A Cognition-Based Method to Ease the Computational Load for an Extended Kalman Filter


Abstract
: The extended Kalman filter (EKF) is the nonlinear model of a Kalman filter (KF). It is a useful parameter estimation method when the observation model and/or the state transition model is not a linear function. However, the computational requirements in EKF are a difficulty for the system. With the help of cognition-based designation and the Taylor expansion method, a novel algorithm is proposed to ease the computational load for EKF in azimuth predicting and localizing under a nonlinear observation model. When there are nonlinear functions and inverse calculations for matrices, this method makes use of the major components (according to current performance and the performance requirements) in the Taylor expansion. As a result, the computational load is greatly lowered and the performance is ensured. Simulation results show that the proposed measure will deliver filtering output with a similar precision compared to the regular EKF. At the same time, the computational load is substantially lowered.1. Introduction
In statistics and parameter estimation, the Kalman filter is a mathematical method named after Rudolf E. Kalman [1,2]. Its purpose is to use observations (measurements), which are observed over time and that contain noise (random processes) and other inaccuracies, to arrive at values that tend to be closer to the true values of the observations and their associated calculated values [1,3].
The Kalman filter is a very useful facility in parameter estimation, target tracking and data fusion [1,4]. One of its conveniences is that, when the observation noise (or measure noise) is Gaussian, the predicting covariance matrix, the filtering gain and the filtering covariance matrix can be calculated offline [1,5]. An example is as follows. In radar target tracking, if the target's state equation and the sensor's measure equation are either linear in the same coordinate and the measure noise is Gaussian with zero mean, then the Kalman filter algorithm is fairly brief, and the request for minimum variance is easy to meet [6,7].
However, the Kalman filter needs a linear observation model, which may be impractical in some circumstances [7,8]. To address the problem when observation models become nonlinear, researchers developed sub-optimal extensions of a Kalman filter. In these methods, the extended Kalman filter (EKF) is the nonlinear version of a Kalman filter [9,10]. It linearizes the estimation of the current mean and covariance [11]. In the scenario of well-defined transition models, the EKF has been considered to be a practical means of nonlinear state estimation [7,12].
The literature on the Kalman filter and EKF is extensive. In distributed sensor and/or collaborative sensor networks, the Kalman filter and EKF are frequently employed in parameter estimation and target tracking [13,14]. For instance, to smooth a tractor global positioning system (GPS) that is sharpened when the tractor moves over rough terrain, an improved Kalman filter is proposed [13]. The novel filter can satisfactorily preprocess the low-cost GPS receiver data [13]. In distributed state estimation for wireless sensor network, when the system process model and observation model are nonlinear, it is proven that the distributed extended Kalman filter can provide an identical state estimation of the system state [15,16]. For estimating the three-dimensional orientation of a rigid body, a quaternion-based EKF is developed [17,18]. Another example shows that EKF is effective at target tracking in the presence of glint noise [19]. The extended Kalman filter can also be employed to an online training forward neural network applied to time series predicting [20]. It is proven that this nonlinear filtering method has some advantages, such as handling additive noises and following the movement of a system when the underlying model is evolving through time [20].
Based on the aforementioned materials, it can be seen that EKF has been widely used. Unfortunately, the computational load is a bottleneck in the implementation of an extended Kalman filter [21]. Due to the limited resources and heavy clutter, this problem may be complicated for an airborne radar system or a space-borne radar system. Since most of the EKF has a nonlinear observation model (as is also true in this work), linearization of the nonlinear observation model is continuously investigated [11]. The work of linearization is greatly affected by a varying scenario, and this raises the computational load when it generates a statistically optimal estimation of the real system state [4]. Therefore, algorithms to lower the computational cost have been addressed [4].
It is clear that the extra computational load brought to EKF compared to a Kalman filter is linearizing the nonlinear observation model in the above-mentioned situation. Therefore, most of these methods introduce the Taylor expansion technology [4,22,23]. The nonlinear observation model is expressed by the Taylor expansion. The frequently-used approach is a one-order Taylor expansion [22,24]. In simple scenarios, it is beneficial for lowering the computational requirements (our previous work showed that the Taylor expansion technology is also helpful for lowering the computational load for a Kalman filter [5]). However, due to the fixed designation, the actual precision will be scenario dependent. For some complicated scenarios (or in complicated processing steps), the output performance may be non-ideal. For smooth points, some of the calculations may be unnecessary. The filter is thus not flexible.
On the other side, cognitive radar and knowledge-aided signal processing are investigated [25,26]. A fully-cognitive radar (active radar) can adapt both its receiver and transmitter in response to statistical variations in the environment in real time [25]. Therefore, it can meet specific remote-sensing objectives in an efficient, reliable and robust manner [25]. For an active radar, there are many available works on target tracking based on cognitive processing [27–29]. However, for a passive radar, the existing work focusing on target tracking based on cognitive processing is limited.
