
New Fast Fall Detection Method Based on Spatio-Temporal Context Tracking of Head by Using Depth Images


Abstract
:1. Introduction
2. Relative Works
2.1. Wearable Sensor-Based Methods
2.2. Ambient Sensor-Based Methods
2.3. Computer Vision-Based Methods
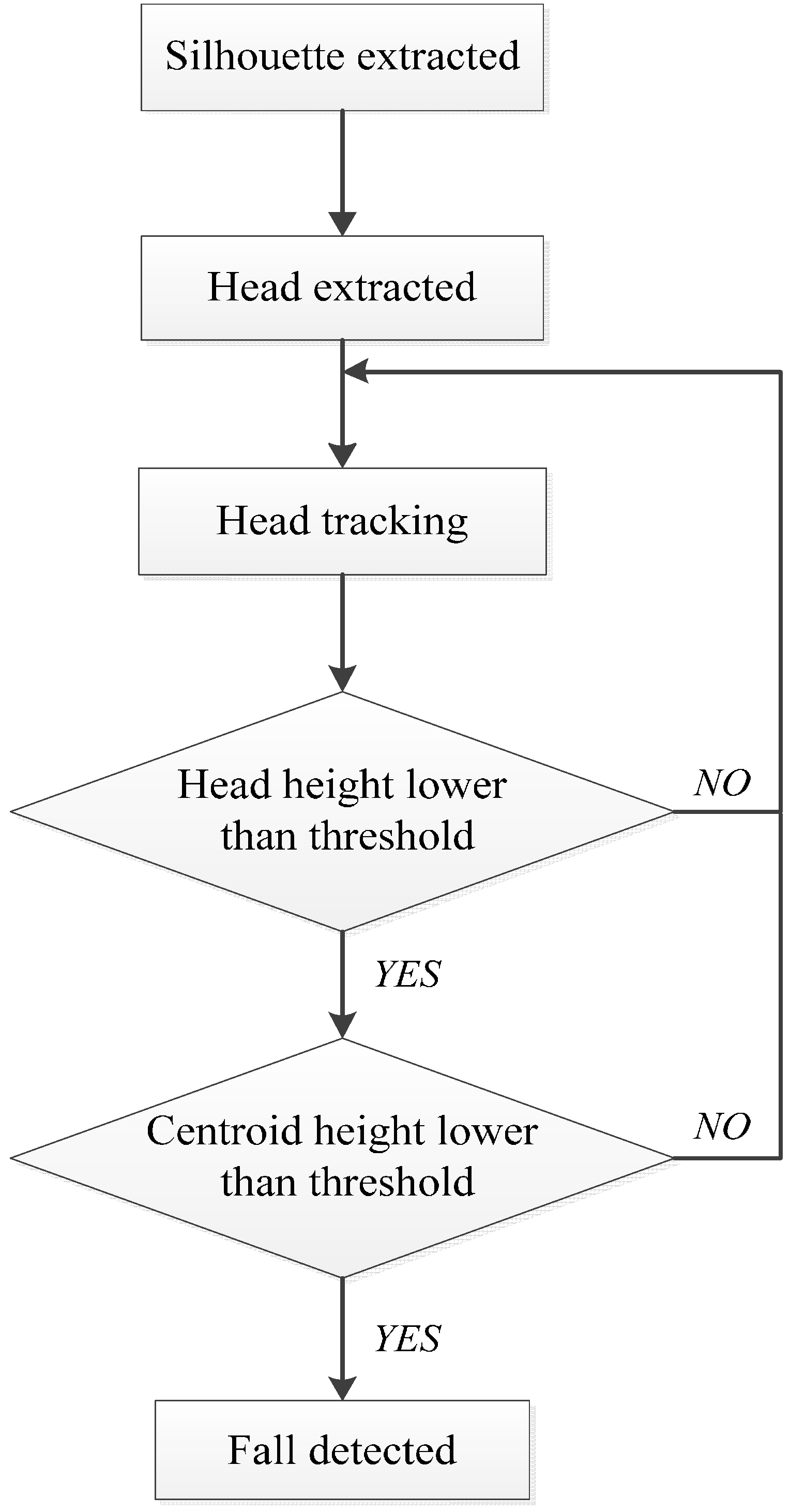
3. The Proposed Method
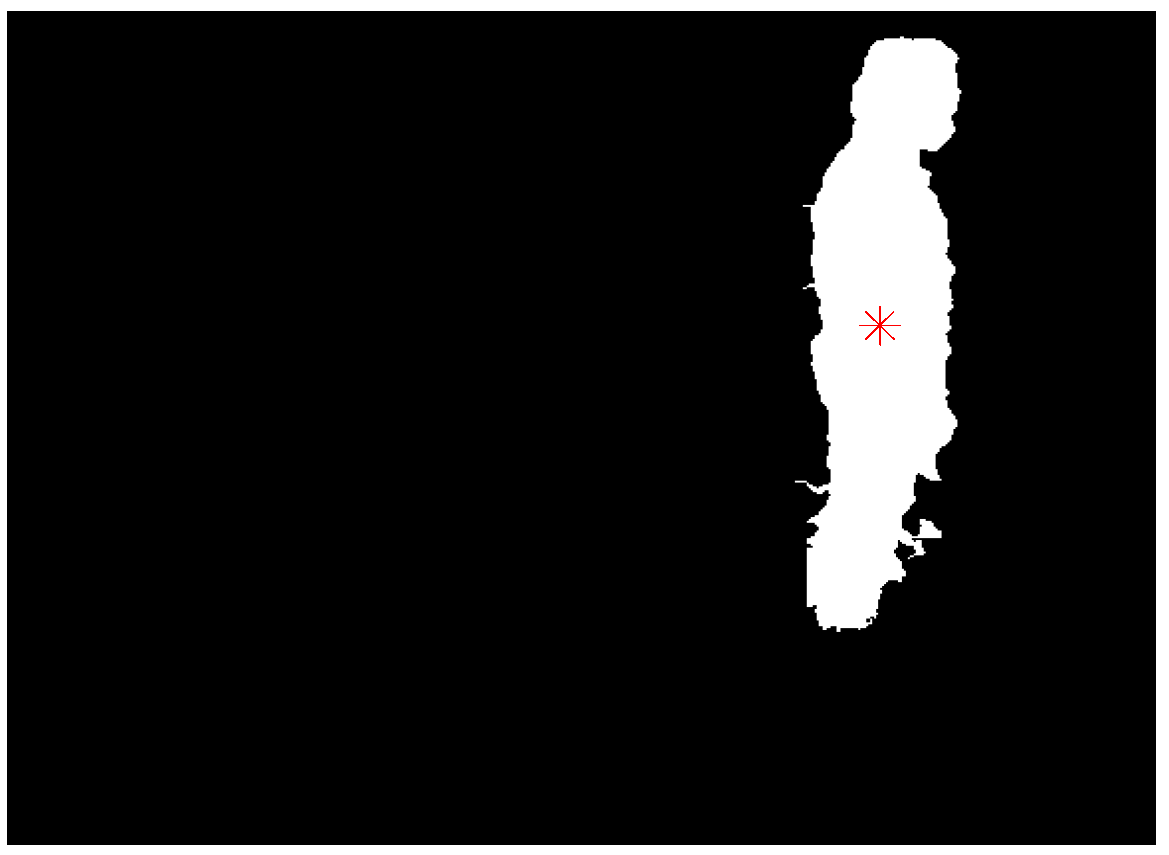
3.1. Foreground and Centroid Extraction
