
FactorsR: An RWizard Application for Identifying the Most Likely Causal Factors in Controlling Species Richness

{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
2.1. FactorsR
2.1.1. Installation and Platform Availability
2.1.2. Software Design
2.1.3. Functions of R Used in FactorsR
2.2. Usage of FactorsR by Applying It to Terrestrial Carnivores
2.2.1. Species Distribution
2.2.2. Extent of Occurrence
2.2.3. Area of Occupancy
2.2.4. Patch Distribution
2.2.5. Area of Occupancy Index and Patch Index
2.2.6. Environmental Variables
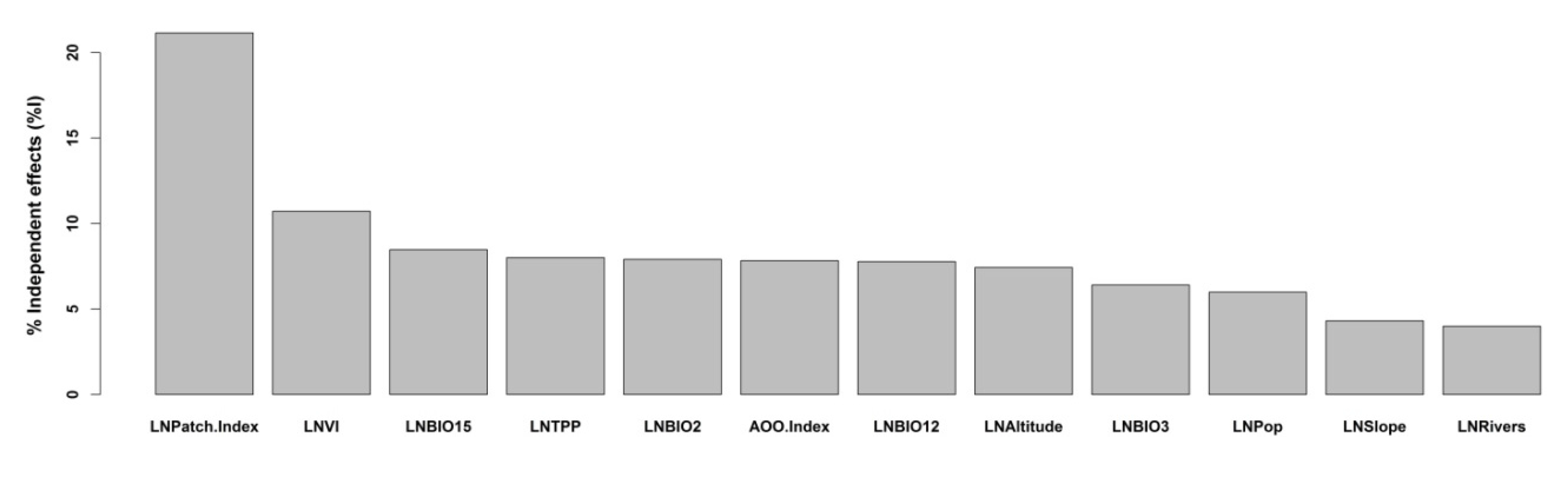
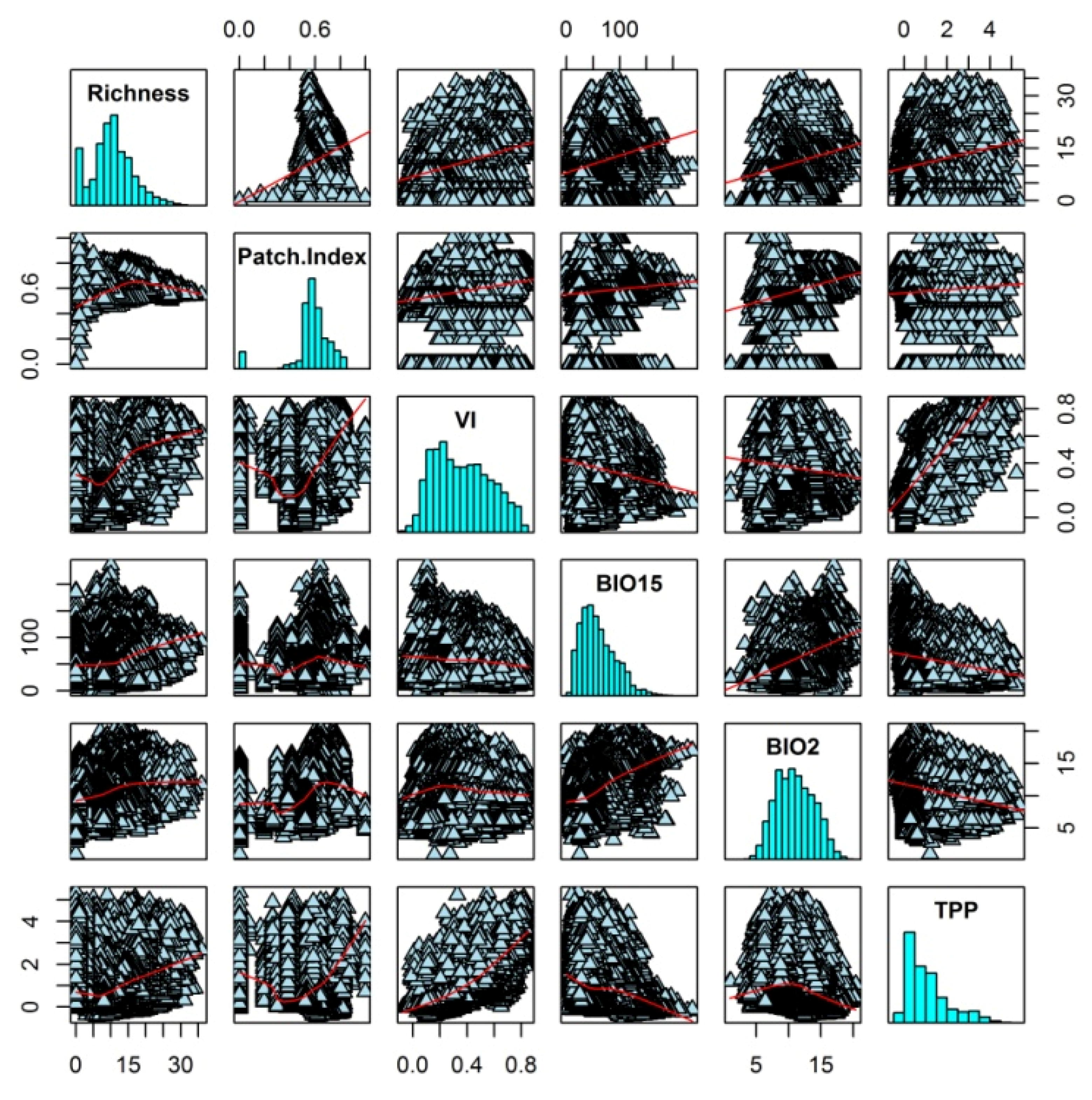
3. Results


4. Discussion

5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gaston, K.J. Global patterns in biodiversity. Nature 2000, 405, 220–227. [Google Scholar] [CrossRef] [PubMed]
- Di Marco, M.; Buchanan, G.M.; Szantoi, Z.; Holmgren, M.; Grottolo Marasini, G.; Gross, D.; Tranquilli, S.; Boitani, L.; Rondinini, C. Drivers of extinction risk in African mammals: The interplay of distribution state, human pressure, conservation response and species biology. Philos. Trans. R. Soc. B 2014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mac Nally, R. Regression and model-building in conservation biology, biogeography and ecology: The distinction between—And reconciliation of—“Predictive” and “explanatory” models. Biodivers. Conserv. 2000, 9, 655–671. [Google Scholar] [CrossRef]
- Chevan, A.; Sutherland, M. Hierarchical partitioning. Am. Stat. 1991, 45, 90–96. [Google Scholar]
- Mac Nally, R. Multiple regression and inference in ecology and conservation biology: Further comments on identifying important predictor variables. Biodivers. Conserv. 2002, 11, 1397–1401. [Google Scholar] [CrossRef]
- Zuur, A.; Ieno, E.N.; Smith, G.M. Analysing Ecological Data; Springer: New York, NY, USA, 2007. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and other Kernel-Based Learning Methods; Cambridge University Press: New York, NY, USA, 2000. [Google Scholar]
- Drake, J.M.; Randin, C.; Guisan, A. Modelling ecological niches with support vector machines. J. Appl. Ecol. 2006, 43, 424–432. [Google Scholar] [CrossRef]
