
A 181 GOPS AKAZE Accelerator Employing Discrete-Time Cellular Neural Networks for Real-Time Feature Extraction

Abstract
:1. Introduction
- The authors believe this to be the first feature extraction design based on the AKAZE algorithm. The AKAZE feature was mapped to an octave-serial architecture (OSA) primarily consisting of a two-dimensional pipeline array. It decreases the hardware resource requirement and also provides sufficient flexibility for the various application fields, characterized as different image resolutions, precision and power consumption.
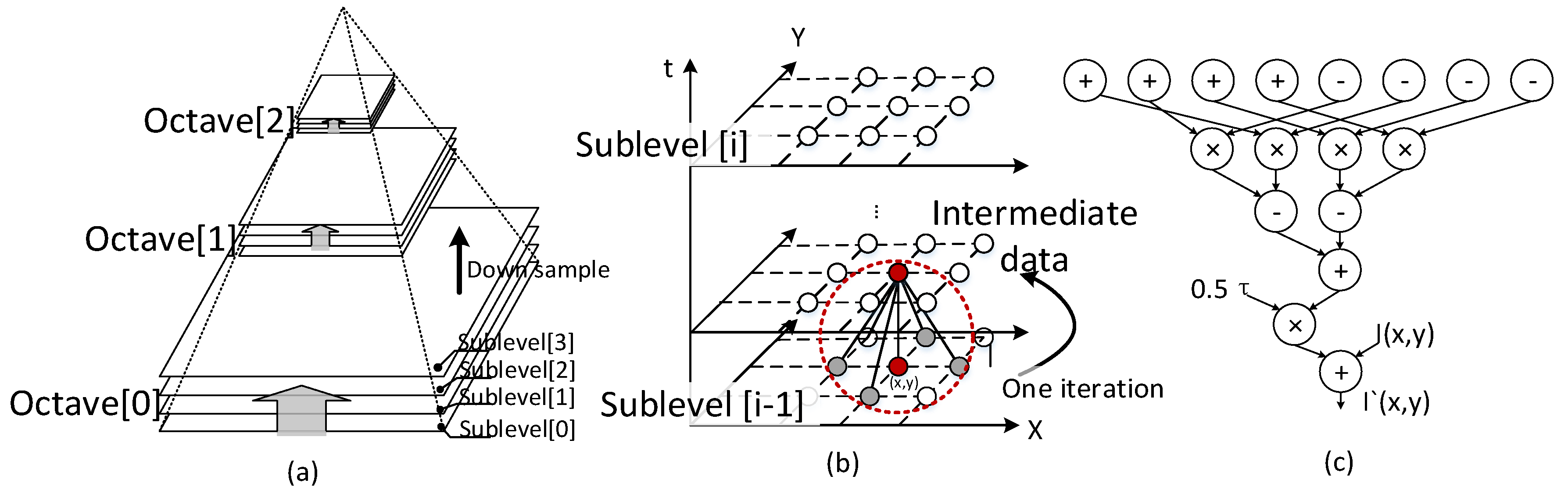
- A substructure consisting of a block-wise discrete-time cellular neural network (B-DTCNN) is presented. It decreases memory demand through the reduction in data dependency.
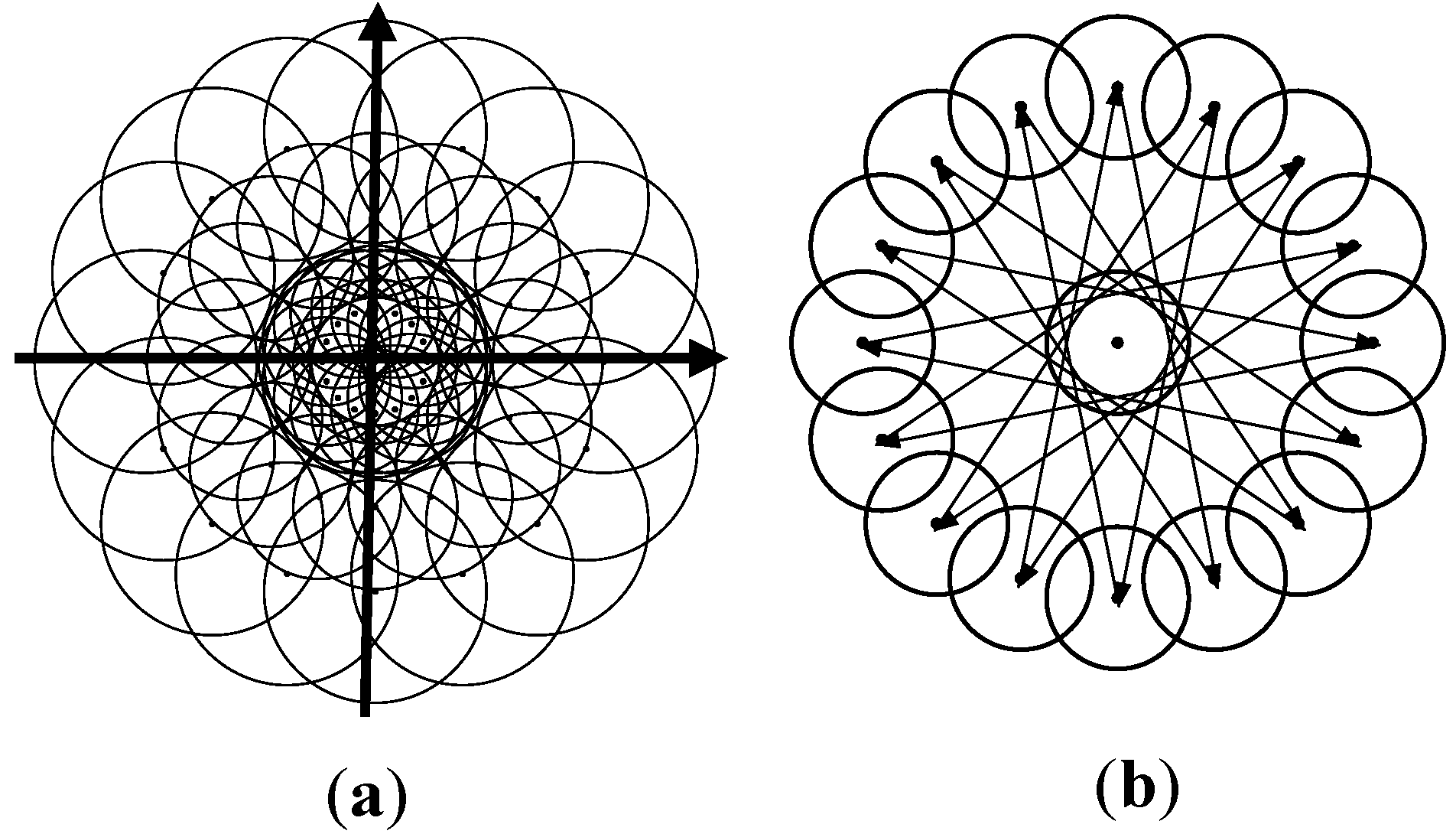
- A hardware-friendly descriptor, termed the robust polar binary descriptor (RPB), is presented. The polar arrangement of the sample pattern, combined with a simplified technique to realize rotation invariance, greatly decreases the memory burden and computational complexity.
