
Maximizing Information Diffusion in the Cyber-physical Integrated Network †

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
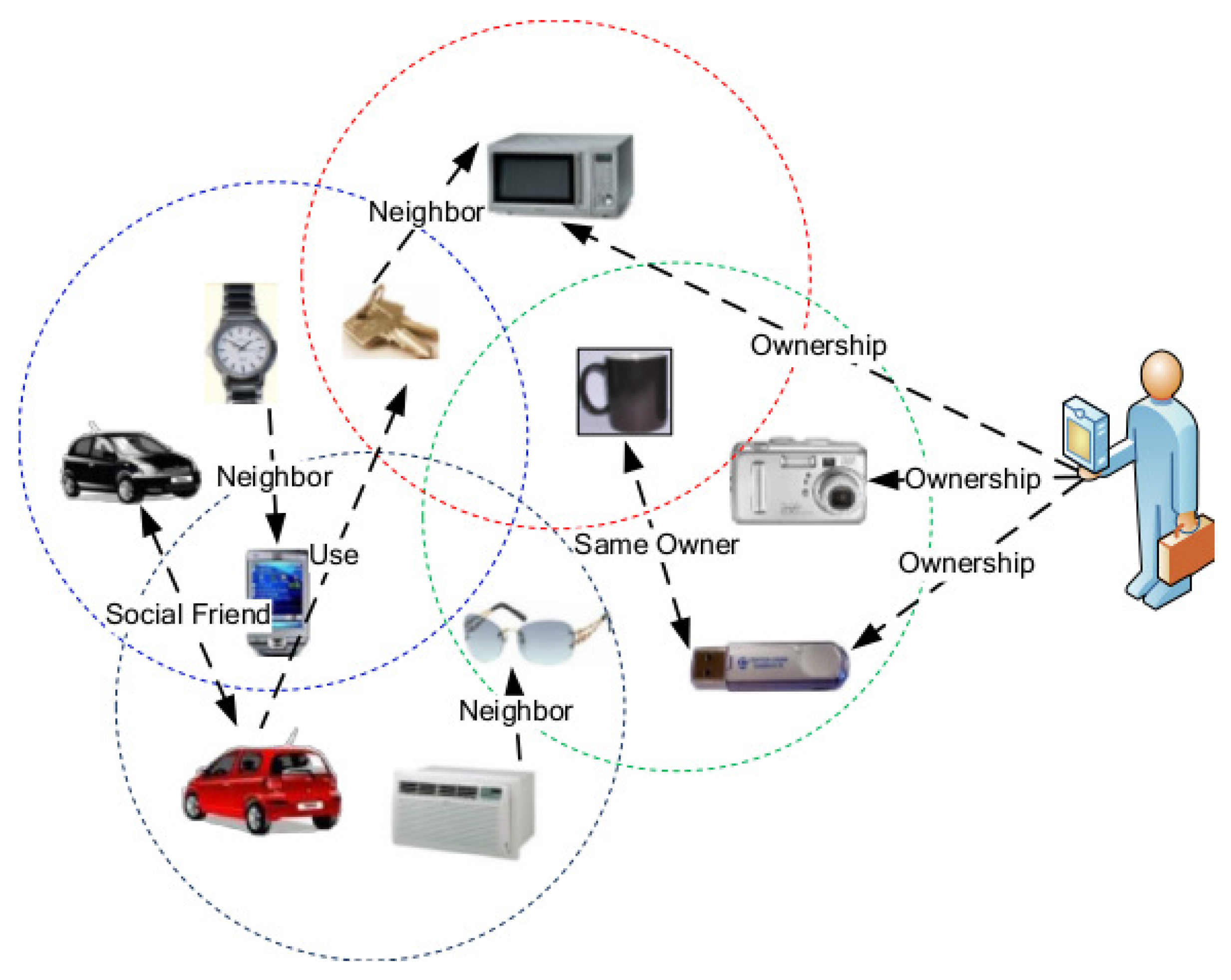
- To the best of our knowledge, this is the first work to investigate the problem of probabilistic information diffusion in the cyber-physical integrated network.
- We proposed a distributed algorithm that can maximize the information diffusion probability.
- We conducted extensive simulations to validate the effectiveness of the proposed algorithm.
2. System Model and Problem Formulation
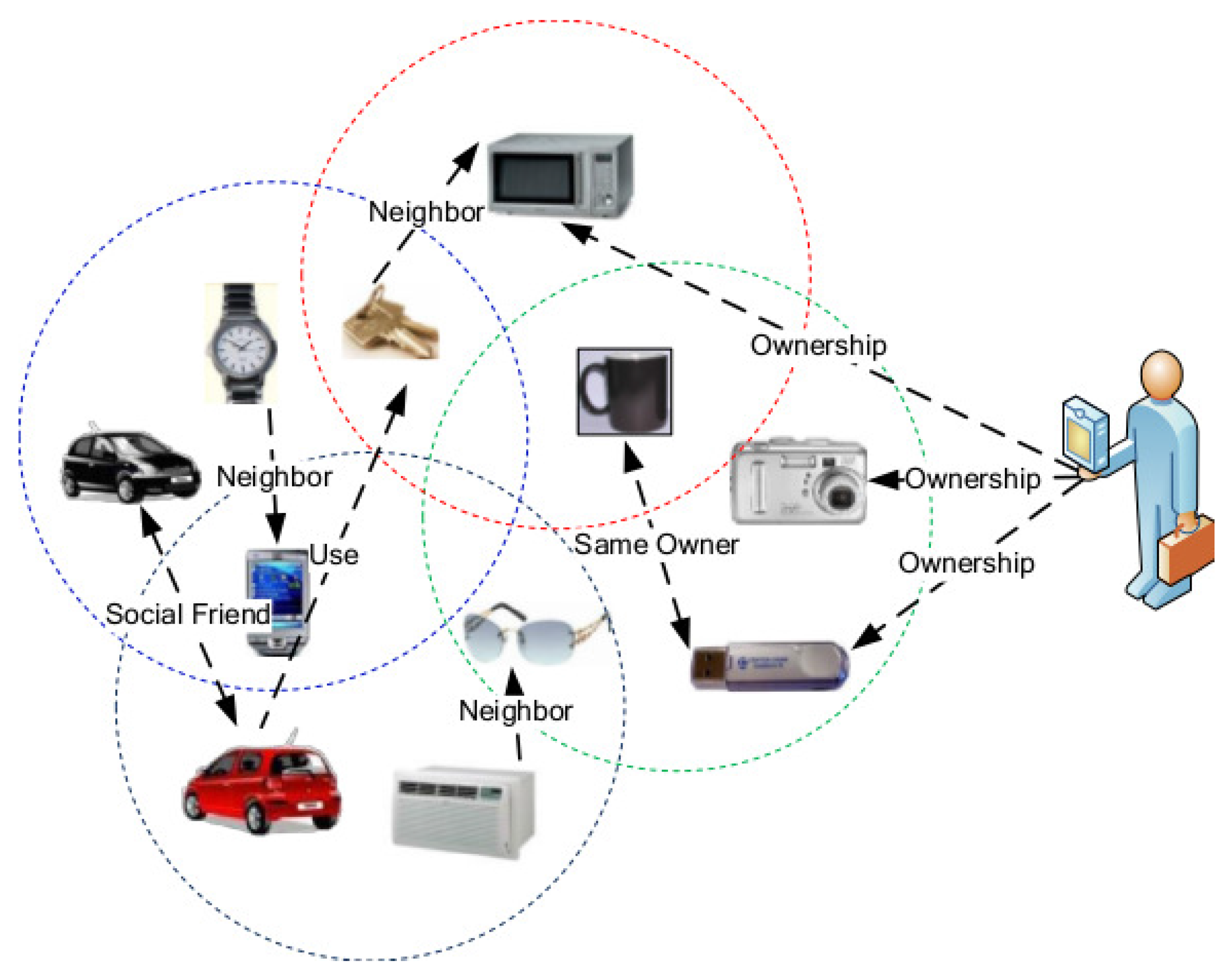
2.1. Integrated Network Model
- u and v enter the data transmission range of each other during the time period.
