Filter-Type Variable Selection Based on Information Measures for Regression Tasks

Abstract
:
1. Introduction
2. Variable Selection for Single and Multi-Output Continuous Variables
2.1. Variable Selection Criterion for Regression
2.2. Estimation of the Conditional Mutual Information for Continuous Regression Variables
2.2.1. Single-Output Regression
2.2.2. Multi-Output Regression
2.2.3. Optimization Strategy
2.2.4. Summary of the Methodology and Algorithmic Structure
- (1)
- Kernel width estimation. Obtain, for each and tuples, the pair of parameters that maximize [Equation (16)].
- (2)
- Kernel density estimation. Obtain the Nadaraya-Watson type Kernel Density estimators and applying Equation (10)
- (3)
- Assessment of the posterior probabilities. Estimate using Equation (14)
- (4)
- Estimation of the conditional entropies. Obtain, for each variable and every possible combination the conditional entropies using Equation (15).
- (5)
- Dissimilarity matrix construction. The distance for the multi-output relevant variable is assessed.
- (6)
- Clustering. Apply a hierarchical clustering strategy based on Ward’s linkage method to find clusters using . The number of clusters is determined by the number of variables to be selected.
- (7)
- Representative selection. For each cluster , select the variable so that: , that is, the variable with the highest mutual information with respect to .
3. Experimental Validation
3.1. Methods for Single-Output Datasets
- The Monteiro et al. method [25] based on a Particle Swarm Optimization (PSO) strategy [26] (Particle-Swarms Variable Selection, PS-FS). It is a wrapper-type method to perform variable selection using an adaptation of an evolutionary computation technique developed by Kennedy and Eberhart [26]. For further details, see [25].
- Forward Stepwise Regression (FSR). Consider a linear regression model. The significance of each variable is determined from its t-statistics with the null hypothesis that the correlation between Y and is 0. The significance of factors is ranked using the p-values (of the t-statistics) and with this order a series of reduced linear models is built.
- Elastic Net (EN). It is a sparsity-based regularization scheme that simultaneously does regression and variable selection. It proposes the use of a penalty which is a weighted sum of the norm and the square of the norm of the coefficient vector formed by the weights of each variable. For further details, see [27].
3.2. Methods for Multi-Output Datasets
3.3. Dataset Description
3.3.1. Single-Output Datasets
- CASI-THERM. It consists of the reflectance values of image pixels that were taken by the Compact Airborne Spectrographic Imager (CASI) sensor [30]. Corresponding thermal measurements for these pixels were also made. The training set is formed by 402 data points. The testing set is formed by 390 data points. The CASI sensor reflectance curves are formed by 144 bands between 370 and 1049 nm.
- CASI-AHS-CHLOR. It consists of the reflectance values of image pixels that were taken by the CASI and the Airborne Hyper-spectral Scanner (AHS) [30] sensors. Corresponding chlorophyll measurements for these pixels were also performed. The training set is formed by 2205 data points. The testing set is formed by 2139 data points. AHS images consist of 63 bands between 455 and 2492 nm. Therefore, the input dimensionality of this set is 207 (the sum of the bands corresponding to the CASI and AHS sensors).
- Bank32NH. It consists of 8192 cases, 4500 for training and 3692 for testing, with 32 continuous variables, corresponding to a simulation of how bank customers choose their banks. It can be found in the DELVE Data Repository [31].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ♯ Training samples | ♯ Test samples | ♯ Input variables |
|---|---|---|---|
| CASI-THERM | 402 | 390 | 144 |
| CASI-AHS-CHLOR | 2,205 | 2,139 | 207 |
| Bank32NH | 4,500 | 3,692 | 32 |
| Boston Housing | 506 | - | 13 |
3.3.2. Multi-Output Datasets
- Parkinson. The objective is to predict two Parkinson disease symptom scores (motor UPDRS and total UPDRS) for patients, based on 19 bio-medical variables, one of them being the label associated to the patient number.
- Tecator. The data consists of 215 near-infrared absorbance spectra of meat samples, recorded on a Tecator Infratec Food Analyzer. Each observation consists of a 100-channel absorbance spectrum in the wavelength range [850,1050] nm, and the content of water, fat and protein. The absorbance is equal to the of the transmittance measured by the spectrometer. The three (output) contents, measured in percentage, are determined by analytic chemistry.
