An Adaptive Failure Detector Based on Quality of Service in Peer-to-Peer Networks

{kind=link}
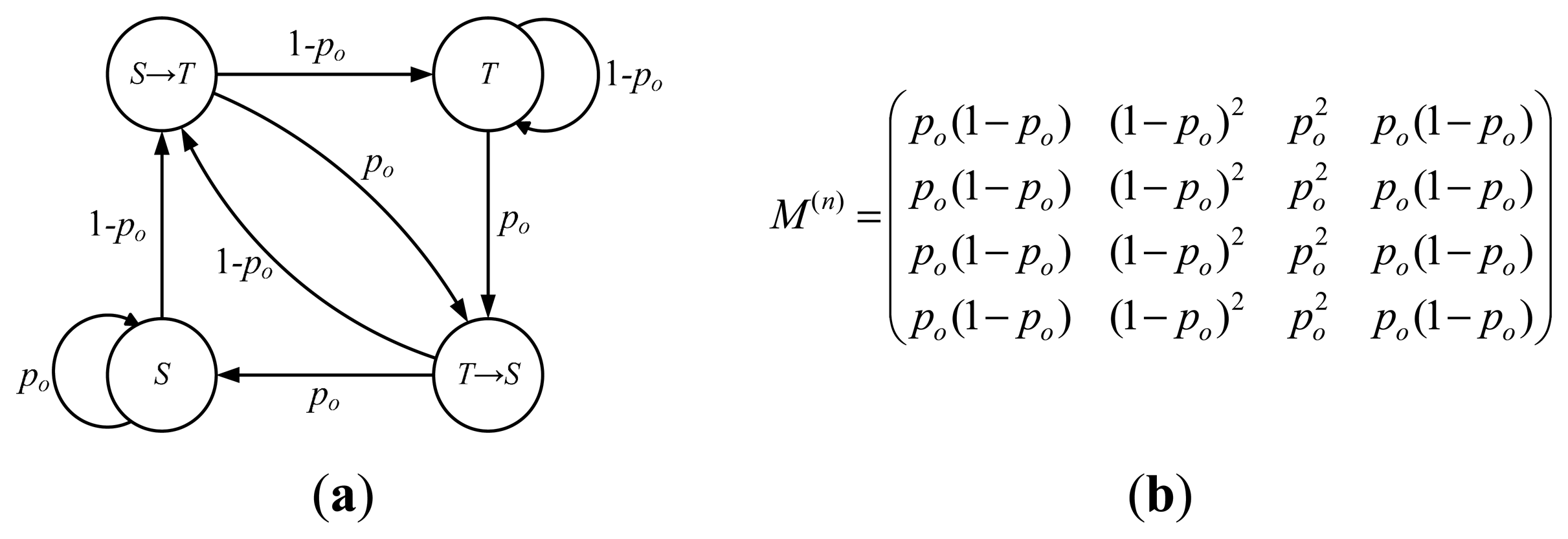{kind=link}
{kind=link}
{kind=link}
Abstract
: The failure detector is one of the fundamental components that maintain high availability of Peer-to-Peer (P2P) networks. Under different network conditions, the adaptive failure detector based on quality of service (QoS) can achieve the detection time and accuracy required by upper applications with lower detection overhead. In P2P systems, complexity of network and high churn lead to high message loss rate. To reduce the impact on detection accuracy, baseline detection strategy based on retransmission mechanism has been employed widely in many P2P applications; however, Chen's classic adaptive model cannot describe this kind of detection strategy. In order to provide an efficient service of failure detection in P2P systems, this paper establishes a novel QoS evaluation model for the baseline detection strategy. The relationship between the detection period and the QoS is discussed and on this basis, an adaptive failure detector (B-AFD) is proposed, which can meet the quantitative QoS metrics under changing network environment. Meanwhile, it is observed from the experimental analysis that B-AFD achieves better detection accuracy and time with lower detection overhead compared to the traditional baseline strategy and the adaptive detectors based on Chen's model. Moreover, B-AFD has better adaptability to P2P network.1. Introduction
Recently, Peer-to-Peer (P2P) network has rapidly become the major computing platform to share resources and services on Internet [1,2]. It can greatly improve network efficiency by taking full advantage of network bandwidth and the computing power of individual network nodes. An important guarantee to maintain the efficiency of P2P network is the high availability in the presence of node failures, as a basic building block for a distributed system of high availability [3], failure detector has always been a hot research topic in the field of P2P networks.
In P2P networks, failure detector provides support for routing recovery and update when failure occurs to maintain the validity of system topology by periodically probing the states of nodes in the system. Quality of Service (QoS) provided by failure detector is an important factor that affects the performance of P2P system, poor accuracy of detection will lead to plenty of unnecessary routing repair and data transfer, which will greatly increase the system overhead, especially in structured P2P networks. The reliability of routing imposes higher requirements on detection time, and the loss of normal packets (sent to failed nodes) has a great impact on the performance of upper applications such as task completion time, network throughput, video frame loss rate, etc. [4]. Meanwhile, the large scale and high churn of P2P networks [5,6] generate heavy detection overhead, which have become the major source of P2P traffic [7]. In the early version of Gnutella, the number of PING messages used for failure detection has exceeded 50% of the entire traffic [8], so far, P2P systems have occupied more than 60% of Internet traffic in China. We can see that detection time, accuracy and overhead all have significant effects on the improvement of P2P system performance. On the other hand, P2P systems may contain participants from any corner of the Internet, different capabilities of processing and network accessing generate complex network environment [9]. For example, comparing a task completed in open network with the one that is completed on a company's internal network, huge difference exists on their network conditions. Therefore, the study of adaptive failure detectors that can ensure the QoS of failure detection with lower overhead according to the changes in network conditions is very significant for building P2P applications.
