
Average Contrastive Divergence for Training Restricted Boltzmann Machines


1
Center for Intelligence Science and Technology, School of Computer Science, Beijing University of Posts and Telecommunications, Beijing 100876, China
2
School of Mathematic and Information Science, Henan Polytechnic University, Jiaozuo 454000, China
*
Author to whom correspondence should be addressed.
Entropy 2016, 18(1), 35; https://doi.org/10.3390/e18010035
Submission received: 22 September 2015
/
Revised: 11 January 2016
/
Accepted: 15 January 2016
/
Published: 21 January 2016
{kind=link}
{kind=link}
{kind=link}
Abstract
:This paper studies contrastive divergence (CD) learning algorithm and proposes a new algorithm for training restricted Boltzmann machines (RBMs). We derive that CD is a biased estimator of the log-likelihood gradient method and make an analysis of the bias. Meanwhile, we propose a new learning algorithm called average contrastive divergence (ACD) for training RBMs. It is an improved CD algorithm, and it is different from the traditional CD algorithm. Finally, we obtain some experimental results. The results show that the new algorithm is a better approximation of the log-likelihood gradient method and outperforms the traditional CD algorithm.
1. Introduction
The learning of restricted Boltzmann machines (RBMs) has been an important and hot topic in machine learning. The learning is an inference process of the model parameters. The general learning algorithm, for example the gradient method, is challenging for training RBMs. Hinton proposed a learning algorithm called the contrastive divergence (CD) algorithm [1]. The CD algorithm has become a popular way to train this model [1,2,3,4,5,6,7]. Recently, more and more researchers have studied the properties of the CD algorithm [6,8,9,10,11,12]. Bengio and Delalleau [6] have given the bias of the expectation of the CD approximation of the log-likelihood gradient for RBMs. Fischer and Igel [13] gave the upper bound on the bias.
This paper provides two main contributions. One is to provide an analysis of the CD algorithm. We derive the bias of the CD approximation of the log-likelihood gradient and provide an analysis of the bias and the approximation error of CD. We generalize the conclusions of Bengio and Delalleau [6]. Our analysis of the approximation error explicitly shows that the expectation of CD is closer to the log-likelihood gradient than CD; the idea of our new learning algorithm is derived from the conclusion. The other is to propose a new algorithm that is called the average contrastive divergence (ACD) algorithm for training RBMs. We show that ACD is a better approximation of the log-likelihood gradient than CD. The ACD algorithm is superior to the traditional CD algorithm.
The rest part of the paper is organized as follows. In Section 2, we introduce the CD algorithm and give some analysis results of CD. In Section 3, we propose a new algorithm, called ACD, for training RBMs and provide a theoretical analysis of ACD. In Section 4, we show that the ACD algorithm is superior to the traditional CD with some experiments. We draw some conclusions in the final section.
2. Contrastive Divergence Algorithm
2.1. Contrastive Divergence Algorithm
Consider a probability distribution over a vector x:
where w is the model parameter, is a normalization constant and is an energy function.
Learning the parameters of the model is an important area. The common learning method is the gradient method. The log-likelihood gradient of the model parameter w given a training datum is:
The first term can be computed exactly; however, the second term is intractable, because its complexity is exponential in the size of the smallest layer. Obtaining unbiased estimates of the log-likelihood gradient using Markov chain Monte Carlo (MCMC) methods typically requires many sampling steps. However, it has been shown that estimates obtained after running the chain for just a few steps can be sufficient for the training of the model. This leads to contrastive divergence (CD) learning.
The idea of k-step contrastive divergence learning (CD-k) is simple: instead of approximating the second term in the log-likelihood gradient by a sample for the RBM distribution (which would require running a Markov chain until the stationary distribution is reached), a Markov chain is run for only k steps. The Markov chain is derived by Gibbs sampling, so it is also called Gibbs chain. The Gibbbs chain is initialized with a training example of the training set and yields the sample after k steps. Each step t consists of sampling from and subsequently sampling from . The gradient Equation (2) with regard to w of the log-likelihood for one training example is approximated by:
The expectation of CD (ECD) can be ascribed by:
where is the empirical distribution function on the samples obtained by the data and running the Markov chain forward for k steps, .
We can obtain the following theorem using the definition of CD, ECD and the log-likelihood gradient. In this paper, we consider the case where both x and h can only take a finite number of values. We assume that there is no pair such that or . This ensures that the Markov chain associated with Gibbs sampling is irreducible, and there exists a unique stationary distribution to which the chain converges. We also assume that is bounded, where , stands for the Euclidean norm in .
Theorem 1.
For a converging Gibbs chain starting at data point , the log-likelihood gradient can be written as:
where
and converges to zero as k goes to infinity.
Using the definition of , we have:
then:
Since is bounded and x and h can only take a finite number of values, so converges to zero as k goes to infinity.
The theorem is proven. ☐
Theorem 1 gives the bias of the CD approximation of the log-likelihood gradient; the bias converges to zero as k goes to infinity. Meanwhile, Theorem 1 gives the approximation error of the CD approximation of the log-likelihood gradient; the error includes two terms and ; is the approximation error of the ECD approximation of the log-likelihood gradient (that is also the bias of CD approximation of the log-likelihood gradient); is a stochastic term; the expectation of the stochastic term is zero. Theorem 1 shows that ECD is closer to the log-likelihood gradient than CD.
