5.1. Security Resiliency Analysis
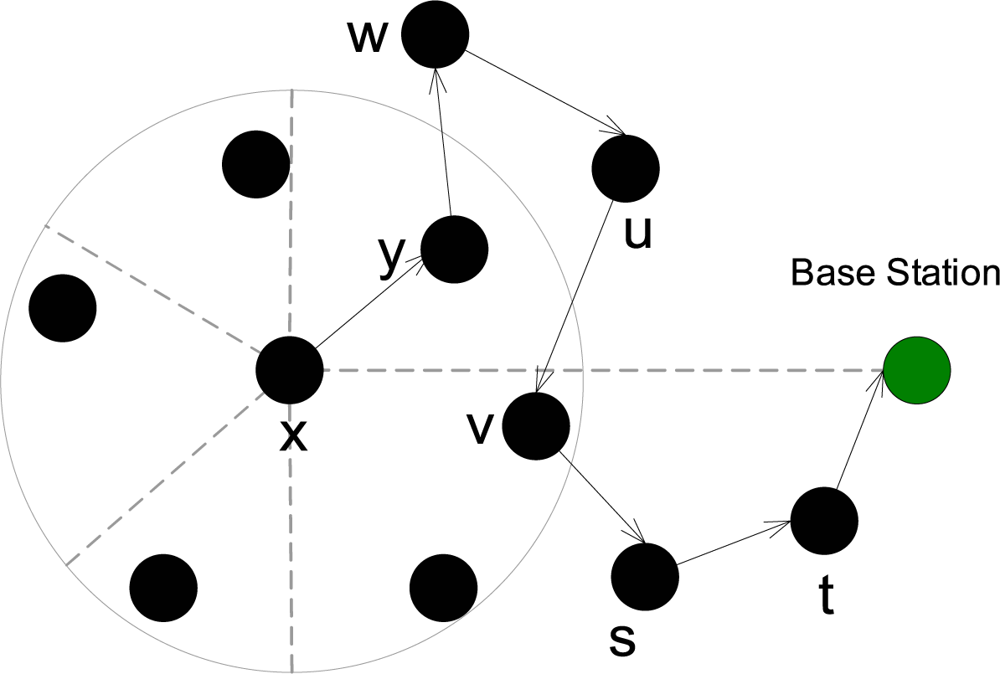
Suppose we have an adversary 𝒜 who strives to defeat our privacy protocols and guess the original source node. We will distinguish between two kinds of nodes. A source node is the original sender of a packet q and a forwarding node is the node that forwards a packet to another node until it reaches the destination. Hence the source node is also a forwarding node. The adversary’s goal is to find out the source node. This analysis assumes that we are using IRL algorithm including our proposed data privacy mechanism. So if the adversary sees a packet, it will trivially know the identity of the last forwarding node (which could possibly be the sender node).
We will deal with separate cases. Case 1 is when the adversary is close to the base station and can eavesdrop on any packet received by the base station. Case 2 deals with the case when the adversary can see any packet within the radio range of a particular node. Case 3 extends this into two or more nodes.
An adversary will try to solve the following problem: Given a packet q and a subset of nodes N′, find out the sender node s. In other words, the algorithm for the adversary takes two inputs and outputs a node s′; Namely 𝒜(q,N′) = s′. If s′ = s, the adversary succeeds in defeating our protocol. We have to find: Pr[𝒜(q,N′) = s], which is the probability for an adversary to find out the sender node. Our assumption is that, from an adversarial perspective, all nodes are equally likely to be senders of a packet. This does not necessarily mean that the network traffic is uniformly distributed. Notice that if the adversary knows beforehand which nodes are more likely to send packets, then no privacy preserving method can prevent the adversary from guessing the most likely senders, since this constitutes the adversary’s a priori knowledge.
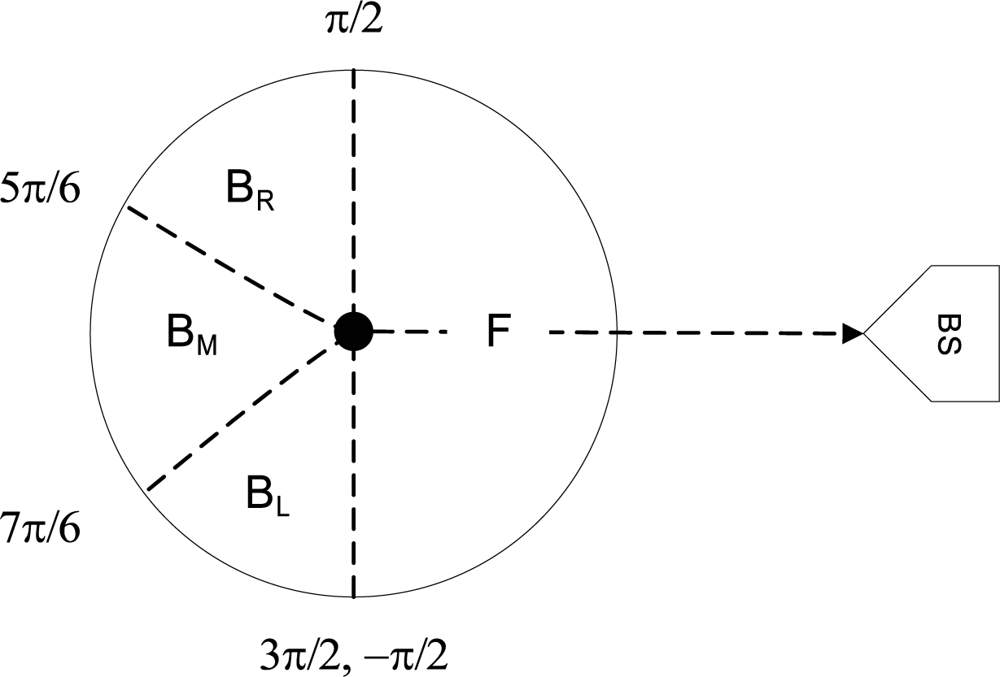
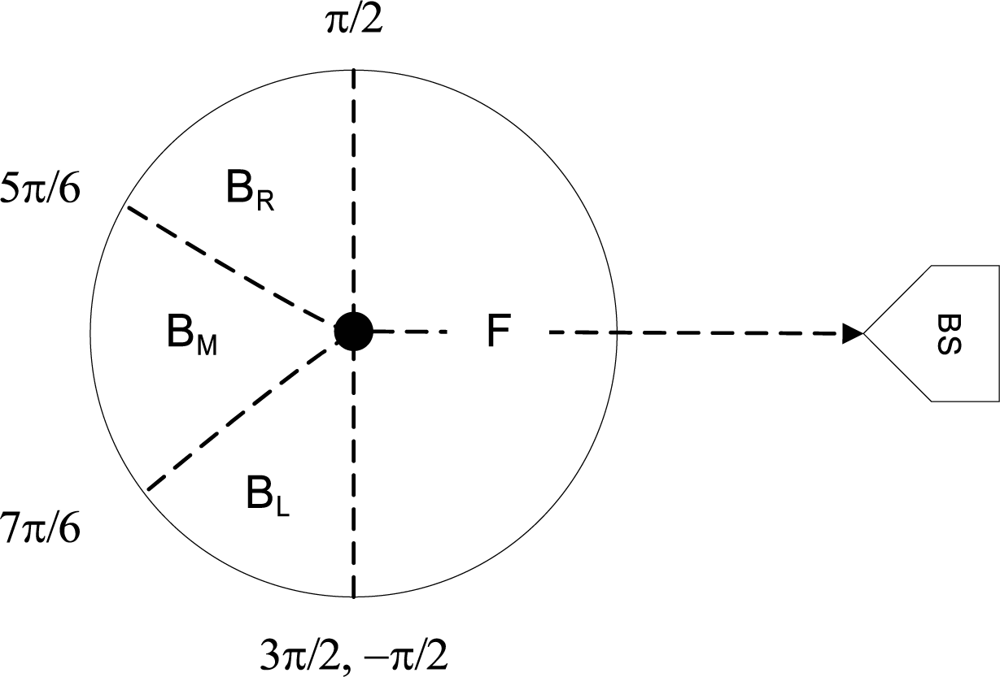
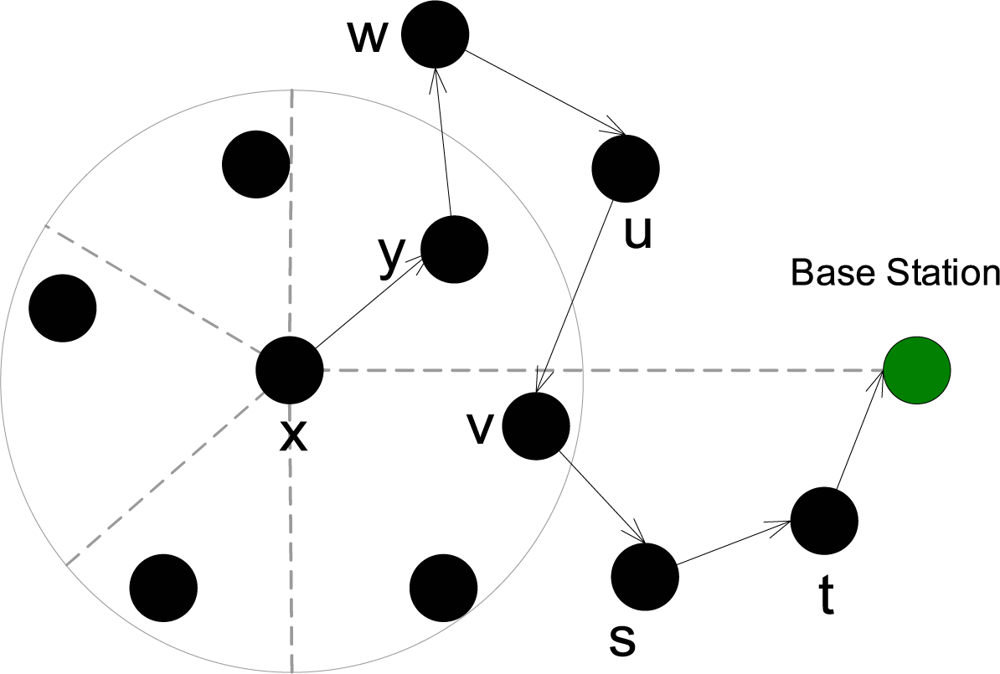
Notations and definitions: Denote a generic node by m. The set of neighbors of m is denoted by Nm, which also includes m itself. The number of forward and backward nodes of m is denoted by mf and mb respectively. If a node a is a backward node of m, then we denote it as a → m. We say that a node a is in the backward set of node m, if a → a1 → . . . ar → m, for some nodes a1, . . . ar where r ≥ 0. For compact notation