In view of the above-mentioned facts, this work investigates a novel fast EKF method when there is a nonlinear observation model (particularly for a passive radar) [5]. The contributions are as follows. With the help of cognitive processing, a new fast EKF method is proposed. The items calculated in the Taylor expansion of the filtering gain and the localizing steps depend on the filtering performance at the last step. As a result, this designation saves time and computational resources. At the same time, it offers an adjustable performance. The designation of a fast EKF algorithm is thus perfected.
This paper is arranged as follows. Firstly, the problem and its background have been analyzed. The key ideas of this work are explained. These are the main contents in Section 1. The rest of the paper is organized as follows:
The variables and their definitions are collected in Section 2.
Section 3 details the processing techniques of an extended Kalman filter.
The majority of our work presents the novel designation for an EKF. The cognition idea and the algorithm are further detailed in Section 4.
Simulation results and the analysis of them are shown in Section 5.
In Section 6, a simple summary is provided.
2. Nomenclature
Variables related to the target's state and observation:
x(k) = [x(k) ẋ(k) y(k) ẏ(k)]T is the target's state. It is a vector (2 × 1), which consists of the position and the velocity in the XoY plane.
z(k) = [θ(k) θ̇(k)]T + w(k) is the observation. It is a vector (2 × 1), which consists of the azimuth and the rate of change in the azimuth of the target. The observation noise is included.
w(k) is the observation noise introduced by the sensor and the propagation effects. It is a vector (2 × 1) in this work. After linearizing the observation model, the observation noises are w0(k) and w1(k).
Δt is the data acquisition period.
Variables related to predicting and filtering:
x̂(k + 1∣k) is the predicting output (by the filter) of the target's state. It is a vector (4 × 1) in this work.
x̂(k∣k) is the filtering output. It is a vector (4 × 1) in this work.
ν(k + 1) is the innovation. It is a vector (2 × 1) in this work.
R(k) is the covariance matrix of the observation noise. It is a matrix with 2 × 2 entries in this work.
P(k + 1∣k) is the covariance matrix of the predicting noise. It is a matrix with 4 × 4 entries in this work.
is the predicting output (by the filter) of the target's azimuth and the rate of change in the azimuth. It is a vector (2 × 1) in this work.
ϕ(k + 1, k) is the transition matrix from time k to time k + 1. It is a matrix with 4 × 4 entries in this work.
C(k + 1) is the observation matrix. It is a matrix with 2 × 4 entries in this work. Different algorithms may have different expressions for the observation matrix. They are named C0(k + 1) and C1(k + 1), respectively.
K(k + 1) is the filtering gain at time k + 1. It is a matrix with 4 × 2 entries in this work.
Variables related to performance evaluation:
For predicting the target's azimuth and the rate of change in the azimuth:
Dpredict(k) is the difference between the predicting output and the observation.
Ppredict (k) is the predicting performance.
ηpredict = [η11 η12]T is the performance bound for predicting.
For estimating the target's state:
Dlocalize(k) is the difference between the filtering output and the localizing result via the observation.
Plocalize(k) is the localizing performance.
ηlocalize = [η21 η22 η23 η24]T is the performance bound for localizing.
Temporal variables:
There are some temporal variables (ψ1(k), ψ2(k), ς, ξ, etc.) defined to facilitate the mathematical description. They are not collected here.
3. The Extended Kalman Filter
As previously mentioned, the EKF is an approximate solution that allows us to extend the Kalman filtering idea to nonlinear observation models [30,31]. The EKF is presented with a classical target tracking application in this work. In signal processing, target localizing is performed, and the target's azimuth (orientation) is predicted.
3.1. The State Vector and the Observation Model
In particular, the state vector and the observation model take the form:
However, only the azimuth and the rate of change in the azimuth of the target are observed by the employed passive radar. Thus,
3.2. The Observation Geometry
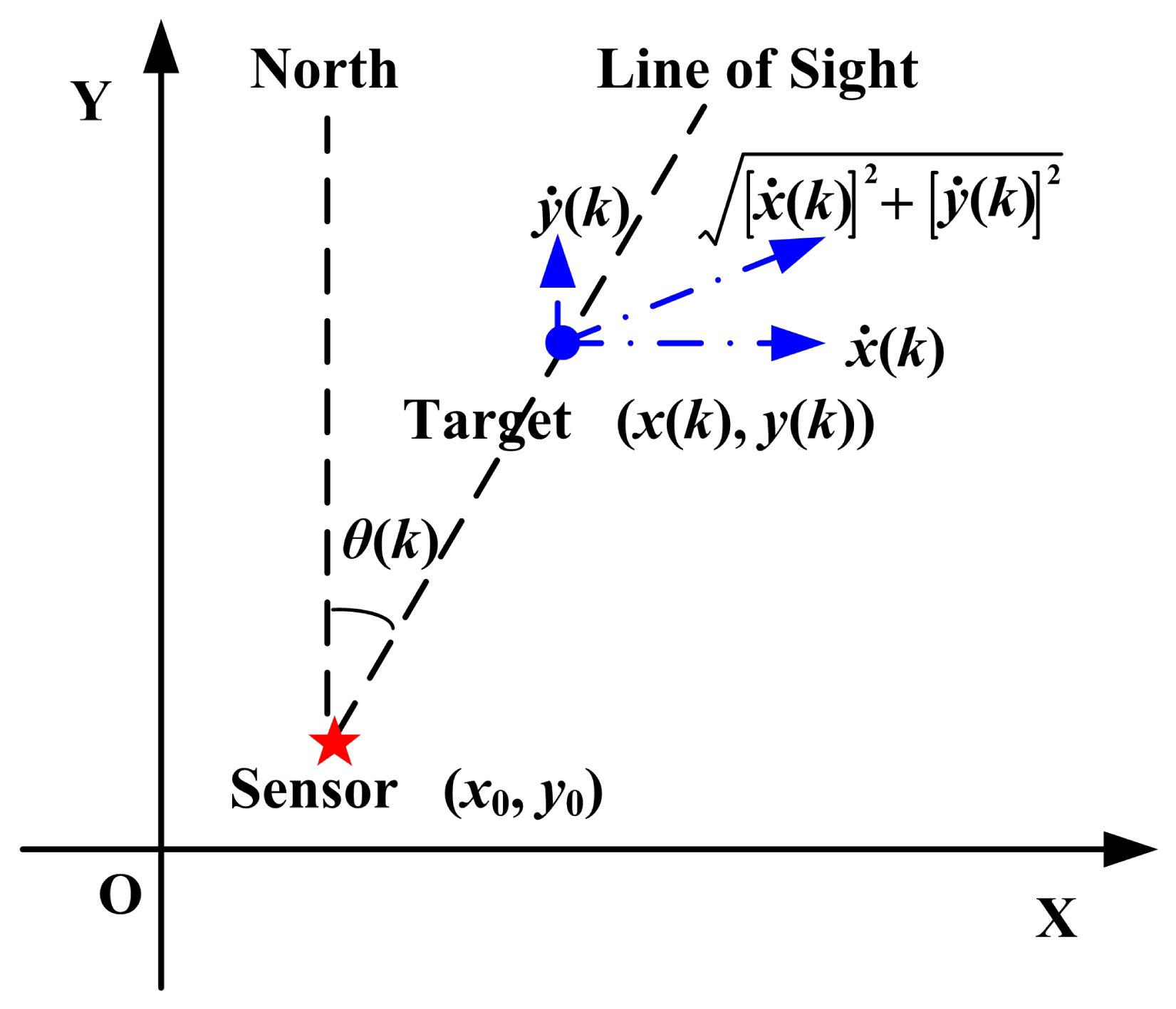
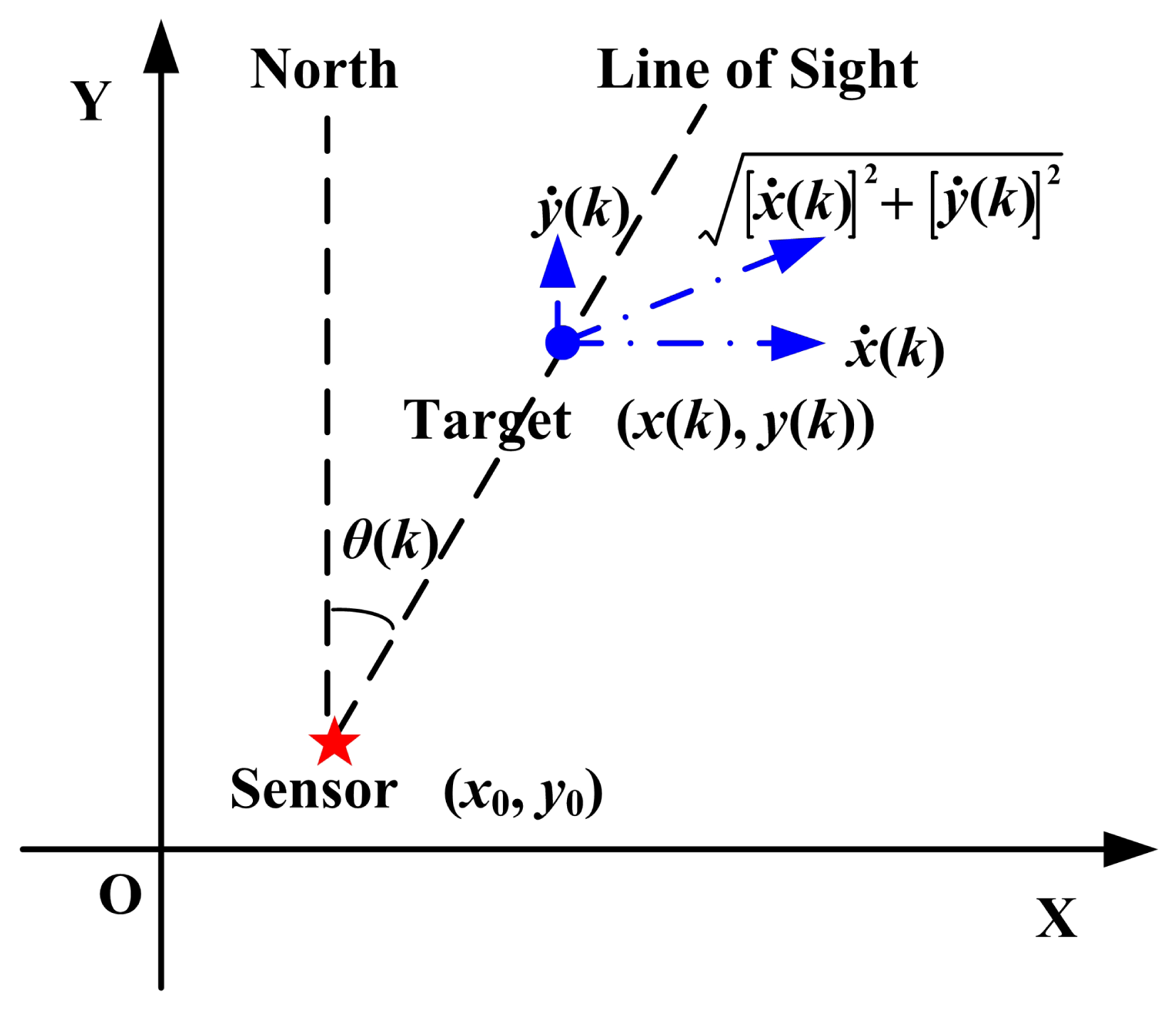
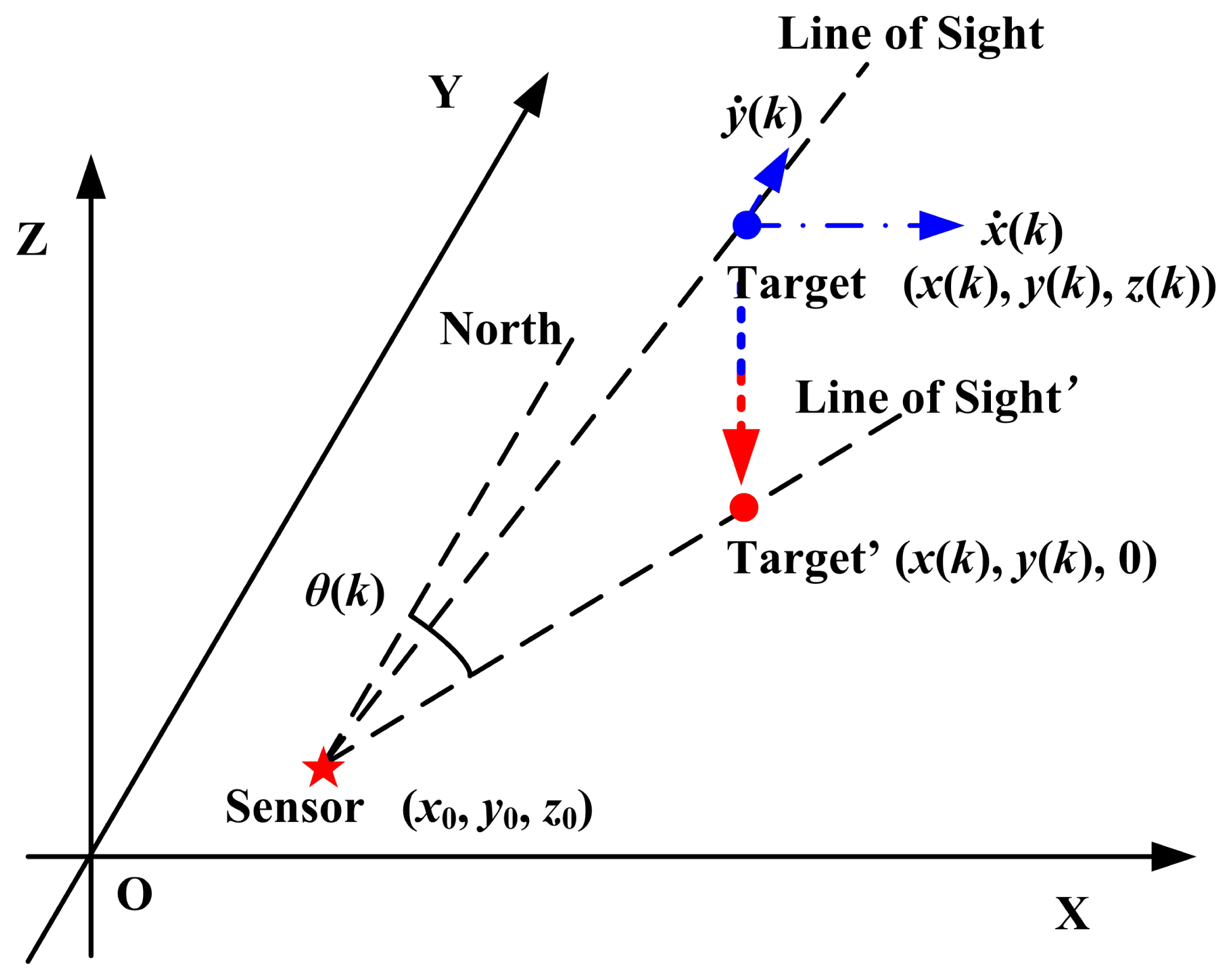
The radar-target geometry is shown in Figure 1. There is no barrier between the radar and the target.
According to Figure 1,
With no loss of generality, the radar's coordinates are set to (0, 0) in the XoY plane. Therefore,
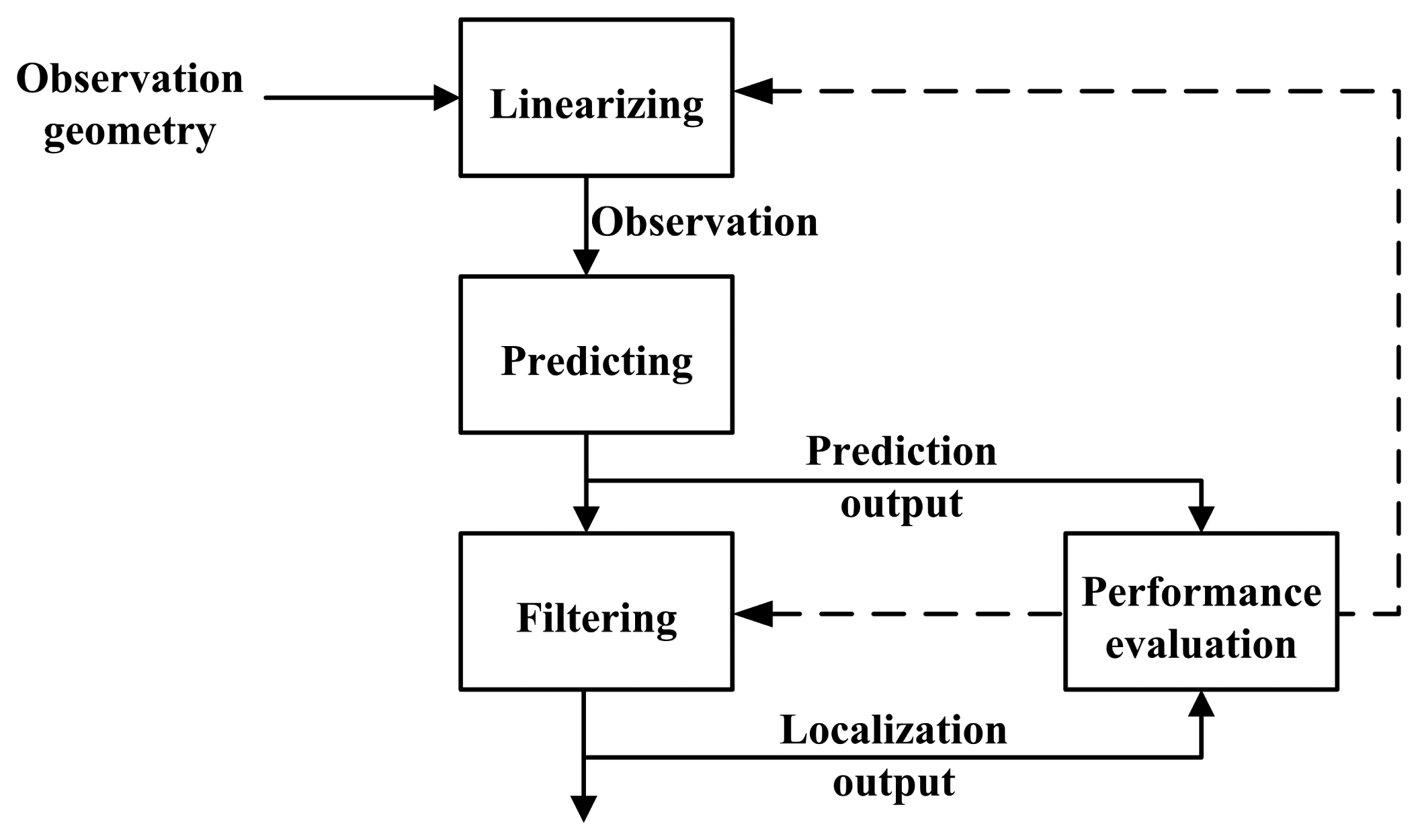
3.3. The Predicting and Filtering Steps
The one-step predicting algorithm and the filtering algorithm are as follows.
One-step predicting:
Innovation:
Filtering:
Determination of parameters and variables:
The transition matrix is a known matrix:
The observation matrix is the linearization solution of the nonlinear observation model, and:
There are three kinds of EKF algorithms in this paper: the normal EKF, a fast EKF and a cognition-based fast EKF. The observation matrix for these algorithms is C0(k), C1(k) and C2(k), respectively. According to the performance evaluation result, C2(k) equals C0(k) or C1(k). In the following texts, the normal EKF (referred to as “EKF-normal”) is the conventional algorithm developed at the very beginning of EKF. The existing fast EKF is implemented according to [32]. The cognition-based fast EKF is the newly proposed method in this work. In the following text, the existing fast EKF may be referred to as “EKF-fast1,” while the proposed fast EKF may be called “EKF-fast2.”
