stage, we determine the amount of sampling desired from all of the possible 3D locations of the object, along with their corresponding orientations, in the entire target space. For the determination of sampling locations, we first define the target space in an arbitrary 3D Cartesian coordinate system. Then, each of the axes is divided to form a 3D grid. It is possible to define the surveillance resolution at each of the 3D grid points by using ; for instance, when the three axes are split every 10 cm in a space, there would be a total of 1000 locations to sample. On the other hand, the orientations that an object can face range from 0° to 360° horizontally, 0° to 180° vertically, and 0 to for their solid angle. To include all of the possible orientations, we divide the angles both horizontally and vertically using an arbitrary location as the center. Using the same idea that applied to the 3D grid points, the surveillance resolution of all of the orientations at a given location can be found by using ; for example, if the sampling was conducted at an interval of 1°, the total orientation samples for a given location will be . When the interval is increased to 10° or 45° to reduce the number of orientation samples, there would be 648 and 32 orientations, respectively. This means that even when orientations are observed at each location, the number of calculations for finding the surveillance resolution reach 32,000 in a 1 m3 with 1000 locations.
The advantage of using such a method to sample at every given interval for both location and orientation seems logical; however, the disadvantage is that each of the defined orientations do not cover the same solid angle, whereby the solid angle covered by each orientation decreases as the vertical angle increases. The vertices of the regular polyhedrons inscribed in a sphere or the center of their faces therefore provide the same solid angle across the orientations for a location. The five regular polyhedrons are the tetrahedron, hexahedron, octahedron, dodecahedron, and icosahedron. For example, assuming a particular location as the center of an icosahedron, orientation sampling can be made facing each of the vertices, which will provide the same solid angle throughout and the number of samples will decrease to 12.
In the third stage, when deriving surveillance resolutions at each of the sampled locations and orientations, we must analyze the visibility of the position from a camera by applying a ray-tracing algorithm. With this algorithm, we define a ray from the position to the perspective center of the camera and determine whether this line is intersected with other obstacles. If an intersection is determined, the position is within the occluded area of the camera and we cannot define the surveillance resolutions at the position. Before applying ray-tracing for each position, we need to compute the horizontal coverage of every camera and the 2D Minimum Bounding Rectangle (MBR) of all of the obstacles in the target area. Although the obstacles are defined in a 3D sense, most of them are extended to the ceiling starting from the ground, with the same horizontal outline such as a pillar. In this case, by examining the 2D overlap, we can determine whether it is overlapped in a 3D sense without a complicated 3D process.
Ray-tracing for the calculation of the surveillance resolution at a position with an orientation by a camera is performed as follows: (1) determine whether the position is within the horizontal coverage of the camera; (2) determine the 2D MBRs of the line between an object point (a sampled position) and the perspective center; (3) check whether there is a 2D overlap between the MBRs of a line and an obstacle; if there is no 2D overlap, stop at this step with no 3D overlap; (4) check whether the line segment intersects with the 2D boundary polygon of the obstacle; if it does, stop at this step because the obstacle has an identical horizontal outline according to the height, signifying that it also intersects with the obstacle in a 3D sense; (5) determine if the line segment intersect with a 3D polyhedron model of the obstacle; and (6) if there is an overlap, the position cannot be identified in the camera image and the surveillance resolution is set to 0.