Most of the current study on QoS-based adaptive failure detector is based on the classic adaptive model proposed by Chen [10], a series of adaptive detectors have been proposed to achieve the quantitative QoS metrics on the dynamic adjustment of detector parameters under different network conditions [10–12]. However, P2P applications covers the entire Internet, complex network conditions and the rapid joining and leaving by large number of nodes make the message loss rate very high, which may easily lead to an increase in false positive rate [13]. Therefore, baseline detection strategy based on retransmission mechanism [4,14] has been widely employed in P2P networks to reduce the impact of message loss on detection results and improve detection accuracy. However, the QoS of baseline strategy cannot be evaluated by Chen's classic model. To address the problem, this paper establishes a novel QoS evaluation model for the baseline detection strategy. The relationship between the detection period and the QoS is discussed and on this basis, a QoS-based adaptive failure detector (B-AFD) is proposed. Under the quantitative control by QoS basic metric [10], B-AFD can adapt to the changing network environment and achieves better accuracy and detection time with lower detection loads. Meanwhile, experimental analysis shows that B-AFD has better adaptability to P2P networks as compared to the traditional baseline strategy and the adaptive detector based on Chen's model.
2. Related Work
2.1. QoS Metrics for Failure Detector
It is well known that in the asynchronous distributed systems with crashed nodes, many important and fundamental problems (e.g., consensus) cannot be solved due to the fact that crashed nodes cannot be distinguished correctly from the nodes that response slowly [15]. Failure detector was first proposed and formally specified by Chandra [16] as an effective way to enhance the computational model for asynchronous system. Currently it has been applied widely in many related fields such as grid computing, cluster management, P2P networks, etc. [17,18]. To evaluate the ability of failure detector to solve consensus problems, Chandra categorized the detection capabilities according to completeness and accuracy. However, in actual systems, an application is much concerned about how fast a failure detector detects crashes and how well it avoids false detections, that is, the detection time and accuracy of failure detector. To evaluate these attributes accurately and quantitatively, Chen et al. proposed a set of quantitative QoS metrics [10,12]. Let T denote the output of failure detector when the monitored node is normal and S denotes the output when the node is failed. T-transition occurs when the output changes from S to T, while S-transition occurs when the output changes from T to S. The QoS provided by failure detector can be quantitatively described by the following basic metrics [10].
Detection time (TD): TD measures the time that elapses from the moment when a node crashes to the time when it starts being suspected (S-transition).
Mistake recurrence time (TMR): TMR measures the time between two consecutive mistakes, it is a random variable representing the time that elapses from an S-transition to the next one.
Mistake duration (TM): TM measures the time it takes the failure detector to correct a mistake, it is a random variable representing the time that elapses from an S-transition to the next T-transition. TMR and TM can specify the detection accuracy.
Based on these three primary metrics, other QoS metrics can be uniquely derived, such as average mistake rate (λM) and query accuracy probability (PA), etc.
2.2. Adaptive Failure Detector
QoS requirement is the main basis for the design of failure detector. Most of failure detectors presented in the literature are implemented using the timeout-based mechanism [19], in which the probing messages are sent out periodically to detect the states of other nodes. Under this mechanism, a detector's behavior can be determined by the failure detection period η and the timeout value δ. As the network conditions (e.g., packets loss rate, transmission delay, etc.) are changing constantly, the QoS of failure detection cannot be guaranteed to meet the design requirements all the time. Therefore, adaptive failure detection algorithms have been proposed to adapt to the changing network conditions by adjusting the parameters η and δ automatically. Initially, such adjustments were achieved by modifying δ according to the prediction of the arrival time for detection messages and a simple trade-off was made between detection time and accuracy. Falai [20] presented the performance comparison of various commonly used prediction methods such as LAST, MEAN, linear sequence etc. After proposing the QoS metrics, Chen [9] presented a classic adaptive model based on the network probability model, and on the basis, many adaptive failure detectors [10–12] are proposed to achieve the quantitative QoS metrics required by upper application with lower detection overhead under different network conditions. However, to reduce the impact on detection accuracy by the high message loss rate resulted from complexity of network and high churn, baseline detection strategy based on retransmission mechanism has been employed widely in P2P systems [4,7,14]. These changes make Chen's classic adaptive model no longer applicable to P2P systems. In order to provide the service of QoS-based adaptive failure detection in P2P systems, this paper establishes a novel QoS evaluation model for the baseline detection strategy that is based on retransmission mechanism and PULL style. Furthermore, a QoS-based adaptive failure detector B-AFD is proposed for P2P networks.