- u and v communicate with each other during the time period.
2.2. Problem Formulation
- the size of S is minimized, min{|S|}.
- the probability for information diffusion is maximized, max{Prob(S)}
3. Algorithm Design and Analysis
3.1. Distributed MPID Algorithm
- a dominator and its neighbors can be dominated by one of its dominator neighbors, then the dominator can be pruned.
- a dominator and its neighbors can be dominated by a set of its dominator neighbors, then the dominator can be pruned.
| Algorithm 1 DMPID algorithm. | |
| Require: Each node knows information of its neighbor and two-hop neighbor. | |
| Ensure: A node knows the probabilities of the links to which it is attached. | |
| 1: | Initially, node v is marked as the dominatee. |
| 2: | For node v, u and w are two of its neighbors |
| 3: | if eu,w does not exist then |
| 4: | the role of v is changed to be the dominator and marked as blue. |
| 5: | if node v is a dominator (has been marked as blue) then |
| 6: | For each v’s neighbor u, that DA(u) ≥ DA(v) |
| 7: | if {u} can dominate N[v], and DA({u}, N[v]) ≥ DA({v}, N(v)) then |
| 8: | v is changed to be potential dominator, and marked as green |
| 9: | For nodes {u1, …, uk} ⊂ N(v), and DA(ui) ≥ DA(v), i = 1, …, k |
| 10: | if Set S = {u1, …, uk} can dominate N[v], and DA(S, N[v]) ≥ DA({v}, N(v)) then |
| 11: | v is changed to be the potential dominator and marked as green |
| 12: | if node v is a potential dominator (has been marked as green) then |
| 13: | For each v’s neighbor u that is a dominatee |
| 14: | if a dominator w ∈ N(v), w ∈ N(u) and Pro(v, u|w) > γ then |
| 15: | v is changed to be the dominator and marked as blue |
| 16: | u is changed to be the dominator and marked as blue |
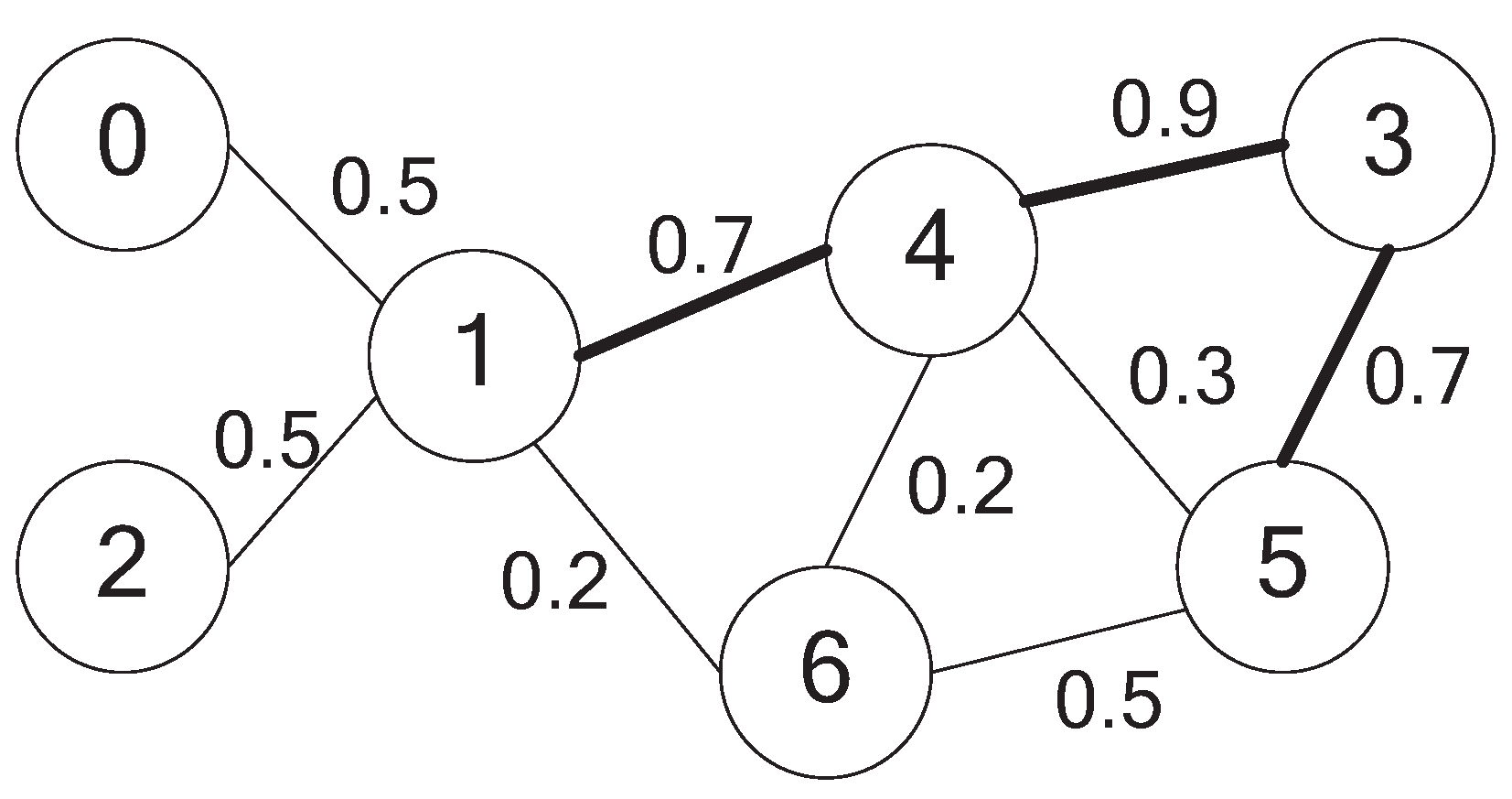
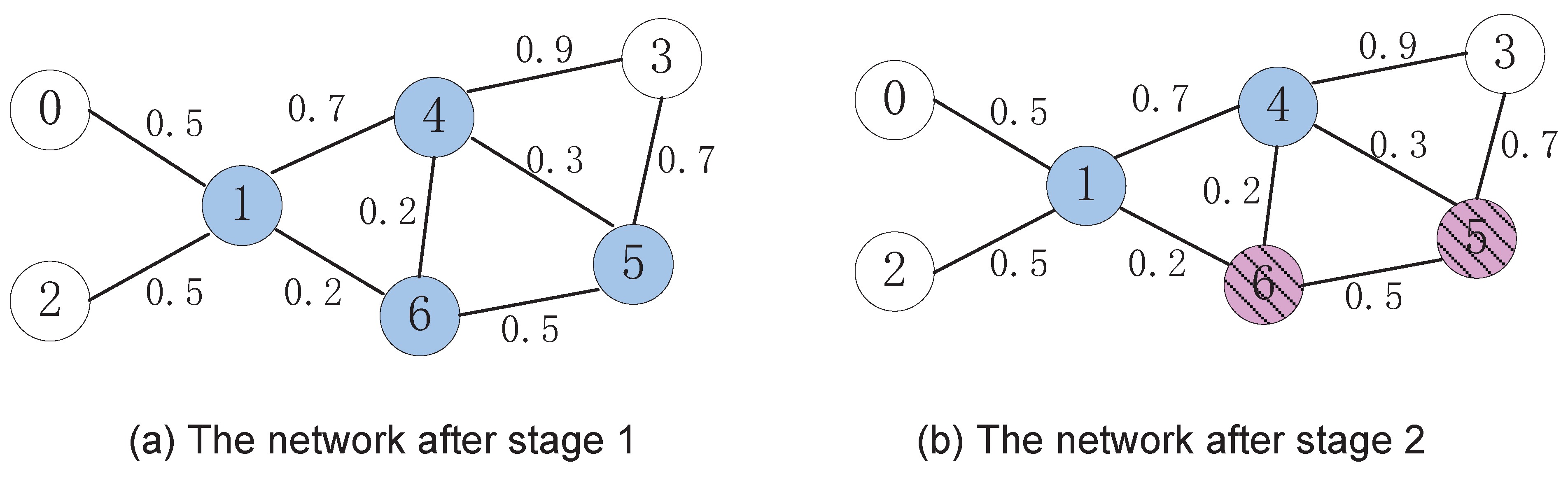
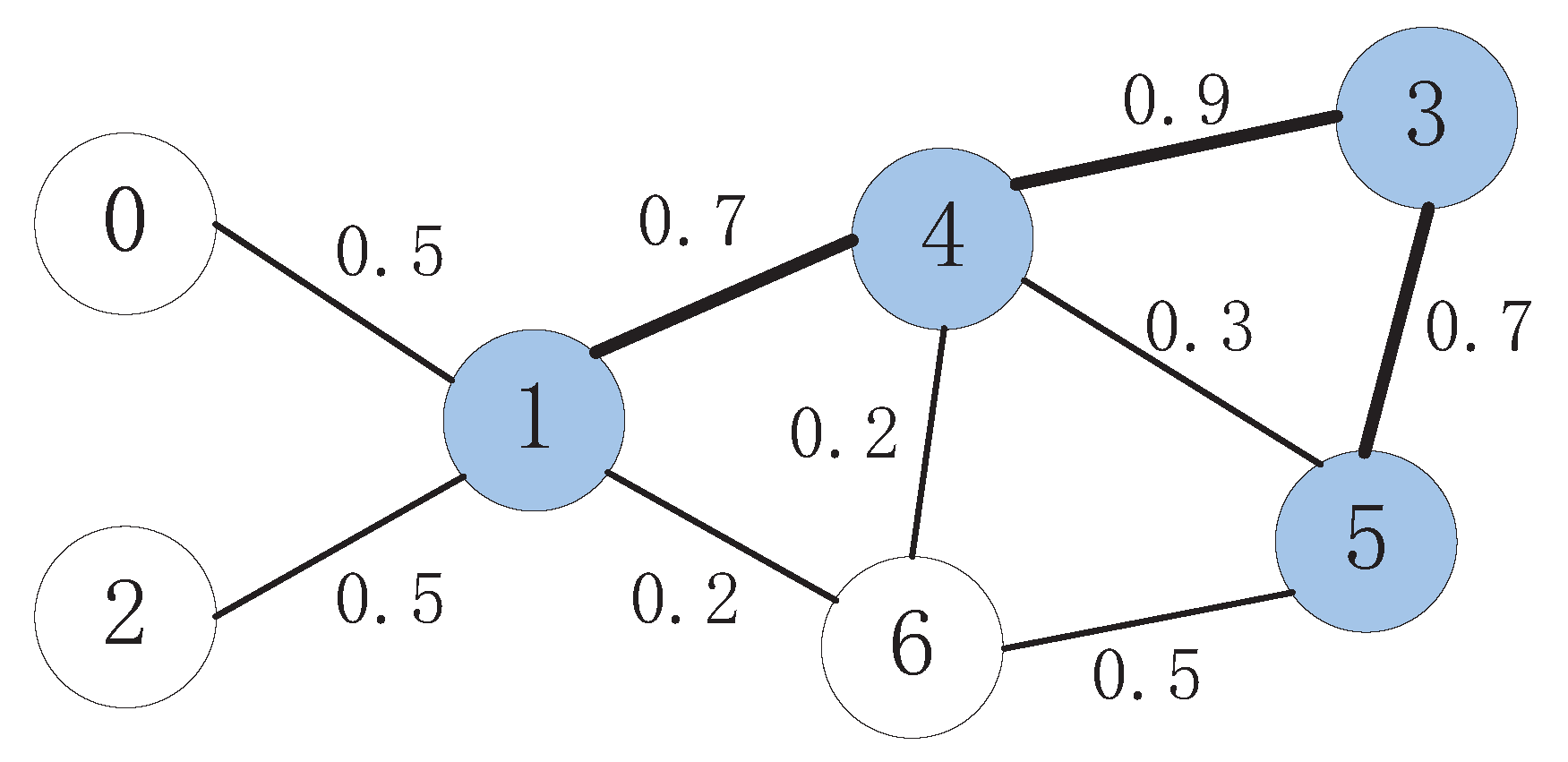
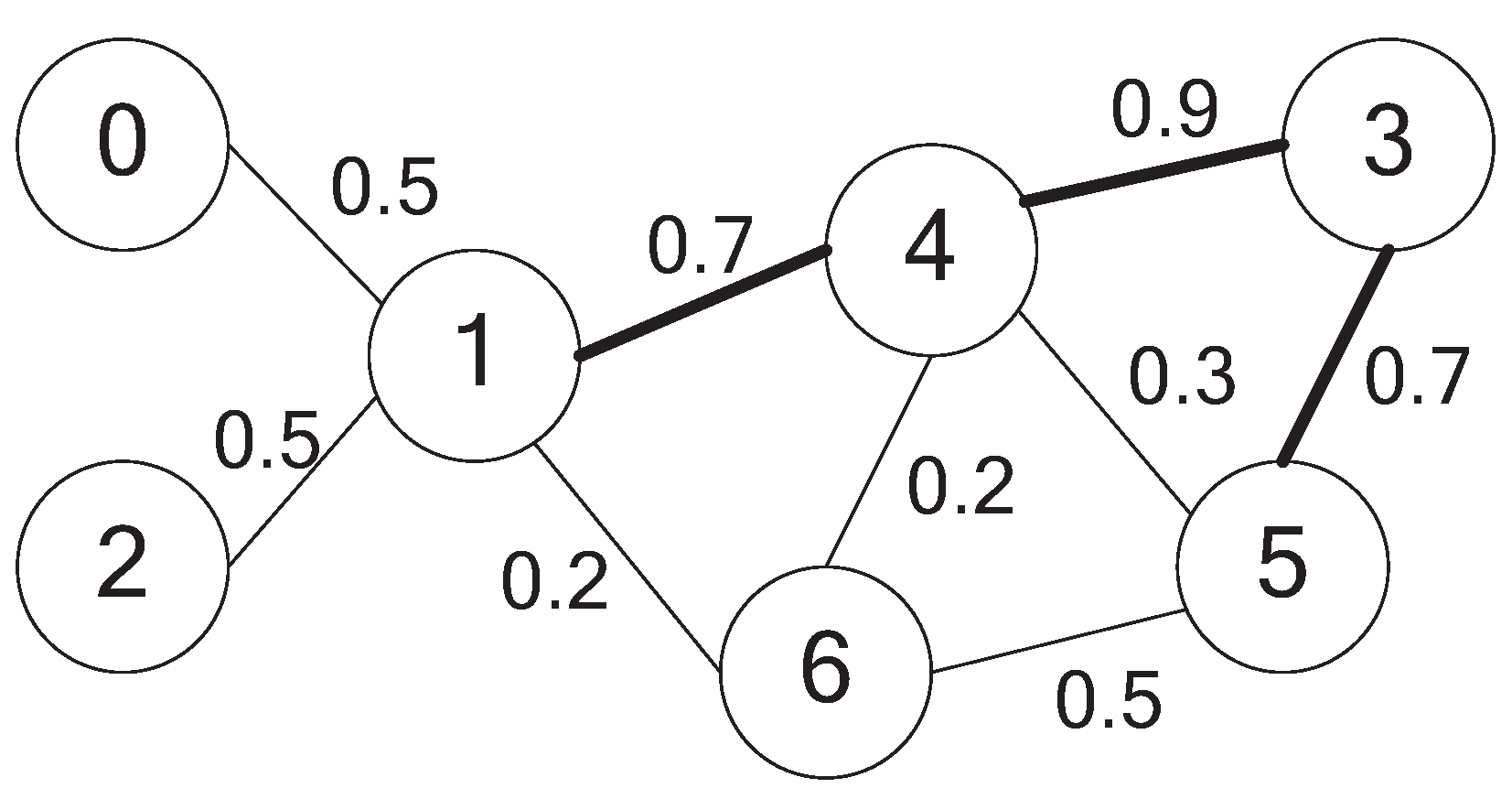
3.2. A Numerical Example
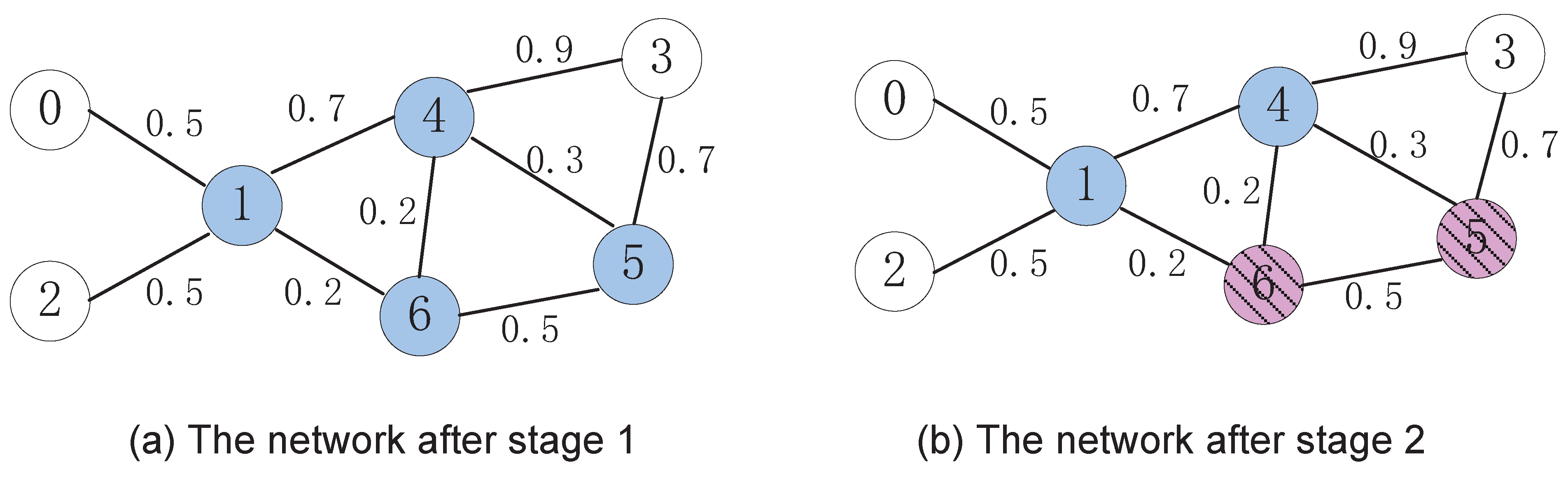
