
Sensor-Aware Recognition and Tracking for Wide-Area Augmented Reality on Mobile Phones


Abstract
:1. Introduction
2. Related Work
2.1. Mobile Visual Recognition
2.2. Camera Tracking on Mobile Phone
3. Sensor-Aware Recognition and Tracking
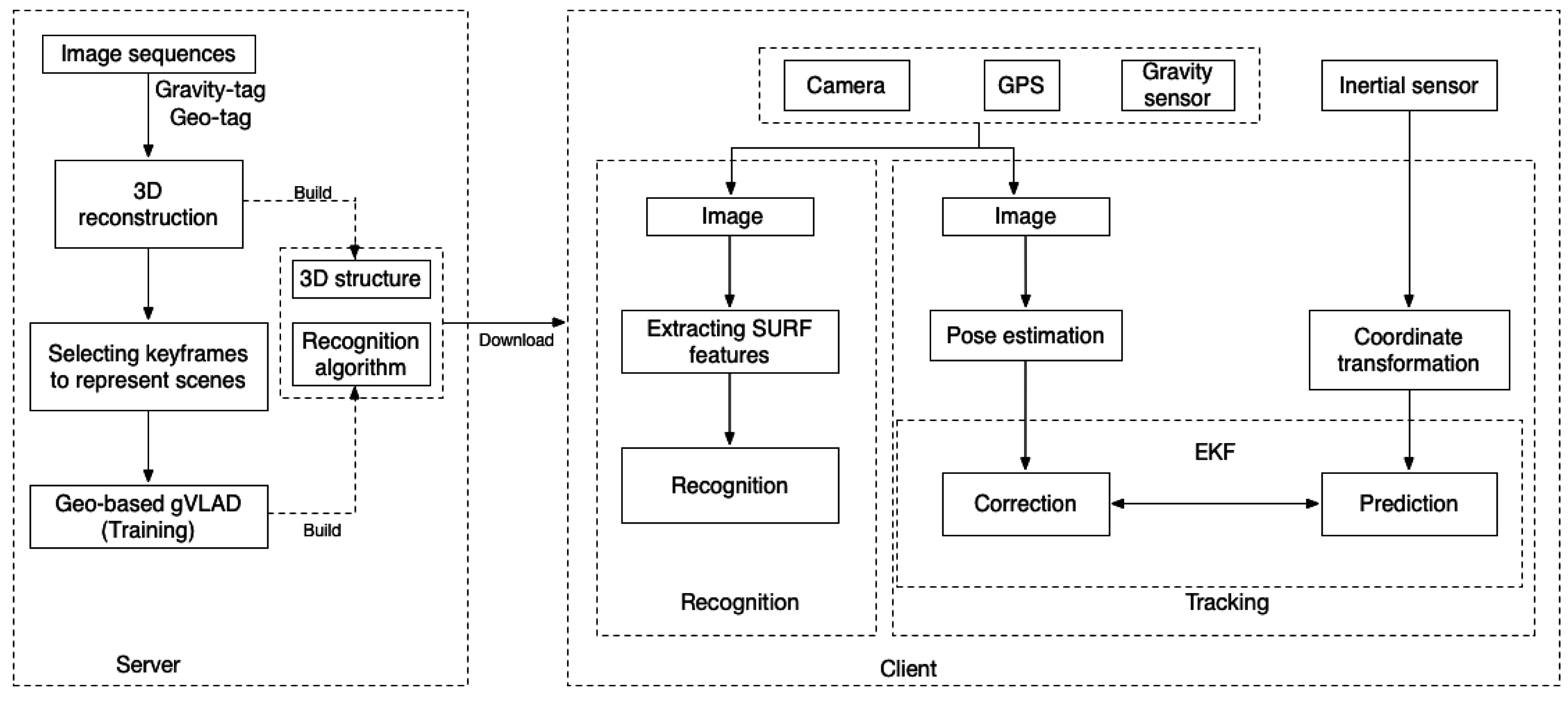
3.1. System Framework
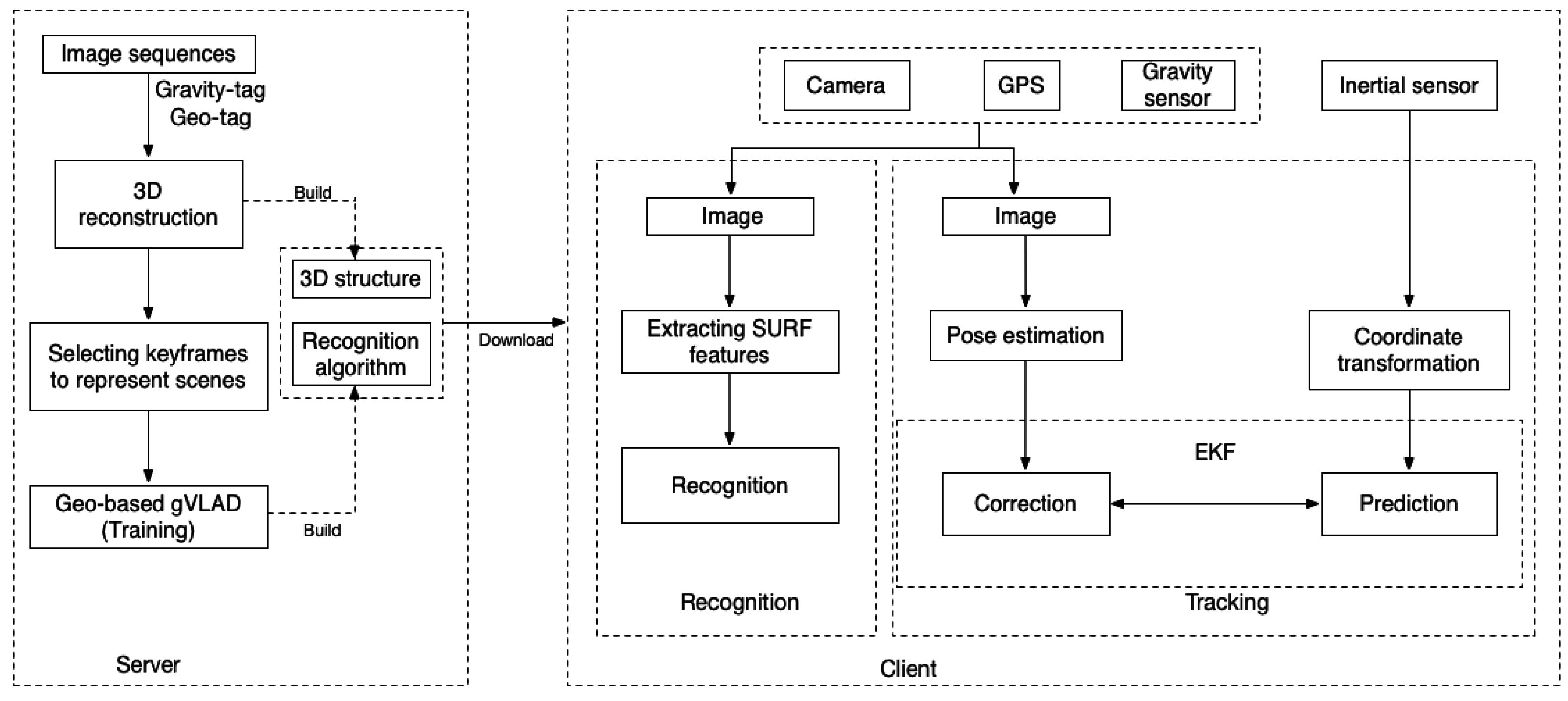
3.2. 3D Reconstruction of Scenes

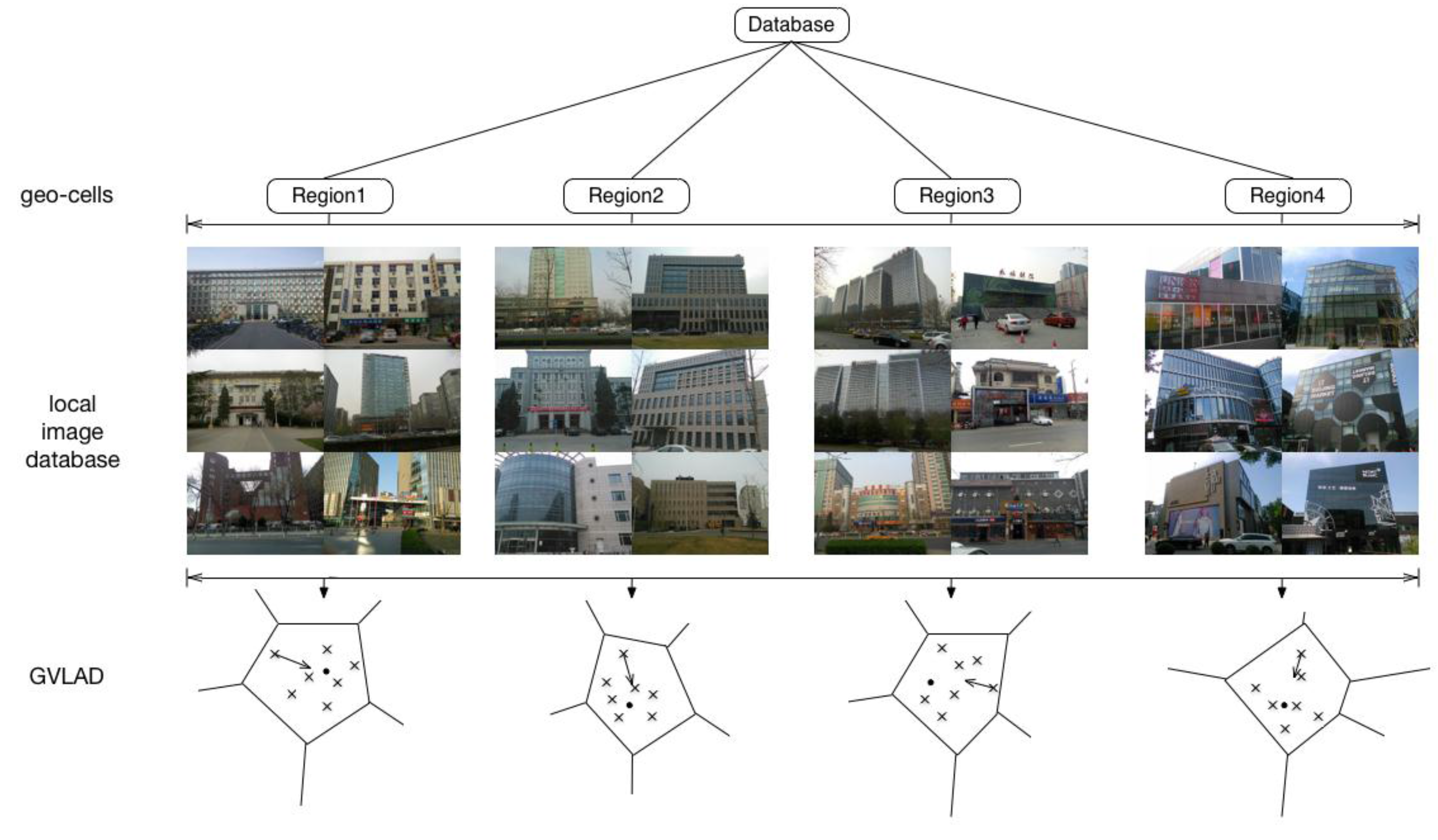
3.3. Scene Recognition Algorithm for Wide-Area Scenes
3.3.1. VLAD Algorithm
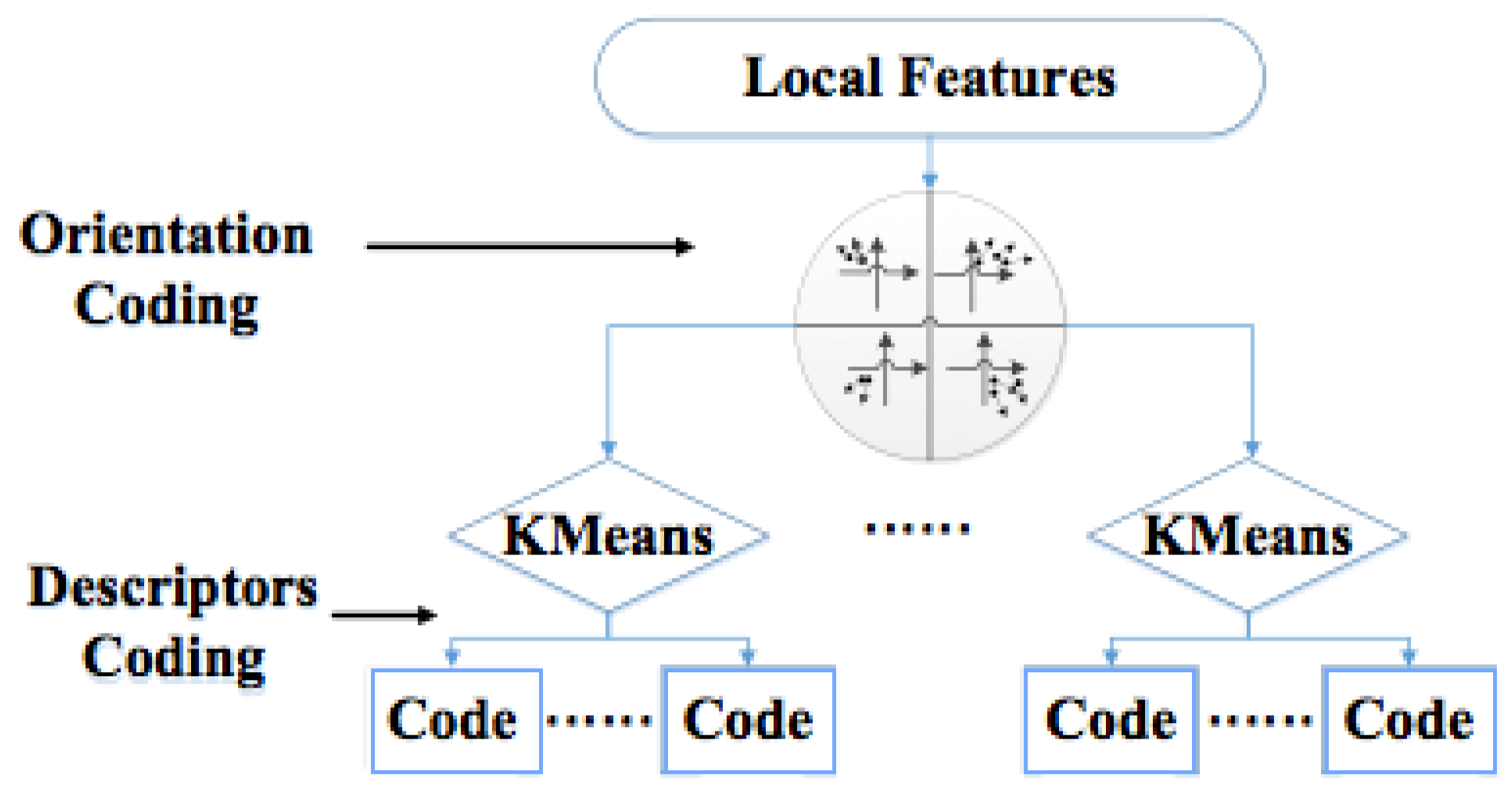
3.3.2. Gravity-Aware VLAD Algorithm
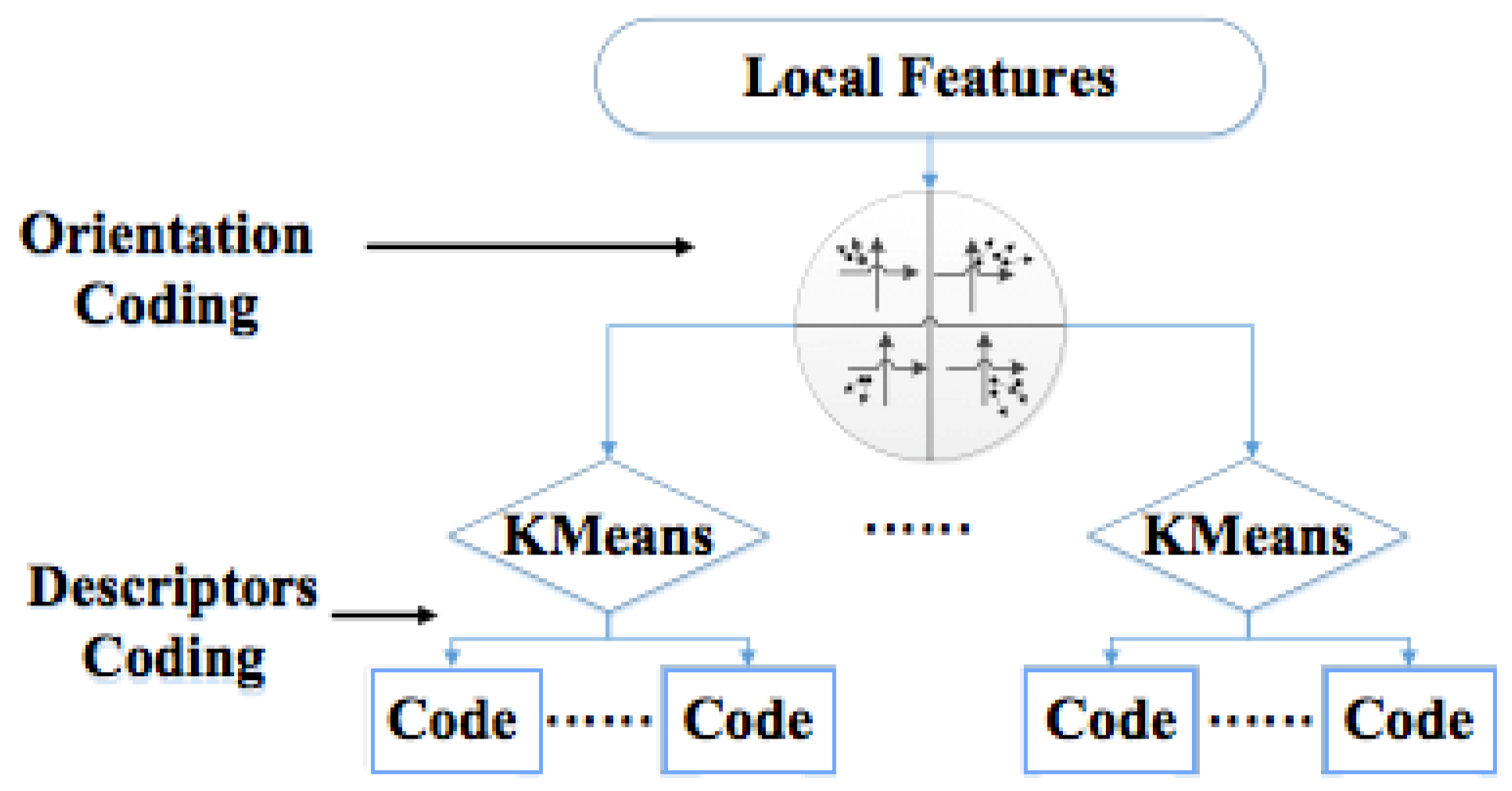
3.3.3. GPS-Aware GVLAD Algorithm