- Basak, D.; Pal, S.; Patranabis, D.C. Support vector regression. Neural Inf. Process. Lett. Rev. 2007, 11, 203–224. [Google Scholar]
- Yao, X.J.; Panaye, A.; Doucet, J.P.; Zhang, R.S.; Chen, H.F.; Liu, M.C.; Hu, Z.D.; Fan, B.T. Comparative study of QSAR/QSPR correlations using support vector machines, radial basis function neural networks, and multiple linear regression. J. Chem. Inf. Comput. Sci. 2004, 44, 1257–1266. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, R.; Torgo, L. A comparative study on predicting algae blooms in Douro River, Portugal. Ecol. Model. 2008, 212, 86–91. [Google Scholar] [CrossRef]
- Al-Anazi, A.F.; Gates, I.D. Support vector regression for porosity prediction in a heterogeneous reservoir: A comparative study. Comput. Geosci. 2010, 36, 1494–1503. [Google Scholar] [CrossRef]
- Chen, S.-T.; Yu, P.-S.; Tang, Y.-H. Statistical downscaling of daily precipitation using support vector machines and multivariate analysis. J. Hydrol. 2010, 385, 13–22. [Google Scholar] [CrossRef]
- Guisande, C.; Patti, B.; Vaamonde, A.; Manjarrés-Hernández, A.; Pelayo-Villamil, P.; García-Roselló, E.; GonzálezDacosta, J.; Heine, J.; Granado-Lorencio, C. Factors affecting species richness of marine elasmobranchs. Biodivers. Conserv. 2013, 22, 1703–1714. [Google Scholar] [CrossRef]
- Pelayo-Villamil, P.; Guisande, C.; Vari, R.P.; Manjarrés-Hernández, A.; García-Roselló, E.; González-Dacosta, J.; Heine, J.; González Vilas, L.; Patti, B.; Quinci, E.M.; et al. Global diversity patterns of freshwater fishes—Potential victims of their own success. Divers. Distrib. 2015, 21, 345–356. [Google Scholar] [CrossRef]
- RWizard Software, Version 1.1. Available online: http://ipez.es/RWizard (accessed on 15 June 2015).
- OpenStreetMap Foundation Wiki Contributors. Available online: http://www.openstreetmap.org (accessed on 3 January 2015).
- Walsh, C.; Mac Nally, R. Hierarchical Partitioning. R Package, ver. 1.0–4. Available online: https://cran.r-project.org/web/packages/hier.part (accessed on 7 January 2015).
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2015. [Google Scholar]
