The Fractality of Polar and Reed–Muller Codes †


Signal Processing and Speech Communication Laboratory, Graz University of Technology, 8010 Graz, Austria
†
This paper is an extended version of our paper published in the 2015 NEWCOM# Emerging Topics in Modulation and CodingWorkshop and in the 2016 International Zürich Seminar on Communications, Zurich, Switzerland, 2–4 March 2016.
Entropy 2018, 20(1), 70; https://doi.org/10.3390/e20010070
Submission received: 16 October 2017
/
Revised: 10 January 2018
/
Accepted: 15 January 2018
/
Published: 17 January 2018
(This article belongs to the Section Information Theory, Probability and Statistics)
{kind=link}
Abstract
:The generator matrices of polar codes and Reed–Muller codes are submatrices of the Kronecker product of a lower-triangular binary square matrix. For polar codes, the submatrix is generated by selecting rows according to their Bhattacharyya parameter, which is related to the error probability of sequential decoding. For Reed–Muller codes, the submatrix is generated by selecting rows according to their Hamming weight. In this work, we investigate the properties of the index sets selecting those rows, in the limit as the blocklength tends to infinity. We compute the Lebesgue measure and the Hausdorff dimension of these sets. We furthermore show that these sets are finely structured and self-similar in a well-defined sense, i.e., they have properties that are common to fractals.
1. Introduction
In his book on fractal geometry, Falconer characterizes a set as a fractal if it has some of the following properties [1] (p. xxviii):
- has a fine structure, i.e., there is detail on arbitrarily small scales
- does not admit a description in traditional geometrical language, neither locally nor globally; it is irregular in some sense
- has some form of self-similarity, at least approximate or statistical
- The fractal dimension of exceeds its topological dimension
- is defined in a simple, often recursive way
In this work, we investigate whether polar codes and Reed–Muller are fractal in above sense. For a blocklength of , these codes are based on the n-fold Kronecker product , where
i.e., on a simple, recursive operation. Based on this, it has long been suspected that Kronecker product-based codes possess a fractal nature. For example, the authors of [2] observed that , when converted to a picture, resembles the Sierpinski triangle. In a personal communication [3], Abbe expressed his suspicion that the set of “good” polarized channels is fractal. Nevertheless, to the best of the author’s knowledge, a definite statement regarding this fractal nature has not been presented yet.
A rate- Kronecker product-based code is uniquely defined by a set of K indices: Its generator matrix is the submatrix of consisting of the rows indexed by . Letting index the K rows of with the largest Hamming weight defines a Reed–Muller code. Alternatively, one can fix the order r of a Reed–Muller code, which defines as the index set of all rows with a Hamming weight at least as large as r (see Section 4). For polar codes, the rows of can be interpreted as a communication channels. Then, a rate- polar code is defined by the set indexing the K channels with the lowest Bhattacharyya parameters [4] (the “good” channels, see Section 2).
Although the sets are important for the construction of polar and Reed–Muller codes, surprisingly little is known about their fractal properties. Recently, Renes, Sutter, and Hassani stated conditions under which the good (bad) channels derived from one binary-input memoryless channel are also good (bad) for another channel [5]. Moreover, the authors of [6,7] observed the self-similar structure of by showing that polar and Reed–Muller codes are decreasing monomial codes.
In this paper, we analyze the fractal properties of for polar codes (Section 3) and Reed–Muller codes (Section 5). In contrast to [6,7], we study the properties of for infinite blocklengths, i.e., for . Specifically, we compute the Hausdorff dimension of , show that it is self-similar, and that it has detail on arbitrarily small scales (e.g., is symmetric and dense in some well-defined containing set). Each of these results is relatively easy to obtain once appropriate definitions have been put in place. Taken as a whole, however, they paint an interesting picture and make a convincing point for the claim that polar and Reed–Muller codes are fractal.
The presented results will improve our understanding of polar and Reed–Muller codes, even though we have to admit that their practical implication (e.g., in code construction) still eludes us. Nevertheless, our results may apply in areas beyond channel coding: Arıkan’s polarization technique was used to polarize Rényi information dimension [8] and to construct high-girth matrices [9]. Moreover, Nasser showed that a sufficient and necessary condition for a binary operation to be polarizing is that it is uniformity preserving and that its inverse is strongly ergodic [10,11]. We are convinced that fractality carries over to these applications as well and that an analysis similar to ours can deepen understanding.
Since we consider the case , the set indexes a subset of , the set of infinite binary sequences. We let and abbreviate . Let where . Let furthermore be a probability space with the Borel field generated by the cylinder sets and a probability measure satisfying . In the following, we represent every infinite binary sequence by a point in the unit interval . The mapping between and is given by
Lemma 1
([12] (Exercises 7–10, p. 80)). Let be the Borel σ-algebra on and let λ be the Lebesgue measure. Let furthermore denote the set of dyadic rationals in the unit interval. Then, the function in (2) satisfies the following properties:
- 1.
- f is measurable
- 2.
- f is bijective on
- 3.