The covariance matrix of the observation noise is:
The covariance matrix of the predicting noise is defined by:
Based on the aforementioned results, the gain matrix is given by:
Equations (8)–(15) are the basic predicting and filtering steps of an EKF. These equations will be applied in different implements of an EKF, only substituting the corresponding variables into them.
3.4. Linearization of the Nonlinear Observation Model
3.4.1. Taylor Expansion of the Nonlinear Observation Model
In order to linearize the observation model, the Taylor expansion method is introduced. Expanding the observation equation in Equation (3) into a Taylor around x̂(k + 1∣k) gives:
It should be noted that the agreement is applied in Equation (16) as follows:
Equation (16) will be further utilized in linearizing the observation model. In this work, the derivatives considered are the first order derivative and the second order derivative:
To ensure a more concise mathematical description, two temporal variables are assigned to the derivatives. This gives:
3.4.2. The Observation Model in the Normal EKF
In Equation (16), ignoring higher powers (than second order) of x(k + 1) − x̂(k + 1∣k) results in:
The first item (in the last line) of the above equation can be written as:
Let:
Ignoring the loss in the approximation, Equation (25) can be written as follows:
The above equation is the linearized observation model for “EKF-normal.” w0(k + 1) is the observation noise. The predicting and filtering steps of the “EKF-normal” algorithm are in accordance with Section 3.3.
3.4.3. The Observation Model in a Widely-Used Fast EKF
In Equation (16), ignoring higher powers (than first order) of x(k + 1) − x̂(k + 1∣k) leads to:
Let:
Then, Equation (29) can be written as follows:
This is the linearized observation model for “EKF-fast1.” w1(k + 1) is the observation noise. The predicting and filtering steps of the “EKF-fast1” are in agreement with Section 3.3.
3.5. Calculation of the Filtering Gain
One of our previous works has focused on fast algorithms for calculating filtering gain [5]. The fundamental three equations are repeated here for convenience (excerpted, translated and reorganized from our Chinese paper with the permission of all of the authors and the publisher [5]).
In Equation (15), let M(k + 1) = C(k + 1)P(k + 1∣k)CT(k + 1) + R(k + 1) and N(k + 1) = M(k + 1) − I. I is the identity matrix. Suppose that λN,i (i = 1, 2) are the eigenvalues of N(k + 1), and λN,m (1 ≤ m ≤ 2) is the one with larger absolute value. Let λM,i (i = 1, 2) be the eigenvalues of M(k + 1), and λM,m (1 ≤ m ≤ 2) is the one with larger absolute value.
In order to calculate filtering gain, there are three cases to be considered.
| λN,m | is smaller than one:
In this situation, the power series of N(k + 1) is convergent. M−1(k + 1) is arrived at by:
λN,m is larger than one:
In this situation, the power series of N(k + 1) is divergent. It is obvious that λM,m > 1 in this case. Let λM,m < ρ1 < λM,m + 1. ρ1 is a real number. M−1(k + 1) is arrived at by:
|λN,m| is larger than one; λN,m is negative:
The power series of N(k + 1) is also divergent in this situation. Let |λM,m| < ρ2 < |λM,m| + 1. ρ2 is also a real number. M−1(k + 1) can be arrived at by:
For all of the above-mentioned three cases, the more items calculated in the power series, a better precision of M−1 (k +1) may be achieved. A better precision of K(k +1) may thus be realized. However, only the first and the second order of N(k + 1) (or, N1(k + 1), N2(k + 1), due to the value of λN,m) are considered in EKF-fast1. The first, the second and the third order of N(k + 1) (or other expressions, due to the value of λN,m) are counted in EKF-normal. The cognition processions of filtering gain in EKF-fast2 will be illustrated in the coming materials.
For all of the EKF algorithms, the result of M−1(k + 1) is further utilized in calculating the filtering gain by Equation (15).
4. The Cognition-Based Algorithm to Ease the Computational Load for the Extended Kalman Filter
4.1. The Idea of the Algorithm
As can be known from Section 3.4, EKF-fast1 considers less items (than the normal EKF does) in Taylor expansion in linearizing the observation model and calculating the filtering gain. The literature shows that more items may ensure better performance in estimation output [11,18]. However, more items introduce much computational load. The additional item may be unnecessary when the target runs smoothly and only light noise is introduced. Therefore, the key points of our designation for EKF-fast2 are:
In linearizing the observation model, there are two solutions: one is Equation (27), while the other is Equation (30). If the localizing performance is no worse than the expected performance, Equation (30) is applied. If the localizing performance is worse than the expected performance, Equation (27) is applied.
In calculating the filtering gain, there are also two approaches. We will illustrate this problem when |λN,m| is smaller than one. The other cases of | λN,m| are similar. If the predicting performance is worse than the expected performance, all of the first order, the second order and the third order of N(k + 1) in Equation (31) will be taken into account. If the predicting performance is no worse than the expected performance, the first order and the second order of N(k + 1) in Equation (31) will be calculated.
The performance is measured with respect to the notion of Euclidean distance. The performance evaluation result is fed back to support the aforementioned decision (on calculation) making.
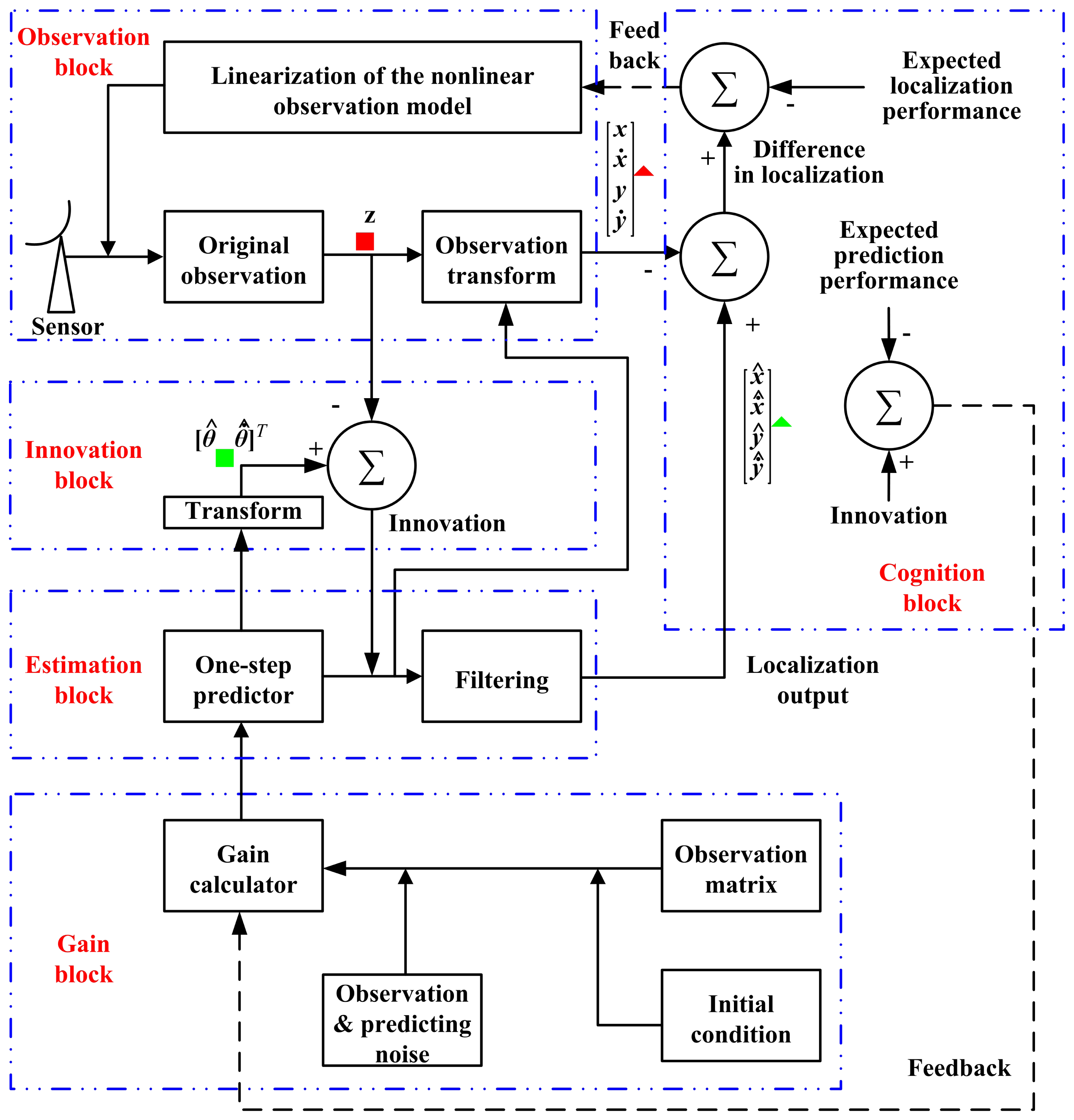
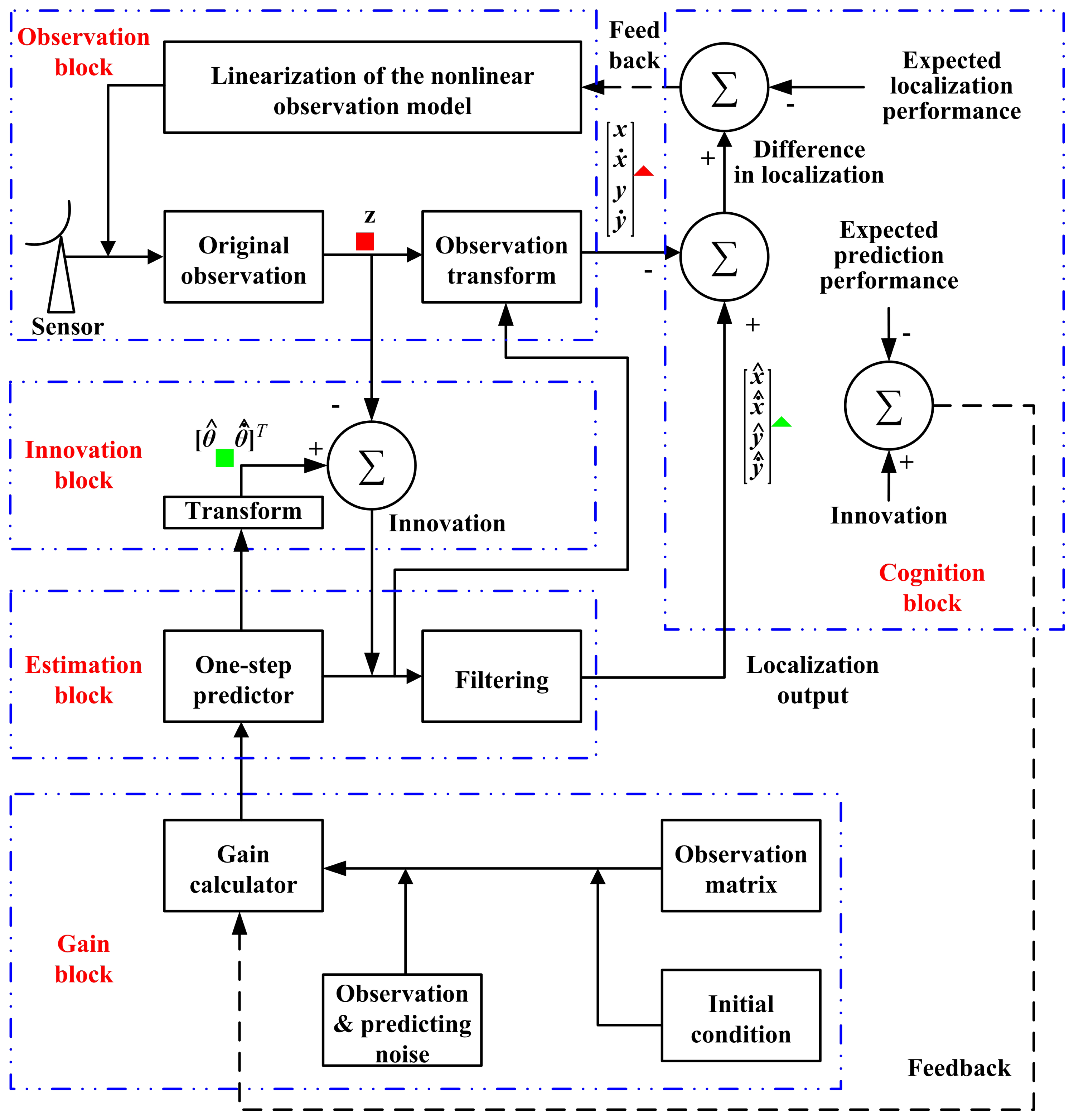
The cognition idea is illustrated in Figure 2, while the block diagram is shown in Figure 3.
