Risk-Association of CYP11A1 Polymorphisms and Breast Cancer Among Han Chinese Women in Southern China

Abstract
:1. Introduction
2. Results and Discussion
2.1. Study Subjects
2.2. Hardy-Weinberg Equilibrium (HWE), Linkage Disequilibrium (LD) and Haplotype Analysis
2.3. Polymorphisms of CYP11A1 and Breast Cancer Risk
3. Experimental Section
3.1. Subjects
3.1.1. Patients of Breast Cancer
3.1.2. Controls
3.2. DNA Extraction
3.3. Genotyping
3.4. Statistical Analysis
4. Conclusions
Supplementary Material
ijms-13-04896-s001.pdfAcknowledgments
- Conflict of InterestThe authors declare no conflict of interest.
References
- Leong, S.P.; Shen, Z.Z.; Liu, T.J.; Agarwal, G.; Tajima, T.; Paik, N.S.; Sandelin, K.; Derossis, A.; Cody, H.; Foulkes, W.D. Is breast cancer the same disease in Asian and Western countries? World J. Surg 2010, 34, 2308–2324. [Google Scholar]
- Mavaddat, N.; Antoniou, A.C.; Easton, D.F.; Garcia-Closas, M. Genetic susceptibility to breast cancer. Mol. Oncol 2010, 4, 174–191. [Google Scholar]
- Begg, C.B.; Haile, R.W.; Borg, A.; Malone, K.E.; Concannon, P.; Thomas, D.C.; Langholz, B.; Bernstein, L.; Olsen, J.H.; Lynch, C.F.; et al. Variation of breast cancer risk among BRCA1/2 carriers. JAMA 2008, 299, 194–201. [Google Scholar]
- Campeau, P.M.; Foulkes, W.D.; Tischkowitz, M.D. Hereditary breast cancer: New genetic developments, new therapeutic avenues. Hum. Genet 2008, 124, 31–42. [Google Scholar]
- CHEK2 Breast Cancer Case-Control Consortium. CHEK2*1100delC and susceptibility to breast cancer: A collaborative analysis involving 10,860 breast cancer cases and 9065 controls from 10 studies. Am. J. Hum. Genet 2004, 74, 1175–1182.
- Rahman, N.; Seal, S.; Thompson, D.; Kelly, P.; Renwick, A.; Elliott, A.; Reid, S.; Spanova, K.; Barfoot, R.; Chagtai, T.; et al. PALB2, which encodes a BRCA2-interacting protein, is a breast cancer susceptibility gene. Nat. Genet 2007, 39, 165–167. [Google Scholar]
- Seal, S.; Thompson, D.; Renwick, A.; Elliott, A.; Kelly, P.; Barfoot, R.; Chagtai, T.; Jayatilake, H.; Ahmed, M.; Spanova, K.; et al. Truncating mutations in the Fanconi anemia J gene BRIP1 are low-penetrance breast cancer susceptibility alleles. Nat. Genet 2006, 38, 1239–1241. [Google Scholar]
- King, M.C.; Marks, J.H.; Mandell, J.B. Breast and ovarian cancer risks due to inherited mutations in BRCA1 and BRCA2. Science 2003, 302, 643–646. [Google Scholar]