- for all ,
Example 1.
Lemma 1 states that f is not injective in general. The reason is that dyadic rationals have a non-unique binary expansion. For example, f maps both and to , where we call the latter binary expansion terminating.
2. Preliminaries for Polar Codes
Let be a binary-input memoryless channel with finite output alphabet , (symmetric) capacity , and with Bhattacharyya parameter
It can be shown using [13] (Proposition 1) that and . We say that the channel W is symmetric if there exists a permutation such that and, for every , .
Arıkan’s polarization technique [13] combines and splits two channel uses of W into one use of a “worse” channel
and one use of a “better” channel
where and . The combining operation encodes two input bits by F in (1); transmitting them via two channel uses of W creates a vector channel. This vector channel can then be split into the two virtual binary-input memoryless channels indicated in (4) and (5). The better (worse) channel obtained by polarization has a larger (smaller) capacity than the original channel W, i.e., —the inequalities are strict if . The sum capacity equals two times the capacity of the original channel, i.e., [13] (Proposition 4). Similarly, polarization has an effect on the Bhattacharyya parameter:
Lemma 2 (Bounds on the Bhattacharyya Parameter).
with equality in if W is a binary erasure channel (BEC).
Proof.
For larger blocklengths , , we apply the polarization procedure recursively and obtain, for ,
where and denote the sequences of zeros and ones obtained by appending 0 and 1 to , respectively. Note that the functions , , and from Lemma 2 are non-negative and non-decreasing and map the unit interval onto itself. Hence, the inequalities in (7) are preserved under composition:
where .
Applying this recursive polarization infinitely often leads to a situation in which almost all channels are either perfect or useless, i.e., either or for . This is the assertion of Arıkan’s polarization theorem:
Proposition 1
([13] (Proposition 10)). With probability one, the limit RV takes values in the set : and .
If we stop the polarization procedure at a finite blocklength for n large enough, then still most of the resulting channels are either almost perfect or almost useless (i.e., the channel capacities are close to one or to zero). The idea of polar coding is to transmit data only on those channels that are almost perfect. The generator matrix of a blocklength- polar code is thus the submatrix of consisting of rows indexed by , where contains the indices corresponding to the K virtual channels with the largest capacities. Determining this set is inherently difficult, since (whenever W is not a BEC) the cardinality of the output alphabet increases exponentially in [15] (Chapter 3.3), [16] (p. 36). Tal and Vardy proposed an approximate construction method based on reducing the output alphabet and showing that the resulting channels are either upgraded or degraded w.r.t. the channel of interest [17] (see also Korada’s PhD thesis [16] (Definition 1.7 & Lemma 1.8)). These upgrading/degrading properties are important tools in our proofs.
Definition 1 (Channel Upgrading and Degrading).
A channel is degraded w.r.t. the channel W (short: ) if there exists a channel such that
A channel is upgraded w.r.t. the channel W (short: ) if there exists a channel such that
Moreover, if and only if .
Upgraded (degraded) channels remains upgraded (degraded) during polarization:
Proof.
3. Fractal Properties of the Sets of Good and Bad Channels
We next investigate the behavior of the set as we let the blocklength tend to infinity, i.e., as . This set indexes all sequences b for which we obtain . With the help of (2), we map these sequences to a subset of the unit interval, which we will call the set of good channels.
Definition 2 (The Good and the Bad Channels).
Let denote the set of good channels, i.e.,
Let denote the set of bad channels, i.e.,
If , then all polarized channels are useless and we have . Similarly, if , then all polarized channels are perfect and we have . We hence assume throughout this section that the channel W is nontrivial, i.e., that .
Proposition 2 (Denseness).
, i.e., the good and bad channels are dense in the unit interval. Moreover, and are dense in .
Proof.
See Appendix A. ☐
It is not really surprising that and are not disjoint; this is a direct consequence of the fact that f is not injective. It is not obvious, however, that the intersection exhausts the set on which f is non-injective. A consequence of this proposition is that there is no interval that contains only good channels. This has implications for code construction techniques. Indeed, the authors of [18,19] suggest that, for a polar code of a given blocklength, one may stop polarizing channels at shorter blocklengths and use copies of these channels rather than their polarization. For example, they suggest to use the channels rather than the channels if is sufficiently large. Such a procedure can be justified if further polarizing to the desired blocklength will lead to including all channels polarized from in the code. Such a justification can never appear for polar codes with unbounded blocklength: Stopping polarizing at a given blocklength for a given polarization sequence and using copies of the resulting channel is equivalent to including a dyadic interval in the index set. This dyadic interval contains, by Proposition 2, bad channels, which shows that this choice is suboptimal.
Proposition 3 (Symmetry).
There exists a function ϑ, defined for almost all values in , that is independent of W and satisfies and . Let be such that is defined. Then, implies . If W is a BEC, then implies .
Proof.