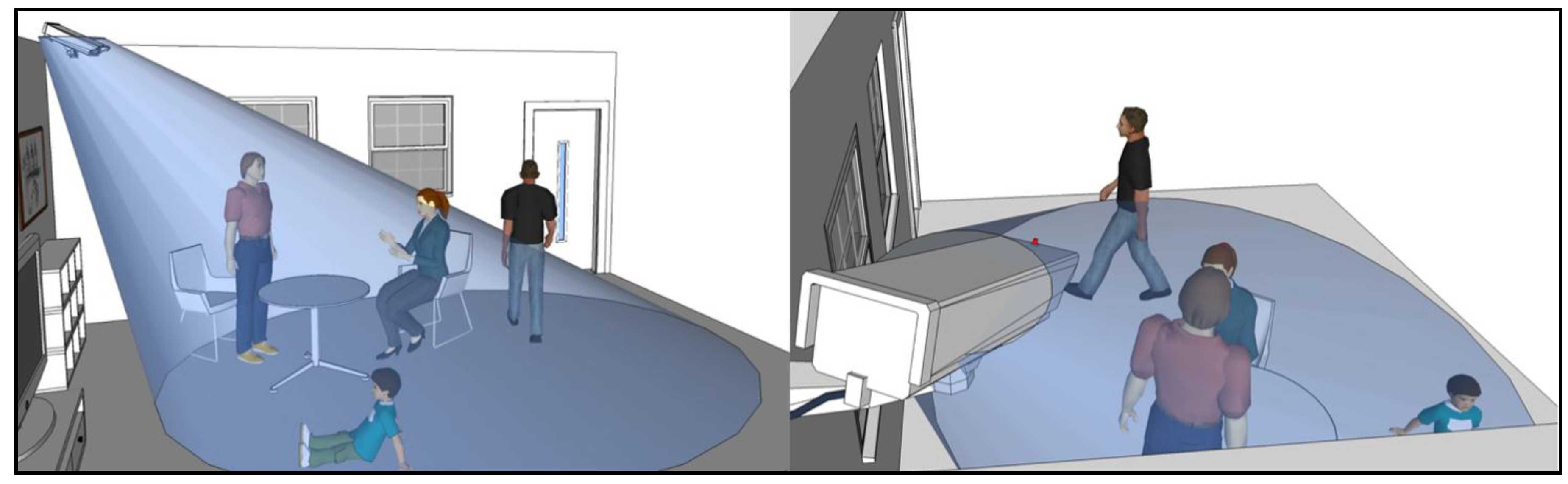
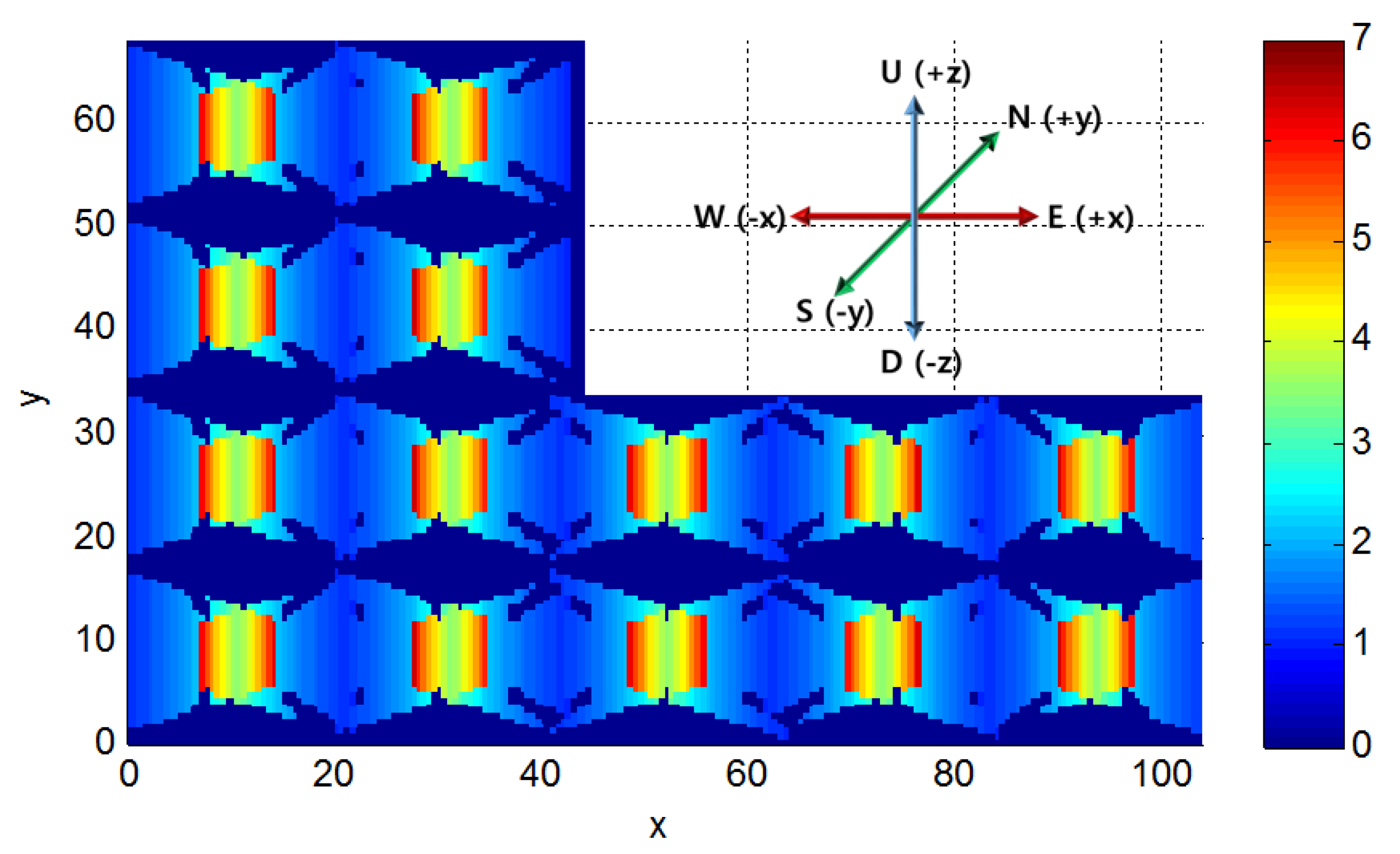
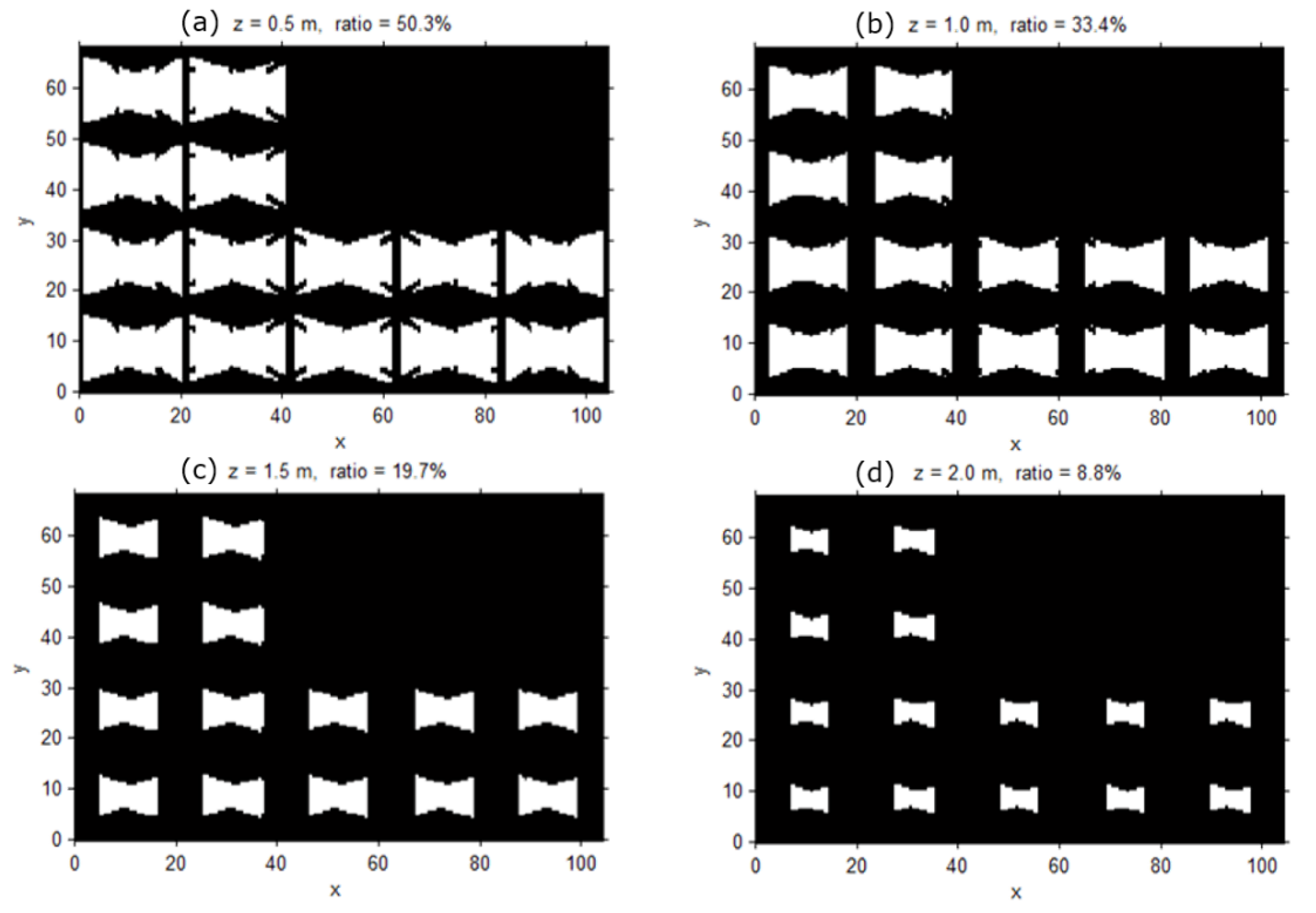
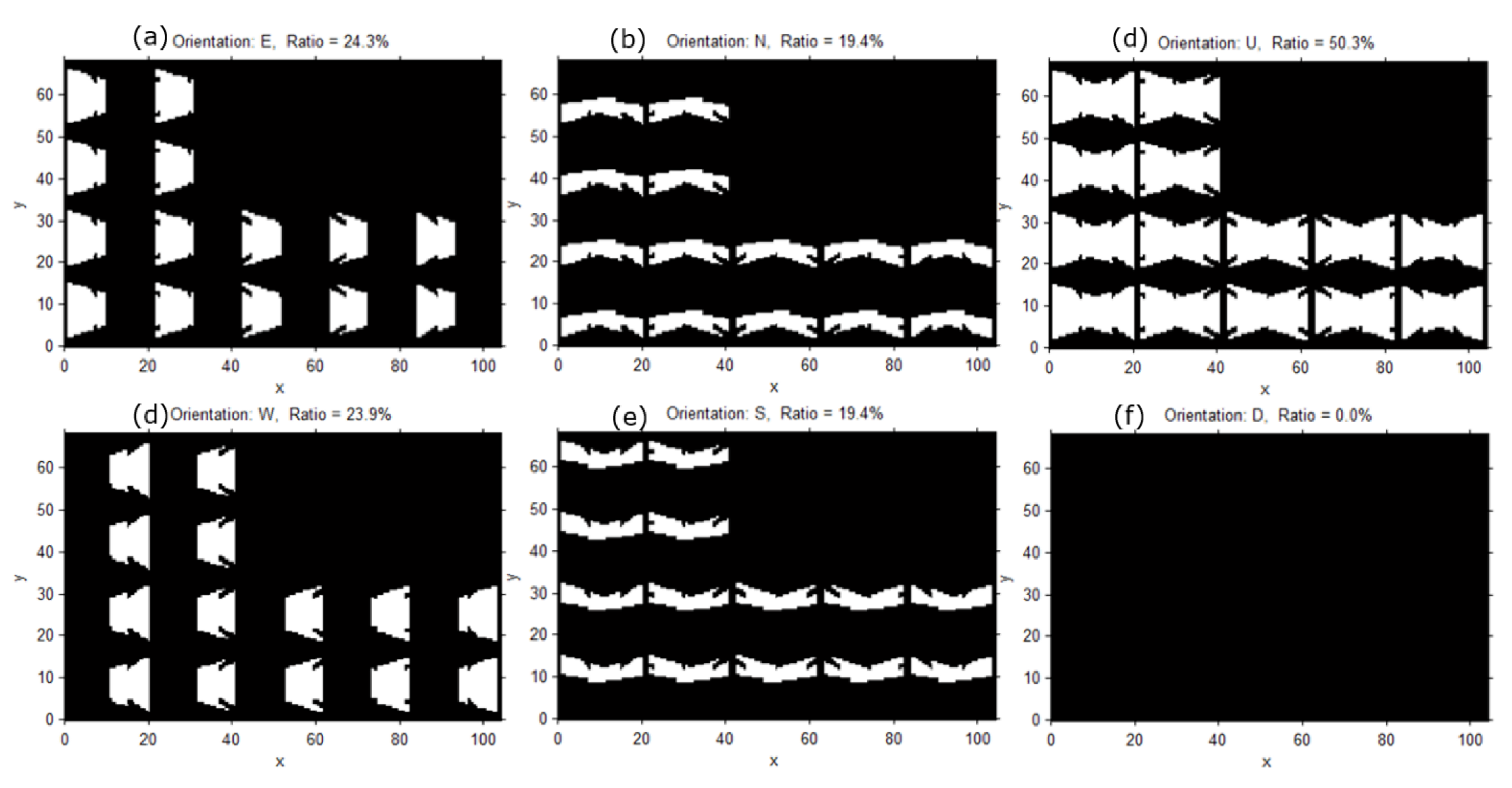
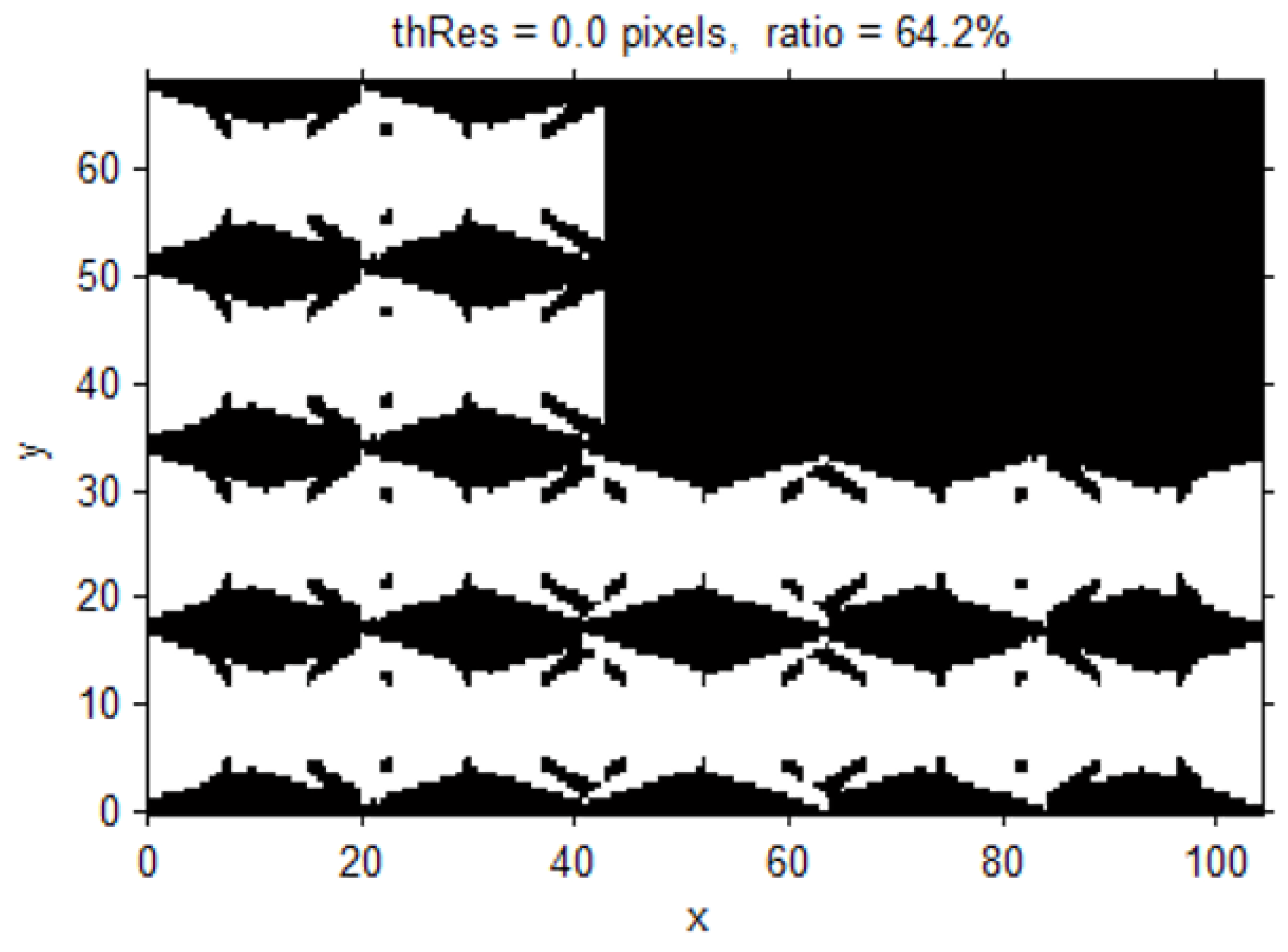
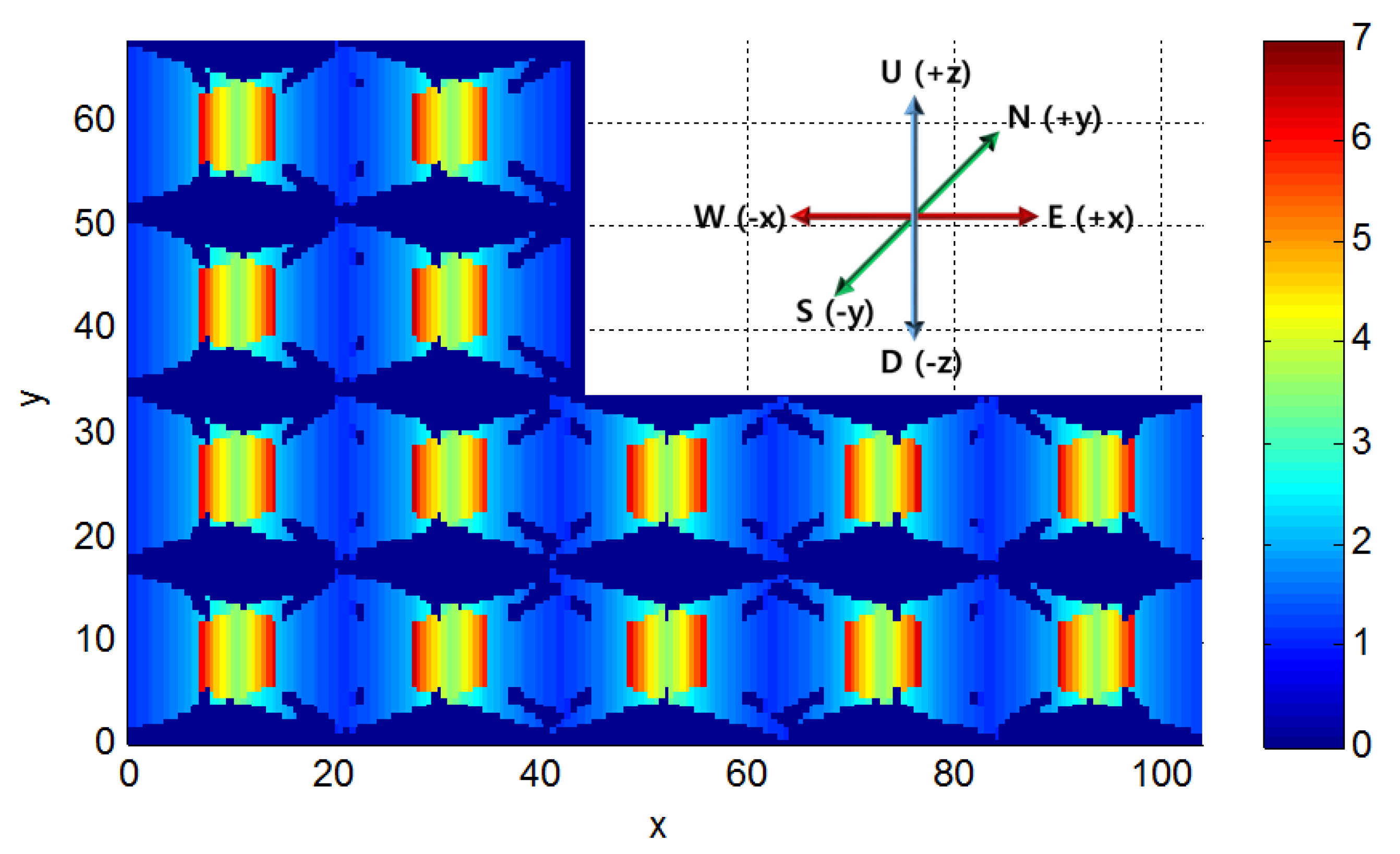
In the final stage, we compute the surveillance coverage index by comparing the achievable resolution with the desired one. Here, we determine the proportion of the instances that reach above the desired resolution among the resolution values computed