- Fletcher, O.; Johnson, N.; Orr, N.; Hosking, F.J.; Gibson, L.J.; Walker, K.; Zelenika, D.; Gut, I.; Heath, S.; Palles, C.; et al. Novel breast cancer susceptibility locus at 9q31.2: Results of a genome-wide association study. J. Nat. Cancer Inst 2011, 103, 425–435. [Google Scholar]
- Li, J.; Humphreys, K.; Heikkinen, T.; Aittomäki, K.; Blomqvist, C.; Pharoah, P.D.; Dunning, A.M.; Ahmed, S.; Hooning, M.J.; Martens, J.W.; et al. A combined analysis of genome-wide association studies in breast cancer. Breast Cancer Res. Treat 2011, 126, 717–727. [Google Scholar]
- Long, J.; Cai, Q.; Sung, H.; Shi, J.; Zhang, B.; Choi, J.Y.; Wen, W.; Delahanty, R.J.; Lu, W.; Gao, Y.T.; et al. Genome-wide association study in East asians identifies novel susceptibility Loci for breast cancer. PLoS Genet 2012, 8. [Google Scholar] [CrossRef] [Green Version]
- Turnbull, C.; Ahmed, S.; Morrison, J.; Pernet, D.; Renwick, A.; Maranian, M.; Seal, S.; Ghoussaini, M.; Hines, S.; Healey, C.S.; et al. Genome-wide association study identifies five new breast cancer susceptibility loci. Nat. Genet 2010, 42, 504–507. [Google Scholar]
- Thomas, G.; Jacobs, K.B.; Kraft, P.; Yeager, M.; Wacholder, S.; Cox, D.G.; Hankinson, S.E.; Hutchinson, A.; Wang, Z.; Yu, K.; et al. A multistage genome-wide association study in breast cancer identifies two new risk alleles at 1p11.2 and 14q24.1 (RAD51L1). Nat. Genet 2009, 41, 579–584. [Google Scholar]
- Key, T.; Appleby, P.; Barnes, I.; Reeves, G. Endogenous sex hormones and breast cancer in postmenopausal women: Reanalysis of nine prospective studies. J. Nat. Cancer Inst 2002, 94, 606–616. [Google Scholar]
- Folkerd, E.J.; Martin, L.A.; Kendall, A.; Dowsett, M. The relationship between factors affecting endogenous oestradiol levels in postmenopausal women and breast cancer. J. Steroid Biochem. Mol. Biol 2006, 102, 250–255. [Google Scholar]
- Sakoda, L.C.; Blackston, C.; Doherty, J.A.; Ray, R.M.; Lin, M.G.; Stalsberg, H.; Gao, D.L.; Feng, Z.; Thomas, D.B.; Chen, C. Polymorphisms in steroid hormone biosynthesis genes and risk of breast cancer and fibrocystic breast conditions in Chinese women. Cancer Epidem. Biomarker. Prev 2008, 17, 1066–1073. [Google Scholar]