3. QoS Evaluation Model
3.1. Baseline Failure Detection Strategy
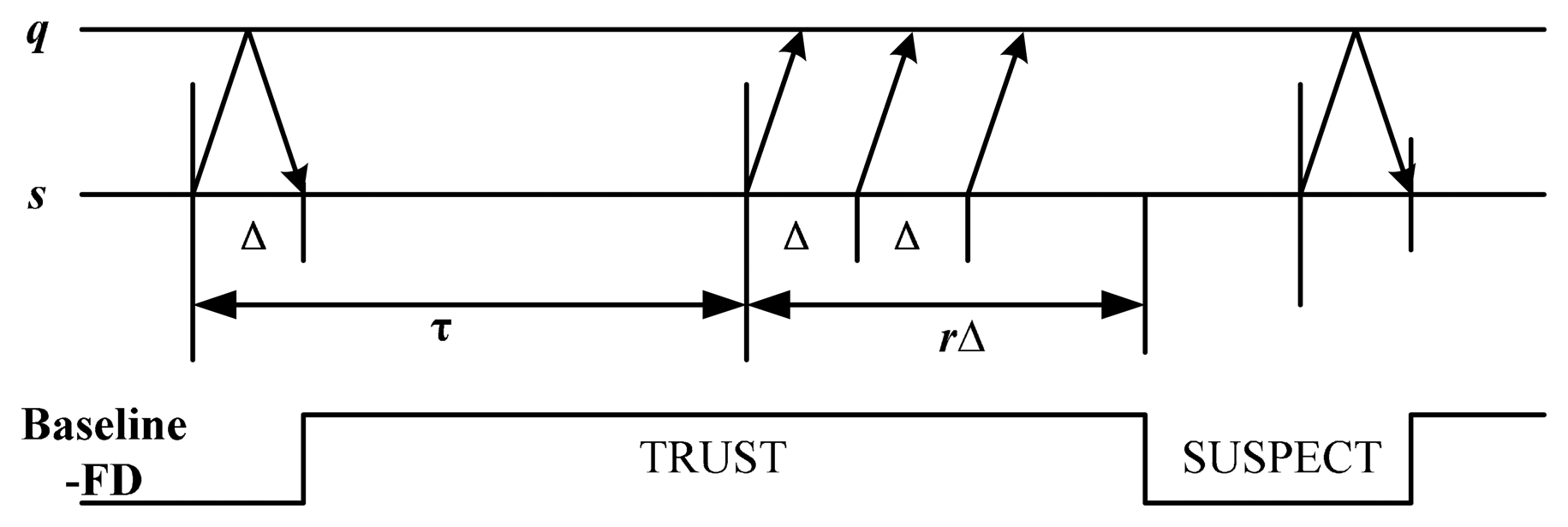
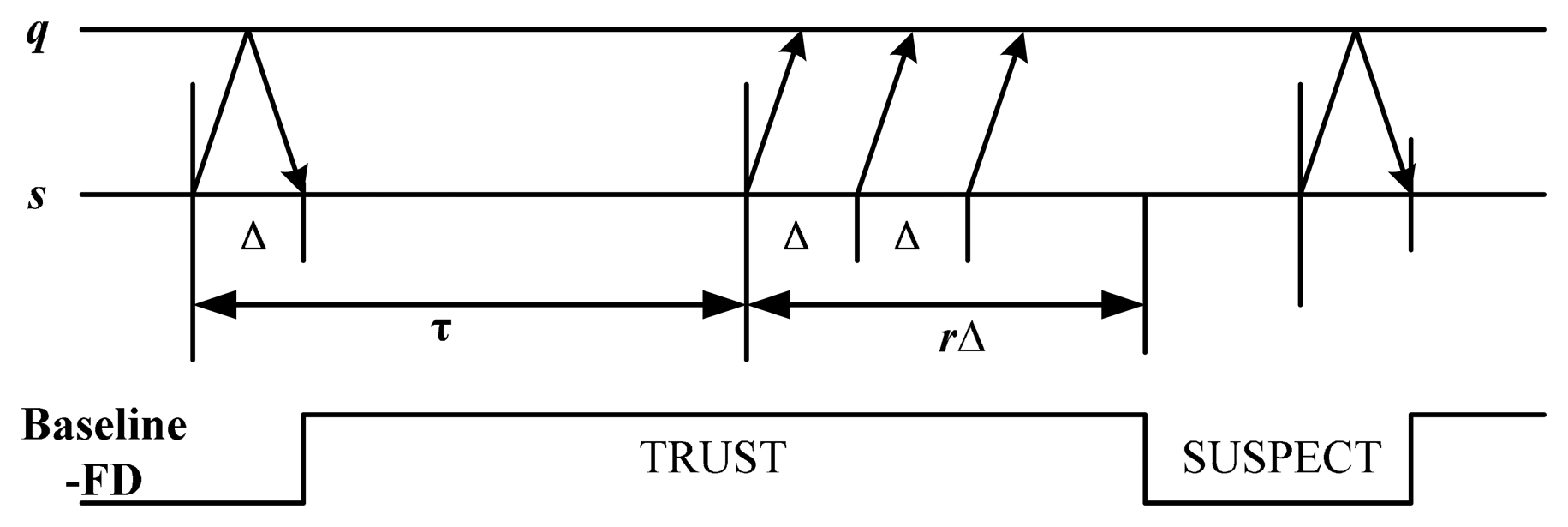
We consider an asynchronous distributed systems which consists of a set of n nodes. The same failure model is employed here as crashing used by Chandra [16]. The channels between nodes are fair-lossy link [21], that is, only a finite number of messages are allowed to be lost, assume the message loss probability is pl. To simply the description, we consider a failure detector module in node s, which detects the state of node q. PULL style [22] is used in the baseline detection strategy and retransmission mechanism is designed in each detection period as shown in Figure 1.
In Figure 1, failure detector module of s sends a probing message “are you alive” to the monitored node q in each detection period (denoted as τ). Node q will send an “ack” message back to acknowledge the receipt of the probing message. If s receives an acknowledge message from q in interval Δ, then the detector output is T. Otherwise, probing packets are sent out periodically at interval Δ. If r consecutive packets cannot receive the “ack” message, then the output of detector is S.
3.2. QoS Analysis
The analysis of QoS evaluation metrics is an important basis for the study of QoS-based adaptive failure detector. Theorem 1 gives the QoS calculation model based on the baseline detection strategy shown in Figure 1.
Theorem 1
In the baseline detection strategy shown in Figure 1, let pl denote the message loss probability, P(D < x) denote the probability distribution of detection message delay (D) and s denote the number of bytes in detection message. We have:
- (1)
Average mistake recurrence time
- (2)
Average mistake duration
- (3)
Detection time TD ≤ τ + rΔ
- (4)
Average detection overhead where p = pl + (1 − pl) P(D > Δ).
The detection message delay is the time that elapses from the sending of probing message to the receipt of “ack” message. We suppose the monitored node q always keeps accurate. For any detection message mqij(i > 0, r ≥ j > 0), the probability that no “ack” is received at time (iτ + jΔ) is pl + (1 − pl) P(D > Δ), that is, the value of p in Theorem 1. To complete the proof of Theorem 1, two lemmas should be given first.
Lemma 1
, where p = pl + (1 − pl) P(D > Δ).
Let {Xi, i > 0} be a random sequence, where random variable Xirepresents the output state of the detector at time (iτ + rΔ). For the baseline strategy in Figure 1, the state space can be defined as G = (T → S, S → T, S, T), e.g., S-transition, T-transition, maintaining S state and maintaining T state. The state transition diagram and the n-step transition probability matrix M(n)(n > 2) for {Xi, i > 0} are shown in Figure 2, where p0is the probability that none of the detection messages is received during a detection period. Thus, we have p0 = pr.