See Appendix B. ☐
Proposition 3 has two implications. The first implication concerns the alignment of the sets and for two different channels W and . Specifically, it is connected to the question whether implies . In general, the answer is negative [5]. Indeed, it may happen that for some , we have despite , i.e., that the polarized channel turns out to be good even though the sufficient condition from Proposition 3 is not fulfilled. Such a situation cannot occur for BECs, as Proposition 3 shows. Hence, the set of good channels for a BEC is also good for any binary-input memoryless channel with a smaller Bhattacharyya parameter [20].
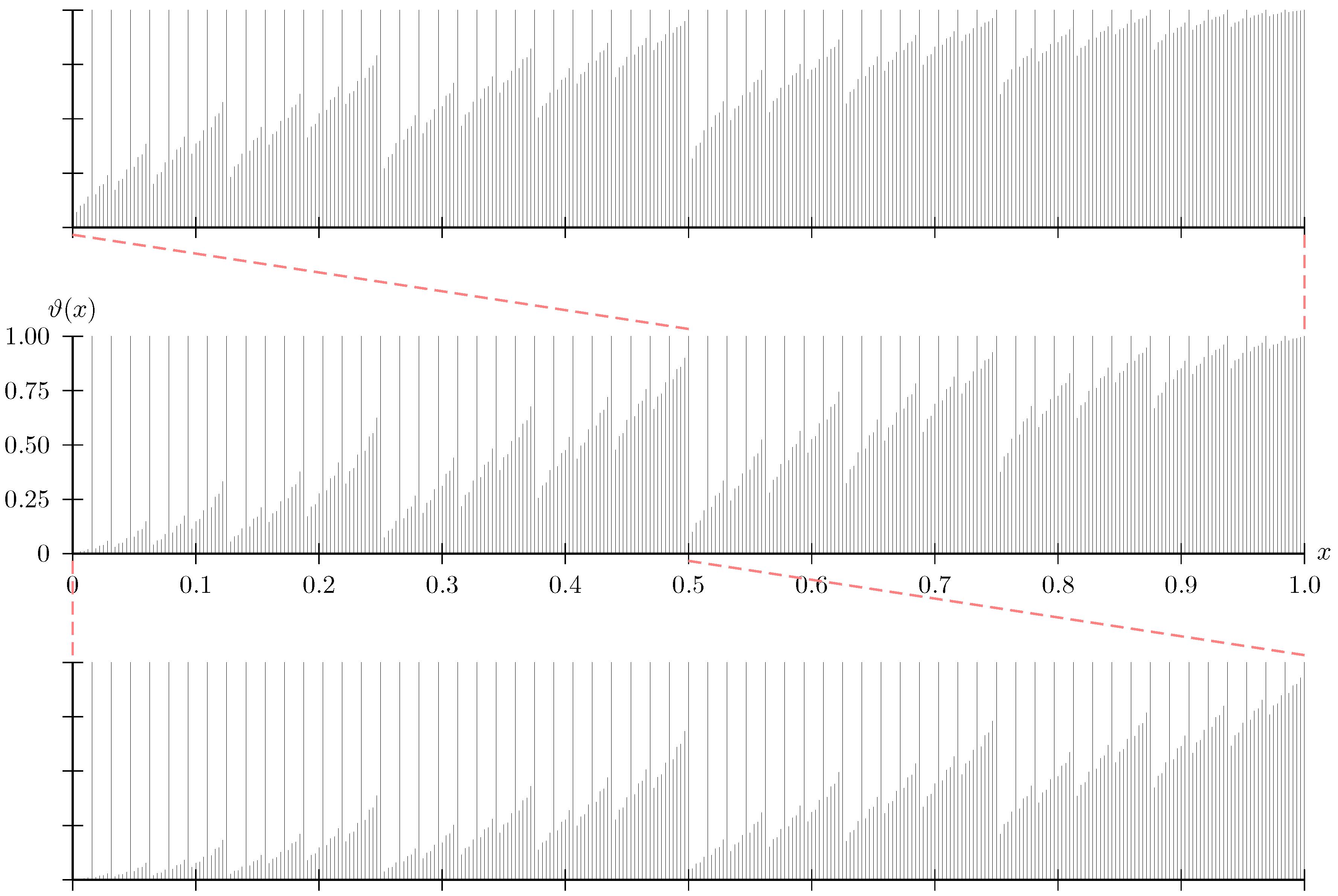
The second implication is that, at least for BECs, the sets and are symmetric. Indeed, if , then implies . This symmetry is visible in the polar fractal that we display in Figure 1.
It is possible to define for . We know from Proposition 2 that dyadic rationals are both good and bad, hence setting for every leads to . (The fact that also is not captured by nor in conflict with this setting.) The question whether the function can be defined for is more interesting. In this case, the binary expansion is unique and recurring, i.e., there is a length-k sequence such that for some . It is straightforward to show that for every non-trivial sequence (i.e., contains zeros and ones), is from to , non-negative, and non-decreasing with vanishing derivatives at 0 and 1. Since this ensures that for z close to zero and for z close to one, the operation constitutes an iterated function system with attracting fixed points at and . Note further that, since corresponds to the recurring part of the binary expansion of x, will be bounded from above by the value to which this iterated function system converges after being initialized with . To show that Proposition 3 holds for requires showing that intersects the identity function only once on , i.e., that there is no attracting fixed point on this open interval. We leave this problem for future investigation.