| Dataset | ♯ Training samples | ♯ Test samples | ♯ Input variables | ♯ Output variables |
|---|---|---|---|---|
| Parkinson | 1,198 | 300 | 18 | 2 |
| Tecator | 172 | 43 | 100 | 3 |
4. Results and Discussion
4.1. Single-Output Regression Datasets

| Variables | PS−FS | FSR | EN | Friedman Test | Quade Test | |
| K = 5 | 2.916 | 3.126 | 4.563 | 3.352 | 6.53 (+) | 7.24 (+) |
| K = 10 | 2.397 | 2.544 | 4.150 | 2.815 | 28.04 (+) | 20.73 (+) |
| k = 15 | 2.196 | 2.292 | 3.782 | 2.549 | 49.13 (+) | 30.43 (+) |
| k = 20 | 2.060 | 2.138 | 3.428 | 2.368 | 84.40 (+) | 26.42 (+) |
| CASI-THERM dataset | ||||||
| Variables | PS−FS | FSR | EN | Friedman Test | Quade Test | |
| K = 5 | 3.326 | 3.389 | 3.642 | 3.438 | 0.08 (−) | 0.02 (−) |
| K = 10 | 3.191 | 3.286 | 3.358 | 3.250 | 1.17 (−) | 0.93 (−) |
| K = 15 | 3.205 | 3.277 | 3.302 | 3.230 | 2.17 (−) | 1.68 (−) |
| K = 20 | 3.202 | 3.291 | 3.283 | 3.241 | 5.64 (+) | 3.05 (−) |
| Bank32NH dataset | ||||||