From the Figure 2, we can see that the value of variable Xi (i > 0) is determined jointly by {mqij, 0 ≤ j ≤ r − 1} and the value of Xi-1. Moreover, it is irrelevant to Xj (0 < j < i −1), that is, P(Xi | Xi−1) = P(Xi | Xi−1, Xi−2, …, X0). Hence, the random sequence {Xi, i > 0} is a finite state Markov chain. Since 0 < p0< 1, we can get that {Xi, i > 0} is a recurrent Markov chain and the state T → S is ergodic from the transition matrix M(n). For state T → S, there exists, the average recurrence time is 1/p0(1 − p0). Consider the time needed for an occurrence of state transition in a detector system as τ, we have E(TMR) = τ/pr (1 − pr).
Lemma 2
In the baseline detection strategy shown in Figure 1, the query accuracy probability is, p = pl + (1 − pl) P(D > Δ).
Proof of Lemma 2
Query accuracy probability PA is the probability that the failure detector's output is T at a random time t. That is, the probability that users get an accurate output when query the failure detector at any time.
Consider any detection period i (i > 0) in baseline strategy, suppose Yi is a random variable representing the time that the detector output is T during the period [iτ, (i + 1)τ]. Let's discuss Yi under two situations:
The final output is T during the detection period [(i − 1) τ, iτ)
In this case, in detection period [iτ, (i + 1)τ), if at least one of the r detection messages have been acknowledged in interval Δ, then the output will keep T during the entire period τ. Otherwise, S-transition will occur at time (iτ + rΔ). Hence, we have E(Yi)T = rΔ · pr + τ ·(1 − pr).
The final output is S during the detection period [(i − 1) τ, iτ)
If the detector's state is S in detection period [(i − 1) τ, iτ), then the moment T-transition occurs in period i depends on the time when the first detection message is acknowledged. Thus, we have
In summary, the time that the detector's output is T during the period [iτ, (i + 1)τ) is
In the above equation, the value of E(Yi) is irrelevant to the detection period i. Hence, the query accuracy probability is
Now we prove Theorem 1 using Lemma 1 and Lemma 2.
Proof of Theorem 1
- (1)
It has been proved by Lemma 1.
- (2)
According to Chen's QoS metrics, we have PA = 1 − E(TM)/E(TMR). Then we get E(TM) = (1 − PA)E(TMR). According to Lemma 2, we have
- (3)
In the detection period i, if node q crashes during [iτ, (i + 1)τ), then the failure will be detected no later than ((i +1τ + rΔ)). Thus, the failure detection time satisfies TD ≤ τ + rΔ.
- (4)
In every detection period of baseline strategy, at most r messages are sent out and no more messages will be sent after the first acknowledgement message is received. In detection period i, suppose there is a random variable Zij,
We have P(Zij = 1) = 1 − p and Zij satisfies the Bernoulli distribution with success probability as 1 − p. Hence, the number of messages Nm sent within a detection period satisfies the geometric distribution that is
Now we can get the average detection loads of the algorithm as .
In summary, Theorem 1 is proved.
4. QoS-Based Adaptive Failure Detector B-AFD
is used to describe the quantitative requirements of system designers on the detection accuracy and time of failure detectors, where is an upper bound on the detection time, is a lower bound on the average mistake recurrence time, and is an upper bound on the average mistake duration. B-AFD is based on baseline failure detection strategy, where parameters r and τ are adjusted automatically to adapt to the dynamic network environment in P2P system so that the requirements of QoS metrics are met with relatively low detection overhead. The B-AFD failure detector is described in Alogorithm 1.
| Alogrithm 1: B-AFD failure detector |
| For node s: |
| detector_module: |
| at time τi: (the ith detection period) |
| (rb, τb)=get_opti_para( ); |
| if ((rb = 0 ∧ τb = 0)) then |
| exit (“QoS cannot be achieved”); |
| τi+1 = τi + τb; j←0; |
| do { |
| send mqij to node q at time |
| τi + jΔ; |
| if (receive maij before |
| τi + (j + 1)Δ) then |
| result ← T; break; |
| else j++; |
| } while(j < rb); |
| if (j ≥ rb) then result ← S; |
| gatherer_module: |
| upon receive maij from q do |
| add(tcurrent-(τi + jΔ)) to WD; |
| For node q: |
| upon receive mqij form s do |
| send maij to s; |
B-AFD failure detector is composed of detector_module and gatherer_module. In detector_module, at most rb probing messages mqij are sent out during each detection period. If none of the messages can receive the corresponding “ack” message maij successfully, the detector outputs S for node q; otherwise, the detector believes that q maintains accurate state. From Alogorithm 1, we can see that function get opti para is the core mechanism in B-AFD for the automatic adaptation to network states, which is called to compute the parameters r and τ at the beginning of each detection period. As shown in Alogorithm 2, the algorithm get opti para uses as input parameters so that the detector can be configured to meet the QoS required by upper applications with the minimum overhead. The gatherer_module in B-AFD creates a sliding window WD with fixed size (w). The detection message delay of the w probing messages that are recently acknowledged is saved to calculate the message loss probability pl and establish samples for the estimation of the probability distribution of detection message delay P(D < x).
| Alogorithm 2: Adaptive configuration of parameters |
| get_opti_para( ) |
| Input: |
| Output: r,τ |
| Step 1: compute p = pl + (1 − pl) P(D > Δ); |
| Step 2: if then return (0,0); |
| Step 3: compute , R = [1, rmax]; |
| compute RL = {r|L(r) ≥ 0, r ∈ R} and RU = {r|U(r) ≥ 0, r ∈ R}; |
| Step 4: if RL ∩ RU ==Ø then return (0,0); |
| Step 5: Compute Output = {(r, τ) | r ∈ RL ∩ RU and τ satisfies (1)}; |
| Step 6: find (rb, τb) ∈ output such that B(rb, τb) = min{B(r,τ) | (r, τ) ∈ output}; |
| Step 7: return (rb, τb) |
Theorem 2
If the return value of the algorithm get_opti_para in Alogorithm 2 satisfies (r > 0) ∧ (τ > 0), then the outputs of the failure detector B-AFD can meet the QoS requirements, else B-AFD cannot achieve the given QoS requirements.
