
GTRF: A Game Theory Approach for Regulating Node Behavior in Real-Time Wireless Sensor Networks

Abstract
:1. Introduction
- (1)
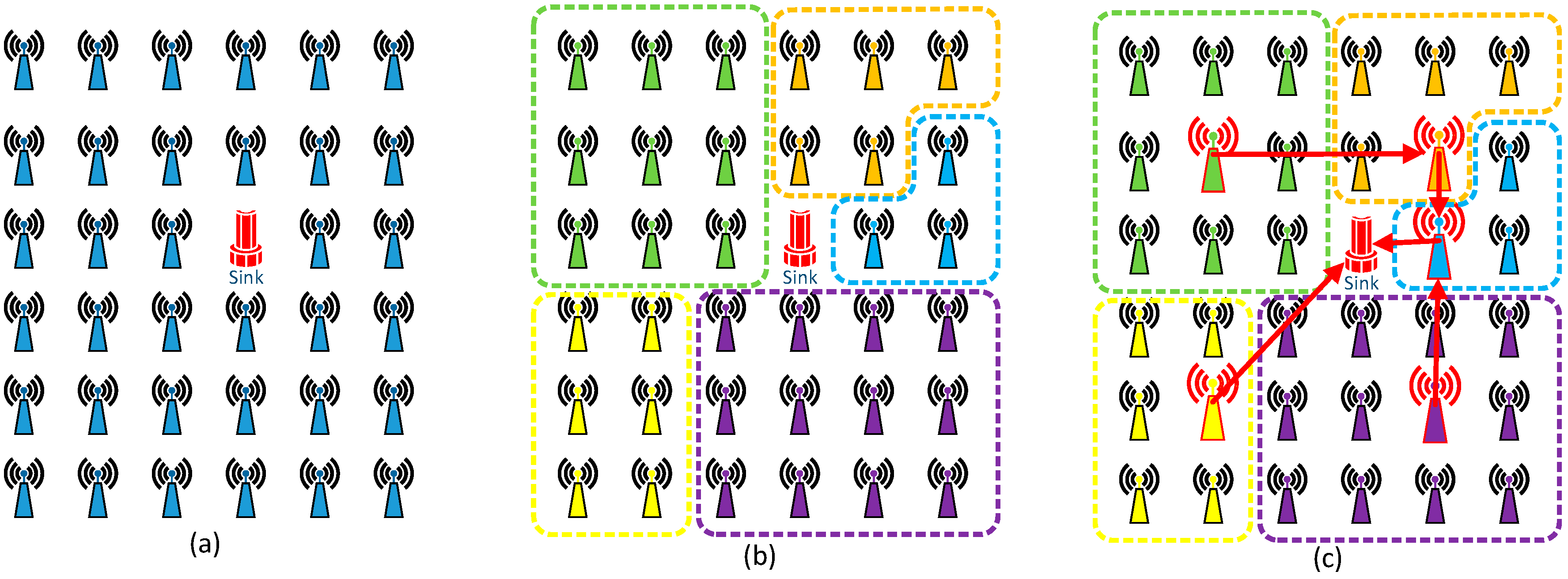
- For ease in controlling nodes’ behaviors, cluster structures are established for grouping nodes into clusters. Therefore, the problem of controlling nodes’ behaviors becomes one of regulating the behaviors of cluster heads and cluster members, respectively. Moreover, a cluster structure is capable of balancing energy consumption in networks.
- (2)
- To regulate nodes’ behaviors within clusters, we develop a VA model, which forces selfish nodes to spontaneously behave as normal nodes so as to maximize their profits. We prove that for selfish nodes behaving as normal nodes is a Nash Equilibrium strategy.
- (3)
- To control nodes’ behaviors among cluster heads, we introduce a jumping transmission model. As selfish nodes are still likely to be selected as cluster heads, in the jumping transmission stage, a feedback mechanism is used which forbids selfish nodes from dropping packets. We also proved that behaving as normal nodes is also a Nash Equilibrium strategy for selfish cluster heads.
2. State of the Art
2.1. Real-Time Routing Protocols
2.2. Game Theory in WSNs
3. Preliminaries
3.1. Game Theory and Nash Equilibrium
3.1.1. Player Set N
3.1.2. Strategy Set
3.1.3. Payoff Function
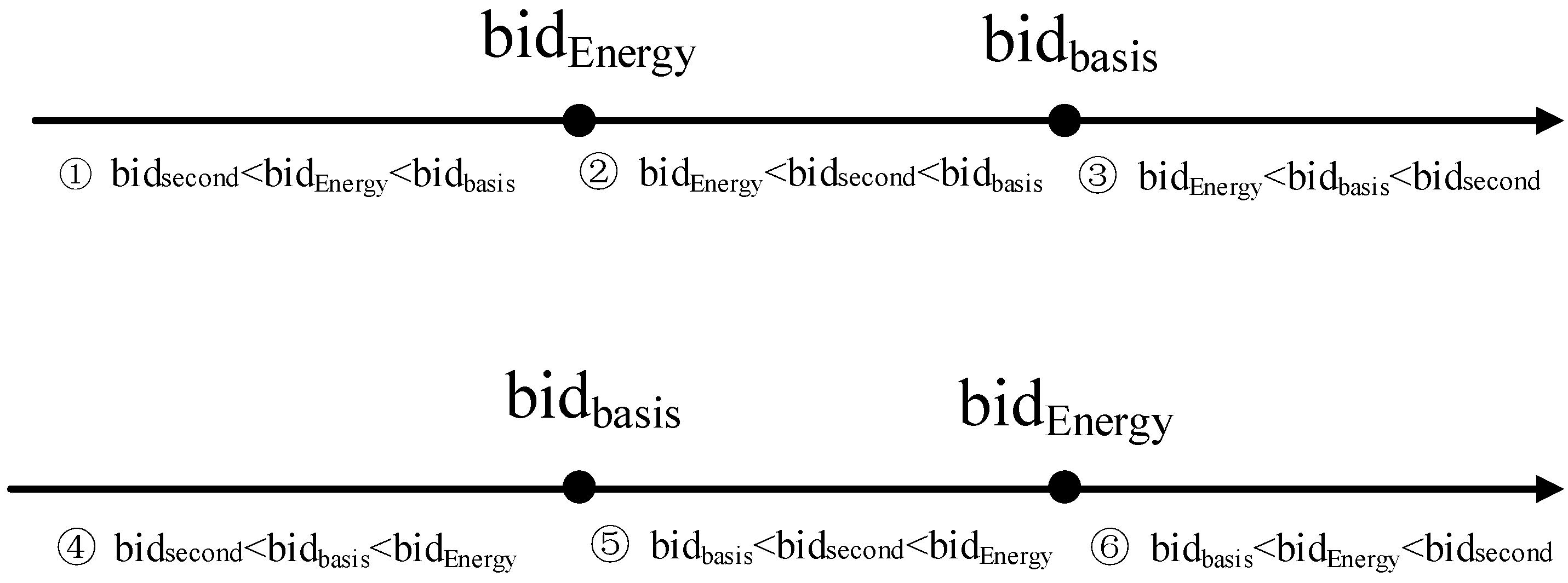
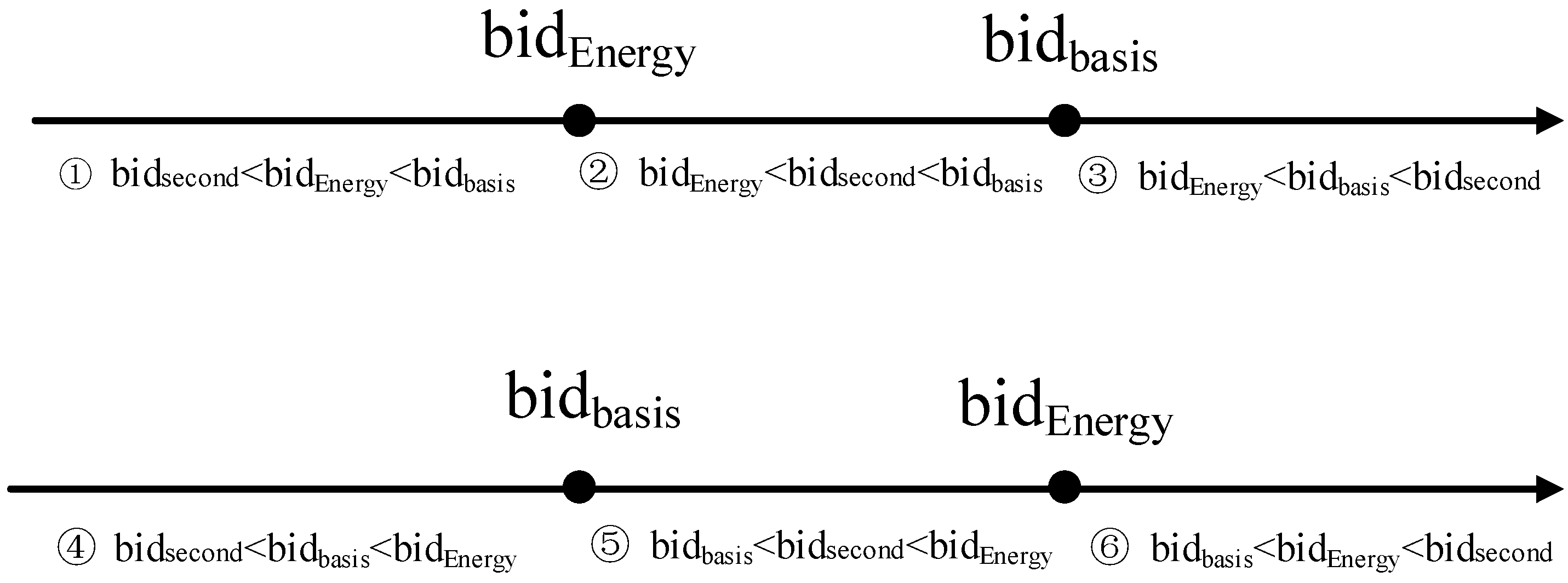
3.2. Auction Bidding Process
3.3. Hypotheses and Definitions
- Definition 1. Neighboring cluster head: A cluster head that locates in the sensing range of another one.
