1. Introduction
The motivation for the constructions in this paper begins with a sample from a one dimensional space that is discrete. We allow for a continuous sample space but assume that this has been suitably discretized into n bins. The simplest underlying structure for the probability assigned to these bins is given by the multinomial distribution. The collection of all multinomial distributions can be identified with the n − 1 simplex Δn−1. We use the geometry of the simplex along with a transformation of its interior
to search for one dimensional subspaces that have good properties for modeling and for inference. In particular, we want families that can be parameterized by the mean, have only unimodal distributions, have desirable test characteristics (such as providing uniformly most powerful unbiased tests) and estimation properties (such as unbiasedness and small variability).
The boundary of the (
n − 1) dimensional simplex Δ
n−1 can be written as the union of simplexes of dimension (
n − 2). This process can be repeated on the simplexes of lower dimension until the boundary consists of the vertices of the original simplex. This construction has statistical relevance to the possible supports for the probability distributions considered on the
n bins. We obtain a dual decomposition for a transformation
Vn−1 (defined in
Equation (5) in Section 5) of
; it is dual in that the result can be obtained by replacing simplexes with cones. The statistical relevance of the conical decomposition is to the possible modes for all the distributions on the
n bins. Since
Vn−1 is the natural parameter space for the distributions in
, one dimensional exponential families are lines in
Vn−1 and these can be related to the cones that partition
Vn−1. One result is that the limiting distribution for any one dimensional exponential family in
is the uniform distribution whose support is determined by the cone that contains the limiting values of the line corresponding to the exponential family.
While one parameter exponential families can be defined quite generally by choosing a sufficient statistic, it can be useful to start with the sufficient statistics from well-known families such as the binomial, Poisson, negative binomial, normal, inverse Gaussian, and Gamma distribution. These exponential families have good modeling and inferential properties that we try to maintain by limiting the extent to which the sufficient statistic is modified. These restrictions lead to considering vectors in Vn−1 that lie in a cone. Examples of how to construct these cones are given.
2. Motivating Examples
One dimensional exponential families such as the binomial or Poisson are the workhorse of parametric inference because of their excellent statistical properties. However, being one dimensional means they do not always fit data very well so an extension to a two (or higher) dimensional exponential family can be pursued in order to preserve the nice inferential structure. An issue with such extension is that, for each extra natural parameter added, we need to choose a new sufficient statistic and this choice can substantially change the shape of the corresponding density functions. For example densities can pass from being unimodal to have multiple modes for some parameter values. To see this, consider the following examples.
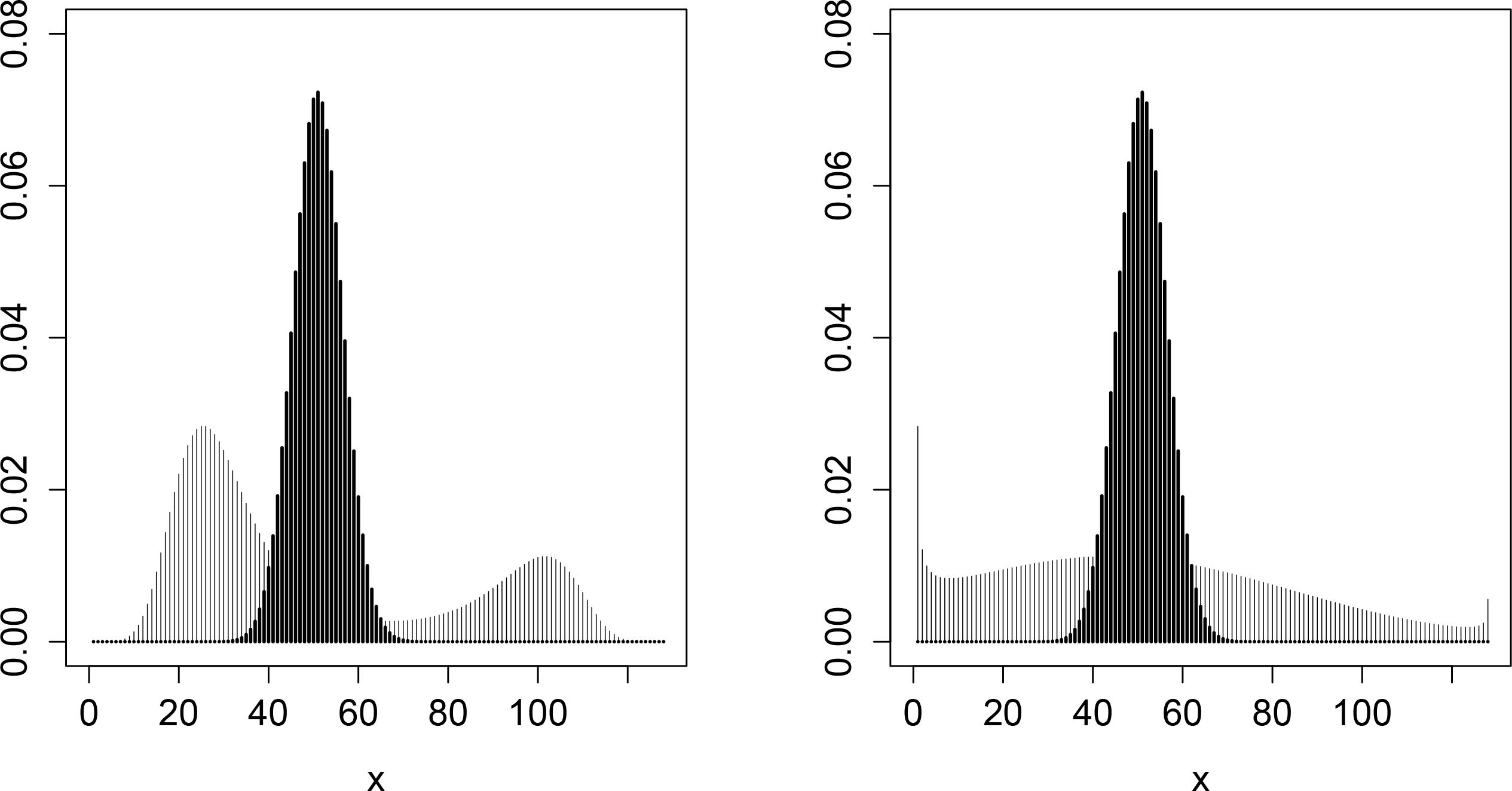
Example 1. Altham [1] considered the so-called multiplicative generalization of the binomial distribution with corresponding densitywhere C is the normalizing constant and where clearly the binomial is recovered when ϕ = 1.