2. Algorithm Optimization
2.1. AKAZE Overview
2.2. AKAZE Analysis
2.3. AKAZE Optimization

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operations | Proposed | Original (SURF-Like) | BRISK (OpenCV) |
|---|---|---|---|
| Extra Random Access | 0 | 218 | 240 |
| Trigonometric Function | 1 | 452 | 1 |
| Addition/Subtraction | 80 | 1746 | 4350 |
| Multiplication | 32 | 452 | 1741 |
| Lookup Tables | 32 | 109 | 3480 |
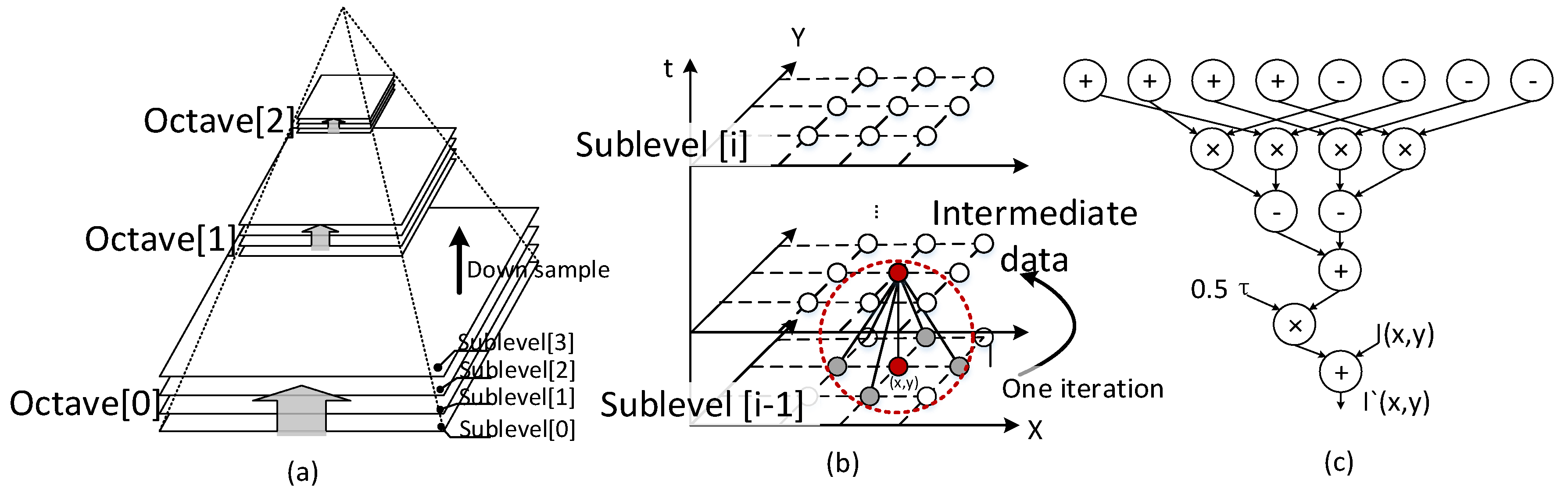
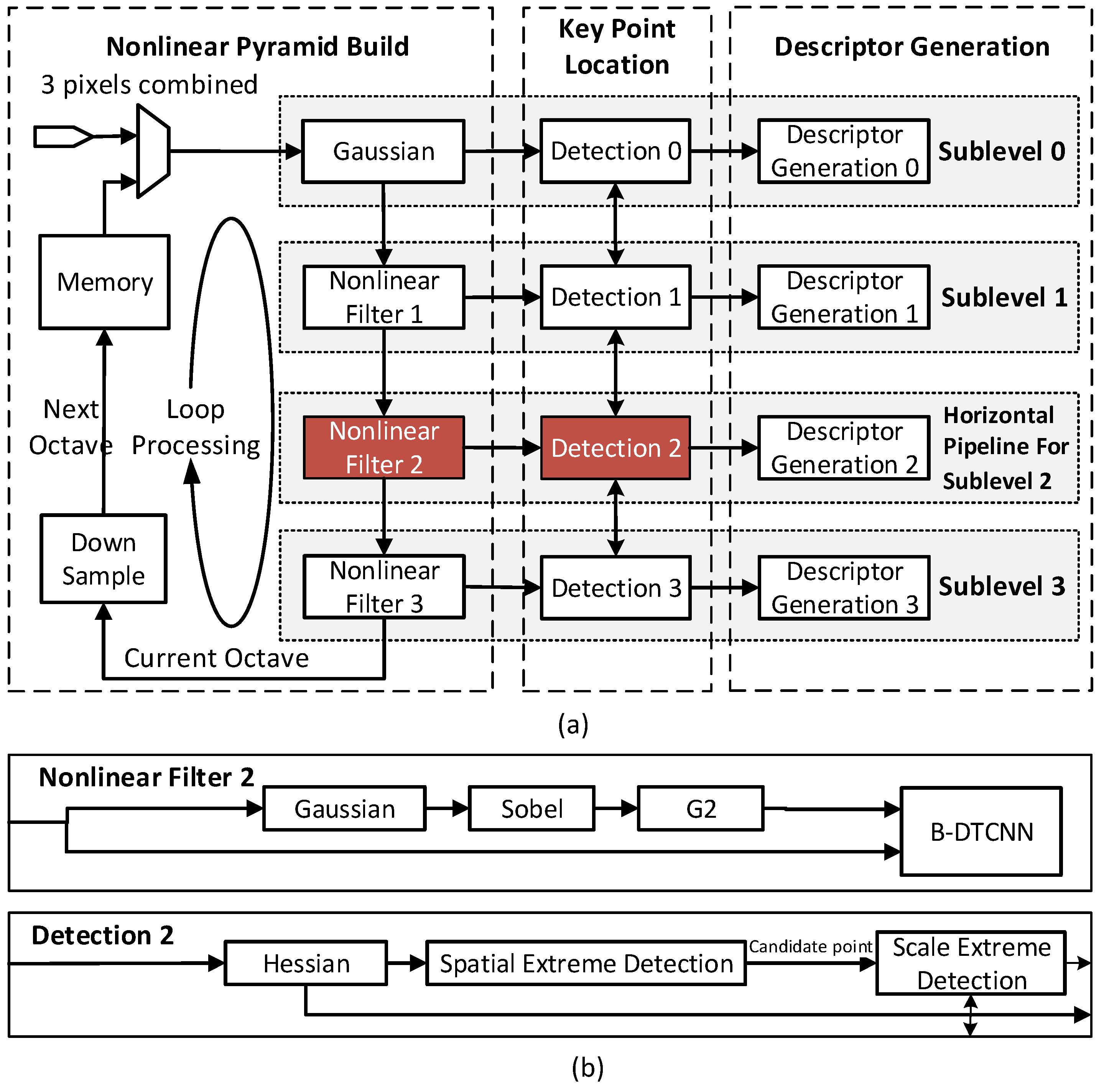
3. Proposed Hardware Architecture

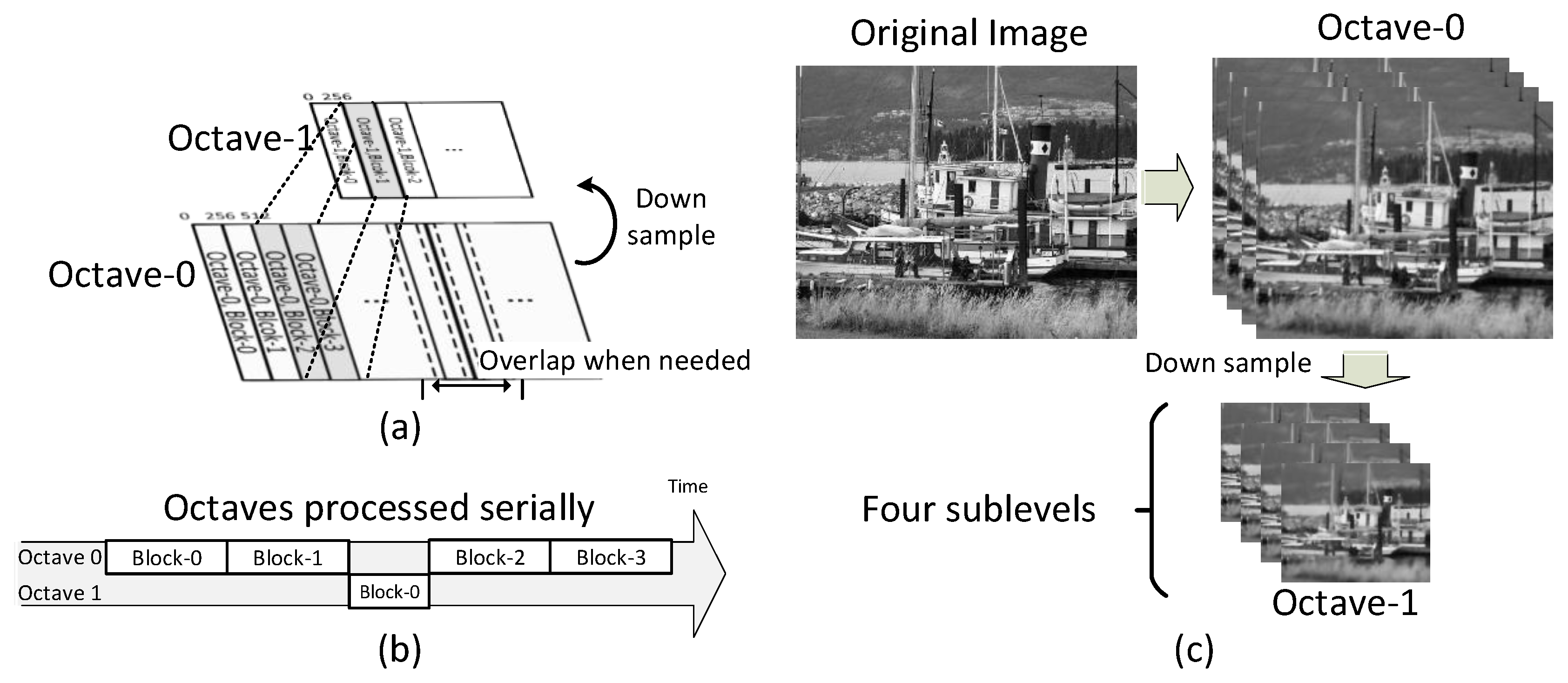
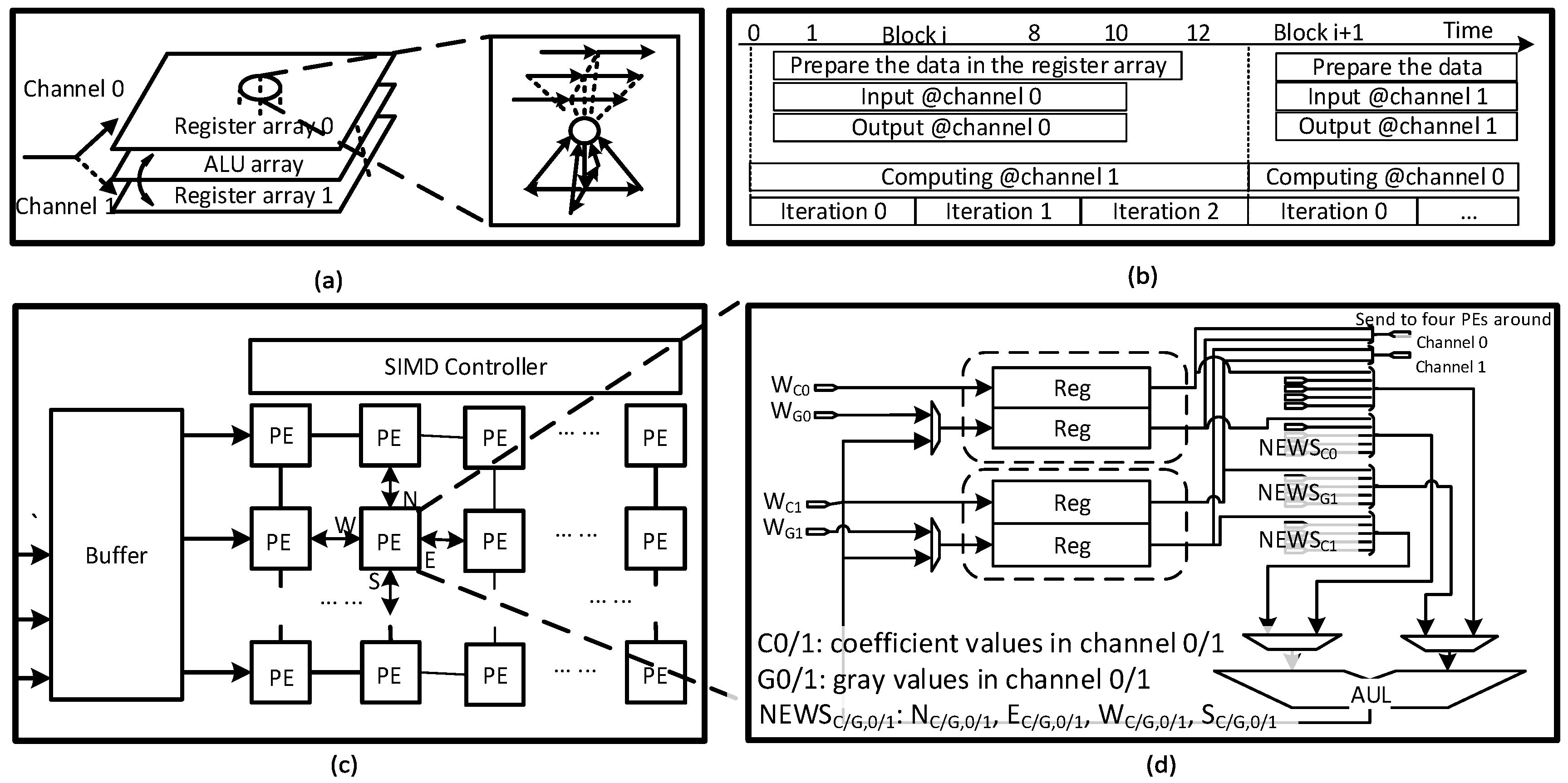
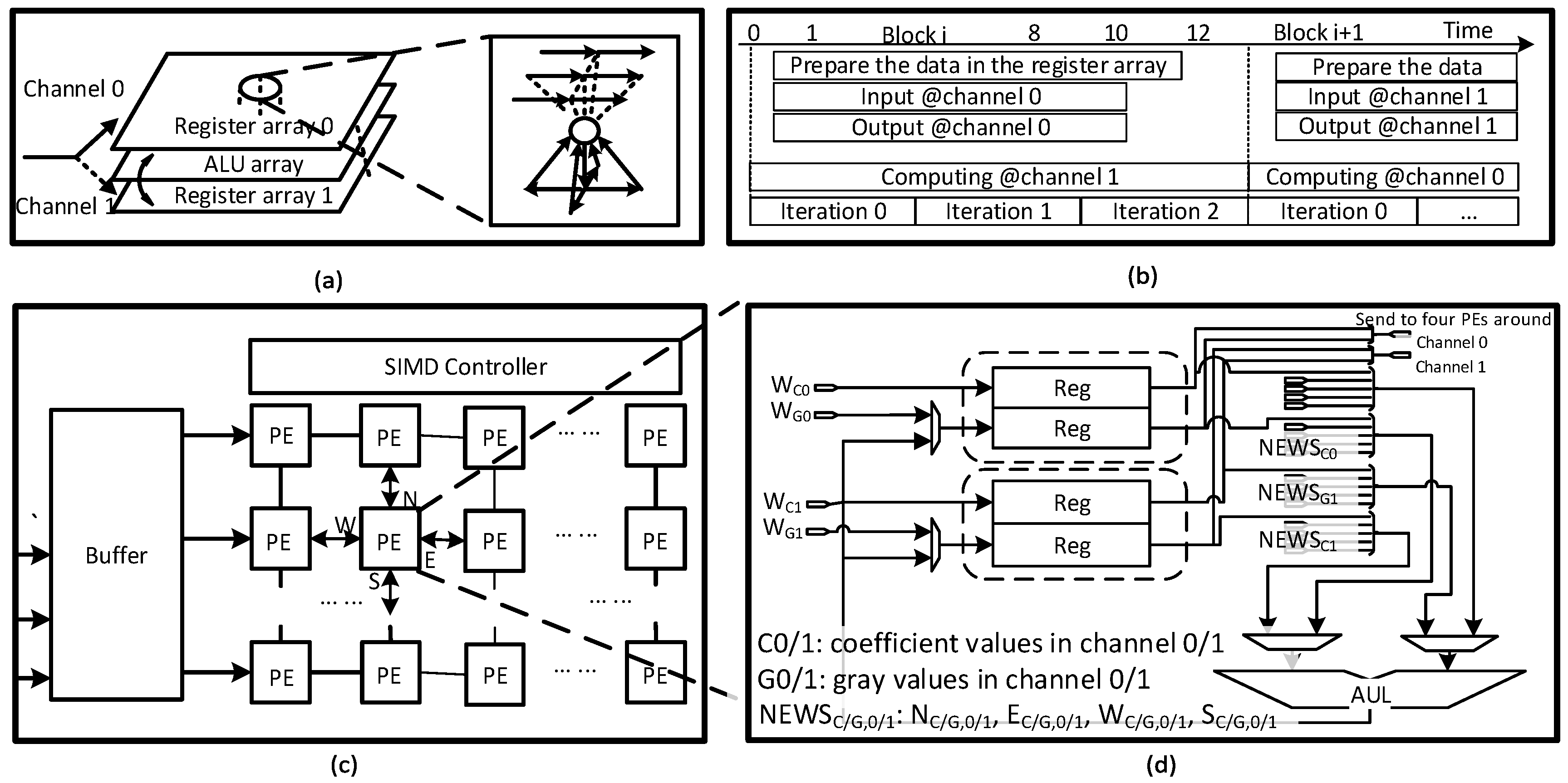
3.1. Octave-Serial System Architecture
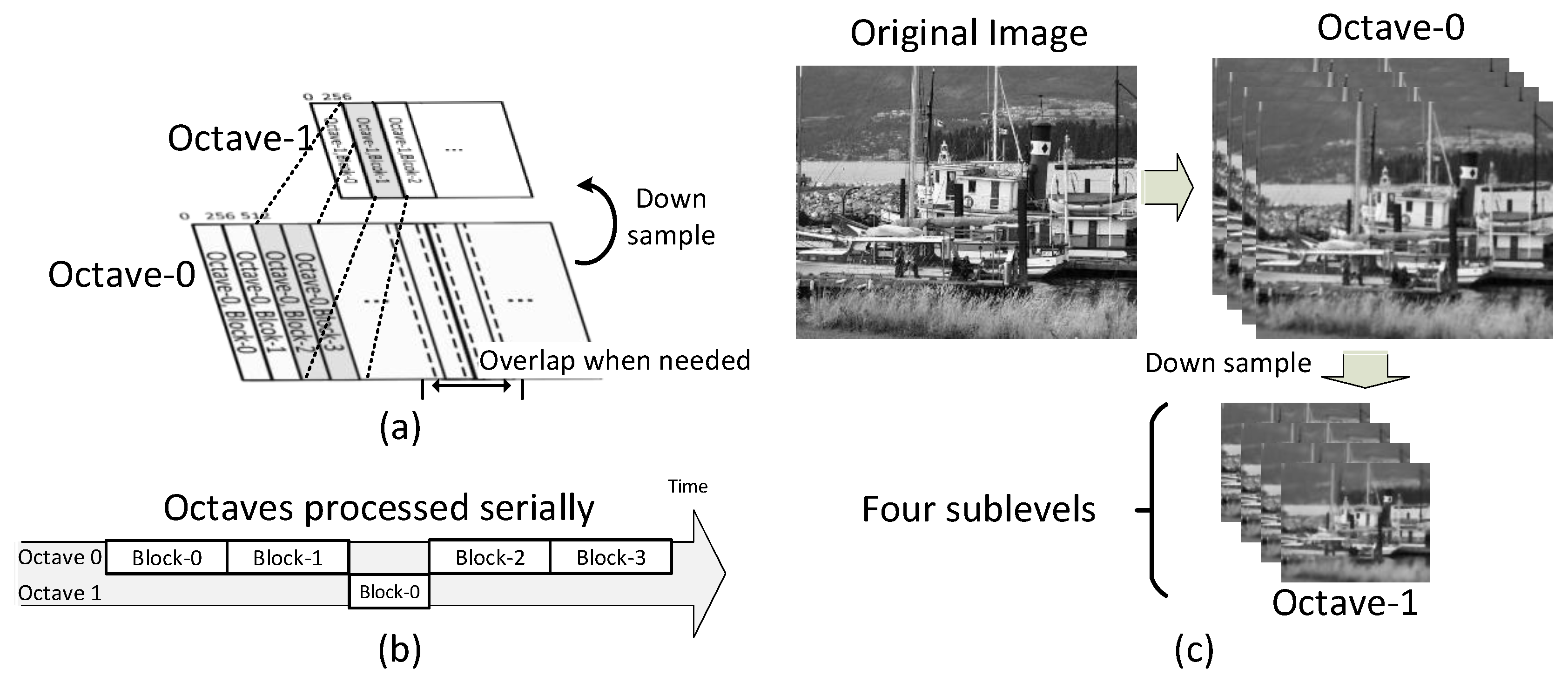