In these two figures, the forward signal is denoted by a solid line, and the dashed line shows the feedback signal. The signal in the filtering closed-loop is all shown by a solid line. In Figure 3, (1) the Z−1 module is a delayer that delays the input signal by a data acquisition period; (2) the localizing output from the filtering branch is marked by a green triangle (
 ), while the localizing output from the observation branch is marked by a red triangle (
), while the localizing output from the observation branch is marked by a red triangle (
 ); and (3) the predicting output from the filtering branch is marked by a green square (
); and (3) the predicting output from the filtering branch is marked by a green square (
 ), while the data from the observation branch is marked by a red square (
), while the data from the observation branch is marked by a red square (
 ).
).
4.2. The Way to Evaluate the Predicting Performance
As mentioned above, the performance is measured with respect to the notion of Euclidean distance.
For the prediction to be employed in performance evaluating, there are two kinds of predicting output: (1) prediction of the target's state; and (2) prediction of the target's azimuth and the rate of change in the azimuth. The difference between these two estimations is only a transform. In the observation block, however, the original observation data are closer to target's true value (azimuth and the rate of change in the azimuth) than the other one (prediction of the target's state in the observation block). Therefore, we evaluate the predicting performance with the prediction of the target's azimuth and the rate of change in the azimuth.
Let be the predicting output (from the estimation block) of the target's azimuth and the rate of change in the azimuth. The difference between the predicting output and the observation reads:
The performance bound for predicting is ηpredict = [η11 η12]T. The predicting performance is given by:
Ppredict(k) will be further used to make a decision on choosing the filtering gain calculating models.
4.3. The Way to Evaluate the Localizing Performance
4.3.1. The “Localizing” Techniques in the Observation Block
As was presented previously, only the azimuth and the rate of change in the azimuth of the target are observed. To know the difference between the localizing output from the estimation block and the observation block, the target's location is resolved from the observation data. Here, we call the subtraction result “difference” instead of “error.” This is because there is an error in both of the estimations (localization based on observation and localization with filtering) when performing the localizing work. However, most of the existing literature has not mentioned this point. The conventional technique is taking (1) the localizing output based on observation as (2) the true state of the target. Readers should notice the difference in the physical properties of these two variables. In this paper, the above-mentioned subtraction result is called “error” only in the experiments, which may be familiar for the readers.
Determination of the position of the target:
As can be obtained from Equation (6),
Combining Equations (36) and (7) gives:
There are four variables to be resolved in Equation (37). To obtain the position for the target, some approximations are introduced. In the data collecting course, ẋ(k + 1) is approximately:
The approximations are excellent as long as the data acquisition period is short and the target's maximum incremental change in acceleration between any two observations is limited. Of course, there is some variation in these approximations due to the specific scenario, but this approximation serves as a good estimation. Moreover, is the unbiased estimation of ẋ(k + 1), and is the unbiased estimation of ẏ(k + 1), respectively. Consequently,
Ignoring the loss in the approximation results in:
Then, y(k + 1) and x(k + 1) are the solutions to Equation (41),
Determination of velocity for the target:
Like the processions mentioned previously, some approximations are introduced in this procedure. In solving ẋ(k + 1), ẏ(k + 1) is approximately . Similarly, in finding ẏ(k + 1), ẋ(k + 1) is approximately . Thus,
Ignoring the minor error in the approximation gives:
Solving Equation (44) yields:
Using the results in Equation (42) leads to:
With Equations (42) and (46), the target's position and velocity are estimated according to the observation data. In this course, there is information support from the estimation block, as is shown in Figure 3. It should be noted that there is observation noise in the observing course. Therefore, when calculating x(k) with (42) and Equation (46)z1(k) will be substituted for θ(k), while θ̇(k) will be replaced by z2(k).
4.3.2. The Way to Evaluate the Performance in Localizing
The difference between the filtering output and the localizing result via the observation reads:
The performance bound for localizing is ηlocalize = [η21 η22 η23 η24]T. The localizing performance is given by:
Plocalize(k) will be further used to configure the method in linearizing the observation model.
4.4. The Cognition Processing
On the basis of the aforementioned work, the cognition processing is easy implement.
The way to ease the computational load in linearizing the observation equation:
In linearizing the observation model, if Plocalize(k) is smaller than two, then the observation Equation (3) is linearized according to Equation (30); if Plocalize(k) is equal to two, then the observation Equation (3) is linearized with respect to Equation (27).
The approach to ease the computational load in determining the filtering gain:
According to the value of λN,m (1 ≤ m ≤ 2), one of Equations (31)–(33) is chosen to compute the filtering gain in EKF-fast2.
In calculating the filtering gain, if Ppredict(k) is smaller than two, then only the first and the second order of N(k + 1) (or N1(k + 1), N2(k + 1), due to the value of λN,m) are considered; if Ppredict(k) equals two, the first, the second and the third order of N(k + 1) (or other expressions, due to the value of λN,m) are all calculated.
A summary of the cognition mechanism:
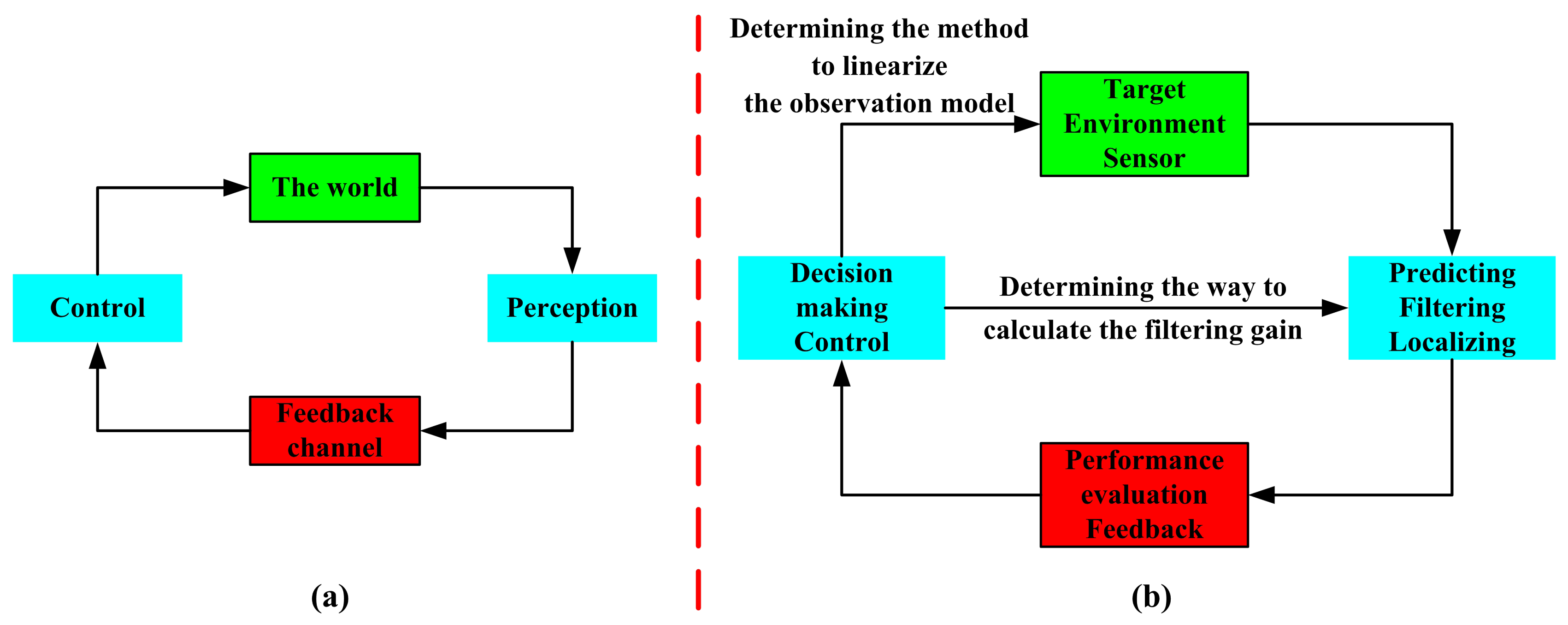
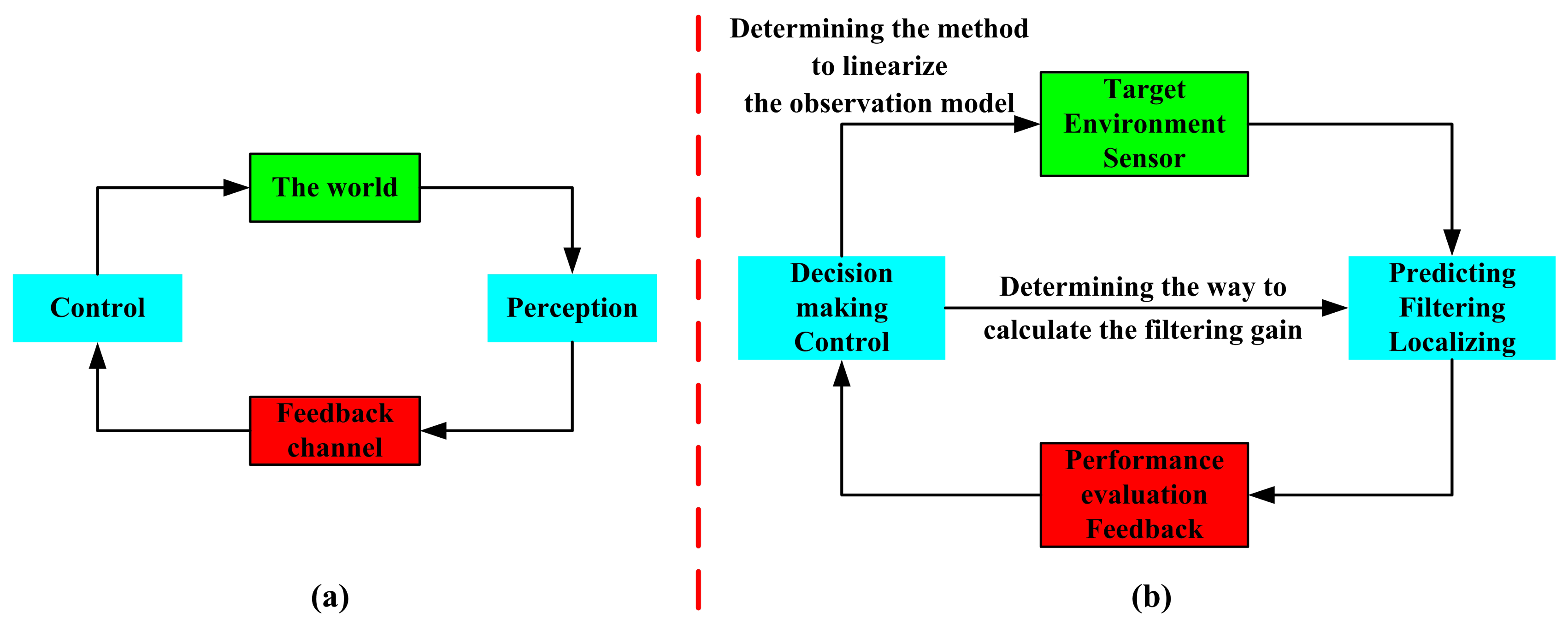
As can be known from all of the above-mentioned materials, the cognition processing focuses on three steps: (1) perception; with the mentioned extended Kalman filter, the azimuth and the rate of change in the azimuth of the target are predicted, and the position of the target is estimated (Section 3.3 and Section 4.3.1); (2) feedback; the prediction performance and the localization performance are evaluated (Section 4.2 and Section 4.3.2); (3) control; according to the forwarded performance evaluation result, the system makes decisions on the method to linearize the observation model and the way to calculate the filtering gain (Section 4.4). These are presented in Figure 4.