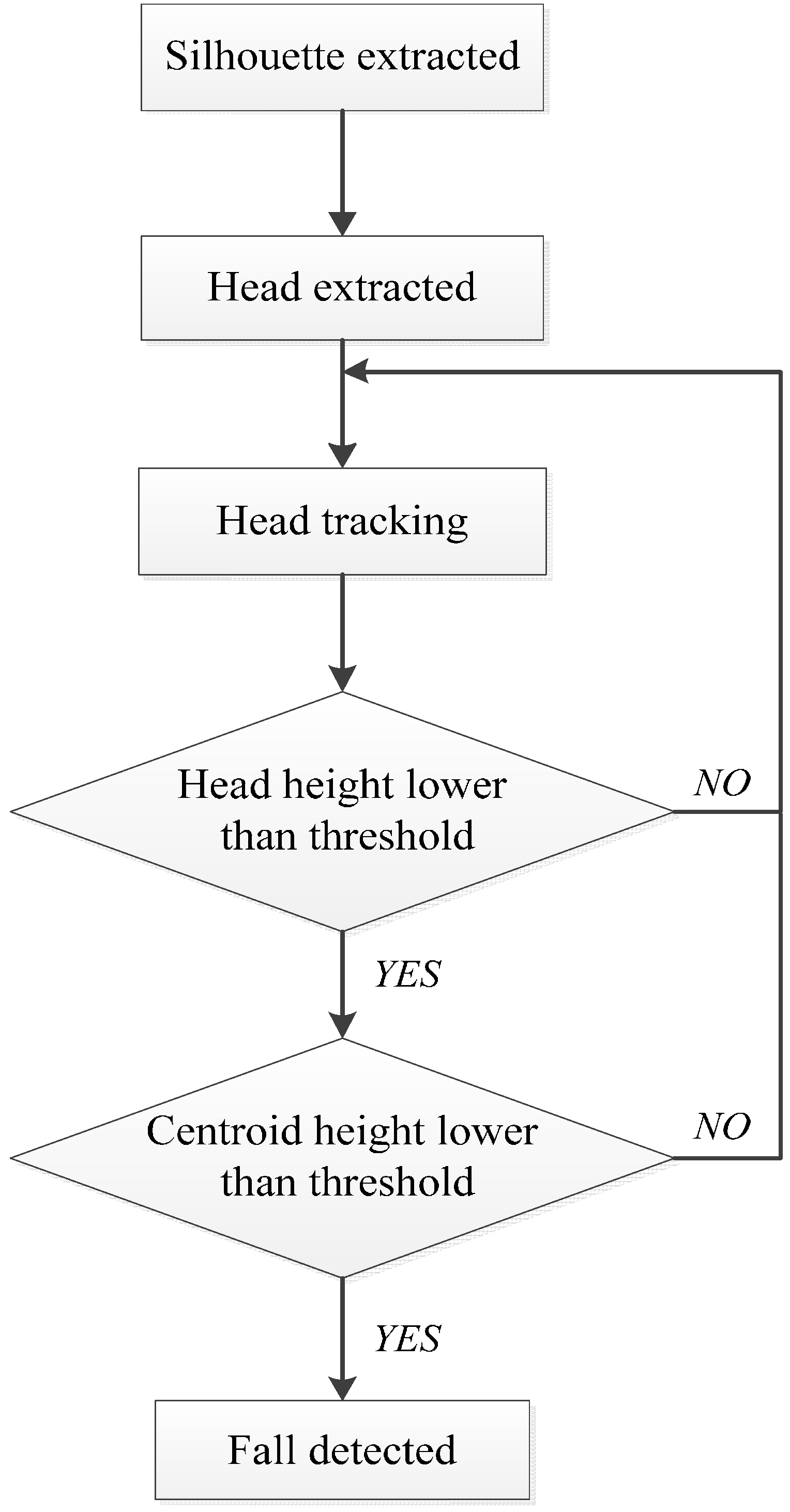

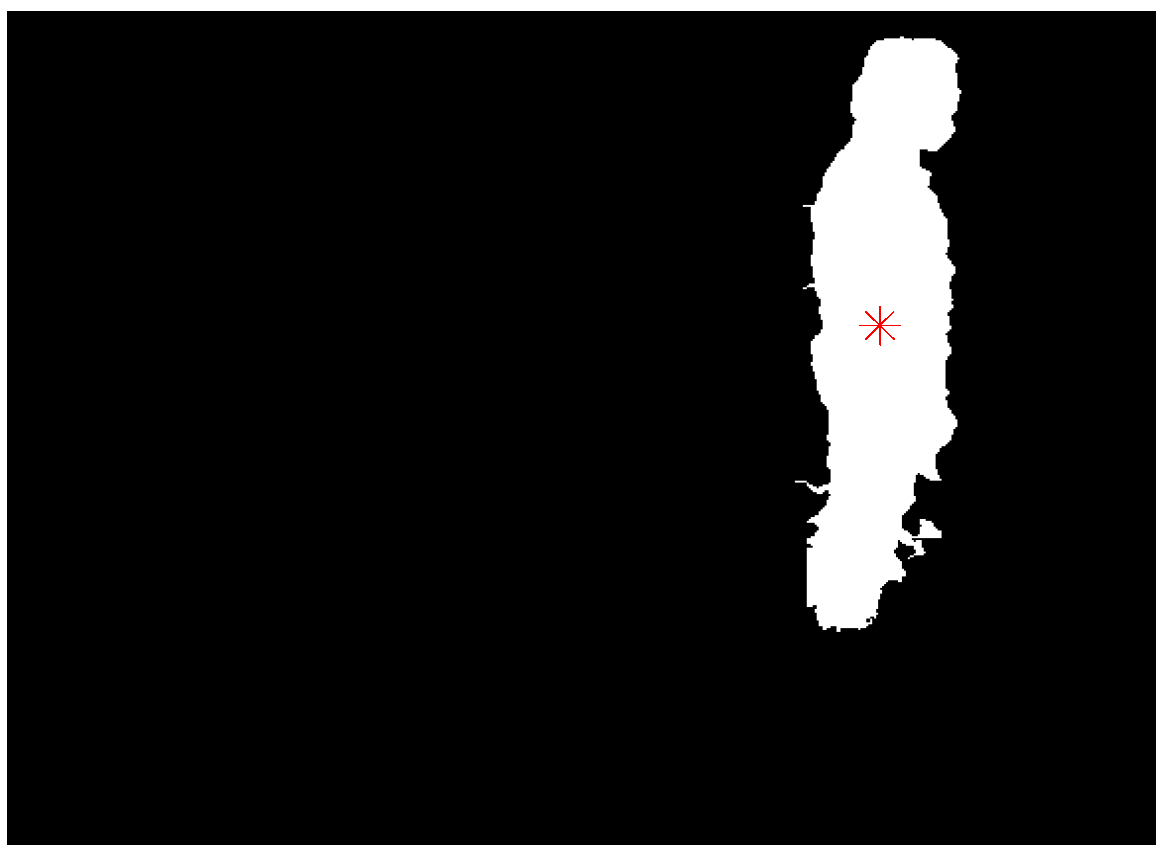
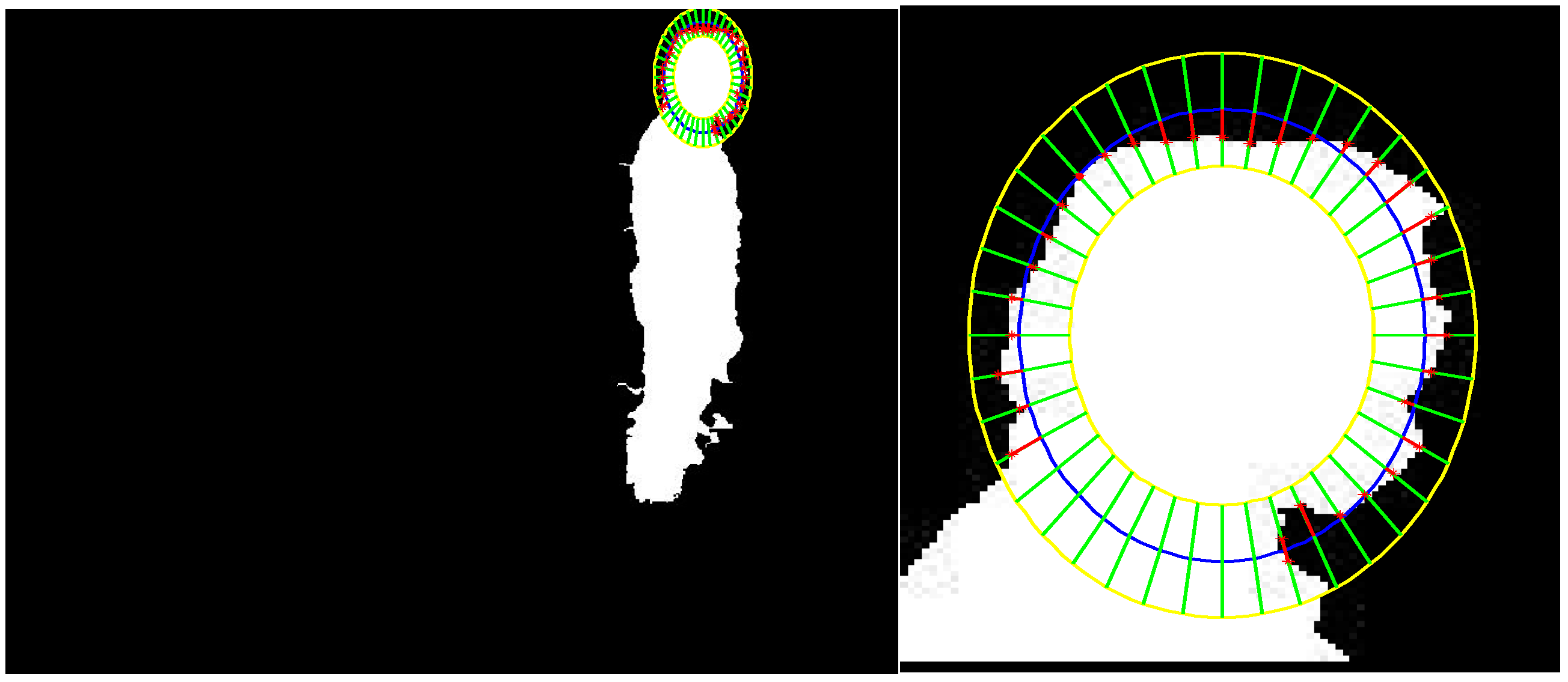
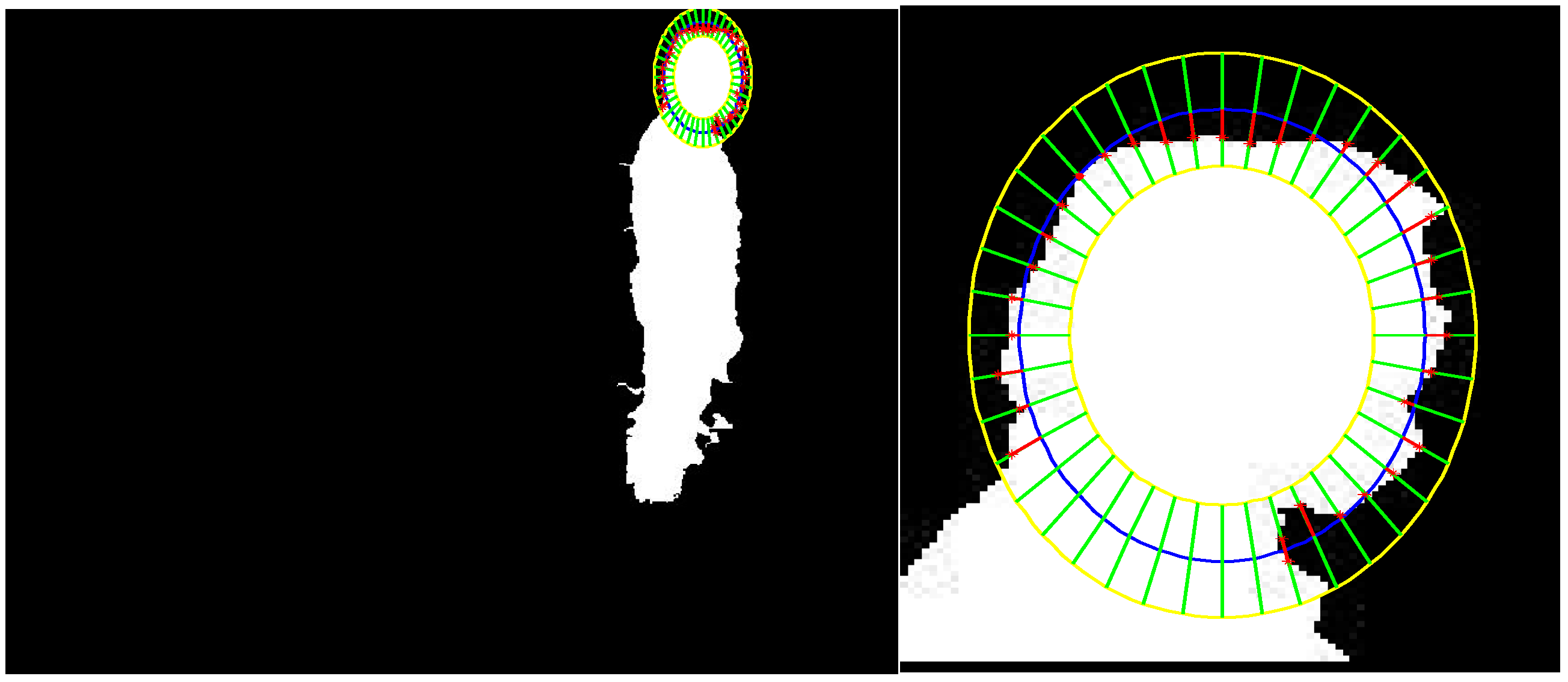
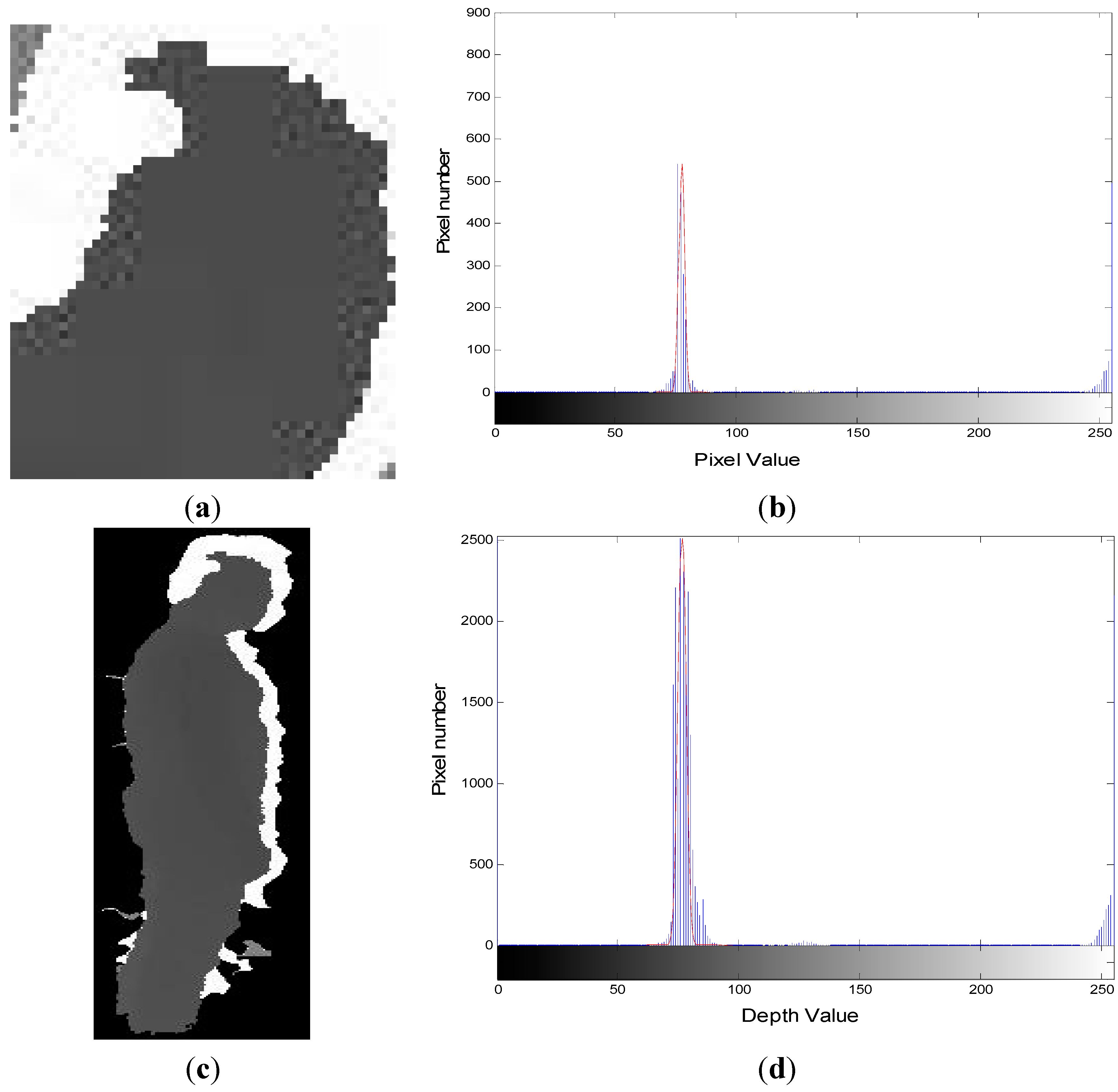
3.2. Head Position Extraction and Head Tracking
3.3. Floor Plane Extraction

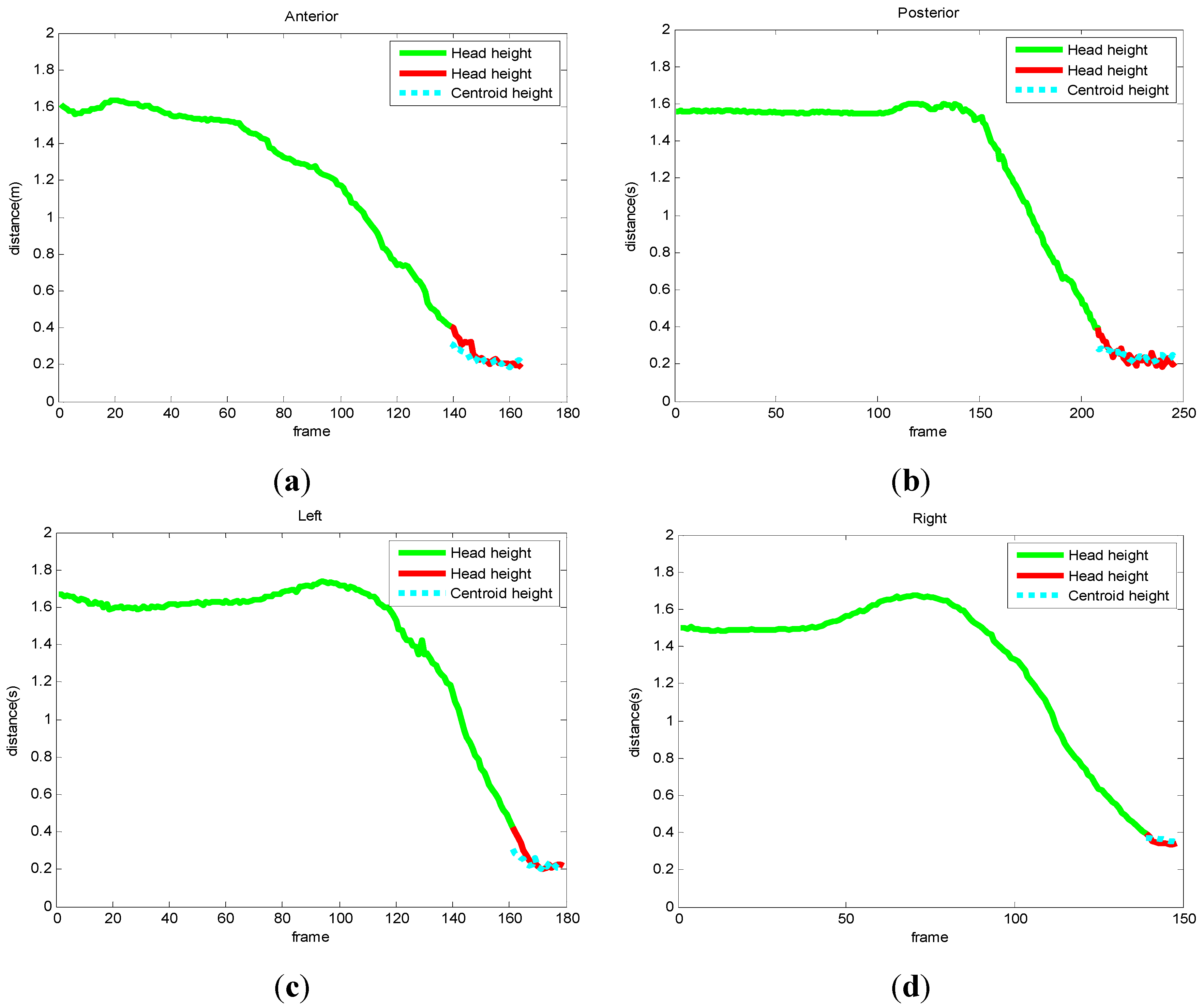
3.4. Fall Detection

4. Experimental Results and Discussion