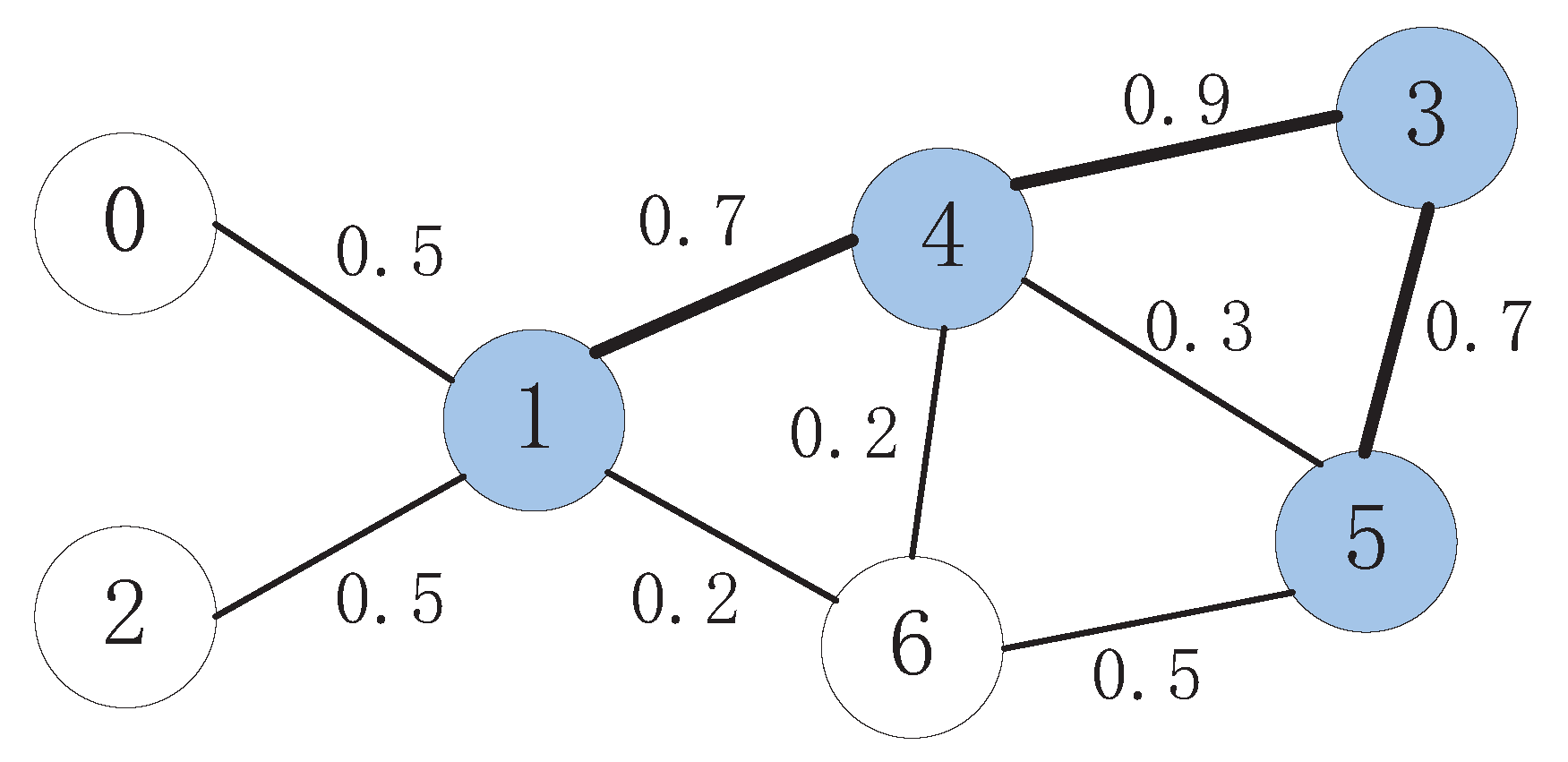
3.3. Analysis
4. Evaluation
4.1. Evaluation Setup
4.2. The Results
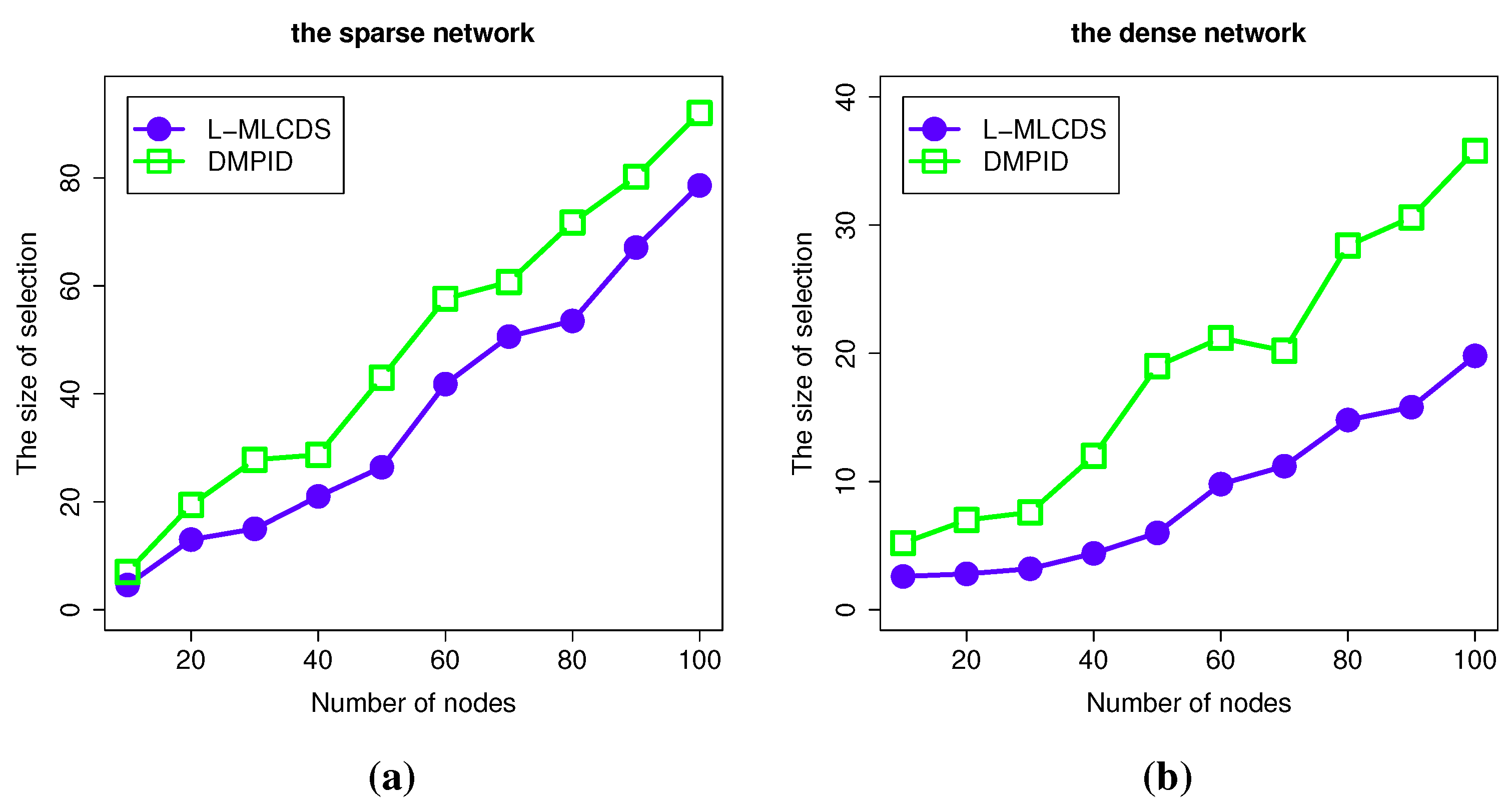
4.2.1. The Size of the Selection
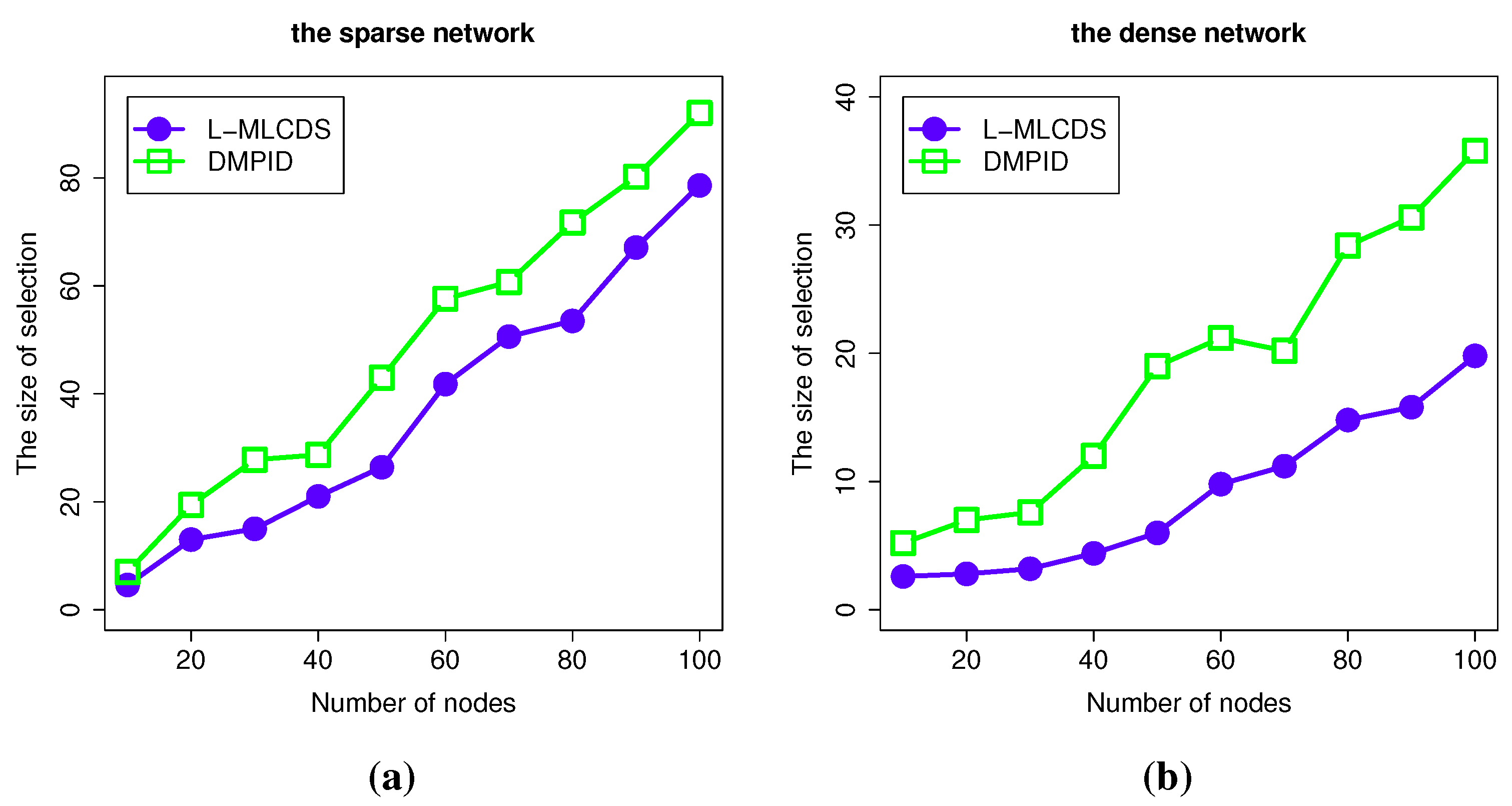
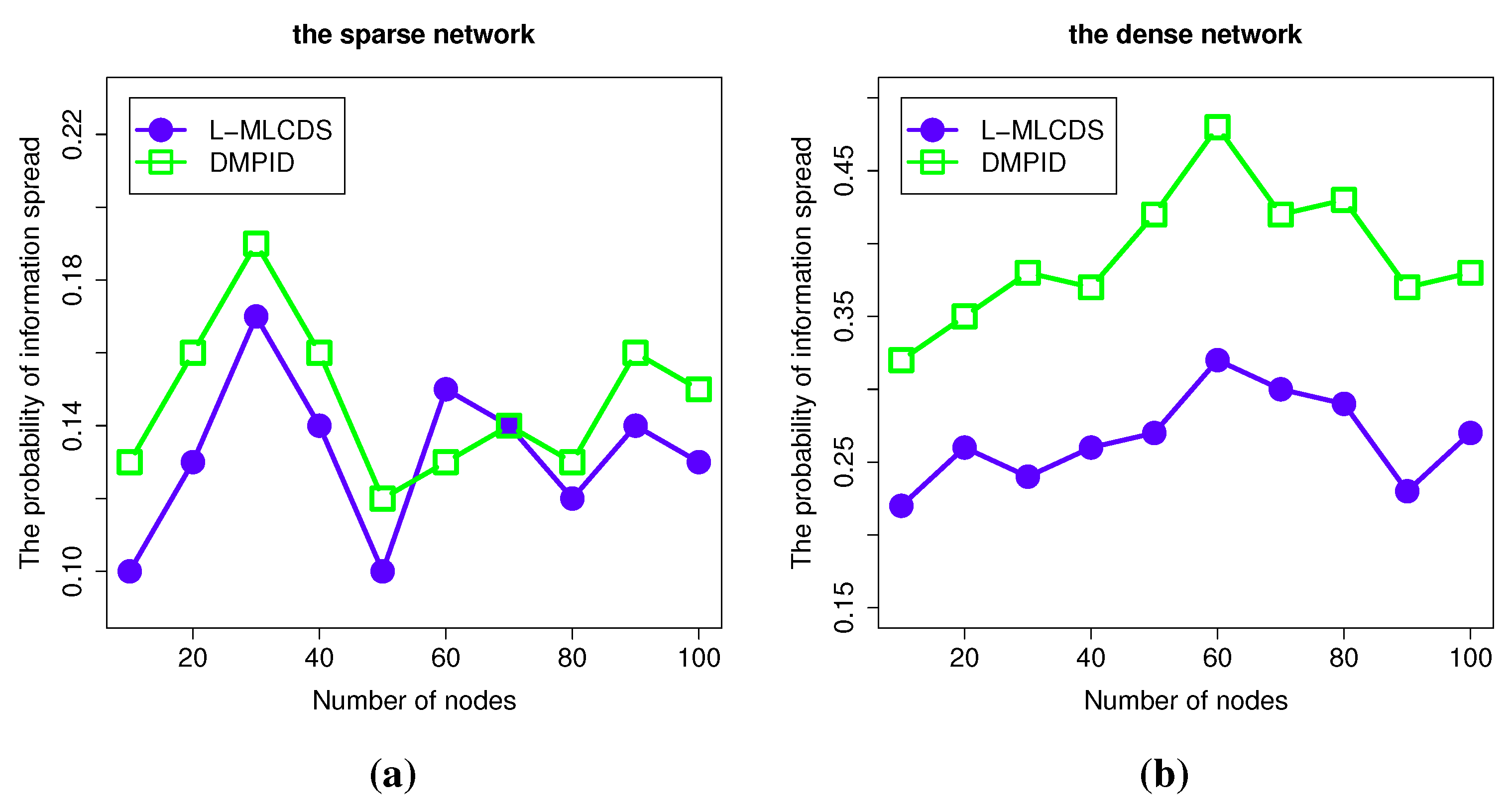
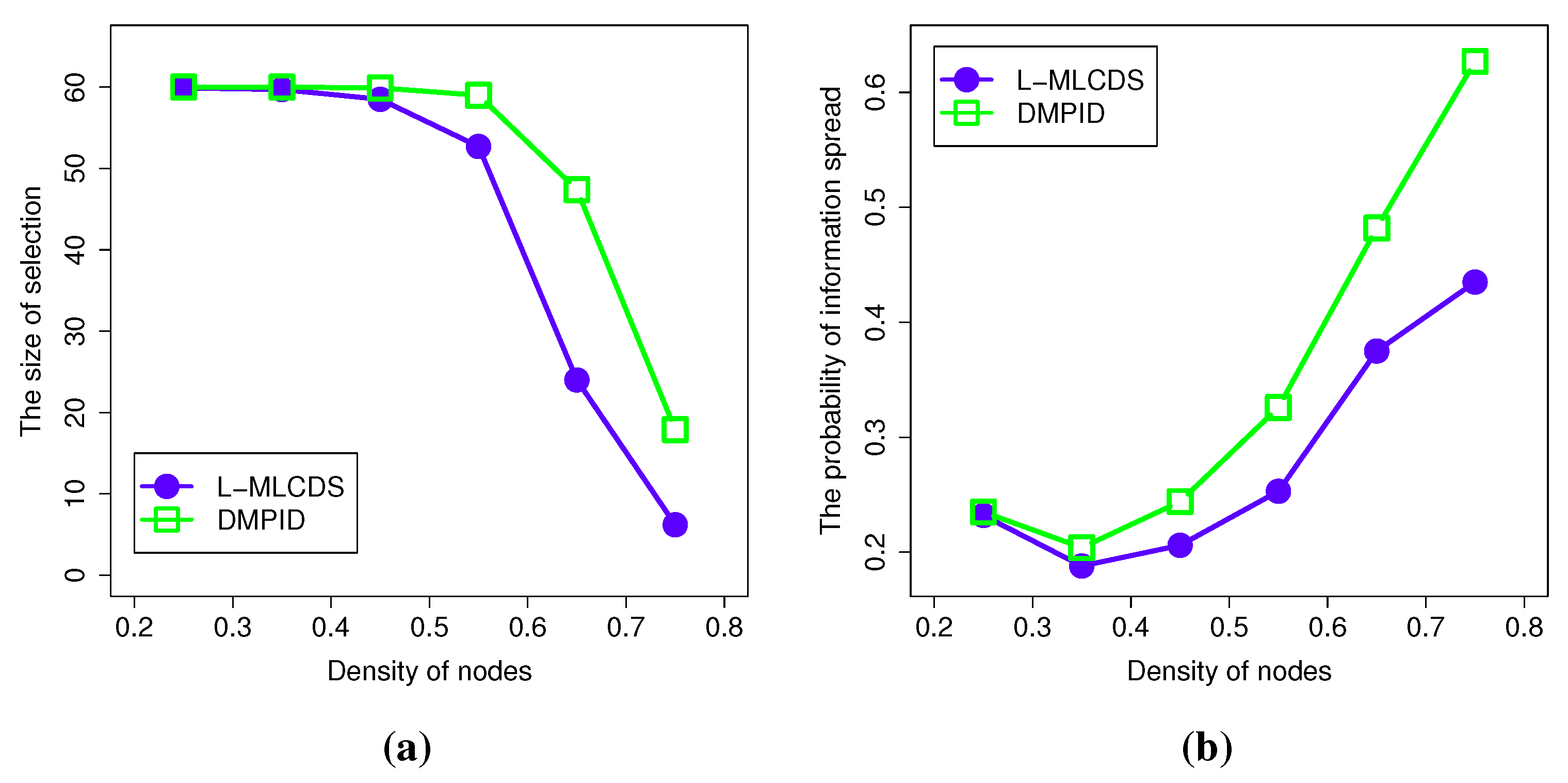
4.2.2. The Information Spread Probability

4.2.3. The Diameter of the Selection

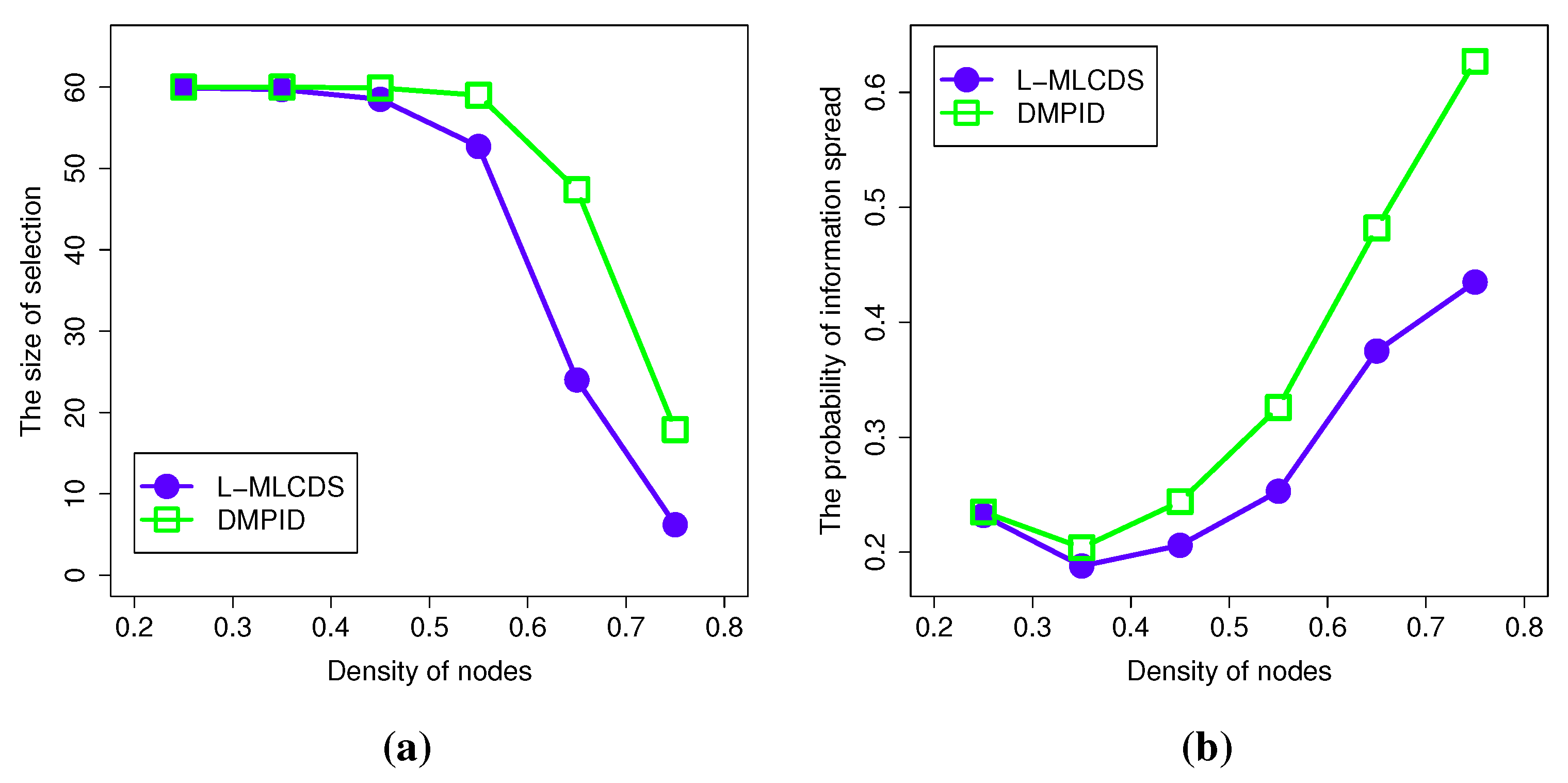
4.2.4. The Density of the Network
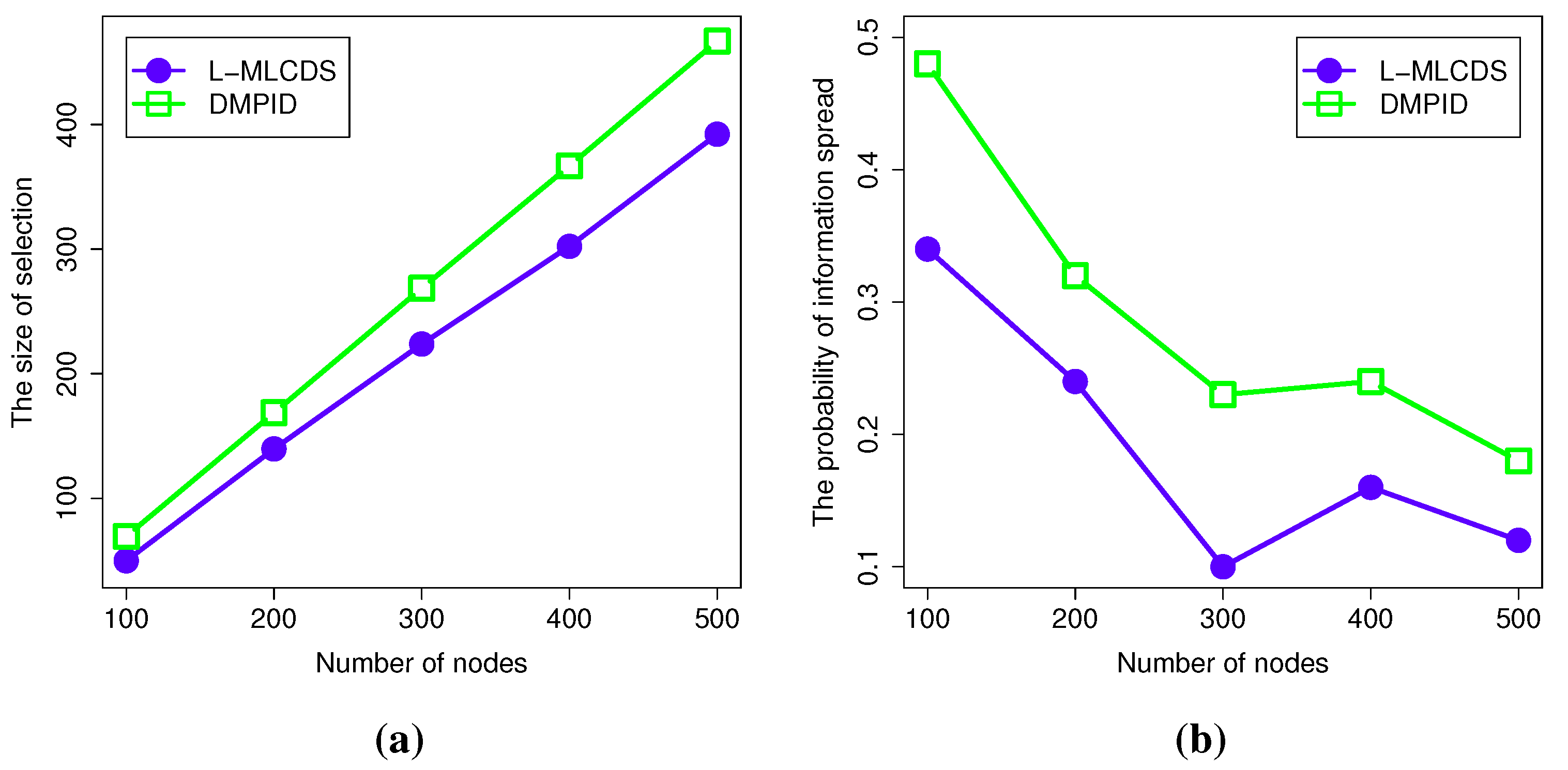
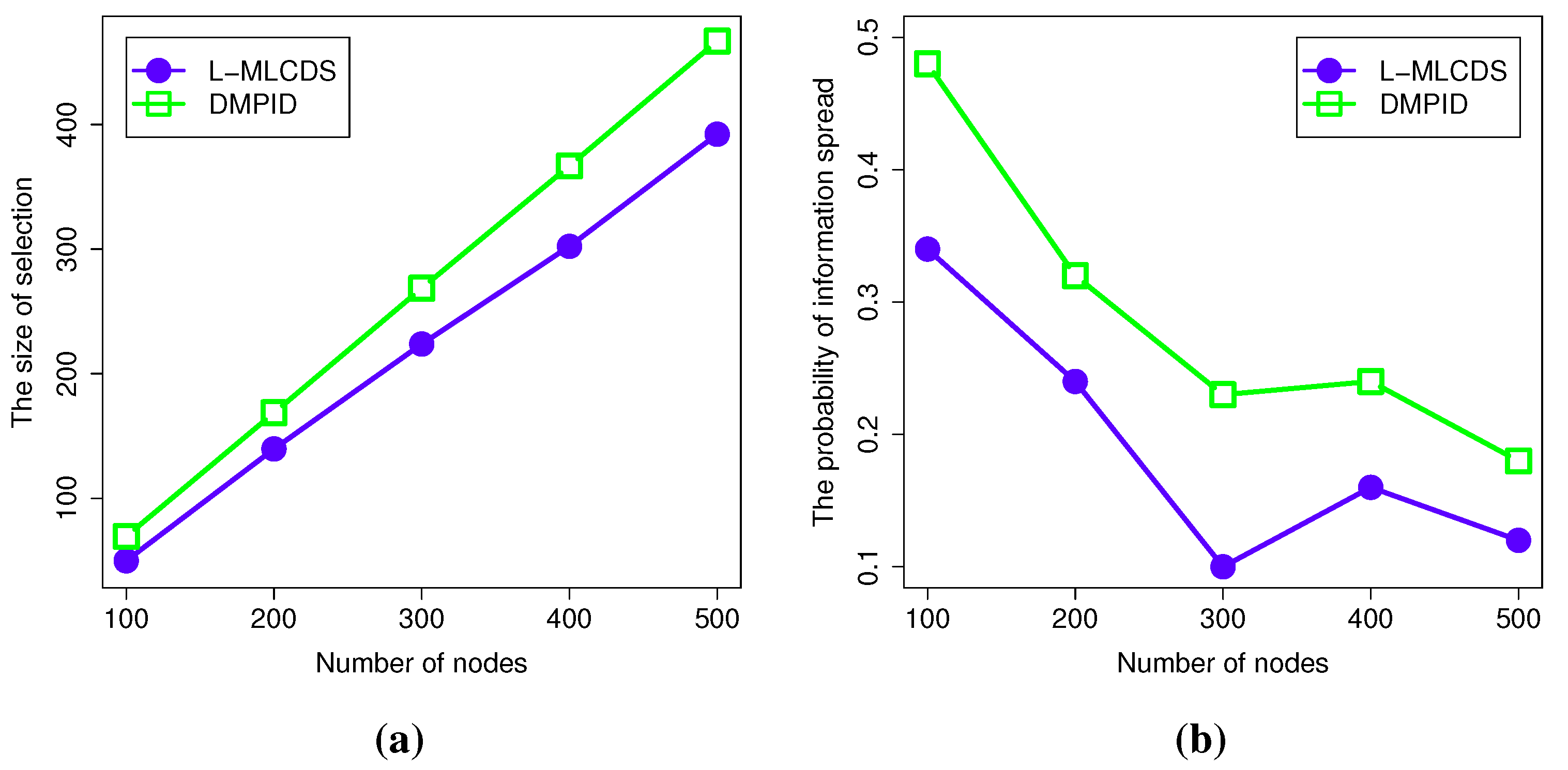
4.2.5. The Results for a Network Generated by the Watts-Strogatz Model
5. Related Work
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Huang, Y.; Ma, X.; Cao, J.; Tao, X.; Lu, J. Concurrent event detection for asynchronous consistency checking of pervasive context. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications, Galveston, TX, USA, 9–13 March 2009; pp. 1–9.