- Zheng, W.; Gao, Y.T.; Shu, X.O.; Wen, W.; Cai, Q.; Dai, Q.; Smith, J.R. Population-based case-control study of CYP11A gene polymorphism and breast cancer risk. Cancer Epidem. Biomarker. Prev 2004, 13, 709–714. [Google Scholar]
- Setiawan, V.W.; Cheng, I.; Stram, D.O.; Giorgi, E.; Pike, M.C.; Van den Berg, D.; Pooler, L.; Burtt, N.P.; Le Marchand, L.; Altshuler, D.; et al. A systematic assessment of common genetic variation in CYP11A and risk of breast cancer. Cancer Res 2006, 66, 12019–12025. [Google Scholar]
- Yaspan, B.L.; Breyer, J.P.; Cai, Q.; Dai, Q.; Elmore, J.B.; Amundson, I.; Bradley, K.M.; Shu, X.O.; Gao, Y.T.; Dupont, W.D.; et al. Haplotype analysis of CYP11A1 identifies promoter variants associated with breast cancer risk. Cancer Res 2007, 67, 5673–5682. [Google Scholar]
- Payne, A.H.; Hales, D.B. Overview of steroidogenic enzymes in the pathway from cholesterol to active steroid hormones. Endocr. Rev 2004, 25, 947–970. [Google Scholar]
- Gao, G.H.; Cao, Y.X.; Yi, L.; Wei, Z.L.; Xu, Y.P.; Yang, C. Polymorphism of CYP11A1 gene in Chinese patients with polycystic ovarian syndrome. Chin. J. Obstet. Gynecol 2010, 45, 191–196. [Google Scholar]
- Celhar, T.; Gersak, K.; Ovcak, Z.; Sedmak, B.; Mlinaric-Rascan, I. The presence of the CYP11A1 (TTTTA)6 allele increases the risk of biochemical relapse in organ confined and low-grade prostate cancer. Cancer Genet. Cytogenet 2008, 187, 28–33. [Google Scholar]
- Kumazawa, T.; Tsuchiya, N.; Wang, L.; Sato, K.; Kamoto, T.; Ogawa, O.; Nakamura, A.; Kato, T.; Habuchi, T. Microsatellite polymorphism of steroid hormone synthesis gene CYP11A1 is associated with advanced prostate cancer. Int. J. Cancer 2004, 110, 140–144. [Google Scholar]
- Terry, K.; McGrath, M.; Lee, I.M.; Buring, J.; de Vivo, I. Genetic variation in CYP11A1 and StAR in relation to endometrial cancer risk. Gynecol. Oncol 2010, 117, 255–259. [Google Scholar]
- Henderson, B.E.; Feigelson, H.S. Hormonal carcinogenesis. Carcinogenesis 2000, 21, 427–433. [Google Scholar]
- Boyd, N.F.; Martin, L.J.; Yaffe, M.J.; Minkin, S. Mammographic density: A hormonally responsive risk factor for breast cancer. J. Br. Menopause Soc 2006, 12, 186–193. [Google Scholar]
- Li, J.; Eriksson, L.; Humphreys, K.; Czene, K.; Liu, J.; Tamimi, R.M.; Lindström, S.; Hunter, D.J.; Vachon, C.M.; Couch, F.J.; et al. Genetic variation in the estrogen metabolic pathway and mammographic density as an intermediate phenotype of breast cancer. Breast Cancer Res 2010, 12. [Google Scholar] [CrossRef]