2.2. Contrastive Divergence Algorithm for RBMs
The RBM structure is a bipartite graph consisting of one layer of observable variables and one layer of hidden variables . The model distribution is given by , where , and the energy function is given by:
with being real-valued parameters, which are denoted by w.
There are some theoretical results about the CD algorithm for training RBMs [6,8,9,10,12]. The theoretical results from Bengio and Delalleau [6] give a good understanding of the CD approximation and the corresponding bias by showing that the log-likelihood gradient can, based on a Markov chain, be expressed as a sum of terms containing the k-th sample:
Theorem 2.
(Bengio and Delalleau, 2009) For a converging Gibbs chain starting at data point , the log-likelihood gradient can be written as:
and the final term converges to zero as k goes to infinity.
The first two terms in Equation (6) just correspond to the expectation of CD (ECD), and the bias of the CD approximation of the log-likelihood gradient is given by the final term; Fischer and Igel have given a bound of the bias [13]. The theorem gives the bias of the CD approximation of the log-likelihood gradient for RBMs; however, Theorem 1 gives the bias of the CD approximation of the log-likelihood gradient for the energy model. Meanwhile, Theorem 1 gives the approximation error of the CD approximation of the log-likelihood gradient. Theorem 2 could be considered as a corollary of Theorem 1. Next, we give the proof of the conclusion.
Theorem 3.
Theorem 2 is the corollary of Theorem 1.
Proof.
In order to prove that Theorem 2 is the corollary of Theorem 1, it is enough to prove . Using and , we have:
and:
then:
Taking conditional expectations with respect to ,
Since:
so we have:
The proof is completed. ☐
Using Theorem 1, we have the following corollary.
Corollary 1.
For a converging Gibbs chain starting at data point , the log-likelihood gradient can be written as:
where is defined in Theorem 1, and the final term converges to zero as k goes to infinity.
The first two terms in Equation (7) just correspond to the CD approximation, and the approximation error of the CD approximation of the log-likelihood gradient for RBMs is given by the final two terms.
3. Average Contrastive Divergence Algorithm
The empirical comparisons of the CD approximation and the true log-likelihood gradient for RBMs show that the bias can lead to a convergence to parameters that do not reach the maximum likelihood. More recently proposed learning algorithms try to obtain better approximations of the log-likelihood gradient [14,15,16,17,18]. In this section, we propose a new algorithm for training RBMs. In Section 2, we know that ECD is closer to the log-likelihood gradient than the traditional CD. It is unfortunate that we cannot calculate ECD as calculating the log-likelihood gradient for the actual problem. We know the fact that the average value of a random variable is approximate to the expectation of the random variable. Hence, we could look for a quality to approximate ECD. This leads to our new learning algorithm, called average contrastive divergence (ACD).
| Algorithm 1 ACD-k-l |
| input: RBM , training batch S. |
| output: gradient approximation and for |
| Initialize for |
| for all the do |
| for do |
| for do |
| for do |
| Sample |
| end for |
| for do |
| Sample |
| end for |
| end for |
| for do |
| end for |
| for do |
| end for |
| for do |
| end for |
| end for |
| end for |
The idea of average contrastive divergence learning (ACD-k-l) is as follows: to approximate the second term in the log-likelihood gradient by the average of l samples for a k-step Gibbs distribution. The samples for the k-step Gibbs distribution of ACD and CD are the same. lThe Gibbs chain is initialized with a training datum of the training set and yields the sample after k steps (each step t consists of sampling from and subsequently sampling from ).lThe k-step Gibbs chain repeats l times. We have samples . The gradient (2) with regard to w of the log-likelihood for the training data is approximated by:
In order to further understand the ACD algorithm, we give the bias of the ACD-k-l approximation of the log-likelihood gradient by the following theorem.
Theorem 4.
For a converging Gibbs chain starting at data point , the log-likelihood gradient can be written as:
where:
is defined in Theorem 1, , and converges to zero as k goes to infinity.
We have:
Since and have the same distribution, we have:
Then, we have:
By the proof of Theorem 1, we have that converges to zero as k goes to infinity. The theorem is proven. ☐
The theorem gives the bias of the ACD approximation of the log-likelihood gradient; the bias is ; the bias converges to zero as k goes to infinity. Meanwhile, the theorem gives the approximation error of the ACD approximation of the log-likelihood gradient, which is denoted by Error; the Error is . We can obtain the approximation error of the CD approximation of the log-likelihood gradient from Theorem 1, which is denoted by Error; the Error is . The following theorem gives the relationship between Error and Error.
Theorem 5.
Proof.
Using the definition of , we have:
The fourth and fifth equalities made use of the fact that and are two independent identically-distributed random variables.
Using the definition of , we have:
Then, we have:
Note that ; according to Theorems 1 and 4, we have:
Then, we have:
The theorem is proven. ☐
Intuitively, the smaller the approximation error of the log-likelihood gradient estimation, the higher the chance of converging to a maximum likelihood solution quickly. Still, even small deviations of a few gradient components can deteriorate the learning process. An important task of proposing a new learning algorithm is to obtain a better approximation of the log-likelihood gradient. We know that ACD and CD have the same bias from Theorems 1 and 4. Theorem 5 gives the relationship of Error and Error. Since and due to the definition of , we can see that the value of Error is not smaller than that of Error with probability one. The conclusion of the theorem shows that ACD is a better approximation than the traditional CD.