- Raychoudhury, V.; Cao, J.; Zhu, W.; Kshemkalyani, A.D. Context Map for Navigating the Physical World. In Proceedings of the IEEE 20th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Garching, Germany, 15–17 February 2012; pp. 146–153.
- Schaudt, O.; Schrader, R. The complexity of connected dominating sets and total dominating sets with specified induced subgraphs. Inf. Process. Lett. 2012, 112, 953–957. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, H.; Chu, X.; Leung, Y.W.; Stojmenovic, I. Constructing Connected-Dominating-Set with Maximum Lifetime in Cognitive Radio Networks. IEEE Trans. Comput. 2013. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of “small-world” networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Iwata, T.; Shah, A.; Ghahramani, Z. Discovering latent influence in online social activities via shared cascade poisson processes. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 266–274.
- Jiang, C.; Chen, Y.; Liu, K.R. Modeling information diffusion dynamics over social networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1095–1099.
- Xia, R.Z.; Jia, Y.; Lin, W.Q.; Li, H. Mining Information Spreading Based on Users’ Retweet Behavior in Twitter. Appl. Mech. Mater. 2013, 380, 2866–2870. [Google Scholar] [CrossRef]
- Scholtes, I.; Wider, N.; Pfitzner, R.; Garas, A.; Tessone, C.J.; Schweitzer, F. Causality-driven slow-down and speed-up of diffusion in non-Markovian temporal networks. Nat. Commun. 2014, 5. [Google Scholar] [CrossRef] [PubMed]
- Jiang, C.; Chen, Y.; Liu, K.R. Evolutionary Dynamics of Information Diffusion Over Social Networks. IEEE Trans. Signal Process. 2014, 62, 4573–4586. [Google Scholar] [CrossRef]
- Banerjee, A.; Chandrasekhar, A.G.; Duflo, E.; Jackson, M.O. Gossip: Identifying Central Individuals in a Social Network; Technical Report; National Bureau of Economic Research: Cambridge, MA, USA, 2014. [Google Scholar]
- Runka, A.; White, T. Towards intelligent control of influence diffusion in social networks. Soc. Netw. Anal. Min. 2015, 5, 1–15. [Google Scholar] [CrossRef]