- Definition 2. Cluster period: The time interval between two continuous cluster head selections.
3.4. Energy Consumption Model
4. GTRF Routing Protocol
4.1. Problem Statement

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Strategy | Meaning |
|---|---|---|
| Sense | {Sense, NSense} | Monitor the environment or not |
| Communicate (Bid) | {Communicate, NCommunicate} | Communicate with other nodes or not |
| Forward (Send) | {Send, NSend} | Forward a packet or not |
- Input: Network parameters, strategy set (i.e., Action strategy and bidding strategy).
- Find: Strategies for node in different situations.
- Such that: , is the maximum.
- Meanwhile: is a Nash Equilibrium point and the corresponding situation reaches Nash Equilibrium.
4.2. GTRF Overview
4.3. VA Model
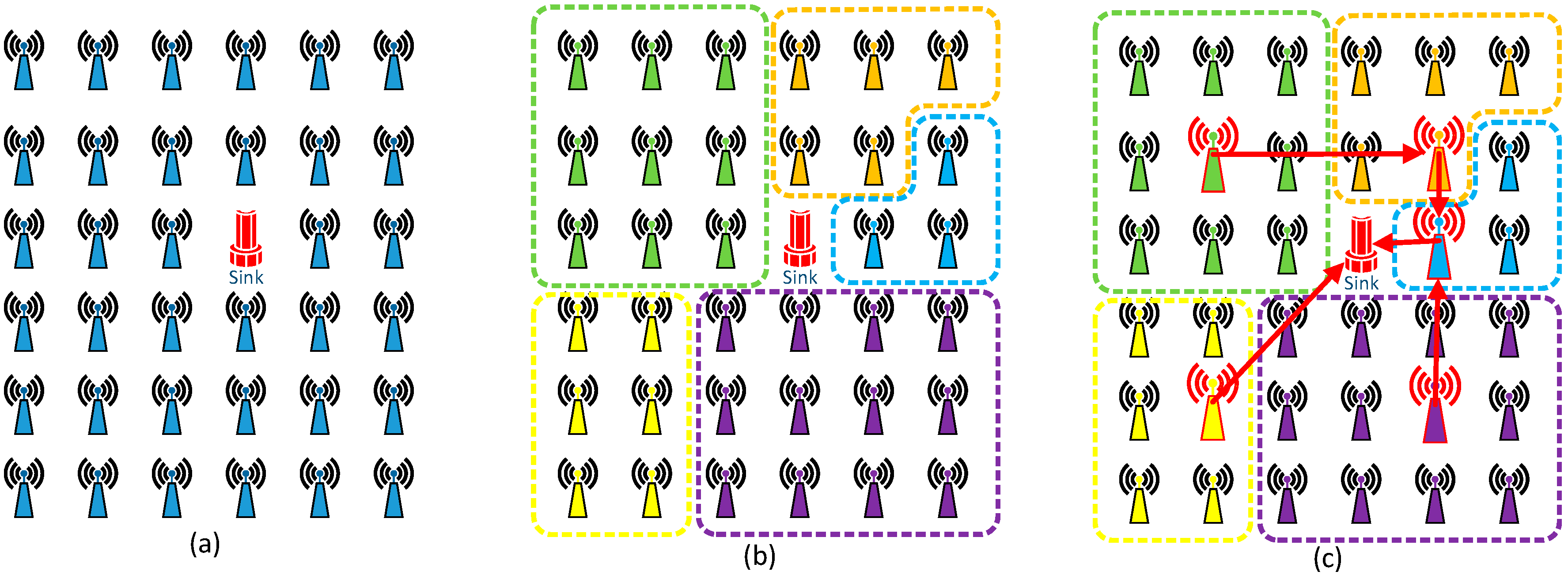
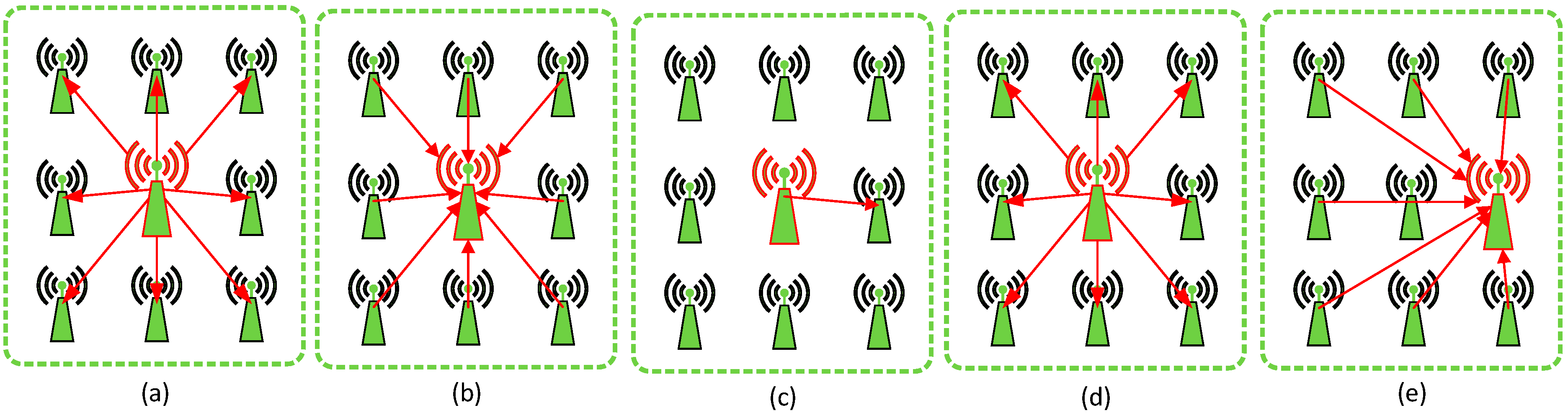
- Step 1
- The cluster head broadcasts a message to notify the beginning of the bidding process (see Figure 2a).
- Step 2
- After receiving the notification message, the bidding process begins. Each node (including the cluster head and all cluster members) determines a bidding value as its remaining energy. When calculating the bidding value, each node should refer to its actual remaining energy so as to bid a proper value. However, this does not mean the bidding value should be exactly the same as the actual remaining energy.
- Step 3
- Each node sends its bidding value to the cluster head in its pre-allocated time slot (see Figure 2b). The cluster head records all bidding values so as to select a new cluster head in the next round.
- Step 4
- The cluster head selects the node whose bidding value is the biggest as the cluster head in the next cluster period (see Figure 2c). Then the cluster will broadcast this information to all nodes within the cluster (see Figure 2d). If the newly selected node is a cluster member, the cluster head will transmit information such as TMDA assignments, node ids and so on to the newly selected node. In the next cluster period, the original cluster head will change its role into a cluster member. Finally, a new cluster head is designated, and the working process begins, each node sends its data to the newly selected cluster head (see Figure 2e). The cluster head collects and aggregates the data and then transmits it to other cluster heads.
- Rule 1
- A node bidding the highest bidiEnergy(j) is regarded to win the auction and it will be designated as the cluster head in the next cluster period. The energy cost of a cluster head is mainly consumed in four actions: sensing energy cost, packet receiving cost, data processing cost and data sending cost. The energy cost of a cluster head is much bigger than that of a cluster member. Therefore, we need to control the energy cost of the cluster head so as to avoid creating big energy consumption gaps between a cluster head and its cluster members.
- Rule 2
- A cluster head consumes at most energy in the ith cluster period. With respect to a cluster member, we also propose a rule for limiting the energy cost.
- Rule 3
- A cluster member consumes more than f will stop working in that cluster period. In the VA model, each node is aware of the rules and must obey them. Since each node seeks the maximum value of the payoff function, it will firstly estimate the profit and then bid bidiEnergy(j). Based on these rules, we prove that, although one or more selfish nodes may exist in a cluster, the best strategy for a cluster member is to behave like a normal node (see Theorem 4 in Section 4.5).
- Rule 4.
- The profit that a node regarded as a faulty node is the minimum.