Proof of Lemma 2
According to the results in Theorem 1, there are , and . The parameters r and τ satisfy the constraint relationship in Equation (1).
According to Equation (1), if τ exists, then it need satisfy
From Equation (2-c), we get (step2), otherwise the detector is unable to meet the given QoS requirements. From Equation (2-d) we have , then the range of r satisfies . Meanwhile, it can be proved that on interval , L(r) is monotonically increasing and U(r)is monotonically decreasing. According to the constraints Equation (2-a,2-b), we can get the upper bound rU and the lower bound rL for parameter r respectively. If rL ≤ rU, that is, the condition RL ∩ RU ≠ Ø is satisfied in step 4, then r ex0ists; otherwise the detector cannot meet the given QoS requirements under current network conditions. In step 5, using Equation (1), the collection Output contains all the combinations of values for (r, τ) which are capable of meeting the QoS requirements. By the screening procedure in step 6, we can get the parameter configuration (rb, τb) which achieves the minimum detection overhead. Therefore, if the return value of get opti para is non-zero, then the outputs of the failure detector B-AFD configured according to that return value will be able to meet the QoS requirements . Theorem 2 is proved.
5. Experimental Results and Analysis
To evaluate the performance of B-AFD, we compare B-AFD with two typical failure detectors. One is traditional baseline detection strategy with fixed parameters (shown in Figure 1), which has been used the most commonly in current P2P environment. This experiment is to verify the improvement on detection accuracy and overhead by the adaptive mechanism in B-AFD. The other one is QoS-based adaptive detector NFD-E [10], which is compared to verify B-AFD's ability of adapting to the complex P2P network environment. To ensure the authenticity of the experiments, some nodes in currently prevalent P2P applications (emule and Bittorrent) are selected as detection objects, the failure detector node located in Harbin City (China).