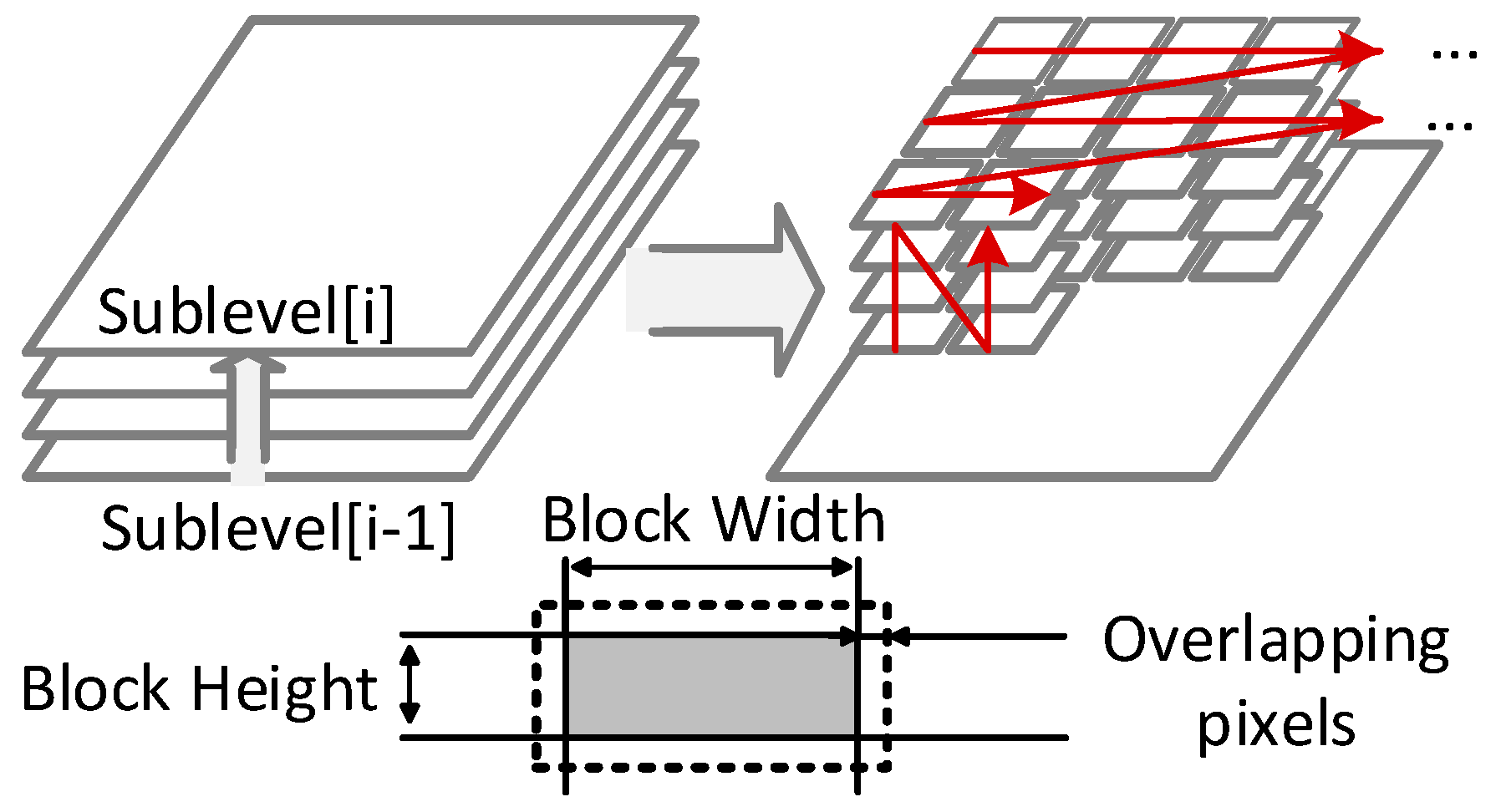
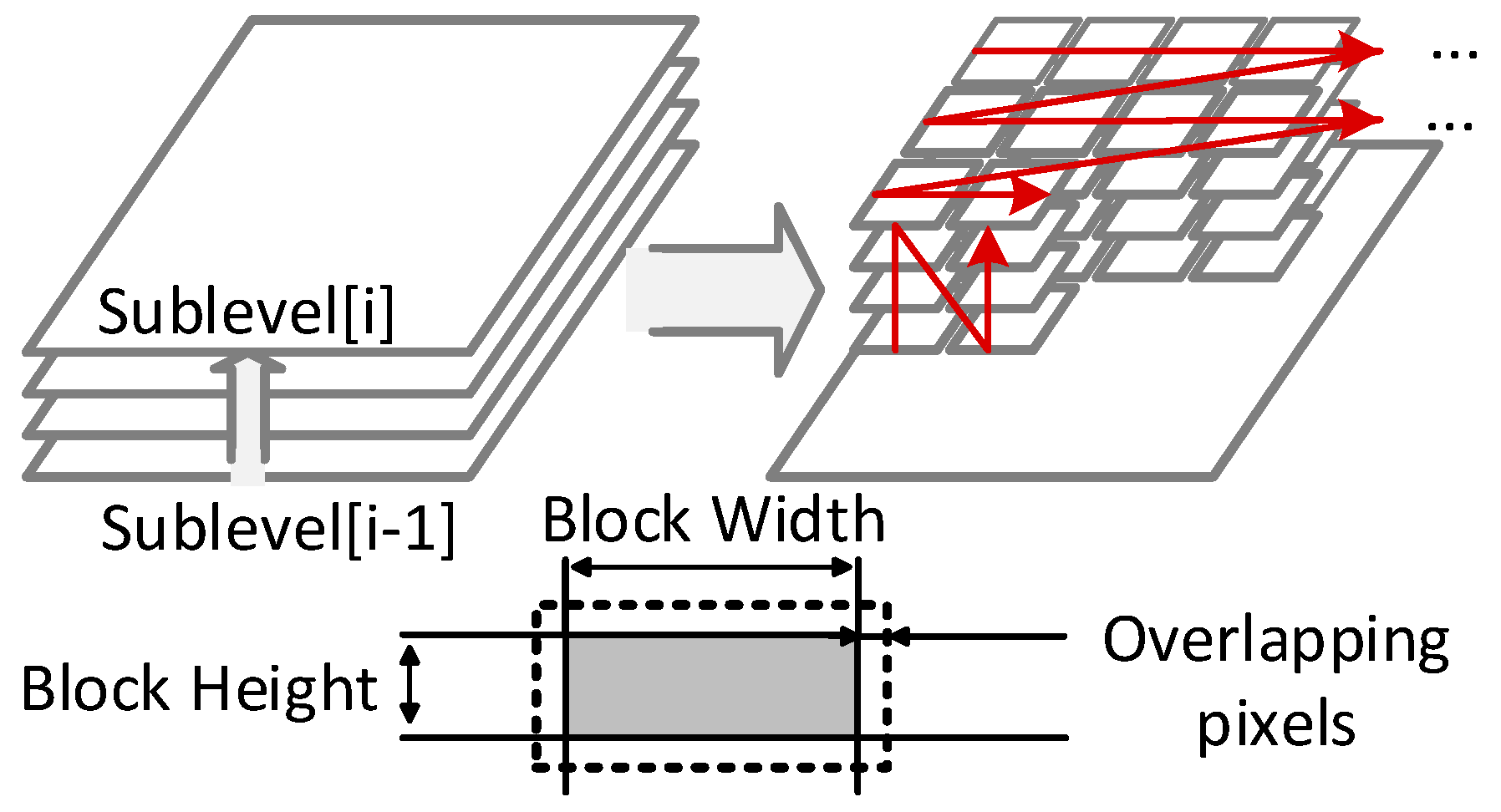
3.2. Block-Serial DTCNN
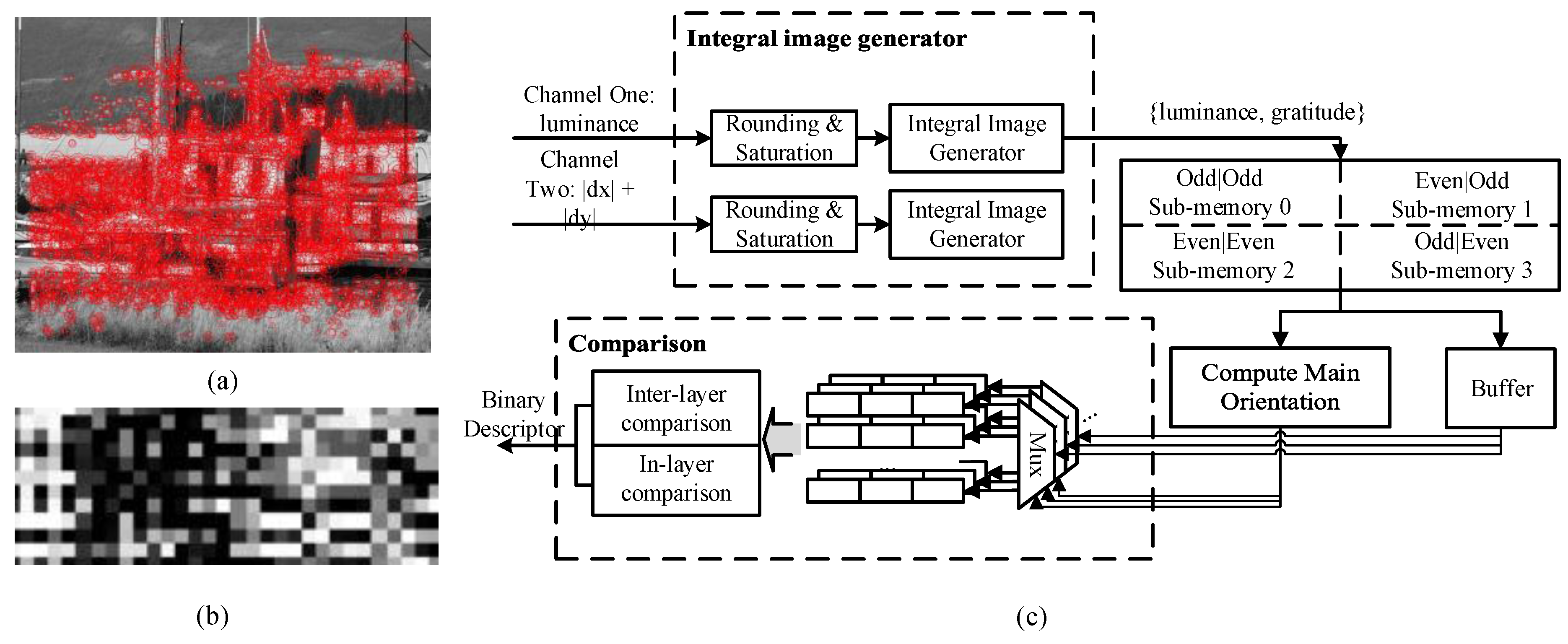
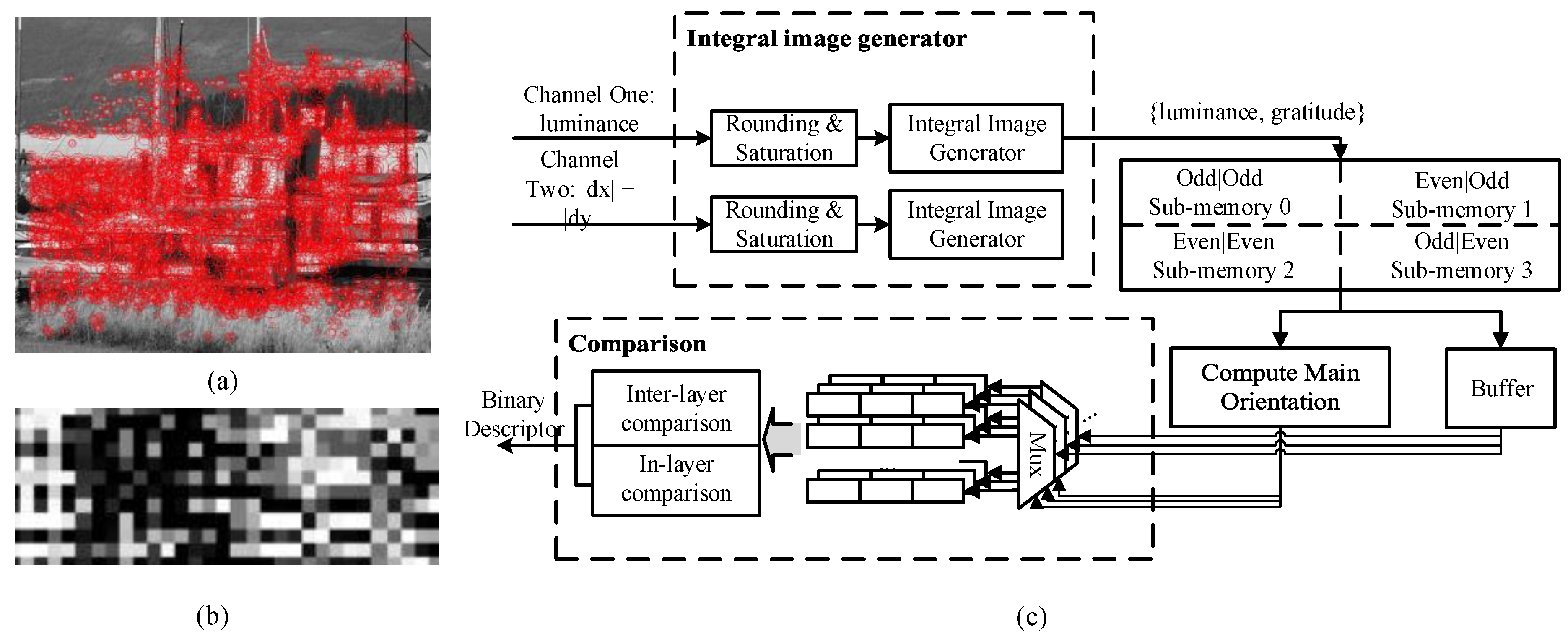
3.3. Robust Polar Binary Descriptor Module
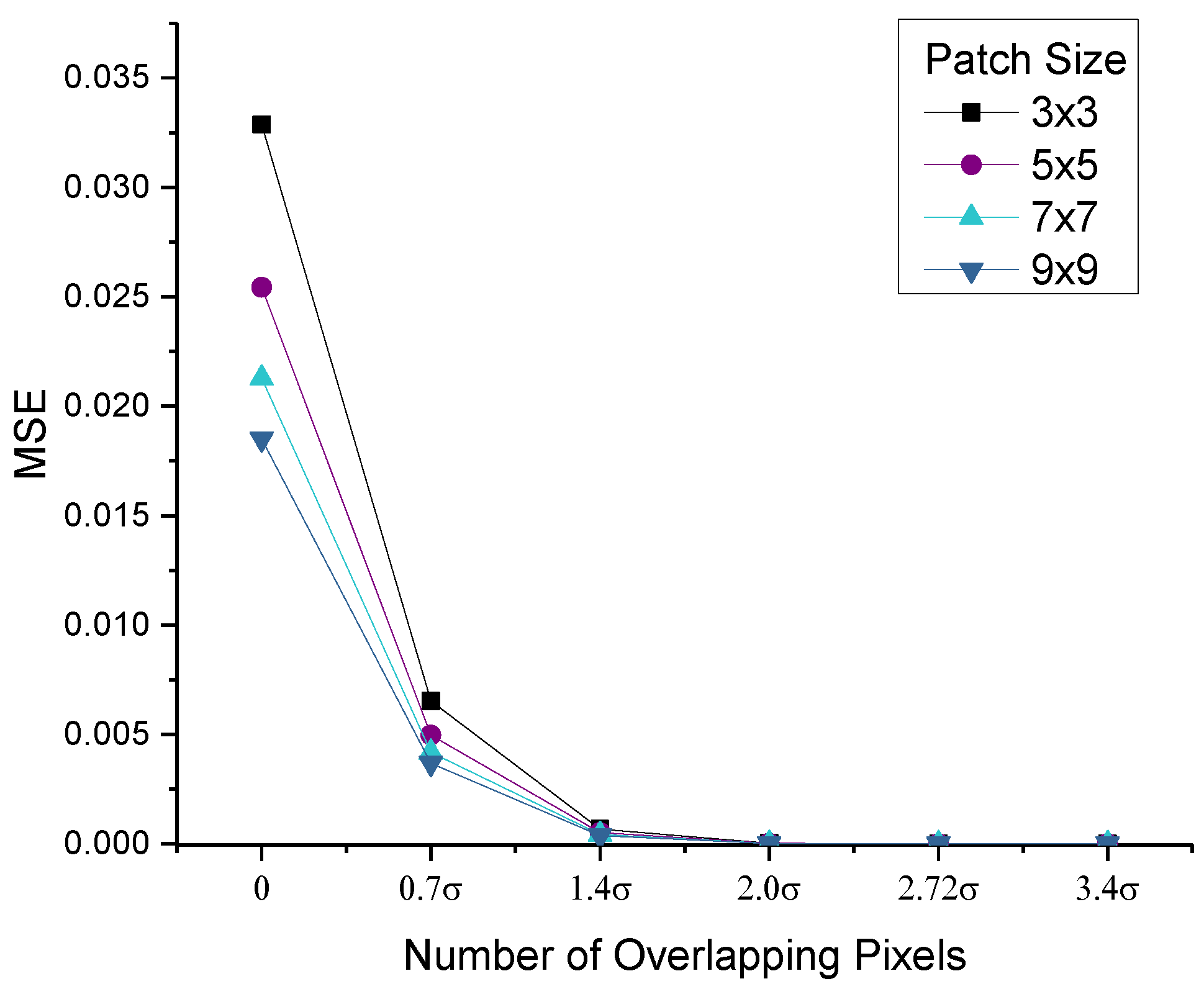
4. Simulation and Verification
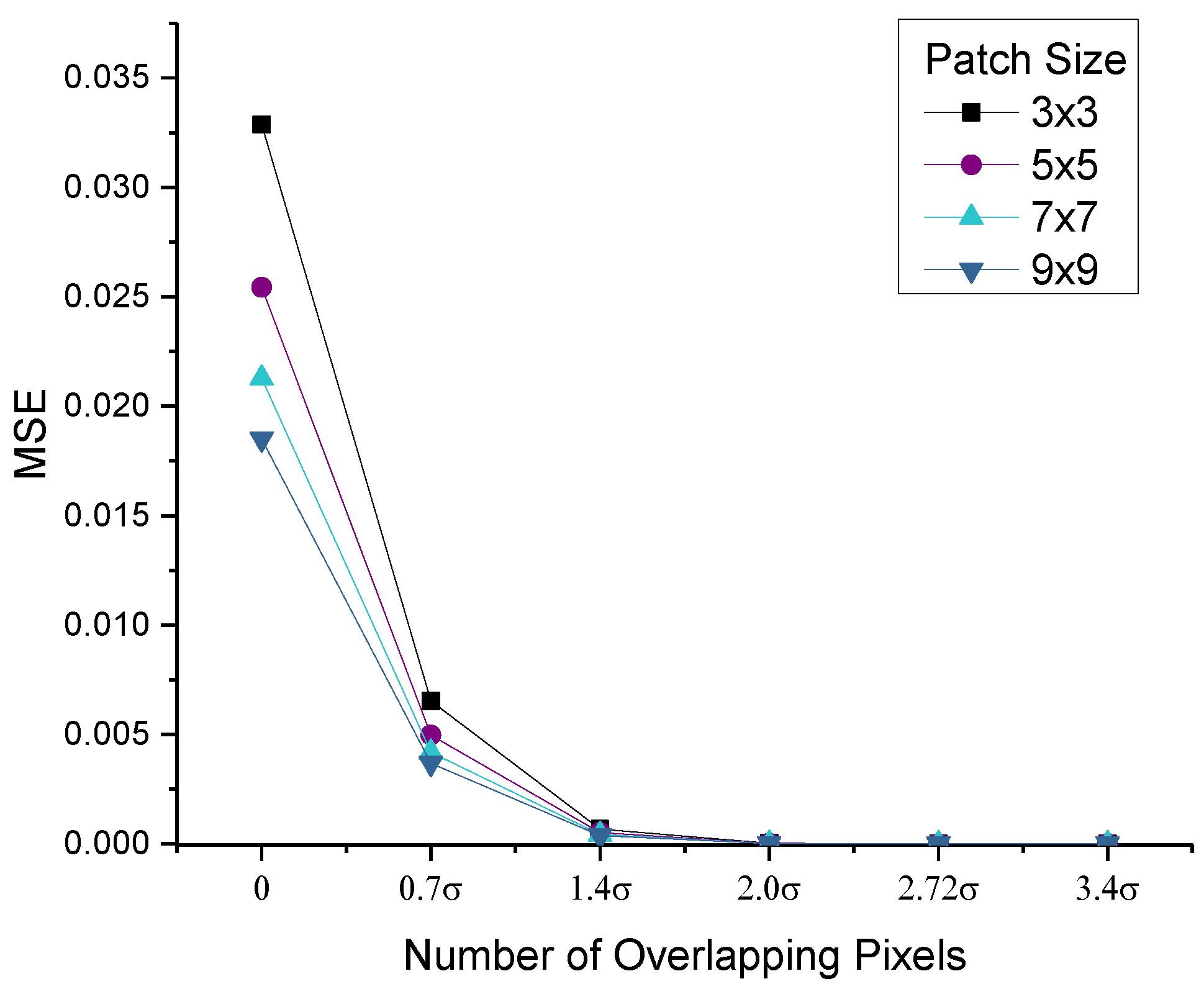
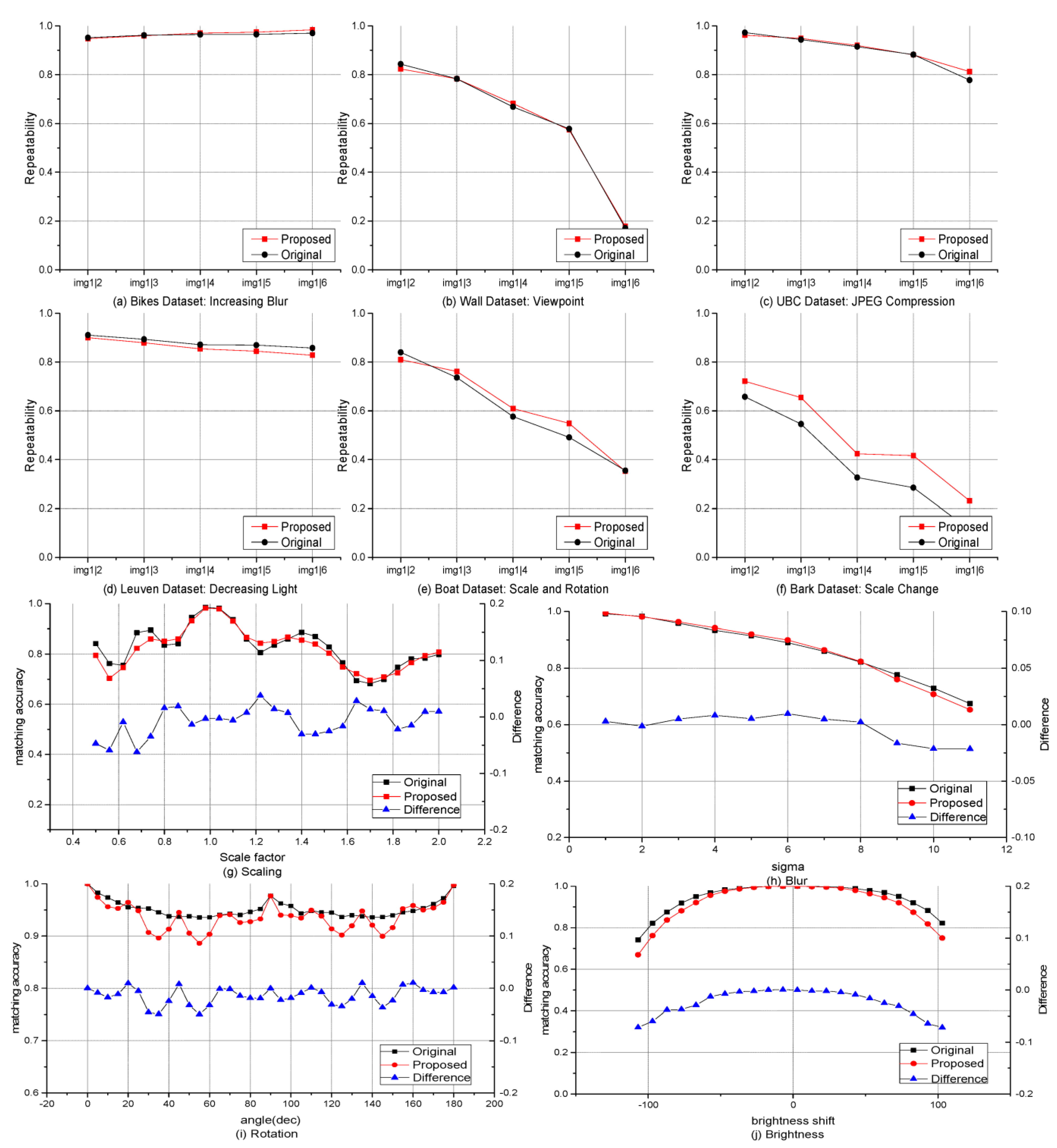
4.1. Feature Accuracy

| Brightness | Gaussian | Viewpoint | Rotation | Scaling | ||
|---|---|---|---|---|---|---|
| Boat | AKAZE | 87.47% | 93.29% | 78.53% | 95.51% | 83.03% |
| Proposed | 83.70% | 93.78% | 78.95% | 93.99% | 82.30% | |
| Trees | AKAZE | 88.97% | 89.45% | 72.66% | 90.74% | 80.26% |
| Proposed | 88.07% | 92.77% | 76.75% | 92.57% | 82.55% | |