By reparametrizing using θ1 = log(
p/(1 −
p))
and θ2 = log(
ϕ)
this density can be expressed in exponential form aswhere T (
x) =
x(
x −
n)
is the added sufficient statistic and where dependence on n has been ignored. Note that the same family is obtained if T (
x) =
x2 is added as a sufficient statistic instead of x(
x −
n)
. If n = 127
and (
θ1,
θ2) = (−0.0122, 0.018)
then density (2) is bimodal as shown in the left panel of Figure 1. The mean μ of this distribution is 50
. Also plotted is the corresponding binomial density with the same mean or equivalently with θ1 = log(50/(127 − 50)) = −0.4318
and θ2 = 0.
As explained by Lovison [2], this distribution has the feature of being under- or over-dispersed with respect to the binomial depending on θ2 being negative or positive, respectively. Furthermore, using the mixed parametrization (
μ,
θ2)
(see [3] for details) it is easy to see that this distribution can be parametrized so that one parameter controls dispersion independently of the mean. In fact, for a fixed mean μ, as θ2 → −∞
f(
x;
θ1,
θ2)
tends to a two point distribution (with support points at the extremes x = 0
and x =
n) or to a degenerate distribution on x =
μ when θ2 → ∞
. Example 2. Double exponential families [4] are two parameter exponential families that extend standard unidimensional exponential families such as the binomial and the Poisson. Similar to the multiplicative binomial in Example 1, the extra parameter involved in double exponential families controls the variance independently of the mean. The density for the so-called double binomial family can be written in the form (2) with and with the particular restriction that θ2 < 1
(see [4] for details). The range θ2 < 0
generates underdispersion and θ2 ∈ [0, 1)
generates overdispersion with respect to the binomial. As shown on the right panel of Figure 1, the double binomial density can also be multimodal where the double binomial density shown has the same mean and variance as the multiplicative binomial shown in the left panel.
These examples show that while extending exponential families can lead to useful modeling properties such as overdispersion, the extension can also result in distributions that are not suitable for modeling. We are interested in the relationship between geometric properties of one dimensional families and the modeling properties of their distributions.
3. Sample Space and Distribution-valued Random Variables
We consider first the general case where the sample space for a single observation
X1 consists of
n bins
We consider the space of all probability distributions
on this sample space
Sn. Each probability distribution in
is defined by the
n-tuple
p whose
ith component is
so that
can be identified with the
n − 1 simplex
where 1 in 1′
p is the vector 1 ∈ ℝ
n each of whose components is 1. We will slightly abuse the notation by using
p to name a point in Δ
n−1, and hence in ℝ
n, as well as the corresponding distribution in
.
The sample space for a random sample of size
N from a distribution
p0 ∈ Δ
n−1 is
There is simple relationship between
and the simplex that we obtain by dividing each component of
x by
N. Although the sample space
can be viewed as formed by compositional data, we will follow a different approach to handle this kind of data compared with the classical approach described by Aitchison [
5] because the data we consider have additional structure.