| Variables | PS−FS | FSR | EN | Friedman Test | Quade Test | |
| K = 5 | 0.096 | 0.095 | 0.095 | 0.095 | 0.48 (−) | 1.03 (−) |
| K = 10 | 0.093 | 0.091 | 0.091 | 0.091 | 4.14 (−) | 6.21 (+) |
| K = 15 | 0.092 | 0.090 | 0.090 | 0.090 | 1.21 (−) | 7.71 (+) |
| K = 20 | 0.092 | 0.090 | 0.090 | 0.090 | 4.83 (+) | 13.08 (+) |
| Boston Housing dataset | ||||||
| Variables | PS−FS | FSR | EN | Friedman Test | Quade Test | |
| K = 5 | 4.427 | 4.370 | 4.801 | 4.625 | 1.43 (−) | 1.44 (−) |
| K = 10 | 4.203 | 4.326 | 4.702 | 4.875 | 6.73 (+) | 5.98 (+) |
| K = 13 | 4.317 | 4.516 | 4.799 | 4.949 | 7.84 (+) | 8.08 (+) |
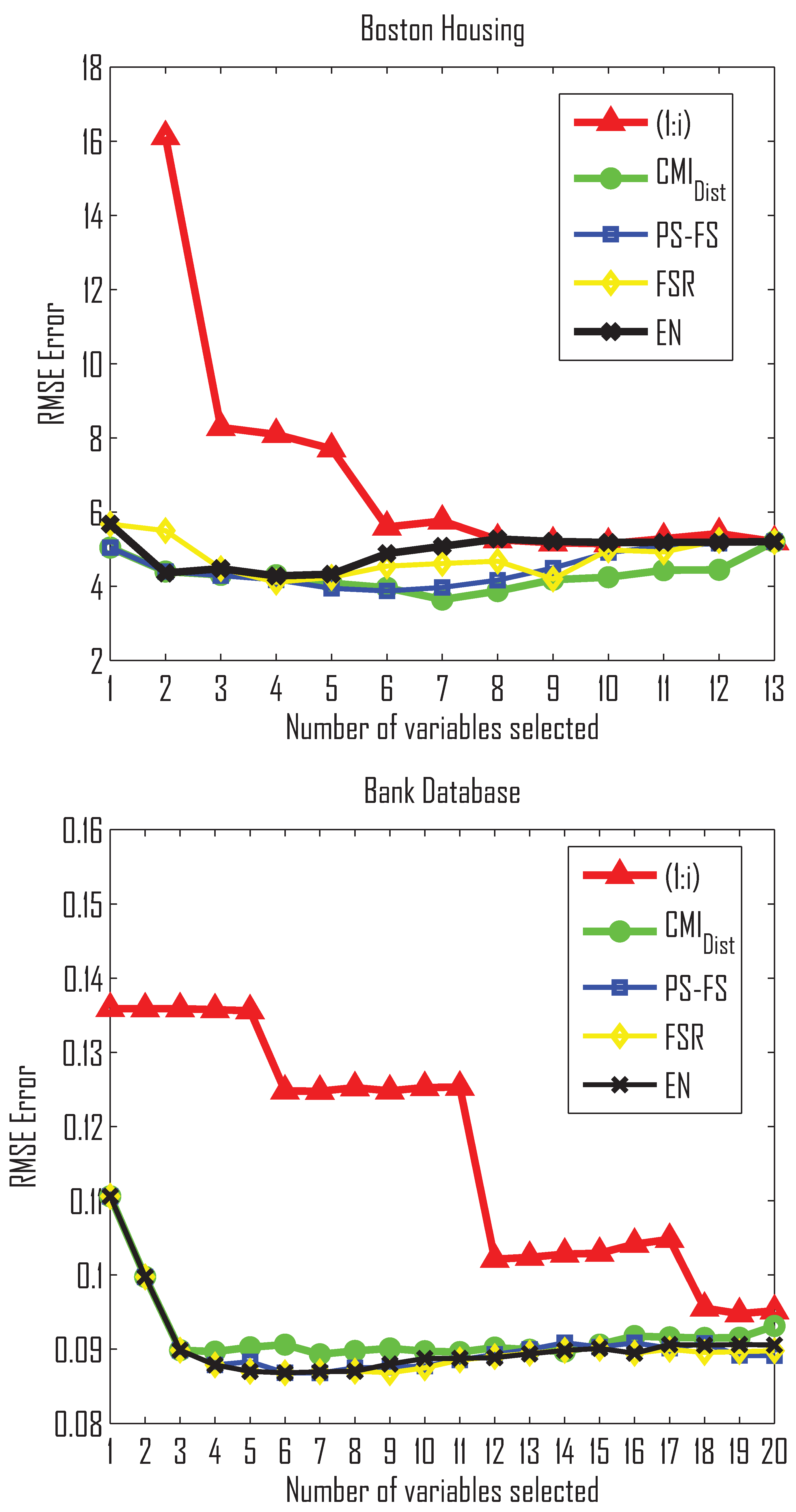
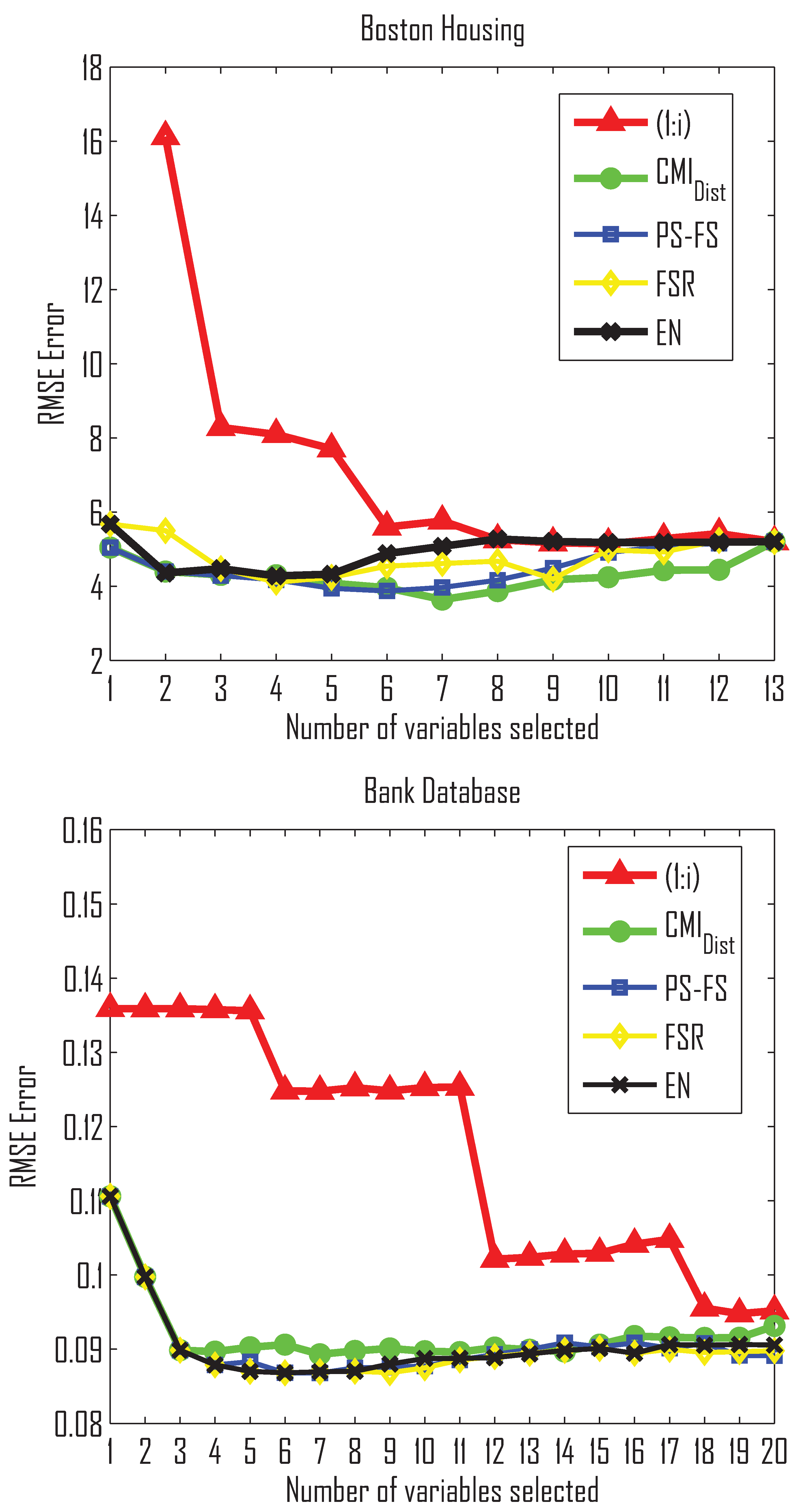
- In Table 3 we see that the proposed method obtains better performance with respect to the rest of methods for all the cases (5, 10, 15 and 20 variables) for the CASI-AHS-CHLOR and CASI-THERM datasets and for two out of the three (10 and 13 variables) for the Boston Housing dataset.