As shown in Figure 4a, for an active radar, the cognitive cycle is: perceiving the world (target and its environment) with a sensor, signal processing with the use of prior knowledge (as well as learning through interactions with the environment), feeding back of the performance, and adapting both its receiver and transmitter in response to statistical variations in the environment in real time [25,26]. Figure 4b shows the realization (in this work) of the corresponding block in Figure 4a, as is described in the former paragraph. It should be noted that this cognitive processing method is effective not only for an active radar, but also useful for a passive radar.
4.5. Summary of the Proposed Algorithm
The processing techniques with the proposed algorithm are summarized as follows:
- (1)
In the initialization phase, the observation model linearizing method and the approach in calculating the filtering gain are in accordance with those in the EKF-normal.
- (2)
In the working phase, the localizing performance is evaluated (in each step). The result is fed back to decide which observation model is to be utilized at the next step. The predicting performance is measured (in each step), and the result is fed back to choose the calculating model for the filtering gain at the next step.
- (3)
The other processions are in agreement with those in Section 3.3.
5. Experiments
To know the performance of the proposed algorithm, experiments are performed. There are two scenarios taken into account: tracking a model aircraft (Scenario 1) and tracking a car on the ground (Scenario 2). In these, all of the above-mentioned algorithms are checked.
The employed ground-based radar is a passive radar (more accurately, it can be described as an electronic surveillance measurement system). It can offer the observation of the target's azimuth and the rate of change in the azimuth. The radar is installed on a hill, so that there is no barrier between the radar and the target. The target is considered as a point-object.
5.1. Tracking a Model Aircraft
5.1.1. Experiment Setup
The target:
