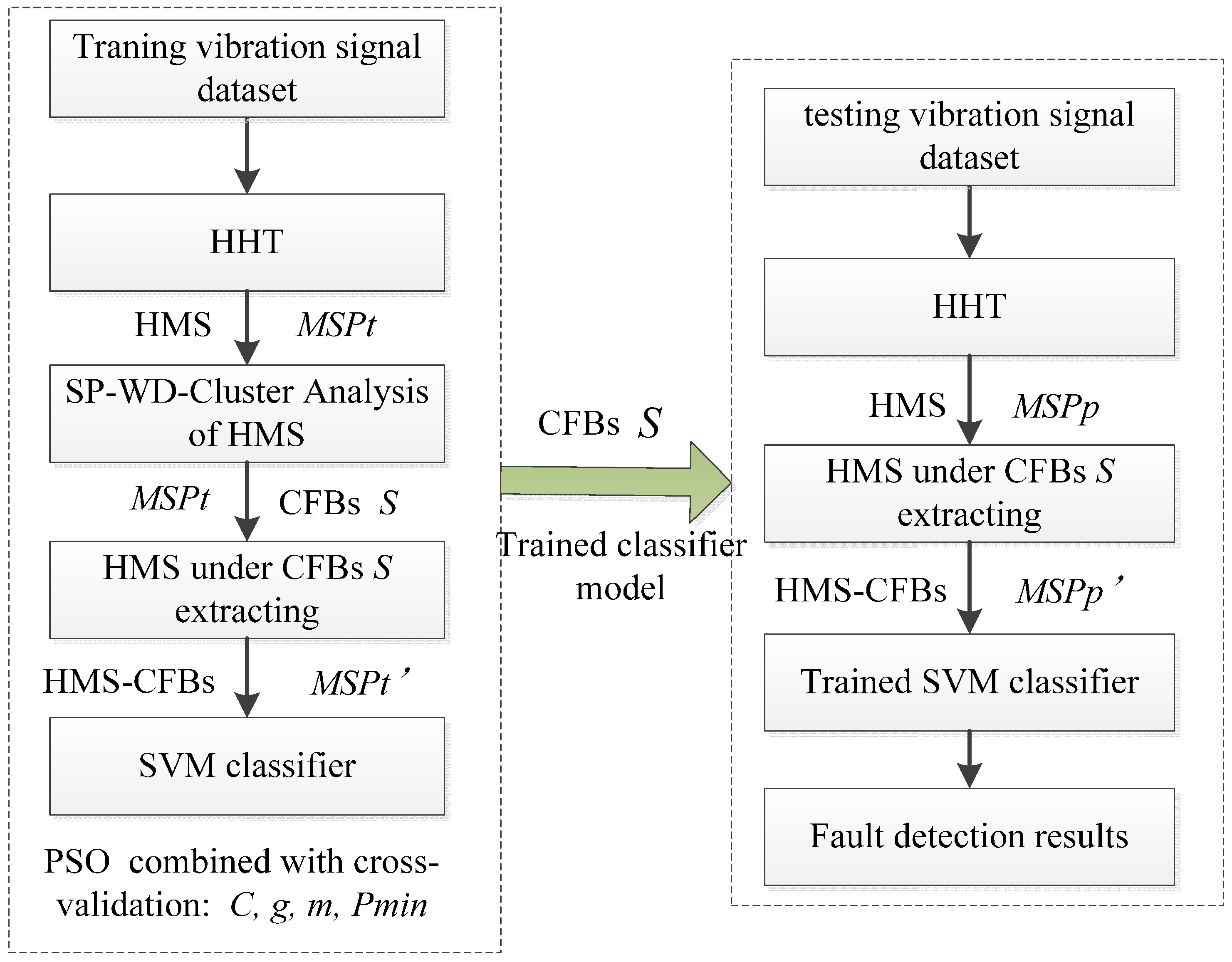
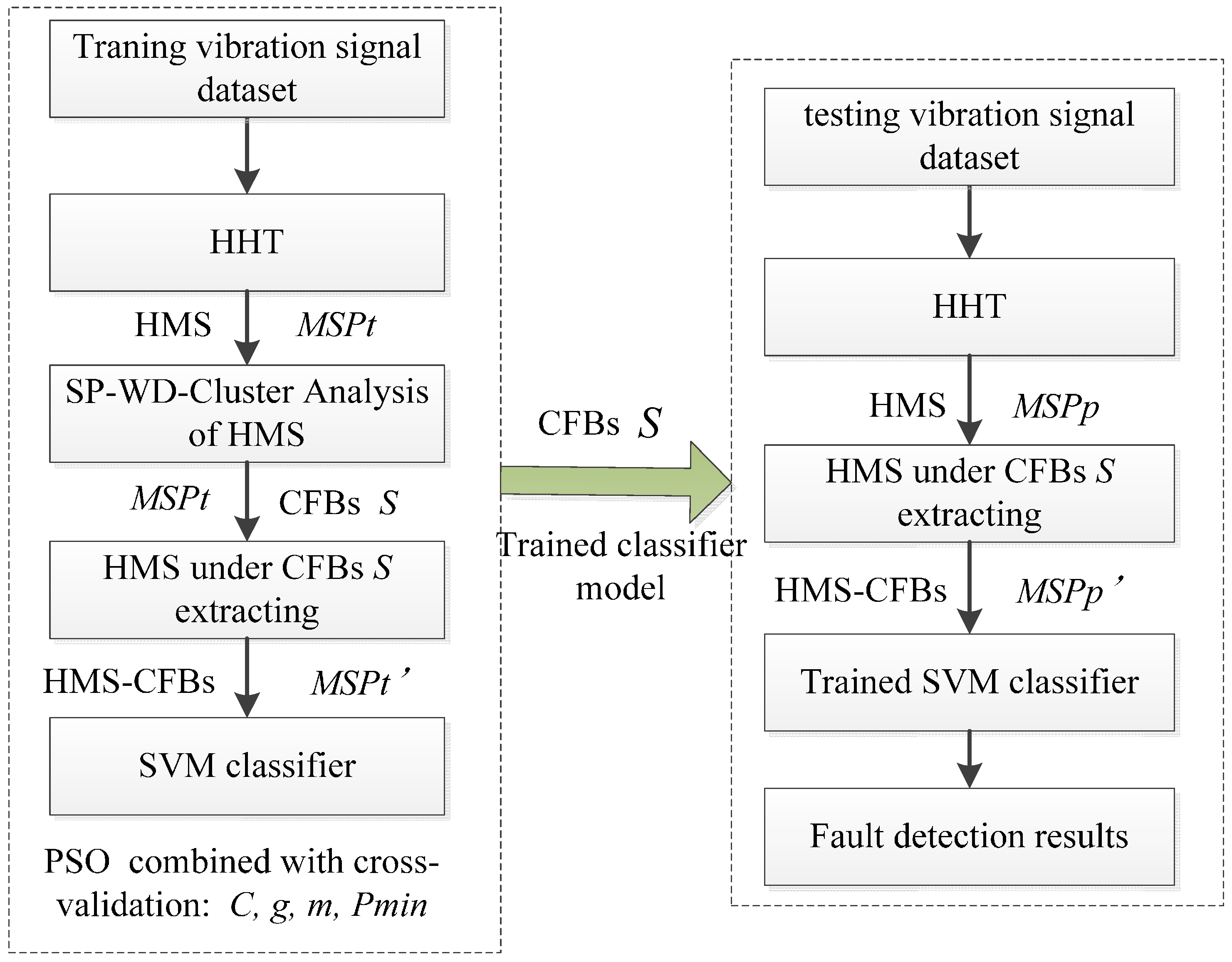
Rolling element bearing is one of the most important and common components in rotary machines and bearings failures may lead to fatal breakdowns of machines and can force unacceptably long time maintenance stops. Fast, accurate and ready detection of the existence and severity of bearing faults is therefore critical. In order to implement and evaluate the proposed WMSC-based REBs fault diagnosis model, we conducted three groups of experiments. In the first group, three REBs fault defects datasets served as accuracy test cases in HHT-WMSC-SVM model fault classification. To test the anti-noise ability of the HHT-WMSC-SVM model in second experiment set, Gauss white noise at different SNRs were added to the REBs fault defect dataset. In the third group, the effects of parameters m and Pmin in WMSC method on the fault classification performance were analyzed by REBs defect dataset adding Gaussian white noise at SNR = 5. For comparison, HHT-SVM and ST-SVM models were additionally employed in the first and second groups of experiments.
4.1. Experiment Setup
The bearing fault signals used in this article come from the bearing data center of Case Western Reserve University (CWRU) [
37]. The bearings used in this work are deep groove ball bearings of the type 6205-2RS JEM SKF at DE and 6203-2RS JEM SKF at FE. Single point faults with fault diameters from 0.007 in to 0.040 in in diameter were introduced separately at the inner raceway, rolling element and outer raceway. Vibration data were recorded for motor loads of zero to three horsepower (motor speeds of 1797 to 1720 RPM).
The accelerometer data at DE are used as original signals for the detection of four kinds of DE motor housing REB conditions, namely: healthy bearing (HB), IRF, ORF and BF. In each fault pattern, 60 samples are acquired from vibration signal in time domain, while each sample contains 2000 continuous data points.
The first two datasets listed in
Table 1, A and B, are used for analysis here, where 20 samples of each fault pattern are randomly designated as the training samples, and the remaining 40 samples serve as testing samples. Contained in dataset A are different bearing defect locations at the same level of defect severity (0.007 in), while dataset B comprises different bearing defect locations at differing levels of defect severity (0.007in and 0.014 in). As shown in
Table 1, there are 240 samples in dataset A (80 samples in the training set, and the remaining 160 samples in the testing set) and 420 samples in dataset B (140 samples in the training set, and the remaining 280 samples in testing set).
Table 1.
Detailed specifics of REB fault datasets A and B.
Table 1.
Detailed specifics of REB fault datasets A and B.
| Dataset | Condition | Defect Size (in) | Rotating Speed | Training Samples | Testing Samples | Label |
|---|
| A | HB | - | 1730 | 20 | 40 | 1 |
| IRF | 0.007 | 1730 | 20 | 40 | 2 |
| BF | 0.007 | 1730 | 20 | 40 | 3 |
| ORF | 0.007 | 1730 | 20 | 40 | 4 |
| B | HB | - | 1730 | 20 | 40 | 1 |
| IRF | 0.007 | 1730 | 20 | 40 | 2 |
| IRF | 0.014 | 1730 | 20 | 40 | 3 |
| BF | 0.007 | 1730 | 20 | 40 | 4 |
| BF | 0.014 | 1730 | 20 | 40 | 5 |
| ORF | 0.007 | 1730 | 20 | 40 | 6 |
| ORF | 0.014 | 1730 | 20 | 40 | 7 |
It is useful for many applications to recognize the “incipient” REBs fault patterns with the model achieved by the “severe” REBs fault data. In order to test the model adaptability in this case, the third dataset, C, are used for analysis here. As show in
Table 2, samples in different bearing defect locations at defect size of 0.014 in are employed as the training set, while the 0.007 in are employed as the testing set.
Table 2.