- Grömping, U. Relative Importance for Linear Regression in R: The Package relaimpo. J. Stat. Softw. 2006, 17, 1–27. [Google Scholar] [CrossRef]
- Grömping, U. Relative Importance of Regressors in Linear Models. R Package, ver. 2.2–2. Available online: https://cran.r-project.org/web/packages/relaimpo (accessed on 30 March 2015).
- Gross, J. Five Omnibus Tests for the Composite Hypothesis of Normality. R Package, ver. 1.0–4. Available online: https://cran.r-project.org/web/packages/nortest (accessed on 14 April 2015).
- Zeileis, A.; Hothorn, T. Diagnostic Checking in Regression Relationships. R News 2002, 2, 7–10. [Google Scholar]
- Hothorn, T.; Zeileis, A. Testing Linear Regression Models. R package, ver. 0.9–34. Available online: https://cran.r-project.org/web/packages/lmtest (accessed on 2 February 2015).
- Fox, J.; Weisberg, S. An R Companion to Applied Regression; Sage Publications: Thousand Oaks, CA, USA, 2011. [Google Scholar]
- Naimi, B. Uncertainty Analysis for Species Distribution Models. R Package, ver. 1.1–15. Available online: https://cran.r-project.org/web/packages/usdm/index.html (accessed on 2 June 2015).
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. Kernlab—An S4 Package for Kernel Methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. Kernel-Based Machine Learning Lab. R Package, ver. 0.9–22. Available online: https://cran.r-project.org/web/packages/kernlab (accessed on 5 May 2015).
- Pelayo-Villamil, P.; Guisande, C.; González-Vilas, L.; Carvajal-Quintero, J.D.; Jiménez-Segura, L.F.; García-Roselló, E.; Heine, J.; González-Dacosta, J.; Manjarrés-Hernández, A.; Vaamonde, A.; et al. ModestR: Una herramienta infromática para el estudio de los ecosistemas acuáticos de Colombia. Actual. Biol. 2012, 34, 225–239. [Google Scholar]
- García-Roselló, E.; Guisande, C.; González-Dacosta, J.; Heine, J.; Pelayo-Villamil, P.; Manjarrés-Hernández, A.; Vaamonde, A.; Granado-Lorencio, C. ModestR: A software tool for managing and analyzing species distribution map databases. Ecography 2013, 36, 1202–1207. [Google Scholar] [CrossRef]
- The IUCN Red List of Threatened Species. Version 2015.1. Available online: http://www.iucnredlist.org (accessed on 15 June 2015).