we will denote this as a →r m, if the IDs of the intermediate nodes are not significant. We will also use the notation →r m to denote a generic node, who is r links (hops) away from m. Define the backward set Cm of m as Cm = {a|a →r m, r ≥ 0}, that is the set of all the possible nodes such that they have a forward link to m. Denote the base station as B. It will also be seen as another node. Let the total number of nodes in the network excluding the base station be N. We will use the term “adversary is in possession of a node” to indicate that the adversary can passively listen to any communication within the radio range of that node.
Claim 1: Suppose 𝒜 is in possession of
B. Let
Bb be the number of backward nodes of the base station (nodes one hop away from the base station). Then for any packet
q received by
B and for large enough
N:
Proof : The adversary can always know the ID of the last forwarding node. Let
Bb be the number of backward nodes to the base station. The packet could only have come from one of the nodes in
NB − {
B} (which only contains backward nodes to
B). Since the nodes are just a hop away from the BS, so they will not send the packet to another node. Hence for large
N we have:
Now let us assume that 𝒜 is in possession of a node m in the network. The following probability estimate gives an upper bound of the probability of success of the adversary. It is an upper bound since it does not include the possibility of a packet sent backwards. When a packet is sent backwards over one or many hops, the probability of success of the adversary decreases since there would be more possible nodes. Thus in this scenario our result would be like an upper bound on the adversary’s limitations.
Claim 2: Suppose 𝒜 is in possession of a node
m. Let
c = |
C→2m| denote the number of backward nodes in backward set
C→2m of some node →
2m. Then,
Proof : Since the adversary is in possession of a node m, it knows its backward and forward nodes. Furthermore, if any of these nodes including the node m itself is the sender of a packet q, then the adversary will know. This is true since the adversary can see all incoming packets to the node m and to its neighbor nodes (the forward and the backward nodes). Thus it can see if the payload of q is not equal to the payload of any q′ being received by these nodes in a given interval of time. If this is the case, then the adversary will know the sender.