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fall Direction | Time for Total Frames (s) | Time for per Frame (ms) | Frame Number |
|---|---|---|---|
| anterior | 3.7241 | 22.8472 | 163 |
| posterior | 5.4960 | 22.3415 | 246 |
| left | 4.1075 | 23.0758 | 178 |
| right | 3.5418 | 23.9311 | 148 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Nihseniorheatlth: About Falls. Available online: http://nihseniorhealth.gov/falls/aboutfalls/01.html (accessed on 31 January 2015).
- Elizabeth, H. The Latest in Falls and Fall Prevention. Available online: http://www.cdc.gov/HomeandRecreational Safety/Falls/fallcost.html (accessed on 25 July 2015).
- Delahoz, Y.S.; Labrador, M.A. Survey on fall detection and fall prevention using wearable and external sensors. Sensors 2014, 14, 19806–19842. [Google Scholar] [CrossRef] [PubMed]
- Nashwa, E.B.; Tan, Q.; Pivot, F.C.; Anthony, L. Fall detection and prevention for the elderly: A review of trends and challenges. Int. J. Smart Sens. Intell. Syst. 2013, 6, 1230–1266. [Google Scholar]
- Feng, W.; Liu, R.; Zhu, M. Fall detection for elderly person care in a vision-based home surveillance environment using a monocular camera. Signal Image Video Process. 2014, 8, 1129–1138. [Google Scholar] [CrossRef]
- Liao, Y.T.; Huang, C.-L.; Hsu, S.-C. Slip and fall event detection using Bayesian Belief Network. Pattern Recognit. 2012, 45, 24–32. [Google Scholar] [CrossRef]
- Wu, G.; Xue, S. Portable preimpact fall detector with inertial sensors. IEEE Trans. Neural Syst. Rehabilit. Eng. 2008, 16, 178–183. [Google Scholar]
- Wang, C.-C.; Chiang, C.-Y.; Lin, P.-Y.; Chou, Y.-C.; Kuo, I.-T.; Huang, C.-N.; Chan, C.-T. Development of a fall detecting system for the elderly residents. In Proceedings of the 2nd IEEE International Conference on Bioinformatics and Biomedical Engineering (iCBBE2008), Shanghai, China, 16–18 May 2008; pp. 1359–1362.