- Luo, Z.; Osborne, M.; Wang, T. Opinion Retrieval in Twitter. In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media (ICWSM 2012), Dublin, Ireland, 4–8 June 2012.
- Yağan, O.; Qian, D.; Zhang, J.; Cochran, D. Conjoining speeds up information diffusion in overlaying social-physical networks. IEEE J. Sel. Areas Commun. 2013, 31, 1038–1048. [Google Scholar] [CrossRef]
- Zurita, G.; Baloian, N. Mobile, collaborative situated knowledge creation for urban planning. Sensors 2012, 12, 6218–6243. [Google Scholar] [CrossRef] [PubMed]
- Qian, D.; Yağan, O.; Yang, L.; Zhang, J.; Xing, K. Diffusion of real-time information in overlaying social-physical networks: Network coupling and clique structure. Netw. Sci. 2013, 3, 43–53. [Google Scholar] [CrossRef]
- Ruan, L.; Du, H.; Jia, X.; Wu, W.; Li, Y.; Ko, K.I. A greedy approximation for minimum connected dominating sets. Theor. Comput. Sci. 2004, 329, 325–330. [Google Scholar] [CrossRef]
- Stojmenovic, I.; Seddigh, M.; Zunic, J. Dominating sets and neighbor elimination-based broadcasting algorithms in wireless networks. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 14–25. [Google Scholar] [CrossRef]
- Ali, A.; Ahmed, M.E.; Piran, M.J.; Suh, D.Y. Resource Optimization Scheme for Multimedia-Enabled Wireless Mesh Networks. Sensors 2014, 14, 14500–14525. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; Lv, S.; Jiao, X.; Wang, X.; Liu, J. Maximizing Information Diffusion in the Cyber-physical Integrated Network. Sensors 2015, 15, 28513-28530. https://doi.org/10.3390/s151128513
Lu H, Lv S, Jiao X, Wang X, Liu J. Maximizing Information Diffusion in the Cyber-physical Integrated Network. Sensors. 2015; 15(11):28513-28530. https://doi.org/10.3390/s151128513
Chicago/Turabian StyleLu, Hongliang, Shaohe Lv, Xianlong Jiao, Xiaodong Wang, and Juan Liu. 2015. "Maximizing Information Diffusion in the Cyber-physical Integrated Network" Sensors 15, no. 11: 28513-28530. https://doi.org/10.3390/s151128513