
Voice Activity Detection Using Fuzzy Entropy and Support Vector Machine

Abstract
:
1. Introduction
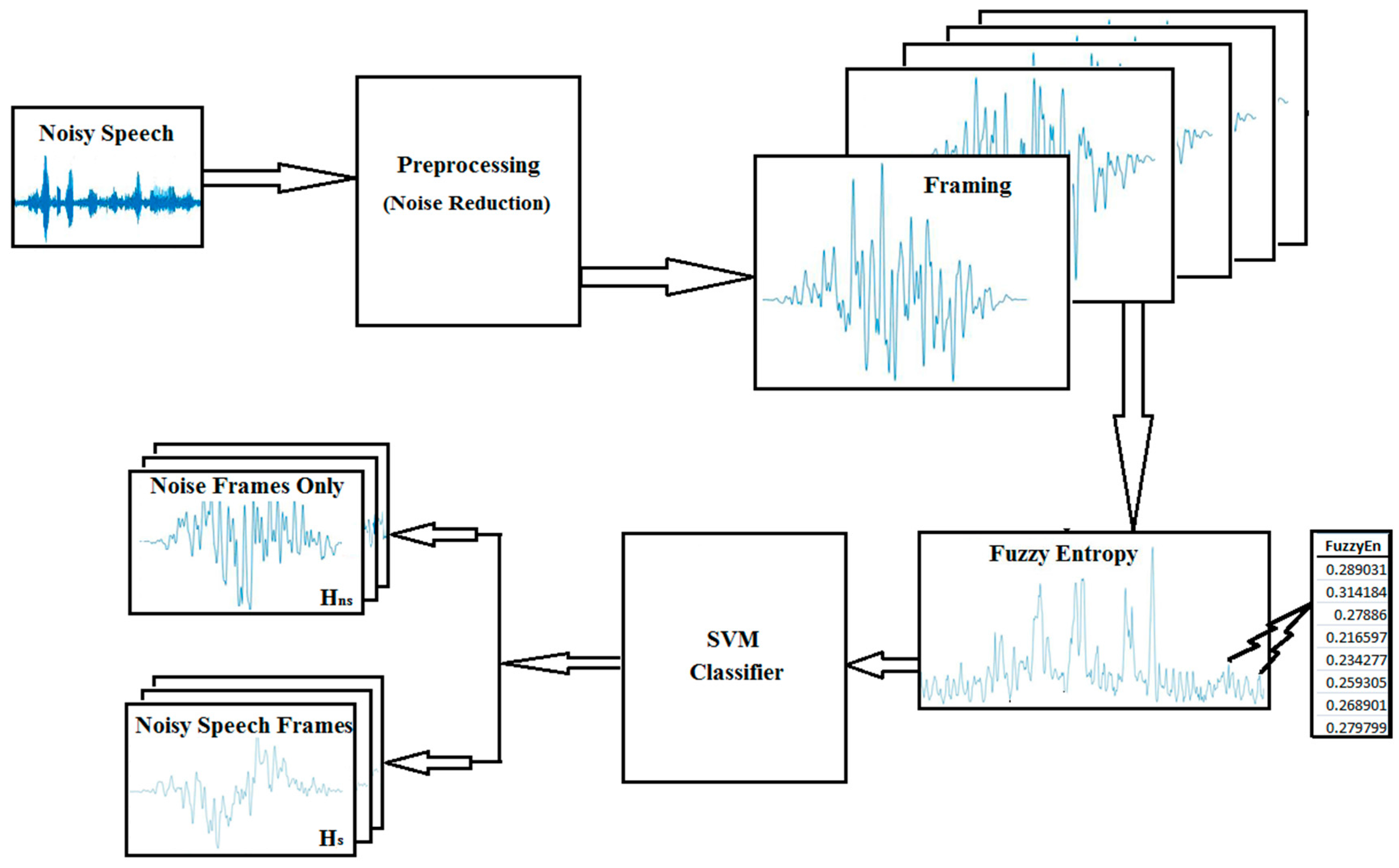
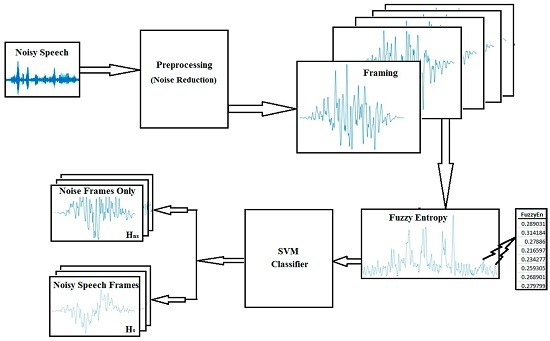
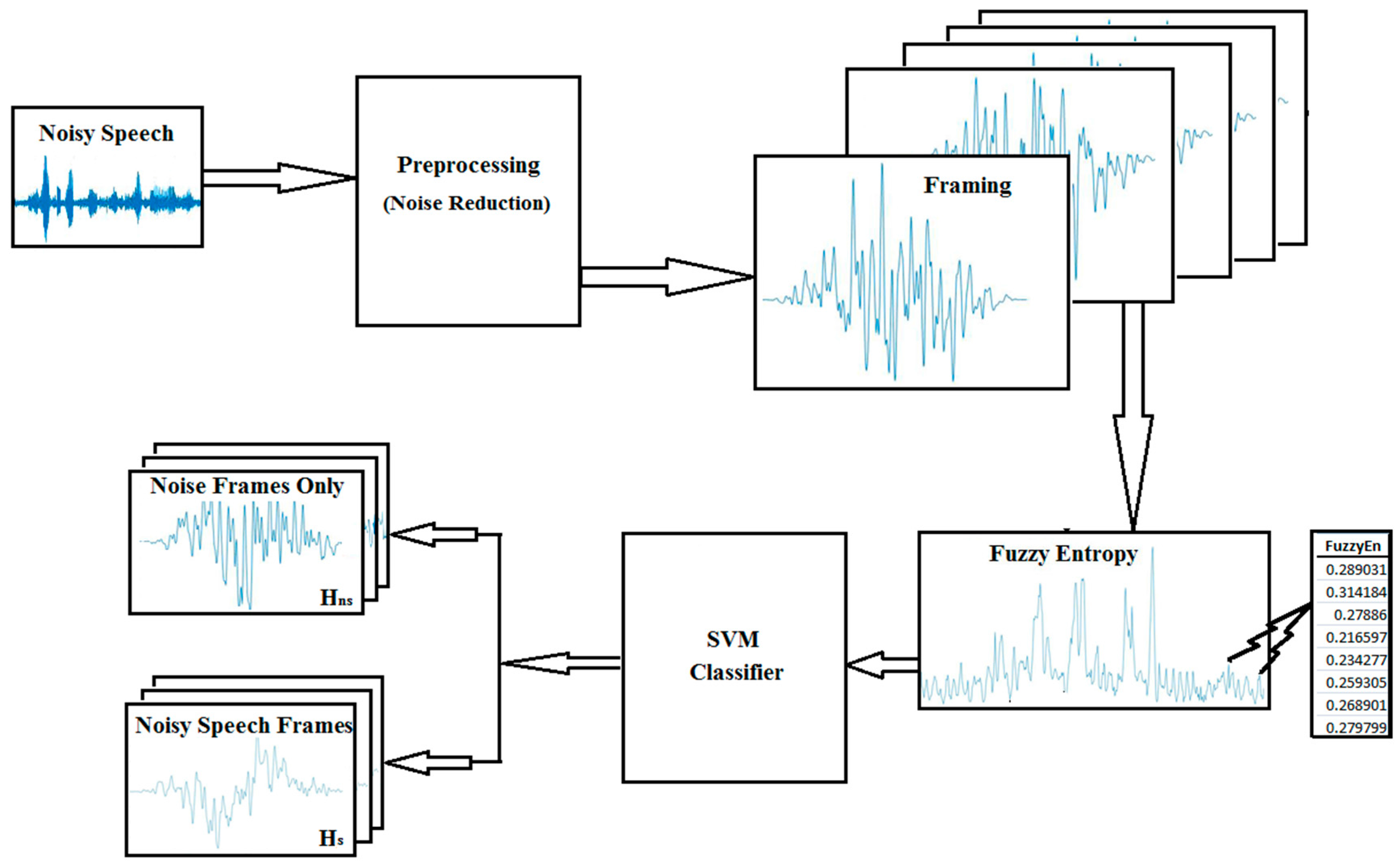
2. Proposed Methodology
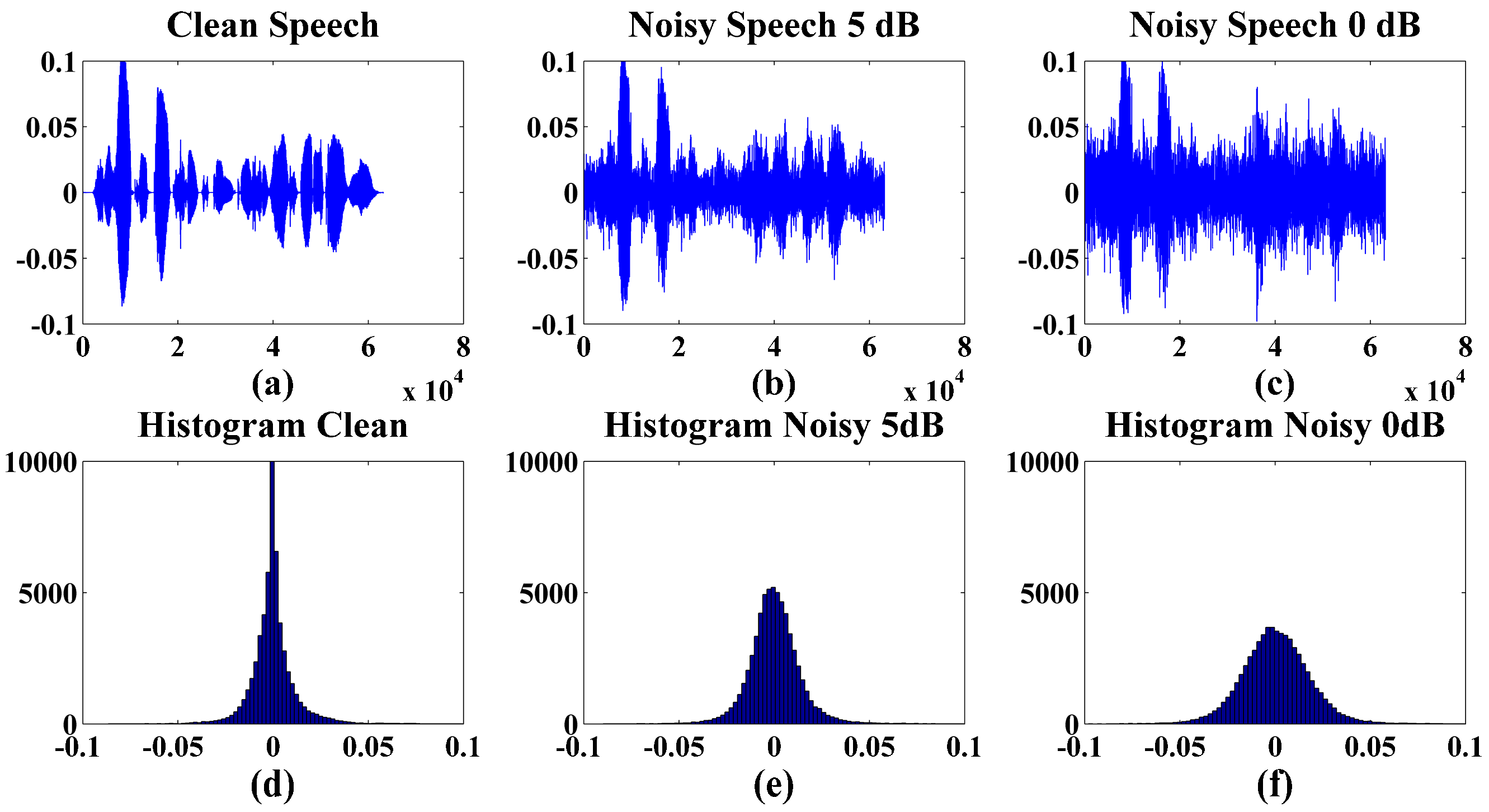
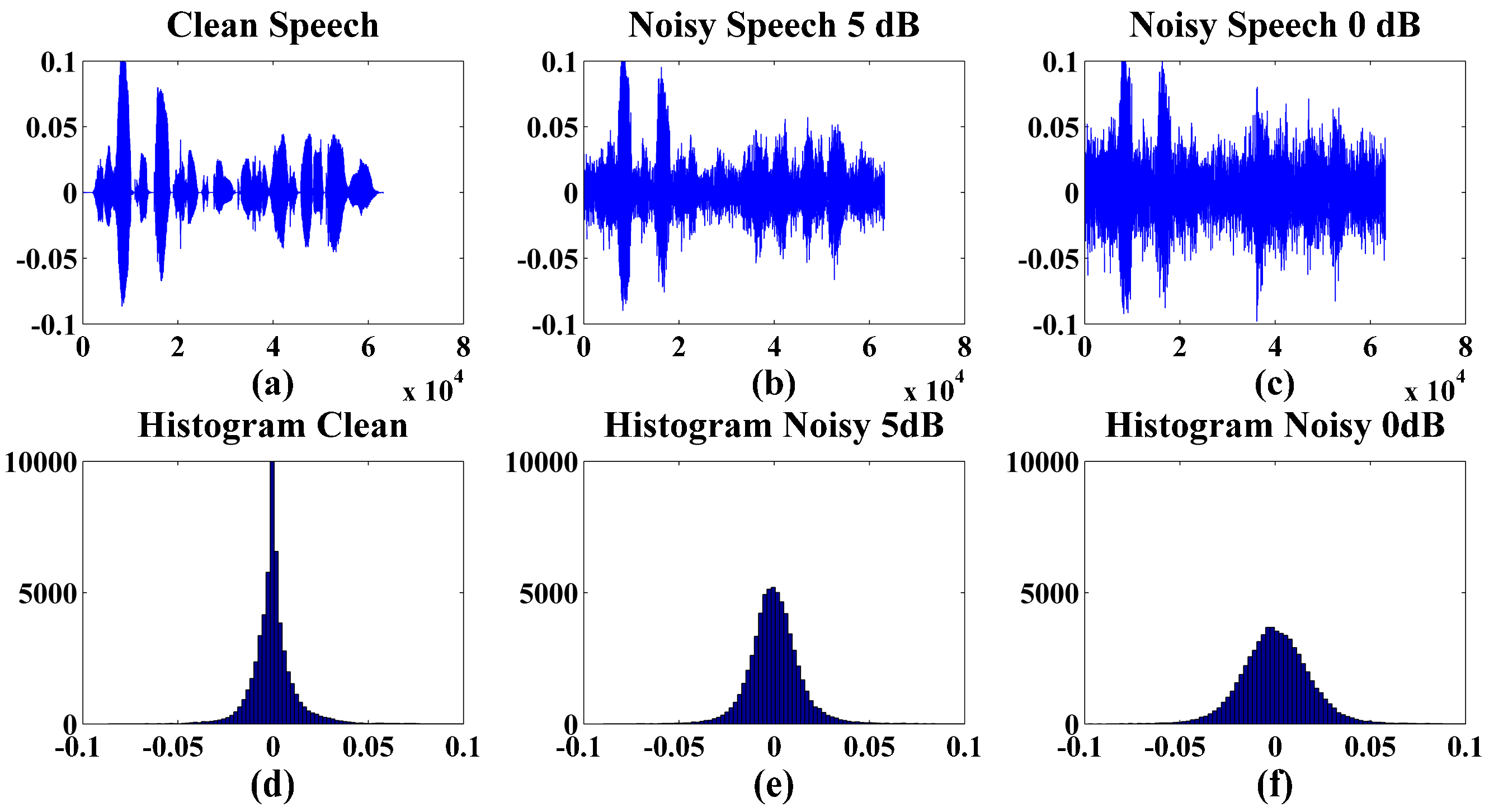
2.1. Preprocessing
2.2. Framing
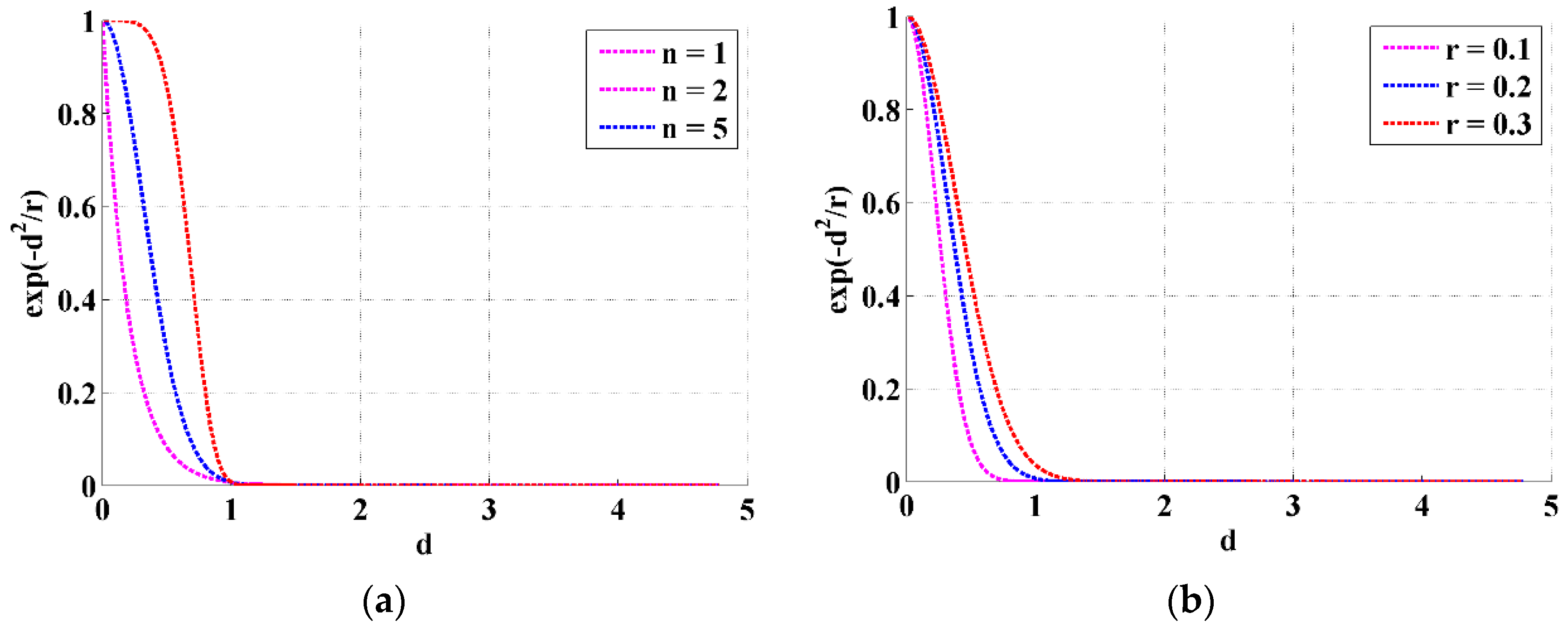
2.3. Feature Extraction—Fuzzy Entropy (FuzzyEn)
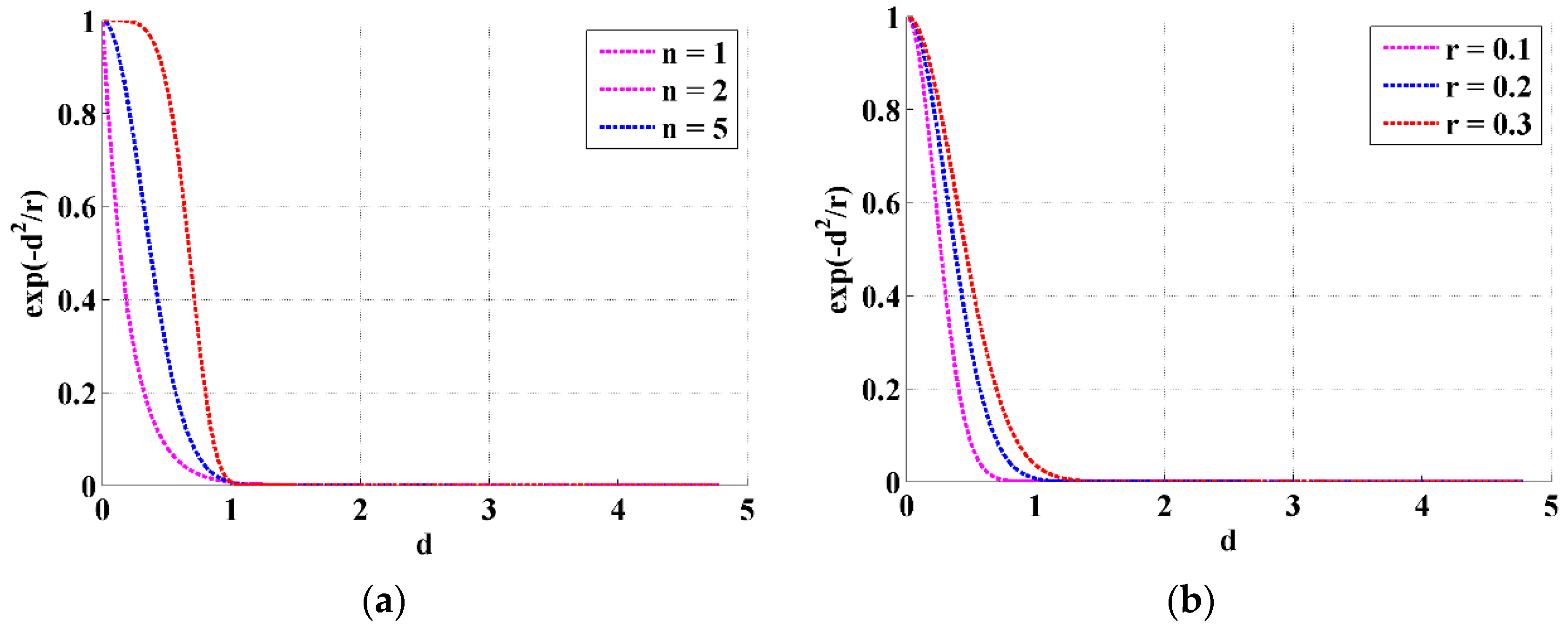
Selection of FuzzyEn Parameters
2.4. Classifier