Now if none of the nodes in
Nm are the senders, then the packet was forwarded by a node
i that is two hops away from
m. The adversary knows the ID of that node through the packet
q. Thus the adversary makes a list of all the possible backward nodes in the backward set of
i. Let that number be denoted by
c. Notice that node
i could also be the possible sender. Hence the total number of possible senders would be
c + 1. We have:
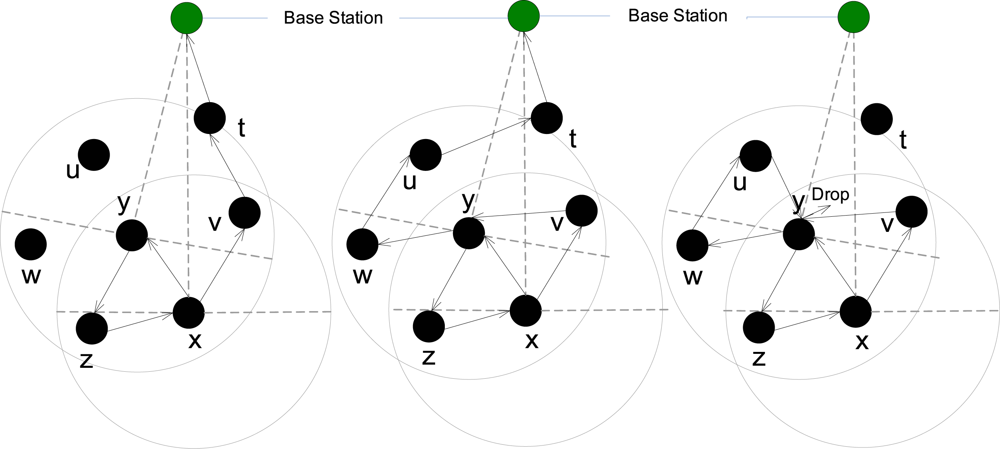
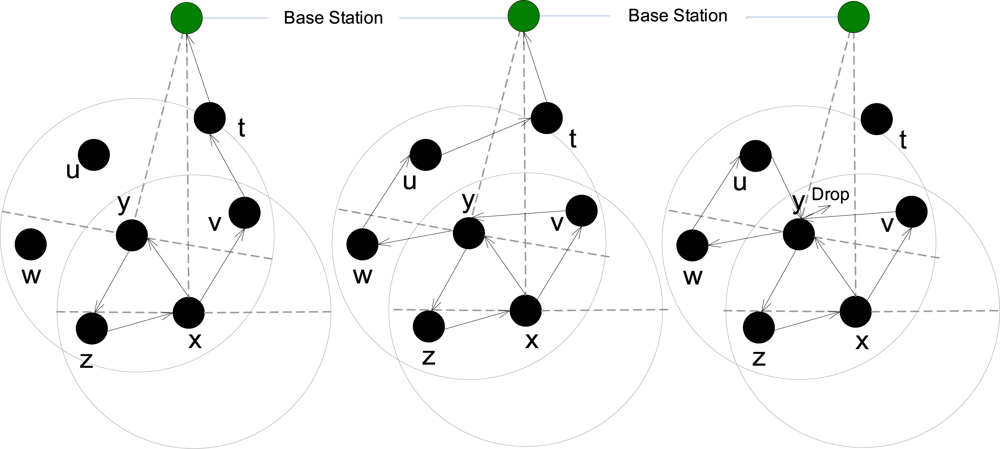
Now, suppose the adversary is in possession of two nodes at the same time; m1 and m2. We can safely assume that Nm1 ∩ Nm2 = φ, since it would be more advantageous to the adversary to cover nodes with non-overlapping radio ranges. The adversary will always know whenever any node in Nm1 or Nm2 is the sender of a packet. How about the case when they are not the senders? There could be two possible cases: without loss of generality, first assume that m2 ∈ Cm1. If the packet q was received by some node in Nm1 and was received by some node in Nm2 before, then the adversary had already checked it when the packet was sent to a node in Nm1. Thus the adversary need only check packets received in Nm1 that were not received by Nm2. In this case, the sender cannot be in Nm2. In any case, the adversary has to find out the backward sets of →2 m1 or →2 m2, depending on where the packet was received. Since, in the adversary’s knowledge, all nodes are equally likely to be senders, the probability of a packet being received at the two sets is the same. In case m2 ∉ Cm1, then the adversary has no real advantage except that it can see packets at two disjoint locations in the network. Thus we only state the case when m2 ∈ Cm1. We have the following result:
Claim 3: Suppose the adversary is in possession of two nodes
m1 and
m2. Assume further that
m2 ∈
Cm1. Let
c1 = |
C→2m1| and
c2 = |
C→2m2| then:
In general, we have:
Claim 4: Let us assume that
A is in possession of
k nodes
mk →
r1 ⋯ →
rk−2 m2 →
rk−1 m1 and let
mf and
mb denote the average number of forward and backward nodes averaged over all the
k nodes. Let
t =
mf +
mb + 1. Let for 1 ≤
i ≤
k,
ci = |
C→2mi|, then:
Observations: The probability is lowest when the adversary is actually at the base station. If the adversary has more nodes in possession, the probability increases linearly, with more success rate when the nodes are actually connected. This also shows that if a packet originates from any node that does not have a backward node, the adversary will always know the sender. This drawback can be avoided by requiring all nodes to have backward nodes. In other words, avoid a tree topology.
The above security resiliency analysis description is for route and location privacy. The security strength of identity and data privacy is mainly dependent on the encryption schemes. If encryption scheme is strong then we can achieve stronger identity and data privacy. If encryption scheme is weak then we have weak identity and data privacy.
5.2. Memory Consumption Analysis
Each sensor node needs to maintain one table that contains the list of neighboring nodes, their direction and their trust states as shown in
Table 2. Node identity can be represent in two bytes [
15,
33]. Four sets of directions can be easily represented in 2 bits. Trust calculation is based on time-based past interaction only. Therefore, the total size required to calculated trust value is 4Δ
t bytes [
22]. Here, Δ
t represents size of time window and 4 bytes are required to store number of successful (2 bytes) and unsuccessful (2 bytes) interactions. Trust value can be represented in one byte. Therefore the size of each record is 3.25 + 4Δ
t bytes (26 + 32Δ
t bits). If we assume that the node has
M neighboring nodes then the total size of the table will be
M(26 + 32Δ
t) bits.
In order to achieve data privacy in the presence of identity anonymity, our proposed scheme uses two keys: one Public key of the base station
and other is shared secret key kx−bs. Therefore, total memory required at the sensor node for our proposed scheme is:
.