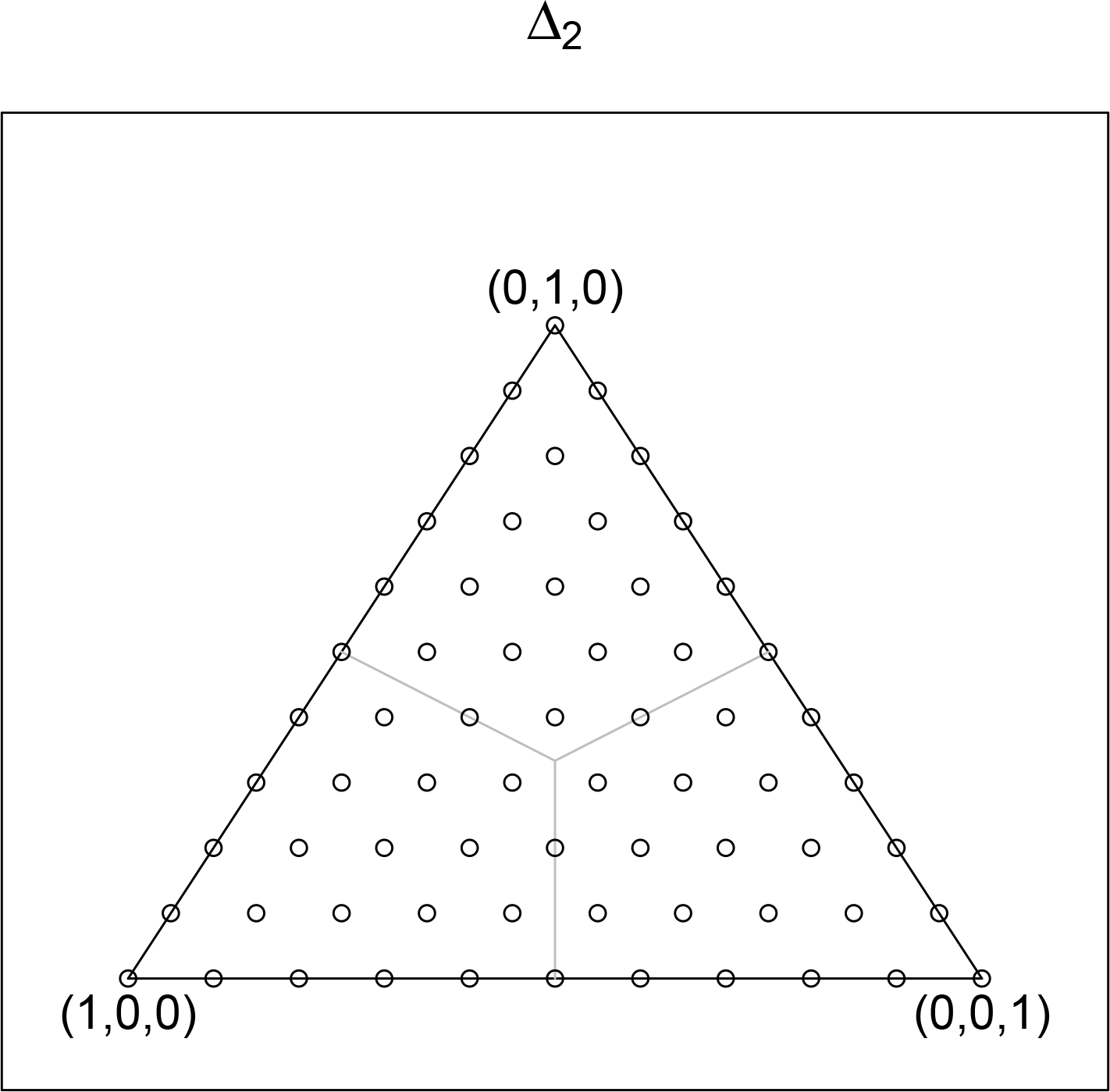
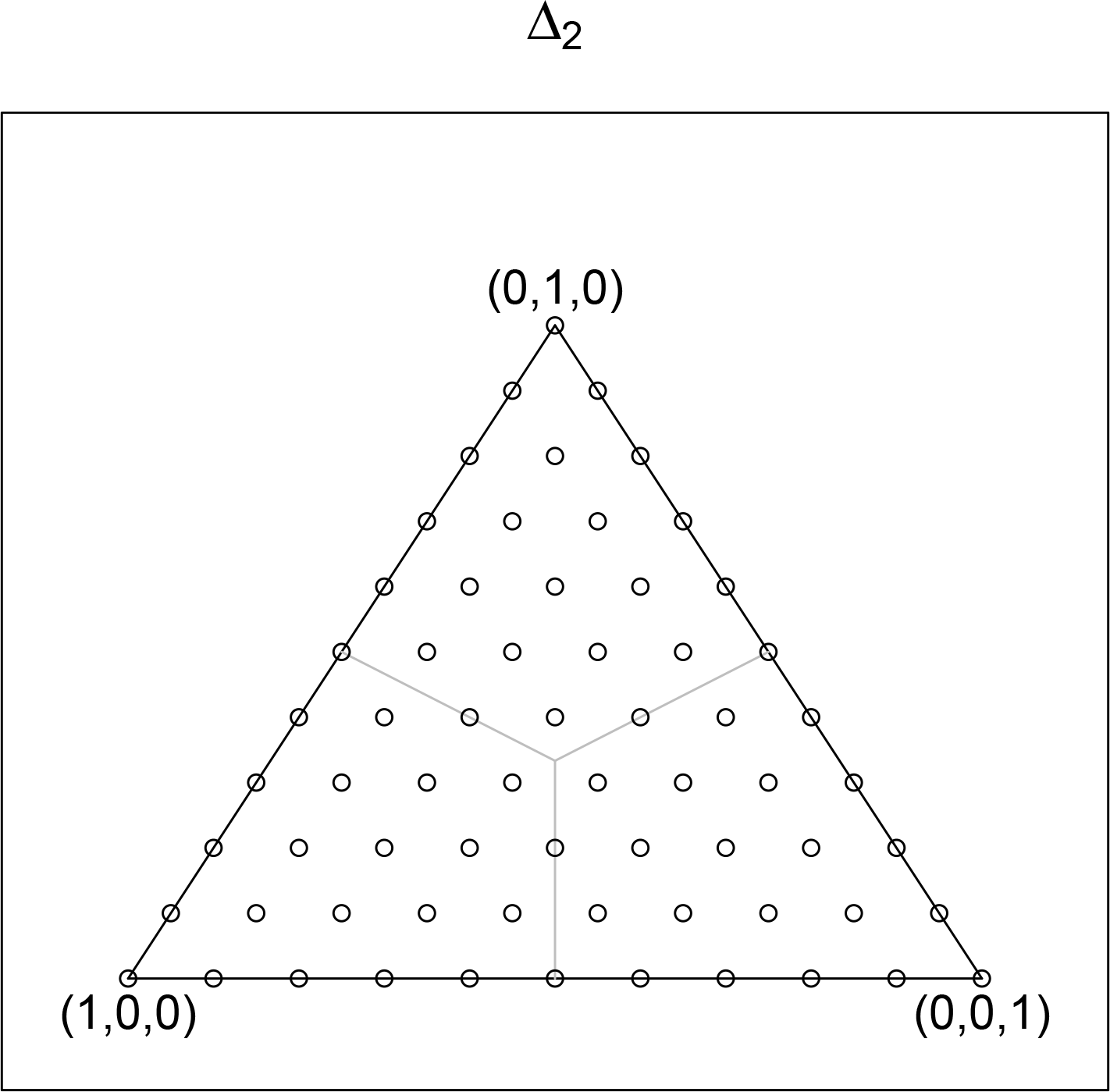
In
Figure 2 the sample space for the sample of size
N = 10 is displayed using open circles. The vertices correspond to the case where all 10 values fall in a single bin. The other points correspond to the less extreme cases. Let
p0 be any point in Δ
n−1. By mapping the multinomial random variable of counts
X to Δ
n−1, we obtain the random distribution
P̂ =
X/N whose values are multinomial distributions each having number of cases
N and probability vector
X/N. Identifying
-valued random variables with distribution-valued random variables provides a natural means for comparing data with probability models using the Kullback–Leibler (KL) divergence.