| Bikes | AKAZE | 90.03% | 95.34% | 77.17% | 91.01% | 82.89% |
| Proposed | 88.03% | 94.69% | 76.81% | 88.32% | 81.76% | |
| Bark | AKAZE | 93.24% | 95.92% | 76.80% | 92.14% | 86.18% |
| Proposed | 90.88% | 95.20% | 76.53% | 93.66% | 84.37% | |
| Graf | AKAZE | 88.37% | 95.96% | 77.92% | 93.23% | 85.00% |
| Proposed | 84.06% | 95.64% | 77.65% | 91.01% | 82.69% | |
| Leuven | AKAZE | 90.80% | 96.36% | 78.73% | 89.27% | 84.83% |
| Proposed | 89.21% | 94.86% | 78.86% | 85.50% | 82.58% | |
| Ubc | AKAZE | 89.43% | 93.25% | 79.24% | 94.43% | 82.33% |
| Proposed | 88.25% | 94.28% | 81.48% | 91.52% | 83.68% | |
| Wall | AKAZE | 87.98% | 89.06% | 77.64% | 93.05% | 82.81% |
| Proposed | 85.09% | 91.68% | 76.48% | 95.09% | 83.58% |

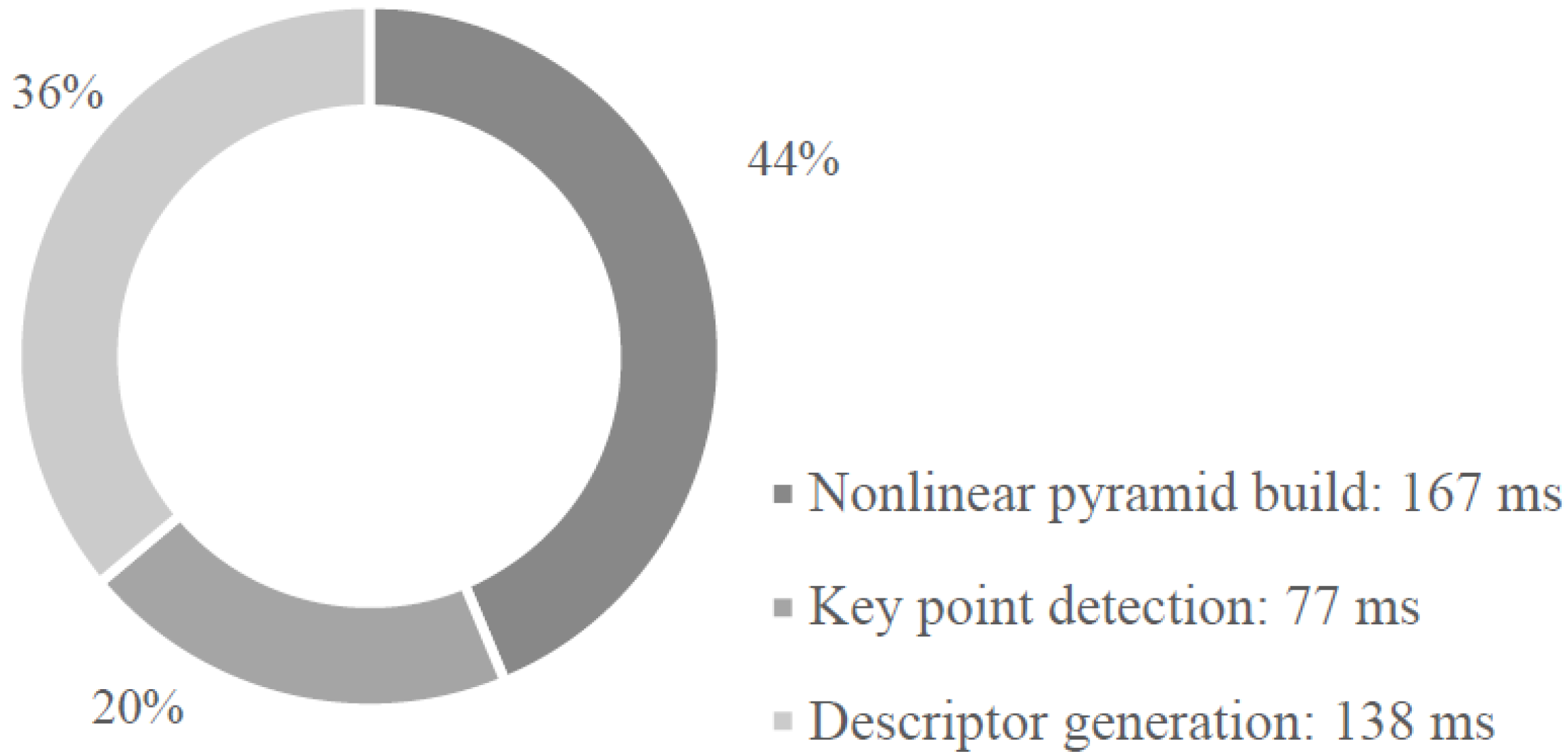
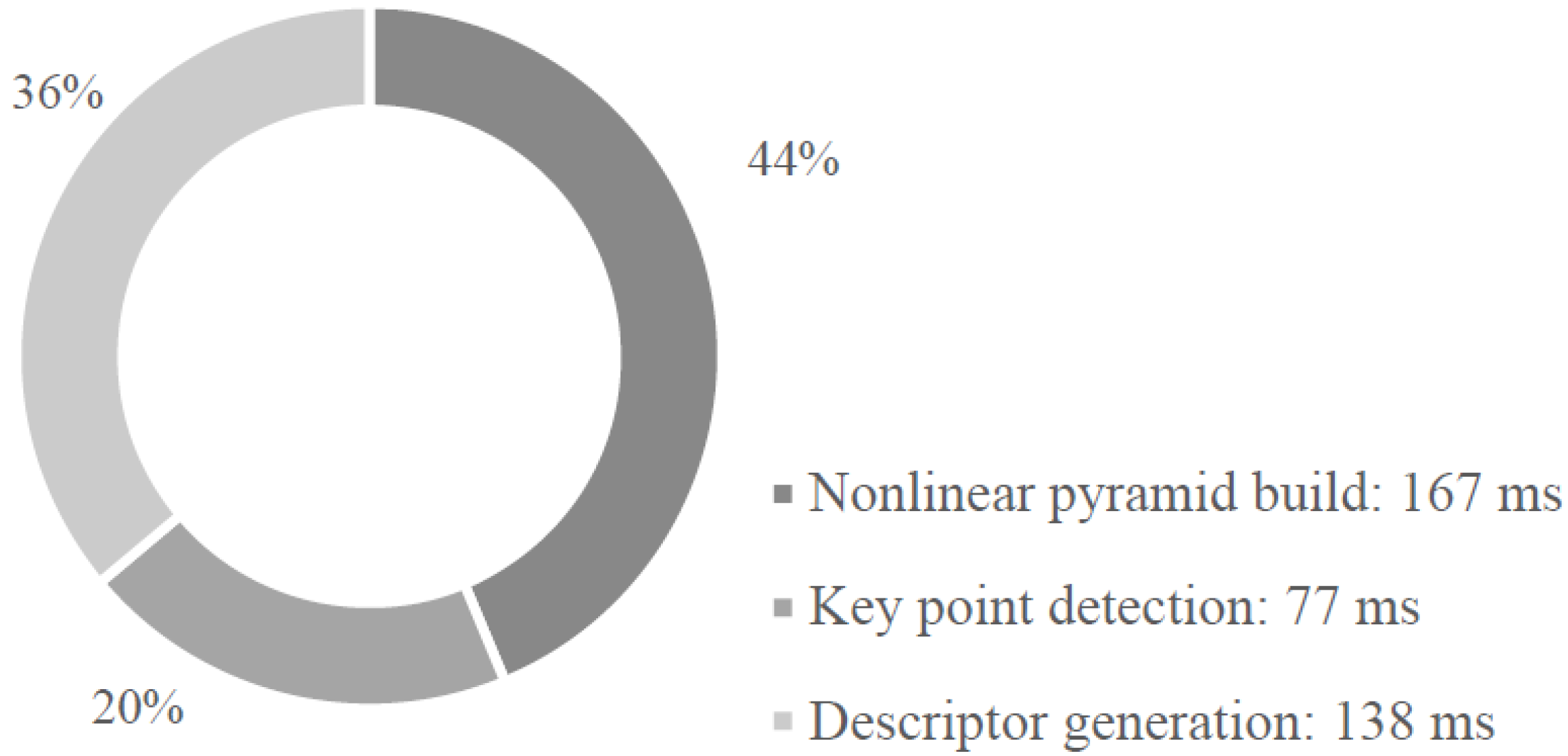
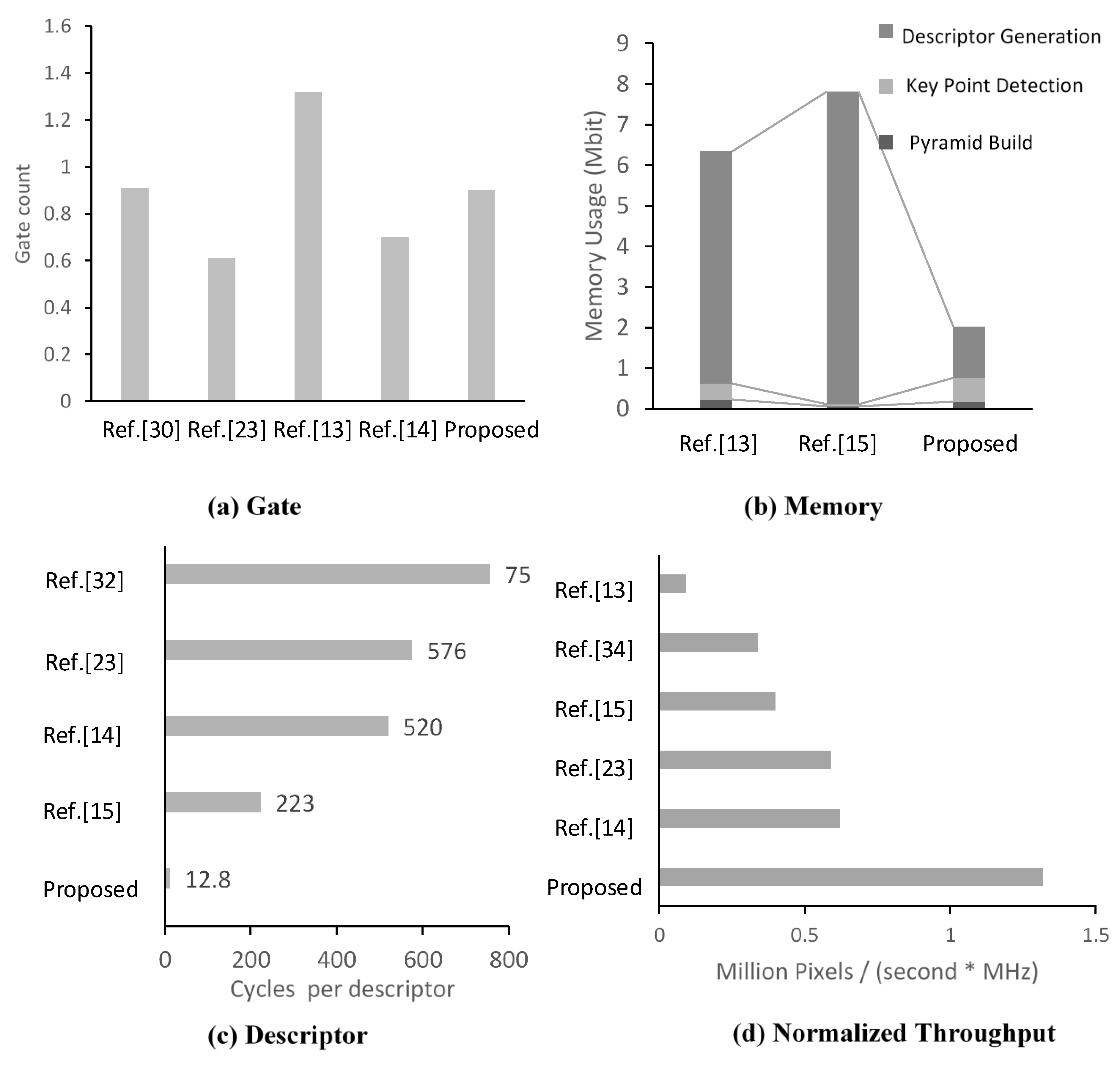
4.2. Hardware Performance
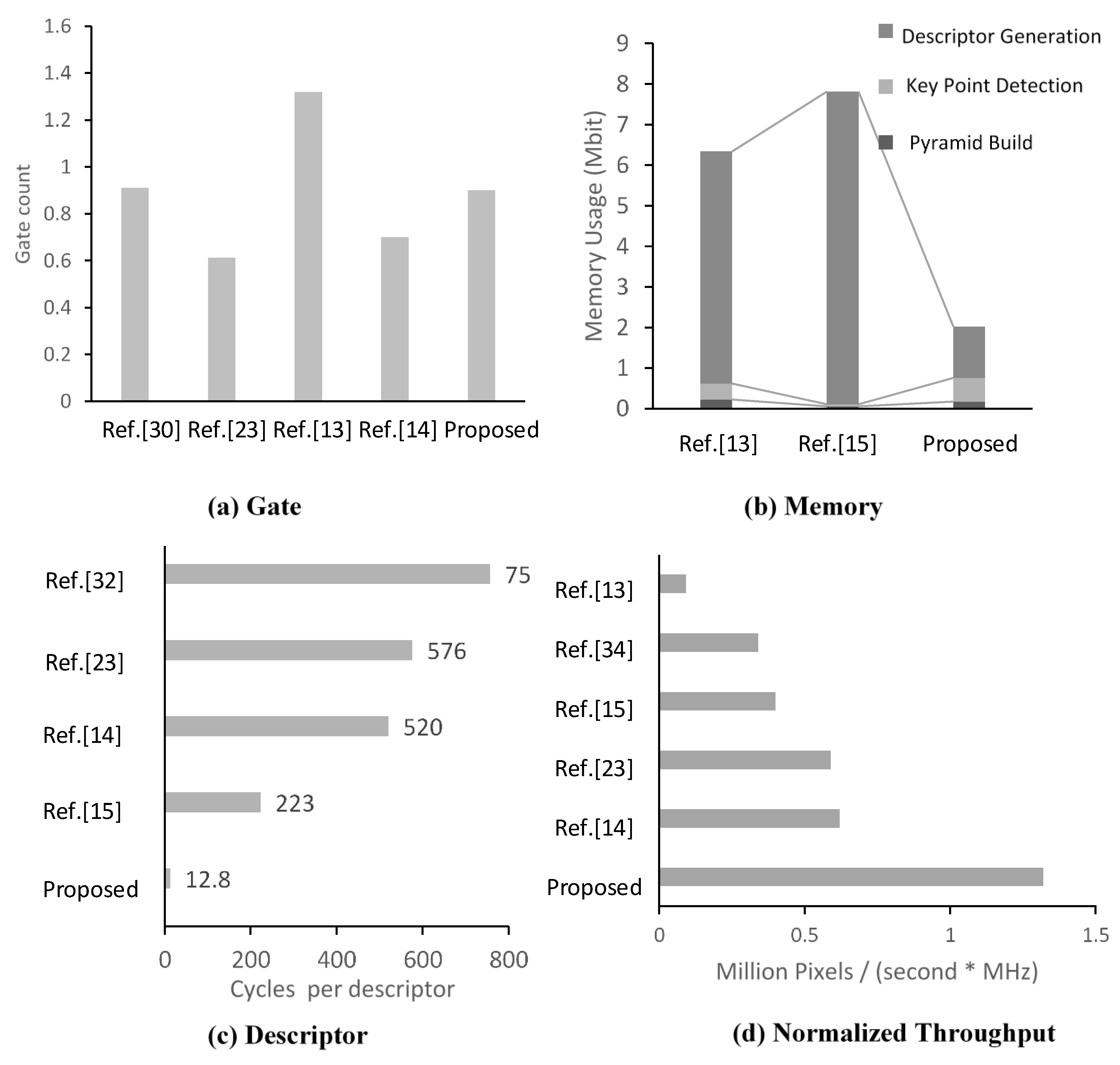

| Reference [23] | Reference [34] | Reference [13] | Reference [14] | Reference [15] | Proposed | Proposed | |
|---|---|---|---|---|---|---|---|
| Approach | SURF | SURF | SIFT | SIFT | SIFT | AKAZE | AKAZE |
| Pyramid 1 | (3, 4) | (1, 5) | (3, 6) | (2, 4) | (2, 4) | (2, 4) | (3, 4) |
| Platform | ASIC | ASIC | ASIC | ASIC | FPGA | ASIC | AISC |
| Frequency | 200 MHz | 27 MHz | 100 MHz | 100 MHz | 100 MHz | 200 MHz | 200 MHz |
| Memory | 3.2 Mb | - | 5.73 Mb | 0.55 Mb | 7.8 Mb | 2.12 Mb | 2.12 Mb |