- Miyaki, K.; Htun, N.C.; Song, Y.; Ikeda, S.; Muramatsu, M.; Shimbo, T. The combined impact of 12 common variants on hypertension in Japanese men, considering GWAS results. J. Hum. Hypertension. 2011. Available online: http://www.nature.com/jhh/journal/vaop/ncurrent/abs/jhh201150a.html accessed on 23 March 2012. [CrossRef]
- Solé, X.; Guinó, E.; Valls, J.; Iniesta, R.; Moreno, V. SNPStats: A web tool for the analysis of association studies. Bioinformatics 2006, 22, 1928–1929. [Google Scholar]
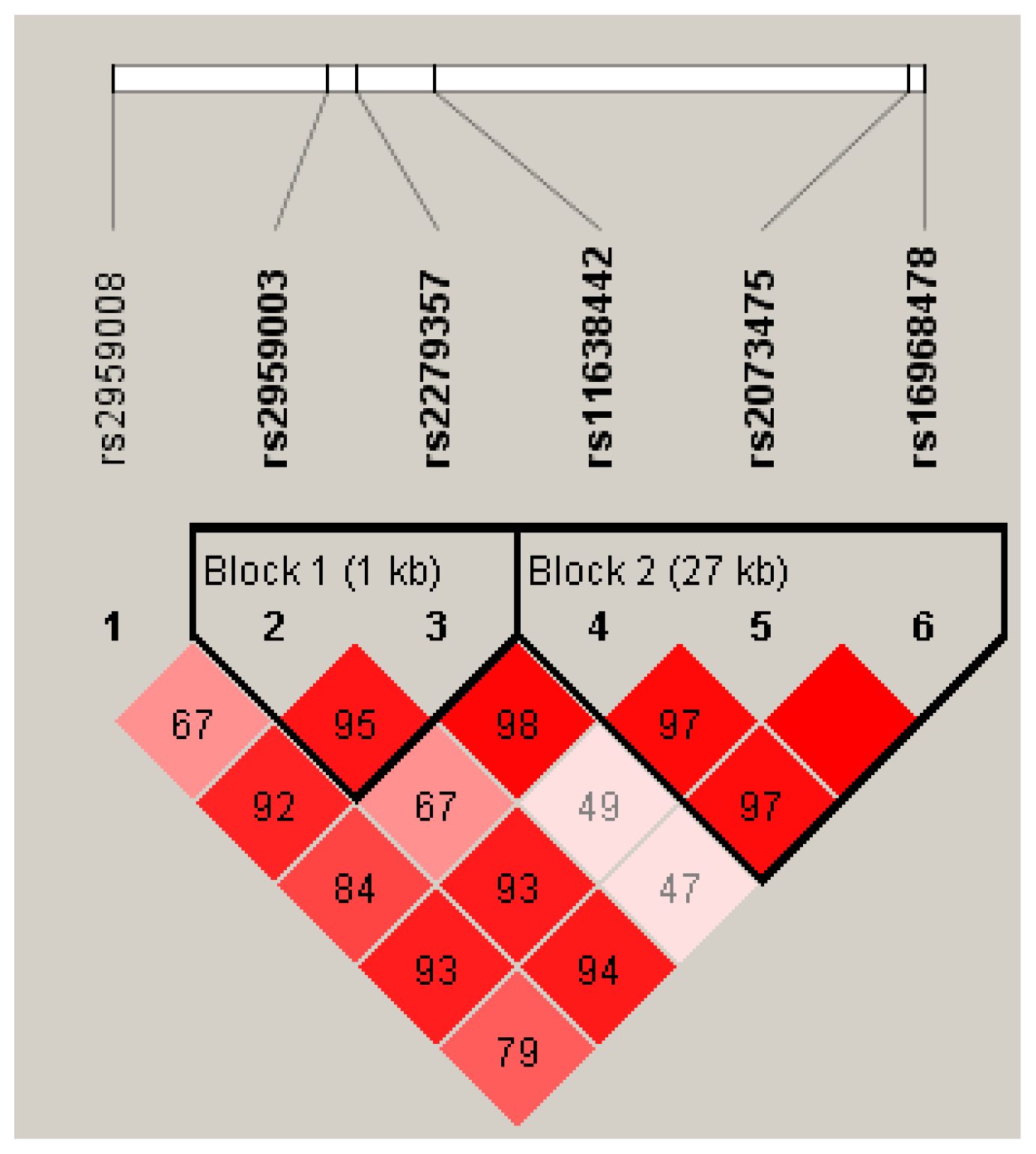

{kind=link}
| SNP | Alleles | MAFa | HWEb (P-value) | |
|---|---|---|---|---|
| Case | Control | |||
| rs2959008 | C/T | 0.36/C | 0.976 | 0.587 |
| rs2959003 | C/T | 0.38/C | 0.852 | 0.519 |
| rs2279357 | C/T | 0.43/T | 0.403 | 0.803 |
| rs11638442 | C/G | 0.22/G | 0.659 | 0.674 |
| rs2073475 | A/G | 0.44/A | 0.951 | 0.765 |
| rs16968478 | A/G | 0.46/G | 0.834 | 0.732 |
| Haplotypea | Frequencies | OR (95% CI)b | P-value | ||
|---|---|---|---|---|---|
| Total | Control | Case | |||
| TTTCAG | 0.2936 | 0.2755 | 0.314 | 1 | - |
| CCCGGA | 0.153 | 0.1567 | 0.1495 | 0.82 (0.62–1.08) | 0.15 |
| CCCCGA | 0.1309 | 0.1495 | 0.1111 | 0.64 (0.48–0.86) | 0.0033 |
| TTCCAG | 0.1273 | 0.1333 | 0.1203 | 0.78 (0.58–1.06) | 0.11 |
| TTTCGA | 0.1177 | 0.1079 | 0.1269 | 1.03 (0.76–1.40) | 0.83 |
| TCCCGA | 0.0673 | 0.071 | 0.0638 | 0.83 (0.57–1.20) | 0.32 |
| rare | 0.1102 | 0.1061 | 0.1145 | 0.92 (0.67–1.28) | 0.64 |
| SNP | Model | Genotype | Control | Case | OR (95% CI) a | P-value |
|---|---|---|---|---|---|---|
| rs2959008 | Codominant | T/T | 205 (37.5%) | 229 (43.2%) | 1 | 0.057 |
| C/T | 264 (48.4%) | 239 (45.1%) | 0.77 (0.59–1.00) | |||
| C/C | 77 (14.1%) | 62 (11.7%) | 0.67 (0.45–0.99) | |||
| Dominant | T/T | 205 (37.5%) | 229 (43.2%) | 1 | 0.023 | |
| C/T-C/C | 341 (62.5%) | 301 (56.8%) | 0.75 (0.58–0.96) | |||
| Recessive | T/T-C/T | 469 (85.9%) | 468 (88.3%) | 1 | 0.16 | |
| C/C | 77 (14.1%) | 62 (11.7%) | 0.77 (0.53–1.11) | |||
| Overdominant | T/T-C/C | 282 (51.6%) | 291 (54.9%) | 1 | 0.2 | |
| C/T | 264 (48.4%) | 239 (45.1%) | 0.85 (0.67–1.09) | |||
| Log-additive | - | - | - | 0.80 (0.67–0.96) | 0.018 | |
| rs2959003 | Codominant | T/T | 196 (36%) | 218 (41.3%) | 1 | 0.092 |
| C/T | 255 (46.9%) | 241 (45.6%) | 0.84 (0.64–1.10) | |||