at all the sampled locations and orientations in the previous stage. The desired resolution can be established or derived from the specified surveillance requirements for recognition and tracking. For example, one may want to monitor every location in the target space with a resolution of 0.5 px/cm required for a meaningful recognition process. Using the resolution values computed in the previous stage, we can easily compute the proportion of the locations monitored with at least the desired resolution and present it as the overall coverage index of the target space. In addition, we can visualize the computed surveillance resolution at each location with different object orientations in the 2D/3D space to visually inspect the weak and strong surveillance areas. Furthermore, we can check the coverage index for a special surveillance sector such as a doorway or moving path in a parking area. In a doorway, one may want to recognize even the faces of the people going in and out through an exit; and for the face recognition, the required resolution of at least 2 px/cm may be assumed. We can also determine how well such a requirement is satisfied in the space of interests in a quantitative way by checking the computed resolution values at all the locations with different orientations within the target space. In addition, we can identify the weak area and propose the location and orientation for additional camera installation to fulfill surveillance requirements. Adding cameras or constructing a CCTV system involves a major expense; therefore, we need an elaborate design for achieving the surveillance purpose before the installation. In addition, there are available so many different cameras with different prices and performance, and thus we can check the surveillance performance by changing the camera models or the camera parameters to derive more optimal camera specifications and configurations.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}