4. Experiments
This section will present some experiments illustrating the ACD algorithm. In the first two experiments, we train an RBM with 12 visible units and 10 hidden units, so that the log-likelihood gradient could be calculated exactly. Then, in the third experiment, we consider the Mixed National Institute of Standards and Technology (MNIST) data task by using the RBM with 500 hidden units.
4.1. The Artificial Data
Popular methods to train RBMs include CD and persistent contrastive divergence (PCD); PCD is also known as stochastic maximum likelihood [14,19]. Since ACD, CD and PCD are biased with respect to the log-likelihood gradient, now we investigate empirically the approximation errors of these algorithms. In our experiments, ACD, CD, PCD and the log-likelihood gradient are tested under exactly the same conditions (unless otherwise stated). It is known that the log-likelihood gradient is intractable for regular-sized RBMs, because its complexity is exponential in the size of the smallest layer, so we consider the small RBM with 12 visible units and 10 hidden units in this section. In our experiments, we randomly generate 100 data points and use 10 data points in each gradient estimate. We consider the square of approximation error (the approximation error has the same results) in order to illustrate Theorem 5. We also assume the bias parameters for all i and j; the learning rate is 0.01.
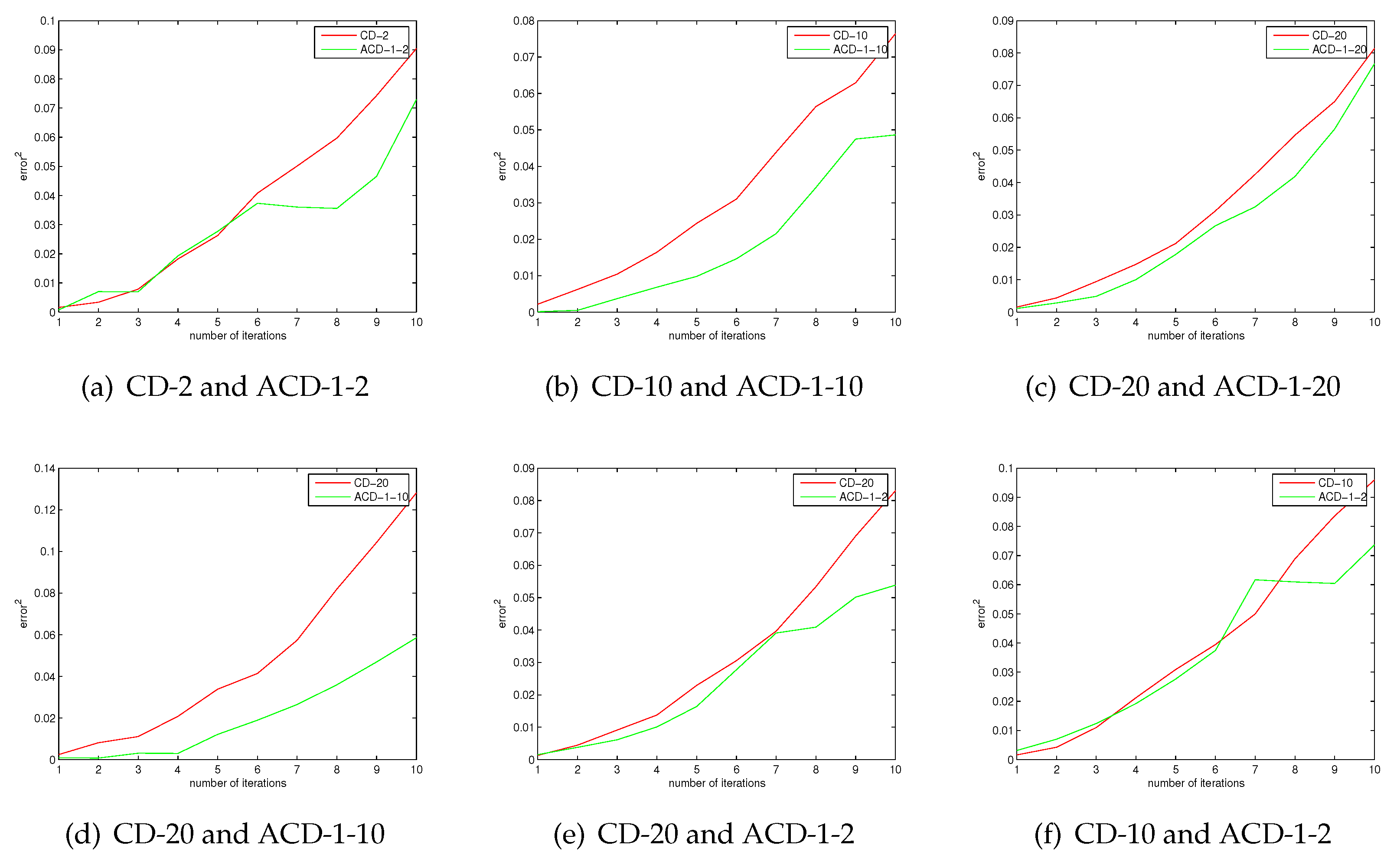