Example 2.
Let , hence . We determine the fixed points of the iterated function system corresponding to one period of the recurring sequence, i.e, the fixed points of . These are given by the roots of , which are , , and . One of these latter nontrivial roots lies outside and is hence irrelevant. The remaining root determines the threshold, .
Now suppose that W is a BEC with Bhattacharyya parameter . Since is a fixed point, we get . This illustrates that Proposition 1 holds only almost surely.
Proposition 4 (Lebesgue Measure & Hausdorff Dimension).
is a Borel set and has Lebesgue measure . is a Borel set and has Lebesgue measure . Therefore, the Hausdorff dimensions of and satisfy .
Proof.
See Appendix C. ☐
Loosely speaking, the Lebesgue measure of is the asymptotic equivalent of the rate of the “infinite-blocklength” polar code for the channel W. The fact that states that the rate approaches the symmetric capacity of W. A positive Lebesgue measure and a Hausdorff dimension equal to one are not indicators of fractality.
The last fractal property we consider is self-similarity. As Falconer notes [1] (p. xxviii), self-similarity often occurs only approximately. What we show in the following proposition is that the set is quasi self-similar. Along the same lines, the quasi self-similarity of can be shown.
Proposition 5 (Self-Similarity).
Let for . is quasi self-similar in the sense that, for all n and all k, is quasi self-similar to its right half:
If W is symmetric, is quasi self-similar:
Proof.
See Appendix D. ☐
In other words, at least for a symmetric channel, is composed of two similar copies of itself (see Figure 1). The self-similarity is closely related to the fact that polar codes are decreasing monomial codes [6] (Theorem 1).
Example 3.
We want to determine whether for a given BEC W. This question translates the questions whether and whether . Along the lines of Example 2, we obtain , , and , i.e., . Since W is a BEC, we can connect this with Proposition 3 and thus obtain the inclusion indicated in Proposition 5.
4. Preliminaries for Reed–Muller Codes
An order-r, length- Reed–Muller code is defined by having a generator matrix composed of all length- sequences with a Hamming weight larger than . For example, we have , while is a single row vector containing only ones (length- repetition code). To make this more precise, let be the Hamming weight of and let be the i-th row of . Then, the generator matrix of an order-r, length- Reed–Muller code consists of the rows of indexed by [4]
To analyze the effect of doubling the block length, note that
Assume that we indicate the rows of by a sequence of binary numbers, i.e., let the i-th row be indexed by . Furthermore, let and denote the sequences of zeros and ones obtained by prepending 0 and 1 to , respectively. Clearly, and . Combining this with (21) yields
Defining , we thus get
and
In Section 5, we will analyze the properties of in the limit as n tends to infinity. An important ingredient in our proofs is the concept of normal numbers.
Definition 3 (Normal Numbers).
A number is called simply normal to base 2() if and only if
In general, a number is simply normal to base M if the fraction of its digits used in its M-ary expansion is . A number is called normal if this property not only holds for digits, but also for subsequences: a number is normal in base M if, for each , the fraction of each length-k sequences used in its M-ary expansion is . It immediately follows that a normal number is simply normal. The converse is in general not true:
Example 4.
Let , hence . x is simply normal to base 2, but not normal (since the sequences 00 and 11 never occur). Let , hence . x is neither normal nor simply normal. Let , hence b is either terminating () or non-terminating (). Dyadic rationals are not simply normal.
Lemma 5
(Borel’s Law of Large Numbers, cf. [21] (Corollary 8.1, p. 70)). Almost all numbers in are simply normal, i.e.,
Despite this result, there are uncountably many numbers in the unit interval which are not normal. Moreover, the set of numbers that are not normal is superfractal, i.e., it has a Hausdorff dimension equal to one although it has zero Lebesgue measure [22].
5. Fractal Properties of the Set of Heavy Codewords
If we let n tend to infinity, the definition of in (23) becomes problematic. Rather than looking at order-r, length- Reed–Muller codes, we investigate order-, length- codes, where we assume that is integer. In other words, we assume that the threshold for the Hamming weight increases linearly with the blocklength. This gives rise to the definition of heavy codewords:
Definition 4 (The Heavy Codewords).
Let denote the set of ρ-heavy codewords, i.e.,
Loosely speaking, the set of heavy codewords corresponds to those rows of that asymptotically have a fractional Hamming weight larger than a given threshold.
Example 5.
. This follows from the fact that 1 is the only number in the unit interval with a binary expansion consisting only of ones. . This follows from the fact that .
Proposition 6 (Denseness).
For all , . Moreover, for , and its complement are dense in .