In Scenario 1, the target is a model aircraft with an FM (frequency modulation) transmitter. The radio frequency is 3.5 GHz. The target is voyaging in a three-dimensional plane. The true track of the target is unknown. Only the observations are recorded.
The observation geometry:
Since the target is moving in a three-dimensional plane, the observation geometry is different from the settings in Section 3.2. The target is projected onto the XoY plane. The azimuth is the angle between the line of sight and the north. The observation geometry is presented in Figure 5. With no loss of generality, the radar's coordinates are set to (0, 0, 0) in this work.
The observation noise:
The observation noise (introduced by the sensor and the propagation effects) for these three algorithms is identical. To ensure the whitening effect of the observation noise in the experiment, the noise is generated by the summation of three independent and identically distributed (i.i.d.) Gaussian noises, whose mean is zero and whose variance is each one. Therefore,
For different algorithms, the actual observation noise is calculated according to the corresponding observation model.
The expected performance:
The expected values of performance metrics for all of the algorithms are:
Azimuth, 0.2°; the rate of change in the azimuth, 0.007°/s.
X position, 3 m; X velocity, 5 m/s.
Y position, 3 m; Y velocity, 5 m/s.
The data rate:
The data acquisition period is 0.1 s for the radar. The data collection work continued 500 s in total.
5.1.2. Simulation Results
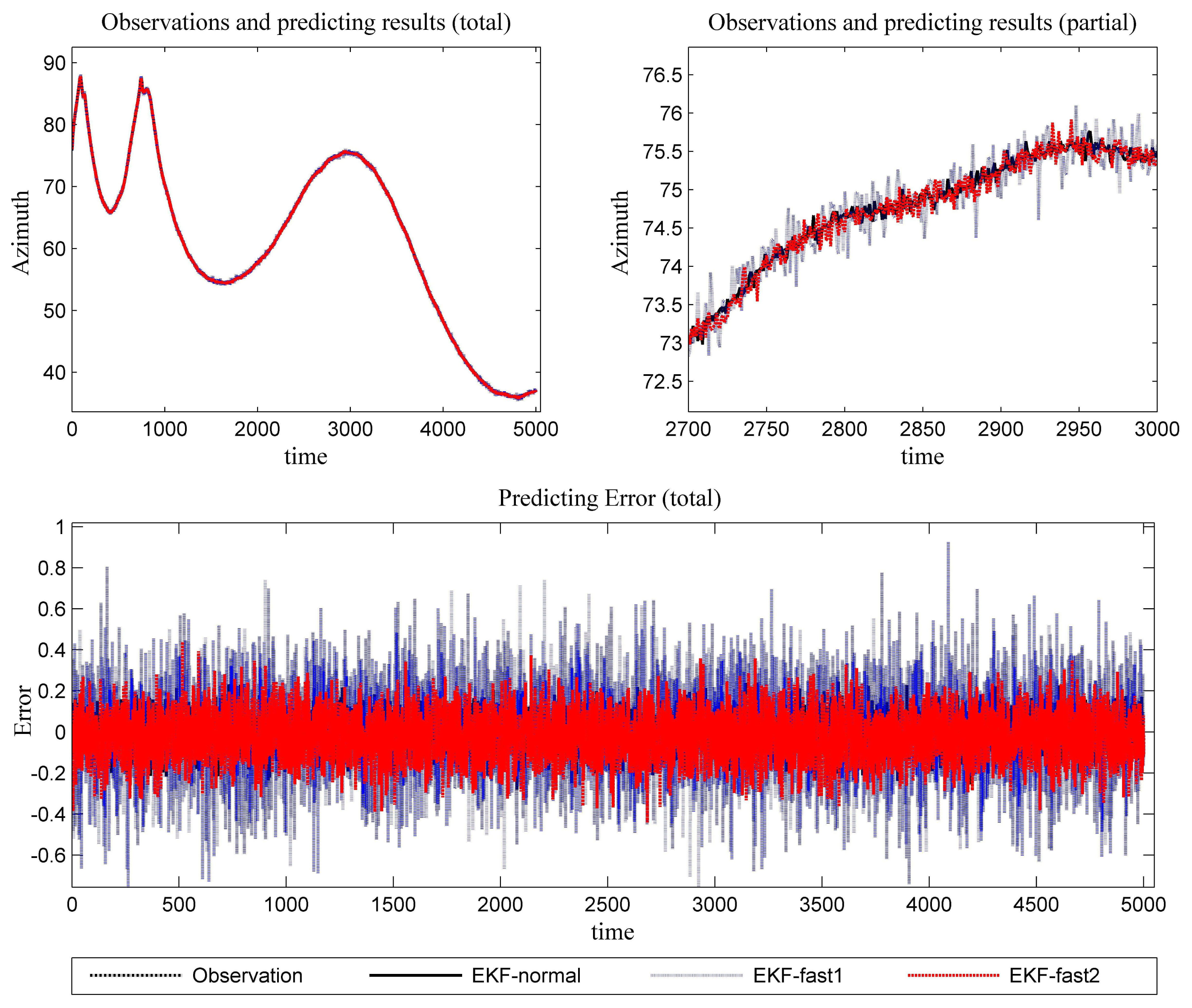
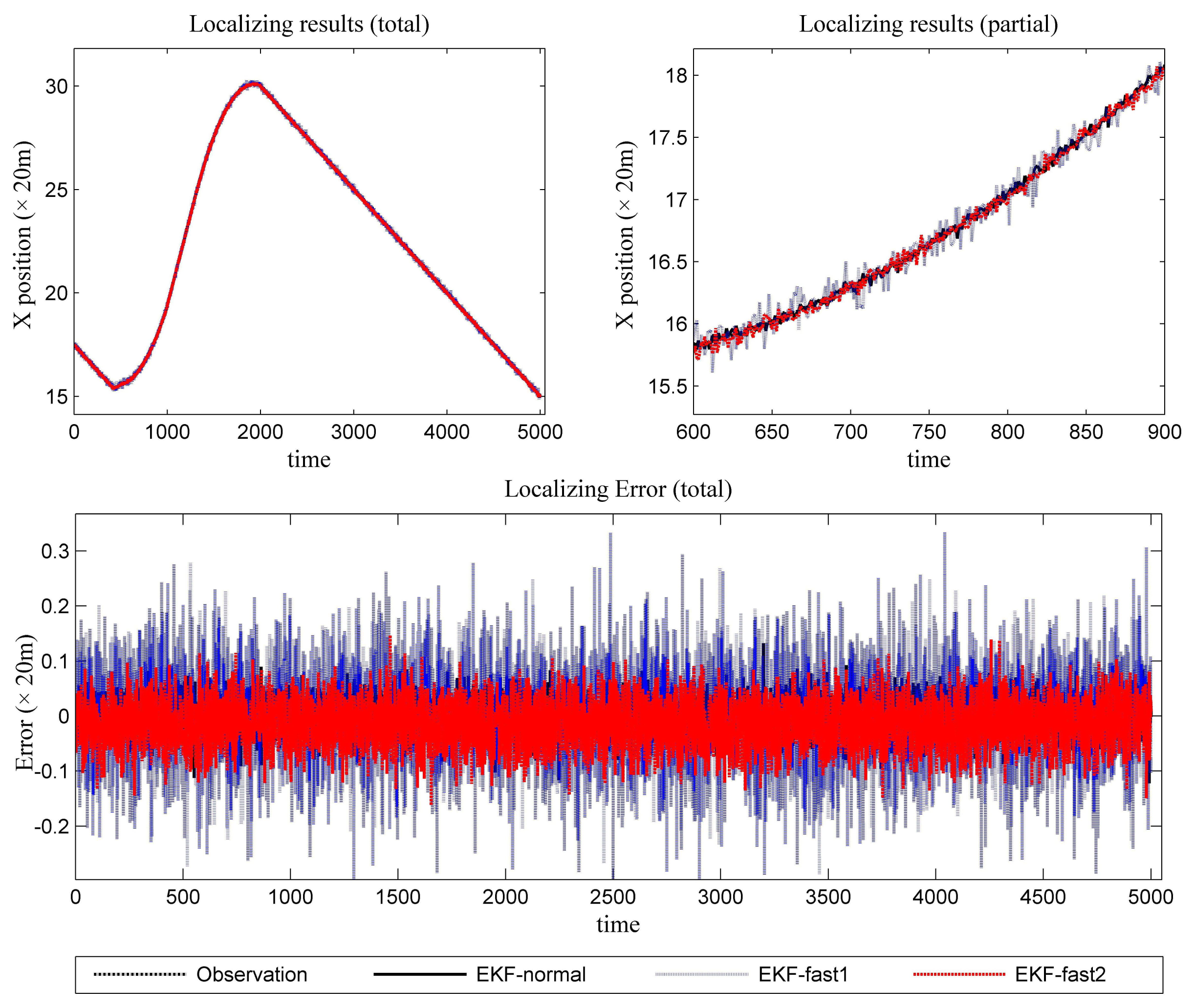
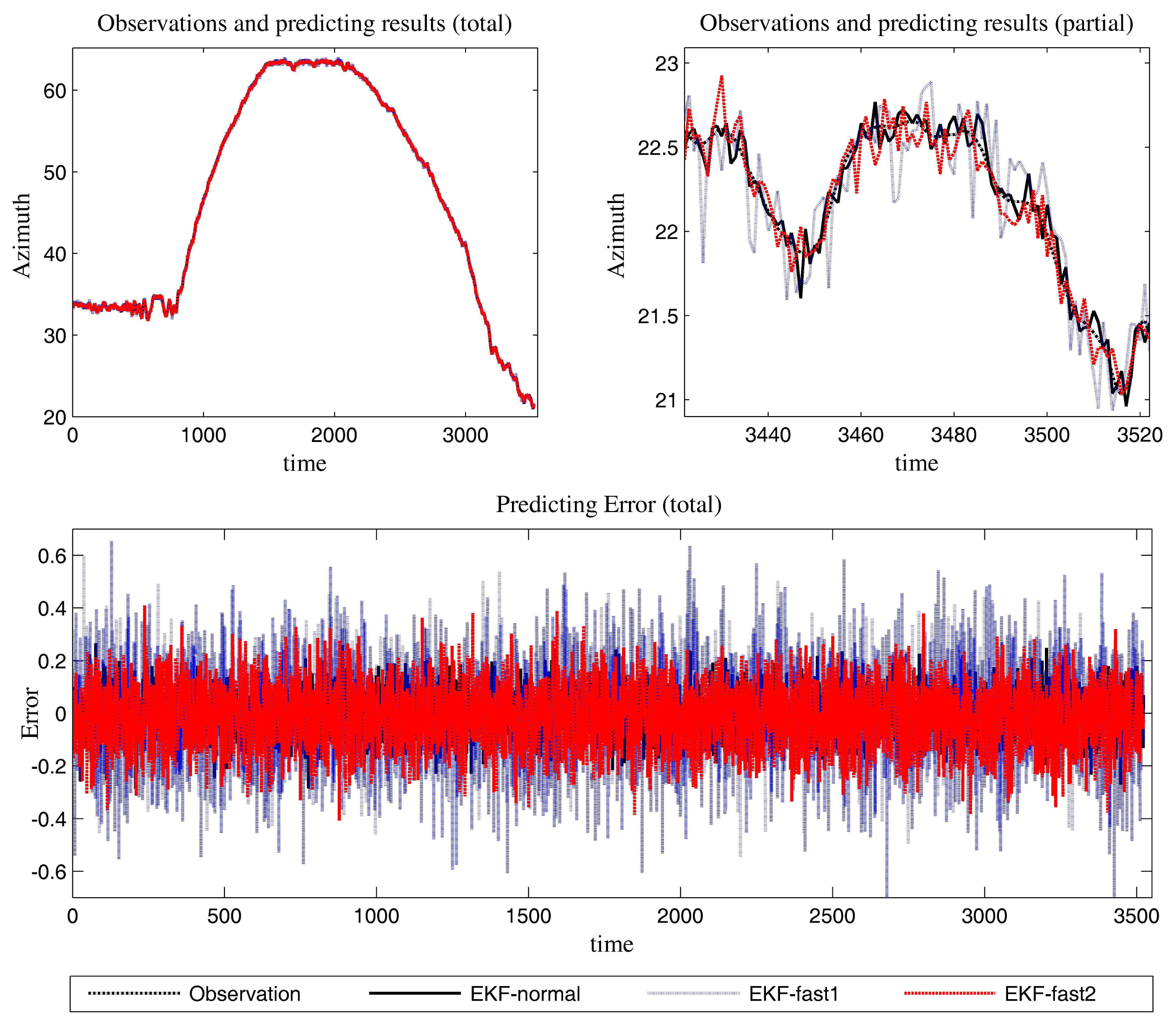
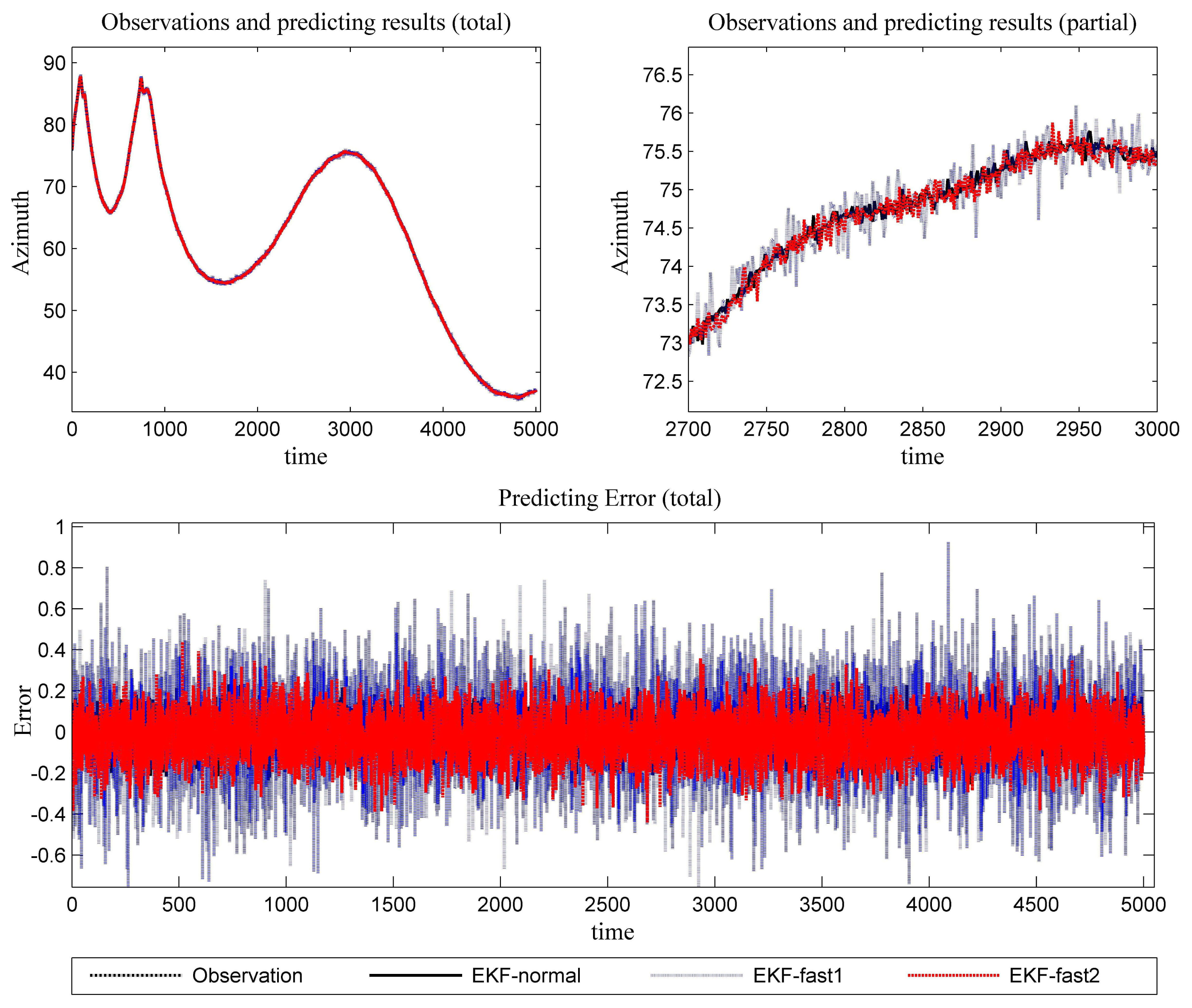
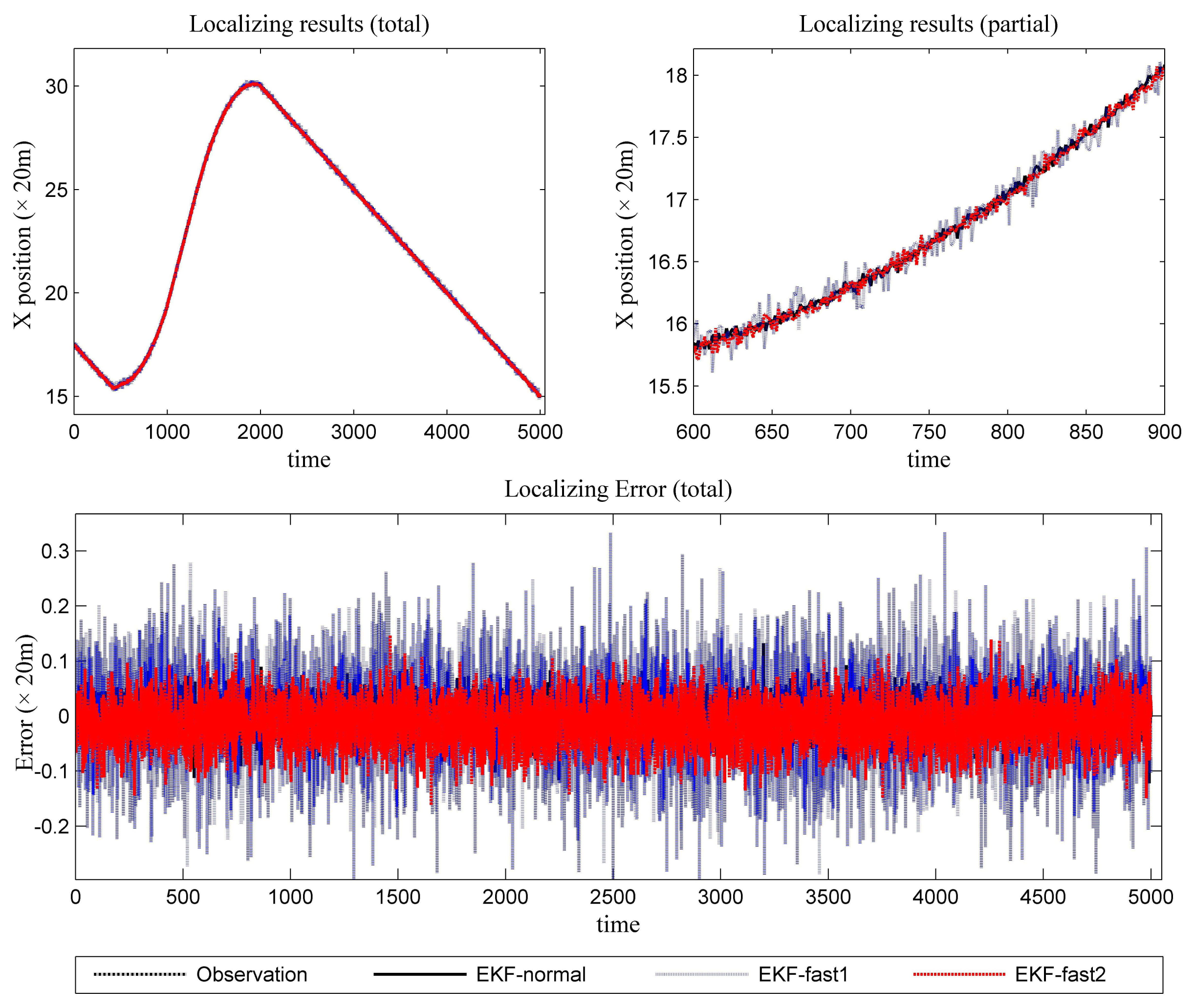
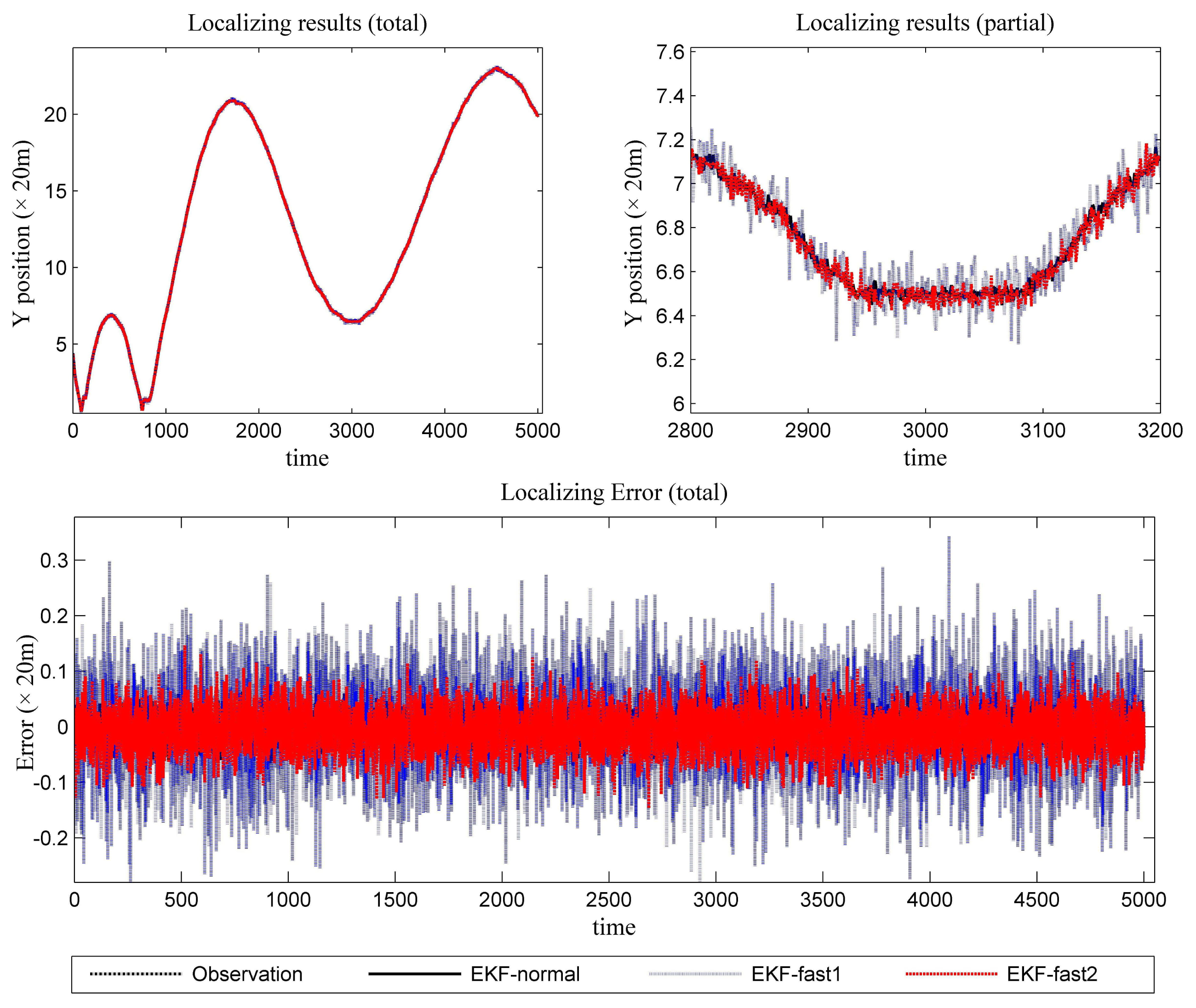
Figure 6 is the estimation results for the azimuth. The filtering results in X position are presented in Figure 7, while the filtering results in the Y position are shown in Figure 8. In these figures: (1) the “error” means “root-mean-square error (RMSE)”; (2) the “observations” are the transformed observations, called “localization based on observation” in the aforementioned texts; and (3) the “localizing results” are the localizing outputs with filtering. These are also true in the next experiment.