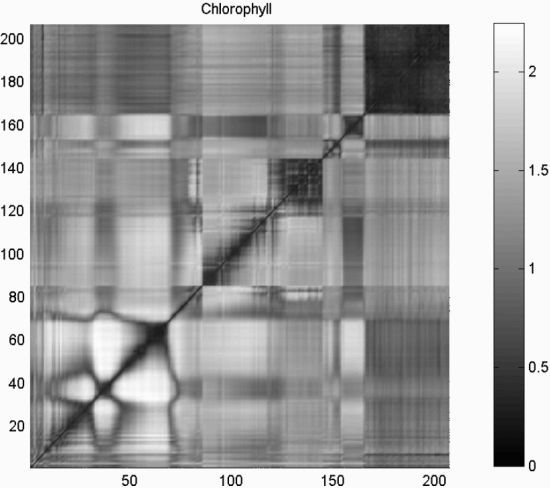
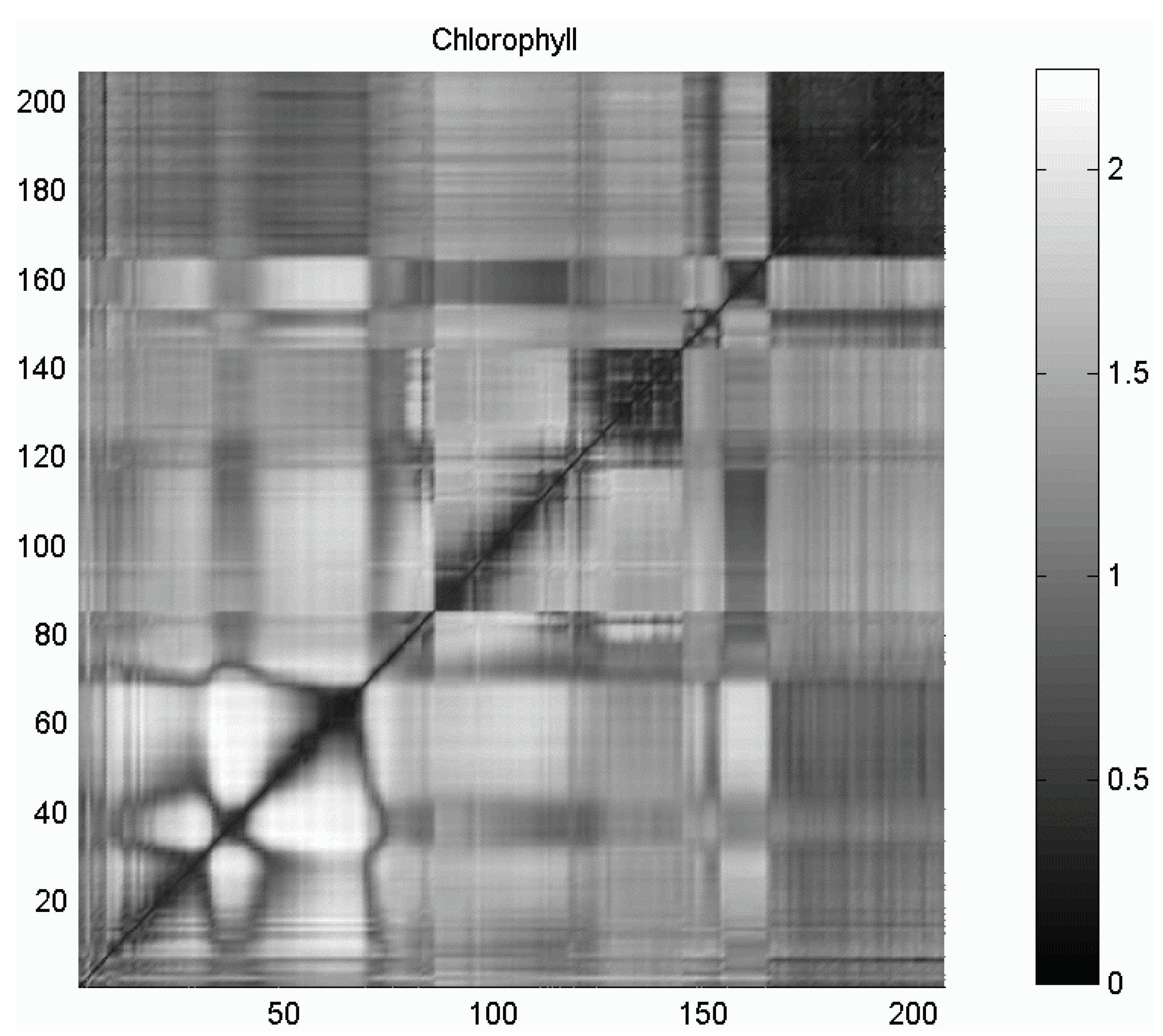
- In the clustering process plays an important role, which can be interpreted as a global strategy to obtain subsets of variables with high relevance in the estimation of the relevant variable Y obtained by the SVR algorithm. The dissimilarity space built from the conditional mutual information distances allows to find relationships between variables.
- The PS-FS method is the second best one in most cases followed by the EN method. PS-FS is a wrapper-type method based on a Neural Network regressor to make an optimal search where the error of the regressor acts as the search criteria.