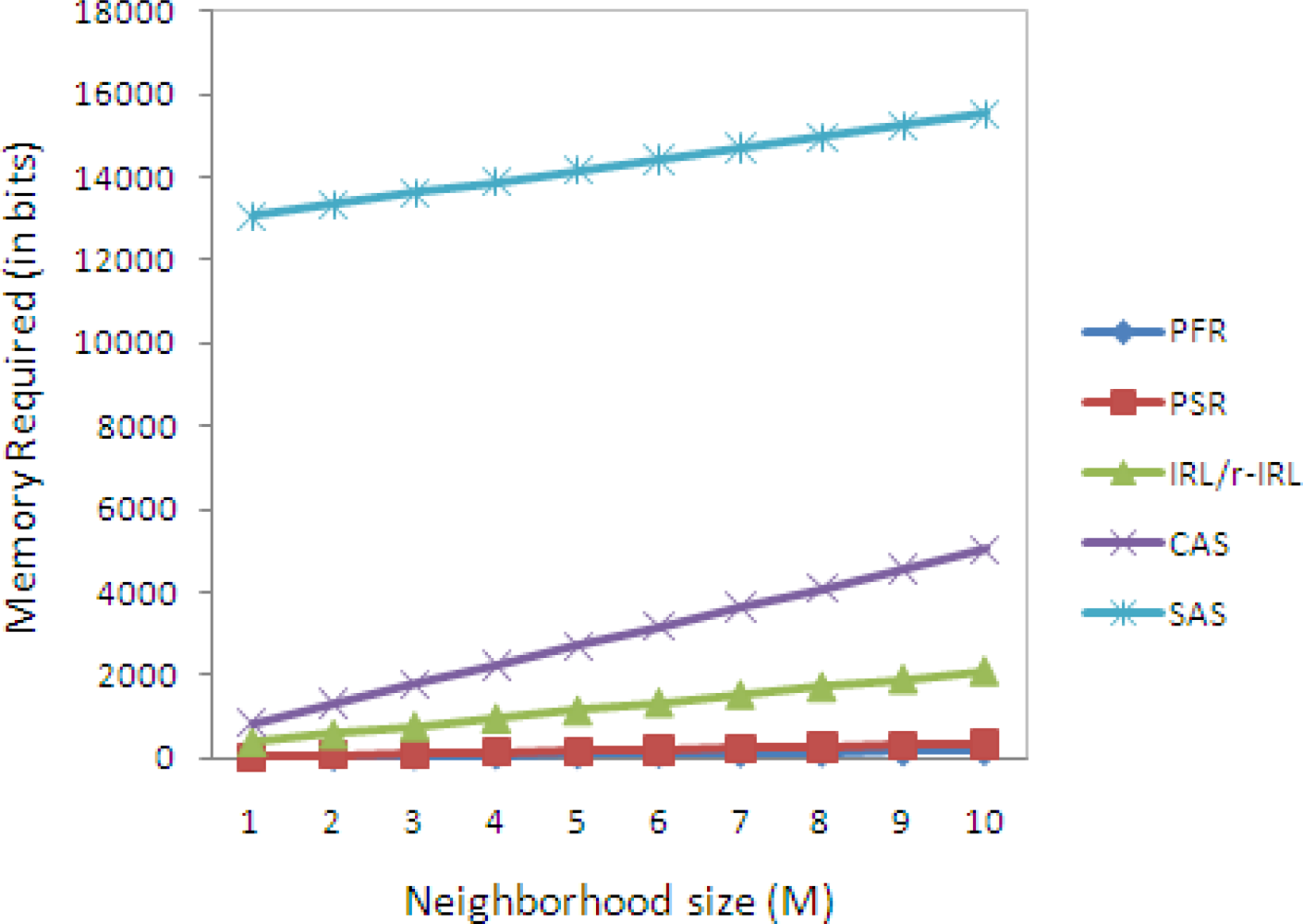
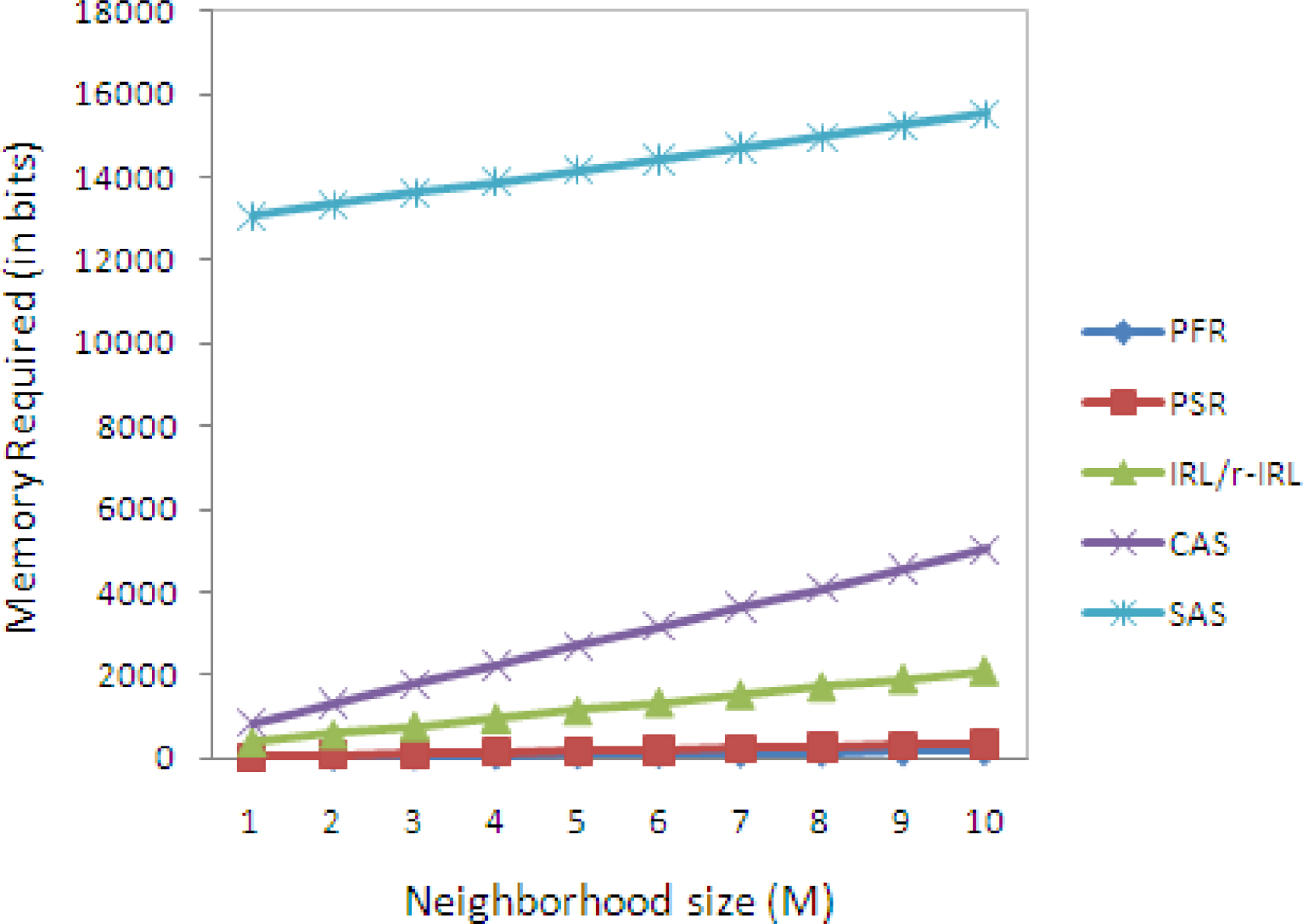
Table 3 shows the memory requirement of various privacy schemes, in which
M represents the neighborhood size,
K represents pseudonym space, 4Δ
t represents size of time window, and
N is the total number of nodes in the network.