2.4.1. Support Vector Machine (SVM)
2.4.2. k-Nearest Neighbor (k-NN)
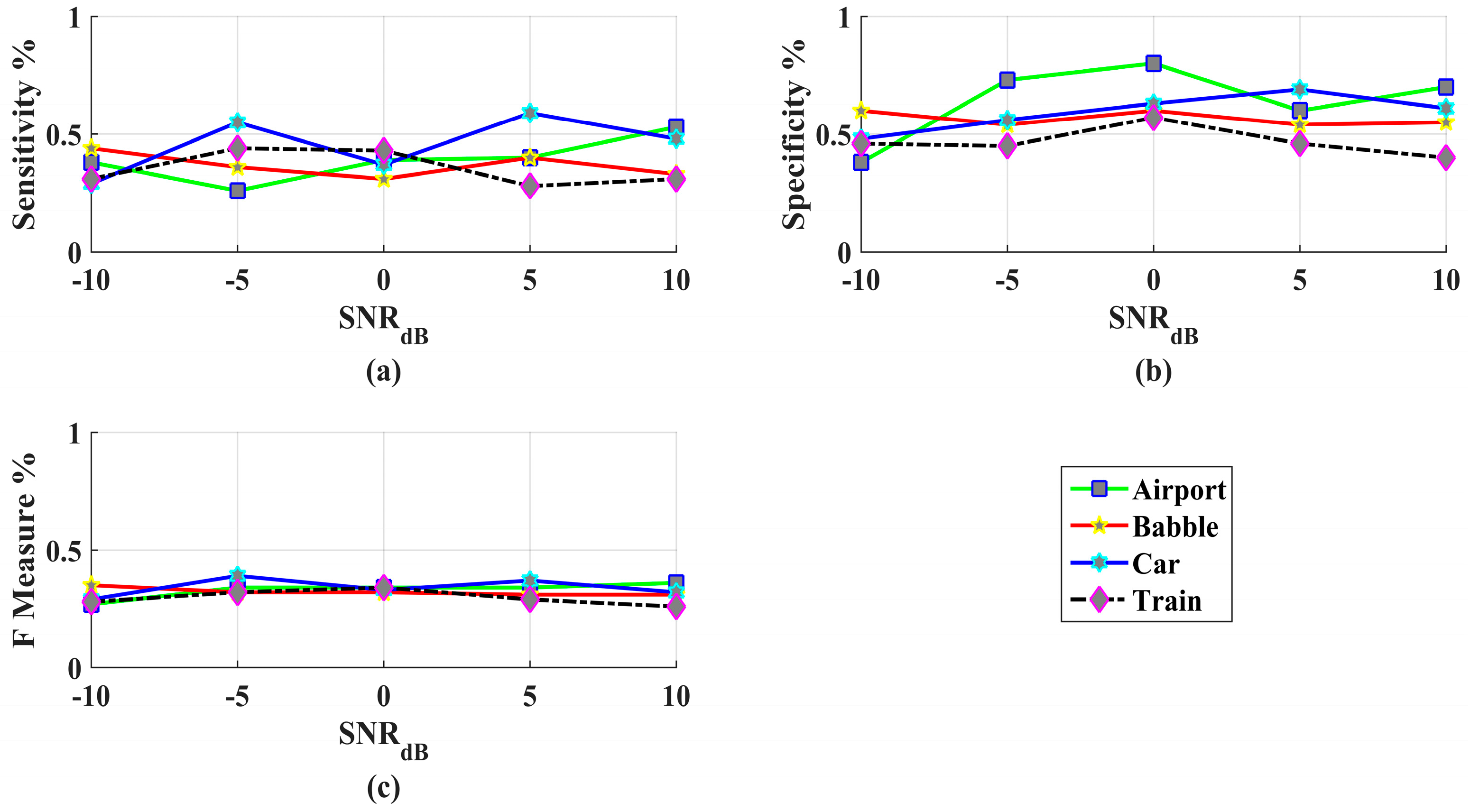
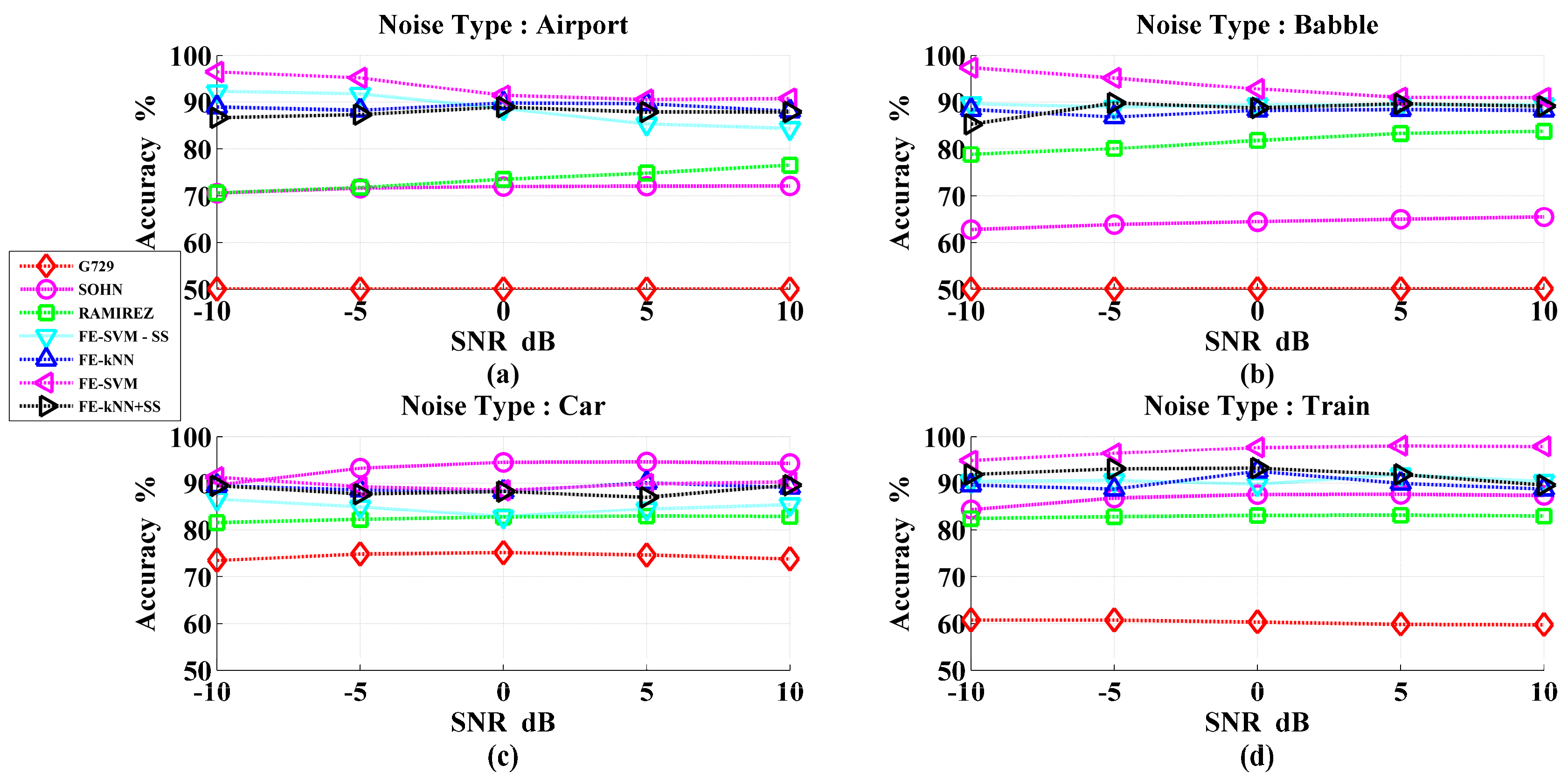
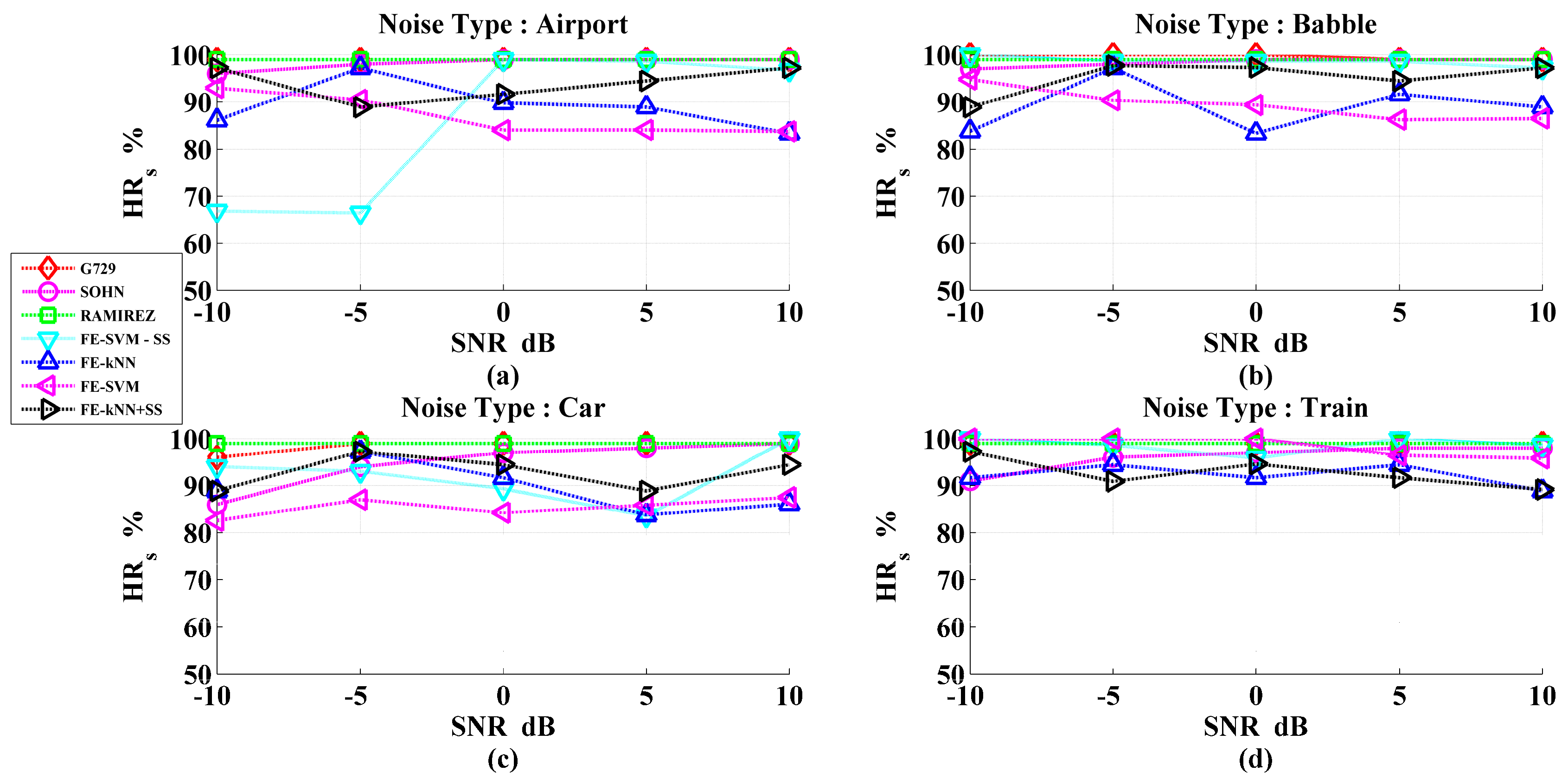
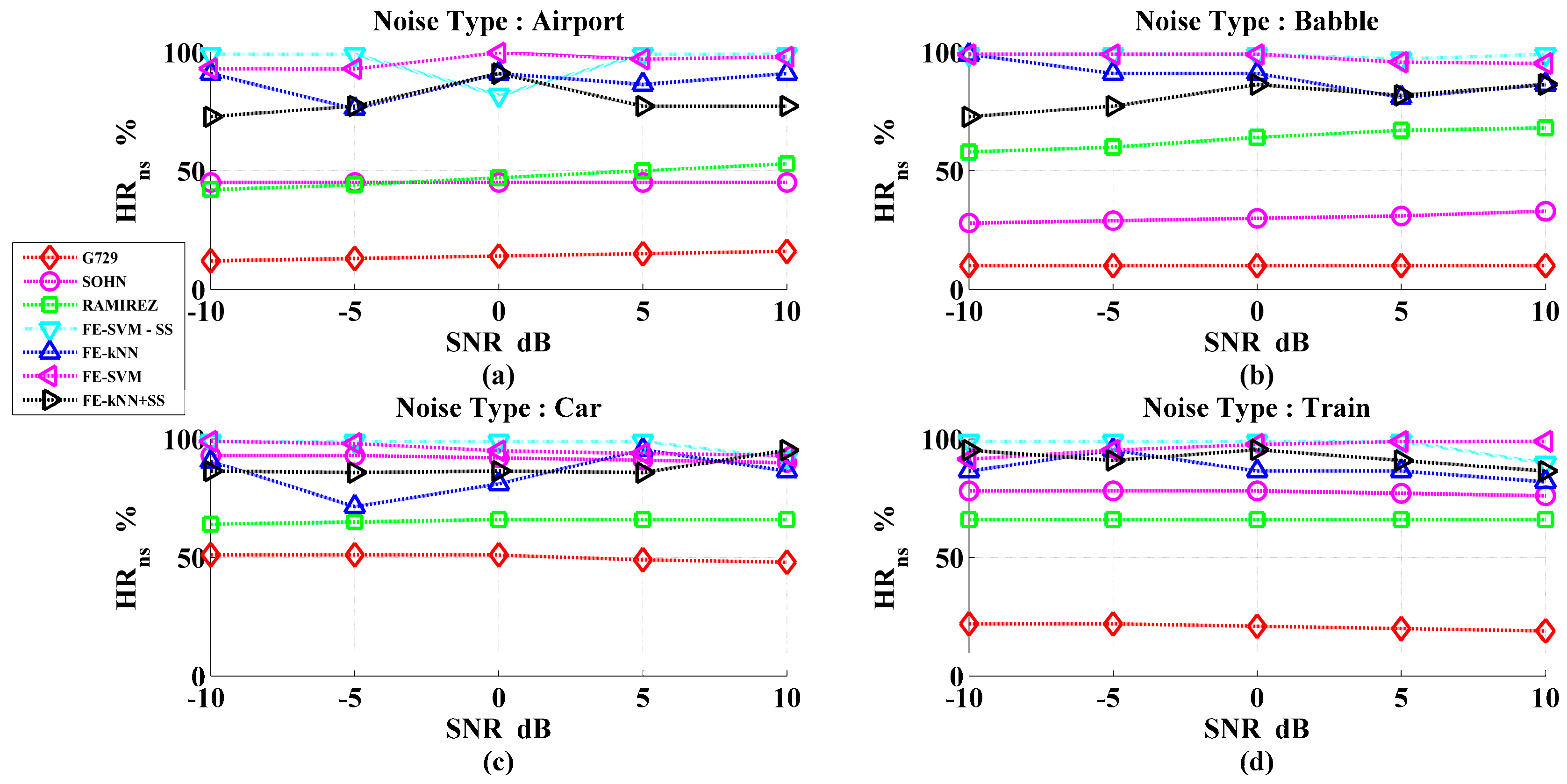
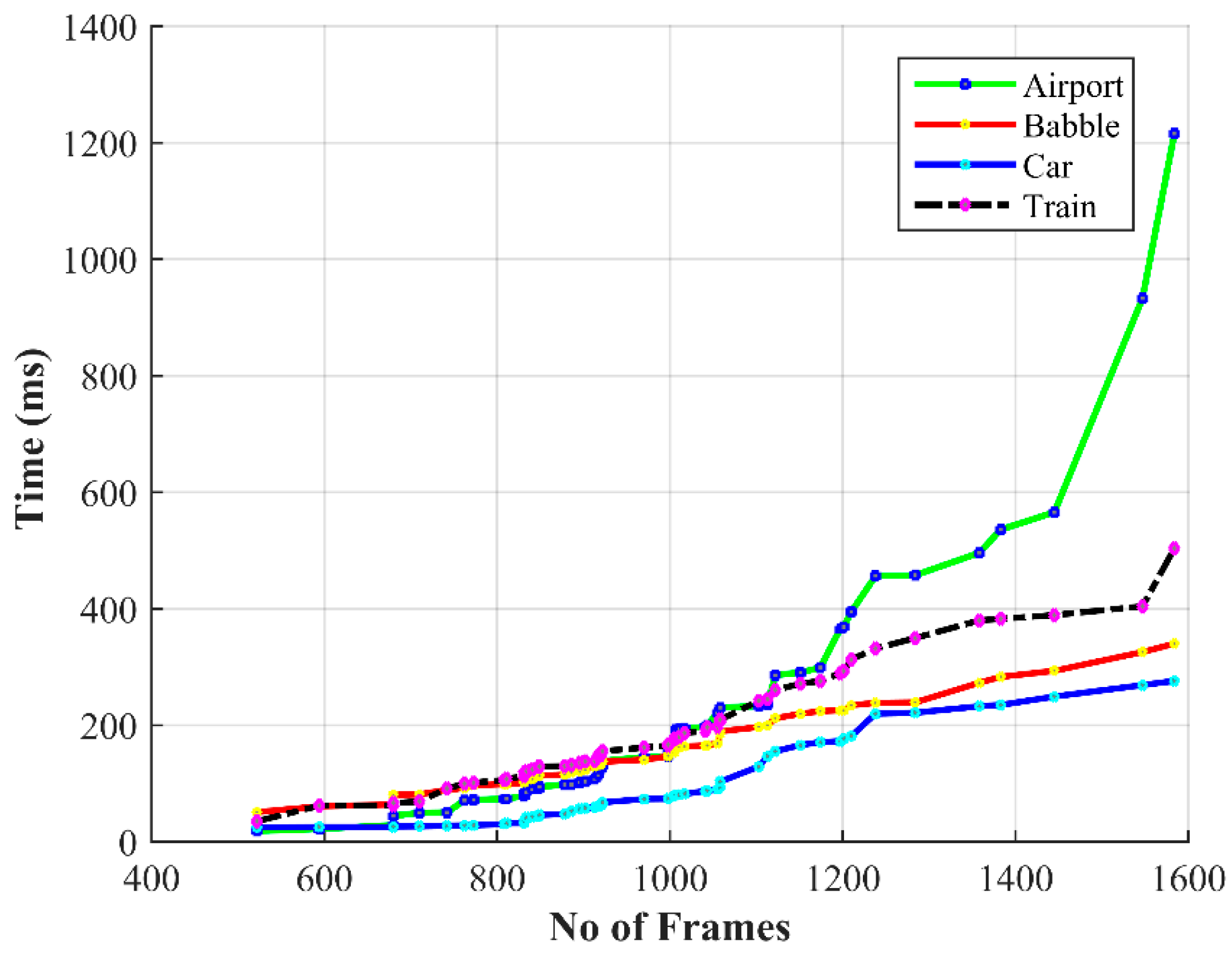
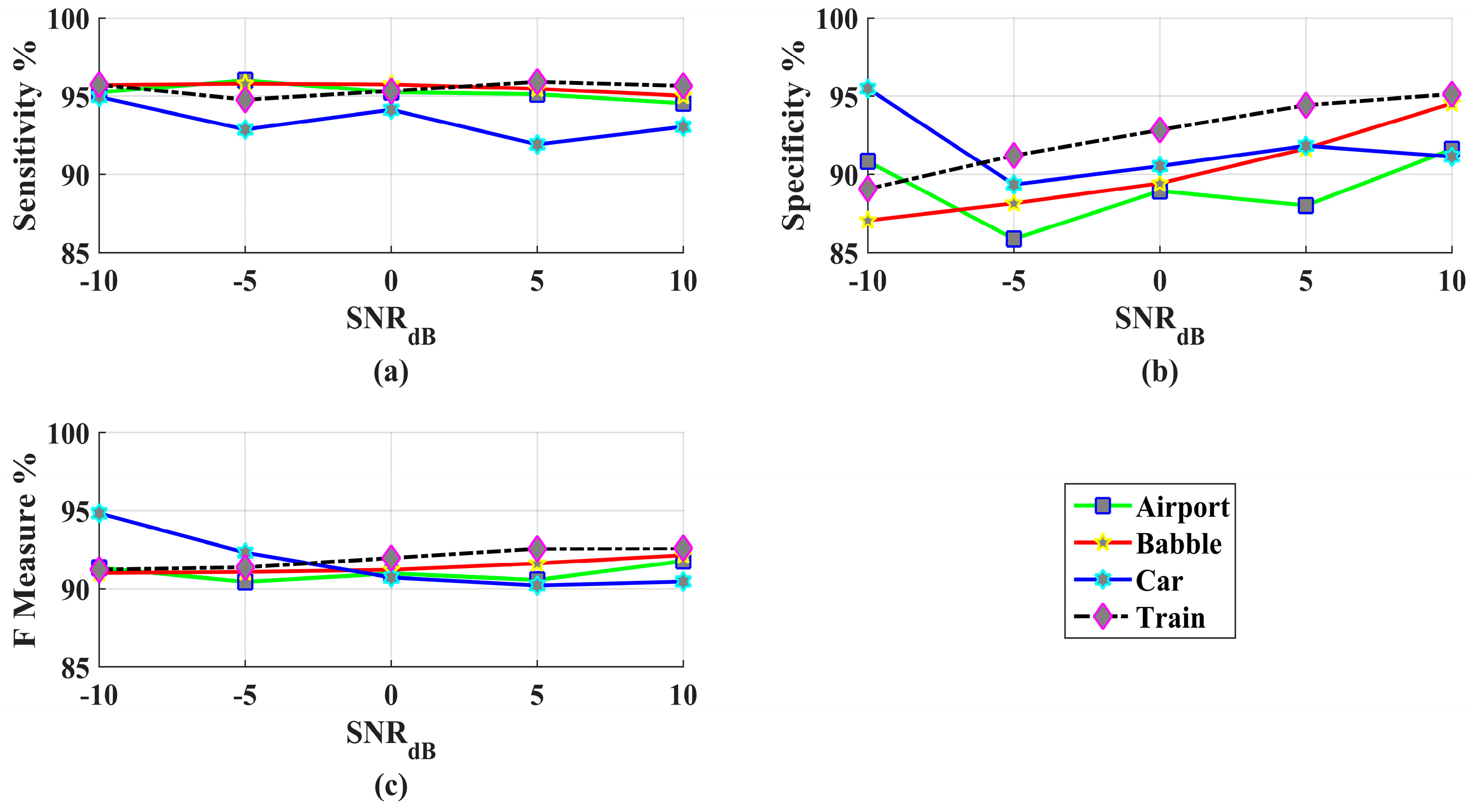
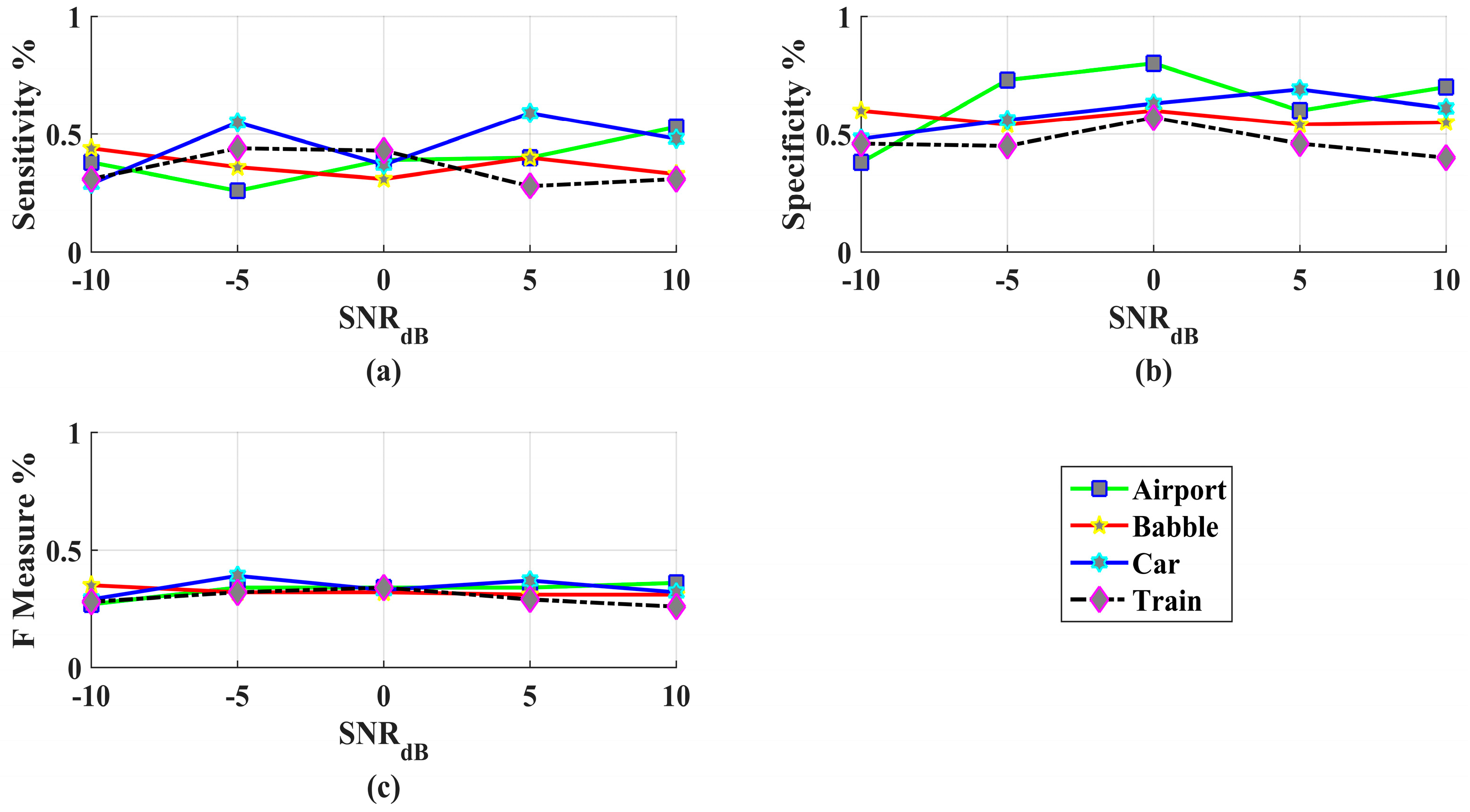
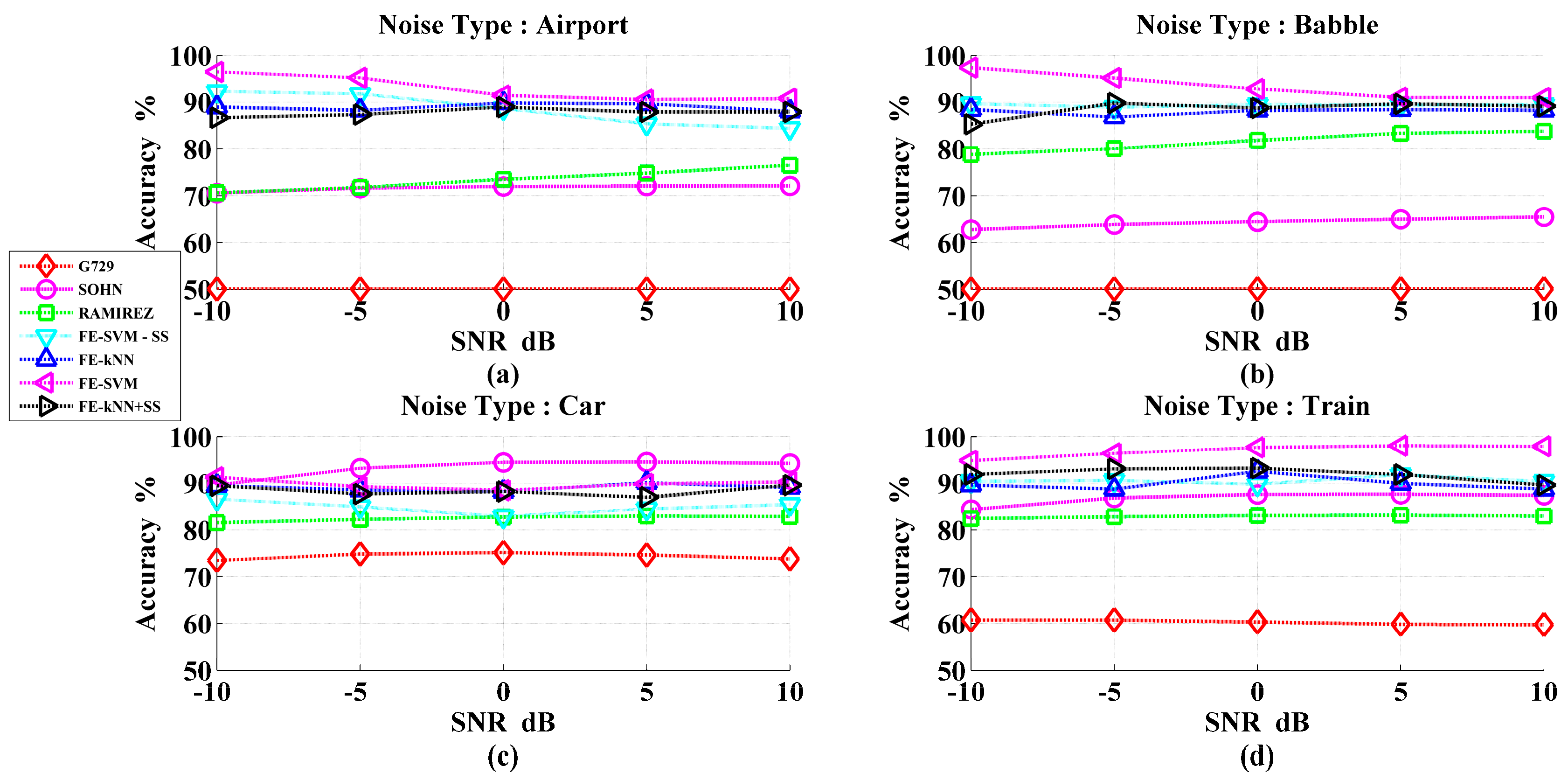
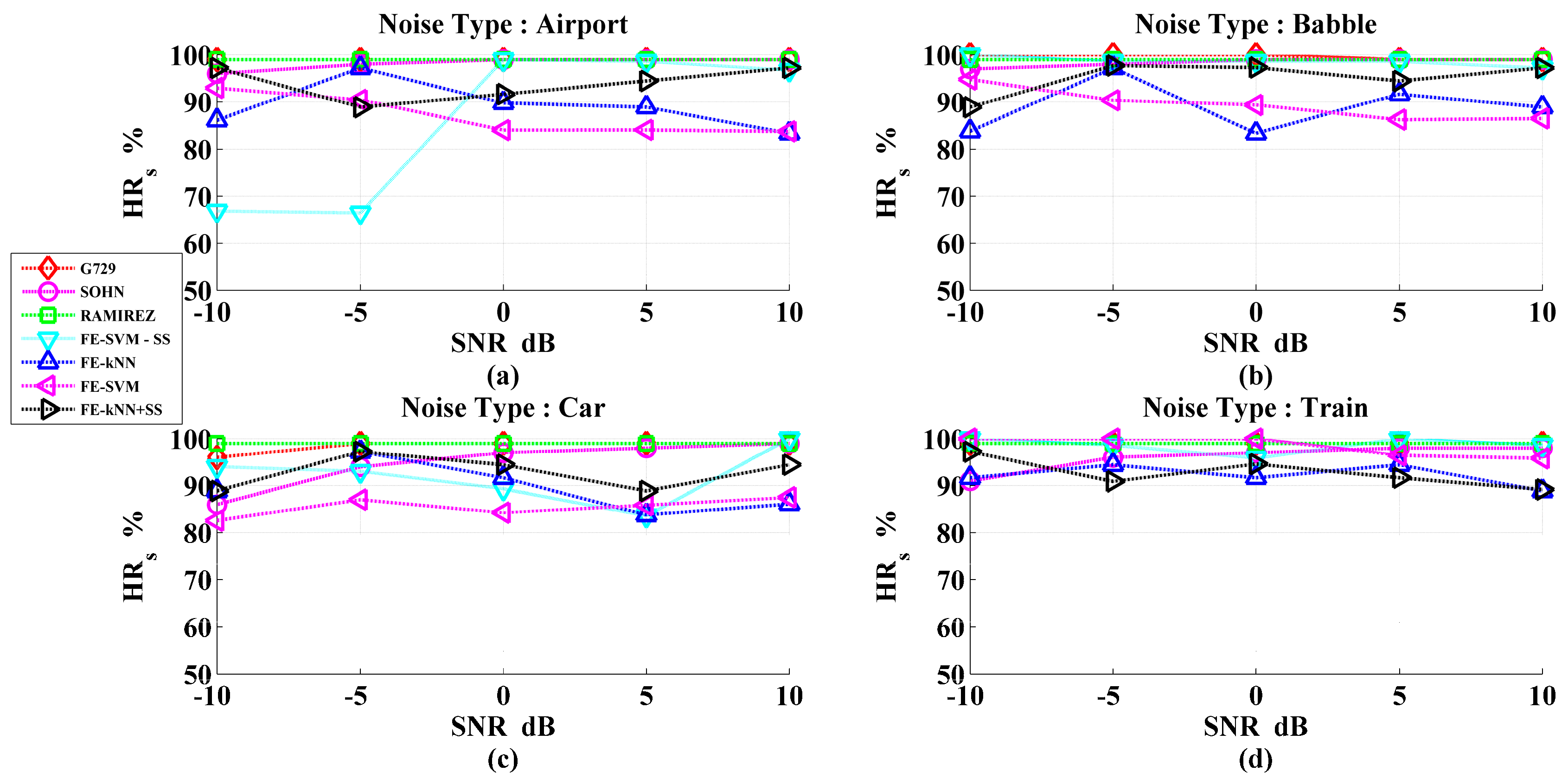
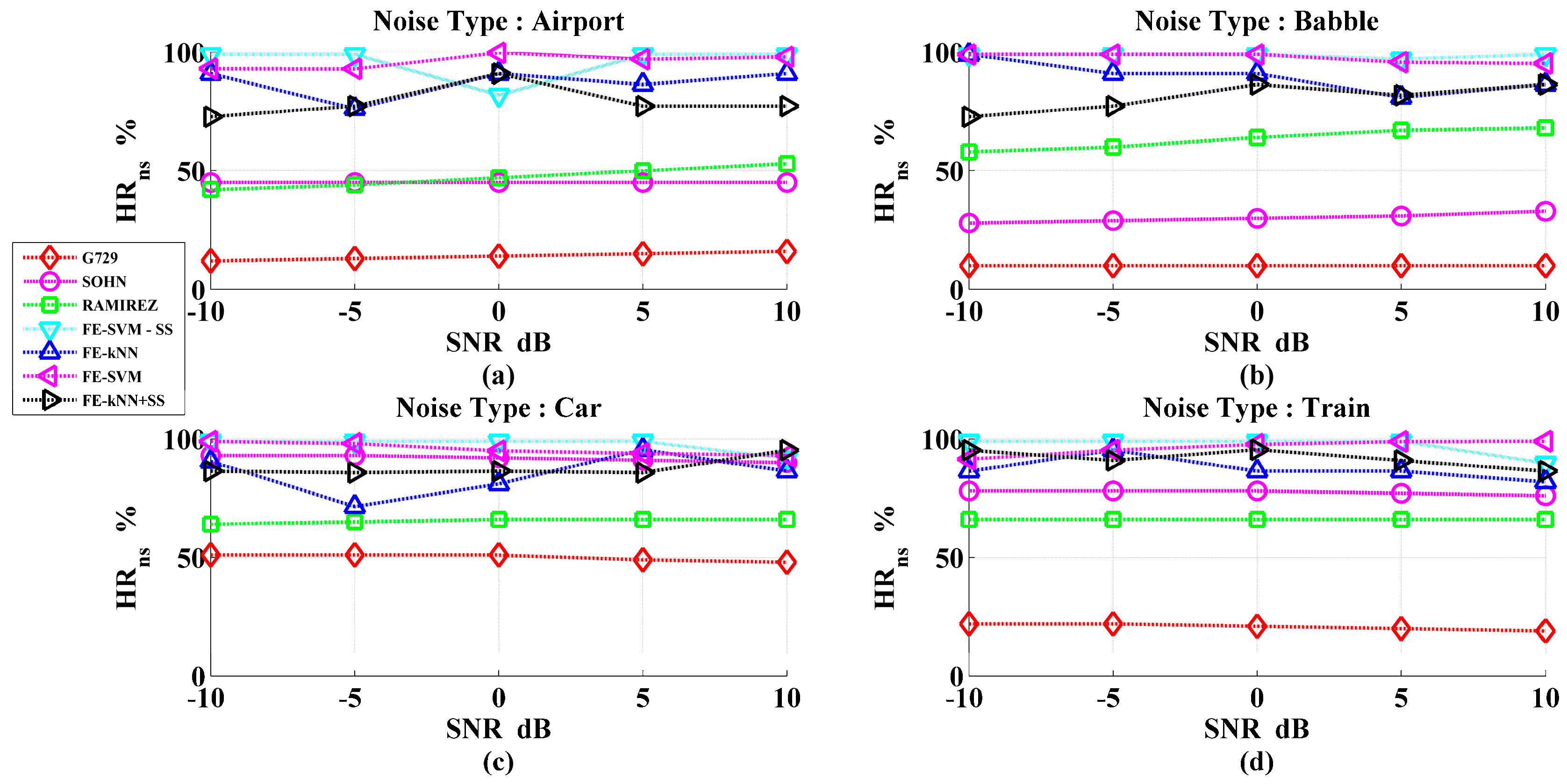
3. Results and Discussions
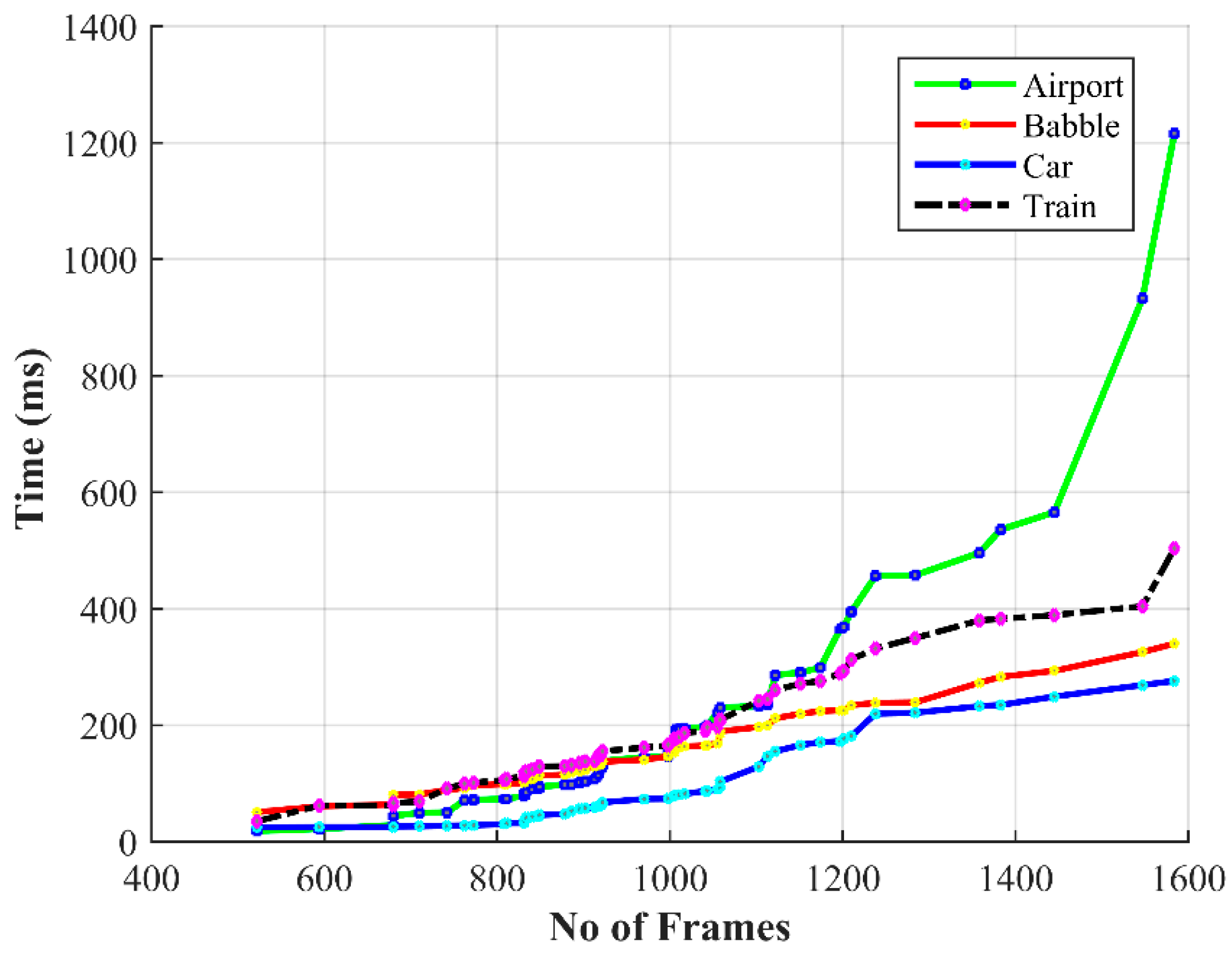