Detailed specifics of REB fault dataset C.
Table 2.
Detailed specifics of REB fault dataset C.
| Dataset | Condition | Rotating Speed | Training Samples/Defect Size (in) | Testing Samples/Defect Size (in) | Label |
|---|
| C | HB | 1730 | 20/- | 40/- | 1 |
| IRF | 1730 | 20/0.014 | 40/0.007 | 2 |
| BF | 1730 | 20/0.014 | 40/0.007 | 3 |
| ORF | 1730 | 20/0.014 | 40/0.007 | 4 |
4.2. Experimental Validation of the Proposed Method
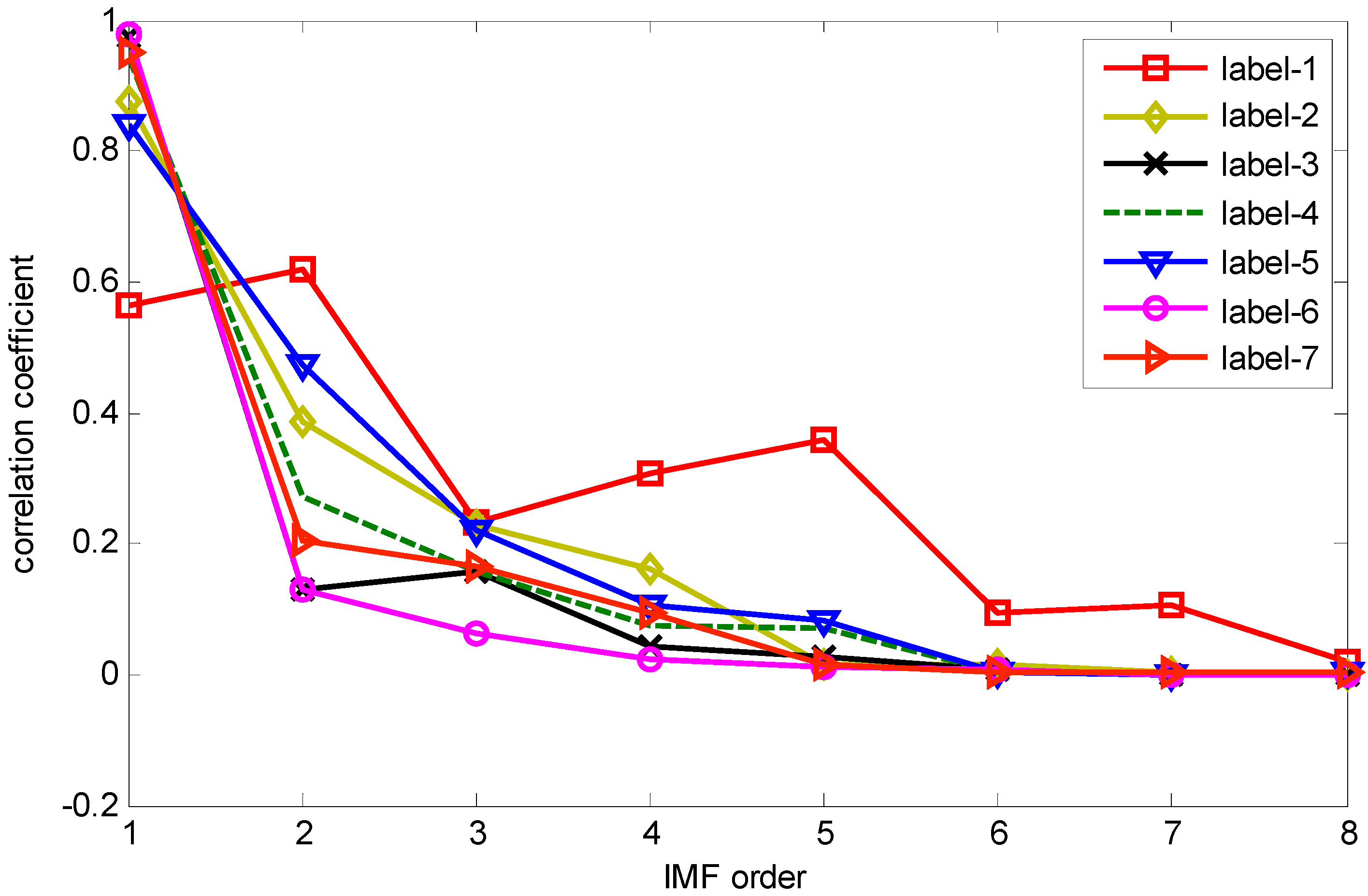
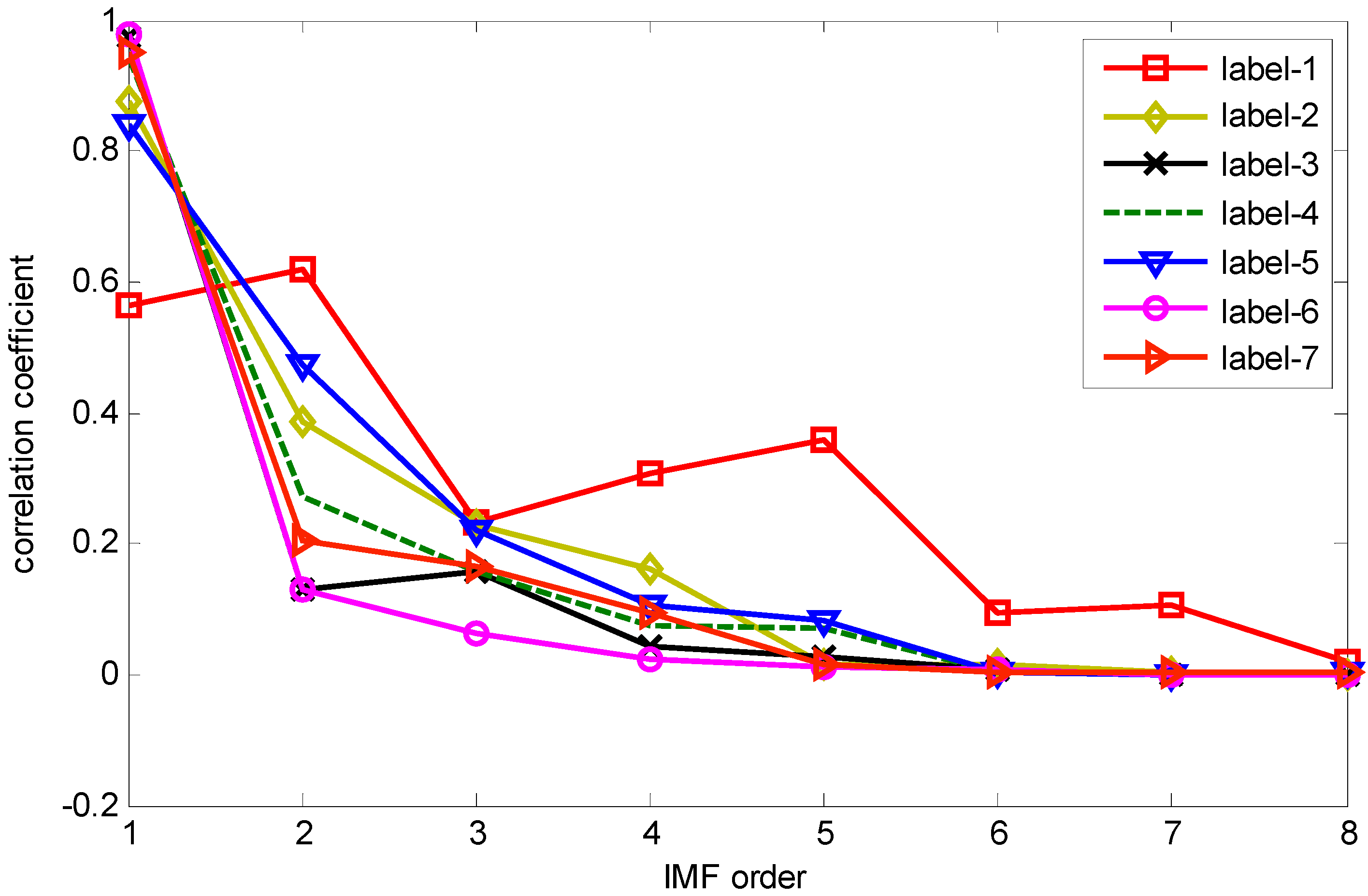
The correlation coefficients between IMF and the original vibration signal are calculated by Equation (10). The IMFs correlation coefficient values of one sample from each label in dataset B are shown in
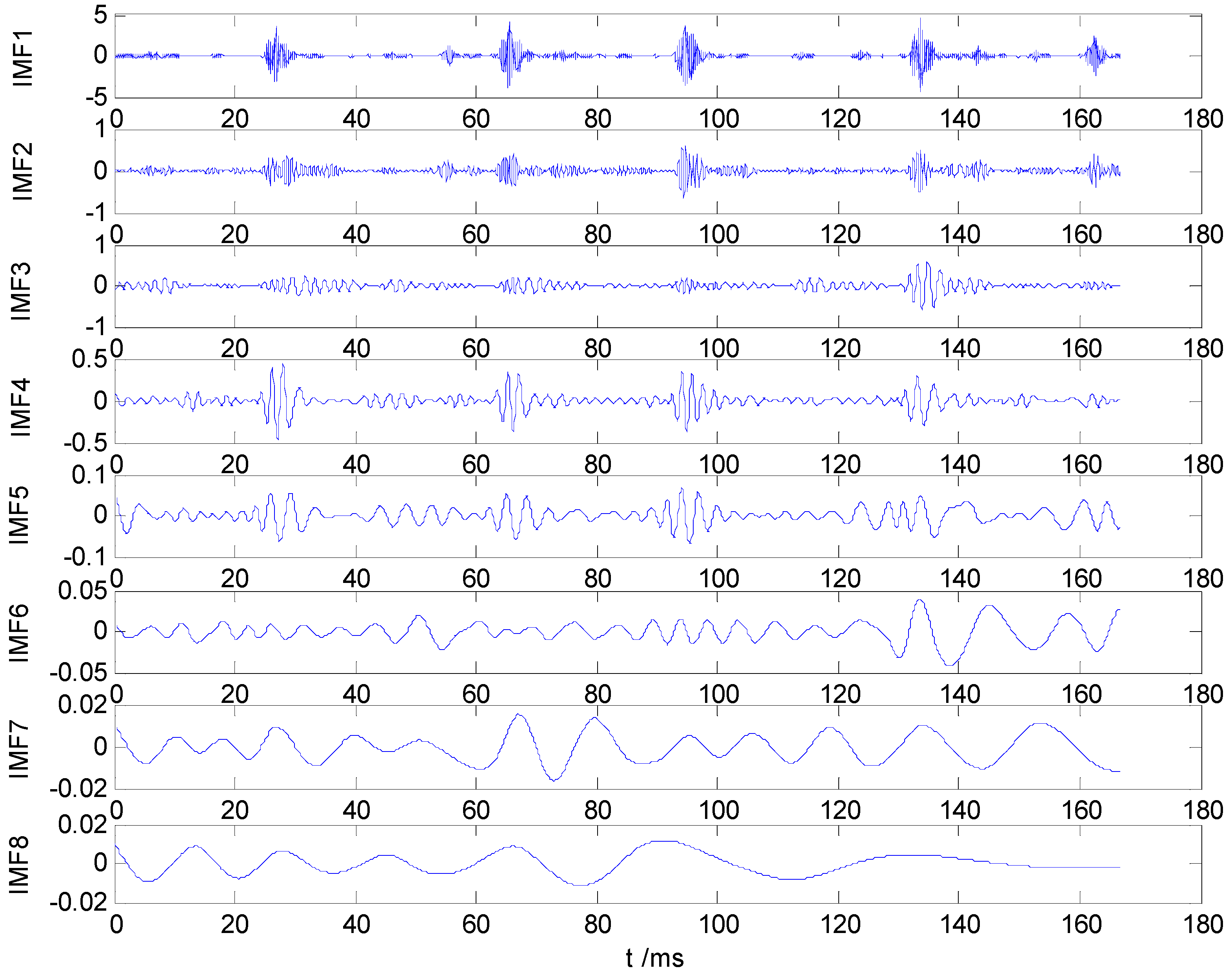
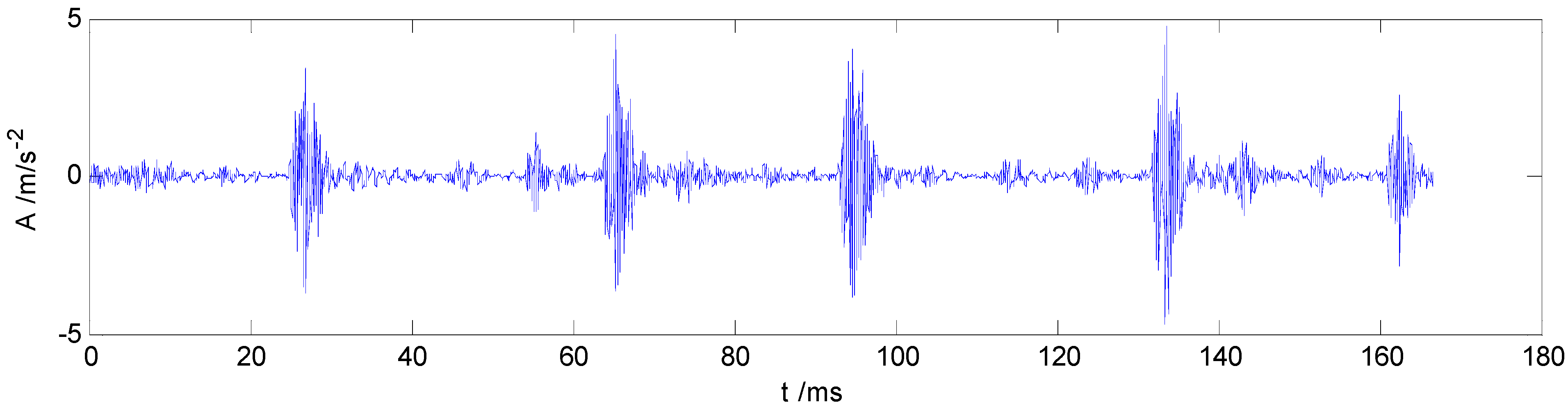
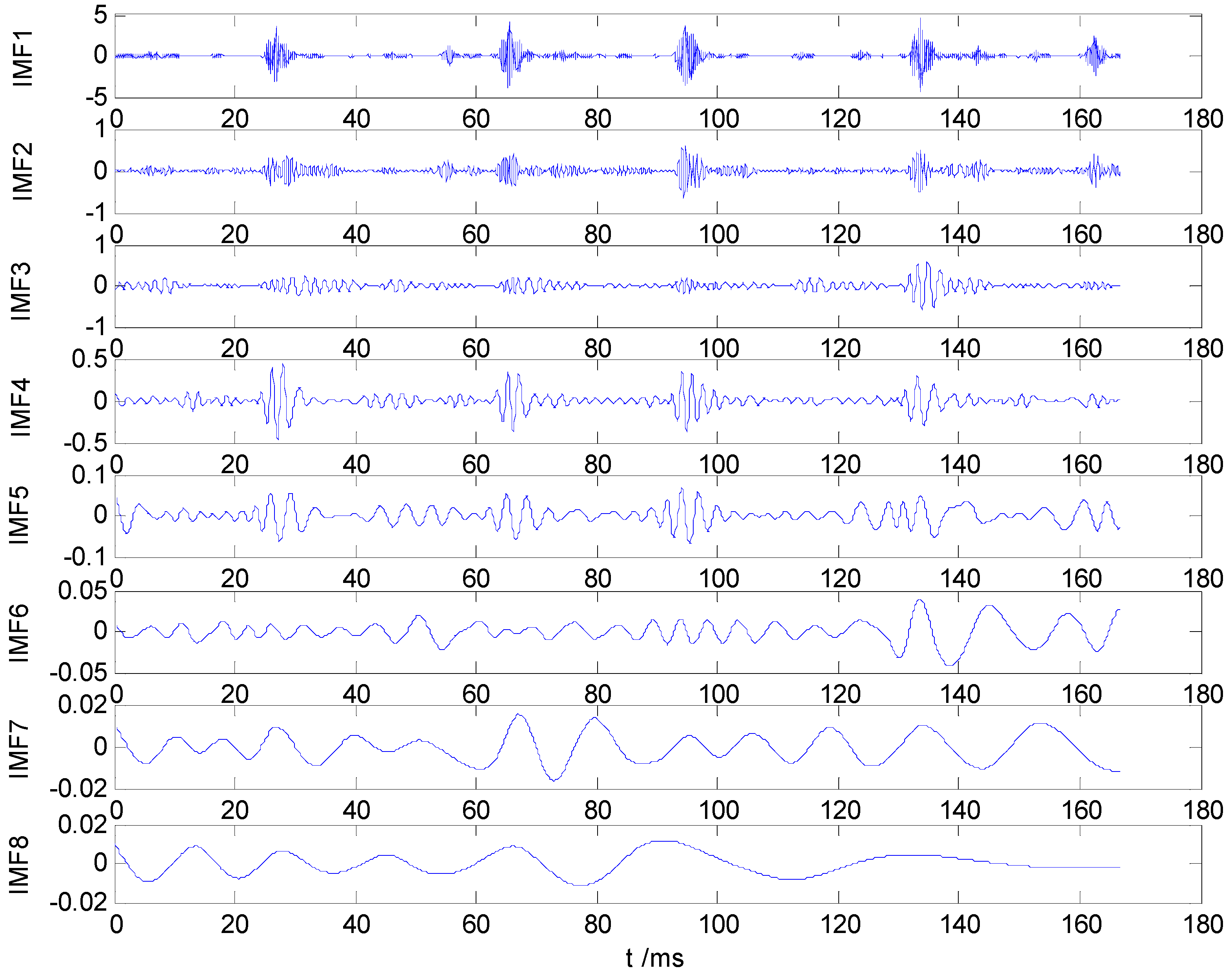
Figure 2, which values indicate that the first five IMF components are most relevant to the original vibration signal. Therefore, IMF1–IMF5 are selected to calculate the HMS. Taking as example the REBs fault vibration signal of label 7 (ORF) in dataset B, one vibration signal sample and the first 8 IMFs from the sample are presented in
Figure 3 and
Figure 4, respectively.
Figure 2.
Correlation coefficient between IMF component and original vibration signal.
Figure 2.
Correlation coefficient between IMF component and original vibration signal.
Figure 3.
The original ORF vibration signal.
Figure 3.
The original ORF vibration signal.
Figure 4.
IMF1–IMF8 of ORF vibration signal.
Figure 4.
IMF1–IMF8 of ORF vibration signal.
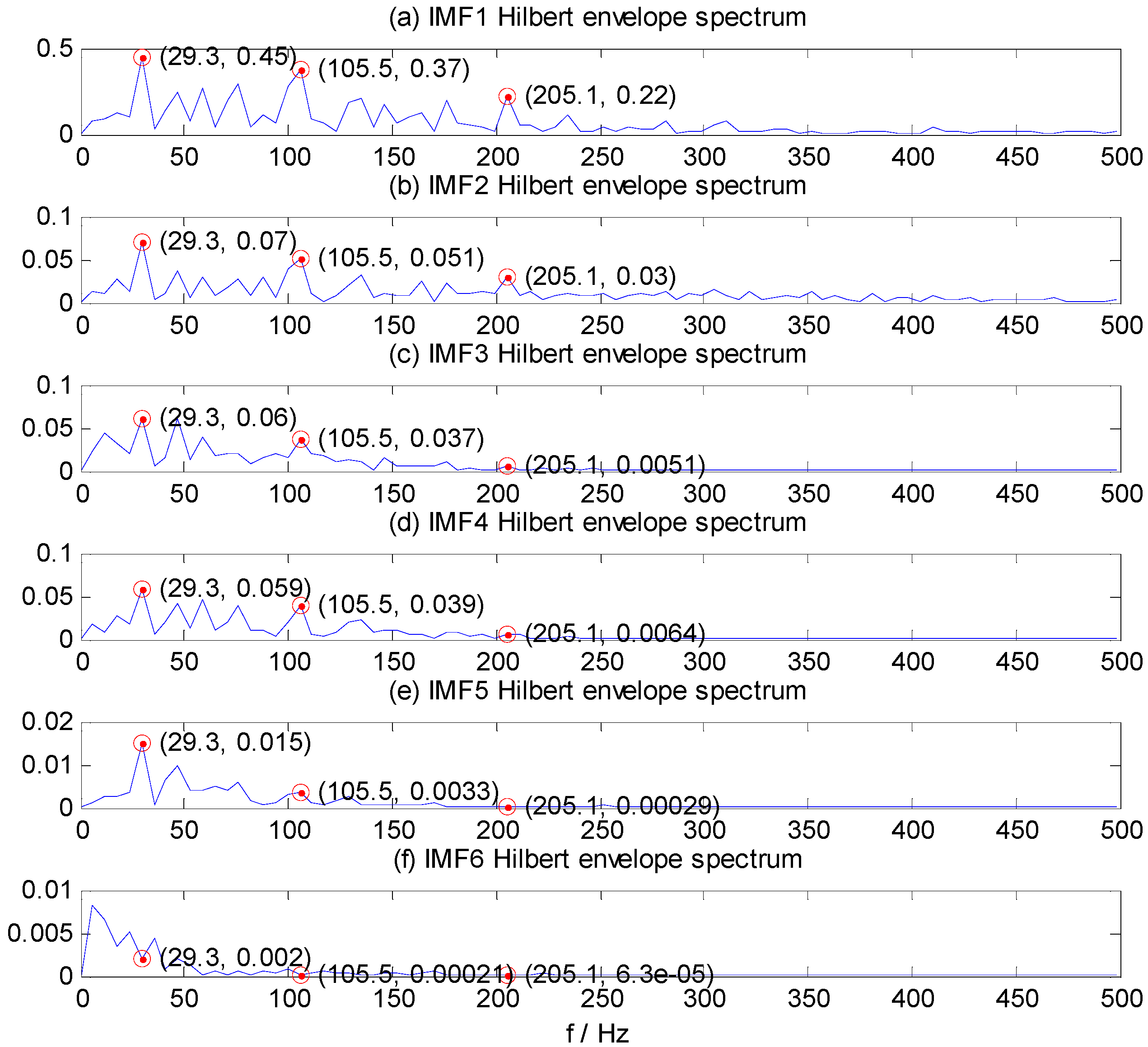
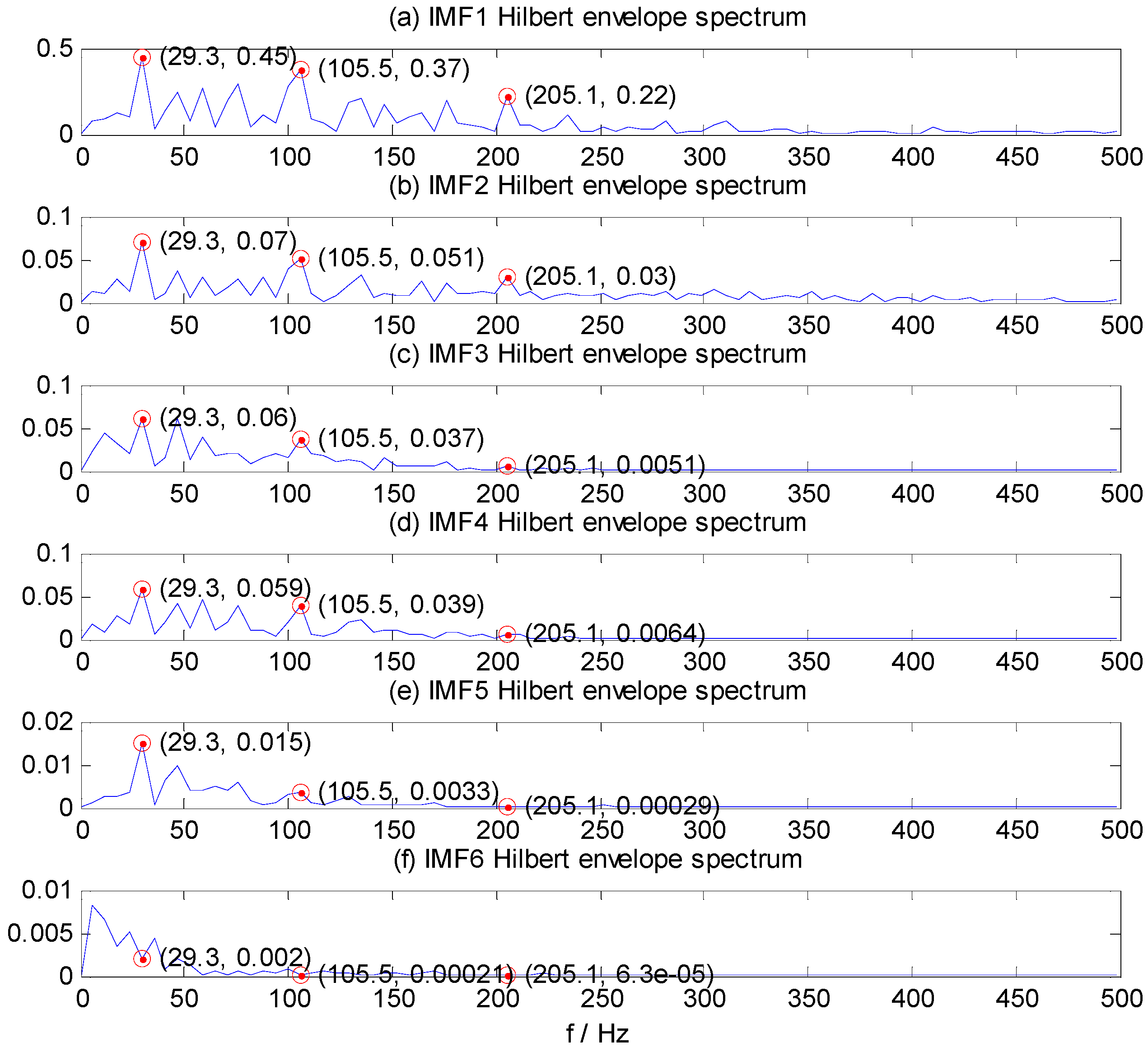
The bearing running frequency is 28 Hz at the machine running speed 1730 r/min, while the bearing ORF characteristic frequency is 103.4 Hz, which can be calculated from the SKF-6205-2RS bearing parameters and the roller bearing fault characteristic frequency theoretical calculation formula.
Figure 5a–f shows the Hilbert envelope spectrum of IMF1–IMF6. In
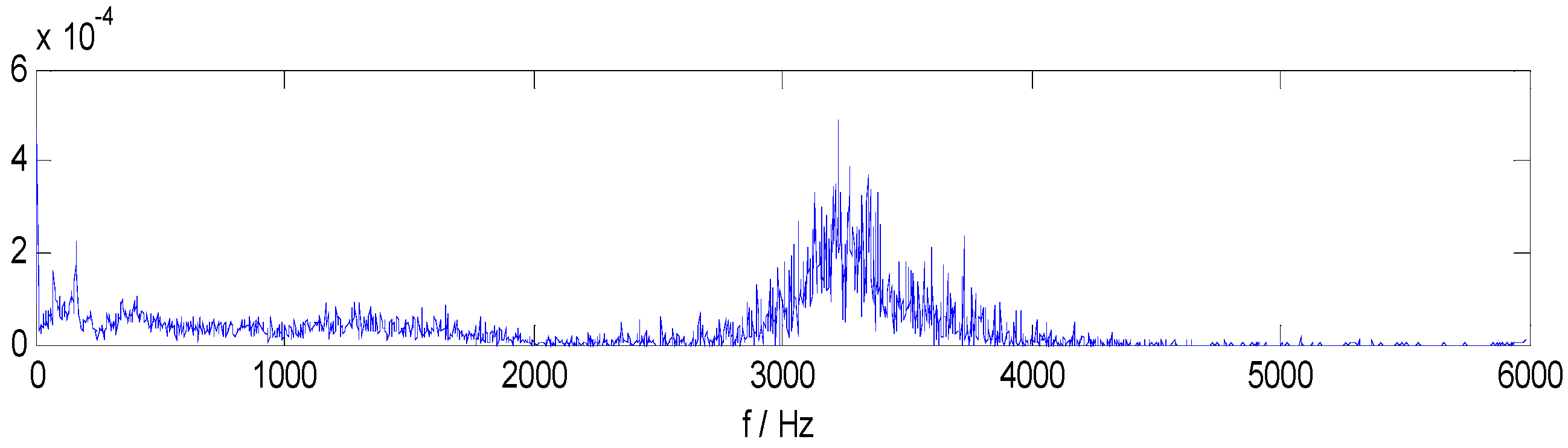