In the Phantom Flood Routing (PFR) [
3] scheme, each sensor node needs to maintain the list of neighbor nodes and these neighbor nodes are divided into two sets. Here we assume that identity of a node is represented by two bytes, and set is distinguished by a single bit. So the total memory required by each node in the PFR scheme is (16+1)
M bits. In the Phantom Single-path Routing (PSR) [
4] scheme, each node maintain the list of neighbor nodes, hop count (2 bytes), and set identification (1 bit). Therefore, the total memory required by each node in the PSR scheme is (16+16+1)
M bits. In the SAS scheme, each node needs
K(4
M+2
N)+16
M bits of memory. Here
M represents the neighborhood size,
K represents pseudonym space and
N is the total number of nodes in the network. For the CAS scheme, each node requires
K(6+7
M)+16
M bits of memory. (See [
5] for more details about the SAS and CAS schemes.)
Let us assume that the sensor node has ten neighbor nodes, then the total memory required by the sensor node by the PFR, PSR, IRL, CAS and SAS is 21.25, 41.25, 260.5, 628 and 1940 bytes respectively, as shown in
Figure 5.
Additionally, cycle prevention strategy (Section 4.2) requires some short term memory to store signature of the packet for short period of time (
δt). In our proposed schemes, signature of the packet comprises of six fields: 1) Sequence number (2 bytes), 2) previous hop identity (2 bytes), 3) next hop identity (2 bytes), 4) payload (variable size), 5) counter (2 bits), and 6)
δt time (4 bytes). So, for each packet sensor node requires 10.25 +
Size (payload) bytes of memory. The packet signature will be removed from the buffer after
δt time. For example, sensor node
x received 20 packets of equal size of payload (e.g., 10 bytes). Then, the total memory required by the sensor node is 20 × (10.25+ 10) = 405 bytes. This additional overhead does not make sensor nodes overloaded because of following reasons:
Let us assume that the amount of traffic is very high and single sensor node needs to store large amount of packets at a time. Then in order to reduce the size of memory, we can use the technique of signature generation code [
39]. This technique allows us to represent single signature code in few bytes. However, this technique is based on Bloom filters [
40] that require the computation of multiple hash values. This may increase the computational cost. Therefore, we need to trade off between memory and computation cost.
5.3. Energy Consumption Analysis
In this section, we will show the efficiency of our routing strategies with existing schemes. Energy is computed based on the communication overhead (including transmission and reception cost, path length) introduced by our proposed routing protocols and compared it with other existing schemes.
We have implemented our IRL and r-IRL routing schemes on Sensor Network Simulator and Emulator (SENSE) [
41]. At the application layer we used constant bit rate component (CBR) that generate constant traffic during simulation between randomly selected source node(s) and the base station. For the simplicity, we assumed that both sensor nodes and the base station are static. Network consists of 300 sensor nodes that are organized into 15 by 20 grid manner. Other simulation parameters are given in
Table 4.
We have compared our proposed IRL and r-IRL algorithms with the four variations of phantom routing schemes [
3,
4] that are:
Phantom single path routing scheme with hop-based approach (PSR-hop).
Phantom single path routing scheme with sector-based approach (PSR-sec).
Phantom flood routing scheme with hop-based approach (PFR-hop).
Phantom flood routing scheme with sector-based approach (PFR-sec).
We did not compared our schemes with the SAS and CAS [
5] schemes because the authors did not propose any routing strategy.
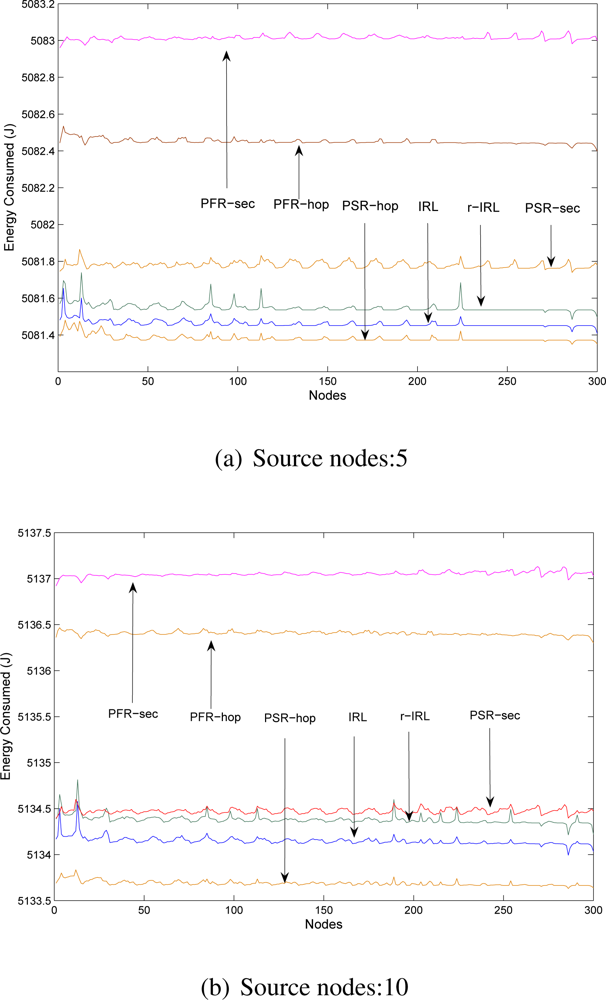
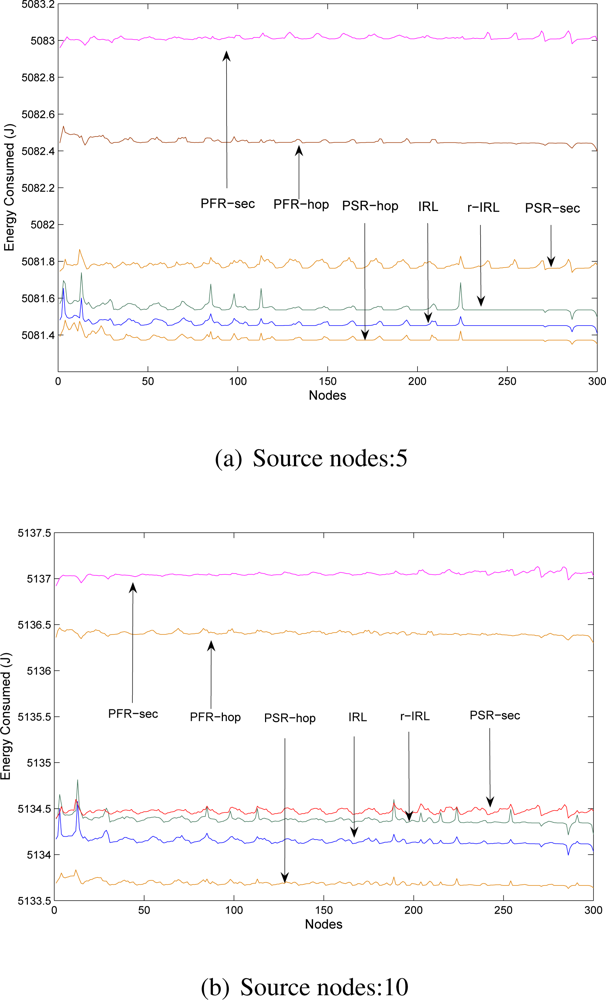
The energy consumption analysis with different scenarios are shown in
Figure 6. For the r-IRL scheme we select
r = 3, which means a single packet will reach the destination via three different routes simultaneously. For phantom routing schemes, we select parameter
hwalk=10 (as recommended in [
3]).