- Ozdemir, A.T.; Barshan, B. Detecting falls with wearable sensors using machine learning techniques. Sensors 2014, 14, 10691–10708. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mubashir, M.; Shao, L.; Seed, L. A survey on fall detection: Principles and approaches. Neurocomputing 2013, 100, 144–152. [Google Scholar] [CrossRef]
- Rimminen, H.; Lindström, J.; Linnavuo, M.; Sepponen, R. Detection of falls among the elderly by a floor sensor using the electric near field. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1475–1476. [Google Scholar] [CrossRef] [PubMed]
- Zigel, Y.; Litvak, D.; Gannot, I. A method for automatic fall detection of elderly people using floor vibrations and sound-Proof of concept on human mimicking doll falls. IEEE Trans. Biomed. Eng. 2009, 56, 2858–2867. [Google Scholar] [CrossRef] [PubMed]
- Yu, M.; Yu, Y.; Rhuma, A.; Naqvi, S.M.; Wang, L.; Chambers, J.A. An online one class support vector machine-based person-specific fall detection system for monitoring an elderly individual in a room environment. IEEE J. Biomed. Health Inf. 2013, 17, 1002–1014. [Google Scholar]
- Anderson, D.; Keller, J.M.; Skubic, M.; Chen, X.; He, Z. Recognizing falls from silhouettes. In Proceedings of the 28th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, New York City, USA, 30 August–3 September 2006; pp. 6388–6391.
- Planinc, R.; Kampel, M. Introducing the use of depth data for fall detection. Pers. Ubiquitous Comput. 2013, 17, 1063–1072. [Google Scholar] [CrossRef]
- Ozcan, K.; Mahabalagiri, A.K.; Casares, M.; Velipasalar, S. Automatic Fall Detection and Activity Classification by a Wearable Embedded Smart Camera. IEEE J. Emerg. Sel. Top. Circuits Syst. 2013, 3, 125–136. [Google Scholar] [CrossRef]
- Gasparrini, S.; Cippitelli, E.; Spinsante, S.; Gambi, E. A depth-based fall detection system using a Kinect sensor. Sensors 2014, 14, 2756–2775. [Google Scholar] [CrossRef] [PubMed]
- Bian, Z.P.; Hou, J.; Chau, L.P.; Magnenat-Thalmann, N. Fall detection based on body part tracking using a depth camera. IEEE J. Biomed. Health Inf. 2015, 19, 430–439. [Google Scholar] [CrossRef] [PubMed]
- Mastorakis, G.; Makris, D. Fall detection system using Kinect’s infrared sensor. J. Real-Time Image Process. 2012, 9, 635–646. [Google Scholar] [CrossRef]
- Rougier, C.; Meunier, J.; St-Arnaud, A.; Rousseau, J. 3D head tracking for fall detection using a single calibrated camera. Image Vis. Comput. 2013, 31, 246–254. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.-H. Fast visual tracking via dense spatio-temporal context learning. In Computer Vision–ECCV 2014; Springer: Zurich, Switzerland, 2014; Volume 8693, pp. 127–141. [Google Scholar]
- Yang, S.-W.; Lin, S.-K. Fall detection for multiple pedestrians using depth image processing technique. Comput. Methods Programs Biomed. 2014, 114, 172–182. [Google Scholar] [CrossRef] [PubMed]
- Stone, E.E.; Skubic, M. Fall detection in homes of older adults using the Microsoft Kinect. IEEE J. Biomed. Health Inf. 2015, 19, 290–301. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Ren, Y.; Hu, H.; Tian, B. New Fast Fall Detection Method Based on Spatio-Temporal Context Tracking of Head by Using Depth Images. Sensors 2015, 15, 23004-23019. https://doi.org/10.3390/s150923004
Yang L, Ren Y, Hu H, Tian B. New Fast Fall Detection Method Based on Spatio-Temporal Context Tracking of Head by Using Depth Images. Sensors. 2015; 15(9):23004-23019. https://doi.org/10.3390/s150923004
Chicago/Turabian StyleYang, Lei, Yanyun Ren, Huosheng Hu, and Bo Tian. 2015. "New Fast Fall Detection Method Based on Spatio-Temporal Context Tracking of Head by Using Depth Images" Sensors 15, no. 9: 23004-23019. https://doi.org/10.3390/s150923004