To know the difference in computational requirements, the time consumption is recorded for each mentioned algorithm in the simulation. The data are presented in Table 1. These results were achieved on a Windows PC with an Intel(R) Celeron(R) CPU 430 with a 1.80-GHz processor. The elapsed time is measured in seconds. Only the filtering time of the algorithms is considered. The duration on sensor orientation, noise and clutter outcome, observation accessing and results output have not been included.
5.1.3. Results Analysis
With the data in Figures 6, 7 and 8 and Table 1, we analyze the simulation results with respect to the scenario.
- (1)
Scenario 1 introduces light noise. As a result, all of the mentioned EKF algorithms work well. The error is acceptable. To achieve a more in-depth understanding of the algorithms, we perform some analysis for the error series. First, the variance of the error series is calculated. Then, the mean of the absolute value for the error series is resolved. The data are presented in Table 2. It is clear that the novel algorithm outperforms the conventional algorithm in estimation work. In light of performance metrics besides the value of RMSE, especially in the aspect of variance, EKF-fast2 is much better than EKF-fast1.
- (2)
Since this experiment involves light noise, EKF-normal and EKF-fast2 can achieve the expected performance throughout almost the entire test. The precision of EKF-fast1 is not ideal, especially at the maneuvering occasions.
- (3)
According to Table 1, the ratios between the elapsed time are:
EKF-fast1:EKF-normal = 54.16%; and EKF-fast2:EKF-normal = 59.70%.
5.2. Tracking a Car on the Ground
5.2.1. Experiment Setup
The target:
A car, namely, the target of interest, is running on a plane. There is a radio transmitter on the car. The radio frequency is 10 GHz. The target is a non-cooperative target. Hence, the programmed track of the target is unknown. Only the observations are recorded.
The observation geometry:
The observation geometry is in accordance with the settings in Section 3.2.
The observation noise:
In Scenario 2, the observation noise is subject to the settings in Section 5.1.1. However, the noise is heavier than the noise in Scenario 1. Therefore, in Equation (52)wn,j(k) ∼ N(0, 6), n = 1, 2, 3; j = 1, 2.
The expected performance:
The expected values of performance metrics for all of the algorithms are:
Azimuth, 0.5°; the rate of change in the azimuth, 0.01°/s.
X position, 12 m; X velocity, 10 m/s.
Y position, 12 m; Y velocity, 10 m/s.
The data rate:
The data acquisition period is 1 s for the radar. The data collection work continued about 3500 s in total.
5.2.2. Simulation Results
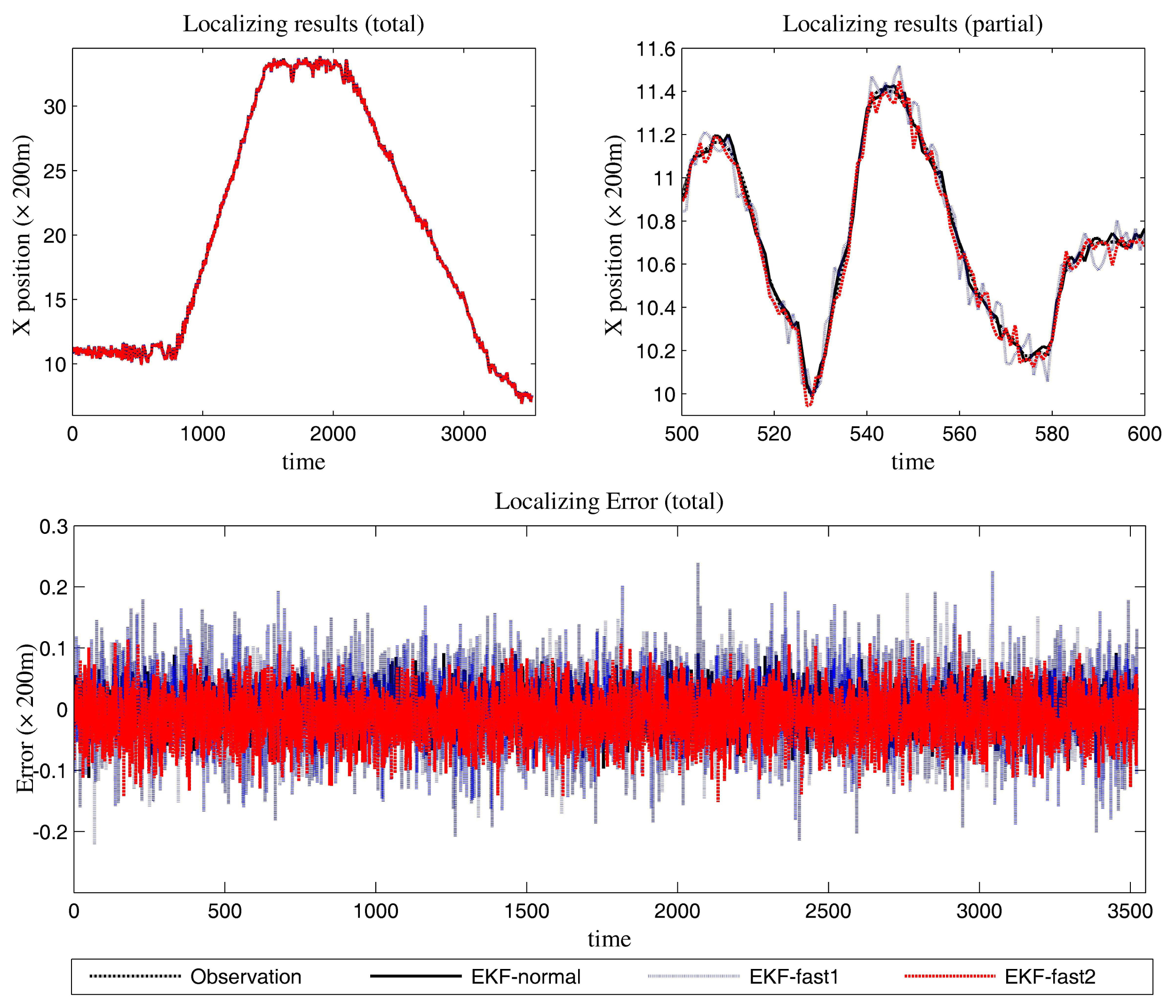
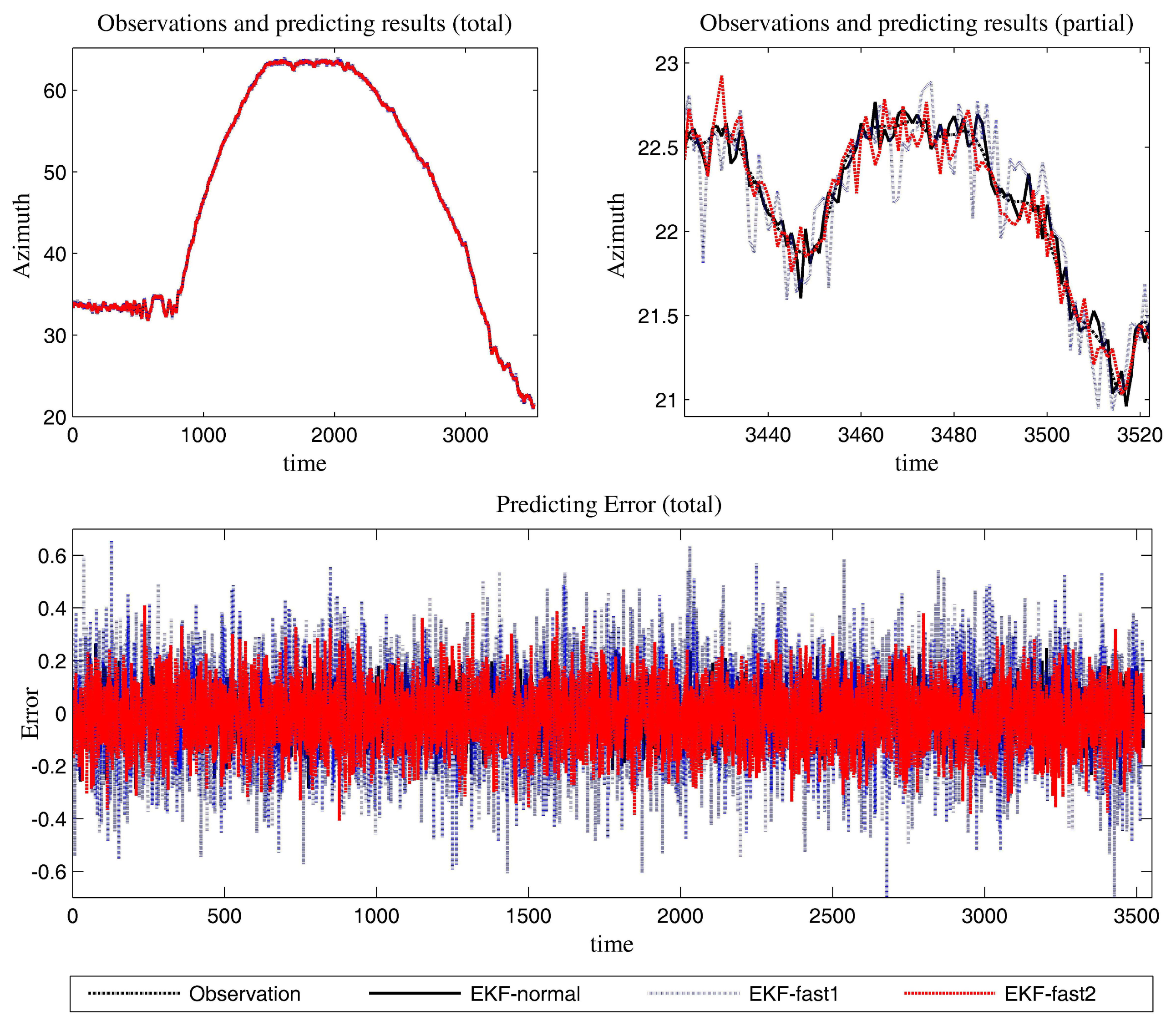
The estimation results of the azimuth are presented in Figure 9.
In Figure 10, the filtering results for the X position are presented. In Figure 11, the filtering results for the Y position are shown.
The time consumption is presented in Table 3. The computer and the method for measuring elapsed time are identical with the former experiment.
5.2.3. Results Analysis
We can gain knowledge from the provided data in Figures 9, 10 and 11 and Table 3:
- (1)
This scenario brings difficulties for the tracking algorithms. However, the mentioned EKF algorithms can all be applied in target tracking. Compared to the performance in Scenario 1, the noise and the target's maneuvering behavior complicate the algorithms. This results in the tracking performance going down for all of the approaches.