Similarly as for polar codes, also Reed–Muller codes are such that no interval is contained in either or its complement (unless in the trivial cases and ). This is again in contrast with the intuition one obtains for Reed–Muller code with finite blocklength. Suppose we fix n to be even and set , i.e., we require that at least one half of the bits in are one. The matrix resembles a Sierpinski triangle, as depicted in [2] (Figure 2). In our notation, the set indexes none of the first rows of , since they cannot have sufficient Hamming weight. Consequently, the transition as creates complications that are not present for finite n, and one needs to depart from intuition based on these finite-blocklength considerations.
Proof.
See Appendix E. ☐
Proposition 7 (Lebesgue Measure & Hausdorff Dimension).
is Lebesgue measurable and has Lebesgue measure
The Hausdorff dimension satisfies
where .
Proof.
See Appendix F. ☐
Loosely speaking, the Lebesgue measure of is the asymptotic equivalent of the rate of the fractional order- Reed–Muller code. As we showed in Proposition 4, the Lebesgue measure of is equal to the symmetric capacity of W. In contrast, the set does not depend on W. Rather, Proposition 7 suggests that the order parameter induces a phase transition for the rate of Reed–Muller codes: If , the “infinite-blocklength” Reed–Muller code consists of almost all (in the sense of Lebesgue measure) possible binary sequences. In contrast, if , the “infinite-blocklength” Reed–Muller code consists of almost no codewords (again, in the sense of Lebesgue measure).
Let us briefly consider the case . For this case, Proposition 7 states that is a Lebesgue null set that has a Hausdorff dimension equal to 1. Thus, the set is a superfractal. Unfortunately, we were not able to give an exact expression for the Hausdorff dimension of for . While the set of all non-normal numbers is superfractal, we are not sure if this holds also for the specific proper subset .
The sets and exhibit self-similarity, i.e., detailed structure on every scale (cf. Figure 1). We next show that also is self-similar. At least for and (cf. Example 5) this is as trivial as the self-similarity of a point or a line. For this self-similarity is more interesting, and related to the fact that Reed–Muller codes are decreasing monomial codes [6] (Proposition 2).
Proposition 8 (Self-Similarity).
Let for . is quasi self-similar in the sense that, for all n and all k, is quasi self-similar:
Proof.
See Appendix G. ☐
6. Discussion and Outlook
That Kronecker product-based codes possess fractal properties has long been suspected. The present manuscript contains several results that back this suspicion with solid mathematical analyses. Specifically, we assumed that the blocklength tends to infinity and investigated the properties of the set of virtual channels that are perfect and the set of codewords that have a fractional Hamming weight no less than . Since both polar codes and Reed–Muller codes are obtained by a simple, recursive procedure, it remains to investigate whether the sets and satisfy any of the following properties [1] (p. xxviii):
- The set has a fine structure, i.e., there is detail on arbitrarily small scales;
- It does not admit a description in traditional geometrical language, neither locally nor globally; it is irregular in some sense;
- It has some form of self-similarity, at least approximate or statistical;
- The fractal dimension of the set exceeds its topological dimension.
Indeed, the sets and possess a fine structure in the sense that they are dense in the unit interval, but that also their complements are dense in the unit interval (cf. Propositions 2 and 6). Therefore, at an arbitrarily small scale, the sets and admit no simple description in geometrical language. Both of these sets are self-similar in a specific sense, as we outlined in Propositions 5 and 8. Finally, while has a fractal dimension of one (cf. Proposition 4), the set has, for a certain range of , a positive (fractional?) Hausdorff dimension despite being a Lebesgue null set. This result, which we proved in Proposition 7, is one of the defining properties of a fractal set.
One reviewer pointed out that our definition of can be complemented by a different one. Specifically, while indexes the codewords with a fractional Hamming weight not smaller than , one could define a set indexing the codewords of a Reed–Muller code with rate R. In other words, while is parameterized via the fractional order of the code, is parameterized via its rate. We expect that the Lebesgue measure of the (adequately defined) set should be R and that, thus, its Hausdorff dimension equals one. An appropriate definition of is tied to the set of a rate-R, length- Reed–Muller code (such as is our Definition 4). Since finding such a definition has so far eluded us, we postpone this investigation to future work.
Another obvious extension of our work are non-binary polar and Reed–Muller codes. For example, consider an matrix with entries from , where q is prime. One can show that this matrix is polarizing as long as it is not upper-triangular [15] (Theorem 5.2). We believe that our analysis can be replicated by considering the ℓ-ary expansion of real numbers in . Along the same lines, it would be interesting to examine the properties of q-ary Reed–Muller codes, e.g., [23,24].
Supplementary Materials
Supplementary material are available online at www.mdpi.com/1099-4300/20/1/70/s1.
Acknowledgments
The author thanks Emmanuel Abbe, Princeton University, and Hamed Hassani, University of Pennsylvania, for fruitful discussions and suggesting material. The author is particularly indebted to Jean-Pierre Tillich, French Institute for Research in Computer Science and Automation (INRIA), for helpful suggestions and generalizing Proposition 5. The author is also indebted anonymous reviewers pointing to a missing step in the proof of Proposition 4 and for extending Proposition 2. This work was supported by TU Graz Open Access Publishing Fund, by the Erwin Schrödinger Fellowship J 3765 of the Austrian Science Fund, and by the German Ministry of Education and Research in the framework of an Alexander von Humboldt Professorship.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Proof of Proposition 2
That follows from the fact that only dyadic rationals have a non-unique binary expansion. In particular, the preimage of consists of two elements, namely
and
By the properties of polarization and with the assumption that , we have that , and hence also . Moreover, it follows from Lemma 2 and (9) that
from which we obtain and . Similarly, with Lemma 2 and (10) we obtain
Hence, and . Since this holds for every , we have that .