In P2P systems, nodes may come from any corner of the Internet with huge difference in network conditions, thereby, the experiments are carried out on two sets of nodes which represent two typical network conditions in P2P networks. One group (dataset 1) contains monitored nodes located in China, which have good network connections with detector node, the message delay and message loss probability are low (pl = 0.39%, E(D) = 125 ms, where E(D) is the expectation of detection message delay). The other group (dataset 2) mainly consists of monitored nodes located in the United States, which have relatively poor connections with detector node (in China), in which the message transmission delay and loss rates are high (pl = 3.65%, E(D) = 412 ms). We choose exponential distribution for detection message delay D with reference to Lakshman's research [23] about failure detector in a P2P storage system, i.e., P(D ≤ x) = 1 − e−x/E(D), for all x > 0.
5.1. Comparisons with the Traditional Baseline Strategy
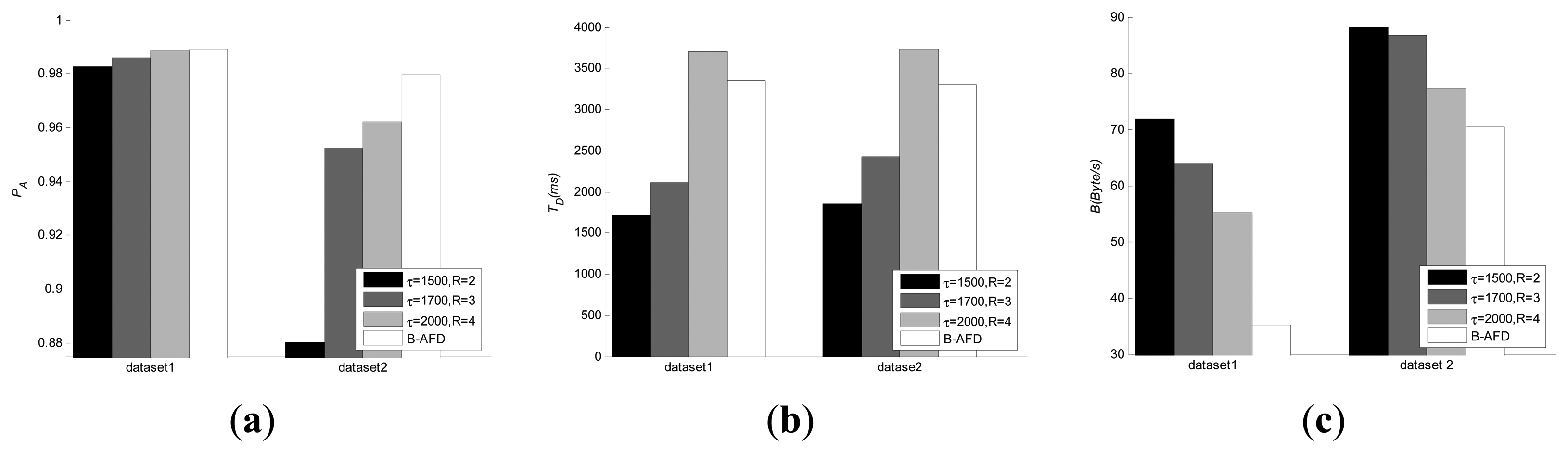
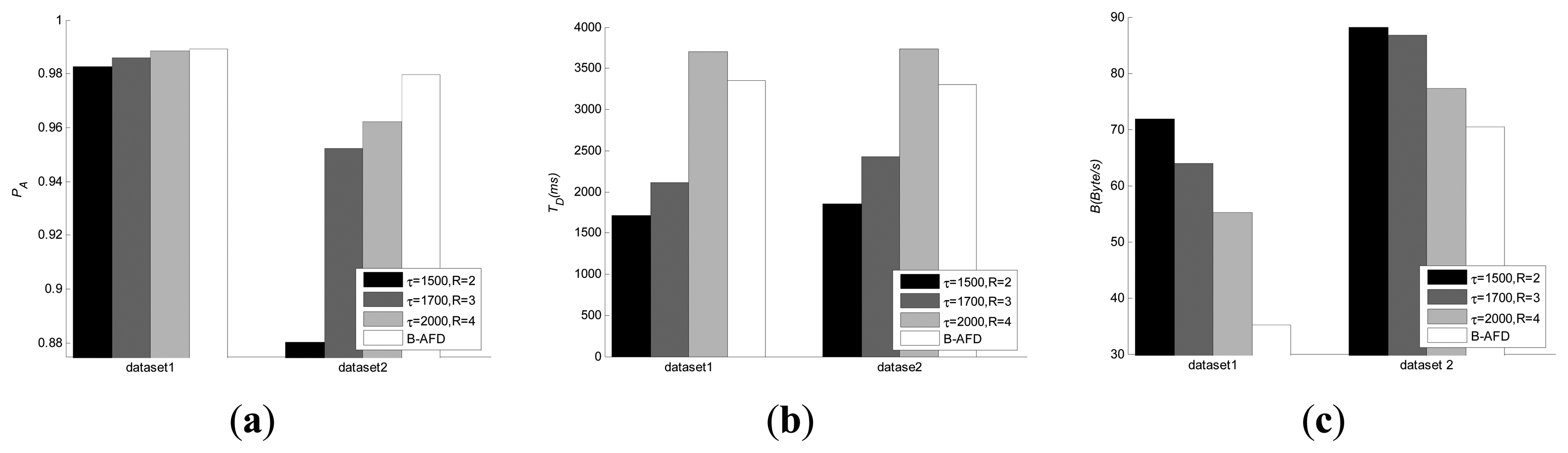
The comparison with baseline strategy is evaluated in three aspects: Detection accuracy, detection time and overhead. Since baseline uses fixed parameters, for fairness, three sets of different parameters are selected for baseline under different network environment. The comparison results are shown in Figure 3.
As we can see from Figure 3, under good network conditions (dataset 1), all the four sets of experiments have achieved high accuracy. Smaller detection period leads to lower detection time, but with higher detection overhead. In the experiments on dataset 2, where the distance of the nodes is far and network condition is poor, the detection accuracy drops significantly for the baseline with smaller detection period. The changes in network conditions make huge difference on QoS, therefore, baseline strategy with fixed period is not applicable to the kind of large-scale distributed systems, such as P2P. Experimental results have shown that B-AFD detectors have good adaptability to different network environment due to the detection parameters adjusted adaptively according to network changing, there is little change in the accuracy and detection time under different network environment and the specified QoS metrics are still satisfied while minimum overhead are maintained. Moreover, Figure 3-c shows that the decrease in overhead is more obvious when the network condition is better.
5.2. Comparisons with NFD-E Adaptive Detector
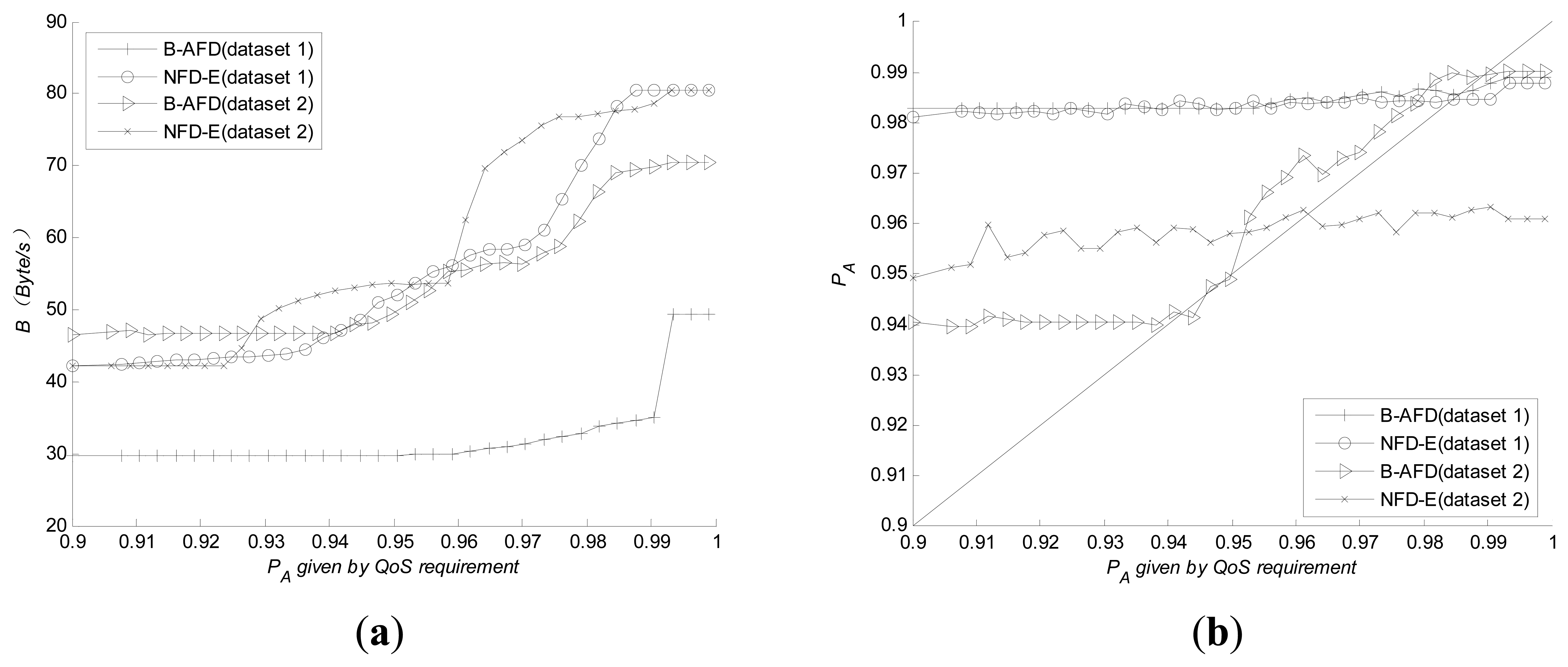
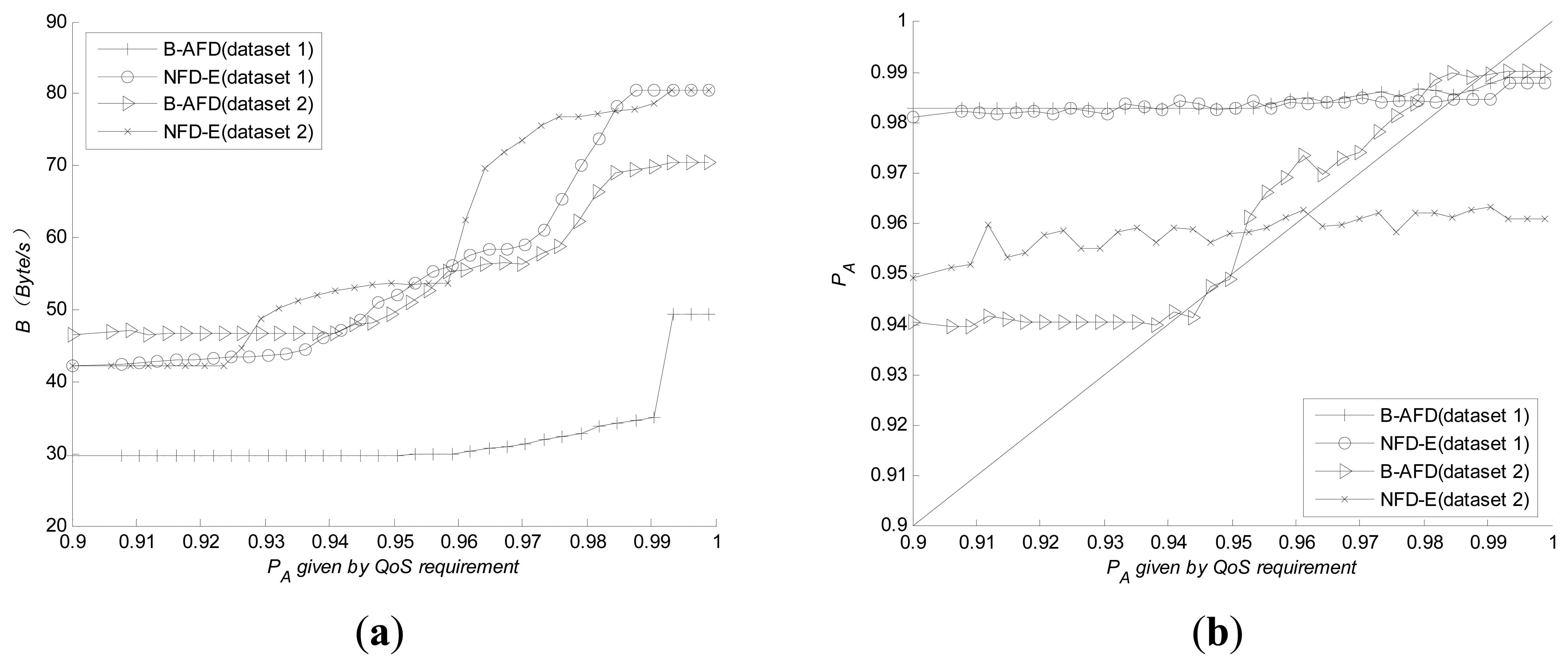