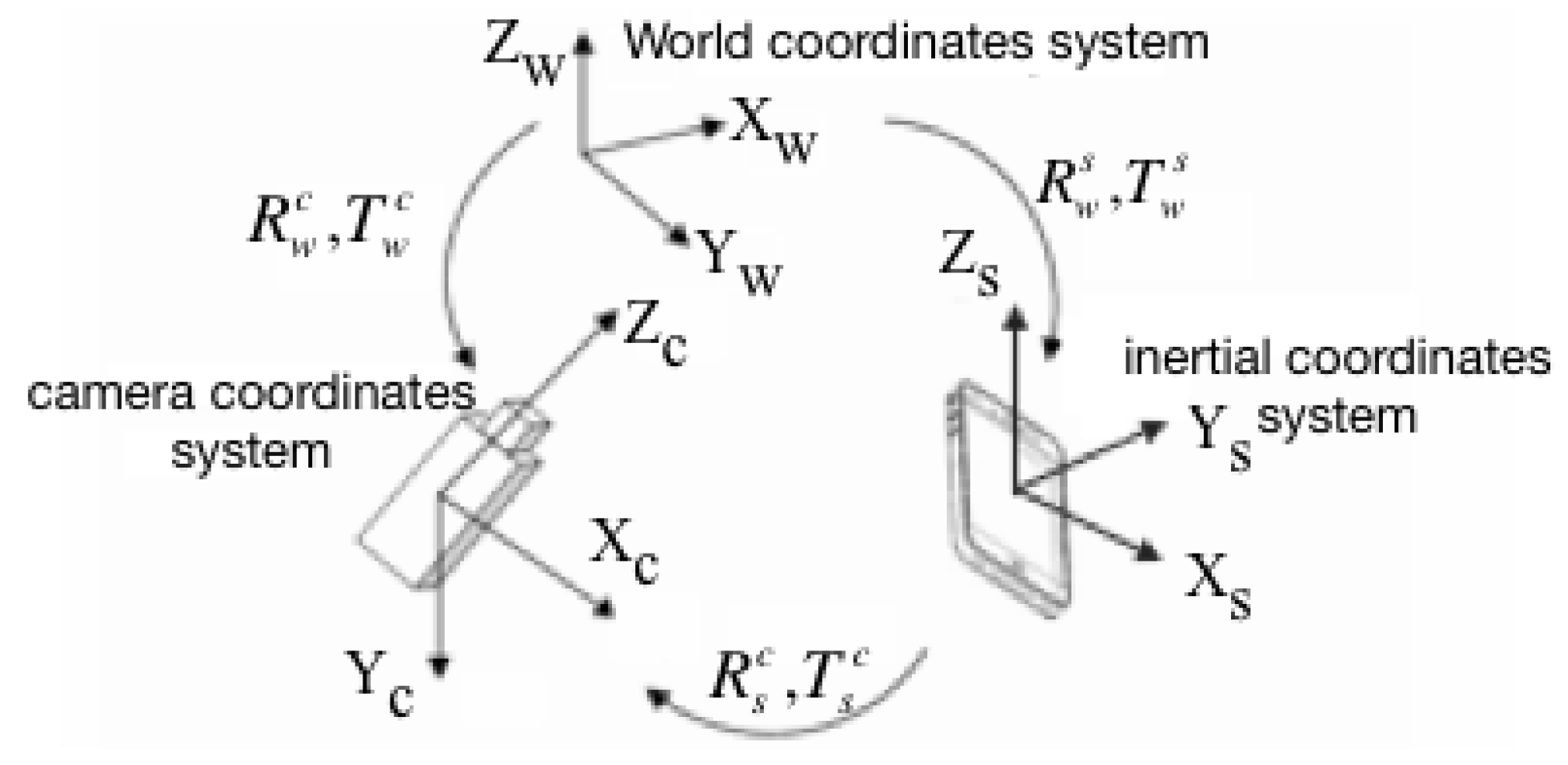
3.4. Sensor-Aware Tracking
3.4.1. Pose Estimation
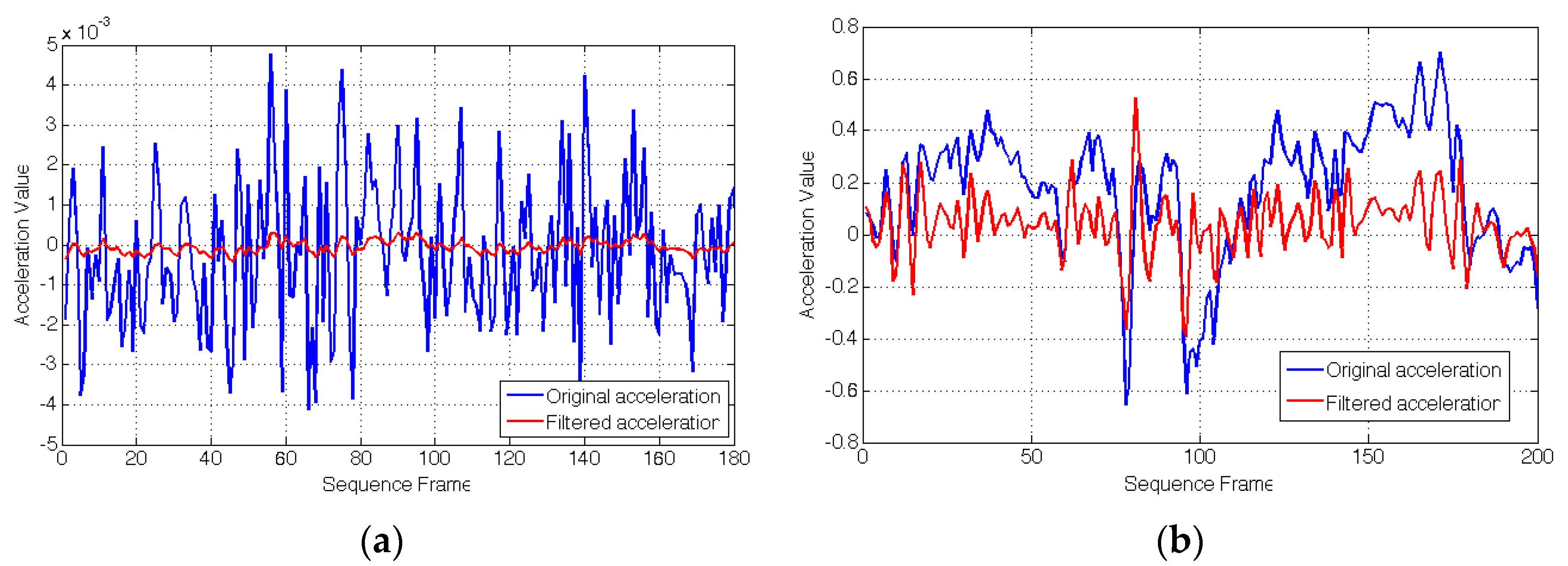
3.4.2. Sensor Fusion

Fusion Core
Failure of Vision Measurements
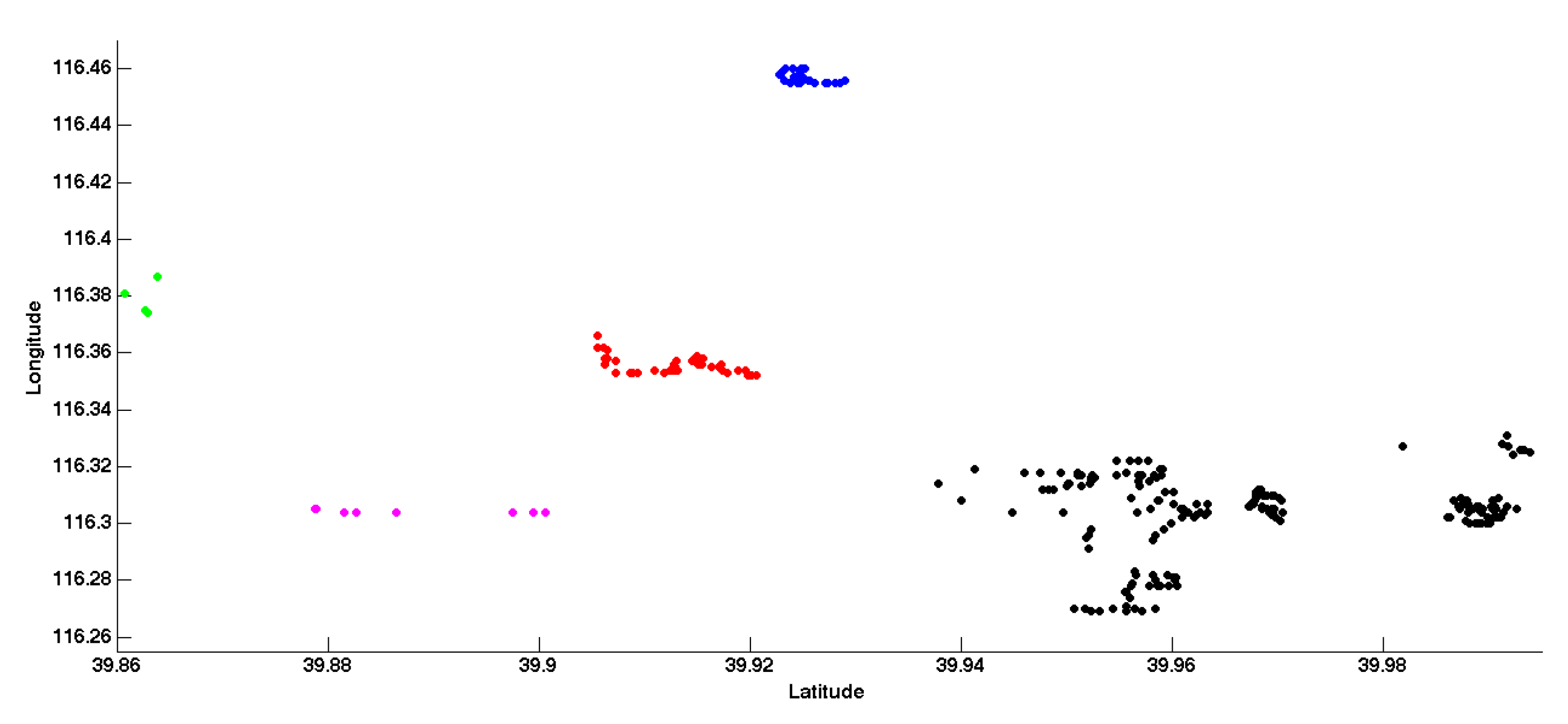
4. Experimental Results
4.1. Recognition Performance



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | K = 64 | K = 128 | K = 256 |
|---|---|---|---|
| VLAD | 0.778 | 0.794 | 0.806 |
| Geo-based VLAD | 0.814 | 0.833 | 0.847 |
| GVLAD | 0.875 | 0.893 | 0.897 |
| Geo-based GVLAD | 0.922 | 0.933 | 0.934 |

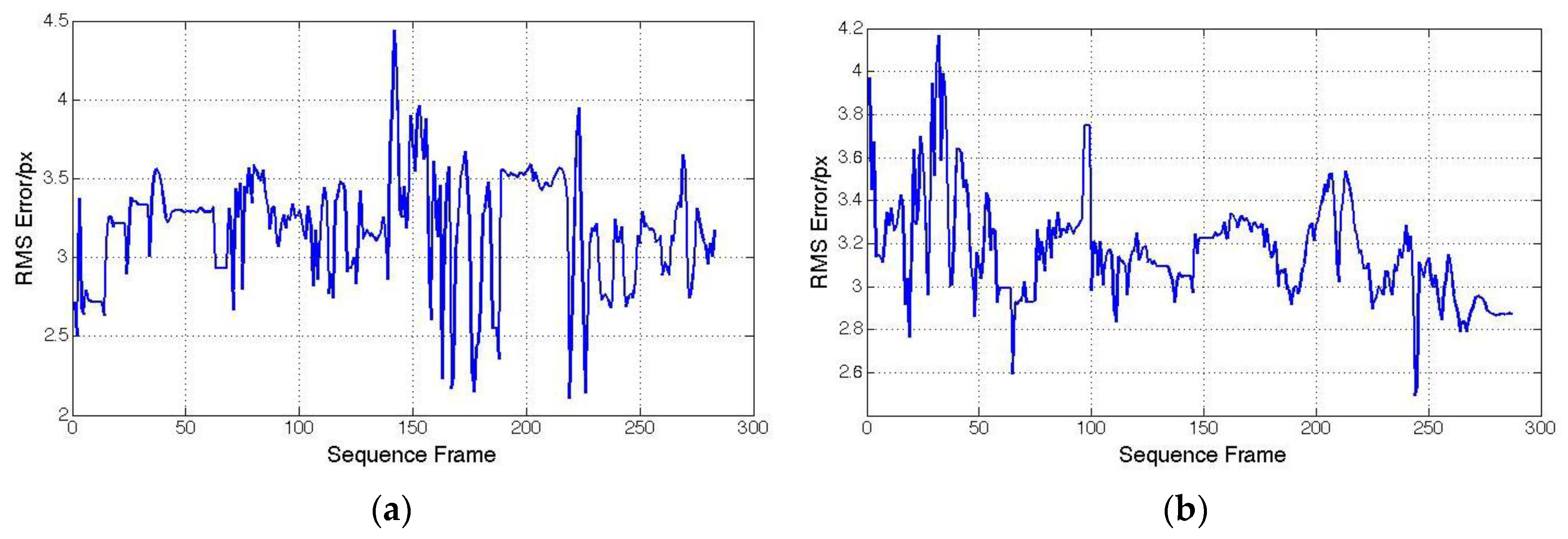
4.2. Hybrid Tracking Performance
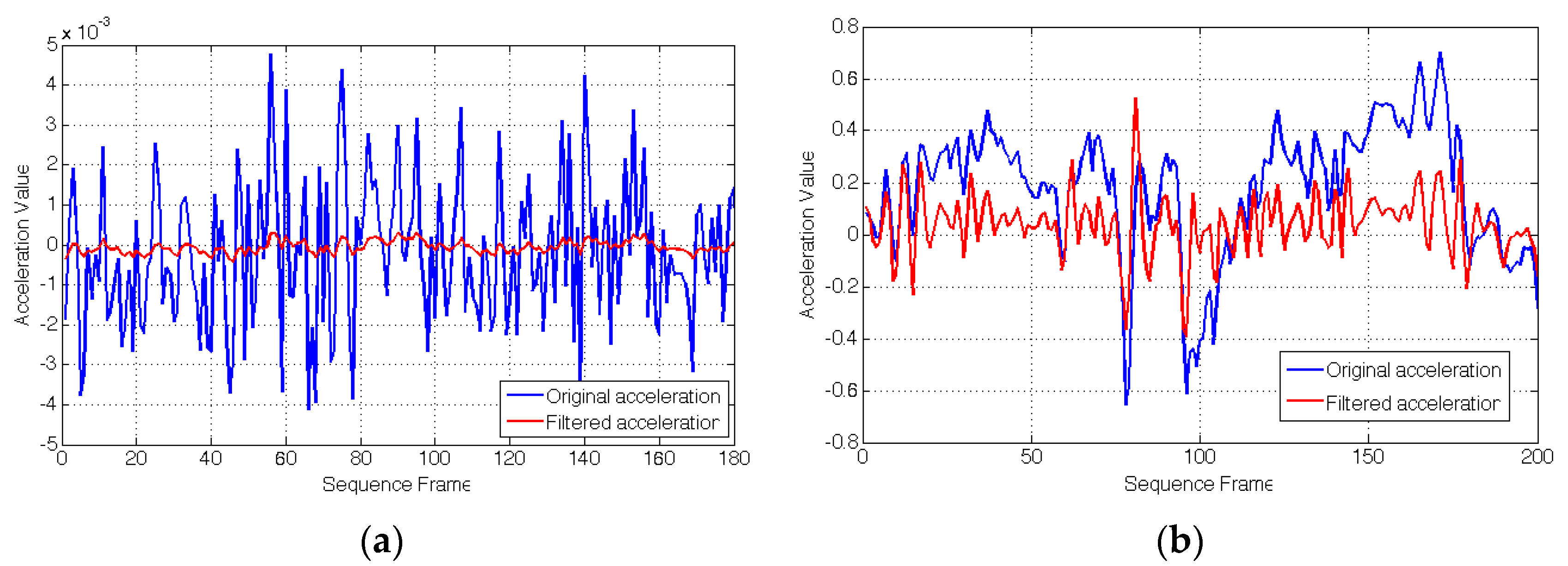