Figure 5a–e, we can see from the IMF1–IMF5 Hilbert envelope spectrum that there are explicit spectral lines near running frequency (29.3 Hz) and double the running frequency. Similarly, there are explicit spectral lines near theoretic fault characteristic frequency (105.5 Hz) and double the fault frequency (205.1 Hz). The HMS expresses cumulative frequency amplitude across the entire measured time period, which contains frequency characteristics of each IMF component. Under different fault conditions, therefore, HMS presents different frequency amplitude distribution characteristics. Here, we select the HMS as the preliminary feature extraction method for REBs fault types detection. The HMS of outer race fault vibration signal sample is shown in
Figure 6.
The research goal here is to demonstrate the effectiveness of the proposed multi REBs faults detection model, and to illustrate the performance of the proposed method in dealing with noise. Hence, the proposed method is compared with ST-SVM and HHT-SVM models, while the ST-SVM model is based on statistical characteristics and HHT-SVM model uses HMS directly as the SVM classifier input. In the ST-SVM model, vibration signal is also decomposed into IMFs by EMD. In accordance with related research [
6,
17,
18,
24,
30], five time domain characteristics and five spectrum statistical characteristics, shown in
Table 3 for 1st–5th IMF components, are selected as the fault features, which means altogether 50 statistical characteristics of each sample will be calculated as the SVM classifier input vector.
Figure 5.
IMF1–IMF6 Hilbert envelope spectrum of ORF vibration signal. (a) IMF1; (b) IMF2; (c) IMF3; (d) IMF4; (e) IMF5;(f) IMF6.
Figure 5.
IMF1–IMF6 Hilbert envelope spectrum of ORF vibration signal. (a) IMF1; (b) IMF2; (c) IMF3; (d) IMF4; (e) IMF5;(f) IMF6.
Figure 6.
HMS of ORF vibration signal.
Figure 6.
HMS of ORF vibration signal.
Table 3.
Statistical characteristic parameters of time domain and frequency domain.
Table 3.
Statistical characteristic parameters of time domain and frequency domain.
| Time–Domain Feature Parameters | Frequency–Domain Feature Parameters |
|---|
| Feature | Equation | Feature | Equation |
| Mean value | | Mean value | |
| Standard deviation | | Standard deviation | |
| Skewness | | Skewness | |
| Kurtosis | | Crest factor | |
| Crest factor | | Shannon entropy | F5 = Equation (16) |
| Here x(i) is time series of an IMF for i = 1,2,…,n, n is the number of data points. | Here sp(k) is the envelope spectrum of an IMF for k = 1,2,…,l, l is the number of spectrum components. |
The energy of