We can compare distributions in Δ
n−1 using the KL divergence
D :
× ↦ ℝ
where
H(
p1,
p2) = − ∑
p1 log(
p2) and
H(
p1) =
H(
p1,
p1) is the entropy of
p1. Note that the arguments to
D and
H are distributions while the logarithm and ratios are defined on points in ℝ
n. Following Wu and Vos [
6], the variance of the random distribution
P̂ is defined to be
and its mean is defined to be
Note that the expectation on the right hand side of the equations above are for real-valued random variables while the expectation on the left hand side of the second equation is for a distribution-valued random variable.
It is not difficult to show that
Ep0 P̂ =
p0 so that
P̂ can be considered an unbiased estimator for
p0. Details are in [
6], which also shows that the KL risk can be decomposed into bias-squared and variance terms:
The distributional variance is related to the entropy
Note that for
N = 1,
H(
P̂) = 0 so that for a single observation the random distribution
P̂ taking values on the vertices of Δ
n−1 has variance equal to the entropy of
p0.
For inference, p0 is unknown but we specify a subspace M ⊂ Δn−1 that contains p0, or at least has distributions that are not too different from p0. Estimates can be obtained by choosing a parameterization for M, say θ, and then considering real-valued functions θ̂ and evaluating these in terms of bias and variance. Bias and variance are useful descriptions when θ describes a feature of the distribution that is of inherent interest. However, if θ is simply a parameterization, or if there are other features that are also of interest, then these quantities are less useful. For inference regarding the distribution p0 we can use a distribution-valued estimator P̂M where the subscript indicates that the estimator is defined to account for the fact that p0 ∈ M.
We will not pursue the details of distribution-valued estimators here; we mention these only because all the subspaces we consider will be exponential families and in this case the maximum likelihood estimator has important properties in terms of distribution variance and distribution bias: when
M is an exponential family, the maximum likelihood estimator is distribution unbiased, and it uniquely minimizes the distribution variance among the class of all distribution unbiased estimators. Furthermore, when
p0 ∉
M then the maximum likelihood estimator is the unique unbiased minimum distribution variance estimator of the distribution in
M that is closest (in terms of KL) to
p0. Extensions of one dimensional exponential families that do not result in exponential families will not enjoy these properties of maximum likelihood estimation. Details of these results that hold for sample spaces more general than
Sn are in [
7].
4. Simplices Δs
One dimensional exponential families on Sn are curves in Δn−1 whose properties will depend on their location within various subspaces of Δn−1. An important collection of subspaces will be indexed by the subsets of Sn. For notational convenience we take Bi to the integer i. Using integers is suggestive of an ordering and a scale structure but at this point these are only being used to indicate distinct bins.
For each
s ⊂
Sn,
where
sc = {
i ∈
Sn :
i ∉
s}. Note that Δ
Sn = Δ
n−1. The interior of Δ
s is
As probability distributions in
,
corresponds to the set of all distributions having support
s. There is a simple and obvious relationship between the dimension of Δ
s, |Δ
s|, and the cardinality of
s, |
s|, which holds for all nonempty
s ⊂
SnThe boundary of Δ
s is defined as
so that
where ⊎ indicates the sets in the union are disjoint. The boundary
∂Δ
s can be written as the union of all simplices of dimension one less than that Δ
sThis boundary property for Δ
s holds because the simplex
n consists of all possible subsets. Each nonempty
s ∈
n specifies one of the possible supports for distribution
P ∈
nwhere we set Δ
∅ = ∅.
5. Cones Λs
The set of all nonempty subsets of the sample space provides a partition of Δ
n−1 based on the support of the distributions in
. The elements in the partition are simplices whose dimension is one less than the cardinality of the indexing set. In most cases we will consider models having support
Sn, that is, models corresponding to
. If we use subsets
s to define the mode rather than support, we obtain a partition of
°, the distributions in
having support
Sn. This partition can be expressed using convex cones in an
n − 1 dimensional plane V
n−1. The dimension of the cones are
n minus the cardinality of the indexing set and the relationship between interiors of cones and their boundaries is analogous to that for simplices expressed in
Equations (3) and
(4).