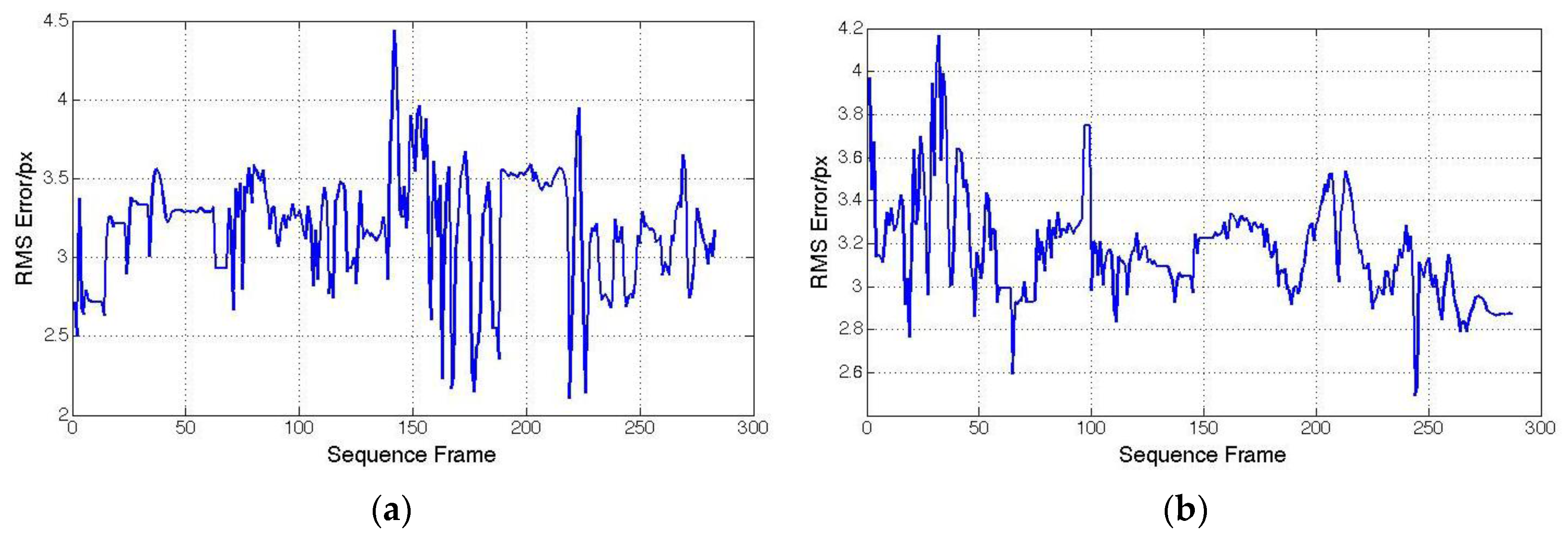


4.3. Computation Time
| Step | Time (ms) | |
|---|---|---|
| Initialization phase | Feature Extraction | 88.4 |
| Feature Matching | 3.4 | |
| Tracking phase | Optical Flow Tracking | 17.1 |
| PROSAC | 2.5 | |
| Pose Estimation | 6.4 | |
| Sensor Fusion (Prediction) | 0.5 | |
| Sensor Fusion (Correction) | 1.4 | |
| Render latency | 0.5 | |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gao, X.; Tian, J.; Liang, X.; Wang, G. ARPP: An Augmented Reality 3D ping-pong game system on Android mobile platform. In Proceedings of the 2014 23rd IEEE on Wireless and Optical Communication Conference (WOCC), Newark, NJ, USA, 9–10 May 2014; pp. 1–6.