NFD-E is a classical adaptive failure detector proposed by Chen [8], which can meet the requirements of quantitative QoS metrics under different network environment as well without retransmission mechanism. Therefore, experiments are carried out to compare B-AFD and NFD-E in two aspects: The overhead needed to meet the same QoS metrics and the capability of adapting to complex network. The results are shown in Figure 4.
To obtain the same detection accuracy, Figure 4a shows that the detection overhead generated by B-AFD is significantly lower than NFD-E, especially when the requirement of detection accuracy is higher. As can be seen from Figure 4b, B-AFD demonstrates better adaptability under poor network conditions. Given the same QoS metrics, from the experimental results of dataset 2, NFD-E is no longer meet the requirement when the query accuracy exceeds 96%. However, nearly 99% of the query accuracy requirements are met by B-AFD under the same network environment. It is clear that the retransmission mechanism can significantly improve the accuracy under poor network conditions without adding overhead. Under good network conditions, B-AFD demonstrates a very close adaptability to NFD-E while keeping obvious advantage in detection overhead as shown in Figure 4. Therefore, B-AFD is more appropriate for the kind of large-scale distributed systems, such as P2P that have wide coverage and complex network conditions, especially for the structured P2P systems whose node routing tables may contain the nodes from internal LAN and the nodes from overseas at the same time.
6. Conclusions
P2P networks have become the major source of Internet traffic. The study of adaptive failure detector with low detection overhead provides an important method to reduce the overhead of P2P networks. To address the challenges posed to failure detection by the complexity of network and high churn in P2P system, this paper establishes a novel QoS evaluation model for the baseline detection strategy based on retransmission mechanism. On this basis, an adaptive failure detector B-AFD is proposed based on the basic QoS metrics . It can adapt to the changing network environment and achieve better detection accuracy and time with lower overhead. Meanwhile, experimental analysis shows that compared to Chen's adaptive detectors, B-AFD achieves better adaptability to the complex network conditions in P2P systems.
Acknowledgments
This project was supported by National Natural Science Foundation of China under (No. 61100029).