l IMF spectrum components
sp(k), can be described as
Shannon entropy, which measures the uncertainty of
sp(k) is defined by
where
Pk is the distribution of the energy probability for each spectrum component, given by
The Shannon entropy is capable of determining the uncertainty and information of any distribution so that provides practical criteria for analyzing and measuring the similarity or dissimilarity between distributions of probability [
6].
The classification results and optimal parameters of three REBs fault detection models for dataset A, B and C are shown in
Table 4,
Table 5 and
Table 6 respectively. In
Table 4, results show that all three of these models can achieve high classification accuracy for dataset A, while the accuracy of the ST-SVM model is slightly lower than that of other two models. However, for fault dataset B, which contains REBs faults both in different locations and at different levels of defect severity, there is a sharp decline in the performance of the ST-SVM model, while the HHT-SVM model and the HHT-WMSC-SVM model maintain good performance.
Table 4.
Bearing fault detection results obtained by the ST-SVM, HHT-SVM and HHT-WMSC-SVM models for dataset A.
Table 4.
Bearing fault detection results obtained by the ST-SVM, HHT-SVM and HHT-WMSC-SVM models for dataset A.
| Label | ST-SVM Classification Accuracy (%) | HHT-SVM Classification Accuracy (%) | HHT-WMSC-SVM Classification Accuracy (%) |
|---|
| C= 0.7 g = 0.1 | C= 0.1 g = 0.25 | C= 2.1 g = 1.3 m = 50 Pmin = 355 |
|---|
| Training | Testing | Training | Testing | Training | Testing |
|---|
| 1 | 20/20 | 39/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 2 | 20/20 | 40/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 3 | 20/20 | 40/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 4 | 20/20 | 39/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| Average | 100% | 98.75% | 100% | 100% | 100% | 100% |
The results in
Table 6 show that the capability of ST-SVM model and HHT-SVM model trained by “severe” REBs fault data are weak to recognize the “incipient” REBs fault patterns. They can only recognize whether the bearing is healthy or not, but lose efficacy in the classification of different fault locations. Nevertheless, the HHT-WMSC-SVM model can achieve relatively high classification accuracy in this case.