Performance Evaluation
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhang, L.; Gao, Y.-C.; Bian, Z.-Z.; Chen, L. Voice activity detection algorithm improvement in multi-rate speech coding of 3GPP. In Proceedings of the 2005 International Conference on Wireless Communications, Networking and Mobile Computing, (WCNM 2005), Wuhan, China, 23–26 September 2005; pp. 1257–1260.
- Karray, L.; Martin, A. Towards improving speech detection robustness for speech recognition in adverse conditions. Speech Commun. 2003, 40, 261–276. [Google Scholar] [CrossRef]
- Freeman, D.K.; Southcott, C.B.; Boyd, I.; Cosier, G. A voice activity detector for pan-European digital cellular mobile telephone service. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Glasgow, Scotland, 23–26 May 1989; pp. 369–372.
- Sangwan, A.; Chiranth, M.C.; Jamadagni, H.S.; Sah, R.; Venkatesha Prasad, R.; Gaurav, V. VAD techniques for real-time speech transmission on the Internet. In Proceedings of the 5th IEEE International Conference on High Speed Networks and Multimedia Communications, Jeju Island, Korea, 3–5 July 2002; pp. 46–50.
- Itoh, K.; Mizushima, M. Environmental noise reduction based on speech/non-speech identification for hearing aids. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; pp. 419–422.
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Makhoul, J.; Berouti, M. Adaptive noise spectral shaping and entropy coding in predictive coding of speech. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 63–73. [Google Scholar] [CrossRef]
- Hsieh, C.-H.; Feng, T.-Y.; Huang, P.-C. Energy-based VAD with grey magnitude spectral subtraction. Speech Commun. 2009, 51, 810–819. [Google Scholar] [CrossRef]
- Kotnik, B.; Kacic, Z.; Horvat, B. A multiconditional robust front-end feature extraction with a noise reduction procedure based on improved spectral subtraction algorithm. In Proceedings of the 7th European Conference on Speech Communication and Technology, Aalborg, Denmark, 3–7 September 2001; pp. 197–200.
- Shi, W.; Zou, Y.; Liu, Y. Long-term auto-correlation statistics based on voice activity detection for strong noisy speech. In Proceedings of the 2014 IEEE China Summit & International Conference on Signal and Information Processing, Xi’an, China, 9–13 July 2014; pp. 100–104.
- Lee, Y.-C.; Ahn, S.-S. Statistical Model-Based VAD algorithm with wavelet transform. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2006, E89-A, 1594–1600. [Google Scholar] [CrossRef]
- Haigh, J.A.; Mason, J.S. Robust voice activity detection using cepstral features. In Proceedings of the IEEE Region 10 Conference on Computer, Communication, Control and Power Engineering, Beijing, China, 19–21 October 1993; pp. 321–324.