Author Contributions
Jian Dong proposed the original idea, took the leadership on this research work. Xiao Ren contributed to implementation of failure detection and design of experiments. Decheng Zuo and Hongwei Liu contributed to data analyzing. All authors contributed to the discussion, to experiment improvements, to the analysis of results, and to the manuscript writing.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Eng, K.L.; Crowcroft, J.; Pias, M.; Sharma, R.; Lim, S. A survey and comparison of peer-to-peer overlay network schemes. IEEE Commun. Surv. Tutor. 2005, 7, 72–93. [Google Scholar]
- Kurian, J.; Sarac, K. A survey on the design, applications, and enhancements of application-layer overlay networks. Acm Comput. Surv. 2012, 43, 1–34. [Google Scholar]
- Xiong, N.; Vasilakos, A.V.; Wu, J.; Yang, Y.R.; Rindos, A.; Zhou, Y.Z.; Song, W.Z.; Pan, Y. A Self-tuning Failure Detection Scheme for Cloud Computing Service. Proceedings of the 26th International Parallel and Distributed Processing Symposium, Shanghai, China, 21–25 May 2012; pp. 668–679.
- Zhuang, S.Q.; Geels, D.; Stoica, I.; Katz, R.H. On failure detection algorithms in overlay networks. Proceedings of the 24th Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM 2005), Miami, FL, USA, 13–17 March 2005; pp. 2112–2123.
- Ohzahata, S.; Kawashima, K. An experimental study of peer behavior in a pure P2P network. J. Syst. Softw. 2011, 84, 21–28. [Google Scholar]
- Benhamida, F.Z.; Challal, Y.; Koudil, M. ALLONE: A New Adaptive Failure Detector Model for Low-Power Lossy Networks. Proceedings of the IEEE Global Communications Conference, Atlanta, GA, USA, 9–13 December 2013; pp. 91–96.
- Castro, M.; Costa, M.; Rowstron, A. Performance and dependability of structured peer-to-peer overlays. Proceedings of the International Conference on Dependable Systems and Networks, Florence, Italy, 28 June–1 July 2004; pp. 9–18.
- Dedinski, I.; Hofmann, A.; Sick, B. Cooperative keep-alives: An efficient outage detection algorithm for p2p overlay networks. Proceedings of the Seventh IEEE International Conference on Peer-to-Peer Computing, Galway, Ireland, 2–5 September 2007; pp. 140–150.
- Tian, J.; Dai, Y. Understanding the dynamic of peer-to-peer systems. Proceedings of the Seventh IEEE International Conference on Peer-to-Peer Computing, Galway, Ireland, 2–5 September 2007; pp. 151–158.
- Chen, W.; Toueg, S.; Aguilera, M.K. On the quality of service of failure detectors. IEEE Trans. Comput. 2000, 51, 13–32. [Google Scholar]
- Bertier, M.; Marin, O.; Sens, P. Implementation and performance evaluation of an adaptable failure detector. Proceedings of the International Conference on Dependable Systems and Networks, Washington, DC, USA, 23–26 June 2002; pp. 354–363.
- Tiejun, M.; Hillston, J.; Anderson, S. On the quality of service of crash-recovery failure detectors. IEEE Trans. Dependable Secur. Comput. 2010, 7, 271–283. [Google Scholar]
- Stutzbach, D.; Rejaie, R. Understanding churn in peer-to-peer networks. Proceedings of the Internet Measurement Conference, Rio de Janeiro, Brazil, 25 October 2006; pp. 189–202.
- Price, R.; Tino, P. Still alive: Extending keep-alive intervals in P2P overlay networks. Proceedings of the 5th International Conference on Collaborative Computing: Networking, Applications and Worksharing, Washington, DC, USA, 11–14 November 2009; pp. 1–10.
- Fischer, M.J.; Lynch, N.A.; Paterson, M.S. Impossibility of distributed consensus with one faulty process. J. ACM 1985, 32, 374–382. [Google Scholar]
- Chandra, T.D.; Toueg, S. Unreliable failure detectors for reliable distributed systems. J. ACM 1996, 43, 225–267. [Google Scholar]
- Lavinia, A.; Dobre, C.; Pop, F.; Cristea, V. A failure detection system for large scale distributed systems. Proceedings of the 2010 International Conference on Complex, Intelligent and Software Intensive Systems (CISIS), Krakow, Poland, 15–18 February 2010; pp. 482–489.
- Costache, S.; Ropars, T.; Morin, C. Towards highly available and self-healing grid services; Le Chesnay, France; Institut National des Sciences Appliquées de Rennes (INRIA), 2010; inria-00476276. [Google Scholar]
- Pasin, M.; Fontaine, S.; Bouchenak, S. Failure detection in large scale systems: A survey. Proceedings of the IEEE Network Operations and Management Symposium Workshops, Bahia, Brazil, 7–11 April 2008; pp. 165–168.
- Falai, L.; Bondavalli, A. Experimental evaluation of the QoS of failure detectors on wide area network. Proceedings of the International Conference on Dependable Systems and Networks, Yokohama, Japan, 28 June–1 July 2005; pp. 624–633.
- Zhang, J.; Chen, W. Implementing uniform reliable broadcast with binary consensus in systems with fair-lossy links. Inf. Process. Lett. 2009, 110, 13–19. [Google Scholar]
- Felber, P.; Defago, X.; Guerraoui, R.; Oser, P. Failure detectors as first class objects. Proceedings of the International Symposium on Distributed Objects and Applications, Edinburgh, UK, 5–6 September 1999; pp. 132–141.
- Lakshman, A.; Malik, P. Cassandra: A decentralized structured storage system. ACM SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar]

© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Dong, J.; Ren, X.; Zuo, D.; Liu, H. An Adaptive Failure Detector Based on Quality of Service in Peer-to-Peer Networks. Sensors 2014, 14, 16617-16629. https://doi.org/10.3390/s140916617
Dong J, Ren X, Zuo D, Liu H. An Adaptive Failure Detector Based on Quality of Service in Peer-to-Peer Networks. Sensors. 2014; 14(9):16617-16629. https://doi.org/10.3390/s140916617
Chicago/Turabian StyleDong, Jian, Xiao Ren, Decheng Zuo, and Hongwei Liu. 2014. "An Adaptive Failure Detector Based on Quality of Service in Peer-to-Peer Networks" Sensors 14, no. 9: 16617-16629. https://doi.org/10.3390/s140916617