4.4. Jumping Transmission Model
| Algorithm 1 Jumping forwarding model | |
| 1: | Network initialization |
| 2: | Cluster construction and initialization |
| 3: | Establish routing tables for all clusters |
| 4: | If intends to transmit a packet then |
| 5: | If () || (congestion, faulty nodes or void region are detected ) then |
| 6: | Select a downstream cluster head that is outside the transmission range (detailed information is given in reference [10]) |
| 7: | Use the jumping transmission method to send from to |
| 8: | Else |
| 9: | Select a downstream cluster head that is inside the transmission range |
| 10: | Use the hop-by-hop transmission method to send from to |
| 11: | Endif |
| 12: | Endif |
| 13: | Adjust transmitting probabilities according to reference [10] |
| Algorithm 2 Feedback message notification model | |
| 1: | Cluster head sends a packet to the Sink |
| 2: | If the Sink receives a packet orignated from cluster head then |
| 3: | The sink will broadcast to notify that packet has been successfully sent to Sink |
| 4: | Endif |
| 5: | If didn’t get the reply from Sink for time then |
| 6: | will from now on directly deliver all packets to Sink |
| 7: | will broadcast that all clusters heads within to Sink are all faulty nodes |
| 7 | Endif |
4.5. Characteristics Analysis
5. Simulation Analysis
| Item | Parameters |
|---|---|
| Routing Protocol | SPEED [6], SPEED-T [6], SPEED-S [6], MMSPEED [8], FTSPEED [9], DMRF [10], GTRF, DMRF Cluster (DMRF + LEACH) |
| MAC Protocol | TDMA |
| Bandwidth | 10 Kb/s |
| Data Packet Size | 1024 bit |
| Region Size | (20 m, 20 m) |
| Node Number | 400, 1000, 2000, 5000, 10,000 |