- Choi, H.; Han, G.C.; Kim, I.J. Smart Booklet: Tour guide system with mobile augmented reality. In Proceedings of the 2014 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–13 January 2014; pp. 353–354.
- Kwik, F.; Bahana, R. Using Augmented Reality to Enhance Aetherpet, a Prototype of a Social Game. Procedia Comput. Sci. 2015, 59, 282–290. [Google Scholar] [CrossRef]
- Kourouthanassis, P.; Boletsis, C.; Bardaki, C.; Chasanidou, D. Tourists responses to mobile augmented reality travel guides: The role of emotions on adoption behavior. Perv. Mob. Comput. 2015, 18, 71–87. [Google Scholar] [CrossRef]
- Shatte, A.; Holdsworth, J.; Lee, I. Mobile augmented reality based context-aware library management system. Expert Syst. Appl. 2014, 41, 2174–2185. [Google Scholar] [CrossRef]
- Pirchheim, C.; Schmalstieg, D.; Reitmayr, G. Handling pure camera rotation in keyframe-based slam. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR’13), Adelaide, Australia, 1–4 October 2013; pp. 229–238.
- Ventura, J.; Arth, C.; Reitmayr, G.; Schmalstieg, D. Global localization from monocular SLAM on a mobile phone. IEEE Trans. Visual. Comput. Graph. 2014, 20, 531–539. [Google Scholar] [CrossRef] [PubMed]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR’07), Nara, Japan, 13–16 November 2007; pp. 225–234.