Compared with statistical characteristics, HMS increase SVM classifier efficiency for the REBs fault classification. Furthermore, we can see that the fault classification performance of the proposed HHT-WMSC-SVM model has advantages over the HHT-SVM model, demonstrating that the WMSC method extracts the salient features in HMS that preserve most of the information related to REBs fault patterns.
Table 5.
Bearing fault detection results obtained by the ST-SVM, HHT-SVM and HHT-WMSC-SVM models for dataset B.
Table 5.
Bearing fault detection results obtained by the ST-SVM, HHT-SVM and HHT-WMSC-SVM models for dataset B.
| Label | ST-SVM Classification Accuracy (%) | HHT-SVM Classification Accuracy (%) | HHT-WMSC-SVM Classification Accuracy (%) |
|---|
| c = 12.1 g = 0.084 | c = 0.1 g = 12.3 | c = 1 g = 7.02 m = 168 Pmin = 375 |
|---|
| Training | Testing | Training | Testing | Training | Testing |
|---|
| 1 | 20/20 | 39/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 2 | 20/20 | 40/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 3 | 20/20 | 35/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 4 | 20/20 | 37/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 5 | 20/20 | 34/40 | 20/20 | 38/40 | 20/20 | 40/40 |
| 6 | 20/20 | 40/40 | 19/20 | 34/40 | 19/20 | 39/40 |
| 7 | 20/20 | 36/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| Average | 100% | 93.21% | 99.29% | 97.14% | 99.29% | 99.64% |
Table 6.
Bearing fault detection results obtained by the ST-SVM, HHT-SVM and HHT-WMSC-SVM models for dataset C.
Table 6.
Bearing fault detection results obtained by the ST-SVM, HHT-SVM and HHT-WMSC-SVM models for dataset C.
| Label | ST-SVM Classification Accuracy (%) | HHT-SVM Classification Accuracy (%) | HHT-WMSC-SVM Classification Accuracy (%) |
|---|
| c = 12 g = 0.03 | c = 1.8 g = 1.12 | c = 3 g = 1.7 m = 78 Pmin = 407 |
|---|
| Training | Testing | Training | Testing | Training | Testing |
|---|
| 1 | 20/20 | 39/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 2 | 20/20 | 0/40 | 20/20 | 40/40 | 20/20 | 40/40 |
| 3 | 20/20 | 0/40 | 20/20 | 0/40 | 20/20 | 38/40 |
| 4 | 20/20 | 5/40 | 20/20 | 0/40 | 20/20 | 37/40 |
| Average | 100% | 27.5% | 100% | 50% | 100% | 96.25% |
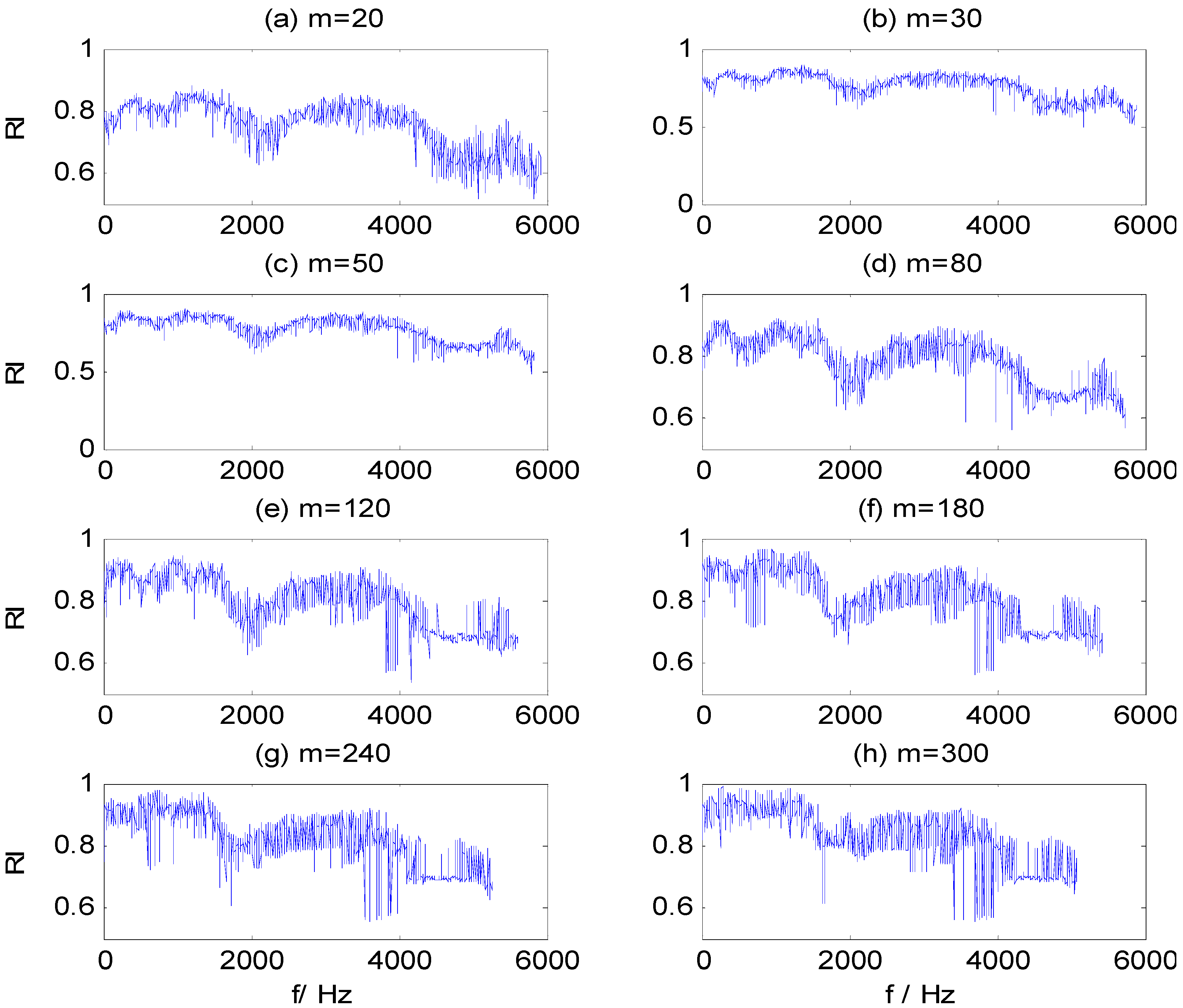
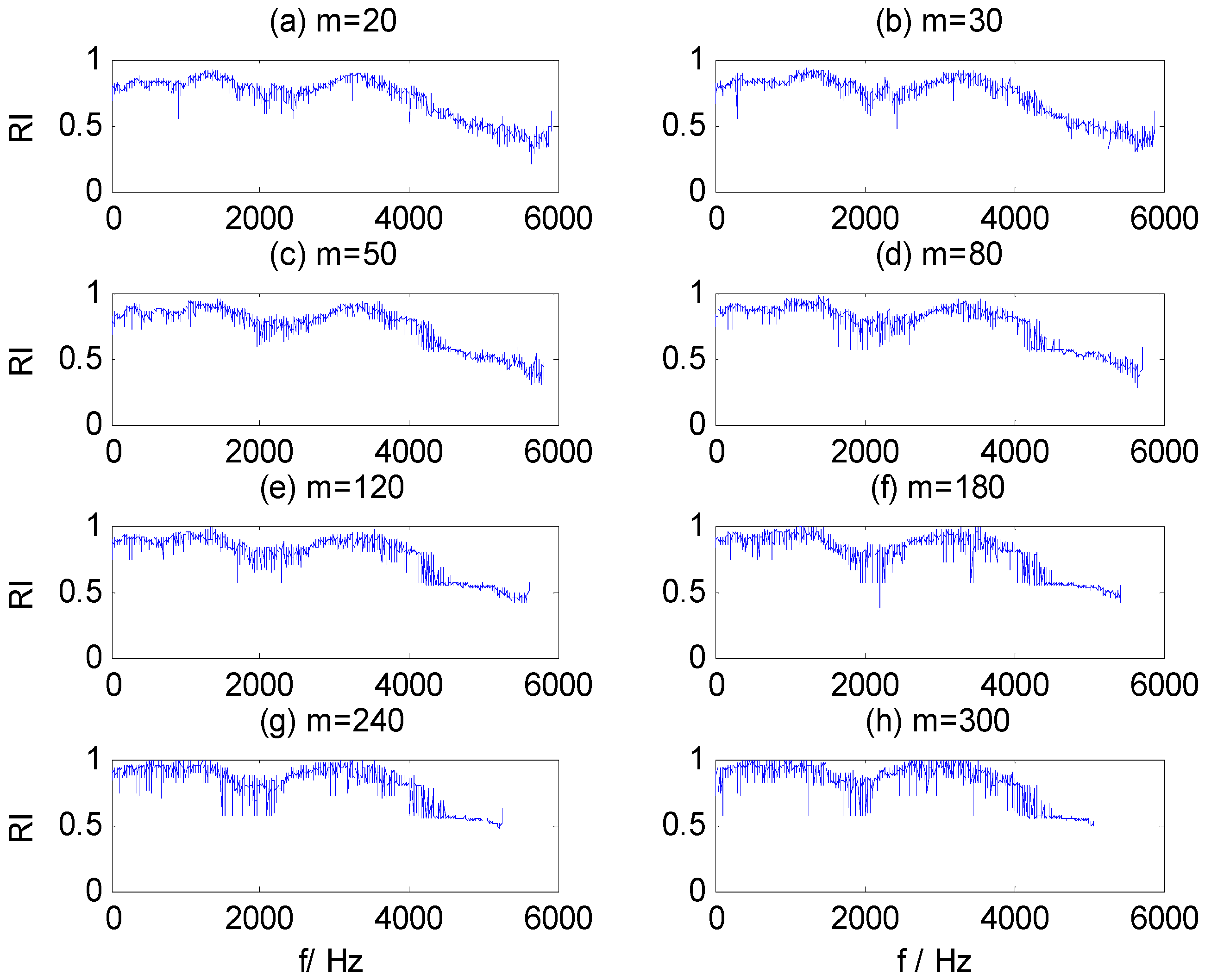
Figure 7a–g contains the RI sequences for dataset B training samples, calculated by WMSC at different window sizes
m, where the x-axis is the start frequency component for the sub-HMS window set and the y-axis is the corresponding RI value. The same figure illustrates that the distribution of RI values presents certain regularity at different window sizes: (1) the RI value is greater in two frequency bands, 1200–1500 Hz and 3300–3700 Hz; and (2) the waveform and change trend of the RI sequences are similar. Furthermore, the extreme RI sequence values increase and variability is aggravated with increased of window size. Appropriate values for WMSC method parameters,
m and
Pmin, are needed to extract optimal CFBs, from which salient HMS features are then extracted.