| Node Distribution | Uniform |
| TDMA Time Slot | 120 ms |
| Cluster Member Sensing Range | 2 m |
| Cluster Head Sensing Range | 5 m |
| Initial Node Energy | 100 J |
| Selfish Node Ratio | 10% |
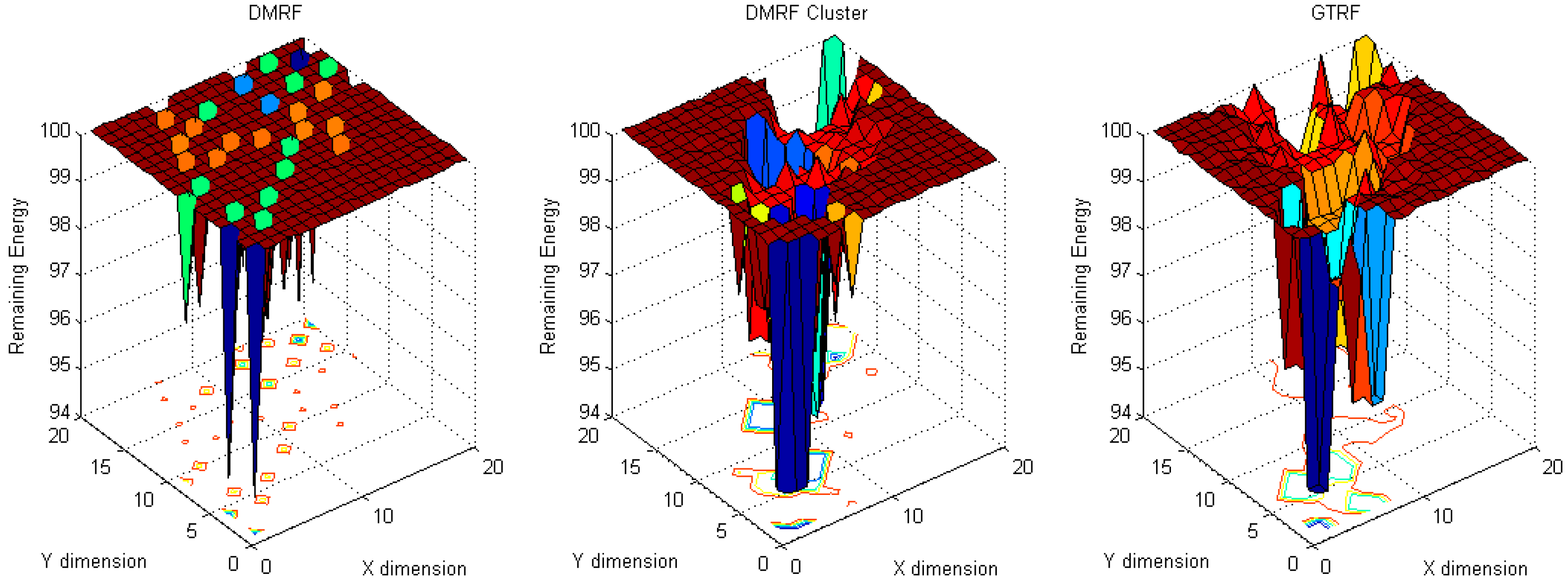
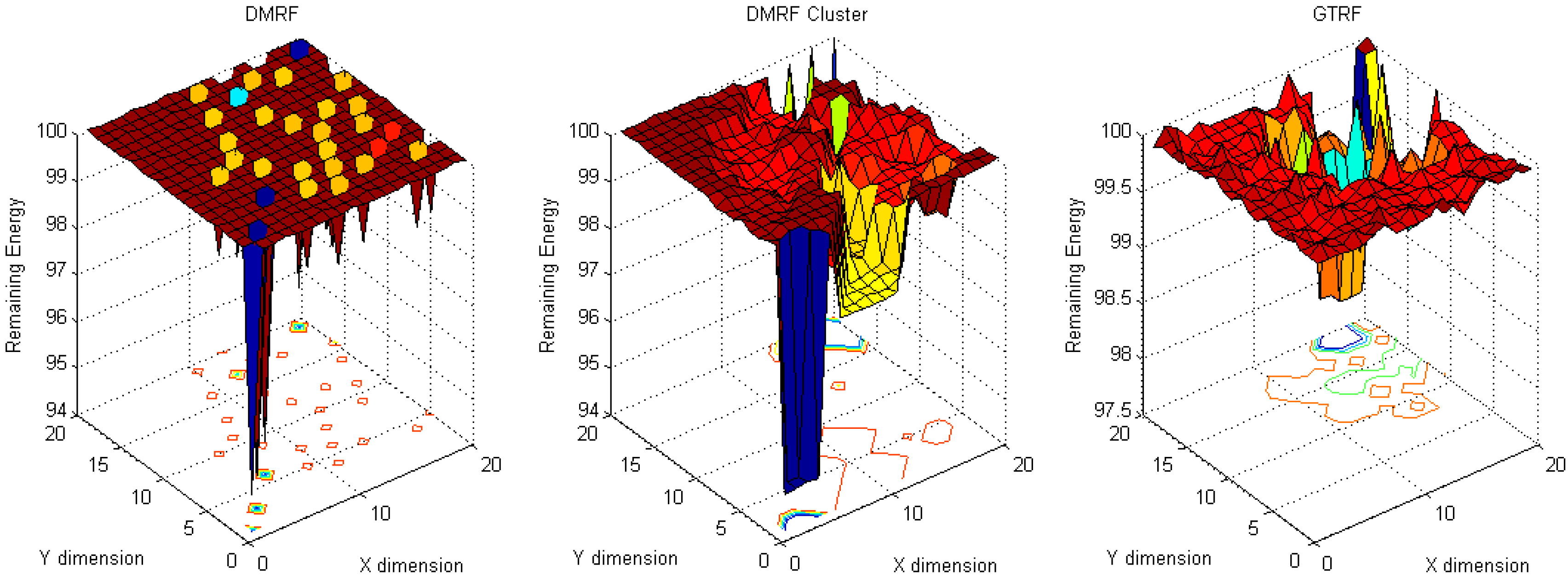
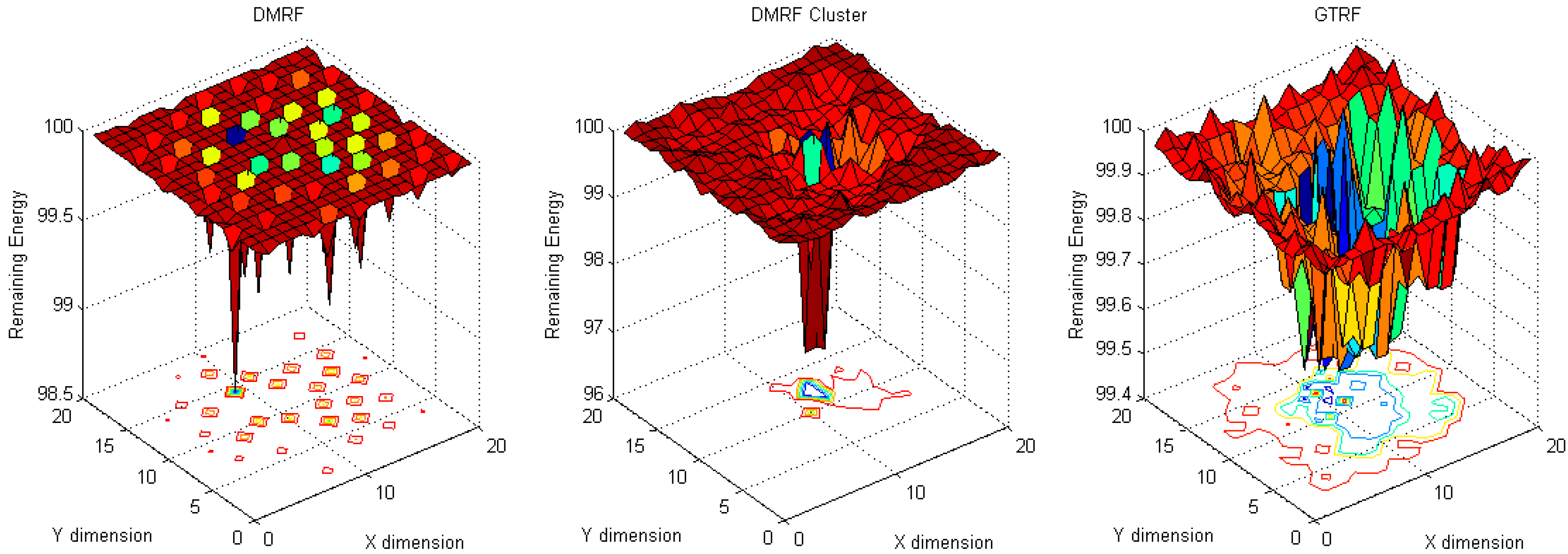
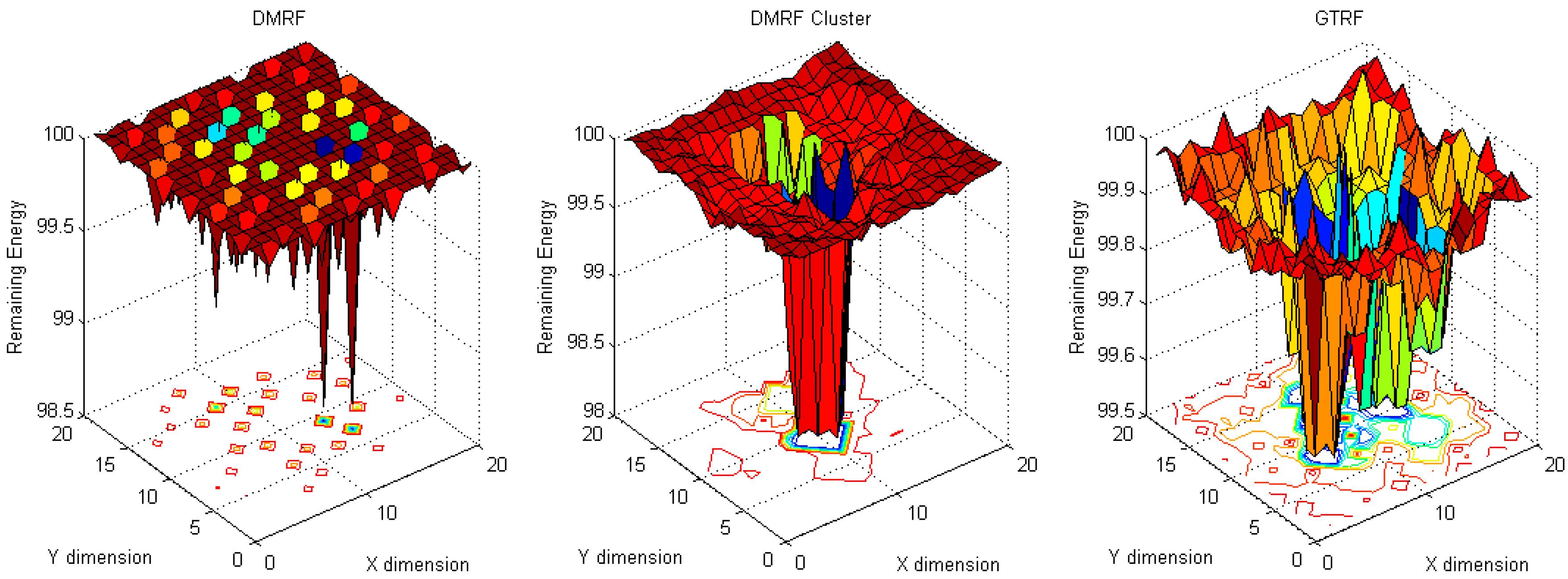
5.1. Energy Cost Distribution
5.1.1. Fixed Sources with Fixed Sink
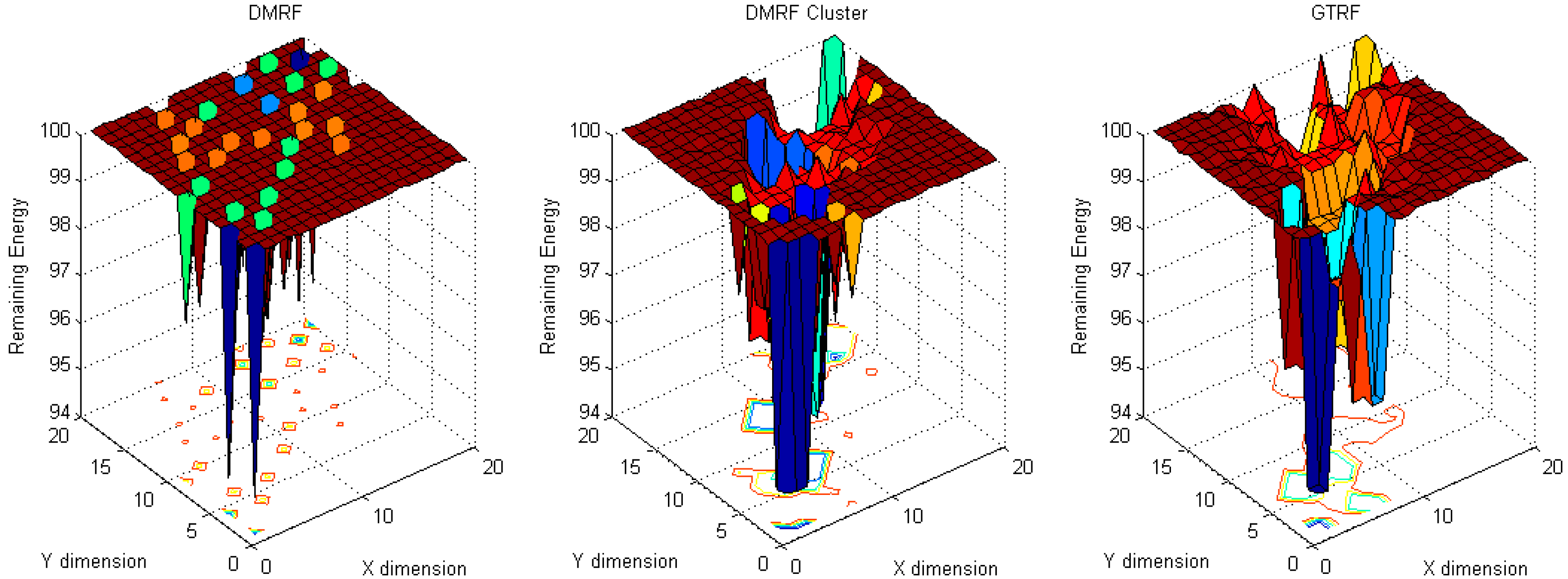

5.1.2. Fixed Sink with Random Source

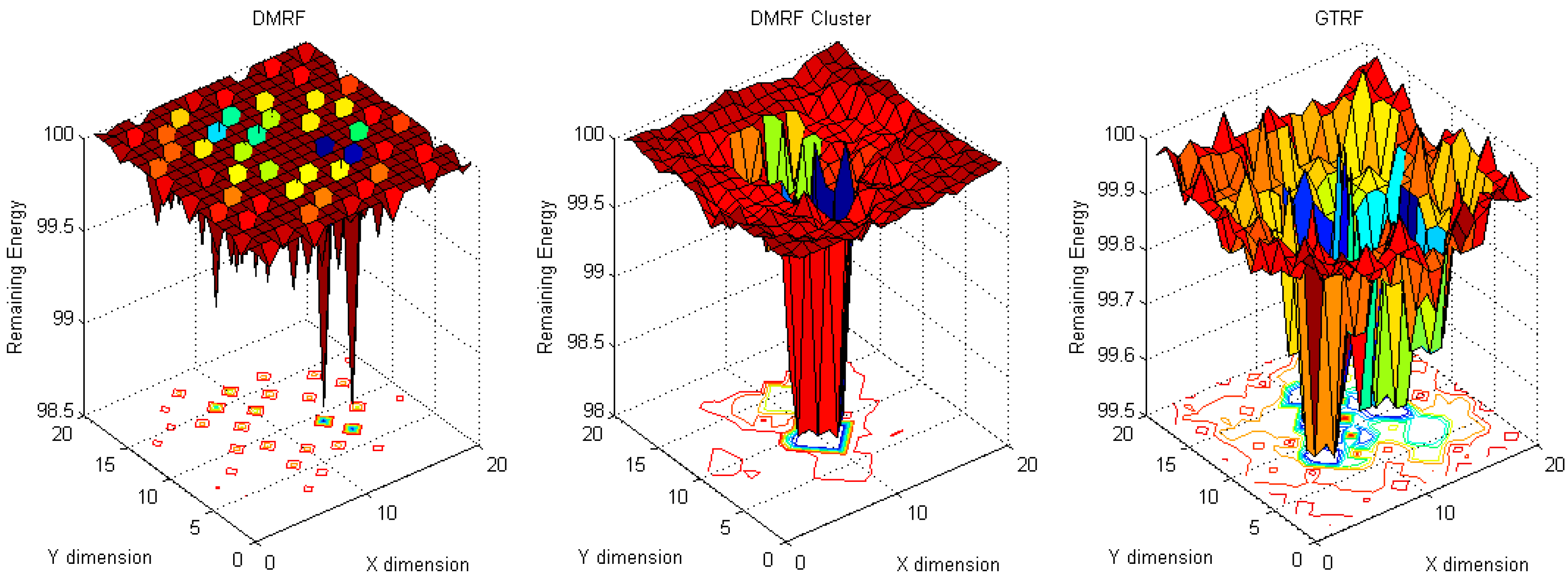
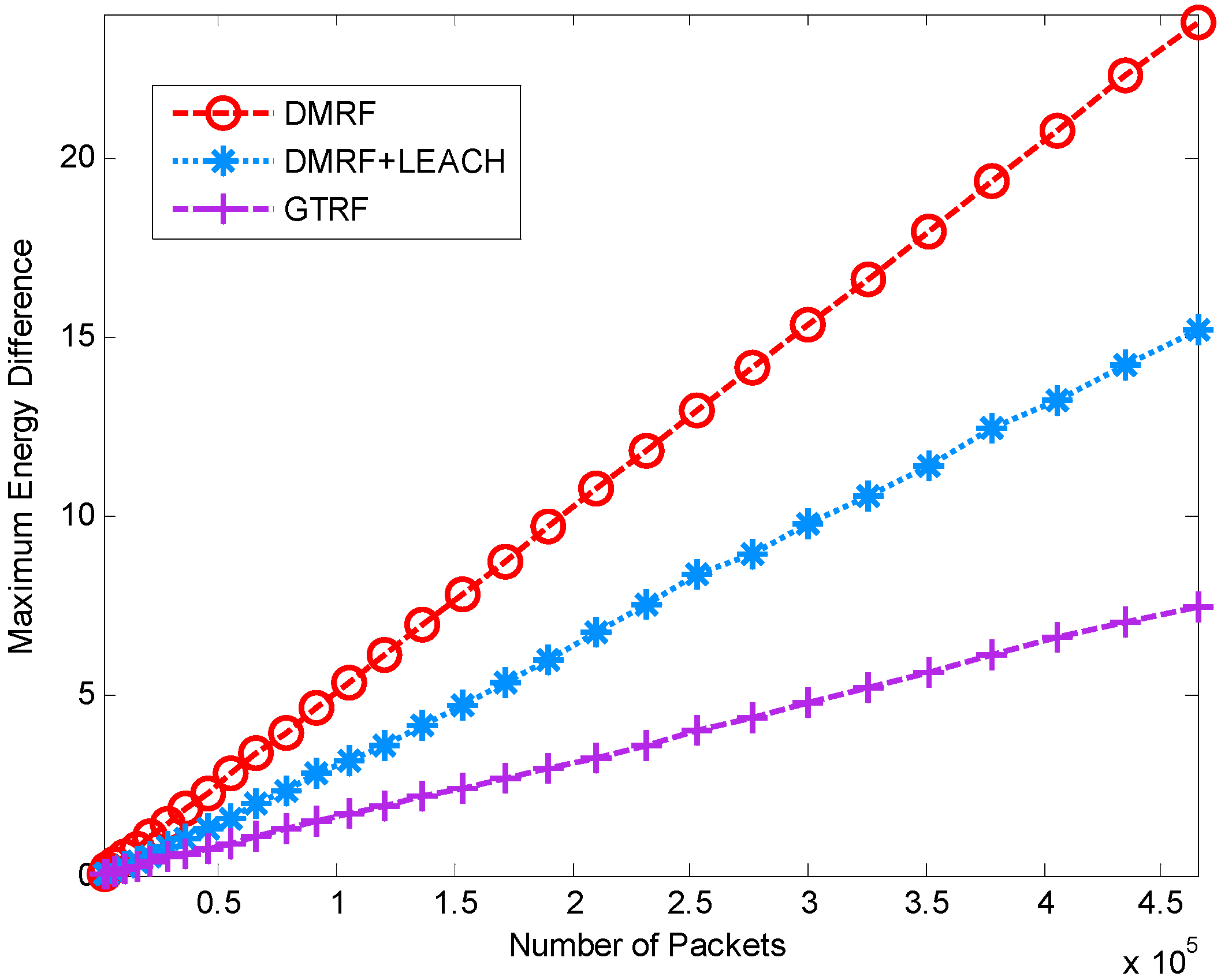
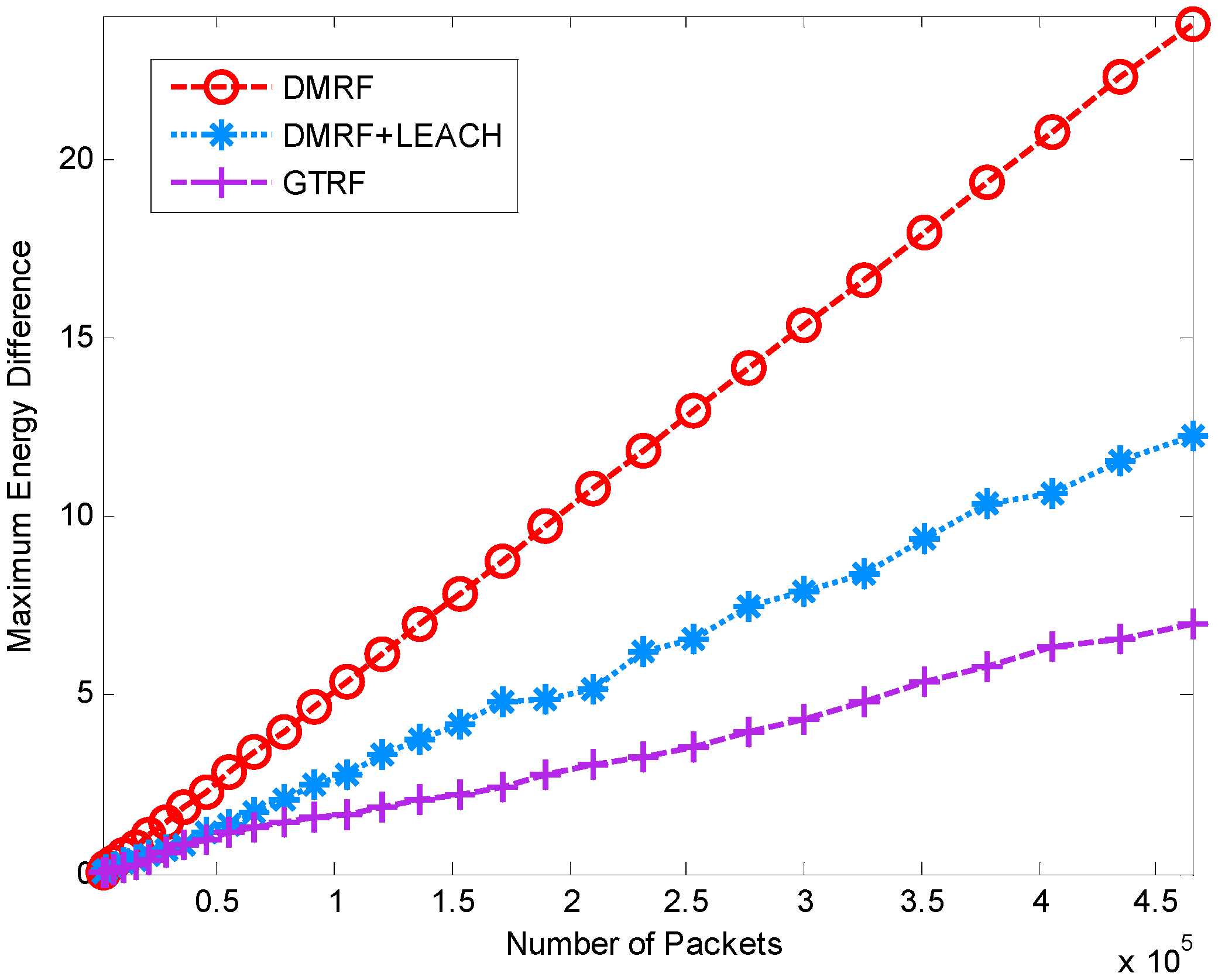
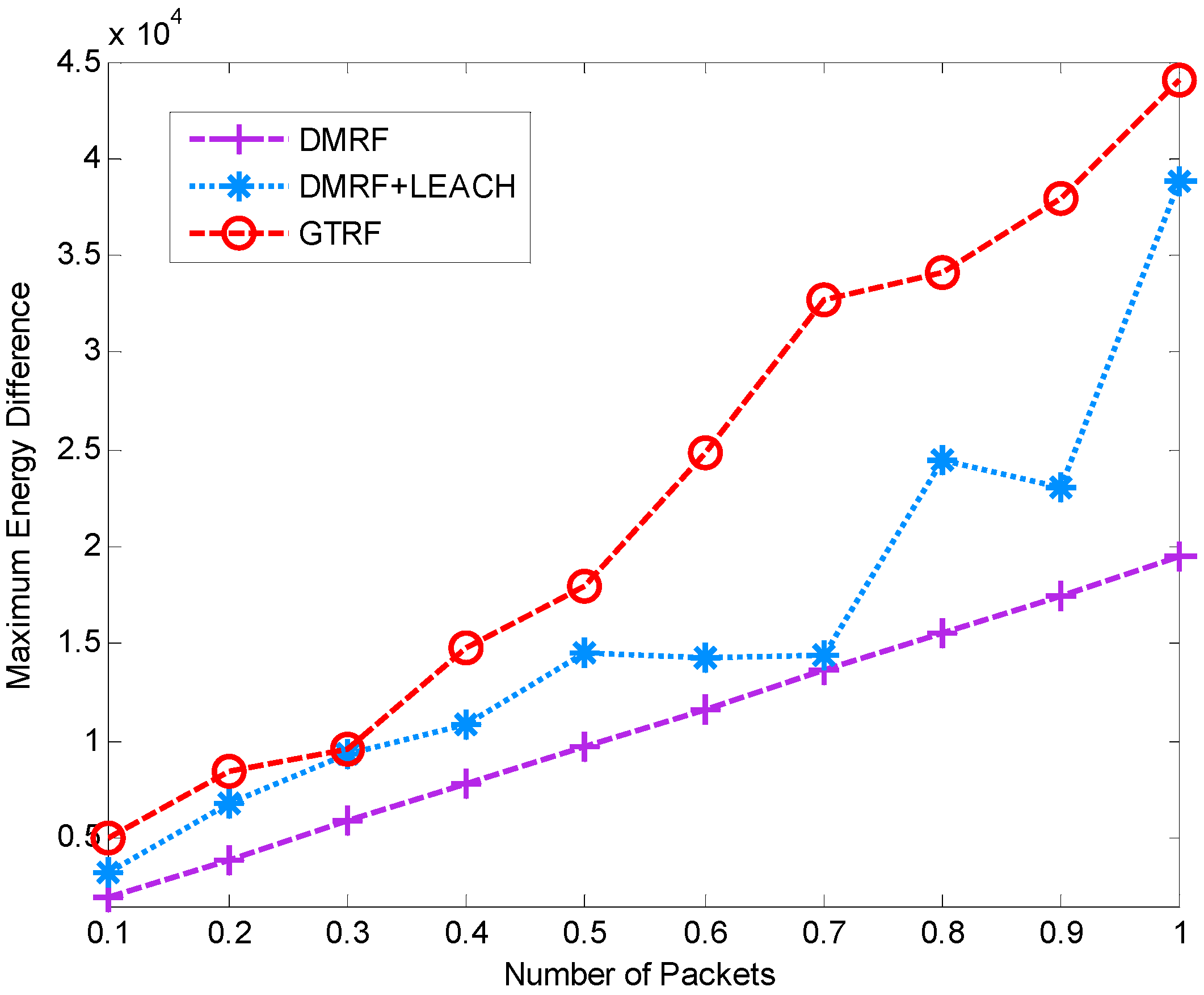
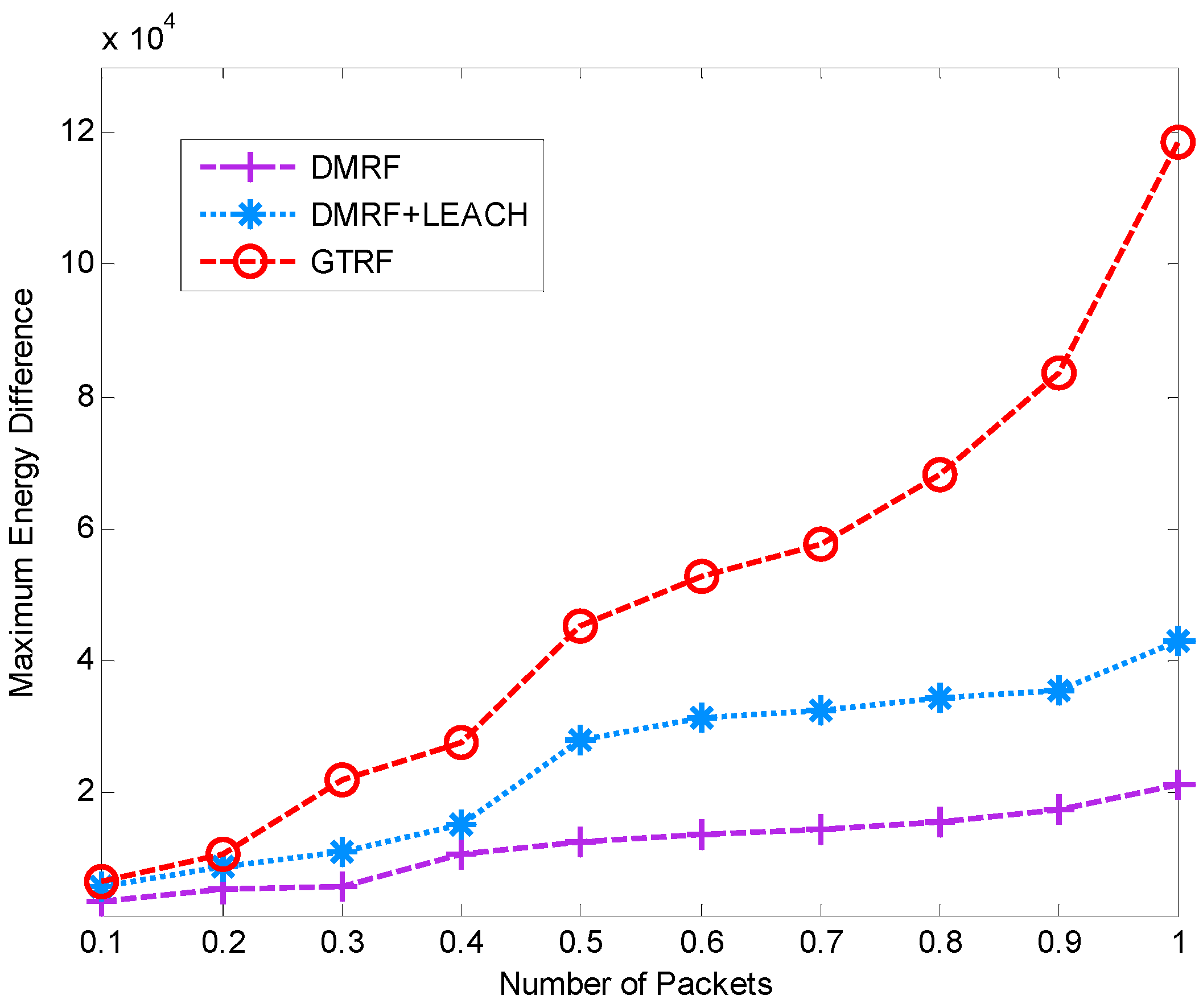
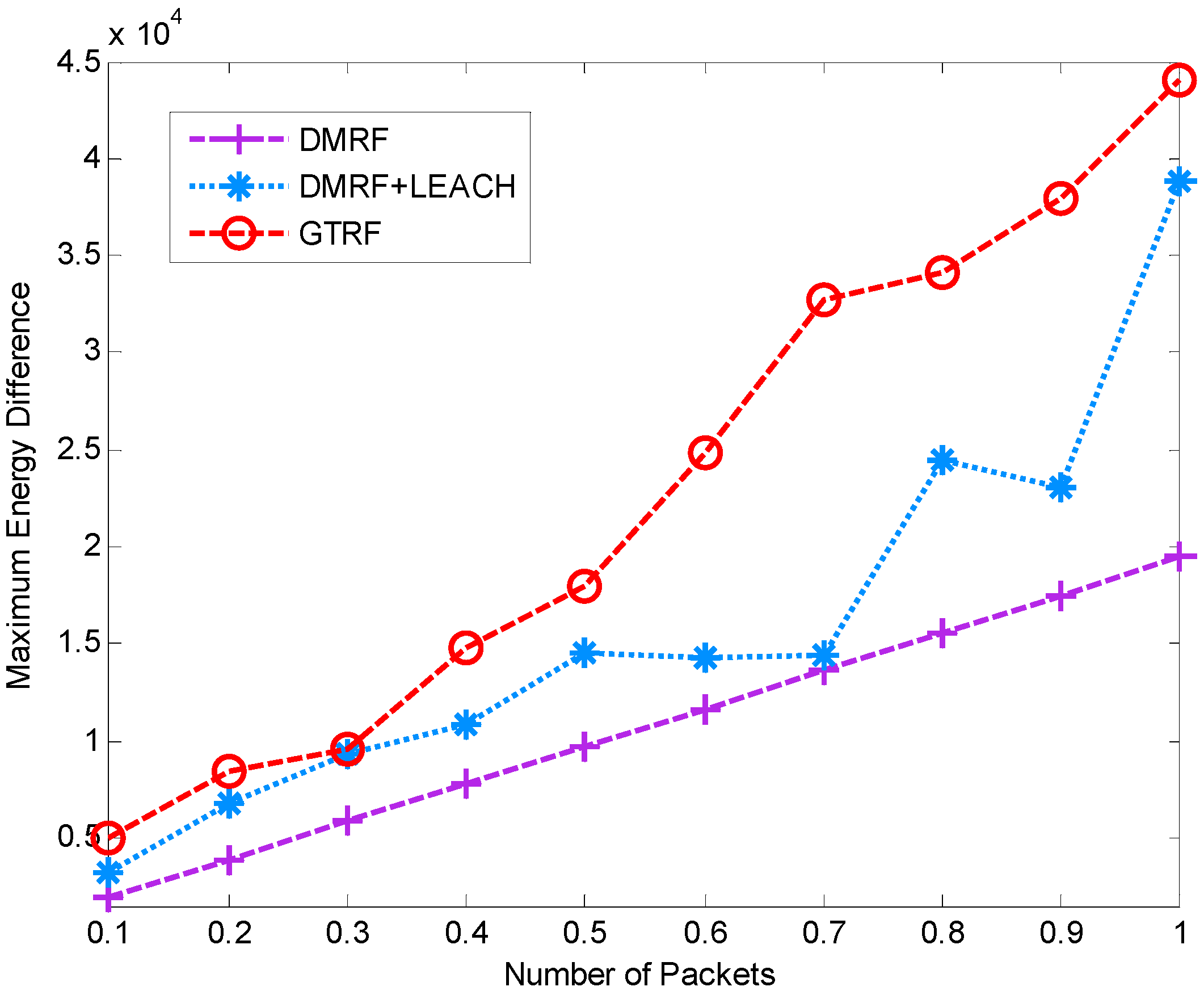
5.1.3. Energy Difference between Maximum Cost and Minimum Cost