- Wagner, D.; Reitmayr, G.; Mulloni, A.; Drummond, T.; Schmalstieg, D. Real-time detection and tracking for augmented reality on mobile phones. IEEE Trans. Visual. Comput. Graph. 2010, 16, 355–368. [Google Scholar] [CrossRef] [PubMed]
- Wagner, D.; Mulloni, A.; Langlotz, T.; Schmalstieg, D. Real-time panoramic mapping and tracking on mobile phones. In Proceedings of the Virtual Reality Conference (VR), Waltham, MA, USA, 20–24 March 2010; pp. 211–218.
- Yeh, T.; Tollmar, K.; Darrell, T. Searching the web with mobile images for location recognition. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; Volume 2.
- Park, D.J.; Kim, C. A Hybrid Bags-of-Feature model for Sports Scene Classification. J. Signal Process. Syst. 2015, 81, 249–263. [Google Scholar] [CrossRef]
- Kawano, Y.; Yanai, K. Foodcam: A real-time food recognition system on a smartphone. Multimed. Tools Appl. 2015, 74, 5263–5287. [Google Scholar] [CrossRef]
- Liu, B.; Liu, J.; Lu, H. Learning representative and discriminative image representation by deep appearance and spatial coding. Comput. Vision Image Underst. 2015, 136, 23–31. [Google Scholar] [CrossRef]
- Chen, D.M.; Tsai, S.S.; Chandrasekhar, V.; Takacs, G.; Singh, J.; Girod, B. Tree histogram coding for mobile image matching. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 30 March–1 April 2009; pp. 143–152.