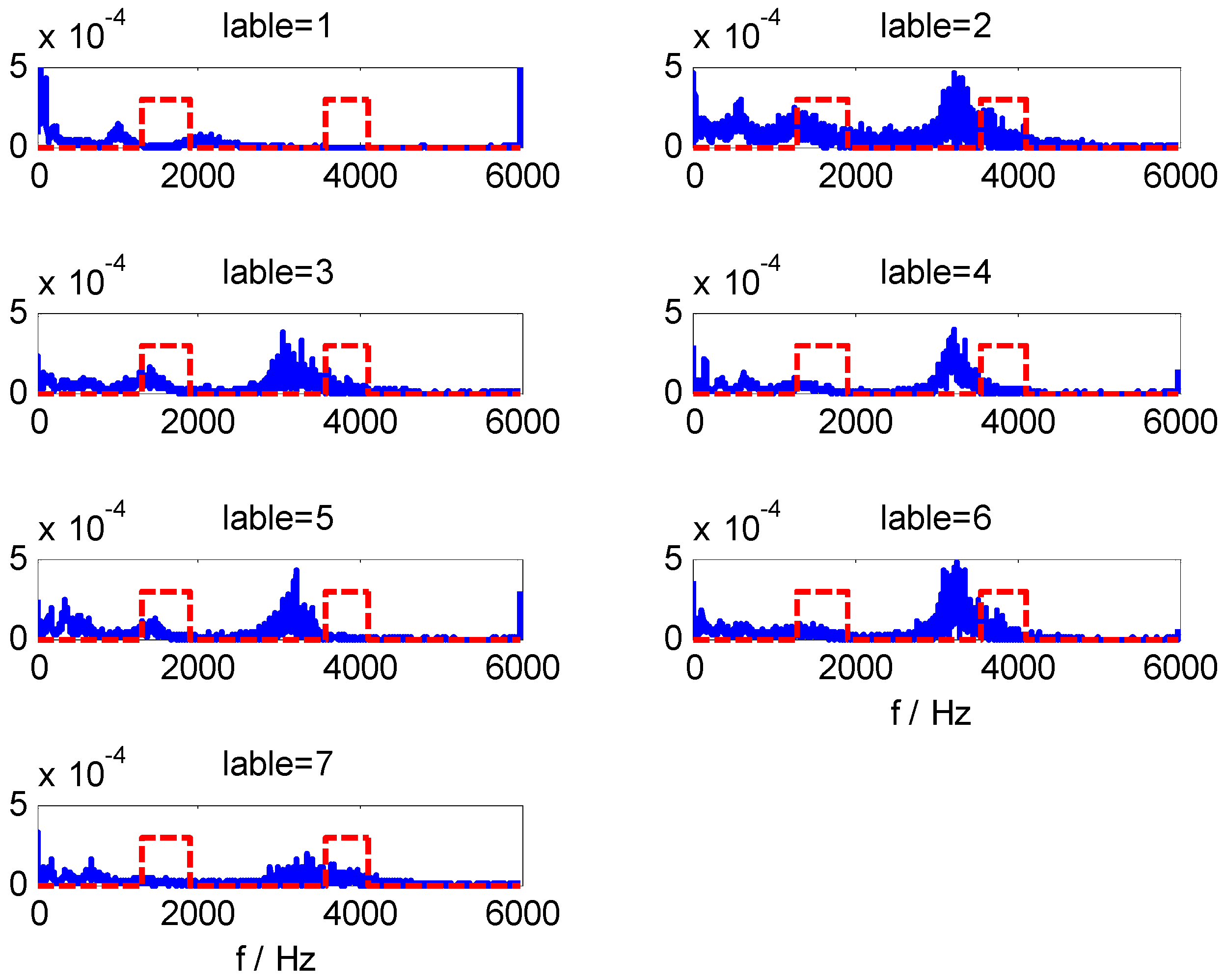
For data set B, we can obtain CFBs by WMSC method using the optimal model parameters
m = 168 and
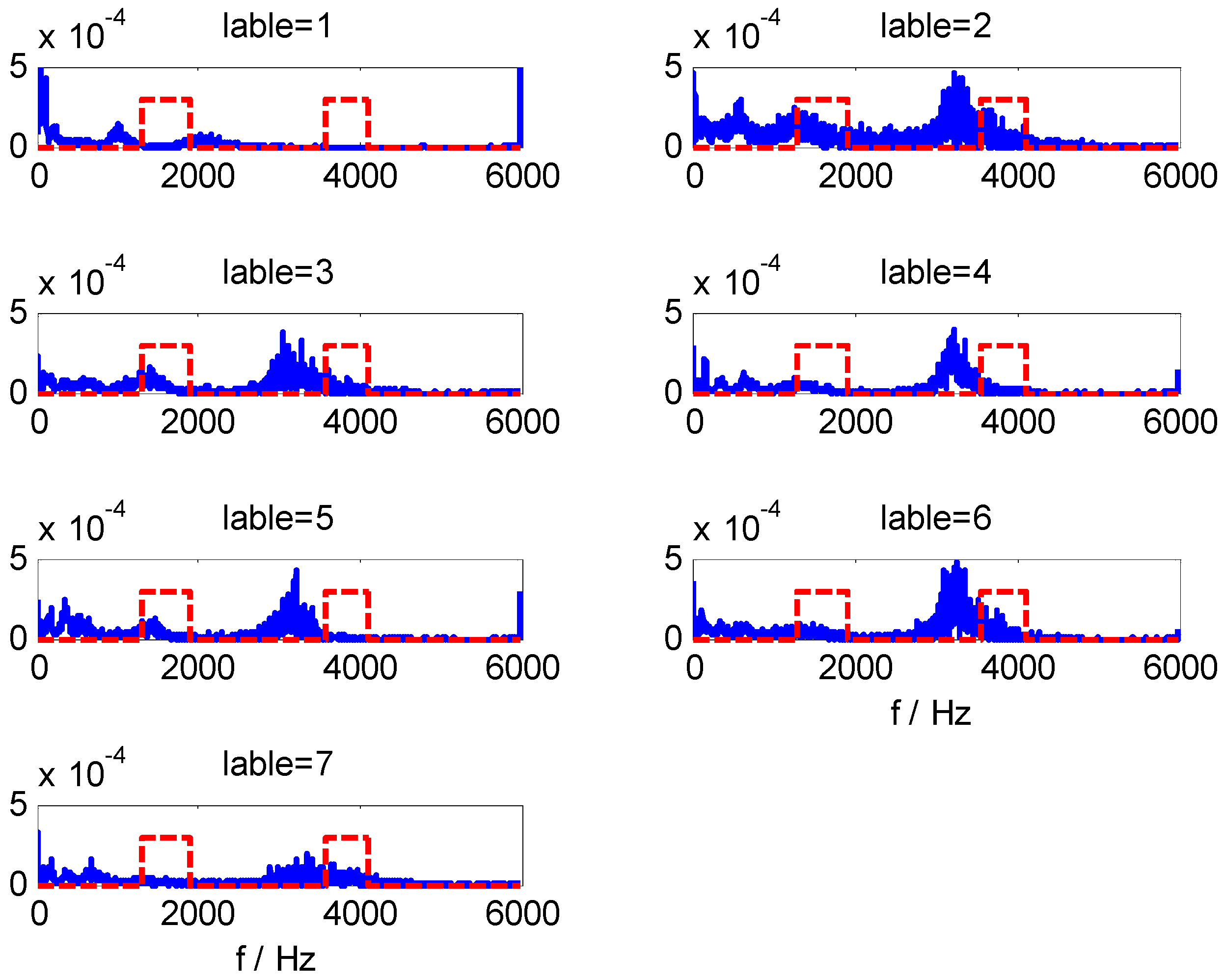
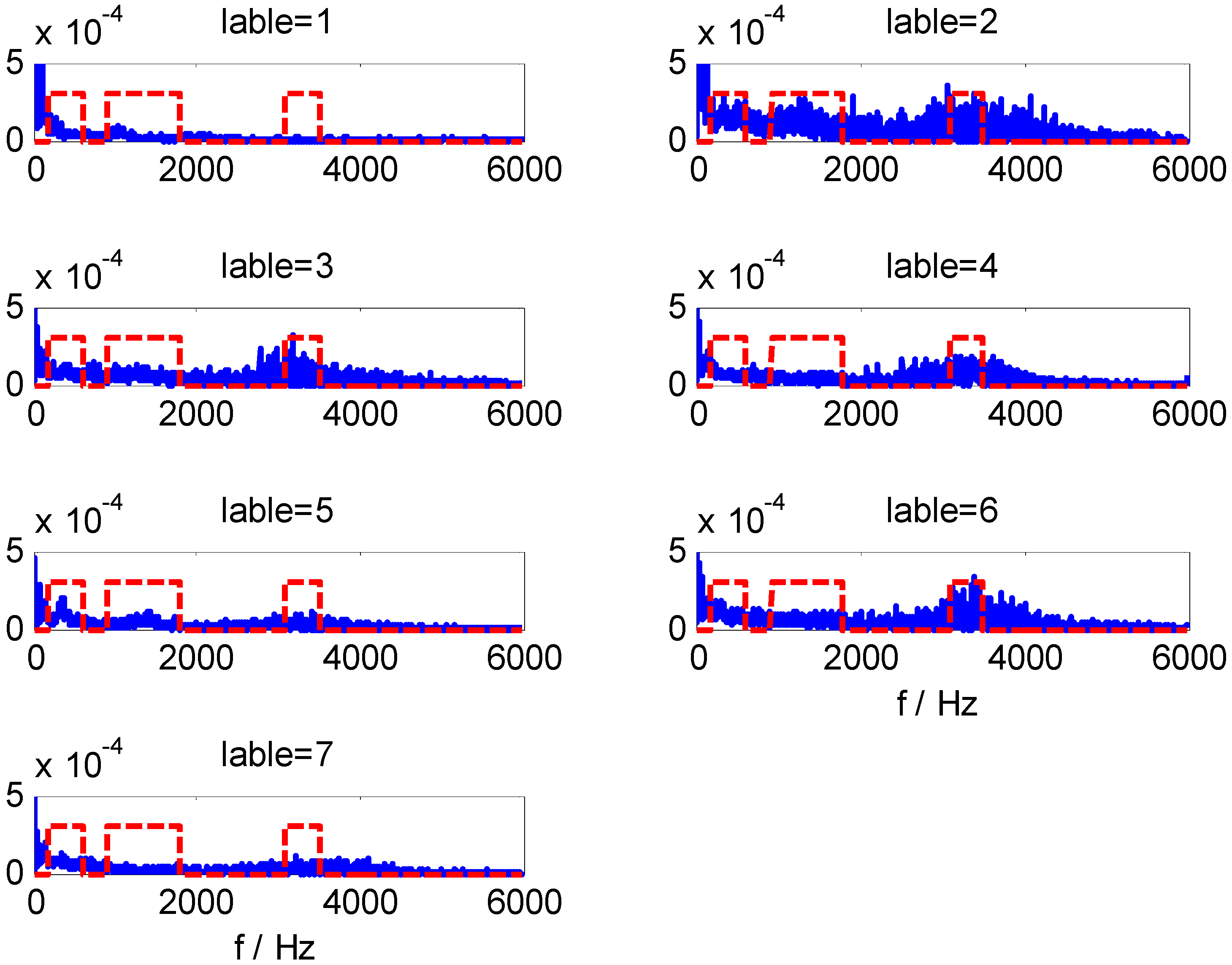
Pmin = 375. The extracted HMS-CFBs of seven samples among different kinds of fault types are shown in
Figure 8, where the HMS curve is blue and the non-zero areas along the red dotted line are the selected CFBs. Comparisons of multiple samples sets (
Figure 8 shows only one sample set in different fault types) confirm the high sensitivity for fault-type identification of extracted HMS-CFBs.