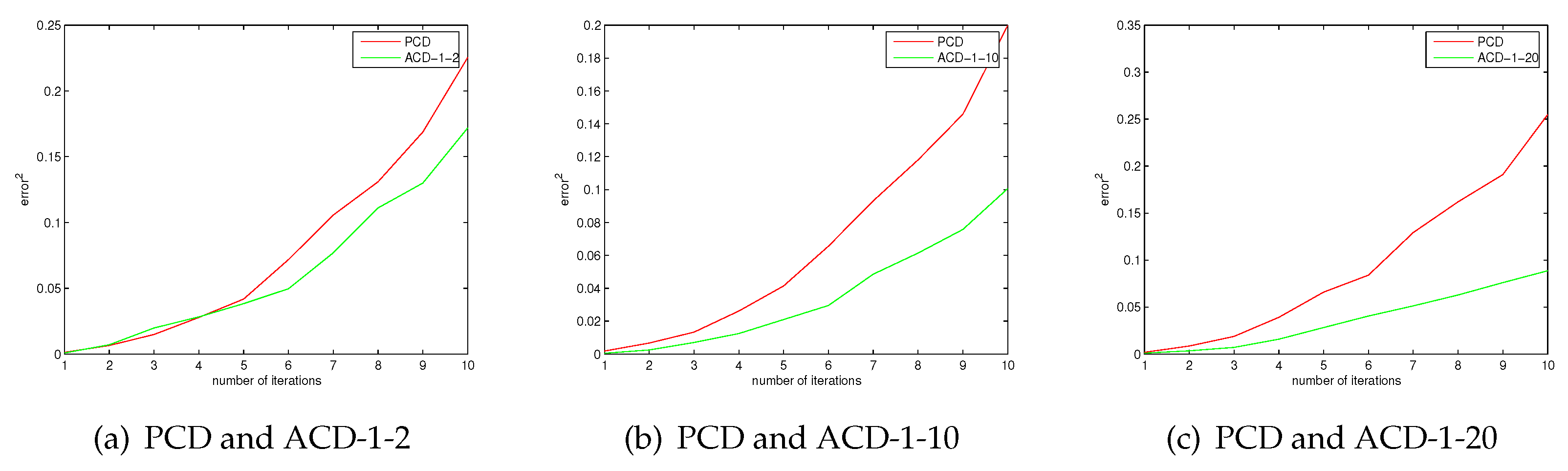
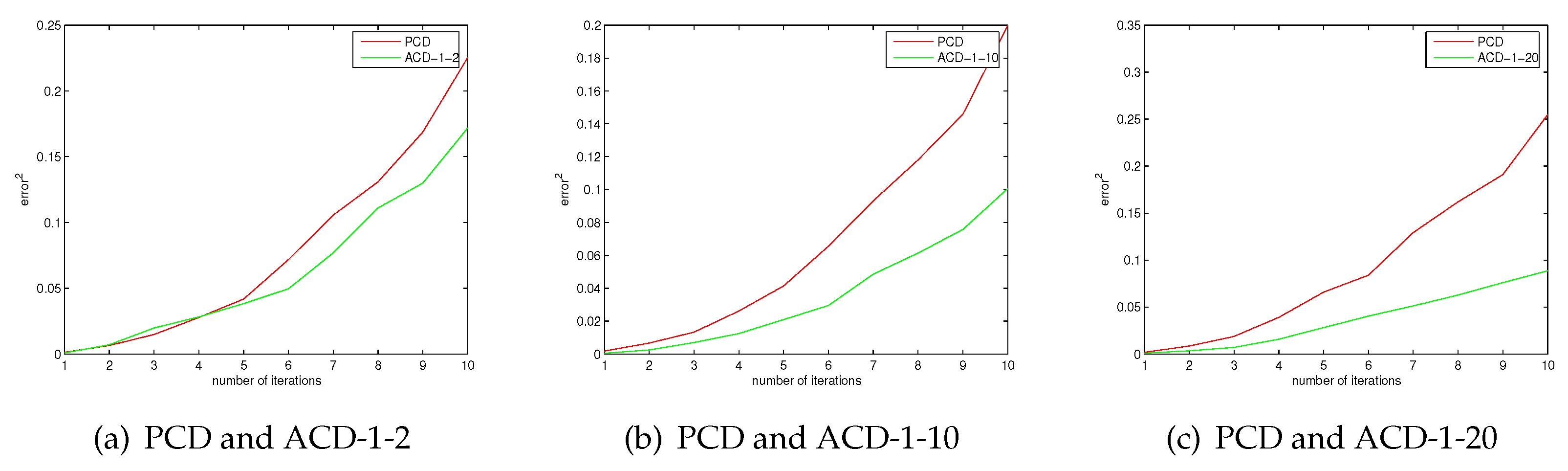
It is known that CD-k is closer to the log-likelihood gradient as k is larger. In the case of the same number of iterations, ACD-1-k and CD-k have same computational complexity. We give the results of 10 iterations. More iterations can be considered, which will require more training time. However, 10 iterations is enough to illustrate the approximation error of these algorithms. Figure 1 shows the approximation error of ACD and CD. The results show that the approximation error of ACD is smaller than that of CD. We can see that ACD is a better approximation of the log-gradient than CD from Figure 1, the experimental results are consistent with the conclusion of Theorem 5. In the case of the same number of iterations, the computational complexity of CD-20 is greater than ACD-1-10; however, Figure 1 shows that the approximation error of ACD-1-10 is smaller than CD-20, even if ACD-1-2 has a smaller approximation error than CD-20. One may find that the approximation error is very small as the number of iterations is small. The reason is that all algorithms are tested under exactly the same conditions. The initialized values of the parameters are the same. Figure 2 shows the approximation errors of ACD and PCD. There are similar experiment results about PCD and ACD. The results show that ACD has smaller approximation errors than PCD.