5.2. Network Lifetime
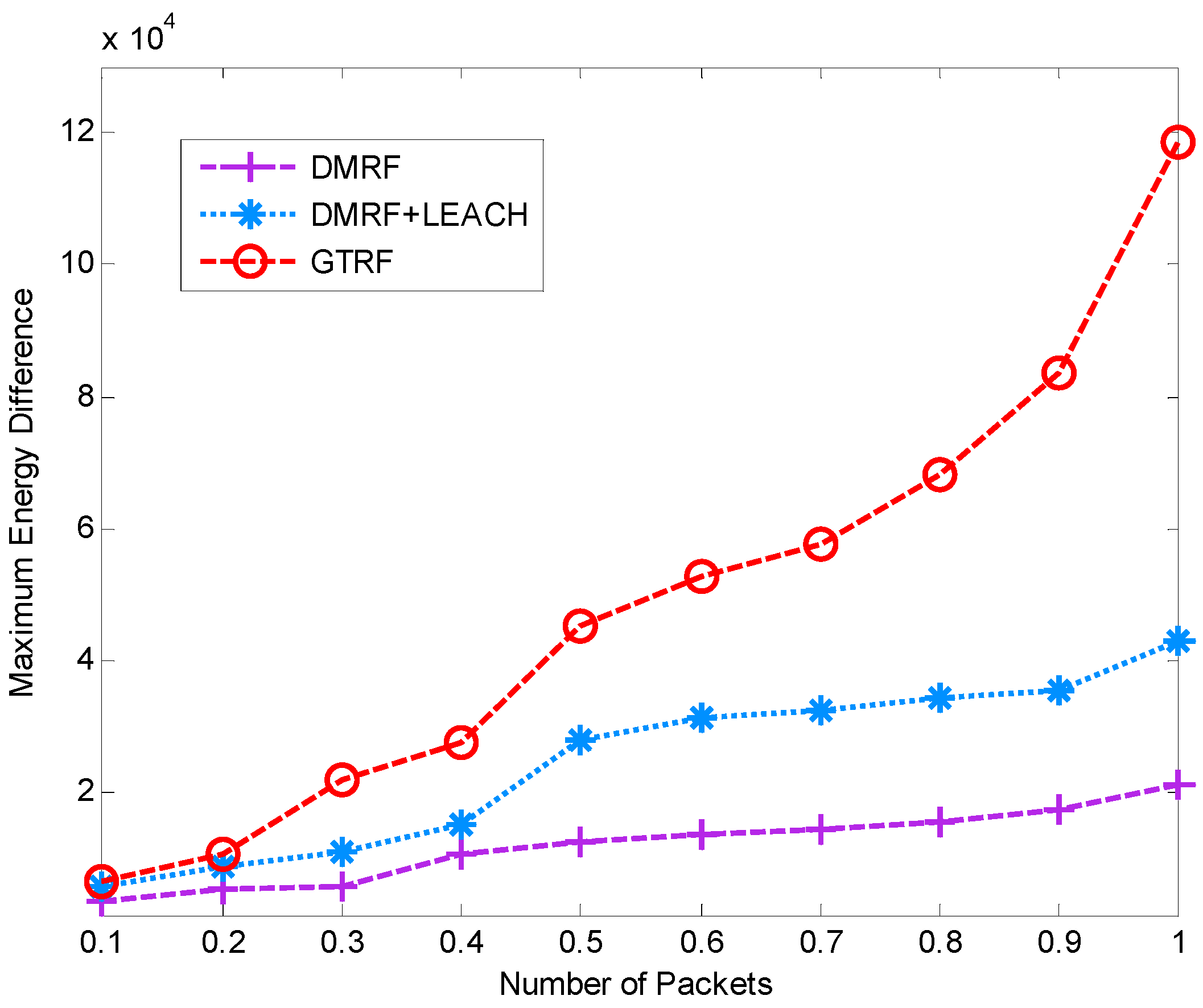
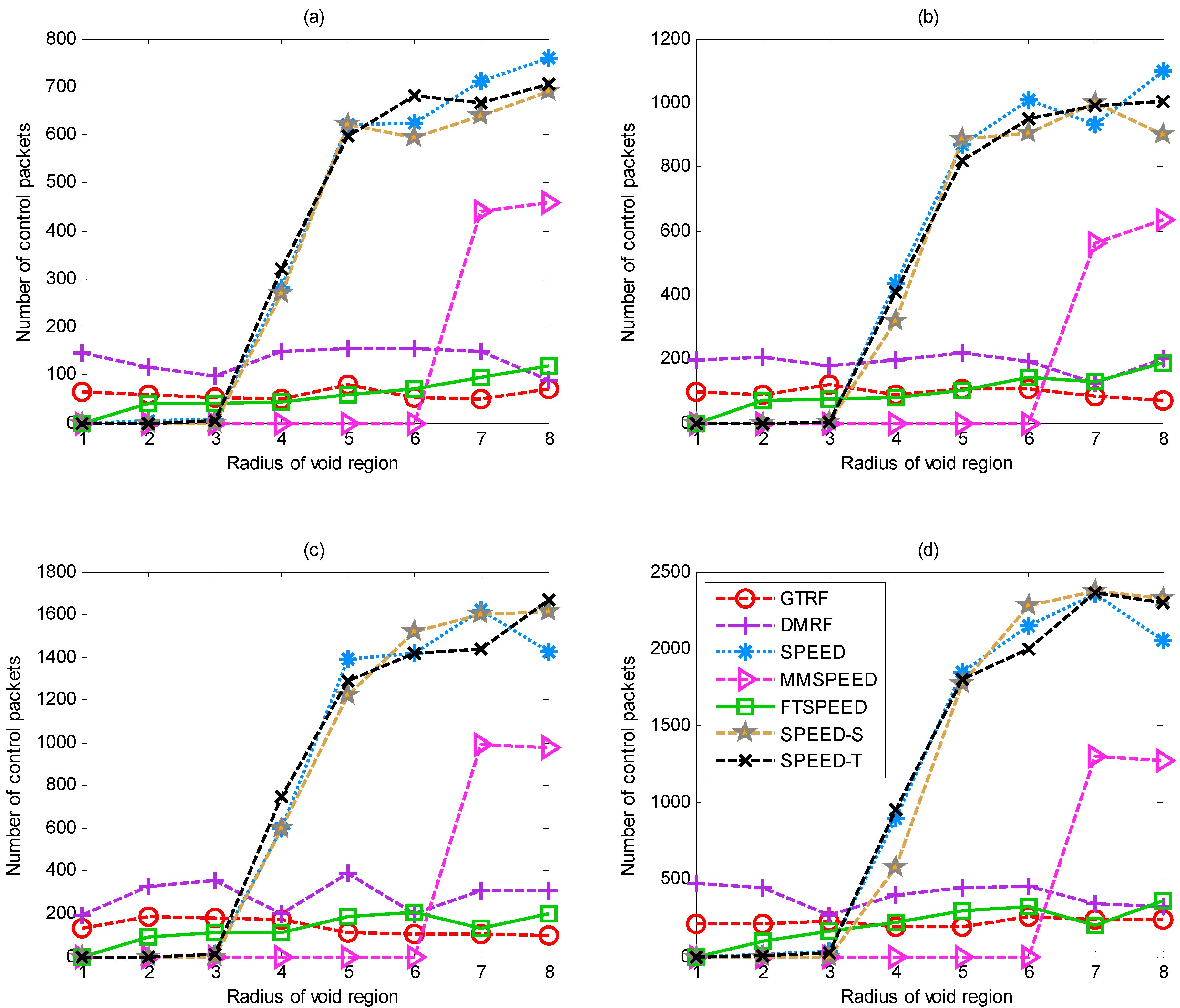
5.3. Control Packets
- (1)
- The cluster head periodically sends the control packets to check the validity of each cluster member.
- (2)
- In the forwarding process, when the void region is detected, the feedback packets will be sent to inform the upstream node that there are selfish nodes located downstream.
- (3)
- When the sink node receives the packets, it will notify the source that the packets have been successfully received by the sink.

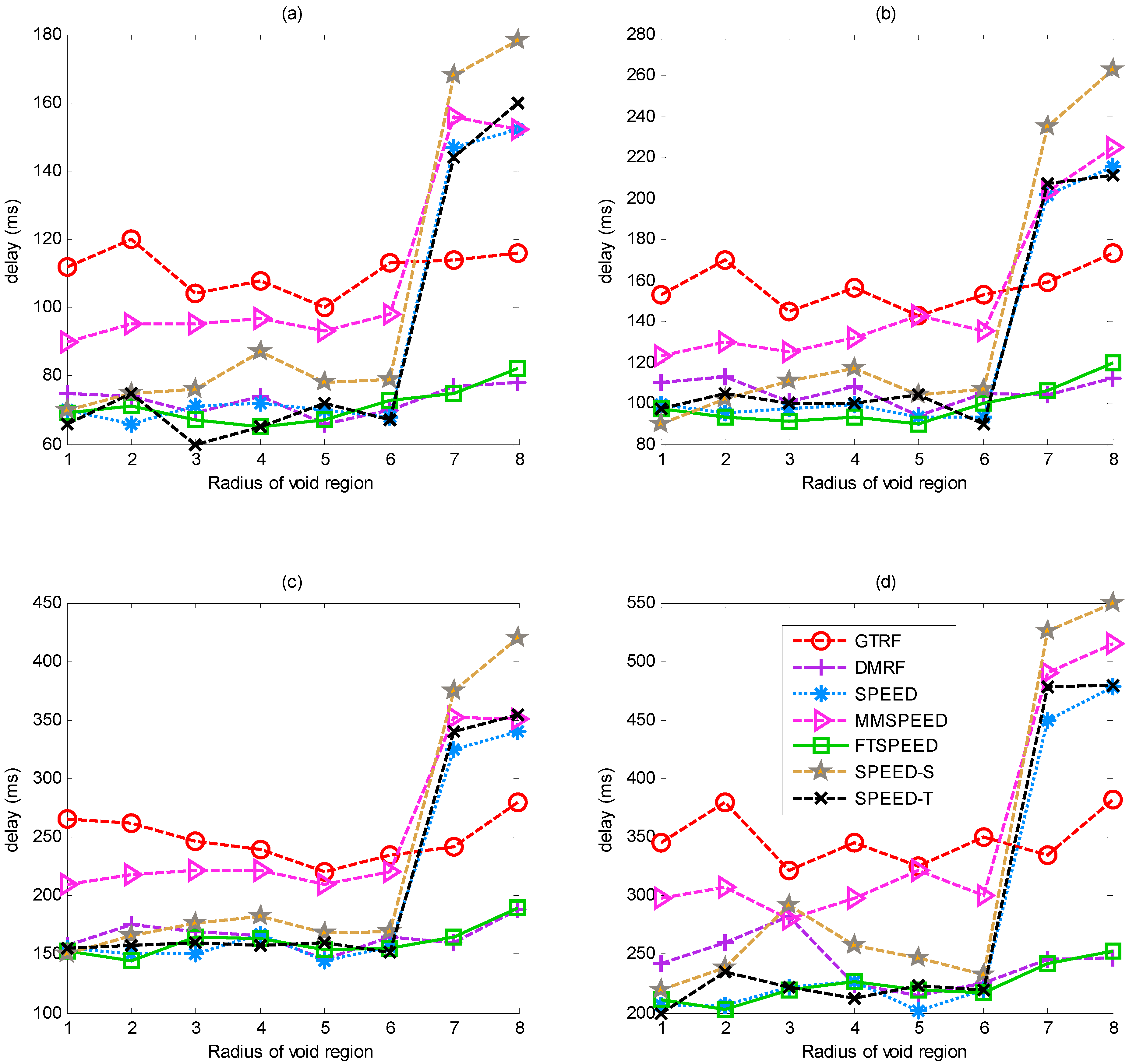
5.4. Delay of Transmission

6. Conclusions and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Akyildiz, I.F.; Melodia, T.; Chowdhury, K.R. A Survey on Wireless Multimedia Sensor Networks. Comput. Netw. 2007, 5, 921–960. [Google Scholar] [CrossRef]
- Nguyen, V.H.; Suh, Y.S. Networked Estimation with an Area-Triggered Transmission Method. Sensors 2008, 8, 897–909. [Google Scholar] [CrossRef]
- Figueiredo, C.S.M.; Nakamura, E.F.; Loureiro, A.A.F. A Hybrid Adaptive Routing Algorithm for Event-Driven Wireless Sensor Networks. Sensors 2009, 9, 7287–7307. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Liu, M.; Zhu, J.; Gong, H. A Community-Based Event Delivery Protocol in Publish/Subscribe Systems for Delay Tolerant Sensor Networks. Sensors 2009, 9, 7580–7594. [Google Scholar] [CrossRef] [PubMed]
- Kargl, F.; Klenk, A.; Schlott, S.; Weber, M. Advanced Detection of Selfish or Malicious Nodes in Ad Hoc Networks. In Proceedings of First European Workshop, ESAS 2004, Heidelberg, Germany, 6 August 2004; pp. 152–165.