Let
be the subspace of ℝ
n of dimension
n−1 of all vectors that sum to zero. For each nonempty
s ∈
Sn define
It is easily checked that Λ
s is a convex cone
The dimension of Λ
s is |Λ
s| =
n −|
s| since each point in
j ∈
sc provides a basis vector
bj whose
ith component is 1 if
i ∈
s or
i =
j and is zero otherwise and |
sc| =
n −|
s|. The interior of Λ
s is
the boundary is
so that
by definition. Note
where the first equality holds because the conditions in the definition of
hold vacuously since
adds no restriction. Likewise, we can extend the definition of Λ
s to include
s = ∅ and since
i ∈ ∅ adds no restriction
Note that Λ
∅ depends on the cardinality of the set
Sn. Since we are considering
n fixed, we will not show this dependence in the notation.
Corresponding to
Equation (3) we have for all nonempty
s that the boundary of the cone Λ
s is the union of all cones having dimension one less than the dimension of Λ
sCorresponding to
Equation (4) we have
The relationship between the simplices Δ and cones Λ is more easily seen if we suppress the sets that index these objects. Let Δ and Δ
* be any two simplices and let Λ and Λ
* be any two convex cones. We only consider cones and simplices that correspond to a nonempty subset of
Sn. Then the
Equations (6) and
(7) for the convex cones are obtained by simply replacing Δ in
Equations (3) and
(4) with Λ:
Equation (9) also holds for the empty set since Δ
∅ = ∅ and Λ
∅ = V
n−1.
6. Vn−1 and °
There is a natural bijection
ϕ between V
n−1 and
defined by
where log(
p) is the vector with
ith component log(
pi) and
m(
p) is defined so that 1
ϕ(
p) = 0. The inverse is
where exp(
v) is the vector with
ith component exp(
vi) and
k(
v) is defined so that 1′ exp(
v) = 1.
Each cone
in the partition
corresponds to one of the 2
n − 1 possible modes for any distribution having support
Sn since
vi >
vj if and only if
φi(
v) >
φj(
v).
7. Vn−1 and Exponential Families in °
We define a line by a pair of vectors
v0,
v1 ∈ V
n−1 with
v1 ≠ 0
Note that
v0 and
v1 are not unique. Applying the inverse transformation
φ to points in
ℓ gives probability densities
which have the exponential family form with
t playing the role of the natural parameter. Therefore, the space V
n−1 is easily recognized as the natural parameter space for the distributions
so that each line
ℓ in V
n−1 corresponds to a one dimensional exponential family.
For each line ℓ(t) there is a value tmax such that {(t): t ≥ tmax} is contained in one of the cones
where s is the subset of Sn with the property that
for all i ∈ s for vectors
. For each line ℓ(t) there is a value tmin such that {(t): t ≤ tmin} is contained in one of the cones
where s′ is the subset of Sn with the property that
for all i ∈ s′ for vectors
. The cones
and
are disjoint and will be called the extremal cones for ℓ. There is at least one other cone
such that
.
Any one dimensional exponential family
ℓ(
t) can be described by an ordered sequence of disjoint cones
where
k =
k(
ℓ) will depend on the family. These are simply the cones that are traversed by
ℓ(
t) between its extremal cones. We take
to be the cone that contains
ℓ(
t) for all sufficiently large
t.
Equation (6) for cones means that
The ordered sequence of cones provides an ordered sequence of unique subsets of
Snthat we call the
modal profile for
ℓ as these are the modes realized by the exponential family
ℓ(
t) between its extremal cones that have modes
s1 and
sk.
Each point on a line ℓ(t) in Vn−1 corresponds to a distribution having support Sn. As t goes to −∞ (+∞) φ((t)) goes to a distribution having support s1 (sk). In fact, these are the uniform distribution on these supports. For every s ⊂ Sn other than ∅ and Sn, the uniform distribution on s is a limiting distribution for some one dimensional exponential family in °.