Figure 1.
The approximation errors of average contrastive divergence (ACD) and CD.
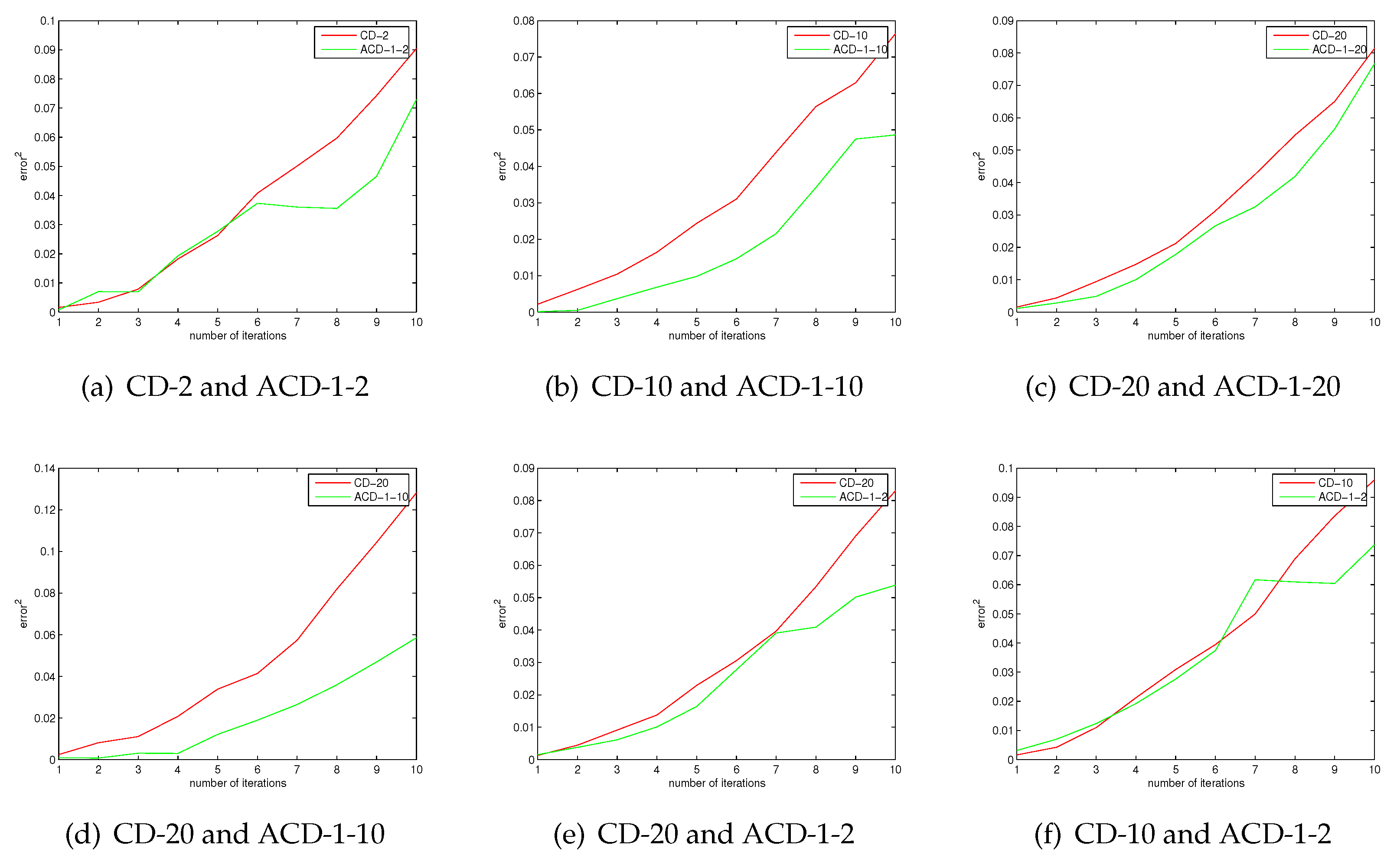
Figure 2.
The approximation errors of ACD and persistent contrastive divergence (PCD).
4.2. The MNIST Task
The dataset is the MNIST dataset of handwritten digital images [20]. The images are 28 by 28 pixels, and the dataset consists of 60,000 training cases and 10,000 test cases. We use the mini-batch strategy for learning by only using a small number of training cases for each gradient estimate. We used 100 training points in each mini-batch for most datasets. Following [14,18,21,22], we set the number of hidden units to 500 in our experiments. One of the evaluations is how well the learned RBM models the test data, i.e., log-likelihood. This is intractable for a regular size of RBMs, because the time complexity of that computation is exponential in the size of the smallest layer (visible and hidden). Salakhutdinov and Murray [23] showed that a Monte Carlo-based method, annealed importance sampling (AIS), can be used to efficiently estimate the normalization constant Z of RBMs [16,23,24,25,26]. We adopt AIS in our experiment, as well.