The proof that and are dense in follows along similar lines. Specifically, we show that between every dyadic rational we can find rational numbers such that and . To this end, fix and . Let further be the terminating binary expansion of , i.e., .
Let be such that and . We can bound the polynomial from above:
The bound crosses z at and at , where can be made arbitrarily close to one for k sufficiently large. Now let , where . It follows that . However, if , hence if k is sufficiently large such that this holds, then . Thus, and .
Recall that is such that and . We next bound the polynomial from below:
which intersects z at , at some root that can be made arbitrarily close to zero for k sufficiently large, and at some root that tends to one if k becomes large. Note further that the slope of equals . By setting k sufficiently large, one can guarantee that this slope is smaller than one on the interval . Now let , where . Suppose further that we have chosen k sufficiently large such that and that the slope of is smaller than one on the interval . We know that on the interval , since this is the case for the lower bound in (A5). However, since the slope of is smaller than one on the interval and since intersects z at one, there can be no further intersection between and z on the interval . Hence, on the interval , and since . Since furthermore , we obtain . Thus, and .
Since both and are in the interval , this shows that between every two dyadic rationals, there are numbers x and that are good and bad. This proves that and are dense in .
Appendix B. Proof of Proposition 3
Lemma A1
Furthermore, the thus constructed RV θ is uniformly distributed on .
It can be easily verified that for . Hence,
Now suppose that and that is defined. If , then . Since, by Lemma A1, implies and , we get . Now set . Since , it follows from the linearity of f that , i.e., if has binary expansion b, then has binary expansion . Therefore, for all for which is defined, we have .
Recall that, by Lemma 2, we have
If , then by Lemma A1, and . If W is a BEC, then (A7) holds with equality. Thus, by Lemma A1, if , then and .
Appendix C. Proof of Proposition 4
For the proof we utilize properties of f derived in the proof of [26] (Theorem 2.1, p. 7). Specifically, let be the set of all binary sequences with infinitely many zeros, i.e., E contains the binary expansion of all numbers and the terminating binary expansions of all numbers . Since is countable, E is a Borel set. The function f restricted to E, , is bijective and measurable (since f is measurable by Lemma 1). Finally, the inverse function is measurable, i.e., for all , , we have .
The set E contains all binary sequences except for non-terminating expansions of dyadic rationals, which lead to good channels by the proof of Proposition 2. Thus, we have
Since this set has probability by Proposition 1, it is a Borel set (otherwise, it would not be measurable). However, since , it follows that is a Borel set of . That is a Borel set can be shown along similar lines, with E containing all binary sequences with infinitely many ones.
Every Borel set is Lebesgue measurable. To evaluate the Lebesgue measure of , note that
Since , we get from Lemma 1 that . By the monotonicity and countable subadditivity of measures, we have
Hence, by Proposition 1, . The proof for the set of good channels follows along the same lines.
Since the one-dimensional Hausdorff measure of a Borel set equals its Lebesgue measure [1] (Equation (3.4), p. 45), it immediately follows that and have a Hausdorff dimension equal to one.
Appendix D. Proof of Proposition 5
Since the dyadic rationals are self-similar and since from Proposition 2, one has for all n and k,
We now treat those values in that are not dyadic rationals. If is the terminating binary expansion of , every value in has a binary expansion for some , where if and only if is odd. Similarly, and since is always odd, every value in has a binary expansion for some . Assume that . Then, by Lemmas 3 and 4, for all a. Hence, if , then . It remains to show that :
Proof for Symmetric Channels.
Since is always even, every value in has a binary expansion for some . Then, by Lemmas 3 and 4, for all a. Hence, if , then . It remains to show that :
☐
Appendix E. Proof of Proposition 6
Note that in Definition 4 we can take the binary logarithm on both sides of the inequality to get the condition
We first show that for every . To this end, consider the non-terminating expansion of , i.e., there is a such that . Hence, for and, for ,
We next show that also is dense in for . We do so by showing that between any two dyadic rationals and , there exists a rational number that is in . Let be the terminating binary expansion of , i.e., . Furthermore, let be such that and . We set and get . One can show that . Hence, choosing , , leads to
This proves that if , from which follows that is dense in .
We finally show that the there exists a non-dyadic rational number such that . From this follows that also the complement of is dense in . To this end, let be such that and . Set . One can show that . Hence, choosing , , leads to
Therefore, if .