The in-depth performance data are shown in Table 4. Furthermore, the novel algorithm outperforms the conventional algorithm in estimation work.
- (2)
The normal EKF (EKF-normal) has the best performance in precision. The existing fast EKF (EKF-fast1) has the least computational requirements. The proposed method (EKF-fast2) has similar performance to EKF-normal. At the same time, the computational load of EKF-fast2 is at a consistent level, as the EKF-fast1 maintains. The reasons for the latter point are plentiful. On the one hand, the cognition processing and the occasionally introduced higher-order Taylor expansion in the linearization bring more computational load to EKF-fast2 than EKF-fast1. On the other hand, EKF-fast2 improves the computation work (compared to EKF-fast1) in resolving the filtering gain.
- (3)
According to Table 3, the ratios between the elapsed time are:
EKF-fast1:EKF-normal = 57.17%; and EKF-fast2:EKF-normal = 60.10%.
Since there are only 2 × 4 entries in C(k) (C0(k), C1(k) and C2(k)) and 2 × 2 entries in M(k), the improvement in lowering the computational requirements is limited. The improvement in complicated applications may be more substantial.
5.3. Comparison between the Existing Technologies and the Proposed Methodology Based on the Simulation Results
Based on the simulation results presented above, a comparison between the existing algorithms and the proposed algorithm is performed in Table 5. The meanings of some symbols are listed below.
L1:Is the algorithm flexible for a complicated scenario?
L2: The precision of the method.
L3: The computational load of the method.
L4: The generalization of the method.
L5: Is the method easy to configure?
According to the information in Table 5, EKF-fast2 is the best choice (among these three methods) for tracking a maneuvering target in a complicated scenario. The observation model is a nonlinear observation model, either an active radar or a passive radar.
6. Conclusions
In this paper, a new fast EKF algorithm is proposed. At the same time, the novel method is verified through simulations. The advantages of this technology are that it is flexible and the cognition capability exists. Compared to the EKF-normal algorithm, it works with better efficiency in an identical scenario. The proposed approach is very simple and yet effective. This cognition processing is especially useful for a passive radar. However, some facts must be admitted here. If the target runs smoothly and only light noise is introduced, then the use of this designation is somewhat exaggerated.
In the future, implementing this designation in radar systems will be considered.
Acknowledgments
The work in this paper has been supported by the National Key Lab Program of Complex Electronic-magnetic Environment Effects (CEMEE) (Luoyang, 471003) under Grant No. CEMEE2014K0204B, the National Science Fund for Distinguished Young Scholars of China under Grant No. 61025006 and the National Natural Science Foundation of China under Grant No. 61171133. Valuable data came freely from Yanhua Wu, which made the simulation (Scenario 1) feasible.
The authors wish to extend their sincere thanks to the editors and reviewers for their careful reading and fruitful suggestions.
All of this support is greatly appreciated.
Author Contributions
Yanpeng Li was responsible for all the theoretical work here, while Xiang Li, Hongqiang Wang and Yuliang Qin collected and sorted the data for the experiments. Bin Deng performed the experiments. Yanpeng Li wrote and revised the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. Trans. ASME J. Basic Eng. 1960, 82D, 34–45. [Google Scholar]
- Kalman Filter. Available online: http://en.wikipedia.org/wiki/Kalman_filter (accessed on 10 September 2013).
- Chui, C.K.; Chen, G.R. Kalman Filtering with Real-Time Applications; Springer-Verlag: Berlin, Germany, 1987. [Google Scholar]
- Di, M.; Joo, E.M.; Beng, L.H. A Comprehensive Study of Kalman Filter and Extended Kalman Filter for Target Tracking in Wireless Sensor Networks. IEEE International Conference on Systems, Man and Cybernetics, 2008. Singapore: 12–15 October 2008; pp. 2792–2797.
- Li, Y.P.; Li, X.; Zhuang, Z.W. A Fast Kalman Algorithm and Its Performance Evaluation. J. Electron. Inf. Technol. 2005, 27, 153–155, In Chinese. [Google Scholar]
- Haykin, S. Kalman Filtering and Neural Networks; Wiley: Hoboken, NJ, USA, 2001. [Google Scholar]
- Yaakov, B.S.; Fortmann, T. E. Tracking and Data Association; Academic Press: New York, NY, USA, 1988. [Google Scholar]
- Bozic, S.M. Digital and Kalman Filtering; Edward Arnold: London, UK, 1979. [Google Scholar]
- Olfati-Saber, R. Kalman-Consensus Filter: Optimality, Stability, and Performance. Proceedings of the 48th IEEE Conference on Decision and Control, 2009 Held Jointly with the 2009 28th Chinese Control Conference, Shanghai, China, 15–18 December 2009; pp. 7036–7042.
- Diversi, R.; Guidorzi, R.; Soverini, U. Kalman Filtering in Extended Noise Environments. IEEE Trans. Autom. Control 2005, 50, 1396–1402. [Google Scholar]
- Yaakov, B.S.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation: Theory, Algorithms and Software; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Farina, A.; Ristic, B.; Benvenuti, D. Tracking a Ballistic Target: Comparison of Several Nonlinear Filters. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 854–867. [Google Scholar]
- Gomez-Gil, J.; Ruiz-Gonzalez, R.; Alonso-Garcia, S.; Gomez-Gil, F.J. A Kalman Filter Implementation for Precision Improvement in Low-Cost GPS Positioning of Tractors. Sensors 2013, 13, 15307–15323. [Google Scholar]
- Gao, W.; Zhang, Y.; Wang, J.G. A Strapdown Interial Navigation System/Beidou/Doppler Velocity Log Integrated Navigation Algorithm Based on a Cubature Kalman Filter. Sensors 2013, 14, 1511–1527. [Google Scholar]
- Long, H.; Qu, Z.H.; Fan, X.P.; Liu, S.Q. Distributed Extended Kalman Filter Based on Consensus Filter for Wireless Sensor Network. Proceedings of the 10th IEEE World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July, 2012; pp. 4315–4319.
- Huang, R.; Patwardhan, S.C.; Biegler, L.T. Robust stability of nonlinear model predictive control based on extended Kalman filter. J. Process Control 2012, 22, 82–89. [Google Scholar]
- Sabatini, A.M. Kalman-Filter-Based Orientation Determination Using InertialMagnetic Sensors: Observability Analysis and Performance Evaluation. Sensors 2013, 13, 9182–9206. [Google Scholar]
- Ligorio, G.; Sabatini, A.M. Extended Kalman Filter-Based Methods for Pose Estimation Using Visual, Inertial and Magnetic Sensors: Comparative Analysis and Performance Evaluation. Sensors 2013, 13, 1919–1941. [Google Scholar]
- Bilik, I.; Tabrikian, J. Maneuvering Target Tracking in the Presence of Glint Using the Nonlinear Gaussian Mixture Kalman Filter. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 246–262. [Google Scholar]
- Wu, X.D.; Wang, Y.N. Extended and Unscented Kalman filtering based feedforward neural networks for time series prediction. Appl. Math. Modell. 2012, 36, 1123–1131. [Google Scholar]
- Sorenson, H.W. Kalman Filtering: Theory and Application; IEEE Press: New York, NY, USA, 1985. [Google Scholar]
- Gustafsson, F.; Hendeby, G. Some Relations between Extended and Unscented Kalman Filters. IEEE Trans. Signal Process. 2012, 60, 545–555. [Google Scholar]
- Tran-Quang, V.; Huu, P.N.; Miyoshi, T. A Collaborative Target Tracking Algorithm Considering Energy Constraint in WSNs. Proceedings of the 19th International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 15–17 September 2011; pp. 167–171.
- Srinath, M.D.; Rajasekaran, P.K. An Introduction to Statistical Signal Processing with Applications; John Wiley & Sons Inc.: New York, NY, USA, 1979. [Google Scholar]
- Haykin, S. Cognitive radar: A way of the future. IEEE Signal Process. Mag. 2006, 23, 30–40. [Google Scholar]
- Guerci, J.R.; Baranoski, E.J. Knowledge-aided adaptive radar at DARPA: An overview. IEEE Signal Process. Mag. 2006, 23, 41–50. [Google Scholar]
- Sira, P.; Li, Y.; Antonia, P.-S.; Morrell, D.; Cochran, D.D.; Rangaswamy, M. Waveform-Agile Sensing for Tracking. IEEE Signal Process. Mag. 2009, 26, 53–64. [Google Scholar]
- Kershaw, D.; Evans, R.J. Optimal Waveform Selection for Tracking System. IEEE Trans. Inf. Theory 1994, 40, 1536–1550. [Google Scholar]
- Niu, R.; Willett, P.; Bar-Shalom, Y. Tracking Considerations in Selection of Radar Waveform For Range and Range-Rate Measurements. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 467–487. [Google Scholar]
- Haykin, S. Adaptive Filter Theory, 4th ed.; Publishing House of Electronics Industry: Beijing, China, 2002. [Google Scholar]
- Han, L.J.; Tian, Z.S.; Sun, D.M. Study of Single Observer Passive Location Based on Extended Kalman Filter. Space Electron. Technol. 2009, 3, 39–4, In Chinese. [Google Scholar]
- Liu, F.S.; Luo, P.F. Statistical Signal Processing; NUDT Press: Changsha, China, 1999. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EKF-normal | EKF-fast1 | EKF-fast2 | |
|---|---|---|---|
| Time | 18.1952 | 10.3964 | 10.8629 |
| EKF-normal | EKF-fast1 | EKF-fast2 | |
|---|---|---|---|
| Variance of the error in the azimuth estimation | 0.0059 | 0.0548 | 0.0133 |
| Variance of the error in the X position estimation | 0.3528 | 3.3555 | 0.6730 |
| Variance of the error in the Y position estimation | 0.1855 | 3.0105 | 0.6235 |
| Mean of the absolute value for the error series (azimuth estimation) | 0.0731 | 0.1870 | 0.0961 |
| Mean of the absolute value for the error series (X position estimation) | 0.4714 | 1.4659 | 0.6867 |
| Mean of the absolute value for the error series (Y position estimation) | 0.3506 | 1.3860 | 0.6407 |
| EKF-normal | EKF-fast1 | EKF-fast2 | |
|---|---|---|---|
| Time | 12.7461 | 7.2870 | 7.6607 |
| EKF-normal | EKF-fast1 | EKF-fast2 | |
|---|---|---|---|
| Variance of the error in the azimuth estimation | 0.0062 | 0.0387 | 0.0095 |
| Variance of the error in the X position estimation | 35.5338 | 160.4177 | 68.2008 |
| Variance of the error in the Y position estimation | 19.1003 | 137.1015 | 59.7653 |
| Mean of the absolute value for the error series (azimuth estimation) | 0.0624 | 0.1547 | 0.0970 |
| Mean of the absolute value for the error series (X position estimation) | 4.7552 | 10.3763 | 6.9058 |
| Mean of the absolute value for the error series (Y position estimation) | 4.4646 | 9.2098 | 6.4645 |
| Aspect | EKF-normal | EKF-fast1 | EKF-fast2 |
|---|---|---|---|
| L1 | × | × | ✓ |
| L2 |  | ■ | |
| L3 | ■ |  | |
| L4 |  | | |
| L5 | | | |
Legend: The following symbols refer to:
 , high achievement;
, high achievement;
 , satisfactory;
, satisfactory;
 , improvement needed; ■, unsatisfactory; ✓, yes; ×, no.
, improvement needed; ■, unsatisfactory; ✓, yes; ×, no.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, X.; Deng, B.; Wang, H.; Qin, Y. A Cognition-Based Method to Ease the Computational Load for an Extended Kalman Filter. Sensors 2014, 14, 23067-23094. https://doi.org/10.3390/s141223067
Li Y, Li X, Deng B, Wang H, Qin Y. A Cognition-Based Method to Ease the Computational Load for an Extended Kalman Filter. Sensors. 2014; 14(12):23067-23094. https://doi.org/10.3390/s141223067
Chicago/Turabian StyleLi, Yanpeng, Xiang Li, Bin Deng, Hongqiang Wang, and Yuliang Qin. 2014. "A Cognition-Based Method to Ease the Computational Load for an Extended Kalman Filter" Sensors 14, no. 12: 23067-23094. https://doi.org/10.3390/s141223067