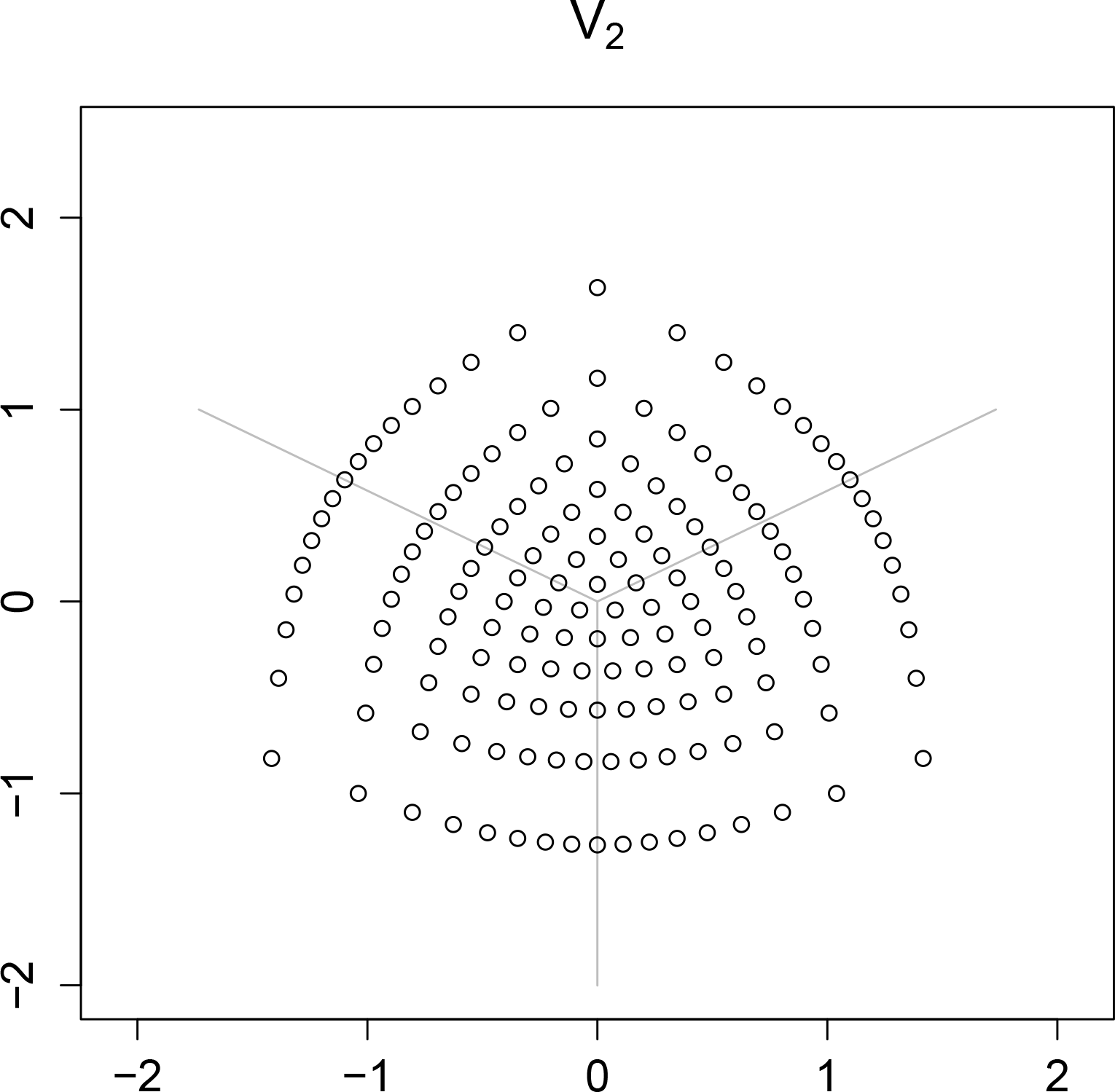
Figure 3 shows
Vn−1 for the two dimensional simplex shown in
Figure 2. The three rays are the one dimensional cones and the spaces between these cones are the two dimensional cones. The origin is the zero dimensional cone. The sample values on the boundary of Δ
2 are not in
V2. Note that the one dimensional cones are line segments in Δ
2.
8. Ordered Bins and the Monotone Likelihood Ratio Property
Let the bins be ordered and assign the first
n integers to the bins to reflect this ordering. We seek to define exponential families that have a modal profile of the form
or a contiguous sub-collection of this profile. Extensions to three or more contiguous modes are clearly possible but not discussed here.
From the definition of modal profile, it follows that a family with modal profile
(11) will have the property that the mode is a non-decreasing function of
t. In addition to this property for the mode, we want the likelihood ratio for any two members of the family to provide the same ordering structure as that of the bins. A family that satisfies this condition is said to have the monotone likelihood ratio property with respect to
x where
x takes the values of the bin labels: 1, 2,...,
n. Let
pθ1 and
pθ2 be two distributions in a one dimensional family parameterized by
θ and let
pθ2/pθ1 be the
n-vector with components
for 1 ≤
j ≤
n. This family has monotone likelihood ratio if for all
θ1 <
θ2 and
j <
j′A family with this property avoids the problem situation where in general the data in the higher numbered bins are evidence for
pθ2 but in going from a particular bin, say
j0 to
j0 +1, the likelihood ratio actually decreases. Exponential families such as the binomial and Poisson have this monotone likelihood ratio property for the bin labels. The monotone likelihood ratio property can be extended to allow for likelihood ratios that are monotone in some function of
x. An important advantage of families with the monotone likelihood ratio property is the existence of uniformly most powerful tests.
To ensure that our exponential families have the monotone likelihood ratio property we consider vectors in the cone Λ
↑ ⊂ Λ
nFrom
Equation (10), the exponential family indexed by
θ is
k(
θ) exp(
v0 +
θv1)
so that the likelihood ratio is monotone in
j if
v1 ∈ Λ
↑.
9. Selecting Vectors in Λ↑
In order to choose
n-dimensional vectors
v ∈ Λ
↑ we will consider a set of infinite dimensional vectors
f. Let
f̄ : ℝ ↦ ℝ and consider
f =
f̄|
ℤ where ℤ is the set of integers. The function
f is represented by a doubly infinite sequence
and we denote the set of all such functions as
While it is not necessary to consider functions
f̄ to define
f, these functions are useful to describe properties of
f, which can be thought of as a discretized version of
f̄.