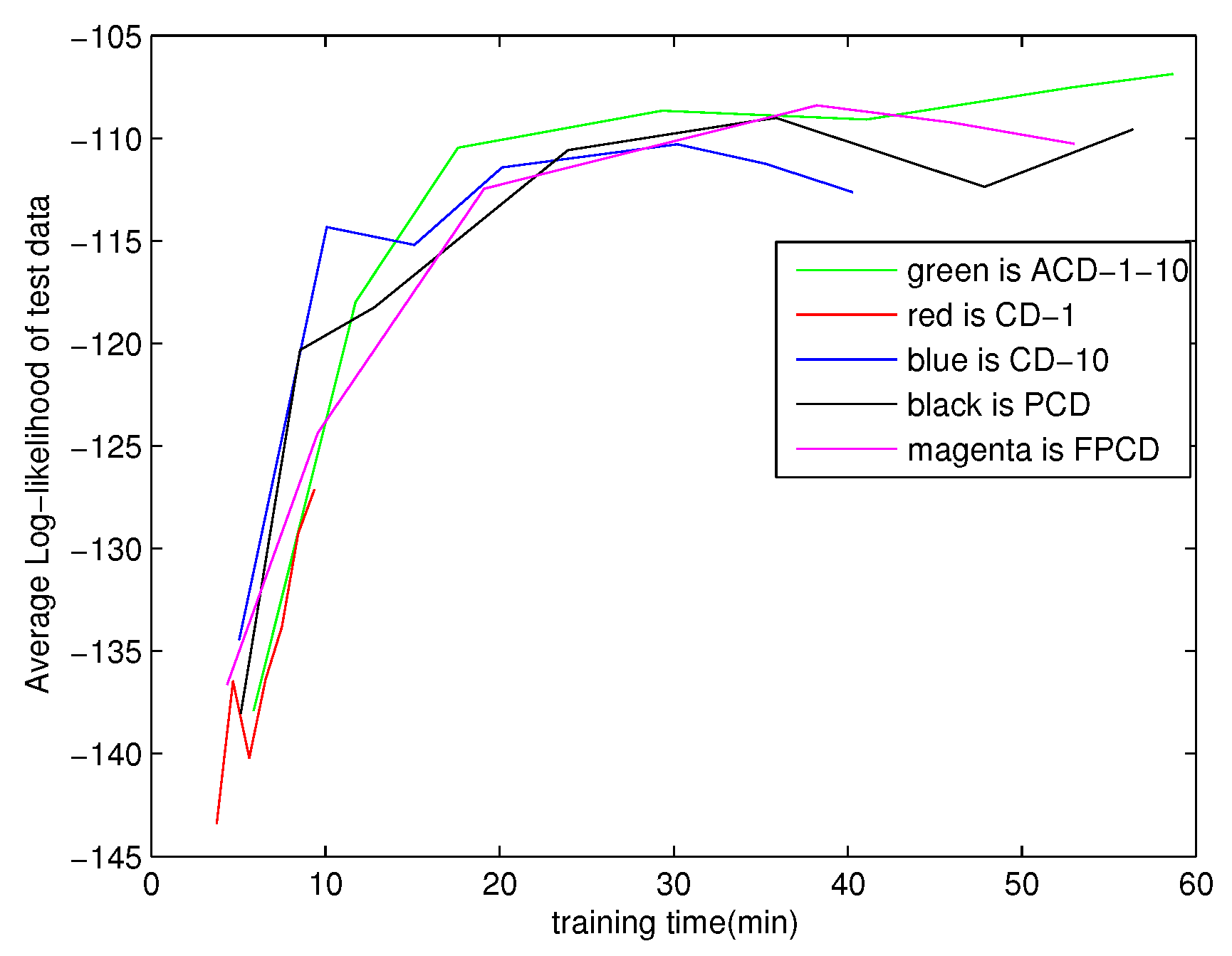
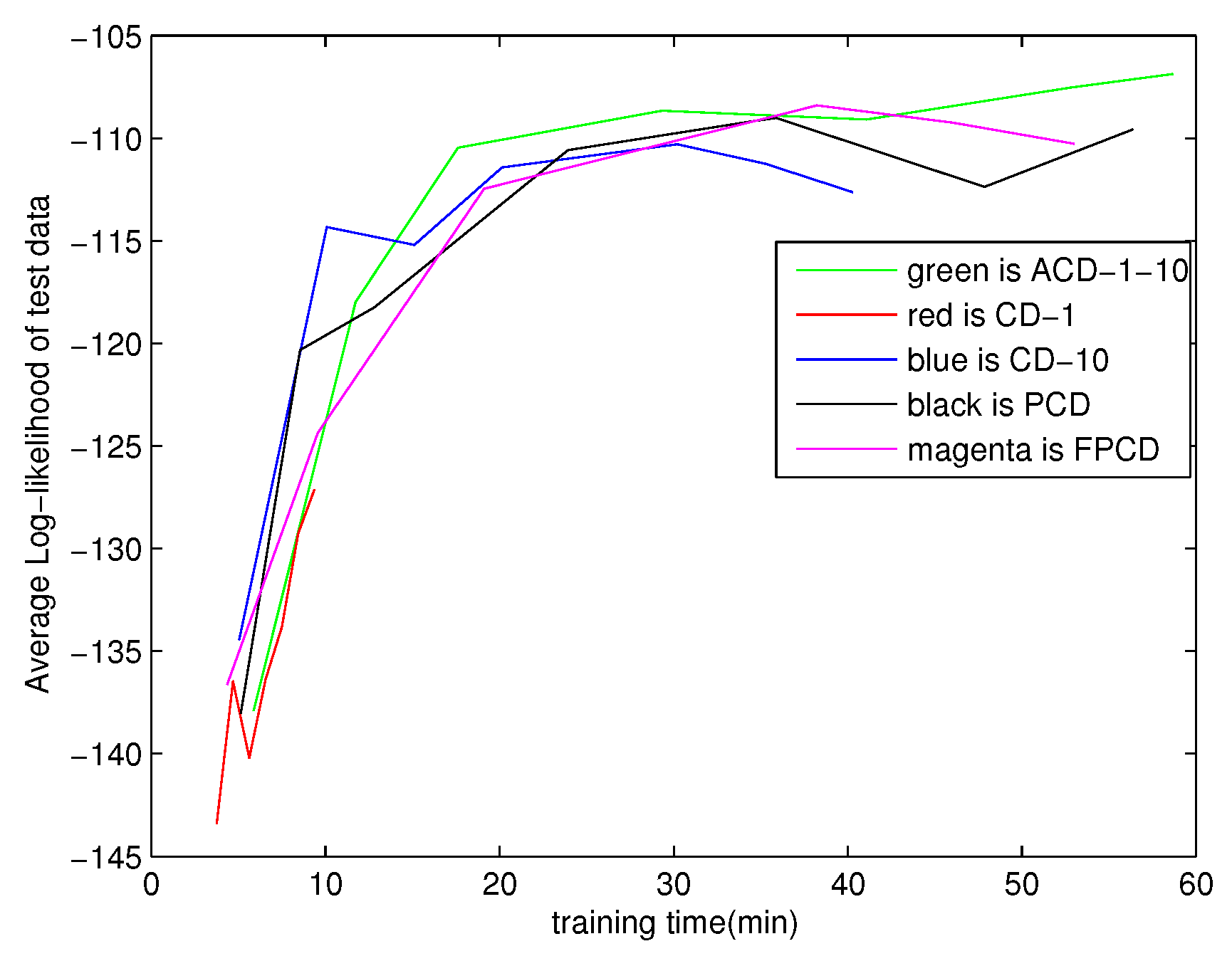
The CD algorithm and the PCD algorithm have become two popular methods for training RBMs. Tieliman and Hinton proposed an improved PCD algorithm called fast PCD (FPCD) [15]. The FPCD algorithm attempts to improve upon PCD’s mixing properties by introducing a group of additional parameters called fast parameters that are only used for sampling. FPCD tries to get out of any single mode of the distribution by these fast learning parameters and achieves better results in approximating the RBMs’ gradient. We consider the CD-1 algorithm, the CD-10 algorithm, the PCD algorithm, the FPCD algorithm and the ACD-1-10 algorithm for the MNIST task. The results on the MNIST task are shown in Figure 3. Figure 3 gives the average log-likelihood on the test dataset. The lower the average log-likelihood on the test dataset is, the more the contribution of the approximation of the gradient is. It is clear that ACD-1-10 outperforms CD-1, CD-10, PCD and FPCD. In the initial stages of training, the result of ACD-1-10 is close to the other algorithms. ACD-1-10 has better performance than the other algorithms with the increase of training time.
Figure 3.
Modeling MNIST data with 500 hidden units (approximation log-likelihood).
5. Conclusions
In this paper, we studied the CD algorithm and proposed a new algorithm for training RBMs. We have given the bias between the CD algorithm and the log-likelihood gradient method. We generalized the conclusions of Bengio and Delalleau; we can obtain their conclusions from our theorems; hence, we gave new proofs and interpretations of their results. Meanwhile, we proposed the ACD algorithm for training RBMs. We gave the bias between the ACD algorithm and the log-likelihood gradient. We experimentally studied the ACD algorithm; the results show that the ACD algorithm is a better approximation of the log-likelihood gradient method than the standard CD and PCD. The ACD algorithm outperforms the other learning algorithms.
Much work still remains. In order to evaluate the learned RBMs, we considered the log-likelihood. We used annealed importance sampling (AIS) to calculate the log-likelihood, but its reliability has not been researched extensively. An effective algorithm is needed. Furthermore, the amount of training time used in our experiments is insufficient to find the asymptotic performance. In Figure 3, one can see, for example, that ACD clearly profits from more training time. It is future work to find out what its performance would be with more training time.
Acknowledgments
The work is supported by the National Science Foundation of China (Nos. 61273365, 11407776) and the National High Technology Research and Development Program of China (No. 2012AA011103).