Figure 6 clearly indicates that, the IRL and r-IRL schemes consume less energy as compared to the PSR-sec, PFR-hop and PFR-sec schemes but slightly consume higher energy as compared to the PSR-hop scheme. This is due to the fact that the IRL and r-IRL algorithms provides more path diversity and packets sometimes took longer paths.
5.4. Path Diversity Analysis
Strength of route privacy is dependent on path diversity. High path diversity provides strong route privacy and low path diversity provides weak rout privacy. Path diversity can be categorized into two types.
Length variation: Path could be long or short and mainly dependent on routing scheme. For example, packets always reach to the destination via shortest path. In this scheme, packets may reach to the destination via longer path if any node is not working properly within the shortest available path. With respect to the route privacy, length variation provides minimum route privacy. If we have longer paths, then it will increase time for an adversary to find out actual source node or vice versa. So, the longer path increases safety time.
Path variation: Each packet may follow different route. It is also dependent on routing strategy. For example, routing scheme make decision about next hop based on the energy level of neighboring nodes. With this approach, one can achieve limited path variation. With respect to the route privacy, if we have more path variation, then it will become clueless for an adversary to guess from where next packet will come.
Our proposed routing strategies (IRL and r-IRL) have both features. Because of the concept of direction (Section 4.1), proposed schemes provide more length variation and because of the randomness (Section 4.2) proposed schemes provide high path variation. Incorporation of both features offer high path diversity.
In order to analyze the path diversity behavior, we have organized 300 sensor nodes in a 10 by 30 grid manner. The rest of simulation parameters are given in
Table 4. In the simulation, a single source node (ID: 224) generates 100 data packets for the base station.
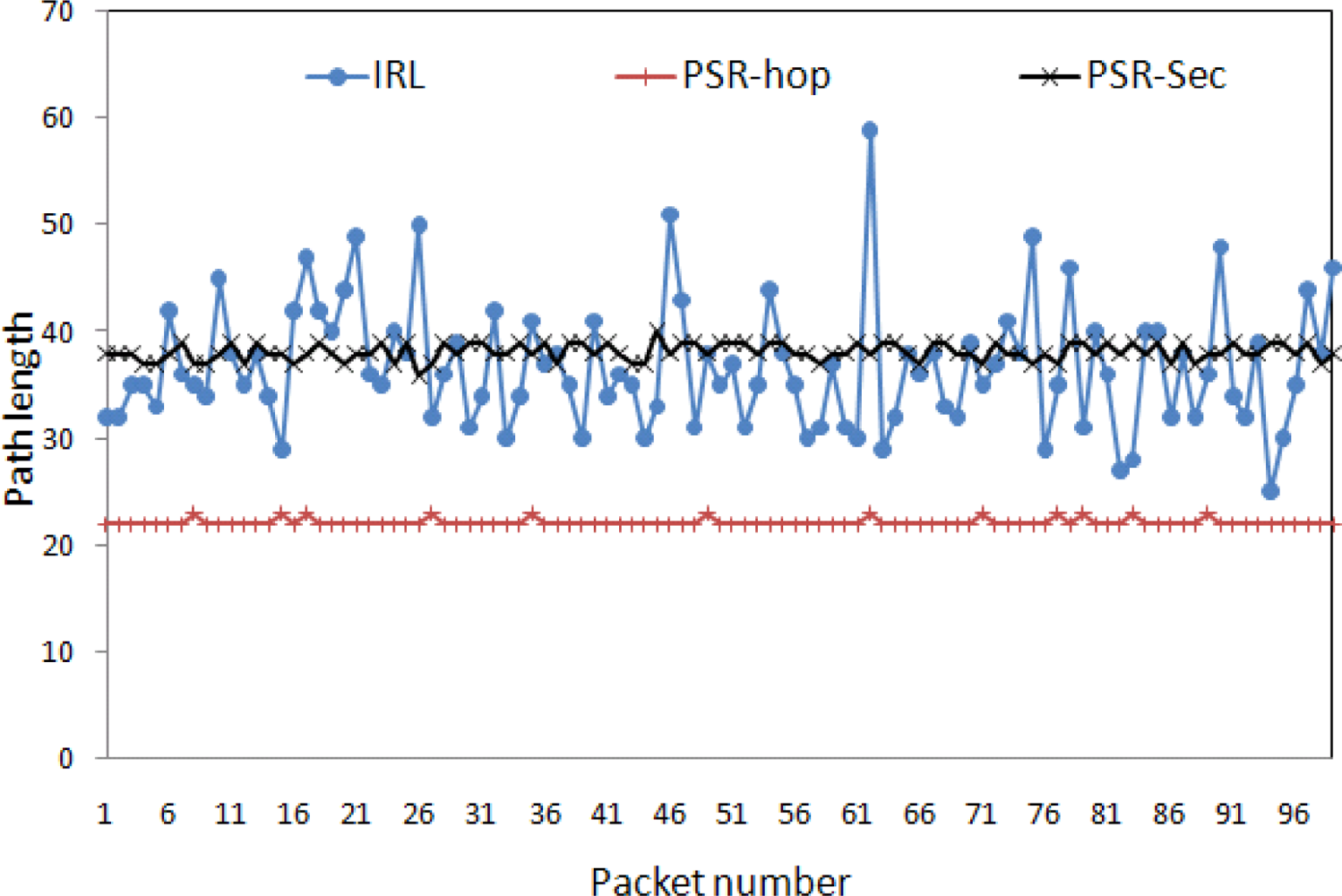
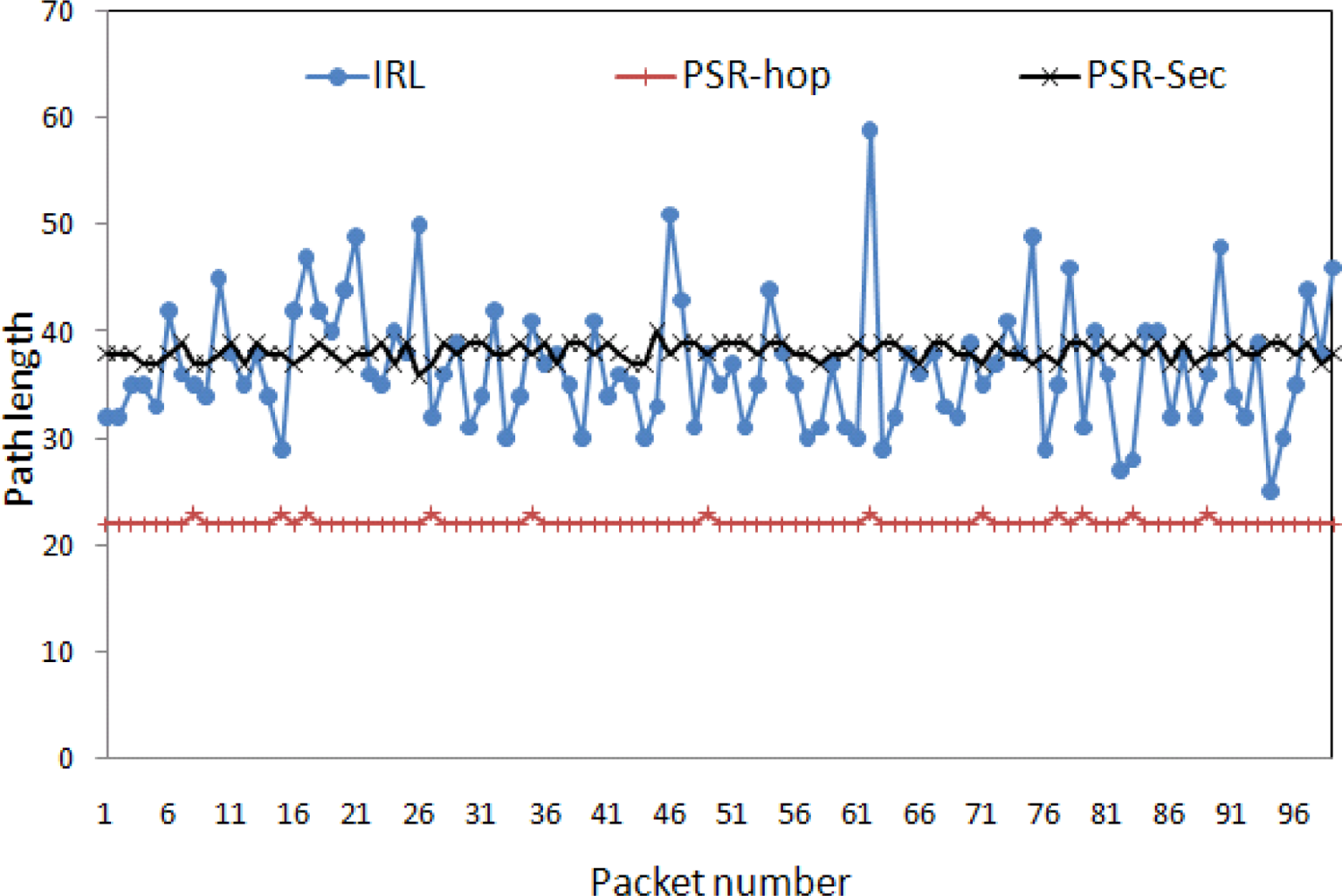
Figure 7 shows the path diversity (in terms of path length) of the IRL, PSR-hop and PSR-sec schemes. The average path taken by the PSR-hop, IRL and PSR-sec is 22.12, 36.81 and 38.17, respectively. It indicates that the IRL scheme incurs more delay as compared with the PSR-hop scheme and less delay as compared with the PSR-sec scheme. This figure also indicates that the IRL scheme has more path variation as compared with the other schemes, which creates more difficulties for the adversary to trace back the source from the captured packets.
Figure 7 also shows that some packets took longer paths in the IRL scheme as compared with others. This is due to the fact that the source or en-route node did not find any trusted node in its forward direction, so the packet is relayed back in the backward direction. If we assume that each node has
p probability to be trusted and all probabilities are independent of each other, then the total probability
Pb for a node
i to relay the packet in the backward direction is:
where
mf represents the number of nodes in the forward direction.