Define the gradient of
f as the function ∇ whose
jth component is
The simplest functions in
are the constant functions
The next simplest functions are those whose gradient is constant. We call these first order functions and denote the set of these as
Functions in
1 are such that changes from one bin to the next bin is the same for all bins. That is, these functions describe constant change. We can write the functions in
1 explicitly as
which shows that each
f ∈
1 is the discretized version of a function
f̄ whose graph is a line in ℝ × ℝ. We obtain a vector
v from
f by defining the
jth component of
v as
. From this definition we see that the intercept
b of
f does not affect
v and that the slope is a scaling factor so that the restriction to first order functions results in a single direction in Λ
↑. This direction defines the one dimensional cone defined by the vector with
vj =
j − (
n +1)/2.
Additional directions can be obtained from the second order functions
If
f ∈
2 then (∇
2f)
j =
a for some
a ∈ ℝ and for all
j ∈ ℤ. Using the fact that
the second order functions can be written explicitly as
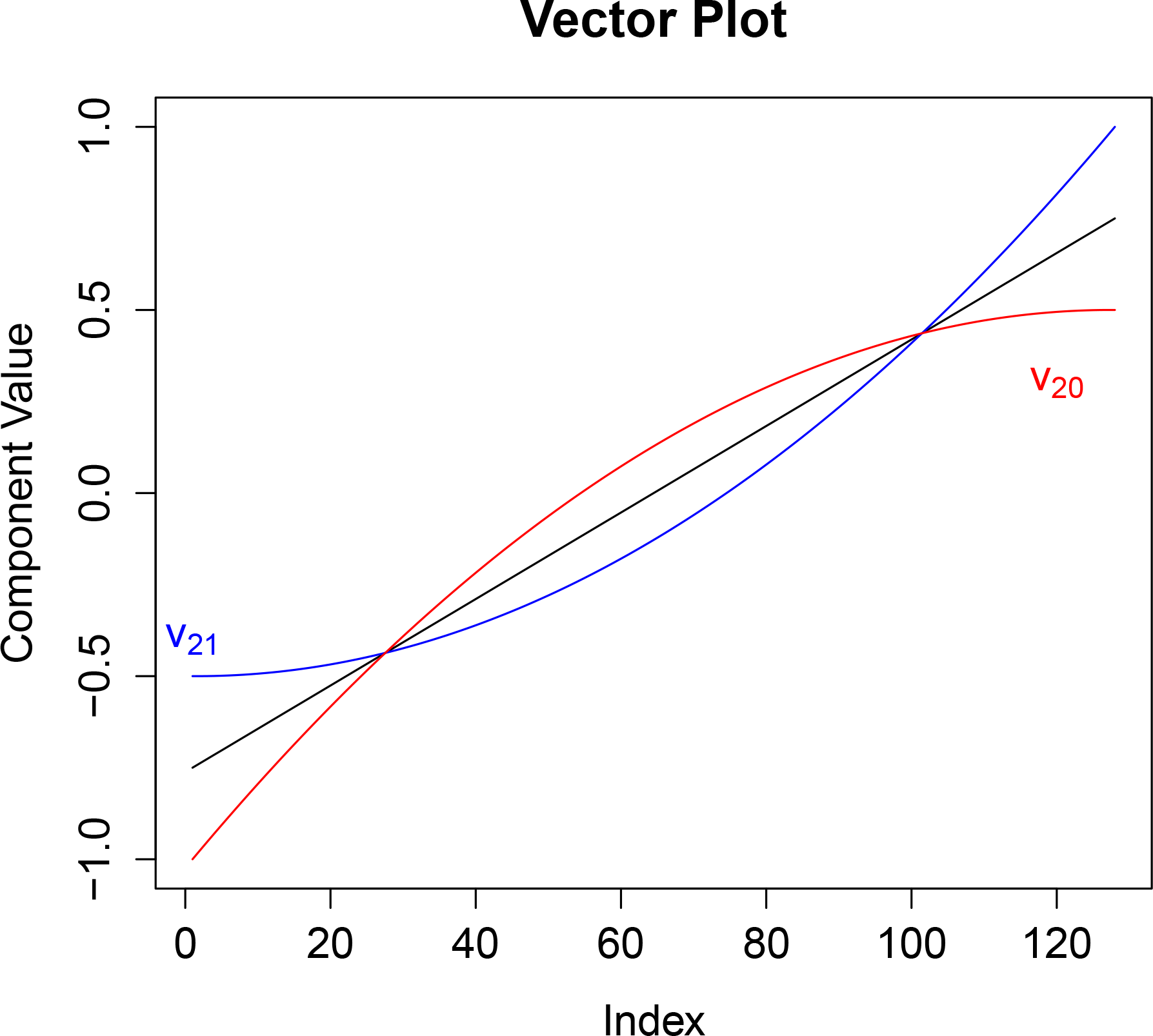
In order for the vector v obtained from f ∈ 2 to be in Λ↑ we need (∇f)j ≥ 0 for j = 1, 2,...,n. With fj = (a/2)j(j + 1) + bj + c we have (∇f)j = aj + b so that for a > 0 we require b ≥ −a and for a < 0 we require b ≥−an. Since we are concerned with the direction rather than the magnitude we can take a = ±1 and the value of c is chosen so the sum of the components is zero.