- Chen, D.M.; Tsai, S.S.; Chandrasekhar, V.; Takacs, G.; Vedantham, R.; Grzeszczuk, R.; Girod, B. Inverted Index Compression for Scalable Image Matching. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 24–26 March 2010; p. 525.
- Perronnin, F.; Liu, Y.; Sánchez, J.; Poirier, H. Large-scale image retrieval with compressed fisher vectors. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3384–3391.
- Jégou, H.; Perronnin, F.; Douze, M.; Sánchez, J.; Pérez, P.; Schmid, C. Aggregating local image descriptors into compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1704–1716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, D.; Tsai, S.; Chandrasekhar, V.; Takacs, G.; Vedantham, R.; Grzeszczuk, R.; Girod, B. Residual enhanced visual vector as a compact signature for mobile visual search. Signal Process. 2013, 93, 2316–2327. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2.
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Guan, T.; He, Y.; Gao, J.; Yang, J. On-device mobile visual location recognition by integrating vision and inertial sensors. IEEE Trans. Multimed. 2013, 15, 1688–1699. [Google Scholar] [CrossRef]
- Zhao, W.L.; Jégou, H.; Gravier, G. Oriented pooling for dense and non-dense rotation-invariant features. In Proceedings of the British Machine Vision Conference, Bristol, UK, 11–14 September 2013.
- Wang, Z.; Di, W.; Bhardwaj, A.; Jagadeesh, V.; Piramuthu, R. Geometric VLAD for large scale image search. 2014; arXiv:1403.3829. [Google Scholar]
- Layar. Available online: https://www.layar.com/ (accessed on 2 December 2015).
- Junaio. Available online: http://www.junaio.com/ (accessed on 2 December 2015).
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2320–2327.
- Prisacariu, V.A.; Kahler, O.; Murray, D.W.; Reid, I.D. Real-Time 3D Tracking and Reconstruction on Mobile Phones. IEEE Trans. Visual. Comput. Graph. 2015, 21, 557–570. [Google Scholar] [CrossRef] [PubMed]
- Wei, B.; Guan, T.; Duan, L.; Yu, J.; Mao, T. Wide area localization and tracking on camera phones for mobile augmented reality systems. Multimed. Syst. 2014, 21, 388–399. [Google Scholar] [CrossRef]
- AR Ivaders. Available online: http://invaders.soulbit7.com/ (accessed on 3 December 2015).
- AR Defender. Available online: https://itunes.apple.com/cn/app/ar-defender-2/id559729773?mt=8 (accessed on 3 December 2015).
- Reitmayr, G.; Drummond, T.W. Going out: Robust model-based tracking for outdoor augmented reality. In Proceedings of the IEEE/ACM International Symposium on Mixed and Augmented Reality (ISMAR 2006), Santa Barbara, CA, USA, 22–25 October 2006; pp. 109–118.
- Oskiper, T.; Samarasekera, S.; Kumar, R. Multi-sensor navigation algorithm using monocular camera, IMU and GPS for large scale augmented reality. In Proceedings of the 2012 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Atlanta, GA, USA, 5–8 November 2012; pp. 71–80.
- Erdem, A.T.; Ercan, A.O. Fusing Inertial Sensor Data in an Extended Kalman Filter for 3D Camera Tracking. IEEE Trans. Image Process. 2015, 24, 538–548. [Google Scholar] [CrossRef] [PubMed]
- Hilsenbeck, S.; Moller, A.; Huitl, R.; Schroth, G.; Kranz, M.; Steinbach, E. Scale-preserving long-term visual odometry for indoor navigation. In Proceedings of the 2012 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sydney, Australia, 13–15 November 2012; pp. 1–10.
- Kundra, L.; Ekler, P.; Charaf, H. Improving orientation estimation in mobiles with built-in camera. In Proceedings of the 2013 IEEE 4th International Conference on Cognitive Infocommunications (CogInfoCom), Budapest, Hungary, 2–5 December 2013; pp. 765–770.
- Hartmann, G.; Huang, F.; Klette, R. Landmark Initialization for Unscented Kalman Filter Sensor Fusion in Monocular Camera Localization. Int. J. Fuzzy Logic Intell. Syst. 2013, 13, 1–10. [Google Scholar] [CrossRef]
- Li, M.; Kim, B.H.; Mourikis, A. Real-time motion tracking on a cellphone using inertial sensing and a rolling-shutter camera. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 4712–4719.
- Dong, Z.; Zhang, G.; Jia, J.; Bao, H. Keyframe-based real-time camera tracking. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 8–12 September 2009; pp. 1538–1545.
- Horn, B.K.P. Closed-form solution of absolute orientation using unit quaternions. J. Opt. Soc. Am. 1987, 4, 629–642. [Google Scholar] [CrossRef]
- Zhang, Z. Flexible camera calibration by viewing a plane from unknown orientations. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 1, pp. 666–673.
- Bleser, G. Towards visual-inertial slam for mobile augmented reality. Ph.D. Thesis, Technical University Kaiserslautern, Kaiserslautern, Germany, May 2009. [Google Scholar]
- Our database. Available online: http://pan.baidu.com/s/1nt1hv8t (accessed on 9 December 2015).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Cao, R.; Wang, Y. Sensor-Aware Recognition and Tracking for Wide-Area Augmented Reality on Mobile Phones. Sensors 2015, 15, 31092-31107. https://doi.org/10.3390/s151229847
Chen J, Cao R, Wang Y. Sensor-Aware Recognition and Tracking for Wide-Area Augmented Reality on Mobile Phones. Sensors. 2015; 15(12):31092-31107. https://doi.org/10.3390/s151229847
Chicago/Turabian StyleChen, Jing, Ruochen Cao, and Yongtian Wang. 2015. "Sensor-Aware Recognition and Tracking for Wide-Area Augmented Reality on Mobile Phones" Sensors 15, no. 12: 31092-31107. https://doi.org/10.3390/s151229847