Appendix F. Proof of Proposition 7
By Example 4, dyadic rationals are not simply normal, hence let be the set of simply normal numbers in . Note that f is bijective on by Lemma 1. We furthermore have , hence is a Lebesgue null set (both and its complement are measurable). Every subset of a Lebesgue null set is a Lebesgue null set and, a fortiori, Lebesgue measurable.
By Lemma 5 we have
Fix . Then,
If , then this limit diverges to infinity, and hence . Thus, is a subset of , hence measurable, from which measurability of follows. Since , we have . If , the limit diverges to minus infinity, and hence . Thus, , from which follows.
Now let . We define a random variable B on our probability space, such that for all , . B is a sequence of independent, identically distributed Bernoulli-1/2 random variables, i.e., for all i we have . We now evaluate
Consider the simple random walk . Let be the number of zero crossings of the sequence and let be the number of zero crossings corresponding to the realization . The event can only happen if the realization of corresponding to b has only finitely many zero crossings, i.e.,
and hence
where the second inequality is due to Fatou’s lemma [27] (Lemma 1.28, p. 23).
With [28] (Chapter III.5, p. 84)
we get
where is [28] (Equation (2.2), p. 75) and is due to Stirling’s approximation [29] (Equation (6.1.38), p. 257). Since this probability tends to zero as , we have by (A19)
Since the set inside the probability measure is thus measurable, we can apply the same reasoning as in the proof of Proposition 4 to argue that is Lebesgue measurable. We then obtain which completes the proof for the Lebesgue measure.
We now turn to the proof of the Hausdorff dimension. For , has full Lebesgue measure. Since every Lebesgue measurable set has a Borel subset with the same Lebesgue measure, and since Hausdorff dimension is monotonic, we have for .
For , we define
for some . Note that . By [30] (cf. [21] (Chapter 8) for further notes), the Hausdorff dimension of this set is given by (Interestingly, in Eggleston’s paper, the dimension was not connected to entropy; it was submitted earlier in the same year as Shannon’s Mathematical Theory of Communication was published).
Reasoning as in the proof for the Lebesgue measure, if and if . As a consequence,
For a countable sequence of sets , Hausdorff dimension satisfies [1] (p. 49)
and hence, by the monotonicity of Hausdorff dimension [1] (p. 48),
where the last equality follows from the fact that the binary entropy function decreases with increasing for . In particular, for , . This completes the proof.
Appendix G. Proof of Proposition 8
The proof follows along the lines of the proof of Proposition 5. Let again be the terminating expansion of and let . The connections between the sequences , , and have been established above. To prove the theorem, we have to show that
This is obtained by
where (A30) equals (A28) and where (A31) equals (A29). The inequalities yield the desired result.
References
- Falconer, K. Fractal Geometry: Mathematical Foundations and Applications, 3rd ed.; John Wiley & Sons: Chichester, UK, 2014. [Google Scholar]
- Kahraman, S.; Viterbo, E.; Çelebi, M.E. Folded Tree Maximum-Likelihood Decoder for Kronecker Product-based Codes. In Proceedings of the Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 2–4 October 2013; pp. 629–636. [Google Scholar]
- Abbe, E.; (Princeton University, Princeton, NJ, USA). Personal communication, 2011.
- Arıkan, E. A Performance Comparison of Polar Codes and Reed–Muller Codes. IEEE Commun. Lett. 2008, 12, 447–449. [Google Scholar] [CrossRef] [Green Version]
- Renes, J.M.; Sutter, D.; Hassani, S.H. Alignment of Polarized Sets. In Proceedings of the 2015 IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015; pp. 2446–2450. [Google Scholar]
- Bardet, M.; Dragoi, V.; Otmani, A.; Tillich, J.P. Algebraic Properties of Polar Codes From a New Polynomial Formalism. arXiv, 2016; arXiv:1601.06215v2. [Google Scholar]
- Bardet, M.; Dragoi, V.; Otmani, A.; Tillich, J.P. Algebraic properties of polar codes from a new polynomial formalism. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 230–234. [Google Scholar]
- Haghighatshoar, S.; Abbe, E. Polarization of the Rényi information dimension for single and multi terminal analog compression. In Proceedings of the 2013 IEEE International Symposium on Information Theory Proceedings (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 779–783. [Google Scholar]
- Abbe, E.; Wigderson, Y. High-Girth matrices and polarization. In Proceedings of the IEEE International Symposium on Information Theory Proceedings (ISIT), Hong Kong, China, 14–19 June 2015; pp. 2461–2465. [Google Scholar]
- Nasser, R. An Ergodic Theory of Binary Operations—Part I: Key Properties. IEEE Trans. Inf. Theory 2016, 62, 6931–6952. [Google Scholar] [CrossRef]
- Nasser, R. An Ergodic Theory of Binary Operations—Part II: Applications to Polarization. IEEE Trans. Inf. Theory 2017, 63, 1063–1083. [Google Scholar] [CrossRef]