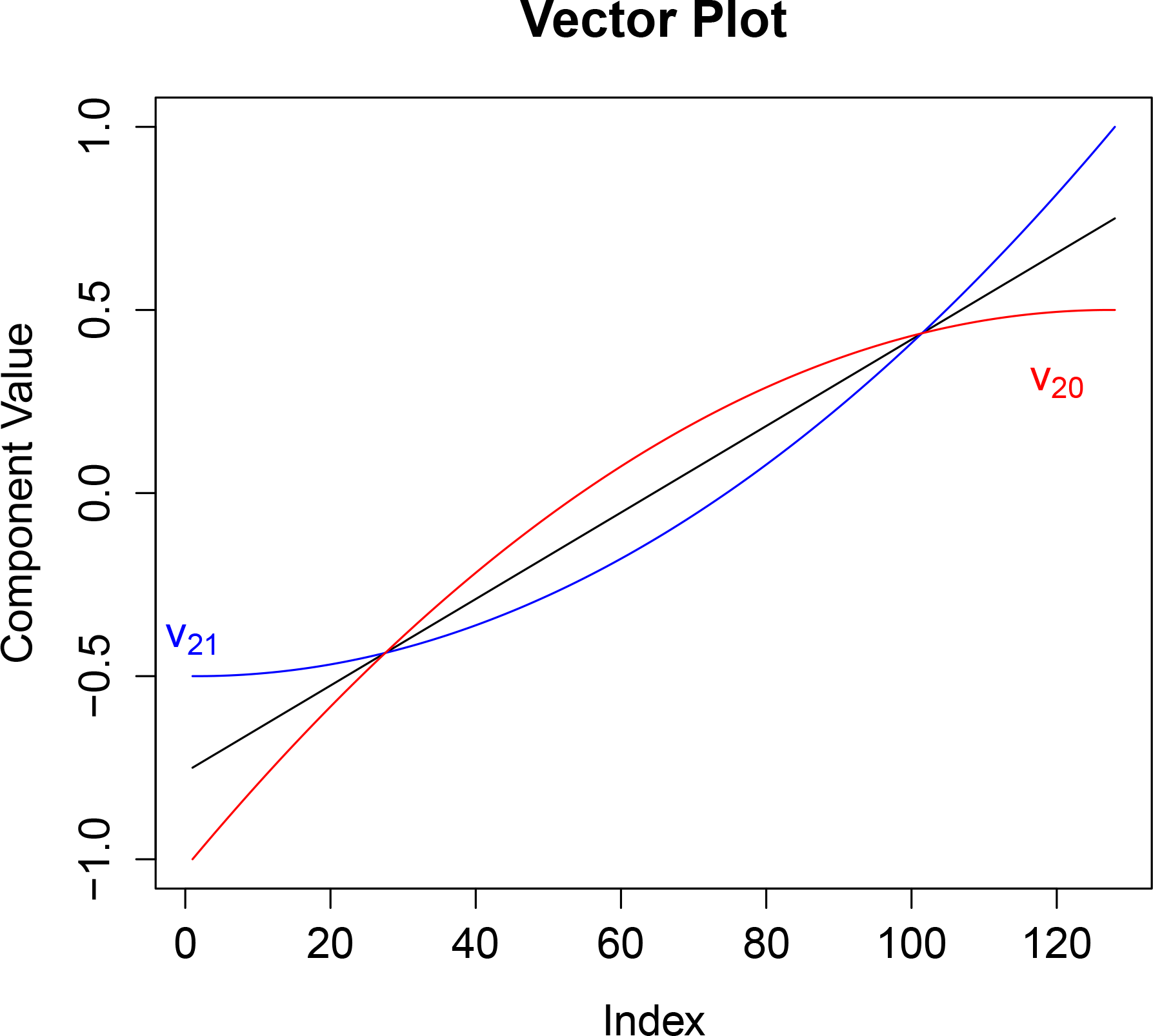
The second order vectors in Λ
↑ consists of the cone defined by the vectors
v20 and
v21 having components defined by
Notice that this cone contains
v1 since
v1 is proportional to
v20 +
v21. Many discrete one dimensional exponential families (e.g., binomial, negative binomial, and Poisson) use the vector
v1. Furthermore, many continuous one dimensional exponential families use the continuous function
f used to define
v1: normal with
σ known, and the gamma and inverse Gaussian distributions with known shape parameter (the shape parameter is the non-scale parameter). The cone defined by
v20 and
v21 allows us to perturb the
v1 direction to obtain related exponential families that we would expect to have similar properties.
Figure 4 shows
v20 and
v21 as well as
v1 = 0.5
v20 + 0.5
v21.
Other vectors can be used to define cones around v1. Looking at common exponential families we see that log(x) and x−1 are sufficient statistics so that these suggest taking f̄(x) = log(x) or f̄ (x) =1/x. These can be further generalized to f̄ (x; λ), which can be the power family or some other family of transformations. The vectors vf0 and vf1 are defined using the discretized f with the constraints that vf0, vf1 ∈ Λ↑ and 0.5vf0 + 0.5vf1 = v1.
An exponential family with sufficient statistic x can be modified by choosing a function f̄ (x) and 0 ≤ α ≤ 1 where α = 0.5 corresponds to the original exponential family and other values perturb this direction. We denote this vector as vfα so that v0 + tvfα is the natural parameter of the modified family.
Figure 4 shows the components of the vectors
v20 and
v21.
Since
v0 is common to each exponential family with natural parameter
ℓ(
t) =
v0 +
tvfα, the monotone likelihood ratio property will hold even if
v0 ∉ Λ
↑. Initial choices for
v0 are suggested by the Poisson, binomial, and negative binomial distributions:
where
c is a constant chosen so that the components sum to 1,
n is the number of bins, and
r is a positive real constant.

{kind=link}
{kind=link}
{kind=link}
{kind=link}