Figure 7.
RI value sequences in different window size m. (a) m = 20; (b) m = 30; (c) m = 50; (d) m = 80; (e) m = 120; (f) m = 180; (g) m = 240; (h) m = 300.
Figure 7.
RI value sequences in different window size m. (a) m = 20; (b) m = 30; (c) m = 50; (d) m = 80; (e) m = 120; (f) m = 180; (g) m = 240; (h) m = 300.
Figure 8.
The extracted HMS-CFBs of samples in different kinds of fault types.
Figure 8.
The extracted HMS-CFBs of samples in different kinds of fault types.
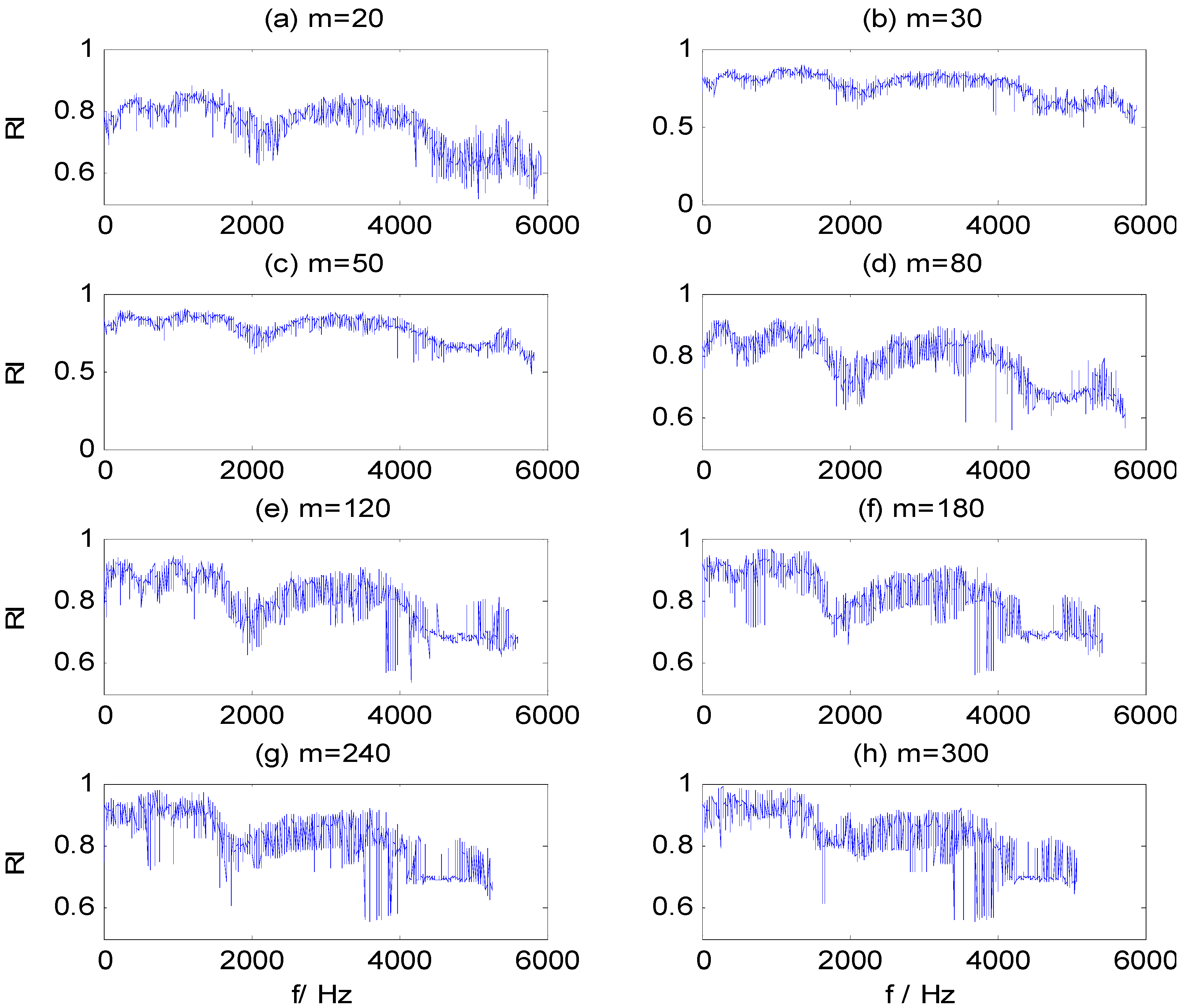
By adding Gauss white noise to the vibration signals of dataset B at different SNR values, we further test the three models, for which
Table 7 shows classification results. It can be seen that the impact on the classification results of these models is very small when SNR exceeds 10. However, when SNR is less than 10, the classification accuracy of ST-SVM and HHT-SVM models are significantly reduced with the decrease of SNR, while the HHT-WMSC-SVM model still maintains high classification accuracy. The result shows that the HMS-CFBs extracted by the WMSC method can reduce unconsidered information that is not sensitive to fault detection and improve the anti-noise ability of the model. For the training samples of dataset B with added noise at SNR = 5, the RI sequences calculated by WMSC at different window sizes
m are shown in
Figure 9a–h. The extracted HMS-CFBs of seven samples in different kinds of fault types are shown in
Figure 10.
Table 7.
Bearing fault detection results obtained by ST-SVM, HHT-SVM and HHT-WMSC-SVM models by adding Gauss white noise in different SNRs for dataset B.
Table 7.
Bearing fault detection results obtained by ST-SVM, HHT-SVM and HHT-WMSC-SVM models by adding Gauss white noise in different SNRs for dataset B.
| SNR | ST-SVM Classification Accuracy (%) | HHT-SVM Classification Accuracy (%) | HHT-WMSC-SVM Classification Accuracy (%) |
|---|
| Training | Testing | Training | Testing | Training | Testing |
|---|
| 3 | 95.71 | 84.64 | 96.42 | 79.64 | 99.28 | 95.00 |
| 5 | 97.85 | 87.85 | 95.00 | 84.29 | 99.28 | 98.57 |
| 7 | 98.57 | 89.64 | 99.28 | 92.86 | 99.28 | 99.28 |
| 9 | 98.57 | 88.57 | 100 | 95.35 | 100 | 98.57 |
| 11 | 98.57 | 90.35 | 100 | 96.42 | 99.28 | 99.28 |
| 13 | 99.20 | 90.00 | 99.28 | 95.71 | 99.28 | 99.28 |
| 15 | 99.29 | 92.50 | 99.28 | 97.50 | 100 | 99.64 |
Figure 9.
RI value sequences in different window sizes m for SNR = 5. (a) m = 20; (b) m = 30; (c) m = 50; (d) m = 80; (e) m = 120; (f) m = 180; (g) m = 240; (h) m = 300.
Figure 9.
RI value sequences in different window sizes m for SNR = 5. (a) m = 20; (b) m = 30; (c) m = 50; (d) m = 80; (e) m = 120; (f) m = 180; (g) m = 240; (h) m = 300.
Figure 10.
The extracted HMS-CFBs of samples in different kinds of fault types for SNR = 5.
Figure 10.
The extracted HMS-CFBs of samples in different kinds of fault types for SNR = 5.
4.3. Parameters Analysis of the Proposed Model
In order to analyze the effects of the parameters
m and
Pmin in WMSC method on fault classification capability, we test the HHT-WMSC-SVM model under different
m and
Pmin parameters on dataset B, adding Gaussian white noise at SNR = 5, while
C and
g parameters are fixed.