- is the worst method in all the cases, with the exception of and for Boston Housing. For the Bank32NH dataset, all methods provide similar results.
- In two out of the four single-output regression datasets that appear in Table 3, when the dimension of the input variable space increases, the performance of the regression methods nevertheless decreases. One reason could be given by the Hughes phenomenon (the curse of dimensionality). Noise and variables considered as noisy may also degrade the quality of the regression.
- Table 4 shows the average RMSE over the four datasets for different sizes of the variable subsets selected. provides the best results for all cases, while the PS-FS method is the second best method.
| Variables | PS−FS | FSR | EN | |
|---|---|---|---|---|
| K = 5 | 2.691 | 2.745 | 3.275 | 2.877 |
| K = 10 | 2.471 | 2.562 | 3.075 | 2.758 |
| K = 15 | 2.451 | 2.543 | 2.995 | 2.705 |
| K = 20 | 1.784 | 1.839 | 2.267 | 1.899 |
4.2. Multi-Output Regression Datasets
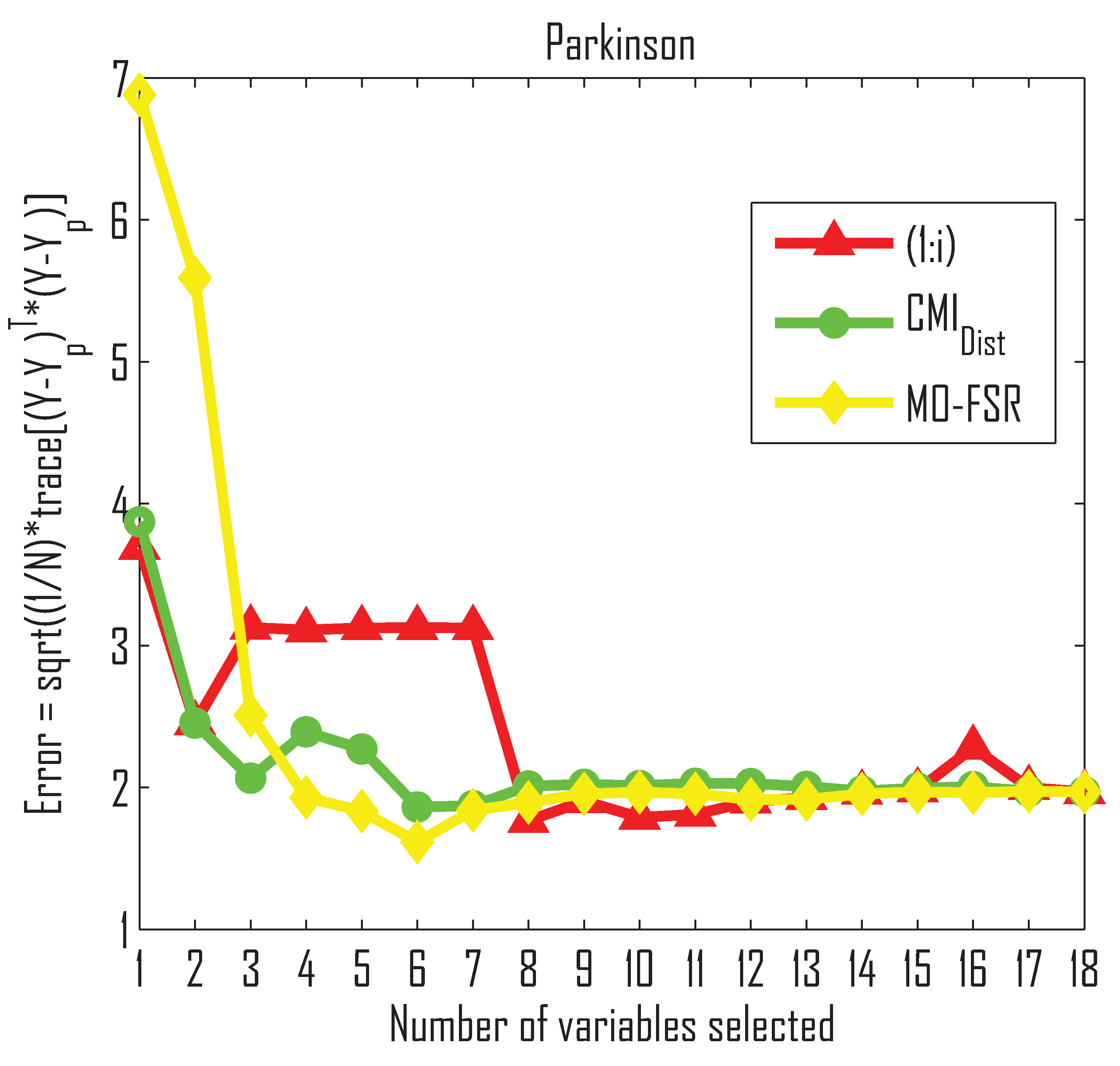
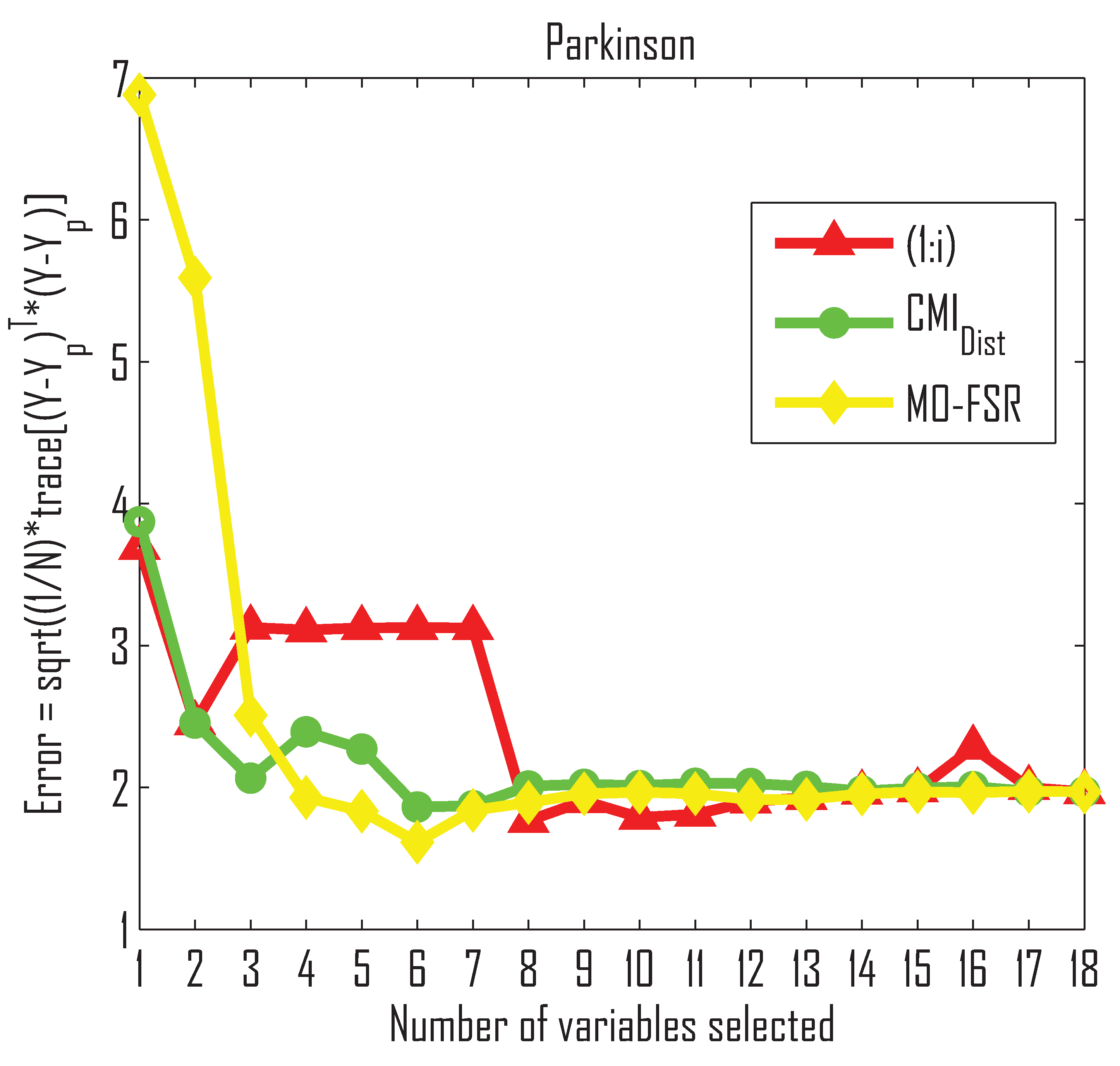
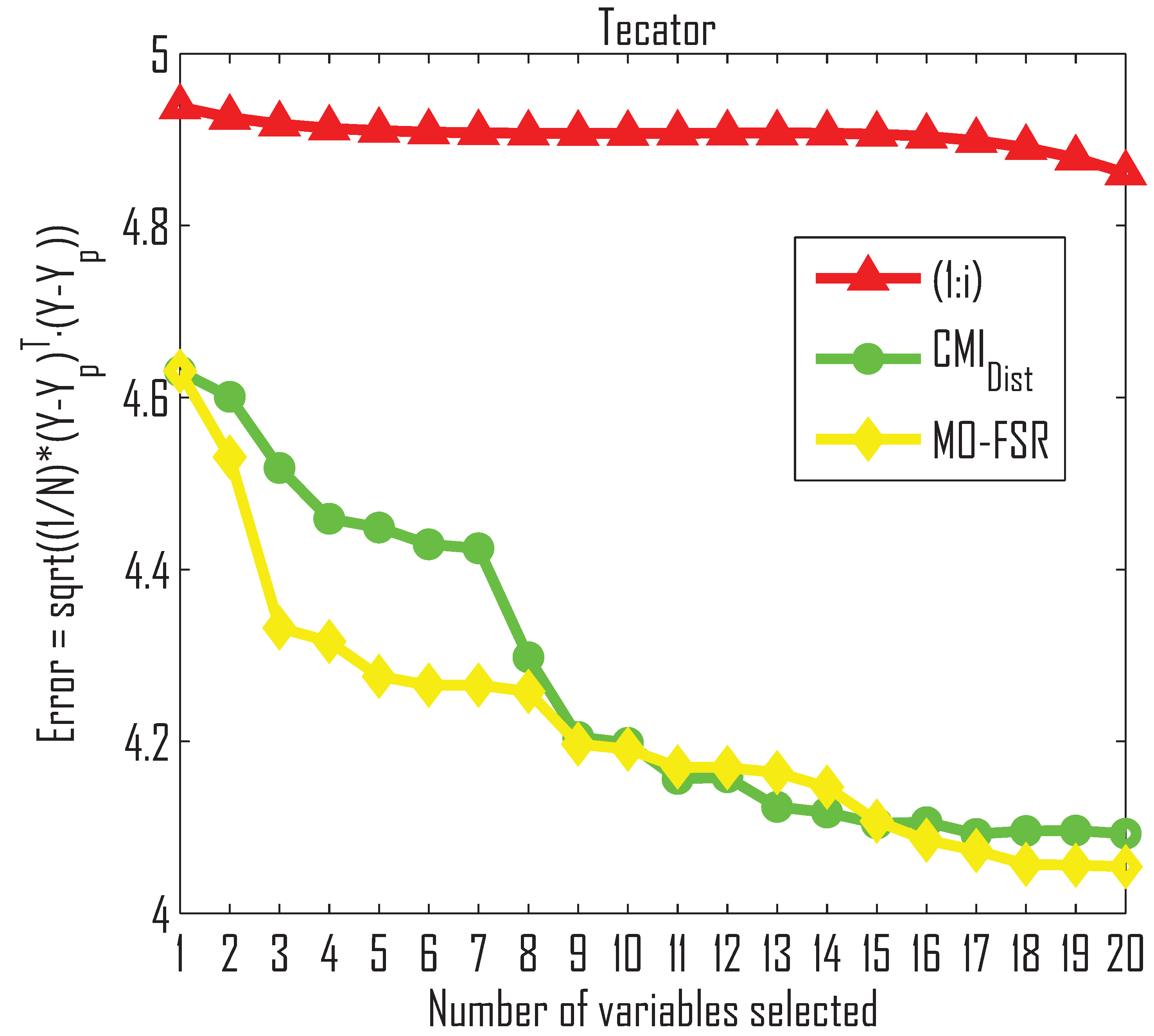