- Ramirez, J.; Segura, J.C.; Benitez, C.; Torre, A.; Rubio, A. Efficient voice activity algorithms using long-term speech information. Speech Commun. 2004, 42, 271–287. [Google Scholar] [CrossRef]
- Kristjansson, T.; Deligne, S.; Olsen, P.A. Voicing features for robust speech detection. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; pp. 369–372.
- Ishizuka, K.; Nakatani, T.; Fujimoto, M.; Miyazaki, N. Noise robust voice activity detection based on periodic to aperiodic component ratio. Speech Commun. 2010, 52, 41–60. [Google Scholar] [CrossRef]
- G.729: A Silence Compression Scheme for G.729 Optimized for Terminals Conforming to Recommendation V.70. Available online: https://www.itu.int/rec/T-REC-G.729-199610-S!AnnB/en (accessed on 10 August 2016).
- Nemer, E.; Goubron, R.; Mahmoud, S. Robust voice activity detection using higher-order statistics in the LPC residual domain. IEEE Trans. Speech Audio Process. 2001, 9, 217–231. [Google Scholar] [CrossRef]
- Harmsen, M.; Fisher, B.; Schramm, H.; Seidl, T.; Deserno, T.M. Support Vector Machine Classification Based on Correlation Prototypes Applied to Bone Age Assessment. IEEE J. Biomed. Health Inform. 2012, 17, 190–197. [Google Scholar] [CrossRef] [PubMed]
- Lan, M.; Tan, C.; Su, J.; Lu, Y. Supervised and traditional term weighting methods for automatic text categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 721–735. [Google Scholar] [CrossRef] [PubMed]
- Mohanty, S.; Bebartta, H.N.D. Performance Comparison of SVM and k-NN for Oriya Character Recognition. Int. J. Adv. Comput. Sci. Appl. 2011, 1, 112–116. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of Surface EMG signal based on Fuzzy Entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef] [PubMed]
- Richman, J.S.; Randall Moorman, J. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [PubMed]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn and SampEn. Med. Eng. Phys. 2009, 31, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Hörtenhuber, M.; Mayer, C.; Bachler, M.; Wassertheurer, S.; Pinho, A.; Koslicki, D. On Entropy-Based Data Mining. In Interactive Knowledge Discovery and Data Mining in Biomedical Informatics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 209–226. [Google Scholar]
- Mayer, C.; Bachler, M.; Hortenhuber, M.; Stocker, C.; Holzinger, A.; Wassertheurer, S. Selection of entropy-measure parameters for knowledge discovery in heart rate variability data. BMC Bioinform. 2014, 15, S2. [Google Scholar] [CrossRef] [PubMed]
- Mayer, C.; Bachler, M.; Holzinger, A.; Stein, P.K.; Wassertheurer, S. The Effect of Threshold Values and Weighting Factors on the Association between Entropy Measures and Mortality after Myocardial Infarction in the Cardiac Arrhythmia Suppression Trial (CAST). Entropy 2016, 18, 129. [Google Scholar] [CrossRef]
- Hariharan, M.; Fook, C.Y.; Sindhu, R.; Adom, A.H.; Yaacob, S. Objective evaluation of speech dysfluencies using wavelet packet transform with sample entropy. Digit. Signal Process. 2013, 23, 952–959. [Google Scholar] [CrossRef]
- Muhammad, N.M.; Yaacob, S.; Nagarajan, R.; Hariharan, M. Comapatients expression analysis under different lighting using k-NN and LDA. Int. J. Signal Process. Image Process. 2010, 1, 249–254. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S.; Dahlgren, N.L. TIMIT Acoustic-Phonetic Continuous Speech Corpus Linguistic Data Consortium. Available online: https://catalog.ldc.upenn.edu/LDC93S1 (accessed on 9 August 2016).
- Beritelli, F.; Casale, S.; Ruggeri, G.; Serano, S. Performance Evaluation and Comparison of G.729/AMR/ Fuzzy Voice Activity Detectors. IEEE Signal Process. Let. 2002, 9, 85–88. [Google Scholar] [CrossRef]
- Hirsch, H.-G.; Pearce, D. The AURORA experimental framework for the performance evaluations of speech recognition systems under noisy conditions. In Proceedings of the ISCA ITRW ASR2000, Paris, France, 18–20 September 2000; pp. 18–20.
- Ma, Y.; Nishihara, A. Efficient voice activity detection algorithm using long-term spectral flatness measure. EURASIP J. Audio Speech Music Process. 2013, 2013. [Google Scholar] [CrossRef]
- Ghosh, P.K.; Tsiartas, A.; Narayanan, S. Robust Voice Activity Detection Using Long-Term Signal Variability. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 600–613. [Google Scholar] [CrossRef]
- Sohn, J.; Kim, N.S. A statistical model-based voice activity detection. IEEE Signal Process. Lett. 1999, 6. [Google Scholar] [CrossRef]
- Davis, A.; Nordholm, S.; Togneri, R. Statistical Voice Activity Detection Using Low-Variance Spectrum Estimation and an Adaptive Threshold. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 412–424. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Noise Type | SNR Levels | ||||
|---|---|---|---|---|---|
| −10 | −5 | 0 | 5 | 10 | |
| SVM, k-NN | SVM, k-NN | SVM, k-NN | SVM, k-NN | SVM, k-NN | |
| Airport | 3.52 ± 0.53, 11.07 ± 1.13 | 4.79 ± 0.96, 11.7 ± 1.86 | 8.56 ± 1.84, 10.21 ± 2.09 | 9.5 ± 1.93, 10.38 ± 2.13 | 9.26 ± 1.89, 11.94 ± 2.23 |
| Babble | 2.61 ± 0.37, 11.59 ± 2.17 | 4.82 ± 0.98, 13.15 ± 1.76 | 7.16 ± 1.47, 11.76 ± 1.74 | 9.02 ± 1.88, 11.59 ± 1.53 | 9.07 ± 1.9, 11.76 ± 1.56 |
| Car | 8.72 ± 0.94, 10.55 ± 1.16 | 10.74 ± 0.98, 11.42 ± 1.01 | 11.49 ± 1.13, 11.76 ± 1.25 | 10.14 ± 1.71, 9.86 ± 1.32 | 9.7 ± 1.62, 10.9 ± 1.8 |
| Train | 5.17± 0.47, 10.38 ± 1.25 | 3.61 ± 0.15, 11.25 ± 2.01 | 2.34 ± 0.11, 7.44 ± 1.51 | 1.97 ± 0.15, 10.03 ± 1.92 | 2.1 ± 0.09, 11.25 ± 1.97 |
| VAD | SOHN | RAMIREZ | G.729B | FE-SVM | FE-k-NN | FE-SVM − SS | FE-k-NN + SS |
|---|---|---|---|---|---|---|---|
| NOISY CONDITIONS | |||||||
| Accuracy | 78.99 ± 2.6 | 80.09 ± 2.8 | 58.69 ± 1.3 | 93.29 ± 2.1 | 88.99 ± 3.1 | 88.34 ± 2.3 | 89.15 ± 2.8 |
| HRs | 96.85 ± 2.1 | 99 ± 0.9 | 99.25 ± 0.4 | 90.09 ± 2.5 | 89.91 ± 3.3 | 83.74 ± 4.8 | 93.62 ± 1.6 |
| HRns | 61.1 ± 4.5 | 60.5 ± 5.5 | 17.78 ± 2.4 | 96.73 ± 0.9 | 87.49 ± 1.9 | 98.02 ± 0.7 | 85.37 ± 2.5 |
| CLEAN CONDITION | |||||||
| Accuracy | 95.75 ± 1.9 | 83.74 ± 2.1 | 94.98 ± 1.9 | 98.28 ± 0.6 | 93.67 ± 2.1 | 90.74 ± 2.8 | 91.81 ± 2.9 |
| HRs | 99.78 ± 0.2 | 100 ± 0 | 100 ± 0 | 97.84 ± 1.9 | 95.78 ± 2.6 | 85.4 ± 5.6 | 94.40 ± 1.4 |
| HRns | 91.7 ± 3.8 | 67.49 | 89.97 ± 3.9 | 100 ± 0 | 96.34 ± 2.3 | 100 ± 0 | 88.81 ± 3.4 |
| OVER ALL PERFORMANCE | |||||||
| Accuracy | 87.37 ± 2.3 | 81.92 ± 2.5 | 76.84 ± 1.6 | 95.76 ± 1.4 | 91.33 ± 2.6 | 89.54 ± 2.6 | 90.48 ± 2.9 |
| HRs | 98.32 ± 1.2 | 99.5 ± 0.5 | 99.63 ± 0.2 | 93.97 ± 2.2 | 92.85 ± 3 | 84.57 ± 5.2 | 94.01 ± 1.5 |
| HRns | 76.4 ± 4.2 | 63.99 ± 4.8 | 53.88 ± 3.2 | 98.37 ± 0.5 | 91.92 ± 2.5 | 99.01 ± 0.4 | 87.09 ± 3 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johny Elton, R.; Vasuki, P.; Mohanalin, J. Voice Activity Detection Using Fuzzy Entropy and Support Vector Machine. Entropy 2016, 18, 298. https://doi.org/10.3390/e18080298
Johny Elton R, Vasuki P, Mohanalin J. Voice Activity Detection Using Fuzzy Entropy and Support Vector Machine. Entropy. 2016; 18(8):298. https://doi.org/10.3390/e18080298
Chicago/Turabian StyleJohny Elton, R., P. Vasuki, and J. Mohanalin. 2016. "Voice Activity Detection Using Fuzzy Entropy and Support Vector Machine" Entropy 18, no. 8: 298. https://doi.org/10.3390/e18080298