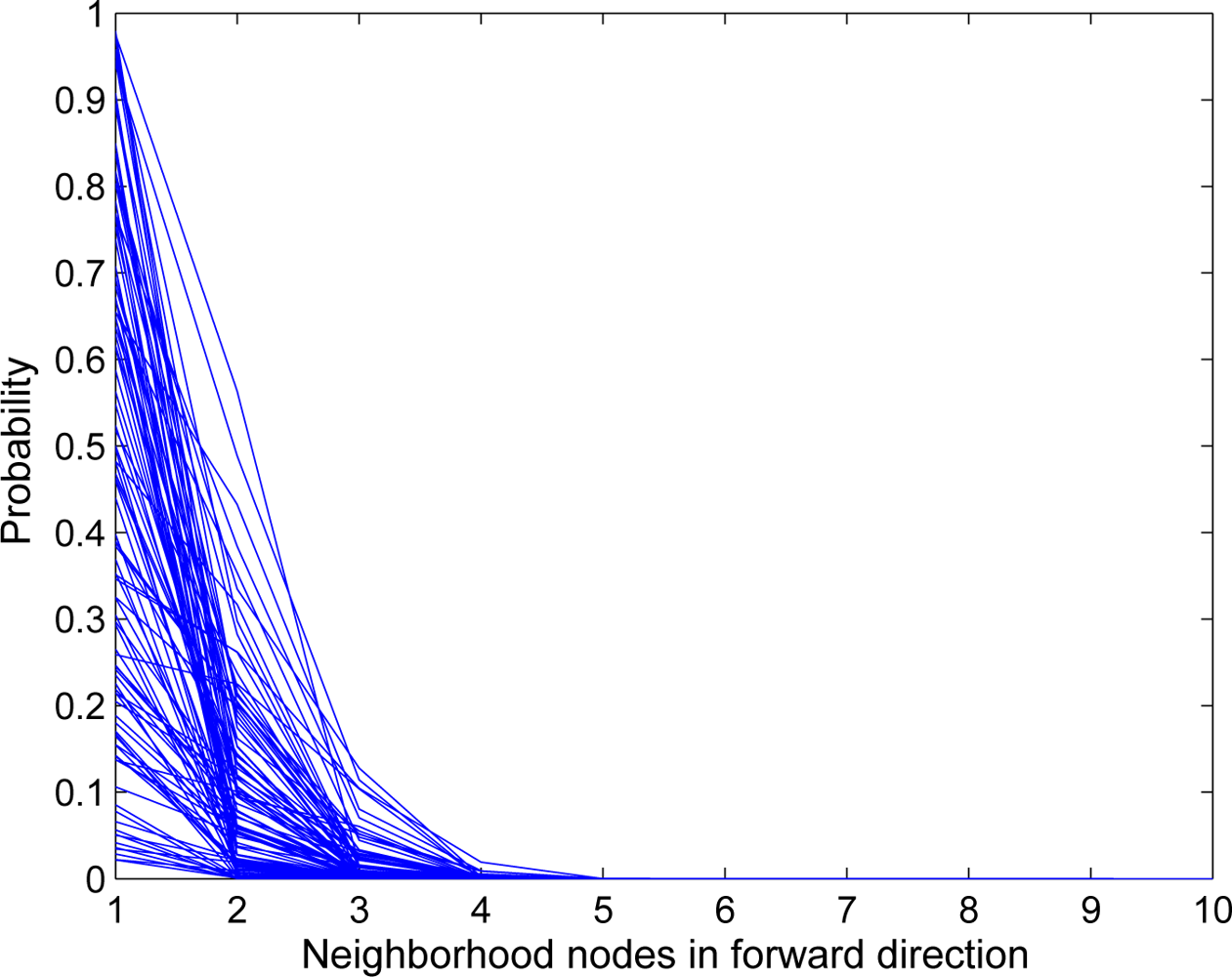
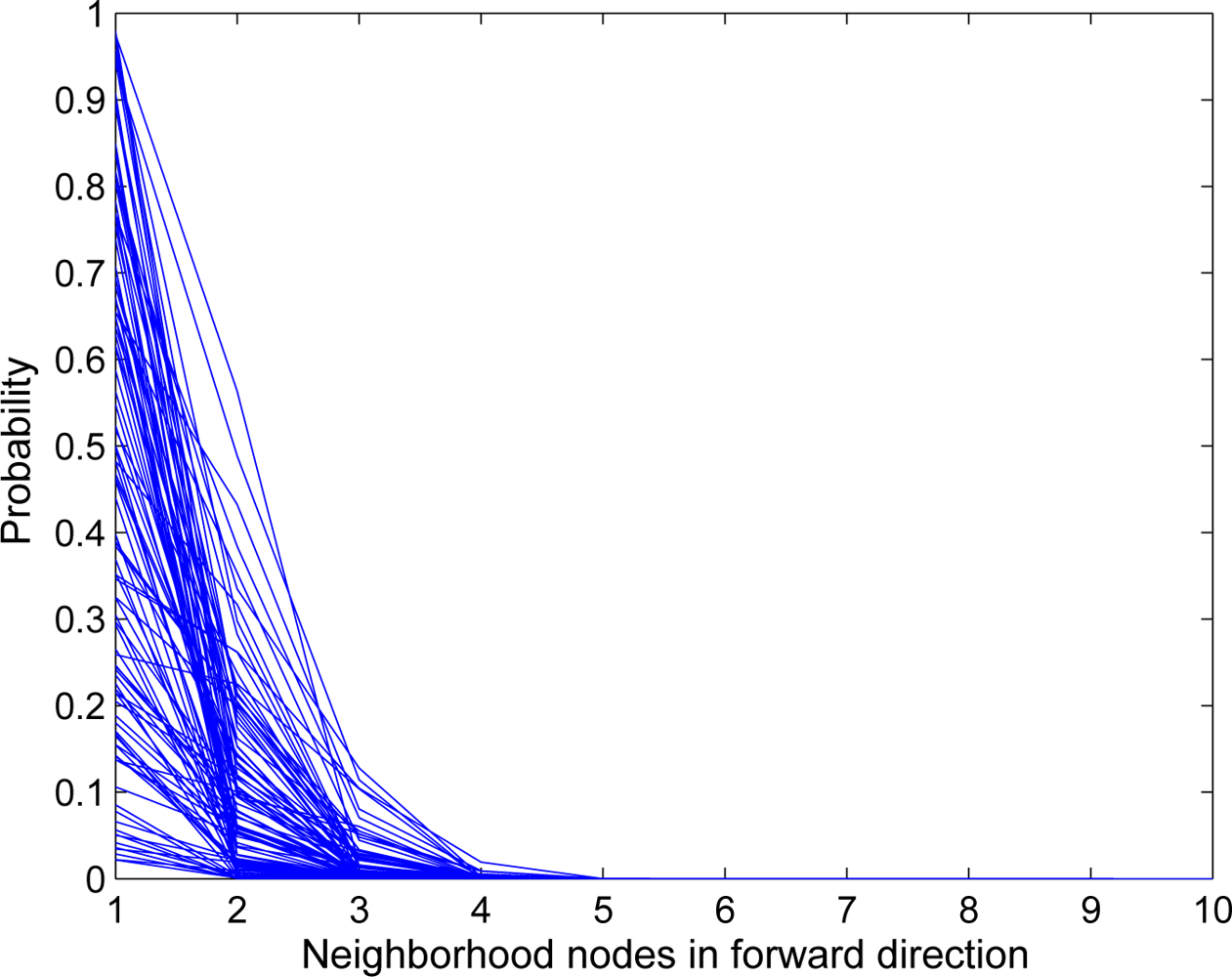
Figure 8 shows the result of 100 simulation runs in which we have assumed that each node has equal probability to be trusted and un-trusted. It shows that, as the neighborhood size increases, the probability of the packet to move in the backward direction decreases sharply.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}