| Gate | 0.6 M | - | 1.32 M | 0.7 M | - | 0.95 M | 0.95 M |
| Resolution | 1920 × 1080 | 640 × 480 | 640 × 480 | 1920 × 1080 | 512 × 512 | 1920 × 1080 | 1920 × 1080 |
| Speed | 57 fps | 30 fps | 30 fps | 30 fps | 153 fps | 127 fps | 121 fps |
| Throughput | 0.118 G | 0.0092 G | 0.0092 G | 0.062 G | 0.040 G | 0.263 G | 0.251 G |
| Throughput per gate 2 (Pixels/s@1 MGate) | 31.2 M | - | 1.31 M | 49.8 M | - | 85.9 M | 81.8 M |
| Throughput per frequency (Pixels/s@1 MHz) | 0.59 M | 0.34 M | 0.092 M | 0.62 M | 0.40 M | 1.3 M | 1.2 M |
| AKAZE Accelerator | |
|---|---|
| Process | TSMC 65 nm1p10m |
| Frequency | 200 MHz |
| Gate | 0.95 M |
| Memory | 2.12 M bit |
| Size | 4 mm × 3.3 mm |
| Speed | 127 fps (1920 × 1080) |
| Stage | Average Operations (Operations/Pixel) |
|---|---|
| Nonlinear Pyramid Build | 290 |
| Key Point Location | 240 |
| Descriptor Generation | 20 |
| Total | 550 |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chong, C.Y.; Kumar, S.P. Sensor networks: Evolution, opportunities, and challenges. Proc. IEEE 2003, 91, 1247–1256. [Google Scholar] [CrossRef]
- Remagnino, P.; Shihab, A.I.; Jones, G.A. Distributed intelligence for multi-camera visual surveillance. Pattern Recognit. 2004, 37, 675–689. [Google Scholar] [CrossRef]
- McCurdy, N.J.; Griswold, W.G. A systems architecture for ubiquitous video. In Proceedings of the 3rd International Conference on Mobile Systems, Applications, and Services, Seattle, WA, USA, 6–8 June 2005; pp. 1–14.