- GBIF Data Portal. Available online: http://data.gbif.org (accessed on 30 June 2015).
- Helgen, K.M.; Pinto, C.M.; Kays, R.; Helgen, L.E.; Tsuchiya, M.T.N.; Quinn, A.; Wilson, D.E.; Maldonado, J.E. Taxonomic revision of the olingos (Bassaricyon), with description of a new species, the Olinguito. ZooKeys 2013, 324, 1–83. [Google Scholar] [CrossRef] [PubMed]
- García-Roselló, E.; Guisande, C.; Heine, J.; Pelayo-Villamil, P.; Manjarrés-Hemández, A.; González-Vilas, L.; González-Dacosta, J.; Vaamonde, A.; Granado-Lorencio, C. Using ModestR to download, import and clean species distribution records. Methods Ecol. Evol. 2014, 5, 708–713. [Google Scholar] [CrossRef]
- García-Roselló, E.; Guisande, C.; Manjarrés-Hernández, A.; González-Dacosta, J.; Heine, J.; Pelayo-Villamil, P.; González-Vilas, L.; Vari, R.P.; Vaamonde, A.; Granado-Lorencio, C.; et al. Can we derive macroecological patterns from primary GBIF data? Glob. Ecol. Biogeogr. 2015, 24, 335–347. [Google Scholar] [CrossRef]
- Crooks, K.R.; Burdett, C.L.; Theobald, D.M.; Rondinini, C.; Boitani, L. Global patterns of fragmentation and connectivity of mammalian carnivore habitat. Philos. Trans. R. Soc. B 2011, 366, 2642–2651. [Google Scholar] [CrossRef] [PubMed]
- Fahrig, L. Effects of habitat fragmentation on biodiversity. Annu. Rev. Ecol. Evol. Syst. 2003, 34, 487–515. [Google Scholar] [CrossRef]
- Guisande, C.; Barreiro, A.; Maneiro, I.; Riveiro, I.; Vergara, A.R.; Vaamonde, A. Tratamiento de Datos; Díaz de Santos: Madrid, Spain, 2006. [Google Scholar]
- Guisande, C.; Vaamonde, A.; Barreiro, A. Tratamiento de Datos con R, Statistica y SPSS; Díaz de Santos: Madrid, Spain, 2011. [Google Scholar]
- Guisande, C.; Vaamonde, A. Gráficos Estadísticos y Mapas con R; Díaz de Santos: Madrid, Spain, 2012. [Google Scholar]
- Kissling, W.D.; Carl, G. Spatial autocorrelation and the selection of simultaneous autoregressive models. Glob. Ecol. Biogeogr. 2008, 17, 59–71. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guisande, C.; Heine, J.; García-Roselló, E.; González-Dacosta, J.; Perez-Schofield, B.J.G.; González-Vilas, L.; Vaamonde, A.; Lobo, J.M. FactorsR: An RWizard Application for Identifying the Most Likely Causal Factors in Controlling Species Richness. Diversity 2015, 7, 385-396. https://doi.org/10.3390/d7040385
Guisande C, Heine J, García-Roselló E, González-Dacosta J, Perez-Schofield BJG, González-Vilas L, Vaamonde A, Lobo JM. FactorsR: An RWizard Application for Identifying the Most Likely Causal Factors in Controlling Species Richness. Diversity. 2015; 7(4):385-396. https://doi.org/10.3390/d7040385
Chicago/Turabian StyleGuisande, Cástor, Juergen Heine, Emilio García-Roselló, Jacinto González-Dacosta, Baltasar J. García Perez-Schofield, Luis González-Vilas, Antonio Vaamonde, and Jorge M. Lobo. 2015. "FactorsR: An RWizard Application for Identifying the Most Likely Causal Factors in Controlling Species Richness" Diversity 7, no. 4: 385-396. https://doi.org/10.3390/d7040385
APA StyleGuisande, C., Heine, J., García-Roselló, E., González-Dacosta, J., Perez-Schofield, B. J. G., González-Vilas, L., Vaamonde, A., & Lobo, J. M. (2015). FactorsR: An RWizard Application for Identifying the Most Likely Causal Factors in Controlling Species Richness. Diversity, 7(4), 385-396. https://doi.org/10.3390/d7040385