Author Contributions
Xuesi Ma proposed the idea of the paper and performed the experiments, wrote the paper. Xiaojie Wang gave the suggestions and revised the paper. Both authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hinton, G.E. Training products of experts by minimizing Contrastive Divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E. Learning multiple layers of representation. Trends Cognit. Sci. 2007, 11, 428–434. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Feng, F.; Li, R.; Wang, X. Deep correspondence restricted Boltzmann machine for cross-modalretrieval. Neurocomputing 2015, 154, 50–60. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layewise training of deep networks. In Advances in Neural Information Processing (NIPS19); Schoőlkopf, B., Platt, J., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2007; pp. 153–160. [Google Scholar]
- Bengio, Y.; Delalleau, O. Justifying and generalizing contrastive divergence. Neural Comput. 2009, 21, 1601–1621. [Google Scholar] [CrossRef] [PubMed]
- Fischer, A.; Igel, C. An Introduction to Restricted Boltzmann Machines; CIARP2012; Springer: Berlin, Germany, 2012; pp. 14–36. [Google Scholar]
- Akaho, S.; Takabatake, K. Information Geometry of Contrastive Divergence; ITSL2008; CSREA Press: Las Vegas, NV, USA, 2008; pp. 3–9. [Google Scholar]
- Sutskever, I.; Tieleman, T. On the convergence properties of Contrastive Divergence. J. Mach. Learn. Res. Proc. Track 2010, 9, 789–795. [Google Scholar]
- Yuille, A. The convergence of contrastive divergence. In Advances in Neural Processing Systems, NIPS17; Saul, L., Weiss, Y., Bottou, L., Eds.; MIT Press: Cambridge, MA, USA, 2005; pp. 1593–1600. [Google Scholar]
- Carreira-Perpinán, M.Á.; Hinton, G.E. On contrastive divergence learning. In Proceedings of the 10th International Workshop on Artificial Intelligence and Statistics (AISTATS), The Society for Artificial Intelligence and Statistics, The Savannah Hotel, Barbados, 6–8 January 2005; pp. 59–66.
- Ma, X.; Wang, X. Convergence analysis of contrastive divergence algorithm based on gradient method with errors. Math. Probl. Eng. 2015, 2015, 350102. [Google Scholar] [CrossRef]
- Fischer, A.; Igel, C. Bounding the bias of contrastive divergence learning. Neural Comput. 2011, 23, 664–673. [Google Scholar] [CrossRef] [PubMed]
- Tieleman, T. Training restricted Boltzmann machines using approximations to the likelihood gradient. In Proceedings of the International Conference on Machine learning (ICML), Helsinki, Finland, 5–9 July 2008; Cohen, W.W., McCallum, A., Roweis, S.T., Eds.; ACM: New York, NY, USA, 2008; pp. 1064–1071. [Google Scholar]
- Tieleman, T.; Hinton, G.E. Using fast weights to improve persistent contrastive divergence. In Proceedings of the International Conference on Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009; Pohoreckyj Danyluk, A., Bottou, L., Littman, M.L., Eds.; ACM: New York, NY, USA, 2009; pp. 1033–1040. [Google Scholar]
- Cho, K.; Raiko, T.; Ilin, A. Parallel tempering is efficient for learning restricted Boltzmann machines. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; IEEE Press: âĂŐPiscataway, NJ, USA, 2010; pp. 3246–3253. [Google Scholar]
- Cho, K.; Raiko, T.; Ilin, A. Enhanced Gradient for Training Restricted Boltzmann Machines. Neural Comput. 2013, 25, 805–831. [Google Scholar] [CrossRef] [PubMed]
- Desjardins, U.; Courville, A.; Bengio, Y.; Vincent, P.; Delalleau, O. Tempered Markov Chain Monte Carlo for Training of Restricted Boltzmann Machines; AISTATS: Sardinia, Italy, 2010; pp. 145–152. [Google Scholar]
- Younes, L. Parametric inference for imperfectly observed gibbsian fields. Probab.Theory Relat. Fields 1989, 82, 625–645. [Google Scholar] [CrossRef]
- LeCun, Y.; Cortes, C.; Burges, C. The MNIST database of handwritten digits. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 2 November 2013).
- Xu, J.; Li, H.; Zhou, S. Improving mixing rate with tempered transition for learning restricted Boltzmann machines. Neurcomputing 2014, 139, 328–335. [Google Scholar] [CrossRef]
- Fischer, A.; Igel, C. Training restricted Boltzmann machines: An introduction. Pattern Recognit. 2014, 47, 25–39. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Murray, I. On the quantitative analysis of deep belief networks. In Proceedings of the International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 872–879.
- Salakhutdinov, R.; Larochelle, H. Efficient Learning of Deep Boltzmann Machines; AISTATS: Sardinia, Italy, 2010; pp. 693–670. [Google Scholar]
- Salakhutdinov, R. Learning Deep Boltzmann Machines Using Adaptive MCMC; ICML2010, Omnipress: Madison, WI, USA, 2010; pp. 943–950. [Google Scholar]
- Salakhutdinov, R.; Hinton, G.E. An efficient learning procedure for deep Boltzmann machines. Neural Comput. 2012, 24, 1967–2006. [Google Scholar] [CrossRef] [PubMed]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ma, X.; Wang, X. Average Contrastive Divergence for Training Restricted Boltzmann Machines. Entropy 2016, 18, 35. https://doi.org/10.3390/e18010035
AMA Style
Ma X, Wang X. Average Contrastive Divergence for Training Restricted Boltzmann Machines. Entropy. 2016; 18(1):35. https://doi.org/10.3390/e18010035
Chicago/Turabian StyleMa, Xuesi, and Xiaojie Wang. 2016. "Average Contrastive Divergence for Training Restricted Boltzmann Machines" Entropy 18, no. 1: 35. https://doi.org/10.3390/e18010035
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.