- He, T.; Stankovic, J.A.; Lu, C.; Abdelzaher, T. SPEED: A Stateless Protocol for Real-Time Communication in Sensor Networks. In Proceedings of 23rd International Conference on Distributed Computing Systems, Washington, DC, USA, 19–22 May 2003; pp. 46–55.
- Li, Y.; Chen, C.S.; Song, Y.-Q.; Wang, Z.; Sun, Y. A Two-hop based Real-time Routing Protocol for Wireless Sensor Networks. In Proceedings of 7th IEEE International Workshop on Factory Communication Systems, Dresden, Germany, 21–23 May 2008; pp. 65–74.
- Felemban, E.; Lee, C.; Ekici, E. MMSPEED: Multipath Multi-SPEED Protocol for QoS Guarantee of Reliability and Timeliness in Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2006, 5, 738–754. [Google Scholar] [CrossRef]
- Zhao, L.; Kan, B.; Xu, Y.; Li, X. FT-SPEED: A Fault-Tolerant, Real-Time Routing Protocol for Wireless Sensor Networks. In Proceedings of 2007 International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 21–25 September 2007; pp. 2531–2534.
- Wu, G.; Lin, C.; Xia, F.; Yao, L.; Zhang, H.; Liu, B. Dynamical Jumping Real-Time Fault-Tolerant Routing Protocol for Wireless Sensor Networks. Sensors 2010, 10, 2416–2437. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Lin, C.; Li, Q.; Wang, J.; Jiang, X. Non-Cooperative Game Based Research on Routing Schemes for Wireless Networks. Chin. J. Comput. 2009, 32, 54–64. [Google Scholar] [CrossRef]
- Felegyhazi, M.; Hubaux, J.P.; Buttyán, L. Nash Equilibria of Packet Forwarding Strategies in Wireless Ad Hoc Networks. IEEE Trans. Mob. Comput. 2006, 5, 463–476. [Google Scholar] [CrossRef]
- Kannan, R.; Iyengar, S.S. Game-theoretic Models for Reliable Path-length and Energy-constrained Routing with Ddata Aggregation in Wireless Sensor Networks. IEEE J. Sel. Areas Commun. 2004, 22, 1141–1150. [Google Scholar] [CrossRef]
- Enrique, H.; Serrat, M.D.; Cano, J.-C.; Calafate, C.T.; Manzoni, P. Improving Selfish Node Detection in MANETs Using a Collaborative Watchdog. IEEE Commun. Lett. 2012, 16, 642–645. [Google Scholar]
- Shailender, G.; Nagpal, C.K.; Singla, C. Impact of Selfish Node Concentration in MANETs. Int. J. Wirel. Mob. Netw. 2011, 3, 29–37. [Google Scholar]
- García Villalba, L.J.; Sandoval Orozco, A.L.; Cabrera, A.T.; Barenco Abbas, C.J. Routing Protocols in Wireless Sensor Networks. Sensors 2009, 9, 8399–8421. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.-L.; Ma, Y.-W.; Lai, C.-P.; Hu, C.-C.; Huang, Y.-M. Multi-Hop Routing Mechanism for Reliable Sensor Computing. Sensors 2009, 9, 10117–10135. [Google Scholar] [CrossRef] [PubMed]
- Vehbi, C.G.; Ozgur, B.A.; Akyildiz, I.F. A Real-Time and Reliable Transport Protocol for Wireless Sensor and Aactor Networks. IEEE/ACM Trans. Netw. 2008, 16, 359–370. [Google Scholar]
- Chao, H.-L.; Chang, C.-L. A Fault-Tolerant Routing Protocol in Wireless Sensor Networks. Int. J. Sens. Netw. 2008, 3, 66–73. [Google Scholar] [CrossRef]
- Aquino, A.L.L.; Nakamura, E.F. Data Centric Sensor Stream Reduction for Real-Time Applications in Wireless Sensor Networks. Sensors 2009, 9, 9666–9688. [Google Scholar] [CrossRef] [PubMed]
- Ding, M.; Cheng, X. Fault-Tolerant Target Tracking in Sensor Networks. In Proceedings of ACM MOBIHOC 2009, New Orleans, LA, USA, 18–21 May 2009; pp. 125–134.
- Jiang, P. A New Method for Node Fault Detection in Wireless Sensor Networks. Sensors 2009, 9, 1282–1294. [Google Scholar] [CrossRef] [PubMed]
- Yim, S.-J.; Choi, Y.-H. An Adaptive Fault-Tolerant Event Detection Scheme for Wireless Sensor Networks. Sensors 2010, 10, 2332–2347. [Google Scholar] [CrossRef] [PubMed]
- Moya, J.M.; Araujo, A.; Banković, Z.; de Goyeneche, J.-M.; Vallejo, J.C.; Malagón, P.; Villanueva, D.; Fraga, D.; Romero, E.; Blesa, J. Improving Security for SCADA Sensor Networks with Reputation Systems and Self-Organizing Maps. Sensors 2009, 9, 9380–9397. [Google Scholar] [CrossRef] [PubMed]
- Seo, J.; Kim, M.; Hur, I.; Choi, W.; Choo, H. DRDT: Distributed and Reliable Data Transmission with Cooperative Nodes for LossyWireless Sensor Networks. Sensors 2010, 10, 2793–2811. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Lin, C.; Yao, L.; Liu, B. A Cluster based WSN Fault Tolerant Protocol. J. Electron. 2010, 27, 43–50. [Google Scholar] [CrossRef]
- Yu, Y.; Li, K.; Zhou, W.; Li, P. Trust Mechanisms in Wireless Sensor Nnetworks: Attack Analysis and Countermeasures. J. Netw. Comput. Appl. 2012, 35, 867–880. [Google Scholar] [CrossRef]
- Demirbas, M. Scalable of Fault-Tolerance for Wireless Sensor Networks. Ph.D. Dissertation, Ohio State University, Columbus, OH, USA, 2005. [Google Scholar]
- Heinzelman, W.; Chandrakasan, A.; Balakrishnan, H. Energy Efficient Communication Protocol for Wireless Mmicro Sensor Nnetworks. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2000; pp. 10–15.
- Buttyan, L.; Hubaux, J.-P. Security and Cooperation in Wireless Networks: Thwarting Malicious and Selfish Behavior in the Age of Ubiquitous Computing; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Lin, C.; Wu, G.; Xia, F.; Li, M.; Yao, L.; Pei, Z. Energy Efficient Ant Colony Algorithms for Data Aggregation in Wireless Sensor Networks. J. Comput. Syst. Sci. 2012, 6, 1686–1702. [Google Scholar] [CrossRef]
- Braccini, C.; Davoli, F.; Marchese, M.; Mongelli, M. Surveying Multidisciplinary Aspects in Real-Time Distributed Coding for Wireless Sensor Networks. Sensors 2015, 15, 2737–2762. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.; Wu, G.; Pirozmand, P. GTRF: A Game Theory Approach for Regulating Node Behavior in Real-Time Wireless Sensor Networks. Sensors 2015, 15, 12932-12958. https://doi.org/10.3390/s150612932
Lin C, Wu G, Pirozmand P. GTRF: A Game Theory Approach for Regulating Node Behavior in Real-Time Wireless Sensor Networks. Sensors. 2015; 15(6):12932-12958. https://doi.org/10.3390/s150612932
Chicago/Turabian StyleLin, Chi, Guowei Wu, and Poria Pirozmand. 2015. "GTRF: A Game Theory Approach for Regulating Node Behavior in Real-Time Wireless Sensor Networks" Sensors 15, no. 6: 12932-12958. https://doi.org/10.3390/s150612932