- The method outperforms MO-FSR for the Parkinson dataset, while MO-FSR outperforms in the Tecator dataset. These experiments show that our method is comparable to MO-FSR.
- The method does not assume that the input and output data are linearly related, whereas MO-FSR does. Therefore, the performance of the selector may depend on the relationship between the input and output values for the datasets.
- The method outperforms MO-FSR for the first three selected variables in the Parkinson dataset, whereas there is no difference for the rest of the selected variables, as can be seen in the Friedman and Quade tests in Table 5. However, in the case of the Tecator dataset (see Figure 4b), the MO-FSR outperforms the up to variable 10, and tends to become equal afterwards.
| Variables | MO−FSR | Friedman Test | Quade Test | |
| K = 5 | 2.611 | 3.749 | 0.17 (−) | 0.87 (−) |
| K = 10 | 2.283 | 2.801 | 1.71 (−) | 0.02 (−) |
| K = 15 | 2.191 | 2.515 | 7.87 (−) | 1.18 (−) |
| K = 18 | 2.156 | 2.424 | 7.59 (−) | 2.36 (−) |
| Tecator dataset | ||||
| Variables | MO−FSR | Friedman Test | Quade Test | |
| K = 5 | 4.531 | 4.417 | 7.11 (−) | 9.92 (−) |
| K = 10 | 4.421 | 4.326 | 38.37 (+) | 28.10 (+) |
| K = 15 | 4.325 | 4.268 | 1.07 (−) | 3.80 (−) |
| K = 20 | 4.268 | 4.217 | 4.82 (−) | 6.22 (−) |
5. Conclusions
Acknowledgments
References
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Verleysen, M.; Rossi, F.; Franois, D. Advances in feature selection with mutual information. Similarity Based Clust. 2009, 5400/2009, 52–69. [Google Scholar]
- Karagiannopoulos, M.; Anyfantis, D.; Kotsiantis, S.B.; Pintelas, P.E. Feature selection for regression problems. In Proceedings of the 8th Hellenic European Research on Computer Mathematics & its Applications, Athens, Greece, 20–22 September 2007.
- Oliveira, A.L.I.; Braga, P.L.; Lima, R.M.F.; Cornélio, M.L. GA-based method for feature selection and parameters optimization for machine learning regression applied to software effort estimation. Inf. Softw. Technol. 2010, 52, 1155–1166. [Google Scholar] [CrossRef]
- Eirola, E.; Liitiäinen, E.; Lendasse, A. Using the delta test for variable selection. In Proceedings of the European Symposium on Artificial Neural Networks—Advances in Computational Intelligence and Learning, Bruges, Belgium, 23–25 April 2008; pp. 25–30.