| C/C | 93 (17.1%) | 69 (13.1%) | 0.67 (0.46–0.97) | |||
| Dominant | T/T | 196 (36%) | 218 (41.3%) | 1 | 0.072 | |
| C/T-C/C | 348 (64%) | 310 (58.7%) | 0.79 (0.62–1.02) | |||
| Recessive | T/T-C/T | 451 (82.9%) | 459 (86.9%) | 1 | 0.078 | |
| C/C | 93 (17.1%) | 69 (13.1%) | 0.74 (0.52–1.04) | |||
| Overdominant | T/T-C/C | 289 (53.1%) | 287 (54.4%) | 1 | 0.62 | |
| C/T | 255 (46.9%) | 241 (45.6%) | 0.94 (0.74–1.20) | |||
| Log-additive | - | - | - | 0.82 (0.69–0.98) | 0.03 | |
| rs2279357 | Codominant | C/C | 193 (35.4%) | 164 (30.9%) | 1 | 0.048 |
| C/T | 265 (48.6%) | 253 (47.7%) | 1.14 (0.87–1.50) | |||
| T/T | 87 (16%) | 113 (21.3%) | 1.56 (1.09–2.22) | |||
| Dominant | C/C | 193 (35.4%) | 164 (30.9%) | 1 | 0.1 | |
| C/T-T/T | 352 (64.6%) | 366 (69.1%) | 1.24 (0.96–1.61) | |||
| Recessive | C/C-C/T | 458 (84%) | 417 (78.7%) | 1 | 0.022 | |
| T/T | 87 (16%) | 113 (21.3%) | 1.44 (1.05–1.98) | |||
| Overdominant | C/C-T/T | 280 (51.4%) | 277 (52.3%) | 1 | 0.82 | |
| C/T | 265 (48.6%) | 253 (47.7%) | 0.97 (0.76–1.24) | |||
| Log-additive | - | - | - | 1.23 (1.04–1.47) | 0.018 | |
| Genotype | Control | Case | χ2 | P-value | OR (95% CI)a | P-value |
|---|---|---|---|---|---|---|
| TT-TT | 77 (14.1%) | 112 (21.1%) | 15.57 | 0.001 | 1.65 (1.18–2.31) | 0.003 |
| TT-CT/CC | 127 (23.3%) | 117 (22.1%) | 1.10 (0.81–1.48) | 0.551 | ||
| CT/CC-TT | 10 (1.8%) | 1 (0.2%) | 0.12 (0.02–0.94) | 0.044 | ||
| CT/CC-CT/CC | 331 (60.7%) | 300 (56.6%) | 1 | - |
© 2012 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Sun, M.; Yang, X.; Ye, C.; Xu, W.; Yao, G.; Chen, J.; Li, M. Risk-Association of CYP11A1 Polymorphisms and Breast Cancer Among Han Chinese Women in Southern China. Int. J. Mol. Sci. 2012, 13, 4896-4905. https://doi.org/10.3390/ijms13044896
Sun M, Yang X, Ye C, Xu W, Yao G, Chen J, Li M. Risk-Association of CYP11A1 Polymorphisms and Breast Cancer Among Han Chinese Women in Southern China. International Journal of Molecular Sciences. 2012; 13(4):4896-4905. https://doi.org/10.3390/ijms13044896
Chicago/Turabian StyleSun, Minying, Xuexi Yang, Changsheng Ye, Weiwen Xu, Guangyu Yao, Jun Chen, and Ming Li. 2012. "Risk-Association of CYP11A1 Polymorphisms and Breast Cancer Among Han Chinese Women in Southern China" International Journal of Molecular Sciences 13, no. 4: 4896-4905. https://doi.org/10.3390/ijms13044896