- Kim, G.; Kim, Y.; Lee, K.; Park, S.; Hong, I.; Bong, K.; Shin, D.; Choi, S.; Oh, J.; Yoo, H.-J. A 1.22 TOPS and 1.52 mW/MHz augmented reality multi-core processor with neural network NoC for HMD applications. In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers, San Francisco, CA, USA, 9–13 February 2014; pp. 182–183.
- Geronimo, D.; Lopez, A.M.; Sappa, A.D.; Graf, T. Survey of Pedestrian Detection for Advanced Driver Assistance Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1239–1258. [Google Scholar] [CrossRef] [PubMed]
- Brown, M.; Lowe, D.G. Recognising panoramas. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 1218–1225.
- Besbes, B.; Apatean, A.; Rogozan, A.; Bensrhair, A. Combining SURF-based local and global features for road obstacle recognition in far infrared images. In Proceedings of the 2010 13th International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010; pp. 1869–1874.
- Park, S.; Kim, S.; Park, M.; Park, S.K. Vision-based global localization for mobile robots with hybrid maps of objects and spatial layouts. Inf. Sci. 2009, 179, 4174–4198. [Google Scholar] [CrossRef]
- Jain, A.K.; Klare, B.; Park, U. Face Matching and Retrieval in Forensics Applications. IEEE Multimed. 2012, 19, 20–28. [Google Scholar] [CrossRef]
- Soro, S.; Heinzelman, W. A Survey of Visual Sensor Networks. Adv. Multimed. 2009, 2009. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, S.; Yan, L.; Cao, Z. An Embedded System-on-Chip Architecture for Real-time Visual Detection and Matching. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 525–538. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Huang, F.C.; Huang, S.Y.; Ker, J.W.; Chen, Y.C. High-Performance SIFT Hardware Accelerator for Real-Time Image Feature Extraction. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 340–351. [Google Scholar] [CrossRef]
- Chiu, L.C.; Chang, T.S.; Chen, J.Y.; Chang, N.Y.C. Fast SIFT Design for Real-Time Visual Feature Extraction. IEEE Trans. Image Process. 2013, 22, 3158–3167. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Li, X.Y.; Zhang, G.J. SIFT Hardware Implementation for Real-Time Image Feature Extraction. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1209–1220. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the Computer Vision—ECCV, Heraklion, Greece, 5–11 September 2010; Volume 6314, pp. 778–792.
- Yang, A.Y.; Maji, S.; Christoudias, C.M.; Darrell, T.; Malik, J.; Sastry, S.S. Multiple-view object recognition in band-limited distributed camera networks. In Proceedings of the ICDSC 2009 Third ACM/IEEE International Conference on Distributed Smart Cameras, Como, Italy, 30 August–2 September 2009; pp. 1–8.
- Park, J.S.; Kim, H.E.; Kim, L.S. A 182 mW 94.3 f/s in Full HD Pattern-Matching Based Image Recognition Accelerator for an Embedded Vision System in 0.13 µm-CMOS Technology. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 832–845. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE Features. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Volume 7577, pp. 214–227.
- Grewenig, S.; Weickert, J.; Bruhn, A. From Box Filtering to Fast Explicit Diffusion. In Pattern Recognition, Proceedings of the 32nd DAGM Symposium, Darmstadt, Germany, 22–24 September 2010; Volume 6376, pp. 533–542.
- Grewenig, S.; Weickert, J.; Schroers, C.; Bruhn, A. Cyclic Schemes for PDE-Based Image Analysis; Technical Report 327; Department of Mathematics, Saarland University: Saarbrücken, Germany, 2013. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.L.; Zhang, W.L.; Deng, C.C.; Yin, S.Y.; Cai, S.S.; Wei, S.J. SURFEX: A 57 fps 1080 P resolution 220 mW silicon implementation for simplified speeded-up robust feature with 65 nm process. In Proceedings of the IEEE 2013 Custom Integrated Circuits Conference, San Jose, CA, USA, 22–25 September 2013; pp. 1–4.
- Bonato, V.; Marques, E.; Constantinides, G.A. A Parallel Hardware Architecture for Scale and Rotation Invariant Feature Detection. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1703–1712. [Google Scholar] [CrossRef]
- Tola, E.; Lepetit, V.; Fua, P. DAISY: An Efficient Dense Descriptor Applied to Wide-Baseline Stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 815–830. [Google Scholar] [CrossRef] [PubMed]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2548–2555.
- Chua, L.O.; Roska, T. The CNN paradigm. IEEE Trans. Circuits Syst. I Fundam. Theory Appl. 1993, 40, 147–156. [Google Scholar] [CrossRef]
- Javier Martinez-Alvarez, J.; Javier Garrigos-Guerrero, F.; Javier Toledo-Moreo, F.; Manuel Ferrandez-Vicente, J. High performance implementation of an FPGA-based sequential DT-CNN. In Nature Inspired Problem-Solving Methods in Knowledge Engineering, Proceedings of the Second International Work-Conference on the Interplay Between Natural and Artificial Computation (IWINAC 2007), La Manga del Mar Menor, Spain, 18–21 June 2007; Volume 4528, pp. 1–9.
- Belt, H.J.W. Word length reduction for the integral image. In Proceedings of the 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 805–808.
- Su, Y.C.; Huang, K.Y.; Chen, T.W.; Tsai, Y.M.; Chien, S.Y.; Chen, L.G. A 52 mW Full HD 160-Degree Object Viewpoint Recognition SoC with Visual Vocabulary Processor for Wearable Vision Applications. IEEE J. Solid-State Circuits 2012, 47, 797–809. [Google Scholar] [CrossRef]
- Visual Feature Benchmark. Available online: https://github.com/BloodAxe/OpenCV-Features-Comparison (accessed on 4 April 2015).
- Deng, W.J.; Zhu, Y.Q.; Feng, H.; Jiang, Z.G. An efficient hardware architecture of the optimised SIFT descriptor generation. In Proceedings of the 2012 22nd International Conference on Field Programmable Logic and Applications, Oslo, Norway, 29–31 August 2012; pp. 345–352.
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. Diannao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. In Proceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems, Salt Lake City, UT, USA, 1–5 May 2014; pp. 269–284.
- Jeon, D.; Henry, M.B.; Kim, Y.; Lee, I.; Zhang, Z.; Blaauw, D.; Sylvester, D. An Energy Efficient Full-Frame Feature Extraction Accelerator with Shift-Latch FIFO in 28 nm CMOS. IEEE J. Solid-State Circuits 2014, 49, 1271–1284. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, G.; Liu, L.; Zhu, W.; Yin, S.; Wei, S. A 181 GOPS AKAZE Accelerator Employing Discrete-Time Cellular Neural Networks for Real-Time Feature Extraction. Sensors 2015, 15, 22509-22529. https://doi.org/10.3390/s150922509
Jiang G, Liu L, Zhu W, Yin S, Wei S. A 181 GOPS AKAZE Accelerator Employing Discrete-Time Cellular Neural Networks for Real-Time Feature Extraction. Sensors. 2015; 15(9):22509-22529. https://doi.org/10.3390/s150922509
Chicago/Turabian StyleJiang, Guangli, Leibo Liu, Wenping Zhu, Shouyi Yin, and Shaojun Wei. 2015. "A 181 GOPS AKAZE Accelerator Employing Discrete-Time Cellular Neural Networks for Real-Time Feature Extraction" Sensors 15, no. 9: 22509-22529. https://doi.org/10.3390/s150922509