- Taylor, M. Measure Theory and Integration; Graduate Studies In Mathematics Series 76; American Mathematical Society: Providence, RI, USA, 2006. [Google Scholar]
- Arıkan, E. Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef] [Green Version]
- Korada, S.B.; Urbanke, R.L. Polar Codes are Optimal for Lossy Source Coding. IEEE Trans. Inf. Theory 2010, 56, 1751–1768. [Google Scholar] [CrossRef]
- Şaşoğlu, E. Polarization and Polar Codes. Found. Trends Commun. Inf. Theory 2011, 8, 259–381. [Google Scholar] [CrossRef]
- Korada, S.B. Polar Codes for Channel and Source Coding. Ph.D. Thesis, École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland, 2009. [Google Scholar]
- Tal, I.; Vardy, A. How to Construct Polar Codes. IEEE Trans. Inf. Theory 2013, 59, 6562–6582. [Google Scholar] [CrossRef]
- El-Khamy, M.; Mahdavifar, H.; Feygin, G.; Lee, J.; Kang, I. Relaxed channel polarization for reduced complexity polar coding. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), New Orleans, LA, USA, 9–12 March 2015; pp. 207–212. [Google Scholar]
- El-Khamy, M.; Mahdavifar, H.; Feygin, G.; Lee, J.; Kang, I. Relaxed Polar Codes. IEEE Trans. Inf. Theory 2017, 63, 1986–2000. [Google Scholar] [CrossRef]
- Hassani, S.H.; Korada, S.; Urbanke, R. The compound capacity of polar codes. In Proceedings of the Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 30 September–2 October 2009; pp. 16–21. [Google Scholar]
- Kuipers, I.; Niederreiter, H. Uniform Distribution of Sequences; John Wiley & Sons: New York, NY, USA, 1974. [Google Scholar]
- Albeverio, S.; Pratsuivytyi, M.; Torbin, G. Topological and fractal properties of real numbers which are not normal. Bull. Sci. Math. 2005, 129, 615–630. [Google Scholar] [CrossRef]
- Kasami, T.; Lin, S.; Peterson, W. New generalizations of the Reed–Muller codes–I: Primitive codes. IEEE Trans. Inf. Theory 1968, 14, 189–199. [Google Scholar] [CrossRef]
- Delsarte, P.; Goethals, J.; Williams, F.M. On generalized Reed–Muller codes and their relatives. Inf. Control 1970, 16, 403–442. [Google Scholar] [CrossRef]
- Hassani, S.H.; Alishahi, K.; Urbanke, R.L. Finite-Length Scaling for Polar Codes. IEEE Trans. Inf. Theory 2014, 60, 5875–5898. [Google Scholar] [CrossRef]
- Parthasarathy, K.R. Probability Measures on Metric Spaces; Academic Press: New York, NY, USA, 1967. [Google Scholar]
- Rudin, W. Real and Complex Analysis, 3rd ed.; McGraw-Hill: New York, NY, USA, 1987. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications, 3rd ed.; John Wiley & Sons: New York, NY, USA, 1968; Volume 1. [Google Scholar]
- Abramowitz, M.; Stegun, I.A. (Eds.) Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, 9th ed.; Dover Publications: New York, NY, USA, 1972. [Google Scholar]
- Eggleston, H.G. The Fractional Dimension of a Set defined by decimal properties. Q. J. Math. 1949, os-20, 31–36. [Google Scholar] [CrossRef]
Figure 1.
The polar fractal. The center plot shows the thresholds for a finite set of values ; the bottom and the top plots show thresholds for equally many values in the sets and , respectively. One can observe how the thresholds are ordered, i.e., thresholds in the top plot exceed those in the center plot, which exceed those in the bottom plot. For a binary erasure channel (BEC) W, the indicator function of is obtained by setting each value in the plot to one (zero) if the Bhattacharyya parameter is smaller (larger) than the threshold. Note that this plot illustrates the behavior of in the limit . Note further that the figure illustrates the symmetry of claimed in Proposition 3. The MATLAB code to generate these thresholds is available as Supplementary Material.
Figure 1.
The polar fractal. The center plot shows the thresholds for a finite set of values ; the bottom and the top plots show thresholds for equally many values in the sets and , respectively. One can observe how the thresholds are ordered, i.e., thresholds in the top plot exceed those in the center plot, which exceed those in the bottom plot. For a binary erasure channel (BEC) W, the indicator function of is obtained by setting each value in the plot to one (zero) if the Bhattacharyya parameter is smaller (larger) than the threshold. Note that this plot illustrates the behavior of in the limit . Note further that the figure illustrates the symmetry of claimed in Proposition 3. The MATLAB code to generate these thresholds is available as Supplementary Material.

© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Geiger, B.C. The Fractality of Polar and Reed–Muller Codes. Entropy 2018, 20, 70. https://doi.org/10.3390/e20010070
AMA Style
Geiger BC. The Fractality of Polar and Reed–Muller Codes. Entropy. 2018; 20(1):70. https://doi.org/10.3390/e20010070
Chicago/Turabian StyleGeiger, Bernhard C. 2018. "The Fractality of Polar and Reed–Muller Codes" Entropy 20, no. 1: 70. https://doi.org/10.3390/e20010070
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.