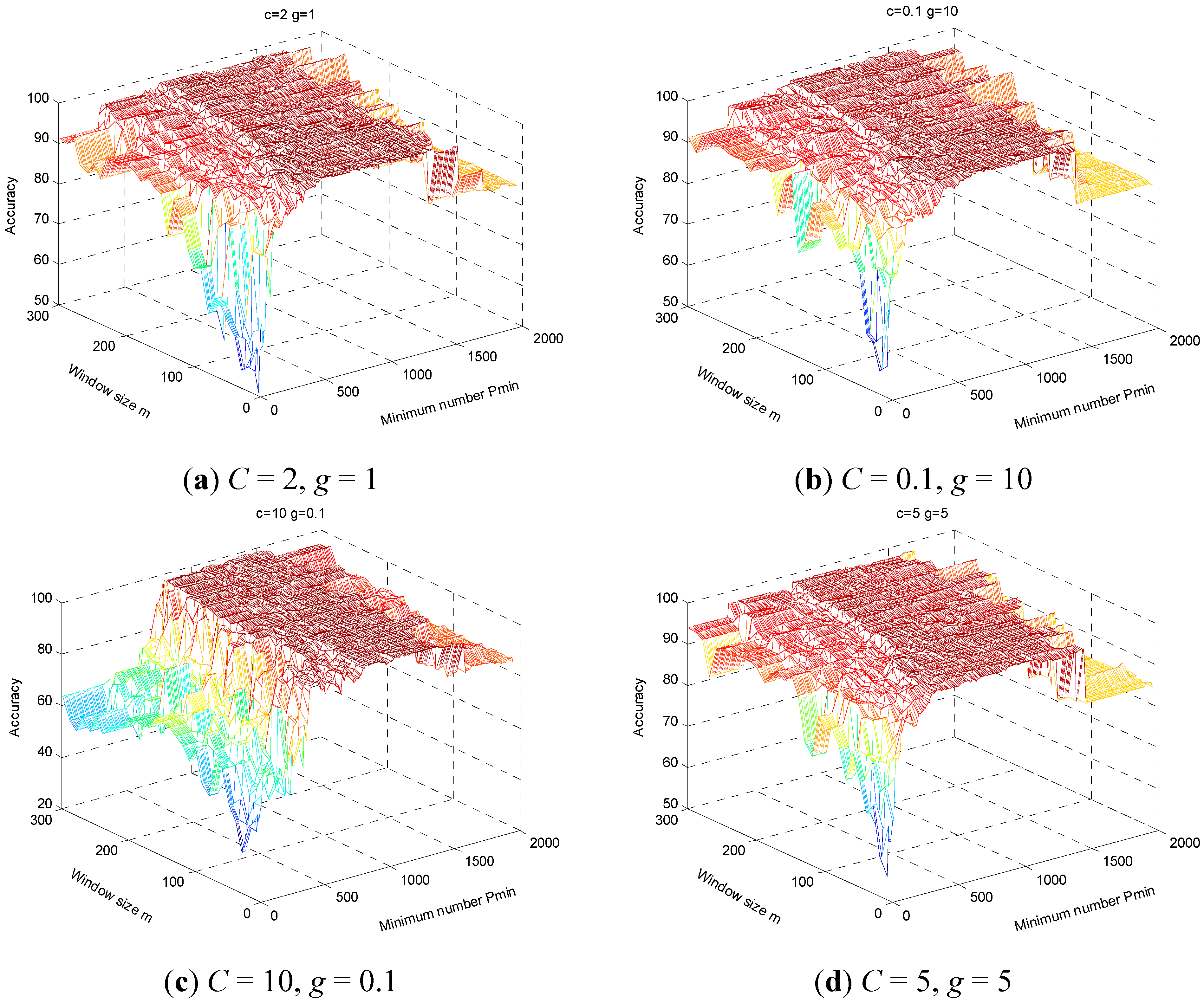
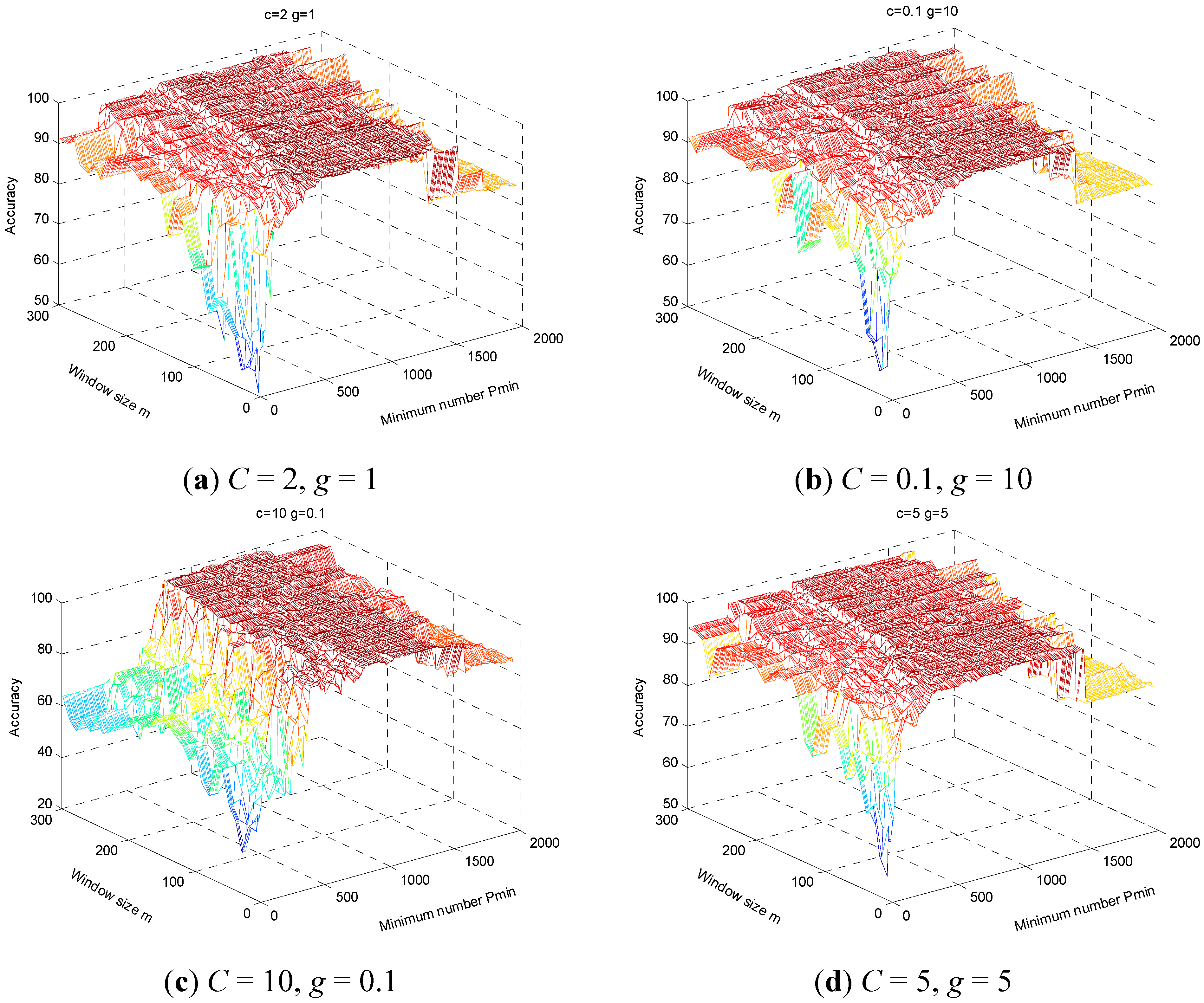
Figure 11 displays results for the above on a three dimensional surface, where the x-axis and y-axis represent the minimum frequency points
Pmin and window size
m, respectively, and the z-axis represents the average classification accuracy. In
Figure 11, parameters
C and
g are fixed to (2, 1), (0.1, 10), (10, 0.1), and (5, 5) (
Figure 11a–d, respectively), the range of
m is 10 ~ 300 and the range of
Pmin is
m~1998. The distribution of classification accuracy presents a strong regularity as follows: (1) the classification accuracy is usually low when
Pmin is less than 300, rising with acceleration until the
Pmin is about 500, and reaching maximum value between 300–800; (2) the model maintains high accuracy when
Pmin is between 500–1300, while classification accuracy begins to decrease when
Pmin is greater than 1500, falling to the same level as that of the HHT-SVM model. Furthermore, classification accuracy is lowest while
m and
Pmin are small (
m < 150,
Pmin < 300), because the extracted features are insufficient to effectively identify fault types, which result shows that the sensitivities to fault types of HMS vary under different frequency bands and some components may influence the effectiveness of the classifier. Improved classification accuracy demands feature extraction, which is more sensitive to the classification target, for which the WMSC method proposed here is suitable.
Figure 11.
The performance of HHT-WMSC-SVM model varies with parameters (m, Pmin) under fixed parameters (C, g).(a) C = 2, g = 1;(b) C = 0.1, g = 10;(c) C = 10, g = 0.1;(d) C = 5, g = 5.
Figure 11.
The performance of HHT-WMSC-SVM model varies with parameters (m, Pmin) under fixed parameters (C, g).(a) C = 2, g = 1;(b) C = 0.1, g = 10;(c) C = 10, g = 0.1;(d) C = 5, g = 5.
4.4. Comparison with Some Previous Works
Table 8 summarizes previous works on automated identification of REBs faults. In [
23,
24,
32], REBs fault locations identification methods were studied, while in other literature, REBs fault locations and fault severities were diagnosed in combination. In [
24], the used dataset was generated by the world pre-eminent NSF Industry/University Cooperative Research Center for Intelligent Maintenance Systems (IMS) and in [
32], datasets were generated using an REBs test bench and locomotive roller bearing test bench, while in other literature, datasets were generated by the Bearing Data Center of CWRU.
Table 8.
Comparison between this paper with some previous research in the literature for REBs fault type and fault severity classification.
Table 8.
Comparison between this paper with some previous research in the literature for REBs fault type and fault severity classification.
| Reference | Features Extraction | Classifier | Fault Types | Training/Testing Samples | Accuracy |
|---|
| [7] | Nine statistical parameters extracted from the paving of wavelet packets at different decomposition depths and sensitive feature selection with DET | C1: SVR
C2: “one-against-one” SVM | D1: 4, HB, IRF, ORF, BF (0.007 in)z D2: 4, HB, IRF, ORF, BF (0.014 in) | 120/240 | C1+D1:100; C1+D2:99.58% C2+D1:97.9%; C2+D2:93.33% |
| [19] | LCD + fuzzy entropy | ANFIS | 7, HB, IRF (0.007, 0.021 in), ORF (0.007, 0.021 in), BF (0.007, 0.021 in) | 70/70 | 100% |
| [23] | Features derived from HOSA of vibration signals + PCA | “one-against all” SVM | 4, HB, IRF, ORF, RF | 234/150 | 96.98 |
| [24] | Time–frequency domain features derived from EMD energy entropy of the first eight IMFs and statistical measurements | ANN | 7, HB, IRD, ORD, RD, IRF, ORF, BF | - | 93% |
| [25] | Time domain features(Range, absolute average, root mean square (RMS) and standard deviation) | Improved ant colony optimization (IACO)-SVM | D1: 4, HB, IRF, ORF, BF (0.007 in) D2: 4, HB, IRF, ORF, BF (0.021 in) | 480/320 | D1: 97.5; D2: 98.25; |
| [30] | Two time–domain features and two frequency–spectrum features | C1: GS-SVM C2: DE-SVM C3: ICDF-BBDE-SVM | 6, IRF, ORF, BF (0.007, 0.021 in) | 420/180 | C1: 98.22; C2:98.28; C3:98.70 |
| [32] | Statistical characteristics in time- and frequency–domains and Statistical characteristics of IMFs, and optimal features selected by bigger distance evaluation criteria | C1: SVM with RBF kernel C2: Wavelet-SVM with Mexican hat kernel C3: Wavelet-SVM with Morlet kernel | D1: 4, HB, IRF, ORF, BF (REBs) D2: 4, HB, IRF, ORF, BF (locomotive roller bearings) | 120/80 | C1+D1:91.25; C2+D1:96.25 C3+D1:97.5 C1+D2:90; C2+D2:97.5; C3+D2:98.75 |
| [33] | Permutation entropy of IMFs decomposed by EEMD | SVM with parameter optimized by ICD | 12, HB, IRF (0.007, 0.014, 0.021, 0.028 in), BF (0.007, 0.014, 0.021, 0.028 in), ORF (0.007, 0.014, 0.021) | 660/990 | 97.91 |
| [37] | F1-F5: SAEMD, KPCA, KFDA, KMFA, SSKMFA | C1: KNN; C2: SVM | 10, HB, IRF (0.007, 0.014, 0.021 in), ORF (0.007, 0.014, 0.021), BF (0.007, 0.014, 0.021, in) | 200/400 | F1+C1:65.5; F2+C1:67.5; F3+C1: 70.75; F4+C1: 75.75; F5+C1: 88.0; F1+C1:88.0; F2+C2: 70.5; F3+C3: 68.25; F4+C4: 98.5; F5+C5: 100; |
Most references in
Table 8 have been tested using the same bearing data set described in this article. In the references, fault features are extracted by statistical characteristics in time domain, frequency domain or time–frequency domain, following, machine learning methods are used for the purpose of fault detection. While, in this article, the entire HMS is choose as the preliminary features for REBs fault diagnosis, which is prove as a feasible solution by the experiment. Meanwhile, in order to remove the redundant and irrelevant information, a CFBs selected method WMSC method is proposed to extract the salient features from the entire HMS.
Table 8 indicates that the usage of CFBs-HMS features along as feature vector yields satisfying result with the most researches. In addition, we test the anti-noise capability of WMSC method by adding Gauss white noise signal at different SNR values to the original vibration signal, which results are very positive.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}