- Fan, J.; Peng, L.; Yao, Q.; Zhang, W. Approximating Conditional density functions using dimension reduction. Acta Math. Appl. Sin. 2009, 25, 445–456. [Google Scholar]
- Rossi, F.; Lendasse, A.; Francois, D.; Wertz, V.; Verleysen, M. Mutual information for the selection of relevant variables in spectrometric nonlinear modelling. Chemom. Intell. Lab. Syst. 2006, 80, 215–226. [Google Scholar] [CrossRef]
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Pudil, P.; Ferri, F.J.; Novovicova, J.; Kittler, J. Floating search methods for feature selection with nonmonotonic criterion functions. Pattern Recogn. 1994, 2, 279–283. [Google Scholar]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Sotoca, J.M.; Pla, F. Supervised feature selection by clustering using conditional mutual information-based distances. Pattern Recogn. 2010, 43, 2068–2081. [Google Scholar] [CrossRef]
- Latorre Carmona, P.; Sotoca, J.M.; Pla, F.; Phoa, F.K.H.; Bioucas Dias, J. Feature selection in regression tasks using conditional mutual information. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA ’11), Las Palmas de Gran Canaria, Spain, 8–10 June 2011; pp. 224–231.
- Ho, S.-W.; Verdu, S. On the interplay between conditional entropy and the error probability. IEEE Trans. Inf. Theory 2010, 56, 5930–5942. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons Inc.: Hoboken, NJ, USA, 1991. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundance. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Kwak, N.; Choi, Ch.-H. Input feature selection for classification problems. IEEE Trans. Neural Netw. 2002, 13, 143–159. [Google Scholar] [CrossRef] [PubMed]
- Ward, J.H. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Yeung, R.W. A First Course in Information Theory; Springer: Berlin, Heidelberg, Germany, 2002. [Google Scholar]
- Ney, H. On the relationship between classification error bounds and training criteria in statistical pattern recognition. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis (IbPRIA ’03), Puerto de Andratx, Mallorca, Spain, 4–6 June 2003; pp. 636–645.
- Fan, J.; Yao, Q.; Tong, H. Estimation of conditional densities and sensitivity measures in nonlinear dynamical systems. Biometrika 1996, 83, 189–206. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Bashtannyk, D.M.; Grunwald, G.K. Estimating and visualizing conditional densities. J. Comput. Graph. Stat. 1996, 5, 315–336. [Google Scholar]
- Holmes, M.P.; Gray, A.; Isbell, C.L. Fast kernel conditional density estimation: A dual-tree Monte Carlo approach. Comput. Stat. Data Anal. 2010, 54, 1707–1718. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on some nonparametric estimates of a density function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer: Berlin, Heidelberg, Germany, 2006. [Google Scholar]
- Monteiro, S.T.; Kosugi, Y. Particle swarms for feature extraction of hyperspectral data. IEICE Trans. Inf. Syst. 2007, E90D, 1038–1046. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948.
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Kolar, M.; Xing, E.P. Ultra-high dimensional multiple output learning with simultaneous orthogonal matching pursuit: Screening approach. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 413–420.
- Obozinski, G.; Taskar, B.; Jordan, M.I. Joint covariate selection and joint subspace selection for multiple classification problems. Stat. Comput. 2010, 20, 231–252. [Google Scholar]
- Moreno, J.F. SEN2FLEX Data Acquisition Report; Technical Report; Universidad de Valencia: Valencia, Spain, 2005. [Google Scholar]
- DELVE data repository. Available online: http://www.cs.toronto.edu/∼delve/ (accessed on 15 February 2012).
- Harrison, D.; Rubinfeld, D.L. Hedonic prices and the demand for clean air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar]
- UCI machine learning repository. Available online: http://archive.ics.uci.edu/ml/ (accessed on 15 February 2012).
- Drucker, H.; Burges, C.; Kaufman, L.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. In Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Sánchez-Fernández, M.P.; de-Prado-Cumplido, M.; Arenas-García, J.; Pérez-Cruz, F. SVM multiregression for non-linear channel estimation in multiple-input multiple-output systems. IEEE Trans. Signal Process. 2004, 58, 2298–2307. [Google Scholar] [CrossRef]
- Kwak, N.; Choi, Ch.-H. Input feature selection by mutual information based on parzen window. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1667–1671. [Google Scholar] [CrossRef]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis; Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Latorre Carmona, P.; Sotoca, J.M.; Pla, F. Filter-Type Variable Selection Based on Information Measures for Regression Tasks. Entropy 2012, 14, 323-343. https://doi.org/10.3390/e14020323
Latorre Carmona P, Sotoca JM, Pla F. Filter-Type Variable Selection Based on Information Measures for Regression Tasks. Entropy. 2012; 14(2):323-343. https://doi.org/10.3390/e14020323
Chicago/Turabian StyleLatorre Carmona, Pedro, José Martínez Sotoca, and Filiberto Pla. 2012. "Filter-Type Variable Selection Based on Information Measures for Regression Tasks" Entropy 14, no. 2: 323-343. https://doi.org/10.3390/e14020323